



 What are the top 10 ways cybercrime and deep fakes and generative AI are exploiting and bullying and potentially killing our children? - What are the top 10 ways cybercrime and deep fakes and generative AI are exploiting and bullying and potentially killing our children? In today's digital age, children face unprecedented risks from cybercrime, deep fakes, and generative AI. These sophisticated technologies are being misused to exploit, bully, and even endanger young lives. As parents, educators, and guardians, understanding these threats is crucial to safeguarding our children's online and offline well-being. This blog explores the top 10 ways these digital dangers are impacting our kids and offers insights on how to protect them.
What are the top 10 ways cybercrime and deep fakes and generative AI are exploiting and bullying and potentially killing our children? - What are the top 10 ways cybercrime and deep fakes and generative AI are exploiting and bullying and potentially killing our children? In today's digital age, children face unprecedented risks from cybercrime, deep fakes, and generative AI. These sophisticated technologies are being misused to exploit, bully, and even endanger young lives. As parents, educators, and guardians, understanding these threats is crucial to safeguarding our children's online and offline well-being. This blog explores the top 10 ways these digital dangers are impacting our kids and offers insights on how to protect them.  AI Innovations in July 2024 - AI Innovations in July 2024. Welcome to our blog series "AI Innovations in July 2024"! As we continue to ride the wave of extraordinary developments from June, the momentum in artificial intelligence shows no signs of slowing down. Last month, we witnessed groundbreaking achievements such as the unveiling of the first quantum AI chip, the successful deployment of autonomous medical drones in remote areas, and significant advancements in natural language understanding that have set new benchmarks for AI-human interaction.
AI Innovations in July 2024 - AI Innovations in July 2024. Welcome to our blog series "AI Innovations in July 2024"! As we continue to ride the wave of extraordinary developments from June, the momentum in artificial intelligence shows no signs of slowing down. Last month, we witnessed groundbreaking achievements such as the unveiling of the first quantum AI chip, the successful deployment of autonomous medical drones in remote areas, and significant advancements in natural language understanding that have set new benchmarks for AI-human interaction. Ace the AWS Certified Data Engineer Exam - Ace the AWS Certified Data Engineer Exam (DEA-C01): Mastering AWS Services for Data Ingestion, Transformation, and Pipeline Orchestration.
Unlock the full potential of AWS and elevate your data engineering skills with “Ace the AWS Certified Data Engineer Exam.” This comprehensive guide is tailored for professionals seeking to master the AWS Certified Data Engineer - Associate certification. Authored by Etienne Noumen, a seasoned Professional Engineer with over 20 years of software engineering experience and 5+ years specializing in AWS data engineering, this book provides an in-depth and practical approach to conquering the certification exam.
Ace the AWS Certified Data Engineer Exam - Ace the AWS Certified Data Engineer Exam (DEA-C01): Mastering AWS Services for Data Ingestion, Transformation, and Pipeline Orchestration.
Unlock the full potential of AWS and elevate your data engineering skills with “Ace the AWS Certified Data Engineer Exam.” This comprehensive guide is tailored for professionals seeking to master the AWS Certified Data Engineer - Associate certification. Authored by Etienne Noumen, a seasoned Professional Engineer with over 20 years of software engineering experience and 5+ years specializing in AWS data engineering, this book provides an in-depth and practical approach to conquering the certification exam.  Wonderland Bedtime Adventures: Diverse Tales for Dreamy Nights - Wonderland Bedtime Adventures: Diverse Tales for Dreamy Nights. Embark on a magical journey with “Wonderland Bedtime Adventures: Diverse Tales for Dreamy Nights” by Etienne Noumen. This enchanting collection of bedtime stories is designed to celebrate the beauty of diversity and inclusivity. With a rich blend of traditional and modern tales, this book introduces young readers to heroes and heroines from all cultures, shapes, sizes, and backgrounds.
Wonderland Bedtime Adventures: Diverse Tales for Dreamy Nights - Wonderland Bedtime Adventures: Diverse Tales for Dreamy Nights. Embark on a magical journey with “Wonderland Bedtime Adventures: Diverse Tales for Dreamy Nights” by Etienne Noumen. This enchanting collection of bedtime stories is designed to celebrate the beauty of diversity and inclusivity. With a rich blend of traditional and modern tales, this book introduces young readers to heroes and heroines from all cultures, shapes, sizes, and backgrounds. AI Innovations in June 2024 - AI Innovations in June 2024
AI Innovations in June 2024 - AI Innovations in June 2024 A Daily Chronicle of AI Innovations in May 2024 - AI Innovations in May 2024
A Daily Chronicle of AI Innovations in May 2024 - AI Innovations in May 2024 SQL Interview Questions and Answers - SQL Interview Questions and Answers
In the world of data-driven decision-making, SQL (Structured Query Language) stands out as the lingua franca for managing relational databases. Whether you are preparing to land your first job in data analytics or aiming to advance further in your tech career, proficiency in SQL is often a crucial requirement. This blog post at Enoumen delves into some of the most commonly asked SQL interview questions that you might encounter during a rigorous screening process. From basic queries to complex data manipulation and optimization problems, we cover a comprehensive range of topics that are designed to not only test your technical knowledge but also enhance your understanding of SQL’s powerful features. Prepare to unlock the secrets to acing your SQL interviews with our detailed explanations and insider tips.
SQL Interview Questions and Answers - SQL Interview Questions and Answers
In the world of data-driven decision-making, SQL (Structured Query Language) stands out as the lingua franca for managing relational databases. Whether you are preparing to land your first job in data analytics or aiming to advance further in your tech career, proficiency in SQL is often a crucial requirement. This blog post at Enoumen delves into some of the most commonly asked SQL interview questions that you might encounter during a rigorous screening process. From basic queries to complex data manipulation and optimization problems, we cover a comprehensive range of topics that are designed to not only test your technical knowledge but also enhance your understanding of SQL’s powerful features. Prepare to unlock the secrets to acing your SQL interviews with our detailed explanations and insider tips. Industries Affected by the Growth of AI Technology - AI is spearheading technological advancements in many areas of the corporate world. Learn about some industries affected by the growth of AI technology.
Industries Affected by the Growth of AI Technology - AI is spearheading technological advancements in many areas of the corporate world. Learn about some industries affected by the growth of AI technology.  A Daily Chronicle of AI Innovations in March 2024 - AI Innovations in March 2024. Welcome to the March 2024 edition of the Daily Chronicle, your gateway to the forefront of Artificial Intelligence innovation! Embark on a captivating journey with us as we unveil the most recent advancements, trends, and revolutionary discoveries in the realm of artificial intelligence. Delve into a world where industry giants converge at events like 'AI Innovations at Work' and where visionary forecasts shape the future landscape of AI. Stay abreast of daily updates as we navigate through the dynamic realm of AI, unraveling its potential impact and exploring cutting-edge developments throughout this enthralling month. Join us on this exhilarating expedition into the boundless possibilities of AI in March 2024.
A Daily Chronicle of AI Innovations in March 2024 - AI Innovations in March 2024. Welcome to the March 2024 edition of the Daily Chronicle, your gateway to the forefront of Artificial Intelligence innovation! Embark on a captivating journey with us as we unveil the most recent advancements, trends, and revolutionary discoveries in the realm of artificial intelligence. Delve into a world where industry giants converge at events like 'AI Innovations at Work' and where visionary forecasts shape the future landscape of AI. Stay abreast of daily updates as we navigate through the dynamic realm of AI, unraveling its potential impact and exploring cutting-edge developments throughout this enthralling month. Join us on this exhilarating expedition into the boundless possibilities of AI in March 2024. Unlocking Nature’s Secrets: The Ultimate Guide to Natural Skin and Hair Care Ingredients - Unlocking Nature's Secrets: The Ultimate Guide to Natural Skin and Hair Care Ingredients. In the realm of skin and hair care, the ingredients we choose to incorporate into our routines play pivotal roles in determining the health and appearance of our skin and hair. From ancient remedies to cutting-edge scientific discoveries, the array of ingredients available today offers a vast palette from which to craft personalized care regimens. In this blog, we delve into the benefits and applications of select ingredients that have garnered attention for their efficacy and natural origins. These include mucin and tallow for their rich moisturizing properties, arrowroot powder for its gentle oil-absorbing capabilities, beef tallow for its skin-nourishing fats, fenugreek for its potent anti-inflammatory effects, raw batana oil for its revered hair strengthening qualities, aloe vera for its unparalleled soothing and hydrating benefits, and azelaic acid and collagen for their transformative effects on skin texture and firmness. By understanding these ingredients, we can make informed choices that align with our skin and hair care goals, leading to healthier, more radiant outcomes.
Unlocking Nature’s Secrets: The Ultimate Guide to Natural Skin and Hair Care Ingredients - Unlocking Nature's Secrets: The Ultimate Guide to Natural Skin and Hair Care Ingredients. In the realm of skin and hair care, the ingredients we choose to incorporate into our routines play pivotal roles in determining the health and appearance of our skin and hair. From ancient remedies to cutting-edge scientific discoveries, the array of ingredients available today offers a vast palette from which to craft personalized care regimens. In this blog, we delve into the benefits and applications of select ingredients that have garnered attention for their efficacy and natural origins. These include mucin and tallow for their rich moisturizing properties, arrowroot powder for its gentle oil-absorbing capabilities, beef tallow for its skin-nourishing fats, fenugreek for its potent anti-inflammatory effects, raw batana oil for its revered hair strengthening qualities, aloe vera for its unparalleled soothing and hydrating benefits, and azelaic acid and collagen for their transformative effects on skin texture and firmness. By understanding these ingredients, we can make informed choices that align with our skin and hair care goals, leading to healthier, more radiant outcomes. Longevity gene therapy and AI – What is on the horizon? - Longevity gene therapy and AI - What is on the horizon? Gene therapy holds promise for extending human lifespan and enhancing healthspan by targeting genes associated with aging processes. Longevity gene therapy, particularly interventions focusing on genes like TERT (telomerase reverse transcriptase), Klotho, and Myostatin, is at the forefront of experimental research. Companies such as Bioviva, Libella, and Minicircle are pioneering these interventions, albeit with varying degrees of transparency and scientific rigor.
Longevity gene therapy and AI – What is on the horizon? - Longevity gene therapy and AI - What is on the horizon? Gene therapy holds promise for extending human lifespan and enhancing healthspan by targeting genes associated with aging processes. Longevity gene therapy, particularly interventions focusing on genes like TERT (telomerase reverse transcriptase), Klotho, and Myostatin, is at the forefront of experimental research. Companies such as Bioviva, Libella, and Minicircle are pioneering these interventions, albeit with varying degrees of transparency and scientific rigor. A Daily Chronicle of AI Innovations in February 2024 - A Daily Chronicle of AI Innovations in February 2024. Welcome to the Daily Chronicle of AI Innovations in February 2024! This month-long blog series will provide you with the latest developments, trends, and breakthroughs in the field of artificial intelligence. From major industry conferences like 'AI Innovations at Work' to bold predictions about the future of AI, we will curate and share daily updates to keep you informed about the rapidly evolving world of AI. Join us on this exciting journey as we explore the cutting-edge advancements and potential impact of AI throughout February 2024.
A Daily Chronicle of AI Innovations in February 2024 - A Daily Chronicle of AI Innovations in February 2024. Welcome to the Daily Chronicle of AI Innovations in February 2024! This month-long blog series will provide you with the latest developments, trends, and breakthroughs in the field of artificial intelligence. From major industry conferences like 'AI Innovations at Work' to bold predictions about the future of AI, we will curate and share daily updates to keep you informed about the rapidly evolving world of AI. Join us on this exciting journey as we explore the cutting-edge advancements and potential impact of AI throughout February 2024. AI Revolution in Healthcare: ChatGPT & Google Bard’s Breakthroughs – Diagnosis, mRNA Tech, Cancer Detection & More - AI Revolution in Healthcare. Dive into the latest AI breakthroughs transforming healthcare since ChatGPT and Google Bard's inception. Discover GPT-4's rapid diagnostics, Moderna & IBM's mRNA tech advancements, cutting-edge cancer detection methods, and more. Stay ahead in AI healthcare news with our comprehensive coverage on AI-powered drug discovery, early Alzheimer's detection, and groundbreaking AI tools in medicine. Join us as we explore each major AI development that's reshaping healthcare.
AI Revolution in Healthcare: ChatGPT & Google Bard’s Breakthroughs – Diagnosis, mRNA Tech, Cancer Detection & More - AI Revolution in Healthcare. Dive into the latest AI breakthroughs transforming healthcare since ChatGPT and Google Bard's inception. Discover GPT-4's rapid diagnostics, Moderna & IBM's mRNA tech advancements, cutting-edge cancer detection methods, and more. Stay ahead in AI healthcare news with our comprehensive coverage on AI-powered drug discovery, early Alzheimer's detection, and groundbreaking AI tools in medicine. Join us as we explore each major AI development that's reshaping healthcare. Best VPN in 2024 According to Reddit - Best VPN in 2024 According to Reddit. The year 2024 has brought about a myriad of changes, and the realm of virtual private networks (VPNs) is no exception. In this ever-evolving landscape, it can be challenging to identify the most reliable and effective VPN service. However, thanks to the collective wisdom of Reddit users, we have gained valuable insights into the best VPNs of 2024. Through extensive real-world feedback and discussions on various subreddits, certain VPN providers have emerged as top contenders for the year. From industry giants like ExpressVPN and NordVPN to the user-friendly Surfshark and the privacy-focused ProtonVPN, Reddit's top-rated VPN picks offer a diverse range of features and capabilities. In this blog, we will delve into the criteria used by Reddit users to evaluate these VPNs, explore the top-recommended services, and provide guidance on selecting the most suitable VPN for your specific needs. Join us as we navigate the complex world of VPNs in 2024, guided by the invaluable insights of the Reddit community.
Best VPN in 2024 According to Reddit - Best VPN in 2024 According to Reddit. The year 2024 has brought about a myriad of changes, and the realm of virtual private networks (VPNs) is no exception. In this ever-evolving landscape, it can be challenging to identify the most reliable and effective VPN service. However, thanks to the collective wisdom of Reddit users, we have gained valuable insights into the best VPNs of 2024. Through extensive real-world feedback and discussions on various subreddits, certain VPN providers have emerged as top contenders for the year. From industry giants like ExpressVPN and NordVPN to the user-friendly Surfshark and the privacy-focused ProtonVPN, Reddit's top-rated VPN picks offer a diverse range of features and capabilities. In this blog, we will delve into the criteria used by Reddit users to evaluate these VPNs, explore the top-recommended services, and provide guidance on selecting the most suitable VPN for your specific needs. Join us as we navigate the complex world of VPNs in 2024, guided by the invaluable insights of the Reddit community. A Daily Chronicle of AI Innovations in January 2024 - A Daily Chronicle of AI Innovations in January 2024. Welcome to 'Navigating the Future,' a premier portal for insightful and up-to-the-minute commentary on the evolving world of Artificial Intelligence in January 2024. In an age where technology outpaces our expectations, we delve deep into the AI cosmos, offering daily snapshots of revolutionary breakthroughs, pivotal industry transitions, and the ingenious minds shaping our digital destiny. Join us on this exhilarating journey as we explore the marvels and pivotal milestones in AI, day by day. Stay informed, stay inspired, and witness the chronicle of AI as it unfolds in real-time.
A Daily Chronicle of AI Innovations in January 2024 - A Daily Chronicle of AI Innovations in January 2024. Welcome to 'Navigating the Future,' a premier portal for insightful and up-to-the-minute commentary on the evolving world of Artificial Intelligence in January 2024. In an age where technology outpaces our expectations, we delve deep into the AI cosmos, offering daily snapshots of revolutionary breakthroughs, pivotal industry transitions, and the ingenious minds shaping our digital destiny. Join us on this exhilarating journey as we explore the marvels and pivotal milestones in AI, day by day. Stay informed, stay inspired, and witness the chronicle of AI as it unfolds in real-time. How to Use WhatsApp Broadcasts and AI for Better ROI: A Comprehensive Guide - How to Use WhatsApp Broadcasts and AI for Better ROI. WhatsApp Broadcasts, akin to digital flyers, offer an unparalleled efficiency in reaching a targeted audience. With impressive statistics like a 98% open rate and 35% click rate, it's no wonder that brands are flocking to this medium. However, the real challenge lies in building a robust broadcast list. Here's how to strategically capture leads and leverage WhatsApp for your business.
How to Use WhatsApp Broadcasts and AI for Better ROI: A Comprehensive Guide - How to Use WhatsApp Broadcasts and AI for Better ROI. WhatsApp Broadcasts, akin to digital flyers, offer an unparalleled efficiency in reaching a targeted audience. With impressive statistics like a 98% open rate and 35% click rate, it's no wonder that brands are flocking to this medium. However, the real challenge lies in building a robust broadcast list. Here's how to strategically capture leads and leverage WhatsApp for your business. 2023 Unveiled: A Kaleidoscope of Search Trends – From Global News to Viral Memes - 2023 Unveiled: A Year in Search - Kaleidoscope of Search Trends - From Global News to Viral Memes.
As we navigate through 2023, the year's search trends offer a fascinating glimpse into our collective curiosities, concerns, and interests. From breaking news and entertainment to culinary delights and technological advancements, these trends paint a vivid picture of our shared experiences and individual pursuits.
2023 Unveiled: A Kaleidoscope of Search Trends – From Global News to Viral Memes - 2023 Unveiled: A Year in Search - Kaleidoscope of Search Trends - From Global News to Viral Memes.
As we navigate through 2023, the year's search trends offer a fascinating glimpse into our collective curiosities, concerns, and interests. From breaking news and entertainment to culinary delights and technological advancements, these trends paint a vivid picture of our shared experiences and individual pursuits. Top 5 unique ways to get better results with ChatGPT - What are the Top 5 unique ways to get better results with ChatGPT?
ChatGPT, an advanced AI language model, often exhibits traits that are strikingly human-like. Understanding and engaging with these characteristics can significantly enhance the quality of your interactions with it. Just like getting to know a person, recognizing and adapting to ChatGPT's unique 'personality' can lead to more fruitful and effective communications.
Top 5 unique ways to get better results with ChatGPT - What are the Top 5 unique ways to get better results with ChatGPT?
ChatGPT, an advanced AI language model, often exhibits traits that are strikingly human-like. Understanding and engaging with these characteristics can significantly enhance the quality of your interactions with it. Just like getting to know a person, recognizing and adapting to ChatGPT's unique 'personality' can lead to more fruitful and effective communications.  What are Educational mobile apps ideas that leverage generative AI without doing the same thing that ChatGPT can do? - What are Educational mobile apps ideas that leverage generative AI without doing the same thing that ChatGPT or Google Bard can do?
What are Educational mobile apps ideas that leverage generative AI without doing the same thing that ChatGPT can do? - What are Educational mobile apps ideas that leverage generative AI without doing the same thing that ChatGPT or Google Bard can do?  Latest Marketing Trends in December 2023 - Latest Marketing Trends in December 2023. Meta plans to launch its social media app, Threads, in Europe within the next few weeks.
TikTok has launched a new website called Creative Cards that provides holiday marketing ideas.
Pinterest has launched a new AI body-type filter to make search more inclusive and healthy.
Elon Musk has told advertisers to “Go F**k Yourself” if they don’t want to run ads on his social media platform, X.
Reddit has gone through a rebranding process, which includes a new logo and typography, new conversation bubbles and colors, and a new Snoo logo.
YouTube is rolling out Shorts Ads to more advertisers.
Latest Marketing Trends in December 2023 - Latest Marketing Trends in December 2023. Meta plans to launch its social media app, Threads, in Europe within the next few weeks.
TikTok has launched a new website called Creative Cards that provides holiday marketing ideas.
Pinterest has launched a new AI body-type filter to make search more inclusive and healthy.
Elon Musk has told advertisers to “Go F**k Yourself” if they don’t want to run ads on his social media platform, X.
Reddit has gone through a rebranding process, which includes a new logo and typography, new conversation bubbles and colors, and a new Snoo logo.
YouTube is rolling out Shorts Ads to more advertisers. What I’ve learned in 20+ years of building startups - What I've learned in 20+ years of building startups.
What I’ve learned in 20+ years of building startups - What I've learned in 20+ years of building startups. A Daily Chronicle of AI Innovations in December 2023 - A Daily Chronicle of AI Innovations in December 2023. Join us at 'Navigating the Future,' your premier destination for unparalleled perspectives on the swift progress and transformative changes in the Artificial Intelligence landscape throughout December 2023. In an era where technology is advancing faster than ever, we immerse ourselves in the AI universe to provide you with daily insights into groundbreaking developments, significant industry shifts, and the visionary thinkers forging our future. Embark with us on this exciting adventure as we uncover the wonders and significant achievements of AI, each and every day.
A Daily Chronicle of AI Innovations in December 2023 - A Daily Chronicle of AI Innovations in December 2023. Join us at 'Navigating the Future,' your premier destination for unparalleled perspectives on the swift progress and transformative changes in the Artificial Intelligence landscape throughout December 2023. In an era where technology is advancing faster than ever, we immerse ourselves in the AI universe to provide you with daily insights into groundbreaking developments, significant industry shifts, and the visionary thinkers forging our future. Embark with us on this exciting adventure as we uncover the wonders and significant achievements of AI, each and every day. Mastering GPT-4: Simplified Guide for Everyday Users - Mastering GPT-4: Simplified Guide for Everyday Users.
Embark on a journey to master GPT-4 with our easy-to-understand guide, 'Unlocking GPT-4: A User-Friendly Guide to Optimizing AI Interactions'. 🌟🤖 This video is perfect for both AI newbies and those looking to enhance their experience with GPT-4. We break down the complexities of GPT-4's settings into simple, practical terms, so you can use this powerful tool more effectively and creatively.
Mastering GPT-4: Simplified Guide for Everyday Users - Mastering GPT-4: Simplified Guide for Everyday Users.
Embark on a journey to master GPT-4 with our easy-to-understand guide, 'Unlocking GPT-4: A User-Friendly Guide to Optimizing AI Interactions'. 🌟🤖 This video is perfect for both AI newbies and those looking to enhance their experience with GPT-4. We break down the complexities of GPT-4's settings into simple, practical terms, so you can use this powerful tool more effectively and creatively. Charlie Munger’s Investment Wisdom: Top 10 Mental Flaws to Avoid for Success! - Charlie Munger's Investment Wisdom: Top 10 Mental Flaws to Avoid for Success!
Dive into the world of investment genius with our video on 'Charlie Munger's Top 10 Investment Principles'!
Charlie Munger’s Investment Wisdom: Top 10 Mental Flaws to Avoid for Success! - Charlie Munger's Investment Wisdom: Top 10 Mental Flaws to Avoid for Success!
Dive into the world of investment genius with our video on 'Charlie Munger's Top 10 Investment Principles'! Decoding GPTs & LLMs: Training, Memory & Advanced Architectures Explained - Decoding GPTs & LLMs: Training, Memory & Advanced Architectures Explained: Dive deep into the world of AI as we explore 'GPTs and LLMs: Pre-Training, Fine-Tuning, Memory, and More!' Understand the intricacies of how these AI models learn through pre-training and fine-tuning, their operational scope within a context window, and the intriguing aspect of their lack of long-term memory.
Decoding GPTs & LLMs: Training, Memory & Advanced Architectures Explained - Decoding GPTs & LLMs: Training, Memory & Advanced Architectures Explained: Dive deep into the world of AI as we explore 'GPTs and LLMs: Pre-Training, Fine-Tuning, Memory, and More!' Understand the intricacies of how these AI models learn through pre-training and fine-tuning, their operational scope within a context window, and the intriguing aspect of their lack of long-term memory. Exploring AI Revolution in Food: How Non-Tech Brands Are Innovating! - Exploring AI Revolution in Food: How Non-Tech Brands Are Innovating!
Uncover the fascinating world of AI integration in the food industry with our deep dive video titled 'How Non-Tech Brands Use AI in the Food Industry'. 🍔🤖 Discover how traditional food brands are revolutionizing their operations, from production to customer experience, using artificial intelligence.
Exploring AI Revolution in Food: How Non-Tech Brands Are Innovating! - Exploring AI Revolution in Food: How Non-Tech Brands Are Innovating!
Uncover the fascinating world of AI integration in the food industry with our deep dive video titled 'How Non-Tech Brands Use AI in the Food Industry'. 🍔🤖 Discover how traditional food brands are revolutionizing their operations, from production to customer experience, using artificial intelligence. Unveiling OpenAI Q*: The Fusion of A* Algorithms & Deep Q-Learning Networks Explained - Embark on a journey of discovery with our podcast, 'What is OpenAI Q*? A Deeper Look at the Q* Model'. Dive into the cutting-edge world of AI as we unravel the mysteries of OpenAI's Q* model, a groundbreaking blend of A* algorithms and Deep Q-learning networks.
Unveiling OpenAI Q*: The Fusion of A* Algorithms & Deep Q-Learning Networks Explained - Embark on a journey of discovery with our podcast, 'What is OpenAI Q*? A Deeper Look at the Q* Model'. Dive into the cutting-edge world of AI as we unravel the mysteries of OpenAI's Q* model, a groundbreaking blend of A* algorithms and Deep Q-learning networks. The Future of Generative AI: From Art to Reality Shaping - The Future of Generative AI: From Art to Reality Shaping. Explore the transformative potential of generative AI in our latest AI Unraveled episode. From AI-driven entertainment to reality-altering technologies, we delve deep into what the future holds. This episode covers how generative AI could revolutionize movie making, impact creative professions, and even extend to DNA alteration. We also discuss its integration in technology over the next decade, from smartphones to fully immersive VR worlds."
The Future of Generative AI: From Art to Reality Shaping - The Future of Generative AI: From Art to Reality Shaping. Explore the transformative potential of generative AI in our latest AI Unraveled episode. From AI-driven entertainment to reality-altering technologies, we delve deep into what the future holds. This episode covers how generative AI could revolutionize movie making, impact creative professions, and even extend to DNA alteration. We also discuss its integration in technology over the next decade, from smartphones to fully immersive VR worlds." A Daily Chronicle of AI Innovations in November 2023 - A Daily Chronicle of AI Innovations in November 2023. Welcome to "Navigating the Future," your go-to hub for unrivaled insights into the rapid advancements and transformations in the realm of Artificial Intelligence during November 2023. As technology evolves at an unprecedented pace, we delve deep into the world of AI, bringing you daily updates on groundbreaking innovations, industry disruptions, and the brilliant minds shaping the future. Stay with us on this thrilling journey as we explore the marvels and milestones of AI, day by day.
A Daily Chronicle of AI Innovations in November 2023 - A Daily Chronicle of AI Innovations in November 2023. Welcome to "Navigating the Future," your go-to hub for unrivaled insights into the rapid advancements and transformations in the realm of Artificial Intelligence during November 2023. As technology evolves at an unprecedented pace, we delve deep into the world of AI, bringing you daily updates on groundbreaking innovations, industry disruptions, and the brilliant minds shaping the future. Stay with us on this thrilling journey as we explore the marvels and milestones of AI, day by day. The TOP 50 Finance Headlines of 2023: Unraveling the Patterns - The TOP 50 Finance Headlines of 2023: Unraveling the Patterns! 2023 was a rollercoaster year in the world of finance, with groundbreaking headlines hitting the news every day. Dive into this detailed analysis as we uncover the TOP 50 finance headlines of the year and decipher the emerging patterns. Whether you're a finance enthusiast, an investor, or someone trying to stay updated, this video is your definitive guide to the financial trends of 2023. Don't forget to subscribe for more insights and hit the like button if you find this content valuable!
The TOP 50 Finance Headlines of 2023: Unraveling the Patterns - The TOP 50 Finance Headlines of 2023: Unraveling the Patterns! 2023 was a rollercoaster year in the world of finance, with groundbreaking headlines hitting the news every day. Dive into this detailed analysis as we uncover the TOP 50 finance headlines of the year and decipher the emerging patterns. Whether you're a finance enthusiast, an investor, or someone trying to stay updated, this video is your definitive guide to the financial trends of 2023. Don't forget to subscribe for more insights and hit the like button if you find this content valuable!  Deciphering the Marketing Landscape: Latest Insights & Trends for 2023 - Deciphering the Marketing Landscape.
In the dynamic world of marketing, trends evolve at a breakneck speed. As consumers become more discerning and digitally connected, their preferences and behavior patterns shift, requiring marketers to stay ahead of the curve. With each passing year, some strategies solidify their ground, while others wane. Dive into our curated compilation of the latest marketing insights and trends for 2023. Whether you're a seasoned marketer or a curious entrepreneur, these findings offer a snapshot of the changing consumer landscape and emerging marketing frontiers. Get ready to recalibrate, reimagine, and reshape your strategies!
Deciphering the Marketing Landscape: Latest Insights & Trends for 2023 - Deciphering the Marketing Landscape.
In the dynamic world of marketing, trends evolve at a breakneck speed. As consumers become more discerning and digitally connected, their preferences and behavior patterns shift, requiring marketers to stay ahead of the curve. With each passing year, some strategies solidify their ground, while others wane. Dive into our curated compilation of the latest marketing insights and trends for 2023. Whether you're a seasoned marketer or a curious entrepreneur, these findings offer a snapshot of the changing consumer landscape and emerging marketing frontiers. Get ready to recalibrate, reimagine, and reshape your strategies! Smart Savings: Top 10 Life Hacks to Lower Your Monthly Expense in USA and Canada - Top 10 Life Hacks to Lower Your Monthly Expense.
Looking to cut down on your monthly bills in North America? Dive into these top 10 life hacks designed specifically for those in the USA and Canada! From shopping tips to lifestyle changes, we've got the ultimate guide to help you save more every month. Don't forget to LIKE, SHARE, and SUBSCRIBE for more money-saving advice!
Smart Savings: Top 10 Life Hacks to Lower Your Monthly Expense in USA and Canada - Top 10 Life Hacks to Lower Your Monthly Expense.
Looking to cut down on your monthly bills in North America? Dive into these top 10 life hacks designed specifically for those in the USA and Canada! From shopping tips to lifestyle changes, we've got the ultimate guide to help you save more every month. Don't forget to LIKE, SHARE, and SUBSCRIBE for more money-saving advice! FIFA’s 2030 World Cup Decision: Multi-Country & Multi-Continent Venue Raises Climate Concerns - FIFA's 2030 World Cup Decision: Multi-Country & Multi-Continent Venue Raises Climate Concerns. In this episode of our podcast, we dive deep into FIFA's groundbreaking announcement that the 2030 World Cup will be spread across six countries and three continents. While this may sound exciting for football fans worldwide, it raises significant questions about FIFA's stance on climate change and its environmental responsibility. Join us as we explore the implications of this decision and discuss its potential environmental impact.
FIFA’s 2030 World Cup Decision: Multi-Country & Multi-Continent Venue Raises Climate Concerns - FIFA's 2030 World Cup Decision: Multi-Country & Multi-Continent Venue Raises Climate Concerns. In this episode of our podcast, we dive deep into FIFA's groundbreaking announcement that the 2030 World Cup will be spread across six countries and three continents. While this may sound exciting for football fans worldwide, it raises significant questions about FIFA's stance on climate change and its environmental responsibility. Join us as we explore the implications of this decision and discuss its potential environmental impact. AI Revolution in October 2023: The Latest Innovations Reshaping the Tech Landscape - AI Revolution in October 2023: The Latest Innovations Reshaping the Tech Landscape
Discover the cutting-edge AI advancements unveiled in October 2023. Stay updated with daily additions, as we bring you breakthroughs and trends revolutionizing the artificial intelligence world.
AI Revolution in October 2023: The Latest Innovations Reshaping the Tech Landscape - AI Revolution in October 2023: The Latest Innovations Reshaping the Tech Landscape
Discover the cutting-edge AI advancements unveiled in October 2023. Stay updated with daily additions, as we bring you breakthroughs and trends revolutionizing the artificial intelligence world. Top 15 AI Educational Apps Ideas that do not exist yet - Top 15 AI Educational Apps Ideas that do not exist yet.
Education and technology have always been close allies, propelling our quest for knowledge to new horizons. The proliferation of mobile devices has opened up avenues for learning that were once thought to be in the realm of science fiction. While there are countless educational apps available on the Apple App Store, there is still an ocean of untapped potential waiting to be explored. The fusion of cutting-edge technology with dynamic pedagogical strategies can redefine the contours of modern education. With that vision in mind, we've curated a list of unique and original iOS mobile app ideas, each poised to revolutionize the educational landscape. Dive in, and let's reimagine the future of learning together.
Top 15 AI Educational Apps Ideas that do not exist yet - Top 15 AI Educational Apps Ideas that do not exist yet.
