How does a database handle pagination?
How does a database handle pagination?
It doesn’t. First, a database is a collection of related data, so I assume you mean DBMS or database language.
Second, pagination is generally a function of the front-end and/or middleware, not the database layer.
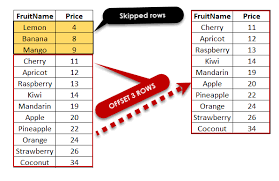
But some database languages provide helpful facilities that aide in implementing pagination. For example, many SQL dialects provide LIMIT and OFFSET clauses that can be used to emit up to n rows starting at a given row number. I.e., a “page” of rows. If the query results are sorted via ORDER BY and are generally unchanged between successive invocations, then that can be used to implement pagination.
That may not be the most efficient or effective implementation, though.
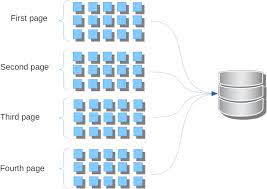
On context of web apps , let’s say there are 100 mn users. One cannot dump all the users in response.
Cache database query results in the middleware layer using Redis or similar and serve out pages of rows from that.
I feel the most efficient solution is still offset and limit. It doesn’t make sense to use a database and then end up putting all of your data in Redis especially data that changes a lot. Redis is not for storing all of your data.
With 30,000 rows in a table, if offset/limit is the only viable or appropriate restriction, then that’s sometimes the way to go.
More often, there’s a much better way of restricting 30,000 rows via some search criteria that significantly reduces the displayed volume of rows — ideally to a single page or a few pages (which are appropriate to cache in Redis.)
It’s unlikely (though it does happen) that users really want to casually browse 30,000 rows, page by page. More often, they want this one record, or these small number of records.
I know for MySQL there is LIMIT offset,size; and for Oracle there is ‘ROW_NUMBER’ or something like that.
But when such ‘paginated’ queries are called back to back, does the database engine actually do the entire ‘select’ all over again and then retrieve a different subset of results each time? Or does it do the overall fetching of results only once, keeps the results in memory or something, and then serves subsets of results from it for subsequent queries based on offset and size?
If it does the full fetch every time, then it seems quite inefficient.
If it does full fetch only once, it must be ‘storing’ the query somewhere somehow, so that the next time that query comes in, it knows that it has already fetched all the data and just needs to extract next page from it. In that case, how will the database engine handle multiple threads? Two threads executing the same query?
something will be quick or slow without taking measurements, and complicate the code in advance to download 12 pages at once and cache them because “it seems to me that it will be faster”.
Answer: First of all, do not make assumptions in advance whether something will be quick or slow without taking measurements, and complicate the code in advance to download 12 pages at once and cache them because “it seems to me that it will be faster”.
YAGNI principle – the programmer should not add functionality until deemed necessary.
Do it in the simplest way (ordinary pagination of one page), measure how it works on production, if it is slow, then try a different method, if the speed is satisfactory, leave it as it is.
From my own practice – an application that retrieves data from a table containing about 80,000 records, the main table is joined with 4-5 additional lookup tables, the whole query is paginated, about 25-30 records per page, about 2500-3000 pages in total. Database is Oracle 12c, there are indexes on a few columns, queries are generated by Hibernate. Measurements on production system at the server side show that an average time (median – 50% percentile) of retrieving one page is about 300 ms. 95% percentile is less than 800 ms – this means that 95% of requests for retrieving a single page is less that 800ms, when we add a transfer time from the server to the user and a rendering time of about 0.5-1 seconds, the total time is less than 2 seconds. That’s enough, users are happy.
