


AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
How does a database handle pagination?
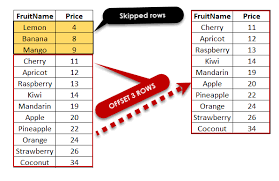
It doesn’t. First, a database is a collection of related data, so I assume you mean DBMS or database language.
Second, pagination is generally a function of the front-end and/or middleware, not the database layer.
But some database languages provide helpful facilities that aide in implementing pagination. For example, many SQL dialects provide LIMIT and OFFSET clauses that can be used to emit up to n rows starting at a given row number. I.e., a “page” of rows. If the query results are sorted via ORDER BY and are generally unchanged between successive invocations, then that can be used to implement pagination.
That may not be the most efficient or effective implementation, though.
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6

 Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more codes)
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more codes)
Active Anti-Aging Eye Gel, Reduces Dark Circles, Puffy Eyes, Crow's Feet and Fine Lines & Wrinkles, Packed with Hyaluronic Acid & Age Defying Botanicals

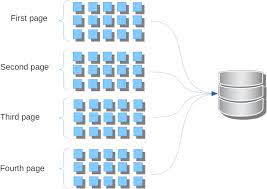
So how do you propose pagination should be done?
On context of web apps , let’s say there are 100 mn users. One cannot dump all the users in response.
Cache database query results in the middleware layer using Redis or similar and serve out pages of rows from that.

What if you have 30, 000 rows plus, do you fetch all of that from the database and cache in Redis?
I feel the most efficient solution is still offset and limit. It doesn’t make sense to use a database and then end up putting all of your data in Redis especially data that changes a lot. Redis is not for storing all of your data.

If you have large data set, you should use offset and limit, getting only what is needed from the database into main memory (and maybe caching those in Redis) at any point in time is very efficient.
With 30,000 rows in a table, if offset/limit is the only viable or appropriate restriction, then that’s sometimes the way to go.
More often, there’s a much better way of restricting 30,000 rows via some search criteria that significantly reduces the displayed volume of rows — ideally to a single page or a few pages (which are appropriate to cache in Redis.)
It’s unlikely (though it does happen) that users really want to casually browse 30,000 rows, page by page. More often, they want this one record, or these small number of records.
Question: This is a general question that applies to MySQL, Oracle DB or whatever else might be out there.
I know for MySQL there is LIMIT offset,size; and for Oracle there is ‘ROW_NUMBER’ or something like that.
But when such ‘paginated’ queries are called back to back, does the database engine actually do the entire ‘select’ all over again and then retrieve a different subset of results each time? Or does it do the overall fetching of results only once, keeps the results in memory or something, and then serves subsets of results from it for subsequent queries based on offset and size?

If it does the full fetch every time, then it seems quite inefficient.
If it does full fetch only once, it must be ‘storing’ the query somewhere somehow, so that the next time that query comes in, it knows that it has already fetched all the data and just needs to extract next page from it. In that case, how will the database engine handle multiple threads? Two threads executing the same query?

something will be quick or slow without taking measurements, and complicate the code in advance to download 12 pages at once and cache them because “it seems to me that it will be faster”.
Answer: First of all, do not make assumptions in advance whether something will be quick or slow without taking measurements, and complicate the code in advance to download 12 pages at once and cache them because “it seems to me that it will be faster”.
YAGNI principle – the programmer should not add functionality until deemed necessary.
Do it in the simplest way (ordinary pagination of one page), measure how it works on production, if it is slow, then try a different method, if the speed is satisfactory, leave it as it is.
From my own practice – an application that retrieves data from a table containing about 80,000 records, the main table is joined with 4-5 additional lookup tables, the whole query is paginated, about 25-30 records per page, about 2500-3000 pages in total. Database is Oracle 12c, there are indexes on a few columns, queries are generated by Hibernate. Measurements on production system at the server side show that an average time (median – 50% percentile) of retrieving one page is about 300 ms. 95% percentile is less than 800 ms – this means that 95% of requests for retrieving a single page is less that 800ms, when we add a transfer time from the server to the user and a rendering time of about 0.5-1 seconds, the total time is less than 2 seconds. That’s enough, users are happy.
And some theory – see this answer to know what is purpose of Pagination pattern