Education and technology have always been close allies, propelling our quest for knowledge to new horizons. The proliferation of mobile devices has opened up avenues for learning that were once thought to be in the realm of science fiction. While there are countless educational apps available on the Apple App Store, there is still an ocean of untapped potential waiting to be explored. The fusion of cutting-edge technology with dynamic pedagogical strategies can redefine the contours of modern education. With that vision in mind, we've curated a list of unique and original iOS mobile app ideas, each poised to revolutionize the educational landscape. Dive in, and let's reimagine the future of learning together. Unlocking Azure AI Fundamentals AI-900 exam - Unlocking Azure AI Fundamentals AI-900 exam.
In today's episode, we'll cover skills measured in Azure AI workloads, machine learning principles, computer vision, and Natural Language Processing, Azure AI Fundamentals Practice Quizzes on topics such as predictive models, computer vision, responsible AI, and machine learning methods, top tips for acing the Microsoft Azure AI Fundamentals AI-900 exam including understanding objectives, practice, engaging with the community, and staying updated, and the Azure AI Fundamentals AI-900 Exam Prep PRO by Djamgatech available on Apple and Windows App Stores.
Unlocking Azure AI Fundamentals AI-900 exam - Unlocking Azure AI Fundamentals AI-900 exam.
In today's episode, we'll cover skills measured in Azure AI workloads, machine learning principles, computer vision, and Natural Language Processing, Azure AI Fundamentals Practice Quizzes on topics such as predictive models, computer vision, responsible AI, and machine learning methods, top tips for acing the Microsoft Azure AI Fundamentals AI-900 exam including understanding objectives, practice, engaging with the community, and staying updated, and the Azure AI Fundamentals AI-900 Exam Prep PRO by Djamgatech available on Apple and Windows App Stores. An Insightful Overview of SAA-C03 Exam Topics Encountered and Reflecting on My SAA-C03 Exam Journey: From Setback to Success - An Insightful Overview of SAA-C03 Exam Topics Encountered; Reflecting on My SAA-C03 Exam Journey: From Setback to Success
The AWS Certified Solutions Architect – Associate (SAA-C03) examination offers a comprehensive set of questions, drawing from a wide spectrum of topics. During my multiple attempts at the examination, I discerned that the questions presented weren't merely repetitive or overly familiar. Instead, they challenged candidates with multi-faceted scenarios, often demanding the selection of multiple correct responses from a diverse set of options. These scenarios were intricately detailed, paired with answer choices that went beyond mere service names. The answers were often elaborate statements, interweaving various AWS features or services.
An Insightful Overview of SAA-C03 Exam Topics Encountered and Reflecting on My SAA-C03 Exam Journey: From Setback to Success - An Insightful Overview of SAA-C03 Exam Topics Encountered; Reflecting on My SAA-C03 Exam Journey: From Setback to Success
The AWS Certified Solutions Architect – Associate (SAA-C03) examination offers a comprehensive set of questions, drawing from a wide spectrum of topics. During my multiple attempts at the examination, I discerned that the questions presented weren't merely repetitive or overly familiar. Instead, they challenged candidates with multi-faceted scenarios, often demanding the selection of multiple correct responses from a diverse set of options. These scenarios were intricately detailed, paired with answer choices that went beyond mere service names. The answers were often elaborate statements, interweaving various AWS features or services. How to analyze your business performance with ChatGPT? - How to analyze your business performance with ChatGPT?
Embark on a comprehensive AI journey as we delve into Meta AI's groundbreaking 'Belebele' dataset, designed to gauge the prowess of text models across diverse languages. Witness Stability AI's remarkable innovation: a Japanese vision-language model tailored to aid the visually impaired. Gain clarity on the intriguing relationship between transformers and Support Vector Machines and address the pressing concern of hallucination within AI language models. Experience the seamless integration of Canva in ChatGPT Plus for effortless graphic creation. Keep up with the latest AI announcements and advancements. Conclude with our top book recommendation, "AI Unraveled", for a profound understanding of the AI universe.
How to analyze your business performance with ChatGPT? - How to analyze your business performance with ChatGPT?
Embark on a comprehensive AI journey as we delve into Meta AI's groundbreaking 'Belebele' dataset, designed to gauge the prowess of text models across diverse languages. Witness Stability AI's remarkable innovation: a Japanese vision-language model tailored to aid the visually impaired. Gain clarity on the intriguing relationship between transformers and Support Vector Machines and address the pressing concern of hallucination within AI language models. Experience the seamless integration of Canva in ChatGPT Plus for effortless graphic creation. Keep up with the latest AI announcements and advancements. Conclude with our top book recommendation, "AI Unraveled", for a profound understanding of the AI universe. Transformers as Support Vector Machines and Are AI models doomed to always hallucinate? - Transformers as Support Vector Machines, Stability AI’s 1st Japanese Vision-Language Model, Are AI models doomed to always hallucinate?, OpenAI Enhances ChatGPT with Canva Plugin, Meta AI's New Dataset Understands 122 Languages, Belebele
Dive into the latest advancements in AI as we explore Meta AI's groundbreaking dataset supporting 122 languages. Learn about the innovative approach of using transformers as Support Vector Machines. Get an exclusive look at Stability AI's premiere Vision-Language Model in Japanese. Plus, discover the implications of AI hallucination and the new Canva plugin enhancement for OpenAI's ChatGPT. Join us for this comprehensive review!
Transformers as Support Vector Machines and Are AI models doomed to always hallucinate? - Transformers as Support Vector Machines, Stability AI’s 1st Japanese Vision-Language Model, Are AI models doomed to always hallucinate?, OpenAI Enhances ChatGPT with Canva Plugin, Meta AI's New Dataset Understands 122 Languages, Belebele
Dive into the latest advancements in AI as we explore Meta AI's groundbreaking dataset supporting 122 languages. Learn about the innovative approach of using transformers as Support Vector Machines. Get an exclusive look at Stability AI's premiere Vision-Language Model in Japanese. Plus, discover the implications of AI hallucination and the new Canva plugin enhancement for OpenAI's ChatGPT. Join us for this comprehensive review! Unlocking Azure Fundamentals AZ900 exam: Testimonials, Tips, and Key Resources to ace the exam and pass the certification - Unlocking Azure Fundamentals AZ900 exam.
Dive deep into the key strategies and insights to master the Microsoft Azure Fundamentals exam (AZ900). Hear from successful candidates, discover invaluable tips, and explore the best resources to guarantee your success.
Unlocking Azure Fundamentals AZ900 exam: Testimonials, Tips, and Key Resources to ace the exam and pass the certification - Unlocking Azure Fundamentals AZ900 exam.
Dive deep into the key strategies and insights to master the Microsoft Azure Fundamentals exam (AZ900). Hear from successful candidates, discover invaluable tips, and explore the best resources to guarantee your success.  Emerging AI Innovations: Top Trends Shaping the Landscape in September 2023 - Emerging AI Innovations: Top Trends Shaping the Landscape in September 2023. In the rapidly evolving world of Artificial Intelligence, September 2023 is witnessing a surge of groundbreaking innovations that are setting the stage for the future. Industry giants like Google, OpenAI, Meta, and others are leading the charge, constantly pushing the boundaries of what's possible. From the astounding capabilities of models like GPT to the promising advancements in Lifelong Learning Machine Systems (LLMS), the AI spectrum is expanding at an unprecedented rate. Generative AI and Discriminative AI are offering a whole new realm of possibilities, crafting a world where machines not only think but also create. Furthermore, the increasing emphasis on Explainable AI underscores the industry's commitment to transparency, ensuring that as AI systems become an integral part of our lives, we're not left in the dark about how they make decisions. Dive in as we unravel the most influential AI trends of September 2023, and explore how these technological marvels are reshaping our world."
Emerging AI Innovations: Top Trends Shaping the Landscape in September 2023 - Emerging AI Innovations: Top Trends Shaping the Landscape in September 2023. In the rapidly evolving world of Artificial Intelligence, September 2023 is witnessing a surge of groundbreaking innovations that are setting the stage for the future. Industry giants like Google, OpenAI, Meta, and others are leading the charge, constantly pushing the boundaries of what's possible. From the astounding capabilities of models like GPT to the promising advancements in Lifelong Learning Machine Systems (LLMS), the AI spectrum is expanding at an unprecedented rate. Generative AI and Discriminative AI are offering a whole new realm of possibilities, crafting a world where machines not only think but also create. Furthermore, the increasing emphasis on Explainable AI underscores the industry's commitment to transparency, ensuring that as AI systems become an integral part of our lives, we're not left in the dark about how they make decisions. Dive in as we unravel the most influential AI trends of September 2023, and explore how these technological marvels are reshaping our world." AI’s promise and peril in cancer research; New AI to go to meetings and take notes for you - AI's promise and peril in cancer research; Tesla's $300M AI cluster is going live today; OpenAI launches ChatGPT Enterprise, the most powerful ChatGPT version yet; Usage of ChatGPT among Americans rises, but only slightly; IBM's new analog AI chip challenges Nvidia; AI's promise and peril in cancer research; Google’s new AI will be able to go to meetings and take notes for you, Google's DeepMind Unveils Invisible Watermark to Spot AI-Generated Images; Live object recognition system using Kinesis and SageMaker; Daily AI Update News from Tesla, OpenAI, Microsoft, DoorDash, Uber, Yahoo, and Quora.
AI’s promise and peril in cancer research; New AI to go to meetings and take notes for you - AI's promise and peril in cancer research; Tesla's $300M AI cluster is going live today; OpenAI launches ChatGPT Enterprise, the most powerful ChatGPT version yet; Usage of ChatGPT among Americans rises, but only slightly; IBM's new analog AI chip challenges Nvidia; AI's promise and peril in cancer research; Google’s new AI will be able to go to meetings and take notes for you, Google's DeepMind Unveils Invisible Watermark to Spot AI-Generated Images; Live object recognition system using Kinesis and SageMaker; Daily AI Update News from Tesla, OpenAI, Microsoft, DoorDash, Uber, Yahoo, and Quora. AI Unraveled Podcast August 2023 – Latest AI News and Trends - AI Unraveled Podcast August 2023 - Latest AI News and Trends.
Welcome to our latest episode! This August 2023, we've set our sights on the most compelling and innovative trends that are shaping the AI industry. We'll take you on a journey through the most notable breakthroughs and advancements in AI technology. From evolving machine learning techniques to breakthrough applications in sectors like healthcare, finance, and entertainment, we will offer insights into the AI trends that are defining the future. Tune in as we dive into a comprehensive exploration of the world of artificial intelligence in August 2023.
AI Unraveled Podcast August 2023 – Latest AI News and Trends - AI Unraveled Podcast August 2023 - Latest AI News and Trends.
Welcome to our latest episode! This August 2023, we've set our sights on the most compelling and innovative trends that are shaping the AI industry. We'll take you on a journey through the most notable breakthroughs and advancements in AI technology. From evolving machine learning techniques to breakthrough applications in sectors like healthcare, finance, and entertainment, we will offer insights into the AI trends that are defining the future. Tune in as we dive into a comprehensive exploration of the world of artificial intelligence in August 2023. Unraveling August 2023: Spotlight on Generative AI - Unraveling August 2023 Welcome to the hub of the most intriguing and newsworthy trends of August 2023! In this era of rapid development, we know it's hard to keep up with the ever-changing world of ai, technology, sports, entertainment, and global events. That's why we've curated this one-stop blog post to provide a comprehensive overview of what's making headlines and shaping conversations. From the mind-bending advancements in artificial intelligence to captivating news from the world of sports and entertainment, we'll guide you through the highlights of the month. So sit back, get comfortable, and join us as we dive into the core of August 2023!
Unraveling August 2023: Spotlight on Generative AI - Unraveling August 2023 Welcome to the hub of the most intriguing and newsworthy trends of August 2023! In this era of rapid development, we know it's hard to keep up with the ever-changing world of ai, technology, sports, entertainment, and global events. That's why we've curated this one-stop blog post to provide a comprehensive overview of what's making headlines and shaping conversations. From the mind-bending advancements in artificial intelligence to captivating news from the world of sports and entertainment, we'll guide you through the highlights of the month. So sit back, get comfortable, and join us as we dive into the core of August 2023! Unlocking AWS CCP CLF-C02 in 2023: Testimonials, Tips, and Key Resources - Unlocking AWS CCP CLF-C02 in 2023: Testimonials, Tips, and Key Resources Embark on a learning journey with Djamgatech Education as we delve into the key insights, expert testimonials, and crucial resources to unlock the AWS Certified Cloud Practitioner (CCP) certification in 2023. We also cover the specifics of the AWS CCP CLF-C02 exam and highlight the new changes to stay ahead in your certification journey
Unlocking AWS CCP CLF-C02 in 2023: Testimonials, Tips, and Key Resources - Unlocking AWS CCP CLF-C02 in 2023: Testimonials, Tips, and Key Resources Embark on a learning journey with Djamgatech Education as we delve into the key insights, expert testimonials, and crucial resources to unlock the AWS Certified Cloud Practitioner (CCP) certification in 2023. We also cover the specifics of the AWS CCP CLF-C02 exam and highlight the new changes to stay ahead in your certification journey  AI Unraveled Podcast July 2023 – Latest AI Trends - AI Unraveled Podcast July 2023 - Latest AI Trends.
Welcome to our latest episode! This July 2023, we've set our sights on the most compelling and innovative trends that are shaping the AI industry. We'll take you on a journey through the most notable breakthroughs and advancements in AI technology. From evolving machine learning techniques to breakthrough applications in sectors like healthcare, finance, and entertainment, we will offer insights into the AI trends that are defining the future. Tune in as we dive into a comprehensive exploration of the world of artificial intelligence in July 2023
AI Unraveled Podcast July 2023 – Latest AI Trends - AI Unraveled Podcast July 2023 - Latest AI Trends.
Welcome to our latest episode! This July 2023, we've set our sights on the most compelling and innovative trends that are shaping the AI industry. We'll take you on a journey through the most notable breakthroughs and advancements in AI technology. From evolving machine learning techniques to breakthrough applications in sectors like healthcare, finance, and entertainment, we will offer insights into the AI trends that are defining the future. Tune in as we dive into a comprehensive exploration of the world of artificial intelligence in July 2023 Unraveling July 2023: Spotlight on Tech, AI, and the Month’s Hottest Trends - Unraveling July 2023: Spotlight on Tech, AI, and the Month's Hottest Trends.
Welcome to the hub of the most intriguing and newsworthy trends of July 2023! In this era of rapid development, we know it's hard to keep up with the ever-changing world of technology, sports, entertainment, and global events. That's why we've curated this one-stop blog post to provide a comprehensive overview of what's making headlines and shaping conversations. From the mind-bending advancements in artificial intelligence to captivating news from the world of sports and entertainment, we'll guide you through the highlights of the month. So sit back, get comfortable, and join us as we dive into the core of July 2023!
Unraveling July 2023: Spotlight on Tech, AI, and the Month’s Hottest Trends - Unraveling July 2023: Spotlight on Tech, AI, and the Month's Hottest Trends.
Welcome to the hub of the most intriguing and newsworthy trends of July 2023! In this era of rapid development, we know it's hard to keep up with the ever-changing world of technology, sports, entertainment, and global events. That's why we've curated this one-stop blog post to provide a comprehensive overview of what's making headlines and shaping conversations. From the mind-bending advancements in artificial intelligence to captivating news from the world of sports and entertainment, we'll guide you through the highlights of the month. So sit back, get comfortable, and join us as we dive into the core of July 2023! AI Unraveled Podcast June 2023- Latest AI Trends - AI Unraveled Podcast June 2023 - Latest AI Trends Welcome, dear readers, to another fascinating edition of our monthly blog: "AI Unraveled Podcast June 2023 - Latest AI Trends". This month, we're stepping into the future, taking a deep dive into the ever-evolving world of Artificial Intelligence. It's no secret that AI is reshaping every facet of our lives, from how we communicate to how we work, play, and even think. In our latest podcast, we'll be your navigators on this complex journey, offering a digestible breakdown of the most groundbreaking advancements, compelling discussions, and controversial debates in AI for June 2023. We'll shed light on the triumphs and the tribulations, the pioneers and the prodigies, the computations and the controversies. So, sit back, plug in, and join us as we unravel the mysteries of AI in this month's edition. Let's dive into the future, together.
AI Unraveled Podcast June 2023- Latest AI Trends - AI Unraveled Podcast June 2023 - Latest AI Trends Welcome, dear readers, to another fascinating edition of our monthly blog: "AI Unraveled Podcast June 2023 - Latest AI Trends". This month, we're stepping into the future, taking a deep dive into the ever-evolving world of Artificial Intelligence. It's no secret that AI is reshaping every facet of our lives, from how we communicate to how we work, play, and even think. In our latest podcast, we'll be your navigators on this complex journey, offering a digestible breakdown of the most groundbreaking advancements, compelling discussions, and controversial debates in AI for June 2023. We'll shed light on the triumphs and the tribulations, the pioneers and the prodigies, the computations and the controversies. So, sit back, plug in, and join us as we unravel the mysteries of AI in this month's edition. Let's dive into the future, together. June 2023 Unwrapped: Exploring the Biggest Trends and Headlines of the Month. - June 2023 Unwrapped: Exploring the Biggest Trends and Headlines of the Month. As the long summer days unfold and the year reaches its midpoint, the world continues to spin at a dizzying pace. Each sunrise brings a cascade of events that shape our global landscape and influence our daily lives. From breakthroughs in technology and leaps in artificial intelligence, to stirring tales of human triumph and unnerving geopolitical twists, every day holds a new surprise.
June 2023 Unwrapped: Exploring the Biggest Trends and Headlines of the Month. - June 2023 Unwrapped: Exploring the Biggest Trends and Headlines of the Month. As the long summer days unfold and the year reaches its midpoint, the world continues to spin at a dizzying pace. Each sunrise brings a cascade of events that shape our global landscape and influence our daily lives. From breakthroughs in technology and leaps in artificial intelligence, to stirring tales of human triumph and unnerving geopolitical twists, every day holds a new surprise. AI Unraveled Podcast – Latest AI Trends May 2023 - AI Unraveled Podcast - Latest AI Trends May 2023
Latest AI Trend on May 17th 2023: Workplace AI: How artificial intelligence will transform the workday, 3 Best AI Voice Cloning Services, revealing biases in AI models for medical imaging, AI Daily updates from Microsoft, Google, Zoom, and Tesla
AI Unraveled Podcast – Latest AI Trends May 2023 - AI Unraveled Podcast - Latest AI Trends May 2023
Latest AI Trend on May 17th 2023: Workplace AI: How artificial intelligence will transform the workday, 3 Best AI Voice Cloning Services, revealing biases in AI models for medical imaging, AI Daily updates from Microsoft, Google, Zoom, and Tesla Discover the Buzz: Exciting Trends Shaping Our World in May 2023 - Exciting Trends Shaping Our World in May 2023. What is trending in May 2023? Welcome to our latest blog post, where we explore the hottest trends of May 2023! In a world that's constantly evolving and changing, it's crucial to stay updated on the latest developments across technology, fashion, entertainment, and lifestyle. In this edition, we dive into the most exciting breakthroughs, innovations, and cultural shifts that have captured the world's attention this month. Join us as we navigate through the trends shaping our lives and preparing us for a fascinating future.
Discover the Buzz: Exciting Trends Shaping Our World in May 2023 - Exciting Trends Shaping Our World in May 2023. What is trending in May 2023? Welcome to our latest blog post, where we explore the hottest trends of May 2023! In a world that's constantly evolving and changing, it's crucial to stay updated on the latest developments across technology, fashion, entertainment, and lifestyle. In this edition, we dive into the most exciting breakthroughs, innovations, and cultural shifts that have captured the world's attention this month. Join us as we navigate through the trends shaping our lives and preparing us for a fascinating future. What is trending in April 2023? - What is trending in April 2023?
Ah, April. The month of showers and fresh starts. We almost forgot what those are considering the last few years have felt like one giant winter (trending: Did global warming really happen?). And while the world has been frozen in an icy slumber, there's no doubt that trends still come and go - some stay for a lifetime, others die quickly in obscurity. So as we enter into this promising new month, why don't we take a peek at what's trending in April 2023? From fashion to technology to politics, let's dig through already up-and-coming trends and see if any stick by summertime!
What is trending in April 2023? - What is trending in April 2023?
Ah, April. The month of showers and fresh starts. We almost forgot what those are considering the last few years have felt like one giant winter (trending: Did global warming really happen?). And while the world has been frozen in an icy slumber, there's no doubt that trends still come and go - some stay for a lifetime, others die quickly in obscurity. So as we enter into this promising new month, why don't we take a peek at what's trending in April 2023? From fashion to technology to politics, let's dig through already up-and-coming trends and see if any stick by summertime! Advanced Guide to Interacting with ChatGPT - Advanced Guide to Interacting with ChatGPT. Interacting with ChatGPT can feel like talking to an artificial intelligence from the future. Conversations are able to flow naturally, and you don't even realize you're interacting with something as powerful as a programmed AI chatbot. And now, for those of us who want more than just casual banter, there's an entire advanced guide to mastering the art of chatting with ChatGPT! So whether you need advice on how to customize your conversations or gain greater insight into what your bot is truly capable of, this guide will help take your robotic conversations up several notches.
Advanced Guide to Interacting with ChatGPT - Advanced Guide to Interacting with ChatGPT. Interacting with ChatGPT can feel like talking to an artificial intelligence from the future. Conversations are able to flow naturally, and you don't even realize you're interacting with something as powerful as a programmed AI chatbot. And now, for those of us who want more than just casual banter, there's an entire advanced guide to mastering the art of chatting with ChatGPT! So whether you need advice on how to customize your conversations or gain greater insight into what your bot is truly capable of, this guide will help take your robotic conversations up several notches. Exploring the Pros and Cons of Visiting All Provinces and Territories in Canada - Exploring the Pros and Cons of Visiting All Provinces and Territories in Canada.
Canada is a vast country, consisting of ten provinces and three territories, each with its unique geography, culture, and tourist attractions. Here are the pros and cons of each province and territory from a tourism and travel perspective:
Exploring the Pros and Cons of Visiting All Provinces and Territories in Canada - Exploring the Pros and Cons of Visiting All Provinces and Territories in Canada.
Canada is a vast country, consisting of ten provinces and three territories, each with its unique geography, culture, and tourist attractions. Here are the pros and cons of each province and territory from a tourism and travel perspective: Exploring the Advantages and Disadvantages of Visiting All 50 States in the US - Exploring the Advantages and Disadvantages of Visiting All 50 States in the US. Are you planning a road trip to explore the United States and wondering which states to include in your itinerary? With 50 diverse states to choose from, each with its unique culture, landscapes, and attractions, it can be a daunting task to decide where to go. To help you make an informed decision, this blog will explore the advantages and disadvantages of visiting all 50 states in the US. From the bustling cities of New York and California to the breathtaking natural wonders of Alaska and Hawaii, we'll cover the pros and cons of each state to help you plan the ultimate American adventure. So, buckle up and join us on a virtual tour of the 50 states!
Exploring the Advantages and Disadvantages of Visiting All 50 States in the US - Exploring the Advantages and Disadvantages of Visiting All 50 States in the US. Are you planning a road trip to explore the United States and wondering which states to include in your itinerary? With 50 diverse states to choose from, each with its unique culture, landscapes, and attractions, it can be a daunting task to decide where to go. To help you make an informed decision, this blog will explore the advantages and disadvantages of visiting all 50 states in the US. From the bustling cities of New York and California to the breathtaking natural wonders of Alaska and Hawaii, we'll cover the pros and cons of each state to help you plan the ultimate American adventure. So, buckle up and join us on a virtual tour of the 50 states!  What is trending in March 2023 - What is trending in March 2023?
It's hard to keep up with the ever-changing trends in our day and age, but have no fear! March 2023 brings a multitude of fun styles and exciting ideas that will get you ahead of the curve. From food and fashion to music and entertainment there is something for everyone. Whether you’re looking for great places to shop or unique experiences, this month has it all! Get ready to explore what’s new in the world so you can stay on top of the trendiest topics. Find out more about what’s trending right now by reading below!
What is trending in March 2023 - What is trending in March 2023?
It's hard to keep up with the ever-changing trends in our day and age, but have no fear! March 2023 brings a multitude of fun styles and exciting ideas that will get you ahead of the curve. From food and fashion to music and entertainment there is something for everyone. Whether you’re looking for great places to shop or unique experiences, this month has it all! Get ready to explore what’s new in the world so you can stay on top of the trendiest topics. Find out more about what’s trending right now by reading below! Artificial Intelligence Frequently Asked Questions - Artificial Intelligence Frequently Asked Questions AI and its related fields -- such as machine learning and data science -- are becoming an increasingly important parts of our lives, so it stands to reason why AI Frequently Asked Questions (FAQs)are a popular choice among many people. AI has the potential to simplify tedious and repetitive tasks while enriching our everyday lives with extraordinary insights - but at the same time, it can also be confusing and even intimidating. AI FAQs offer valuable insight into the mechanics of AI, helping us become better-informed about AI’s capabilities, limitations, and ethical considerations. Ultimately, AI FAQs provide us with a deeper understanding of AI as well as a platform for healthy debate.
Artificial Intelligence Frequently Asked Questions - Artificial Intelligence Frequently Asked Questions AI and its related fields -- such as machine learning and data science -- are becoming an increasingly important parts of our lives, so it stands to reason why AI Frequently Asked Questions (FAQs)are a popular choice among many people. AI has the potential to simplify tedious and repetitive tasks while enriching our everyday lives with extraordinary insights - but at the same time, it can also be confusing and even intimidating. AI FAQs offer valuable insight into the mechanics of AI, helping us become better-informed about AI’s capabilities, limitations, and ethical considerations. Ultimately, AI FAQs provide us with a deeper understanding of AI as well as a platform for healthy debate. Everything You Need To Know about Super Bowl LVII - Everything You Need To Know about Super Bowl LVII
Super Bowl LVII: Odds - Predictions - Live Streams - Trends on Field - Commercials - Songs - Food and Drinks - Dips Super Bowl LVII is just around the corner, and it is sure to be an exciting event. Each year, the Super Bowl brings together people from all walks of life to watch one of the most highly anticipated games in professional sports. But it's not all about the game—there are many other aspects that make this annual tradition so special. From live streaming to commercial trends, delicious food and drinks to halftime performances, let’s take a look at what you need to know about Super Bowl LVII.
Everything You Need To Know about Super Bowl LVII - Everything You Need To Know about Super Bowl LVII
Super Bowl LVII: Odds - Predictions - Live Streams - Trends on Field - Commercials - Songs - Food and Drinks - Dips Super Bowl LVII is just around the corner, and it is sure to be an exciting event. Each year, the Super Bowl brings together people from all walks of life to watch one of the most highly anticipated games in professional sports. But it's not all about the game—there are many other aspects that make this annual tradition so special. From live streaming to commercial trends, delicious food and drinks to halftime performances, let’s take a look at what you need to know about Super Bowl LVII.  10 Unhealthy Habits That Can Negatively Impact Your Brain Health - 10 Unhealthy Habits That Can Negatively Impact Your Brain Health. Our brains are powerful and complex organs that help us learn and grow. But, like any other part of our body, our brains can suffer if we don't take proper care of them. In fact, certain habits can do more harm than good, leading to impaired mental function and even brain diseases such as Alzheimer's or dementia. Let’s take a look at the top ten unhealthiest habits for your brain.
10 Unhealthy Habits That Can Negatively Impact Your Brain Health - 10 Unhealthy Habits That Can Negatively Impact Your Brain Health. Our brains are powerful and complex organs that help us learn and grow. But, like any other part of our body, our brains can suffer if we don't take proper care of them. In fact, certain habits can do more harm than good, leading to impaired mental function and even brain diseases such as Alzheimer's or dementia. Let’s take a look at the top ten unhealthiest habits for your brain.  What are people searching for in February 2023 - What are people searching for in February 2023 Trends come and go, but one thing people always do is search. By February 2023, Google's top searches could range from style to sports to the small, everyday moments that people gravitate towards. No matter what questions, needs or interests fill our lives by then, people can be sure information will be only a few clicks away. So whether someone is searching for their favorite Chicago Bears player's records in February 2023, or trying out a trendy hairstyle - they can trust that Google has got them covered.
What are people searching for in February 2023 - What are people searching for in February 2023 Trends come and go, but one thing people always do is search. By February 2023, Google's top searches could range from style to sports to the small, everyday moments that people gravitate towards. No matter what questions, needs or interests fill our lives by then, people can be sure information will be only a few clicks away. So whether someone is searching for their favorite Chicago Bears player's records in February 2023, or trying out a trendy hairstyle - they can trust that Google has got them covered.  Financing Black Businesses in Canada and USA: Challenges and Opportunities - Financing Black Businesses in Canada and USA: Challenges and Opportunities. Access to capital continues to be a major obstacle for entrepreneurs of color, especially for Black entrepreneurs. Despite this, the growth of Black-owned businesses has been remarkable. According to a report from the US Census Bureau’s Survey of Business Owners (SBO), the number of Black-owned businesses doubled between 2007 and 2012, reaching 2.6 million in 2014. However, many of these businesses face significant challenges when it comes to securing financing from traditional financial institutions. This blog will discuss the experiences of Black entrepreneurs in securing financing for their businesses and explore alternative financing options that may support the development and growth of Black enterprises.
Financing Black Businesses in Canada and USA: Challenges and Opportunities - Financing Black Businesses in Canada and USA: Challenges and Opportunities. Access to capital continues to be a major obstacle for entrepreneurs of color, especially for Black entrepreneurs. Despite this, the growth of Black-owned businesses has been remarkable. According to a report from the US Census Bureau’s Survey of Business Owners (SBO), the number of Black-owned businesses doubled between 2007 and 2012, reaching 2.6 million in 2014. However, many of these businesses face significant challenges when it comes to securing financing from traditional financial institutions. This blog will discuss the experiences of Black entrepreneurs in securing financing for their businesses and explore alternative financing options that may support the development and growth of Black enterprises.  How to use Google Search and ChatGPT side be side? - How to use Google Search and ChatGPT side by side? Google Search and ChatGPT can work side by side. Google Search can be used to find specific information on the internet, while ChatGPT can be used to understand and generate human-like text. They can be integrated together in various ways, such as providing answers to user queries by combining information found through Google Search with the language generation capabilities of ChatGPT. It could be used to provide more accurate, complete and human-like answers to the user.
How to use Google Search and ChatGPT side be side? - How to use Google Search and ChatGPT side by side? Google Search and ChatGPT can work side by side. Google Search can be used to find specific information on the internet, while ChatGPT can be used to understand and generate human-like text. They can be integrated together in various ways, such as providing answers to user queries by combining information found through Google Search with the language generation capabilities of ChatGPT. It could be used to provide more accurate, complete and human-like answers to the user. Examining the Fragmented Data on Black Entrepreneurship in North America - Examining the Fragmented Data on Black Entrepreneurship in North America In order to accurately assess and support Black entrepreneurship, it is important to have a standardized framework for collecting and analyzing data. Unfortunately, the current data on Black entrepreneurship in the United States and Canada is fragmented and inconsistent. This makes it difficult to accurately assess measures of success or failure among Black entrepreneurs. In this blog post, we will discuss how to reconcile this fragmented data and the methods that should be used to standardize measures and assessments of Black entrepreneurship.
