

AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
Welcome to AWS Certified Developer Associate Exam Preparation: Definition and Objectives, Top 65 Questions and Answers dump, White papers, Courses, Labs and Training Materials, Exam info and details, References, Jobs, Others AWS Certificates
What is the AWS Certified Developer Associate Exam?
This AWS Certified Developer-Associate Examination is intended for individuals who perform a
Developer role. It validates an examinee’s ability to:
- Demonstrate an understanding of core AWS services, uses, and basic AWS architecture best practices.
- Demonstrate proficiency in developing, deploying, and debugging cloud-based applications using AWS.
There are no prerequisites for taking the Developer-Associate examination, but here are the recommended AWS Knowledge:
- One or more years of hands-on experience developing and maintaining an AWS based application
- In-depth knowledge of at least one high-level programming language
- Understanding of core AWS services, uses, and basic AWS architecture best practices
- Proficiency in developing, deploying, and debugging cloud-based applications using AWS
- Ability to use the AWS service APIs, AWS CLI, and SDKs to write applications
- Ability to identify key features of AWS services
- Understanding of the AWS shared responsibility model
- Understanding of application lifecycle management
- Ability to use a CI/CD pipeline to deploy applications on AWS
- Ability to use or interact with AWS services
- Ability to apply a basic understanding of cloud-native applications to write code
- Ability to write code using AWS security best practices (e.g., not using secret and access keys in the code, instead using IAM roles)
- Ability to author, maintain, and debug code modules on AWS
- Proficiency writing code for serverless applications
- Understanding of the use of containers in the development process
AWS Certified Developer – Associate Practice Questions And Answers Dump
Q0: Your application reads commands from an SQS queue and sends them to web services hosted by your
partners. When a partner’s endpoint goes down, your application continually returns their commands to the queue. The repeated attempts to deliver these commands use up resources. Commands that can’t be delivered must not be lost.
How can you accommodate the partners’ broken web services without wasting your resources?
- A. Create a delay queue and set DelaySeconds to 30 seconds
- B. Requeue the message with a VisibilityTimeout of 30 seconds.
- C. Create a dead letter queue and set the Maximum Receives to 3.
- D. Requeue the message with a DelaySeconds of 30 seconds.


Top
Q1: A developer is writing an application that will store data in a DynamoDB table. The ratio of reads operations to write operations will be 1000 to 1, with the same data being accessed frequently.
What should the Developer enable on the DynamoDB table to optimize performance and minimize costs?
- A. Amazon DynamoDB auto scaling
- B. Amazon DynamoDB cross-region replication
- C. Amazon DynamoDB Streams
- D. Amazon DynamoDB Accelerator


Top
Q2: You are creating a DynamoDB table with the following attributes:
- PurchaseOrderNumber (partition key)
- CustomerID
- PurchaseDate
- TotalPurchaseValue
One of your applications must retrieve items from the table to calculate the total value of purchases for a
particular customer over a date range. What secondary index do you need to add to the table?
- A. Local secondary index with a partition key of CustomerID and sort key of PurchaseDate; project the
TotalPurchaseValue attribute - B. Local secondary index with a partition key of PurchaseDate and sort key of CustomerID; project the
TotalPurchaseValue attribute - C. Global secondary index with a partition key of CustomerID and sort key of PurchaseDate; project the
TotalPurchaseValue attribute - D. Global secondary index with a partition key of PurchaseDate and sort key of CustomerID; project the
TotalPurchaseValue attribute
Top

Q3: When referencing the remaining time left for a Lambda function to run within the function’s code you would use:
- A. The event object
- B. The timeLeft object
- C. The remains object
- D. The context object
Top

Q4: What two arguments does a Python Lambda handler function require?
- A. invocation, zone
- B. event, zone
- C. invocation, context
- D. event, context
Q5: Lambda allows you to upload code and dependencies for function packages:
- A. Only from a directly uploaded zip file
- B. Only via SFTP
- C. Only from a zip file in AWS S3
- D. From a zip file in AWS S3 or uploaded directly from elsewhere

Q6: A Lambda deployment package contains:
- A. Function code, libraries, and runtime binaries
- B. Only function code
- C. Function code and libraries not included within the runtime
- D. Only libraries not included within the runtime
Q7: You are attempting to SSH into an EC2 instance that is located in a public subnet. However, you are currently receiving a timeout error trying to connect. What could be a possible cause of this connection issue?
- A. The security group associated with the EC2 instance has an inbound rule that allows SSH traffic, but does not have an outbound rule that allows SSH traffic.
- B. The security group associated with the EC2 instance has an inbound rule that allows SSH traffic AND has an outbound rule that explicitly denies SSH traffic.
- C. The security group associated with the EC2 instance has an inbound rule that allows SSH traffic AND the associated NACL has both an inbound and outbound rule that allows SSH traffic.
- D. The security group associated with the EC2 instance does not have an inbound rule that allows SSH traffic AND the associated NACL does not have an outbound rule that allows SSH traffic.
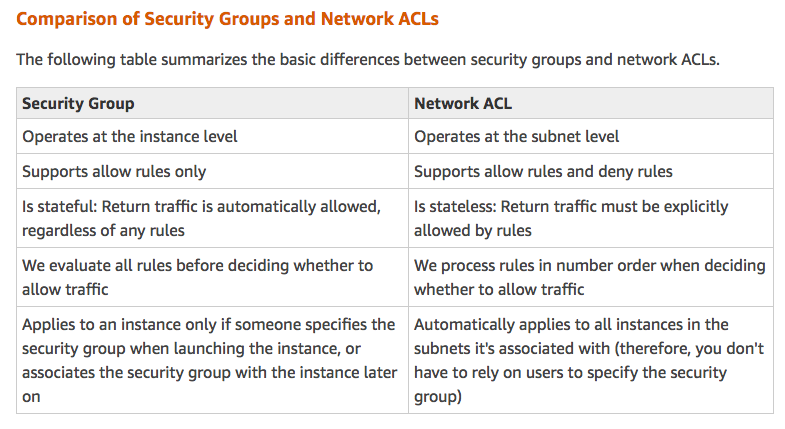
Top
Q8: You have instances inside private subnets and a properly configured bastion host instance in a public subnet. None of the instances in the private subnets have a public or Elastic IP address. How can you connect an instance in the private subnet to the open internet to download system updates?
- A. Create and assign EIP to each instance
- B. Create and attach a second IGW to the VPC.
- C. Create and utilize a NAT Gateway
- D. Connect to a VPN
Top
Q9: What feature of VPC networking should you utilize if you want to create “elasticity” in your application’s architecture?
- A. Security Groups
- B. Route Tables
- C. Elastic Load Balancer
- D. Auto Scaling
Top
Q10: Lambda allows you to upload code and dependencies for function packages:
- A. Only from a directly uploaded zip file
- B. Only from a directly uploaded zip file
- C. Only from a zip file in AWS S3
- D. From a zip file in AWS S3 or uploaded directly from elsewhere

