


AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
What are some ways to increase precision or recall in machine learning?
What are some ways to Boost Precision and Recall in Machine Learning?
Sensitivity vs Specificity?
In machine learning, recall is the ability of the model to find all relevant instances in the data while precision is the ability of the model to correctly identify only the relevant instances. A high recall means that most relevant results are returned while a high precision means that most of the returned results are relevant. Ideally, you want a model with both high recall and high precision but often there is a trade-off between the two. In this blog post, we will explore some ways to increase recall or precision in machine learning.
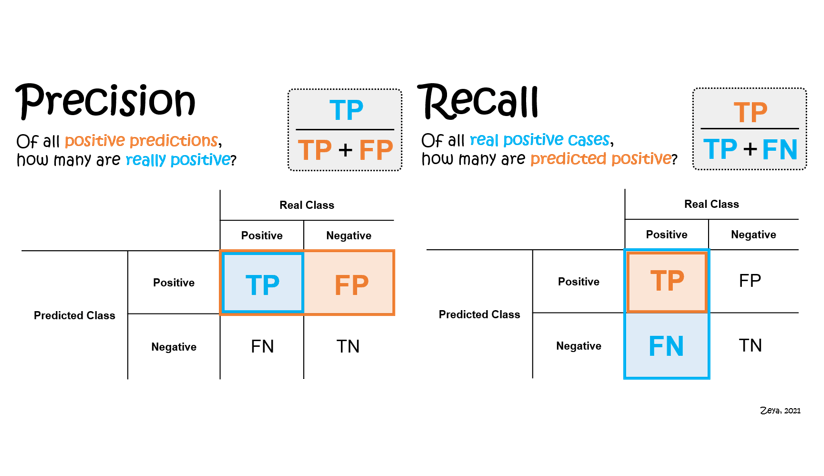
There are two main ways to increase recall:
by increasing the number of false positives or by decreasing the number of false negatives. To increase the number of false positives, you can lower your threshold for what constitutes a positive prediction. For example, if you are trying to predict whether or not an email is spam, you might lower the threshold for what constitutes spam so that more emails are classified as spam. This will result in more false positives (emails that are not actually spam being classified as spam) but will also increase recall (more actual spam emails being classified as spam).
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6

 Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more codes)
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more codes)
Active Anti-Aging Eye Gel, Reduces Dark Circles, Puffy Eyes, Crow's Feet and Fine Lines & Wrinkles, Packed with Hyaluronic Acid & Age Defying Botanicals


To decrease the number of false negatives,
you can increase your threshold for what constitutes a positive prediction. For example, going back to the spam email prediction example, you might raise the threshold for what constitutes spam so that fewer emails are classified as spam. This will result in fewer false negatives (actual spam emails not being classified as spam) but will also decrease recall (fewer actual spam emails being classified as spam).

There are two main ways to increase precision:
by increasing the number of true positives or by decreasing the number of true negatives. To increase the number of true positives, you can raise your threshold for what constitutes a positive prediction. For example, using the spam email prediction example again, you might raise the threshold for what constitutes spam so that fewer emails are classified as spam. This will result in more true positives (emails that are actually spam being classified as spam) but will also decrease precision (more non-spam emails being classified as spam).

To decrease the number of true negatives,
you can lower your threshold for what constitutes a positive prediction. For example, going back to the spam email prediction example once more, you might lower the threshold for what constitutes spam so that more emails are classified as spam. This will result in fewer true negatives (emails that are not actually spam not being classified as spam) but will also decrease precision (more non-spam emails being classified as spam).

