



Top 60 AWS Solution Architect Associate Exam Tips
SAA Exam Prep App urls

Solution Architect FREE version:
Google Play Store (Android)
Apple Store (iOS)
Pwa: Web
Amazon android: Amazon App Store (Android)
Microsoft/Windows10:
0 In a nutshell, below are the resources and apps that you need for SAA-C03 Exam Prep:
- Study material by Adrian Cantrill ($40) or Joyjeet Banerjee ($50)
- PRO Quiz and Practice Exams by Djamgatech ($9.99) [iOS – Android]
- Quiz and Practice Exams by Djamgatech [Web – android – iOS – windows] (FREE or $5)
- Practice tests by Tutorial Dojo ($15)
- AWS labs and practices at AWS Qwiklabs ($25-50)
- Extra: $30 for Marek’s course on Udemy
- Extra: You can check out Practice exams by Ken Adams for solutions architect. (SAA-C02 – Updated June 2021)
Read FAQs and learn more about the following topics in details: Load Balancing, DynamoDB, EBS, Multi-AZ RDS, Aurora, EFS, DynamoDB, NLB, ALB, Aurora, Auto Scalling, DynamoDB(latency), Aurora(performance), Multi-AZ RDS(high availability), Throughput Optimized EBS (highly sequential), Read the quizlet note cards about Cloudwatch, CloudTrail, KMS, ElasticBeanstalk, OpsWorks here. Read Dexter’s Barely passed AWS Cram Notes about RPO vs RTO, HA vs FT, Undifferentiated Heavy Lifting, Access Management Basics, Shared Responsibility Model, Cloud Service Models
AWS topics for SAA-CO1 and SAA-CO2
1
Know what instance types can be launched from which types of AMIs, and which instance types require an HVM AMI
AWS HVM AMI
2

Understand bastion hosts, and which subnet one might live on. Bastion hosts are instances that sit within your public subnet and are typically accessed using SSH or RDP. Once remote connectivity has been established with the bastion host, it then acts as a ‘jump’ server, allowing you to use SSH or RDP to login to other instances (within private subnets) deeper within your network. When properly configured through the use of security groups and Network ACLs, the bastion essentially acts as a bridge to your private instances via the Internet.”
Bastion Hosts
3
Know the difference between Directory Service’s AD Connector and Simple AD. Use Simple AD if you need an inexpensive Active Directory–compatible service with the common directory features. AD Connector lets you simply connect your existing on-premises Active Directory to AWS.
AD Connector and Simple AD
4
Know how to enable cross-account access with IAM: To delegate permission to access a resource, you create an IAM role that has two policies attached. The permissions policy grants the user of the role the needed permissions to carry out the desired tasks on the resource. The trust policy specifies which trusted accounts are allowed to grant its users permissions to assume the role. The trust policy on the role in the trusting account is one-half of the permissions. The other half is a permissions policy attached to the user in the trusted account that allows that user to switch to, or assume the role.
Enable cross-account access with IAM
5

Have a good understanding of how Route53 supports all of the different DNS record types, and when you would use certain ones over others.
Route 53 supports all of the different DNS record types
6
Advertise with us - Post Your Good Content Here
We are ranked in the Top 20 on Google
AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
Know which services have native encryption at rest within the region, and which do not.
AWS Services with native Encryption at rest
7

Know which services allow you to retain full admin privileges of the underlying EC2 instances
EC2 Full admin privilege
8
Know When Elastic IPs are free or not: If you associate additional EIPs with that instance, you will be charged for each additional EIP associated with that instance per hour on a pro rata basis. Additional EIPs are only available in Amazon VPC. To ensure efficient use of Elastic IP addresses, we impose a small hourly charge when these IP addresses are not associated with a running instance or when they are associated with a stopped instance or unattached network interface.
When are AWS Elastic IPs Free or not?
9
Know what are the four high level categories of information Trusted Advisor supplies.
#AWS Trusted advisor

