


AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
How to Replace all instances of a string in a file?
- Open the file in read mode using the
open()function. - Read the contents of the file into a string using the
read()method. - Use the
replace()method to replace all instances of the target string with the new string. - Open the file in write mode using the
open()function. - Write the modified string to the file using the
write()method. - Close the file using the
close()method.
Here is an example code snippet:

This will replace all instances of old_string with new_string in the file file.txt.
# Open the file in read mode
with open(‘file.txt’, ‘r’) as f:
# Read the contents of the file into a string
contents = f.read()
# Replace all instances of the target string
contents = contents.replace(‘old_string’, ‘new_string’)
# Open the file in write mode
with open(‘file.txt’, ‘w’) as f:
# Write the modified string to the file
f.write(contents)
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6

 Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more codes)
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more codes)
# Close the file
f.close()
Shell script to replace all instances of a string in a file on Linux & Windows.
On Linux via bash script
sed “s/$stringToReplace/$replaceWith/g” $File_Name > $File_Name
On Windows using Powershell
( get-content $File_Name ) | % { $_ -replace $stringToReplace, $replaceWith } | set-content $File_Name
On Windows using Batch
set str=teh cat in teh hat
echo.%str%
set str=%str:teh=the%
echo.%str%Script Output:
teh cat in teh hat
the cat in the hatOn Windows or Linux using Perl
perl -pi.orig -e “s///g;”
On Windows or Linux using Python
Source:

Search all files containing a specific string
AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
How to search all files containing a specific string on Linux and Windows?
On Linux
grep -rnw ‘directory’ -e “pattern”
grep –include=\*.{txt,log} -rnw ‘directory’ -e “pattern”
This will only search for files with .txt or .log extension.
grep –exclude=*.txt -rnw ‘directory’ -e “pattern”
This will exclude files with .txt extensions.
On Windows
CD Location
FINDSTR /L /S /I /N /C:”pattern” *.log
Browse the internet via command line
AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
How to browse the internet via command line on Linux and Windows?
On Linux
lynx http://google.ca
If you don’t have lynx on your linux installation, you will have to install it. On Linux Red hat, install it like this:
yum list lynx (to check the availability of the package)
yum -y install lynx (to install the package)
you can also use: curl -0 http://yoursite/index.html to get the source code of a specific file.
On Windows
start /max http://google.ca
Will open the url using your default browser.
Check how many CPU cores on Windows and on Linux
AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
How to check how many CPU cores I have on Windows & Linux?
What is a core in a CPU?
In summary, a core is a small CPU or processor built into a big CPU or CPU socket. It can independently perform or process all computational tasks. From this perspective, we can consider a core to be a smaller CPU or a smaller processor within a big processor.
Today, CPUs have been two and 18 cores, each of which can work on a different task. A core can work on one task, while another core works a different task, so the more cores a CPU has, the more efficient it is.
Open a command prompt (Windows) or Terminal (Linux) and type:
- Windows: WMIC CPU Get /Format:List


- Linux: cat /proc/cpuinfo | grep processor | wc -l
For more details on Linux: ls /sys/devices/system/cpu/
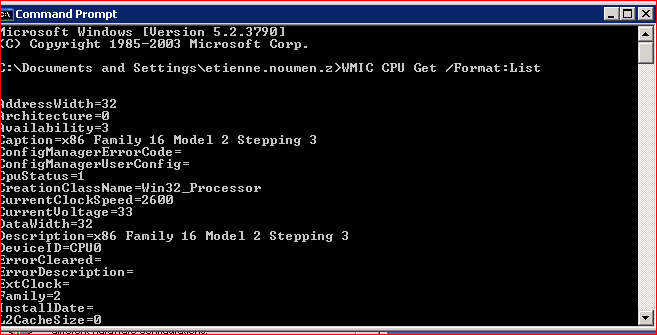
What does 4 CPU cores mean?
A quad-core CPU has four processing cores in a single chip. It is similar to a dual-core CPU, but has four separate processors (rather than two), which can process instructions at the same time.
Linux & App Servers Monitoring Tricks
AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
LINUX & APPLICATION SERVERS MONITORING TRICKS
Objective:
- Prevent server from going down,
- detect what caused the server to go down,
- get servers back after failure.
- Explain what caused the server to fail
I – Regularly watch your monitoring tool(s) (Nagios, Wily,top, …..)
On some of those tools, you can see a graph of the apps CPU Load Average, CPU Used Percentage, Disk Usage percentage, memory used percentage, Network Bandwidth, Swap Used percentage.
II – Check ulimit count (Number of files opened by applications like tomcat, oracle,…)
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more codes)
[Server]# ulimit -n
1024
If the number of files opened is getting closer to ulimit count (1024), increase the ulimit and talk to dev to identify and fix the process that is causing that.
To increase ulimit count for a specific application account, run the command ulimit –n [value]
Ulimit can be set to whatever you want. Its one of those things that’s put in place as a throttle to keep things from going too nuts. Some systems will actually just set it to unlimited.
III- Port Monitoring
Check number of connections to ports used by your apps
IV- Thread dump (stack trace of all threads ) If you have a high cpu percentage