To summarize,
there are a few ways to increase precision or recall in machine learning. One way is to use a different evaluation metric. For example, if you are trying to maximize precision, you can use the F1 score, which is a combination of precision and recall. Another way to increase precision or recall is to adjust the threshold for classification. This can be done by changing the decision boundary or by using a different algorithm altogether.
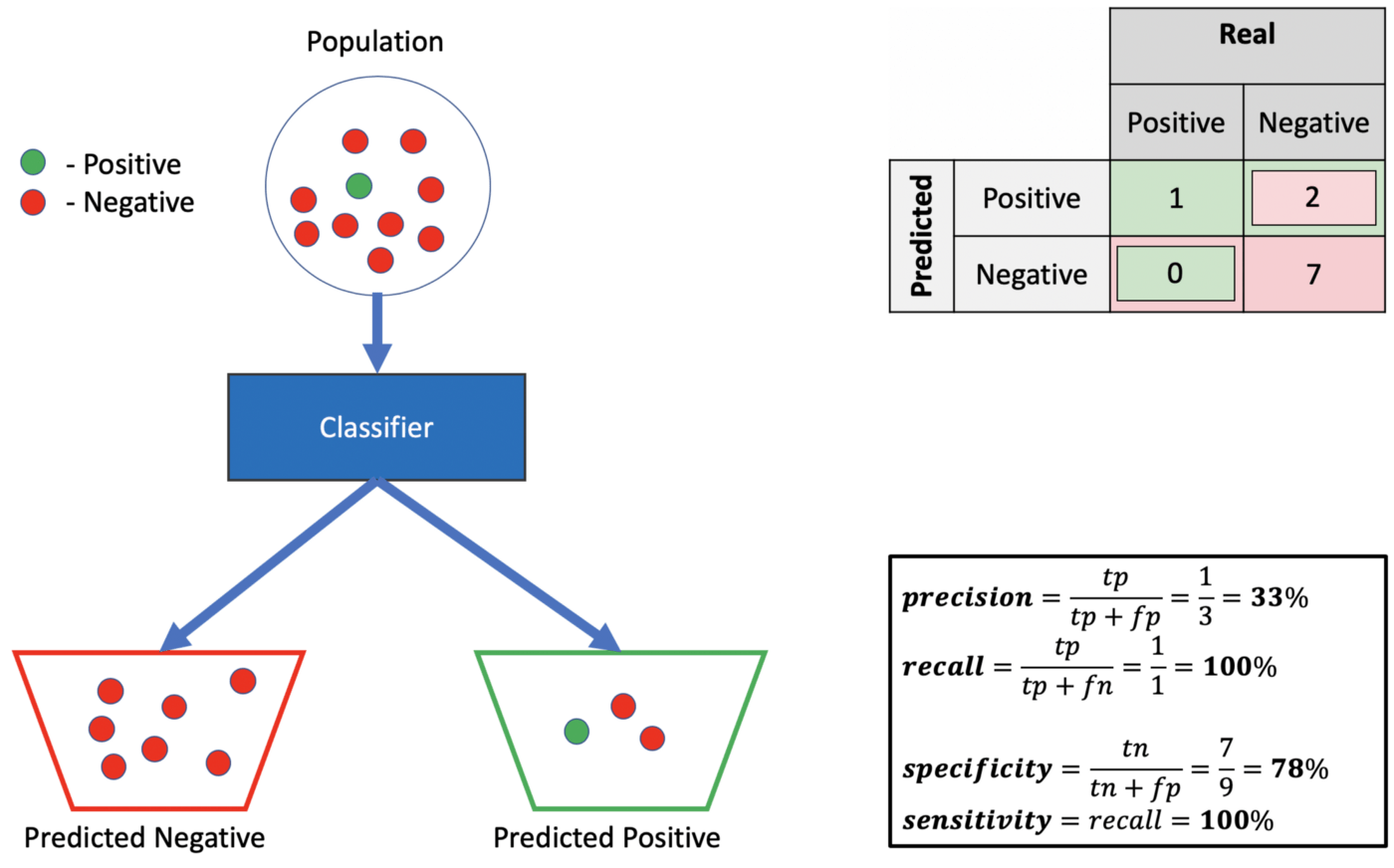
Sensitivity vs Specificity
In machine learning, sensitivity and specificity are two measures of the performance of a model. Sensitivity is the proportion of true positives that are correctly predicted by the model, while specificity is the proportion of true negatives that are correctly predicted by the model.
Google Colab For Machine Learning
State of the Google Colab for ML (October 2022)
Google introduced computing units, which you can purchase just like any other cloud computing unit you can from AWS or Azure etc. With Pro you get 100, and with Pro+ you get 500 computing units. GPU, TPU and option of High-RAM effects how much computing unit you use hourly. If you don’t have any computing units, you can’t use “Premium” tier gpus (A100, V100) and even P100 is non-viable.
Google Colab Pro+ comes with Premium tier GPU option, meanwhile in Pro if you have computing units you can randomly connect to P100 or T4. After you use all of your computing units, you can buy more or you can use T4 GPU for the half or most of the time (there can be a lot of times in the day that you can’t even use a T4 or any kinds of GPU). In free tier, offered gpus are most of the time K80 and P4, which performs similar to a 750ti (entry level gpu from 2014) with more VRAM.
For your consideration, T4 uses around 2, and A100 uses around 15 computing units hourly.
Based on the current knowledge, computing units costs for GPUs tend to fluctuate based on some unknown factor.
Considering those:
- For hobbyists and (under)graduate school duties, it will be better to use your own gpu if you have something with more than 4 gigs of VRAM and better than 750ti, or atleast purchase google pro to reach T4 even if you have no computing units remaining.
- For small research companies, and non-trivial research at universities, and probably for most of the people Colab now probably is not a good option.
- Colab Pro+ can be considered if you want Pro but you don’t sit in front of your computer, since it disconnects after 90 minutes of inactivity in your computer. But this can be overcomed with some scripts to some extend. So for most of the time Colab Pro+ is not a good option.
If you have anything more to say, please let me know so I can edit this post with them. Thanks!

Conclusion:
In machine learning, precision and recall trade off against each other; increasing one often decreases the other. There is no single silver bullet solution for increasing either precision or recall; it depends on your specific use case which one is more important and which methods will work best for boosting whichever metric you choose. In this blog post, we explored some methods for increasing either precision or recall; hopefully this gives you a starting point for improving your own models!
What are some ways we can use machine learning and artificial intelligence for algorithmic trading in the stock market?