Q11: You’re writing a script with an AWS SDK that uses the AWS API Actions and want to create AMIs for non-EBS backed AMIs for you. Which API call should occurs in the final process of creating an AMI?
- A. RegisterImage
- B. CreateImage
- C. ami-register-image
- D. ami-create-image
Q12: When dealing with session state in EC2-based applications using Elastic load balancers which option is generally thought of as the best practice for managing user sessions?
- A. Having the ELB distribute traffic to all EC2 instances and then having the instance check a caching solution like ElastiCache running Redis or Memcached for session information
- B. Permenantly assigning users to specific instances and always routing their traffic to those instances
- C. Using Application-generated cookies to tie a user session to a particular instance for the cookie duration
- D. Using Elastic Load Balancer generated cookies to tie a user session to a particular instance
Unlock the Secrets of Africa: Master African History, Geography, Culture, People, Cuisine, Economics, Languages, Music, Wildlife, Football, Politics, Animals, Tourism, Science and Environment with the Top 1000 Africa Quiz and Trivia. Get Yours Now!
"Become a Canada Expert: Ace the Citizenship Test and Impress Everyone with Your Knowledge of Canadian History, Geography, Government, Culture, People, Languages, Travel, Wildlife, Hockey, Tourism, Sceneries, Arts, and Data Visualization. Get the Top 1000 Canada Quiz Now!"
Q13: Which API call would best be used to describe an Amazon Machine Image?
- A. ami-describe-image
- B. ami-describe-images
- C. DescribeImage
- D. DescribeImages
Q14: What is one key difference between an Amazon EBS-backed and an instance-store backed instance?
- A. Autoscaling requires using Amazon EBS-backed instances
- B. Virtual Private Cloud requires EBS backed instances
- C. Amazon EBS-backed instances can be stopped and restarted without losing data
- D. Instance-store backed instances can be stopped and restarted without losing data
Q15: After having created a new Linux instance on Amazon EC2, and downloaded the .pem file (called Toto.pem) you try and SSH into your IP address (54.1.132.33) using the following command.
ssh -i my_key.pem ec2-user@52.2.222.22
However you receive the following error.
@@@@@@@@ WARNING: UNPROTECTED PRIVATE KEY FILE! @ @@@@@@@@@@@@@@@@@@@
What is the most probable reason for this and how can you fix it?
- A. You do not have root access on your terminal and need to use the sudo option for this to work.
- B. You do not have enough permissions to perform the operation.
- C. Your key file is encrypted. You need to use the -u option for unencrypted not the -i option.
- D. Your key file must not be publicly viewable for SSH to work. You need to modify your .pem file to limit permissions.
Q16: You have an EBS root device on /dev/sda1 on one of your EC2 instances. You are having trouble with this particular instance and you need to either Stop/Start, Reboot or Terminate the instance but you do NOT want to lose any data that you have stored on /dev/sda1. However, you are unsure if changing the instance state in any of the aforementioned ways will cause you to lose data stored on the EBS volume. Which of the below statements best describes the effect each change of instance state would have on the data you have stored on /dev/sda1?
- A. Whether you stop/start, reboot or terminate the instance it does not matter because data on an EBS volume is not ephemeral and the data will not be lost regardless of what method is used.
- B. If you stop/start the instance the data will not be lost. However if you either terminate or reboot the instance the data will be lost.
- C. Whether you stop/start, reboot or terminate the instance it does not matter because data on an EBS volume is ephemeral and it will be lost no matter what method is used.
- D. The data will be lost if you terminate the instance, however the data will remain on /dev/sda1 if you reboot or stop/start the instance because data on an EBS volume is not ephemeral.
Q17: EC2 instances are launched from Amazon Machine Images (AMIs). A given public AMI:
- A. Can only be used to launch EC2 instances in the same AWS availability zone as the AMI is stored
- B. Can only be used to launch EC2 instances in the same country as the AMI is stored
- C. Can only be used to launch EC2 instances in the same AWS region as the AMI is stored
- D. Can be used to launch EC2 instances in any AWS region
Q18: Which of the following statements is true about the Elastic File System (EFS)?
- A. EFS can scale out to meet capacity requirements and scale back down when no longer needed
- B. EFS can be used by multiple EC2 instances simultaneously
- C. EFS cannot be used by an instance using EBS
- D. EFS can be configured on an instance before launch just like an IAM role or EBS volumes
Q19: IAM Policies, at a minimum, contain what elements?
- A. ID
- B. Effects
- C. Resources
- D. Sid
- E. Principle
- F. Actions
Q20: What are the main benefits of IAM groups?
- A. The ability to create custom permission policies.
- B. Assigning IAM permission policies to more than one user at a time.
- C. Easier user/policy management.
- D. Allowing EC2 instances to gain access to S3.
Q21: What are benefits of using AWS STS?
- A. Grant access to AWS resources without having to create an IAM identity for them
- B. Since credentials are temporary, you don’t have to rotate or revoke them
- C. Temporary security credentials can be extended indefinitely
- D. Temporary security credentials can be restricted to a specific region
Q22: What should the Developer enable on the DynamoDB table to optimize performance and minimize costs?
- A. Amazon DynamoDB auto scaling
- B. Amazon DynamoDB cross-region replication
- C. Amazon DynamoDB Streams
- D. Amazon DynamoDB Accelerator
Top
Q23: A Developer has been asked to create an AWS Elastic Beanstalk environment for a production web application which needs to handle thousands of requests. Currently the dev environment is running on a t1 micro instance. How can the Developer change the EC2 instance type to m4.large?
- A. Use CloudFormation to migrate the Amazon EC2 instance type of the environment from t1 micro to m4.large.
- B. Create a saved configuration file in Amazon S3 with the instance type as m4.large and use the same during environment creation.
- C. Change the instance type to m4.large in the configuration details page of the Create New Environment page.
- D. Change the instance type value for the environment to m4.large by using update autoscaling group CLI command.
Q24: What statements are true about Availability Zones (AZs) and Regions?
- A. There is only one AZ in each AWS Region
- B. AZs are geographically separated inside a region to help protect against natural disasters affecting more than one at a time.
- C. AZs can be moved between AWS Regions based on your needs
- D. There are (almost always) two or more AZs in each AWS Region
Q25: An AWS Region contains:
- A. Edge Locations
- B. Data Centers
- C. AWS Services
- D. Availability Zones
Top
Q26: Which read request in DynamoDB returns a response with the most up-to-date data, reflecting the updates from all prior write operations that were successful?
- A. Eventual Consistent Reads
- B. Conditional reads for Consistency
- C. Strongly Consistent Reads
- D. Not possible
Top
Q27: You’ve been asked to move an existing development environment on the AWS Cloud. This environment consists mainly of Docker based containers. You need to ensure that minimum effort is taken during the migration process. Which of the following step would you consider for this requirement?
- A. Create an Opswork stack and deploy the Docker containers
- B. Create an application and Environment for the Docker containers in the Elastic Beanstalk service