[Server]# kill -3 (The output is printed in catalina.out) to see what is causing this and send it to developers.
V- Disk space /[drive_name] filling up quickly
Identify the file(s) that are filling up the disks. Most of the time ,it will be logs files.
[Server]# du -ks /[drive_name]/* | sort -nr | head
5719076 /[drive_name]/catalina
3675672 /[drive_name]/data
3287436 /[drive_name]/source
2044316 /[drive_name]/servers
319404 /[drive_name]/images
16 /[drive_name]/lost+found
By running this command on the larger folder, that will lead you to the files that eat the disk space.
Back up, remove or empty the file in question given that it won’t break the system.
If the log files are responsible for the disk filling up, let the developer know about it so that they can solve it. In the meantime, empty the log file with the command:
[Log_File_Location]# echo -n > Large_Log_File_Name.log

VI- Watch catalina.out and log4j.out after staging and live deploy, especially when you are restarting the servers.
[Server]# tail -f log4j.log
VII- Start app servers properly
Before restarting app servers, make sure there is no app pid running for that specific server.
[Server_Name]$ ps -ef | grep oracle
Kill the pid for that server.

IX – Cpu Load level
I would say that if we peak under 70% CPU during high traffic, we are doing well and have room. A good level to be ticking over at would be 30% used.
[Server]# top
top – 12:37:29 up 47 days, 23:09, 4 users, load average: 0.20, 0.20, 0.22
Tasks: 189 total, 1 running, 178 sleeping, 10 stopped, 0 zombie
Cpu(s): 1.2%us, 0.1%sy, 0.0%ni, 97.5%id, 1.0%wa, 0.0%hi, 0.1%si, 0.0%st

X- Server specific status pings (To assure the server are up and serving contents)
Write scripts for this
XI- Garbage collection stats
If you are interested in any garbage collection stats there’s the gc.log files on each of the appservers (bad thing about it is it doesn’t do any date stamping so you can see how memory fluctuates but its a difficult to create a chart over time). In the past I’ve thought it might be good idea to write a cron that archived it daily so that you could at least break things down day by day.
XII- DB Connection

XIII- Load Average Monitoring script
Set up a cron that just email sysadmin when the load average is above 3.
XIV – Find out who is monopolizing or eating the CPUs
[Server]# ps -eo pcpu,pid,user,args | sort -k 1 -r | head -10
Active Hydrating Toner, Anti-Aging Replenishing Advanced Face Moisturizer, with Vitamins A, C, E & Natural Botanicals to Promote Skin Balance & Collagen Production, 6.7 Fl Oz



Age Defying 0.3% Retinol Serum, Anti-Aging Dark Spot Remover for Face, Fine Lines & Wrinkle Pore Minimizer, with Vitamin E & Natural Botanicals


Firming Moisturizer, Advanced Hydrating Facial Replenishing Cream, with Hyaluronic Acid, Resveratrol & Natural Botanicals to Restore Skin's Strength, Radiance, and Resilience, 1.75 Oz

Skin Stem Cell Serum


Smartphone 101 - Pick a smartphone for me - android or iOS - Apple iPhone or Samsung Galaxy or Huawei or Xaomi or Google Pixel
Can AI Really Predict Lottery Results? We Asked an Expert.