- MySQL for Beginners: Managing Tables(Part-4).by Tamanna shaikh (Database on Medium) on April 18, 2024 at 6:53 am
Welcome to our most recent MySQL for Beginners article! We’re going to focus on tables today as the foundation of database administration…Continue reading on Medium »
- How to Install MySQL on Ubuntu 22.04 Serverby Rainer Regan (Database on Medium) on April 18, 2024 at 6:15 am
MySQL is one of the most popular database management systems that have been used in many apps. It’s renowned for its compatibility with…Continue reading on Medium »
- STRUCTURED QUERY LANGUAGE (SQL) BASICSby Obulipurusothaman K (Database on Medium) on April 17, 2024 at 11:33 pm
STRUCTURED QUERY LANGUAGE(SQL)Continue reading on Medium »
- Transferências mais recentes — 17/04/2024by Tudo pelo Futebol (Database on Medium) on April 17, 2024 at 10:48 pm
Continue reading on Medium »
- Últimas Transferencias — 17/04/2024by Todo por el Fútbol (Database on Medium) on April 17, 2024 at 10:48 pm
Continue reading on Medium »
- Latest Transfers — 04/17/2024by Everything for Football (Database on Medium) on April 17, 2024 at 10:48 pm
Continue reading on Medium »
- Do any of these databases (MySQL, MariaDB?) have a decent GUI that people can use as opposed to having to do things via the console? I want to have an actual interface do navigate things from or see what is in the database..not just do things via the console?by /u/savant78 (Database) on April 17, 2024 at 10:34 pm
databases that actually have a decent GUI as opposed to just doing things via the console? submitted by /u/savant78 [link] [comments]
- Últimos Jogadores Atualizados — 17/04/2024by Tudo pelo Futebol (Database on Medium) on April 17, 2024 at 8:14 pm
Continue reading on Medium »
- Últimos Jugadores Actualizados — 17/04/2024by Todo por el Fútbol (Database on Medium) on April 17, 2024 at 8:14 pm
Continue reading on Medium »
- Last Updated Players — 04/17/2024by Everything for Football (Database on Medium) on April 17, 2024 at 8:14 pm
Continue reading on Medium »
- Transaction And Concurrency Control in DBMS.by Advait Thakar (Database on Medium) on April 17, 2024 at 5:40 pm
Okay guys, a real quick question…Continue reading on Medium »
- Maintain order of list items in DBby /u/Taka-tak (Database) on April 17, 2024 at 2:05 pm
In my React.js application I have a list of todos like this and their order can be changed Todo 1 Todo 2 Todo 3 Let's say I move the Todo 3 to top, Now the list becomes Todo 3 Todo 1 Todo 2 I want to persist the order in DB. How can I achieve this? I am using MySQL submitted by /u/Taka-tak [link] [comments]
- Free Virtual Distributed SQL Event - April 24thby /u/Yugabeing1 (Database) on April 17, 2024 at 11:53 am
If you're interested in distributed databases there is a free virtual event next week. r/YugabyteDB's Distributed SQL Summit (DSS) Asia (April 24th) is aimed at people interested in adopting a modern data ecosystem and simplifying their database modernization. You can find out more and register here➡️https://events.ringcentral.com/canvas/events/distributed-sql-summit-asia-2024/registration submitted by /u/Yugabeing1 [link] [comments]
- Help - Best book to learn about using databases in Academic researchby /u/LoganDeya (Database) on April 17, 2024 at 6:30 am
Hello. I am a complete beginner and know very little about databases, but I would like to read about it and learn. I have done some internet research on books and manuals for beginners, and titles like "Designing data intensive applications", "Database internals" and "Mysql crash course" have come up. However, by reading the book description, they all seem to be business-oriented. While my interest in databases is purely to learn how to store data in a way that makes it easy to compare information (I suppose then I should learn about SPQL?), for academic research. Any recommendations or advice? submitted by /u/LoganDeya [link] [comments]
- Choice of multi tenant database architecture for Saas inventory management app ?by /u/Prestigious_Ebb5260 (Database) on April 17, 2024 at 1:55 am
I am building an inventory management SaaS for mobile and web. I’ll be managing with a single web server. But for db, I am stuck between if I should go for Approach 1: A Database per organisation Vs Approach 2: One database shared between all organisations where each record in every table is identified by an organisation id My analysis so far is, Approach 1: - data isolated completely (peace of mind) - customer with low data will not be affected by an adjacent high data customer - moving the db around to different server can get easy - though not an intention, can convert to a custom solution at later point have no idea about scalability- is it difficult? managing backups could be difficult? Approach 2: - data isolation created with row level security of Postgres (less peace of mind though an unrealistic fear at times) - performance issues due to mixing up of high and low usage customers - easy maintenance - easy scalable ? - managing backups is easy What else am I missing ? Please do suggest me a choice about it ? submitted by /u/Prestigious_Ebb5260 [link] [comments]
- Looking for general guidance on data separation and what you use when it comes to your apps (Dapper, EF, other)by /u/80sPimpNinja (Database) on April 16, 2024 at 8:51 pm
I am building an app in Maui and was going to use SQLite as the database. I want to be able to also expand this app to ASP.net and possibly a Windows application at a later date. I want to use SQLite as the database and want to keep it as independent as I can from the main application. So down the road I can add in a different DB if I need to . I was reading the Maui docs and they suggest using the sqlite-net-pcl nuget package as the ORM, possibly because it is tailored for mobile apps? But the problem I see with this is I wouldn't be able to use this ORM for ASP.net or another framework that isn't mobile focused. So would I be better off using Dapper? or EF? for the sake of expansion and the ease of having it work on all frameworks? Or is there a way I can use sqlite-net-pcl with all frameworks? I have used Dapper before but never tried EF. Wasn't sure if one of these options would be a better solution. Thank you for the guidance! submitted by /u/80sPimpNinja [link] [comments]
- Help in transforming this into 2NFby /u/KaizenCyrus (Database) on April 16, 2024 at 9:23 am
submitted by /u/KaizenCyrus [link] [comments]
- A student trying to learn Entity Relationship Diagrams, please helpby /u/9342134o_C (Database) on April 16, 2024 at 4:21 am
So I was assigned to make a payroll management system, and my first task was to create an ERD out of it. i would just like to know if what I'm doing is right? Or am I missing some entities or attributes? It's just a simple payroll management system. Any help would be appreciated thanks ! https://preview.redd.it/drp4kewzpruc1.png?width=1212&format=png&auto=webp&s=0e504f6bcd6ca424e48d5ed2aa7c9fe4f974f6d7 submitted by /u/9342134o_C [link] [comments]
- Entity Relationship Diagram - html navigationby /u/Genuine-User (Database) on April 15, 2024 at 5:17 pm
I was looking for a way to create an ERD that can also get generated into html structure that can be navigated. I saw what Dataedo can do, which looks really amazing. But their pricing seems very high, and I don't see that I can purchase just the ER diagram tool. Are there any similar tools/vendors that can do something like what Dataedo does? What is important is that I can edit the description of tables/columns/objects (etc) in the XML files and then maybe use a tool to generate the HTML that can be served locally or thrown into a web app in Azure or something. submitted by /u/Genuine-User [link] [comments]
- Building a weather data warehouse part I: Loading a trillion rows of weather data into TimescaleDBby /u/DeadDolphinResearch (Database) on April 15, 2024 at 5:04 pm
submitted by /u/DeadDolphinResearch [link] [comments]
- Database beginnerby /u/Exotic_Ad4675 (Database) on April 15, 2024 at 2:35 pm
I am building a world database of schools for an awareness project at work. All the information is public, but I have to find it separately in each of the schools websites, which given its an international database, will take me ages. Is there a shortcut? Thanks! submitted by /u/Exotic_Ad4675 [link] [comments]
- Looking for a team of people to do our database and create appby /u/captaingirl2 (Database) on April 15, 2024 at 1:35 pm
