


AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
What are some ways to increase precision or recall in machine learning?
What are some ways to Boost Precision and Recall in Machine Learning?
Sensitivity vs Specificity?
In machine learning, recall is the ability of the model to find all relevant instances in the data while precision is the ability of the model to correctly identify only the relevant instances. A high recall means that most relevant results are returned while a high precision means that most of the returned results are relevant. Ideally, you want a model with both high recall and high precision but often there is a trade-off between the two. In this blog post, we will explore some ways to increase recall or precision in machine learning.
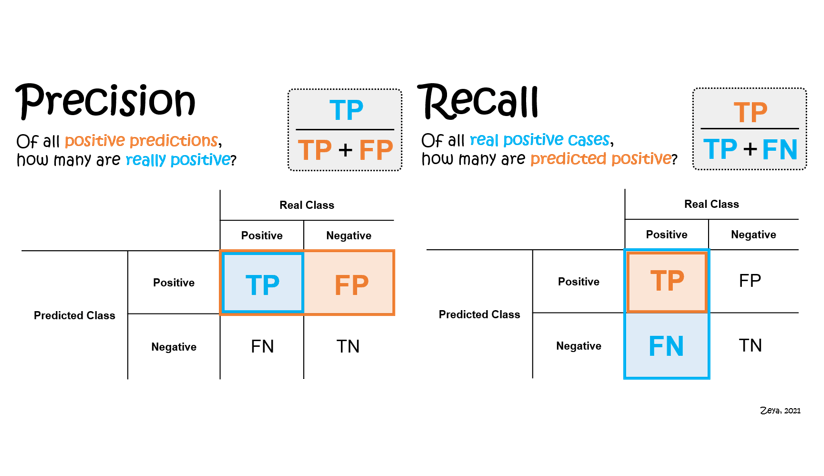
There are two main ways to increase recall:
by increasing the number of false positives or by decreasing the number of false negatives. To increase the number of false positives, you can lower your threshold for what constitutes a positive prediction. For example, if you are trying to predict whether or not an email is spam, you might lower the threshold for what constitutes spam so that more emails are classified as spam. This will result in more false positives (emails that are not actually spam being classified as spam) but will also increase recall (more actual spam emails being classified as spam).
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6

 Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more codes)
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more codes)
Active Anti-Aging Eye Gel, Reduces Dark Circles, Puffy Eyes, Crow's Feet and Fine Lines & Wrinkles, Packed with Hyaluronic Acid & Age Defying Botanicals


To decrease the number of false negatives,
you can increase your threshold for what constitutes a positive prediction. For example, going back to the spam email prediction example, you might raise the threshold for what constitutes spam so that fewer emails are classified as spam. This will result in fewer false negatives (actual spam emails not being classified as spam) but will also decrease recall (fewer actual spam emails being classified as spam).

There are two main ways to increase precision:
by increasing the number of true positives or by decreasing the number of true negatives. To increase the number of true positives, you can raise your threshold for what constitutes a positive prediction. For example, using the spam email prediction example again, you might raise the threshold for what constitutes spam so that fewer emails are classified as spam. This will result in more true positives (emails that are actually spam being classified as spam) but will also decrease precision (more non-spam emails being classified as spam).

To decrease the number of true negatives,
you can lower your threshold for what constitutes a positive prediction. For example, going back to the spam email prediction example once more, you might lower the threshold for what constitutes spam so that more emails are classified as spam. This will result in fewer true negatives (emails that are not actually spam not being classified as spam) but will also decrease precision (more non-spam emails being classified as spam).

