


AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
2022 AWS Certified Developer Associate Exam Preparation: Questions and Answers Dump.
Welcome to AWS Certified Developer Associate Exam Preparation:
Definition and Objectives, Top 100 Questions and Answers dump, White papers, Courses, Labs and Training Materials, Exam info and details, References, Jobs, Others AWS Certificates

What is the AWS Certified Developer Associate Exam?
This AWS Certified Developer-Associate Examination is intended for individuals who perform a Developer role. It validates an examinee’s ability to:
- Demonstrate an understanding of core AWS services, uses, and basic AWS architecture best practices
- Demonstrate proficiency in developing, deploying, and debugging cloud-based applications by using AWS
Recommended general IT knowledge
The target candidate should have the following:
– In-depth knowledge of at least one high-level programming language
– Understanding of application lifecycle management
– The ability to write code for serverless applications
– Understanding of the use of containers in the development process
Recommended AWS knowledge
The target candidate should be able to do the following:
- Use the AWS service APIs, CLI, and software development kits (SDKs) to write applications
- Identify key features of AWS services
- Understand the AWS shared responsibility model
- Use a continuous integration and continuous delivery (CI/CD) pipeline to deploy applications on AWS
- Use and interact with AWS services
- Apply basic understanding of cloud-native applications to write code
- Write code by using AWS security best practices (for example, use IAM roles instead of secret and access keys in the code)
- Author, maintain, and debug code modules on AWS
What is considered out of scope for the target candidate?
The following is a non-exhaustive list of related job tasks that the target candidate is not expected to be able to perform. These items are considered out of scope for the exam:
– Design architectures (for example, distributed system, microservices)
– Design and implement CI/CD pipelines
- Administer IAM users and groups
- Administer Amazon Elastic Container Service (Amazon ECS)
- Design AWS networking infrastructure (for example, Amazon VPC, AWS Direct Connect)
- Understand compliance and licensing
Exam content
Response types
There are two types of questions on the exam:
– Multiple choice: Has one correct response and three incorrect responses (distractors)
– Multiple response: Has two or more correct responses out of five or more response options
Select one or more responses that best complete the statement or answer the question. Distractors, or incorrect answers, are response options that a candidate with incomplete knowledge or skill might choose.
Distractors are generally plausible responses that match the content area.
Unanswered questions are scored as incorrect; there is no penalty for guessing. The exam includes 50 questions that will affect your score.
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6

 Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more codes)
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more codes)
Unscored content
The exam includes 15 unscored questions that do not affect your score. AWS collects information about candidate performance on these unscored questions to evaluate these questions for future use as scored questions. These unscored questions are not identified on the exam.
Exam results
The AWS Certified Developer – Associate (DVA-C01) exam is a pass or fail exam. The exam is scored against a minimum standard established by AWS professionals who follow certification industry best practices and guidelines.
Your results for the exam are reported as a scaled score of 100–1,000. The minimum passing score is 720.
Your score shows how you performed on the exam as a whole and whether you passed. Scaled scoring models help equate scores across multiple exam forms that might have slightly different difficulty levels.
Your score report could contain a table of classifications of your performance at each section level. This information is intended to provide general feedback about your exam performance. The exam uses a compensatory scoring model, which means that you do not need to achieve a passing score in each section. You need to pass only the overall exam.
Each section of the exam has a specific weighting, so some sections have more questions than other sections have. The table contains general information that highlights your strengths and weaknesses. Use caution when interpreting section-level feedback.

Content outline
This exam guide includes weightings, test domains, and objectives for the exam. It is not a comprehensive listing of the content on the exam. However, additional context for each of the objectives is available to help guide your preparation for the exam. The following table lists the main content domains and their weightings. The table precedes the complete exam content outline, which includes the additional context.
The percentage in each domain represents only scored content.

Domain 1: Deployment 22%
Domain 2: Security 26%
Domain 3: Development with AWS Services 30%
Domain 4: Refactoring 10%
Domain 5: Monitoring and Troubleshooting 12%
Domain 1: Deployment
1.1 Deploy written code in AWS using existing CI/CD pipelines, processes, and patterns.
– Commit code to a repository and invoke build, test and/or deployment actions
– Use labels and branches for version and release management
– Use AWS CodePipeline to orchestrate workflows against different environments
– Apply AWS CodeCommit, AWS CodeBuild, AWS CodePipeline, AWS CodeStar, and AWS
CodeDeploy for CI/CD purposes
– Perform a roll back plan based on application deployment policy
1.2 Deploy applications using AWS Elastic Beanstalk.
– Utilize existing supported environments to define a new application stack
– Package the application
– Introduce a new application version into the Elastic Beanstalk environment
– Utilize a deployment policy to deploy an application version (i.e., all at once, rolling, rolling with batch, immutable)
– Validate application health using Elastic Beanstalk dashboard
– Use Amazon CloudWatch Logs to instrument application logging

1.3 Prepare the application deployment package to be deployed to AWS.
– Manage the dependencies of the code module (like environment variables, config files and static image files) within the package
– Outline the package/container directory structure and organize files appropriately
– Translate application resource requirements to AWS infrastructure parameters (e.g., memory, cores)
1.4 Deploy serverless applications.
– Given a use case, implement and launch an AWS Serverless Application Model (AWS SAM) template
– Manage environments in individual AWS services (e.g., Differentiate between Development, Test, and Production in Amazon API Gateway)
Domain 2: Security
2.1 Make authenticated calls to AWS services.
– Communicate required policy based on least privileges required by application.
– Assume an IAM role to access a service
– Use the software development kit (SDK) credential provider on-premises or in the cloud to access AWS services (local credentials vs. instance roles)
2.2 Implement encryption using AWS services.
– Encrypt data at rest (client side; server side; envelope encryption) using AWS services
– Encrypt data in transit

2.3 Implement application authentication and authorization.
– Add user sign-up and sign-in functionality for applications with Amazon Cognito identity or user pools
– Use Amazon Cognito-provided credentials to write code that access AWS services.
– Use Amazon Cognito sync to synchronize user profiles and data
– Use developer-authenticated identities to interact between end user devices, backend
authentication, and Amazon Cognito
Domain 3: Development with AWS Services
3.1 Write code for serverless applications.
– Compare and contrast server-based vs. serverless model (e.g., micro services, stateless nature of serverless applications, scaling serverless applications, and decoupling layers of serverless applications)
– Configure AWS Lambda functions by defining environment variables and parameters (e.g., memory, time out, runtime, handler)
– Create an API endpoint using Amazon API Gateway
– Create and test appropriate API actions like GET, POST using the API endpoint
– Apply Amazon DynamoDB concepts (e.g., tables, items, and attributes)
– Compute read/write capacity units for Amazon DynamoDB based on application requirements
– Associate an AWS Lambda function with an AWS event source (e.g., Amazon API Gateway, Amazon CloudWatch event, Amazon S3 events, Amazon Kinesis)
– Invoke an AWS Lambda function synchronously and asynchronously

3.2 Translate functional requirements into application design.
– Determine real-time vs. batch processing for a given use case
– Determine use of synchronous vs. asynchronous for a given use case
– Determine use of event vs. schedule/poll for a given use case
– Account for tradeoffs for consistency models in an application design
Domain 4: Refactoring
4.1 Optimize applications to best use AWS services and features.
Implement AWS caching services to optimize performance (e.g., Amazon ElastiCache, Amazon API Gateway cache)
Apply an Amazon S3 naming scheme for optimal read performance
4.2 Migrate existing application code to run on AWS.
– Isolate dependencies
– Run the application as one or more stateless processes
– Develop in order to enable horizontal scalability
– Externalize state
Domain 5: Monitoring and Troubleshooting

5.1 Write code that can be monitored.
– Create custom Amazon CloudWatch metrics
– Perform logging in a manner available to systems operators
– Instrument application source code to enable tracing in AWS X-Ray
5.2 Perform root cause analysis on faults found in testing or production.
– Interpret the outputs from the logging mechanism in AWS to identify errors in logs
– Check build and testing history in AWS services (e.g., AWS CodeBuild, AWS CodeDeploy, AWS CodePipeline) to identify issues
– Utilize AWS services (e.g., Amazon CloudWatch, VPC Flow Logs, and AWS X-Ray) to locate a specific faulty component
Which key tools, technologies, and concepts might be covered on the exam?
The following is a non-exhaustive list of the tools and technologies that could appear on the exam.
This list is subject to change and is provided to help you understand the general scope of services, features, or technologies on the exam.
The general tools and technologies in this list appear in no particular order.
AWS services are grouped according to their primary functions. While some of these technologies will likely be covered more than others on the exam, the order and placement of them in this list is no indication of relative weight or importance:
– Analytics
– Application Integration
– Containers
– Cost and Capacity Management
– Data Movement
– Developer Tools
– Instances (virtual machines)
– Management and Governance
– Networking and Content Delivery
– Security
– Serverless
AWS services and features
Analytics:
– Amazon Elasticsearch Service (Amazon ES)
– Amazon Kinesis
Application Integration:
– Amazon EventBridge (Amazon CloudWatch Events)
– Amazon Simple Notification Service (Amazon SNS)
– Amazon Simple Queue Service (Amazon SQS)
– AWS Step Functions
Compute:
– Amazon EC2
– AWS Elastic Beanstalk
– AWS Lambda
Containers:
– Amazon Elastic Container Registry (Amazon ECR)
– Amazon Elastic Container Service (Amazon ECS)
– Amazon Elastic Kubernetes Services (Amazon EKS)
Database:
– Amazon DynamoDB
– Amazon ElastiCache
– Amazon RDS
Developer Tools:
– AWS CodeArtifact
– AWS CodeBuild
– AWS CodeCommit
– AWS CodeDeploy
– Amazon CodeGuru
– AWS CodePipeline
– AWS CodeStar
– AWS Fault Injection Simulator
– AWS X-Ray

Management and Governance:
– AWS CloudFormation
– Amazon CloudWatch
Networking and Content Delivery:
– Amazon API Gateway
– Amazon CloudFront
– Elastic Load Balancing
Security, Identity, and Compliance:
– Amazon Cognito
– AWS Identity and Access Management (IAM)
– AWS Key Management Service (AWS KMS)
Storage:
– Amazon S3
Out-of-scope AWS services and features
The following is a non-exhaustive list of AWS services and features that are not covered on the exam.
These services and features do not represent every AWS offering that is excluded from the exam content.
Services or features that are entirely unrelated to the target job roles for the exam are excluded from this list because they are assumed to be irrelevant.
Out-of-scope AWS services and features include the following:
– AWS Application Discovery Service
– Amazon AppStream 2.0
– Amazon Chime
– Amazon Connect
– AWS Database Migration Service (AWS DMS)
– AWS Device Farm
– Amazon Elastic Transcoder
– Amazon GameLift
– Amazon Lex
– Amazon Machine Learning (Amazon ML)
– AWS Managed Services
– Amazon Mobile Analytics
– Amazon Polly
– Amazon QuickSight
– Amazon Rekognition
– AWS Server Migration Service (AWS SMS)
– AWS Service Catalog
– AWS Shield Advanced
– AWS Shield Standard
– AWS Snow Family
– AWS Storage Gateway
– AWS WAF
– Amazon WorkMail
– Amazon WorkSpaces
To succeed with the real exam, do not memorize the answers below. It is very important that you understand why a question is right or wrong and the concepts behind it by carefully reading the reference documents in the answers.
AWS Certified Developer – Associate Practice Questions And Answers Dump
Q0: Your application reads commands from an SQS queue and sends them to web services hosted by your
partners. When a partner’s endpoint goes down, your application continually returns their commands to the queue. The repeated attempts to deliver these commands use up resources. Commands that can’t be delivered must not be lost.
How can you accommodate the partners’ broken web services without wasting your resources?
- A. Create a delay queue and set DelaySeconds to 30 seconds
- B. Requeue the message with a VisibilityTimeout of 30 seconds.
- C. Create a dead letter queue and set the Maximum Receives to 3.
- D. Requeue the message with a DelaySeconds of 30 seconds.

Top
Q1: A developer is writing an application that will store data in a DynamoDB table. The ratio of reads operations to write operations will be 1000 to 1, with the same data being accessed frequently.
What should the Developer enable on the DynamoDB table to optimize performance and minimize costs?
- A. Amazon DynamoDB auto scaling
- B. Amazon DynamoDB cross-region replication
- C. Amazon DynamoDB Streams
- D. Amazon DynamoDB Accelerator
Top
Q2: You are creating a DynamoDB table with the following attributes:
- PurchaseOrderNumber (partition key)
- CustomerID
- PurchaseDate
- TotalPurchaseValue
One of your applications must retrieve items from the table to calculate the total value of purchases for a
particular customer over a date range. What secondary index do you need to add to the table?
- A. Local secondary index with a partition key of CustomerID and sort key of PurchaseDate; project the
TotalPurchaseValue attribute - B. Local secondary index with a partition key of PurchaseDate and sort key of CustomerID; project the
TotalPurchaseValue attribute - C. Global secondary index with a partition key of CustomerID and sort key of PurchaseDate; project the
TotalPurchaseValue attribute - D. Global secondary index with a partition key of PurchaseDate and sort key of CustomerID; project the
TotalPurchaseValue attribute

Top
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:

Q3: When referencing the remaining time left for a Lambda function to run within the function’s code you would use:
- A. The event object
- B. The timeLeft object
- C. The remains object
- D. The context object
Top
Q4: What two arguments does a Python Lambda handler function require?
- A. invocation, zone
- B. event, zone
- C. invocation, context
- D. event, context
Q5: Lambda allows you to upload code and dependencies for function packages:
- A. Only from a directly uploaded zip file
- B. Only via SFTP
- C. Only from a zip file in AWS S3
- D. From a zip file in AWS S3 or uploaded directly from elsewhere
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q6: A Lambda deployment package contains:
- A. Function code, libraries, and runtime binaries
- B. Only function code
- C. Function code and libraries not included within the runtime
- D. Only libraries not included within the runtime
Q7: You are attempting to SSH into an EC2 instance that is located in a public subnet. However, you are currently receiving a timeout error trying to connect. What could be a possible cause of this connection issue?
- A. The security group associated with the EC2 instance has an inbound rule that allows SSH traffic, but does not have an outbound rule that allows SSH traffic.
- B. The security group associated with the EC2 instance has an inbound rule that allows SSH traffic AND has an outbound rule that explicitly denies SSH traffic.
- C. The security group associated with the EC2 instance has an inbound rule that allows SSH traffic AND the associated NACL has both an inbound and outbound rule that allows SSH traffic.
- D. The security group associated with the EC2 instance does not have an inbound rule that allows SSH traffic AND the associated NACL does not have an outbound rule that allows SSH traffic.
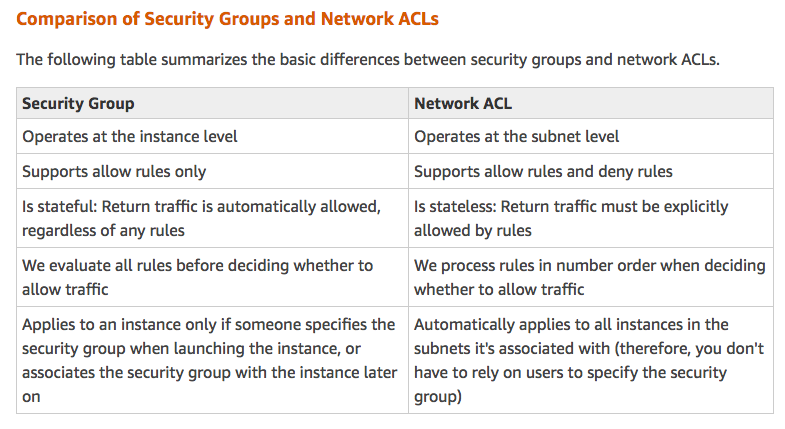
Top
Q8: You have instances inside private subnets and a properly configured bastion host instance in a public subnet. None of the instances in the private subnets have a public or Elastic IP address. How can you connect an instance in the private subnet to the open internet to download system updates?
- A. Create and assign EIP to each instance
- B. Create and attach a second IGW to the VPC.
- C. Create and utilize a NAT Gateway
- D. Connect to a VPN
Top
Q9: What feature of VPC networking should you utilize if you want to create “elasticity” in your application’s architecture?
- A. Security Groups
- B. Route Tables
- C. Elastic Load Balancer
- D. Auto Scaling
Top
Q10: Lambda allows you to upload code and dependencies for function packages:
- A. Only from a directly uploaded zip file
- B. Only from a directly uploaded zip file
- C. Only from a zip file in AWS S3
- D. From a zip file in AWS S3 or uploaded directly from elsewhere
Q11: You’re writing a script with an AWS SDK that uses the AWS API Actions and want to create AMIs for non-EBS backed AMIs for you. Which API call should occurs in the final process of creating an AMI?
- A. RegisterImage
- B. CreateImage
- C. ami-register-image
- D. ami-create-image
Q12: When dealing with session state in EC2-based applications using Elastic load balancers which option is generally thought of as the best practice for managing user sessions?
- A. Having the ELB distribute traffic to all EC2 instances and then having the instance check a caching solution like ElastiCache running Redis or Memcached for session information
- B. Permenantly assigning users to specific instances and always routing their traffic to those instances
- C. Using Application-generated cookies to tie a user session to a particular instance for the cookie duration
- D. Using Elastic Load Balancer generated cookies to tie a user session to a particular instance
Q13: Which API call would best be used to describe an Amazon Machine Image?
- A. ami-describe-image
- B. ami-describe-images
- C. DescribeImage
- D. DescribeImages
Q14: What is one key difference between an Amazon EBS-backed and an instance-store backed instance?
- A. Autoscaling requires using Amazon EBS-backed instances
- B. Virtual Private Cloud requires EBS backed instances
- C. Amazon EBS-backed instances can be stopped and restarted without losing data
- D. Instance-store backed instances can be stopped and restarted without losing data
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q15: After having created a new Linux instance on Amazon EC2, and downloaded the .pem file (called Toto.pem) you try and SSH into your IP address (54.1.132.33) using the following command.
ssh -i my_key.pem ec2-user@52.2.222.22
However you receive the following error.
@@@@@@@@ WARNING: UNPROTECTED PRIVATE KEY FILE! @ @@@@@@@@@@@@@@@@@@@
What is the most probable reason for this and how can you fix it?
- A. You do not have root access on your terminal and need to use the sudo option for this to work.
- B. You do not have enough permissions to perform the operation.
- C. Your key file is encrypted. You need to use the -u option for unencrypted not the -i option.
- D. Your key file must not be publicly viewable for SSH to work. You need to modify your .pem file to limit permissions.
Q16: You have an EBS root device on /dev/sda1 on one of your EC2 instances. You are having trouble with this particular instance and you need to either Stop/Start, Reboot or Terminate the instance but you do NOT want to lose any data that you have stored on /dev/sda1. However, you are unsure if changing the instance state in any of the aforementioned ways will cause you to lose data stored on the EBS volume. Which of the below statements best describes the effect each change of instance state would have on the data you have stored on /dev/sda1?
- A. Whether you stop/start, reboot or terminate the instance it does not matter because data on an EBS volume is not ephemeral and the data will not be lost regardless of what method is used.
- B. If you stop/start the instance the data will not be lost. However if you either terminate or reboot the instance the data will be lost.
- C. Whether you stop/start, reboot or terminate the instance it does not matter because data on an EBS volume is ephemeral and it will be lost no matter what method is used.
- D. The data will be lost if you terminate the instance, however the data will remain on /dev/sda1 if you reboot or stop/start the instance because data on an EBS volume is not ephemeral.
Q17: EC2 instances are launched from Amazon Machine Images (AMIs). A given public AMI:
- A. Can only be used to launch EC2 instances in the same AWS availability zone as the AMI is stored
- B. Can only be used to launch EC2 instances in the same country as the AMI is stored
- C. Can only be used to launch EC2 instances in the same AWS region as the AMI is stored
- D. Can be used to launch EC2 instances in any AWS region
Q18: Which of the following statements is true about the Elastic File System (EFS)?
- A. EFS can scale out to meet capacity requirements and scale back down when no longer needed
- B. EFS can be used by multiple EC2 instances simultaneously
- C. EFS cannot be used by an instance using EBS
- D. EFS can be configured on an instance before launch just like an IAM role or EBS volumes
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q19: IAM Policies, at a minimum, contain what elements?
- A. ID
- B. Effects
- C. Resources
- D. Sid
- E. Principle
- F. Actions
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q20: What are the main benefits of IAM groups?
- A. The ability to create custom permission policies.
- B. Assigning IAM permission policies to more than one user at a time.
- C. Easier user/policy management.
- D. Allowing EC2 instances to gain access to S3.
Q21: What are benefits of using AWS STS?
- A. Grant access to AWS resources without having to create an IAM identity for them
- B. Since credentials are temporary, you don’t have to rotate or revoke them
- C. Temporary security credentials can be extended indefinitely
- D. Temporary security credentials can be restricted to a specific region
Q22: What should the Developer enable on the DynamoDB table to optimize performance and minimize costs?
- A. Amazon DynamoDB auto scaling
- B. Amazon DynamoDB cross-region replication
- C. Amazon DynamoDB Streams
- D. Amazon DynamoDB Accelerator
Top
Q23: A Developer has been asked to create an AWS Elastic Beanstalk environment for a production web application which needs to handle thousands of requests. Currently the dev environment is running on a t1 micro instance. How can the Developer change the EC2 instance type to m4.large?
- A. Use CloudFormation to migrate the Amazon EC2 instance type of the environment from t1 micro to m4.large.
- B. Create a saved configuration file in Amazon S3 with the instance type as m4.large and use the same during environment creation.
- C. Change the instance type to m4.large in the configuration details page of the Create New Environment page.
- D. Change the instance type value for the environment to m4.large by using update autoscaling group CLI command.
Q24: What statements are true about Availability Zones (AZs) and Regions?
- A. There is only one AZ in each AWS Region
- B. AZs are geographically separated inside a region to help protect against natural disasters affecting more than one at a time.
- C. AZs can be moved between AWS Regions based on your needs
- D. There are (almost always) two or more AZs in each AWS Region
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q25: An AWS Region contains:
- A. Edge Locations
- B. Data Centers
- C. AWS Services
- D. Availability Zones
Top
Q26: Which read request in DynamoDB returns a response with the most up-to-date data, reflecting the updates from all prior write operations that were successful?
- A. Eventual Consistent Reads
- B. Conditional reads for Consistency
- C. Strongly Consistent Reads
- D. Not possible
Top
Q27: You’ ve been asked to move an existing development environment on the AWS Cloud. This environment consists mainly of Docker based containers. You need to ensure that minimum effort is taken during the migration process. Which of the following step would you consider for this requirement?
- A. Create an Opswork stack and deploy the Docker containers
- B. Create an application and Environment for the Docker containers in the Elastic Beanstalk service
- C. Create an EC2 Instance. Install Docker and deploy the necessary containers.
- D. Create an EC2 Instance. Install Docker and deploy the necessary containers. Add an Autoscaling Group for scalability of the containers.
Top
Q28: You’ve written an application that uploads objects onto an S3 bucket. The size of the object varies between 200 – 500 MB. You’ve seen that the application sometimes takes a longer than expected time to upload the object. You want to improve the performance of the application. Which of the following would you consider?
- A. Create multiple threads and upload the objects in the multiple threads
- B. Write the items in batches for better performance
- C. Use the Multipart upload API
- D. Enable versioning on the Bucket
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Top
Q29: A security system monitors 600 cameras, saving image metadata every 1 minute to an Amazon DynamoDb table. Each sample involves 1kb of data, and the data writes are evenly distributed over time. How much write throughput is required for the target table?
- A. 6000
- B. 10
- C. 3600
- D. 600
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q30: What two arguments does a Python Lambda handler function require?
- A. invocation, zone
- B. event, zone
- C. invocation, context
- D. event, context
Top
Q31: Lambda allows you to upload code and dependencies for function packages:
- A. Only from a directly uploaded zip file
- B. Only via SFTP
- C. Only from a zip file in AWS S3
- D. From a zip file in AWS S3 or uploaded directly from elsewhere
Top
Q32: A Lambda deployment package contains:
- A. Function code, libraries, and runtime binaries
- B. Only function code
- C. Function code and libraries not included within the runtime
- D. Only libraries not included within the runtime
Top
Q33: You have instances inside private subnets and a properly configured bastion host instance in a public subnet. None of the instances in the private subnets have a public or Elastic IP address. How can you connect an instance in the private subnet to the open internet to download system updates?
- A. Create and assign EIP to each instance
- B. Create and attach a second IGW to the VPC.
- C. Create and utilize a NAT Gateway
- D. Connect to a VPN
Top
Q34: What feature of VPC networking should you utilize if you want to create “elasticity” in your application’s architecture?
- A. Security Groups
- B. Route Tables
- C. Elastic Load Balancer
- D. Auto Scaling
Top
Q30: Lambda allows you to upload code and dependencies for function packages:
- A. Only from a directly uploaded zip file
- B. Only from a directly uploaded zip file
- C. Only from a zip file in AWS S3
- D. From a zip file in AWS S3 or uploaded directly from elsewhere
Answer:
Top
Q31: An organization is using an Amazon ElastiCache cluster in front of their Amazon RDS instance. The organization would like the Developer to implement logic into the code so that the cluster only retrieves data from RDS when there is a cache miss. What strategy can the Developer implement to achieve this?
- A. Lazy loading
- B. Write-through
- C. Error retries
- D. Exponential backoff
Answer:
Top
Q32: A developer is writing an application that will run on Ec2 instances and read messages from SQS queue. The nessages will arrive every 15-60 seconds. How should the Developer efficiently query the queue for new messages?
- A. Use long polling
- B. Set a custom visibility timeout
- C. Use short polling
- D. Implement exponential backoff
Top
Q33: You are using AWS SAM to define a Lambda function and configure CodeDeploy to manage deployment patterns. With new Lambda function working as per expectation which of the following will shift traffic from original Lambda function to new Lambda function in the shortest time frame?
- A. Canary10Percent5Minutes
- B. Linear10PercentEvery10Minutes
- C. Canary10Percent15Minutes
- D. Linear10PercentEvery1Minute
Top
Q34: You are using AWS SAM templates to deploy a serverless application. Which of the following resource will embed application from Amazon S3 buckets?
- A. AWS::Serverless::Api
- B. AWS::Serverless::Application
- C. AWS::Serverless::Layerversion
- D. AWS::Serverless::Function
Top
Q35: You are using AWS Envelope Encryption for encrypting all sensitive data. Which of the followings is True with regards to Envelope Encryption?
- A. Data is encrypted be encrypting Data key which is further encrypted using encrypted Master Key.
- B. Data is encrypted by plaintext Data key which is further encrypted using encrypted Master Key.
- C. Data is encrypted by encrypted Data key which is further encrypted using plaintext Master Key.
- D. Data is encrypted by plaintext Data key which is further encrypted using plaintext Master Key.
Top
Q36: You are developing an application that will be comprised of the following architecture –
- A set of Ec2 instances to process the videos.
- These (Ec2 instances) will be spun up by an autoscaling group.
- SQS Queues to maintain the processing messages.
- There will be 2 pricing tiers.
How will you ensure that the premium customers videos are given more preference?
- A. Create 2 Autoscaling Groups, one for normal and one for premium customers
- B. Create 2 set of Ec2 Instances, one for normal and one for premium customers
- C. Create 2 SQS queus, one for normal and one for premium customers
- D. Create 2 Elastic Load Balancers, one for normal and one for premium customers.
Top
Q37: You are developing an application that will interact with a DynamoDB table. The table is going to take in a lot of read and write operations. Which of the following would be the ideal partition key for the DynamoDB table to ensure ideal performance?
- A. CustomerID
- B. CustomerName
- C. Location
- D. Age
Top
Q38: A developer is making use of AWS services to develop an application. He has been asked to develop the application in a manner to compensate any network delays. Which of the following two mechanisms should he implement in the application?
- A. Multiple SQS queues
- B. Exponential backoff algorithm
- C. Retries in your application code
- D. Consider using the Java sdk.
Top
Q39: An application is being developed that is going to write data to a DynamoDB table. You have to setup the read and write throughput for the table. Data is going to be read at the rate of 300 items every 30 seconds. Each item is of size 6KB. The reads can be eventual consistent reads. What should be the read capacity that needs to be set on the table?
- A. 10
- B. 20
- C. 6
- D. 30
Top
Q40: You are in charge of deploying an application that will be hosted on an EC2 Instance and sit behind an Elastic Load balancer. You have been requested to monitor the incoming connections to the Elastic Load Balancer. Which of the below options can suffice this requirement?
- A. Use AWS CloudTrail with your load balancer
- B. Enable access logs on the load balancer
- C. Use a CloudWatch Logs Agent
- D. Create a custom metric CloudWatch lter on your load balancer
Top
Q41: A static web site has been hosted on a bucket and is now being accessed by users. One of the web pages javascript section has been changed to access data which is hosted in another S3 bucket. Now that same web page is no longer loading in the browser. Which of the following can help alleviate the error?
- A. Enable versioning for the underlying S3 bucket.
- B. Enable Replication so that the objects get replicated to the other bucket
- C. Enable CORS for the bucket
- D. Change the Bucket policy for the bucket to allow access from the other bucket
Top
Q42: Your mobile application includes a photo-sharing service that is expecting tens of thousands of users at launch. You will leverage Amazon Simple Storage Service (S3) for storage of the user Images, and you must decide how to authenticate and authorize your users for access to these images. You also need to manage the storage of these images. Which two of the following approaches should you use? Choose two answers from the options below
- A. Create an Amazon S3 bucket per user, and use your application to generate the S3 URL for the appropriate content.
- B. Use AWS Identity and Access Management (IAM) user accounts as your application-level user database, and offload the burden of authentication from your application code.
- C. Authenticate your users at the application level, and use AWS Security Token Service (STS)to grant token-based authorization to S3 objects.
- D. Authenticate your users at the application level, and send an SMS token message to the user. Create an Amazon S3 bucket with the same name as the SMS message token, and move the user’s objects to that bucket.
Top
Q43: Your current log analysis application takes more than four hours to generate a report of the top 10 users of your web application. You have been asked to implement a system that can report this information in real time, ensure that the report is always up to date, and handle increases in the number of requests to your web application. Choose the option that is cost-effective and can fulfill the requirements.
- A. Publish your data to CloudWatch Logs, and congure your application to Autoscale to handle the load on demand.
- B. Publish your log data to an Amazon S3 bucket. Use AWS CloudFormation to create an Auto Scaling group to scale your post-processing application which is congured to pull down your log les stored an Amazon S3
- C. Post your log data to an Amazon Kinesis data stream, and subscribe your log-processing application so that is congured to process your logging data.
- D. Create a multi-AZ Amazon RDS MySQL cluster, post the logging data to MySQL, and run a map reduce job to retrieve the required information on user counts.
Answer:
Top
Q44: You’ve been instructed to develop a mobile application that will make use of AWS services. You need to decide on a data store to store the user sessions. Which of the following would be an ideal data store for session management?
- A. AWS Simple Storage Service
- B. AWS DynamoDB
- C. AWS RDS
- D. AWS Redshift
Answer:
Top
Q45: Your application currently interacts with a DynamoDB table. Records are inserted into the table via the application. There is now a requirement to ensure that whenever items are updated in the DynamoDB primary table , another record is inserted into a secondary table. Which of the below feature should be used when developing such a solution?
- A. AWS DynamoDB Encryption
- B. AWS DynamoDB Streams
- C. AWS DynamoDB Accelerator
- D. AWSTable Accelerator
Top
Q46: An application has been making use of AWS DynamoDB for its back-end data store. The size of the table has now grown to 20 GB , and the scans on the table are causing throttling errors. Which of the following should now be implemented to avoid such errors?
- A. Large Page size
- B. Reduced page size
- C. Parallel Scans
- D. Sequential scans
Top
Q47: Which of the following is correct way of passing a stage variable to an HTTP URL ? (Select TWO.)
- A. http://example.com/${}/prod
- B. http://example.com/${stageVariables.}/prod
- C. http://${stageVariables.}.example.com/dev/operation
- D. http://${stageVariables}.example.com/dev/operation
- E. http://${}.example.com/dev/operation
- F. http://example.com/${stageVariables}/prod
Top
Q48: Your company is planning on creating new development environments in AWS. They want to make use of their existing Chef recipes which they use for their on-premise configuration for servers in AWS. Which of the following service would be ideal to use in this regard?
- A. AWS Elastic Beanstalk
- B. AWS OpsWork
- C. AWS Cloudformation
- D. AWS SQS
Top
Q49: Your company has developed a web application and is hosting it in an Amazon S3 bucket configured for static website hosting. The users can log in to this app using their Google/Facebook login accounts. The application is using the AWS SDK for JavaScript in the browser to access data stored in an Amazon DynamoDB table. How can you ensure that API keys for access to your data in DynamoDB are kept secure?
- A. Create an Amazon S3 role in IAM with access to the specific DynamoDB tables, and assign it to the bucket hosting your website
- B. Configure S3 bucket tags with your AWS access keys for your bucket hosing your website so that the application can query them for access.
- C. Configure a web identity federation role within IAM to enable access to the correct DynamoDB resources and retrieve temporary credentials
- D. Store AWS keys in global variables within your application and configure the application to use these credentials when making requests.
Top
Q50: Your application currently makes use of AWS Cognito for managing user identities. You want to analyze the information that is stored in AWS Cognito for your application. Which of the following features of AWS Cognito should you use for this purpose?
- A. Cognito Data
- B. Cognito Events
- C. Cognito Streams
- D. Cognito Callbacks
Top
Q51: You’ve developed a set of scripts using AWS Lambda. These scripts need to access EC2 Instances in a VPC. Which of the following needs to be done to ensure that the AWS Lambda function can access the resources in the VPC. Choose 2 answers from the options given below
- A. Ensure that the subnet ID’s are mentioned when conguring the Lambda function
- B. Ensure that the NACL ID’s are mentioned when conguring the Lambda function
- C. Ensure that the Security Group ID’s are mentioned when conguring the Lambda function
- D. Ensure that the VPC Flow Log ID’s are mentioned when conguring the Lambda function
Top
Q52: You’ve currently been tasked to migrate an existing on-premise environment into Elastic Beanstalk. The application does not make use of Docker containers. You also can’t see any relevant environments in the beanstalk service that would be suitable to host your application. What should you consider doing in this case?
- A. Migrate your application to using Docker containers and then migrate the app to the Elastic Beanstalk environment.
- B. Consider using Cloudformation to deploy your environment to Elastic Beanstalk
- C. Consider using Packer to create a custom platform
- D. Consider deploying your application using the Elastic Container Service
Top
Q53: Company B is writing 10 items to the Dynamo DB table every second. Each item is 15.5Kb in size. What would be the required provisioned write throughput for best performance? Choose the correct answer from the options below.
- A. 10
- B. 160
- C. 155
- D. 16
Top
Q54: Which AWS Service can be used to automatically install your application code onto EC2, on premises systems and Lambda?
- A. CodeCommit
- B. X-Ray
- C. CodeBuild
- D. CodeDeploy
Top
Q55: Which AWS service can be used to compile source code, run tests and package code?
- A. CodePipeline
- B. CodeCommit
- C. CodeBuild
- D. CodeDeploy
Top
Q56: How can your prevent CloudFormation from deleting your entire stack on failure? (Choose 2)
- A. Set the Rollback on failure radio button to No in the CloudFormation console
- B. Set Termination Protection to Enabled in the CloudFormation console
- C. Use the –disable-rollback flag with the AWS CLI
- D. Use the –enable-termination-protection protection flag with the AWS CLI
Q57: Which of the following practices allows multiple developers working on the same application to merge code changes frequently, without impacting each other and enables the identification of bugs early on in the release process?
- A. Continuous Integration
- B. Continuous Deployment
- C. Continuous Delivery
- D. Continuous Development
Q58: When deploying application code to EC2, the AppSpec file can be written in which language?
- A. JSON
- B. JSON or YAML
- C. XML
- D. YAML
Q59: Part of your CloudFormation deployment fails due to a mis-configuration, by defaukt what will happen?
- A. CloudFormation will rollback only the failed components
- B. CloudFormation will rollback the entire stack
- C. Failed component will remain available for debugging purposes
- D. CloudFormation will ask you if you want to continue with the deployment
Top
Q60: You want to receive an email whenever a user pushes code to CodeCommit repository, how can you configure this?
- A. Create a new SNS topic and configure it to poll for CodeCommit eveents. Ask all users to subscribe to the topic to receive notifications
- B. Configure a CloudWatch Events rule to send a message to SES which will trigger an email to be sent whenever a user pushes code to the repository.
- C. Configure Notifications in the console, this will create a CloudWatch events rule to send a notification to a SNS topic which will trigger an email to be sent to the user.
- D. Configure a CloudWatch Events rule to send a message to SQS which will trigger an email to be sent whenever a user pushes code to the repository.
Top
Q61: Which AWS service can be used to centrally store and version control your application source code, binaries and libraries
- A. CodeCommit
- B. CodeBuild
- C. CodePipeline
- D. ElasticFileSystem
Top
Q62: You are using CloudFormation to create a new S3 bucket, which of the following sections would you use to define the properties of your bucket?
- A. Conditions
- B. Parameters
- C. Outputs
- D. Resources
Top
Q63: You are deploying a number of EC2 and RDS instances using CloudFormation. Which section of the CloudFormation template would you use to define these?
- A. Transforms
- B. Outputs
- C. Resources
- D. Instances
Top
Q64: Which AWS service can be used to fully automate your entire release process?
- A. CodeDeploy
- B. CodePipeline
- C. CodeCommit
- D. CodeBuild
Top
Q65: You want to use the output of your CloudFormation stack as input to another CloudFormation stack. Which sections of the CloudFormation template would you use to help you configure this?
- A. Outputs
- B. Transforms
- C. Resources
- D. Exports
Top
Q66: You have some code located in an S3 bucket that you want to reference in your CloudFormation template. Which section of the template can you use to define this?
- A. Inputs
- B. Resources
- C. Transforms
- D. Files
Top
Q67: You are deploying an application to a number of Ec2 instances using CodeDeploy. What is the name of the file
used to specify source files and lifecycle hooks?
- A. buildspec.yml
- B. appspec.json
- C. appspec.yml
- D. buildspec.json
Q68: Which of the following approaches allows you to re-use pieces of CloudFormation code in multiple templates, for common use cases like provisioning a load balancer or web server?
- A. Share the code using an EBS volume
- B. Copy and paste the code into the template each time you need to use it
- C. Use a cloudformation nested stack
- D. Store the code you want to re-use in an AMI and reference the AMI from within your CloudFormation template.
Q69: In the CodeDeploy AppSpec file, what are hooks used for?
- A. To reference AWS resources that will be used during the deployment
- B. Hooks are reserved for future use
- C. To specify files you want to copy during the deployment.
- D. To specify, scripts or function that you want to run at set points in the deployment lifecycle
Q70: Which command can you use to encrypt a plain text file using CMK?
- A. aws kms-encrypt
- B. aws iam encrypt
- C. aws kms encrypt
- D. aws encrypt
Q72: Which of the following is an encrypted key used by KMS to encrypt your data
- A. Custmoer Mamaged Key
- B. Encryption Key
- C. Envelope Key
- D. Customer Master Key
Q73: Which of the following statements are correct? (Choose 2)
- A. The Customer Master Key is used to encrypt and decrypt the Envelope Key or Data Key
- B. The Envelope Key or Data Key is used to encrypt and decrypt plain text files.
- C. The envelope Key or Data Key is used to encrypt and decrypt the Customer Master Key.
- D. The Customer MasterKey is used to encrypt and decrypt plain text files.
Q74: Which of the following statements is correct in relation to kMS/ (Choose 2)
- A. KMS Encryption keys are regional
- B. You cannot export your customer master key
- C. You can export your customer master key.
- D. KMS encryption Keys are global
Q75: A developer is preparing a deployment package for a Java implementation of an AWS Lambda function. What should the developer include in the deployment package? (Select TWO.)
A. Compiled application code
B. Java runtime environment
C. References to the event sources
D. Lambda execution role
E. Application dependencies
Q76: A developer uses AWS CodeDeploy to deploy a Python application to a fleet of Amazon EC2 instances that run behind an Application Load Balancer. The instances run in an Amazon EC2 Auto Scaling group across multiple Availability Zones. What should the developer include in the CodeDeploy deployment package?
A. A launch template for the Amazon EC2 Auto Scaling group
B. A CodeDeploy AppSpec file
C. An EC2 role that grants the application access to AWS services
D. An IAM policy that grants the application access to AWS services
Q76: A company is working on a project to enhance its serverless application development process. The company hosts applications on AWS Lambda. The development team regularly updates the Lambda code and wants to use stable code in production. Which combination of steps should the development team take to configure Lambda functions to meet both development and production requirements? (Select TWO.)
A. Create a new Lambda version every time a new code release needs testing.
B. Create two Lambda function aliases. Name one as Production and the other as Development. Point the Production alias to a production-ready unqualified Amazon Resource Name (ARN) version. Point the Development alias to the $LATEST version.
C. Create two Lambda function aliases. Name one as Production and the other as Development. Point the Production alias to the production-ready qualified Amazon Resource Name (ARN) version. Point the Development alias to the variable LAMBDA_TASK_ROOT.
D. Create a new Lambda layer every time a new code release needs testing.
E. Create two Lambda function aliases. Name one as Production and the other as Development. Point the Production alias to a production-ready Lambda layer Amazon Resource Name (ARN). Point the Development alias to the $LATEST layer ARN.
Q77: Each time a developer publishes a new version of an AWS Lambda function, all the dependent event source mappings need to be updated with the reference to the new version’s Amazon Resource Name (ARN). These updates are time consuming and error-prone. Which combination of actions should the developer take to avoid performing these updates when publishing a new Lambda version? (Select TWO.)
A. Update event source mappings with the ARN of the Lambda layer.
B. Point a Lambda alias to a new version of the Lambda function.
C. Create a Lambda alias for each published version of the Lambda function.
D. Point a Lambda alias to a new Lambda function alias.
E. Update the event source mappings with the Lambda alias ARN.
Q78: A company wants to store sensitive user data in Amazon S3 and encrypt this data at rest. The company must manage the encryption keys and use Amazon S3 to perform the encryption. How can a developer meet these requirements?
A. Enable default encryption for the S3 bucket by using the option for server-side encryption with customer-provided encryption keys (SSE-C).
B. Enable client-side encryption with an encryption key. Upload the encrypted object to the S3 bucket.
C. Enable server-side encryption with Amazon S3 managed encryption keys (SSE-S3). Upload an object to the S3 bucket.
D. Enable server-side encryption with customer-provided encryption keys (SSE-C). Upload an object to the S3 bucket.
Q79: A company is developing a Python application that submits data to an Amazon DynamoDB table. The company requires client-side encryption of specific data items and end-to-end protection for the encrypted data in transit and at rest. Which combination of steps will meet the requirement for the encryption of specific data items? (Select TWO.)
A. Generate symmetric encryption keys with AWS Key Management Service (AWS KMS).
B. Generate asymmetric encryption keys with AWS Key Management Service (AWS KMS).
C. Use generated keys with the DynamoDB Encryption Client.
D. Use generated keys to configure DynamoDB table encryption with AWS managed customer master keys (CMKs).
E. Use generated keys to configure DynamoDB table encryption with AWS owned customer master keys (CMKs).
Q80: A company is developing a REST API with Amazon API Gateway. Access to the API should be limited to users in the existing Amazon Cognito user pool. Which combination of steps should a developer perform to secure the API? (Select TWO.)
A. Create an AWS Lambda authorizer for the API.
B. Create an Amazon Cognito authorizer for the API.
C. Configure the authorizer for the API resource.
D. Configure the API methods to use the authorizer.
E. Configure the authorizer for the API stage.
Q81: A developer is implementing a mobile app to provide personalized services to app users. The application code makes calls to Amazon S3 and Amazon Simple Queue Service (Amazon SQS). Which options can the developer use to authenticate the app users? (Select TWO.)
A. Authenticate to the Amazon Cognito identity pool directly.
B. Authenticate to AWS Identity and Access Management (IAM) directly.
C. Authenticate to the Amazon Cognito user pool directly.
D. Federate authentication by using Login with Amazon with the users managed with AWS Security Token Service (AWS STS).
E. Federate authentication by using Login with Amazon with the users managed with the Amazon Cognito user pool.
Question: A company is implementing several order processing workflows. Each workflow is implemented by using AWS Lambda functions for each task. Which combination of steps should a developer follow to implement these workflows? (Select TWO.)
A. Define a AWS Step Functions task for each Lambda function.
B. Define a AWS Step Functions task for each workflow.
C. Write code that polls the AWS Step Functions invocation to coordinate each workflow.
D. Define an AWS Step Functions state machine for each workflow.
E. Define an AWS Step Functions state machine for each Lambda function.
Answer: A. D.
Notes: Step Functions is based on state machines and tasks. A state machine is a workflow. Tasks perform work by coordinating with other AWS services, such as Lambda. A state machine is a workflow. It can be used to express a workflow as a number of states, their relationships, and their input and output. You can coordinate individual tasks with Step Functions by expressing your workflow as a finite state machine, written in the Amazon States Language.
ReferenceText: Getting Started with AWS Step Functions.
ReferenceUrl: https://aws.amazon.com/step-functions/getting-started/
Category: Development
Welcome to AWS Certified Developer Associate Exam Preparation: Definition and Objectives, Top 100 Questions and Answers dump, White papers, Courses, Labs and Training Materials, Exam info and details, References, Jobs, Others AWS Certificates
What is the AWS Certified Developer Associate Exam?
This AWS Certified Developer-Associate Examination is intended for individuals who perform a Developer role. It validates an examinee’s ability to:
- Demonstrate an understanding of core AWS services, uses, and basic AWS architecture best practices
- Demonstrate proficiency in developing, deploying, and debugging cloud-based applications by using AWS
Recommended general IT knowledge
The target candidate should have the following:
– In-depth knowledge of at least one high-level programming language
– Understanding of application lifecycle management
– The ability to write code for serverless applications
– Understanding of the use of containers in the development process
Recommended AWS knowledge
The target candidate should be able to do the following:
- Use the AWS service APIs, CLI, and software development kits (SDKs) to write applications
- Identify key features of AWS services
- Understand the AWS shared responsibility model
- Use a continuous integration and continuous delivery (CI/CD) pipeline to deploy applications on AWS
- Use and interact with AWS services
- Apply basic understanding of cloud-native applications to write code
- Write code by using AWS security best practices (for example, use IAM roles instead of secret and access keys in the code)
- Author, maintain, and debug code modules on AWS
What is considered out of scope for the target candidate?
The following is a non-exhaustive list of related job tasks that the target candidate is not expected to be able to perform. These items are considered out of scope for the exam:
– Design architectures (for example, distributed system, microservices)
– Design and implement CI/CD pipelines
- Administer IAM users and groups
- Administer Amazon Elastic Container Service (Amazon ECS)
- Design AWS networking infrastructure (for example, Amazon VPC, AWS Direct Connect)
- Understand compliance and licensing
Exam content
Response types
There are two types of questions on the exam:
– Multiple choice: Has one correct response and three incorrect responses (distractors)
– Multiple response: Has two or more correct responses out of five or more response options
Select one or more responses that best complete the statement or answer the question. Distractors, or incorrect answers, are response options that a candidate with incomplete knowledge or skill might choose.
Distractors are generally plausible responses that match the content area.
Unanswered questions are scored as incorrect; there is no penalty for guessing. The exam includes 50 questions that will affect your score.
Unscored content
The exam includes 15 unscored questions that do not affect your score. AWS collects information about candidate performance on these unscored questions to evaluate these questions for future use as scored questions. These unscored questions are not identified on the exam.
Exam results
The AWS Certified Developer – Associate (DVA-C01) exam is a pass or fail exam. The exam is scored against a minimum standard established by AWS professionals who follow certification industry best practices and guidelines.
Your results for the exam are reported as a scaled score of 100–1,000. The minimum passing score is 720.
Your score shows how you performed on the exam as a whole and whether you passed. Scaled scoring models help equate scores across multiple exam forms that might have slightly different difficulty levels.
Your score report could contain a table of classifications of your performance at each section level. This information is intended to provide general feedback about your exam performance. The exam uses a compensatory scoring model, which means that you do not need to achieve a passing score in each section. You need to pass only the overall exam.
Each section of the exam has a specific weighting, so some sections have more questions than other sections have. The table contains general information that highlights your strengths and weaknesses. Use caution when interpreting section-level feedback.
Content outline
This exam guide includes weightings, test domains, and objectives for the exam. It is not a comprehensive listing of the content on the exam. However, additional context for each of the objectives is available to help guide your preparation for the exam. The following table lists the main content domains and their weightings. The table precedes the complete exam content outline, which includes the additional context.
The percentage in each domain represents only scored content.
Domain 1: Deployment 22%
Domain 2: Security 26%
Domain 3: Development with AWS Services 30%
Domain 4: Refactoring 10%
Domain 5: Monitoring and Troubleshooting 12%
Domain 1: Deployment
1.1 Deploy written code in AWS using existing CI/CD pipelines, processes, and patterns.
– Commit code to a repository and invoke build, test and/or deployment actions
– Use labels and branches for version and release management
– Use AWS CodePipeline to orchestrate workflows against different environments
– Apply AWS CodeCommit, AWS CodeBuild, AWS CodePipeline, AWS CodeStar, and AWS
CodeDeploy for CI/CD purposes
– Perform a roll back plan based on application deployment policy
1.2 Deploy applications using AWS Elastic Beanstalk.
– Utilize existing supported environments to define a new application stack
– Package the application
– Introduce a new application version into the Elastic Beanstalk environment
– Utilize a deployment policy to deploy an application version (i.e., all at once, rolling, rolling with batch, immutable)
– Validate application health using Elastic Beanstalk dashboard
– Use Amazon CloudWatch Logs to instrument application logging
1.3 Prepare the application deployment package to be deployed to AWS.
– Manage the dependencies of the code module (like environment variables, config files and static image files) within the package
– Outline the package/container directory structure and organize files appropriately
– Translate application resource requirements to AWS infrastructure parameters (e.g., memory, cores)
1.4 Deploy serverless applications.
– Given a use case, implement and launch an AWS Serverless Application Model (AWS SAM) template
– Manage environments in individual AWS services (e.g., Differentiate between Development, Test, and Production in Amazon API Gateway)
Domain 2: Security
2.1 Make authenticated calls to AWS services.
– Communicate required policy based on least privileges required by application.
– Assume an IAM role to access a service
– Use the software development kit (SDK) credential provider on-premises or in the cloud to access AWS services (local credentials vs. instance roles)
2.2 Implement encryption using AWS services.
– Encrypt data at rest (client side; server side; envelope encryption) using AWS services
– Encrypt data in transit
2.3 Implement application authentication and authorization.
– Add user sign-up and sign-in functionality for applications with Amazon Cognito identity or user pools
– Use Amazon Cognito-provided credentials to write code that access AWS services.
– Use Amazon Cognito sync to synchronize user profiles and data
– Use developer-authenticated identities to interact between end user devices, backend
authentication, and Amazon Cognito
Domain 3: Development with AWS Services
3.1 Write code for serverless applications.
– Compare and contrast server-based vs. serverless model (e.g., micro services, stateless nature of serverless applications, scaling serverless applications, and decoupling layers of serverless applications)
– Configure AWS Lambda functions by defining environment variables and parameters (e.g., memory, time out, runtime, handler)
– Create an API endpoint using Amazon API Gateway
– Create and test appropriate API actions like GET, POST using the API endpoint
– Apply Amazon DynamoDB concepts (e.g., tables, items, and attributes)
– Compute read/write capacity units for Amazon DynamoDB based on application requirements
– Associate an AWS Lambda function with an AWS event source (e.g., Amazon API Gateway, Amazon CloudWatch event, Amazon S3 events, Amazon Kinesis)
– Invoke an AWS Lambda function synchronously and asynchronously
3.2 Translate functional requirements into application design.
– Determine real-time vs. batch processing for a given use case
– Determine use of synchronous vs. asynchronous for a given use case
– Determine use of event vs. schedule/poll for a given use case
– Account for tradeoffs for consistency models in an application design
Domain 4: Refactoring
4.1 Optimize applications to best use AWS services and features.
Implement AWS caching services to optimize performance (e.g., Amazon ElastiCache, Amazon API Gateway cache)
Apply an Amazon S3 naming scheme for optimal read performance
4.2 Migrate existing application code to run on AWS.
– Isolate dependencies
– Run the application as one or more stateless processes
– Develop in order to enable horizontal scalability
– Externalize state
Domain 5: Monitoring and Troubleshooting
5.1 Write code that can be monitored.
– Create custom Amazon CloudWatch metrics
– Perform logging in a manner available to systems operators
– Instrument application source code to enable tracing in AWS X-Ray
5.2 Perform root cause analysis on faults found in testing or production.
– Interpret the outputs from the logging mechanism in AWS to identify errors in logs
– Check build and testing history in AWS services (e.g., AWS CodeBuild, AWS CodeDeploy, AWS CodePipeline) to identify issues
– Utilize AWS services (e.g., Amazon CloudWatch, VPC Flow Logs, and AWS X-Ray) to locate a specific faulty component
Which key tools, technologies, and concepts might be covered on the exam?
The following is a non-exhaustive list of the tools and technologies that could appear on the exam.
This list is subject to change and is provided to help you understand the general scope of services, features, or technologies on the exam.
The general tools and technologies in this list appear in no particular order.
AWS services are grouped according to their primary functions. While some of these technologies will likely be covered more than others on the exam, the order and placement of them in this list is no indication of relative weight or importance:
– Analytics
– Application Integration
– Containers
– Cost and Capacity Management
– Data Movement
– Developer Tools
– Instances (virtual machines)
– Management and Governance
– Networking and Content Delivery
– Security
– Serverless
AWS services and features
Analytics:
– Amazon Elasticsearch Service (Amazon ES)
– Amazon Kinesis
Application Integration:
– Amazon EventBridge (Amazon CloudWatch Events)
– Amazon Simple Notification Service (Amazon SNS)
– Amazon Simple Queue Service (Amazon SQS)
– AWS Step Functions
Compute:
– Amazon EC2
– AWS Elastic Beanstalk
– AWS Lambda
Containers:
– Amazon Elastic Container Registry (Amazon ECR)
– Amazon Elastic Container Service (Amazon ECS)
– Amazon Elastic Kubernetes Services (Amazon EKS)
Database:
– Amazon DynamoDB
– Amazon ElastiCache
– Amazon RDS
Developer Tools:
– AWS CodeArtifact
– AWS CodeBuild
– AWS CodeCommit
– AWS CodeDeploy
– Amazon CodeGuru
– AWS CodePipeline
– AWS CodeStar
– AWS Fault Injection Simulator
– AWS X-Ray
Management and Governance:
– AWS CloudFormation
– Amazon CloudWatch
Networking and Content Delivery:
– Amazon API Gateway
– Amazon CloudFront
– Elastic Load Balancing
Security, Identity, and Compliance:
– Amazon Cognito
– AWS Identity and Access Management (IAM)
– AWS Key Management Service (AWS KMS)
Storage:
– Amazon S3
Out-of-scope AWS services and features
The following is a non-exhaustive list of AWS services and features that are not covered on the exam.
These services and features do not represent every AWS offering that is excluded from the exam content.
Services or features that are entirely unrelated to the target job roles for the exam are excluded from this list because they are assumed to be irrelevant.
Out-of-scope AWS services and features include the following:
– AWS Application Discovery Service
– Amazon AppStream 2.0
– Amazon Chime
– Amazon Connect
– AWS Database Migration Service (AWS DMS)
– AWS Device Farm
– Amazon Elastic Transcoder
– Amazon GameLift
– Amazon Lex
– Amazon Machine Learning (Amazon ML)
– AWS Managed Services
– Amazon Mobile Analytics
– Amazon Polly
– Amazon QuickSight
– Amazon Rekognition
– AWS Server Migration Service (AWS SMS)
– AWS Service Catalog
– AWS Shield Advanced
– AWS Shield Standard
– AWS Snow Family
– AWS Storage Gateway
– AWS WAF
– Amazon WorkMail
– Amazon WorkSpaces
To succeed with the real exam, do not memorize the answers below. It is very important that you understand why a question is right or wrong and the concepts behind it by carefully reading the reference documents in the answers.
AWS Certified Developer – Associate Practice Questions And Answers Dump
Q0: Your application reads commands from an SQS queue and sends them to web services hosted by your
partners. When a partner’s endpoint goes down, your application continually returns their commands to the queue. The repeated attempts to deliver these commands use up resources. Commands that can’t be delivered must not be lost.
How can you accommodate the partners’ broken web services without wasting your resources?
- A. Create a delay queue and set DelaySeconds to 30 seconds
- B. Requeue the message with a VisibilityTimeout of 30 seconds.
- C. Create a dead letter queue and set the Maximum Receives to 3.
- D. Requeue the message with a DelaySeconds of 30 seconds.

