

AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
Definition and Objectives, Top 80 Questions and Answers Dump, White papers, Exam info and details, References, Jobs, Others AWS Certificates
What is the AWS Certified Cloud Practitioner Exam?
The AWS Cloud Practitioner Exam is an introduction to AWS services and the intention is to examine the candidates ability to define what the AWS cloud is and its global infrastructure. It provides an overview of AWS core services security aspects, pricing and support services. The main objective is to provide an overall understanding about the Amazon Web Services Cloud platform. The course helps you get the conceptual understanding of the AWS and can help you know about the basics of AWS and cloud computing, including the services, cases and benefits.
AWS Certified Cloud Practitioner Exam Prep Questions and Answers
Which of the following service is most useful when a Disaster Recovery method is triggered in AWS.
- A. Amazon Route 53
- B. Amazon SNS
- C. Amazon SQS
- D. Amazon Inspector
Answer:
Top
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6

 Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more codes)
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more codes)
Active Anti-Aging Eye Gel, Reduces Dark Circles, Puffy Eyes, Crow's Feet and Fine Lines & Wrinkles, Packed with Hyaluronic Acid & Age Defying Botanicals

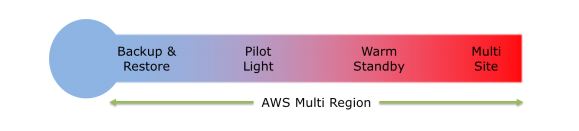
Which of the following disaster recovery deployment mechanisms that has the highest downtime
- A. Pilot light
- B. Warm standby
- C. Multi Site
- D. Backup and Restore
Answer:


Your company is planning to host resources in the AWS Cloud. They want to use services which can be used to decouple resources hosted on the cloud. Which of the following services can help fulfil this requirement?
- A. AWS EBS Volumes
- B. AWS EBS Snapshots
- C. AWS Glacier
- D. AWS SQS
Answer:
Top
If you have a set of frequently accessed files that are used on a daily basis, what S3 storage class should you store them in?
- A. Infrequent Access
- B. Fast Access
- C. Reduced Redundancy
- D. Standard
Answer:
What is the availability and durability rating of S3 Standard Storage Class?
Choose the correct answer:
- A. 99.999999999% Durability and 99.99% Availability
- B. 99.999999999% Availability and 99.90% Durability
- C. 99.999999999% Durability and 99.00% Availability
- D. 99.999999999% Availability and 99.99% Durability
Answer:

What AWS database is primarily used to analyze data using standard SQL formatting with compatibility for your existing business intelligence tools
- A. Redshift
- B. RDS
- C. DynamoDB
- D. ElastiCache
Answer:

What are the benefits of DynamoDB?
Choose the 3 correct answers:
- A. Single-digit millisecond latency.
- B. Supports multiple known NoSQL database engines like MariaDB and Oracle NoSQL.
- C. Supports both document and key-value store data models.
- D. Automatic scaling of throughput capacity.
Answer:

Which of the following are the benefits of AWS Organizations?
Choose the 2 correct answers:
- A. Analyze cost before migrating to AWS.
- B. Centrally manage access polices across multiple AWS accounts.
- C. Automate AWS account creation and management.
- D. Provide technical help (by AWS) for issues in your AWS account.
Answer:
There is a requirement hosting a set of servers in the Cloud for a short period of 3 months. Which of the following types of instances should be chosen to be cost effective.
- A. Spot Instances
- B. On-Demand
- C. No Upfront costs Reserved
- D. Partial Upfront costs Reserved
Answer:
Which of the following is not a disaster recovery deployment technique.
- A. Pilot light
- B. Warm standby
- C. Single Site
- D. Multi-Site
Answer:
Top
Which of the following are attributes to the costing for using the Simple Storage Service. Choose 2 answers from the options given below
- A. The storage class used for the objects stored.
- B. Number of S3 buckets.
- C. The total size in gigabytes of all objects stored.
- D. Using encryption in S3
Answer:
What endpoints are possible to send messages to with Simple Notification Service?
Choose the 3 correct answers:
- A. SQS
- B. SMS
- C. FTP
- D. Lambda
Answer:

What service helps you to aggregate logs from your EC2 instance? Choose one answer from the options below:
- A. SQS
- B. S3
- C. Cloudtrail
- D. Cloudwatch Logs
Answer:
A company is deploying a new two-tier web application in AWS. The company wants to store their most frequently used data so that the response time for the application is improved. Which AWS service provides the solution for the company’s requirements?
- A. MySQL Installed on two Amazon EC2 Instances in a single Availability Zone
- B. Amazon RDS for MySQL with Multi-AZ
- C. Amazon ElastiCache
- D. Amazon DynamoDB
Answer:
Top
You have a distributed application that periodically processes large volumes of data across multiple Amazon EC2 Instances. The application is designed to recover gracefully from Amazon EC2 instance failures. You are required to accomplish this task in the most cost-effective way. Which of the following will meet
your requirements?
- A. Spot Instances
- B. Reserved Instances
- C. Dedicated Instances
On-Demand Instances
Answer:
Top
Which of the following features is associated with a Subnet in a VPC to protect against Incoming traffic requests?
- A. AWS Inspector
- B. Subnet Groups
- C. Security Groups
- D. NACL
Answer:
Top
A company is deploying a two-tier, highly available web application to AWS. Which service provides durable storage for static content while utilizing Overall CPU resources for the web tier?
- A. Amazon EBC volume.
- B. Amazon S3
- C. Amazon EC2 instance store
- D. Amazon RDS instance
Answer:
Top
What are characteristics of Amazon S3?
Choose 2 answers from the options given below.
- A. S3 allows you to store objects of virtually unlimited size.
- B. S3 allows you to store unlimited amounts of data.
- C. S3 should be used to host relational database.
- D. Objects are directly accessible via a URL.
Answer:
When working on the costing for on-demand EC2 instances , which are the following are attributes which determine the costing of the EC2 Instance. Choose 3 answers from the options given below
- A. Instance Type
- B. AMI Type
- C. Region
- D. Edge location
Answer:
You have a mission-critical application which must be globally available at all times. If this is the case, which of the below deployment mechanisms would you employ
- A. Deployment to multiple edge locations
- B. Deployment to multiple Availability Zones
- D. Deployment to multiple Data Centers
- D. Deployment to multiple Regions
Answer:
Which of the following are right principles when designing cloud based systems. Choose 2 answers from the options below
- A. Build Tightly-coupled components
- B. Build loosely-coupled components
- C. Assume everything will fail
- D. Use as many services as possible
Answer:
You have 2 accounts in your AWS account. One for the Dev and the other for QA. All are part of
consolidated billing. The master account has purchase 3 reserved instances. The Dev department is currently using 2 reserved instances. The QA team is planning on using 3 instances which of the same instance type. What is the pricing tier of the instances that can be used by the QA Team?
- A. No Reserved and 3 on-demand
- B. One Reserved and 2 on-demand
- C. Two Reserved and 1 on-demand
- D. Three Reserved and no on-demand
Answer:
Which one of the following features is normally present in all of AWS Support plans
- A. 24/7 access to Customer Service
- B. Access to all features in the Trusted Advisor
- C. A technical Account Manager
- D. A dedicated support person
Answer:

Which of the following storage mechanisms can be used to store messages effectively which can be used across distributed systems?
- A. Amazon Glacier
- B. Amazon EBS Volumes
- C. Amazon EBS Snapshots
- D. Amazon SQS
Answer:
You are exploring what services AWS has off-hand. You have a large number of data sets that need to be processed. Which of the following services can help fulfil this requirement.
- A. EMR
- B. S3
- C. Glacier
- D. Storage Gateway
Answer:
Which of the following services allows you to analyze EC2 Instances against pre-defined security templates to check for vulnerabilities
- A. AWS Trusted Advisor
- B. AWS Inspector
- C. AWS WAF
- D. AWS Shield
Answer:
Top
Your company is planning to offload some of the batch processing workloads on to AWS. These jobs can be interrupted and resumed at any time. Which of the following instance types would be the most cost effective to use for this purpose.
- A. On-Demand
- B. Spot
- C. Full Upfront Reserved
- D. Partial Upfront Reserved
Answer:
Which of the following is not a category recommendation given by the AWS Trusted Advisor?
- A. Security
- B. High Availability
- C. Performance
- D. Fault tolerance
Answer:

Which of the below cannot be used to get data onto Amazon Glacier.
- A. AWS Glacier API
- B. AWS Console
- C. AWS Glacier SDK
- D. AWS S3 Lifecycle policies
Answer:
Which of the following from AWS can be used to transfer petabytes of data from on-premise locations to the AWS Cloud.
- A. AWS Import/Export
- B. AWS EC2
- C. AWS Snowball
- D. AWS Transfer
Answer:
Which of the following services allows you to analyze EC2 Instances against pre-defined security templates to check for vulnerabilities
- A. AWS Trusted Advisor
- B. AWS Inspector
- C. AWS WAF
- D. AWS Shield
Answer:
Top
Your company wants to move an existing Oracle database to the AWS Cloud. Which of the following services can help facilitate this move.
- A. AWS Database Migration Service
- B. AWS VM Migration Service
- C. AWS Inspector
- D. AWS Trusted Advisor
Answer:
Top
Which of the following features of AWS RDS allows for offloading reads of the database.
- A. Cross region replication
- B. Creating Read Replica’s
- C. Using snapshots
- D. Using Multi-AZ feature
Answer:
Top
Which of the following does AWS perform on its behalf for EBS volumes to make it less prone to failure?
- A. Replication of the volume across Availability Zones
- B. Replication of the volume in the same Availability Zone
- C. Replication of the volume across Regions
- D. Replication of the volume across Edge locations
Answer:
Your company is planning to host a large ecommerce application on the AWS Cloud. One of their major concerns is Internet attacks such as DDos attacks. Which of the following services can help mitigate this concern. Choose 2 answers from the options given below
- A. A. Cloudfront
- B. AWS Shield
- C. C. AWS EC2
- D. AWS Config
Answer:
Which of the following are 2 ways that AWS allows to link accounts
- A. Consolidating billing
- B. AWS Organizations
- C. Cost Explorer
- D. IAM
Answer:
Which of the following helps in DDos protection. Choose 2 answers from the options given below
- A. Cloudfront
- B. AWS Shield
- C. AWS EC2
- D. AWS Config
Answer:
Which of the following can be used to call AWS services from programming languages
- A. AWS SDK
- B. AWS Console
- C. AWS CLI
- D. AWS IAM
Answer:
A company wants to host a self-managed database in AWS. How would you ideally implement this solution?
- A. Using the AWS DynamoDB service
- B. Using the AWS RDS service
- C. Hosting a database on an EC2 Instance
- D. Using the Amazon Aurora service
Answer:
When creating security groups, which of the following is a responsibility of the customer. Choose 2 answers from the options given below.
- A. Giving a name and description for the security group
- B. Defining the rules as per the customer requirements.
- C. Ensure the rules are applied immediately
- D. Ensure the security groups are linked to the Elastic Network interface
Answer:
There is a requirement to host a database server for a minimum period of one year. Which of the following would result in the least cost?
- A. Spot Instances
- B. On-Demand
- C. No Upfront costs Reserved
- D. Partial Upfront costs Reserved
Answer:
which of the below can be used to import data into Amazon Glacier?
Choose 3 answers from the options given below:
- A. AWS Glacier API
- B. AWS Console
- C. AWS Glacier SDK
- D. AWS S3 Lifecycle policies
Answer:
Which of the following can be used to secure EC2 Instances hosted in AWS. Choose 2 answers
- A. Usage of Security Groups
- B. Usage of AMI’s
- C. Usage of Network Access Control Lists
- D. Usage of the Internet gateway
Answer:
Which of the following can be used to host virtual servers on AWS
- A. AWS IAM
- B. AWS Server
- C. AWS EC2
- D. AWS Regions
Answer:
You plan to deploy an application on AWS. This application needs to be PCI Compliant. Which of the below steps are needed to ensure the compliance? Choose 2 answers from the below list:
- A. Chhose AWS services which are PCI Compliant
- B. Ensure the right steps are taken during application development for PCI Compliance
- C. Encure the AWS Services are made PCI Compliant
- D. Do an audit after the deployment of the application for PCI Compliance.
Answer:
Top
Which tool can you use to forecast your AWS spending?
- A. AWS organizations
- B. Amazon Dev pay
- C. AWS Trusted Advisor
- D. AWS Cost explorer
Answer:
The Trusted Advisor service provides insight regarding which four categories of an AWS account?
- A. Security, fault tolerance, high availability, performance and Service Limits
- B. Security, access control, high availability, performance and Service Limits
- C. Performance, cost optimization, Security, fault tolerance and Service Limits
- D. Performance, cost optimization, Access Control, Connectivity, and Service Limits
Answer:
Top
As per the AWS Acceptable Use Policy, penetration testing of EC2 instances
- A. May be performed by AWS, and will be performed by AWS upon customer request
- B. May be performed by AWS, and is periodically performed by AWS
- C. Are expressly prohibited under all circumtances
- D. May be performed by the customer on their own instances with prior authorization from AWS
- E. May be performed by the customer on their own instances, only if performed from EC2 instances
Answer:
Top
What is the AWS feature that enables fast, easy, and secure transfers of files over long distances between your client and your Amazon S3 bucket
- A. File Transfer
- B. HTTP Transfer
- C. Transfer Acceleration