- C. Create an EC2 Instance. Install Docker and deploy the necessary containers.
- D. Create an EC2 Instance. Install Docker and deploy the necessary containers. Add an Autoscaling Group for scalability of the containers.
Top
Q28: You’ve written an application that uploads objects onto an S3 bucket. The size of the object varies between 200 – 500 MB. You’ve seen that the application sometimes takes a longer than expected time to upload the object. You want to improve the performance of the application. Which of the following would you consider?
- A. Create multiple threads and upload the objects in the multiple threads
- B. Write the items in batches for better performance
- C. Use the Multipart upload API
- D. Enable versioning on the Bucket
Top
Q29: A security system monitors 600 cameras, saving image metadata every 1 minute to an Amazon DynamoDb table. Each sample involves 1kb of data, and the data writes are evenly distributed over time. How much write throughput is required for the target table?
- A. 6000
- B. 10
- C. 3600
- D. 600
Q30: What two arguments does a Python Lambda handler function require?
- A. invocation, zone
- B. event, zone
- C. invocation, context
- D. event, context
Top
Q31: Lambda allows you to upload code and dependencies for function packages:
- A. Only from a directly uploaded zip file
- B. Only via SFTP
- C. Only from a zip file in AWS S3
- D. From a zip file in AWS S3 or uploaded directly from elsewhere
Top
Q32: A Lambda deployment package contains:
- A. Function code, libraries, and runtime binaries
- B. Only function code
- C. Function code and libraries not included within the runtime
- D. Only libraries not included within the runtime
Top
Q33: You have instances inside private subnets and a properly configured bastion host instance in a public subnet. None of the instances in the private subnets have a public or Elastic IP address. How can you connect an instance in the private subnet to the open internet to download system updates?
- A. Create and assign EIP to each instance
- B. Create and attach a second IGW to the VPC.
- C. Create and utilize a NAT Gateway
- D. Connect to a VPN
Top
Q34: What feature of VPC networking should you utilize if you want to create “elasticity” in your application’s architecture?
- A. Security Groups
- B. Route Tables
- C. Elastic Load Balancer
- D. Auto Scaling
Top
Q30: Lambda allows you to upload code and dependencies for function packages:
- A. Only from a directly uploaded zip file
- B. Only from a directly uploaded zip file
- C. Only from a zip file in AWS S3
- D. From a zip file in AWS S3 or uploaded directly from elsewhere
Answer:
Top
Q31: An organization is using an Amazon ElastiCache cluster in front of their Amazon RDS instance. The organization would like the Developer to implement logic into the code so that the cluster only retrieves data from RDS when there is a cache miss. What strategy can the Developer implement to achieve this?
- A. Lazy loading
- B. Write-through
- C. Error retries
- D. Exponential backoff
Answer:
Top
Q32: A developer is writing an application that will run on Ec2 instances and read messages from SQS queue. The messages will arrive every 15-60 seconds. How should the Developer efficiently query the queue for new messages?
- A. Use long polling
- B. Set a custom visibility timeout
- C. Use short polling
- D. Implement exponential backoff
Top
Q33: You are using AWS SAM to define a Lambda function and configure CodeDeploy to manage deployment patterns. With new Lambda function working as per expectation which of the following will shift traffic from original Lambda function to new Lambda function in the shortest time frame?
- A. Canary10Percent5Minutes
- B. Linear10PercentEvery10Minutes
- C. Canary10Percent15Minutes
- D. Linear10PercentEvery1Minute
Top
Q34: You are using AWS SAM templates to deploy a serverless application. Which of the following resource will embed application from Amazon S3 buckets?
- A. AWS::Serverless::Api
- B. AWS::Serverless::Application
- C. AWS::Serverless::Layerversion
- D. AWS::Serverless::Function
Top
Q35: You are using AWS Envelope Encryption for encrypting all sensitive data. Which of the followings is True with regards to Envelope Encryption?
- A. Data is encrypted be encrypting Data key which is further encrypted using encrypted Master Key.
- B. Data is encrypted by plaintext Data key which is further encrypted using encrypted Master Key.
- C. Data is encrypted by encrypted Data key which is further encrypted using plaintext Master Key.
- D. Data is encrypted by plaintext Data key which is further encrypted using plaintext Master Key.
Top
Q36: You are developing an application that will be comprised of the following architecture –
- A set of Ec2 instances to process the videos.
- These (Ec2 instances) will be spun up by an autoscaling group.
- SQS Queues to maintain the processing messages.
- There will be 2 pricing tiers.
How will you ensure that the premium customers videos are given more preference?
- A. Create 2 Autoscaling Groups, one for normal and one for premium customers
- B. Create 2 set of Ec2 Instances, one for normal and one for premium customers
- C. Create 2 SQS queus, one for normal and one for premium customers
- D. Create 2 Elastic Load Balancers, one for normal and one for premium customers.
Top
Q37: You are developing an application that will interact with a DynamoDB table. The table is going to take in a lot of read and write operations. Which of the following would be the ideal partition key for the DynamoDB table to ensure ideal performance?
- A. CustomerID
- B. CustomerName
- C. Location
- D. Age
Top
Q38: A developer is making use of AWS services to develop an application. He has been asked to develop the application in a manner to compensate any network delays. Which of the following two mechanisms should he implement in the application?
- A. Multiple SQS queues
- B. Exponential backoff algorithm
- C. Retries in your application code
- D. Consider using the Java sdk.
Top
Q39: An application is being developed that is going to write data to a DynamoDB table. You have to setup the read and write throughput for the table. Data is going to be read at the rate of 300 items every 30 seconds. Each item is of size 6KB. The reads can be eventual consistent reads. What should be the read capacity that needs to be set on the table?
- A. 10
- B. 20
- C. 6
- D. 30
Top
Q40: You are in charge of deploying an application that will be hosted on an EC2 Instance and sit behind an Elastic Load balancer. You have been requested to monitor the incoming connections to the Elastic Load Balancer. Which of the below options can suffice this requirement?
- A. Use AWS CloudTrail with your load balancer
- B. Enable access logs on the load balancer
- C. Use a CloudWatch Logs Agent
- D. Create a custom metric CloudWatch lter on your load balancer
Top
Q41: A static web site has been hosted on a bucket and is now being accessed by users. One of the web pages javascript section has been changed to access data which is hosted in another S3 bucket. Now that same web page is no longer loading in the browser. Which of the following can help alleviate the error?
- A. Enable versioning for the underlying S3 bucket.
- B. Enable Replication so that the objects get replicated to the other bucket
- C. Enable CORS for the bucket
- D. Change the Bucket policy for the bucket to allow access from the other bucket
Top
Q42: Your mobile application includes a photo-sharing service that is expecting tens of thousands of users at launch. You will leverage Amazon Simple Storage Service (S3) for storage of the user Images, and you must decide how to authenticate and authorize your users for access to these images. You also need to manage the storage of these images. Which two of the following approaches should you use? Choose two answers from the options below