To summarize,
there are a few ways to increase precision or recall in machine learning. One way is to use a different evaluation metric. For example, if you are trying to maximize precision, you can use the F1 score, which is a combination of precision and recall. Another way to increase precision or recall is to adjust the threshold for classification. This can be done by changing the decision boundary or by using a different algorithm altogether.
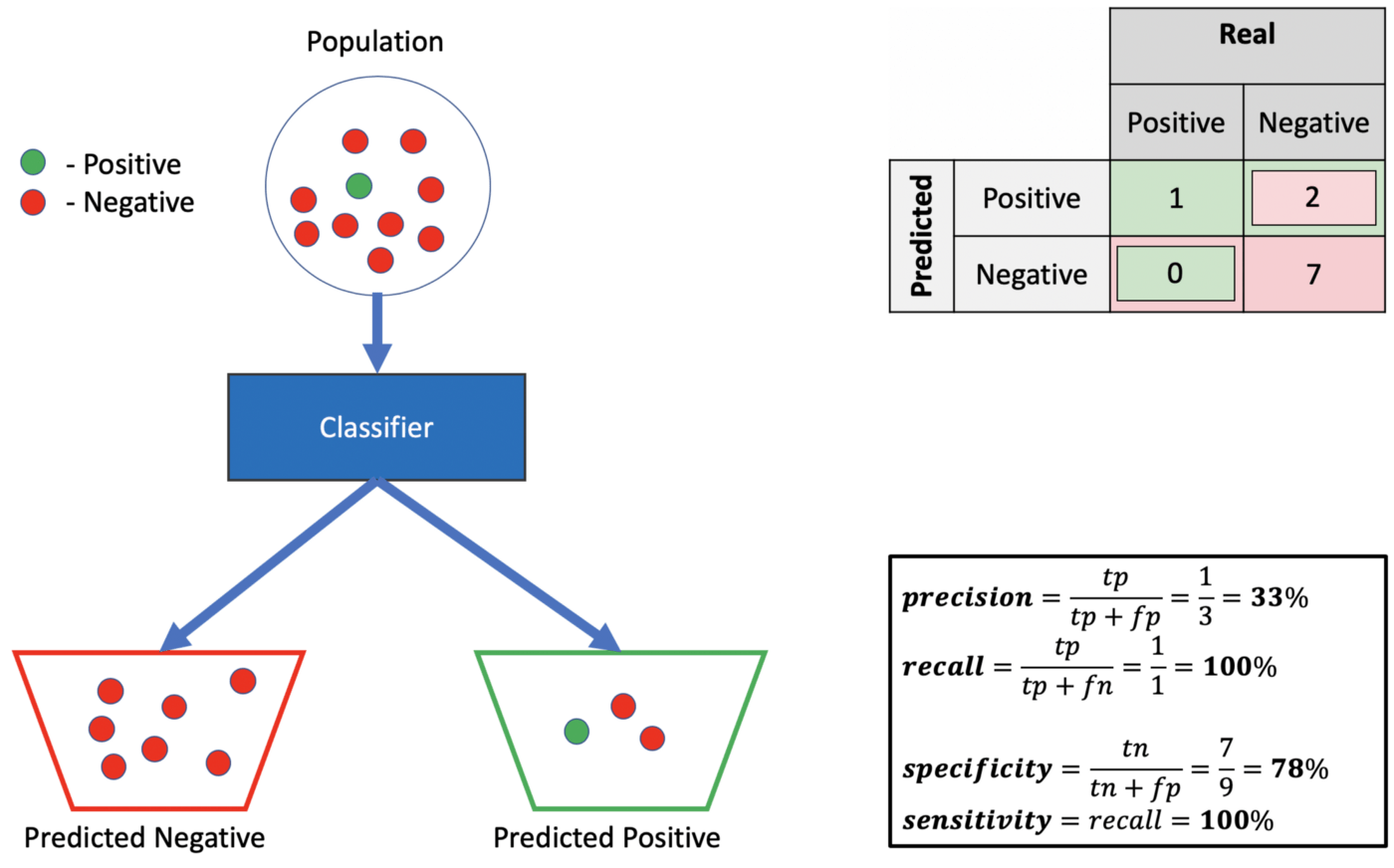
Sensitivity vs Specificity
In machine learning, sensitivity and specificity are two measures of the performance of a model. Sensitivity is the proportion of true positives that are correctly predicted by the model, while specificity is the proportion of true negatives that are correctly predicted by the model.
Google Colab For Machine Learning
State of the Google Colab for ML (October 2022)
Google introduced computing units, which you can purchase just like any other cloud computing unit you can from AWS or Azure etc. With Pro you get 100, and with Pro+ you get 500 computing units. GPU, TPU and option of High-RAM effects how much computing unit you use hourly. If you don’t have any computing units, you can’t use “Premium” tier gpus (A100, V100) and even P100 is non-viable.
Google Colab Pro+ comes with Premium tier GPU option, meanwhile in Pro if you have computing units you can randomly connect to P100 or T4. After you use all of your computing units, you can buy more or you can use T4 GPU for the half or most of the time (there can be a lot of times in the day that you can’t even use a T4 or any kinds of GPU). In free tier, offered gpus are most of the time K80 and P4, which performs similar to a 750ti (entry level gpu from 2014) with more VRAM.
For your consideration, T4 uses around 2, and A100 uses around 15 computing units hourly.
Based on the current knowledge, computing units costs for GPUs tend to fluctuate based on some unknown factor.
Considering those:
- For hobbyists and (under)graduate school duties, it will be better to use your own gpu if you have something with more than 4 gigs of VRAM and better than 750ti, or atleast purchase google pro to reach T4 even if you have no computing units remaining.
- For small research companies, and non-trivial research at universities, and probably for most of the people Colab now probably is not a good option.
- Colab Pro+ can be considered if you want Pro but you don’t sit in front of your computer, since it disconnects after 90 minutes of inactivity in your computer. But this can be overcomed with some scripts to some extend. So for most of the time Colab Pro+ is not a good option.
If you have anything more to say, please let me know so I can edit this post with them. Thanks!

Conclusion:
In machine learning, precision and recall trade off against each other; increasing one often decreases the other. There is no single silver bullet solution for increasing either precision or recall; it depends on your specific use case which one is more important and which methods will work best for boosting whichever metric you choose. In this blog post, we explored some methods for increasing either precision or recall; hopefully this gives you a starting point for improving your own models!
What are some ways we can use machine learning and artificial intelligence for algorithmic trading in the stock market?