Machine Learning and Data Science Breaking News 2022 – 2023
- [Project] AI powered products in storesby /u/Complete-Holiday-610 (Machine Learning) on April 19, 2024 at 6:42 am
I am working on a project regarding marketing of AI powered products in Retail stores. I am trying to find some products that market ‘AI’ as the forefront feature, eg Samsung’s BeSpoke AI series, Bmw’s AI automated driving etc. Need them to be physical products so I can go to stores and do research and survey. Any kind of help is appreciated. submitted by /u/Complete-Holiday-610 [link] [comments]
- [Discussion] Are there specific technical/scientific breakthroughs that have allowed the significant jump in maximum context length across multiple large language models recently?by /u/analyticalmonk (Machine Learning) on April 19, 2024 at 6:28 am
Latest releases of models such as GPT-4 and Claude have a significant jump in the maximum context length (4/8k -> 128k+). The progress in terms of number of tokens that can be processed by these models sound remarkable in % terms. What has led to this? Is this something that's happened purely because of increased compute becoming available during training? Are there algorithmic advances that have led to this? submitted by /u/analyticalmonk [link] [comments]
- [D] Is neurips reviewer invitation email out this year?by /u/noname139713 (Machine Learning) on April 19, 2024 at 5:35 am
Used to receive invitation by this time of the year. Maybe I am forgotten. submitted by /u/noname139713 [link] [comments]
- Probability for Machine Learning [D]by /u/AffectionateCoyote86 (Machine Learning) on April 19, 2024 at 4:47 am
I'm a recent engineering graduate who's switching roles from traditional software engineering ones to ML/AI focused ones. I've gone through an introductory probability course in my undergrad, but the recent developments such as diffusion models, or even some relatively older ones like VAEs or GANs require an advanced understanding of probability theory. I'm finding the math/concepts related to probability hard to follow when I read up on these models. Any suggestions on how to bridge the knowledge gap? submitted by /u/AffectionateCoyote86 [link] [comments]
- [D] How to evaluate RAG - both retrieval and generation, when all I have is a set of PDF documents?by /u/awinml1 (Machine Learning) on April 19, 2024 at 4:43 am
Say I have 1000 PDF docs that I use as input to a RAG Pipeline. I want to to evaluate different steps of the RAG pipeline so that I can measure: - Which embedding models work better for my data? - Which rerankers work and are they required? - Which LLMs give the most factual and coherent answers? How do I evaluate these steps of the pipeline? Based on my research, I found that most frameworks require labels for both retrieval and generation evaluation. How do I go about creating this data using a LLM? Are there any other techniques? Some things I found: For retrieval: Use a LLM to generate synthetic ranked labels for retrieval. Which LLM should I use? What best practices should I follow? Any code that I can look at for this? For Generated Text: - Generate Synthetic labels like the above for each generation. - Use a LLM as a judge to Rate each generation based on the context it got and the question asked. Which LLMs would you recommend? What techniques worked for you guys? submitted by /u/awinml1 [link] [comments]
- [Project] RL projectby /u/Valuable-Wishbone276 (Machine Learning) on April 19, 2024 at 4:36 am
Hi everyone. I want to build this idea of mine for a class project, and I wanted some input from others. I want to build an AI algorithm that can play the game Drift Hunters (https://drift-hunters.co/drift-hunters-games). I imagine I have to build some reinforcement learning program, though I'm not sure exactly how to organize state representations and input data. I also imagine that I'd need my screen to be recorded for a continuous period of time to collect data. I chose this game since it's got three very basic commands(turn left, turn right, and drive forward) and the purpose of the game(which never ends) is to maximize drift score. Any ideas are much appreciated. lmk if u still need more info. Thanks everyone. submitted by /u/Valuable-Wishbone276 [link] [comments]
- [R] Unifying Bias and Unfairness in Information Retrieval: A Survey of Challenges and Opportunities with Large Language Modelsby /u/KID_2_2 (Machine Learning) on April 19, 2024 at 4:34 am
PDF: https://arxiv.org/abs/2404.11457 GitHub: https://github.com/KID-22/LLM-IR-Bias-Fairness-Survey Abstract: With the rapid advancement of large language models (LLMs), information retrieval (IR) systems, such as search engines and recommender systems, have undergone a significant paradigm shift. This evolution, while heralding new opportunities, introduces emerging challenges, particularly in terms of biases and unfairness, which may threaten the information ecosystem. In this paper, we present a comprehensive survey of existing works on emerging and pressing bias and unfairness issues in IR systems when the integration of LLMs. We first unify bias and unfairness issues as distribution mismatch problems, providing a groundwork for categorizing various mitigation strategies through distribution alignment. Subsequently, we systematically delve into the specific bias and unfairness issues arising from three critical stages of LLMs integration into IR systems: data collection, model development, and result evaluation. In doing so, we meticulously review and analyze recent literature, focusing on the definitions, characteristics, and corresponding mitigation strategies associated with these issues. Finally, we identify and highlight some open problems and challenges for future work, aiming to inspire researchers and stakeholders in the IR field and beyond to better understand and mitigate bias and unfairness issues of IR in this LLM era. https://preview.redd.it/3glvv92v6dvc1.png?width=2331&format=png&auto=webp&s=af66f2bf082620882f09ea744eda88cf06c67112 https://preview.redd.it/d48pt3sw6dvc1.png?width=1126&format=png&auto=webp&s=2343460399473bde3f5e37c0bbcfdc88ffc81efb submitted by /u/KID_2_2 [link] [comments]