Djamgatech

Read Photos and PDFs Aloud for me iOS
Read Photos and PDFs Aloud for me android
Read Photos and PDFs Aloud For me Windows 10/11
Read Photos and PDFs Aloud For Amazon
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more)
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6(Email us for more)



FREE 10000+ Quiz Trivia and and Brain Teasers for All Topics including Cloud Computing, General Knowledge, History, Television, Music, Art, Science, Movies, Films, US History, Soccer Football, World Cup, Data Science, Machine Learning, Geography, etc....

List of Freely available programming books - What is the single most influential book every Programmers should read
- Bjarne Stroustrup - The C++ Programming Language
- Brian W. Kernighan, Rob Pike - The Practice of Programming
- Donald Knuth - The Art of Computer Programming
- Ellen Ullman - Close to the Machine
- Ellis Horowitz - Fundamentals of Computer Algorithms
- Eric Raymond - The Art of Unix Programming
- Gerald M. Weinberg - The Psychology of Computer Programming
- James Gosling - The Java Programming Language
- Joel Spolsky - The Best Software Writing I
- Keith Curtis - After the Software Wars
- Richard M. Stallman - Free Software, Free Society
- Richard P. Gabriel - Patterns of Software
- Richard P. Gabriel - Innovation Happens Elsewhere
- Code Complete (2nd edition) by Steve McConnell
- The Pragmatic Programmer
- Structure and Interpretation of Computer Programs
- The C Programming Language by Kernighan and Ritchie
- Introduction to Algorithms by Cormen, Leiserson, Rivest & Stein
- Design Patterns by the Gang of Four
- Refactoring: Improving the Design of Existing Code
- The Mythical Man Month
- The Art of Computer Programming by Donald Knuth
- Compilers: Principles, Techniques and Tools by Alfred V. Aho, Ravi Sethi and Jeffrey D. Ullman
- Gödel, Escher, Bach by Douglas Hofstadter
- Clean Code: A Handbook of Agile Software Craftsmanship by Robert C. Martin
- Effective C++
- More Effective C++
- CODE by Charles Petzold
- Programming Pearls by Jon Bentley
- Working Effectively with Legacy Code by Michael C. Feathers
- Peopleware by Demarco and Lister
- Coders at Work by Peter Seibel
- Surely You're Joking, Mr. Feynman!
- Effective Java 2nd edition
- Patterns of Enterprise Application Architecture by Martin Fowler
- The Little Schemer
- The Seasoned Schemer
- Why's (Poignant) Guide to Ruby
- The Inmates Are Running The Asylum: Why High Tech Products Drive Us Crazy and How to Restore the Sanity
- The Art of Unix Programming
- Test-Driven Development: By Example by Kent Beck
- Practices of an Agile Developer
- Don't Make Me Think
- Agile Software Development, Principles, Patterns, and Practices by Robert C. Martin
- Domain Driven Designs by Eric Evans
- The Design of Everyday Things by Donald Norman
- Modern C++ Design by Andrei Alexandrescu
- Best Software Writing I by Joel Spolsky
- The Practice of Programming by Kernighan and Pike
- Pragmatic Thinking and Learning: Refactor Your Wetware by Andy Hunt
- Software Estimation: Demystifying the Black Art by Steve McConnel
- The Passionate Programmer (My Job Went To India) by Chad Fowler
- Hackers: Heroes of the Computer Revolution
- Algorithms + Data Structures = Programs
- Writing Solid Code
- JavaScript - The Good Parts
- Getting Real by 37 Signals
- Foundations of Programming by Karl Seguin