Examining the Fragmented Data on Black Entrepreneurship in North America - Examining the Fragmented Data on Black Entrepreneurship in North America In order to accurately assess and support Black entrepreneurship, it is important to have a standardized framework for collecting and analyzing data. Unfortunately, the current data on Black entrepreneurship in the United States and Canada is fragmented and inconsistent. This makes it difficult to accurately assess measures of success or failure among Black entrepreneurs. In this blog post, we will discuss how to reconcile this fragmented data and the methods that should be used to standardize measures and assessments of Black entrepreneurship.  What are the pros and cons of Xiaomi tablets compared to iPad and Microsoft Surface tablets - What are the pros and cons of Xiaomi tablets compared to iPad and Microsoft Surface tablets
What are the pros and cons of Xiaomi tablets compared to iPad and Microsoft Surface tablets - What are the pros and cons of Xiaomi tablets compared to iPad and Microsoft Surface tablets  Optimizing Your Blog for Google’s 2023 Algorithm Update - Optimizing Your Blog for Google's 2023 Algorithm Update
How to structure a blog to be compliant with Google latest search algorithm in 2023? Every few years, Google releases an algorithm update that affects the way search engine results are ranked. As a writer or blogger, it is important to stay abreast of the latest SEO trends and ensure that your blog is structured in a way that complies with Google’s requirements. This article will outline how you can optimize your blog for the upcoming 2023 algorithm update.
Optimizing Your Blog for Google’s 2023 Algorithm Update - Optimizing Your Blog for Google's 2023 Algorithm Update
How to structure a blog to be compliant with Google latest search algorithm in 2023? Every few years, Google releases an algorithm update that affects the way search engine results are ranked. As a writer or blogger, it is important to stay abreast of the latest SEO trends and ensure that your blog is structured in a way that complies with Google’s requirements. This article will outline how you can optimize your blog for the upcoming 2023 algorithm update.  What are top 10 Healthy meal prep ideas for weight loss? How can AI help with weight loss? - What are top 10 Healthy meal prep ideas for weight loss? When it comes to healthy eating and weight loss, meal prep is essential. Eating healthy meals and controlling your portions can help you reach your healthy lifestyle goals in no time. With that in mind, we’ve rounded up our top 10 healthy meal prep ideas for you to use while working towards your desired weight loss goals. Focusing on healthy, nutrient-dense foods such as lean proteins, healthy fats, non-starchy vegetables, legumes and complex carbohydrates is the key to creating healthy meals for weight loss. Once you've figured out which healthy foods you need to focus on in order to lose weight successfully, let the fun meal prepping begin! Meal prepping isn't only great for losing weight; it's also an excellent way to save time (and money) throughout busy weekdays. So next time you're looking for a healthy lunch or dinner idea that also boosts your weight loss efforts - check out our top 10 healthy meal ideas!
What are top 10 Healthy meal prep ideas for weight loss? How can AI help with weight loss? - What are top 10 Healthy meal prep ideas for weight loss? When it comes to healthy eating and weight loss, meal prep is essential. Eating healthy meals and controlling your portions can help you reach your healthy lifestyle goals in no time. With that in mind, we’ve rounded up our top 10 healthy meal prep ideas for you to use while working towards your desired weight loss goals. Focusing on healthy, nutrient-dense foods such as lean proteins, healthy fats, non-starchy vegetables, legumes and complex carbohydrates is the key to creating healthy meals for weight loss. Once you've figured out which healthy foods you need to focus on in order to lose weight successfully, let the fun meal prepping begin! Meal prepping isn't only great for losing weight; it's also an excellent way to save time (and money) throughout busy weekdays. So next time you're looking for a healthy lunch or dinner idea that also boosts your weight loss efforts - check out our top 10 healthy meal ideas! How do you protect yourself against future potential policy changes that would affect your retirement account withdrawals in early retirement? - How do you protect yourself against future potential policy changes that would affect your retirement account withdrawals in early retirement? Protecting your future finance in the wake of any sudden policy changes that can affect retirement account withdrawals in early retirement can be daunting, but with an understanding of the basics of finance and investment, you can empower yourself to be proactive. Ensure that you are keeping a close eye on changes, new investments schemes, and other opportunities. Making wise decisions regarding financial investments to protect your retirement account can go a long way in safeguarding yourself against future potential policy changes. Preparing for the worst is always wise - make sure your finances are diversified and compliant with changing regulations so you will have back-up plans even if suddenly policies change.
How do you protect yourself against future potential policy changes that would affect your retirement account withdrawals in early retirement? - How do you protect yourself against future potential policy changes that would affect your retirement account withdrawals in early retirement? Protecting your future finance in the wake of any sudden policy changes that can affect retirement account withdrawals in early retirement can be daunting, but with an understanding of the basics of finance and investment, you can empower yourself to be proactive. Ensure that you are keeping a close eye on changes, new investments schemes, and other opportunities. Making wise decisions regarding financial investments to protect your retirement account can go a long way in safeguarding yourself against future potential policy changes. Preparing for the worst is always wise - make sure your finances are diversified and compliant with changing regulations so you will have back-up plans even if suddenly policies change. Google Workspace – Docs – Drive – Sheets – Slides – How To - Google Workspace - Docs - Drive - Sheets - Slides - Forms - How To Top 10 Google Workspace Tips and Tricks Top 10 Google Docs Tips and Tricks Top 10 Google Sheets Tips and Tricks Top 10 Google Drive Tips and Tricks Top 10 Google Sheets Tips and Tricks Top 10 Google Slides Tips and Tricks Top 10 Google Forms Tips and Tricks
Google Workspace – Docs – Drive – Sheets – Slides – How To - Google Workspace - Docs - Drive - Sheets - Slides - Forms - How To Top 10 Google Workspace Tips and Tricks Top 10 Google Docs Tips and Tricks Top 10 Google Sheets Tips and Tricks Top 10 Google Drive Tips and Tricks Top 10 Google Sheets Tips and Tricks Top 10 Google Slides Tips and Tricks Top 10 Google Forms Tips and Tricks How can I oblige tensorflow to use all gpu power? - How can I oblige tensorflow to use all gpu power? TensorFlow, a popular open-source machine learning library, is designed to automatically utilize the available GPU resources on a device. By default, TensorFlow will use all available GPU resources when training or running a model.
How can I oblige tensorflow to use all gpu power? - How can I oblige tensorflow to use all gpu power? TensorFlow, a popular open-source machine learning library, is designed to automatically utilize the available GPU resources on a device. By default, TensorFlow will use all available GPU resources when training or running a model. How can I add ChatGPT to my web site? - How can I add ChatGPT to my web site? ChatGPT is a powerful chatbot platform powered by machine learning and AI. Whether you're looking to monitor user conversations or automate customer service, ChatGPT can be embedded on your website so that visitors can have real-time interactions with an intelligent chatbot. Integrating ChatGPT is easy and efficient, allowing your website to become interfaced with cutting edge AI technology within minutes. ChatGPT is the perfect way for businesses to drive engagement and collect valuable data from customer conversations in order to advance their product roadmap and streamline services.
How can I add ChatGPT to my web site? - How can I add ChatGPT to my web site? ChatGPT is a powerful chatbot platform powered by machine learning and AI. Whether you're looking to monitor user conversations or automate customer service, ChatGPT can be embedded on your website so that visitors can have real-time interactions with an intelligent chatbot. Integrating ChatGPT is easy and efficient, allowing your website to become interfaced with cutting edge AI technology within minutes. ChatGPT is the perfect way for businesses to drive engagement and collect valuable data from customer conversations in order to advance their product roadmap and streamline services. What are some practical applications of machine learning that can be used by a regular person on their phone? - What are some practical applications of machine learning that can be used by a regular person on their phone?
What are some practical applications of machine learning that can be used by a regular person on their phone? - What are some practical applications of machine learning that can be used by a regular person on their phone?  Top 10 tips to protect your debit or credit card from being hacked? - Top 10 tips to protect your debit or credit card from being hacked? How do you protect your debit or credit card from being hacked? Protecting your debit or credit cards from being hacked can be daunting. However, following a few security and privacy best practices can ensure you don't become the victim of cyberfraud. Keeping your PINs and security codes safe - and not sharing them with anyone - is the foundation for protecting your financial data from malicious hackers. Upgrading to EMV-chip security on your credit cards offers an extra layer of protection against unauthorized access, while only making purchases on reliable websites that encrypt information helps minimize the risks posed by online shopping scams. Finally, tracking your card transactions regularly will alert you to any suspicious activity right away, allowing you to report it to your bank before further damage is done.
Top 10 tips to protect your debit or credit card from being hacked? - Top 10 tips to protect your debit or credit card from being hacked? How do you protect your debit or credit card from being hacked? Protecting your debit or credit cards from being hacked can be daunting. However, following a few security and privacy best practices can ensure you don't become the victim of cyberfraud. Keeping your PINs and security codes safe - and not sharing them with anyone - is the foundation for protecting your financial data from malicious hackers. Upgrading to EMV-chip security on your credit cards offers an extra layer of protection against unauthorized access, while only making purchases on reliable websites that encrypt information helps minimize the risks posed by online shopping scams. Finally, tracking your card transactions regularly will alert you to any suspicious activity right away, allowing you to report it to your bank before further damage is done. What are 10 ways to fix one AirPod that dies faster? - What are 10 ways to fix one AirPod that dies faster? AirPods are an integral part of staying connected to music, podcasts, audiobooks, and more. But when one AirPod dies faster than the other, tune-out time becomes a big problem. If this issue has been plaguing you, fear not: there are numerous ways to fix the AirPod that runs out juice much sooner than its partner! The first solution is to check the battery life of both AirPods with your iPhone or iPad and make sure that they’re both working as expected. If all else fails, try taking a look around your house to make sure your AirPod hasn't gone on a little expedition of his own! Of course, if this still doesn't solve your AirPod dilemma then perhaps it's time for a visit back to Apple so they can help remedy your audial fiasco. With these 10 foolproof tips for fixing AirPods that die before their time, shoddy sound quality will soon be nothing more than a distant memory!
What are 10 ways to fix one AirPod that dies faster? - What are 10 ways to fix one AirPod that dies faster? AirPods are an integral part of staying connected to music, podcasts, audiobooks, and more. But when one AirPod dies faster than the other, tune-out time becomes a big problem. If this issue has been plaguing you, fear not: there are numerous ways to fix the AirPod that runs out juice much sooner than its partner! The first solution is to check the battery life of both AirPods with your iPhone or iPad and make sure that they’re both working as expected. If all else fails, try taking a look around your house to make sure your AirPod hasn't gone on a little expedition of his own! Of course, if this still doesn't solve your AirPod dilemma then perhaps it's time for a visit back to Apple so they can help remedy your audial fiasco. With these 10 foolproof tips for fixing AirPods that die before their time, shoddy sound quality will soon be nothing more than a distant memory!  Is it possible to sideload an app or game onto the Xbox One? - Is it possible to sideload an app or game onto the Xbox One? If you have been looking for a way to sideload an app or game onto your Xbox One console, then you're in luck! This is actually quite simple and can be done with just a few steps. First, go to the Microsoft Store online and find the app or game you want to sideload. Next, download the file onto your computer. Finally, connect a USB drive to your computer and copy the sideloaded files onto it. Then, disconnect the USB drive and plug it into your Xbox One console - and voila! You should now be able to sideload apps or games directly onto your Xbox One. Be sure to check out our blog which has more tips on sideloding apps on Xbox One.
Is it possible to sideload an app or game onto the Xbox One? - Is it possible to sideload an app or game onto the Xbox One? If you have been looking for a way to sideload an app or game onto your Xbox One console, then you're in luck! This is actually quite simple and can be done with just a few steps. First, go to the Microsoft Store online and find the app or game you want to sideload. Next, download the file onto your computer. Finally, connect a USB drive to your computer and copy the sideloaded files onto it. Then, disconnect the USB drive and plug it into your Xbox One console - and voila! You should now be able to sideload apps or games directly onto your Xbox One. Be sure to check out our blog which has more tips on sideloding apps on Xbox One. What is the difference between a heuristic and a machine learning algorithm? - What is the difference between a heuristic and a machine learning algorithm? Machine learning algorithms and heuristics are two distinct approaches to problem solving - while both can often yield successful outcomes, they differ in a few key ways. Machine learning algorithms rely heavily on data input, meaning that the more data the algorithm receives, the more it can understand and learn about a specific situation or problem. Heuristics on the other hand use sets of rules and experience to address more complex problems - this approach often results in quicker problem solving due to less ‘thinking’ required on behalf of the algorithm. To sum it up, algorithms are best utilized by AI systems when large amounts of data is available, whereas heuristics prove most effective when context knowledge is at play. It's all a matter of which approach works best for your particular problem!
What is the difference between a heuristic and a machine learning algorithm? - What is the difference between a heuristic and a machine learning algorithm? Machine learning algorithms and heuristics are two distinct approaches to problem solving - while both can often yield successful outcomes, they differ in a few key ways. Machine learning algorithms rely heavily on data input, meaning that the more data the algorithm receives, the more it can understand and learn about a specific situation or problem. Heuristics on the other hand use sets of rules and experience to address more complex problems - this approach often results in quicker problem solving due to less ‘thinking’ required on behalf of the algorithm. To sum it up, algorithms are best utilized by AI systems when large amounts of data is available, whereas heuristics prove most effective when context knowledge is at play. It's all a matter of which approach works best for your particular problem! What is trending in January 2023? - What is trending in January 2023? January 2023 is definitely starting off with a bang! Trending topics, as determined by Google Trend analysis and Google Search results, bring attention to people’s shifts in interests. Right now it looks like the list of items people are interested in is expansive, from new generations of technology to movies and health trends. This is indicative of how adaptive humans can be—we’re always ready and willing to learn something new! Watching top searches evolve is one way to gain insight into the broader events happening around us. It will certainly be interesting to see what else comes up in January 2023!
What is trending in January 2023? - What is trending in January 2023? January 2023 is definitely starting off with a bang! Trending topics, as determined by Google Trend analysis and Google Search results, bring attention to people’s shifts in interests. Right now it looks like the list of items people are interested in is expansive, from new generations of technology to movies and health trends. This is indicative of how adaptive humans can be—we’re always ready and willing to learn something new! Watching top searches evolve is one way to gain insight into the broader events happening around us. It will certainly be interesting to see what else comes up in January 2023! What are some ethical concerns regarding artificial intelligence and its future development? - What are some ethical concerns regarding artificial intelligence and its future development? Debate about the ethical concerns surrounding artificial intelligence (AI) and machine learning have been becoming increasingly prominent. Issues such as safe AI and ethical AI are of utmost importance when it comes to continued development in this field, and if proper oversight is not account for these could easily become part of an unwanted dystopian future. Regulations need to be made with regards to how machine learning algorithms are developed and executed, while due diligence is taken to ensure that no negative affects are caused from its use. This sort of regulation is necessary so as to ensure the AI being produced is both responsible and well-monitored; accounting for any human bias or negative externalities created by machine learning algorithms.
What are some ethical concerns regarding artificial intelligence and its future development? - What are some ethical concerns regarding artificial intelligence and its future development? Debate about the ethical concerns surrounding artificial intelligence (AI) and machine learning have been becoming increasingly prominent. Issues such as safe AI and ethical AI are of utmost importance when it comes to continued development in this field, and if proper oversight is not account for these could easily become part of an unwanted dystopian future. Regulations need to be made with regards to how machine learning algorithms are developed and executed, while due diligence is taken to ensure that no negative affects are caused from its use. This sort of regulation is necessary so as to ensure the AI being produced is both responsible and well-monitored; accounting for any human bias or negative externalities created by machine learning algorithms.  What are some Canadian startups that use artificial intelligence/machine learning? - What are some Canadian startups that use artificial intelligence/machine learning? Canada's tech sector is booming with machine learning and artificial intelligence, and a number of young startups are leading the charge. From big-picture machine learning apps to AI solutions for every industry imaginable, Canadian startups are innovating in a powerful way. Sentenai, for example, uses machine learning to process data in real-time to create predictive analytics that can help businesses make faster decisions. Robokiller uses AI to block spam calls, while Caribou Labs develops solutions that use machine learning to help industrial organizations increase productivity. These examples show just how much potential lies within Canada's AI startup scene -- and there is much more still being discovered!
What are some Canadian startups that use artificial intelligence/machine learning? - What are some Canadian startups that use artificial intelligence/machine learning? Canada's tech sector is booming with machine learning and artificial intelligence, and a number of young startups are leading the charge. From big-picture machine learning apps to AI solutions for every industry imaginable, Canadian startups are innovating in a powerful way. Sentenai, for example, uses machine learning to process data in real-time to create predictive analytics that can help businesses make faster decisions. Robokiller uses AI to block spam calls, while Caribou Labs develops solutions that use machine learning to help industrial organizations increase productivity. These examples show just how much potential lies within Canada's AI startup scene -- and there is much more still being discovered! Top 200 Canada History Geography and Citizenship Test Quiz? - What are the Top 200 Canada History Geography and Citizenship Test Quiz? Canada has long been known for its natural beauty and stunning sceneries, encapsulated in our vast parks and wildlife reserves. For those interested in learning more about all this land can hold, there are more than 200 quizzes available on Canadian history, geography, government, citizenship tests, culture, people, economics, languages, travel and even hockey! Further still, dedicated tourists can learn about the incredible variety of beautiful Canadian sceneries and data visualizations across the country. Discovering the unique Canadian roots can have many exciting benefits for the modern citizen of today.
Carry on!
Top 200 Canada History Geography and Citizenship Test Quiz? - What are the Top 200 Canada History Geography and Citizenship Test Quiz? Canada has long been known for its natural beauty and stunning sceneries, encapsulated in our vast parks and wildlife reserves. For those interested in learning more about all this land can hold, there are more than 200 quizzes available on Canadian history, geography, government, citizenship tests, culture, people, economics, languages, travel and even hockey! Further still, dedicated tourists can learn about the incredible variety of beautiful Canadian sceneries and data visualizations across the country. Discovering the unique Canadian roots can have many exciting benefits for the modern citizen of today.
Carry on! What is The Most Accurate Machine Learning Algorithm for Predictive Modeling? - What is The Most Accurate Machine Learning Algorithm for Predictive Modeling? Machine learning algorithms are powerful tools used to automate predictive modeling. With predictive modeling, data scientists and machine learning engineers can build models that accurately predict future outcomes. But which machine learning algorithm is the most accurate when it comes to predictive modeling? Let’s take a look.
What is The Most Accurate Machine Learning Algorithm for Predictive Modeling? - What is The Most Accurate Machine Learning Algorithm for Predictive Modeling? Machine learning algorithms are powerful tools used to automate predictive modeling. With predictive modeling, data scientists and machine learning engineers can build models that accurately predict future outcomes. But which machine learning algorithm is the most accurate when it comes to predictive modeling? Let’s take a look.- What is Google answer to ChatGPT? - What is Google answer to ChatGPT? Artificial Intelligence (AI) has been around for decades. From its humble beginnings in the 1950s, AI has come a long way and is now an integral part of many aspects of our lives. One of the most important areas where AI plays a role is in natural language processing (NLP). NLP enables computers to understand and respond to human language, paving the way for more advanced conversations between humans and machines. One of the most recent developments in this field is ChatGPT, a conversational AI developed by OpenAI that utilizes supervised learning and reinforcement learning to enable computers to chat with humans. So what exactly is ChatGPT and how does it work? Let’s find out!
 What are the Top 10 Christmas song or music in 2022? - What are the Top 10 Christmas song or music in 2022? It's that time of year again! Christmas music is already playing in stores and on the radio, and people are busy making their holiday plans. As we head into the holiday season, let's take a look at some of the most popular Christmas songs of 2022.
What are the Top 10 Christmas song or music in 2022? - What are the Top 10 Christmas song or music in 2022? It's that time of year again! Christmas music is already playing in stores and on the radio, and people are busy making their holiday plans. As we head into the holiday season, let's take a look at some of the most popular Christmas songs of 2022.  Top 10 luxury cars that are completely overpriced considering the poor workmanship and lack of features? - Top 10 luxury cars that are completely overpriced considering the poor workmanship and lack of features? There are a number of luxury cars on the market that are completely overpriced considering the poor workmanship and lack of features. Ford, Buick, Lincoln, Dodge, Jeep, Chevrolet, Chrysler, GMC, Ram, Tesla, Cadillac, and Volvo are all examples of cars that fall into this category. While these cars may have a certain level of prestige associated with them, they simply do not live up to the hype in terms of quality or value. In many cases, you can find cars that offer better workmanship and more features for a fraction of the price. So if you're looking for a luxury car that won't break the bank, be sure to do your research before making a purchase.
Top 10 luxury cars that are completely overpriced considering the poor workmanship and lack of features? - Top 10 luxury cars that are completely overpriced considering the poor workmanship and lack of features? There are a number of luxury cars on the market that are completely overpriced considering the poor workmanship and lack of features. Ford, Buick, Lincoln, Dodge, Jeep, Chevrolet, Chrysler, GMC, Ram, Tesla, Cadillac, and Volvo are all examples of cars that fall into this category. While these cars may have a certain level of prestige associated with them, they simply do not live up to the hype in terms of quality or value. In many cases, you can find cars that offer better workmanship and more features for a fraction of the price. So if you're looking for a luxury car that won't break the bank, be sure to do your research before making a purchase.  What are the top 10 trending questions and answers related to protests and lockdowns in China in 2022 - What are the top 10 trending questions and answers related to protests and lockdowns in China in 2022? China has been in the headlines a lot lately due to the protests and lockdowns that have been occurring throughout the country. China has been facing many protests since early November of 2022. The main reasons for the protests are China's zero covid policy, the lockdown of China, the white paper revolution, and the CCP. China's zero covid policy is a policy that is meant to stop the spread of covid by only allowing people who have been vaccinated to enter the country. The lockdown of China is still occurring in some cities because of covid. The white paper revolution is a protest against China's censorship. The CCP is a political party in China that has been accused of human rights violations. The lockdowns in China are proving to be very difficult for the people living there. Many people are not able to leave their homes or see their families. This has caused a lot of anger and frustration among the people of China. The situation in China is still very fluid and it is hard to say what will happen next.
What are the top 10 trending questions and answers related to protests and lockdowns in China in 2022 - What are the top 10 trending questions and answers related to protests and lockdowns in China in 2022? China has been in the headlines a lot lately due to the protests and lockdowns that have been occurring throughout the country. China has been facing many protests since early November of 2022. The main reasons for the protests are China's zero covid policy, the lockdown of China, the white paper revolution, and the CCP. China's zero covid policy is a policy that is meant to stop the spread of covid by only allowing people who have been vaccinated to enter the country. The lockdown of China is still occurring in some cities because of covid. The white paper revolution is a protest against China's censorship. The CCP is a political party in China that has been accused of human rights violations. The lockdowns in China are proving to be very difficult for the people living there. Many people are not able to leave their homes or see their families. This has caused a lot of anger and frustration among the people of China. The situation in China is still very fluid and it is hard to say what will happen next. What are the top 10 tips to recognize intelligent people without talking to them? - What are the top 10 tips to recognize intelligent people without talking to them? We've all met them. The person who you can just tell is smart, without having to talk to them. But how can you recognize these intelligent people without talking to them? Here are some tips!
What are the top 10 tips to recognize intelligent people without talking to them? - What are the top 10 tips to recognize intelligent people without talking to them? We've all met them. The person who you can just tell is smart, without having to talk to them. But how can you recognize these intelligent people without talking to them? Here are some tips! What are the top 200 African History and Geography quizzes? - What are the top 200 African History and Geography quizzes? How well do you know Africa? Test your knowledge with this Africa history and geography quiz. Africa is the world's second largest continent, and it is home to a stunning diversity of cultures, languages, and landscapes. From the Sahara Desert to the rainforests of the Congo Basin, Africa boasts a huge variety of geography. And its history is just as rich, from ancient civilizations like Egypt and Ethiopia to European colonization and the struggle for independence. So whether you're an Africa expert or just getting started, this quiz will help you test your knowledge of this amazing continent. Africa is a vast and fascinating continent with a rich history and diverse culture. To test your knowledge of Africa, take this Africa History and Geography Quiz. See how much you know about the people, places, and events that have shaped Africa over the centuries. AFRICAN HISTORY, AFRICAN GEOGRAPHY, AFRICAN CULTURE, AFRICAN PEOPLE, AFRICAN CUISINE, AFRICAN ECONOMICS, AFRICAN LANGUAGES , AFRICAN MUSIC, AFRICAN WILDLIFE, AFRICAN FOOTBALL, AFRICAN POLITICS, AFRICAN ANIMALS, AFRICAN TOURISM, AFRICAN SCIENCE, AFRICAN ENVIRONMENT
What are the top 200 African History and Geography quizzes? - What are the top 200 African History and Geography quizzes? How well do you know Africa? Test your knowledge with this Africa history and geography quiz. Africa is the world's second largest continent, and it is home to a stunning diversity of cultures, languages, and landscapes. From the Sahara Desert to the rainforests of the Congo Basin, Africa boasts a huge variety of geography. And its history is just as rich, from ancient civilizations like Egypt and Ethiopia to European colonization and the struggle for independence. So whether you're an Africa expert or just getting started, this quiz will help you test your knowledge of this amazing continent. Africa is a vast and fascinating continent with a rich history and diverse culture. To test your knowledge of Africa, take this Africa History and Geography Quiz. See how much you know about the people, places, and events that have shaped Africa over the centuries. AFRICAN HISTORY, AFRICAN GEOGRAPHY, AFRICAN CULTURE, AFRICAN PEOPLE, AFRICAN CUISINE, AFRICAN ECONOMICS, AFRICAN LANGUAGES , AFRICAN MUSIC, AFRICAN WILDLIFE, AFRICAN FOOTBALL, AFRICAN POLITICS, AFRICAN ANIMALS, AFRICAN TOURISM, AFRICAN SCIENCE, AFRICAN ENVIRONMENT macOS Stuck on Checking for Updates? 4 Solutions - macOS Stuck on Checking for Updates? 4 Solutions Macs are renowned for their reliability and streamlined user experience. However, even the best computers can sometimes run into problems. One common issue is when MacOS gets stuck on the "Checking for Updates" screen. This can be frustrating, but there are a few steps you can take to fix the problem.
macOS Stuck on Checking for Updates? 4 Solutions - macOS Stuck on Checking for Updates? 4 Solutions Macs are renowned for their reliability and streamlined user experience. However, even the best computers can sometimes run into problems. One common issue is when MacOS gets stuck on the "Checking for Updates" screen. This can be frustrating, but there are a few steps you can take to fix the problem. Can AI predicts US Mid-Terms 2022 Election Winners? - Can AI predicts US Mid-Terms 2022 Election Winners? As the race for the US Mid-Terms in 2022 heats up, many are wondering if AI will be able to predict the winners. While AI has become quite adept at analyzing data and making predictions, US elections are notoriously unpredictable. In 2018, for example, the Democrats unexpectedly lost control of the House, despite predictions that they would maintain a majority. And in 2020, Donald Trump shocked the world by winning reelection, despite most polls showing he would lose. So can AI really predict who will win in 2022? The answer is maybe. AI will be able to take into account a wide range of factors, from poll numbers to fundraising totals to social media buzz. But ultimately, US elections are still largely determined by factors that are impossible to predict, such as which candidate gets the most votes on Election Day. As a result, predicting the US Mid-Term winners in 2022 is still very much a guessing game.
Can AI predicts US Mid-Terms 2022 Election Winners? - Can AI predicts US Mid-Terms 2022 Election Winners? As the race for the US Mid-Terms in 2022 heats up, many are wondering if AI will be able to predict the winners. While AI has become quite adept at analyzing data and making predictions, US elections are notoriously unpredictable. In 2018, for example, the Democrats unexpectedly lost control of the House, despite predictions that they would maintain a majority. And in 2020, Donald Trump shocked the world by winning reelection, despite most polls showing he would lose. So can AI really predict who will win in 2022? The answer is maybe. AI will be able to take into account a wide range of factors, from poll numbers to fundraising totals to social media buzz. But ultimately, US elections are still largely determined by factors that are impossible to predict, such as which candidate gets the most votes on Election Day. As a result, predicting the US Mid-Term winners in 2022 is still very much a guessing game.  How to Know if Your Dataset Has Enough Features for Logistic or Multinomial Classification - How to Know if Your Dataset Has Enough Features for Logistic or Multinomial Classification. In machine learning, logistic and multinomial classification are two of the most popular methods for categorizing data. But before you can use either of these methods, you need to make sure that your dataset has enough features. In this blog post, we'll show you how to determine whether your dataset has enough features for logistic or multinomial classification.
How to Know if Your Dataset Has Enough Features for Logistic or Multinomial Classification - How to Know if Your Dataset Has Enough Features for Logistic or Multinomial Classification. In machine learning, logistic and multinomial classification are two of the most popular methods for categorizing data. But before you can use either of these methods, you need to make sure that your dataset has enough features. In this blog post, we'll show you how to determine whether your dataset has enough features for logistic or multinomial classification.  Can AI predicts the tournament winner and golden booth for the FIFA World Cup Football Soccer 2022 in Qatar? - Can AI predicts the tournament winner and golden booth for the FIFA World Cup Football Soccer 2022 in Qatar? With the FIFA World Cup looming soon, fans around the world are wondering who will take home the coveted trophy. While many people have their own opinion on who the favorite is, one thing is for sure: no one knows for sure. However, that hasn't stopped people from trying to predict the outcome using various methods, including artificial intelligence (AI). So, can AI accurately predict the winner of the 2022 FIFA World Cup? Let's take a look.
