


AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
What is The Most Accurate Machine Learning Algorithm for Predictive Modeling?
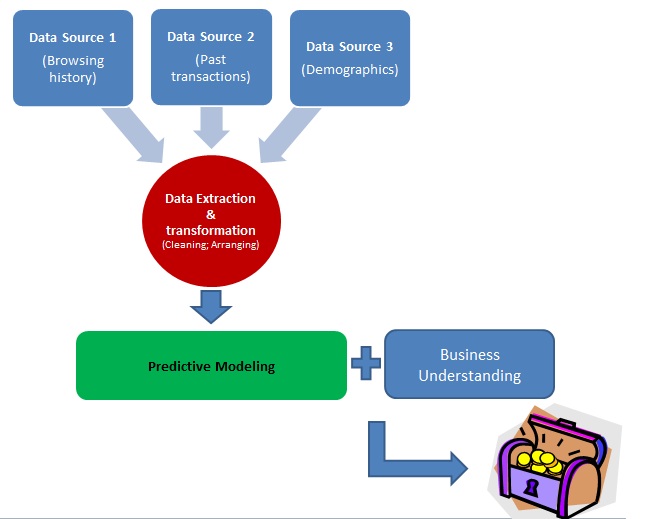
When it comes to predictive modeling, machine learning algorithms play a pivotal role in helping data scientists and machine learning engineers make accurate predictions about the future. But which algorithm is the most accurate for predictive modeling? Let’s take a look at the various kinds of algorithms available and explore which one is best suited for predictive modeling.
Types of Machine Learning Algorithms
The first step in choosing an algorithm is understanding the types of algorithms used in machine learning. There are three main categories of algorithms used in machine learning: supervised learning, unsupervised learning, and reinforcement learning. Supervised learning is when data scientists use labeled data to teach the system what to do. Unsupervised learning uses unlabeled data to let the system learn on its own. Reinforcement learning focuses on taking action based on reward systems.
Which Algorithm Is Best For Predictive Modeling?
When it comes to predictive modeling, there are several different algorithms that can be used depending on your specific needs and goals. Generally speaking, supervised algorithms such as linear regression and logistic regression are often more accurate for predicting future outcomes than unsupervised or reinforcement learning algorithms due to their ability to learn from previously labeled data sets. Support vector machines (SVMs) are also widely used for predictive modeling due to their accuracy and ability to create non-linear decision boundaries.

Another popular choice for predictive modeling is artificial neural networks (ANNs). ANNs are composed of multiple layers of neurons that allow them to recognize patterns within large datasets quickly and accurately. ANNs have been proven time and time again as one of the most effective methods for predictive modeling due to their ability to process complex information faster than other types of models. However, they can be computationally intensive and require more training data than other models, making them less suitable for smaller datasets or applications with limited computing resources.
The most accurate machine learning algorithm for predictive modeling really depends on the type of data you’re working with. For example, if your data is structured, then linear regression might be the best option. Linear regression is a supervised learning algorithm that uses a linear approach to find relationships between input variables and output variables. It’s often used in econometrics and finance as well as other areas where forecasting and trend-based predictions are important.
If your data is unstructured, then a more sophisticated algorithm like recurrent neural networks (RNNs) might be better suited for the task at hand. RNNs are deep learning algorithms that use feedback loops to remember input data over time, allowing them to make more accurate predictions based on past events or patterns. This makes them particularly useful for applications such as natural language processing or speech recognition, where patterns need to be identified across long sequences of data.
Finally, if you need a balance of accuracy and speed, then support vector machines (SVMs) may be your best bet. SVMs are supervised learning algorithms that identify hyperplanes that separate classes of data points in order to make predictions about new data points. They are known for their high accuracy rates but can also run quickly due to their efficient implementation methods.
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6

 Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more codes)
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more codes)
Active Anti-Aging Eye Gel, Reduces Dark Circles, Puffy Eyes, Crow's Feet and Fine Lines & Wrinkles, Packed with Hyaluronic Acid & Age Defying Botanicals

Conclusion:
In conclusion, when it comes to choosing a machine learning algorithm for predictive modeling, there is no “one size fits all” solution; rather, it depends on your specific needs and goals as well as the dataset you have available. In general, supervised models such as linear regression and logistic regression are often more accurate than unsupervised or reinforcement learning models, while support vector machines (SVMs) offer non-linear decision boundaries with high accuracy levels when properly tuned. Artificial neural networks (ANNs) are also popular choices because they provide incredibly fast processing speeds and can handle complex information with ease; however they require more training data than other types of models which may not be feasible in some cases due to resource constraints or small datasets available. Ultimately, choosing an algorithm requires careful consideration of your specific requirements in order to select the most suitable option for your application’s needs.