- D. S3 Acceleration
Answer:
Top
What best describes an AWS region?
Choose the correct answer:
- A. The physical networking connections between Availability Zones.
- B. A specific location where an AWS data center is located.
- C. A collection of DNS servers.
- D. An isolated collection of AWS Availability Zones, of which there are many placed all around the world.
Answer:
Top
Question: Which of the following is a factor when calculating Total Cost of Ownership (TCO) for the AWS Cloud?
- A. The number of servers migrated to AWS
- B. The number of users migrated to AWS
- C. The number of passwords migrated to AWS
- D. The number of keys migrated to AWS
Answer:
Which AWS Services can be used to store files? Choose 2 answers from the options given below:
- A. Amazon CloudWatch
- B. Amazon Simple Storage Service (Amazon S3)
- C. Amazon Elastic Block Store (Amazon EBS)
- D. AWS COnfig
- D. AWS Amazon Athena
Answer:
Question: What best describes Amazon Web Services (AWS)?
Choose the correct answer:
- A. AWS is the cloud.
- B. AWS only provides compute and storage services.
- C. AWS is a cloud services provider.
- D. None of the above.
Answer:
Question: Which AWS service can be used as a global content delivery network (CDN) service?
- A. Amazon SES
- B. Amazon CouldTrail
- C. Amazon CloudFront
- D. Amazon S3
Answer:
What best describes the concept of fault tolerance?
Choose the correct answer:
- A. The ability for a system to withstand a certain amount of failure and still remain functional.
- B. The ability for a system to grow in size, capacity, and/or scope.
- C. The ability for a system to be accessible when you attempt to access it.
- D. The ability for a system to grow and shrink based on demand.
Answer:
Question: The firm you work for is considering migrating to AWS. They are concerned about cost and the initial investment needed. Which of the following features of AWS pricing helps lower the initial investment amount needed? Choose 2 answers from the options given below:
- A. The ability to choose the lowest cost vendor.
- B. The ability to pay as you go
- C. No upfront costs
- D. Discounts for upfront payments
Answer:
What best describes the concept of elasticity?
Choose the correct answer:
- A. The ability for a system to grow in size, capacity, and/or scope.
- B. The ability for a system to grow and shrink based on demand.
- C. The ability for a system to withstand a certain amount of failure and still remain functional.
- D. ability for a system to be accessible when you attempt to access it.
Answer:
Question: Your company has
started using AWS. Your IT Security team is concerned with the
security of hosting resources in the Cloud. Which AWS service provides security optimization recommendations that could help the IT Security team secure resources using AWS?
- A. AWS API Gateway
- B. Reserved Instances
- C. AWS Trusted Advisor
- D. AWS Spot Instances
Answer:
What is the relationship between AWS global infrastructure and the concept of high availability?
Choose the correct answer:
- A. AWS is centrally located in one location and is subject to widespread outages if something happens at that one location.
- B. AWS regions and Availability Zones allow for redundant architecture to be placed in isolated parts of the world.
- C. Each AWS region handles a different AWS services, and you must use all regions to fully use AWS.
- D. None of the above
Answer
Question: You are hosting a number of EC2 Instances on AWS. You are looking to monitor CPU Utilization on the Instance. Which service would you use to collect and track performance metrics for AWS services?
- A. Amazon CloudFront
- B. Amazon CloudSearch
- C. Amazon CloudWatch
- D. AWS Managed Services
Answer:
Question: Which of the following support plans give access to all the checks in the Trusted Advisor service. Choose 2 answers from the options given below:
- A. Basic
- B. Business
- C. Enterprise
Answer:
Question: Which of the following in AWS maps to a separate geographic location?
- A. AWS Region
- B. AWS Data Centers
- C. AWS Availability Zone
Answer:
What best describes the concept of scalability?
Choose the correct answer:
- A. The ability for a system to grow and shrink based on demand.
- B. The ability for a system to grow in size, capacity, and/or scope.
- C. The ability for a system be be accessible when you attempt to access it.
- D. The ability for a system to withstand a certain amount of failure and still remain functional.
Answer
Question: If you wanted to monitor all events in your AWS account, which of the below services would you use?
- A. AWS CloudWatch
- B. AWS CloudWatch logs
- C. AWS Config
- D. AWS CloudTrail
Answer:
What are the four primary benefits of using the cloud/AWS?
Choose the correct answer:
- A. Fault tolerance, scalability, elasticity, and high availability.
- B. Elasticity, scalability, easy access, limited storage.
- C. Fault tolerance, scalability, sometimes available, unlimited storage
- D. Unlimited storage, limited compute capacity, fault tolerance, and high availability.
Answer:
What best describes a simplified definition of the “cloud”?
Choose the correct answer:
- A. All the computers in your local home network.
- B. Your internet service provider
- C. A computer located somewhere else that you are utilizing in some capacity.
- D. An on-premisis data center that your company owns.