Hello, Not sure if I am in the correct sub. However, I am looking for a person to set up a database and an app for a website. We're trying to cut cost within reason and preferably looking for people based in Australia, New Zealand. We're trying to avoid currency costs exchange so preferably outside of USA and Western Europe but I will consider all responses. If you need more information just let me know or dm me a message. submitted by /u/captaingirl2 [link] [comments]
- Deadlock prevention with upgradable keysby /u/Volume999 (Database) on April 15, 2024 at 12:25 pm
Hello! I am building a database system and want to add Deadlock prevention (Wait-die), but have some questions regarding consistency and aborts. Let's say I have T1 and T2, S(X) - read lock, U(X) - update lock, W(X) - write lock: T1: R(X) W(X) T2: R(X) W(X) Both transactions will receive an S(X) lock and then will try to upgrade to W(X). This, of course, leads to deadlock (sad for deadlock prevention mechanism) My question: How do I deal with this? Transactions release R(X) and try to get W(X) - Consistency violation I thought about adding a U(X) lock that is exclusive to U(X) and W(X) but is not limiting S(X). So T1 will receive U(X) and will be able to upgrade to W(X). The problem is what to do with T2? I cannot let it wait for T1 to finish, because then the consistency is violated. Should I then abort and restart T2 instead? Another issue is, how to understand which type of lock to receive - provided I can't infer from the API the access pattern (kind of like how updates use U(X) lock in SQL databases) I haven't been able to find an answer online on this matter, but if anyone knows some - would also be appreciated! submitted by /u/Volume999 [link] [comments]
- If your database is a MariaDB database, when you put it up on the server, is it just a .mariadb file, or how exactly does that work? I have been reading up on how a person queries one with JavaScript/Python, and, I think wikipedia actually use MariaDB..so, it seemed good as a database?by /u/savant78 (Database) on April 15, 2024 at 10:27 am
database that is a MariaDB database? submitted by /u/savant78 [link] [comments]
- How to make your DB fast by using Cachingby /u/totally_random_man (Database) on April 15, 2024 at 10:25 am
I made this video (https://www.youtube.com/watch?v=_JGgGR3Rp60) a while back about different caching strategies. In it, I explain: Side Cache Read-Through Cache Write-Through Cache Write-Behind Cache Write-Around Cache. Having a good handle on these has been very important for us at Superthread as one of our key differentiators is speed at scale. btw. Superthread is an all-in-one project management software and wiki for small teams. I hope that some of you find it useful & interesting. submitted by /u/totally_random_man [link] [comments]
- Great Youtube channel for learning about databasesby /u/EkkosFatNuts (Database) on April 14, 2024 at 3:12 pm
Heyo, I stumbled upon this youtuber that seems to be a lecturer at an university putting all of his material online. It's compact and divided into seperate 3-20 min videos, and handles a ton of database stuff. If you're stuck w/ something or need some extra info, you might find it on there. Just here to drop this off for a future google-searcher 😉 The channel is called Theoretical Computer Science, @ TheComputerScience, has about 2k subs. submitted by /u/EkkosFatNuts [link] [comments]
- I was looking at using database MariaDB, but, if a person wants to query MariaDB from an html page, do they have to have a python file or something as an intermediate that receives the POST or GET request and then that queries MariaDB, or does the html query MariaDB directly?by /u/savant78 (Database) on April 14, 2024 at 11:12 am
when using a database, such as MariaDB on a server, is the database queried directly by the html that teh client uses, or, does the client query data in the database by sending a POST or GET to for ex an intermediate fle, such as a python file, and then that python file queries the database and then returns the data to the client? submitted by /u/savant78 [link] [comments]
- Whats the best laptop(2024)by /u/rohit_1824 (Database) on April 14, 2024 at 8:18 am
I'm looking for a laptop to install Linux Oracle on it. I also have a Macbook but it does have some serious compatibility issues with Oracle and I'm pursuing the database so install some other database-related software too. So please suggest to me some laptops that are decent to run Oracle or tell me the specs I tried to find offline market submitted by /u/rohit_1824 [link] [comments]
- Help with School Projectby /u/JedLongtree1029 (Database) on April 13, 2024 at 9:00 pm
Hello, I’m a student using MySQL for the first time. For one of my classes I have a project where I need to make a database system that a business can use to keep track of clients and orders. I used visual studio to make an application which connects to a local MySQL server that runs on my laptop. I used mamp and phpMyAdmin in order to run the server. The application works as it should, however I need to turn in the project to my professor along with the database and all of the records within it. My question is since the server runs locally on my computer, how can my professor use the application and access the database server? Is there a way to access the server from another computer? Thank you, I would really appreciate any help. submitted by /u/JedLongtree1029 [link] [comments]
- Suggestions for Database of IT Helpdesk Systemby /u/someunknownmf (Database) on April 13, 2024 at 3:35 am
I'm fairly new to using MySQL, rather this is my first project for academic purposes. The "helpdesk system" that the database is for, it's managed through calls and not tickets. Now, is there a more "organized" or "optimized" way of coming up with my mock data? I have a table for "Employees", "Equipments", and "Specialists". From there, the database sort of just branches out to "Calls", "Issues", and "Solutions" where I have to utilize some of the data I input in the first three tables which I mentioned. Is there a more logical way of doing this? I mainly use Mockaroo for my mock data but of course, it wouldn't "generate" the same dataset despite inserting the same field and same data type. For example, in my "Calls" table, some of my FKs are an employee's first and last name which is named "Caller_FName" and "Caller_LName". But I have to come up with 15 rows or so of that, I've tried manually doing it initially but because of the number of data of course it wouldn't be the "advisable" way right? Is there some other website or application I could use along with generating "text" data about the description of an issue being handled in the helpdesk system? submitted by /u/someunknownmf [link] [comments]
- Suggestions for Simple Database and Front Endby /u/OwnFun4911 (Database) on April 12, 2024 at 5:30 pm
I am tasked with designing a database, which a team of around 15 users will need access to. The database will store doctors. I will be receiving Excel files containing the data, I will need to load into the DB, and my users will later on pull from this DB using some filtering. I'd like to keep the DB and front end separate... maybe like an Access DB and Excel front end? We are a Microsoft shop. Any suggestions? submitted by /u/OwnFun4911 [link] [comments]
- Designing the database Schemaby /u/hugh57231 (Database) on April 12, 2024 at 4:52 pm
A new feature that we’re adding is a user being able to create their own tables, similar to something like google sheets but limited to a certain number of types. These types are things like Number, Text, URL, email, DateTime, etc. I’m really confused on the best way to represent this in my database. Since this is a common feature by many applications, is there a common pattern used for something like this ? We use Postgres btw. submitted by /u/hugh57231 [link] [comments]
- cannot pull from my database, any ideas why? desperately need help 🙁by /u/AspectBilly (Database) on April 12, 2024 at 4:46 pm