Tunnel Boring Machine Process Control | Predictive Modelling
Tunneling process control is the feedback between the observed behavior of the tunnel boring machine (TBM) with predictions and observations. In this paper, examples of using predictive models to improve the feedback analysis and allow the engineer to readily undertake forecasts related to productivity and ground behavior are presented. These predictive models, which can be developed for TBM parameters (e.g., face pressure), ground behavior (e.g., volume loss), maintenance strategies, and construction logistics are updated/improved as the TBM progresses through the ground and the relationship between geotechnical conditions and TBM performance becomes better understood. This feedback ensures tunneling is achieved safely and effectively while maximizing productivity and minimizing risks.

INTRODUCTION
Real-time data acquisition and delivery for analysis have become standard practice in tunneling projects. This includes both TBM and instrumentation/monitoring data, providing an opportunity for real-time feedback analysis between construction activities and ground behavior. The real-time feedback in turn provides opportunities to assess and modify predictions and expectations with respect to TBM parameters and settlement control, and aid maintenance strategies and project planning and tendering.

With the advances made in both academia and industry, the understanding of the tunneling process and prediction of expected behaviors during mechanized shield tunneling has produced a number of prediction models that have been adopted and applied to design and construction planning.
Furthermore, more and more data than ever before is collected during construction, which enables comparison between predictions and observations, as well as improving the predictions with the added knowledge from the data.
However, due to the ongoing activities and progress of the tunnel construction, there is a need to be able to rapidly and efficiently make comparisons between predictions and observations and even update the predictions in at least a semi-automated manner. Furthermore, this feedback analysis should be easily applied to the process control and save significant time and money on the project. This paper presents several example use cases for developing and updating predictive models for feedback analysis and process control.
Read full article here : https://www.maxwellgeosystems.com/articles/using-predictive-modeling-tbm-process-control
Top 100 Data Science and Data Analytics and Data Engineering Interview Questions and Answers

What is the difference between regression, time series forecasting, and causal inference?
Regression, time series forecasting, and causal inference are all statistical techniques that can be used to analyze data and make predictions. Here is a brief overview of each:
Regression: Regression is a statistical technique used to model the relationship between a dependent variable and one or more independent variables. It is used to predict the value of the dependent variable based on the values of the independent variables.
Time series forecasting: Time series forecasting is a statistical technique used to predict future values of a series of data points based on past values. It is often used to make predictions about time-dependent data, such as sales or stock prices.
Causal inference: Causal inference is a statistical technique used to determine the cause-and-effect relationship between two variables. It is used to identify the potential causal relationships between variables, and to estimate the effect of one variable on another.
Overall, these techniques are used for different purposes and involve different approaches to data analysis. Regression is used to predict the value of a dependent variable based on independent variables, time series forecasting is used to predict future values of a series of data points based on past values, and causal inference is used to identify and estimate the causal relationships between variables.

What are some of the most acclaimed books about artificial intelligence and its applications?
There are many books that have been written about artificial intelligence (AI) and its applications, and the following are a few that are highly acclaimed:
- “Superintelligence: Paths, Dangers, and Strategies” by Nick Bostrom: This book explores the potential future development of AI and the risks and opportunities it may present.
- “Deep Learning” by Ian Goodfellow, Yoshua Bengio, and Aaron Courville: This book is a comprehensive introduction to deep learning, a type of machine learning that has achieved remarkable results in a wide range of applications.
- “The Master Algorithm” by Pedro Domingos: This book explores the idea of a “master algorithm” that could learn anything that can be learned and achieve superhuman intelligence.
- “Thinking, Fast and Slow” by Daniel Kahneman: This book is a best-selling work that explores the psychological biases and cognitive heuristics that shape our decision-making and how they can be influenced by AI.
- “The Singularity Trap” by Federico Pistono: This book discusses the potential risks and unintended consequences of AI and the need for responsible development and regulation.
These are just a few examples, and there are many other books that explore different aspects of AI and its applications.
Active Hydrating Toner, Anti-Aging Replenishing Advanced Face Moisturizer, with Vitamins A, C, E & Natural Botanicals to Promote Skin Balance & Collagen Production, 6.7 Fl Oz



Age Defying 0.3% Retinol Serum, Anti-Aging Dark Spot Remover for Face, Fine Lines & Wrinkle Pore Minimizer, with Vitamin E & Natural Botanicals


Firming Moisturizer, Advanced Hydrating Facial Replenishing Cream, with Hyaluronic Acid, Resveratrol & Natural Botanicals to Restore Skin's Strength, Radiance, and Resilience, 1.75 Oz

Skin Stem Cell Serum


Smartphone 101 - Pick a smartphone for me - android or iOS - Apple iPhone or Samsung Galaxy or Huawei or Xaomi or Google Pixel
Can AI Really Predict Lottery Results? We Asked an Expert.





