What are some ways to Boost Precision and Recall in Machine Learning?
Sensitivity vs Specificity?
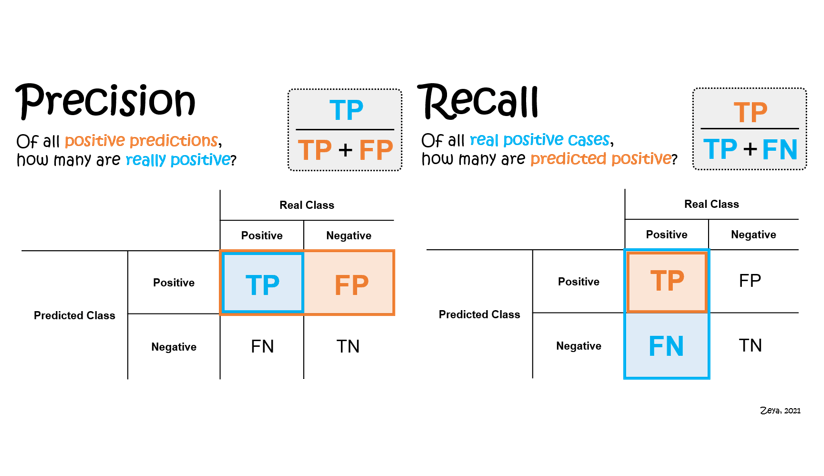
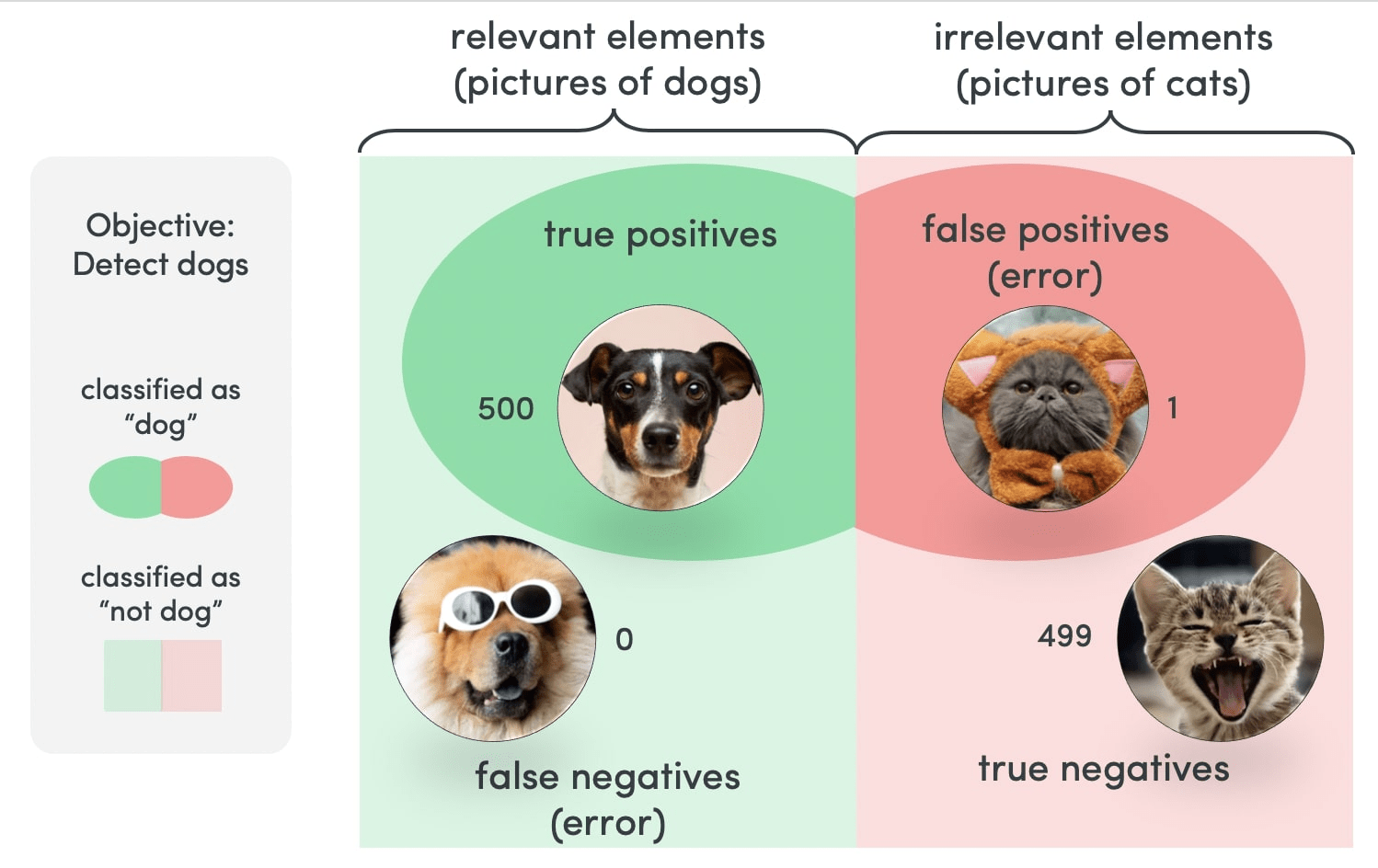
In machine learning, recall is the ability of the model to find all relevant instances in the data while precision is the ability of the model to correctly identify only the relevant instances. A high recall means that most relevant results are returned while a high precision means that most of the returned results are relevant. Ideally, you want a model with both high recall and high precision but often there is a trade-off between the two. In this blog post, we will explore some ways to increase recall or precision in machine learning.
by increasing the number of false positives or by decreasing the number of false negatives. To increase the number of false positives, you can lower your threshold for what constitutes a positive prediction. For example, if you are trying to predict whether or not an email is spam, you might lower the threshold for what constitutes spam so that more emails are classified as spam. This will result in more false positives (emails that are not actually spam being classified as spam) but will also increase recall (more actual spam emails being classified as spam).
you can increase your threshold for what constitutes a positive prediction. For example, going back to the spam email prediction example, you might raise the threshold for what constitutes spam so that fewer emails are classified as spam. This will result in fewer false negatives (actual spam emails not being classified as spam) but will also decrease recall (fewer actual spam emails being classified as spam).
by increasing the number of true positives or by decreasing the number of true negatives. To increase the number of true positives, you can raise your threshold for what constitutes a positive prediction. For example, using the spam email prediction example again, you might raise the threshold for what constitutes spam so that fewer emails are classified as spam. This will result in more true positives (emails that are actually spam being classified as spam) but will also decrease precision (more non-spam emails being classified as spam).
you can lower your threshold for what constitutes a positive prediction. For example, going back to the spam email prediction example once more, you might lower the threshold for what constitutes spam so that more emails are classified as spam. This will result in fewer true negatives (emails that are not actually spam not being classified as spam) but will also decrease precision (more non-spam emails being classified as spam).
there are a few ways to increase precision or recall in machine learning. One way is to use a different evaluation metric. For example, if you are trying to maximize precision, you can use the F1 score, which is a combination of precision and recall. Another way to increase precision or recall is to adjust the threshold for classification. This can be done by changing the decision boundary or by using a different algorithm altogether.