Hi, I'm a bit of a noob with databases so I'm unsure if this is an issue for here or for the SQLite (Have already tried flask but their solutions lead me to think this is a issue with the DB) page or something else, so apologies for that off the bat. But here is my issue. I'm attempting to connect to my database and this seems to work since the print statement returns "Connected to database successfully!". My form seems to be working correctly too as the output does give the username and password. When I attempt to print the results of the query however, this does not seem to get any data, just returning []. The database does exist and is in the same directory, i would add an image however, it seems to delete them:/ Does anyone know what the issue would be here? I have been stuck looking for a solution for a week and this is my last resort. Once again, apologies if this is the incorrect subreddit, I'm just stuck and running out of time. If this isn't correct, please could you point me in the right direction:) Some extra info: I created the database using command line and then populated this database using a software called TablePlus (not sure if the issue could just be that?). The code and the database are within the same folder (Should i add something?) app.py #----------------------------------- #IMPORTS import sqlite3 from flask import Flask, render_template, request #----------------------------------- #SETUP app = Flask(__name__) #----------------------------------- #ROUTES @app.route('/', methods=[ 'GET', 'POST']) def index(): if request.method == 'POST': #----------------------------------- #SQLITE connection = sqlite3.connect("user_data.db") cursor = connection.cursor() if connection: print("Connected to database successfully!") else: print("Error connecting to database!") #----------------------------------- #HTML FORM name = request.form['name'] password = request.form['password'] print(name, password) #----------------------------------- #QUERY query = "SELECT name,password FROM users where name= '"+name+"' and password='"+password+"'" #query = "SELECT name,password FROM users where name='billy' and password='mullen';" #print(f"Executing query: {query}") cursor.execute(query) results = cursor.fetchall() print(results) #----------------------------------- #VALIDATION if len(results) == 0: print('login failed try again') else: return render_template("logged_in.html") return render_template( "index.html" ) if __name__ == '__main__': app.run(debug=True) index.html <!DOCTYPE html> <html lang="en"> <head> <title>login page</title> </head> <body> <centre> <h1>Login Page</h1> <form method = "POST"> <br><br> <input type ="name" name = "name" placeholder = "Username"> <br> <input type ="password" name = "password" placeholder = "password"> <br> <input type="submit" name="submit"> </form> </centre> </body> </html> Output: WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Running on http://127.0.0.1:5000 Press CTRL+C to quit * Restarting with stat * Debugger is active! * Debugger PIN: 375-394-052 127.0.0.1 - - [12/Apr/2024 16:15:15] "GET / HTTP/1.1" 200 - Connected to database successfully! billy mullen [] login failed try again 127.0.0.1 - - [12/Apr/2024 16:15:52] "POST / HTTP/1.1" 200 - file feedback when using command prompt: sqlite> SELECT name,password FROM users where name='billy' and password='mullen'; billy|mullen sqlite> submitted by /u/AspectBilly [link] [comments]
- clarifying db vs db engine with clickhouseby /u/No_Dependent_8959 (Database) on April 12, 2024 at 4:00 pm
this is rather a clarification on the category, classifying olap type software: what is considered a “database” and what is an “db engine”. I always thought that there should be a clear separation between them. my definition: - a database is where i actually manage, have control over both storage & processing e.g. mysql. - an engine is only the compute/processor without managing storage of X GB, e.g. sitting on top of s3 - hive, trino. so in case of OLAP db clickhouse, depending on deployment - clickhouse can be categorized as both database and engine? e.g. if I create a click house database with a fixed storage of 100GB - a cluster of 3 servers - then its a db. if I created a click house cluster on top of s3 - then this is an engine without need to manage storage. depending on deployment clickhouse can be similar to hive(atop hdfs), presto/trino that only includes processing engine? submitted by /u/No_Dependent_8959 [link] [comments]
- Seeking career advice as L3 database administratorby /u/Large-Alternative802 (Database) on April 12, 2024 at 2:21 pm
I am 31M, I am working as L3/Team Lead SQL server database administrator in my current organisation. I have around 8+ yrs of SQL database administrator experience in my biodata. In which I have experience of 1yrs 8 months in back office and 1yrs 10 month experience as application support. After this job I switched my profile to SQL server database administrator and I show all my experience as SQL server administrator. Now I am seeking advice for my career advancement. I want to know what should I do to increase my skills and my pay scale? submitted by /u/Large-Alternative802 [link] [comments]
Budget to start a web app built on the MEAN stack
AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
I want to start a web app built on the MEAN stack (mongoDB, express.js, angular, and node.js). How much would it cost me to host this site? What resources are there for hosting websites built on the MEAN stack?
I went through the same questions and concerns and I actually tried a couple of different cloud providers for similar environments and machines.
Web Apps Feed
- At Digital Ocean, you can get a fully loaded machine to develop and host at $5 per month (512 MB RAM, 20 GB disk ). You can even get a $10 credit by using this link of mine.[1] It is very easy to sign up and start. Just don’t use their web console to connect to your host. It is slow. I recommend using ssh client to connect and it is very fast.
- GoDaddy will charge you around 8$ per month for a similar MEAN stack host (512 MB RAM, 1 core processor, 20 Gb disk ) for your MEAN Stack development.
- Azure use bitmani’s mean stack on minimum DS1_V2 machine (1core, 3.5 gB RAM) and your average cost will be $52 per month if you never shut down the machine. The set up is a little bit more complicated that Digital Ocean, but very doable. I also recommend ssh to connect to the server and develop.
- AWS also offers Bitmani’s MEAN stack on EC2 instances similar to Azure DS1V2 described above and it is around $55 per month.
- Other suggestions
All those solutions will work fine and it all depends on your budget. If you are cheap like me and don’t have a big budget, go with Digital Ocean and start with $10 off with this code.
Basic Gotcha Linux Questions for IT DevOps and SysAdmin Interviews
AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
Some IT DevOps, SysAdmin, Developer positions require the knowledge of basic linux Operating System. Most of the time, we know the answer but forget them when we don’t practice very often. This refresher will help you prepare for the linux portion of your IT interview by answering some gotcha Linux Questions for IT DevOps and SysAdmin Interviews.
Latest Linux Feeds
I- Networking:
- How many bytes are there in a MAC address?
48.
MAC, Media Access Control, address is a globally unique identifier assigned to network devices, and therefore it is often referred to as hardware or physical address. MAC addresses are 6-byte (48-bits) in length, and are written in MM:MM:MM:SS:SS:SS format. - What are the different parts of a TCP packet?
The term TCP packet appears in both informal and formal usage, whereas in more precise terminology segment refers to the TCP protocol data unit (PDU), datagram to the IP PDU, and frame to the data link layer PDU: … A TCP segment consists of a segment header and a data section. - Networking: Which command is used to initialize an interface, assign IP address, etc.
ifconfig (interface configuration). The equivalent command for Dos is ipconfig.
Other useful networking commands are: Ping, traceroute, netstat, dig, nslookup, route, lsof - What’s the difference between TCP and UDP; Between DNS TCP and UDP?
There are two types of Internet Protocol (IP) traffic. They are TCP or Transmission Control Protocol and UDP or User Datagram Protocol. TCP is connection oriented – once a connection is established, data can be sent bidirectional. UDP is a simpler, connectionless Internet protocol.
The reality is that DNS queries can also use TCP port 53 if UDP port 53 is not accepted.
DNS uses TCP for Zone Transfer over port :53.
DNS uses UDP for DNS Queries over port :53. - What are defaults ports used by http, telnet, ftp, smtp, dns, , snmp, squid?
All those services are part of the Application level of the TCP/IP protocol.
http => 80
telnet => 23
ftp => 20 (data transfer), 21 (Connection established)
smtp => 25
dns => 53
snmp => 161
dhcp => 67 (server), 68 (Client)
ssh => 22
squid => 3128 - How many host available in a subnet (Class B and C Networks)