- Computer Graphics: Principles and Practice in C (2nd Edition)
- Thinking in Java by Bruce Eckel
- The Elements of Computing Systems
- Refactoring to Patterns by Joshua Kerievsky
- Modern Operating Systems by Andrew S. Tanenbaum
- The Annotated Turing
- Things That Make Us Smart by Donald Norman
- The Timeless Way of Building by Christopher Alexander
- The Deadline: A Novel About Project Management by Tom DeMarco
- The C++ Programming Language (3rd edition) by Stroustrup
- Patterns of Enterprise Application Architecture
- Computer Systems - A Programmer's Perspective
- Agile Principles, Patterns, and Practices in C# by Robert C. Martin
- Growing Object-Oriented Software, Guided by Tests
- Framework Design Guidelines by Brad Abrams
- Object Thinking by Dr. David West
- Advanced Programming in the UNIX Environment by W. Richard Stevens
- Hackers and Painters: Big Ideas from the Computer Age
- The Soul of a New Machine by Tracy Kidder
- CLR via C# by Jeffrey Richter
- The Timeless Way of Building by Christopher Alexander
- Design Patterns in C# by Steve Metsker
- Alice in Wonderland by Lewis Carol
- Zen and the Art of Motorcycle Maintenance by Robert M. Pirsig
- About Face - The Essentials of Interaction Design
- Here Comes Everybody: The Power of Organizing Without Organizations by Clay Shirky
- The Tao of Programming
- Computational Beauty of Nature
- Writing Solid Code by Steve Maguire
- Philip and Alex's Guide to Web Publishing
- Object-Oriented Analysis and Design with Applications by Grady Booch
- Effective Java by Joshua Bloch
- Computability by N. J. Cutland
- Masterminds of Programming
- The Tao Te Ching
- The Productive Programmer
- The Art of Deception by Kevin Mitnick
- The Career Programmer: Guerilla Tactics for an Imperfect World by Christopher Duncan
- Paradigms of Artificial Intelligence Programming: Case studies in Common Lisp
- Masters of Doom
- Pragmatic Unit Testing in C# with NUnit by Andy Hunt and Dave Thomas with Matt Hargett
- How To Solve It by George Polya
- The Alchemist by Paulo Coelho
- Smalltalk-80: The Language and its Implementation
- Writing Secure Code (2nd Edition) by Michael Howard
- Introduction to Functional Programming by Philip Wadler and Richard Bird
- No Bugs! by David Thielen
- Rework by Jason Freid and DHH
- JUnit in Action
#BlackOwned #BlackEntrepreneurs #BlackBuniness #AWSCertified #AWSCloudPractitioner #AWSCertification #AWSCLFC02 #CloudComputing #AWSStudyGuide #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AWSBasics #AWSCertified #AWSMachineLearning #AWSCertification #AWSSpecialty #MachineLearning #AWSStudyGuide #CloudComputing #DataScience #AWSCertified #AWSSolutionsArchitect #AWSArchitectAssociate #AWSCertification #AWSStudyGuide #CloudComputing #AWSArchitecture #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AzureFundamentals #AZ900 #MicrosoftAzure #ITCertification #CertificationPrep #StudyMaterials #TechLearning #MicrosoftCertified #AzureCertification #TechBooks
Top 1000 Canada Quiz and trivia: CANADA CITIZENSHIP TEST- HISTORY - GEOGRAPHY - GOVERNMENT- CULTURE - PEOPLE - LANGUAGES - TRAVEL - WILDLIFE - HOCKEY - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Top 1000 Africa Quiz and trivia: HISTORY - GEOGRAPHY - WILDLIFE - CULTURE - PEOPLE - LANGUAGES - TRAVEL - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Exploring the Pros and Cons of Visiting All Provinces and Territories in Canada.