- A. Create an Amazon S3 bucket per user, and use your application to generate the S3 URL for the appropriate content.
- B. Use AWS Identity and Access Management (IAM) user accounts as your application-level user database, and offload the burden of authentication from your application code.
- C. Authenticate your users at the application level, and use AWS Security Token Service (STS)to grant token-based authorization to S3 objects.
- D. Authenticate your users at the application level, and send an SMS token message to the user. Create an Amazon S3 bucket with the same name as the SMS message token, and move the user’s objects to that bucket.
Top
Q43: Your current log analysis application takes more than four hours to generate a report of the top 10 users of your web application. You have been asked to implement a system that can report this information in real time, ensure that the report is always up to date, and handle increases in the number of requests to your web application. Choose the option that is cost-effective and can fulfill the requirements.
- A. Publish your data to CloudWatch Logs, and congure your application to Autoscale to handle the load on demand.
- B. Publish your log data to an Amazon S3 bucket. Use AWS CloudFormation to create an Auto Scaling group to scale your post-processing application which is congured to pull down your log les stored an Amazon S3
- C. Post your log data to an Amazon Kinesis data stream, and subscribe your log-processing application so that is congured to process your logging data.
- D. Create a multi-AZ Amazon RDS MySQL cluster, post the logging data to MySQL, and run a map reduce job to retrieve the required information on user counts.
Answer:
Top
Q44: You’ve been instructed to develop a mobile application that will make use of AWS services. You need to decide on a data store to store the user sessions. Which of the following would be an ideal data store for session management?
- A. AWS Simple Storage Service
- B. AWS DynamoDB
- C. AWS RDS
- D. AWS Redshift
Answer:
Top
Q45: Your application currently interacts with a DynamoDB table. Records are inserted into the table via the application. There is now a requirement to ensure that whenever items are updated in the DynamoDB primary table , another record is inserted into a secondary table. Which of the below feature should be used when developing such a solution?
- A. AWS DynamoDB Encryption
- B. AWS DynamoDB Streams
- C. AWS DynamoDB Accelerator
- D. AWSTable Accelerator
Top
Q46: An application has been making use of AWS DynamoDB for its back-end data store. The size of the table has now grown to 20 GB , and the scans on the table are causing throttling errors. Which of the following should now be implemented to avoid such errors?
- A. Large Page size
- B. Reduced page size
- C. Parallel Scans
- D. Sequential scans
Top
Q47: Which of the following is correct way of passing a stage variable to an HTTP URL ? (Select TWO.)
- A. http://example.com/${}/prod
- B. http://example.com/${stageVariables.}/prod
- C. http://${stageVariables.}.example.com/dev/operation
- D. http://${stageVariables}.example.com/dev/operation
- E. http://${}.example.com/dev/operation
- F. http://example.com/${stageVariables}/prod
Top
Q48: Your company is planning on creating new development environments in AWS. They want to make use of their existing Chef recipes which they use for their on-premise configuration for servers in AWS. Which of the following service would be ideal to use in this regard?
- A. AWS Elastic Beanstalk
- B. AWS OpsWork
- C. AWS Cloudformation
- D. AWS SQS
Top
Q49: Your company has developed a web application and is hosting it in an Amazon S3 bucket configured for static website hosting. The users can log in to this app using their Google/Facebook login accounts. The application is using the AWS SDK for JavaScript in the browser to access data stored in an Amazon DynamoDB table. How can you ensure that API keys for access to your data in DynamoDB are kept secure?
- A. Create an Amazon S3 role in IAM with access to the specific DynamoDB tables, and assign it to the bucket hosting your website
- B. Configure S3 bucket tags with your AWS access keys for your bucket hosing your website so that the application can query them for access.
- C. Configure a web identity federation role within IAM to enable access to the correct DynamoDB resources and retrieve temporary credentials
- D. Store AWS keys in global variables within your application and configure the application to use these credentials when making requests.
Top
Q50: Your application currently makes use of AWS Cognito for managing user identities. You want to analyze the information that is stored in AWS Cognito for your application. Which of the following features of AWS Cognito should you use for this purpose?
- A. Cognito Data
- B. Cognito Events
- C. Cognito Streams
- D. Cognito Callbacks
Top
Q51: You’ve developed a set of scripts using AWS Lambda. These scripts need to access EC2 Instances in a VPC. Which of the following needs to be done to ensure that the AWS Lambda function can access the resources in the VPC. Choose 2 answers from the options given below
- A. Ensure that the subnet ID’s are mentioned when configuring the Lambda function
- B. Ensure that the NACL ID’s are mentioned when configuring the Lambda function
- C. Ensure that the Security Group ID’s are mentioned when configuring the Lambda function
- D. Ensure that the VPC Flow Log ID’s are mentioned when configuring the Lambda function
Top
Q52: You’ve currently been tasked to migrate an existing on-premise environment into Elastic Beanstalk. The application does not make use of Docker containers. You also can’t see any relevant environments in the beanstalk service that would be suitable to host your application. What should you consider doing in this case?
- A. Migrate your application to using Docker containers and then migrate the app to the Elastic Beanstalk environment.
- B. Consider using Cloudformation to deploy your environment to Elastic Beanstalk
- C. Consider using Packer to create a custom platform
- D. Consider deploying your application using the Elastic Container Service
Top
Q53: Company B is writing 10 items to the Dynamo DB table every second. Each item is 15.5Kb in size. What would be the required provisioned write throughput for best performance? Choose the correct answer from the options below.
- A. 10
- B. 160
- C. 155
- D. 16
Top
Q54: Which AWS Service can be used to automatically install your application code onto EC2, on premises systems and Lambda?
- A. CodeCommit
- B. X-Ray
- C. CodeBuild
- D. CodeDeploy
Top
Q55: Which AWS service can be used to compile source code, run tests and package code?
- A. CodePipeline
- B. CodeCommit
- C. CodeBuild
- D. CodeDeploy
Top
Q56: How can your prevent CloudFormation from deleting your entire stack on failure? (Choose 2)
- A. Set the Rollback on failure radio button to No in the CloudFormation console
- B. Set Termination Protection to Enabled in the CloudFormation console
- C. Use the –disable-rollback flag with the AWS CLI
- D. Use the –enable-termination-protection protection flag with the AWS CLI
Q57: Which of the following practices allows multiple developers working on the same application to merge code changes frequently, without impacting each other and enables the identification of bugs early on in the release process?
- A. Continuous Integration
- B. Continuous Deployment
- C. Continuous Delivery
- D. Continuous Development
Q58: When deploying application code to EC2, the AppSpec file can be written in which language?
- A. JSON
- B. JSON or YAML
- C. XML
- D. YAML
Q59: Part of your CloudFormation deployment fails due to a mis-configuration, by defaukt what will happen?