Machine Learning and Data Science Breaking News 2022 – 2023
- Using Cloud Compute and Parallelizationby /u/MonBabbie (Data Science) on April 16, 2024 at 4:07 pm
I’m running transformer models from Hugging Face on my laptop with python/jupyter notebooks. These notebooks take hours to run and I’d like to learn how to accelerate them. I believe my next steps are working with a cloud computing service to offload my code onto stronger computers, as well as editing my code to make use of parallelization. Does anyone have recommendations on services and/or resources for how to get started? I’m probably going to start looking into some sort of aws service (sagemaker?) and my friend mentioned dask to me, so I’ll look into that as well. Right now my code is calling these models using the standard pipeline method within a list comprehension. I believe I’ll need to change that, as I’m expecting that to not be parallelizable. Any advice? I’ve got a data frame with many rows and I’m trying to run a model on text within these rows for things like sentiment analysis and zero shot classification. Thank you! submitted by /u/MonBabbie [link] [comments]
- Validation setby /u/Top-Blueberry-6128 (Data Science) on April 16, 2024 at 2:21 pm
Can someone explain the validation set? In a professional way like market-wise, how can it be a game changer? My whole knowledge about it is to plot it to check the model's performance and for early stopping, but that's it. submitted by /u/Top-Blueberry-6128 [link] [comments]
- Rule based, Recommendation Based Embeddingby /u/serdarkaracay (Data Science) on April 16, 2024 at 1:11 pm
Hello Coders I would like to share an experience and know your opinions. I embedded about 12K+ order lists from a takeaway order system. I used Cohere english v3 and openai text embeding v3 for the embed. I prepared questions for the embed I would like large pizza, green pepper and corn questions with semantic parser. The output answers of these questions vegan pizza, vegan burger added pepperoni topping coke side topping did not satisfy me. Complementary and suggestion answers gave one quality and one poor quality output. Of course, these embed algorithms are usually based on conise similar. I suddenly had the suspicion that I should use embed for this type of rule based, match based, recommended. I believe that I can do the attached data with my own nlp libraries with more enrichment metadata tags without embedding. I would be glad if you share your ideas, especially if I can use llm in Out of vocabulary (OOV) detection contexts. Thank you. submitted by /u/serdarkaracay [link] [comments]
- Loading a trillion rows of weather data into TimescaleDBby /u/DeadDolphinResearch (Data Science) on April 16, 2024 at 12:36 pm
submitted by /u/DeadDolphinResearch [link] [comments]
- Interview Advice - Sales and Marketing Predictive Modellingby /u/Mayukhsen1301 (Data Science) on April 16, 2024 at 8:40 am
Its hard as an international to get internships in this market but thankfully I had the fortune to interview for a few F250 companies. I seem to be missing out for fine margins. One company team technical lead said that i would be a good fit but since there was just 1 opening, I got referred to another team to apply . This happened quite a few times with others except i wasnt referred to other teams. I prepared for wrong things in that interview. I was able to answer all but it was thinking on spot and beating around the bush which definitely didn't help . Someone who knew it would sound more sure and knowledgeable and will get the edge .I know where i could have improved 🙁 This maybe my last opportunity to bag summer internship this year. I want to give my best and try to leave no stone unturned. It would be great of someone with experience in predictive Modelling in sales and marketing can tell me about some work done and commonly used questions / techniques. I did google and chatgpt but some real world / production level insights and some commonly used models and methods MLOps of this domain would help me a lot. Appreciate your support in the above matter submitted by /u/Mayukhsen1301 [link] [comments]
- [D] Do Swin transformers perform poorly at linear probing?by /u/Mad_Scientist2027 (Machine Learning) on April 16, 2024 at 8:17 am
I had been training some Swin transformers using SimMIM for a paper and noticed that the linear probing accuracy on ImageNet1k was horrendous. While I was using the smallest Swin model, Swin-T, the performance after the 25th epoch was barely 2.5% top1 (ViT-T attains ~5% top1 while ViT-B does 7% after a similar number of epochs). I wanted to know if someone had done similar experimentation with Swin transformers and if using them in linear evaluation is a lost cause. Any help is appreciated. Thanks in advance. submitted by /u/Mad_Scientist2027 [link] [comments]
- [D] Where to find ICML 2024 workshops?by /u/Stinein (Machine Learning) on April 16, 2024 at 7:21 am
Does anyone know where to find information about what workshops will be held at ICML 2024? The workshop acceptance notifications were released March 27, but the workshops don't appear to be published on the ICML website yet. Thanks! submitted by /u/Stinein [link] [comments]
- Stanford releases their rather comprehensive (500 page) "2004 AI Index Report summarizing the state of AI today.by /u/Appropriate_Ant_4629 (Machine Learning) on April 16, 2024 at 7:19 am
submitted by /u/Appropriate_Ant_4629 [link] [comments]
- Help in creating a chatbotby /u/ssiddharth408 (Data Science) on April 16, 2024 at 7:04 am
I want to create a chatbot that can fetch data from database and answer questions. For example, I have a database with details of employees. Now If i ask chatbot how many people join after January 2024 that chatbot will return answer based on data stored in database. How to achieve this and what approch to use? submitted by /u/ssiddharth408 [link] [comments]
- [R] Unified Training of Universal Time Series Forecasting Transformersby /u/SeawaterFlows (Machine Learning) on April 16, 2024 at 6:45 am