- How much does the topic of a MS Stat thesis matter when hiring?by /u/Direct-Touch469 (Data Science) on April 19, 2024 at 3:12 am
I’m going to be starting my Masters Thesis in my stats program. I have narrowed down two projects with different faculty members. One of them is entirely self guided, and that advisor doesn’t really have any expertise in this area and the other one is basically with another faculty member but the research topic is within his domain, so he can help me, but the application strays too far from what industry I want to be in. Project 1: Causal Machine Learning, and nonparametric estimation for identifying heterogenous treatment effects in advertising/marketing data. There’s a dataset by a company in the marketing/adtech space that they have made public, and is essentially an open dataset related to shopping transactions, and demographics of shoppers, and information on marketing campaigns that were run by the company. Ideally this would be a causal inference project, where I get to actually learn causal inference and causal (double) machine learning on my own, and apply it to this dataset. No new methods being created, just a standalone causal inference analysis and basically I walk away with learning a new area of statistics and a way to solve causal problems. My advisors background is nonparametric regression so he would be able to give me advice on the estimators being used (some of the methods use random forests, tree based methods, splines, kernel methods etc.) so he could be of help in that sense. But he knows nothing about causal inference. So I’d be on my own on this one. I want to take on this project despite it being quite isolated because I want to signal to my future employer that I can work on data science problems involving causal inference. I only have 1 year, so id have to self learn causal inference + do the analysis + the paper. Project 2: Bayesian Dimension Reduction in gene expression data Another advisor works in the area of dimension reduction, and broadly works in genomics. The project he was proposing for me was an actual opportunity to create some new methods. So much more on the research side than doing an analysis like project 1. It involves looking at Bayesian approaches to doing common dimension reduction techniques like PCA, Factor Analysis etc. From this paper I’d walk away with a good opporuntity to dive deeper into Bayesian inference, and work on methods research. I’ve never done a bayes project before, despite just taking a class on it. The cons to this is I don’t really have any interest working in bioinformatics, but this research is within the realm of my advisor so he can actually help me. The other con, is I don’t want my future employer to think I’m not qualified for tasks involving causal inference because I worked on dimension reduction, and with applications to genetic data, which is not really the industry I want to be in. Does anyone have any input on this? Does choosing a topic not related to causal inference lessen my chances of getting a job involving that? Do people care what my thesis topic is? Or does the MS in Stats signal that I could work on causal inference? submitted by /u/Direct-Touch469 [link] [comments]
- [D] ANN for recommendations with already seen itemsby /u/overflozz (Machine Learning) on April 19, 2024 at 1:10 am
Trying to implement a recommender model for an equivalent of a dating app, where I don't want to recommend someone if they have already been seen by the current user. For the embeddings ANN search, I've looked into Pinecone, VertexAI and Qdrant, but it seems that the filtering is usually limited to larger categories (e.g country). I haven't examples of filters of the type : `{user_id: {not_in: ['123', '456' , ... ]}}`. A user might have already seen 1000s of recommendations. What is the usual approach for this type of history-aware ANN? submitted by /u/overflozz [link] [comments]
- Developments outside the world of LLMs and GenAIby /u/madhav1113 (Data Science) on April 19, 2024 at 1:03 am
Hi everyone, I want to know if there are developments and research topics that are outside/completely orthogonal to LLMs and generative AI. To be honest, I am bored of LLMs. I don't care about the performance of Model X vs Models A,B,C,D etc. Moreover, at least 8 out of 10 projects in my organization are focused on generative AI and RAG. While I understand the usefulness of these ideas, I think there's an overload of information that is not particularly helpful for my brain. Personally, I am interested in scientific machine learning- drug discovery, climate change, physics simulations. If there are other research areas that you are aware of, please feel free to share. From a "long term career perspective", I want to transition to companies that work on problems in imaging and communications (I have a background in signal/image processing and computer vision). I am very much interested in novel imaging techniques that use some kind of computational imaging and ML algorithms. Qualcomm and Samsung come to my mind- but I could be wrong. submitted by /u/madhav1113 [link] [comments]