Top
Q1: A developer is writing an application that will store data in a DynamoDB table. The ratio of reads operations to write operations will be 1000 to 1, with the same data being accessed frequently.
What should the Developer enable on the DynamoDB table to optimize performance and minimize costs?
- A. Amazon DynamoDB auto scaling
- B. Amazon DynamoDB cross-region replication
- C. Amazon DynamoDB Streams
- D. Amazon DynamoDB Accelerator
Top
Q2: You are creating a DynamoDB table with the following attributes:
- PurchaseOrderNumber (partition key)
- CustomerID
- PurchaseDate
- TotalPurchaseValue
One of your applications must retrieve items from the table to calculate the total value of purchases for a
particular customer over a date range. What secondary index do you need to add to the table?
- A. Local secondary index with a partition key of CustomerID and sort key of PurchaseDate; project the
TotalPurchaseValue attribute - B. Local secondary index with a partition key of PurchaseDate and sort key of CustomerID; project the
TotalPurchaseValue attribute - C. Global secondary index with a partition key of CustomerID and sort key of PurchaseDate; project the
TotalPurchaseValue attribute - D. Global secondary index with a partition key of PurchaseDate and sort key of CustomerID; project the
TotalPurchaseValue attribute
Top
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q3: When referencing the remaining time left for a Lambda function to run within the function’s code you would use:
- A. The event object
- B. The timeLeft object
- C. The remains object
- D. The context object
Top
Q4: What two arguments does a Python Lambda handler function require?
- A. invocation, zone
- B. event, zone
- C. invocation, context
- D. event, context
Q5: Lambda allows you to upload code and dependencies for function packages:
- A. Only from a directly uploaded zip file
- B. Only via SFTP
- C. Only from a zip file in AWS S3
- D. From a zip file in AWS S3 or uploaded directly from elsewhere
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q6: A Lambda deployment package contains:
- A. Function code, libraries, and runtime binaries
- B. Only function code
- C. Function code and libraries not included within the runtime
- D. Only libraries not included within the runtime
Q7: You are attempting to SSH into an EC2 instance that is located in a public subnet. However, you are currently receiving a timeout error trying to connect. What could be a possible cause of this connection issue?
- A. The security group associated with the EC2 instance has an inbound rule that allows SSH traffic, but does not have an outbound rule that allows SSH traffic.
- B. The security group associated with the EC2 instance has an inbound rule that allows SSH traffic AND has an outbound rule that explicitly denies SSH traffic.
- C. The security group associated with the EC2 instance has an inbound rule that allows SSH traffic AND the associated NACL has both an inbound and outbound rule that allows SSH traffic.
- D. The security group associated with the EC2 instance does not have an inbound rule that allows SSH traffic AND the associated NACL does not have an outbound rule that allows SSH traffic.
Top
Q8: You have instances inside private subnets and a properly configured bastion host instance in a public subnet. None of the instances in the private subnets have a public or Elastic IP address. How can you connect an instance in the private subnet to the open internet to download system updates?
- A. Create and assign EIP to each instance
- B. Create and attach a second IGW to the VPC.
- C. Create and utilize a NAT Gateway
- D. Connect to a VPN
Top
Q9: What feature of VPC networking should you utilize if you want to create “elasticity” in your application’s architecture?
- A. Security Groups
- B. Route Tables
- C. Elastic Load Balancer
- D. Auto Scaling
Top
Q10: Lambda allows you to upload code and dependencies for function packages:
- A. Only from a directly uploaded zip file
- B. Only from a directly uploaded zip file
- C. Only from a zip file in AWS S3
- D. From a zip file in AWS S3 or uploaded directly from elsewhere
Q11: You’re writing a script with an AWS SDK that uses the AWS API Actions and want to create AMIs for non-EBS backed AMIs for you. Which API call should occurs in the final process of creating an AMI?
- A. RegisterImage
- B. CreateImage
- C. ami-register-image
- D. ami-create-image
Q12: When dealing with session state in EC2-based applications using Elastic load balancers which option is generally thought of as the best practice for managing user sessions?
- A. Having the ELB distribute traffic to all EC2 instances and then having the instance check a caching solution like ElastiCache running Redis or Memcached for session information
- B. Permenantly assigning users to specific instances and always routing their traffic to those instances
- C. Using Application-generated cookies to tie a user session to a particular instance for the cookie duration
- D. Using Elastic Load Balancer generated cookies to tie a user session to a particular instance
Q13: Which API call would best be used to describe an Amazon Machine Image?
- A. ami-describe-image
- B. ami-describe-images
- C. DescribeImage
- D. DescribeImages
Q14: What is one key difference between an Amazon EBS-backed and an instance-store backed instance?
- A. Autoscaling requires using Amazon EBS-backed instances
- B. Virtual Private Cloud requires EBS backed instances
- C. Amazon EBS-backed instances can be stopped and restarted without losing data
- D. Instance-store backed instances can be stopped and restarted without losing data
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q15: After having created a new Linux instance on Amazon EC2, and downloaded the .pem file (called Toto.pem) you try and SSH into your IP address (54.1.132.33) using the following command.
ssh -i my_key.pem ec2-user@52.2.222.22
However you receive the following error.
@@@@@@@@ WARNING: UNPROTECTED PRIVATE KEY FILE! @ @@@@@@@@@@@@@@@@@@@
What is the most probable reason for this and how can you fix it?
- A. You do not have root access on your terminal and need to use the sudo option for this to work.
- B. You do not have enough permissions to perform the operation.
- C. Your key file is encrypted. You need to use the -u option for unencrypted not the -i option.
- D. Your key file must not be publicly viewable for SSH to work. You need to modify your .pem file to limit permissions.
Q16: You have an EBS root device on /dev/sda1 on one of your EC2 instances. You are having trouble with this particular instance and you need to either Stop/Start, Reboot or Terminate the instance but you do NOT want to lose any data that you have stored on /dev/sda1. However, you are unsure if changing the instance state in any of the aforementioned ways will cause you to lose data stored on the EBS volume. Which of the below statements best describes the effect each change of instance state would have on the data you have stored on /dev/sda1?
- A. Whether you stop/start, reboot or terminate the instance it does not matter because data on an EBS volume is not ephemeral and the data will not be lost regardless of what method is used.
- B. If you stop/start the instance the data will not be lost. However if you either terminate or reboot the instance the data will be lost.
- C. Whether you stop/start, reboot or terminate the instance it does not matter because data on an EBS volume is ephemeral and it will be lost no matter what method is used.
- D. The data will be lost if you terminate the instance, however the data will remain on /dev/sda1 if you reboot or stop/start the instance because data on an EBS volume is not ephemeral.
Q17: EC2 instances are launched from Amazon Machine Images (AMIs). A given public AMI:
- A. Can only be used to launch EC2 instances in the same AWS availability zone as the AMI is stored
- B. Can only be used to launch EC2 instances in the same country as the AMI is stored
- C. Can only be used to launch EC2 instances in the same AWS region as the AMI is stored
- D. Can be used to launch EC2 instances in any AWS region
Q18: Which of the following statements is true about the Elastic File System (EFS)?
- A. EFS can scale out to meet capacity requirements and scale back down when no longer needed
- B. EFS can be used by multiple EC2 instances simultaneously
- C. EFS cannot be used by an instance using EBS
- D. EFS can be configured on an instance before launch just like an IAM role or EBS volumes
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q19: IAM Policies, at a minimum, contain what elements?
- A. ID
- B. Effects
- C. Resources
- D. Sid
- E. Principle
- F. Actions
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q20: What are the main benefits of IAM groups?
- A. The ability to create custom permission policies.
- B. Assigning IAM permission policies to more than one user at a time.
- C. Easier user/policy management.
- D. Allowing EC2 instances to gain access to S3.
Q21: What are benefits of using AWS STS?
- A. Grant access to AWS resources without having to create an IAM identity for them
- B. Since credentials are temporary, you don’t have to rotate or revoke them
- C. Temporary security credentials can be extended indefinitely
- D. Temporary security credentials can be restricted to a specific region
Q22: What should the Developer enable on the DynamoDB table to optimize performance and minimize costs?
- A. Amazon DynamoDB auto scaling
- B. Amazon DynamoDB cross-region replication
- C. Amazon DynamoDB Streams
- D. Amazon DynamoDB Accelerator
Top
Q23: A Developer has been asked to create an AWS Elastic Beanstalk environment for a production web application which needs to handle thousands of requests. Currently the dev environment is running on a t1 micro instance. How can the Developer change the EC2 instance type to m4.large?
- A. Use CloudFormation to migrate the Amazon EC2 instance type of the environment from t1 micro to m4.large.
- B. Create a saved configuration file in Amazon S3 with the instance type as m4.large and use the same during environment creation.
- C. Change the instance type to m4.large in the configuration details page of the Create New Environment page.
- D. Change the instance type value for the environment to m4.large by using update autoscaling group CLI command.
Q24: What statements are true about Availability Zones (AZs) and Regions?
- A. There is only one AZ in each AWS Region
- B. AZs are geographically separated inside a region to help protect against natural disasters affecting more than one at a time.
- C. AZs can be moved between AWS Regions based on your needs
- D. There are (almost always) two or more AZs in each AWS Region
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q25: An AWS Region contains:
- A. Edge Locations
- B. Data Centers
- C. AWS Services
- D. Availability Zones
Top
Q26: Which read request in DynamoDB returns a response with the most up-to-date data, reflecting the updates from all prior write operations that were successful?
- A. Eventual Consistent Reads
- B. Conditional reads for Consistency
- C. Strongly Consistent Reads
- D. Not possible
Top
Q27: You’ ve been asked to move an existing development environment on the AWS Cloud. This environment consists mainly of Docker based containers. You need to ensure that minimum effort is taken during the migration process. Which of the following step would you consider for this requirement?
- A. Create an Opswork stack and deploy the Docker containers
- B. Create an application and Environment for the Docker containers in the Elastic Beanstalk service
- C. Create an EC2 Instance. Install Docker and deploy the necessary containers.
- D. Create an EC2 Instance. Install Docker and deploy the necessary containers. Add an Autoscaling Group for scalability of the containers.
Top
Q28: You’ve written an application that uploads objects onto an S3 bucket. The size of the object varies between 200 – 500 MB. You’ve seen that the application sometimes takes a longer than expected time to upload the object. You want to improve the performance of the application. Which of the following would you consider?
- A. Create multiple threads and upload the objects in the multiple threads
- B. Write the items in batches for better performance
- C. Use the Multipart upload API
- D. Enable versioning on the Bucket
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Top
Q29: A security system monitors 600 cameras, saving image metadata every 1 minute to an Amazon DynamoDb table. Each sample involves 1kb of data, and the data writes are evenly distributed over time. How much write throughput is required for the target table?
- A. 6000
- B. 10
- C. 3600
- D. 600
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q30: What two arguments does a Python Lambda handler function require?
- A. invocation, zone
- B. event, zone
- C. invocation, context
- D. event, context
Top
Q31: Lambda allows you to upload code and dependencies for function packages:
- A. Only from a directly uploaded zip file
- B. Only via SFTP
- C. Only from a zip file in AWS S3
- D. From a zip file in AWS S3 or uploaded directly from elsewhere
Top
Q32: A Lambda deployment package contains:
- A. Function code, libraries, and runtime binaries
- B. Only function code
- C. Function code and libraries not included within the runtime
- D. Only libraries not included within the runtime
Top
Q33: You have instances inside private subnets and a properly configured bastion host instance in a public subnet. None of the instances in the private subnets have a public or Elastic IP address. How can you connect an instance in the private subnet to the open internet to download system updates?
- A. Create and assign EIP to each instance
- B. Create and attach a second IGW to the VPC.
- C. Create and utilize a NAT Gateway
- D. Connect to a VPN
Top
Q34: What feature of VPC networking should you utilize if you want to create “elasticity” in your application’s architecture?
- A. Security Groups
- B. Route Tables
- C. Elastic Load Balancer
- D. Auto Scaling
Top
Q30: Lambda allows you to upload code and dependencies for function packages:
- A. Only from a directly uploaded zip file
- B. Only from a directly uploaded zip file
- C. Only from a zip file in AWS S3
- D. From a zip file in AWS S3 or uploaded directly from elsewhere
Answer:
Top
Q31: An organization is using an Amazon ElastiCache cluster in front of their Amazon RDS instance. The organization would like the Developer to implement logic into the code so that the cluster only retrieves data from RDS when there is a cache miss. What strategy can the Developer implement to achieve this?
- A. Lazy loading
- B. Write-through
- C. Error retries
- D. Exponential backoff
Answer:
Top
Q32: A developer is writing an application that will run on Ec2 instances and read messages from SQS queue. The nessages will arrive every 15-60 seconds. How should the Developer efficiently query the queue for new messages?
- A. Use long polling
- B. Set a custom visibility timeout
- C. Use short polling
- D. Implement exponential backoff
Top
Q33: You are using AWS SAM to define a Lambda function and configure CodeDeploy to manage deployment patterns. With new Lambda function working as per expectation which of the following will shift traffic from original Lambda function to new Lambda function in the shortest time frame?
- A. Canary10Percent5Minutes
- B. Linear10PercentEvery10Minutes
- C. Canary10Percent15Minutes
- D. Linear10PercentEvery1Minute
Top
Q34: You are using AWS SAM templates to deploy a serverless application. Which of the following resource will embed application from Amazon S3 buckets?
- A. AWS::Serverless::Api
- B. AWS::Serverless::Application
- C. AWS::Serverless::Layerversion
- D. AWS::Serverless::Function
Top
Q35: You are using AWS Envelope Encryption for encrypting all sensitive data. Which of the followings is True with regards to Envelope Encryption?
- A. Data is encrypted be encrypting Data key which is further encrypted using encrypted Master Key.
- B. Data is encrypted by plaintext Data key which is further encrypted using encrypted Master Key.
- C. Data is encrypted by encrypted Data key which is further encrypted using plaintext Master Key.
- D. Data is encrypted by plaintext Data key which is further encrypted using plaintext Master Key.
Top
Q36: You are developing an application that will be comprised of the following architecture –
- A set of Ec2 instances to process the videos.
- These (Ec2 instances) will be spun up by an autoscaling group.
- SQS Queues to maintain the processing messages.
- There will be 2 pricing tiers.
How will you ensure that the premium customers videos are given more preference?
- A. Create 2 Autoscaling Groups, one for normal and one for premium customers
- B. Create 2 set of Ec2 Instances, one for normal and one for premium customers
- C. Create 2 SQS queus, one for normal and one for premium customers
- D. Create 2 Elastic Load Balancers, one for normal and one for premium customers.
Top
Q37: You are developing an application that will interact with a DynamoDB table. The table is going to take in a lot of read and write operations. Which of the following would be the ideal partition key for the DynamoDB table to ensure ideal performance?
- A. CustomerID
- B. CustomerName
- C. Location
- D. Age
Top
Q38: A developer is making use of AWS services to develop an application. He has been asked to develop the application in a manner to compensate any network delays. Which of the following two mechanisms should he implement in the application?
- A. Multiple SQS queues
- B. Exponential backoff algorithm
- C. Retries in your application code
- D. Consider using the Java sdk.
Top
Q39: An application is being developed that is going to write data to a DynamoDB table. You have to setup the read and write throughput for the table. Data is going to be read at the rate of 300 items every 30 seconds. Each item is of size 6KB. The reads can be eventual consistent reads. What should be the read capacity that needs to be set on the table?
- A. 10
- B. 20
- C. 6
- D. 30
Top
Q40: You are in charge of deploying an application that will be hosted on an EC2 Instance and sit behind an Elastic Load balancer. You have been requested to monitor the incoming connections to the Elastic Load Balancer. Which of the below options can suffice this requirement?
- A. Use AWS CloudTrail with your load balancer
- B. Enable access logs on the load balancer
- C. Use a CloudWatch Logs Agent
- D. Create a custom metric CloudWatch lter on your load balancer
Top
Q41: A static web site has been hosted on a bucket and is now being accessed by users. One of the web pages javascript section has been changed to access data which is hosted in another S3 bucket. Now that same web page is no longer loading in the browser. Which of the following can help alleviate the error?
- A. Enable versioning for the underlying S3 bucket.
- B. Enable Replication so that the objects get replicated to the other bucket
- C. Enable CORS for the bucket
- D. Change the Bucket policy for the bucket to allow access from the other bucket
Top
Q42: Your mobile application includes a photo-sharing service that is expecting tens of thousands of users at launch. You will leverage Amazon Simple Storage Service (S3) for storage of the user Images, and you must decide how to authenticate and authorize your users for access to these images. You also need to manage the storage of these images. Which two of the following approaches should you use? Choose two answers from the options below
- A. Create an Amazon S3 bucket per user, and use your application to generate the S3 URL for the appropriate content.
- B. Use AWS Identity and Access Management (IAM) user accounts as your application-level user database, and offload the burden of authentication from your application code.
- C. Authenticate your users at the application level, and use AWS Security Token Service (STS)to grant token-based authorization to S3 objects.
- D. Authenticate your users at the application level, and send an SMS token message to the user. Create an Amazon S3 bucket with the same name as the SMS message token, and move the user’s objects to that bucket.
Top
Q43: Your current log analysis application takes more than four hours to generate a report of the top 10 users of your web application. You have been asked to implement a system that can report this information in real time, ensure that the report is always up to date, and handle increases in the number of requests to your web application. Choose the option that is cost-effective and can fulfill the requirements.
- A. Publish your data to CloudWatch Logs, and congure your application to Autoscale to handle the load on demand.
- B. Publish your log data to an Amazon S3 bucket. Use AWS CloudFormation to create an Auto Scaling group to scale your post-processing application which is congured to pull down your log les stored an Amazon S3
- C. Post your log data to an Amazon Kinesis data stream, and subscribe your log-processing application so that is congured to process your logging data.
- D. Create a multi-AZ Amazon RDS MySQL cluster, post the logging data to MySQL, and run a map reduce job to retrieve the required information on user counts.
Answer:
Top
Q44: You’ve been instructed to develop a mobile application that will make use of AWS services. You need to decide on a data store to store the user sessions. Which of the following would be an ideal data store for session management?
- A. AWS Simple Storage Service
- B. AWS DynamoDB
- C. AWS RDS
- D. AWS Redshift
Answer:
Top
Q45: Your application currently interacts with a DynamoDB table. Records are inserted into the table via the application. There is now a requirement to ensure that whenever items are updated in the DynamoDB primary table , another record is inserted into a secondary table. Which of the below feature should be used when developing such a solution?
- A. AWS DynamoDB Encryption
- B. AWS DynamoDB Streams
- C. AWS DynamoDB Accelerator
- D. AWSTable Accelerator
Top
Q46: An application has been making use of AWS DynamoDB for its back-end data store. The size of the table has now grown to 20 GB , and the scans on the table are causing throttling errors. Which of the following should now be implemented to avoid such errors?
- A. Large Page size
- B. Reduced page size
- C. Parallel Scans
- D. Sequential scans
Top
Q47: Which of the following is correct way of passing a stage variable to an HTTP URL ? (Select TWO.)
- A. http://example.com/${}/prod
- B. http://example.com/${stageVariables.}/prod
- C. http://${stageVariables.}.example.com/dev/operation
- D. http://${stageVariables}.example.com/dev/operation
- E. http://${}.example.com/dev/operation
- F. http://example.com/${stageVariables}/prod
Top
Q48: Your company is planning on creating new development environments in AWS. They want to make use of their existing Chef recipes which they use for their on-premise configuration for servers in AWS. Which of the following service would be ideal to use in this regard?
- A. AWS Elastic Beanstalk
- B. AWS OpsWork
- C. AWS Cloudformation
- D. AWS SQS
Top
Q49: Your company has developed a web application and is hosting it in an Amazon S3 bucket configured for static website hosting. The users can log in to this app using their Google/Facebook login accounts. The application is using the AWS SDK for JavaScript in the browser to access data stored in an Amazon DynamoDB table. How can you ensure that API keys for access to your data in DynamoDB are kept secure?
- A. Create an Amazon S3 role in IAM with access to the specific DynamoDB tables, and assign it to the bucket hosting your website
- B. Configure S3 bucket tags with your AWS access keys for your bucket hosing your website so that the application can query them for access.
- C. Configure a web identity federation role within IAM to enable access to the correct DynamoDB resources and retrieve temporary credentials
- D. Store AWS keys in global variables within your application and configure the application to use these credentials when making requests.
Top
Q50: Your application currently makes use of AWS Cognito for managing user identities. You want to analyze the information that is stored in AWS Cognito for your application. Which of the following features of AWS Cognito should you use for this purpose?
- A. Cognito Data
- B. Cognito Events
- C. Cognito Streams
- D. Cognito Callbacks
Top
Q51: You’ve developed a set of scripts using AWS Lambda. These scripts need to access EC2 Instances in a VPC. Which of the following needs to be done to ensure that the AWS Lambda function can access the resources in the VPC. Choose 2 answers from the options given below
- A. Ensure that the subnet ID’s are mentioned when conguring the Lambda function
- B. Ensure that the NACL ID’s are mentioned when conguring the Lambda function
- C. Ensure that the Security Group ID’s are mentioned when conguring the Lambda function
- D. Ensure that the VPC Flow Log ID’s are mentioned when conguring the Lambda function
Top
Q52: You’ve currently been tasked to migrate an existing on-premise environment into Elastic Beanstalk. The application does not make use of Docker containers. You also can’t see any relevant environments in the beanstalk service that would be suitable to host your application. What should you consider doing in this case?
- A. Migrate your application to using Docker containers and then migrate the app to the Elastic Beanstalk environment.
- B. Consider using Cloudformation to deploy your environment to Elastic Beanstalk
- C. Consider using Packer to create a custom platform
- D. Consider deploying your application using the Elastic Container Service
Top
Q53: Company B is writing 10 items to the Dynamo DB table every second. Each item is 15.5Kb in size. What would be the required provisioned write throughput for best performance? Choose the correct answer from the options below.
- A. 10
- B. 160
- C. 155
- D. 16
Top
Q54: Which AWS Service can be used to automatically install your application code onto EC2, on premises systems and Lambda?
- A. CodeCommit
- B. X-Ray
- C. CodeBuild
- D. CodeDeploy
Top
Q55: Which AWS service can be used to compile source code, run tests and package code?
- A. CodePipeline
- B. CodeCommit
- C. CodeBuild
- D. CodeDeploy
Top
Q56: How can your prevent CloudFormation from deleting your entire stack on failure? (Choose 2)
- A. Set the Rollback on failure radio button to No in the CloudFormation console
- B. Set Termination Protection to Enabled in the CloudFormation console
- C. Use the –disable-rollback flag with the AWS CLI
- D. Use the –enable-termination-protection protection flag with the AWS CLI
Q57: Which of the following practices allows multiple developers working on the same application to merge code changes frequently, without impacting each other and enables the identification of bugs early on in the release process?
- A. Continuous Integration
- B. Continuous Deployment
- C. Continuous Delivery
- D. Continuous Development
Q58: When deploying application code to EC2, the AppSpec file can be written in which language?
- A. JSON
- B. JSON or YAML
- C. XML
- D. YAML
Q59: Part of your CloudFormation deployment fails due to a mis-configuration, by defaukt what will happen?
- A. CloudFormation will rollback only the failed components
- B. CloudFormation will rollback the entire stack
- C. Failed component will remain available for debugging purposes
- D. CloudFormation will ask you if you want to continue with the deployment
Top
Q60: You want to receive an email whenever a user pushes code to CodeCommit repository, how can you configure this?
- A. Create a new SNS topic and configure it to poll for CodeCommit eveents. Ask all users to subscribe to the topic to receive notifications
- B. Configure a CloudWatch Events rule to send a message to SES which will trigger an email to be sent whenever a user pushes code to the repository.
- C. Configure Notifications in the console, this will create a CloudWatch events rule to send a notification to a SNS topic which will trigger an email to be sent to the user.
- D. Configure a CloudWatch Events rule to send a message to SQS which will trigger an email to be sent whenever a user pushes code to the repository.
Top
Q61: Which AWS service can be used to centrally store and version control your application source code, binaries and libraries
- A. CodeCommit
- B. CodeBuild
- C. CodePipeline
- D. ElasticFileSystem
Top
Q62: You are using CloudFormation to create a new S3 bucket, which of the following sections would you use to define the properties of your bucket?
- A. Conditions
- B. Parameters
- C. Outputs
- D. Resources
Top
Q63: You are deploying a number of EC2 and RDS instances using CloudFormation. Which section of the CloudFormation template would you use to define these?
- A. Transforms
- B. Outputs
- C. Resources
- D. Instances
Top
Q64: Which AWS service can be used to fully automate your entire release process?
- A. CodeDeploy
- B. CodePipeline
- C. CodeCommit
- D. CodeBuild
Top
Q65: You want to use the output of your CloudFormation stack as input to another CloudFormation stack. Which sections of the CloudFormation template would you use to help you configure this?
- A. Outputs
- B. Transforms
- C. Resources
- D. Exports
Top
Q66: You have some code located in an S3 bucket that you want to reference in your CloudFormation template. Which section of the template can you use to define this?
- A. Inputs
- B. Resources
- C. Transforms
- D. Files
Top
Q67: You are deploying an application to a number of Ec2 instances using CodeDeploy. What is the name of the file
used to specify source files and lifecycle hooks?
- A. buildspec.yml
- B. appspec.json
- C. appspec.yml
- D. buildspec.json
Q68: Which of the following approaches allows you to re-use pieces of CloudFormation code in multiple templates, for common use cases like provisioning a load balancer or web server?
- A. Share the code using an EBS volume
- B. Copy and paste the code into the template each time you need to use it
- C. Use a cloudformation nested stack
- D. Store the code you want to re-use in an AMI and reference the AMI from within your CloudFormation template.
Q69: In the CodeDeploy AppSpec file, what are hooks used for?
- A. To reference AWS resources that will be used during the deployment
- B. Hooks are reserved for future use
- C. To specify files you want to copy during the deployment.
- D. To specify, scripts or function that you want to run at set points in the deployment lifecycle
Q70: Which command can you use to encrypt a plain text file using CMK?
- A. aws kms-encrypt
- B. aws iam encrypt
- C. aws kms encrypt
- D. aws encrypt
Q72: Which of the following is an encrypted key used by KMS to encrypt your data
- A. Custmoer Mamaged Key
- B. Encryption Key
- C. Envelope Key
- D. Customer Master Key
Q73: Which of the following statements are correct? (Choose 2)
- A. The Customer Master Key is used to encrypt and decrypt the Envelope Key or Data Key
- B. The Envelope Key or Data Key is used to encrypt and decrypt plain text files.
- C. The envelope Key or Data Key is used to encrypt and decrypt the Customer Master Key.
- D. The Customer MasterKey is used to encrypt and decrypt plain text files.
Q74: Which of the following statements is correct in relation to kMS/ (Choose 2)
- A. KMS Encryption keys are regional
- B. You cannot export your customer master key
- C. You can export your customer master key.
- D. KMS encryption Keys are global
Q75: A developer is preparing a deployment package for a Java implementation of an AWS Lambda function. What should the developer include in the deployment package? (Select TWO.)
A. Compiled application code
B. Java runtime environment
C. References to the event sources
D. Lambda execution role
E. Application dependencies
Q76: A developer uses AWS CodeDeploy to deploy a Python application to a fleet of Amazon EC2 instances that run behind an Application Load Balancer. The instances run in an Amazon EC2 Auto Scaling group across multiple Availability Zones. What should the developer include in the CodeDeploy deployment package?
A. A launch template for the Amazon EC2 Auto Scaling group
B. A CodeDeploy AppSpec file
C. An EC2 role that grants the application access to AWS services
D. An IAM policy that grants the application access to AWS services
Q76: A company is working on a project to enhance its serverless application development process. The company hosts applications on AWS Lambda. The development team regularly updates the Lambda code and wants to use stable code in production. Which combination of steps should the development team take to configure Lambda functions to meet both development and production requirements? (Select TWO.)
A. Create a new Lambda version every time a new code release needs testing.
B. Create two Lambda function aliases. Name one as Production and the other as Development. Point the Production alias to a production-ready unqualified Amazon Resource Name (ARN) version. Point the Development alias to the $LATEST version.
C. Create two Lambda function aliases. Name one as Production and the other as Development. Point the Production alias to the production-ready qualified Amazon Resource Name (ARN) version. Point the Development alias to the variable LAMBDA_TASK_ROOT.
D. Create a new Lambda layer every time a new code release needs testing.
E. Create two Lambda function aliases. Name one as Production and the other as Development. Point the Production alias to a production-ready Lambda layer Amazon Resource Name (ARN). Point the Development alias to the $LATEST layer ARN.
Q77: Each time a developer publishes a new version of an AWS Lambda function, all the dependent event source mappings need to be updated with the reference to the new version’s Amazon Resource Name (ARN). These updates are time consuming and error-prone. Which combination of actions should the developer take to avoid performing these updates when publishing a new Lambda version? (Select TWO.)
A. Update event source mappings with the ARN of the Lambda layer.
B. Point a Lambda alias to a new version of the Lambda function.
C. Create a Lambda alias for each published version of the Lambda function.
D. Point a Lambda alias to a new Lambda function alias.
E. Update the event source mappings with the Lambda alias ARN.
Q78: A company wants to store sensitive user data in Amazon S3 and encrypt this data at rest. The company must manage the encryption keys and use Amazon S3 to perform the encryption. How can a developer meet these requirements?
A. Enable default encryption for the S3 bucket by using the option for server-side encryption with customer-provided encryption keys (SSE-C).
B. Enable client-side encryption with an encryption key. Upload the encrypted object to the S3 bucket.
C. Enable server-side encryption with Amazon S3 managed encryption keys (SSE-S3). Upload an object to the S3 bucket.
D. Enable server-side encryption with customer-provided encryption keys (SSE-C). Upload an object to the S3 bucket.
Q79: A company is developing a Python application that submits data to an Amazon DynamoDB table. The company requires client-side encryption of specific data items and end-to-end protection for the encrypted data in transit and at rest. Which combination of steps will meet the requirement for the encryption of specific data items? (Select TWO.)
A. Generate symmetric encryption keys with AWS Key Management Service (AWS KMS).
B. Generate asymmetric encryption keys with AWS Key Management Service (AWS KMS).
C. Use generated keys with the DynamoDB Encryption Client.
D. Use generated keys to configure DynamoDB table encryption with AWS managed customer master keys (CMKs).
E. Use generated keys to configure DynamoDB table encryption with AWS owned customer master keys (CMKs).
Q80: A company is developing a REST API with Amazon API Gateway. Access to the API should be limited to users in the existing Amazon Cognito user pool. Which combination of steps should a developer perform to secure the API? (Select TWO.)
A. Create an AWS Lambda authorizer for the API.
B. Create an Amazon Cognito authorizer for the API.
C. Configure the authorizer for the API resource.
D. Configure the API methods to use the authorizer.
E. Configure the authorizer for the API stage.
Q81: A developer is implementing a mobile app to provide personalized services to app users. The application code makes calls to Amazon S3 and Amazon Simple Queue Service (Amazon SQS). Which options can the developer use to authenticate the app users? (Select TWO.)
A. Authenticate to the Amazon Cognito identity pool directly.
B. Authenticate to AWS Identity and Access Management (IAM) directly.
C. Authenticate to the Amazon Cognito user pool directly.
D. Federate authentication by using Login with Amazon with the users managed with AWS Security Token Service (AWS STS).
E. Federate authentication by using Login with Amazon with the users managed with the Amazon Cognito user pool.
Q82: A company is implementing several order processing workflows. Each workflow is implemented by using AWS Lambda functions for each task. Which combination of steps should a developer follow to implement these workflows? (Select TWO.)
A. Define a AWS Step Functions task for each Lambda function.
B. Define a AWS Step Functions task for each workflow.
C. Write code that polls the AWS Step Functions invocation to coordinate each workflow.
D. Define an AWS Step Functions state machine for each workflow.
E. Define an AWS Step Functions state machine for each Lambda function.
Q83: A company is migrating a web service to the AWS Cloud. The web service accepts requests by using HTTP (port 80). The company wants to use an AWS Lambda function to process HTTP requests. Which application design will satisfy these requirements?
A. Create an Amazon API Gateway API. Configure proxy integration with the Lambda function.
B. Create an Amazon API Gateway API. Configure non-proxy integration with the Lambda function.
C. Configure the Lambda function to listen to inbound network connections on port 80.
D. Configure the Lambda function as a target in the Application Load Balancer target group.
Q84: A company is developing an image processing application. When an image is uploaded to an Amazon S3 bucket, a number of independent and separate services must be invoked to process the image. The services do not have to be available immediately, but they must process every image. Which application design satisfies these requirements?
A. Configure an Amazon S3 event notification that publishes to an Amazon Simple Queue Service (Amazon SQS) queue. Each service pulls the message from the same queue.
B. Configure an Amazon S3 event notification that publishes to an Amazon Simple Notification Service (Amazon SNS) topic. Each service subscribes to the same topic.
C. Configure an Amazon S3 event notification that publishes to an Amazon Simple Queue Service (Amazon SQS) queue. Subscribe a separate Amazon Simple Notification Service (Amazon SNS) topic for each service to an Amazon SQS queue.
D. Configure an Amazon S3 event notification that publishes to an Amazon Simple Notification Service (Amazon SNS) topic. Subscribe a separate Simple Queue Service (Amazon SQS) queue for each service to the Amazon SNS topic.
Q85: A developer wants to implement Amazon EC2 Auto Scaling for a Multi-AZ web application. However, the developer is concerned that user sessions will be lost during scale-in events. How can the developer store the session state and share it across the EC2 instances?
A. Write the sessions to an Amazon Kinesis data stream. Configure the application to poll the stream.
B. Publish the sessions to an Amazon Simple Notification Service (Amazon SNS) topic. Subscribe each instance in the group to the topic.
C. Store the sessions in an Amazon ElastiCache for Memcached cluster. Configure the application to use the Memcached API.