10
Know how to troubleshoot a connection time out error when trying to connect to an instance in your VPC. You need a security group rule that allows inbound traffic from your public IP address on the proper port, you need a route that sends all traffic destined outside the VPC (0.0.0.0/0) to the Internet gateway for the VPC, the network ACLs must allow inbound and outbound traffic from your public IP address on the proper port, etc.
#AWS Connection time out error
11
Be able to identify multiple possible use cases and eliminate non-use cases for SWF.
#AWS
12
Understand how you might set up consolidated billing and cross-account access such that individual divisions resources are isolated from each other, but corporate IT can oversee all of it.
#AWS Set up consolidated billing
13
Know how you would go about making changes to an Auto Scaling group, fully understanding what you can and can’t change. “You can only specify one launch configuration for an Auto Scaling group at a time, and you can’t modify a launch configuration after you’ve created it. Therefore, if you want to change the launch configuration for your Auto Scaling group, you must create a launch configuration and then update your Auto Scaling group with the new launch configuration. When you change the launch configuration for your Auto Scaling group, any new instances are launched using the new configuration parameters, but existing instances are not affected.
#AWS Make Change to Auto Scaling group
14
Know how you would go about making changes to an Auto Scaling group, fully understanding what you can and can’t change. “You can only specify one launch configuration for an Auto Scaling group at a time, and you can’t modify a launch configuration after you’ve created it. Therefore, if you want to change the launch configuration for your Auto Scaling group, you must create a launch configuration and then update your Auto Scaling group with the new launch configuration. When you change the launch configuration for your Auto Scaling group, any new instances are launched using the new configuration parameters, but existing instances are not affected.
#AWS Make Change to Auto Scaling group
15
Know which field you use to run a script upon launching your instance.
#AWS User data script
16
Know how DynamoDB (durable, and you can pay for strong consistency), Elasticache (great for speed, not so durable), and S3 (eventual consistency results in lower latency) compare to each other in terms of durability and low latency.
#AWS DynamoDB consistency
17
Know the difference between bucket policies, IAM policies, and ACLs for use with S3, and examples of when you would use each. “With IAM policies, companies can grant IAM users fine-grained control to their Amazon S3 bucket or objects while also retaining full control over everything the users do. With bucket policies, companies can define rules which apply broadly across all requests to their Amazon S3 resources, such as granting write privileges to a subset of Amazon S3 resources. Customers can also restrict access based on an aspect of the request, such as HTTP referrer and IP address. With ACLs, customers can grant specific permissions (i.e. READ, WRITE, FULL_CONTROL) to specific users for an individual bucket or object.
#AWS Difference between bucket policies
18
Know when and how you can encrypt snapshots.
#AWS EBS Encryption
19
Understand how you can use ELB cross-zone load balancing to ensure even distribution of traffic to EC2 instances in multiple AZs registered with a load balancer.
#AWS ELB cross-zone load balancing

20
How would you allow users to log into the AWS console using active directory integration. Here is a link to some good reference material.
#AWS og into the AWS console using active directory integration
21
Spot instances are good for cost optimization, even if it seems you might need to fall back to On-Demand instances if you wind up getting kicked off them and the timeline grows tighter. The primary (but still not only) factor seems to be whether you can gracefully handle instances that die on you–which is pretty much how you should always design everything, anyway!
#AWS Spot instances
22
The term “use case” is not the same as “function” or “capability”. A use case is something that your app/system will need to accomplish, not just behaviour that you will get from that service. In particular, a use case doesn’t require that the service be a 100% turnkey solution for that situation, just that the service plays a valuable role in enabling it.
#AWS use case
23
There might be extra, unnecessary information in some of the questions (red herrings), so try not to get thrown off by them. Understand what services can and can’t do, but don’t ignore “obvious”-but-still-correct answers in favour of super-tricky ones.
#AWS Exam Answers: Distractors
24

If you don’t know what they’re trying to ask, in a question, just move on and come back to it later (by using the helpful “mark this question” feature in the exam tool). You could easily spend way more time than you should on a single confusing question if you don’t triage and move on.
#AWS Exa: Skip Questions that are vague and come back to them later
25
Some exam questions required you to understand features and use cases of: VPC peering, cross-account access, DirectConnect, snapshotting EBS RAID arrays, DynamoDB, spot instances, Glacier, AWS/user security responsibilities, etc.
#AWS
26
The 30 Day constraint in the S3 Lifecycle Policy before transitioning to S3-IA and S3-One Zone IA storage classes
#AWS S3 lifecycle policy
27

Enabling Cross-region snapshot copy for an AWS KMS-encrypted cluster
Redis Auth / Amazon MQ / IAM DB Authentication
#AWS Cross-region snapshot copy for an AWS KMS-encrypted cluster
28
Know that FTP is using TCP and not UDP (Helpful for questions where you are asked to troubleshoot the network flow)
TCP and UDP