Can AI predicts the tournament winner and golden booth for the FIFA World Cup Football Soccer 2022 in Qatar? - Can AI predicts the tournament winner and golden booth for the FIFA World Cup Football Soccer 2022 in Qatar? With the FIFA World Cup looming soon, fans around the world are wondering who will take home the coveted trophy. While many people have their own opinion on who the favorite is, one thing is for sure: no one knows for sure. However, that hasn't stopped people from trying to predict the outcome using various methods, including artificial intelligence (AI). So, can AI accurately predict the winner of the 2022 FIFA World Cup? Let's take a look.  How Microsoft’s Cortana Stacks Up Against Siri and Alexa in Terms of Intelligence? - How Microsoft's Cortana Stacks Up Against Siri and Alexa in Terms of Intelligence? It seems like everyone these days has a voice assistant. Whether you're using Apple's Siri, Amazon's Alexa, or Microsoft's Cortana, these handy little programs are always there to help you with the weather forecast, setting timers, and playing your favorite tunes. But how do they stack up against each other in terms of intelligence? Let's take a closer look.
How Microsoft’s Cortana Stacks Up Against Siri and Alexa in Terms of Intelligence? - How Microsoft's Cortana Stacks Up Against Siri and Alexa in Terms of Intelligence? It seems like everyone these days has a voice assistant. Whether you're using Apple's Siri, Amazon's Alexa, or Microsoft's Cortana, these handy little programs are always there to help you with the weather forecast, setting timers, and playing your favorite tunes. But how do they stack up against each other in terms of intelligence? Let's take a closer look.  What Would Be the Best Way to Prove That an AI Is Sentient and Not Just Mimicking Human Behavior? - What Would Be the Best Way to Prove That an AI Is Sentient and Not Just Mimicking Human Behavior?
What Would Be the Best Way to Prove That an AI Is Sentient and Not Just Mimicking Human Behavior? - What Would Be the Best Way to Prove That an AI Is Sentient and Not Just Mimicking Human Behavior?  Will No-Code and AI ever make us all software developers? - Will No-Code and AI ever make us all software developers? In recent years, there has been a growing trend of "no-code" platforms and tools that allow users to create complex applications without a single line of code. At the same time, artificial intelligence is becoming more and more advanced, capable of completing tasks that were once considered impossible for machines to do. So, the question is: will no-code platforms and AI ever make us all software developers? Let's take a look.
Will No-Code and AI ever make us all software developers? - Will No-Code and AI ever make us all software developers? In recent years, there has been a growing trend of "no-code" platforms and tools that allow users to create complex applications without a single line of code. At the same time, artificial intelligence is becoming more and more advanced, capable of completing tasks that were once considered impossible for machines to do. So, the question is: will no-code platforms and AI ever make us all software developers? Let's take a look.- How AI is Impacting Smartphone Longevity – Best Smartphones 2023 - How AI is Impacting Smartphone Longevity - Best Smartphone 2023 One of the ways AI can help improve smartphone longevity is through battery optimization. Battery optimization is the process of making sure that your smartphone's battery is being used in the most efficient way possible. AI can help by learning your usage patterns and making adjustments accordingly. For example, if you typically use your phone for browsing the web and checking social media in the morning, AI can make sure that your battery is charged enough to last throughout the day.
 How to make your laptop last longer with AI – Best laptops in 2022 – 2023 - How to make your laptop last longer with AI - Best laptopn in 2022-2023 With the rapid development of technology, it's no surprise that laptops are becoming more and more advanced. In fact, many laptops now come equipped with artificial intelligence (AI) capabilities. But what does this mean for the longevity of your laptop? Will AI help or hinder your laptop's lifespan? Let's take a closer look.
How to make your laptop last longer with AI – Best laptops in 2022 – 2023 - How to make your laptop last longer with AI - Best laptopn in 2022-2023 With the rapid development of technology, it's no surprise that laptops are becoming more and more advanced. In fact, many laptops now come equipped with artificial intelligence (AI) capabilities. But what does this mean for the longevity of your laptop? Will AI help or hinder your laptop's lifespan? Let's take a closer look. Can AI Really Predict Lottery Results? We Asked an Expert. - Can AI Really Predict Lottery Results? We Asked an Expert. We've all been there. You're in the grocery store line, idly scratching off a lottery ticket, when you start to daydream about what you would do with all that money. A new house? A yacht? Early retirement? But then reality sets in and you remember your chances of winning are pretty much nil. Or are they? We recently came across an article claiming that artificial intelligence can predict lottery results with near-perfect accuracy. This got us thinking: could AI really be used to beat the odds and guarantee a win? We decided to ask an expert.
Can AI Really Predict Lottery Results? We Asked an Expert. - Can AI Really Predict Lottery Results? We Asked an Expert. We've all been there. You're in the grocery store line, idly scratching off a lottery ticket, when you start to daydream about what you would do with all that money. A new house? A yacht? Early retirement? But then reality sets in and you remember your chances of winning are pretty much nil. Or are they? We recently came across an article claiming that artificial intelligence can predict lottery results with near-perfect accuracy. This got us thinking: could AI really be used to beat the odds and guarantee a win? We decided to ask an expert.  AI and The Climate Bill: Why We Should All Be Incentivized to Save the Planet - AI and the Climate Bill: Why We Should All Be Incentivized to Save the Planet. As global temperatures continue to rise, it's more important than ever that we all do our part to save the planet. That's why I'm a big proponent of the climate bill that was just introduced in Congress. This bill would provide a much-needed financial incentive for people to make greener choices that would help reduce their carbon footprint. Here's a closer look at why this bill is so important and how it would work.
AI and The Climate Bill: Why We Should All Be Incentivized to Save the Planet - AI and the Climate Bill: Why We Should All Be Incentivized to Save the Planet. As global temperatures continue to rise, it's more important than ever that we all do our part to save the planet. That's why I'm a big proponent of the climate bill that was just introduced in Congress. This bill would provide a much-needed financial incentive for people to make greener choices that would help reduce their carbon footprint. Here's a closer look at why this bill is so important and how it would work.  What is the Best Machine Learning Algorithms for Imbalanced Datasets - What is the Best Machine Learning Algorithms for Imbalanced Datasets In machine learning, imbalanced datasets are those where one class heavily outnumbers the others. This can be due to the nature of the problem or simply because more data is available for one class than the others. Either way, imbalanced datasets can pose a challenge for machine learning algorithms. In this blog post, we'll take a look at which machine learning algorithms are best suited for imbalanced datasets and why they tend to perform better than others.
What is the Best Machine Learning Algorithms for Imbalanced Datasets - What is the Best Machine Learning Algorithms for Imbalanced Datasets In machine learning, imbalanced datasets are those where one class heavily outnumbers the others. This can be due to the nature of the problem or simply because more data is available for one class than the others. Either way, imbalanced datasets can pose a challenge for machine learning algorithms. In this blog post, we'll take a look at which machine learning algorithms are best suited for imbalanced datasets and why they tend to perform better than others. Google’s Carbon Copy: Is Google’s Carbon Programming language the Right Successor to C++? - Is Google's Carbon Programming language the Right Successor to C++? For years, C++ has been the go-to language for high-performance systems programming. But with the rise of multicore processors and GPUs, the need for a language that can take advantage of parallelism has never been greater. Enter Carbon, Google's answer to the problem. But is it the right successor to C++?
Google’s Carbon Copy: Is Google’s Carbon Programming language the Right Successor to C++? - Is Google's Carbon Programming language the Right Successor to C++? For years, C++ has been the go-to language for high-performance systems programming. But with the rise of multicore processors and GPUs, the need for a language that can take advantage of parallelism has never been greater. Enter Carbon, Google's answer to the problem. But is it the right successor to C++? - Benefits and Drawbacks of Working Remotely in Africa: Has Africa fully embraced hybrid teams, digital workspace and the use of remote workers? - Benefits and Drawbacks of Working Remotely in Africa Has Africa fully embraced hybrid teams, digital workspace and the use of remote workers There are a number of advantages to working remotely in Africa. First, it allows businesses to tap into a larger pool of talent. With more people working remotely, businesses can hire the best employees, regardless of location. Second, it can help reduce costs. With no need for office space or equipment, businesses can save money by having employees work remotely. Finally, it can promote a better work-life balance. With no need to commute, employees can have more time for family and hobbies.
 What is machine learning and how does Netflix use it for its recommendation engine? - What is machine learning and how does Netflix use it for its recommendation engine? Machine learning is a field of artificial intelligence that Netflix uses to create its recommendation algorithm. The goal of machine learning is to teach computers to learn from data and make predictions based on that data. To do this, Netflix employs Machine Learning Engineers, Data Scientists, and software developers to design and build algorithms that can automatically improve over time. The Netflix recommendations engine is just one example of how machine learning can be used to improve the user experience. By understanding what users watch and why, the recommendations engine can provide tailored suggestions that help users find new shows and movies to enjoy. Machine learning is also used for other Netflix features, such as predicting which shows a user might be interested in watching next, or detecting inappropriate content. In a world where data is becoming increasingly important, machine learning will continue to play a vital role in helping Netflix deliver a great experience to its users.
What is machine learning and how does Netflix use it for its recommendation engine? - What is machine learning and how does Netflix use it for its recommendation engine? Machine learning is a field of artificial intelligence that Netflix uses to create its recommendation algorithm. The goal of machine learning is to teach computers to learn from data and make predictions based on that data. To do this, Netflix employs Machine Learning Engineers, Data Scientists, and software developers to design and build algorithms that can automatically improve over time. The Netflix recommendations engine is just one example of how machine learning can be used to improve the user experience. By understanding what users watch and why, the recommendations engine can provide tailored suggestions that help users find new shows and movies to enjoy. Machine learning is also used for other Netflix features, such as predicting which shows a user might be interested in watching next, or detecting inappropriate content. In a world where data is becoming increasingly important, machine learning will continue to play a vital role in helping Netflix deliver a great experience to its users. 
 What are the top 10 algorithms every software engineer should know by heart? - What are the top 10 algorithms every software engineer should know by heart? As a software engineer, you're expected to know a lot about algorithms. After all, they are the bread and butter of your trade. But with so many different algorithms out there, how can you possibly keep track of them all? Never fear! We've compiled a list of the top 10 algorithms every software engineer should know by heart. From sorting and searching to graph theory and dynamic programming, these are the algorithms that will make you a master of your craft. So without further ado, let's get started!
What are the top 10 algorithms every software engineer should know by heart? - What are the top 10 algorithms every software engineer should know by heart? As a software engineer, you're expected to know a lot about algorithms. After all, they are the bread and butter of your trade. But with so many different algorithms out there, how can you possibly keep track of them all? Never fear! We've compiled a list of the top 10 algorithms every software engineer should know by heart. From sorting and searching to graph theory and dynamic programming, these are the algorithms that will make you a master of your craft. So without further ado, let's get started!  What are some ways we can use machine learning and artificial intelligence for algorithmic trading in the stock market? - What are some ways we can use machine learning and artificial intelligence for algorithmic trading in the stock market? Machine learning is a subfield of artificial intelligence (AI) that focuses on the development of computer programs that can access data and use it to learn for themselves. In recent years, machine learning has made great strides in a number of different industries, and the stock market is no exception. Here, we'll take a look at how machine learning can be used for algorithmic trading in the stock market.
What are some ways we can use machine learning and artificial intelligence for algorithmic trading in the stock market? - What are some ways we can use machine learning and artificial intelligence for algorithmic trading in the stock market? Machine learning is a subfield of artificial intelligence (AI) that focuses on the development of computer programs that can access data and use it to learn for themselves. In recent years, machine learning has made great strides in a number of different industries, and the stock market is no exception. Here, we'll take a look at how machine learning can be used for algorithmic trading in the stock market.  What are some ways to increase precision or recall in machine learning? - What are some ways to increase precision or recall in machine learning? In machine learning, recall is the ability of the model to find all relevant instances in the data while precision is the ability of the model to correctly identify only the relevant instances. A high recall means that most relevant results are returned while a high precision means that most of the returned results are relevant. Ideally, you want a model with both high recall and high precision but often there is a trade-off between the two. In this blog post, we will explore some ways to increase recall or precision in machine learning
What are some ways to increase precision or recall in machine learning? - What are some ways to increase precision or recall in machine learning? In machine learning, recall is the ability of the model to find all relevant instances in the data while precision is the ability of the model to correctly identify only the relevant instances. A high recall means that most relevant results are returned while a high precision means that most of the returned results are relevant. Ideally, you want a model with both high recall and high precision but often there is a trade-off between the two. In this blog post, we will explore some ways to increase recall or precision in machine learning  How can I get someone’s IP from WhatsApp? - How can I get someone's IP from WhatsApp? First the person must be online
Your phone must be rooted
And then install busybox
And then install any command prompt from google playstore like termux
Close anything that uses internet by clicking disable on all apps who use internet
and then open whatsapp and try to make a voice call or a video call with that person
and then during the call open Termux and type this command : netstat -n
If the connection was really peer 2 peer as whatsapp says his IP must be one of the foreign IP Addresses you would see on their Terminal.
How can I get someone’s IP from WhatsApp? - How can I get someone's IP from WhatsApp? First the person must be online
Your phone must be rooted
And then install busybox
And then install any command prompt from google playstore like termux
Close anything that uses internet by clicking disable on all apps who use internet
and then open whatsapp and try to make a voice call or a video call with that person
and then during the call open Termux and type this command : netstat -n
If the connection was really peer 2 peer as whatsapp says his IP must be one of the foreign IP Addresses you would see on their Terminal. What are the top 3 methods used to find Autoregressive Parameters in Data Science? - What are the top 3 methods used to find Autoregressive Parameters in Data Science? In order to find autoregressive parameters, you will first need to understand what autoregression is. Autoregression is a statistical method used to create a model that describes data as a function of linear regression of lagged values of the dependent variable. In other words, it is a model that uses past values of a dependent variable in order to predict future values of the same dependent variable.
What are the top 3 methods used to find Autoregressive Parameters in Data Science? - What are the top 3 methods used to find Autoregressive Parameters in Data Science? In order to find autoregressive parameters, you will first need to understand what autoregression is. Autoregression is a statistical method used to create a model that describes data as a function of linear regression of lagged values of the dependent variable. In other words, it is a model that uses past values of a dependent variable in order to predict future values of the same dependent variable. How do you make a Python loop faster? - How do you make a Python loop faster? Programmers are always looking for ways to make their code more efficient. One way to do this is to use a faster loop. Python is a high-level programming language that is widely used by developers and software engineers. It is known for its readability and ease of use. However, one downside of Python is that its loops can be slow. This can be a problem when you need to process large amounts of data. There are several ways to make Python loops faster. One way is to use a faster looping construct, such as C. Another way is to use an optimized library, such as NumPy. Finally, you can vectorize your code, which means converting it into a format that can be run on a GPU or other parallel computing platform. By using these techniques, you can significantly speed up your Python code.
How do you make a Python loop faster? - How do you make a Python loop faster? Programmers are always looking for ways to make their code more efficient. One way to do this is to use a faster loop. Python is a high-level programming language that is widely used by developers and software engineers. It is known for its readability and ease of use. However, one downside of Python is that its loops can be slow. This can be a problem when you need to process large amounts of data. There are several ways to make Python loops faster. One way is to use a faster looping construct, such as C. Another way is to use an optimized library, such as NumPy. Finally, you can vectorize your code, which means converting it into a format that can be run on a GPU or other parallel computing platform. By using these techniques, you can significantly speed up your Python code. What are the top 10 most insane myths about computer programmers? - What are the top 10 most insane myths about computer programmers? 1. Programmers are all socially awkward nerds who live in their parents' basements.
2. Programmers only care about computers and have no other interests.
3. Programmers are all genius-level intellects with photographic memories.
4. Programmers can code anything they set their minds to, no matter how complex or impossible it may seem.
5. Programmers only work on solitary projects and never collaborate with others.
6. Programmers write code that is completely error-free on the first try.
7. All programmers use the same coding languages and tools.
8. Programmers can easily find jobs anywhere in the world thanks to the worldwide demand for their skills.
9. Programmers always work in dark, cluttered rooms with dozens of monitors surrounding them.
10. Programmers can't have successful personal lives because they spend all their time working on code."
What are the top 10 most insane myths about computer programmers? - What are the top 10 most insane myths about computer programmers? 1. Programmers are all socially awkward nerds who live in their parents' basements.
2. Programmers only care about computers and have no other interests.
3. Programmers are all genius-level intellects with photographic memories.
4. Programmers can code anything they set their minds to, no matter how complex or impossible it may seem.
5. Programmers only work on solitary projects and never collaborate with others.
6. Programmers write code that is completely error-free on the first try.
7. All programmers use the same coding languages and tools.
8. Programmers can easily find jobs anywhere in the world thanks to the worldwide demand for their skills.
9. Programmers always work in dark, cluttered rooms with dozens of monitors surrounding them.
10. Programmers can't have successful personal lives because they spend all their time working on code." What are the top 5 common Python patterns when using dictionaries? - What are the top 5 common Python patterns when using dictionaries? In Python, a dictionary is a data structure that allows you to store data in a key/value format. This is similar to a Map in Java. A dictionary is mutable, which means you can add, remove, and update elements in a dictionary. Dictionaries are unordered, which means that the order in which you add elements to a dictionary is not preserved. There are many different ways to use dictionaries in Python. In this blog post, we will explore some of the most popular patterns for using dictionaries in Python.
What are the top 5 common Python patterns when using dictionaries? - What are the top 5 common Python patterns when using dictionaries? In Python, a dictionary is a data structure that allows you to store data in a key/value format. This is similar to a Map in Java. A dictionary is mutable, which means you can add, remove, and update elements in a dictionary. Dictionaries are unordered, which means that the order in which you add elements to a dictionary is not preserved. There are many different ways to use dictionaries in Python. In this blog post, we will explore some of the most popular patterns for using dictionaries in Python. Top 10 ways for software engineers or developers to gain more power in their companies? - Top 10 ways for software engineers or developers to gain more power in their companies? 1. Get involved in decision-making processes.
2. Speak up when you have an idea or perspective to share.
3. Become a mentor or coach to others.
4. Be a thought leader by writing blog posts or articles, giving talks, or teaching classes.
5. Develop relationships with people in other departments or companies.
6. Join or create employee resource groups.
7. Serve on committees or working groups.
8. Volunteer for special projects.
9. Network outside of work hours.
10. Make sure your performance review focuses on your accomplishments.
Top 10 ways for software engineers or developers to gain more power in their companies? - Top 10 ways for software engineers or developers to gain more power in their companies? 1. Get involved in decision-making processes.
2. Speak up when you have an idea or perspective to share.
3. Become a mentor or coach to others.
4. Be a thought leader by writing blog posts or articles, giving talks, or teaching classes.
5. Develop relationships with people in other departments or companies.
6. Join or create employee resource groups.
7. Serve on committees or working groups.
8. Volunteer for special projects.
9. Network outside of work hours.
10. Make sure your performance review focuses on your accomplishments.  Which programming language produces binaries that are the most difficult to reverse engineer? - Which programming language produces binaries that are the most difficult to reverse engineer? Reverse engineering is the process of taking something apart in order to figure out how it works. In the context of software, this usually means taking a compiled binary and figuring out what high-level programming language it was written in, as well as what the program is supposed to do. This can be difficult for a number of reasons, but one of the biggest factors is the level of optimization that was applied to the code during compilation.
Which programming language produces binaries that are the most difficult to reverse engineer? - Which programming language produces binaries that are the most difficult to reverse engineer? Reverse engineering is the process of taking something apart in order to figure out how it works. In the context of software, this usually means taking a compiled binary and figuring out what high-level programming language it was written in, as well as what the program is supposed to do. This can be difficult for a number of reasons, but one of the biggest factors is the level of optimization that was applied to the code during compilation.
 What are the top 10 Wonders of computing and software engineering? - What are the top 10 Wonders of computing and software engineering? Computer science and software engineering are fascinating fields that continue to evolve and surprise us. In this blog post, we'll explore the top 10 wonders of computer science and software engineering. From self-driving cars to artificial intelligence, these are the technologies that are shaping our world.
What are the top 10 Wonders of computing and software engineering? - What are the top 10 Wonders of computing and software engineering? Computer science and software engineering are fascinating fields that continue to evolve and surprise us. In this blog post, we'll explore the top 10 wonders of computer science and software engineering. From self-driving cars to artificial intelligence, these are the technologies that are shaping our world. What are the top 100 Free IQ Test Questions and Answers – Train and Elevate Your Brain - What are the top 100 Free IQ Test Questions and Answers - Train and Elevate Your Brain. Mensa IQ tests are among the most popular intelligence tests in the world. But what are they for? In this blog post, we'll be discussing the different Mensa IQ tests and what they're meant to assess. 1. The first Mensa IQ test is called the Culture Fair Intelligence Test, or CFIT. This test is designed to minimize the influence of cultural biases on a person's score. The CFIT is made up of four subtests, each of which measures a different type of cognitive ability.
2. The second Mensa IQ test is called the Stanford-Binet Intelligence Scale, or SBIS. The SBIS is a revision of an earlier intelligence test that was used by the US military to screen recruits during World War I. Today, the SBIS is commonly used to diagnose learning disabilities in children.
3. The third Mensa IQ test is called the Universal Nonverbal Intelligence Test, or UNIT. As its name suggests, the UNIT is a nonverbal intelligence test that can be administered to people of all ages, regardless of their native language.
4. The fourth and final Mensa IQ test is called the Wright Scale of Human Ability, or WSHA. The WSHA was developed by William Herschel Wright, a British psychologist who also served as the first president of Mensa International. Like the other tests on this list, the WSHA consists of four subtests that measure different aspects of cognitive ability.
What are the top 100 Free IQ Test Questions and Answers – Train and Elevate Your Brain - What are the top 100 Free IQ Test Questions and Answers - Train and Elevate Your Brain. Mensa IQ tests are among the most popular intelligence tests in the world. But what are they for? In this blog post, we'll be discussing the different Mensa IQ tests and what they're meant to assess. 1. The first Mensa IQ test is called the Culture Fair Intelligence Test, or CFIT. This test is designed to minimize the influence of cultural biases on a person's score. The CFIT is made up of four subtests, each of which measures a different type of cognitive ability.
2. The second Mensa IQ test is called the Stanford-Binet Intelligence Scale, or SBIS. The SBIS is a revision of an earlier intelligence test that was used by the US military to screen recruits during World War I. Today, the SBIS is commonly used to diagnose learning disabilities in children.
3. The third Mensa IQ test is called the Universal Nonverbal Intelligence Test, or UNIT. As its name suggests, the UNIT is a nonverbal intelligence test that can be administered to people of all ages, regardless of their native language.
4. The fourth and final Mensa IQ test is called the Wright Scale of Human Ability, or WSHA. The WSHA was developed by William Herschel Wright, a British psychologist who also served as the first president of Mensa International. Like the other tests on this list, the WSHA consists of four subtests that measure different aspects of cognitive ability.  How to find common elements in two unsorted arrays with sizes n and m avoiding double for loop? - How to find common elements in two unsorted arrays with sizes n and m avoiding double for loop? One of the most straight forward ways to find common elements in two arrays is by using a double for loop. This approach is simple to understand and implement but it is not very efficient. The time complexity of this algorithm is O(n*m) where n and m are the size of the two arrays respectively. The reason for this is because we are looping through both arrays completely which takes a lot of time. Furthermore, this approach also uses a lot of extra space because we are storing the common elements in a new list.
How to find common elements in two unsorted arrays with sizes n and m avoiding double for loop? - How to find common elements in two unsorted arrays with sizes n and m avoiding double for loop? One of the most straight forward ways to find common elements in two arrays is by using a double for loop. This approach is simple to understand and implement but it is not very efficient. The time complexity of this algorithm is O(n*m) where n and m are the size of the two arrays respectively. The reason for this is because we are looping through both arrays completely which takes a lot of time. Furthermore, this approach also uses a lot of extra space because we are storing the common elements in a new list.  Simple Linear Regression vs. Multiple Linear Regression vs. MANOVA: A Data Scientist’s Guide - Simple Linear Regression vs. Multiple Linear Regression vs. MANOVA: A Data Scientist's Guide As a data scientist, it's important to understand the difference between simple linear regression, multiple linear regression, and MANOVA. This will come in handy when you're working with different datasets and trying to figure out which one to use. Here's a quick overview of each method:
Simple Linear Regression vs. Multiple Linear Regression vs. MANOVA: A Data Scientist’s Guide - Simple Linear Regression vs. Multiple Linear Regression vs. MANOVA: A Data Scientist's Guide As a data scientist, it's important to understand the difference between simple linear regression, multiple linear regression, and MANOVA. This will come in handy when you're working with different datasets and trying to figure out which one to use. Here's a quick overview of each method: What’s the difference between a proxy and a VPN and why is one security stronger than the other? Which security feature is stronger and why? - What's the difference between a proxy and a VPN and why is one security stronger than the other? Which security feature is stronger and why? In the digital age, proxy servers and VPNs have become increasingly popular as people strive to protect their online privacy and security. But what exactly are these two devices, and how do they differ? A proxy server is a computer that acts as an intermediary between your device and the internet. When you connect to the internet through a proxy, your data is routed through the proxy server before it reaches its destination. This allows you to mask your IP address and remain anonymous online. VPNs, on the other hand, encrypt your data before it leaves your device. This creates a private tunnel that cannot be accessed by anyone except for you and the VPN server. As a result, VPNs offer a higher level of security than proxy servers. However, proxy servers are typically faster and more reliable than VPNs, making them a good choice for online activities that don't require a high level of security, such as web browsing or streaming video.
What’s the difference between a proxy and a VPN and why is one security stronger than the other? Which security feature is stronger and why? - What's the difference between a proxy and a VPN and why is one security stronger than the other? Which security feature is stronger and why? In the digital age, proxy servers and VPNs have become increasingly popular as people strive to protect their online privacy and security. But what exactly are these two devices, and how do they differ? A proxy server is a computer that acts as an intermediary between your device and the internet. When you connect to the internet through a proxy, your data is routed through the proxy server before it reaches its destination. This allows you to mask your IP address and remain anonymous online. VPNs, on the other hand, encrypt your data before it leaves your device. This creates a private tunnel that cannot be accessed by anyone except for you and the VPN server. As a result, VPNs offer a higher level of security than proxy servers. However, proxy servers are typically faster and more reliable than VPNs, making them a good choice for online activities that don't require a high level of security, such as web browsing or streaming video. What are the Top 10 AWS jobs you can get with an AWS certification in 2022 plus AWS Interview Questions - What are the Top 10 AWS jobs you can get with an AWS certification in 2022 plus AWS Interview Questions. AWS certified professionals are in high demand across a variety of industries. AWS certs can open the door to a number of AWS jobs, including cloud engineer, solutions architect, and DevOps engineer. Here are the top 10 AWS jobs you can get with an AWS certification. 1. Cloud Engineer: Cloud engineers are responsible for designing, implementing, and managing cloud solutions. They work with customers to understand their needs and then design and implement the best cloud solution for their business. 2. Solutions Architect: Solutions architects work with customers to understand their business needs and then design and implement AWS solutions that meet those needs. They must have a deep understanding of AWS services and how they can be used to solve customer problems. 3. DevOps Engineer: DevOps engineers are responsible for developing and maintaining AWS infrastructure. They work closely with developers to ensure that code is deployed quickly and efficiently. They also work with operations teams to ensure that AWS infrastructure is scalable and reliable. 4. System Administrator: System administrators are responsible for managing AWS systems. They work with customers to provision and configure AWS resources, and they also monitor and troubleshoot AWS systems. 5. Database Administrator: Database administrators are responsible for designing, implementing, and maintaining databases on AWS. They work closely with developers to ensure that data is stored securely and efficiently. They also work with operations teams to ensure that database systems are highly available and scalable. 6. Network Administrator: Network administrators are responsible for designing, implementing, and managing networking solutions on AWS. They work closely with customers to understand their networking needs and then design and implement the best solution for their business. 7. Security Engineer: Security engineers are responsible for designing, implementing, and managing security solutions on AWS. They work closely with customers to understand their security needs and then design and implement the best security solution for their business. 8. Support Engineer: Support engineers are responsible for providing technical support to AWS customers. They work closely with customers to troubleshoot problems and provide resolution within agreed upon SLAs. 9 Sales Engineer: Sales engineers are responsible for working with sales teams to generate new business opportunities through the use of AWS products and services .They must have a deep understanding of AWS products and how they can be used by potential customers to solve their business problems .