- [D] Has anyone tried distilling large language models the old way?by /u/miladink (Machine Learning) on April 19, 2024 at 12:11 am
So, nowadays, everyone is distilling rationales gathered from a large language model to another relatively smaller model. However, I remember from the old days that we did we train the small network to match the logits of the large network when doing distillation. Is this forgotten /tried and did not work today? submitted by /u/miladink [link] [comments]
- [D] Combining models of different modalitiesby /u/hophophop1233 (Machine Learning) on April 18, 2024 at 9:55 pm
What's the process/approach:architecture of combining multiple models of different modality to generate sane output? Just curious what your experiences have been. Any pointers or links to research would be handy. submitted by /u/hophophop1233 [link] [comments]
- Exposing the True Context Capabilities of Leading LLMs [R]by /u/ParsaKhaz (Machine Learning) on April 18, 2024 at 9:34 pm
I've been examining the real-world context limits of large language models (LLMs), and I wanted to share some enlightening findings from a recent benchmark (RULER) that cuts through the noise. What’s the RULER Benchmark? Developed by NVIDIA, RULER is a benchmark designed to test LLMs' ability to handle long-context information. It's more intricate than the common retrieval-focused NIAH benchmark. RULER evaluates models based on their performance in understanding and using longer pieces of text. Table highlighting RULER benchmark results and effective context lengths of leading LLMs Performance Highlights from the Study: Llama2-7B (chat): Shows decent initial performance but doesn't sustain at higher context lengths. GPT-4: Outperforms others significantly, especially at greater lengths of context, maintaining above 80% accuracy. Command-R (35B): Performs comparably well, slightly behind GPT-4. Yi (34B): Shows strong performance, particularly up to 32K context length. Mixtral (8x7B): Similar to Yi, holds up well until 32K context. Mistral (7B): Drops off in performance as context increases, more so after 32K. ChatGLM (6B): Struggles with longer contexts, showing a steep decline. LWM (7B): Comparable to ChatGLM, with a noticeable decrease in longer contexts. Together (7B): Faces difficulties maintaining accuracy as context length grows. LongChat (13B): Fares reasonably up to 4K but drops off afterwards. LongAlpaca (13B): Shows the most significant drop in performance as context lengthens. Key Takeaways: All models experience a performance drop as the context length increases, without exception. The claimed context length by LLMs often doesn't translate into effective processing ability at those lengths. GPT-4 emerges as a strong leader but isn't immune to decreased accuracy at extended lengths. Why Does This Matter? As AI developers, it’s critical to look beyond the advertised capabilities of LLMs. Understanding the effective context length can help us make informed decisions when integrating these models into applications. What's Missing in the Evaluation? Notably, Google’s Gemini and Claude 3 were not part of the evaluated models. RULER is now open-sourced, paving the way for further evaluations and transparency in the field. Sources I recycled a lot of this (and tried to make it more digestible and easy to read) from the following post, further sources available here: Harmonious.ai Weekly paper roundup: RULER: real context size of LLMs (4/8/2024) submitted by /u/ParsaKhaz [link] [comments]
- [P] Exploring Fair AI Solutions with New Data Quality Initiativeby /u/ComplexAnalysis42 (Machine Learning) on April 18, 2024 at 9:29 pm
Hello Reddit! We're a group of students from Carnegie Mellon passionate about data. We've been working on a project that tackles one of the biggest challenges in AI today: data bias. Our tool is designed to audit your datasets and generate synthetic, privacy-safe data that helps promote fairness in AI applications. Here’s why we think it could be a game-changer: Detect and Correct Data Biases: Ensures your AI models are built on fair and balanced data. Enhance Data Quality: Improves the reliability and performance of your AI systems. Generate Synthetic Data: Expands your dataset without compromising privacy. We believe in a future where data-driven technologies are equitable and just, and we're eager to contribute to making that a reality. We’d love to get your insights and feedback to further refine our tool. Join Us in Shaping the Future of Fair AI Are you interested in AI fairness? Do you have experiences with biased data or ideas on how to address these issues? Let’s start a conversation! Comment here or send us a DM. We’re here to discuss and collaborate on getting you the data you deserve! submitted by /u/ComplexAnalysis42 [link] [comments]
- Is pursuing DS instead of SWE a bad idea?by /u/---Imperator--- (Data Science) on April 18, 2024 at 8:00 pm