Paper: https://arxiv.org/abs/2402.02592 Code: https://github.com/SalesforceAIResearch/uni2ts Models: https://huggingface.co/collections/Salesforce/moirai-10-r-models-65c8d3a94c51428c300e0742 Dataset: https://huggingface.co/datasets/Salesforce/lotsa_data Blog post: https://blog.salesforceairesearch.com/moirai/ Abstract: Deep learning for time series forecasting has traditionally operated within a one-model-per-dataset framework, limiting its potential to leverage the game-changing impact of large pre-trained models. The concept of universal forecasting, emerging from pre-training on a vast collection of time series datasets, envisions a single Large Time Series Model capable of addressing diverse downstream forecasting tasks. However, constructing such a model poses unique challenges specific to time series data: i) cross-frequency learning, ii) accommodating an arbitrary number of variates for multivariate time series, and iii) addressing the varying distributional properties inherent in large-scale data. To address these challenges, we present novel enhancements to the conventional time series Transformer architecture, resulting in our proposed Masked Encoder-based Universal Time Series Forecasting Transformer (Moirai). Trained on our newly introduced Large-scale Open Time Series Archive (LOTSA) featuring over 27B observations across nine domains, Moirai achieves competitive or superior performance as a zero-shot forecaster when compared to full-shot models. Code, model weights, and data will be released. submitted by /u/SeawaterFlows [link] [comments]
- [R] Fine-Tuning Enhances Existing Mechanisms: A Case Study on Entity Trackingby /u/SeawaterFlows (Machine Learning) on April 16, 2024 at 6:29 am
arXiv: https://arxiv.org/abs/2402.14811 OpenReview: https://openreview.net/forum?id=8sKcAWOf2D Code: https://github.com/Nix07/finetuning Models: https://huggingface.co/nikhil07prakash/float-7b Project page: https://finetuning.baulab.info/ Abstract: Fine-tuning on generalized tasks such as instruction following, code generation, and mathematics has been shown to enhance language models' performance on a range of tasks. Nevertheless, explanations of how such fine-tuning influences the internal computations in these models remain elusive. We study how fine-tuning affects the internal mechanisms implemented in language models. As a case study, we explore the property of entity tracking, a crucial facet of language comprehension, where models fine-tuned on mathematics have substantial performance gains. We identify the mechanism that enables entity tracking and show that (i) in both the original model and its fine-tuned versions primarily the same circuit implements entity tracking. In fact, the entity tracking circuit of the original model on the fine-tuned versions performs better than the full original model. (ii) The circuits of all the models implement roughly the same functionality: Entity tracking is performed by tracking the position of the correct entity in both the original model and its fine-tuned versions. (iii) Performance boost in the fine-tuned models is primarily attributed to its improved ability to handle the augmented positional information. To uncover these findings, we employ: Patch Patching, DCM, which automatically detects model components responsible for specific semantics, and CMAP, a new approach for patching activations across models to reveal improved mechanisms. Our findings suggest that fine-tuning enhances, rather than fundamentally alters, the mechanistic operation of the model. submitted by /u/SeawaterFlows [link] [comments]
- [D] Architectureby /u/Bolehlaf (Machine Learning) on April 16, 2024 at 6:21 am
What type of architecture are you using for ML application? Are you using microservices or something else? submitted by /u/Bolehlaf [link] [comments]
- Feeding Model Prediction Back in as Feature [Discussion]by /u/Fuzzy_Lock_5557 (Machine Learning) on April 16, 2024 at 5:53 am
I am using models to make classifications. Is it good practice to train a model to make a probability prediction on a training and test set and then to add the resulting probabilities back into a new model with the probability as a feature? Flow: Train/Test Model predict_proba to get probability Train another model with the same features as the first + the probability The second model is significantly more accurate, but I am skeptical. submitted by /u/Fuzzy_Lock_5557 [link] [comments]
- [P] Yolov8 related query for detection of pedestrians using mobile phones while walking.by /u/gh0st_taskforce_141 (Machine Learning) on April 16, 2024 at 5:03 am
So, I am working on this project where I am assigned with the task to detect pedestrians that are using mobile phones on road and fine them. So how this system works is exactly like the one with cars where the car number plate is read, then it is looked up on the database and a fine is deducted from the owner's account. Now, I've worked on face recognition / attendance systems before as there are thousands of models out there and I have looked at plenty of those codes before, but this is my first time working with yolo and I don't even do image processing but could not turn down my professor, which brings me here to ask for help from ya'll here. I have got all the other parts down, and a teammate is working on the fine deduction process but am stuck on how to implement the step where the face is to be recognized only when the person is holding the phone and only of the person(s) holding the phone. submitted by /u/gh0st_taskforce_141 [link] [comments]
- [R] Megalodon: Efficient LLM Pretraining and Inference with Unlimited Context Lengthby /u/we_are_mammals (Machine Learning) on April 16, 2024 at 4:51 am
submitted by /u/we_are_mammals [link] [comments]
- [D]Train keras object detection model for edge TPU(coral)[D]by /u/Sad-Anywhere-2204 (Machine Learning) on April 16, 2024 at 4:34 am