What are the Top 10 AWS jobs you can get with an AWS certification in 2022 plus AWS Interview Questions - What are the Top 10 AWS jobs you can get with an AWS certification in 2022 plus AWS Interview Questions. AWS certified professionals are in high demand across a variety of industries. AWS certs can open the door to a number of AWS jobs, including cloud engineer, solutions architect, and DevOps engineer. Here are the top 10 AWS jobs you can get with an AWS certification. 1. Cloud Engineer: Cloud engineers are responsible for designing, implementing, and managing cloud solutions. They work with customers to understand their needs and then design and implement the best cloud solution for their business. 2. Solutions Architect: Solutions architects work with customers to understand their business needs and then design and implement AWS solutions that meet those needs. They must have a deep understanding of AWS services and how they can be used to solve customer problems. 3. DevOps Engineer: DevOps engineers are responsible for developing and maintaining AWS infrastructure. They work closely with developers to ensure that code is deployed quickly and efficiently. They also work with operations teams to ensure that AWS infrastructure is scalable and reliable. 4. System Administrator: System administrators are responsible for managing AWS systems. They work with customers to provision and configure AWS resources, and they also monitor and troubleshoot AWS systems. 5. Database Administrator: Database administrators are responsible for designing, implementing, and maintaining databases on AWS. They work closely with developers to ensure that data is stored securely and efficiently. They also work with operations teams to ensure that database systems are highly available and scalable. 6. Network Administrator: Network administrators are responsible for designing, implementing, and managing networking solutions on AWS. They work closely with customers to understand their networking needs and then design and implement the best solution for their business. 7. Security Engineer: Security engineers are responsible for designing, implementing, and managing security solutions on AWS. They work closely with customers to understand their security needs and then design and implement the best security solution for their business. 8. Support Engineer: Support engineers are responsible for providing technical support to AWS customers. They work closely with customers to troubleshoot problems and provide resolution within agreed upon SLAs. 9 Sales Engineer: Sales engineers are responsible for working with sales teams to generate new business opportunities through the use of AWS products and services .They must have a deep understanding of AWS products and how they can be used by potential customers to solve their business problems .  What are the Top 5 things that can say a lot about a software engineer or programmer’s quality? - What are the Top 5 things that can say a lot about a software engineer or programmer's quality? When it comes to the quality of a software engineer or programmer, there are a few key things that can give you a good indication. First, take a look at their code quality. A good software engineer will take pride in their work and produce clean, well-organized code. They will also be able to explain their code concisely and confidently. Another thing to look for is whether they are up-to-date on the latest coding technologies and trends. A good programmer will always be learning and keeping up with the latest industry developments. Finally, pay attention to how they handle difficult problems. A good software engineer will be able to think creatively and come up with innovative solutions to complex issues. If you see these qualities in a software engineer or programmer, chances are they are of high quality.
What are the Top 5 things that can say a lot about a software engineer or programmer’s quality? - What are the Top 5 things that can say a lot about a software engineer or programmer's quality? When it comes to the quality of a software engineer or programmer, there are a few key things that can give you a good indication. First, take a look at their code quality. A good software engineer will take pride in their work and produce clean, well-organized code. They will also be able to explain their code concisely and confidently. Another thing to look for is whether they are up-to-date on the latest coding technologies and trends. A good programmer will always be learning and keeping up with the latest industry developments. Finally, pay attention to how they handle difficult problems. A good software engineer will be able to think creatively and come up with innovative solutions to complex issues. If you see these qualities in a software engineer or programmer, chances are they are of high quality. How to Protect Yourself from Man-in-the-Middle Attacks: Tips for Safer Communication - How to Protect Yourself from Man-in-the-Middle Attacks: Tips for Safer Communication Man-in-the-middle attacks are one of the most common types of cyberattacks. They occur when a attacker intercepts communication between two parties and impersonates one or both of them. This can allow the attacker to gain access to sensitive information, such as passwords or financial data. Man-in-the-middle attacks can be very difficult to detect, but there are some steps you can take to protect yourself. First, be aware of the warning signs of a man-in-the-middle attack. These include unexpected changes in login pages, unexpected requests for personal information, and unusual account activity. If you see any of these warning signs, do not enter any sensitive information and contact the company or individual involved immediately. Second, use strong security measures, such as two-factor authentication, to protect your accounts. This will make it more difficult for attackers to gain access to your information. Finally, keep your software and operating system up to date with the latest security patches. This will help to close any potential vulnerabilities that could be exploited by attackers. By following these tips, you can help to keep yourself safe from man-in-the-middle attacks.
How to Protect Yourself from Man-in-the-Middle Attacks: Tips for Safer Communication - How to Protect Yourself from Man-in-the-Middle Attacks: Tips for Safer Communication Man-in-the-middle attacks are one of the most common types of cyberattacks. They occur when a attacker intercepts communication between two parties and impersonates one or both of them. This can allow the attacker to gain access to sensitive information, such as passwords or financial data. Man-in-the-middle attacks can be very difficult to detect, but there are some steps you can take to protect yourself. First, be aware of the warning signs of a man-in-the-middle attack. These include unexpected changes in login pages, unexpected requests for personal information, and unusual account activity. If you see any of these warning signs, do not enter any sensitive information and contact the company or individual involved immediately. Second, use strong security measures, such as two-factor authentication, to protect your accounts. This will make it more difficult for attackers to gain access to your information. Finally, keep your software and operating system up to date with the latest security patches. This will help to close any potential vulnerabilities that could be exploited by attackers. By following these tips, you can help to keep yourself safe from man-in-the-middle attacks. What is Problem Formulation in Machine Learning and Top 4 examples of Problem Formulation in Machine Learning? - What is Problem Formulation in Machine Learning and Top 4 examples of Problem Formulation in Machine Learning? Problem formulation is an essential part of the machine learning pipeline. Machine learning problems can be classified into four types: regression, classification, clustering, and ranking. Each type of problem has its own set of challenges and requires a different approach. For example, regression problems involve predicting a continuous value, such as the price of a stock, while classification problems involve predicting a discrete label, such as whether an email is spam or not. Clustering problems involve grouping data points into clusters, while ranking problems involve ordering data points from most to least similar. In each case, the goal is to find a model that can generalize from the training data to the test data. The choice of model will depend on the type of problem and the nature of the data. For instance, linear models are often used for regression problems, while decision trees are often used for classification problems. The challenge in machine learning is to find a model that performs well on the training data but also generalizes well to unseen data. This is where problem formulation comes in. By carefully defining the problem and choosing an appropriate model, we can increase the chances of finding a solution that works well in practice.
What is Problem Formulation in Machine Learning and Top 4 examples of Problem Formulation in Machine Learning? - What is Problem Formulation in Machine Learning and Top 4 examples of Problem Formulation in Machine Learning? Problem formulation is an essential part of the machine learning pipeline. Machine learning problems can be classified into four types: regression, classification, clustering, and ranking. Each type of problem has its own set of challenges and requires a different approach. For example, regression problems involve predicting a continuous value, such as the price of a stock, while classification problems involve predicting a discrete label, such as whether an email is spam or not. Clustering problems involve grouping data points into clusters, while ranking problems involve ordering data points from most to least similar. In each case, the goal is to find a model that can generalize from the training data to the test data. The choice of model will depend on the type of problem and the nature of the data. For instance, linear models are often used for regression problems, while decision trees are often used for classification problems. The challenge in machine learning is to find a model that performs well on the training data but also generalizes well to unseen data. This is where problem formulation comes in. By carefully defining the problem and choosing an appropriate model, we can increase the chances of finding a solution that works well in practice. What are the Greenest or Least Environmentally Friendly Programming Languages? - What are the Greenest or Least Environmentally Friendly Programming Languages? Are you looking for a new programming language to learn? If you're interested in something that is both green and energy efficient, you might want to consider the Groeningen Programming Language (GPL). Developed by a team of researchers at the University of Groningen in the Netherlands, GPL is a relatively new language that is based on the C and C++ programming languages. Python and Rust are also used in its development. GPL is designed to be used for developing energy efficient applications. Its syntax is similar to other popular programming languages, so it should be relatively easy for experienced programmers to learn. And since it's open source, you can download and use it for free. So why not give GPL a try? It just might be the perfect language for your next project.
What are the Greenest or Least Environmentally Friendly Programming Languages? - What are the Greenest or Least Environmentally Friendly Programming Languages? Are you looking for a new programming language to learn? If you're interested in something that is both green and energy efficient, you might want to consider the Groeningen Programming Language (GPL). Developed by a team of researchers at the University of Groningen in the Netherlands, GPL is a relatively new language that is based on the C and C++ programming languages. Python and Rust are also used in its development. GPL is designed to be used for developing energy efficient applications. Its syntax is similar to other popular programming languages, so it should be relatively easy for experienced programmers to learn. And since it's open source, you can download and use it for free. So why not give GPL a try? It just might be the perfect language for your next project. Why is there a lack of diversity among software engineers in tech companies in USA and Canada? - Why is there a lack of diversity among software engineers in tech companies in USA and Canada? Technology is a rapidly growing industry with a huge demand for qualified software engineers. However, there is a lack of diversity among software engineers in tech companies in the USA and Canada. Women and minorities are greatly underrepresented in the field of software engineering. This is due to several factors, including the misogynistic and racist culture of many tech companies. The lack of diversity among software engineers has a negative impact on the quality of products and services offered by tech companies. It also limits the ability of these companies to innovate and serve a wide range of customers. In order to increase diversity among software engineers, tech companies need to change their hiring practices and create an inclusive environment that values all types of people.
Why is there a lack of diversity among software engineers in tech companies in USA and Canada? - Why is there a lack of diversity among software engineers in tech companies in USA and Canada? Technology is a rapidly growing industry with a huge demand for qualified software engineers. However, there is a lack of diversity among software engineers in tech companies in the USA and Canada. Women and minorities are greatly underrepresented in the field of software engineering. This is due to several factors, including the misogynistic and racist culture of many tech companies. The lack of diversity among software engineers has a negative impact on the quality of products and services offered by tech companies. It also limits the ability of these companies to innovate and serve a wide range of customers. In order to increase diversity among software engineers, tech companies need to change their hiring practices and create an inclusive environment that values all types of people.- How do we know that the Top 3 Voice Recognition Devices like Siri Alexa and Ok Google are not spying on us? - How do we know that the Top 3 Voice Recognition Devices like Siri Alexa and Ok Google are not spying on us? Machine learning is a field of artificial intelligence (AI) concerned with the design and development of algorithms that learn from data. Machine learning algorithms have been used for a variety of tasks, including voice recognition, image classification, and spam detection. In recent years, there has been growing concern about the use of machine learning for surveillance and spying. However, it is important to note that machine learning is not necessarily synonymous with spying. Machine learning algorithms can be used for good or ill, depending on how they are designed and deployed. When it comes to voice-activated assistants such as Siri, Alexa, and OK Google, the primary concern is privacy. These assistants are constantly listening for their wake words, which means they may be recording private conversations without the user's knowledge or consent. While it is possible that these recordings could be used for nefarious purposes, it is also important to remember that machine learning algorithms are not perfect. There is always the possibility that recordings could be misclassified or misinterpreted. As such, it is important to weigh the risks and benefits of using voice-activated assistants before making a decision about whether or not to use them.
 What are some jobs or professions that have become or will soon become obsolete due to technology, automation, and artificial intelligence? - What are some jobs or professions that have become or will soon become obsolete due to technology, automation, and artificial intelligence? Technology, automation, and artificial intelligence are changing the world as we know it. They are making some jobs obsolete and giving rise to new professions. For example, machine learning is automating many tasks that were previously done by human beings, such as data entry and analysis. As a result, many jobs that require these skills are disappearing. In their place, new jobs are being created for people who can code algorithms and train machine learning models. Similarly, artificial intelligence is changing the landscape of many professions. It is being used to automate tasks such as customer service, financial analysis, and even medical diagnosis. As a result, many jobs that have traditionally relied on human expertise are now being performed by machines. While this change can be disruptive, it also opens up new opportunities for people with the right skills.
What are some jobs or professions that have become or will soon become obsolete due to technology, automation, and artificial intelligence? - What are some jobs or professions that have become or will soon become obsolete due to technology, automation, and artificial intelligence? Technology, automation, and artificial intelligence are changing the world as we know it. They are making some jobs obsolete and giving rise to new professions. For example, machine learning is automating many tasks that were previously done by human beings, such as data entry and analysis. As a result, many jobs that require these skills are disappearing. In their place, new jobs are being created for people who can code algorithms and train machine learning models. Similarly, artificial intelligence is changing the landscape of many professions. It is being used to automate tasks such as customer service, financial analysis, and even medical diagnosis. As a result, many jobs that have traditionally relied on human expertise are now being performed by machines. While this change can be disruptive, it also opens up new opportunities for people with the right skills. - What are some good datasets for Data Science and Machine Learning? - What are some good datasets for Data Science and Machine Learning? A dataset is a collection of data, usually presented in tabular form. Good datasets for Data Science and Machine Learning are typically those that are well-structured (easy to read and understand) and large enough to provide enough data points to train a model. The best datasets are often those that are open and freely available - such as the popular Iris dataset. However, there are also many commercial datasets available for purchase. In general, good datasets for Data Science and Machine Learning should be:
- Well-structured
- Large enough to provide enough data points
- Open and freely available whenever possible
 What is the single most influential book every Programmers should read - What is the single most influential book every Programmers should read
As a programmer, you are constantly learning new technologies and skills. But what is the one book that you should read to help you become a better programmer? That's a tough question, but we're here to help. Keep reading to find out the most influential book for programmers.
What is the single most influential book every Programmers should read - What is the single most influential book every Programmers should read
As a programmer, you are constantly learning new technologies and skills. But what is the one book that you should read to help you become a better programmer? That's a tough question, but we're here to help. Keep reading to find out the most influential book for programmers. What are popular hobbies among Software Engineers? - What are popular hobbies among Software Engineers? Software engineers are a unique bunch. They're passionate about their work and love to spend their free time tinkering with code. But what are they like outside of work? What are some of their favorite hobbies? We took a look at some popular pastimes among software engineers and compiled a list for you. Check it out!
What are popular hobbies among Software Engineers? - What are popular hobbies among Software Engineers? Software engineers are a unique bunch. They're passionate about their work and love to spend their free time tinkering with code. But what are they like outside of work? What are some of their favorite hobbies? We took a look at some popular pastimes among software engineers and compiled a list for you. Check it out! Programming Languages used for Autopilot in Self Driving Cars like Tesla, Audi, BMW, Mercedes Benz, Volvo, Infiniti - What are Programming Languages used for Autopilot in Self Driving Cars like Tesla, Audi, BMW, Mercedes Benz, Volvo, Infiniti? Most self-driving cars on the market today use C programming language for their vehicle software. This is because C is a very robust and stable language that can be trusted for mission-critical applications. In addition, C is relatively easy to learn and has a wide range of features that make it well suited for automotive applications. However, there are some drawbacks to using C for self-driving cars. First, it is not a very concise language, so the code can be quite long and difficult to read. Second, C does not have built-in support for object-oriented programming, which is becoming increasingly important in the world of autonomous vehicles. As a result, many carmakers are starting to explore other languages for their autopilot systems, such as Java and Python.
Programming Languages used for Autopilot in Self Driving Cars like Tesla, Audi, BMW, Mercedes Benz, Volvo, Infiniti - What are Programming Languages used for Autopilot in Self Driving Cars like Tesla, Audi, BMW, Mercedes Benz, Volvo, Infiniti? Most self-driving cars on the market today use C programming language for their vehicle software. This is because C is a very robust and stable language that can be trusted for mission-critical applications. In addition, C is relatively easy to learn and has a wide range of features that make it well suited for automotive applications. However, there are some drawbacks to using C for self-driving cars. First, it is not a very concise language, so the code can be quite long and difficult to read. Second, C does not have built-in support for object-oriented programming, which is becoming increasingly important in the world of autonomous vehicles. As a result, many carmakers are starting to explore other languages for their autopilot systems, such as Java and Python. Google interview questions for various roles and How to Ace the Google Software Engineering Interview? - Google interview questions for various roles and How to Ace the Google Software Engineering Interview? Google is one of the most sought-after employers in the world, known for their cutting-edge technology and innovative products. If you're lucky enough to land an interview with Google, you can expect to be asked some challenging questions. Google is known for their brainteasers and algorithmic questions, so it's important to brush up on your coding skills before the interview. However, Google also values creativity and out-of-the-box thinking, so don't be afraid to think outside the box when answering questions. product managers need to be able to think strategically about Google's products, while software engineers will need to demonstrate their technical expertise. No matter what role you're interviewing for, remember to stay calm and confident, and you'll be sure to ace the Google interview.
Google interview questions for various roles and How to Ace the Google Software Engineering Interview? - Google interview questions for various roles and How to Ace the Google Software Engineering Interview? Google is one of the most sought-after employers in the world, known for their cutting-edge technology and innovative products. If you're lucky enough to land an interview with Google, you can expect to be asked some challenging questions. Google is known for their brainteasers and algorithmic questions, so it's important to brush up on your coding skills before the interview. However, Google also values creativity and out-of-the-box thinking, so don't be afraid to think outside the box when answering questions. product managers need to be able to think strategically about Google's products, while software engineers will need to demonstrate their technical expertise. No matter what role you're interviewing for, remember to stay calm and confident, and you'll be sure to ace the Google interview. What are the pros and cons of working as a software engineer for Google or Microsoft versus starting your own startup like Zoom or Uber or Airbnb did when they started out? - What are the pros and cons of working as a software engineer for Google or Microsoft versus starting your own startup like Zoom or Uber or Airbnb did when they started out? Google and Microsoft are two of the most well-known and successful companies in the tech industry. They are both known for their cutting-edge products and their strong work culture. There are also some major differences between working at Google or Microsoft versus starting your own startup. Google and Microsoft are both very large companies, with hundreds of thousands of employees. They are also both very well established, with years of experience in the tech industry. Startups, on the other hand, are much smaller and less established. This can be both good and bad.
What are the pros and cons of working as a software engineer for Google or Microsoft versus starting your own startup like Zoom or Uber or Airbnb did when they started out? - What are the pros and cons of working as a software engineer for Google or Microsoft versus starting your own startup like Zoom or Uber or Airbnb did when they started out? Google and Microsoft are two of the most well-known and successful companies in the tech industry. They are both known for their cutting-edge products and their strong work culture. There are also some major differences between working at Google or Microsoft versus starting your own startup. Google and Microsoft are both very large companies, with hundreds of thousands of employees. They are also both very well established, with years of experience in the tech industry. Startups, on the other hand, are much smaller and less established. This can be both good and bad. What is the Top Job in AI? Data Scientist or Machine Learning Engineer? - What is the Top Job in AI? Data Scientist or Machine Learning Engineer? A data scientist is someone who creates programming code and combines it with statistical knowledge to create insights from data. Machine learning (ML) is a field of inquiry devoted to understanding and building methods that 'learn', that is, methods that leverage data to improve performance on some set of tasks.
The top job in all of AI is the machine learning engineer and NOT the data scientist.
What is the Top Job in AI? Data Scientist or Machine Learning Engineer? - What is the Top Job in AI? Data Scientist or Machine Learning Engineer? A data scientist is someone who creates programming code and combines it with statistical knowledge to create insights from data. Machine learning (ML) is a field of inquiry devoted to understanding and building methods that 'learn', that is, methods that leverage data to improve performance on some set of tasks.
The top job in all of AI is the machine learning engineer and NOT the data scientist.  Will software engineers ever stop being in demand? - Will software engineers ever stop being in demand? A software engineer is a person who applies the principles of software engineering to design, develop, maintain, test, and evaluate computer software. The term programmer is sometimes used as a synonym, but may also lack connotations of engineering education or skills.
The question is "Will software engineers ever stop being in demand?" There are two schools of thought. Those with a background in business see developers as commodities and fully believe that programmers will program themselves out of a job field. The idea is that in some distant future, jobs like project manager, product manager, and marketing manager will still be critical but programmers themselves will be extinct as a result of the tools they created.
Will software engineers ever stop being in demand? - Will software engineers ever stop being in demand? A software engineer is a person who applies the principles of software engineering to design, develop, maintain, test, and evaluate computer software. The term programmer is sometimes used as a synonym, but may also lack connotations of engineering education or skills.
The question is "Will software engineers ever stop being in demand?" There are two schools of thought. Those with a background in business see developers as commodities and fully believe that programmers will program themselves out of a job field. The idea is that in some distant future, jobs like project manager, product manager, and marketing manager will still be critical but programmers themselves will be extinct as a result of the tools they created.  Requirements For Access to Electronics For Kids During Vacation - Requirements For Access to Electronics For Kids During Vacation We are living in a world where electronics are accessible easily and makes it very easy for our kids to get addicted to. It is important to create some boundaries to allow our kids to not get addicted to electronics and at the same time give them some access.
Requirements For Access to Electronics For Kids During Vacation - Requirements For Access to Electronics For Kids During Vacation We are living in a world where electronics are accessible easily and makes it very easy for our kids to get addicted to. It is important to create some boundaries to allow our kids to not get addicted to electronics and at the same time give them some access. Is it better economically to run a car into the ground before buying a new one? Data driven answer - Is it better economically to run a car into the ground before buying a new one? Data driven answer Is it better to drive your car into the ground before buying a new one? You might think that’s an odd question, but there’s some logic to it. We all know cars are expensive, and many people feel they have to buy a new one as soon as theirs starts to show its age. But is that really the best way to go? Let’s take a closer look at the numbers. The advice I’ve always had (and followed) is that you should always EITHER: Buy a new car - keep it for 3 years - then trade it for a new one….OR…
Buy a new car and keep it until it goes to the car crusher.
Is it better economically to run a car into the ground before buying a new one? Data driven answer - Is it better economically to run a car into the ground before buying a new one? Data driven answer Is it better to drive your car into the ground before buying a new one? You might think that’s an odd question, but there’s some logic to it. We all know cars are expensive, and many people feel they have to buy a new one as soon as theirs starts to show its age. But is that really the best way to go? Let’s take a closer look at the numbers. The advice I’ve always had (and followed) is that you should always EITHER: Buy a new car - keep it for 3 years - then trade it for a new one….OR…
Buy a new car and keep it until it goes to the car crusher.- Is it good useful meaningful worthwhile to use register variables in C++? - Is it good useful meaningful worthwhile to use register variables in C++? The register keyword has been largely ignored by compilers for decades. In C, it prevents you from taking the address of a variable. But otherwise, most compilers ignore the hint it offers.
 Techies and Geek Inspired Movies and TV Shows – Netflix Amazon Prime Video HBO YouTube TV - Techies and Geek Inspired Movies and TV Shows - Netflix Amazon Prime Video HBO YouTube TV If you're a movie buff or a geek, there's no doubt you love spending your free time watching films and TV shows that inspire your passions. And in the age of Netflix, Amazon Prime Video, and HBO, there's no shortage of inspiring content to watch. This blog post takes a look at some of the best geeky and tech-inspired movies and TV shows available on streaming services today. So whether you're a die-hard Star Wars fan or you can't get enough of Andy Griffith reruns, there's something for everyone in this roundup! As a software engineer who works long hours and go to kids activities after work, TV shows and movies help me relax after work.
This blog is an aggregate of trailers, questions and answers about of Geek inspired Movies and TV Shows.
Techies and Geek Inspired Movies and TV Shows – Netflix Amazon Prime Video HBO YouTube TV - Techies and Geek Inspired Movies and TV Shows - Netflix Amazon Prime Video HBO YouTube TV If you're a movie buff or a geek, there's no doubt you love spending your free time watching films and TV shows that inspire your passions. And in the age of Netflix, Amazon Prime Video, and HBO, there's no shortage of inspiring content to watch. This blog post takes a look at some of the best geeky and tech-inspired movies and TV shows available on streaming services today. So whether you're a die-hard Star Wars fan or you can't get enough of Andy Griffith reruns, there's something for everyone in this roundup! As a software engineer who works long hours and go to kids activities after work, TV shows and movies help me relax after work.
This blog is an aggregate of trailers, questions and answers about of Geek inspired Movies and TV Shows. - What are some coding anti-patterns that can easily slip through code reviews? - What are some coding anti-patterns that can easily slip through code reviews? Programmers are a notoriously irritable bunch. We're constantly getting in arguments with each other about the best way to do things. This is largely because there is no one "right" way to code - it's more of an art than a science. However, there are some coding practices that are universally agreed to be bad form. These are known as "coding anti-patterns," and they can easily slip through code reviews if you're not careful.
 Algorithm and Tricks to save up to 30 cents per litre on Gas in USA and Canada - Algorithm and Tricks to save up to 30 cents per litre on Gas in USA and Canada Gas is getting very expensive and we are trying to help consumers save on Gas by providing you daily tricks to help you savc up to 30 cents per litre on Gas in USA and Canada.
Algorithm and Tricks to save up to 30 cents per litre on Gas in USA and Canada - Algorithm and Tricks to save up to 30 cents per litre on Gas in USA and Canada Gas is getting very expensive and we are trying to help consumers save on Gas by providing you daily tricks to help you savc up to 30 cents per litre on Gas in USA and Canada.  What is the tech stack behind Google Search Engine? - What is the tech stack behind Google Search Engine? The technology stack that powers the Google Search Engine is immensely complex, and includes a number of sophisticated algorithms, technologies, and infrastructure components. At the heart of the system is the PageRank algorithm, which ranks pages based on a number of factors, including the number and quality of links to the page. The algorithm is constantly being refined and updated, in order to deliver more relevant and accurate results. In addition to the PageRank algorithm, Google also uses a number of other algorithms, including the Latent Semantic Indexing algorithm, which helps to index and retrieve documents based on their meaning. The search engine also makes use of a massive infrastructure, which includes hundreds of thousands of servers around the world.
What is the tech stack behind Google Search Engine? - What is the tech stack behind Google Search Engine? The technology stack that powers the Google Search Engine is immensely complex, and includes a number of sophisticated algorithms, technologies, and infrastructure components. At the heart of the system is the PageRank algorithm, which ranks pages based on a number of factors, including the number and quality of links to the page. The algorithm is constantly being refined and updated, in order to deliver more relevant and accurate results. In addition to the PageRank algorithm, Google also uses a number of other algorithms, including the Latent Semantic Indexing algorithm, which helps to index and retrieve documents based on their meaning. The search engine also makes use of a massive infrastructure, which includes hundreds of thousands of servers around the world.- Financial Independence and Legit Side Money Ideas For Techies and Geeks - Financial Independence and Legit Side Money Ideas For Techies and Geeks This blog is about Clever Questions, Answers, Posts, discussions, links about::
Financial Independence (FIRE),
NFTs,
options,
entrepreneurship,
legit side hustle,
money making ideas,
money making from home,
bier money,
make money from web scraping,
- CyberSecurity – What are some things that get a bad rap, but are actually quite secure? - CyberSecurity - What are some things that get a bad rap, but are actually quite secure?
1- PGP
2- Very long passwords that are actually a sentence
- Programming, Coding and Algorithms Questions and Answers - Programming, Coding and Algorithms Questions and Answers Coding is a complex process that requires precision and attention to detail. While there are many resources available to help learn programming, it is important to avoid making some common mistakes. One mistake is assuming that programming is easy and does not require any prior knowledge or experience. This can lead to frustration and discouragement when coding errors occur. Another mistake is trying to learn too much at once. Coding is a vast field with many different languages and concepts. It is important to focus on one area at a time and slowly build up skills. Finally, another mistake is not practicing regularly. Coding is like any other skill- it takes practice and repetition to improve. By avoiding these mistakes, students will be well on their way to becoming proficient programmers.