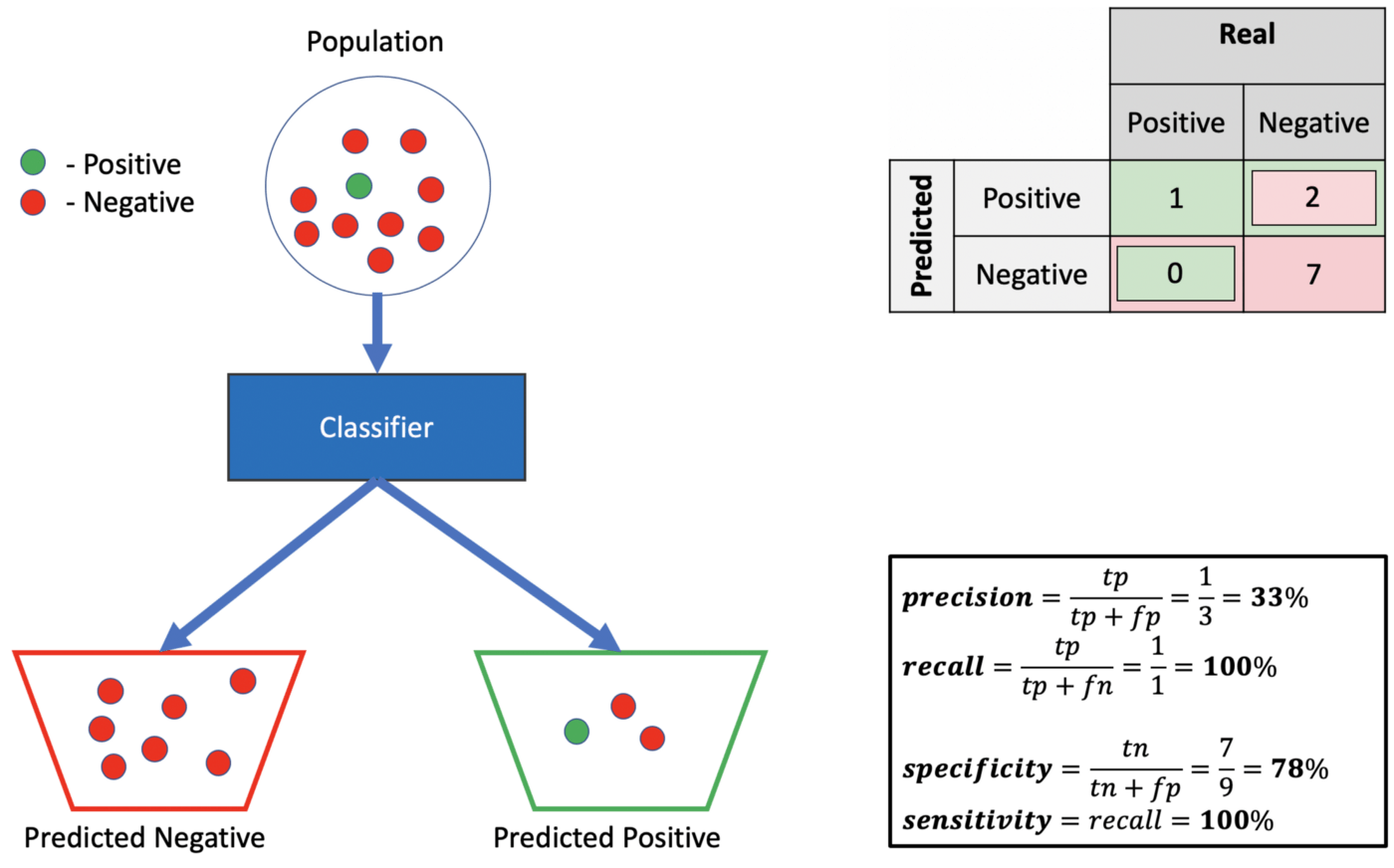
In machine learning, sensitivity and specificity are two measures of the performance of a model. Sensitivity is the proportion of true positives that are correctly predicted by the model, while specificity is the proportion of true negatives that are correctly predicted by the model.
Google introduced computing units, which you can purchase just like any other cloud computing unit you can from AWS or Azure etc. With Pro you get 100, and with Pro+ you get 500 computing units. GPU, TPU and option of High-RAM effects how much computing unit you use hourly. If you don’t have any computing units, you can’t use “Premium” tier gpus (A100, V100) and even P100 is non-viable.
Google Colab Pro+ comes with Premium tier GPU option, meanwhile in Pro if you have computing units you can randomly connect to P100 or T4. After you use all of your computing units, you can buy more or you can use T4 GPU for the half or most of the time (there can be a lot of times in the day that you can’t even use a T4 or any kinds of GPU). In free tier, offered gpus are most of the time K80 and P4, which performs similar to a 750ti (entry level gpu from 2014) with more VRAM.