D. Write the sessions to an Amazon Elastic Block Store (Amazon EBS) volume. Mount the volume to each instance in the group.
Q86: A developer is integrating a legacy web application that runs on a fleet of Amazon EC2 instances with an Amazon DynamoDB table. There is no AWS SDK for the programming language that was used to implement the web application. Which combination of steps should the developer perform to make an API call to Amazon DynamoDB from the instances? (Select TWO.)
A. Make an HTTPS POST request to the DynamoDB API endpoint for the AWS Region. In the request body, include an XML document that contains the request attributes.
B. Make an HTTPS POST request to the DynamoDB API endpoint for the AWS Region. In the request body, include a JSON document that contains the request attributes.
C. Sign the requests by using AWS access keys and Signature Version 4.
D. Use an EC2 SSH key to calculate Signature Version 4 of the request.
E. Provide the signature value through the HTTP X-API-Key header.
Q87: A developer has written several custom applications that read and write to the same Amazon DynamoDB table. Each time the data in the DynamoDB table is modified, this change should be sent to an external API. Which combination of steps should the developer perform to accomplish this task? (Select TWO.)
A. Configure an AWS Lambda function to poll the stream and call the external API.
B. Configure an event in Amazon EventBridge (Amazon CloudWatch Events) that publishes the change to an Amazon Managed Streaming for Apache Kafka (Amazon MSK) data stream.
C. Create a trigger in the DynamoDB table to publish the change to an Amazon Kinesis data stream.
D. Deliver the stream to an Amazon Simple Notification Service (Amazon SNS) topic and subscribe the API to the topic.
E. Enable DynamoDB Streams on the table.
Q88: A company is migrating the create, read, update, and delete (CRUD) functionality of an existing Java web application to AWS Lambda. Which minimal code refactoring is necessary for the CRUD operations to run in the Lambda function?
A. Implement a Lambda handler function.
B. Import an AWS X-Ray package.
C. Rewrite the application code in Python.
D. Add a reference to the Lambda execution role.
Q89: A company plans to use AWS log monitoring services to monitor an application that runs on premises. Currently, the application runs on a recent version of Ubuntu Server and outputs the logs to a local file. Which combination of steps should a developer perform to accomplish this goal? (Select TWO.)
A. Update the application code to include calls to the agent API for log collection.
B. Install the Amazon Elastic Container Service (Amazon ECS) container agent on the server.
C. Install the unified Amazon CloudWatch agent on the server.
D. Configure the long-term AWS credentials on the server to enable log collection by the agent.
E. Attach an IAM role to the server to enable log collection by the agent.
Q90: A developer wants to monitor invocations of an AWS Lambda function by using Amazon CloudWatch Logs. The developer added a number of print statements to the function code that write the logging information to the stdout stream. After running the function, the developer does not see any log data being generated. Why does the log data NOT appear in the CloudWatch logs?
A. The log data is not written to the stderr stream.
B. Lambda function logging is not automatically enabled.
C. The execution role for the Lambda function did not grant permissions to write log data to CloudWatch Logs.
D. The Lambda function outputs the logs to an Amazon S3 bucket.
Q91: Which of the following are best practices you should implement into ongoing deployments of your application? (Select THREE.)
A. Use stage variables to manage secrets across environments
B. Create account-specific AWS SAM templates for each environment
C. Use an AutoPublish alias
D. Use traffic shifting with pre- and post-deployment hooks
E. Test throughout the pipeline
Q92: You are handing off maintenance of your new serverless application to an incoming team lead. Which recommendations would you make? (Select THREE.)
A. Keep up to date with the quotas and payload sizes for each AWS service you are using
B. Analyze production access patterns to identify potential improvements
C. Design your services to extend their life as long as possible
D. Minimize changes to your production application
E. Compare the value of using the latest first-class integrations versus using Lambda between AWS services
Top
Q56: How can your prevent CloudFormation from deleting your entire stack on failure? (Choose 2)
- A. Set the Rollback on failure radio button to No in the CloudFormation console
- B. Set Termination Protection to Enabled in the CloudFormation console
- C. Use the –disable-rollback flag with the AWS CLI
- D. Use the –enable-termination-protection protection flag with the AWS CLI
Q57: Which of the following practices allows multiple developers working on the same application to merge code changes frequently, without impacting each other and enables the identification of bugs early on in the release process?
- A. Continuous Integration
- B. Continuous Deployment
- C. Continuous Delivery
- D. Continuous Development
Q58: When deploying application code to EC2, the AppSpec file can be written in which language?
- A. JSON
- B. JSON or YAML
- C. XML
- D. YAML
Q59: Part of your CloudFormation deployment fails due to a mis-configuration, by defaukt what will happen?
- A. CloudFormation will rollback only the failed components
- B. CloudFormation will rollback the entire stack
- C. Failed component will remain available for debugging purposes
- D. CloudFormation will ask you if you want to continue with the deployment
Top
Q60: You want to receive an email whenever a user pushes code to CodeCommit repository, how can you configure this?
- A. Create a new SNS topic and configure it to poll for CodeCommit eveents. Ask all users to subscribe to the topic to receive notifications
- B. Configure a CloudWatch Events rule to send a message to SES which will trigger an email to be sent whenever a user pushes code to the repository.
- C. Configure Notifications in the console, this will create a CloudWatch events rule to send a notification to a SNS topic which will trigger an email to be sent to the user.
- D. Configure a CloudWatch Events rule to send a message to SQS which will trigger an email to be sent whenever a user pushes code to the repository.
Top
Q61: Which AWS service can be used to centrally store and version control your application source code, binaries and libraries
- A. CodeCommit
- B. CodeBuild
- C. CodePipeline
- D. ElasticFileSystem
Top
Q62: You are using CloudFormation to create a new S3 bucket, which of the following sections would you use to define the properties of your bucket?
- A. Conditions
- B. Parameters
- C. Outputs
- D. Resources
Top
Q63: You are deploying a number of EC2 and RDS instances using CloudFormation. Which section of the CloudFormation template would you use to define these?
- A. Transforms
- B. Outputs
- C. Resources
- D. Instances
Top
Q64: Which AWS service can be used to fully automate your entire release process?
- A. CodeDeploy
- B. CodePipeline
- C. CodeCommit
- D. CodeBuild
Top
Q65: You want to use the output of your CloudFormation stack as input to another CloudFormation stack. Which sections of the CloudFormation template would you use to help you configure this?
- A. Outputs
- B. Transforms
- C. Resources
- D. Exports
Top
Q66: You have some code located in an S3 bucket that you want to reference in your CloudFormation template. Which section of the template can you use to define this?
- A. Inputs
- B. Resources
- C. Transforms
- D. Files
Top
Q67: You are deploying an application to a number of Ec2 instances using CodeDeploy. What is the name of the file
used to specify source files and lifecycle hooks?
- A. buildspec.yml
- B. appspec.json
- C. appspec.yml
- D. buildspec.json
Q68: Which of the following approaches allows you to re-use pieces of CloudFormation code in multiple templates, for common use cases like provisioning a load balancer or web server?
- A. Share the code using an EBS volume
- B. Copy and paste the code into the template each time you need to use it
- C. Use a cloudformation nested stack
- D. Store the code you want to re-use in an AMI and reference the AMI from within your CloudFormation template.
Q69: In the CodeDeploy AppSpec file, what are hooks used for?
- A. To reference AWS resources that will be used during the deployment
- B. Hooks are reserved for future use
- C. To specify files you want to copy during the deployment.
- D. To specify, scripts or function that you want to run at set points in the deployment lifecycle
Q70: Which command can you use to encrypt a plain text file using CMK?
- A. aws kms-encrypt
- B. aws iam encrypt
- C. aws kms encrypt
- D. aws encrypt
Q72: Which of the following is an encrypted key used by KMS to encrypt your data
- A. Custmoer Mamaged Key
- B. Encryption Key
- C. Envelope Key
- D. Customer Master Key
Q73: Which of the following statements are correct? (Choose 2)
- A. The Customer Master Key is used to encrypt and decrypt the Envelope Key or Data Key
- B. The Envelope Key or Data Key is used to encrypt and decrypt plain text files.
- C. The envelope Key or Data Key is used to encrypt and decrypt the Customer Master Key.
- D. The Customer MasterKey is used to encrypt and decrypt plain text files.
Q74: Which of the following statements is correct in relation to kMS/ (Choose 2)
- A. KMS Encryption keys are regional
- B. You cannot export your customer master key
- C. You can export your customer master key.
- D. KMS encryption Keys are global
Q75: A developer is preparing a deployment package for a Java implementation of an AWS Lambda function. What should the developer include in the deployment package? (Select TWO.)
A. Compiled application code
B. Java runtime environment
C. References to the event sources
D. Lambda execution role
E. Application dependencies
Q76: A developer uses AWS CodeDeploy to deploy a Python application to a fleet of Amazon EC2 instances that run behind an Application Load Balancer. The instances run in an Amazon EC2 Auto Scaling group across multiple Availability Zones. What should the developer include in the CodeDeploy deployment package?
A. A launch template for the Amazon EC2 Auto Scaling group
B. A CodeDeploy AppSpec file
C. An EC2 role that grants the application access to AWS services
D. An IAM policy that grants the application access to AWS services
Q76: A company is working on a project to enhance its serverless application development process. The company hosts applications on AWS Lambda. The development team regularly updates the Lambda code and wants to use stable code in production. Which combination of steps should the development team take to configure Lambda functions to meet both development and production requirements? (Select TWO.)
A. Create a new Lambda version every time a new code release needs testing.
B. Create two Lambda function aliases. Name one as Production and the other as Development. Point the Production alias to a production-ready unqualified Amazon Resource Name (ARN) version. Point the Development alias to the $LATEST version.
C. Create two Lambda function aliases. Name one as Production and the other as Development. Point the Production alias to the production-ready qualified Amazon Resource Name (ARN) version. Point the Development alias to the variable LAMBDA_TASK_ROOT.
D. Create a new Lambda layer every time a new code release needs testing.
E. Create two Lambda function aliases. Name one as Production and the other as Development. Point the Production alias to a production-ready Lambda layer Amazon Resource Name (ARN). Point the Development alias to the $LATEST layer ARN.
Q77: Each time a developer publishes a new version of an AWS Lambda function, all the dependent event source mappings need to be updated with the reference to the new version’s Amazon Resource Name (ARN). These updates are time consuming and error-prone. Which combination of actions should the developer take to avoid performing these updates when publishing a new Lambda version? (Select TWO.)
A. Update event source mappings with the ARN of the Lambda layer.
B. Point a Lambda alias to a new version of the Lambda function.
C. Create a Lambda alias for each published version of the Lambda function.
D. Point a Lambda alias to a new Lambda function alias.
E. Update the event source mappings with the Lambda alias ARN.
Q78: A company wants to store sensitive user data in Amazon S3 and encrypt this data at rest. The company must manage the encryption keys and use Amazon S3 to perform the encryption. How can a developer meet these requirements?
A. Enable default encryption for the S3 bucket by using the option for server-side encryption with customer-provided encryption keys (SSE-C).
B. Enable client-side encryption with an encryption key. Upload the encrypted object to the S3 bucket.
C. Enable server-side encryption with Amazon S3 managed encryption keys (SSE-S3). Upload an object to the S3 bucket.
D. Enable server-side encryption with customer-provided encryption keys (SSE-C). Upload an object to the S3 bucket.
Q79: A company is developing a Python application that submits data to an Amazon DynamoDB table. The company requires client-side encryption of specific data items and end-to-end protection for the encrypted data in transit and at rest. Which combination of steps will meet the requirement for the encryption of specific data items? (Select TWO.)
A. Generate symmetric encryption keys with AWS Key Management Service (AWS KMS).
B. Generate asymmetric encryption keys with AWS Key Management Service (AWS KMS).
C. Use generated keys with the DynamoDB Encryption Client.
D. Use generated keys to configure DynamoDB table encryption with AWS managed customer master keys (CMKs).
E. Use generated keys to configure DynamoDB table encryption with AWS owned customer master keys (CMKs).
Q80: A company is developing a REST API with Amazon API Gateway. Access to the API should be limited to users in the existing Amazon Cognito user pool. Which combination of steps should a developer perform to secure the API? (Select TWO.)
A. Create an AWS Lambda authorizer for the API.
B. Create an Amazon Cognito authorizer for the API.
C. Configure the authorizer for the API resource.
D. Configure the API methods to use the authorizer.
E. Configure the authorizer for the API stage.
Q81: A developer is implementing a mobile app to provide personalized services to app users. The application code makes calls to Amazon S3 and Amazon Simple Queue Service (Amazon SQS). Which options can the developer use to authenticate the app users? (Select TWO.)
A. Authenticate to the Amazon Cognito identity pool directly.
B. Authenticate to AWS Identity and Access Management (IAM) directly.
C. Authenticate to the Amazon Cognito user pool directly.
D. Federate authentication by using Login with Amazon with the users managed with AWS Security Token Service (AWS STS).
E. Federate authentication by using Login with Amazon with the users managed with the Amazon Cognito user pool.
Question: A company is implementing several order processing workflows. Each workflow is implemented by using AWS Lambda functions for each task. Which combination of steps should a developer follow to implement these workflows? (Select TWO.)
A. Define a AWS Step Functions task for each Lambda function.
B. Define a AWS Step Functions task for each workflow.
C. Write code that polls the AWS Step Functions invocation to coordinate each workflow.
D. Define an AWS Step Functions state machine for each workflow.
E. Define an AWS Step Functions state machine for each Lambda function.
Answer: A. D.
Notes: Step Functions is based on state machines and tasks. A state machine is a workflow. Tasks perform work by coordinating with other AWS services, such as Lambda. A state machine is a workflow. It can be used to express a workflow as a number of states, their relationships, and their input and output. You can coordinate individual tasks with Step Functions by expressing your workflow as a finite state machine, written in the Amazon States Language.
ReferenceText: Getting Started with AWS Step Functions.
ReferenceUrl: https://aws.amazon.com/step-functions/getting-started/
Category: Development
Welcome to AWS Certified Developer Associate Exam Preparation: Definition and Objectives, Top 100 Questions and Answers dump, White papers, Courses, Labs and Training Materials, Exam info and details, References, Jobs, Others AWS Certificates
What is the AWS Certified Developer Associate Exam?
This AWS Certified Developer-Associate Examination is intended for individuals who perform a Developer role. It validates an examinee’s ability to:
- Demonstrate an understanding of core AWS services, uses, and basic AWS architecture best practices
- Demonstrate proficiency in developing, deploying, and debugging cloud-based applications by using AWS
Recommended general IT knowledge
The target candidate should have the following:
– In-depth knowledge of at least one high-level programming language
– Understanding of application lifecycle management
– The ability to write code for serverless applications
– Understanding of the use of containers in the development process
Recommended AWS knowledge
The target candidate should be able to do the following:
- Use the AWS service APIs, CLI, and software development kits (SDKs) to write applications
- Identify key features of AWS services
- Understand the AWS shared responsibility model
- Use a continuous integration and continuous delivery (CI/CD) pipeline to deploy applications on AWS
- Use and interact with AWS services
- Apply basic understanding of cloud-native applications to write code
- Write code by using AWS security best practices (for example, use IAM roles instead of secret and access keys in the code)
- Author, maintain, and debug code modules on AWS
What is considered out of scope for the target candidate?
The following is a non-exhaustive list of related job tasks that the target candidate is not expected to be able to perform. These items are considered out of scope for the exam:
– Design architectures (for example, distributed system, microservices)
– Design and implement CI/CD pipelines
- Administer IAM users and groups
- Administer Amazon Elastic Container Service (Amazon ECS)
- Design AWS networking infrastructure (for example, Amazon VPC, AWS Direct Connect)
- Understand compliance and licensing
Exam content
Response types
There are two types of questions on the exam:
– Multiple choice: Has one correct response and three incorrect responses (distractors)
– Multiple response: Has two or more correct responses out of five or more response options
Select one or more responses that best complete the statement or answer the question. Distractors, or incorrect answers, are response options that a candidate with incomplete knowledge or skill might choose.
Distractors are generally plausible responses that match the content area.
Unanswered questions are scored as incorrect; there is no penalty for guessing. The exam includes 50 questions that will affect your score.
Unscored content
The exam includes 15 unscored questions that do not affect your score. AWS collects information about candidate performance on these unscored questions to evaluate these questions for future use as scored questions. These unscored questions are not identified on the exam.
Exam results
The AWS Certified Developer – Associate (DVA-C01) exam is a pass or fail exam. The exam is scored against a minimum standard established by AWS professionals who follow certification industry best practices and guidelines.
Your results for the exam are reported as a scaled score of 100–1,000. The minimum passing score is 720.
Your score shows how you performed on the exam as a whole and whether you passed. Scaled scoring models help equate scores across multiple exam forms that might have slightly different difficulty levels.
Your score report could contain a table of classifications of your performance at each section level. This information is intended to provide general feedback about your exam performance. The exam uses a compensatory scoring model, which means that you do not need to achieve a passing score in each section. You need to pass only the overall exam.
Each section of the exam has a specific weighting, so some sections have more questions than other sections have. The table contains general information that highlights your strengths and weaknesses. Use caution when interpreting section-level feedback.
Content outline
This exam guide includes weightings, test domains, and objectives for the exam. It is not a comprehensive listing of the content on the exam. However, additional context for each of the objectives is available to help guide your preparation for the exam. The following table lists the main content domains and their weightings. The table precedes the complete exam content outline, which includes the additional context.
The percentage in each domain represents only scored content.
Domain 1: Deployment 22%
Domain 2: Security 26%
Domain 3: Development with AWS Services 30%
Domain 4: Refactoring 10%
Domain 5: Monitoring and Troubleshooting 12%
Domain 1: Deployment
1.1 Deploy written code in AWS using existing CI/CD pipelines, processes, and patterns.
– Commit code to a repository and invoke build, test and/or deployment actions
– Use labels and branches for version and release management
– Use AWS CodePipeline to orchestrate workflows against different environments
– Apply AWS CodeCommit, AWS CodeBuild, AWS CodePipeline, AWS CodeStar, and AWS
CodeDeploy for CI/CD purposes
– Perform a roll back plan based on application deployment policy
1.2 Deploy applications using AWS Elastic Beanstalk.
– Utilize existing supported environments to define a new application stack
– Package the application
– Introduce a new application version into the Elastic Beanstalk environment
– Utilize a deployment policy to deploy an application version (i.e., all at once, rolling, rolling with batch, immutable)
– Validate application health using Elastic Beanstalk dashboard
– Use Amazon CloudWatch Logs to instrument application logging
1.3 Prepare the application deployment package to be deployed to AWS.
– Manage the dependencies of the code module (like environment variables, config files and static image files) within the package
– Outline the package/container directory structure and organize files appropriately
– Translate application resource requirements to AWS infrastructure parameters (e.g., memory, cores)
1.4 Deploy serverless applications.
– Given a use case, implement and launch an AWS Serverless Application Model (AWS SAM) template
– Manage environments in individual AWS services (e.g., Differentiate between Development, Test, and Production in Amazon API Gateway)
Domain 2: Security
2.1 Make authenticated calls to AWS services.
– Communicate required policy based on least privileges required by application.
– Assume an IAM role to access a service
– Use the software development kit (SDK) credential provider on-premises or in the cloud to access AWS services (local credentials vs. instance roles)
2.2 Implement encryption using AWS services.
– Encrypt data at rest (client side; server side; envelope encryption) using AWS services
– Encrypt data in transit
2.3 Implement application authentication and authorization.
– Add user sign-up and sign-in functionality for applications with Amazon Cognito identity or user pools
– Use Amazon Cognito-provided credentials to write code that access AWS services.
– Use Amazon Cognito sync to synchronize user profiles and data
– Use developer-authenticated identities to interact between end user devices, backend
authentication, and Amazon Cognito
Domain 3: Development with AWS Services
3.1 Write code for serverless applications.
– Compare and contrast server-based vs. serverless model (e.g., micro services, stateless nature of serverless applications, scaling serverless applications, and decoupling layers of serverless applications)
– Configure AWS Lambda functions by defining environment variables and parameters (e.g., memory, time out, runtime, handler)
– Create an API endpoint using Amazon API Gateway
– Create and test appropriate API actions like GET, POST using the API endpoint
– Apply Amazon DynamoDB concepts (e.g., tables, items, and attributes)
– Compute read/write capacity units for Amazon DynamoDB based on application requirements
– Associate an AWS Lambda function with an AWS event source (e.g., Amazon API Gateway, Amazon CloudWatch event, Amazon S3 events, Amazon Kinesis)
– Invoke an AWS Lambda function synchronously and asynchronously
3.2 Translate functional requirements into application design.
– Determine real-time vs. batch processing for a given use case
– Determine use of synchronous vs. asynchronous for a given use case
– Determine use of event vs. schedule/poll for a given use case
– Account for tradeoffs for consistency models in an application design
Domain 4: Refactoring
4.1 Optimize applications to best use AWS services and features.
Implement AWS caching services to optimize performance (e.g., Amazon ElastiCache, Amazon API Gateway cache)
Apply an Amazon S3 naming scheme for optimal read performance
4.2 Migrate existing application code to run on AWS.
– Isolate dependencies
– Run the application as one or more stateless processes
– Develop in order to enable horizontal scalability
– Externalize state
Domain 5: Monitoring and Troubleshooting
5.1 Write code that can be monitored.
– Create custom Amazon CloudWatch metrics
– Perform logging in a manner available to systems operators
– Instrument application source code to enable tracing in AWS X-Ray
5.2 Perform root cause analysis on faults found in testing or production.
– Interpret the outputs from the logging mechanism in AWS to identify errors in logs
– Check build and testing history in AWS services (e.g., AWS CodeBuild, AWS CodeDeploy, AWS CodePipeline) to identify issues
– Utilize AWS services (e.g., Amazon CloudWatch, VPC Flow Logs, and AWS X-Ray) to locate a specific faulty component
Which key tools, technologies, and concepts might be covered on the exam?
The following is a non-exhaustive list of the tools and technologies that could appear on the exam.
This list is subject to change and is provided to help you understand the general scope of services, features, or technologies on the exam.
The general tools and technologies in this list appear in no particular order.
AWS services are grouped according to their primary functions. While some of these technologies will likely be covered more than others on the exam, the order and placement of them in this list is no indication of relative weight or importance:
– Analytics
– Application Integration
– Containers
– Cost and Capacity Management
– Data Movement
– Developer Tools
– Instances (virtual machines)
– Management and Governance
– Networking and Content Delivery
– Security
– Serverless
AWS services and features
Analytics:
– Amazon Elasticsearch Service (Amazon ES)
– Amazon Kinesis
Application Integration:
– Amazon EventBridge (Amazon CloudWatch Events)
– Amazon Simple Notification Service (Amazon SNS)
– Amazon Simple Queue Service (Amazon SQS)
– AWS Step Functions
Compute:
– Amazon EC2
– AWS Elastic Beanstalk
– AWS Lambda
Containers:
– Amazon Elastic Container Registry (Amazon ECR)
– Amazon Elastic Container Service (Amazon ECS)
– Amazon Elastic Kubernetes Services (Amazon EKS)
Database:
– Amazon DynamoDB
– Amazon ElastiCache
– Amazon RDS
Developer Tools:
– AWS CodeArtifact
– AWS CodeBuild
– AWS CodeCommit
– AWS CodeDeploy
– Amazon CodeGuru
– AWS CodePipeline
– AWS CodeStar
– AWS Fault Injection Simulator
– AWS X-Ray
Management and Governance:
– AWS CloudFormation
– Amazon CloudWatch
Networking and Content Delivery:
– Amazon API Gateway
– Amazon CloudFront
– Elastic Load Balancing
Security, Identity, and Compliance:
– Amazon Cognito
– AWS Identity and Access Management (IAM)
– AWS Key Management Service (AWS KMS)
Storage:
– Amazon S3
Out-of-scope AWS services and features
The following is a non-exhaustive list of AWS services and features that are not covered on the exam.
These services and features do not represent every AWS offering that is excluded from the exam content.
Services or features that are entirely unrelated to the target job roles for the exam are excluded from this list because they are assumed to be irrelevant.
Out-of-scope AWS services and features include the following:
– AWS Application Discovery Service
– Amazon AppStream 2.0
– Amazon Chime
– Amazon Connect
– AWS Database Migration Service (AWS DMS)
– AWS Device Farm
– Amazon Elastic Transcoder
– Amazon GameLift
– Amazon Lex
– Amazon Machine Learning (Amazon ML)
– AWS Managed Services
– Amazon Mobile Analytics
– Amazon Polly
– Amazon QuickSight
– Amazon Rekognition
– AWS Server Migration Service (AWS SMS)
– AWS Service Catalog
– AWS Shield Advanced
– AWS Shield Standard
– AWS Snow Family
– AWS Storage Gateway
– AWS WAF
– Amazon WorkMail
– Amazon WorkSpaces
To succeed with the real exam, do not memorize the answers below. It is very important that you understand why a question is right or wrong and the concepts behind it by carefully reading the reference documents in the answers.
AWS Certified Developer – Associate Practice Questions And Answers Dump
Q0: Your application reads commands from an SQS queue and sends them to web services hosted by your
partners. When a partner’s endpoint goes down, your application continually returns their commands to the queue. The repeated attempts to deliver these commands use up resources. Commands that can’t be delivered must not be lost.
How can you accommodate the partners’ broken web services without wasting your resources?
- A. Create a delay queue and set DelaySeconds to 30 seconds
- B. Requeue the message with a VisibilityTimeout of 30 seconds.
- C. Create a dead letter queue and set the Maximum Receives to 3.
- D. Requeue the message with a DelaySeconds of 30 seconds.
Top
Q1: A developer is writing an application that will store data in a DynamoDB table. The ratio of reads operations to write operations will be 1000 to 1, with the same data being accessed frequently.
What should the Developer enable on the DynamoDB table to optimize performance and minimize costs?
- A. Amazon DynamoDB auto scaling
- B. Amazon DynamoDB cross-region replication
- C. Amazon DynamoDB Streams
- D. Amazon DynamoDB Accelerator
Top
Q2: You are creating a DynamoDB table with the following attributes:
- PurchaseOrderNumber (partition key)
- CustomerID
- PurchaseDate
- TotalPurchaseValue
One of your applications must retrieve items from the table to calculate the total value of purchases for a
particular customer over a date range. What secondary index do you need to add to the table?
- A. Local secondary index with a partition key of CustomerID and sort key of PurchaseDate; project the
TotalPurchaseValue attribute - B. Local secondary index with a partition key of PurchaseDate and sort key of CustomerID; project the
TotalPurchaseValue attribute - C. Global secondary index with a partition key of CustomerID and sort key of PurchaseDate; project the
TotalPurchaseValue attribute - D. Global secondary index with a partition key of PurchaseDate and sort key of CustomerID; project the
TotalPurchaseValue attribute
Top
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q3: When referencing the remaining time left for a Lambda function to run within the function’s code you would use:
- A. The event object
- B. The timeLeft object
- C. The remains object
- D. The context object
Top
Q4: What two arguments does a Python Lambda handler function require?
- A. invocation, zone
- B. event, zone
- C. invocation, context
- D. event, context
Q5: Lambda allows you to upload code and dependencies for function packages:
- A. Only from a directly uploaded zip file
- B. Only via SFTP
- C. Only from a zip file in AWS S3
- D. From a zip file in AWS S3 or uploaded directly from elsewhere
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q6: A Lambda deployment package contains:
- A. Function code, libraries, and runtime binaries
- B. Only function code
- C. Function code and libraries not included within the runtime
- D. Only libraries not included within the runtime
Q7: You are attempting to SSH into an EC2 instance that is located in a public subnet. However, you are currently receiving a timeout error trying to connect. What could be a possible cause of this connection issue?
- A. The security group associated with the EC2 instance has an inbound rule that allows SSH traffic, but does not have an outbound rule that allows SSH traffic.
- B. The security group associated with the EC2 instance has an inbound rule that allows SSH traffic AND has an outbound rule that explicitly denies SSH traffic.
- C. The security group associated with the EC2 instance has an inbound rule that allows SSH traffic AND the associated NACL has both an inbound and outbound rule that allows SSH traffic.
- D. The security group associated with the EC2 instance does not have an inbound rule that allows SSH traffic AND the associated NACL does not have an outbound rule that allows SSH traffic.
Top
Q8: You have instances inside private subnets and a properly configured bastion host instance in a public subnet. None of the instances in the private subnets have a public or Elastic IP address. How can you connect an instance in the private subnet to the open internet to download system updates?
- A. Create and assign EIP to each instance
- B. Create and attach a second IGW to the VPC.
- C. Create and utilize a NAT Gateway
- D. Connect to a VPN
Top
Q9: What feature of VPC networking should you utilize if you want to create “elasticity” in your application’s architecture?
- A. Security Groups
- B. Route Tables
- C. Elastic Load Balancer
- D. Auto Scaling
Top
Q10: Lambda allows you to upload code and dependencies for function packages:
- A. Only from a directly uploaded zip file
- B. Only from a directly uploaded zip file
- C. Only from a zip file in AWS S3
- D. From a zip file in AWS S3 or uploaded directly from elsewhere
Q11: You’re writing a script with an AWS SDK that uses the AWS API Actions and want to create AMIs for non-EBS backed AMIs for you. Which API call should occurs in the final process of creating an AMI?
- A. RegisterImage
- B. CreateImage
- C. ami-register-image
- D. ami-create-image
Q12: When dealing with session state in EC2-based applications using Elastic load balancers which option is generally thought of as the best practice for managing user sessions?
- A. Having the ELB distribute traffic to all EC2 instances and then having the instance check a caching solution like ElastiCache running Redis or Memcached for session information
- B. Permenantly assigning users to specific instances and always routing their traffic to those instances
- C. Using Application-generated cookies to tie a user session to a particular instance for the cookie duration
- D. Using Elastic Load Balancer generated cookies to tie a user session to a particular instance
Q13: Which API call would best be used to describe an Amazon Machine Image?
- A. ami-describe-image
- B. ami-describe-images
- C. DescribeImage
- D. DescribeImages
Q14: What is one key difference between an Amazon EBS-backed and an instance-store backed instance?
- A. Autoscaling requires using Amazon EBS-backed instances
- B. Virtual Private Cloud requires EBS backed instances
- C. Amazon EBS-backed instances can be stopped and restarted without losing data
- D. Instance-store backed instances can be stopped and restarted without losing data
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q15: After having created a new Linux instance on Amazon EC2, and downloaded the .pem file (called Toto.pem) you try and SSH into your IP address (54.1.132.33) using the following command.
ssh -i my_key.pem ec2-user@52.2.222.22
However you receive the following error.
@@@@@@@@ WARNING: UNPROTECTED PRIVATE KEY FILE! @ @@@@@@@@@@@@@@@@@@@
What is the most probable reason for this and how can you fix it?
- A. You do not have root access on your terminal and need to use the sudo option for this to work.
- B. You do not have enough permissions to perform the operation.
- C. Your key file is encrypted. You need to use the -u option for unencrypted not the -i option.
- D. Your key file must not be publicly viewable for SSH to work. You need to modify your .pem file to limit permissions.
Q16: You have an EBS root device on /dev/sda1 on one of your EC2 instances. You are having trouble with this particular instance and you need to either Stop/Start, Reboot or Terminate the instance but you do NOT want to lose any data that you have stored on /dev/sda1. However, you are unsure if changing the instance state in any of the aforementioned ways will cause you to lose data stored on the EBS volume. Which of the below statements best describes the effect each change of instance state would have on the data you have stored on /dev/sda1?
- A. Whether you stop/start, reboot or terminate the instance it does not matter because data on an EBS volume is not ephemeral and the data will not be lost regardless of what method is used.
- B. If you stop/start the instance the data will not be lost. However if you either terminate or reboot the instance the data will be lost.
- C. Whether you stop/start, reboot or terminate the instance it does not matter because data on an EBS volume is ephemeral and it will be lost no matter what method is used.
- D. The data will be lost if you terminate the instance, however the data will remain on /dev/sda1 if you reboot or stop/start the instance because data on an EBS volume is not ephemeral.
Q17: EC2 instances are launched from Amazon Machine Images (AMIs). A given public AMI:
- A. Can only be used to launch EC2 instances in the same AWS availability zone as the AMI is stored
- B. Can only be used to launch EC2 instances in the same country as the AMI is stored
- C. Can only be used to launch EC2 instances in the same AWS region as the AMI is stored
- D. Can be used to launch EC2 instances in any AWS region
Q18: Which of the following statements is true about the Elastic File System (EFS)?
- A. EFS can scale out to meet capacity requirements and scale back down when no longer needed
- B. EFS can be used by multiple EC2 instances simultaneously
- C. EFS cannot be used by an instance using EBS
- D. EFS can be configured on an instance before launch just like an IAM role or EBS volumes
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q19: IAM Policies, at a minimum, contain what elements?
- A. ID
- B. Effects
- C. Resources
- D. Sid
- E. Principle
- F. Actions
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q20: What are the main benefits of IAM groups?
- A. The ability to create custom permission policies.
- B. Assigning IAM permission policies to more than one user at a time.
- C. Easier user/policy management.
- D. Allowing EC2 instances to gain access to S3.
Q21: What are benefits of using AWS STS?
- A. Grant access to AWS resources without having to create an IAM identity for them
- B. Since credentials are temporary, you don’t have to rotate or revoke them
- C. Temporary security credentials can be extended indefinitely
- D. Temporary security credentials can be restricted to a specific region
Q22: What should the Developer enable on the DynamoDB table to optimize performance and minimize costs?
- A. Amazon DynamoDB auto scaling
- B. Amazon DynamoDB cross-region replication
- C. Amazon DynamoDB Streams
- D. Amazon DynamoDB Accelerator
Top
Q23: A Developer has been asked to create an AWS Elastic Beanstalk environment for a production web application which needs to handle thousands of requests. Currently the dev environment is running on a t1 micro instance. How can the Developer change the EC2 instance type to m4.large?