 As a web developer can you explain why React is needed? - As a web developer can you explain why React is needed?
The specific rationale for React is state management and efficient page updates, it’s underlying power comes not just from the structure and tooling provided by it being a framework, but also the shadow-DOM and component lifecycle that along with state management empower greater interactivity without very slow inefficient page updates.
As a web developer can you explain why React is needed? - As a web developer can you explain why React is needed?
The specific rationale for React is state management and efficient page updates, it’s underlying power comes not just from the structure and tooling provided by it being a framework, but also the shadow-DOM and component lifecycle that along with state management empower greater interactivity without very slow inefficient page updates.- Why can’t a macOs be installed in a Windows computer? - Why can't a macOs be installed in a Windows computer?
that to happen.
Not because they want to extract more money from hardware sales (Apple hardware is actually cheap for the quality you get anyway), not because they wouldn’t sell OS X as a product if they could.
 How does a database handle pagination? - How does a database handle pagination?
Some database languages provide helpful facilities that aide in implementing pagination. For example, many SQL dialects provide LIMIT and OFFSET clauses that can be used to emit up to n rows starting at a given row number. I.e., a “page” of rows. If the query results are sorted via ORDER BY and are generally unchanged between successive invocations, then that can be used to implement pagination.
How does a database handle pagination? - How does a database handle pagination?
Some database languages provide helpful facilities that aide in implementing pagination. For example, many SQL dialects provide LIMIT and OFFSET clauses that can be used to emit up to n rows starting at a given row number. I.e., a “page” of rows. If the query results are sorted via ORDER BY and are generally unchanged between successive invocations, then that can be used to implement pagination.
 How many spaces is a tab in Java, Rust, C++, Python, C#, Powershell, Golang, Javascript - How many spaces is a tab in Java, Rust, C++, Python, C#, Powershell, Golang, Javascript. A tab is not made out of spaces. It is a tab, whether in Java, Python, Rust, or generic text file editing. It is represented by a single Unicode character, U+0009.
How many spaces is a tab in Java, Rust, C++, Python, C#, Powershell, Golang, Javascript - How many spaces is a tab in Java, Rust, C++, Python, C#, Powershell, Golang, Javascript. A tab is not made out of spaces. It is a tab, whether in Java, Python, Rust, or generic text file editing. It is represented by a single Unicode character, U+0009. Tech Jobs and Career at FAANG (now MAANGM): Facebook Meta Amazon Apple Netflix Google Microsoft - Tech Jobs and Career at FAANG (now MAANGM): Facebook Meta Amazon Apple Netflix Google Microsoft. The FAANG companies (Facebook, Amazon, Apple, Netflix, Google, and Microsoft) are some of the most sought-after employers in the tech industry. They offer competitive salaries and benefits, and their employees are at the forefront of innovation. This blog is about Clever Questions, Answers, Resources, Feeds, Discussions about Tech jobs and careers at MAANGM companies including: Amazon
AWS
Netflix
Google (Alphabet)
Microsoft
Tech Jobs and Career at FAANG (now MAANGM): Facebook Meta Amazon Apple Netflix Google Microsoft - Tech Jobs and Career at FAANG (now MAANGM): Facebook Meta Amazon Apple Netflix Google Microsoft. The FAANG companies (Facebook, Amazon, Apple, Netflix, Google, and Microsoft) are some of the most sought-after employers in the tech industry. They offer competitive salaries and benefits, and their employees are at the forefront of innovation. This blog is about Clever Questions, Answers, Resources, Feeds, Discussions about Tech jobs and careers at MAANGM companies including: Amazon
AWS
Netflix
Google (Alphabet)
Microsoft AWS Azure Google Cloud Certifications Testimonials and Dumps - AWS Azure Google Cloud Certifications Testimonials and Dumps
Do you want to become a Professional DevOps Engineer, a cloud Solutions Architect, a Cloud Engineer or a modern Developer or IT Professional, a versatile Product Manager, a hip Project Manager? Therefore Cloud skills and certifications can be just the thing you need to make the move into cloud or to level up and advance your career.
AWS Azure Google Cloud Certifications Testimonials and Dumps - AWS Azure Google Cloud Certifications Testimonials and Dumps
Do you want to become a Professional DevOps Engineer, a cloud Solutions Architect, a Cloud Engineer or a modern Developer or IT Professional, a versatile Product Manager, a hip Project Manager? Therefore Cloud skills and certifications can be just the thing you need to make the move into cloud or to level up and advance your career.  Food For Thought – Top 100 Delicious Homemade Cuisine From All over the World - Food For Thought - Top 100 Delicious Homemade Cuisine From All over the World
Who doesn't remember their favourite food from home when they were growing up? That delicious taste stays with us forever. We can move all over the World, but the thought of our favourite home-cooked meals always make us happy.
Food For Thought – Top 100 Delicious Homemade Cuisine From All over the World - Food For Thought - Top 100 Delicious Homemade Cuisine From All over the World
Who doesn't remember their favourite food from home when they were growing up? That delicious taste stays with us forever. We can move all over the World, but the thought of our favourite home-cooked meals always make us happy. Breaking News – Top Stories - Breaking News - Top Stories, Google Trends, updated hourly Breaking News - Top Stories From all over the world. World News. Hourly Updated News Feed from Reddit, Twitter, Medium, Quora and top news agency and media around the world (CNN, Fox News, USA Today, MSNBC, ABC News, Al Jazeera, CBC, BBC, SkyNews, etc.).
Breaking News – Top Stories - Breaking News - Top Stories, Google Trends, updated hourly Breaking News - Top Stories From all over the world. World News. Hourly Updated News Feed from Reddit, Twitter, Medium, Quora and top news agency and media around the world (CNN, Fox News, USA Today, MSNBC, ABC News, Al Jazeera, CBC, BBC, SkyNews, etc.). Facebook, Instagram, Apple and Google Apps Search Ads Secrets – Make Money From Your Products - Apple and Google Apps Search Ads Secrets There are billions of Apps out there and it is becoming harder and harder to stand out. You don't want to spend countless of hours developing your dream app just to have less than 10 downloads per month.
This blog is an aggregate of the best secrets of Apple and Google Apps search ads for successful App developers.
Facebook, Instagram, Apple and Google Apps Search Ads Secrets – Make Money From Your Products - Apple and Google Apps Search Ads Secrets There are billions of Apps out there and it is becoming harder and harder to stand out. You don't want to spend countless of hours developing your dream app just to have less than 10 downloads per month.
This blog is an aggregate of the best secrets of Apple and Google Apps search ads for successful App developers. Azure Solutions Architect Expert Certification Questions And Answers Dumps - Azure Solutions Architect Expert Certification Questions And Answers Dumps This exam measures your ability to accomplish the following technical tasks: design identity, governance, and monitoring solutions; design data storage solutions; design business continuity solutions; and design infrastructure solutions. Top 50 Azure Solutions Architect Expert Certification Questions And Answers Dumps
Azure Solutions Architect Expert Certification Questions And Answers Dumps - Azure Solutions Architect Expert Certification Questions And Answers Dumps This exam measures your ability to accomplish the following technical tasks: design identity, governance, and monitoring solutions; design data storage solutions; design business continuity solutions; and design infrastructure solutions. Top 50 Azure Solutions Architect Expert Certification Questions And Answers Dumps Top 100 Data Science and Data Analytics and Data Engineering Interview Questions and Answers - Top 100 Data Science and Data Analytics and Data Engineering Interview Questions and Answers Data Science is a blend of various tools, algorithms, and machine learning principles with the goal to discover hidden patterns from the raw data. How is this different from what statisticians have been doing for years? The answer lies in the difference between explaining and predicting: statisticians work a posteriori, explaining the results and designing a plan; data scientists use historical data to make predictions.
Top 100 Data Science and Data Analytics and Data Engineering Interview Questions and Answers - Top 100 Data Science and Data Analytics and Data Engineering Interview Questions and Answers Data Science is a blend of various tools, algorithms, and machine learning principles with the goal to discover hidden patterns from the raw data. How is this different from what statisticians have been doing for years? The answer lies in the difference between explaining and predicting: statisticians work a posteriori, explaining the results and designing a plan; data scientists use historical data to make predictions. Machine Learning Engineer Interview Questions and Answers - Machine Learning Engineer Interview Questions and Answers:
Machine learning is the study of computer algorithms that improve automatically through experience. It is seen as a subset of artificial intelligence. Machine Learning explores the study and construction of algorithms that can learn from and make predictions on data. You select a model to train and then manually perform feature extraction. Used to devise complex models and algorithms that lend themselves to a prediction which in commercial use is known as predictive analytics.
Machine Learning Engineer Interview Questions and Answers - Machine Learning Engineer Interview Questions and Answers:
Machine learning is the study of computer algorithms that improve automatically through experience. It is seen as a subset of artificial intelligence. Machine Learning explores the study and construction of algorithms that can learn from and make predictions on data. You select a model to train and then manually perform feature extraction. Used to devise complex models and algorithms that lend themselves to a prediction which in commercial use is known as predictive analytics. DevOps Interviews Question and Answers and Scripts - DevOps Interviews Question and Answers and Scripts. Below are several dozens DevOps Interviews Question and Answers and Scripts to help you get into the top Corporations in the world including FAANGM (Facebook, Apple, Amazon, Netflix, Google and Microsoft).
DevOps Interviews Question and Answers and Scripts - DevOps Interviews Question and Answers and Scripts. Below are several dozens DevOps Interviews Question and Answers and Scripts to help you get into the top Corporations in the world including FAANGM (Facebook, Apple, Amazon, Netflix, Google and Microsoft). What are the top 10 Commandments of Options Trading Strategies - 10 Commandments of Options Trading Strategies Option strategies are the simultaneous, and often mixed, buying or selling of one or more options that differ in one or more of the options' variables. Call options, simply known as calls, give the buyer a right to buy a particular stock at that option's strike price. Conversely, put options, simply known as puts, give the buyer the right to sell a particular stock at the option's strike price. This is often done to gain exposure to a specific type of opportunity or risk while eliminating other risks as part of a trading strategy. A very straightforward strategy might simply be the buying or selling of a single option; however, option strategies often refer to a combination of simultaneous buying and or selling of options.
What are the top 10 Commandments of Options Trading Strategies - 10 Commandments of Options Trading Strategies Option strategies are the simultaneous, and often mixed, buying or selling of one or more options that differ in one or more of the options' variables. Call options, simply known as calls, give the buyer a right to buy a particular stock at that option's strike price. Conversely, put options, simply known as puts, give the buyer the right to sell a particular stock at the option's strike price. This is often done to gain exposure to a specific type of opportunity or risk while eliminating other risks as part of a trading strategy. A very straightforward strategy might simply be the buying or selling of a single option; however, option strategies often refer to a combination of simultaneous buying and or selling of options. How crypto could change the world and Why Cryptocurrency was invented in the first place. - How crypto could change the world and Why Cryptocurrency was invented in the first place. People used to pay each other in gold and silver. Difficult to transport. Difficult to divide. Paper money was invented. A claim to gold in a bank vault. Easier to transport and divide. Banks gave out more paper money than they had gold in the vault. They ran “fractional reserves”. A real money maker. But every now and then, banks collapsed because of runs on the bank.
How crypto could change the world and Why Cryptocurrency was invented in the first place. - How crypto could change the world and Why Cryptocurrency was invented in the first place. People used to pay each other in gold and silver. Difficult to transport. Difficult to divide. Paper money was invented. A claim to gold in a bank vault. Easier to transport and divide. Banks gave out more paper money than they had gold in the vault. They ran “fractional reserves”. A real money maker. But every now and then, banks collapsed because of runs on the bank. - Data Sciences – Top 400 Open Datasets – Data Visualization – Data Analytics – Big Data – Data Lakes - Data Sciences - Top 400 Open Datasets - Data Visualization - Data Analytics - Big Data - Data Lakes Data science is an interdisciplinary field that uses scientific methods, processes, algorithms and systems to extract knowledge and insights from structured and unstructured data, and apply knowledge and actionable insights from data across a broad range of application domains.
In this blog, we are going to provide popular open source data sets, data visualization, data analytics and data lakes.
 Djamgatech: Multilingual and Platform Independent Cloud Certification and Education App for AWS, Azure, Google Cloud - Djamgatech: Multilingual and Platform Independent Cloud Certification and Education App for AWS, Azure, Google Cloud. Djamgatech is the ultimate Cloud Education Certification App. It is an EduFlix App for AWS, Azure, Google Cloud Certification Prep, School Subjects, Python, Math, SAT, etc.
Djamgatech: Multilingual and Platform Independent Cloud Certification and Education App for AWS, Azure, Google Cloud - Djamgatech: Multilingual and Platform Independent Cloud Certification and Education App for AWS, Azure, Google Cloud. Djamgatech is the ultimate Cloud Education Certification App. It is an EduFlix App for AWS, Azure, Google Cloud Certification Prep, School Subjects, Python, Math, SAT, etc. 
 Jobs, Career, Salary, Total Compensation, Interview Tips at FAANGM: Facebook, Apple, Amazon, Netflix, Google, Microsoft - Jobs, Career, Salary, Total Compensation, Interview Tips at FAANGM: Facebook, Apple, Amazon, Netflix, Google, Microsoft. This blog is about Clever Questions, Answers, Resources, Links, Discussions, Tips about jobs and careers at FAANGM companies: Facebook, Apple, Amazon, AWS, Netflix, Google, Microsoft, Linkedin.
Jobs, Career, Salary, Total Compensation, Interview Tips at FAANGM: Facebook, Apple, Amazon, Netflix, Google, Microsoft - Jobs, Career, Salary, Total Compensation, Interview Tips at FAANGM: Facebook, Apple, Amazon, Netflix, Google, Microsoft. This blog is about Clever Questions, Answers, Resources, Links, Discussions, Tips about jobs and careers at FAANGM companies: Facebook, Apple, Amazon, AWS, Netflix, Google, Microsoft, Linkedin. Electric Cars – Autonomous Cars – Self driving cars : Tesla, CyberTruck, EV, Volt, Wayne, Nissan Leaf, Electric Bikes, e-bikes, i-cars, smart cars - Electric Cars - Autonomous Cars - Self driving cars BNEF outlines that electric vehicles (EVs) will hit 10% of global passenger vehicle sales in 2025, with that number rising to 28% in 2030 and 58% in 2040. According to the study, EVs currently make up 3% of global car sales.
Electric Cars – Autonomous Cars – Self driving cars : Tesla, CyberTruck, EV, Volt, Wayne, Nissan Leaf, Electric Bikes, e-bikes, i-cars, smart cars - Electric Cars - Autonomous Cars - Self driving cars BNEF outlines that electric vehicles (EVs) will hit 10% of global passenger vehicle sales in 2025, with that number rising to 28% in 2030 and 58% in 2040. According to the study, EVs currently make up 3% of global car sales. Microsoft Azure Administrator Certification Questions and Answers Dumps – AZ 104 - Microsoft Azure Administrator Certification Questions and Answers Dumps - AZ 104 Microsoft Azure Administrator AZ 104 is one of the most popular Microsoft Azure Administrator certification exams. To pass this exam, you need to have a good understanding of Microsoft Azure and its various components. The best way to prepare for this exam is to use this Microsoft AZ 104 dumps. These dumps will help you to understand the Microsoft Azure platform and its various features. In addition, you will also get an idea about the types of questions that are asked in this exam. With the help of these dumps, you can easily pass the Microsoft AZ 104 exam. Below are the top 100 Microsoft Azure Administrator Certification Questions and Answers Dumps
Microsoft Azure Administrator Certification Questions and Answers Dumps – AZ 104 - Microsoft Azure Administrator Certification Questions and Answers Dumps - AZ 104 Microsoft Azure Administrator AZ 104 is one of the most popular Microsoft Azure Administrator certification exams. To pass this exam, you need to have a good understanding of Microsoft Azure and its various components. The best way to prepare for this exam is to use this Microsoft AZ 104 dumps. These dumps will help you to understand the Microsoft Azure platform and its various features. In addition, you will also get an idea about the types of questions that are asked in this exam. With the help of these dumps, you can easily pass the Microsoft AZ 104 exam. Below are the top 100 Microsoft Azure Administrator Certification Questions and Answers Dumps Videoconferencing Tools: Zoom vs Microsoft Teams vs Google Meet vs GoToMeeting vs WebEx vs Slack – making the right choice - Videoconferencing Tools: Zoom vs Microsoft Teams vs Google Meet vs GoToMeeting vs WebEx vs Slack - making the right choice
Videoconferencing Tools: Zoom vs Microsoft Teams vs Google Meet vs GoToMeeting vs WebEx vs Slack – making the right choice - Videoconferencing Tools: Zoom vs Microsoft Teams vs Google Meet vs GoToMeeting vs WebEx vs Slack - making the right choice Top 50 Google Certified Cloud Professional Architect Exam Questions and Answers Dumps - Top 50 Google Certified Cloud Professional Architect Exam Questions and Answers Dumps. GCP, or the Google Cloud Platform, is a cloud-computing platform that provides users with access to a variety of GCP services. The GCP exam is designed to test a candidate's ability to design, implement, and manage GCP solutions. The GCP questions cover a wide range of topics, from basic GCP concepts to advanced GCP features. To become a GCP Certified Professional, you must pass the GCP exam. However, before you can take the exam, you must first complete the GCP Quiz. The GCP Quiz is designed to help you prepare for the GCP exam by testing your knowledge of GCP concepts. After you complete the GCP Quiz, you will be able to access the GCP Practice Exam. The GCP Practice Exam is an online exam that allows you to test your knowledge of GCP concepts. After you pass the GCP Practice Exam, you will be eligible to take the GCP exam.
Top 50 Google Certified Cloud Professional Architect Exam Questions and Answers Dumps - Top 50 Google Certified Cloud Professional Architect Exam Questions and Answers Dumps. GCP, or the Google Cloud Platform, is a cloud-computing platform that provides users with access to a variety of GCP services. The GCP exam is designed to test a candidate's ability to design, implement, and manage GCP solutions. The GCP questions cover a wide range of topics, from basic GCP concepts to advanced GCP features. To become a GCP Certified Professional, you must pass the GCP exam. However, before you can take the exam, you must first complete the GCP Quiz. The GCP Quiz is designed to help you prepare for the GCP exam by testing your knowledge of GCP concepts. After you complete the GCP Quiz, you will be able to access the GCP Practice Exam. The GCP Practice Exam is an online exam that allows you to test your knowledge of GCP concepts. After you pass the GCP Practice Exam, you will be eligible to take the GCP exam.  List of the most commonly recurring words in Video Game Titles – Mobile Game Name Generator - List of the most commonly recurring words in Video Game Titles - Mobile Game Name Generator /u/BDMayhem analyzed 4000 "hardcore" mobile games for Android, and made a list of the most commonly recurring words in the Game Titles.
List of the most commonly recurring words in Video Game Titles – Mobile Game Name Generator - List of the most commonly recurring words in Video Game Titles - Mobile Game Name Generator /u/BDMayhem analyzed 4000 "hardcore" mobile games for Android, and made a list of the most commonly recurring words in the Game Titles. Google Cloud 101 – Google Associate Cloud Engineer Exam Preparation: Questions and Answers Dumps - Google Associate Cloud Engineer Exam Preparation: Questions and Answers Dumps This blog includes the top 40 Google Associate Cloud Engineer exam preparation questions and answers dumps, google cloud questions and answers around the web, google cloud latest news, Google Cloud Developer Cheat Sheet, All Google Cloud Services in 4 words or less
Google Cloud 101 – Google Associate Cloud Engineer Exam Preparation: Questions and Answers Dumps - Google Associate Cloud Engineer Exam Preparation: Questions and Answers Dumps This blog includes the top 40 Google Associate Cloud Engineer exam preparation questions and answers dumps, google cloud questions and answers around the web, google cloud latest news, Google Cloud Developer Cheat Sheet, All Google Cloud Services in 4 words or less AZ-900: Microsoft Azure Fundamentals – Top 100 Questions and Answers Dumps - AZ-900: Microsoft Azure Fundamentals - Top 100 Questions and Answers Dumps Azure Fundamentals exam is an opportunity to prove knowledge of cloud concepts (20%), Azure services (20%), Azure workloads, security and privacy in Azure (30%), as well as Azure pricing and support (25%). This blog also includes Azure Services Cheat Sheet.
The exam is intended for candidates who are just beginning to work with cloud-based solutions and services or are new to Azure.
Candidates should be familiar with the general technology concepts, including concepts of
networking, storage, compute, application support, and application development.
Azure Fundamentals can be used to prepare for other Azure role-based or specialty
certifications, but it is not a prerequisite for any of them.
AZ-900: Microsoft Azure Fundamentals – Top 100 Questions and Answers Dumps - AZ-900: Microsoft Azure Fundamentals - Top 100 Questions and Answers Dumps Azure Fundamentals exam is an opportunity to prove knowledge of cloud concepts (20%), Azure services (20%), Azure workloads, security and privacy in Azure (30%), as well as Azure pricing and support (25%). This blog also includes Azure Services Cheat Sheet.
The exam is intended for candidates who are just beginning to work with cloud-based solutions and services or are new to Azure.
Candidates should be familiar with the general technology concepts, including concepts of
networking, storage, compute, application support, and application development.
Azure Fundamentals can be used to prepare for other Azure role-based or specialty
certifications, but it is not a prerequisite for any of them. How to Make Money From Web Scraping? The Top 20 Tips - How to Make Money From Web Scraping? Web scraping can be a very useful skill to learn for anyone looking to start or further their career in data. Web scraping is the process of extracting data from websites, and it can be used to collect everything from images to contact information. While it may sound complicated, web scraping is actually quite simple once you get the hang of it. And best of all, it's a skill that can be used to make money. There are a number of ways to make money from web scraping. One popular way is to use web scraping for sport arbitrage. Sport arbitrage is the practice of betting on two different outcomes of the same event in order to profit from the difference in odds. Web scrapers can be used to quickly and easily find arbitrage opportunities by comparing the odds of different bookmakers.
How to Make Money From Web Scraping? The Top 20 Tips - How to Make Money From Web Scraping? Web scraping can be a very useful skill to learn for anyone looking to start or further their career in data. Web scraping is the process of extracting data from websites, and it can be used to collect everything from images to contact information. While it may sound complicated, web scraping is actually quite simple once you get the hang of it. And best of all, it's a skill that can be used to make money. There are a number of ways to make money from web scraping. One popular way is to use web scraping for sport arbitrage. Sport arbitrage is the practice of betting on two different outcomes of the same event in order to profit from the difference in odds. Web scrapers can be used to quickly and easily find arbitrage opportunities by comparing the odds of different bookmakers. Machine Learning 101 – Top 200 AWS and Google Certified Machine Learning Specialty Questions and Answers Dumps - Top 200 AWS and Google Certified Machine Learning Specialty Questions and Answers Dumps This blog is the best way is the best way to prepare for your upcoming AWS Certified Machine Learning Specialty and Google Certified Professional Machine Learning Engineer exam. With over 100 questions and answers, this blog provides quizzes similar that are very similar to the real exam. It also includes the option to show and hide answers. Additionally, there are machine learning interview questions and detailed answers, as well as cheat sheets and illustrations. This blog is the best way to make sure you are well-prepared for your AWS Certified Machine Learning Specialty Exam.
Machine Learning 101 – Top 200 AWS and Google Certified Machine Learning Specialty Questions and Answers Dumps - Top 200 AWS and Google Certified Machine Learning Specialty Questions and Answers Dumps This blog is the best way is the best way to prepare for your upcoming AWS Certified Machine Learning Specialty and Google Certified Professional Machine Learning Engineer exam. With over 100 questions and answers, this blog provides quizzes similar that are very similar to the real exam. It also includes the option to show and hide answers. Additionally, there are machine learning interview questions and detailed answers, as well as cheat sheets and illustrations. This blog is the best way to make sure you are well-prepared for your AWS Certified Machine Learning Specialty Exam. - Laptop 101 – Pick a laptop for me – MacOS or Windows or Chrome – Apple MacBook or Google ChromeBook or Microsoft Surface or Dell or HP or Lenovo - Laptop 101 - Pick a laptop for me - MacOS or Windows or Chrome - Apple MacBook or Google ChromeBook or Microsoft Surface or Dell or Hp or Lenovo
- What is trending today – What are people searching today? - What is trending today - What are people searching today? 3.5 billion Google searches are made every day and 1.2 trillion searches per year worldwide.
Google Search is one of the most popular ways people use the internet. Not only is it a great way to find information, but it's also a great way to stay up-to-date on current trends. Google Search statistics show that there are billions of Google Searches conducted every single day. These searches cover a wide range of topics, from general interest to specific niche interests. And, thanks to Google's algorithms, these searches can be customized to provide the most relevant results for each individual user. This customization means that people can find exactly what they're looking for, whether it's the latest news on a trending topic or more information on a specific subject. Google Search is an essential tool for anyone who wants to stay up-to-date on current trends.
- Smartphone 101 – Pick a smartphone for me – android or iOS – Apple iPhone or Samsung Galaxy or Huawei or Xaomi or Google Pixel - Smartphone 101 - Pick a smartphone for me. When it comes to choosing a smartphone, there are a few things you need to take into account. First, what operating system do you prefer? Android or iOS? Then, what brand do you prefer? Apple, Samsung, Huawei, Xiaomi, or Google? Finally, what model of phone do you like best? The iPhone 14 Pro Max, the Galaxy S23 Plus, the Huawei Mate 50 Pro, the Xiaomi Mi 13 Pro 5G, or the Google Pixel 7 Pro?
- Loans Debts Mortgages Finances Calculators – Unit and Currency Converters - Loans Debts Mortgages Finances Calculators - Unit and Currency Converters At some stage, we all need or want more money than we have. Funding a new set of wheels is the number one reason to take out a personal loan. Perhaps unsurprisingly, men are more likely than women to take out a personal loan. According to our survey, 69.05% of men said they’ve taken out a loan compared to 62.09% of women.what to expect when taking out a loan? what is the total cost of a loan? Use these calculators below to find out.
 CyberSecurity 101 and Top 25 AWS Certified Security Specialty Questions and Answers Dumps - CyberSecurity 101 and Top 25 AWS Certified Security Specialty Questions and Answers Dumps Top 100 AWS Certified Specialty Exam Practice Quiz including Questions and Answers and References.
Almost 4.57 billion people were active internet users as of July 2020, encompassing 59 percent of the global population. 94% of enterprises use cloud. 77% of organizations worldwide have at least one application running on the cloud. This results in an exponential growth of cyber attacks. Therefore, CyberSecurity is one the biggest challenge to individuals and organizations worldwide: 158,727 cyber attacks per hour, 2,645 per minute and 44 every second of every day.
CyberSecurity 101 and Top 25 AWS Certified Security Specialty Questions and Answers Dumps - CyberSecurity 101 and Top 25 AWS Certified Security Specialty Questions and Answers Dumps Top 100 AWS Certified Specialty Exam Practice Quiz including Questions and Answers and References.
Almost 4.57 billion people were active internet users as of July 2020, encompassing 59 percent of the global population. 94% of enterprises use cloud. 77% of organizations worldwide have at least one application running on the cloud. This results in an exponential growth of cyber attacks. Therefore, CyberSecurity is one the biggest challenge to individuals and organizations worldwide: 158,727 cyber attacks per hour, 2,645 per minute and 44 every second of every day. - Big Data and Data Analytics 101 – Top 100 AWS Certified Data Analytics Specialty Certification Questions and Answers Dumps - Top 100 AWS Certified Data Analytics Specialty Certification Questions and Answers Dumps. If you're looking to take your data analytics career to the next level, then this AWS Data Analytics Specialty Certification Exam Preparation blog is a must-read! With over 100 exam questions and answers, plus data science and data analytics interview questions, cheat sheets and more, you'll be fully prepared to ace the DAS-C01 exam. If you're looking to take your data analytics career to the next level, then this AWS Data Analytics Specialty Certification Exam Preparation blog is a must-read! With over 100 exam questions and answers, plus data science and data analytics interview questions, cheat sheets and more, you'll be fully prepared to ace the DAS-C01 exam.
 Networking 101 and Top 20 AWS Certified Advanced Networking Specialty Questions and Answers Dumps - Networking 101 and Top 20 AWS Certified Advanced Networking Specialty Questions and Answers Dumps. The AWS Certified Advanced Networking – Specialty (ANS-C00) examination is intended for individuals who perform complex networking tasks. This examination validates advanced technical skills and experience in designing and implementing AWS and hybrid IT network architectures at scale. The AWS Certified Advanced Networking – Specialty (ANS-C00) examination is intended for individuals who perform complex networking tasks. This examination validates advanced technical skills and experience in designing and implementing AWS and hybrid IT network architectures at scale.
Networking 101 and Top 20 AWS Certified Advanced Networking Specialty Questions and Answers Dumps - Networking 101 and Top 20 AWS Certified Advanced Networking Specialty Questions and Answers Dumps. The AWS Certified Advanced Networking – Specialty (ANS-C00) examination is intended for individuals who perform complex networking tasks. This examination validates advanced technical skills and experience in designing and implementing AWS and hybrid IT network architectures at scale. The AWS Certified Advanced Networking – Specialty (ANS-C00) examination is intended for individuals who perform complex networking tasks. This examination validates advanced technical skills and experience in designing and implementing AWS and hybrid IT network architectures at scale.- Top 20 AWS Certified Associate SysOps Administrator Practice Quiz – Questions and Answers Dumps - Top 20 AWS Certified Associate SysOps Administrator Practice Quiz - Questions and Answers Dumps The AWS Certified SysOps Administrator - Associate (SOA-C01) examination is intended for individuals who have technical expertise in deployment, management, and operations on AWS.
 RPA: How to reset Blue Prism admin password - RPA: How to reset Blue Prism admin password To reset the Blue Prism admin password, you will need to access the Blue Prism database and update the password for the admin account. Here are the general steps you can follow: Stop the Blue Prism service.
Open SQL Server Management Studio and connect to the Blue Prism database.
Run the following SQL query to update the password for the admin account:
Copy code
UPDATE [dbo].[User]
SET Password = 'newpassword'
WHERE UserName = 'admin'
Replace 'newpassword' with the desired new password.
Start the Blue Prism service.
Log in to the Blue Prism application using the new admin password.
Please note that the above steps are just general guidelines, and the exact steps may vary depending on your specific Blue Prism installation. It is always recommended to take a backup of the database before making any changes.
RPA: How to reset Blue Prism admin password - RPA: How to reset Blue Prism admin password To reset the Blue Prism admin password, you will need to access the Blue Prism database and update the password for the admin account. Here are the general steps you can follow: Stop the Blue Prism service.
Open SQL Server Management Studio and connect to the Blue Prism database.
Run the following SQL query to update the password for the admin account:
Copy code
UPDATE [dbo].[User]
SET Password = 'newpassword'
WHERE UserName = 'admin'
Replace 'newpassword' with the desired new password.
Start the Blue Prism service.
Log in to the Blue Prism application using the new admin password.
Please note that the above steps are just general guidelines, and the exact steps may vary depending on your specific Blue Prism installation. It is always recommended to take a backup of the database before making any changes. Top 30 AWS Certified Developer Associate Exam Tips - Top 30 AWS Certified Developer Associate Exam Tips:
Understand some basic code samples such as JSON code, config files, and IAM policy documents. LAMBDA [10-15% of Exam]Invocation types, Using notifications and event source mappings, Concurrency and throttling, X-Ray and Amazon SQS DLQs, Versions and aliases, Blue/green deployment, Packaging and deployment, VPC connections (with Internet/NAT GW), Lambda as ELB target, Dependencies, Environment variables (inc. encrypting them)
etc.
Top 30 AWS Certified Developer Associate Exam Tips - Top 30 AWS Certified Developer Associate Exam Tips:
Understand some basic code samples such as JSON code, config files, and IAM policy documents. LAMBDA [10-15% of Exam]Invocation types, Using notifications and event source mappings, Concurrency and throttling, X-Ray and Amazon SQS DLQs, Versions and aliases, Blue/green deployment, Packaging and deployment, VPC connections (with Internet/NAT GW), Lambda as ELB target, Dependencies, Environment variables (inc. encrypting them)
etc.  Top 60 AWS Solution Architect Associate Exam Tips - Top 60 AWS Solution Architect Associate Exam Tips Study material by Adrian Cantrill ($40) or Joyjeet Banerjee ($50)
PRO Quiz and Practice Exams by Djamgatech ($9.99) [iOS - Android]
Quiz and Practice Exams by Djamgatech [Web - android - iOS - windows] (FREE or $5)
Practice tests by Tutorial Dojo ($15)
AWS labs and practices at AWS Qwiklabs ($25-50)
Extra: $30 for Marek's course on Udemy
Top 60 AWS Solution Architect Associate Exam Tips - Top 60 AWS Solution Architect Associate Exam Tips Study material by Adrian Cantrill ($40) or Joyjeet Banerjee ($50)
PRO Quiz and Practice Exams by Djamgatech ($9.99) [iOS - Android]
Quiz and Practice Exams by Djamgatech [Web - android - iOS - windows] (FREE or $5)
Practice tests by Tutorial Dojo ($15)
AWS labs and practices at AWS Qwiklabs ($25-50)
Extra: $30 for Marek's course on Udemy  AWS certification exam quiz apps for all platforms - AWS certification exam quiz apps for all platforms. AWS (Amazon Web Services) is a popular cloud computing platform that offers a range of services including computing, storage, networking, and more. AWS offers a variety of certification exams to validate the skills and knowledge of professionals who work with its technologies. These certification exams are designed to test a wide range of knowledge and skills, including technical expertise, problem-solving abilities, and understanding of AWS services. To prepare for an AWS certification exam, you may consider using a variety of resources including training courses, practice exams, and quiz apps. These resources can help you become familiar with the exam format, the types of questions that may be asked, and the knowledge and skills that will be tested.
AWS certification exam quiz apps for all platforms - AWS certification exam quiz apps for all platforms. AWS (Amazon Web Services) is a popular cloud computing platform that offers a range of services including computing, storage, networking, and more. AWS offers a variety of certification exams to validate the skills and knowledge of professionals who work with its technologies. These certification exams are designed to test a wide range of knowledge and skills, including technical expertise, problem-solving abilities, and understanding of AWS services. To prepare for an AWS certification exam, you may consider using a variety of resources including training courses, practice exams, and quiz apps. These resources can help you become familiar with the exam format, the types of questions that may be asked, and the knowledge and skills that will be tested.- What are some common reasons why a blog doesn’t rank on Google? - What are some common reasons why a blog doesn't rank on Google? Any content destined to the public that doesn't rank on Google or Bing is destined to be obscure and gets no visibility. Writing any blog post or article is not enough to be ranked on Google or Bing, the top 2 search engines in the world. There are several common reasons why a blog might not rank well on Google: Lack of high-quality content: Google values high-quality, informative, and original content. If your blog lacks these qualities, it may struggle to rank well on Google.
Poor website design and user experience: Google values websites that are easy to navigate and provide a good user experience. If your blog has a cluttered or poorly designed layout, or if it is difficult to use, it may struggle to rank well on Google.
Lack of backlinks: Google uses backlinks, or links from other websites to your blog, as a signal of the quality and relevance of your content. If your blog lacks backlinks, it may struggle to rank well on Google.
- What are some financial software products that do not require you to store data in the cloud? - What are some financial software products that do not require you to store data in the cloud? There are several financial software products that do not require you to store data in the cloud, including: Quicken: a personal finance management software that allows users to manage their finances on their own computer.
Microsoft Money: a personal finance management software that was discontinued in 2010, but is still available for download and can be used on a user's own computer.
GnuCash: a free and open-source personal and small-business financial-accounting software.
Moneydance: a personal finance management software for Windows, Mac and Linux that stores data locally.
AceMoney: a personal finance software for Windows and Mac that stores data locally.
It's worth noting that some of the software above may have a mobile or web version that sync with the desktop version but still, the data is stored on the local device.
- What are the corresponding Azure and Google Cloud services for each of the AWS services? - What are the corresponding Azure and Google Cloud services for each of the AWS services? What are unique distinctions and similarities between AWS, Azure and Google Cloud services? For each AWS service, what is the equivalent Azure and Google Cloud service? For each Azure service, what is the corresponding Google Service? AWS Services vs Azure vs Google Services? Side by side comparison between AWS, Google Cloud and Azure Service?
 Pros and Cons of Cloud Computing - What are the Pros of using cloud computing?
What are characteristics of cloud computing?
Trade Capital expense for variable expense
Benefit from massive economies of scale
Stop guessing capacity
Increase speed and agility
Stop spending money on running and maintaining data centers
Go global in minutes.
Pros and Cons of Cloud Computing - What are the Pros of using cloud computing?
What are characteristics of cloud computing?
Trade Capital expense for variable expense
Benefit from massive economies of scale
Stop guessing capacity
Increase speed and agility
Stop spending money on running and maintaining data centers
Go global in minutes.- Cloud User insurance and Cloud Provider Insurance - Cloud User insurance and Cloud Provider Insurance. As cloud user, cloud customer, company storing customer data in the cloud, you probably have a lot of personal or private data hosted in various infrastructure in the cloud. Losing that data or having the data accessed by hackers or unauthorized third party can be very harmful both financially and emotionally to you or your customers. A cloud User or Customer Insurance can protect you against data lost or stolen data.
- What are good competitors to G-Suite? - Office 365 comes to mind. Office 365 is a line of subscription services offered by Microsoft as part of the Microsoft Office product line. The brand encompasses plans that allow use of the Microsoft Office software suite over the life of the subscription, as well as cloud-based software as a service products for business environments, such as hosted Exchange Server, Skype for Business Server, and SharePoint, among …
- What are the top 10 biggest lessons you have learned from the corporate world? - What are the top 10 biggest lessons you have learned from the corporate world? The importance of teamwork and collaboration: Working in a corporate environment often requires you to work as part of a team and to collaborate with others to achieve common goals. The value of communication: Effective communication is essential in the corporate world, both when interacting with colleagues and when dealing with clients or customers. The need for adaptability: The corporate world is constantly changing, and it is important to be able to adapt to new situations and challenges as they arise. The importance of professionalism: Maintaining a professional demeanor and following appropriate workplace protocols is crucial in the corporate world. The need for time management and organization: In a corporate environment, it is important to be able to manage your time and resources effectively and to stay organized. The importance of developing strong problem-solving skills: Working in a corporate environment often requires you to solve complex problems and make decisions under pressure. The value of networking: Building strong professional relationships and networking with others in your industry can be beneficial for your career development. The importance of learning and development: Continuing to learn and grow as a professional is important in the corporate world, both for your own development and for the success of your organization. The need for conflict resolution skills: Conflicts and misunderstandings are a normal part of working in a corporate environment, and it is important to have the skills to resolve these conflicts effectively.
- How does using a VPN or Proxy or TOR or private browsing protects your online activity? - How does using a VPN or Proxy or TOR or private browsing protects your online activity? There are several ways that using a virtual private network (VPN), proxy, TOR, or private browsing can protect your online activity: VPN: A VPN encrypts your internet connection and routes your traffic through a secure server, making it harder for others to track your online activity. This can protect you from hackers, government surveillance, and other types of online threats. Proxy: A proxy acts as an intermediary between your device and the internet. When you use a proxy, your internet traffic is routed through the proxy server, which can mask your IP address and make it harder for others to track your online activity. TOR: The TOR network is a decentralized network of servers that routes your internet traffic through multiple servers to obscure your IP address and location. This can make it more difficult for others to track your online activity. Private browsing: Private browsing mode, also known as "incognito mode," is a feature that is available in most modern web browsers. When you use private browsing, your web browser does not store any information about your browsing activity, including cookies, history, or cache. This can make it harder for others to track your online activity. Overall, using a VPN, proxy, TOR, or private browsing can help protect your online activity by making it harder for others to track your internet usage and by providing an additional layer of security. However, it is important to note that these tools are not foolproof and cannot completely guarantee your online privacy. It is always a good idea to be aware of your online activity and take steps to protect your personal information.
- What is the programming model and best language for Hadoop and Spark? Python or Java? - What is the programming model and best language for Hadoop and Spark? Python or Java? Hadoop is an open-source software framework for storing data and running applications on clusters of commodity hardware. It provides massive storage for any kind of data, enormous processing power and the ability to handle virtually limitless concurrent tasks or jobs. Apache Hadoop is used mainly for Data Analysis.
 What is the best app for finding people to join group activity in USA and Canada for free? - What is the best app for finding people to join group activity in USA and Canada for free?
What is the best app for finding people to join group activity in USA and Canada for free? - What is the best app for finding people to join group activity in USA and Canada for free?- Top 10 legal side business that can make you $1000-$2000 a week? - Top 10 legal side business that can make you $1000-$2000 a week? Here are 10 legal side businesses that have the potential to make you $1000-$2000 a week: Freelance writing or editing: If you have writing or editing skills, you can offer your services as a freelancer. You can find clients through online platforms such as Upwork or Freelancer, or you can reach out to businesses and individuals directly. Online tutoring: If you have expertise in a particular subject or educational field, you can offer online tutoring services. You can use platforms like VIPKid or iTutorGroup to find students, or you can advertise your services on social media or through your own website. Graphic design: If you have design skills, you can offer your services as a graphic designer. You can find clients through online platforms such as 99designs or Fiverr, or you can reach out to businesses and individuals directly. Web design and development: If you have skills in web design and development, you can offer your services to businesses and individuals who need a website or need to update their existing website. You can find clients through online platforms such as Upwork or Freelancer, or you can advertise your services on social media or through your own website. Virtual assisting: If you have organizational and administrative skills, you can offer your services as a virtual assistant. You can find clients through online platforms such as Upwork or Freelancer, or you can reach out to businesses and individuals directly. Social media management: If you have experience with social media platforms and know how to create and implement social media strategies, you can offer your services to businesses and individuals as a social media manager. You can find clients through online platforms such as Upwork or Freelancer, or you can reach out to businesses and individuals directly. Event planning: If you have event planning skills, you can offer your services to businesses and individuals who need help organizing events. You can find clients through online platforms such as Eventbrite or Thumbtack, or you can advertise your services on social media or through your own website. E-commerce: If you have a product or service that you can sell online, you can set up an e-commerce business. You can use
- Top 10 Financial Tips for Young Adults in USA and Canada - Top 10 Financial Tips for Young Adults in USA and Canada This blog is geared towards young adults, particularly young first and second generation immigrants like me who don't have any real estate and assets inherited from their parents here in Canada and USA. In this blog, I will help answer the following questions below based on my own experience and extensive research
 Free and Effective Internet Marketing in USA and Canada: Top 10 Tips to Sell Online at No Cost - Free and Effective Internet Marketing in USA and Canada: Top 10 Tips to Sell Online at No Cost Utilize social media platforms: Create a presence on popular social media platforms like Facebook, Instagram, and Twitter. These platforms are free to use and can be leveraged to reach a large audience. Use influencer marketing: Partner with influencers in your niche to promote your products. Influencers have a large following and can help you reach a wider audience. Optimize your website for SEO: Optimize your website for search engines to increase visibility and drive traffic to your site. Create valuable content: Create valuable content such as blog posts, videos, and infographics to attract and engage potential customers. Use email marketing: Collect email addresses from your website visitors and use them to send promotional emails.
Free and Effective Internet Marketing in USA and Canada: Top 10 Tips to Sell Online at No Cost - Free and Effective Internet Marketing in USA and Canada: Top 10 Tips to Sell Online at No Cost Utilize social media platforms: Create a presence on popular social media platforms like Facebook, Instagram, and Twitter. These platforms are free to use and can be leveraged to reach a large audience. Use influencer marketing: Partner with influencers in your niche to promote your products. Influencers have a large following and can help you reach a wider audience. Optimize your website for SEO: Optimize your website for search engines to increase visibility and drive traffic to your site. Create valuable content: Create valuable content such as blog posts, videos, and infographics to attract and engage potential customers. Use email marketing: Collect email addresses from your website visitors and use them to send promotional emails.- Top 100 AWS Solutions Architect Associate Certification Exam Questions and Answers Dump SAA-C03 - What are the Top 100 AWS Solutions Architect Associate Certification Exam Questions and Answers Dump SAA-C03 AWS Certified Solutions Architects are responsible for designing, deploying, and managing AWS cloud applications. The AWS Cloud Solutions Architect Associate exam validates an examinee's ability to effectively demonstrate knowledge of how to design and deploy secure and robust applications on AWS technologies. The AWS Solutions Architect Associate training provides an overview of key AWS services, security, architecture, pricing, and support. The AWS Certified Solutions Architect - Associate (SAA-C03) Examination is a required examination for the AWS Certified Solutions Architect - Professional level. Successful completion of this examination can lead to a salary raise or promotion for those in cloud roles.
 AWS Certification Preparation: AWS Ec2 Facts, Faqs and Summaries, Top 10 Questions and Answers Dump - AWS Certification Preparation: AWS Ec2 Facts, Faqs and Summaries, Top 10 Questions and Answers Dump
Amazon Elastic Compute Cloud
(Amazon EC2) is a web service that provides secure, resizable compute capacity in the cloud. It is designed to make web-scale cloud computing easier for developers. Amazon Elastic Compute Cloud (EC2) forms a central part of Amazon.com's cloud-computing platform, Amazon Web Services (AWS), by allowing users to rent virtual computers on which to run their own computer applications.
AWS Certification Preparation: AWS Ec2 Facts, Faqs and Summaries, Top 10 Questions and Answers Dump - AWS Certification Preparation: AWS Ec2 Facts, Faqs and Summaries, Top 10 Questions and Answers Dump
Amazon Elastic Compute Cloud
(Amazon EC2) is a web service that provides secure, resizable compute capacity in the cloud. It is designed to make web-scale cloud computing easier for developers. Amazon Elastic Compute Cloud (EC2) forms a central part of Amazon.com's cloud-computing platform, Amazon Web Services (AWS), by allowing users to rent virtual computers on which to run their own computer applications.  AWS Certification Preparation: AWS IAM Facts, Faqs, Summaries and Top 10 Questions and Answers Dump - AWS Certification Preparation: AWS IAM Facts, Faqs, Summaries and Top 10 Questions and Answers Dump. IAM is a framework of policies and technologies for ensuring that the proper people in an enterprise have the appropriate access to technology resources. IdM systems fall under the overarching umbrella of IT security and Data Management . AWS Identity and Access Management (IAM) is a web service that helps you securely control access to AWS resources. You use IAM to control who is authenticated (signed in) and authorized (has permissions) to use resources.
AWS Certification Preparation: AWS IAM Facts, Faqs, Summaries and Top 10 Questions and Answers Dump - AWS Certification Preparation: AWS IAM Facts, Faqs, Summaries and Top 10 Questions and Answers Dump. IAM is a framework of policies and technologies for ensuring that the proper people in an enterprise have the appropriate access to technology resources. IdM systems fall under the overarching umbrella of IT security and Data Management . AWS Identity and Access Management (IAM) is a web service that helps you securely control access to AWS resources. You use IAM to control who is authenticated (signed in) and authorized (has permissions) to use resources. AWS Certification Exams Prep: Serverless Facts and Summaries and Question and Answers - AWS Certification Exams Prep: Serverless Facts and Summaries and Question and Answers Serverless computing is a cloud-computing execution model in which the cloud provider runs the server, and dynamically manages the allocation of machine resources. Pricing is based on the actual amount of resources consumed by an application, rather than on pre-purchased units of capacity. It can be a form of utility computing.
AWS Certification Exams Prep: Serverless Facts and Summaries and Question and Answers - AWS Certification Exams Prep: Serverless Facts and Summaries and Question and Answers Serverless computing is a cloud-computing execution model in which the cloud provider runs the server, and dynamically manages the allocation of machine resources. Pricing is based on the actual amount of resources consumed by an application, rather than on pre-purchased units of capacity. It can be a form of utility computing.  AWS Developer and Deployment Theory: Facts and Summaries and Questions/Answers - AWS Developer and Deployment Theory: Facts and Summaries and Questions/Answers The AWS Developer is responsible for designing, deploying, and developing cloud applications on AWS platform
AWS Developer and Deployment Theory: Facts and Summaries and Questions/Answers - AWS Developer and Deployment Theory: Facts and Summaries and Questions/Answers The AWS Developer is responsible for designing, deploying, and developing cloud applications on AWS platform AWS Certification Exam Prep: DynamoDB Facts, Summaries and Questions/Answers. - AWS Certification Exam Prep: DynamoDB facts and summaries, AWS DynamoDB Top 10 Questions and Answers Dump Amazon DynamoDB explained
Fully Managed
Fast, consistent Performance
Fine-grained access control
Flexible
AWS DynamoDB Facts and Summaries
AWS DynamoDB Questions and Answers Dumps
AWS Certification Exam Prep: DynamoDB Facts, Summaries and Questions/Answers. - AWS Certification Exam Prep: DynamoDB facts and summaries, AWS DynamoDB Top 10 Questions and Answers Dump Amazon DynamoDB explained
Fully Managed
Fast, consistent Performance
Fine-grained access control
Flexible
AWS DynamoDB Facts and Summaries
AWS DynamoDB Questions and Answers Dumps  AWS Certification Exam Prep: S3 Facts, Summaries, Questions and Answers - AWS Certification Exam Prep: S3 Facts, Summaries, Questions and Answers S3 is a universal namespace, meaning each S3 bucket you create must have a unique name that is not being used by anyone else in the world.
S3 is object based: i.e allows you to upload files.Files can be from 0 Bytes to 5 TBS3 has unlimited storage.
Files are stored in Buckets.
Read after write consistency for PUTS of new Objects
Eventual Consistency for overwrite PUTS and DELETES (can take some time to propagate)
AWS Certification Exam Prep: S3 Facts, Summaries, Questions and Answers - AWS Certification Exam Prep: S3 Facts, Summaries, Questions and Answers S3 is a universal namespace, meaning each S3 bucket you create must have a unique name that is not being used by anyone else in the world.
S3 is object based: i.e allows you to upload files.Files can be from 0 Bytes to 5 TBS3 has unlimited storage.
Files are stored in Buckets.
Read after write consistency for PUTS of new Objects
Eventual Consistency for overwrite PUTS and DELETES (can take some time to propagate) 2022 AWS Certified Developer Associate Exam Preparation: Questions and Answers Dump - 2022 AWS Certified Developer Associate Exam Preparation: Questions and Answers Dump A developer is writing an application that will store data in a DynamoDB table. The ratio of reads operations to write operations will be 1000 to 1, with the same data being accessed frequently. What should the Developer enable on the DynamoDB table to optimize performance and minimize costs?
2022 AWS Certified Developer Associate Exam Preparation: Questions and Answers Dump - 2022 AWS Certified Developer Associate Exam Preparation: Questions and Answers Dump A developer is writing an application that will store data in a DynamoDB table. The ratio of reads operations to write operations will be 1000 to 1, with the same data being accessed frequently. What should the Developer enable on the DynamoDB table to optimize performance and minimize costs? Top 100 AWS Certified Cloud Practitioner Exam Preparation Questions and Answers Dumps - Top 100 AWS Certified Cloud Practitioner Exam Preparation Questions and Answers Dumps Top 100 AWS CCP CLF-C01 Questions and Answers Dumps, White papers, Courses, Labs and Training Materials, Exam info and details, References, Jobs, Others AWS Certificates, AWS Cloud Support Engineer Job Interview Prep, Top 20 AWS Training Q&A , AWS Web Services Cheat Sheet, Latest Products & Services @ AWS RE:INVENT, I Passed AWS CCP Testimonials
Top 100 AWS Certified Cloud Practitioner Exam Preparation Questions and Answers Dumps - Top 100 AWS Certified Cloud Practitioner Exam Preparation Questions and Answers Dumps Top 100 AWS CCP CLF-C01 Questions and Answers Dumps, White papers, Courses, Labs and Training Materials, Exam info and details, References, Jobs, Others AWS Certificates, AWS Cloud Support Engineer Job Interview Prep, Top 20 AWS Training Q&A , AWS Web Services Cheat Sheet, Latest Products & Services @ AWS RE:INVENT, I Passed AWS CCP Testimonials The Appeal of a Career as a Professional Arborist - If a career as a professional arborist appeals to you then this post is for you. We’re talking about the responsibilities and the rewards of arboriculture.
The Appeal of a Career as a Professional Arborist - If a career as a professional arborist appeals to you then this post is for you. We’re talking about the responsibilities and the rewards of arboriculture. Understanding the Different Types of Thermometers - There’s more than one thermometer and it doesn’t always go in the medicine cabinet. We’re exploring the different types of thermometers in this read.
Understanding the Different Types of Thermometers - There’s more than one thermometer and it doesn’t always go in the medicine cabinet. We’re exploring the different types of thermometers in this read. Should Your Business Use Generative AI for Its Ad Images? - Generative AI can serve businesses in many ways, but should companies be using AI-generated images within their advertising campaigns at this time?
Should Your Business Use Generative AI for Its Ad Images? - Generative AI can serve businesses in many ways, but should companies be using AI-generated images within their advertising campaigns at this time? Why Every Remote Worker Needs an Ergonomic Keyboard - Remote workers have the luxury of staying comfortable at home but the responsibility to maintain productivity—an ergonomic keyboard can help.
Why Every Remote Worker Needs an Ergonomic Keyboard - Remote workers have the luxury of staying comfortable at home but the responsibility to maintain productivity—an ergonomic keyboard can help. Why the Oil and Gas Industry Is a Lucrative Career Choice - The oil and gas industry is more than pumping gas and inflated prices. The career opportunities are lucrative and compelling for many of these reasons.
Why the Oil and Gas Industry Is a Lucrative Career Choice - The oil and gas industry is more than pumping gas and inflated prices. The career opportunities are lucrative and compelling for many of these reasons. Everything You Need To Know about Thermal Foggers - Read here to discover the power and efficiency of thermal foggers and learn more about how these versatile, effective sanitization tools work.
Everything You Need To Know about Thermal Foggers - Read here to discover the power and efficiency of thermal foggers and learn more about how these versatile, effective sanitization tools work.
Show All Posts
Active Hydrating Toner, Anti-Aging Replenishing Advanced Face Moisturizer, with Vitamins A, C, E & Natural Botanicals to Promote Skin Balance & Collagen Production, 6.7 Fl Oz