For your consideration, T4 uses around 2, and A100 uses around 15 computing units hourly.
Based on the current knowledge, computing units costs for GPUs tend to fluctuate based on some unknown factor.
Considering those:
If you have anything more to say, please let me know so I can edit this post with them. Thanks!
I'm in a senior DS role right now. This is my first data job after being a professor for a few years post PhD. I'm a modeler, that's my main focus on the job, which I absolutely love. However, the client (I'm a consultant) uses SAS miner and guide, and does not use Python at all. Partially because they always have and partially for security concerns. As I build my models, realistically the biggest issue is making sure I do things that our (imo outdated) tech stack can handle. I'd love to do a sexy GNN network based model for example but right now we struggle to execute a random forest. The experience I'm getting is great, I'll be about to make some solid quantifiable improvements, and I'm not looking to move jobs in the next <3 years. However, I worry that if I go on the market in the future, my lack of experience putting Python into prod will be an issue. Hopefully at that point I'll have some promotions under my belt and will be moreso managing a team than running code. If I'm in the future applying for more senior positions, will they care so much about what tools I've been using versus my experience leading a team/communicating with the business, etc? submitted by /u/math_vet [link] [comments]
Hi, Currently I have a one note where I track different pieces of company desired goals/targets through the year. Some of the things they care about : 1) certs / continuing education 2) speaking events 3) individual contributions (projects etc) How are some of the ways you track your progress? And if you don’t…why? Any way you can resell yourself every review is great ammunition imo. submitted by /u/Texas_Badger [link] [comments]
I’m tasked with figuring out how to separate syntax and semantics for a given text. To be more concrete, is there a way to say two text convey the same idea just with a different way of expressing it. The only method I know is to use embeddings and compare the cosine similarities of it but I don’t think that cuts it. I am pretty new to NLP and any recommendation is helpful submitted by /u/justinhjy1004 [link] [comments]
Our work on analysing linear time series forecasting models was accepted to ICML. ArxiV: https://arxiv.org/abs/2403.14587 Abstract: Despite their simplicity, linear models perform well at time series forecasting, even when pitted against deeper and more expensive models. A number of variations to the linear model have been proposed, often including some form of feature normalisation that improves model generalisation. In this paper we analyse the sets of functions expressible using these linear model architectures. In so doing we show that several popular variants of linear models for time series forecasting are equivalent and functionally indistinguishable from standard, unconstrained linear regression. We characterise the model classes for each linear variant. We demonstrate that each model can be reinterpreted as unconstrained linear regression over a suitably augmented feature set, and therefore admit closed-form solutions when using a mean-squared loss function. We provide experimental evidence that the models under inspection learn nearly identical solutions, and finally demonstrate that the simpler closed form solutions are superior forecasters across 72% of test settings. Summary Several popular works have argued that linear regression is sufficient for forecasting (DLinear and FITs are examples for the discerning reader). It turns out that if you do the maths these models are essentially equivalent. We do the math and also the experiments. Perhaps most interestingly: the ordinary least squares (OLS) solution is almost always better than other linear models trained using gradient descent. Importantly: we did not do a hyper parameter search to set, for example, the regularisation coefficient. We reserve that for future work. OLS is extremely efficient - a model can be fit in the order of milliseconds if set up right. Finally, although we don't go to lengths to show this: many of our results are superior to large and complex models, begging the question of when and where such models are effective. submitted by /u/Gramious [link] [comments]
submitted by /u/vijayabhaskar96 [link] [comments]
Hello, I’m coming with question to maybe more experienced professionals or even people which are recruiting. In most job postings I see for DS, MLE, MLOps etc I see requirement of at least 3 YOE. In my personal experience I saw lot of devs with 1 YOE having much more knowledge and wider range of skills then devs with 6 YOE writing code in PHP and using only excel. I assume most people having less experience in their resume would be dropped immediately in early stage of reviewing candidates because of this factor. What’s the deal with this time boundary and is it really that important? submitted by /u/jesteartyste [link] [comments]