- How DNS works?
When you enter a URL into your Web browser, your DNS server uses its resources to resolve the name into the IP address for the appropriate Web server. - What is the difference between class A, class B and class C IP addresses?
Class A Network (/ 8 Prefixes)
This network is 8-bit network prefix. IP address range from 0.0.0.0 to 127.255.255.255
Class B Networks (/16 Prefixes)
This network is 16-bit network prefix. IP address range from 128.0.0.0 to 191.255.255.255Class C Networks (/24 Prefixes)
This network is 24-bit network prefix.IP address range from 192.0.0.0 to 223.255.255.255 - Difference between ospf and bgp?
The first reason is that BGP is more scalable than OSPF. , and this, normal igp like ospf cannot perform. Generally speaking OSPF and BGP are routing protocols for two different things. OSPF is an IGP (Interior Gateway Protocol) and is used internally within a companies network to provide routing.

II- Operating System
1&1 Web Hosting![]()
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more codes)
Active Anti-Aging Eye Gel, Reduces Dark Circles, Puffy Eyes, Crow's Feet and Fine Lines & Wrinkles, Packed with Hyaluronic Acid & Age Defying Botanicals
- How to find the Operating System version?
$uname -a
To check the distribution for redhat for example: $cat /etc/redhat –release - How to list all the process running?
top
To list java processes, ps -ef | grep java
To list processes on a specific port:
netstat -aon | findstr :port_number
lsof -i:80 - How to check disk space?
df shows the amount of disk space used and available.
du displays the amount of disk used by the specified files and for each subdirectories.
To drill down and find out which file is filling up a drive: du -ks /drive_name/* | sort -nr | head - How to check memory usage?
free or cat /proc/meminfo - What is the load average?
It is the average sum of the number of process waiting in the queue and the number of process currently executing over the period of 1, 5 and 15 minutes. Use top to find the load average. - What is a load balancer?
A load balancer is a device that acts as a reverse proxy and distributes network or application traffic across a number of servers. Load balancers are used to increase capacity (concurrent users) and reliability of applications. - What is the Linux Kernel?
The Linux Kernel is a low-level systems software whose main role is to manage hardware resources for the user. It is also used to provide an interface for user-level interaction. - What is the default kill signal?
There are many different signals that can be sent (see signal for a full list), although the signals in which users are generally most interested are SIGTERM (“terminate”) and SIGKILL (“kill”). The default signal sent is SIGTERM.
kill 1234
kill -s TERM 1234
kill -TERM 1234
kill -15 1234 - Describe Linux boot process
BIOS => MBR => GRUB => KERNEL => INIT => RUN LEVEL
As power comes up, the BIOS (Basic Input/Output System) is given control and executes MBR (Master Boot Record). The MBR executes GRUB (Grand Unified Boot Loader). GRUB executes Kernel. Kernel executes /sbin/init. Init executes run level programs. Run level programs are executed from /etc/rc.d/rc*.d
Mac OS X Boot Process:Boot ROM Firmware. Part of Hardware system
BootROM firmware is activatedPOST Power-On Self Test
initializes some hardware interfaces and verifies that sufficient memory is available and in a good state.EFI Extensible Firmware Interface
EFI does basic hardware initialization and selects which operating system to use.BOOTX boot.efi boot loader
load the kernel environmentRooting/Kernel The init routine of the kernel is executed
boot loader starts the kernel’s initialization procedure
Various Mach/BSD data structures are initialized by the kernel.
The I/O Kit is initialized.
The kernel starts /sbin/mach_initRun Level mach_init starts /sbin/init
init determines the runlevel, and runs /etc/rc.boot, which sets up the machine enough to run single-user.
rc.boot figures out the type of boot (Multi-User, Safe, CD-ROM, Network etc.) - List services enabled at a particular run level
chkconfig –list | grep 5:0n
Enable|Disable a service at a specific run level: chkconfig on|off –level 5 - How do you stop a bash fork bomb?
Create a fork bomb by editing limits.conf:
root hard nproc 512
Drop a fork bomb as below:
:(){ :|:& };:
Assuming you have access to shell:
kill -STOP
killall -STOP -u user1
killall -KILL -u user1 - What is a fork?
fork is an operation whereby a process creates a copy of itself. It is usually a system call, implemented in the kernel. Fork is the primary (and historically, only) method of process creation on Unix-like operating systems. - What is the D state?
D state code means that process is in uninterruptible sleep, and that may mean different things but it is usually I/O.
III- File System
- What is umask?
umask is “User File Creation Mask”, which determines the settings of a mask that controls which file permissions are set for files and directories when they are created. - What is the role of the swap space?
A swap space is a certain amount of space used by Linux to temporarily hold some programs that are running concurrently. This happens when RAM does not have enough memory to hold all programs that are executing.
- What is the role of the swap space?
A swap space is a certain amount of space used by Linux to temporarily hold some programs that are running concurrently. This happens when RAM does not have enough memory to hold all programs that are executing. - What is the null device in Linux?
The null device is typically used for disposing of unwanted output streams of a process, or as a convenient empty file for input streams. This is usually done by redirection. The /dev/null device is a special file, not a directory, so one cannot move a whole file or directory into it with the Unix mv command.You might receive the “Bad file descriptor” error message if /dev/null has been deleted or overwritten. You can infer this cause when file system is reported as read-only at the time of booting through error messages, such as“/dev/null: Read-only filesystem” and “dup2: bad file descriptor”.
In Unix and related computer operating systems, a file descriptor (FD, less frequently fildes) is an abstract indicator (handle) used to access a file or other input/output resource, such as a pipe or network socket. - What is a inode?
The inode is a data structure in a Unix-style file system that describes a filesystem object such as a file or a directory. Each inode stores the attributes and disk block location(s) of the object’s data.
IV- Databases
- What is the difference between a document store and a relational database?
In a relational database system you must define a schema before adding records to a database. The schema is the structure described in a formal language supported by the database and provides a blueprint for the tables in a database and the relationships between tables of data. Within a table, you need to define constraints in terms of rows and named columns as well as the type of data that can be stored in each column.In contrast, a document-oriented database contains documents, which are records that describe the data in the document, as well as the actual data. Documents can be as complex as you choose; you can use nested data to provide additional sub-categories of information about your object. You can also use one or more document to represent a real-world object. - How to optimise a slow DB?
- Rewrite the queries
- Change indexing strategy
- Change schema
- Use an external cache
- Server tuning and beyond
- How would you build a 1 Petabyte storage with commodity hardware?
Using JBODs with large capacity disks with Linux in a distributed storage system stacking nodes until 1PB is reached.
JBOD (which stands for “just a bunch of disks”) generally refers to a collection of hard disks that have not been configured to act as a redundant array of independent disks (RAID) array.