Age Defying 0.3% Retinol Serum, Anti-Aging Dark Spot Remover for Face, Fine Lines & Wrinkle Pore Minimizer, with Vitamin E & Natural Botanicals


Firming Moisturizer, Advanced Hydrating Facial Replenishing Cream, with Hyaluronic Acid, Resveratrol & Natural Botanicals to Restore Skin's Strength, Radiance, and Resilience, 1.75 Oz

Skin Stem Cell Serum


Smartphone 101 - Pick a smartphone for me - android or iOS - Apple iPhone or Samsung Galaxy or Huawei or Xaomi or Google Pixel
Can AI Really Predict Lottery Results? We Asked an Expert.




Djamgatech

Read Photos and PDFs Aloud for me iOS
Read Photos and PDFs Aloud for me android
Read Photos and PDFs Aloud For me Windows 10/11
Read Photos and PDFs Aloud For Amazon
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more)
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6(Email us for more)



FREE 10000+ Quiz Trivia and and Brain Teasers for All Topics including Cloud Computing, General Knowledge, History, Television, Music, Art, Science, Movies, Films, US History, Soccer Football, World Cup, Data Science, Machine Learning, Geography, etc....


List of Freely available programming books - What is the single most influential book every Programmers should read
- Bjarne Stroustrup - The C++ Programming Language
- Brian W. Kernighan, Rob Pike - The Practice of Programming
- Donald Knuth - The Art of Computer Programming
- Ellen Ullman - Close to the Machine
- Ellis Horowitz - Fundamentals of Computer Algorithms
- Eric Raymond - The Art of Unix Programming
- Gerald M. Weinberg - The Psychology of Computer Programming
- James Gosling - The Java Programming Language
- Joel Spolsky - The Best Software Writing I
- Keith Curtis - After the Software Wars
- Richard M. Stallman - Free Software, Free Society
- Richard P. Gabriel - Patterns of Software
- Richard P. Gabriel - Innovation Happens Elsewhere
- Code Complete (2nd edition) by Steve McConnell
- The Pragmatic Programmer
- Structure and Interpretation of Computer Programs
- The C Programming Language by Kernighan and Ritchie
- Introduction to Algorithms by Cormen, Leiserson, Rivest & Stein
- Design Patterns by the Gang of Four
- Refactoring: Improving the Design of Existing Code
- The Mythical Man Month
- The Art of Computer Programming by Donald Knuth
- Compilers: Principles, Techniques and Tools by Alfred V. Aho, Ravi Sethi and Jeffrey D. Ullman
- Gödel, Escher, Bach by Douglas Hofstadter
- Clean Code: A Handbook of Agile Software Craftsmanship by Robert C. Martin
- Effective C++
- More Effective C++
- CODE by Charles Petzold
- Programming Pearls by Jon Bentley
- Working Effectively with Legacy Code by Michael C. Feathers
- Peopleware by Demarco and Lister
- Coders at Work by Peter Seibel
- Surely You're Joking, Mr. Feynman!
- Effective Java 2nd edition
- Patterns of Enterprise Application Architecture by Martin Fowler
- The Little Schemer
- The Seasoned Schemer
- Why's (Poignant) Guide to Ruby
- The Inmates Are Running The Asylum: Why High Tech Products Drive Us Crazy and How to Restore the Sanity
- The Art of Unix Programming
- Test-Driven Development: By Example by Kent Beck
- Practices of an Agile Developer
- Don't Make Me Think
- Agile Software Development, Principles, Patterns, and Practices by Robert C. Martin
- Domain Driven Designs by Eric Evans
- The Design of Everyday Things by Donald Norman
- Modern C++ Design by Andrei Alexandrescu
- Best Software Writing I by Joel Spolsky
- The Practice of Programming by Kernighan and Pike
- Pragmatic Thinking and Learning: Refactor Your Wetware by Andy Hunt
- Software Estimation: Demystifying the Black Art by Steve McConnel
- The Passionate Programmer (My Job Went To India) by Chad Fowler
- Hackers: Heroes of the Computer Revolution
- Algorithms + Data Structures = Programs
- Writing Solid Code
- JavaScript - The Good Parts
- Getting Real by 37 Signals
- Foundations of Programming by Karl Seguin
- Computer Graphics: Principles and Practice in C (2nd Edition)
- Thinking in Java by Bruce Eckel
- The Elements of Computing Systems
- Refactoring to Patterns by Joshua Kerievsky
- Modern Operating Systems by Andrew S. Tanenbaum
- The Annotated Turing
- Things That Make Us Smart by Donald Norman
- The Timeless Way of Building by Christopher Alexander
- The Deadline: A Novel About Project Management by Tom DeMarco
- The C++ Programming Language (3rd edition) by Stroustrup
- Patterns of Enterprise Application Architecture
- Computer Systems - A Programmer's Perspective
- Agile Principles, Patterns, and Practices in C# by Robert C. Martin
- Growing Object-Oriented Software, Guided by Tests
- Framework Design Guidelines by Brad Abrams
- Object Thinking by Dr. David West
- Advanced Programming in the UNIX Environment by W. Richard Stevens
- Hackers and Painters: Big Ideas from the Computer Age
- The Soul of a New Machine by Tracy Kidder
- CLR via C# by Jeffrey Richter
- The Timeless Way of Building by Christopher Alexander
- Design Patterns in C# by Steve Metsker
- Alice in Wonderland by Lewis Carol
- Zen and the Art of Motorcycle Maintenance by Robert M. Pirsig
- About Face - The Essentials of Interaction Design
- Here Comes Everybody: The Power of Organizing Without Organizations by Clay Shirky
- The Tao of Programming
- Computational Beauty of Nature
- Writing Solid Code by Steve Maguire
- Philip and Alex's Guide to Web Publishing
- Object-Oriented Analysis and Design with Applications by Grady Booch
- Effective Java by Joshua Bloch
- Computability by N. J. Cutland
- Masterminds of Programming
- The Tao Te Ching
- The Productive Programmer
- The Art of Deception by Kevin Mitnick
- The Career Programmer: Guerilla Tactics for an Imperfect World by Christopher Duncan
- Paradigms of Artificial Intelligence Programming: Case studies in Common Lisp
- Masters of Doom
- Pragmatic Unit Testing in C# with NUnit by Andy Hunt and Dave Thomas with Matt Hargett
- How To Solve It by George Polya
- The Alchemist by Paulo Coelho
- Smalltalk-80: The Language and its Implementation
- Writing Secure Code (2nd Edition) by Michael Howard
- Introduction to Functional Programming by Philip Wadler and Richard Bird
- No Bugs! by David Thielen
- Rework by Jason Freid and DHH
- JUnit in Action
#BlackOwned #BlackEntrepreneurs #BlackBuniness #AWSCertified #AWSCloudPractitioner #AWSCertification #AWSCLFC02 #CloudComputing #AWSStudyGuide #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AWSBasics #AWSCertified #AWSMachineLearning #AWSCertification #AWSSpecialty #MachineLearning #AWSStudyGuide #CloudComputing #DataScience #AWSCertified #AWSSolutionsArchitect #AWSArchitectAssociate #AWSCertification #AWSStudyGuide #CloudComputing #AWSArchitecture #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AzureFundamentals #AZ900 #MicrosoftAzure #ITCertification #CertificationPrep #StudyMaterials #TechLearning #MicrosoftCertified #AzureCertification #TechBooks
Top 1000 Canada Quiz and trivia: CANADA CITIZENSHIP TEST- HISTORY - GEOGRAPHY - GOVERNMENT- CULTURE - PEOPLE - LANGUAGES - TRAVEL - WILDLIFE - HOCKEY - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Top 1000 Africa Quiz and trivia: HISTORY - GEOGRAPHY - WILDLIFE - CULTURE - PEOPLE - LANGUAGES - TRAVEL - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Exploring the Pros and Cons of Visiting All Provinces and Territories in Canada.


Exploring the Advantages and Disadvantages of Visiting All 50 States in the USA

Health Health, a science-based community to discuss health news and the coronavirus (COVID-19) pandemic
- The pull-out method: Why this common contraceptive fails to deliverby /u/Kampala_Dispatch on July 26, 2024 at 7:51 pm
submitted by /u/Kampala_Dispatch [link] [comments]
- Health Canada data reveals surprising number of adverse cannabis reactions (spoiler: it's small)by /u/carajuana_readit on July 26, 2024 at 5:49 pm
submitted by /u/carajuana_readit [link] [comments]
- Online portals deliver scary health news before doctors can weigh inby /u/washingtonpost on July 26, 2024 at 4:37 pm
submitted by /u/washingtonpost [link] [comments]
- Vaccine 'sharply cuts risk of dementia' new study findsby /u/SubstantialSnow7114 on July 26, 2024 at 1:53 pm
submitted by /u/SubstantialSnow7114 [link] [comments]
- Calls to limit sexual partners as mpox makes a resurgence in Australiaby /u/boppinmule on July 26, 2024 at 12:31 pm
submitted by /u/boppinmule [link] [comments]
Today I Learned (TIL) You learn something new every day; what did you learn today? Submit interesting and specific facts about something that you just found out here.
- TIL that in Thailand, if your spouse cheats on you, you can legally sue their lover for damages and can receive up to 5,000,000 THB ($140,000 USD) or more under Section 1523 of the Thai Civil and Commercial Codeby /u/Mavrokordato on July 26, 2024 at 6:57 pm
submitted by /u/Mavrokordato [link] [comments]
- TIL that with a population of 170 million people, Bangladesh is the most populous country to have never won a medal at the Olympic Games.by /u/Blackraven2007 on July 26, 2024 at 6:49 pm
submitted by /u/Blackraven2007 [link] [comments]
- TIL a psychologist got himself admitted to a mental hospital by claiming he heard the words "empty", "hollow" and "thud" in his head. Then, it took him two months to convince them he was sane, after agreeing he was insane and accepting medication.by /u/Hadeverse-050 on July 26, 2024 at 6:44 pm
submitted by /u/Hadeverse-050 [link] [comments]
- TIL Senator John Edwards of NC, USA cheated on his wife and had a child with another woman. He tried to deny it but eventually caved and admitted his mistake. He used campaign funds and was indicted by a grand jury. His life story inspired the show "The Good Wife" by Robert & Michelle Kingby /u/AdvisorPast637 on July 26, 2024 at 6:09 pm
submitted by /u/AdvisorPast637 [link] [comments]
- TIL Zhang Shuhong was a Chinese businessman who committed suicide after toys made at his factory for Fisher-Price (a division of Mattel) were found to contain lead paintby /u/Hopeful-Candle-4884 on July 26, 2024 at 4:43 pm
submitted by /u/Hopeful-Candle-4884 [link] [comments]
Reddit Science This community is a place to share and discuss new scientific research. Read about the latest advances in astronomy, biology, medicine, physics, social science, and more. Find and submit new publications and popular science coverage of current research.
- Human decision makers who possess the authority to override ML predictions may impede the self-correction of discriminatory models and even induce initially unbiased models to become discriminatory with timeby /u/f1u82ypd on July 26, 2024 at 6:29 pm
submitted by /u/f1u82ypd [link] [comments]
- Study uses Game of Thrones (GOT) to advance understanding of face blindness: Psychologists have used the TV series GOT to understand how the brain enables us to recognise faces. Their findings provide new insights into prosopagnosia or face blindness, a condition that impairs facial recognition.by /u/AnnaMouse247 on July 26, 2024 at 5:14 pm
submitted by /u/AnnaMouse247 [link] [comments]
- Specific genes may be related to the trajectory of recovery for stroke survivors, study finds. Researchers say genetic variants were strongly associated with depression, PTSD and cognitive health outcomes. Findings may provide useful insights for developing targeted therapies.by /u/AnnaMouse247 on July 26, 2024 at 5:08 pm
submitted by /u/AnnaMouse247 [link] [comments]
- New experimental drug shows promise in clearing HIV from brain: originally developed to treat cancer, study finds that by targeting infected cells in the brain, drug may clear virus from hidden areas that have been a major challenge in HIV treatment.by /u/AnnaMouse247 on July 26, 2024 at 4:57 pm
submitted by /u/AnnaMouse247 [link] [comments]
- Rapid diagnosis sepsis tests could decrease result wait times from days to hours, researchers report in Natureby /u/Science_News on July 26, 2024 at 3:50 pm
submitted by /u/Science_News [link] [comments]
Reddit Sports Sports News and Highlights from the NFL, NBA, NHL, MLB, MLS, and leagues around the world.
- Canada's men's and women's soccer teams have relied on drones and spying for years, sources sayby /u/FireLychee on July 26, 2024 at 3:37 am
submitted by /u/FireLychee [link] [comments]
- After a grueling Tour de France, top riders are racing to recover for Paris Olympics time trialby /u/Oldtimer_2 on July 26, 2024 at 12:54 am
submitted by /u/Oldtimer_2 [link] [comments]
- Canada WNT coach Bev Priestman suspended, sent home from Olympics amid spying scandalby /u/Oldtimer_2 on July 26, 2024 at 12:49 am
submitted by /u/Oldtimer_2 [link] [comments]
- 'End of an Era': TNT's 'Inside the NBA' Ending After NBA Chooses Amazonby /u/lame_building14 on July 26, 2024 at 12:36 am
submitted by /u/lame_building14 [link] [comments]
- Canada axes coach from Olympics over drone useby /u/chief_sitass on July 26, 2024 at 12:31 am
submitted by /u/chief_sitass [link] [comments]
Turn your dream into reality with Google Workspace: It’s free for the first 14 days.
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes:
 96DRHDRA9J7GTN6
96DRHDRA9J7GTN6
63F733CLLY7R7MM
63F7D7CPD9XXUVT
63FLKQHWV3AEEE6
63JGLWWK36CP7WM
63KKR9EULQRR7VE
63KNY4N7VHCUA9R
63LDXXFYU6VXDG9
63MGNRCKXURAYWC
63NGNDVVXJP4N99
63P4G3ELRPADKQU
With Google Workspace, Get custom email @yourcompany, Work from anywhere; Easily scale up or down
Google gives you the tools you need to run your business like a pro. Set up custom email, share files securely online, video chat from any device, and more.
Google Workspace provides a platform, a common ground, for all our internal teams and operations to collaboratively support our primary business goal, which is to deliver quality information to our readers quickly.
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE
C37HCAQRVR7JTFK
C3AE76E7WATCTL9
C3C3RGUF9VW6LXE
C3D9LD4L736CALC
C3EQXV674DQ6PXP
C3G9M3JEHXM3XC7
C3GGR3H4TRHUD7L
C3LVUVC3LHKUEQK
C3PVGM4CHHPMWLE
C3QHQ763LWGTW4C
Even if you’re small, you want people to see you as a professional business. If you’re still growing, you need the building blocks to get you where you want to be. I’ve learned so much about business through Google Workspace—I can’t imagine working without it. (Email us for more codes)
AWS Certified Developer Associate Exam Prep
Welcome to AWS Certified Developer Associate Exam Preparation: Definition and Objectives, Top 65 Questions and Answers dump, White papers, Courses, Labs and Training Materials, Exam info and details, References, Jobs, Others AWS Certificates
What is the AWS Certified Developer Associate Exam?
This AWS Certified Developer-Associate Examination is intended for individuals who perform a
Developer role. It validates an examinee’s ability to:
- Demonstrate an understanding of core AWS services, uses, and basic AWS architecture best practices.
- Demonstrate proficiency in developing, deploying, and debugging cloud-based applications using AWS.
There are no prerequisites for taking the Developer-Associate examination, but here are the recommended AWS Knowledge:
- One or more years of hands-on experience developing and maintaining an AWS based application
- In-depth knowledge of at least one high-level programming language
- Understanding of core AWS services, uses, and basic AWS architecture best practices
- Proficiency in developing, deploying, and debugging cloud-based applications using AWS
- Ability to use the AWS service APIs, AWS CLI, and SDKs to write applications
- Ability to identify key features of AWS services
- Understanding of the AWS shared responsibility model
- Understanding of application lifecycle management
- Ability to use a CI/CD pipeline to deploy applications on AWS
- Ability to use or interact with AWS services
- Ability to apply a basic understanding of cloud-native applications to write code
- Ability to write code using AWS security best practices (e.g., not using secret and access keys in the code, instead using IAM roles)
- Ability to author, maintain, and debug code modules on AWS
- Proficiency writing code for serverless applications
- Understanding of the use of containers in the development process
AWS Certified Developer – Associate Practice Questions And Answers Dump
Q0: Your application reads commands from an SQS queue and sends them to web services hosted by your
partners. When a partner’s endpoint goes down, your application continually returns their commands to the queue. The repeated attempts to deliver these commands use up resources. Commands that can’t be delivered must not be lost.
How can you accommodate the partners’ broken web services without wasting your resources?
- A. Create a delay queue and set DelaySeconds to 30 seconds
- B. Requeue the message with a VisibilityTimeout of 30 seconds.
- C. Create a dead letter queue and set the Maximum Receives to 3.
- D. Requeue the message with a DelaySeconds of 30 seconds.
Top
Q1: A developer is writing an application that will store data in a DynamoDB table. The ratio of reads operations to write operations will be 1000 to 1, with the same data being accessed frequently.
What should the Developer enable on the DynamoDB table to optimize performance and minimize costs?
- A. Amazon DynamoDB auto scaling
- B. Amazon DynamoDB cross-region replication
- C. Amazon DynamoDB Streams
- D. Amazon DynamoDB Accelerator