Hey folks, Recently spent time measuring the Time to First Token (TTFT) of various large language models (LLMs) when deployed within Docker containers, and the findings were quite interesting. For those who don't know, TTFT measures the speed from when you send a query to when you get the first response. Here are the key findings: Performance Across Token Sizes: Libraries like Triton-vLLM and vLLM are super quick (~25 milliseconds) with fewer tokens but slow down significantly (200-300 milliseconds) with more tokens. CTranslate-2 and Deepspeed-mii also slow down as you increase the token count. However, vLLM keeps things quick and efficient, even with more tokens. Handling Big Inputs: Libraries like Deepspeed-mii, vLLM, TGI, and Triton-vLLM can handle more tokens but get slower the more you push them. This shows some challenges in scaling up. Best Token Responses: While everything runs smoothly up to about 100 tokens, performance drops after 500 tokens. The ideal number of tokens for the quickest response seems to be around 20, with times ranging from about 25 to 60 milliseconds depending on the model. https://preview.redd.it/6n03xwbqddyc1.jpg?width=1600&format=pjpg&auto=webp&s=9464d6f85a2cdab685fc8e7cd7031a85600f00c1 These findings might help you pick the right models and libraries and set your expectations. Keen to hear if anyone else has tested TTFT or has tips on library performance! submitted by /u/rbgo404 [link] [comments]
I'm looking for an ML community that builds and collaborates together. Builds open source projects or works on collaborations. Anyone know of such a community? I'm building a neural net from scratch in Golang for timeseries prediction and would be nice to bounce some ideas, find devs to work with. submitted by /u/dismouse [link] [comments]
If you have an idea for a new weird kind of distance metric, how would you go about evaluating and comparing it's performance to other well known metrics for similar vector types? I'm not really talking about computational performance but that it's somehow better at capturing the intuitive difference between vectors in that space. submitted by /u/datashri [link] [comments]
Hello, I'm doing a research project in which we have to generate Timeseries data (Tabular) using diffusion models. For this purpose I'm using DDPM (Denoising Diffusion Probabilistic Models) for data Generation. I have different columns in my dataset and one of the column is Datetime timestamp which is like this format ('hh-mm-ss dd-mm-yyyy'). So my timestamp is in string format and i have to encode it in order to move forward with the training. The issue I'm facing is that when i pass my data through my model for data Generation it is generating all the other columns (Numerical) but it's giving me string error with my timestamp colum because it's in string format. I perform Ordinal encoding on my timestamp but the generated data is far different than the timestamp. When i perform Encoding (ordinal encoding) the timestamp value converted from ('hh-mm-ss dd-mm-yyyy') to 75290 like this. But when i pass into model and generate data it gives me totally different results like 12.5. so it's giving me totally different results and can't decode it back to my timestamp. Can anyone help me regarding this that how can i perform encoding on my timestamp that it can capture the original dynamics of timestamp and also generate the data similar to that so se can decode the generated data back to timestamp value after decoder generation. submitted by /u/Alarming-East1193 [link] [comments]
Short version: give me some examples of client deliverables in the field of ML. Will help to judge where I stand to start freelance consulting. Hi, I am an SWE learning ML on the side. My day to day job doesn’t have much exposure to ML but a lot of GPU stuff. I started learning ML and am at a stage where I can implement some models from research papers. Looking for some examples in the real world what are some deliverables that you have successfully done for a client. This would greatly help to understand where I stand in terms of taking up full time consultancy. Does it even make sense in the age of this humongous models to start an independent consultancy? submitted by /u/SmallTimeCSGuy [link] [comments]
I am curious. Anyone works in traditional enterprises like banking manufacturing actually using gen ai? If yes how? submitted by /u/digital-bolkonsky [link] [comments]
In the diffusion paper they say their model’s codelength gap in train and test is at most 0.03 bits per dimension, ehich suggests that the midel doesn’t overfit. But what does it even mean that the model is overfitted in the diffusion case? Does it then only denoise into images from the training set? Cheers! submitted by /u/Error40404 [link] [comments]