V- Scripting
- What is @INC in Perl?
The @INC Array. @INC is a special Perl variable that is the equivalent to the shell’s PATH variable. Whereas PATH contains a list of directories to search for executables, @INC contains a list of directories from which Perl modules and libraries can be loaded. - Strings comparison – operator – for loop – if statement


- Sort access log file by http Response Codes
Via Shell using linux commands
cat sample_log.log | cut -d ‘”‘ -f3 | cut -d ‘ ‘ -f2 | sort | uniq -c | sort -rn - Sort access log file by http Response Codes Using awk
awk ‘{print $9}’ sample_log.log | sort | uniq -c | sort -rn - Find broken links from access log file
awk ‘($9 ~ /404/)’ sample_log.log | awk ‘{print $7}’ sample_log.log | sort | uniq -c | sort -rn - Most requested page:
awk -F\” ‘{print $2}’ sample_log.log | awk ‘{print $2}’ | sort | uniq -c | sort -r - Count all occurrences of a word in a file
grep -o “user” sample_log.log | wc -w
Learn more at http://career.guru99.com/top-50-linux-interview-questions/
Real Time Linux Jobs
Install and run your first noSQL MongoDB on Mac OSX

AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
Install and run your first noSQL MongoDB on Mac OSX
Classified as a NoSQL database, MongoDB is an open source, document-oriented database designed with both scalability and developer agility in mind. Instead of storing your data in tables and rows as you would with a relational database, in MongoDB you store JSON-like documents with dynamic schemas; This makes the integration of data in certain types of application easier and faster.
Why?
MongoDB can help you make a difference to the business. Tens of thousands of organizations, from startups to the largest companies and government agencies, choose MongoDB because it lets them build applications that weren’t possible before. With MongoDB, these organizations move faster than they could with relational databases at one tenth of the cost. With MongoDB, you can do things you could never do before.
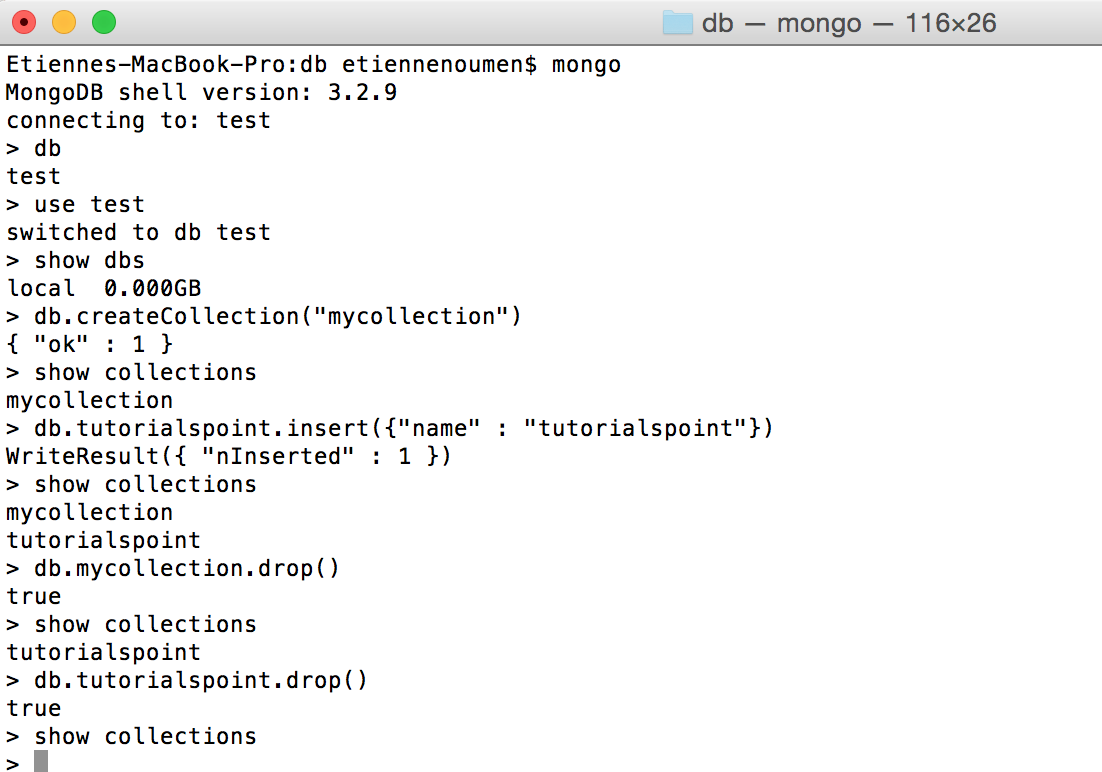
- Install Homebrew
$ /usr/bin/ruby -e “$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)”
Homebrew installs the stuff you need that Apple didn’t.
$ brew install wget - Install MongoDB
$ brew install mongodb - Run MongoDB
Create the data directory: $ mkdir -p /data/db
Set permissions for the data directory:$ chown -R you:yourgroup /data/db then chmod -R 775 /data/db
Run MongoDB (as non root): $ mongod - Begin using MongoDB.(MongoDB will be running as soon as you ran mongod above)Open another terminal and run: mongo
- Install Homebrew
References: https://docs.mongodb.com/manual/tutorial/install-mongodb-on-os-x/
Active Hydrating Toner, Anti-Aging Replenishing Advanced Face Moisturizer, with Vitamins A, C, E & Natural Botanicals to Promote Skin Balance & Collagen Production, 6.7 Fl Oz



Age Defying 0.3% Retinol Serum, Anti-Aging Dark Spot Remover for Face, Fine Lines & Wrinkle Pore Minimizer, with Vitamin E & Natural Botanicals


Firming Moisturizer, Advanced Hydrating Facial Replenishing Cream, with Hyaluronic Acid, Resveratrol & Natural Botanicals to Restore Skin's Strength, Radiance, and Resilience, 1.75 Oz

Skin Stem Cell Serum


Smartphone 101 - Pick a smartphone for me - android or iOS - Apple iPhone or Samsung Galaxy or Huawei or Xaomi or Google Pixel
Can AI Really Predict Lottery Results? We Asked an Expert.