I've a CS degree and I'm currently working as a new grad Data Analyst. Aside from building dashboards and reports, I also do a lot of data engineering and some ML modelling. I'm planning to get a CS Masters after 1 - 2 years of work, then switch to DS. But looking at this sub, it seems like a lot of people recommend switching to SWE instead? I do enjoy software engineering work so I wouldn't mind the transition, but I'm interested in ML and thought DS would be a good career path for that. Is Data Science really a dying field and pay less than SWE? I even heard that switching from DS to SWE is more difficult than the other way around, because any SWE learning ML can do DS work. And I've seen people saying that SWE is more stable and easier to get a job than DS. Is any of this true? submitted by /u/---Imperator--- [link] [comments]
- [P] Llama 3 70B powered coding copilot extensionby /u/geepytee (Machine Learning) on April 18, 2024 at 7:29 pm
Was super excited to read the news from Meta this morning, particularly around the HumanEval scores the 70B model got. Thought it'd be useful to make the new Llama 3 70B available to anyone that wants to try it, so I added it to my VS Code coding copilot extension double.bot. Also making it free for the first 50 messages so everyone gets a chance to try it while we wait for the quantized versions to run locally submitted by /u/geepytee [link] [comments]
- Data Science is fun!by /u/Wqrped (Data Science) on April 18, 2024 at 7:17 pm
Hi everyone, I’m a marketing major about to graduate in May. A year and a half ago I took basic hypothesis testing/linear modeling class to try out an analytics certificate at my school, and I fell in love with statistics for the first time. When I began looking for job/internship opportunities around that time I was worried because while I didn’t mind marketing, I also didn’t love it. That’s when I made the decision to continue my degree in business, and work every week towards becoming a data analyst (and eventually, a data scientist! But I’m patient, and I wanted to wait until I’m ready. There’s a lot to statistics/programming, as I now know… lol). It’s been a long and very hard road. But I now have a job as a data analyst and I’m working on a large machine learning personal project now. I see a lot of negative discussion in this sub (which is entirely fair); however, I just wanted you all to know that as someone who is not taking the traditional route into data science, I think your job is awesome. I think what you do is fascinating and what statistical modeling might accomplish in the future is inspiring. Have a great day, and I hope I have the pleasure of meeting some of you in the field one day. submitted by /u/Wqrped [link] [comments]
- [D] Llama-3 (7B and 70B) on a medical domain benchmarkby /u/aadityaura (Machine Learning) on April 18, 2024 at 6:45 pm
Llama-3 is making waves in the AI community. I was curious how it will perform in the medical domain, Here are the evaluation results for Llama-3 (7B and 70B) on a medical domain benchmark consisting of 9 diverse datasets https://preview.redd.it/sdwx5tglxbvc1.png?width=1464&format=png&auto=webp&s=d32585a69244d44c83e2b1e8a85301a7a8676ea2 I'll be fine-tuning, evaluating & releasing Llama-3 & different LLMs over the next few days on different Medical and Legal benchmarks. Follow the updates here: https://twitter.com/aadityaura https://preview.redd.it/9egbcayv9avc1.png?width=1344&format=png&auto=webp&s=436a972421d5568e1a544962b8cfd1c7b14efe04 submitted by /u/aadityaura [link] [comments]
- [D] Data Scientist: job preparation guide 2024by /u/xandie985 (Machine Learning) on April 18, 2024 at 6:35 pm
I have been hunting jobs for almost 4 months now. It was after 2 years, that I opened my eyes to the outside world and in the beginning, the world fell apart because I wasn't aware of how much the industry has changed and genAI and LLMs were now mandatory things. Before, I was just limited to using chatGPT as UI. So, after preparing for so many months it felt as if I was walking in circles and running across here and there without an in-depth understanding of things. I went through around 40+ job posts and studied their requirements, (for a medium seniority DS position). So, I created a plan and then worked on each task one by one. Here, if anyone is interested, you can take a look at the important tools and libraries, that are relevant for the job hunt. Github, Notion I am open to your suggestions and edits, Happy preparation! submitted by /u/xandie985 [link] [comments]
- Data Scientist: job preparation guide 2024by /u/xandie985 (Data Science) on April 18, 2024 at 6:31 pm
I have been hunting jobs for almost 4 months now. It was after 2 years, that I opened my eyes to the outside world and in the beginning, the world fell apart because I wasn't aware of how much the industry has changed and genAI and LLMs were now mandatory things. Before, I was just limited to using chatGPT as UI. So, after preparing for so many months it felt as if I was walking in circles and running across here and there without an in-depth understanding of things. I went through around 40+ job posts and studied their requirements, (for a medium seniority DS position). So, I created a plan and then worked on each task one by one. Here, if anyone is interested, you can take a look at the important tools and libraries, that are relevant for the job hunt. Github, Notion I am open to your suggestions and edits, Happy preparation! submitted by /u/xandie985 [link] [comments]
Top 100 Data Science and Data Analytics and Data Engineering Interview Questions and Answers
What are some good datasets for Data Science and Machine Learning?
Active Hydrating Toner, Anti-Aging Replenishing Advanced Face Moisturizer, with Vitamins A, C, E & Natural Botanicals to Promote Skin Balance & Collagen Production, 6.7 Fl Oz