- A. CloudFormation will rollback only the failed components
- B. CloudFormation will rollback the entire stack
- C. Failed component will remain available for debugging purposes
- D. CloudFormation will ask you if you want to continue with the deployment
Q60: You want to receive an email whenever a user pushes code to CodeCommit repository, how can you configure this?
- A. Create a new SNS topic and configure it to poll for CodeCommit eveents. Ask all users to subscribe to the topic to receive notifications
- B. Configure a CloudWatch Events rule to send a message to SES which will trigger an email to be sent whenever a user pushes code to the repository.
- C. Configure Notifications in the console, this will create a CloudWatch events rule to send a notification to a SNS topic which will trigger an email to be sent to the user.
- D. Configure a CloudWatch Events rule to send a message to SQS which will trigger an email to be sent whenever a user pushes code to the repository.
Q61: Which AWS service can be used to centrally store and version control your application source code, binaries and libraries
- A. CodeCommit
- B. CodeBuild
- C. CodePipeline
- D. ElasticFileSystem
Q62: You are using CloudFormation to create a new S3 bucket,
which of the following sections would you use to define the properties of your bucket?
- A. Conditions
- B. Parameters
- C. Outputs
- D. Resources
Q63: You are deploying a number of EC2 and RDS instances using CloudFormation. Which section of the CloudFormation template
would you use to define these?
- A. Transforms
- B. Outputs
- C. Resources
- D. Instances
Q64: Which AWS service can be used to fully automate your entire release process?
- A. CodeDeploy
- B. CodePipeline
- C. CodeCommit
- D. CodeBuild
Q65: You want to use the output of your CloudFormation stack as input to another CloudFormation stack. Which sections of the CloudFormation template would you use to help you configure this?
- A. Outputs
- B. Transforms
- C. Resources
- D. Exports
Q66: You have some code located in an S3 bucket that you want to reference in your CloudFormation template. Which section of the template can you use to define this?
- A. Inputs
- B. Resources
- C. Transforms
- D. Files
Q67: You are deploying an application to a number of Ec2 instances using CodeDeploy. What is the name of the file
used to specify source files and lifecycle hooks?
- A. buildspec.yml
- B. appspec.json
- C. appspec.yml
- D. buildspec.json
Q68: Which of the following approaches allows you to re-use pieces of CloudFormation code in multiple templates, for common use cases like provisioning a load balancer or web server?
- A. Share the code using an EBS volume
- B. Copy and paste the code into the template each time you need to use it
- C. Use a cloudformation nested stack
- D. Store the code you want to re-use in an AMI and reference the AMI from within your CloudFormation template.
Q69: In the CodeDeploy AppSpec file, what are hooks used for?
- A. To reference AWS resources that will be used during the deployment
- B. Hooks are reserved for future use
- C. To specify files you want to copy during the deployment.
- D. To specify, scripts or function that you want to run at set points in the deployment lifecycle
Q70: Which command can you use to encrypt a plain text file using CMK?
- A. aws kms-encrypt
- B. aws iam encrypt
- C. aws kms encrypt
- D. aws encrypt
Q72: Which of the following is an encrypted key used by KMS to encrypt your data
- A. Custmoer Mamaged Key
- B. Encryption Key
- C. Envelope Key
- D. Customer Master Key
Q73: Which of the following statements are correct? (Choose 2)
- A. The Customer Master Key is used to encrypt and decrypt the Envelope Key or Data Key
- B. The Envelope Key or Data Key is used to encrypt and decrypt plain text files.
- C. The envelope Key or Data Key is used to encrypt and decrypt the Customer Master Key.
- D. The Customer MasterKey is used to encrypt and decrypt plain text files.
Q74: Which of the following statements is correct in relation to kMS/ (Choose 2)
- A. KMS Encryption keys are regional
- B. You cannot export your customer master key
- C. You can export your customer master key.
- D. KMS encryption Keys are global
AWS Certified Developer Associate exam: Whitepapers
AWS has provided whitepapers to help you understand the technical concepts. Below are the recommended whitepapers for the AWS Certified Developer – Associate Exam.
- Overview of Amazon Web Services
- Architecting for the Cloud: AWS Best Practices
- AWS Security Best Practices whitepaper, August 2016
- AWS Well-Architected Framework whitepaper, November 2017 Version 1.3 DVA-C01 Page |2
- Architecting for the Cloud AWS Best Practices whitepaper, February, 2016
- Practicing Continuous Integration and Continuous Delivery on AWS Accelerating Software Delivery with DevOps whitepaper, June 2017
- Microservices on AWS whitepaper, September 2017
- Serverless Architectures with AWS Lambda whitepaper, November 2017
- Optimizing Enterprise Economics with Serverless Architectures whitepaper, October 2017
- Running Containerized Microservices on AWS whitepaper, November 2017
- Blue/Green Deployments on AWS whitepaper, August 2016
Online Training and Labs for AWS Certified Developer Associates Exam
AWS Developer Associates Jobs
AWS Certified Developer-Associate Exam info and details, How To:
The AWS Certified Developer Associate exam is a multiple choice, multiple answer exam. Here is the Exam Overview:
- Certification Name: AWS Certified Developer Associate.
- Prerequisites for the Exam: None.
- Exam Pattern: Multiple Choice Questions
- The AWS Certified Developer-Associate Examination (DVA-C01) is a pass or fail exam. The examination is scored against a minimum standard established by AWS professionals guided by certification industry best practices and guidelines.
- Your results for the examination are reported as a score from 100 – 1000, with a minimum passing score of 720.
- Exam fees: US $150
- Exam Guide on AWS Website
- Available languages for tests: English, Japanese, Korean, Simplified Chinese
- Read AWS whitepapers
- Register for certification account here.
- Prepare for Certification Here
Exam Content Outline
Domain % of Examination Domain 1: Deployment (22%)
1.1 Deploy written code in AWS using existing CI/CD pipelines, processes, and patterns.
1.2 Deploy applications using Elastic Beanstalk.
1.3 Prepare the application deployment package to be deployed to AWS.
1.4 Deploy serverless applications22% Domain 2: Security (26%)
2.1 Make authenticated calls to AWS services.
2.2 Implement encryption using AWS services.
2.3 Implement application authentication and authorization.26% Domain 3: Development with AWS Services (30%)
3.1 Write code for serverless applications.
3.2 Translate functional requirements into application design.
3.3 Implement application design into application code.
3.4 Write code that interacts with AWS services by using APIs, SDKs, and AWS CLI.30% Domain 4: Refactoring
4.1 Optimize application to best use AWS services and features.
4.2 Migrate existing application code to run on AWS.10% Domain 5: Monitoring and Troubleshooting (10%)
5.1 Write code that can be monitored.
5.2 Perform root cause analysis on faults found in testing or production.10% TOTAL 100%
AWS Certified Developer Associate exam: Additional Information for reference
Below are some useful reference links that would help you to learn about AWS Certified Developer Associate Exam.
- Developing on AWS: An instructor-led live or virtual 3-day course
- https://aws.amazon.com/certification/faqs/
- AWS Digital Training: Application Services, Developer Tools, and other services covered on the exam
- Prepare for AWS Certification
- AWS EC2 Instance info
- AWS Certified Developer Associate Exam Guide
Other Relevant and Recommended AWS Certifications