For a client I need to train an object detection model that is able to run on a coral board for edge TPU inference, there are some examples that simplify the process using TensorFlow Lite Model Maker or some other examples using kerasCV(not for edge TPU) but for this client we are looking to use pure keras because there are some requirements that cannot be achieved with the model maker(as far as I know, correct me if wrong), especifically: Need to calculate some additional metrics(ex: some obtained with coco evaluator) Need to track the metrics in tensorboard during training to compare different runs, different datasets, perform early stopping, detect under/over fitting, etc. Has anyone performed something similar? Or has any examples or ideas? submitted by /u/Sad-Anywhere-2204 [link] [comments]
- [D] Any recent ML server build guides or recommendations?by /u/freshairproject (Machine Learning) on April 16, 2024 at 3:39 am
I see build guides for nvidia RTX 2000, 3000 series, but none for 4000-series. Unfortunately the knowledge shared has aged rather quickly as GPUs have gotten fatter, longer, taller. Has anyone managed to fit multiple rtx4090 in a single ML server? If so, any suggestions? Thank you submitted by /u/freshairproject [link] [comments]
- RAG Redefined: Ready-to-Deploy RAG for Organizations at Scale [D]by /u/AssistanceOk2217 (Machine Learning) on April 16, 2024 at 3:25 am
One-Size-Fits-Most RAG: Your RAG, Ready to Go w/ Cognita Full Article https://preview.redd.it/v8vaad4vfruc1.png?width=1044&format=png&auto=webp&s=a8f6353ecc9cf2b911733bd1780ef12d17d7d826 Part 3 of the 'Cognita' Exploration Series This article is the third part of a series exploring the Cognita RAG framework. It builds upon Part 2, which provides a technical perspective, and Part 1, which explains the underlying concepts. What's This Article About? Explains how organizations can leverage Cognita to implement a comprehensive RAG framework quickly, without starting from scratch. Highlights Cognita's modular architecture, enabling organizations to scale individual components independently, ensuring seamless growth and adaptability. Why Read This Article? Highlights the challenges organizations face in extracting relevant insights from vast amounts of data, where traditional methods often fall short. Introduces the concept of "Retrieval Augmented Generation" (RAG) as a solution, and Cognita as a pre-built, open-source RAG product. Emphasizes how Cognita can revolutionize the way organizations handle and leverage data, without the need for extensive technical expertise or resources. Let's Get Cooking! Walks through the various tasks users can perform using Cognita's user-friendly interface, without technical expertise. Tasks include creating data sources, collections, data ingestion, selecting collections, configuring language models (LLMs), selecting document retrievers, writing prompts, and asking queries. Let's Set Up Provides a comprehensive step-by-step guide for setting up the Ready2DeployRAG4OrgAtScale environment. Covers prerequisites, cloning repositories, creating and activating a virtual environment, starting the backend server, installing Yarn, and setting up the frontend. submitted by /u/AssistanceOk2217 [link] [comments]
- Diffusion versus Auto-regressive models for image generation. Which is better? [D] [R]by /u/InstinctsInFlow (Machine Learning) on April 16, 2024 at 1:27 am
Hello all, I am new to this field of image generation using transformer models. I am curious about the above two mentioned approaches. Particularly in light of this paper "Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction" (results). It looks like these AR (auto-regressive) models seem to be better especially when scaled up compared to DiTs (Diffusion Transformers). Their main inference benefits seem to come from the low sampling efficiency of DiT. However, I have my doubts regarding this. Apart from the fact that major AI powerhouses have adopted diffusion models, there is a solid theory backing diffusion models being capable of generating any image distribution. Apart from that, there are no results of the above VAR paper for small models (something I am also interested in). So here are my questions: Are there any DiT distillation papers which improve the sampling efficiency? I could not find any transformer ones, all were U-Net based. Is there any theory backing AR transformer models for image generation (or for any generative task for that matter)? Is this VAR paper better purely because people haven't yet explored DiT well enough? Or AR model supremacy is what is expected? If you were to pick between the two based on potential performance (from a research point of view) and success, what would you pick and why? (I'm biased, so reasons pro-diffusion is appreciated) If you can answer any question or any opinion related to the matter please comment.. submitted by /u/InstinctsInFlow [link] [comments]
- Why are Data Scientists still needed when Machine Learning Engineers are a thing?by /u/CadeOCarimbo (Data Science) on April 15, 2024 at 11:06 pm
I've worked in a company in which there were different teams for DS and MLE with very distinct responsibilities. DS were responsible for talking with business stakeholders, understanding the project goals, talking with data engineers and analysts to assess data availability, do the whole data science project cycle and then deploying the model as a flask API using infrastructure built by the MLE team. However, I have seen more and more MLE jobs in which their responsibilities are much broader than that. Some of them expect MLEs to actually build the model themselves. I might be wrong here but it seems like the average ML Engineer could do everything that is expected from an average data science position, but an average data Scientist would really struggle at an average ML Engineer position. submitted by /u/CadeOCarimbo [link] [comments]
Top 100 Data Science and Data Analytics and Data Engineering Interview Questions and Answers
What are some good datasets for Data Science and Machine Learning?
Active Hydrating Toner, Anti-Aging Replenishing Advanced Face Moisturizer, with Vitamins A, C, E & Natural Botanicals to Promote Skin Balance & Collagen Production, 6.7 Fl Oz