Answer
Top
Question: Your development team is planning to host a development environment on the cloud. This consists of EC2 and RDS instances. This environment will probably only be required for 2 months. Which types of instances would you use for this purpose?
- A. On-Demand
- B. Spot
- C. Reserved
- D. Dedicated
Answer:
Question: Which of the following can be used to secure EC2 Instances?
- A. Security Groups
- B. EC2 Lists
- C. AWS Configs
- D. AWS CloudWatch
Answer:
Exam Topics:
The AWS Cloud Practitioner exam is broken down into 4 domains
- Cloud Concepts
- Security
- Technology
- Billing and Pricing.
What is the purpose of a DNS server?
Choose the correct answer:
- A. To act as an internet search engine.
- B. To protect you from hacking attacks.
- C. To convert common language domain names to IP addresses.
- D. To serve web application content.
Answer:
What best describes the concept of high availability?
Choose the correct answer:
- A. The ability for a system to grow in size, capacity, and/or scope.
- B. The ability for a system to withstand a certain amount of failure and still remain functional.
- C. The ability for a system to grow and shrink based on demand.
- D. The ability for a system to be accessible when you attempt to access it.
Answer:
Top
What is the major difference between AWS’s RDS and DynamoDB database services?
Choose the correct answer:
- A. RDS offers NoSQL database options, and DynamoDB offers SQL database options.
- B. RDS offers one SQL database option, and DynamoDB offers many NoSQL database options.
- C. RDS offers SQL database options, and DynamoDB offers a NoSQL database option.
- D. None of the above
Answer:
What are two open source in-memory engines supported by ElastiCache?
Choose the 2 correct answers:
- A. CacheIt
- B. Aurora
- C. MemcacheD
- D. Redis
Answer:
What AWS database service is used for data warehousing of petabytes of data?
Choose the correct answer:
- A. RDS
- B. Elasticache
- C. Redshift
- D. DynamoDB
Answer:
Which AWS service uses a combination of publishers and subscribers?
Choose the correct answer:
- A. Lambda
- B. RDS
- C. EC2
- D. SNS
Answer:
What SQL database engine options are available in RDS?
Choose the 3 correct answers:
- A. MySQL
- B. MongoDB
- C. PostgreSQL
- D. MariaDB
Answer:
What is the name of AWS’s RDS SQL database engine?
Choose the correct answer:
- A. Lightsail
- B. Aurora
- C. MySQL
- D. SNS
Answer:
Under what circumstances would you choose to use the AWS service CloudTrail?
Choose the correct answer:
- A. When you want to log what actions various IAM users are taking in your AWS account.
- B. When you want a serverless compute platform.
- C. When you want to collect and view resource metrics.
- D. When you want to send SMS notifications based on events that occur in your account.
Answer:
If you want to monitor the average CPU usage of your EC2 instances, which AWS service should you use?
Choose the correct answer:
- A. CloudMonitor
- B. CloudTrail
- C. CloudWatch
- D. None of the above
Answer:
What is AWS’s relational database service?
Choose the correct answer:
- A. ElastiCache
- B. DymamoDB
- C. RDS
- D. Redshift
Answer:
If you want to have SMS or email notifications sent to various members of your department with status updates on resources in your AWS account, what service should you choose?
Choose the correct answer:
- A. SNS
- B. GetSMS
- C. RDS
- D. STS
Answer:
AWS Certified Cloud Practitioner Exam Whitepapers:
AWS has provided whitepapers to help you understand the technical concepts. Below are the recommended whitepapers.
- Overview of Amazon Web Services
- Architecting for the Cloud: AWS Best Practices
- How AWS Pricing works whitepaper.
- The Total Cost of (Non) Ownership of Web Application in the Cloud
- Compare AWS Support Plans
Online Training and Labs for AWS Cloud Certified Practitioner Exam
AWS Cloud Practitioners Jobs
AWS Cloud Practitioner Exam info and details, How To:
The AWS Certified Cloud Practitioner Exam is a multiple choice, multiple answer exam. Here is the Exam Overview:
- Certification Name: AWS Certified Cloud Practitioner.
- Prerequisites for the Exam: None.
- Exam Pattern: Multiple Choice Questions
- Number of Questions: 65
- Duration: 90 mins
- Exam fees: US $100
- Exam Guide on AWS Website
- Available languages for tests: English, Japanese, Korean, Simplified Chinese
- Read AWS whitepapers
- Register for certification account here.
- Prepare for Certification Here
Additional Information for reference
Below are some useful reference links that would help you to learn about AWS Practitioner Exam.
- AWS certified cloud practitioner/
- certification faqs
- AWS Cloud Practitioner Certification Exam on Quora
Other Relevant and Recommended AWS Certifications
 AWS Certification Exams Roadmap
AWS Certification Exams Roadmap- AWS Certified Cloud Practitioner
- AWS Certified Solutions Architect – Associate
- AAWS Certified Developer – Associate
- AWS Certified SysOps Administrator – Associate
- AWS Certified Solutions Architect – Professional
- AWS Certified DevOps Engineer – Professional
- AWS Certified Big Data Specialty
- AWS Certified Advanced Networking.
- AWS Certified Security – Specialty
Active Hydrating Toner, Anti-Aging Replenishing Advanced Face Moisturizer, with Vitamins A, C, E & Natural Botanicals to Promote Skin Balance & Collagen Production, 6.7 Fl Oz