Djamgatech

Read Photos and PDFs Aloud for me iOS
Read Photos and PDFs Aloud for me android
Read Photos and PDFs Aloud For me Windows 10/11
Read Photos and PDFs Aloud For Amazon
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more)
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6(Email us for more)



FREE 10000+ Quiz Trivia and and Brain Teasers for All Topics including Cloud Computing, General Knowledge, History, Television, Music, Art, Science, Movies, Films, US History, Soccer Football, World Cup, Data Science, Machine Learning, Geography, etc....

List of Freely available programming books - What is the single most influential book every Programmers should read
- Bjarne Stroustrup - The C++ Programming Language
- Brian W. Kernighan, Rob Pike - The Practice of Programming
- Donald Knuth - The Art of Computer Programming
- Ellen Ullman - Close to the Machine
- Ellis Horowitz - Fundamentals of Computer Algorithms
- Eric Raymond - The Art of Unix Programming
- Gerald M. Weinberg - The Psychology of Computer Programming
- James Gosling - The Java Programming Language
- Joel Spolsky - The Best Software Writing I
- Keith Curtis - After the Software Wars
- Richard M. Stallman - Free Software, Free Society
- Richard P. Gabriel - Patterns of Software
- Richard P. Gabriel - Innovation Happens Elsewhere
- Code Complete (2nd edition) by Steve McConnell
- The Pragmatic Programmer
- Structure and Interpretation of Computer Programs
- The C Programming Language by Kernighan and Ritchie
- Introduction to Algorithms by Cormen, Leiserson, Rivest & Stein
- Design Patterns by the Gang of Four
- Refactoring: Improving the Design of Existing Code
- The Mythical Man Month
- The Art of Computer Programming by Donald Knuth
- Compilers: Principles, Techniques and Tools by Alfred V. Aho, Ravi Sethi and Jeffrey D. Ullman
- Gödel, Escher, Bach by Douglas Hofstadter
- Clean Code: A Handbook of Agile Software Craftsmanship by Robert C. Martin
- Effective C++
- More Effective C++
- CODE by Charles Petzold
- Programming Pearls by Jon Bentley
- Working Effectively with Legacy Code by Michael C. Feathers
- Peopleware by Demarco and Lister
- Coders at Work by Peter Seibel
- Surely You're Joking, Mr. Feynman!
- Effective Java 2nd edition
- Patterns of Enterprise Application Architecture by Martin Fowler
- The Little Schemer
- The Seasoned Schemer
- Why's (Poignant) Guide to Ruby
- The Inmates Are Running The Asylum: Why High Tech Products Drive Us Crazy and How to Restore the Sanity
- The Art of Unix Programming
- Test-Driven Development: By Example by Kent Beck
- Practices of an Agile Developer
- Don't Make Me Think
- Agile Software Development, Principles, Patterns, and Practices by Robert C. Martin
- Domain Driven Designs by Eric Evans
- The Design of Everyday Things by Donald Norman
- Modern C++ Design by Andrei Alexandrescu
- Best Software Writing I by Joel Spolsky
- The Practice of Programming by Kernighan and Pike
- Pragmatic Thinking and Learning: Refactor Your Wetware by Andy Hunt
- Software Estimation: Demystifying the Black Art by Steve McConnel
- The Passionate Programmer (My Job Went To India) by Chad Fowler
- Hackers: Heroes of the Computer Revolution
- Algorithms + Data Structures = Programs
- Writing Solid Code
- JavaScript - The Good Parts
- Getting Real by 37 Signals
- Foundations of Programming by Karl Seguin