Age Defying 0.3% Retinol Serum, Anti-Aging Dark Spot Remover for Face, Fine Lines & Wrinkle Pore Minimizer, with Vitamin E & Natural Botanicals


Firming Moisturizer, Advanced Hydrating Facial Replenishing Cream, with Hyaluronic Acid, Resveratrol & Natural Botanicals to Restore Skin's Strength, Radiance, and Resilience, 1.75 Oz

Skin Stem Cell Serum


Smartphone 101 - Pick a smartphone for me - android or iOS - Apple iPhone or Samsung Galaxy or Huawei or Xaomi or Google Pixel
Can AI Really Predict Lottery Results? We Asked an Expert.





Djamgatech

Read Photos and PDFs Aloud for me iOS
Read Photos and PDFs Aloud for me android
Read Photos and PDFs Aloud For me Windows 10/11
Read Photos and PDFs Aloud For Amazon
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more)
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6(Email us for more)



FREE 10000+ Quiz Trivia and and Brain Teasers for All Topics including Cloud Computing, General Knowledge, History, Television, Music, Art, Science, Movies, Films, US History, Soccer Football, World Cup, Data Science, Machine Learning, Geography, etc....

List of Freely available programming books - What is the single most influential book every Programmers should read
- Bjarne Stroustrup - The C++ Programming Language
- Brian W. Kernighan, Rob Pike - The Practice of Programming
- Donald Knuth - The Art of Computer Programming
- Ellen Ullman - Close to the Machine
- Ellis Horowitz - Fundamentals of Computer Algorithms
- Eric Raymond - The Art of Unix Programming
- Gerald M. Weinberg - The Psychology of Computer Programming
- James Gosling - The Java Programming Language
- Joel Spolsky - The Best Software Writing I
- Keith Curtis - After the Software Wars
- Richard M. Stallman - Free Software, Free Society
- Richard P. Gabriel - Patterns of Software
- Richard P. Gabriel - Innovation Happens Elsewhere
- Code Complete (2nd edition) by Steve McConnell
- The Pragmatic Programmer
- Structure and Interpretation of Computer Programs
- The C Programming Language by Kernighan and Ritchie
- Introduction to Algorithms by Cormen, Leiserson, Rivest & Stein
- Design Patterns by the Gang of Four
- Refactoring: Improving the Design of Existing Code
- The Mythical Man Month
- The Art of Computer Programming by Donald Knuth
- Compilers: Principles, Techniques and Tools by Alfred V. Aho, Ravi Sethi and Jeffrey D. Ullman
- Gödel, Escher, Bach by Douglas Hofstadter
- Clean Code: A Handbook of Agile Software Craftsmanship by Robert C. Martin
- Effective C++
- More Effective C++
- CODE by Charles Petzold
- Programming Pearls by Jon Bentley
- Working Effectively with Legacy Code by Michael C. Feathers
- Peopleware by Demarco and Lister
- Coders at Work by Peter Seibel
- Surely You're Joking, Mr. Feynman!
- Effective Java 2nd edition
- Patterns of Enterprise Application Architecture by Martin Fowler
- The Little Schemer
- The Seasoned Schemer
- Why's (Poignant) Guide to Ruby
- The Inmates Are Running The Asylum: Why High Tech Products Drive Us Crazy and How to Restore the Sanity
- The Art of Unix Programming
- Test-Driven Development: By Example by Kent Beck
- Practices of an Agile Developer
- Don't Make Me Think
- Agile Software Development, Principles, Patterns, and Practices by Robert C. Martin
- Domain Driven Designs by Eric Evans
- The Design of Everyday Things by Donald Norman
- Modern C++ Design by Andrei Alexandrescu
- Best Software Writing I by Joel Spolsky
- The Practice of Programming by Kernighan and Pike
- Pragmatic Thinking and Learning: Refactor Your Wetware by Andy Hunt
- Software Estimation: Demystifying the Black Art by Steve McConnel