- A. Use CloudFormation to migrate the Amazon EC2 instance type of the environment from t1 micro to m4.large.
- B. Create a saved configuration file in Amazon S3 with the instance type as m4.large and use the same during environment creation.
- C. Change the instance type to m4.large in the configuration details page of the Create New Environment page.
- D. Change the instance type value for the environment to m4.large by using update autoscaling group CLI command.
Q24: What statements are true about Availability Zones (AZs) and Regions?
- A. There is only one AZ in each AWS Region
- B. AZs are geographically separated inside a region to help protect against natural disasters affecting more than one at a time.
- C. AZs can be moved between AWS Regions based on your needs
- D. There are (almost always) two or more AZs in each AWS Region
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q25: An AWS Region contains:
- A. Edge Locations
- B. Data Centers
- C. AWS Services
- D. Availability Zones
Top
Q26: Which read request in DynamoDB returns a response with the most up-to-date data, reflecting the updates from all prior write operations that were successful?
- A. Eventual Consistent Reads
- B. Conditional reads for Consistency
- C. Strongly Consistent Reads
- D. Not possible
Top
Q27: You’ ve been asked to move an existing development environment on the AWS Cloud. This environment consists mainly of Docker based containers. You need to ensure that minimum effort is taken during the migration process. Which of the following step would you consider for this requirement?
- A. Create an Opswork stack and deploy the Docker containers
- B. Create an application and Environment for the Docker containers in the Elastic Beanstalk service
- C. Create an EC2 Instance. Install Docker and deploy the necessary containers.
- D. Create an EC2 Instance. Install Docker and deploy the necessary containers. Add an Autoscaling Group for scalability of the containers.
Top
Q28: You’ve written an application that uploads objects onto an S3 bucket. The size of the object varies between 200 – 500 MB. You’ve seen that the application sometimes takes a longer than expected time to upload the object. You want to improve the performance of the application. Which of the following would you consider?
- A. Create multiple threads and upload the objects in the multiple threads
- B. Write the items in batches for better performance
- C. Use the Multipart upload API
- D. Enable versioning on the Bucket
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Top
Q29: A security system monitors 600 cameras, saving image metadata every 1 minute to an Amazon DynamoDb table. Each sample involves 1kb of data, and the data writes are evenly distributed over time. How much write throughput is required for the target table?
- A. 6000
- B. 10
- C. 3600
- D. 600
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q30: What two arguments does a Python Lambda handler function require?
- A. invocation, zone
- B. event, zone
- C. invocation, context
- D. event, context
Top
Q31: Lambda allows you to upload code and dependencies for function packages:
- A. Only from a directly uploaded zip file
- B. Only via SFTP
- C. Only from a zip file in AWS S3
- D. From a zip file in AWS S3 or uploaded directly from elsewhere
Top
Q32: A Lambda deployment package contains:
- A. Function code, libraries, and runtime binaries
- B. Only function code
- C. Function code and libraries not included within the runtime
- D. Only libraries not included within the runtime
Top
Q33: You have instances inside private subnets and a properly configured bastion host instance in a public subnet. None of the instances in the private subnets have a public or Elastic IP address. How can you connect an instance in the private subnet to the open internet to download system updates?
- A. Create and assign EIP to each instance
- B. Create and attach a second IGW to the VPC.
- C. Create and utilize a NAT Gateway
- D. Connect to a VPN
Top
Q34: What feature of VPC networking should you utilize if you want to create “elasticity” in your application’s architecture?
- A. Security Groups
- B. Route Tables
- C. Elastic Load Balancer
- D. Auto Scaling
Top
Q30: Lambda allows you to upload code and dependencies for function packages:
- A. Only from a directly uploaded zip file
- B. Only from a directly uploaded zip file
- C. Only from a zip file in AWS S3
- D. From a zip file in AWS S3 or uploaded directly from elsewhere
Answer:
Top
Q31: An organization is using an Amazon ElastiCache cluster in front of their Amazon RDS instance. The organization would like the Developer to implement logic into the code so that the cluster only retrieves data from RDS when there is a cache miss. What strategy can the Developer implement to achieve this?
- A. Lazy loading
- B. Write-through
- C. Error retries
- D. Exponential backoff
Answer:
Top
Q32: A developer is writing an application that will run on Ec2 instances and read messages from SQS queue. The nessages will arrive every 15-60 seconds. How should the Developer efficiently query the queue for new messages?
- A. Use long polling
- B. Set a custom visibility timeout
- C. Use short polling
- D. Implement exponential backoff
Top
Q33: You are using AWS SAM to define a Lambda function and configure CodeDeploy to manage deployment patterns. With new Lambda function working as per expectation which of the following will shift traffic from original Lambda function to new Lambda function in the shortest time frame?
- A. Canary10Percent5Minutes
- B. Linear10PercentEvery10Minutes
- C. Canary10Percent15Minutes
- D. Linear10PercentEvery1Minute
Top
Q34: You are using AWS SAM templates to deploy a serverless application. Which of the following resource will embed application from Amazon S3 buckets?
- A. AWS::Serverless::Api
- B. AWS::Serverless::Application
- C. AWS::Serverless::Layerversion
- D. AWS::Serverless::Function
Top
Q35: You are using AWS Envelope Encryption for encrypting all sensitive data. Which of the followings is True with regards to Envelope Encryption?
- A. Data is encrypted be encrypting Data key which is further encrypted using encrypted Master Key.
- B. Data is encrypted by plaintext Data key which is further encrypted using encrypted Master Key.
- C. Data is encrypted by encrypted Data key which is further encrypted using plaintext Master Key.
- D. Data is encrypted by plaintext Data key which is further encrypted using plaintext Master Key.
Top
Q36: You are developing an application that will be comprised of the following architecture –
- A set of Ec2 instances to process the videos.
- These (Ec2 instances) will be spun up by an autoscaling group.
- SQS Queues to maintain the processing messages.
- There will be 2 pricing tiers.
How will you ensure that the premium customers videos are given more preference?
- A. Create 2 Autoscaling Groups, one for normal and one for premium customers
- B. Create 2 set of Ec2 Instances, one for normal and one for premium customers
- C. Create 2 SQS queus, one for normal and one for premium customers
- D. Create 2 Elastic Load Balancers, one for normal and one for premium customers.
Top
Q37: You are developing an application that will interact with a DynamoDB table. The table is going to take in a lot of read and write operations. Which of the following would be the ideal partition key for the DynamoDB table to ensure ideal performance?
- A. CustomerID
- B. CustomerName
- C. Location
- D. Age
Top
Q38: A developer is making use of AWS services to develop an application. He has been asked to develop the application in a manner to compensate any network delays. Which of the following two mechanisms should he implement in the application?
- A. Multiple SQS queues
- B. Exponential backoff algorithm
- C. Retries in your application code
- D. Consider using the Java sdk.
Top
Q39: An application is being developed that is going to write data to a DynamoDB table. You have to setup the read and write throughput for the table. Data is going to be read at the rate of 300 items every 30 seconds. Each item is of size 6KB. The reads can be eventual consistent reads. What should be the read capacity that needs to be set on the table?
- A. 10
- B. 20
- C. 6
- D. 30
Top
Q40: You are in charge of deploying an application that will be hosted on an EC2 Instance and sit behind an Elastic Load balancer. You have been requested to monitor the incoming connections to the Elastic Load Balancer. Which of the below options can suffice this requirement?
- A. Use AWS CloudTrail with your load balancer
- B. Enable access logs on the load balancer
- C. Use a CloudWatch Logs Agent
- D. Create a custom metric CloudWatch lter on your load balancer
Top
Q41: A static web site has been hosted on a bucket and is now being accessed by users. One of the web pages javascript section has been changed to access data which is hosted in another S3 bucket. Now that same web page is no longer loading in the browser. Which of the following can help alleviate the error?
- A. Enable versioning for the underlying S3 bucket.
- B. Enable Replication so that the objects get replicated to the other bucket
- C. Enable CORS for the bucket
- D. Change the Bucket policy for the bucket to allow access from the other bucket
Top
Q42: Your mobile application includes a photo-sharing service that is expecting tens of thousands of users at launch. You will leverage Amazon Simple Storage Service (S3) for storage of the user Images, and you must decide how to authenticate and authorize your users for access to these images. You also need to manage the storage of these images. Which two of the following approaches should you use? Choose two answers from the options below
- A. Create an Amazon S3 bucket per user, and use your application to generate the S3 URL for the appropriate content.
- B. Use AWS Identity and Access Management (IAM) user accounts as your application-level user database, and offload the burden of authentication from your application code.
- C. Authenticate your users at the application level, and use AWS Security Token Service (STS)to grant token-based authorization to S3 objects.
- D. Authenticate your users at the application level, and send an SMS token message to the user. Create an Amazon S3 bucket with the same name as the SMS message token, and move the user’s objects to that bucket.
Top
Q43: Your current log analysis application takes more than four hours to generate a report of the top 10 users of your web application. You have been asked to implement a system that can report this information in real time, ensure that the report is always up to date, and handle increases in the number of requests to your web application. Choose the option that is cost-effective and can fulfill the requirements.
- A. Publish your data to CloudWatch Logs, and congure your application to Autoscale to handle the load on demand.
- B. Publish your log data to an Amazon S3 bucket. Use AWS CloudFormation to create an Auto Scaling group to scale your post-processing application which is congured to pull down your log les stored an Amazon S3
- C. Post your log data to an Amazon Kinesis data stream, and subscribe your log-processing application so that is congured to process your logging data.
- D. Create a multi-AZ Amazon RDS MySQL cluster, post the logging data to MySQL, and run a map reduce job to retrieve the required information on user counts.
Answer:
Top
Q44: You’ve been instructed to develop a mobile application that will make use of AWS services. You need to decide on a data store to store the user sessions. Which of the following would be an ideal data store for session management?
- A. AWS Simple Storage Service
- B. AWS DynamoDB
- C. AWS RDS
- D. AWS Redshift
Answer:
Top
Q45: Your application currently interacts with a DynamoDB table. Records are inserted into the table via the application. There is now a requirement to ensure that whenever items are updated in the DynamoDB primary table , another record is inserted into a secondary table. Which of the below feature should be used when developing such a solution?
- A. AWS DynamoDB Encryption
- B. AWS DynamoDB Streams
- C. AWS DynamoDB Accelerator
- D. AWSTable Accelerator
Top
Q46: An application has been making use of AWS DynamoDB for its back-end data store. The size of the table has now grown to 20 GB , and the scans on the table are causing throttling errors. Which of the following should now be implemented to avoid such errors?
- A. Large Page size
- B. Reduced page size
- C. Parallel Scans
- D. Sequential scans
Top
Q47: Which of the following is correct way of passing a stage variable to an HTTP URL ? (Select TWO.)
- A. http://example.com/${}/prod
- B. http://example.com/${stageVariables.}/prod
- C. http://${stageVariables.}.example.com/dev/operation
- D. http://${stageVariables}.example.com/dev/operation
- E. http://${}.example.com/dev/operation
- F. http://example.com/${stageVariables}/prod
Top
Q48: Your company is planning on creating new development environments in AWS. They want to make use of their existing Chef recipes which they use for their on-premise configuration for servers in AWS. Which of the following service would be ideal to use in this regard?
- A. AWS Elastic Beanstalk
- B. AWS OpsWork
- C. AWS Cloudformation
- D. AWS SQS
Top
Q49: Your company has developed a web application and is hosting it in an Amazon S3 bucket configured for static website hosting. The users can log in to this app using their Google/Facebook login accounts. The application is using the AWS SDK for JavaScript in the browser to access data stored in an Amazon DynamoDB table. How can you ensure that API keys for access to your data in DynamoDB are kept secure?
- A. Create an Amazon S3 role in IAM with access to the specific DynamoDB tables, and assign it to the bucket hosting your website
- B. Configure S3 bucket tags with your AWS access keys for your bucket hosing your website so that the application can query them for access.
- C. Configure a web identity federation role within IAM to enable access to the correct DynamoDB resources and retrieve temporary credentials
- D. Store AWS keys in global variables within your application and configure the application to use these credentials when making requests.
Top
Q50: Your application currently makes use of AWS Cognito for managing user identities. You want to analyze the information that is stored in AWS Cognito for your application. Which of the following features of AWS Cognito should you use for this purpose?
- A. Cognito Data
- B. Cognito Events
- C. Cognito Streams
- D. Cognito Callbacks
Top
Q51: You’ve developed a set of scripts using AWS Lambda. These scripts need to access EC2 Instances in a VPC. Which of the following needs to be done to ensure that the AWS Lambda function can access the resources in the VPC. Choose 2 answers from the options given below
- A. Ensure that the subnet ID’s are mentioned when conguring the Lambda function
- B. Ensure that the NACL ID’s are mentioned when conguring the Lambda function
- C. Ensure that the Security Group ID’s are mentioned when conguring the Lambda function
- D. Ensure that the VPC Flow Log ID’s are mentioned when conguring the Lambda function
Top
Q52: You’ve currently been tasked to migrate an existing on-premise environment into Elastic Beanstalk. The application does not make use of Docker containers. You also can’t see any relevant environments in the beanstalk service that would be suitable to host your application. What should you consider doing in this case?
- A. Migrate your application to using Docker containers and then migrate the app to the Elastic Beanstalk environment.
- B. Consider using Cloudformation to deploy your environment to Elastic Beanstalk
- C. Consider using Packer to create a custom platform
- D. Consider deploying your application using the Elastic Container Service
Top
Q53: Company B is writing 10 items to the Dynamo DB table every second. Each item is 15.5Kb in size. What would be the required provisioned write throughput for best performance? Choose the correct answer from the options below.
- A. 10
- B. 160
- C. 155
- D. 16
Top
Q54: Which AWS Service can be used to automatically install your application code onto EC2, on premises systems and Lambda?
- A. CodeCommit
- B. X-Ray
- C. CodeBuild
- D. CodeDeploy
Top
Q55: Which AWS service can be used to compile source code, run tests and package code?
- A. CodePipeline
- B. CodeCommit
- C. CodeBuild
- D. CodeDeploy
Top
Q56: How can your prevent CloudFormation from deleting your entire stack on failure? (Choose 2)
- A. Set the Rollback on failure radio button to No in the CloudFormation console
- B. Set Termination Protection to Enabled in the CloudFormation console
- C. Use the –disable-rollback flag with the AWS CLI
- D. Use the –enable-termination-protection protection flag with the AWS CLI
Q57: Which of the following practices allows multiple developers working on the same application to merge code changes frequently, without impacting each other and enables the identification of bugs early on in the release process?
- A. Continuous Integration
- B. Continuous Deployment
- C. Continuous Delivery
- D. Continuous Development
Q58: When deploying application code to EC2, the AppSpec file can be written in which language?
- A. JSON
- B. JSON or YAML
- C. XML
- D. YAML
Q59: Part of your CloudFormation deployment fails due to a mis-configuration, by defaukt what will happen?
- A. CloudFormation will rollback only the failed components
- B. CloudFormation will rollback the entire stack
- C. Failed component will remain available for debugging purposes
- D. CloudFormation will ask you if you want to continue with the deployment
Top
Q60: You want to receive an email whenever a user pushes code to CodeCommit repository, how can you configure this?
- A. Create a new SNS topic and configure it to poll for CodeCommit eveents. Ask all users to subscribe to the topic to receive notifications
- B. Configure a CloudWatch Events rule to send a message to SES which will trigger an email to be sent whenever a user pushes code to the repository.
- C. Configure Notifications in the console, this will create a CloudWatch events rule to send a notification to a SNS topic which will trigger an email to be sent to the user.
- D. Configure a CloudWatch Events rule to send a message to SQS which will trigger an email to be sent whenever a user pushes code to the repository.
Top
Q61: Which AWS service can be used to centrally store and version control your application source code, binaries and libraries
- A. CodeCommit
- B. CodeBuild
- C. CodePipeline
- D. ElasticFileSystem
Top
Q62: You are using CloudFormation to create a new S3 bucket, which of the following sections would you use to define the properties of your bucket?
- A. Conditions
- B. Parameters
- C. Outputs
- D. Resources
Top
Q63: You are deploying a number of EC2 and RDS instances using CloudFormation. Which section of the CloudFormation template would you use to define these?
- A. Transforms
- B. Outputs
- C. Resources
- D. Instances
Top
Q64: Which AWS service can be used to fully automate your entire release process?
- A. CodeDeploy
- B. CodePipeline
- C. CodeCommit
- D. CodeBuild
Top
Q65: You want to use the output of your CloudFormation stack as input to another CloudFormation stack. Which sections of the CloudFormation template would you use to help you configure this?
- A. Outputs
- B. Transforms
- C. Resources
- D. Exports
Top
Q66: You have some code located in an S3 bucket that you want to reference in your CloudFormation template. Which section of the template can you use to define this?
- A. Inputs
- B. Resources
- C. Transforms
- D. Files
Top
Q67: You are deploying an application to a number of Ec2 instances using CodeDeploy. What is the name of the file
used to specify source files and lifecycle hooks?
- A. buildspec.yml
- B. appspec.json
- C. appspec.yml
- D. buildspec.json
Q68: Which of the following approaches allows you to re-use pieces of CloudFormation code in multiple templates, for common use cases like provisioning a load balancer or web server?
- A. Share the code using an EBS volume
- B. Copy and paste the code into the template each time you need to use it
- C. Use a cloudformation nested stack
- D. Store the code you want to re-use in an AMI and reference the AMI from within your CloudFormation template.
Q69: In the CodeDeploy AppSpec file, what are hooks used for?
- A. To reference AWS resources that will be used during the deployment
- B. Hooks are reserved for future use
- C. To specify files you want to copy during the deployment.
- D. To specify, scripts or function that you want to run at set points in the deployment lifecycle
Q70: Which command can you use to encrypt a plain text file using CMK?
- A. aws kms-encrypt
- B. aws iam encrypt
- C. aws kms encrypt
- D. aws encrypt
Q72: Which of the following is an encrypted key used by KMS to encrypt your data
- A. Custmoer Mamaged Key
- B. Encryption Key
- C. Envelope Key
- D. Customer Master Key
Q73: Which of the following statements are correct? (Choose 2)
- A. The Customer Master Key is used to encrypt and decrypt the Envelope Key or Data Key
- B. The Envelope Key or Data Key is used to encrypt and decrypt plain text files.
- C. The envelope Key or Data Key is used to encrypt and decrypt the Customer Master Key.
- D. The Customer MasterKey is used to encrypt and decrypt plain text files.
Q74: Which of the following statements is correct in relation to kMS/ (Choose 2)
- A. KMS Encryption keys are regional
- B. You cannot export your customer master key
- C. You can export your customer master key.
- D. KMS encryption Keys are global
Q75: A developer is preparing a deployment package for a Java implementation of an AWS Lambda function. What should the developer include in the deployment package? (Select TWO.)
A. Compiled application code
B. Java runtime environment
C. References to the event sources
D. Lambda execution role
E. Application dependencies
Q76: A developer uses AWS CodeDeploy to deploy a Python application to a fleet of Amazon EC2 instances that run behind an Application Load Balancer. The instances run in an Amazon EC2 Auto Scaling group across multiple Availability Zones. What should the developer include in the CodeDeploy deployment package?
A. A launch template for the Amazon EC2 Auto Scaling group
B. A CodeDeploy AppSpec file
C. An EC2 role that grants the application access to AWS services
D. An IAM policy that grants the application access to AWS services
Q76: A company is working on a project to enhance its serverless application development process. The company hosts applications on AWS Lambda. The development team regularly updates the Lambda code and wants to use stable code in production. Which combination of steps should the development team take to configure Lambda functions to meet both development and production requirements? (Select TWO.)
A. Create a new Lambda version every time a new code release needs testing.
B. Create two Lambda function aliases. Name one as Production and the other as Development. Point the Production alias to a production-ready unqualified Amazon Resource Name (ARN) version. Point the Development alias to the $LATEST version.
C. Create two Lambda function aliases. Name one as Production and the other as Development. Point the Production alias to the production-ready qualified Amazon Resource Name (ARN) version. Point the Development alias to the variable LAMBDA_TASK_ROOT.
D. Create a new Lambda layer every time a new code release needs testing.
E. Create two Lambda function aliases. Name one as Production and the other as Development. Point the Production alias to a production-ready Lambda layer Amazon Resource Name (ARN). Point the Development alias to the $LATEST layer ARN.
Q77: Each time a developer publishes a new version of an AWS Lambda function, all the dependent event source mappings need to be updated with the reference to the new version’s Amazon Resource Name (ARN). These updates are time consuming and error-prone. Which combination of actions should the developer take to avoid performing these updates when publishing a new Lambda version? (Select TWO.)
A. Update event source mappings with the ARN of the Lambda layer.
B. Point a Lambda alias to a new version of the Lambda function.
C. Create a Lambda alias for each published version of the Lambda function.
D. Point a Lambda alias to a new Lambda function alias.
E. Update the event source mappings with the Lambda alias ARN.
Q78: A company wants to store sensitive user data in Amazon S3 and encrypt this data at rest. The company must manage the encryption keys and use Amazon S3 to perform the encryption. How can a developer meet these requirements?
A. Enable default encryption for the S3 bucket by using the option for server-side encryption with customer-provided encryption keys (SSE-C).
B. Enable client-side encryption with an encryption key. Upload the encrypted object to the S3 bucket.
C. Enable server-side encryption with Amazon S3 managed encryption keys (SSE-S3). Upload an object to the S3 bucket.
D. Enable server-side encryption with customer-provided encryption keys (SSE-C). Upload an object to the S3 bucket.
Q79: A company is developing a Python application that submits data to an Amazon DynamoDB table. The company requires client-side encryption of specific data items and end-to-end protection for the encrypted data in transit and at rest. Which combination of steps will meet the requirement for the encryption of specific data items? (Select TWO.)
A. Generate symmetric encryption keys with AWS Key Management Service (AWS KMS).
B. Generate asymmetric encryption keys with AWS Key Management Service (AWS KMS).
C. Use generated keys with the DynamoDB Encryption Client.
D. Use generated keys to configure DynamoDB table encryption with AWS managed customer master keys (CMKs).
E. Use generated keys to configure DynamoDB table encryption with AWS owned customer master keys (CMKs).
Q80: A company is developing a REST API with Amazon API Gateway. Access to the API should be limited to users in the existing Amazon Cognito user pool. Which combination of steps should a developer perform to secure the API? (Select TWO.)
A. Create an AWS Lambda authorizer for the API.
B. Create an Amazon Cognito authorizer for the API.
C. Configure the authorizer for the API resource.
D. Configure the API methods to use the authorizer.
E. Configure the authorizer for the API stage.
Q81: A developer is implementing a mobile app to provide personalized services to app users. The application code makes calls to Amazon S3 and Amazon Simple Queue Service (Amazon SQS). Which options can the developer use to authenticate the app users? (Select TWO.)
A. Authenticate to the Amazon Cognito identity pool directly.
B. Authenticate to AWS Identity and Access Management (IAM) directly.
C. Authenticate to the Amazon Cognito user pool directly.
D. Federate authentication by using Login with Amazon with the users managed with AWS Security Token Service (AWS STS).
E. Federate authentication by using Login with Amazon with the users managed with the Amazon Cognito user pool.
Q82: A company is implementing several order processing workflows. Each workflow is implemented by using AWS Lambda functions for each task. Which combination of steps should a developer follow to implement these workflows? (Select TWO.)
A. Define a AWS Step Functions task for each Lambda function.
B. Define a AWS Step Functions task for each workflow.
C. Write code that polls the AWS Step Functions invocation to coordinate each workflow.
D. Define an AWS Step Functions state machine for each workflow.
E. Define an AWS Step Functions state machine for each Lambda function.
Q83: A company is migrating a web service to the AWS Cloud. The web service accepts requests by using HTTP (port 80). The company wants to use an AWS Lambda function to process HTTP requests. Which application design will satisfy these requirements?
A. Create an Amazon API Gateway API. Configure proxy integration with the Lambda function.
B. Create an Amazon API Gateway API. Configure non-proxy integration with the Lambda function.
C. Configure the Lambda function to listen to inbound network connections on port 80.
D. Configure the Lambda function as a target in the Application Load Balancer target group.
Q84: A company is developing an image processing application. When an image is uploaded to an Amazon S3 bucket, a number of independent and separate services must be invoked to process the image. The services do not have to be available immediately, but they must process every image. Which application design satisfies these requirements?
A. Configure an Amazon S3 event notification that publishes to an Amazon Simple Queue Service (Amazon SQS) queue. Each service pulls the message from the same queue.
B. Configure an Amazon S3 event notification that publishes to an Amazon Simple Notification Service (Amazon SNS) topic. Each service subscribes to the same topic.
C. Configure an Amazon S3 event notification that publishes to an Amazon Simple Queue Service (Amazon SQS) queue. Subscribe a separate Amazon Simple Notification Service (Amazon SNS) topic for each service to an Amazon SQS queue.
D. Configure an Amazon S3 event notification that publishes to an Amazon Simple Notification Service (Amazon SNS) topic. Subscribe a separate Simple Queue Service (Amazon SQS) queue for each service to the Amazon SNS topic.
Q85: A developer wants to implement Amazon EC2 Auto Scaling for a Multi-AZ web application. However, the developer is concerned that user sessions will be lost during scale-in events. How can the developer store the session state and share it across the EC2 instances?
A. Write the sessions to an Amazon Kinesis data stream. Configure the application to poll the stream.
B. Publish the sessions to an Amazon Simple Notification Service (Amazon SNS) topic. Subscribe each instance in the group to the topic.
C. Store the sessions in an Amazon ElastiCache for Memcached cluster. Configure the application to use the Memcached API.
D. Write the sessions to an Amazon Elastic Block Store (Amazon EBS) volume. Mount the volume to each instance in the group.
Q86: A developer is integrating a legacy web application that runs on a fleet of Amazon EC2 instances with an Amazon DynamoDB table. There is no AWS SDK for the programming language that was used to implement the web application. Which combination of steps should the developer perform to make an API call to Amazon DynamoDB from the instances? (Select TWO.)
A. Make an HTTPS POST request to the DynamoDB API endpoint for the AWS Region. In the request body, include an XML document that contains the request attributes.
B. Make an HTTPS POST request to the DynamoDB API endpoint for the AWS Region. In the request body, include a JSON document that contains the request attributes.
C. Sign the requests by using AWS access keys and Signature Version 4.
D. Use an EC2 SSH key to calculate Signature Version 4 of the request.
E. Provide the signature value through the HTTP X-API-Key header.
Q87: A developer has written several custom applications that read and write to the same Amazon DynamoDB table. Each time the data in the DynamoDB table is modified, this change should be sent to an external API. Which combination of steps should the developer perform to accomplish this task? (Select TWO.)
A. Configure an AWS Lambda function to poll the stream and call the external API.
B. Configure an event in Amazon EventBridge (Amazon CloudWatch Events) that publishes the change to an Amazon Managed Streaming for Apache Kafka (Amazon MSK) data stream.
C. Create a trigger in the DynamoDB table to publish the change to an Amazon Kinesis data stream.
D. Deliver the stream to an Amazon Simple Notification Service (Amazon SNS) topic and subscribe the API to the topic.
E. Enable DynamoDB Streams on the table.
Q88: A company is migrating the create, read, update, and delete (CRUD) functionality of an existing Java web application to AWS Lambda. Which minimal code refactoring is necessary for the CRUD operations to run in the Lambda function?
A. Implement a Lambda handler function.
B. Import an AWS X-Ray package.
C. Rewrite the application code in Python.
D. Add a reference to the Lambda execution role.
Q89: A company plans to use AWS log monitoring services to monitor an application that runs on premises. Currently, the application runs on a recent version of Ubuntu Server and outputs the logs to a local file. Which combination of steps should a developer perform to accomplish this goal? (Select TWO.)
A. Update the application code to include calls to the agent API for log collection.
B. Install the Amazon Elastic Container Service (Amazon ECS) container agent on the server.
C. Install the unified Amazon CloudWatch agent on the server.
D. Configure the long-term AWS credentials on the server to enable log collection by the agent.
E. Attach an IAM role to the server to enable log collection by the agent.
Q90: A developer wants to monitor invocations of an AWS Lambda function by using Amazon CloudWatch Logs. The developer added a number of print statements to the function code that write the logging information to the stdout stream. After running the function, the developer does not see any log data being generated. Why does the log data NOT appear in the CloudWatch logs?
A. The log data is not written to the stderr stream.
B. Lambda function logging is not automatically enabled.
C. The execution role for the Lambda function did not grant permissions to write log data to CloudWatch Logs.
D. The Lambda function outputs the logs to an Amazon S3 bucket.
Q91: Which of the following are best practices you should implement into ongoing deployments of your application? (Select THREE.)
A. Use stage variables to manage secrets across environments
B. Create account-specific AWS SAM templates for each environment
C. Use an AutoPublish alias
D. Use traffic shifting with pre- and post-deployment hooks
E. Test throughout the pipeline
Q92: You are handing off maintenance of your new serverless application to an incoming team lead. Which recommendations would you make? (Select THREE.)
A. Keep up to date with the quotas and payload sizes for each AWS service you are using
B. Analyze production access patterns to identify potential improvements
C. Design your services to extend their life as long as possible
D. Minimize changes to your production application
E. Compare the value of using the latest first-class integrations versus using Lambda between AWS services
Q93: You are handing off maintenance of your new serverless application to an incoming team lead. Which recommendations would you make? (Select THREE.)
A. Keep up to date with the quotas and payload sizes for each AWS service you are using
B. Analyze production access patterns to identify potential improvements
C. Design your services to extend their life as long as possible
D. Minimize changes to your production application
E. Compare the value of using the latest first-class integrations versus using Lambda between AWS services
Q94: Your application needs to connect to an Amazon RDS instance on the backend. What is the best recommendation to the developer whose function must read from and write to the Amazon RDS instance?
A. Initialize the number of connections you want outside of the handler
B. Use the database TTL setting to clean up connections
C. Use reserved concurrency to limit the number of concurrent functions that would try to write to the database
D. Use the database proxy feature to provide connection pooling for the functions
Question 95: A developer reports that a third-party library they need cannot be shared in the Lambda invocation environment. Which suggestion would you make?
A. Decrease the deployment package size
B. Set a provisioned concurrency of one so that the library doesn’t need to be shared across environments
C. Use reserved concurrency for the function that needs to use the library
D. Load the third-party library onto an Amazon EFS volume
AWS Certified Developer Associate exam: Whitepapers
AWS has provided whitepapers to help you understand the technical concepts. Below are the recommended whitepapers for the AWS Certified Developer – Associate Exam.
- Overview of Amazon Web Services
- Architecting for the Cloud: AWS Best Practices
- AWS Security Best Practices whitepaper, August 2016
- AWS Well-Architected Framework whitepaper, November 2017 Version 1.3 DVA-C01 Page |2
- Architecting for the Cloud AWS Best Practices whitepaper, February, 2016
- Practicing Continuous Integration and Continuous Delivery on AWS Accelerating Software Delivery with DevOps whitepaper, June 2017
- Microservices on AWS whitepaper, September 2017
- Serverless Architectures with AWS Lambda whitepaper, November 2017
- Optimizing Enterprise Economics with Serverless Architectures whitepaper, October 2017
- Running Containerized Microservices on AWS whitepaper, November 2017
- Blue/Green Deployments on AWS whitepaper, August 2016
Online Training and Labs for AWS Certified Developer Associates Exam
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
AWS Developer Associates Jobs
AWS Certified Developer-Associate Exam info and details, How To:
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
The AWS Certified Developer Associate exam is a multiple choice, multiple answer exam. Here is the Exam Overview:
- Certification Name: AWS Certified Developer Associate.
- Prerequisites for the Exam: None.
- Exam Pattern: Multiple Choice Questions
- The AWS Certified Developer-Associate Examination (DVA-C01) is a pass or fail exam. The examination is scored against a minimum standard established by AWS professionals guided by certification industry best practices and guidelines.
- Your results for the examination are reported as a score from 100 – 1000, with a minimum passing score of 720.
- Exam fees: US $150
- Exam Guide on AWS Website
- Available languages for tests: English, Japanese, Korean, Simplified Chinese
- Read AWS whitepapers
- Register for certification account here.
- Prepare for Certification Here
Exam Content Outline
Domain % of Examination Domain 1: Deployment (22%)
1.1 Deploy written code in AWS using existing CI/CD pipelines, processes, and patterns.
1.2 Deploy applications using Elastic Beanstalk.
1.3 Prepare the application deployment package to be deployed to AWS.
1.4 Deploy serverless applications22% Domain 2: Security (26%)
2.1 Make authenticated calls to AWS services.
2.2 Implement encryption using AWS services.
2.3 Implement application authentication and authorization.26% Domain 3: Development with AWS Services (30%)
3.1 Write code for serverless applications.
3.2 Translate functional requirements into application design.
3.3 Implement application design into application code.
3.4 Write code that interacts with AWS services by using APIs, SDKs, and AWS CLI.30% Domain 4: Refactoring
4.1 Optimize application to best use AWS services and features.
4.2 Migrate existing application code to run on AWS.10% Domain 5: Monitoring and Troubleshooting (10%)
5.1 Write code that can be monitored.
5.2 Perform root cause analysis on faults found in testing or production.10% TOTAL 100%
AWS Certified Developer Associate exam: Additional Information for reference
Below are some useful reference links that would help you to learn about AWS Certified Developer Associate Exam.
- Developing on AWS: An instructor-led live or virtual 3-day course
- https://aws.amazon.com/certification/faqs/
- AWS Digital Training: Application Services, Developer Tools, and other services covered on the exam
- Prepare for AWS Certification
- AWS EC2 Instance info
- AWS Certified Developer Associate Exam Guide
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Other Relevant and Recommended AWS Certifications