And some theory – see this answer to know what is purpose of Pagination pattern
submitted by /u/saipeerdb [link] [comments]
Hi all, I'm currently designing a mobile application that will allow users to upload items with any number of attributes to a database. I'm not going to limit the attributes user can enter, they could potentially create new ones every time they upload an item. Right now, I'm not planning to do a lot of querying around these attributes but there will be a need for at least for some analytics revolving those. Originally I was planning to use Postgres and just store the attributes as a JSON in a text field. While running queries around that is a bit more painful, I've done this before and it works. However, I'm now wondering whether I should use MongoDB as it is geared more towards unstructured data. It seems like overall a more appropriate choice. My hesitation stems from the fact I'm not as familiar with MongoDB and not being able to use SQL would really slow me down. I'd love any thoughts supporting either one or even a different database altogether. Would be very grateful for any input. Many thanks submitted by /u/MiyagiJunior [link] [comments]
Baserow is a powerful platform for organizing, managing, and analyzing data.Continue reading on Medium »
To demonstrate the practical feasibility of the formalism proposed to the public in a series of papers we published, we are currently…Continue reading on Medium »
I own https://scabidi.com, and I want to own servers instead of rent them from Hostinger, Is there a way to get servers to show someone else's address, this is just a database I would continue to host the website from Hostinger, but it would connect to my database to get things like users. submitted by /u/Mrcool654321 [link] [comments]
I know there isn't a universal standard for the Crow's Foot Diagrams but I was wondering about the common practice around the situations bellow. How do you represent weak entity sets? I've been drawing them as normal entities with double borders, and double lines connected to the identifying entity. Is there a more standard/common way, because this is something I made up as I couldn't find any example? Do you or do you not include FK atributes? If entity A has a 1:M Relation with Entity B through a B_pk attribute in the A schema, should you include the attribute in the diagram. I know you don't include it in a Chen diagram but example I see of Crow's Foot vary Disjoint vs Overlaping Specialization. How do you represent them? submitted by /u/xyzb206 [link] [comments]
Welcome to the world of database management! Have you ever felt that you are lost in a sea of data, struggling to keep your head up? You…Continue reading on Medium »
In SQL Server, `READPAST` and `UPDLOCK` are table hint options used to control the behavior of SQL operations, particularly in scenarios…Continue reading on Medium »
Dive into Neo4j Graph Databases and Generative AI, exploring how these technologies revolutionize data exploration. Discover Neo4j…Continue reading on Cubed »
As businesses expand, their data requirements often surpass their current database setup. Scaling up your database can be a daunting task…Continue reading on Medium »
In the modern data-driven landscape, being immediately aware of changes in your database is essential. As part of the monitoring system…Continue reading on Locale »
Hi! I am Katya, a member of the START mobile testing team.Continue reading on STARTteam »
안녕하세요. 브릭메이트 Arnold 입니다.Continue reading on Medium »
Hello everyone! I was hoping to get some enlightenment here on Reddit. Long story short: I got my engineering degree in Information Technologies on a web development area in Mexico. Two years ago, I had to move to the States and start an admin job. I always loved how databases were created and considered myself to be really good at finding the connections between all the tables created in a database and the commands. We were taught mainly relational systems (mySQL) at my college. I’m wishing to get myself into this field. My dream has always been to be very prepared and knowledgeable. For that reason, I have been thinking about getting a masters so I can create some networking and try to apply for an internship. Everything at this moment feels so vague to me. I’d like to get some advice on where I could start since I know that the database field is extensive and has a lot of branches. Any advice is well taken. submitted by /u/Ok_Entertainer4352 [link] [comments]
Ok guys so this is about my homework. Our assignment is to make a database on a theme we choose by ourselves and then make a website/web app to visualise different aspects. I made a music shop database and now I am asking if any of you know how to easily implement what I said above. I gotta say I hate frontend but as a last resort, I will go ahead and practice my HTML, CSS, PHP skills. submitted by /u/Roti23 [link] [comments]