- AWS Certified Cloud Practitioner
- AWS Certified Solutions Architect – Associate
- AAWS Certified Developer – Associate
- AWS Certified SysOps Administrator – Associate
- AWS Certified Solutions Architect – Professional
- AWS Certified DevOps Engineer – Professional
- AWS Certified Big Data Specialty
- AWS Certified Advanced Networking.
- AWS Certified Security – Specialty
Active Hydrating Toner, Anti-Aging Replenishing Advanced Face Moisturizer, with Vitamins A, C, E & Natural Botanicals to Promote Skin Balance & Collagen Production, 6.7 Fl Oz



Age Defying 0.3% Retinol Serum, Anti-Aging Dark Spot Remover for Face, Fine Lines & Wrinkle Pore Minimizer, with Vitamin E & Natural Botanicals


Firming Moisturizer, Advanced Hydrating Facial Replenishing Cream, with Hyaluronic Acid, Resveratrol & Natural Botanicals to Restore Skin's Strength, Radiance, and Resilience, 1.75 Oz

Skin Stem Cell Serum


Smartphone 101 - Pick a smartphone for me - android or iOS - Apple iPhone or Samsung Galaxy or Huawei or Xaomi or Google Pixel
Can AI Really Predict Lottery Results? We Asked an Expert.





Djamgatech

Read Photos and PDFs Aloud for me iOS
Read Photos and PDFs Aloud for me android
Read Photos and PDFs Aloud For me Windows 10/11
Read Photos and PDFs Aloud For Amazon
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more)
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6(Email us for more)



FREE 10000+ Quiz Trivia and and Brain Teasers for All Topics including Cloud Computing, General Knowledge, History, Television, Music, Art, Science, Movies, Films, US History, Soccer Football, World Cup, Data Science, Machine Learning, Geography, etc....