submitted by /u/PraiseChrist420 [link] [comments]
Looking to be able to search for the price of any given food you’d find in the grocery store. Aware of any datasets that have this information? submitted by /u/LettucePilgrim [link] [comments]
I did a Masters years ago, and we had an internship requirement as part of it. The university had a bunch of big-name employers come in over the course of a week, and we could sign up to interview with them. I'm curious how other grad programs did or did not help you get a job. submitted by /u/Dangerous_Media_2218 [link] [comments]
Hi all, I'm trying to build a personal project on synthetic dataset generation. Been researching + laying out an initial structure for the project. The main question I have is can FLAN-T5 be used for data generation / mass text generation? I can't seem to find examples of people using it for that use-case. I've looked at mixtral-instruct models aswell. I am trying to avoid GPT4 due to cost. Please let me know of any other LMs that could be good for my purposes submitted by /u/Theredeemer08 [link] [comments]
I know the market is fucked for less experienced candidates. What’s the market like for people with 5+ years experience at a FAANG as well as a graduate + undergraduate degree from a top tier institution? Is it just the new grad market that’s fucked or the L5/L6 market too? submitted by /u/Terrible-Hamster-342 [link] [comments]
Hello all, Wanted to ask if any of y'all had experience with using quantized/binned version of feature sets and/or goal sets to improve performance for sequence learners for time-series problems. I'm not very strong on NLP so sorry for any of the mistakes that may follow Set-up: f(X) -> ŷ with the goal of |ŷ-y| < eps X is a feature set with features that are hopefully informative on y, with varying frequencies of information, such as simple moving average with varying windows for each feature dimension, as a toy example. X and y are noisy Motivation I have seen some recent work modifying univariate time-series forecasting problems so they are digestible for LLMs, in particular : Chronos: Learning the Language of Time Series The general method is Scale a time series in some way, such as dividing each sequence by mean absolute value bin these values to make the possible values now discrete add start / end token to be digestible by LLMs and then use to forecast Hurrah now we have a time-series that can be passed into an LLM Quantization for RNNs rather than LLM Taking a step back, rather than using the above transformation for use with LLMs, I'm wondering if anyone here have used these techniques to make a time-series more amenable for an RNN. The two important parts of the transformation are (1) the scaling technique and (2) the number of bins N. As N -> infinity we get the same precision as the original time-series. Quantization as a function Q(.) can be applied to either X,y or both. Benefits I had in mind: Using integers as references to bins for faster/easier trading reduce noise in signal possibility of using feature embedding? Hopefully this was clear. Any help is appreciated. submitted by /u/HungryhungryUgolino [link] [comments]
AI engineers report burnout and rushed rollouts as ‘rat race’ to stay competitive hits tech industry Summary from article: Artificial intelligence engineers at top tech companies told CNBC that the pressure to roll out AI tools at breakneck speed has come to define their jobs. They say that much of their work is assigned to appease investors rather than to solve problems for end users, and that they are often chasing OpenAI. Burnout is an increasingly common theme as AI workers say their employers are pursuing projects without regard for the technology’s effect on climate change, surveillance and other potential real-world harms. An especially poignant quote from the article: An AI engineer who works at a retail surveillance startup told CNBC that he’s the only AI engineer at a company of 40 people and that he handles any responsibility related to AI, which is an overwhelming task. He said the company’s investors have inaccurate views on the capabilities of AI, often asking him to build certain things that are “impossible for me to deliver.” submitted by /u/bregav [link] [comments]
Offering employees, coworkers, teammates, and students constructive feedback is a vital part of growth on…
Millennials should avoid delaying the inevitable and look into various retirement investment pathways. Here’s why…
For most people, a satisfactory career is essential for leading a happy life. However, ensuring…
The pipeline industry is more than pipework and construction, and we explore those details in…
SQL Interview Questions and Answers In the world of data-driven decision-making, SQL (Structured Query Language)…
{kind=link}
{kind=link}
{kind=link}
{kind=link}