- Computer Graphics: Principles and Practice in C (2nd Edition)
- Thinking in Java by Bruce Eckel
- The Elements of Computing Systems
- Refactoring to Patterns by Joshua Kerievsky
- Modern Operating Systems by Andrew S. Tanenbaum
- The Annotated Turing
- Things That Make Us Smart by Donald Norman
- The Timeless Way of Building by Christopher Alexander
- The Deadline: A Novel About Project Management by Tom DeMarco
- The C++ Programming Language (3rd edition) by Stroustrup
- Patterns of Enterprise Application Architecture
- Computer Systems - A Programmer's Perspective
- Agile Principles, Patterns, and Practices in C# by Robert C. Martin
- Growing Object-Oriented Software, Guided by Tests
- Framework Design Guidelines by Brad Abrams
- Object Thinking by Dr. David West
- Advanced Programming in the UNIX Environment by W. Richard Stevens
- Hackers and Painters: Big Ideas from the Computer Age
- The Soul of a New Machine by Tracy Kidder
- CLR via C# by Jeffrey Richter
- The Timeless Way of Building by Christopher Alexander
- Design Patterns in C# by Steve Metsker
- Alice in Wonderland by Lewis Carol
- Zen and the Art of Motorcycle Maintenance by Robert M. Pirsig
- About Face - The Essentials of Interaction Design
- Here Comes Everybody: The Power of Organizing Without Organizations by Clay Shirky
- The Tao of Programming
- Computational Beauty of Nature
- Writing Solid Code by Steve Maguire
- Philip and Alex's Guide to Web Publishing
- Object-Oriented Analysis and Design with Applications by Grady Booch
- Effective Java by Joshua Bloch
- Computability by N. J. Cutland
- Masterminds of Programming
- The Tao Te Ching
- The Productive Programmer
- The Art of Deception by Kevin Mitnick
- The Career Programmer: Guerilla Tactics for an Imperfect World by Christopher Duncan
- Paradigms of Artificial Intelligence Programming: Case studies in Common Lisp
- Masters of Doom
- Pragmatic Unit Testing in C# with NUnit by Andy Hunt and Dave Thomas with Matt Hargett
- How To Solve It by George Polya
- The Alchemist by Paulo Coelho
- Smalltalk-80: The Language and its Implementation
- Writing Secure Code (2nd Edition) by Michael Howard
- Introduction to Functional Programming by Philip Wadler and Richard Bird
- No Bugs! by David Thielen
- Rework by Jason Freid and DHH
- JUnit in Action
#BlackOwned #BlackEntrepreneurs #BlackBuniness #AWSCertified #AWSCloudPractitioner #AWSCertification #AWSCLFC02 #CloudComputing #AWSStudyGuide #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AWSBasics #AWSCertified #AWSMachineLearning #AWSCertification #AWSSpecialty #MachineLearning #AWSStudyGuide #CloudComputing #DataScience #AWSCertified #AWSSolutionsArchitect #AWSArchitectAssociate #AWSCertification #AWSStudyGuide #CloudComputing #AWSArchitecture #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AzureFundamentals #AZ900 #MicrosoftAzure #ITCertification #CertificationPrep #StudyMaterials #TechLearning #MicrosoftCertified #AzureCertification #TechBooks
Top 1000 Canada Quiz and trivia: CANADA CITIZENSHIP TEST- HISTORY - GEOGRAPHY - GOVERNMENT- CULTURE - PEOPLE - LANGUAGES - TRAVEL - WILDLIFE - HOCKEY - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Top 1000 Africa Quiz and trivia: HISTORY - GEOGRAPHY - WILDLIFE - CULTURE - PEOPLE - LANGUAGES - TRAVEL - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Exploring the Pros and Cons of Visiting All Provinces and Territories in Canada.