Hi guys. I know this may be a stupid question but I would ask anyway because I'm a noob. Is it better to offload some of the operations done by database operations (such as joins) in postgres (or any database, for that matter) to some algorithm outside the database to speed up database operations or are databases built for handling large amounts of reads and writes in addition to extra-computation, particularly for large amounts of data? I am talking about times when there is a huge amount of reads and writes to that database. I was thinking that the amount of joins in my queries would slow down operations as the size of the tables grow bigger and I cannot help but feel that I'm stuck in a bad case of premature optimization. The joins were supposed to be replaced by data streams that allow us to continous reads and writes without worrying about anything else. submitted by /u/steve_335 [link] [comments]
I am studying about ERM in our database class now. the Professor said that some relationships cannot be implemented in the database like 1:1 , C:C, M:1, M:C, 1:M, C:M, CM:M, CM:CM, M:M The only thing was recommended were CM:1 , CM:C, and 1:C I cannot get it in my head why is this? can someone clear this up for me or give practical examples about this concept? submitted by /u/Outrageous_Fox9730 [link] [comments]
This blog post serves as an all-in-one resource for securing your PostgreSQL Database Environment, offering comprehensive insights not easily found elsewhere. I will delve into the details of database security, uncovering the integration of robust tools like Patroni, Etcd, and Pgbackrest and demonstrate how TLS can be implemented to secure data in transit for Etcd, Patroni and Pgbackrest. I hope you'll find it valuable. https://insanedba.blogspot.com/2024/04/secure-postgresql-patroni-etcd.html submitted by /u/riddinck [link] [comments]
I’m currently working on improving our system for verifying and updating physician and clinic information in our database. Currently, our workflow involves the following steps: Data Entry via MS Forms: We fill out physician info via MS Forms and submit their details. Automation with Power Automate: Submissions trigger a Power Automate flow that updates our SQL Server database and emails our leadership team about new or updated entries. Approval and Processing: Updates are then processed and, if necessary, go through an approval process via MS Approvals. While this system works for data entry, it's not proactive in maintaining up-to-date information. We send out empty forms that physicians fill from scratch, which is time-consuming and not user-friendly. What I Want to Achieve: Pre-filled Data Forms: Allow physicians to select their names from a list, view the information we currently hold in a user-friendly format, and make updates as needed. Seamless Updates and Notifications: If updates are made, these should trigger a Power Automate flow to email and notify our leadership team, possibly go through an approval process (like MS Approvals), and subsequently update the SQL database record. The Challenge: We have a tool for data entry (MS Forms) but lack a straightforward method or workflow to retrieve and display current information from the database for user verification and updates. Questions for the Community: Has anyone implemented a similar system that integrates data retrieval with user updates in a user-friendly interface? What tools or platforms would you recommend that can seamlessly integrate with SQL Server and Power Automate for such a functionality? I'm looking for any advice, tool recommendations, or insights that could help streamline this process and make it more efficient. Thank you in advance for your help! submitted by /u/downvoted_your_mom [link] [comments]
I’m currently working on improving our system for verifying and updating physician and clinic information in our database. Currently, our workflow involves the following steps: Data Entry via MS Forms: We fill out physician info via MS Forms and submit their details. Automation with Power Automate: Submissions trigger a Power Automate flow that updates our SQL Server database and emails our leadership team about new or updated entries. Approval and Processing: Updates are then processed and, if necessary, go through an approval process via MS Approvals. While this system works for data entry, it's not proactive in maintaining up-to-date information. We send out empty forms that physicians fill from scratch, which is time-consuming and not user-friendly. What I Want to Achieve: Pre-filled Data Forms: Allow physicians to select their names from a list, view the information we currently hold in a user-friendly format, and make updates as needed. Seamless Updates and Notifications: If updates are made, these should trigger a Power Automate