The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
- AWS Certified Cloud Practitioner
- AWS Certified Solutions Architect – Associate
- AAWS Certified Developer – Associate
- AWS Certified SysOps Administrator – Associate
- AWS Certified Solutions Architect – Professional
- AWS Certified DevOps Engineer – Professional
- AWS Certified Big Data Specialty
- AWS Certified Advanced Networking.
- AWS Certified Security – Specialty
Other AWS Facts and Summaries and Questions/Answers Dump
- AWS S3 facts and summaries and Q&A Dump
- AWS DynamoDB facts and summaries and Questions and Answers Dump
- AWS EC2 facts and summaries and Questions and Answers Dump
- AWS Serverless facts and summaries and Questions and Answers Dump
- AWS Developer and Deployment Theory facts and summaries and Questions and Answers Dump
- AWS IAM facts and summaries and Questions and Answers Dump
- AWS Lambda facts and summaries and Questions and Answers Dump
- AWS SQS facts and summaries and Questions and Answers Dump
- AWS RDS facts and summaries and Questions and Answers Dump
- AWS ECS facts and summaries and Questions and Answers Dump
- AWS CloudWatch facts and summaries and Questions and Answers Dump
- AWS SES facts and summaries and Questions and Answers Dump
- AWS EBS facts and summaries and Questions and Answers Dump
- AWS ELB facts and summaries and Questions and Answers Dump
- AWS Autoscaling facts and summaries and Questions and Answers Dump
- AWS VPC facts and summaries and Questions and Answers Dump
- AWS KMS facts and summaries and Questions and Answers Dump
- AWS Elastic Beanstalk facts and summaries and Questions and Answers Dump
- AWS CodeBuild facts and summaries and Questions and Answers Dump
- AWS CodeDeploy facts and summaries and Questions and Answers Dump
- AWS CodePipeline facts and summaries and Questions and Answers Dump
AWS Certified Developer Associate exam: Whitepapers
AWS has provided whitepapers to help you understand the technical concepts. Below are the recommended whitepapers for the AWS Certified Developer – Associate Exam.
- Overview of Amazon Web Services
- Architecting for the Cloud: AWS Best Practices
- AWS Security Best Practices whitepaper, August 2016
- AWS Well-Architected Framework whitepaper, November 2017 Version 1.3 DVA-C01 Page |2
- Architecting for the Cloud AWS Best Practices whitepaper, February, 2016
- Practicing Continuous Integration and Continuous Delivery on AWS Accelerating Software Delivery with DevOps whitepaper, June 2017
- Microservices on AWS whitepaper, September 2017
- Serverless Architectures with AWS Lambda whitepaper, November 2017
- Optimizing Enterprise Economics with Serverless Architectures whitepaper, October 2017
- Running Containerized Microservices on AWS whitepaper, November 2017
- Blue/Green Deployments on AWS whitepaper, August 2016
Online Training and Labs for AWS Certified Developer Associates Exam
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
AWS Developer Associates Jobs
AWS Certified Developer-Associate Exam info and details, How To:
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
The AWS Certified Developer Associate exam is a multiple choice, multiple answer exam. Here is the Exam Overview:
- Certification Name: AWS Certified Developer Associate.
- Prerequisites for the Exam: None.
- Exam Pattern: Multiple Choice Questions
- The AWS Certified Developer-Associate Examination (DVA-C01) is a pass or fail exam. The examination is scored against a minimum standard established by AWS professionals guided by certification industry best practices and guidelines.
- Your results for the examination are reported as a score from 100 – 1000, with a minimum passing score of 720.
- Exam fees: US $150
- Exam Guide on AWS Website
- Available languages for tests: English, Japanese, Korean, Simplified Chinese
- Read AWS whitepapers
- Register for certification account here.
- Prepare for Certification Here
Exam Content Outline
Domain % of Examination Domain 1: Deployment (22%)
1.1 Deploy written code in AWS using existing CI/CD pipelines, processes, and patterns.
1.2 Deploy applications using Elastic Beanstalk.
1.3 Prepare the application deployment package to be deployed to AWS.
1.4 Deploy serverless applications22% Domain 2: Security (26%)
2.1 Make authenticated calls to AWS services.
2.2 Implement encryption using AWS services.
2.3 Implement application authentication and authorization.26% Domain 3: Development with AWS Services (30%)
3.1 Write code for serverless applications.
3.2 Translate functional requirements into application design.
3.3 Implement application design into application code.
3.4 Write code that interacts with AWS services by using APIs, SDKs, and AWS CLI.30% Domain 4: Refactoring
4.1 Optimize application to best use AWS services and features.
4.2 Migrate existing application code to run on AWS.10% Domain 5: Monitoring and Troubleshooting (10%)
5.1 Write code that can be monitored.
5.2 Perform root cause analysis on faults found in testing or production.10% TOTAL 100%
In this AWS tutorial, we are going to discuss how we can make the best use of AWS services to build a highly scalable, and fault tolerant configuration of EC2 instances. The use of Load Balancers and Auto Scaling Groups falls under a number of best practices in AWS, including Performance Efficiency, Reliability and high availability.
Before we dive into this hands-on tutorial on how exactly we can build this solution, let’s have a brief recap on what an Auto Scaling group is, and what a Load balancer is.
Autoscaling group (ASG)
An Autoscaling group (ASG) is a logical grouping of instances which can scale up and scale down depending on pre-configured settings. By setting Scaling policies of your ASG, you can choose how many EC2 instances are launched and terminated based on your application’s load. You can do this based on manual, dynamic, scheduled or predictive scaling.
Elastic Load Balancer (ELB)
An Elastic Load Balancer (ELB) is a name describing a number of services within AWS designed to distribute traffic across multiple EC2 instances in order to provide enhanced scalability, availability, security and more. The particular type of Load Balancer we will be using today is an Application Load Balancer (ALB). The ALB is a Layer 7 Load Balancer designed to distribute HTTP/HTTPS traffic across multiple nodes – with added features such as TLS termination, Sticky Sessions and Complex routing configurations.
Getting Started
First of all, we open our AWS management console and head to the EC2 management console.
We scroll down on the left-hand side and select ‘Launch Templates’. A Launch Template is a configuration template which defines the settings for EC2 instances launched by the ASG.
Under Launch Templates, we will select “Create launch template”.
We specify the name ‘MyTestTemplate’ and use the same text in the description.
Under the ‘Auto Scaling guidance’ box, tick the box which says ‘Provide guidance to help me set up a template that I can use with EC2 Auto Scaling’ and scroll down to launch template contents.
When it comes to choosing our AMI (Amazon Machine Image) we can choose the Amazon Linux 2 under ‘Quick Start’.
The Amazon Linux 2 AMI is free tier eligible, and easy to use for our demonstration purposes.
Next, we select the ‘t2.micro’ under instance types, as this is also free tier eligible.
Under Network Settings, we create a new Security Group called ExampleSG in our default VPC, allowing HTTP access to everyone. It should look like this.
AWS Certified Developer Associate exam: Additional Information for reference
Below are some useful reference links that would help you to learn about AWS Certified Developer Associate Exam.
- Developing on AWS: An instructor-led live or virtual 3-day course
- https://aws.amazon.com/certification/faqs/
- AWS Digital Training: Application Services, Developer Tools, and other services covered on the exam
- Prepare for AWS Certification
- AWS EC2 Instance info
- AWS Certified Developer Associate Exam Guide
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Other Relevant and Recommended AWS Certifications
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
- AWS Certified Cloud Practitioner
- AWS Certified Solutions Architect – Associate
- AAWS Certified Developer – Associate
- AWS Certified SysOps Administrator – Associate
- AWS Certified Solutions Architect – Professional
- AWS Certified DevOps Engineer – Professional
- AWS Certified Big Data Specialty
- AWS Certified Advanced Networking.
- AWS Certified Security – Specialty
Other AWS Facts and Summaries and Questions/Answers Dump
- AWS S3 facts and summaries and Q&A Dump
- AWS DynamoDB facts and summaries and Questions and Answers Dump
- AWS EC2 facts and summaries and Questions and Answers Dump
- AWS Serverless facts and summaries and Questions and Answers Dump
- AWS Developer and Deployment Theory facts and summaries and Questions and Answers Dump
- AWS IAM facts and summaries and Questions and Answers Dump
- AWS Lambda facts and summaries and Questions and Answers Dump
- AWS SQS facts and summaries and Questions and Answers Dump
- AWS RDS facts and summaries and Questions and Answers Dump
- AWS ECS facts and summaries and Questions and Answers Dump
- AWS CloudWatch facts and summaries and Questions and Answers Dump
- AWS SES facts and summaries and Questions and Answers Dump
- AWS EBS facts and summaries and Questions and Answers Dump
- AWS ELB facts and summaries and Questions and Answers Dump
- AWS Autoscaling facts and summaries and Questions and Answers Dump
- AWS VPC facts and summaries and Questions and Answers Dump
- AWS KMS facts and summaries and Questions and Answers Dump
- AWS Elastic Beanstalk facts and summaries and Questions and Answers Dump
- AWS CodeBuild facts and summaries and Questions and Answers Dump
- AWS CodeDeploy facts and summaries and Questions and Answers Dump
- AWS CodePipeline facts and summaries and Questions and Answers Dump
AWS Certifications Breaking News and Top Stories
- Difference between Docker and Amazon Elastic Container Registry (ECR): Is Docker superior?by /u/DigitalSplendid
Created a new container on AWS Lightsail. Need to understand if there are two ways to deploy a container through their menu options: Deployments or Images? Are Docker and ECR competing products? Is Docker superior to ECR? The reason is it appears AWS LIghtsail itself has made apparently mandatory to use Docker if images option chosen. Also when Deployments menu clicked: "Enter the image reference from a public registry, such as DockerHub." So they are mentioning DockerHub and not their own ECR! submitted by /u/DigitalSplendid [link] [comments]
- Does this mean I pass the AWS ML Specialty?by /u/Soyun12
This is the email I got https://preview.redd.it/4696fjpuqbyc1.jpg?width=750&format=pjpg&auto=webp&s=b9e8d66906ba7093e358557896812271224e21b1 submitted by /u/Soyun12 [link] [comments]
- AWS CCP for GRC professionals?by /u/Head_Astronaut_2442
I have 6 years of experience in cyber risk & governance and am a CISSP holder. I’m looking to develop fundamental cloud literacy and demonstrate to future employees that I have understanding of the cloud / generally pad my resume. Is the CCP an appropriate certificate? submitted by /u/Head_Astronaut_2442 [link] [comments]
- Who to contact for support? Is there is a support phone number I can call?by /u/qqpp_ddbb
So I've been throttled for over 24 hours now in amazon bedrock and I put in a support ticket, to no avail. Is there a phone number I can call to speak with support? It seems ridiculous that I'm being throttled/rate limited this hard for such a low number of requests. Here's some metrics. Let me know if more info is needed. I'm new to this stuff, sorry.. https://i.postimg.cc/GpQP5mrk/Metrics-Cloud-Watch-us-west-2.png Thanks in advance submitted by /u/qqpp_ddbb [link] [comments]
- Need help reconnecting to AWS VM for assignment.by /u/clashofcam
Hello, I've been troubleshooting for a while. I edited my Network Settings in my AWS windows 2019 VM. I believe I messed up the DNS. As soon as I clicked "OK" I got kicked off the virtual machine. I've tried tinkering with different things in the console but I cannot figure out how to change it to auto assign the DNS so I can get back on the Virtual machine. Any help is appreciated. Thank you! submitted by /u/clashofcam [link] [comments]
- S3 Cross Account Accessby /u/MrStu56
Hello all, I'm hoping someone can help me here with an issue I'm battling with when it comes to cross account S3 access. I can't quite get my head around the permissions required, or perhaps more accurately where those permissions should be applied, and in which account. Here's the scenario: I have created a bucket in account A called test-100-bucket. In that bucket are the folders: "working", "ClientAccess" and "store". I'm looking to grant: List, Put, Get, Delete (i.e full read/write) on "working" and "ClientAccess" to a group of users in Account B called "AccountB/Wranglers" I'm looking to grant List, Put, Get, Delete (ie. full read/write) on "ClientAccess" (and any subfolders /*) to a specific user in AccountA (Lets call them AccountA/Client). AccountA/Client should not be able to see any of the other folders. I'm looking to restrict access to "store", so that AccountB/Wranglers can put, list, get but should not be able to delete anything. As the bucket owner I should be able to destroy the bucket and all the objects when required. Can someone help me with: What permissions are needed for the AccountB/Wranglers (and where those permissions are applied). Do I need an account or group in AccountA to handle this? What bucket policy(?) I need to apply to restrict the ClientAccess folder. What bucket or user policy (or both?) is needed for the "store" folder. Hope you can help, I've asked AmazonQ, ChatGPT and done a few youtube vids as well as the documentation but still can't seem to get it to work. If anyone has a good resource, (in crayons at this point) I'm happy to take a look. submitted by /u/MrStu56 [link] [comments]
- Bedrock Agents with Guardrailsby /u/ProfessorHuman
Has anyone used guardrails with agents? I don’t see a way to associate a guardrail with an agent. Either in the api documentation or in the console. I see you can specify a guardrail in the invoke_model method of boto3 but that’s not with an agent. Docs seem to suggest it’s possible. But I see reference anywhere to how. submitted by /u/ProfessorHuman [link] [comments]
- boto3 not finding (IAM) credentials when running docker container on ECS task, but does work locally... why not?by /u/that_dogs_wilin
Hi, I'm new to setting things up on AWS so apologies in advance for dumb questions or if I use the wrong terminology (please correct me!). Here's what I'm trying to do: I want to create a docker container that will install necessary packages, and then run a python script. The python script will run for a bit and then write some output file, my_cool_dict.json. Then, I want to upload this file to my S3 bucket, and the task is done. Here's what I've done so far: I followed some AWS documentation. For setting up the AWS CLI, I did their recommended best practice of configuring AWS CLI to use the IAM identity center, here. I did the recommended SSO token provider config, and I know it works because I can locally push stuff to my S3 bucket, etc. I created an S3 bucket, and a ECR repository for my docker image. In IAM, I created a role, ecs_task_with_logging. To that role, I attached the policies AmazonECSTaskExecutionRolePolicy (so it can run an ECS task) and AmazonS3FullAccess (so it can upload to my S3 bucket). Locally, I built a docker image and pushed it to my ECR repo. In ECS, I created a cluster, then created a task definition that references the correct image URI, and the executionRoleArn of the role above. I also set up logging with python's logging lib / made a log group with CloudWatch / added the logging stuff to the task definition. To run the task, I go to the cluster, go to the Tasks tab, and use the default options, except for selecting "Task" under "Deployment configuration", and selecting the task definition. So I know all of that works, because the following successfully works: if my python script only does logging.info("Script finished running!"), I see it in CloudWatch! Therefore, I know the process of building the image, pushing it to ECR, creating the task definition, and running it on my ECS cluster must all work. I added s3 = boto3.client("s3") and s3.upload_file() to my python script. If I simply run the python script locally, this works (the file appears in the bucket). So I know the boto3 code is fine. If I do aws s3 cp my_cool_dict.json s3://my-bucket/my_cool_dict.json just in the terminal, it works. The step I'm struggling with is uploading the file from my container to my S3 bucket. If I try running the image even locally (which should just be running the script that just worked), I get the error botocore.exceptions.NoCredentialsError: Unable to locate credentials. If instead of using boto3, I put the aws s3 cp ... command in the Dockerfile, I get upload failed: ./my_cool_dict.json to s3://my-bucket/my_cool_dict.json Unable to locate credentials. Similarly, when I run the image (with either of those methods) on ECS, I get the same errors. Can anyone point me to something I could try to figure out why it can't find the credentials? submitted by /u/that_dogs_wilin [link] [comments]
- Cost alert for the unknown account. Help wanted.by /u/moondaddi80
On 30 April, I suddenly received a COST ALERT email. --- qouted start --- AWS Budget Notification April 30, 2024 AWS Account ************ Dear AWS Customer, You requested that we alert you when the actual cost associated with your My Monthly Cost Budget budget exceeds $4.25 for the current month. The month actual cost associated with this budget is $4.27. You can find additional details below and by accessing the AWS Budgets dashboard. Budget Name Budget Type Budgeted Amount Alert Type Alert Threshold ACTUAL Amount My Monthly Cost Budget Cost $5.00 ACTUAL > $4.25 $4.27 --- quoted end --- And today I got another email. --- quoted start --- AWS Budget Notification May 03, 2024 AWS Account ************ Dear AWS Customer, You requested that we alert you when the forecasted cost associated with your My Monthly Cost Budget budget exceeds $5.00 for the current month. The month forecasted cost associated with this budget is $10.04. You can find additional details below and by accessing the AWS Budgets dashboard. Budget Name Budget Type Budgeted Amount Alert Type Alert Threshold FORECASTED Amount My Monthly Cost Budget Cost $5.00 FORECASTED > $5.00 $10.04 --- quoted end --- I contacted AWS CS and they told me that if I don't know my sign in credential, they can't discuss anything related to the account further. So they asked me to give them the TRANSACTION ID, CREDIT CARD NO., etc. that was charged. But I couldn't give them a transaction information yet, because I got an email but the charge hasn't happened on my credit card yet. The email I received the COST ALERT from is the account I had when I used AWS a few years ago, but I signed out and deleted the account after the 1 yr free-tier ended, so now when I try to log in to AWS with this email, it gives me an error saying the account doesn't exist. What I'm wondering now are these things. from the cost alert email, it seems like the cost budget is $5, but when I look at the second cost alert, it shows $10 as the forecasted amount. Is this a situation where the cost will continue to increase until the end of the month because it exceeds the budget? Or will the cost only be incurred up to the budgeted amount of $5? In the body of the email, there is an AWS Account 12 digits no. Is there any way I can log in with this? Luckily, I found the password for that AWS account in the password management application I use. submitted by /u/moondaddi80 [link] [comments]
- SES Email Sending Request Refusedby /u/barcodez
I've used AWS for years, almost since the beginning at huge and large companies. Love it and always thought it was great for innovation and small companies as it really made things super easy for people to try out an idea without doing any heavy investment. So naturally when I wanted to try out an idea I picked AWS. I won't go into too much detail but the idea involves sending some email for registration (standard stuff) and some notifications on account status, so I've configured all my settings and written some prototype code using the sandbox, and naturally wanted to try things with some external email accounts (belonging to me at first, then some friends and then maybe a few referrals if things look good). Thus I requested production access. I send a quick note explaining briefly what I was doing and 24hrs later got a note saying we need more info. Fair enough they need to protect their email servers reputations. I wrote a pretty long explanation covering off all the points they were interested in but did explain it was a prototype so (a.) I don't have examples of templates, it will just be short ASCII messages for now, (b.) I'd only need to send a few emails whilst I get started (c.) bounces, complaints and unsubscribes would be handled etc. I was refused, more over I was told in no uncertain terms I was considered a threat to other users of the service and for security reasons they won't tell me why. I'm bit annoyed if I'm honest because I don't want to have to build out everything to answer some questions and provide templates when I'm really just fleshing out an idea, and sending <100 emails a month if that. Glad I've found out sooner rather than later. I'm considering just installing a mail server on EC2 with an elastic IP but having managed mail servers before I know it's a time sink and for very little reward and concerned they might take issue with this. I appreciate email is the wild west but this level of gatekeeping around smtp is a bit anti innovation in my view. Should I just get on building the prototype and send mail some other way in the hope that once I have more answers they will enable me or is it too risky? Anyone else been refused at the early stages and got accepted later? submitted by /u/barcodez [link] [comments]
- Protection for unprotected port being probed in AWSby /u/lowkib
Hey Guys, So I have a scenario i would like some help with to get some ideas. AWS Guard duty has alerted us that one of our unprotected ports is being probed from malicious IP's which are located in Russia and Poland. The port has been probed over 300 times this month. Although I know public facing port's tend to get probed and this is relatively normal the port open is related to our PAM solution which significantly increases the risk as this is the protection for our infrastructure and essentially our whole company. It has already been confirmed that the port can not be closed as it needs to be open for the PAM Solution to work effectively. So now the question is how do we protect this instance while keeping the port open? Does anyone have any ideas.. The ideas i've thought of are.. Using some sort of VPN and whitelisting only know IP's to access our infrastructure. Using a WAF on the instance. This is looking like it would be significant work and change to our infrastructure as the instance in question has an network load balancer attached to it and you cannot directly add WAF's to instances with network load balancers. I believe its possible but would have to re-design alot.. So my question is what would you guys do in this suitation? Any suggestions. Appreciate any help submitted by /u/lowkib [link] [comments]
- CDK vs terraformby /u/LaserBoy9000
I’ve never used terraform before but understand that it’s the original scalable solve to the IaC problem. I have however used CDK quite often over the last year; I found that getting up to speed with TS was painful at first but that type constraints were ultimately really helpful when debugging issues. Anyway, I’m curious what the community’s thoughts are on these tools. The obvious point to TF is that with some tweaks, GCP, Azure etc could be swapped out for AWS and vice versa. But I’d imagine that CDK gives you the most granular control over AWS resources and the ability to leverage new AWS features quickly. Thoughts? submitted by /u/LaserBoy9000 [link] [comments]
- Evaluating the Impact of CloudFront on S3 Transfer Acceleration for Infrequent File Access in Private Cloud Storageby /u/yccheok
My use case involves providing private cloud storage to individual users. Therefore, the same file will only be accessed by the same user, once every few days or even months. I am currently using S3 Transfer Acceleration to improve upload and download speeds. Here is my code snippet: s3_client = boto3.client( 's3', config=Config(s3={'use_accelerate_endpoint': True}) ) s3_client.generate_presigned_url In such a case, will CloudFront still be able to contribute to improving download and upload speeds? It seems to me that caching might not play a significant role here if a file is accessed only once throughout a day. submitted by /u/yccheok [link] [comments]
- API data formats for internal Amazon services...by /u/crimson117
Amazon famously mandated all systems must communicate over APIs two decades ago. How did this play out in terms of API request/response data structures? Was it all over the place? Was it a common set of fields/properties that each api conformed to? submitted by /u/crimson117 [link] [comments]
- My personal website, hosted on AWS for years with no charges (minimal traffic), suddenly getting billed $8/monthby /u/not_listed
For years I've been hosting my personal website on AWS (simple S3) with like max 30 visits per month, so never amounted to any billing. A few months ago I finally set up HTTPS support on my AWS account (by adding Cloudfront distribution) No change in traffic, but now have been getting billed $8 a month. The charges cited are: AWS WAF Global-RuleV2 ($3) AWS WAF Global-WebACLV2 ($5) Can I avoid these charges some how? If it makes a difference: I'm almost never in AWS, this personal website was just a set it and forget it thing. NameSilo is my domain manager submitted by /u/not_listed [link] [comments]
- A couple noob questions about AMI choice. How risky is it choosing community AMIs ? How relevant is "Verified Provider" green seal ? What is the pricing for Community AMIs ?by /u/Mykoliux-1
Hello. I am new to AWS and I wanted to launch an EC2 Instance to host my hobby project. I chose to use Alpine Linux for this and the most minimum EC2 size available (either t3.nano or t4g.nano). I started to look for appropriate Amazon Machine Image (AMI) and in the marketplace I found "Alpine Linux on AWS", but it costs 0.006 USD/hour (4.32 USD/month). But I also saw some free alternatives in the "Community AMIs" section with "Verified Provider" seal. I was curious how risky is it to use community AMIs compared to Marketplace AMIs ? Is it safe to use AMIs with "Verified Provider" seal from Community section ? Are all "Community AMIs" free, because after selecting the one I need I can't check the price anywhere, it just has certain info (published date, architecture, etc.) ? submitted by /u/Mykoliux-1 [link] [comments]
- one custom domain name to rule them allby /u/ManicQin
Hi! We have multiple api gateways for internal services that we supply to our teams. Until now we had a few and it we was still easy to use aws' api gateway url. our api gateways are deployed as stacks with their lambdas and needed resources. Team A deploys their service and team B deploys theirs. I want with minimum interference to the teams, to give a joint api that will redirect the requests to the correct apis. Lets say that if team A's service url is https://AAAAAA.execute-api.us-east-1.amazonaws.com/hello and B's service url is https://AAAAAA.execute-api.us-east-1.amazonaws.com/bye I want a new api gateway: https://www.example.com/A_services/hello https://www.example.com/B_services/bye Can I use api gateway to redirect a call to another? (is that what happens when choosing HTTP integration on method creation?) Can I use it with private rest apis? Also I want a simple service discovery for the teams. How can I implement it? I thought about using boto3 to query the api gateway and retrieve all resources. I can run from a lambda and retrieve the information from the api: https://www.example.com/discovery Is there a better way? submitted by /u/ManicQin [link] [comments]
- WebSocket doesn't work in ec2 instance amazon linuxby /u/Temporary_Ask_0
I have created a server that uses a websocket for chat screen, when i connect my app with my local server the websockets work perfect it shows new send message immidiently etc, but when i connect my app with my ec2 server that i have git cloned my exact same source code the web sockets return this GET /socket.io/?EIO=4&transport=websocket 404 , all the other fetches post etc works perfect in the ec2 instance. Note when i connect in the local server and connect to the web socket i dont get in my console a get log like the one above If other information is needed let me know submitted by /u/Temporary_Ask_0 [link] [comments]
- Passed SAA-C03!by /u/oradb2
Will start by thanking everyone here for their valuable input which was definitely helpful! I have been preparing on and off for about 6 months - was using Stephane Maarek's udemy course but was able to complete only 60-70% of it but it certainly seems like a nice resource! Got to know about TD tests here so ordered them and started using them about a month back - used topics mode first then review mode(did 4 tests only). I also used TD's study guide(about 340 pages) which I find pretty good - but I think you can find most of the similar information in cheat sheets as well. When I get to know about the retake promotion, I thought let me just write the exam with my current level and may be I will prepare in more detail for my second try 🙂 I was shocked(pleasantly of course) to clear the exam with 744! Here is my take for the future exam takes - hoping it will help you guys in some way: Like many people have said here, you are never fully ready so trust yourself and go for it, you should be fine(assuming you are at least at a certain level) I personally find the exam little hard - the reason could be that probably I was not that well prepared ! I tried to read about ALL the services and their details from TD's study guide but I noticed that the exam focused more on the core services(S3,EC2,ELB,VPC,RDS,Route 53,WAF to name a few) - you should be very very thorough with these core services and you would do well! I use AWS every day at work(managing RDS) so probably that might have helped me All the best on your AWS certification journey guys! submitted by /u/oradb2 [link] [comments]
- Vouchersby /u/Important-Limit7092
Can i use a 50% voucher to buy a full exam voucher? Thank you. submitted by /u/Important-Limit7092 [link] [comments]
- Can I keep code and infra separate to support multiple deploymentby /u/HDAxom
This came up during one of design discussion and I want to validate this. I have mostly worked on serverless on AWS , have not tried ECS or EKS or any containerized application on any platform. We have a spring boot application deployed on ECS cluster ( with Fargate) , These two - app and infra is in same codebase and for some reason , other would also need access to this spring boot app and may deploy on own existing ECS cluster or EKS etc , so infra can change. My thinking is as long as I keep app and infra separate even in same codebase , publish app to artifactory , anyone should be able to download the app and create own infra around it - use EKS or ECS cluster or on-premise deployment. They are not bound by my container. I have given a start script that can be configured in container to boot and this set up would work. I could try technical feasibility but I was hoping to get an insight here in case someone have view! Also if this is a good practice - basically providing an application with or without container to be consumed by others. Also not sure if this is AWS question 🙂 but since we work exclusively on AWS , I would want feasibility here. submitted by /u/HDAxom [link] [comments]
- AWS Lambda function (SAM) - How can I handle binary data from containerized application? (.Net)by /u/gangelofilho
Hi Guys! I'm trying to build an api that basically receives an docx file and return the docx file processed. I trying to use lambda from aws because I want to make this project free for anyone to use. The main application is written in c#/.Net. The container runs internally a node.Js application, which is called by the main app (.Net), just to process equations (this lib is only available in node, thats why I had to do this to work). So now that I have the container working just fine, I wanted to use it in a lambda. I Tried everything to make it happen, but Im not beeing able to make it work. I Tried everything from those tutorials: 1, 2, 3, 4 I have the source code here, hosted on my Github. If anyone here could help me with anything, I would be glad. This is the first project that im trying to create using AWS, by myself. AWS is so hard to learn!! Thanks submitted by /u/gangelofilho [link] [comments]
- Options for running Python script on EC2by /u/DiabloSpear
Hi guys, I just started my AWS journey and wanted to see if I am taking the right path. I have a Python script that I want to run - this downloads data from internet and runs a simple neural network. My plan is like below. Upload my Python code to EC2 and download data from internet and upload to S3. Upload the data from S3 to EC2 (might seem redundant from step 1, but I wanted to practice transferring data between EC2 and S3, thus transferring data from EC2-> S3 -> EC2). Run the neural network. I think I am running into trouble on Step 1. One way I can think of is I can upload Python script onto S3 and import into EC2 instance and then run it? How would I run python script that is on my local PC in EC2? I read some blogs saying that you can use SSH, but I am not that savvy with terminals and shell?(I honestly do not even know what they mean...I am mostly from math background when it comes to machine learning) so I would like to stick with using the EC2 instance launch or Session manager, unless I must use SSH. I also read on this sub that I can use Lambda - what is the main difference between Lambda and EC2? Thanks so much for the answers. submitted by /u/DiabloSpear [link] [comments]
- Do aws certification on behalf meby /u/Early_Task3572
Anyone knows any company or person to do aws certificacion on behalf me that not scam me? submitted by /u/Early_Task3572 [link] [comments]
- How to deploy a general purpose DL pipeline on AWS?by /u/mr_birrd
As I could just not find any clear description of my problem I come here and hope you can help me. I have a general machine learning pipeline with a lot of code and different libraries, custom CUDA, Pytorch, etc., and I want to deploy it on AWS. I have a single prediction function which could be called that returns some data (images/point clouds). I will have a seperated website that will call the model over a REST API. How do I deploy the model? I found out I need to dockerize, but how? What functions are expected for deployment, what structure, etc.? All I found are tutorials where I run experiments using sklearn on Sagemaker, but this is not suitable. Thank you for any links or hints! submitted by /u/mr_birrd [link] [comments]
- Bastion host shutting down "randomly"by /u/steadyvibin
Hi all, We have an EC2 instance which we are using as a bastion host. We use this to sometimes get a production console but mostly as an entry point for a data transfer tool (Census) to migrate some of our database from RDS to an external warehouse. We noticed our EC2 instance would shut down randomly throughout the day. So installed the cloudwatch agent so we could monitor more metrics. The machine was not running out of memory, CPU or disk. So I went to check the logs are there were no errors happening when the machine shut down. The user session would just be stopped. So to test a theory I got a production console which would just print something out to the console every 15 seconds. This completely stopped the machine from going down. The instance is running an ubuntu image. Has anyone experienced any similar problems or have any advice? I can provide more details if needed. submitted by /u/steadyvibin [link] [comments]
- .NET on AWS show featuring David Fowler and Norm Johanson!by /u/fbouteruche
Monday 6th will be an amazing day! The .NET on AWS show will feature David Fowler and Norm Johanson all together to discuss .NET Aspire and AWS. 💻 Brandon Minnick, MBA and myself are so excited to welcome those amazing engineers 😍 It will be at 8am PST / 5pm CESTDo not miss this episode, set a reminder by clicking here 👇 https://www.twitch.tv/aws/schedule?segmentID=cde4f63f-52fe-4ee1-9628-2fd055d0227b submitted by /u/fbouteruche [link] [comments]
- Exam voucherby /u/Purple_Newspaper_133
Hello all Where and how do I get exam voucher or any sort of discount so I can schedule an exam? Btw I still have active school email id from my college. Thanks submitted by /u/Purple_Newspaper_133 [link] [comments]
- Dear APIGW, does "data out" mean data traversing the APIGW or egress to internet?by /u/Avansay
assuming this flow does data coming off of lambda2 incur 2 egress fees or just 1 at [firstapigw] ? user --get--> (internet) -- get --> [firstapigw] --> lambda1 --> [AnotherApigw] --> lambda2 submitted by /u/Avansay [link] [comments]
- Can I use my PayPal Balance to pay for AWS Certifications?by /u/MatthewGalloway
Or do they only accept credit cards submitted by /u/MatthewGalloway [link] [comments]
- Route 53 questionby /u/Nblearchangel
I have a small hobby business and tried buying some domains a few years ago. I was successful with a couple but the .com I really wanted was taken. I contacted godaddy to help broker the purchase but realized quickly the domain I wanted was way more expensive than I could afford. I canceled my service with godaddy and forgot about it. Fast forward to today. I was randomly going through my aws bill and saw I actually have that domain listed in the UI. How is that possible? I definitely did not buy the domain. submitted by /u/Nblearchangel [link] [comments]
- OnVue app on M2 Mac is freezing when launching the test simulationby /u/Snoo-44996
I tried disabling stage manager and removing browser lock. Still I get the freezing circle. submitted by /u/Snoo-44996 [link] [comments]
- CCPby /u/Upper_Aspect_4353
Hi guys, I've been preparing for the CCP (Cloud practitioner exam) which is the main section that I should need to focus on? As i have only a month to pass this exam. I've preparing through Stephane ccp course. submitted by /u/Upper_Aspect_4353 [link] [comments]
- Passed my CCP/CLF-02 exam yesterday!by /u/togamayo_mich
Score: 821/1000 (Hoped for an 850-900, but that should do) Background: I do development and QA work at a large tech consultancy. We get AWS exam vouchers, but must show that we completed a relevant course before receiving one. I used GCP in a previous dev job, so I know how to use platform's UI for doing specific tasks but didn't bother to learn cloud theory (one thing I regret). For learning and noting the concepts, I used: Amazon Cloud Quest for the Cloud Practitioner hands-on activities and some trivia questions from shooting drones. AWS Cloud Practitioner Essentials for the theory and course completion confirmation. While it doesn't cover all the smaller details, it does cover the major details that I can build my notes off. I also like how the course uses a coffee shop as an analogy for the cloud. AWS documentation, whitepapers, and the service pages (be it its overview, features, or pricing) in both English and German. Kanani Nirav's practice exams #1-10 for uncovering patchable knowledge gaps. As I'm a power Notion user who learns best from taking and concising notes, I used this Notion template for: Organizing notes by exam guide domain and then task statement, before using the "knowledge of" and "skills in" bullet points to understand which concepts to include for each statement. For example, all of my notes under "Understand the benefits of and strategies for migration to the AWS Cloud" (1.3) cover the Cloud Adoption Framework and its action plan, the 6 "R's" of migration, the Snow transfer device family (Snowcone, Snowball, Snowmobile), the Amazon Transfer family, and misc migration-and-transfer related services such as DataSync. Tracking my practice exam attempts and answers. For incorrect answers, I noted the correct answer and (in some cases) why my answer was incorrect, such as "Use Config for auditing AWS change management, not CloudWatch". I also noted the corresponding concept(s) (in our case Config and CloudWatch) in the "topics to revisit" section, so I can re-study those concepts before taking another practice exam (and if applicable, adding more information to my notes). I repeated this process daily until I hit mid-80s the day before my exam. I booked my exam in-person as I'd rather avoid the same outcomes as some of the e-exam horror stories here. Smooth check-in process, I got a dry-erase board and marker as scrap, and I can stretch while sitting if needed. I also got my pass/fail results immediately after submitting my exam 50 minutes and two checks later. (If you're in Greater Vancouver, this is Ashton Testing Centre.) What's next? I'm interested in learning the concepts that'll help me get the respective Solutions Architect and Developer Associate certifications, but am unsure about where to start. Thankfully one of our senior technical architects (and mentors) holds both certificates, so I'm connecting with her tomorrow to understand how her certificates help her with day-to-day tasks (let alone her career). This should help me decide which certificate exam to prepare for first! submitted by /u/togamayo_mich [link] [comments]
- What would you do?by /u/OkAcanthocephala1450
My manager asked me to colaborate with some devs to create a platform for infra provisioning. Basically what they try to do is like a computer vision scan of diagram and asking AI to create the code and ask user to provide input variables. The problem is that the second step is unnecessary ,since we do have preconfigured templates that just an Api call is enough to get the template ,ask for variables and create the infrastructure. I said ,it is unnecessary to integrate AI(Bedrock) ,since it would just be complex and very very slow. They said , if we dont use ,it will not be AI integrated then. What am i supposed to do? Continue supporting them on this stupid idea of integrating "AI" or what.. submitted by /u/OkAcanthocephala1450 [link] [comments]
- Barely passed SAA, but passed!!! U can do it!by /u/Spirited_Ad_490
A little background: I started studying for cloud practitioner back in September and got it in January, been lurking in here ever since. For the last 3 months, I have been studying for SAA and I passed the test a couple days ago. I used Skill Builder to study. I assume any of the other courses would be similar and possibly even better. I used TD practice exams as well. I never scored more than 50% on any of them. I am not good at taking tests and find it so hard to focus. The TD cheat sheets are the most helpful. Definitely check those out, especially the ones that compare services. Each time I got a question wrong I would open the cheat sheet for that service and take notes on it. Exam had lot of basic services like s3, ec2 and whatever you'd expect. TD practice tests test you on a lot of random services that might not be on the exam. Dont ONLY focus on those, make sure you know the basic ones super well. I think I scored so low because I focused on knowing each service and not mastering the basic ones. You need a good balance of both. Scored a 735/1000 but after I took it I genuinely had no idea if I passed or not. Got the credly badge in about 4 hours and the cert in about 9. Not like CP where they tell you right away. submitted by /u/Spirited_Ad_490 [link] [comments]
- Pearson Vue rescheduleby /u/Sad-Buddy-5293
Hello I wanted to know if it is possible to reschedule for my Pearson Vue Exam for AWS in less then 24 hours if you are sick. I cant write this exam in my current condition and seems I am unable to reschedule the exam I am writing Tomorrow. submitted by /u/Sad-Buddy-5293 [link] [comments]