Exploring the Advantages and Disadvantages of Visiting All 50 States in the USA

Health Health, a science-based community to discuss health news and the coronavirus (COVID-19) pandemic
- Parents of boy whose heart stopped for 19 hours were stunned when it started beating againby /u/nbcnews on May 9, 2024 at 6:36 pm
submitted by /u/nbcnews [link] [comments]
- How bird flu caught the dairy industry off guardby /u/scientificamerican on May 9, 2024 at 5:41 pm
submitted by /u/scientificamerican [link] [comments]
- Bill aims to ban potentially hazardous water beads sold as children’s toysby /u/nbcnews on May 9, 2024 at 3:49 pm
submitted by /u/nbcnews [link] [comments]
- AstraZeneca pulls its COVID-19 vaccines from the European marketby /u/taylor325 on May 9, 2024 at 3:48 pm
submitted by /u/taylor325 [link] [comments]
- Medical residents are starting to avoid states with abortion bans, data showsby /u/mainevent45 on May 9, 2024 at 12:54 pm
submitted by /u/mainevent45 [link] [comments]
Today I Learned (TIL) You learn something new every day; what did you learn today? Submit interesting and specific facts about something that you just found out here.
- TIL that the Radio City Rockettes didn’t allow Black dancers in until 1987, claiming that their skin tone would distract from the group’s consistent look.by /u/TertioRationem3 on May 9, 2024 at 3:19 pm
submitted by /u/TertioRationem3 [link] [comments]
- TIL that in November 1923, due to the hyperinflation in Germany post-WW1, one US dollar was worth 4,210,500,000,000 German Marksby /u/9oRo on May 9, 2024 at 3:10 pm
submitted by /u/9oRo [link] [comments]
- TIL that composer Peter Warlock locked his cat outside so it wouldn't die with him before committing suicide by gassing himself.by /u/redfuroff on May 9, 2024 at 2:00 pm
submitted by /u/redfuroff [link] [comments]
- TIL that Andy Dick has been to rehab 20 times.by /u/KragwellCoast on May 9, 2024 at 1:47 pm
submitted by /u/KragwellCoast [link] [comments]
- TIL Alzheimer’s can pass between humans in rare medical accidentsby /u/Spirited-Travel113 on May 9, 2024 at 12:38 pm
submitted by /u/Spirited-Travel113 [link] [comments]
Reddit Science This community is a place to share and discuss new scientific research. Read about the latest advances in astronomy, biology, medicine, physics, social science, and more. Find and submit new publications and popular science coverage of current research.
- The carbon dioxide removal gapby /u/ILikeNeurons on May 9, 2024 at 3:30 pm
submitted by /u/ILikeNeurons [link] [comments]
- Iron serves as a gas pedal driving certain immune cells that cause inflammation in the lungs during an allergic asthma attack – and blocking or limiting iron may reduce the severity of symptomsby /u/giuliomagnifico on May 9, 2024 at 2:58 pm
submitted by /u/giuliomagnifico [link] [comments]
- Researchers discover that individuals with higher levels of narcissism, particularly those exhibiting traits of agentic extraversion, are more likely to set unrealistic future goals.by /u/chrisdh79 on May 9, 2024 at 2:25 pm
submitted by /u/chrisdh79 [link] [comments]
- Centralized industrialization of pork in Europe and America contributes to the global spread of Salmonella entericaby /u/uniofwarwick on May 9, 2024 at 2:02 pm
submitted by /u/uniofwarwick [link] [comments]
- THC lingers in breastmilk with no clear peak point: When breastfeeding mothers used cannabis, its psychoactive component THC showed up in the milk produced. Unlike alcohol, when THC was detected in milk there was no consistent time when its concentration peaked and started to decline.by /u/mvea on May 9, 2024 at 11:44 am
submitted by /u/mvea [link] [comments]
Reddit Sports Sports News and Highlights from the NFL, NBA, NHL, MLB, MLS, and leagues around the world.
- Keefe fired as Maple Leafs coach, no replacement namedby /u/Oldtimer_2 on May 9, 2024 at 3:23 pm
submitted by /u/Oldtimer_2 [link] [comments]
- Yankees slugger Giancarlo Stanton hits 119.9 mph home run, hardest-hit ball in majors this seasonby /u/Oldtimer_2 on May 9, 2024 at 12:58 pm
submitted by /u/Oldtimer_2 [link] [comments]
- Hornets hire Celtics assistant Charles Lee as head coachby /u/Oldtimer_2 on May 9, 2024 at 12:53 pm
submitted by /u/Oldtimer_2 [link] [comments]
- Wimbledon girls finalist suspended for doping on pro tourby /u/Oldtimer_2 on May 9, 2024 at 12:52 pm
submitted by /u/Oldtimer_2 [link] [comments]
- Tiger Woods gets early look at Valhalla ahead of PGA Championshipby /u/PrincessBananas85 on May 9, 2024 at 10:16 am
submitted by /u/PrincessBananas85 [link] [comments]