Age Defying 0.3% Retinol Serum, Anti-Aging Dark Spot Remover for Face, Fine Lines & Wrinkle Pore Minimizer, with Vitamin E & Natural Botanicals


Firming Moisturizer, Advanced Hydrating Facial Replenishing Cream, with Hyaluronic Acid, Resveratrol & Natural Botanicals to Restore Skin's Strength, Radiance, and Resilience, 1.75 Oz

Skin Stem Cell Serum


Smartphone 101 - Pick a smartphone for me - android or iOS - Apple iPhone or Samsung Galaxy or Huawei or Xaomi or Google Pixel
Can AI Really Predict Lottery Results? We Asked an Expert.





Djamgatech

Read Photos and PDFs Aloud for me iOS
Read Photos and PDFs Aloud for me android
Read Photos and PDFs Aloud For me Windows 10/11
Read Photos and PDFs Aloud For Amazon
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more)
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6(Email us for more)



FREE 10000+ Quiz Trivia and and Brain Teasers for All Topics including Cloud Computing, General Knowledge, History, Television, Music, Art, Science, Movies, Films, US History, Soccer Football, World Cup, Data Science, Machine Learning, Geography, etc....

List of Freely available programming books - What is the single most influential book every Programmers should read
- Bjarne Stroustrup - The C++ Programming Language
- Brian W. Kernighan, Rob Pike - The Practice of Programming
- Donald Knuth - The Art of Computer Programming
- Ellen Ullman - Close to the Machine
- Ellis Horowitz - Fundamentals of Computer Algorithms
- Eric Raymond - The Art of Unix Programming
- Gerald M. Weinberg - The Psychology of Computer Programming
- James Gosling - The Java Programming Language
- Joel Spolsky - The Best Software Writing I
- Keith Curtis - After the Software Wars
- Richard M. Stallman - Free Software, Free Society
- Richard P. Gabriel - Patterns of Software
- Richard P. Gabriel - Innovation Happens Elsewhere
- Code Complete (2nd edition) by Steve McConnell
- The Pragmatic Programmer
- Structure and Interpretation of Computer Programs
- The C Programming Language by Kernighan and Ritchie
- Introduction to Algorithms by Cormen, Leiserson, Rivest & Stein
- Design Patterns by the Gang of Four
- Refactoring: Improving the Design of Existing Code
- The Mythical Man Month
- The Art of Computer Programming by Donald Knuth
- Compilers: Principles, Techniques and Tools by Alfred V. Aho, Ravi Sethi and Jeffrey D. Ullman
- Gödel, Escher, Bach by Douglas Hofstadter
- Clean Code: A Handbook of Agile Software Craftsmanship by Robert C. Martin
- Effective C++
- More Effective C++
- CODE by Charles Petzold
- Programming Pearls by Jon Bentley
- Working Effectively with Legacy Code by Michael C. Feathers
- Peopleware by Demarco and Lister
- Coders at Work by Peter Seibel
- Surely You're Joking, Mr. Feynman!
- Effective Java 2nd edition
- Patterns of Enterprise Application Architecture by Martin Fowler
- The Little Schemer
- The Seasoned Schemer
- Why's (Poignant) Guide to Ruby
- The Inmates Are Running The Asylum: Why High Tech Products Drive Us Crazy and How to Restore the Sanity
- The Art of Unix Programming
- Test-Driven Development: By Example by Kent Beck
- Practices of an Agile Developer
- Don't Make Me Think
- Agile Software Development, Principles, Patterns, and Practices by Robert C. Martin
- Domain Driven Designs by Eric Evans
- The Design of Everyday Things by Donald Norman
- Modern C++ Design by Andrei Alexandrescu
- Best Software Writing I by Joel Spolsky
- The Practice of Programming by Kernighan and Pike
- Pragmatic Thinking and Learning: Refactor Your Wetware by Andy Hunt
- Software Estimation: Demystifying the Black Art by Steve McConnel
- The Passionate Programmer (My Job Went To India) by Chad Fowler
- Hackers: Heroes of the Computer Revolution
- Algorithms + Data Structures = Programs
- Writing Solid Code
- JavaScript - The Good Parts
- Getting Real by 37 Signals
- Foundations of Programming by Karl Seguin
- Computer Graphics: Principles and Practice in C (2nd Edition)
- Thinking in Java by Bruce Eckel
- The Elements of Computing Systems
- Refactoring to Patterns by Joshua Kerievsky
- Modern Operating Systems by Andrew S. Tanenbaum
- The Annotated Turing
- Things That Make Us Smart by Donald Norman
- The Timeless Way of Building by Christopher Alexander
- The Deadline: A Novel About Project Management by Tom DeMarco
- The C++ Programming Language (3rd edition) by Stroustrup
- Patterns of Enterprise Application Architecture
- Computer Systems - A Programmer's Perspective
- Agile Principles, Patterns, and Practices in C# by Robert C. Martin
- Growing Object-Oriented Software, Guided by Tests
- Framework Design Guidelines by Brad Abrams
- Object Thinking by Dr. David West
- Advanced Programming in the UNIX Environment by W. Richard Stevens
- Hackers and Painters: Big Ideas from the Computer Age
- The Soul of a New Machine by Tracy Kidder
- CLR via C# by Jeffrey Richter
- The Timeless Way of Building by Christopher Alexander
- Design Patterns in C# by Steve Metsker
- Alice in Wonderland by Lewis Carol
- Zen and the Art of Motorcycle Maintenance by Robert M. Pirsig
- About Face - The Essentials of Interaction Design
- Here Comes Everybody: The Power of Organizing Without Organizations by Clay Shirky
- The Tao of Programming
- Computational Beauty of Nature
- Writing Solid Code by Steve Maguire
- Philip and Alex's Guide to Web Publishing
- Object-Oriented Analysis and Design with Applications by Grady Booch
- Effective Java by Joshua Bloch
- Computability by N. J. Cutland
- Masterminds of Programming
- The Tao Te Ching
- The Productive Programmer
- The Art of Deception by Kevin Mitnick
- The Career Programmer: Guerilla Tactics for an Imperfect World by Christopher Duncan
- Paradigms of Artificial Intelligence Programming: Case studies in Common Lisp
- Masters of Doom
- Pragmatic Unit Testing in C# with NUnit by Andy Hunt and Dave Thomas with Matt Hargett
- How To Solve It by George Polya
- The Alchemist by Paulo Coelho
- Smalltalk-80: The Language and its Implementation
- Writing Secure Code (2nd Edition) by Michael Howard
- Introduction to Functional Programming by Philip Wadler and Richard Bird
- No Bugs! by David Thielen
- Rework by Jason Freid and DHH
- JUnit in Action
#BlackOwned #BlackEntrepreneurs #BlackBuniness #AWSCertified #AWSCloudPractitioner #AWSCertification #AWSCLFC02 #CloudComputing #AWSStudyGuide #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AWSBasics #AWSCertified #AWSMachineLearning #AWSCertification #AWSSpecialty #MachineLearning #AWSStudyGuide #CloudComputing #DataScience #AWSCertified #AWSSolutionsArchitect #AWSArchitectAssociate #AWSCertification #AWSStudyGuide #CloudComputing #AWSArchitecture #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AzureFundamentals #AZ900 #MicrosoftAzure #ITCertification #CertificationPrep #StudyMaterials #TechLearning #MicrosoftCertified #AzureCertification #TechBooks
Top 1000 Canada Quiz and trivia: CANADA CITIZENSHIP TEST- HISTORY - GEOGRAPHY - GOVERNMENT- CULTURE - PEOPLE - LANGUAGES - TRAVEL - WILDLIFE - HOCKEY - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Top 1000 Africa Quiz and trivia: HISTORY - GEOGRAPHY - WILDLIFE - CULTURE - PEOPLE - LANGUAGES - TRAVEL - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Exploring the Pros and Cons of Visiting All Provinces and Territories in Canada.