List of Freely available programming books - What is the single most influential book every Programmers should read
- Bjarne Stroustrup - The C++ Programming Language
- Brian W. Kernighan, Rob Pike - The Practice of Programming
- Donald Knuth - The Art of Computer Programming
- Ellen Ullman - Close to the Machine
- Ellis Horowitz - Fundamentals of Computer Algorithms
- Eric Raymond - The Art of Unix Programming
- Gerald M. Weinberg - The Psychology of Computer Programming
- James Gosling - The Java Programming Language
- Joel Spolsky - The Best Software Writing I
- Keith Curtis - After the Software Wars
- Richard M. Stallman - Free Software, Free Society
- Richard P. Gabriel - Patterns of Software
- Richard P. Gabriel - Innovation Happens Elsewhere
- Code Complete (2nd edition) by Steve McConnell
- The Pragmatic Programmer
- Structure and Interpretation of Computer Programs
- The C Programming Language by Kernighan and Ritchie
- Introduction to Algorithms by Cormen, Leiserson, Rivest & Stein
- Design Patterns by the Gang of Four
- Refactoring: Improving the Design of Existing Code
- The Mythical Man Month
- The Art of Computer Programming by Donald Knuth
- Compilers: Principles, Techniques and Tools by Alfred V. Aho, Ravi Sethi and Jeffrey D. Ullman
- Gödel, Escher, Bach by Douglas Hofstadter
- Clean Code: A Handbook of Agile Software Craftsmanship by Robert C. Martin
- Effective C++
- More Effective C++
- CODE by Charles Petzold
- Programming Pearls by Jon Bentley
- Working Effectively with Legacy Code by Michael C. Feathers
- Peopleware by Demarco and Lister
- Coders at Work by Peter Seibel
- Surely You're Joking, Mr. Feynman!
- Effective Java 2nd edition
- Patterns of Enterprise Application Architecture by Martin Fowler
- The Little Schemer
- The Seasoned Schemer
- Why's (Poignant) Guide to Ruby
- The Inmates Are Running The Asylum: Why High Tech Products Drive Us Crazy and How to Restore the Sanity
- The Art of Unix Programming
- Test-Driven Development: By Example by Kent Beck
- Practices of an Agile Developer
- Don't Make Me Think
- Agile Software Development, Principles, Patterns, and Practices by Robert C. Martin
- Domain Driven Designs by Eric Evans
- The Design of Everyday Things by Donald Norman
- Modern C++ Design by Andrei Alexandrescu
- Best Software Writing I by Joel Spolsky
- The Practice of Programming by Kernighan and Pike
- Pragmatic Thinking and Learning: Refactor Your Wetware by Andy Hunt
- Software Estimation: Demystifying the Black Art by Steve McConnel
- The Passionate Programmer (My Job Went To India) by Chad Fowler
- Hackers: Heroes of the Computer Revolution
- Algorithms + Data Structures = Programs
- Writing Solid Code
- JavaScript - The Good Parts
- Getting Real by 37 Signals
- Foundations of Programming by Karl Seguin
- Computer Graphics: Principles and Practice in C (2nd Edition)
- Thinking in Java by Bruce Eckel
- The Elements of Computing Systems
- Refactoring to Patterns by Joshua Kerievsky
- Modern Operating Systems by Andrew S. Tanenbaum
- The Annotated Turing
- Things That Make Us Smart by Donald Norman
- The Timeless Way of Building by Christopher Alexander
- The Deadline: A Novel About Project Management by Tom DeMarco
- The C++ Programming Language (3rd edition) by Stroustrup
- Patterns of Enterprise Application Architecture
- Computer Systems - A Programmer's Perspective
- Agile Principles, Patterns, and Practices in C# by Robert C. Martin
- Growing Object-Oriented Software, Guided by Tests
- Framework Design Guidelines by Brad Abrams
- Object Thinking by Dr. David West
- Advanced Programming in the UNIX Environment by W. Richard Stevens
- Hackers and Painters: Big Ideas from the Computer Age
- The Soul of a New Machine by Tracy Kidder
- CLR via C# by Jeffrey Richter
- The Timeless Way of Building by Christopher Alexander
- Design Patterns in C# by Steve Metsker
- Alice in Wonderland by Lewis Carol
- Zen and the Art of Motorcycle Maintenance by Robert M. Pirsig
- About Face - The Essentials of Interaction Design
- Here Comes Everybody: The Power of Organizing Without Organizations by Clay Shirky
- The Tao of Programming
- Computational Beauty of Nature
- Writing Solid Code by Steve Maguire
- Philip and Alex's Guide to Web Publishing
- Object-Oriented Analysis and Design with Applications by Grady Booch
- Effective Java by Joshua Bloch
- Computability by N. J. Cutland
- Masterminds of Programming
- The Tao Te Ching
- The Productive Programmer
- The Art of Deception by Kevin Mitnick
- The Career Programmer: Guerilla Tactics for an Imperfect World by Christopher Duncan
- Paradigms of Artificial Intelligence Programming: Case studies in Common Lisp
- Masters of Doom
- Pragmatic Unit Testing in C# with NUnit by Andy Hunt and Dave Thomas with Matt Hargett
- How To Solve It by George Polya
- The Alchemist by Paulo Coelho
- Smalltalk-80: The Language and its Implementation
- Writing Secure Code (2nd Edition) by Michael Howard
- Introduction to Functional Programming by Philip Wadler and Richard Bird
- No Bugs! by David Thielen
- Rework by Jason Freid and DHH
- JUnit in Action
#BlackOwned #BlackEntrepreneurs #BlackBuniness #AWSCertified #AWSCloudPractitioner #AWSCertification #AWSCLFC02 #CloudComputing #AWSStudyGuide #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AWSBasics #AWSCertified #AWSMachineLearning #AWSCertification #AWSSpecialty #MachineLearning #AWSStudyGuide #CloudComputing #DataScience #AWSCertified #AWSSolutionsArchitect #AWSArchitectAssociate #AWSCertification #AWSStudyGuide #CloudComputing #AWSArchitecture #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AzureFundamentals #AZ900 #MicrosoftAzure #ITCertification #CertificationPrep #StudyMaterials #TechLearning #MicrosoftCertified #AzureCertification #TechBooks
Top 1000 Canada Quiz and trivia: CANADA CITIZENSHIP TEST- HISTORY - GEOGRAPHY - GOVERNMENT- CULTURE - PEOPLE - LANGUAGES - TRAVEL - WILDLIFE - HOCKEY - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Top 1000 Africa Quiz and trivia: HISTORY - GEOGRAPHY - WILDLIFE - CULTURE - PEOPLE - LANGUAGES - TRAVEL - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Exploring the Pros and Cons of Visiting All Provinces and Territories in Canada.