- The Passionate Programmer (My Job Went To India) by Chad Fowler
- Hackers: Heroes of the Computer Revolution
- Algorithms + Data Structures = Programs
- Writing Solid Code
- JavaScript - The Good Parts
- Getting Real by 37 Signals
- Foundations of Programming by Karl Seguin
- Computer Graphics: Principles and Practice in C (2nd Edition)
- Thinking in Java by Bruce Eckel
- The Elements of Computing Systems
- Refactoring to Patterns by Joshua Kerievsky
- Modern Operating Systems by Andrew S. Tanenbaum
- The Annotated Turing
- Things That Make Us Smart by Donald Norman
- The Timeless Way of Building by Christopher Alexander
- The Deadline: A Novel About Project Management by Tom DeMarco
- The C++ Programming Language (3rd edition) by Stroustrup
- Patterns of Enterprise Application Architecture
- Computer Systems - A Programmer's Perspective
- Agile Principles, Patterns, and Practices in C# by Robert C. Martin
- Growing Object-Oriented Software, Guided by Tests
- Framework Design Guidelines by Brad Abrams
- Object Thinking by Dr. David West
- Advanced Programming in the UNIX Environment by W. Richard Stevens
- Hackers and Painters: Big Ideas from the Computer Age
- The Soul of a New Machine by Tracy Kidder
- CLR via C# by Jeffrey Richter
- The Timeless Way of Building by Christopher Alexander
- Design Patterns in C# by Steve Metsker
- Alice in Wonderland by Lewis Carol
- Zen and the Art of Motorcycle Maintenance by Robert M. Pirsig
- About Face - The Essentials of Interaction Design
- Here Comes Everybody: The Power of Organizing Without Organizations by Clay Shirky
- The Tao of Programming
- Computational Beauty of Nature
- Writing Solid Code by Steve Maguire
- Philip and Alex's Guide to Web Publishing
- Object-Oriented Analysis and Design with Applications by Grady Booch
- Effective Java by Joshua Bloch
- Computability by N. J. Cutland
- Masterminds of Programming
- The Tao Te Ching
- The Productive Programmer
- The Art of Deception by Kevin Mitnick
- The Career Programmer: Guerilla Tactics for an Imperfect World by Christopher Duncan
- Paradigms of Artificial Intelligence Programming: Case studies in Common Lisp
- Masters of Doom
- Pragmatic Unit Testing in C# with NUnit by Andy Hunt and Dave Thomas with Matt Hargett
- How To Solve It by George Polya
- The Alchemist by Paulo Coelho
- Smalltalk-80: The Language and its Implementation
- Writing Secure Code (2nd Edition) by Michael Howard
- Introduction to Functional Programming by Philip Wadler and Richard Bird
- No Bugs! by David Thielen
- Rework by Jason Freid and DHH
- JUnit in Action
#BlackOwned #BlackEntrepreneurs #BlackBuniness #AWSCertified #AWSCloudPractitioner #AWSCertification #AWSCLFC02 #CloudComputing #AWSStudyGuide #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AWSBasics #AWSCertified #AWSMachineLearning #AWSCertification #AWSSpecialty #MachineLearning #AWSStudyGuide #CloudComputing #DataScience #AWSCertified #AWSSolutionsArchitect #AWSArchitectAssociate #AWSCertification #AWSStudyGuide #CloudComputing #AWSArchitecture #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AzureFundamentals #AZ900 #MicrosoftAzure #ITCertification #CertificationPrep #StudyMaterials #TechLearning #MicrosoftCertified #AzureCertification #TechBooks
Top 1000 Canada Quiz and trivia: CANADA CITIZENSHIP TEST- HISTORY - GEOGRAPHY - GOVERNMENT- CULTURE - PEOPLE - LANGUAGES - TRAVEL - WILDLIFE - HOCKEY - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Top 1000 Africa Quiz and trivia: HISTORY - GEOGRAPHY - WILDLIFE - CULTURE - PEOPLE - LANGUAGES - TRAVEL - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Exploring the Pros and Cons of Visiting All Provinces and Territories in Canada.