Age Defying 0.3% Retinol Serum, Anti-Aging Dark Spot Remover for Face, Fine Lines & Wrinkle Pore Minimizer, with Vitamin E & Natural Botanicals


Firming Moisturizer, Advanced Hydrating Facial Replenishing Cream, with Hyaluronic Acid, Resveratrol & Natural Botanicals to Restore Skin's Strength, Radiance, and Resilience, 1.75 Oz

Skin Stem Cell Serum


Smartphone 101 - Pick a smartphone for me - android or iOS - Apple iPhone or Samsung Galaxy or Huawei or Xaomi or Google Pixel
Can AI Really Predict Lottery Results? We Asked an Expert.





Djamgatech

Read Photos and PDFs Aloud for me iOS
Read Photos and PDFs Aloud for me android
Read Photos and PDFs Aloud For me Windows 10/11
Read Photos and PDFs Aloud For Amazon
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more)
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6(Email us for more)



FREE 10000+ Quiz Trivia and and Brain Teasers for All Topics including Cloud Computing, General Knowledge, History, Television, Music, Art, Science, Movies, Films, US History, Soccer Football, World Cup, Data Science, Machine Learning, Geography, etc....

List of Freely available programming books - What is the single most influential book every Programmers should read
- Bjarne Stroustrup - The C++ Programming Language
- Brian W. Kernighan, Rob Pike - The Practice of Programming
- Donald Knuth - The Art of Computer Programming
- Ellen Ullman - Close to the Machine
- Ellis Horowitz - Fundamentals of Computer Algorithms
- Eric Raymond - The Art of Unix Programming
- Gerald M. Weinberg - The Psychology of Computer Programming
- James Gosling - The Java Programming Language
- Joel Spolsky - The Best Software Writing I
- Keith Curtis - After the Software Wars
- Richard M. Stallman - Free Software, Free Society
- Richard P. Gabriel - Patterns of Software
- Richard P. Gabriel - Innovation Happens Elsewhere
- Code Complete (2nd edition) by Steve McConnell
- The Pragmatic Programmer
- Structure and Interpretation of Computer Programs
- The C Programming Language by Kernighan and Ritchie
- Introduction to Algorithms by Cormen, Leiserson, Rivest & Stein
- Design Patterns by the Gang of Four
- Refactoring: Improving the Design of Existing Code
- The Mythical Man Month
- The Art of Computer Programming by Donald Knuth
- Compilers: Principles, Techniques and Tools by Alfred V. Aho, Ravi Sethi and Jeffrey D. Ullman
- Gödel, Escher, Bach by Douglas Hofstadter
- Clean Code: A Handbook of Agile Software Craftsmanship by Robert C. Martin
- Effective C++
- More Effective C++
- CODE by Charles Petzold
- Programming Pearls by Jon Bentley
- Working Effectively with Legacy Code by Michael C. Feathers
- Peopleware by Demarco and Lister
- Coders at Work by Peter Seibel
- Surely You're Joking, Mr. Feynman!
- Effective Java 2nd edition
- Patterns of Enterprise Application Architecture by Martin Fowler
- The Little Schemer
- The Seasoned Schemer
- Why's (Poignant) Guide to Ruby
- The Inmates Are Running The Asylum: Why High Tech Products Drive Us Crazy and How to Restore the Sanity
- The Art of Unix Programming
- Test-Driven Development: By Example by Kent Beck
- Practices of an Agile Developer
- Don't Make Me Think
- Agile Software Development, Principles, Patterns, and Practices by Robert C. Martin
- Domain Driven Designs by Eric Evans
- The Design of Everyday Things by Donald Norman
- Modern C++ Design by Andrei Alexandrescu
- Best Software Writing I by Joel Spolsky
- The Practice of Programming by Kernighan and Pike
- Pragmatic Thinking and Learning: Refactor Your Wetware by Andy Hunt
- Software Estimation: Demystifying the Black Art by Steve McConnel