Exploring the Advantages and Disadvantages of Visiting All 50 States in the USA

Health Health, a science-based community to discuss health news and the coronavirus (COVID-19) pandemic
- CDC and FDA investigate fake 'Botox' injections!by /u/sbgroup65 on April 18, 2024 at 10:39 pm
submitted by /u/sbgroup65 [link] [comments]
- Cocaine seems to hijack brain pathways that prioritize food and waterby /u/dead_planets_society on April 18, 2024 at 7:10 pm
submitted by /u/dead_planets_society [link] [comments]
- The Bone-Marrow Transplant Revolutionby /u/theatlantic on April 18, 2024 at 6:42 pm
submitted by /u/theatlantic [link] [comments]
- Heat caused record-high rates of health emergencies in some parts of the US last year, CDC report showsby /u/cnn on April 18, 2024 at 6:19 pm
submitted by /u/cnn [link] [comments]
- Microplastics can travel to the brain and other vital organs after ingestion, new study findsby /u/Unusual-State1827 on April 18, 2024 at 1:14 pm
submitted by /u/Unusual-State1827 [link] [comments]
Today I Learned (TIL) You learn something new every day; what did you learn today? Submit interesting and specific facts about something that you just found out here.
- TIL that George Orwell was spied on by a Soviet secret agent named Hugh O'Donnell, code-name O'Brien. In a coincidence, (book spoiler) Orwell wrote Nineteen Eighty-Four to have a spy named O'Brien betray the main character, without knowing about the Soviet spy codenamed "O'Brien."by /u/RollingNightSky on April 19, 2024 at 1:44 am
submitted by /u/RollingNightSky [link] [comments]
- TIL 1700s Persian emperor Nader Shah kept fried peas on his person at all time, which he would eat if he didn't have time to prepare a proper mealby /u/GallicHeritage00 on April 19, 2024 at 12:58 am
submitted by /u/GallicHeritage00 [link] [comments]
- TIL of Manfred Ramminger, a German architect who stole an American missile for the Soviet Union by walking into a West German air base, hauling the missile out in a wheelbarrow, driving it wrapped in a carpet, and finally disassembling it and shipping it to Moscow through commercial airmail.by /u/zhuquanzhong on April 18, 2024 at 11:20 pm
submitted by /u/zhuquanzhong [link] [comments]
- TIL about Hanns Scharff, a German Luftwaffe interrogator during the Second World War who is considered the "father of modern interrogation techniques". After the war he became a famous mosaic artisan who amongt other things created the 15-foot arched cinderella mosaic walls in Disneylandby /u/news_doge on April 18, 2024 at 9:43 pm
submitted by /u/news_doge [link] [comments]
- TIL that Ford Bronco sales surged by 23.3% after O.J. Simpson's infamous chase and the trial.by /u/8004MikeJones on April 18, 2024 at 9:40 pm
submitted by /u/8004MikeJones [link] [comments]
Reddit Science This community is a place to share and discuss new scientific research. Read about the latest advances in astronomy, biology, medicine, physics, social science, and more. Find and submit new publications and popular science coverage of current research.
- Two lifeforms merge in once-in-a-billion-years evolutionary eventby /u/Archchancellor on April 19, 2024 at 2:54 am
submitted by /u/Archchancellor [link] [comments]
- Scientists found 7 astrophysical tau neutrinos—particles that are notoriously difficult to detect—in an analysis of data from the IceCube Neutrino Observatory. A tau neutrino produces a tau lepton—a heavy cousin of the electron—that emits a photon ball both when it is produced and when it decays.by /u/MistWeaver80 on April 19, 2024 at 12:42 am
submitted by /u/MistWeaver80 [link] [comments]
- Study shows that the immune system of the Zebrafish is involved in their ability to regenerate their heart after injury.by /u/AtomicPotatoLord on April 18, 2024 at 11:42 pm
submitted by /u/AtomicPotatoLord [link] [comments]
- Exposure to sexualized images leads to heightened self-objectification among viewers and a tendency to dehumanize the individuals depicted. Moreover, the act of generating hashtags for these images amplifies this effect, with tags often focusing unduly on body parts.by /u/mvea on April 18, 2024 at 10:48 pm
submitted by /u/mvea [link] [comments]
- High-intensity aerobic exercise improved cognitive function in both lean individuals and obese individuals with normal glucose tolerance. In contrast, the cognitive function of obese individuals with impaired glucose tolerance did not show any improvement following the exercise session.by /u/mvea on April 18, 2024 at 10:45 pm
submitted by /u/mvea [link] [comments]
Reddit Sports Sports News and Highlights from the NFL, NBA, NHL, MLB, MLS, and leagues around the world.
- Two-time world champion Kento Momota announces retirement from badminton at 29 amid physical and mental tollby /u/kundu123 on April 19, 2024 at 5:49 am
submitted by /u/kundu123 [link] [comments]
- Albany NFL draft hopeful AJ Simon dies at age 25by /u/Oldtimer_2 on April 19, 2024 at 5:26 am
submitted by /u/Oldtimer_2 [link] [comments]
- Geno Auriemma says one-and-done rule could 'ruin' women's college basketballby /u/PrincessBananas85 on April 19, 2024 at 3:33 am
submitted by /u/PrincessBananas85 [link] [comments]
- Caitlin Clark blocks Antonio Brown after inappropriate posts on social mediaby /u/kundu123 on April 19, 2024 at 2:43 am
submitted by /u/kundu123 [link] [comments]
- Judge denies request for Bob Baffert-trained Arkansas Derby winner Muth to run in Kentucky Derbyby /u/Oldtimer_2 on April 19, 2024 at 2:05 am
submitted by /u/Oldtimer_2 [link] [comments]