Exploring the Advantages and Disadvantages of Visiting All 50 States in the USA

Health Health, a science-based community to discuss health news and the coronavirus (COVID-19) pandemic
- Warning as microplastics escape gut to "infiltrate" brainby /u/newsweek on April 16, 2024 at 2:56 pm
submitted by /u/newsweek [link] [comments]
- Report highlights inequalities and hidden suffering among people living with breast cancer | Many people with breast cancer ‘systematically left behind’, say researchersby /u/chrisdh79 on April 16, 2024 at 10:54 am
submitted by /u/chrisdh79 [link] [comments]
- Drugmakers' low U.S. taxes belie their high salesby /u/Maxcactus on April 16, 2024 at 9:59 am
submitted by /u/Maxcactus [link] [comments]
- Why homeless people are losing health coverage in Medicaid mix-upsby /u/Maxcactus on April 16, 2024 at 9:56 am
submitted by /u/Maxcactus [link] [comments]
- Drugmakers' low U.S. taxes belie their high salesby /u/rustyseapants on April 16, 2024 at 7:17 am
submitted by /u/rustyseapants [link] [comments]
Today I Learned (TIL) You learn something new every day; what did you learn today? Submit interesting and specific facts about something that you just found out here.
- TIL People who post their fitness routine on social media are more likely to have psychological problems.by /u/ParadoxicalState on April 16, 2024 at 1:43 pm
submitted by /u/ParadoxicalState [link] [comments]
- TIL olympic sailor Francisco Gonzalez killed 44 people on a plane by shooting both the pilotsby /u/zTRU5T on April 16, 2024 at 1:01 pm
submitted by /u/zTRU5T [link] [comments]
- TIL Academy Award winning actor Jack Palance was Ukranian. His birth name was Volodymyr Ivanovich Palahniuk.by /u/OxD3ADD3AD on April 16, 2024 at 12:27 pm
submitted by /u/OxD3ADD3AD [link] [comments]
- TIL Japan Air Lines Flight 123, being flown by a Boeing 747, crashed on August 12, 1986 due to complications from improper repairs made to the plane by Boeing after a tailstrike in 1978. The crash of Flight 123 is the deadliest single-aircraft accident in aviation history.by /u/NeverEnoughMuppets on April 16, 2024 at 10:29 am
submitted by /u/NeverEnoughMuppets [link] [comments]
- TIL the most dangerous ant in the world is the bulldog ant (Myrmecia pyriformis) in Australia. In attack it uses its sting and jaws simultaneously. There have been at least three human fatalities since 1936, the latest a Victorian farmer in 1988by /u/jacknunn on April 16, 2024 at 10:23 am
submitted by /u/jacknunn [link] [comments]
Reddit Science This community is a place to share and discuss new scientific research. Read about the latest advances in astronomy, biology, medicine, physics, social science, and more. Find and submit new publications and popular science coverage of current research.
- O.J. Simpson feared he had CTE but his family gives a ‘hard no’ to brain studyby /u/reviewjournal on April 16, 2024 at 3:04 pm
submitted by /u/reviewjournal [link] [comments]
- Study have observed that individuals who are the least physically active also tend to consume the most alcohol, and a significant portion of them also smoke, while healthier behaviors were similarly interrelated. These patterns remain relatively stable in middle adulthoodby /u/giuliomagnifico on April 16, 2024 at 2:57 pm
submitted by /u/giuliomagnifico [link] [comments]
- Shadowbanning: Some marginalized social media users believe their content is suppressed. Social media allows users to express themselves, but some marginalized groups say social media platforms restrict the visibility of their online posts, according to a new University of Michigan study.by /u/umichnews on April 16, 2024 at 2:23 pm
submitted by /u/umichnews [link] [comments]
- Researchers at the University of Rochester in New York have found blinking provides information to the brain about the overall big picture of a visual sceneby /u/newsweek on April 16, 2024 at 1:12 pm
submitted by /u/newsweek [link] [comments]
- Leveraging gamers and video game technology can dramatically boost scientific research according to a new study | 4.5 million gamers around the world have advanced medical science by helping to reconstruct microbial evolutionary histories.by /u/chrisdh79 on April 16, 2024 at 12:19 pm
submitted by /u/chrisdh79 [link] [comments]
Reddit Sports Sports News and Highlights from the NFL, NBA, NHL, MLB, MLS, and leagues around the world.
- Do you think Skip and Stephen A, have contributed to the downfall of sports media?by /u/Only_Firefighter4517 on April 16, 2024 at 2:58 pm
(Shameless plug) I was researching why sports media is the that it currently is and it took me down a rabbit hole of exploring the rise of sports media biggest figures, Skip and Stephen A. I came to the conclusion that the rise of these two figures have consequences led to overall decline in quality of sports journalism. Is it just a coincidence? submitted by /u/Only_Firefighter4517 [link] [comments]
- NFL quarterback Russell Wilson has spoken out in support of WNBA players after learning of the salary rookie Caitlin Clark stands to earnby /u/TinyLaughingLamp on April 16, 2024 at 2:54 pm
submitted by /u/TinyLaughingLamp [link] [comments]
- Buffalo Sabres fire head coach Don Granato after extending playoff drought to 13th seasonby /u/Oldtimer_2 on April 16, 2024 at 2:17 pm
submitted by /u/Oldtimer_2 [link] [comments]
- O.J. Simpson lawyer says Fred Goldman's claim 'will be accepted'by /u/PrincessBananas85 on April 16, 2024 at 2:08 pm
submitted by /u/PrincessBananas85 [link] [comments]
- Lionel Messi Voted MLS Player of the Matchday for Matchday 9by /u/Present-Party4402 on April 16, 2024 at 12:58 pm
submitted by /u/Present-Party4402 [link] [comments]