flow to email and notify our leadership team, possibly go through an approval process (like MS Approvals), and subsequently update the SQL database record. The Challenge: We have a tool for data entry (MS Forms) but lack a straightforward method or workflow to retrieve and display current information from the database for user verification and updates. Questions for the Community: Has anyone implemented a similar system that integrates data retrieval with user updates in a user-friendly interface? What tools or platforms would you recommend that can seamlessly integrate with SQL Server and Power Automate for such a functionality? I'm looking for any advice, tool recommendations, or insights that could help streamline this process and make it more efficient. Thank you in advance for your help! submitted by /u/ubisoftsponsored [link] [comments]
submitted by /u/dine-ssh [link] [comments]
Hi everybody, I am having some serious issues finding the right Graph database for my real-time Knowledge graph application. The use case is: - Insert nodes and edges to the database in real-time (every cpl seconds) - Run graph queries: subgraphs, paths - Algorithms: similarities, centrality, betweenness etc... - Writes: ~100 nodes, 500 edges per minute - Reads: real-time backend for my app (with 1 minute caching) So far, I've tried 2 graph databases unsuccessfully: Neo4J: It looks and works great, but is incredibly expensive and completely out of budget Memgraph: It looks and works great, but has some production level bugs that make it unusable I've already spent months deploying to Neo4J and migrating to Memgraph. Memgraph is now failing in production and I'm a bit fed up with Graph solutions so I'd love to hear the community's advice and feedback. Which graph database should I use for my use case? The criteria are, I thought, quite simple: Mature with large enough community + docs Accessible pricing (30/50 month for lowest tier) Known to power large apps in prod Built-in graph algorithms (similarity, path etc...) On-disk or In-memory is irrelevant: just want the DB to actually work I'm running my stack on Azure. Thanks submitted by /u/Affectionate_One9482 [link] [comments]
I currently have a (relational) database in Access, however I wanted to create apps so I can search/change the data without looking at a ugly table. I've been looking at Azure, specifically the Azure SQL Database, as somewhere to host my database. The problems I've seen with Azure are: Azure seems expensive (My database is ~6 tables, with the largest having ~45k records) The learning curve for it seems steep I exported the many tables to SharePoints lists (put them in a SharePoint site), so I could use PowerApps (and because we have pictures that take up too much space on Access). This worked for a little bit, but I felt this was not how I should be storing my data (in SharePoint lists) and SharePoint/SharePoint lists felt restrictive. Ultimately I would like somewhere to have my database where I can create mobile/web/desktop apps myself and others can use to view/manipulate the data in the database. My database is (relatively) small, so that's what pulling me away from Azure. submitted by /u/stupldGuy [link] [comments]
We’ve just started learning normalization in university, but I’m kind of struggling to wrap my head around it. I understand the partial and transitive dependencies, but I can’t understand why there are attributes that are dependent on Customer_Name. Sorry if this is a dumb question but I’m still very new to this. submitted by /u/TelesticXP [link] [comments]
Hey I have been working on a personal project which requires me to store financial data. I have scripts which pull information on a daily basis and write to my local machine. I am now trying to shift the writing of this information off my local machine to a database online, so I can automate the process and not need to manually run the scripts. A simple relational database will do, I don't need anything fancy. Do you guys know of any resources which would help me best achieve this? I was planning on going with Fly.io but wanted to get some advice first. submitted by /u/Bob_ination [link] [comments]
Hello, I'm a junior software engineer seeking advice from those with more experience. I have been programming in C# for two years, primarily on projects where data storage was already set up. I am now planning to develop a full-stack Blazor application and am uncertain about which technology would best meet my needs. I've experimented with both Entity Framework and Microsoft Table Storage but haven't yet decided on either. I need a database solution that can adapt as my application's classes evolve over time. It's crucial that the application remains functional during beta testing, even as I make changes to property names and attributes without disrupting the entire system. What would you recommend? submitted by /u/Tricky_Peanut8626 [link] [comments]