Top
Q2: You are creating a DynamoDB table with the following attributes:
- PurchaseOrderNumber (partition key)
- CustomerID
- PurchaseDate
- TotalPurchaseValue
One of your applications must retrieve items from the table to calculate the total value of purchases for a
particular customer over a date range. What secondary index do you need to add to the table?
- A. Local secondary index with a partition key of CustomerID and sort key of PurchaseDate; project the
TotalPurchaseValue attribute - B. Local secondary index with a partition key of PurchaseDate and sort key of CustomerID; project the
TotalPurchaseValue attribute - C. Global secondary index with a partition key of CustomerID and sort key of PurchaseDate; project the
TotalPurchaseValue attribute - D. Global secondary index with a partition key of PurchaseDate and sort key of CustomerID; project the
TotalPurchaseValue attribute
Top
Q3: When referencing the remaining time left for a Lambda function to run within the function’s code you would use:
- A. The event object
- B. The timeLeft object
- C. The remains object
- D. The context object
Top
Q4: What two arguments does a Python Lambda handler function require?
- A. invocation, zone
- B. event, zone
- C. invocation, context
- D. event, context
Q5: Lambda allows you to upload code and dependencies for function packages:
- A. Only from a directly uploaded zip file
- B. Only via SFTP
- C. Only from a zip file in AWS S3
- D. From a zip file in AWS S3 or uploaded directly from elsewhere
Q6: A Lambda deployment package contains:
- A. Function code, libraries, and runtime binaries
- B. Only function code
- C. Function code and libraries not included within the runtime
- D. Only libraries not included within the runtime
Q7: You are attempting to SSH into an EC2 instance that is located in a public subnet. However, you are currently receiving a timeout error trying to connect. What could be a possible cause of this connection issue?
- A. The security group associated with the EC2 instance has an inbound rule that allows SSH traffic, but does not have an outbound rule that allows SSH traffic.
- B. The security group associated with the EC2 instance has an inbound rule that allows SSH traffic AND has an outbound rule that explicitly denies SSH traffic.
- C. The security group associated with the EC2 instance has an inbound rule that allows SSH traffic AND the associated NACL has both an inbound and outbound rule that allows SSH traffic.
- D. The security group associated with the EC2 instance does not have an inbound rule that allows SSH traffic AND the associated NACL does not have an outbound rule that allows SSH traffic.
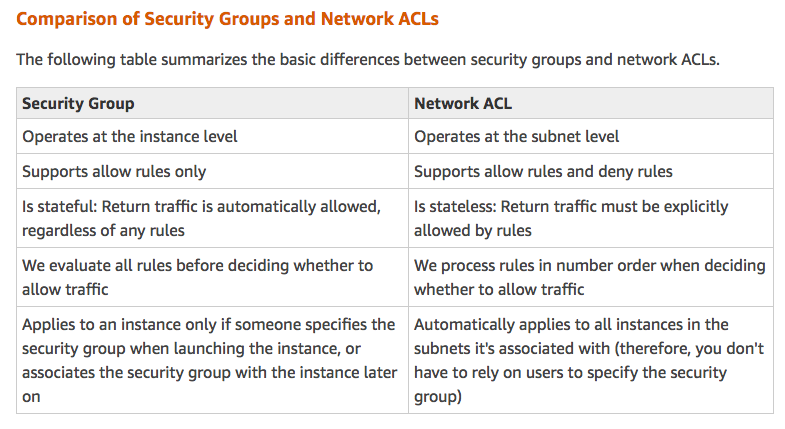
Top
Q8: You have instances inside private subnets and a properly configured bastion host instance in a public subnet. None of the instances in the private subnets have a public or Elastic IP address. How can you connect an instance in the private subnet to the open internet to download system updates?
- A. Create and assign EIP to each instance
- B. Create and attach a second IGW to the VPC.
- C. Create and utilize a NAT Gateway
- D. Connect to a VPN
Top
Q9: What feature of VPC networking should you utilize if you want to create “elasticity” in your application’s architecture?
- A. Security Groups
- B. Route Tables
- C. Elastic Load Balancer
- D. Auto Scaling
Top
Q10: Lambda allows you to upload code and dependencies for function packages:
- A. Only from a directly uploaded zip file
- B. Only from a directly uploaded zip file
- C. Only from a zip file in AWS S3
- D. From a zip file in AWS S3 or uploaded directly from elsewhere
Q11: You’re writing a script with an AWS SDK that uses the AWS API Actions and want to create AMIs for non-EBS backed AMIs for you. Which API call should occurs in the final process of creating an AMI?
- A. RegisterImage
- B. CreateImage
- C. ami-register-image
- D. ami-create-image
Q12: When dealing with session state in EC2-based applications using Elastic load balancers which option is generally thought of as the best practice for managing user sessions?
- A. Having the ELB distribute traffic to all EC2 instances and then having the instance check a caching solution like ElastiCache running Redis or Memcached for session information
- B. Permenantly assigning users to specific instances and always routing their traffic to those instances
- C. Using Application-generated cookies to tie a user session to a particular instance for the cookie duration
- D. Using Elastic Load Balancer generated cookies to tie a user session to a particular instance
Q13: Which API call would best be used to describe an Amazon Machine Image?
- A. ami-describe-image
- B. ami-describe-images
- C. DescribeImage
- D. DescribeImages
Q14: What is one key difference between an Amazon EBS-backed and an instance-store backed instance?
- A. Autoscaling requires using Amazon EBS-backed instances
- B. Virtual Private Cloud requires EBS backed instances
- C. Amazon EBS-backed instances can be stopped and restarted without losing data
- D. Instance-store backed instances can be stopped and restarted without losing data
Q15: After having created a new Linux instance on Amazon EC2, and downloaded the .pem file (called Toto.pem) you try and SSH into your IP address (54.1.132.33) using the following command.
ssh -i my_key.pem ec2-user@52.2.222.22
However you receive the following error.
@@@@@@@@ WARNING: UNPROTECTED PRIVATE KEY FILE! @ @@@@@@@@@@@@@@@@@@@
What is the most probable reason for this and how can you fix it?
- A. You do not have root access on your terminal and need to use the sudo option for this to work.
- B. You do not have enough permissions to perform the operation.
- C. Your key file is encrypted. You need to use the -u option for unencrypted not the -i option.
- D. Your key file must not be publicly viewable for SSH to work. You need to modify your .pem file to limit permissions.
Q16: You have an EBS root device on /dev/sda1 on one of your EC2 instances. You are having trouble with this particular instance and you need to either Stop/Start, Reboot or Terminate the instance but you do NOT want to lose any data that you have stored on /dev/sda1. However, you are unsure if changing the instance state in any of the aforementioned ways will cause you to lose data stored on the EBS volume. Which of the below statements best describes the effect each change of instance state would have on the data you have stored on /dev/sda1?
- A. Whether you stop/start, reboot or terminate the instance it does not matter because data on an EBS volume is not ephemeral and the data will not be lost regardless of what method is used.
- B. If you stop/start the instance the data will not be lost. However if you either terminate or reboot the instance the data will be lost.
- C. Whether you stop/start, reboot or terminate the instance it does not matter because data on an EBS volume is ephemeral and it will be lost no matter what method is used.
- D. The data will be lost if you terminate the instance, however the data will remain on /dev/sda1 if you reboot or stop/start the instance because data on an EBS volume is not ephemeral.

Q17: EC2 instances are launched from Amazon Machine Images (AMIs). A given public AMI:
- A. Can only be used to launch EC2 instances in the same AWS availability zone as the AMI is stored
- B. Can only be used to launch EC2 instances in the same country as the AMI is stored
- C. Can only be used to launch EC2 instances in the same AWS region as the AMI is stored
- D. Can be used to launch EC2 instances in any AWS region
Q18: Which of the following statements is true about the Elastic File System (EFS)?
- A. EFS can scale out to meet capacity requirements and scale back down when no longer needed
- B. EFS can be used by multiple EC2 instances simultaneously
- C. EFS cannot be used by an instance using EBS
- D. EFS can be configured on an instance before launch just like an IAM role or EBS volumes
Q19: IAM Policies, at a minimum, contain what elements?
- A. ID
- B. Effects
- C. Resources
- D. Sid
- E. Principle
- F. Actions
Q20: What are the main benefits of IAM groups?
- A. The ability to create custom permission policies.
- B. Assigning IAM permission policies to more than one user at a time.
- C. Easier user/policy management.
- D. Allowing EC2 instances to gain access to S3.
Q21: What are benefits of using AWS STS?
- A. Grant access to AWS resources without having to create an IAM identity for them
- B. Since credentials are temporary, you don’t have to rotate or revoke them
- C. Temporary security credentials can be extended indefinitely
- D. Temporary security credentials can be restricted to a specific region
Q22: What should the Developer enable on the DynamoDB table to optimize performance and minimize costs?
- A. Amazon DynamoDB auto scaling
- B. Amazon DynamoDB cross-region replication
- C. Amazon DynamoDB Streams
- D. Amazon DynamoDB Accelerator
Top
Q23: A Developer has been asked to create an AWS Elastic Beanstalk environment for a production web application which needs to handle thousands of requests. Currently the dev environment is running on a t1 micro instance. How can the Developer change the EC2 instance type to m4.large?
- A. Use CloudFormation to migrate the Amazon EC2 instance type of the environment from t1 micro to m4.large.
- B. Create a saved configuration file in Amazon S3 with the instance type as m4.large and use the same during environment creation.
- C. Change the instance type to m4.large in the configuration details page of the Create New Environment page.
- D. Change the instance type value for the environment to m4.large by using update autoscaling group CLI command.
Q24: What statements are true about Availability Zones (AZs) and Regions?
- A. There is only one AZ in each AWS Region
- B. AZs are geographically separated inside a region to help protect against natural disasters affecting more than one at a time.
- C. AZs can be moved between AWS Regions based on your needs
- D. There are (almost always) two or more AZs in each AWS Region
Q25: An AWS Region contains:
- A. Edge Locations
- B. Data Centers
- C. AWS Services
- D. Availability Zones
Top
Q26: Which read request in DynamoDB returns a response with the most up-to-date data, reflecting the updates from all prior write operations that were successful?
- A. Eventual Consistent Reads
- B. Conditional reads for Consistency
- C. Strongly Consistent Reads
- D. Not possible
Top
Q27: You’ve been asked to move an existing development environment on the AWS Cloud. This environment consists mainly of Docker based containers. You need to ensure that minimum effort is taken during the migration process. Which of the following step would you consider for this requirement?
- A. Create an Opswork stack and deploy the Docker containers
- B. Create an application and Environment for the Docker containers in the Elastic Beanstalk service
- C. Create an EC2 Instance. Install Docker and deploy the necessary containers.
- D. Create an EC2 Instance. Install Docker and deploy the necessary containers. Add an Autoscaling Group for scalability of the containers.
Top
Q28: You’ve written an application that uploads objects onto an S3 bucket. The size of the object varies between 200 – 500 MB. You’ve seen that the application sometimes takes a longer than expected time to upload the object. You want to improve the performance of the application. Which of the following would you consider?
- A. Create multiple threads and upload the objects in the multiple threads
- B. Write the items in batches for better performance
- C. Use the Multipart upload API
- D. Enable versioning on the Bucket
Top
Q29: A security system monitors 600 cameras, saving image metadata every 1 minute to an Amazon DynamoDb table. Each sample involves 1kb of data, and the data writes are evenly distributed over time. How much write throughput is required for the target table?
- A. 6000
- B. 10
- C. 3600
- D. 600
Q30: What two arguments does a Python Lambda handler function require?
- A. invocation, zone
- B. event, zone
- C. invocation, context
- D. event, context
Top
Q31: Lambda allows you to upload code and dependencies for function packages:
- A. Only from a directly uploaded zip file
- B. Only via SFTP
- C. Only from a zip file in AWS S3
- D. From a zip file in AWS S3 or uploaded directly from elsewhere
Top
Q32: A Lambda deployment package contains:
- A. Function code, libraries, and runtime binaries
- B. Only function code
- C. Function code and libraries not included within the runtime
- D. Only libraries not included within the runtime
Top
Q33: You have instances inside private subnets and a properly configured bastion host instance in a public subnet. None of the instances in the private subnets have a public or Elastic IP address. How can you connect an instance in the private subnet to the open internet to download system updates?
- A. Create and assign EIP to each instance
- B. Create and attach a second IGW to the VPC.
- C. Create and utilize a NAT Gateway
- D. Connect to a VPN
Top
Q34: What feature of VPC networking should you utilize if you want to create “elasticity” in your application’s architecture?
- A. Security Groups
- B. Route Tables
- C. Elastic Load Balancer
- D. Auto Scaling
Top
Q30: Lambda allows you to upload code and dependencies for function packages:
- A. Only from a directly uploaded zip file
- B. Only from a directly uploaded zip file
- C. Only from a zip file in AWS S3
- D. From a zip file in AWS S3 or uploaded directly from elsewhere
Answer:
Top
Q31: An organization is using an Amazon ElastiCache cluster in front of their Amazon RDS instance. The organization would like the Developer to implement logic into the code so that the cluster only retrieves data from RDS when there is a cache miss. What strategy can the Developer implement to achieve this?
- A. Lazy loading
- B. Write-through
- C. Error retries
- D. Exponential backoff
Answer:
Top
Q32: A developer is writing an application that will run on Ec2 instances and read messages from SQS queue. The messages will arrive every 15-60 seconds. How should the Developer efficiently query the queue for new messages?
- A. Use long polling
- B. Set a custom visibility timeout
- C. Use short polling
- D. Implement exponential backoff
Top
Q33: You are using AWS SAM to define a Lambda function and configure CodeDeploy to manage deployment patterns. With new Lambda function working as per expectation which of the following will shift traffic from original Lambda function to new Lambda function in the shortest time frame?
- A. Canary10Percent5Minutes
- B. Linear10PercentEvery10Minutes
- C. Canary10Percent15Minutes
- D. Linear10PercentEvery1Minute
Top
Q34: You are using AWS SAM templates to deploy a serverless application. Which of the following resource will embed application from Amazon S3 buckets?
- A. AWS::Serverless::Api
- B. AWS::Serverless::Application
- C. AWS::Serverless::Layerversion
- D. AWS::Serverless::Function
Top
Q35: You are using AWS Envelope Encryption for encrypting all sensitive data. Which of the followings is True with regards to Envelope Encryption?
- A. Data is encrypted be encrypting Data key which is further encrypted using encrypted Master Key.
- B. Data is encrypted by plaintext Data key which is further encrypted using encrypted Master Key.
- C. Data is encrypted by encrypted Data key which is further encrypted using plaintext Master Key.
- D. Data is encrypted by plaintext Data key which is further encrypted using plaintext Master Key.
Top
Q36: You are developing an application that will be comprised of the following architecture –
- A set of Ec2 instances to process the videos.
- These (Ec2 instances) will be spun up by an autoscaling group.
- SQS Queues to maintain the processing messages.
- There will be 2 pricing tiers.
How will you ensure that the premium customers videos are given more preference?
- A. Create 2 Autoscaling Groups, one for normal and one for premium customers
- B. Create 2 set of Ec2 Instances, one for normal and one for premium customers
- C. Create 2 SQS queus, one for normal and one for premium customers
- D. Create 2 Elastic Load Balancers, one for normal and one for premium customers.
Top
Q37: You are developing an application that will interact with a DynamoDB table. The table is going to take in a lot of read and write operations. Which of the following would be the ideal partition key for the DynamoDB table to ensure ideal performance?
- A. CustomerID
- B. CustomerName
- C. Location
- D. Age
Top
Q38: A developer is making use of AWS services to develop an application. He has been asked to develop the application in a manner to compensate any network delays. Which of the following two mechanisms should he implement in the application?
- A. Multiple SQS queues
- B. Exponential backoff algorithm
- C. Retries in your application code
- D. Consider using the Java sdk.
Top
Q39: An application is being developed that is going to write data to a DynamoDB table. You have to setup the read and write throughput for the table. Data is going to be read at the rate of 300 items every 30 seconds. Each item is of size 6KB. The reads can be eventual consistent reads. What should be the read capacity that needs to be set on the table?
- A. 10
- B. 20
- C. 6
- D. 30
Top
Q40: You are in charge of deploying an application that will be hosted on an EC2 Instance and sit behind an Elastic Load balancer. You have been requested to monitor the incoming connections to the Elastic Load Balancer. Which of the below options can suffice this requirement?
- A. Use AWS CloudTrail with your load balancer
- B. Enable access logs on the load balancer
- C. Use a CloudWatch Logs Agent
- D. Create a custom metric CloudWatch lter on your load balancer
Top
Q41: A static web site has been hosted on a bucket and is now being accessed by users. One of the web pages javascript section has been changed to access data which is hosted in another S3 bucket. Now that same web page is no longer loading in the browser. Which of the following can help alleviate the error?
- A. Enable versioning for the underlying S3 bucket.
- B. Enable Replication so that the objects get replicated to the other bucket
- C. Enable CORS for the bucket
- D. Change the Bucket policy for the bucket to allow access from the other bucket
Top
Q42: Your mobile application includes a photo-sharing service that is expecting tens of thousands of users at launch. You will leverage Amazon Simple Storage Service (S3) for storage of the user Images, and you must decide how to authenticate and authorize your users for access to these images. You also need to manage the storage of these images. Which two of the following approaches should you use? Choose two answers from the options below
- A. Create an Amazon S3 bucket per user, and use your application to generate the S3 URL for the appropriate content.
- B. Use AWS Identity and Access Management (IAM) user accounts as your application-level user database, and offload the burden of authentication from your application code.
- C. Authenticate your users at the application level, and use AWS Security Token Service (STS)to grant token-based authorization to S3 objects.
- D. Authenticate your users at the application level, and send an SMS token message to the user. Create an Amazon S3 bucket with the same name as the SMS message token, and move the user’s objects to that bucket.
Top
Q43: Your current log analysis application takes more than four hours to generate a report of the top 10 users of your web application. You have been asked to implement a system that can report this information in real time, ensure that the report is always up to date, and handle increases in the number of requests to your web application. Choose the option that is cost-effective and can fulfill the requirements.
- A. Publish your data to CloudWatch Logs, and congure your application to Autoscale to handle the load on demand.
- B. Publish your log data to an Amazon S3 bucket. Use AWS CloudFormation to create an Auto Scaling group to scale your post-processing application which is congured to pull down your log les stored an Amazon S3
- C. Post your log data to an Amazon Kinesis data stream, and subscribe your log-processing application so that is congured to process your logging data.
- D. Create a multi-AZ Amazon RDS MySQL cluster, post the logging data to MySQL, and run a map reduce job to retrieve the required information on user counts.
Answer:
Top
Q44: You’ve been instructed to develop a mobile application that will make use of AWS services. You need to decide on a data store to store the user sessions. Which of the following would be an ideal data store for session management?
- A. AWS Simple Storage Service
- B. AWS DynamoDB
- C. AWS RDS
- D. AWS Redshift
Answer:
Top
Q45: Your application currently interacts with a DynamoDB table. Records are inserted into the table via the application. There is now a requirement to ensure that whenever items are updated in the DynamoDB primary table , another record is inserted into a secondary table. Which of the below feature should be used when developing such a solution?
- A. AWS DynamoDB Encryption
- B. AWS DynamoDB Streams
- C. AWS DynamoDB Accelerator
- D. AWSTable Accelerator
Top
Q46: An application has been making use of AWS DynamoDB for its back-end data store. The size of the table has now grown to 20 GB , and the scans on the table are causing throttling errors. Which of the following should now be implemented to avoid such errors?
- A. Large Page size
- B. Reduced page size
- C. Parallel Scans
- D. Sequential scans
Top
Q47: Which of the following is correct way of passing a stage variable to an HTTP URL ? (Select TWO.)
- A. http://example.com/${}/prod
- B. http://example.com/${stageVariables.}/prod
- C. http://${stageVariables.}.example.com/dev/operation
- D. http://${stageVariables}.example.com/dev/operation
- E. http://${}.example.com/dev/operation
- F. http://example.com/${stageVariables}/prod
Top
Q48: Your company is planning on creating new development environments in AWS. They want to make use of their existing Chef recipes which they use for their on-premise configuration for servers in AWS. Which of the following service would be ideal to use in this regard?
- A. AWS Elastic Beanstalk
- B. AWS OpsWork
- C. AWS Cloudformation
- D. AWS SQS
Top
Q49: Your company has developed a web application and is hosting it in an Amazon S3 bucket configured for static website hosting. The users can log in to this app using their Google/Facebook login accounts. The application is using the AWS SDK for JavaScript in the browser to access data stored in an Amazon DynamoDB table. How can you ensure that API keys for access to your data in DynamoDB are kept secure?
- A. Create an Amazon S3 role in IAM with access to the specific DynamoDB tables, and assign it to the bucket hosting your website
- B. Configure S3 bucket tags with your AWS access keys for your bucket hosing your website so that the application can query them for access.
- C. Configure a web identity federation role within IAM to enable access to the correct DynamoDB resources and retrieve temporary credentials
- D. Store AWS keys in global variables within your application and configure the application to use these credentials when making requests.
Top
Q50: Your application currently makes use of AWS Cognito for managing user identities. You want to analyze the information that is stored in AWS Cognito for your application. Which of the following features of AWS Cognito should you use for this purpose?
- A. Cognito Data
- B. Cognito Events
- C. Cognito Streams
- D. Cognito Callbacks
Top
Q51: You’ve developed a set of scripts using AWS Lambda. These scripts need to access EC2 Instances in a VPC. Which of the following needs to be done to ensure that the AWS Lambda function can access the resources in the VPC. Choose 2 answers from the options given below
- A. Ensure that the subnet ID’s are mentioned when configuring the Lambda function
- B. Ensure that the NACL ID’s are mentioned when configuring the Lambda function
- C. Ensure that the Security Group ID’s are mentioned when configuring the Lambda function
- D. Ensure that the VPC Flow Log ID’s are mentioned when configuring the Lambda function
Top
Q52: You’ve currently been tasked to migrate an existing on-premise environment into Elastic Beanstalk. The application does not make use of Docker containers. You also can’t see any relevant environments in the beanstalk service that would be suitable to host your application. What should you consider doing in this case?
- A. Migrate your application to using Docker containers and then migrate the app to the Elastic Beanstalk environment.
- B. Consider using Cloudformation to deploy your environment to Elastic Beanstalk
- C. Consider using Packer to create a custom platform
- D. Consider deploying your application using the Elastic Container Service
Top
Q53: Company B is writing 10 items to the Dynamo DB table every second. Each item is 15.5Kb in size. What would be the required provisioned write throughput for best performance? Choose the correct answer from the options below.
- A. 10
- B. 160
- C. 155
- D. 16
Top
Q54: Which AWS Service can be used to automatically install your application code onto EC2, on premises systems and Lambda?
- A. CodeCommit
- B. X-Ray
- C. CodeBuild
- D. CodeDeploy
Top
Q55: Which AWS service can be used to compile source code, run tests and package code?
- A. CodePipeline
- B. CodeCommit
- C. CodeBuild
- D. CodeDeploy
Top
Q56: How can your prevent CloudFormation from deleting your entire stack on failure? (Choose 2)
- A. Set the Rollback on failure radio button to No in the CloudFormation console
- B. Set Termination Protection to Enabled in the CloudFormation console
- C. Use the –disable-rollback flag with the AWS CLI
- D. Use the –enable-termination-protection protection flag with the AWS CLI
Q57: Which of the following practices allows multiple developers working on the same application to merge code changes frequently, without impacting each other and enables the identification of bugs early on in the release process?
- A. Continuous Integration
- B. Continuous Deployment
- C. Continuous Delivery
- D. Continuous Development
Q58: When deploying application code to EC2, the AppSpec file can be written in which language?
- A. JSON
- B. JSON or YAML
- C. XML
- D. YAML
Q59: Part of your CloudFormation deployment fails due to a mis-configuration, by defaukt what will happen?
- A. CloudFormation will rollback only the failed components
- B. CloudFormation will rollback the entire stack
- C. Failed component will remain available for debugging purposes
- D. CloudFormation will ask you if you want to continue with the deployment
Q60: You want to receive an email whenever a user pushes code to CodeCommit repository, how can you configure this?
- A. Create a new SNS topic and configure it to poll for CodeCommit eveents. Ask all users to subscribe to the topic to receive notifications
- B. Configure a CloudWatch Events rule to send a message to SES which will trigger an email to be sent whenever a user pushes code to the repository.
- C. Configure Notifications in the console, this will create a CloudWatch events rule to send a notification to a SNS topic which will trigger an email to be sent to the user.
- D. Configure a CloudWatch Events rule to send a message to SQS which will trigger an email to be sent whenever a user pushes code to the repository.
Q61: Which AWS service can be used to centrally store and version control your application source code, binaries and libraries
- A. CodeCommit
- B. CodeBuild
- C. CodePipeline
- D. ElasticFileSystem
Q62: You are using CloudFormation to create a new S3 bucket,
which of the following sections would you use to define the properties of your bucket?
- A. Conditions
- B. Parameters
- C. Outputs
- D. Resources
Q63: You are deploying a number of EC2 and RDS instances using CloudFormation. Which section of the CloudFormation template
would you use to define these?
- A. Transforms
- B. Outputs
- C. Resources
- D. Instances
Q64: Which AWS service can be used to fully automate your entire release process?
- A. CodeDeploy
- B. CodePipeline
- C. CodeCommit
- D. CodeBuild
Q65: You want to use the output of your CloudFormation stack as input to another CloudFormation stack. Which sections of the CloudFormation template would you use to help you configure this?
- A. Outputs
- B. Transforms
- C. Resources
- D. Exports
Q66: You have some code located in an S3 bucket that you want to reference in your CloudFormation template. Which section of the template can you use to define this?
- A. Inputs
- B. Resources
- C. Transforms
- D. Files
Q67: You are deploying an application to a number of Ec2 instances using CodeDeploy. What is the name of the file
used to specify source files and lifecycle hooks?
- A. buildspec.yml
- B. appspec.json
- C. appspec.yml
- D. buildspec.json
Q68: Which of the following approaches allows you to re-use pieces of CloudFormation code in multiple templates, for common use cases like provisioning a load balancer or web server?
- A. Share the code using an EBS volume
- B. Copy and paste the code into the template each time you need to use it
- C. Use a cloudformation nested stack
- D. Store the code you want to re-use in an AMI and reference the AMI from within your CloudFormation template.
Q69: In the CodeDeploy AppSpec file, what are hooks used for?
- A. To reference AWS resources that will be used during the deployment
- B. Hooks are reserved for future use
- C. To specify files you want to copy during the deployment.
- D. To specify, scripts or function that you want to run at set points in the deployment lifecycle
Q70: Which command can you use to encrypt a plain text file using CMK?
- A. aws kms-encrypt
- B. aws iam encrypt
- C. aws kms encrypt
- D. aws encrypt
Q72: Which of the following is an encrypted key used by KMS to encrypt your data
- A. Custmoer Mamaged Key
- B. Encryption Key
- C. Envelope Key
- D. Customer Master Key
Q73: Which of the following statements are correct? (Choose 2)
- A. The Customer Master Key is used to encrypt and decrypt the Envelope Key or Data Key
- B. The Envelope Key or Data Key is used to encrypt and decrypt plain text files.
- C. The envelope Key or Data Key is used to encrypt and decrypt the Customer Master Key.
- D. The Customer MasterKey is used to encrypt and decrypt plain text files.
Q74: Which of the following statements is correct in relation to kMS/ (Choose 2)
- A. KMS Encryption keys are regional
- B. You cannot export your customer master key
- C. You can export your customer master key.
- D. KMS encryption Keys are global
AWS Certified Developer Associate exam: Whitepapers
AWS has provided whitepapers to help you understand the technical concepts. Below are the recommended whitepapers for the AWS Certified Developer – Associate Exam.
- Overview of Amazon Web Services
- Architecting for the Cloud: AWS Best Practices
- AWS Security Best Practices whitepaper, August 2016
- AWS Well-Architected Framework whitepaper, November 2017 Version 1.3 DVA-C01 Page |2
- Architecting for the Cloud AWS Best Practices whitepaper, February, 2016
- Practicing Continuous Integration and Continuous Delivery on AWS Accelerating Software Delivery with DevOps whitepaper, June 2017
- Microservices on AWS whitepaper, September 2017
- Serverless Architectures with AWS Lambda whitepaper, November 2017
- Optimizing Enterprise Economics with Serverless Architectures whitepaper, October 2017
- Running Containerized Microservices on AWS whitepaper, November 2017
- Blue/Green Deployments on AWS whitepaper, August 2016
Online Training and Labs for AWS Certified Developer Associates Exam
AWS Developer Associates Jobs
AWS Certified Developer-Associate Exam info and details, How To:
The AWS Certified Developer Associate exam is a multiple choice, multiple answer exam. Here is the Exam Overview:
- Certification Name: AWS Certified Developer Associate.
- Prerequisites for the Exam: None.
- Exam Pattern: Multiple Choice Questions
- The AWS Certified Developer-Associate Examination (DVA-C01) is a pass or fail exam. The examination is scored against a minimum standard established by AWS professionals guided by certification industry best practices and guidelines.
- Your results for the examination are reported as a score from 100 – 1000, with a minimum passing score of 720.
- Exam fees: US $150
- Exam Guide on AWS Website
- Available languages for tests: English, Japanese, Korean, Simplified Chinese
- Read AWS whitepapers
- Register for certification account here.
- Prepare for Certification Here
Exam Content Outline
Domain % of Examination Domain 1: Deployment (22%)
1.1 Deploy written code in AWS using existing CI/CD pipelines, processes, and patterns.
1.2 Deploy applications using Elastic Beanstalk.
1.3 Prepare the application deployment package to be deployed to AWS.
1.4 Deploy serverless applications22% Domain 2: Security (26%)
2.1 Make authenticated calls to AWS services.
2.2 Implement encryption using AWS services.
2.3 Implement application authentication and authorization.26% Domain 3: Development with AWS Services (30%)
3.1 Write code for serverless applications.
3.2 Translate functional requirements into application design.
3.3 Implement application design into application code.
3.4 Write code that interacts with AWS services by using APIs, SDKs, and AWS CLI.30% Domain 4: Refactoring
4.1 Optimize application to best use AWS services and features.
4.2 Migrate existing application code to run on AWS.10% Domain 5: Monitoring and Troubleshooting (10%)
5.1 Write code that can be monitored.
5.2 Perform root cause analysis on faults found in testing or production.10% TOTAL 100%
AWS Certified Developer Associate exam: Additional Information for reference
Below are some useful reference links that would help you to learn about AWS Certified Developer Associate Exam.
- Developing on AWS: An instructor-led live or virtual 3-day course
- https://aws.amazon.com/certification/faqs/
- AWS Digital Training: Application Services, Developer Tools, and other services covered on the exam
- Prepare for AWS Certification
- AWS EC2 Instance info
- AWS Certified Developer Associate Exam Guide
Other Relevant and Recommended AWS Certifications

- AWS Certified Cloud Practitioner
- AWS Certified Solutions Architect – Associate
- AAWS Certified Developer – Associate
- AWS Certified SysOps Administrator – Associate
- AWS Certified Solutions Architect – Professional
- AWS Certified DevOps Engineer – Professional
- AWS Certified Big Data Specialty
- AWS Certified Advanced Networking.
- AWS Certified Security – Specialty