Exploring the Advantages and Disadvantages of Visiting All 50 States in the USA

Health Health, a science-based community to discuss health news and the coronavirus (COVID-19) pandemic
- CDC and FDA investigate fake 'Botox' injections!by /u/sbgroup65 on April 18, 2024 at 10:39 pm
submitted by /u/sbgroup65 [link] [comments]
- Cocaine seems to hijack brain pathways that prioritize food and waterby /u/dead_planets_society on April 18, 2024 at 7:10 pm
submitted by /u/dead_planets_society [link] [comments]
- The Bone-Marrow Transplant Revolutionby /u/theatlantic on April 18, 2024 at 6:42 pm
submitted by /u/theatlantic [link] [comments]
- Heat caused record-high rates of health emergencies in some parts of the US last year, CDC report showsby /u/cnn on April 18, 2024 at 6:19 pm
submitted by /u/cnn [link] [comments]
- Microplastics can travel to the brain and other vital organs after ingestion, new study findsby /u/Unusual-State1827 on April 18, 2024 at 1:14 pm
submitted by /u/Unusual-State1827 [link] [comments]
Today I Learned (TIL) You learn something new every day; what did you learn today? Submit interesting and specific facts about something that you just found out here.
- TIL that George Orwell was spied on by a Soviet secret agent named Hugh O'Donnell, code-name O'Brien. In a coincidence, (book spoiler) Orwell wrote Nineteen Eighty-Four to have a spy named O'Brien betray the main character, without knowing about the Soviet spy codenamed "O'Brien."by /u/RollingNightSky on April 19, 2024 at 1:44 am
submitted by /u/RollingNightSky [link] [comments]
- TIL 1700s Persian emperor Nader Shah kept fried peas on his person at all time, which he would eat if he didn't have time to prepare a proper mealby /u/GallicHeritage00 on April 19, 2024 at 12:58 am
submitted by /u/GallicHeritage00 [link] [comments]
- TIL of Manfred Ramminger, a German architect who stole an American missile for the Soviet Union by walking into a West German air base, hauling the missile out in a wheelbarrow, driving it wrapped in a carpet, and finally disassembling it and shipping it to Moscow through commercial airmail.by /u/zhuquanzhong on April 18, 2024 at 11:20 pm
submitted by /u/zhuquanzhong [link] [comments]
- TIL about Hanns Scharff, a German Luftwaffe interrogator during the Second World War who is considered the "father of modern interrogation techniques". After the war he became a famous mosaic artisan who amongt other things created the 15-foot arched cinderella mosaic walls in Disneylandby /u/news_doge on April 18, 2024 at 9:43 pm
submitted by /u/news_doge [link] [comments]
- TIL that Ford Bronco sales surged by 23.3% after O.J. Simpson's infamous chase and the trial.by /u/8004MikeJones on April 18, 2024 at 9:40 pm
submitted by /u/8004MikeJones [link] [comments]
Reddit Science This community is a place to share and discuss new scientific research. Read about the latest advances in astronomy, biology, medicine, physics, social science, and more. Find and submit new publications and popular science coverage of current research.
- Two lifeforms merge in once-in-a-billion-years evolutionary eventby /u/Archchancellor on April 19, 2024 at 2:54 am
submitted by /u/Archchancellor [link] [comments]
- Scientists found 7 astrophysical tau neutrinos—particles that are notoriously difficult to detect—in an analysis of data from the IceCube Neutrino Observatory. A tau neutrino produces a tau lepton—a heavy cousin of the electron—that emits a photon ball both when it is produced and when it decays.by /u/MistWeaver80 on April 19, 2024 at 12:42 am
submitted by /u/MistWeaver80 [link] [comments]
- Study shows that the immune system of the Zebrafish is involved in their ability to regenerate their heart after injury.by /u/AtomicPotatoLord on April 18, 2024 at 11:42 pm
submitted by /u/AtomicPotatoLord [link] [comments]
- Exposure to sexualized images leads to heightened self-objectification among viewers and a tendency to dehumanize the individuals depicted. Moreover, the act of generating hashtags for these images amplifies this effect, with tags often focusing unduly on body parts.by /u/mvea on April 18, 2024 at 10:48 pm
submitted by /u/mvea [link] [comments]
- High-intensity aerobic exercise improved cognitive function in both lean individuals and obese individuals with normal glucose tolerance. In contrast, the cognitive function of obese individuals with impaired glucose tolerance did not show any improvement following the exercise session.by /u/mvea on April 18, 2024 at 10:45 pm
submitted by /u/mvea [link] [comments]
Reddit Sports Sports News and Highlights from the NFL, NBA, NHL, MLB, MLS, and leagues around the world.
- NFL finds 'insufficient evidence' to punish Ravens' Zay Flowersby /u/PrincessBananas85 on April 19, 2024 at 8:48 am
submitted by /u/PrincessBananas85 [link] [comments]
- Coco Gauff vs Caitlin Clark? Tennis star says she would love to go head-to-head vs. Clarkby /u/kundu123 on April 19, 2024 at 8:44 am
Gauff played basketball earlier in her childhood. She said her father, Corey, who played college basketball at Georgia State University, encouraged her to play basketball before she focused solely on tennis. submitted by /u/kundu123 [link] [comments]
- Two-time world champion Kento Momota announces retirement from badminton at 29 amid physical and mental tollby /u/kundu123 on April 19, 2024 at 5:49 am
submitted by /u/kundu123 [link] [comments]
- Albany NFL draft hopeful AJ Simon dies at age 25by /u/Oldtimer_2 on April 19, 2024 at 5:26 am
submitted by /u/Oldtimer_2 [link] [comments]
- Geno Auriemma says one-and-done rule could 'ruin' women's college basketballby /u/PrincessBananas85 on April 19, 2024 at 3:33 am
submitted by /u/PrincessBananas85 [link] [comments]