Speed up all spatial operations and functions in Oracle Database with SPATIAL_VECTOR_ACCELERATION parameter. https://insanedba.blogspot.com/2024/04/speed-up-all-spatial-ops.html submitted by /u/riddinck [link] [comments]
or do they have thousands of mariadb databases inside of a mariadb database? I don't really know the structure of their databases that they use for these organizations? submitted by /u/savant78 [link] [comments]
Hi everyone! I am struggling a lot with finding data via ORBIS & WRDS in the Amadeus database. I have tried numerous ways and downloaded sets of data through their web queries, but I feel I am not getting the right data. I need to get data on Global Ultimate Owners in Europe and their subsidiaries, but I am struggling to find a dataset that contains both these conditions within on set to be able to refine from there onwards with other criteria. Does anyone maybe have any advice they can share on how to get the GUOs and their subsidiaries in one set or if this is possible? ORBIS does not allow more than a certain number of companies to be downloaded which makes this task more difficult. I would really appreciate any advice as I have no experience in this area at all. submitted by /u/zoefrommann [link] [comments]
Hello guys. Recently, I have learnt MySql. Now I want to be more professional. But I have no idea about What shall I do. How can I use it on real life work. Thank you. submitted by /u/No-Confidence-8182 [link] [comments]
submitted by /u/xheavenx1 [link] [comments]
submitted by /u/idk00999 [link] [comments]
Desktop database clients have always felt clunky to me. After 10 years of programming, I still find myself struggling with basic tasks—like securely configuring access or just trying to pull data from a different device. Every time I'm away from my main setup, it feels like I'm locked out of my own data. These hurdles slow me down and remind me why we need to push for web-based solutions that are not just powerful, but also intuitive and accessible right from the browser. At Hoopdev we are building a Clojurescript client and Golang server that keeps what’s best about database clients while modernizing the experience in the web. As of today, we’re launching our Free plan and anyone can start using it. It works with any browser. We’ve built: 1) Schema navigation and autocompletion that works with any db 2) Grouped outputs: so you can easily copy, search, and share query outputs 3) AI-powered Data Masking and Community-sourced Workflows [0]: so you can build your own middlewares 4) The ability to share your outputs with teammates: no more pasting long unformatted SQL into Slack 5) Runbooks: save your team’s common queries into a Git repo so your teammates can run them form a web form. We built a new type of language server that runs on Kubernetes, it is a lightweight Golang GRPC proxy that can scan and modify layer 7 packets in real-time (this is what enables real-time AI data masking). UI uses Clojurescript. You can self-host the full solution. Our business model is to make the database client so useful for individuals and small teams that their companies will want to pay for the team and security features. We will never sell your data. You will notice that a log-in is required and that we do collect usage data and crash reports. We do so because we’re spinning up backend resources for each user and also to keep improving the product. We’ll soon allow users to opt out of usage data. You can see our privacy policy here [1]. It is early, but we are confident that even today the experience is meaningfully better than in many desktop database clients. Please give it a shot and let us know how it goes: https://hoop.dev/databases Follow us on Twitter [2]. Let me know what you think! Ask me anything! [0] https://github.com/hoophq/plugin-secretsmanager [1] https://hoop.dev/docs/more/privacy-policy [2] https://twitter.com/hoopdotdev submitted by /u/andriosr [link] [comments]
Let's say R(A,B,C,D,E,F,G,H,I,J,K) Functional Dependencies: A -> C,D,E A,B,G,H -> I,J,K,F J,I,G,H -> A,F,B If JIGH is the minimal superkey. Since (G,H) is part of the msk and also in another functional dependency (A,B,G,H -> I,J,K,F). Does it consider as a partial functional dependency? submitted by /u/ValianxD [link] [comments]
For most people, a satisfactory career is essential for leading a happy life. However, ensuring…
The pipeline industry is more than pipework and construction, and we explore those details in…
SQL Interview Questions and Answers In the world of data-driven decision-making, SQL (Structured Query Language)…
Before you make the decision to switch your home’s interest service provider, take the time…
AI Innovations in April 2024. Welcome to the April 2024 edition of the Daily Chronicle,…
{kind=link}
{kind=link}