Djamgatech

Read Photos and PDFs Aloud for me iOS
Read Photos and PDFs Aloud for me android
Read Photos and PDFs Aloud For me Windows 10/11
Read Photos and PDFs Aloud For Amazon
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more)
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6(Email us for more)



FREE 10000+ Quiz Trivia and and Brain Teasers for All Topics including Cloud Computing, General Knowledge, History, Television, Music, Art, Science, Movies, Films, US History, Soccer Football, World Cup, Data Science, Machine Learning, Geography, etc....

List of Freely available programming books - What is the single most influential book every Programmers should read
- Bjarne Stroustrup - The C++ Programming Language
- Brian W. Kernighan, Rob Pike - The Practice of Programming
- Donald Knuth - The Art of Computer Programming
- Ellen Ullman - Close to the Machine
- Ellis Horowitz - Fundamentals of Computer Algorithms
- Eric Raymond - The Art of Unix Programming
- Gerald M. Weinberg - The Psychology of Computer Programming
- James Gosling - The Java Programming Language
- Joel Spolsky - The Best Software Writing I
- Keith Curtis - After the Software Wars
- Richard M. Stallman - Free Software, Free Society
- Richard P. Gabriel - Patterns of Software
- Richard P. Gabriel - Innovation Happens Elsewhere
- Code Complete (2nd edition) by Steve McConnell
- The Pragmatic Programmer
- Structure and Interpretation of Computer Programs
- The C Programming Language by Kernighan and Ritchie
- Introduction to Algorithms by Cormen, Leiserson, Rivest & Stein
- Design Patterns by the Gang of Four
- Refactoring: Improving the Design of Existing Code
- The Mythical Man Month
- The Art of Computer Programming by Donald Knuth
- Compilers: Principles, Techniques and Tools by Alfred V. Aho, Ravi Sethi and Jeffrey D. Ullman
- Gödel, Escher, Bach by Douglas Hofstadter
- Clean Code: A Handbook of Agile Software Craftsmanship by Robert C. Martin
- Effective C++
- More Effective C++
- CODE by Charles Petzold
- Programming Pearls by Jon Bentley
- Working Effectively with Legacy Code by Michael C. Feathers
- Peopleware by Demarco and Lister
- Coders at Work by Peter Seibel
- Surely You're Joking, Mr. Feynman!
- Effective Java 2nd edition
- Patterns of Enterprise Application Architecture by Martin Fowler
- The Little Schemer
- The Seasoned Schemer
- Why's (Poignant) Guide to Ruby
- The Inmates Are Running The Asylum: Why High Tech Products Drive Us Crazy and How to Restore the Sanity
- The Art of Unix Programming
- Test-Driven Development: By Example by Kent Beck
- Practices of an Agile Developer
- Don't Make Me Think
- Agile Software Development, Principles, Patterns, and Practices by Robert C. Martin
- Domain Driven Designs by Eric Evans
- The Design of Everyday Things by Donald Norman
- Modern C++ Design by Andrei Alexandrescu
- Best Software Writing I by Joel Spolsky
- The Practice of Programming by Kernighan and Pike
- Pragmatic Thinking and Learning: Refactor Your Wetware by Andy Hunt
- Software Estimation: Demystifying the Black Art by Steve McConnel
- The Passionate Programmer (My Job Went To India) by Chad Fowler
- Hackers: Heroes of the Computer Revolution
- Algorithms + Data Structures = Programs
- Writing Solid Code
- JavaScript - The Good Parts
- Getting Real by 37 Signals
- Foundations of Programming by Karl Seguin
- Computer Graphics: Principles and Practice in C (2nd Edition)
- Thinking in Java by Bruce Eckel
- The Elements of Computing Systems
- Refactoring to Patterns by Joshua Kerievsky
- Modern Operating Systems by Andrew S. Tanenbaum
- The Annotated Turing
- Things That Make Us Smart by Donald Norman
- The Timeless Way of Building by Christopher Alexander
- The Deadline: A Novel About Project Management by Tom DeMarco
- The C++ Programming Language (3rd edition) by Stroustrup
- Patterns of Enterprise Application Architecture
- Computer Systems - A Programmer's Perspective
- Agile Principles, Patterns, and Practices in C# by Robert C. Martin
- Growing Object-Oriented Software, Guided by Tests
- Framework Design Guidelines by Brad Abrams
- Object Thinking by Dr. David West
- Advanced Programming in the UNIX Environment by W. Richard Stevens
- Hackers and Painters: Big Ideas from the Computer Age
- The Soul of a New Machine by Tracy Kidder
- CLR via C# by Jeffrey Richter
- The Timeless Way of Building by Christopher Alexander
- Design Patterns in C# by Steve Metsker
- Alice in Wonderland by Lewis Carol
- Zen and the Art of Motorcycle Maintenance by Robert M. Pirsig
- About Face - The Essentials of Interaction Design
- Here Comes Everybody: The Power of Organizing Without Organizations by Clay Shirky
- The Tao of Programming
- Computational Beauty of Nature
- Writing Solid Code by Steve Maguire
- Philip and Alex's Guide to Web Publishing
- Object-Oriented Analysis and Design with Applications by Grady Booch
- Effective Java by Joshua Bloch
- Computability by N. J. Cutland
- Masterminds of Programming
- The Tao Te Ching
- The Productive Programmer
- The Art of Deception by Kevin Mitnick
- The Career Programmer: Guerilla Tactics for an Imperfect World by Christopher Duncan
- Paradigms of Artificial Intelligence Programming: Case studies in Common Lisp
- Masters of Doom
- Pragmatic Unit Testing in C# with NUnit by Andy Hunt and Dave Thomas with Matt Hargett
- How To Solve It by George Polya
- The Alchemist by Paulo Coelho
- Smalltalk-80: The Language and its Implementation
- Writing Secure Code (2nd Edition) by Michael Howard
- Introduction to Functional Programming by Philip Wadler and Richard Bird
- No Bugs! by David Thielen
- Rework by Jason Freid and DHH
- JUnit in Action
#BlackOwned #BlackEntrepreneurs #BlackBuniness #AWSCertified #AWSCloudPractitioner #AWSCertification #AWSCLFC02 #CloudComputing #AWSStudyGuide #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AWSBasics #AWSCertified #AWSMachineLearning #AWSCertification #AWSSpecialty #MachineLearning #AWSStudyGuide #CloudComputing #DataScience #AWSCertified #AWSSolutionsArchitect #AWSArchitectAssociate #AWSCertification #AWSStudyGuide #CloudComputing #AWSArchitecture #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AzureFundamentals #AZ900 #MicrosoftAzure #ITCertification #CertificationPrep #StudyMaterials #TechLearning #MicrosoftCertified #AzureCertification #TechBooks
Top 1000 Canada Quiz and trivia: CANADA CITIZENSHIP TEST- HISTORY - GEOGRAPHY - GOVERNMENT- CULTURE - PEOPLE - LANGUAGES - TRAVEL - WILDLIFE - HOCKEY - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Top 1000 Africa Quiz and trivia: HISTORY - GEOGRAPHY - WILDLIFE - CULTURE - PEOPLE - LANGUAGES - TRAVEL - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Exploring the Pros and Cons of Visiting All Provinces and Territories in Canada.