Exploring the Advantages and Disadvantages of Visiting All 50 States in the USA

Health Health, a science-based community to discuss health news and the coronavirus (COVID-19) pandemic
- Dad has a spot on his neck- should i be concerned? He isn’t taking this seriously (I’m 17F)by /u/hjawol on April 26, 2024 at 2:16 am
submitted by /u/hjawol [link] [comments]
- FDA says traces of the bird flu virus have been found in 1 in 5 samples of pasteurized milk, providing a more detailed picture of how much of the milk supply has been impacted.by /u/nbcnews on April 25, 2024 at 10:21 pm
submitted by /u/nbcnews [link] [comments]
- CDC describes first known cases of HIV transmitted via cosmetic injectionsby /u/nbcnews on April 25, 2024 at 7:59 pm
submitted by /u/nbcnews [link] [comments]
- U.S. orders cow testing for bird flu after grocery milk tests positiveby /u/Illuminatih0ttie on April 25, 2024 at 6:59 pm
submitted by /u/Illuminatih0ttie [link] [comments]
- Why Idaho’s hospitals are having pregnant patients airlifted out of stateby /u/nbcnews on April 25, 2024 at 3:41 pm
submitted by /u/nbcnews [link] [comments]
Today I Learned (TIL) You learn something new every day; what did you learn today? Submit interesting and specific facts about something that you just found out here.
- TIL second breakfast is an actual thing, not an invention of Tolkein. It's a traditional meal in parts of central Europe, namely Poland, Slovakia, Hungary, and Bavaria and typically consists of meats and pastries, with coffee to drink.by /u/VLenin2291 on April 26, 2024 at 2:33 am
submitted by /u/VLenin2291 [link] [comments]
- TIL Plants receive more energy on a cloudy day in the summer than on a sunny day in the winter.by /u/Starza on April 26, 2024 at 1:49 am
submitted by /u/Starza [link] [comments]
- TIL that Jay Penske, son of the founder of Penske Corporation, owns the media company that owns Rolling Stone, Variety, Billboard, The Hollywood Reporter, Deadline Hollywood, Robb Report, IndieWire, TVLine, and the Golden Globes.by /u/nuttybudd on April 26, 2024 at 1:26 am
submitted by /u/nuttybudd [link] [comments]
- TIL Daughter from California syndrome is a phrase used in the medical profession to describe a situation in which a disengaged relative challenges the care a dying elderly patient is being given, or insists that the medical team pursue aggressive measures to prolong the patient's lifeby /u/Majorpain2006 on April 26, 2024 at 1:23 am
submitted by /u/Majorpain2006 [link] [comments]
- TIL there are freshwater jellyfish in nearly every state in the USA and there have been since the early 1900sby /u/JTML99 on April 25, 2024 at 11:31 pm
submitted by /u/JTML99 [link] [comments]
Reddit Science This community is a place to share and discuss new scientific research. Read about the latest advances in astronomy, biology, medicine, physics, social science, and more. Find and submit new publications and popular science coverage of current research.
- Traffic noise causes lifelong harm to baby birds. A new experiment on developing birds shows traffic noise can slow their growth and lead to lifelong impairments. The finding raises new concerns about the effect of noise pollution on wildlife—and humans as well.by /u/MistWeaver80 on April 26, 2024 at 3:09 am
submitted by /u/MistWeaver80 [link] [comments]
- The positive impact of conservation actionby /u/No_Neat2502 on April 26, 2024 at 1:53 am
submitted by /u/No_Neat2502 [link] [comments]
- Voluntary corporate emissions targets not enough to create real climate actionby /u/No_Neat2502 on April 26, 2024 at 1:36 am
submitted by /u/No_Neat2502 [link] [comments]
- A new study, revealing that tickling can serve as a sufficient sexual stimulus for many, with some individuals even experiencing orgasms from tickling alone | This study suggests that our understanding of what can provoke sexual pleasure might be broader than traditionally thought.by /u/chrisdh79 on April 26, 2024 at 12:28 am
submitted by /u/chrisdh79 [link] [comments]
- Scientists have devised a way to detect a distinction between illegal elephant ivory and legal mammoth tusk ivory with a new laser tech using Raman spectroscopy | A non-destructive laser technology swiftly detects illegal elephant ivory.by /u/chrisdh79 on April 26, 2024 at 12:23 am
submitted by /u/chrisdh79 [link] [comments]
Reddit Sports Sports News and Highlights from the NFL, NBA, NHL, MLB, MLS, and leagues around the world.
- Thinking Basketball: The Suns can’t even dribble around the Wolves!by /u/executivesphere on April 26, 2024 at 12:16 am
submitted by /u/executivesphere [link] [comments]
- Report: Eagles sign A.J. Brown to 3-year, $96M extensionby /u/Oldtimer_2 on April 25, 2024 at 11:54 pm
submitted by /u/Oldtimer_2 [link] [comments]
- Steph Curry named Clutch Player of the Yearby /u/Oldtimer_2 on April 25, 2024 at 11:49 pm
submitted by /u/Oldtimer_2 [link] [comments]
- Report: 49ers shopping Brandon Aiyuk or Deebo Samuel to move up in 1st roundby /u/Oldtimer_2 on April 25, 2024 at 11:30 pm
submitted by /u/Oldtimer_2 [link] [comments]
- Reggie Bush plans to continue with defamation lawsuit vs. NCAAby /u/PrincessBananas85 on April 25, 2024 at 10:00 pm
submitted by /u/PrincessBananas85 [link] [comments]