- Passed SAA-C03by /u/MFiziK
Took me about 2.5 months, but I finally passed the Associate Solutions Architect exam after passing the Cloud Practitioner in January. A little background about me: I am a software engineer who graduated last May but still do not have any actual hands-on experience using any AWS services. I knew I would be using AWS soon in my new role, so I thought I should get familiar with it all. I followed everyone's advice on here and used Stephane Maarek's course on Udemy and reviewed questions on Tutorial Dojo. For the course, I recommend doing your best with watching all the hands-on tutorials and even trying them. I always got lazy on those lectures but eventually went back because a practice problem or two would end up asking something that you would need hands-on experience for. For the most part, I just kept working on the practice exams on TD until I was comfortably getting 70s/80s on them like everyone suggested. The exam itself is very focused on the core services like EC2, ELBs, Autoscaling groups, networking, and databases like Aurora, so definitely do not brush past these sections at all. Thank you for all the recommendations everyone, and I am happy to answer any questions that others may have. Also, good luck to anyone that's taking it soon! submitted by /u/MFiziK [link] [comments]
- Passed DVA Yesterdayby /u/stone4789
The Pearson software was super laggy between every question, so it took twice as long as it should have. However, I passed and I’m probably never doing another one. I have SAA and ML, hopefully this will help me transition out of data science for good some day. If you’re prepping for the DVA, focus on lambdas and APIs. Luckily that’s all I’ve been doing at work lately. submitted by /u/stone4789 [link] [comments]
- I just passed AWS CCP and now Ill study for AWS SAA but I only have one month available!by /u/saske2k20
Im happy that I passed on AWS CCP (Stephane + Skill Builder) but now Ill focus on study to AWS SAA, I already have the Stephane course + TD, but I feel I have a big gap knowledge on AWS CCP, the recommendations are to to Cantrill course in this case, but the problem is the available time. I dont think Ill be able to finish and learn cantrill course + tests + labs on the time I have. Do you guys think considering the time it would be worth focus on stephane only to pass and as soon I pass do the cantrill course to fulfill all the gaps? Thanks edit : typo submitted by /u/saske2k20 [link] [comments]
- Whats the most efficient roadmap?by /u/mildy-responsible
Hello my fellow redditors, I have been working temporarily in the Oracle cloud infrastructure for about a year. I have come to realize that although oracle is cool I want to move towards AWS. I was wondering what is the most efficient/best way to get the solutions architect certification I checked the site and they have this new program called the AWS Skillbuilder. It’s a $30 a month subscription. I don’t know if I should get that is still a good option? When I do get this CERT, what would you recommend be my next step? submitted by /u/mildy-responsible [link] [comments]
- I have Professional and Specialty Level AWS Certification Exam Voucher, can I apply this voucher for associate level exam.?by /u/AfterOcelot2727
submitted by /u/AfterOcelot2727 [link] [comments]
- Finally passed the AWS SAA in my 2nd attempt!!by /u/Begin_hunt
Hello everyone, I have finally passed the AWS SAA-CO3 in my second attempt and here are my experiences/thoughts with the exam preparation and what went wrong in my first attempt. I’m currently working as an Information Security Engineer at a financial institution. As the majority of my job involves working with AWS cloud, I wanted to challenge myself to learn new AWS services and pass the AWS Solutions Architect Associate certification (SAA). So, the goal was set, and now it’s time to execute my plans. Domains: The AWS SAA examination tests individuals based on four key domains: Designing Secure Architectures, Designing Resilient Architectures, Designing High-Performing Architectures, and Designing Cost-Optimized Architectures. You can find the AWS SAA exam guide to understand these areas in detail Link Preparation: After reading through the exam guide, I started my preparation with a Udemy course taught by the instructor Stephane Maarek. Stephane has well-structured course material that covers both the theoretical and practical aspects of the services. I would highly recommend starting with this course. It took me about 2 months to complete this course. I spent roughly 2 hours every day at night after work, and this helped me understand the services better. Small daily improvements or repetitions do matter in the long run. Later, I solved practice papers from Stephane and scored about 65–75% on the exams. I felt that the exam wording was a bit off in Stephane Maarek exam papers and it caused some confusion when I knew the right answer. Nonetheless, after completing several practice tests, I felt confident enough to tackle the exam and gave my first attempt, scoring 680 and failing. This hit me hard as I was so close to clearing the exam. Identifying gaps: After my first attempt, I took some time off and started to identify my weak areas such as Designing Cost-Optimized, Resilient architectures and improving them. I had come across Tutorials Dojo (TD) practice tests and found them helpful. I’d highly recommend these learning materials and practice tests to supplement your knowledge. I also enjoyed solving practice tests from TD as they were worded very clearly and provided real-world architecture-based questions. I felt really confident after solving the practice tests and was scoring around 70–75% on these tests. SAA Exam: On the day of the exam, I did feel a bit nervous but I got used to the exam pattern as I had given multiple practice tests at this point. My strategy was to answer 5 questions in 10 minutes. This helped me to keep track of time and focus on one question at a time. Submitted the exam and received an email by midnight from the AWS congratulating and awarding a credly badge. AWS Cert resources: Here are the resources I have used to pass the examination: Stephane Maarek Udemy course: Link Stephane Maarek practice tests: Link Tutorials Dojo practice tests: Link Tip: Focus on understanding the services and their implementation use cases, as several services are different but do similar jobs. Hope this helps 🙂 Good luck!! submitted by /u/Begin_hunt [link] [comments]
- Passed SAA-C03!!by /u/Acceptable-Drink-495
Hi guys!! I passed SAA with 815. Started preparing from Dec and I planned to give the exam by mid march. I was ready to give the exam but i had few interviews scheduled the entire march so postponed it and btw i also got a job on 1st April. Yayyyy! Just a little background about me, i worked as a Patent Analyst for almost 3 years but it was not my calling. I wanted to get into IT. I also shifted to another country the same time i left this job. So from last 2 years i was trying to get a job in IT but there was a language barrier and also i had no experience in IT. Ya so coming back to the topic, I used Adrian Cantrill course which was just a chef kiss🤌🏻, AWS documentation and TD cheatsheets and TD practice exam(in feb end). A week before the exam i just went back to the cantrill course to brush up on all the architectures and a day before the exam gave all the TD practice exam again. I mostly got. Above 80% so felt confident. I huge thanks to this sub as i got to know about the course and the TD practice test from here. And also all the other members who mentioned few services they came across in the exam. My suggestion: Focus more on the core services that in cantrill course and everything related to them like auto scaling, Encryption , Backups for all storage and DB services. But also do refer to the documentation if you have doubts. For core services like S3, EBS,RDS, Aurora, DynamoDB, VPC,EC2 you should know things in depth You can skip few services that you come across during TD test which are just mentioned once or twice. Also do checkout all the post by other members of the sub who gave the exam, I made sure I understand all the services they have mentioned and it reallllllly helped! All the best to everyone else giving the exam! submitted by /u/Acceptable-Drink-495 [link] [comments]
- Tips for Jon Bonso Udemy SAA?by /u/YoinkWB
Hello. Just got CCP and moving onto SSA. for CCP I mainly used ExamPro course. Watched lectured and made Anki flash cards from all the notes and questions then moved onto the practice exams. Trying the Udemy Jon Bonso course now. Is this just a collection of practice exams with explanations for each question after? How did you utilize this material? If it matters, I started with 0 background in CSPs. Studied a few hours each day for about 2 weeks and passed CCP exam last night. Thanks. submitted by /u/YoinkWB [link] [comments]
- Has anyone passed the Developer Associate DVA-C02 exam only using Neal Davis's course?by /u/r2dev0
I have a few years of very light AWS experience with EC2, S3, and DynamoDB. I completed Neal's course and passed his exam with an 86% after a few tries. Is his exam pretty close to the real exam and if I am able to do okay with his exam, should I have a good chance of passing? submitted by /u/r2dev0 [link] [comments]
- AWS Certification Studyby /u/dojlee22
I want to try to start aws cloud certification study. Which place has the best online class? submitted by /u/dojlee22 [link] [comments]
- Finally Got itby /u/Breif7
Finally Got my Saa certificate! It took me about 3 months of preparation and thanks to the TD practice exams they give a more solid idea of what the actual exam is going to be like Now that I have my certificate, I have some experience as a full-stack developer for web applications, where I could start looking for a job related to web applications. And they mentioned certain additional benefits like the sme program, someone knows what it refers to or what I have to do to participate. Thank you submitted by /u/Breif7 [link] [comments]
- I created a FREE AWS Cloud Practitioner Preparation Exam web app📚💻by /u/fabricio85
You can check out the quiz here. As someone who has gone through the challenge of obtaining this certification, I know how important it is to have access to quality study materials. That's why I decided to create this side project to help those pursuing this achievement but may not have the means to acquire paid resources. Throughout the practice exam, you'll find hundreds of questions covering the main topics of the actual exam. My goal is to provide a study experience that closely mirrors the real exam, so you can get used to the question format, the main knowledge domains, and enhance your overall knowledge. But don't underestimate hands-on practice! I strongly suggest using AWS Skillbuilder for practical work! There are two types of practice exams: a "basic" one (35 questions, 40 minutes long) and a "full" one (65 questions, 90 minutes long). Both feature random questions for better studying! Key features: Real-time score tracking: No need to wait until the end to see how you're doing! The practice exam displays your percentage score as you progress through the questions. Review your answers: At the end of the practice exam, you can review which questions you answered correctly and incorrectly. This is one of the best methods for reinforcing your knowledge and learning from your mistakes. Completely free: No hidden costs or subscriptions. I believe everyone should have access to quality study materials, regardless of their financial situation. I'm already working on something similar to SAA. Feel free to connect with me on LinkedIn to stay updated! submitted by /u/fabricio85 [link] [comments]
- HI I am currently studying for the AWS Cloud Practitioner Exam. It seems like the questions are just asking what a certain function/resource does in AWS or when would be a good time to use a certain function/resource based on a certain scenario? Am I missing any curveballs?by /u/orozcotech
submitted by /u/orozcotech [link] [comments]
Reference: https://enoumen.com/2019/06/23/aws-solution-architect-associate-exam-prep-facts-and-summaries-questions-and-answers-dump/
AWS Certified Developer Associate exam: Whitepapers
AWS has provided whitepapers to help you understand the technical concepts. Below are the recommended whitepapers for the AWS Certified Developer – Associate Exam.
- Overview of Amazon Web Services
- Architecting for the Cloud: AWS Best Practices
- AWS Security Best Practices whitepaper, August 2016
- AWS Well-Architected Framework whitepaper, November 2017 Version 1.3 DVA-C01 Page |2
- Architecting for the Cloud AWS Best Practices whitepaper, February, 2016
- Practicing Continuous Integration and Continuous Delivery on AWS Accelerating Software Delivery with DevOps whitepaper, June 2017
- Microservices on AWS whitepaper, September 2017
- Serverless Architectures with AWS Lambda whitepaper, November 2017
- Optimizing Enterprise Economics with Serverless Architectures whitepaper, October 2017
- Running Containerized Microservices on AWS whitepaper, November 2017
- Blue/Green Deployments on AWS whitepaper, August 2016
Online Training and Labs for AWS Certified Developer Associates Exam
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
AWS Developer Associates Jobs
AWS Certified Developer-Associate Exam info and details, How To:
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
The AWS Certified Developer Associate exam is a multiple choice, multiple answer exam. Here is the Exam Overview:
- Certification Name: AWS Certified Developer Associate.
- Prerequisites for the Exam: None.
- Exam Pattern: Multiple Choice Questions
- The AWS Certified Developer-Associate Examination (DVA-C01) is a pass or fail exam. The examination is scored against a minimum standard established by AWS professionals guided by certification industry best practices and guidelines.
- Your results for the examination are reported as a score from 100 – 1000, with a minimum passing score of 720.
- Exam fees: US $150
- Exam Guide on AWS Website
- Available languages for tests: English, Japanese, Korean, Simplified Chinese
- Read AWS whitepapers
- Register for certification account here.
- Prepare for Certification Here
Exam Content Outline
Domain % of Examination Domain 1: Deployment (22%)
1.1 Deploy written code in AWS using existing CI/CD pipelines, processes, and patterns.
1.2 Deploy applications using Elastic Beanstalk.
1.3 Prepare the application deployment package to be deployed to AWS.
1.4 Deploy serverless applications22% Domain 2: Security (26%)
2.1 Make authenticated calls to AWS services.
2.2 Implement encryption using AWS services.
2.3 Implement application authentication and authorization.26% Domain 3: Development with AWS Services (30%)
3.1 Write code for serverless applications.
3.2 Translate functional requirements into application design.
3.3 Implement application design into application code.
3.4 Write code that interacts with AWS services by using APIs, SDKs, and AWS CLI.30% Domain 4: Refactoring
4.1 Optimize application to best use AWS services and features.
4.2 Migrate existing application code to run on AWS.10% Domain 5: Monitoring and Troubleshooting (10%)
5.1 Write code that can be monitored.
5.2 Perform root cause analysis on faults found in testing or production.10% TOTAL 100%
AWS Certified Developer Associate exam: Additional Information for reference
Below are some useful reference links that would help you to learn about AWS Certified Developer Associate Exam.
- Developing on AWS: An instructor-led live or virtual 3-day course
- https://aws.amazon.com/certification/faqs/
- AWS Digital Training: Application Services, Developer Tools, and other services covered on the exam
- Prepare for AWS Certification
- AWS EC2 Instance info
- AWS Certified Developer Associate Exam Guide
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Other Relevant and Recommended AWS Certifications
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
- AWS Certified Cloud Practitioner
- AWS Certified Solutions Architect – Associate
- AAWS Certified Developer – Associate
- AWS Certified SysOps Administrator – Associate
- AWS Certified Solutions Architect – Professional
- AWS Certified DevOps Engineer – Professional
- AWS Certified Big Data Specialty
- AWS Certified Advanced Networking.
- AWS Certified Security – Specialty
Other AWS Facts and Summaries and Questions/Answers Dump
- AWS S3 facts and summaries and Q&A Dump
- AWS DynamoDB facts and summaries and Questions and Answers Dump
- AWS EC2 facts and summaries and Questions and Answers Dump
- AWS Serverless facts and summaries and Questions and Answers Dump
- AWS Developer and Deployment Theory facts and summaries and Questions and Answers Dump
- AWS IAM facts and summaries and Questions and Answers Dump
- AWS Lambda facts and summaries and Questions and Answers Dump
- AWS SQS facts and summaries and Questions and Answers Dump
- AWS RDS facts and summaries and Questions and Answers Dump
- AWS ECS facts and summaries and Questions and Answers Dump
- AWS CloudWatch facts and summaries and Questions and Answers Dump
- AWS SES facts and summaries and Questions and Answers Dump
- AWS EBS facts and summaries and Questions and Answers Dump
- AWS ELB facts and summaries and Questions and Answers Dump
- AWS Autoscaling facts and summaries and Questions and Answers Dump
- AWS VPC facts and summaries and Questions and Answers Dump
- AWS KMS facts and summaries and Questions and Answers Dump
- AWS Elastic Beanstalk facts and summaries and Questions and Answers Dump
- AWS CodeBuild facts and summaries and Questions and Answers Dump
- AWS CodeDeploy facts and summaries and Questions and Answers Dump
- AWS CodePipeline facts and summaries and Questions and Answers Dump
AWS Certified Developer Associate exam: Whitepapers
AWS has provided whitepapers to help you understand the technical concepts. Below are the recommended whitepapers for the AWS Certified Developer – Associate Exam.
- Overview of Amazon Web Services
- Architecting for the Cloud: AWS Best Practices
- AWS Security Best Practices whitepaper, August 2016
- AWS Well-Architected Framework whitepaper, November 2017 Version 1.3 DVA-C01 Page |2
- Architecting for the Cloud AWS Best Practices whitepaper, February, 2016
- Practicing Continuous Integration and Continuous Delivery on AWS Accelerating Software Delivery with DevOps whitepaper, June 2017
- Microservices on AWS whitepaper, September 2017
- Serverless Architectures with AWS Lambda whitepaper, November 2017
- Optimizing Enterprise Economics with Serverless Architectures whitepaper, October 2017
- Running Containerized Microservices on AWS whitepaper, November 2017
- Blue/Green Deployments on AWS whitepaper, August 2016
Online Training and Labs for AWS Certified Developer Associates Exam
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
AWS Developer Associates Jobs
AWS Certified Developer-Associate Exam info and details, How To:
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
The AWS Certified Developer Associate exam is a multiple choice, multiple answer exam. Here is the Exam Overview:
- Certification Name: AWS Certified Developer Associate.
- Prerequisites for the Exam: None.
- Exam Pattern: Multiple Choice Questions
- The AWS Certified Developer-Associate Examination (DVA-C01) is a pass or fail exam. The examination is scored against a minimum standard established by AWS professionals guided by certification industry best practices and guidelines.
- Your results for the examination are reported as a score from 100 – 1000, with a minimum passing score of 720.
- Exam fees: US $150
- Exam Guide on AWS Website
- Available languages for tests: English, Japanese, Korean, Simplified Chinese
- Read AWS whitepapers
- Register for certification account here.
- Prepare for Certification Here
Exam Content Outline
Domain % of Examination Domain 1: Deployment (22%)
1.1 Deploy written code in AWS using existing CI/CD pipelines, processes, and patterns.
1.2 Deploy applications using Elastic Beanstalk.
1.3 Prepare the application deployment package to be deployed to AWS.
1.4 Deploy serverless applications22% Domain 2: Security (26%)
2.1 Make authenticated calls to AWS services.
2.2 Implement encryption using AWS services.
2.3 Implement application authentication and authorization.26% Domain 3: Development with AWS Services (30%)
3.1 Write code for serverless applications.
3.2 Translate functional requirements into application design.
3.3 Implement application design into application code.
3.4 Write code that interacts with AWS services by using APIs, SDKs, and AWS CLI.30% Domain 4: Refactoring
4.1 Optimize application to best use AWS services and features.
4.2 Migrate existing application code to run on AWS.10% Domain 5: Monitoring and Troubleshooting (10%)
5.1 Write code that can be monitored.
5.2 Perform root cause analysis on faults found in testing or production.10% TOTAL 100%
In this AWS tutorial, we are going to discuss how we can make the best use of AWS services to build a highly scalable, and fault tolerant configuration of EC2 instances. The use of Load Balancers and Auto Scaling Groups falls under a number of best practices in AWS, including Performance Efficiency, Reliability and high availability.
Before we dive into this hands-on tutorial on how exactly we can build this solution, let’s have a brief recap on what an Auto Scaling group is, and what a Load balancer is.
Autoscaling group (ASG)
An Autoscaling group (ASG) is a logical grouping of instances which can scale up and scale down depending on pre-configured settings. By setting Scaling policies of your ASG, you can choose how many EC2 instances are launched and terminated based on your application’s load. You can do this based on manual, dynamic, scheduled or predictive scaling.
Elastic Load Balancer (ELB)
An Elastic Load Balancer (ELB) is a name describing a number of services within AWS designed to distribute traffic across multiple EC2 instances in order to provide enhanced scalability, availability, security and more. The particular type of Load Balancer we will be using today is an Application Load Balancer (ALB). The ALB is a Layer 7 Load Balancer designed to distribute HTTP/HTTPS traffic across multiple nodes – with added features such as TLS termination, Sticky Sessions and Complex routing configurations.
Getting Started
First of all, we open our AWS management console and head to the EC2 management console.
We scroll down on the left-hand side and select ‘Launch Templates’. A Launch Template is a configuration template which defines the settings for EC2 instances launched by the ASG.
Under Launch Templates, we will select “Create launch template”.
We specify the name ‘MyTestTemplate’ and use the same text in the description.
Under the ‘Auto Scaling guidance’ box, tick the box which says ‘Provide guidance to help me set up a template that I can use with EC2 Auto Scaling’ and scroll down to launch template contents.
When it comes to choosing our AMI (Amazon Machine Image) we can choose the Amazon Linux 2 under ‘Quick Start’.
The Amazon Linux 2 AMI is free tier eligible, and easy to use for our demonstration purposes.
Next, we select the ‘t2.micro’ under instance types, as this is also free tier eligible.
Under Network Settings, we create a new Security Group called ExampleSG in our default VPC, allowing HTTP access to everyone. It should look like this.
AWS Certified Developer Associate exam: Additional Information for reference
Below are some useful reference links that would help you to learn about AWS Certified Developer Associate Exam.
- Developing on AWS: An instructor-led live or virtual 3-day course
- https://aws.amazon.com/certification/faqs/
- AWS Digital Training: Application Services, Developer Tools, and other services covered on the exam
- Prepare for AWS Certification
- AWS EC2 Instance info
- AWS Certified Developer Associate Exam Guide
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Other Relevant and Recommended AWS Certifications
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
- AWS Certified Cloud Practitioner
- AWS Certified Solutions Architect – Associate
- AAWS Certified Developer – Associate
- AWS Certified SysOps Administrator – Associate
- AWS Certified Solutions Architect – Professional
- AWS Certified DevOps Engineer – Professional
- AWS Certified Big Data Specialty
- AWS Certified Advanced Networking.
- AWS Certified Security – Specialty
Other AWS Facts and Summaries and Questions/Answers Dump
- AWS S3 facts and summaries and Q&A Dump
- AWS DynamoDB facts and summaries and Questions and Answers Dump
- AWS EC2 facts and summaries and Questions and Answers Dump
- AWS Serverless facts and summaries and Questions and Answers Dump
- AWS Developer and Deployment Theory facts and summaries and Questions and Answers Dump
- AWS IAM facts and summaries and Questions and Answers Dump
- AWS Lambda facts and summaries and Questions and Answers Dump
- AWS SQS facts and summaries and Questions and Answers Dump
- AWS RDS facts and summaries and Questions and Answers Dump
- AWS ECS facts and summaries and Questions and Answers Dump
- AWS CloudWatch facts and summaries and Questions and Answers Dump
- AWS SES facts and summaries and Questions and Answers Dump
- AWS EBS facts and summaries and Questions and Answers Dump
- AWS ELB facts and summaries and Questions and Answers Dump
- AWS Autoscaling facts and summaries and Questions and Answers Dump
- AWS VPC facts and summaries and Questions and Answers Dump
- AWS KMS facts and summaries and Questions and Answers Dump
- AWS Elastic Beanstalk facts and summaries and Questions and Answers Dump
- AWS CodeBuild facts and summaries and Questions and Answers Dump
- AWS CodeDeploy facts and summaries and Questions and Answers Dump
- AWS CodePipeline facts and summaries and Questions and Answers Dump
AWS Certifications Breaking News and Top Stories
- Difference between Docker and Amazon Elastic Container Registry (ECR): Is Docker superior?by /u/DigitalSplendid
Created a new container on AWS Lightsail. Need to understand if there are two ways to deploy a container through their menu options: Deployments or Images? Are Docker and ECR competing products? Is Docker superior to ECR? The reason is it appears AWS LIghtsail itself has made apparently mandatory to use Docker if images option chosen. Also when Deployments menu clicked: "Enter the image reference from a public registry, such as DockerHub." So they are mentioning DockerHub and not their own ECR! submitted by /u/DigitalSplendid [link] [comments]
- Does this mean I pass the AWS ML Specialty?by /u/Soyun12
This is the email I got https://preview.redd.it/4696fjpuqbyc1.jpg?width=750&format=pjpg&auto=webp&s=b9e8d66906ba7093e358557896812271224e21b1 submitted by /u/Soyun12 [link] [comments]
- AWS CCP for GRC professionals?by /u/Head_Astronaut_2442
I have 6 years of experience in cyber risk & governance and am a CISSP holder. I’m looking to develop fundamental cloud literacy and demonstrate to future employees that I have understanding of the cloud / generally pad my resume. Is the CCP an appropriate certificate? submitted by /u/Head_Astronaut_2442 [link] [comments]
- Who to contact for support? Is there is a support phone number I can call?by /u/qqpp_ddbb
So I've been throttled for over 24 hours now in amazon bedrock and I put in a support ticket, to no avail. Is there a phone number I can call to speak with support? It seems ridiculous that I'm being throttled/rate limited this hard for such a low number of requests. Here's some metrics. Let me know if more info is needed. I'm new to this stuff, sorry.. https://i.postimg.cc/GpQP5mrk/Metrics-Cloud-Watch-us-west-2.png Thanks in advance submitted by /u/qqpp_ddbb [link] [comments]
- Need help reconnecting to AWS VM for assignment.by /u/clashofcam
Hello, I've been troubleshooting for a while. I edited my Network Settings in my AWS windows 2019 VM. I believe I messed up the DNS. As soon as I clicked "OK" I got kicked off the virtual machine. I've tried tinkering with different things in the console but I cannot figure out how to change it to auto assign the DNS so I can get back on the Virtual machine. Any help is appreciated. Thank you! submitted by /u/clashofcam [link] [comments]
- S3 Cross Account Accessby /u/MrStu56
Hello all, I'm hoping someone can help me here with an issue I'm battling with when it comes to cross account S3 access. I can't quite get my head around the permissions required, or perhaps more accurately where those permissions should be applied, and in which account. Here's the scenario: I have created a bucket in account A called test-100-bucket. In that bucket are the folders: "working", "ClientAccess" and "store". I'm looking to grant: List, Put, Get, Delete (i.e full read/write) on "working" and "ClientAccess" to a group of users in Account B called "AccountB/Wranglers" I'm looking to grant List, Put, Get, Delete (ie. full read/write) on "ClientAccess" (and any subfolders /*) to a specific user in AccountA (Lets call them AccountA/Client). AccountA/Client should not be able to see any of the other folders. I'm looking to restrict access to "store", so that AccountB/Wranglers can put, list, get but should not be able to delete anything. As the bucket owner I should be able to destroy the bucket and all the objects when required. Can someone help me with: What permissions are needed for the AccountB/Wranglers (and where those permissions are applied). Do I need an account or group in AccountA to handle this? What bucket policy(?) I need to apply to restrict the ClientAccess folder. What bucket or user policy (or both?) is needed for the "store" folder. Hope you can help, I've asked AmazonQ, ChatGPT and done a few youtube vids as well as the documentation but still can't seem to get it to work. If anyone has a good resource, (in crayons at this point) I'm happy to take a look. submitted by /u/MrStu56 [link] [comments]
- Bedrock Agents with Guardrailsby /u/ProfessorHuman
Has anyone used guardrails with agents? I don’t see a way to associate a guardrail with an agent. Either in the api documentation or in the console. I see you can specify a guardrail in the invoke_model method of boto3 but that’s not with an agent. Docs seem to suggest it’s possible. But I see reference anywhere to how. submitted by /u/ProfessorHuman [link] [comments]
- boto3 not finding (IAM) credentials when running docker container on ECS task, but does work locally... why not?by /u/that_dogs_wilin
Hi, I'm new to setting things up on AWS so apologies in advance for dumb questions or if I use the wrong terminology (please correct me!). Here's what I'm trying to do: I want to create a docker container that will install necessary packages, and then run a python script. The python script will run for a bit and then write some output file, my_cool_dict.json. Then, I want to upload this file to my S3 bucket, and the task is done. Here's what I've done so far: I followed some AWS documentation. For setting up the AWS CLI, I did their recommended best practice of configuring AWS CLI to use the IAM identity center, here. I did the recommended SSO token provider config, and I know it works because I can locally push stuff to my S3 bucket, etc. I created an S3 bucket, and a ECR repository for my docker image. In IAM, I created a role, ecs_task_with_logging. To that role, I attached the policies AmazonECSTaskExecutionRolePolicy (so it can run an ECS task) and AmazonS3FullAccess (so it can upload to my S3 bucket). Locally, I built a docker image and pushed it to my ECR repo. In ECS, I created a cluster, then created a task definition that references the correct image URI, and the executionRoleArn of the role above. I also set up logging with python's logging lib / made a log group with CloudWatch / added the logging stuff to the task definition. To run the task, I go to the cluster, go to the Tasks tab, and use the default options, except for selecting "Task" under "Deployment configuration", and selecting the task definition. So I know all of that works, because the following successfully works: if my python script only does logging.info("Script finished running!"), I see it in CloudWatch! Therefore, I know the process of building the image, pushing it to ECR, creating the task definition, and running it on my ECS cluster must all work. I added s3 = boto3.client("s3") and s3.upload_file() to my python script. If I simply run the python script locally, this works (the file appears in the bucket). So I know the boto3 code is fine. If I do aws s3 cp my_cool_dict.json s3://my-bucket/my_cool_dict.json just in the terminal, it works. The step I'm struggling with is uploading the file from my container to my S3 bucket. If I try running the image even locally (which should just be running the script that just worked), I get the error botocore.exceptions.NoCredentialsError: Unable to locate credentials. If instead of using boto3, I put the aws s3 cp ... command in the Dockerfile, I get upload failed: ./my_cool_dict.json to s3://my-bucket/my_cool_dict.json Unable to locate credentials. Similarly, when I run the image (with either of those methods) on ECS, I get the same errors. Can anyone point me to something I could try to figure out why it can't find the credentials? submitted by /u/that_dogs_wilin [link] [comments]
- Cost alert for the unknown account. Help wanted.by /u/moondaddi80
On 30 April, I suddenly received a COST ALERT email. --- qouted start --- AWS Budget Notification April 30, 2024 AWS Account ************ Dear AWS Customer, You requested that we alert you when the actual cost associated with your My Monthly Cost Budget budget exceeds $4.25 for the current month. The month actual cost associated with this budget is $4.27. You can find additional details below and by accessing the AWS Budgets dashboard. Budget Name Budget Type Budgeted Amount Alert Type Alert Threshold ACTUAL Amount My Monthly Cost Budget Cost $5.00 ACTUAL > $4.25 $4.27 --- quoted end --- And today I got another email. --- quoted start --- AWS Budget Notification May 03, 2024 AWS Account ************ Dear AWS Customer, You requested that we alert you when the forecasted cost associated with your My Monthly Cost Budget budget exceeds $5.00 for the current month. The month forecasted cost associated with this budget is $10.04. You can find additional details below and by accessing the AWS Budgets dashboard. Budget Name Budget Type Budgeted Amount Alert Type Alert Threshold FORECASTED Amount My Monthly Cost Budget Cost $5.00 FORECASTED > $5.00 $10.04 --- quoted end --- I contacted AWS CS and they told me that if I don't know my sign in credential, they can't discuss anything related to the account further. So they asked me to give them the TRANSACTION ID, CREDIT CARD NO., etc. that was charged. But I couldn't give them a transaction information yet, because I got an email but the charge hasn't happened on my credit card yet. The email I received the COST ALERT from is the account I had when I used AWS a few years ago, but I signed out and deleted the account after the 1 yr free-tier ended, so now when I try to log in to AWS with this email, it gives me an error saying the account doesn't exist. What I'm wondering now are these things. from the cost alert email, it seems like the cost budget is $5, but when I look at the second cost alert, it shows $10 as the forecasted amount. Is this a situation where the cost will continue to increase until the end of the month because it exceeds the budget? Or will the cost only be incurred up to the budgeted amount of $5? In the body of the email, there is an AWS Account 12 digits no. Is there any way I can log in with this? Luckily, I found the password for that AWS account in the password management application I use. submitted by /u/moondaddi80 [link] [comments]
- SES Email Sending Request Refusedby /u/barcodez
I've used AWS for years, almost since the beginning at huge and large companies. Love it and always thought it was great for innovation and small companies as it really made things super easy for people to try out an idea without doing any heavy investment. So naturally when I wanted to try out an idea I picked AWS. I won't go into too much detail but the idea involves sending some email for registration (standard stuff) and some notifications on account status, so I've configured all my settings and written some prototype code using the sandbox, and naturally wanted to try things with some external email accounts (belonging to me at first, then some friends and then maybe a few referrals if things look good). Thus I requested production access. I send a quick note explaining briefly what I was doing and 24hrs later got a note saying we need more info. Fair enough they need to protect their email servers reputations. I wrote a pretty long explanation covering off all the points they were interested in but did explain it was a prototype so (a.) I don't have examples of templates, it will just be short ASCII messages for now, (b.) I'd only need to send a few emails whilst I get started (c.) bounces, complaints and unsubscribes would be handled etc. I was refused, more over I was told in no uncertain terms I was considered a threat to other users of the service and for security reasons they won't tell me why. I'm bit annoyed if I'm honest because I don't want to have to build out everything to answer some questions and provide templates when I'm really just fleshing out an idea, and sending <100 emails a month if that. Glad I've found out sooner rather than later. I'm considering just installing a mail server on EC2 with an elastic IP but having managed mail servers before I know it's a time sink and for very little reward and concerned they might take issue with this. I appreciate email is the wild west but this level of gatekeeping around smtp is a bit anti innovation in my view. Should I just get on building the prototype and send mail some other way in the hope that once I have more answers they will enable me or is it too risky? Anyone else been refused at the early stages and got accepted later? submitted by /u/barcodez [link] [comments]
I Passed AWS Developer Associate Certification DVA-C01 Testimonials
Passed DVA-C01
Passed the certified developer associate this week.
Primary study was Stephane Maarek’s course on Udemy.
I also used the Practice Exams by Stephane Maarek and Abhishek Singh.
I used Stephane’s course and practice exams for the Solutions Architect Associate as well, and find his course does a good job preparing you to pass the exams.
The practice exams were more challenging than the actual exam, so they are a good gauge to see if you are ready for the exam.
Haven’t decided if I’ll do another associate level certification next or try for the solutions architect professional.
Cleared AWS Certified Developer – Associate (DVA-C01)
I cleared Developer associate exam yesterday. I scored 873.
Actual Exam Exp: More questions were focused on mainly on Lambda, API, Dynamodb, cloudfront, cognito(must know proper difference between user pool and identity pool)
3 questions I found were just for redis vs memecached (so maybe you can focus more here also to know exact use case& difference.) other topic were cloudformation, beanstalk, sts, ec2. Exam was mix of too easy and too tough for me. some questions were one liner and somewhere too long.
Resources: The main resources I used was udemy. Course of Stéphane Maarek and practice exams of Neal Davis and Stéphane Maarek. These exams proved really good and they even helped me in focusing the area which I lacked. And they are up to the level to actual exam, I found 3-4 exact same questions in actual exam(This might be just luck ! ). so I feel, the course of stephane is more than sufficient and you can trust it. I have achieved solution architect associate previously so I knew basic things, so I took around 2 weeks for preparation and revised the Stephen’s course as much as possible. Parallelly I gave the mentioned exams as well, which guided me where to focus more.
Thanks to all of you and feel free to comment/DM me, if you think I can help you in anyway for achieving the same.
Passed the Developer Associate. My Notes.
There was more SNS “fan out” options. None of the Udemy or Tutorial Dojo tests had that.
They aren’t joking about the 30 min check I and expiring your exam if you don’t check in at least 15 mins before hand.
When you finish do a pass over review for multi select questions and check the number required.
Review again and look for gotcha phrases like “least operational cost”, “fastest solution”, “most secure”, and “least expensive”. Change your answers of you put on what “you” would do.
Watch out for questions that mention services that don’t really have anything to do with the problem.
Look at every service mentioned in the question. You can probably think of a better stack for the solution but just adhere to what the present.
If you are clueless of an answer start by ruling out the ones you KNOW are wrong and then guess.
Take as many practice exams like tutorial dojo as you can. On review filter out the review for “incorrect”. Open another tab on the subject and read up or book mark it.
I would get 50-60% first pass at each exam. Then 85-95% after reading the answer and the open tabs and book marks.
If taking the Pearson proctored online test down load the OnVue App as soon as you can. Installing that thing made me miss the 15 min window and I had to rebook and pay. Their checkin is confusing between all the cert portals and their own site. Just use the “Manage Pearson Exams” from the aws cert portal to force auth to theirs.
New versions of the Developer (Associate) and DevOps Engineer (Professional) exams in Feb/March 2023
AWS Certified Developer – Associate
Current version: DVA-C01
New version: DVA-C02
Last day to take the current exam: 2023-02-27
Registration open for the updated exam: 2023-01-31
First day to take the updated exam: 2023-02-28
AWS Certified DevOps Engineer – Professional
Current version: DOP-C01
New version: DOP-C02
Last day to take the current exam: 2023-03-06
Registration open for the updated exam: 2023-01-31
First day to take the updated exam: 2023-03-07
Both updates were posted on 2022-10-04 on https://aws.amazon.com/certification/coming-soon/. The exam guides and practice questions are also available there.
Passed DVA-C01 scored 910
Past January as usual I chose some goals to achieve during 2022, including to obtain an AWS certification. In February I started studying using the Pluralsight platform. The course for developers is a good introduction but is messy sometimes. At the end of the course I had a big picture of the main AWS services but I was really confused by all the different topics. Pluralsight offers alsl some labs that allowed me to practice with AWS services because I my work wasn’t related to cloud.
Then a senior engineer suggested me to study using ACloudGuru platform and I loved their contents. They focus only on the details necessary for the exam. During the videos they show useful list to summarize services and tables to compare them. Moreover they offer a quite unrestricted playground where to put your hands. So i could try their labs but also try my first cloudformation scripts and lambdas. There are also 4 practice exams that are very similar to real questions. Even though their platform is buggy sometimes, the subscription was worth it.
At the same time I purchased the pack of practice questions from Jon Bonso on Udemy and indeed the answer explainations are very detailed and very useful.
For practicing more, I was adding wrong questions to the Anki desktop application but I was revising them on my phone whenever I could. I ended up with 150 different questions on Anki.
In the meantime, in August I left my software engineer job because my boss told me that I was not able to work with cloud technologies. In september I started a new job as cloud engineer in a new company. Finally, in October I passed the Developer Associate exam and I scored 910.
I put a lot of effort into prepare the exam and eventually i got it! However I believe this is just my first step and I want to keep studying. My next objective is the Solutions Architect Associate certification.