- The Passionate Programmer (My Job Went To India) by Chad Fowler
- Hackers: Heroes of the Computer Revolution
- Algorithms + Data Structures = Programs
- Writing Solid Code
- JavaScript - The Good Parts
- Getting Real by 37 Signals
- Foundations of Programming by Karl Seguin
- Computer Graphics: Principles and Practice in C (2nd Edition)
- Thinking in Java by Bruce Eckel
- The Elements of Computing Systems
- Refactoring to Patterns by Joshua Kerievsky
- Modern Operating Systems by Andrew S. Tanenbaum
- The Annotated Turing
- Things That Make Us Smart by Donald Norman
- The Timeless Way of Building by Christopher Alexander
- The Deadline: A Novel About Project Management by Tom DeMarco
- The C++ Programming Language (3rd edition) by Stroustrup
- Patterns of Enterprise Application Architecture
- Computer Systems - A Programmer's Perspective
- Agile Principles, Patterns, and Practices in C# by Robert C. Martin
- Growing Object-Oriented Software, Guided by Tests
- Framework Design Guidelines by Brad Abrams
- Object Thinking by Dr. David West
- Advanced Programming in the UNIX Environment by W. Richard Stevens
- Hackers and Painters: Big Ideas from the Computer Age
- The Soul of a New Machine by Tracy Kidder
- CLR via C# by Jeffrey Richter
- The Timeless Way of Building by Christopher Alexander
- Design Patterns in C# by Steve Metsker
- Alice in Wonderland by Lewis Carol
- Zen and the Art of Motorcycle Maintenance by Robert M. Pirsig
- About Face - The Essentials of Interaction Design
- Here Comes Everybody: The Power of Organizing Without Organizations by Clay Shirky
- The Tao of Programming
- Computational Beauty of Nature
- Writing Solid Code by Steve Maguire
- Philip and Alex's Guide to Web Publishing
- Object-Oriented Analysis and Design with Applications by Grady Booch
- Effective Java by Joshua Bloch
- Computability by N. J. Cutland
- Masterminds of Programming
- The Tao Te Ching
- The Productive Programmer
- The Art of Deception by Kevin Mitnick
- The Career Programmer: Guerilla Tactics for an Imperfect World by Christopher Duncan
- Paradigms of Artificial Intelligence Programming: Case studies in Common Lisp
- Masters of Doom
- Pragmatic Unit Testing in C# with NUnit by Andy Hunt and Dave Thomas with Matt Hargett
- How To Solve It by George Polya
- The Alchemist by Paulo Coelho
- Smalltalk-80: The Language and its Implementation
- Writing Secure Code (2nd Edition) by Michael Howard
- Introduction to Functional Programming by Philip Wadler and Richard Bird
- No Bugs! by David Thielen
- Rework by Jason Freid and DHH
- JUnit in Action
#BlackOwned #BlackEntrepreneurs #BlackBuniness #AWSCertified #AWSCloudPractitioner #AWSCertification #AWSCLFC02 #CloudComputing #AWSStudyGuide #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AWSBasics #AWSCertified #AWSMachineLearning #AWSCertification #AWSSpecialty #MachineLearning #AWSStudyGuide #CloudComputing #DataScience #AWSCertified #AWSSolutionsArchitect #AWSArchitectAssociate #AWSCertification #AWSStudyGuide #CloudComputing #AWSArchitecture #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AzureFundamentals #AZ900 #MicrosoftAzure #ITCertification #CertificationPrep #StudyMaterials #TechLearning #MicrosoftCertified #AzureCertification #TechBooks
Top 1000 Canada Quiz and trivia: CANADA CITIZENSHIP TEST- HISTORY - GEOGRAPHY - GOVERNMENT- CULTURE - PEOPLE - LANGUAGES - TRAVEL - WILDLIFE - HOCKEY - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Top 1000 Africa Quiz and trivia: HISTORY - GEOGRAPHY - WILDLIFE - CULTURE - PEOPLE - LANGUAGES - TRAVEL - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Exploring the Pros and Cons of Visiting All Provinces and Territories in Canada.