Exploring the Advantages and Disadvantages of Visiting All 50 States in the USA

Health Health, a science-based community to discuss health news and the coronavirus (COVID-19) pandemic
- Proposed CA bill would ban methylene chloride from decaf coffee productionby /u/lurker_bee on April 17, 2024 at 3:37 pm
submitted by /u/lurker_bee [link] [comments]
- Single injection of ketamine can reduce postpartum depression by 75%by /u/euronews-english on April 17, 2024 at 3:16 pm
submitted by /u/euronews-english [link] [comments]
- Noise can hurt your heart, disrupt your endocrine system, and make it difficult to think and learnby /u/scientificamerican on April 17, 2024 at 2:06 pm
submitted by /u/scientificamerican [link] [comments]
- Researchers Identify the Bacteria Responsible for Meningitis in Babies | A milestone study has identified that 50% of neonatal meningitis infections are caused by two types of E. coli.by /u/chrisdh79 on April 17, 2024 at 12:20 pm
submitted by /u/chrisdh79 [link] [comments]
- Nestlé adds sugar to infant milk sold in poorer countries, report finds | Swiss food firm’s infant formula and cereal sold in global south ignore WHO anti-obesity guidelines for Europe, says Public Eyeby /u/chrisdh79 on April 17, 2024 at 11:16 am
submitted by /u/chrisdh79 [link] [comments]
Today I Learned (TIL) You learn something new every day; what did you learn today? Submit interesting and specific facts about something that you just found out here.
- TIL that most hotel rooms in the USA do not have ceiling lights. This is done mostly for cost reasons. Money is saved by not having to run wire to a ceiling box, drywall around it and then install the overhead light itself.by /u/-Appleaday- on April 18, 2024 at 2:42 am
submitted by /u/-Appleaday- [link] [comments]
- TIL: America’s Nuclear Sponge. Montana, North Dakota, Wyoming, Nebraska and Colorado contain the nuclear silos that would be a primary target of WW3.by /u/SilentWalrus92 on April 18, 2024 at 12:11 am
submitted by /u/SilentWalrus92 [link] [comments]
- TIL a Chinese destroyer sank because an officer dumped his girlfriend. She committed suicide, leading to him being discharged, so he decided to detonate the depth charges on the ship, causing it to sink at port and kill 134 sailors.by /u/zhuquanzhong on April 17, 2024 at 11:15 pm
submitted by /u/zhuquanzhong [link] [comments]
- TIL The United States once had a 36-year-old vice president back in 1857. John C. Breckinridge is still the only person under 40 to serve as president or vice president.by /u/bankrobba on April 17, 2024 at 8:43 pm
submitted by /u/bankrobba [link] [comments]
- TIL that "Killing baby Hitler" is an ethical and theoretical physics experiment. It explores the idea of time-traveling to assassinate infant Adolf Hitler, delving into ethical consequences and temporal paradoxes.by /u/DennisHoffmanOqng on April 17, 2024 at 8:42 pm
submitted by /u/DennisHoffmanOqng [link] [comments]
Reddit Science This community is a place to share and discuss new scientific research. Read about the latest advances in astronomy, biology, medicine, physics, social science, and more. Find and submit new publications and popular science coverage of current research.
- Long COVID immune abnormalities largely resolved at 24 months, providing optimism that long COVID symptoms resolve over timeby /u/unsw on April 18, 2024 at 2:33 am
submitted by /u/unsw [link] [comments]
- UC Riverside demonstrates RNAi vaccine that works against multiple strains and in the immunocompromisedby /u/bug-hunter on April 18, 2024 at 12:56 am
submitted by /u/bug-hunter [link] [comments]
- Vaccination programmes save health systems billions, says new modelling. Report from the Office of Health Economics reveals adult immunisation returns up to 19 times the initial investment.by /u/mvea on April 17, 2024 at 9:56 pm
submitted by /u/mvea [link] [comments]
- Mentally stimulating work plays key role in staving off dementia, study finds. People in routine and repetitive jobs found to have 31% greater risk of disease in later life, and 66% higher risk of mild cognitive problems.by /u/mvea on April 17, 2024 at 9:54 pm
submitted by /u/mvea [link] [comments]
- Enormous ancient sea reptile identified from amateur fossil find.by /u/NinjaDiscoJesus on April 17, 2024 at 9:06 pm
submitted by /u/NinjaDiscoJesus [link] [comments]
Reddit Sports Sports News and Highlights from the NFL, NBA, NHL, MLB, MLS, and leagues around the world.
- Sixers get gritty win vs. Heat, will play Knicks in 1st roundby /u/Oldtimer_2 on April 18, 2024 at 3:30 am
submitted by /u/Oldtimer_2 [link] [comments]
- Caitlin Clark nearing endorsement deal with Nike: Sourcesby /u/BCLetsRide69 on April 18, 2024 at 2:07 am
submitted by /u/BCLetsRide69 [link] [comments]
- Kucherov joins McDavid in 100-assist clubby /u/Oldtimer_2 on April 18, 2024 at 1:26 am
submitted by /u/Oldtimer_2 [link] [comments]
- 100 days until Paris Olympics 2024: Dates, athletes and everything to knowby /u/Oldtimer_2 on April 18, 2024 at 12:12 am
submitted by /u/Oldtimer_2 [link] [comments]
- River Seine Olympics opening remains on track, organizers sayby /u/PrincessBananas85 on April 18, 2024 at 12:10 am
submitted by /u/PrincessBananas85 [link] [comments]