Top 100 AWS Solutions Architect Associate Certification Exam Questions and Answers Dump SAA-C03
Top 60 AWS Solution Architect Associate Exam Tips
Active Hydrating Toner, Anti-Aging Replenishing Advanced Face Moisturizer, with Vitamins A, C, E & Natural Botanicals to Promote Skin Balance & Collagen Production, 6.7 Fl Oz



Age Defying 0.3% Retinol Serum, Anti-Aging Dark Spot Remover for Face, Fine Lines & Wrinkle Pore Minimizer, with Vitamin E & Natural Botanicals


Firming Moisturizer, Advanced Hydrating Facial Replenishing Cream, with Hyaluronic Acid, Resveratrol & Natural Botanicals to Restore Skin's Strength, Radiance, and Resilience, 1.75 Oz

Skin Stem Cell Serum


Smartphone 101 - Pick a smartphone for me - android or iOS - Apple iPhone or Samsung Galaxy or Huawei or Xaomi or Google Pixel
Can AI Really Predict Lottery Results? We Asked an Expert.




Djamgatech

Read Photos and PDFs Aloud for me iOS
Read Photos and PDFs Aloud for me android
Read Photos and PDFs Aloud For me Windows 10/11
Read Photos and PDFs Aloud For Amazon
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more)
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6(Email us for more)



FREE 10000+ Quiz Trivia and and Brain Teasers for All Topics including Cloud Computing, General Knowledge, History, Television, Music, Art, Science, Movies, Films, US History, Soccer Football, World Cup, Data Science, Machine Learning, Geography, etc....

List of Freely available programming books - What is the single most influential book every Programmers should read
- Bjarne Stroustrup - The C++ Programming Language
- Brian W. Kernighan, Rob Pike - The Practice of Programming
- Donald Knuth - The Art of Computer Programming
- Ellen Ullman - Close to the Machine
- Ellis Horowitz - Fundamentals of Computer Algorithms
- Eric Raymond - The Art of Unix Programming
- Gerald M. Weinberg - The Psychology of Computer Programming
- James Gosling - The Java Programming Language
- Joel Spolsky - The Best Software Writing I
- Keith Curtis - After the Software Wars
- Richard M. Stallman - Free Software, Free Society
- Richard P. Gabriel - Patterns of Software
- Richard P. Gabriel - Innovation Happens Elsewhere
- Code Complete (2nd edition) by Steve McConnell
- The Pragmatic Programmer
- Structure and Interpretation of Computer Programs
- The C Programming Language by Kernighan and Ritchie
- Introduction to Algorithms by Cormen, Leiserson, Rivest & Stein
- Design Patterns by the Gang of Four
- Refactoring: Improving the Design of Existing Code
- The Mythical Man Month
- The Art of Computer Programming by Donald Knuth
- Compilers: Principles, Techniques and Tools by Alfred V. Aho, Ravi Sethi and Jeffrey D. Ullman
- Gödel, Escher, Bach by Douglas Hofstadter
- Clean Code: A Handbook of Agile Software Craftsmanship by Robert C. Martin
- Effective C++
- More Effective C++
- CODE by Charles Petzold
- Programming Pearls by Jon Bentley
- Working Effectively with Legacy Code by Michael C. Feathers
- Peopleware by Demarco and Lister
- Coders at Work by Peter Seibel
- Surely You're Joking, Mr. Feynman!
- Effective Java 2nd edition
- Patterns of Enterprise Application Architecture by Martin Fowler
- The Little Schemer
- The Seasoned Schemer
- Why's (Poignant) Guide to Ruby
- The Inmates Are Running The Asylum: Why High Tech Products Drive Us Crazy and How to Restore the Sanity
- The Art of Unix Programming
- Test-Driven Development: By Example by Kent Beck
- Practices of an Agile Developer
- Don't Make Me Think
- Agile Software Development, Principles, Patterns, and Practices by Robert C. Martin
- Domain Driven Designs by Eric Evans
- The Design of Everyday Things by Donald Norman
- Modern C++ Design by Andrei Alexandrescu
- Best Software Writing I by Joel Spolsky
- The Practice of Programming by Kernighan and Pike
- Pragmatic Thinking and Learning: Refactor Your Wetware by Andy Hunt
- Software Estimation: Demystifying the Black Art by Steve McConnel
- The Passionate Programmer (My Job Went To India) by Chad Fowler
- Hackers: Heroes of the Computer Revolution
- Algorithms + Data Structures = Programs
- Writing Solid Code
- JavaScript - The Good Parts
- Getting Real by 37 Signals
- Foundations of Programming by Karl Seguin
- Computer Graphics: Principles and Practice in C (2nd Edition)
- Thinking in Java by Bruce Eckel
- The Elements of Computing Systems
- Refactoring to Patterns by Joshua Kerievsky
- Modern Operating Systems by Andrew S. Tanenbaum
- The Annotated Turing
- Things That Make Us Smart by Donald Norman
- The Timeless Way of Building by Christopher Alexander
- The Deadline: A Novel About Project Management by Tom DeMarco
- The C++ Programming Language (3rd edition) by Stroustrup
- Patterns of Enterprise Application Architecture
- Computer Systems - A Programmer's Perspective
- Agile Principles, Patterns, and Practices in C# by Robert C. Martin
- Growing Object-Oriented Software, Guided by Tests
- Framework Design Guidelines by Brad Abrams
- Object Thinking by Dr. David West
- Advanced Programming in the UNIX Environment by W. Richard Stevens
- Hackers and Painters: Big Ideas from the Computer Age
- The Soul of a New Machine by Tracy Kidder
- CLR via C# by Jeffrey Richter
- The Timeless Way of Building by Christopher Alexander
- Design Patterns in C# by Steve Metsker
- Alice in Wonderland by Lewis Carol
- Zen and the Art of Motorcycle Maintenance by Robert M. Pirsig
- About Face - The Essentials of Interaction Design
- Here Comes Everybody: The Power of Organizing Without Organizations by Clay Shirky
- The Tao of Programming
- Computational Beauty of Nature
- Writing Solid Code by Steve Maguire
- Philip and Alex's Guide to Web Publishing
- Object-Oriented Analysis and Design with Applications by Grady Booch
- Effective Java by Joshua Bloch
- Computability by N. J. Cutland
- Masterminds of Programming
- The Tao Te Ching
- The Productive Programmer
- The Art of Deception by Kevin Mitnick
- The Career Programmer: Guerilla Tactics for an Imperfect World by Christopher Duncan
- Paradigms of Artificial Intelligence Programming: Case studies in Common Lisp
- Masters of Doom
- Pragmatic Unit Testing in C# with NUnit by Andy Hunt and Dave Thomas with Matt Hargett
- How To Solve It by George Polya
- The Alchemist by Paulo Coelho
- Smalltalk-80: The Language and its Implementation
- Writing Secure Code (2nd Edition) by Michael Howard
- Introduction to Functional Programming by Philip Wadler and Richard Bird
- No Bugs! by David Thielen
- Rework by Jason Freid and DHH
- JUnit in Action
#BlackOwned #BlackEntrepreneurs #BlackBuniness #AWSCertified #AWSCloudPractitioner #AWSCertification #AWSCLFC02 #CloudComputing #AWSStudyGuide #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AWSBasics #AWSCertified #AWSMachineLearning #AWSCertification #AWSSpecialty #MachineLearning #AWSStudyGuide #CloudComputing #DataScience #AWSCertified #AWSSolutionsArchitect #AWSArchitectAssociate #AWSCertification #AWSStudyGuide #CloudComputing #AWSArchitecture #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AzureFundamentals #AZ900 #MicrosoftAzure #ITCertification #CertificationPrep #StudyMaterials #TechLearning #MicrosoftCertified #AzureCertification #TechBooks
Top 1000 Canada Quiz and trivia: CANADA CITIZENSHIP TEST- HISTORY - GEOGRAPHY - GOVERNMENT- CULTURE - PEOPLE - LANGUAGES - TRAVEL - WILDLIFE - HOCKEY - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Top 1000 Africa Quiz and trivia: HISTORY - GEOGRAPHY - WILDLIFE - CULTURE - PEOPLE - LANGUAGES - TRAVEL - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Exploring the Pros and Cons of Visiting All Provinces and Territories in Canada.


Exploring the Advantages and Disadvantages of Visiting All 50 States in the USA

Health Health, a science-based community to discuss health news and the coronavirus (COVID-19) pandemic
- Report finds Nestlé adds sugars to baby food in low-income countriesby /u/nbcnews on May 4, 2024 at 12:20 am
submitted by /u/nbcnews [link] [comments]
- Santa Cruz County Health Alert: Feeling Angry? Your Blood Vessels May Be Suffering. Doctor Explainsby /u/robertovertical on May 4, 2024 at 12:13 am
submitted by /u/robertovertical [link] [comments]
- TikTok’s Raw Milk Influencers Are Going to Give Us All Bird Fluby /u/mcgillhufflepuff on May 3, 2024 at 11:23 pm
submitted by /u/mcgillhufflepuff [link] [comments]
- Mount Horeb shooting: ‘People in every community need to be mindful of the warning signs.’ Most mass school shootings in rural, suburban schools, data showby /u/jms1225 on May 3, 2024 at 10:10 pm
submitted by /u/jms1225 [link] [comments]
- Abortion restrictions are spreading, even though science shows they’re harmfulby /u/scientificamerican on May 3, 2024 at 8:36 pm
submitted by /u/scientificamerican [link] [comments]
Today I Learned (TIL) You learn something new every day; what did you learn today? Submit interesting and specific facts about something that you just found out here.
- TIL that Sara Blakely, founder of Spanx, bombed the LSAT, was rejected from the role of Goofy at Disney World, and was stuck selling fax machines for a living. She was named the youngest female self-made billionaire in 2012.by /u/Brendawg324 on May 4, 2024 at 2:10 am
submitted by /u/Brendawg324 [link] [comments]
- TIL Ayman al zawahiri (2nd in command to bin laden) was killed by a drone made of 6 large blades known as “the ginsu”by /u/Sea-Canary-6880 on May 4, 2024 at 2:07 am
submitted by /u/Sea-Canary-6880 [link] [comments]
- TIL in 2007, a couple dissatisfied with their marriage went to online forums and unknowingly began talking with each other and discussing their marriage issues. When the husband and wife tried to cheat on their spouse with this "new person", they were in for a shock. They divorced soon after.by /u/Ok-Indication-5121 on May 4, 2024 at 1:55 am
submitted by /u/Ok-Indication-5121 [link] [comments]
- TIL there is some chimpanzee populations that inhabit the savanna and act differently then the forest populations for example using caves, filtering drinking water, walking more on two legs than forest chimpz do and more. There is an Arte documentary on YouTube with them filtering water.by /u/TheCriticalGerman on May 4, 2024 at 1:46 am
submitted by /u/TheCriticalGerman [link] [comments]
- TIL Megabats have a wingspan of up to 5 feet (1.5 meters)by /u/hablogato on May 4, 2024 at 1:35 am
submitted by /u/hablogato [link] [comments]
Reddit Science This community is a place to share and discuss new scientific research. Read about the latest advances in astronomy, biology, medicine, physics, social science, and more. Find and submit new publications and popular science coverage of current research.
- Scientists identify the brain cells that regulate inflammation, and pinpoint how they keep tabs on the immune responseby /u/ore-aba on May 4, 2024 at 2:10 am
submitted by /u/ore-aba [link] [comments]
- Copper coating turns touchscreens into bacteria killers | In tests, the TANCS was found to kill 99.9% of applied bacteria within two hours. It also remained intact and effective after being subjected to the equivalent of being wiped down with cleansers twice a day for two years.by /u/chrisdh79 on May 4, 2024 at 1:01 am
submitted by /u/chrisdh79 [link] [comments]
- New study suggests that specific traits of psychopathy, antisociality and callousness, are significant predictors of risky sexual practices among young adults. These behaviors include unprotected sex, having multiple sexual partners, and engaging in sex under the influence of drugs or alcohol.by /u/mvea on May 3, 2024 at 11:10 pm
submitted by /u/mvea [link] [comments]
- Behavioural therapy and sleep: a lifeline for night workers. Research found applying behavioural therapy to night work can reduce the harmful effects of atypical work schedules. Specifically, it can improve daytime sleep and lower levels of drowsiness, anxiety and depression.by /u/Wagamaga on May 3, 2024 at 9:01 pm
submitted by /u/Wagamaga [link] [comments]
- New technique for predicting protein dynamics may prove big breakthrough for drug discoveryby /u/-Sunrise-Parabellum on May 3, 2024 at 8:19 pm
submitted by /u/-Sunrise-Parabellum [link] [comments]
Reddit Sports Sports News and Highlights from the NFL, NBA, NHL, MLB, MLS, and leagues around the world.
- Vancouver Canucks blank Nashville Predators in G6, on to 2nd round of Stanley Cup Playoffsby /u/SkepticalZebra on May 4, 2024 at 3:52 am
submitted by /u/SkepticalZebra [link] [comments]
- England's Kim, 16, youngest to make PGA Tour cut in 11 yearsby /u/PrincessBananas85 on May 4, 2024 at 3:03 am
submitted by /u/PrincessBananas85 [link] [comments]
- Donovan Mitchell’s playoff masterpiece not enough as Cavs lose Game 6 to Orlando Magic, 103-96by /u/Oldtimer_2 on May 4, 2024 at 2:11 am
submitted by /u/Oldtimer_2 [link] [comments]
- Artur Beterbiev vs. Dmitry Bivol: Undisputed unification fight postponed after Beterbiev suffers injuryby /u/Oldtimer_2 on May 4, 2024 at 12:26 am
submitted by /u/Oldtimer_2 [link] [comments]
- Jets QB Aaron Rodgers to have no restrictions when OTAs openby /u/PrincessBananas85 on May 3, 2024 at 11:38 pm
submitted by /u/PrincessBananas85 [link] [comments]