Exploring the Advantages and Disadvantages of Visiting All 50 States in the USA

Health Health, a science-based community to discuss health news and the coronavirus (COVID-19) pandemic
- Proposed CA bill would ban methylene chloride from decaf coffee productionby /u/lurker_bee on April 17, 2024 at 3:37 pm
submitted by /u/lurker_bee [link] [comments]
- Single injection of ketamine can reduce postpartum depression by 75%by /u/euronews-english on April 17, 2024 at 3:16 pm
submitted by /u/euronews-english [link] [comments]
- Noise can hurt your heart, disrupt your endocrine system, and make it difficult to think and learnby /u/scientificamerican on April 17, 2024 at 2:06 pm
submitted by /u/scientificamerican [link] [comments]
- Researchers Identify the Bacteria Responsible for Meningitis in Babies | A milestone study has identified that 50% of neonatal meningitis infections are caused by two types of E. coli.by /u/chrisdh79 on April 17, 2024 at 12:20 pm
submitted by /u/chrisdh79 [link] [comments]
- Nestlé adds sugar to infant milk sold in poorer countries, report finds | Swiss food firm’s infant formula and cereal sold in global south ignore WHO anti-obesity guidelines for Europe, says Public Eyeby /u/chrisdh79 on April 17, 2024 at 11:16 am
submitted by /u/chrisdh79 [link] [comments]
Today I Learned (TIL) You learn something new every day; what did you learn today? Submit interesting and specific facts about something that you just found out here.
- TIL that most hotel rooms in the USA do not have ceiling lights. This is done mostly for cost reasons. Money is saved by not having to run wire to a ceiling box, drywall around it and then install the overhead light itself.by /u/-Appleaday- on April 18, 2024 at 2:42 am
submitted by /u/-Appleaday- [link] [comments]
- TIL: America’s Nuclear Sponge. Montana, North Dakota, Wyoming, Nebraska and Colorado contain the nuclear silos that would be a primary target of WW3.by /u/SilentWalrus92 on April 18, 2024 at 12:11 am
submitted by /u/SilentWalrus92 [link] [comments]
- TIL a Chinese destroyer sank because an officer dumped his girlfriend. She committed suicide, leading to him being discharged, so he decided to detonate the depth charges on the ship, causing it to sink at port and kill 134 sailors.by /u/zhuquanzhong on April 17, 2024 at 11:15 pm
submitted by /u/zhuquanzhong [link] [comments]
- TIL The United States once had a 36-year-old vice president back in 1857. John C. Breckinridge is still the only person under 40 to serve as president or vice president.by /u/bankrobba on April 17, 2024 at 8:43 pm
submitted by /u/bankrobba [link] [comments]
- TIL that "Killing baby Hitler" is an ethical and theoretical physics experiment. It explores the idea of time-traveling to assassinate infant Adolf Hitler, delving into ethical consequences and temporal paradoxes.by /u/DennisHoffmanOqng on April 17, 2024 at 8:42 pm
submitted by /u/DennisHoffmanOqng [link] [comments]
Reddit Science This community is a place to share and discuss new scientific research. Read about the latest advances in astronomy, biology, medicine, physics, social science, and more. Find and submit new publications and popular science coverage of current research.
- Long COVID immune abnormalities largely resolved at 24 months, providing optimism that long COVID symptoms resolve over timeby /u/unsw on April 18, 2024 at 2:33 am
submitted by /u/unsw [link] [comments]
- UC Riverside demonstrates RNAi vaccine that works against multiple strains and in the immunocompromisedby /u/bug-hunter on April 18, 2024 at 12:56 am
submitted by /u/bug-hunter [link] [comments]
- Vaccination programmes save health systems billions, says new modelling. Report from the Office of Health Economics reveals adult immunisation returns up to 19 times the initial investment.by /u/mvea on April 17, 2024 at 9:56 pm
submitted by /u/mvea [link] [comments]
- Mentally stimulating work plays key role in staving off dementia, study finds. People in routine and repetitive jobs found to have 31% greater risk of disease in later life, and 66% higher risk of mild cognitive problems.by /u/mvea on April 17, 2024 at 9:54 pm
submitted by /u/mvea [link] [comments]
- Enormous ancient sea reptile identified from amateur fossil find.by /u/NinjaDiscoJesus on April 17, 2024 at 9:06 pm
submitted by /u/NinjaDiscoJesus [link] [comments]
Reddit Sports Sports News and Highlights from the NFL, NBA, NHL, MLB, MLS, and leagues around the world.
- Sixers get gritty win vs. Heat, will play Knicks in 1st roundby /u/Oldtimer_2 on April 18, 2024 at 3:30 am
submitted by /u/Oldtimer_2 [link] [comments]
- Caitlin Clark nearing endorsement deal with Nike: Sourcesby /u/BCLetsRide69 on April 18, 2024 at 2:07 am
submitted by /u/BCLetsRide69 [link] [comments]
- Kucherov joins McDavid in 100-assist clubby /u/Oldtimer_2 on April 18, 2024 at 1:26 am
submitted by /u/Oldtimer_2 [link] [comments]
- 100 days until Paris Olympics 2024: Dates, athletes and everything to knowby /u/Oldtimer_2 on April 18, 2024 at 12:12 am
submitted by /u/Oldtimer_2 [link] [comments]
- River Seine Olympics opening remains on track, organizers sayby /u/PrincessBananas85 on April 18, 2024 at 12:10 am
submitted by /u/PrincessBananas85 [link] [comments]