30
Kinesis Sharding:
#AWS Kinesis Sharding
31
Handling SSL Certificates in ELB ( Wildcard certificate vs SNI )
#AWS Handling SSL Certificates in ELB ( Wildcard certificate vs SNI )
32
Difference between OAI, Signed URL (CloudFront) and Pre-signed URL (S3)
#AWS Difference between OAI, Signed URL (CloudFront) and Pre-signed URL (S3)
33
Different types of Aurora Endpoints
#AWS Different types of Aurora Endpoints
34
The Default Termination Policy for Auto Scaling Group (Oldest launch configuration vs Instance Protection)
#AWS Default Termination Policy for Auto Scaling Group
35
Watch Acloud Guru Videos Lectures while commuting / lunch break – Reschedule the exam if you are not yet ready
#AWS ACloud Guru
36
Watch Linux Academy Videos Lectures while commuting / lunch break – Reschedule the exam if you are not yet ready
#AWS Linux Academy
37
Watch Udemy Videos Lectures while commuting / lunch break – Reschedule the exam if you are not yet ready
#AWS Linux Academy
38
The Udemy practice test interface is good that it pinpoints your weak areas, so what I did was to re-watch all the videos that I got the wrong answers. Since I was able to gauge my exam readiness, I decided to reschedule my exam for 2 more weeks, to help me focus on completing the practice tests.
#AWS Udemy
39
Use AWS Cheatsheets – I also found the cheatsheets provided by Tutorials Dojo very helpful. In my opinion, it is better than Jayendrapatil Patil’s blog since it contains more updated information that complements your review notes.
#AWS Cheat Sheet
40
Watch this exam readiness 3hr video, it very recent webinar this provides what is expected in the exam.
#AWS Exam Prep Video
41
Start off watching Ryan’s videos. Try and completely focus on the hands on. Take your time to understand what you are trying to learn and achieve in those LAB Sessions.
#AWS Exam Prep Video
42
Do not rush into completing the videos. Take your time and hone the basics. Focus and spend a lot of time for the back bone of AWS infrastructure – Compute/EC2 section, Storage (S3/EBS/EFS), Networking (Route 53/Load Balancers), RDS, VPC, Route 3. These sections are vast, with lot of concepts to go over and have loads to learn. Trust me you will need to thoroughly understand each one of them to ensure you pass the certification comfortably.
#AWS Exam Prep Video
43
Make sure you go through resources section and also AWS documentation for each components. Go over FAQs. If you have a question, please post it in the community. Trust me, each answer here helps you understand more about AWS.
#AWS Faqs
44
Like any other product/service, each AWS offering has a different flavor. I will take an example of EC2 (Spot/Reserved/Dedicated/On Demand etc.). Make sure you understand what they are, what are the pros/cons of each of these flavors. Applies for all other offerings too.
#AWS Services
45
Ensure to attend all quizzes after each section. Please do not treat these quizzes as your practice exams. These quizzes are designed to mostly test your knowledge on the section you just finished. The exam itself is designed to test you with scenarios and questions, where in you will need to recall and apply your knowledge of different AWS technologies/services you learn over multiple lectures.
#AWS Services
46
I, personally, do not recommend to attempt a practice exam or simulator exam until you have done all of the above. It was a little overwhelming for me. I had thoroughly gone over the videos. And understood the concepts pretty well, but once I opened exam simulator I felt the questions were pretty difficult. I also had a feeling that videos do not cover lot of topics. But later I realized, given the vastness of AWS Services and offerings it is really difficult to encompass all these services and their details in the course content. The fact that these services keep changing so often, does not help
#AWS Services
47
Go back and make a note of all topics, that you felt were unfamiliar for you. Go through the resources section and fiund links to AWS documentation. After going over them, you shoud gain at least 5-10% more knowledge on AWS. Have expectations from the online courses as a way to get thorough understanding of basics and strong foundations for your AWS knowledge. But once you are done with videos. Make sure you spend a lot of time on AWS documentation and FAQs. There are many many topics/sub topics which may not be covered in the course and you would need to know, atleast their basic functionalities, to do well in the exam.
#AWS Services
48
Once you start taking practice exams, it may seem really difficult at the beginning. So, please do not panic if you find the questions complicated or difficult. IMO they are designed or put in a way to sound complicated but they are not. Be calm and read questions very carefully. In my observation, many questions have lot of information which sometimes is not relevant to the solution you are expected to provide. Read the question slowly and read it again until you understand what is expected out of it.
#AWS Services
49
With each practice exam you will come across topics that you may need to scale your knowledge on or learn them from scratch.
#AWS Services
50
With each test and the subsequent revision, you will surely feel more confident.
There are 130 mins for questions. 2 mins for each question which is plenty of time.
At least take 8-10 practice tests. The ones on udemy/tutorialdojo are really good. If you are a acloudguru member. The exam simulator is really good.
Manage your time well. Keep patience. I saw someone mention in one of the discussions that do not under estimate the mental focus/strength needed to sit through 130 mins solving these questions. And it is really true.
Do not give away or waste any of those precious 130 mins. While answering flag/mark questions you think you are not completely sure. My advice is, even if you finish early, spend your time reviewing the answers. I could review 40 of my answers at the end of test. And I at least rectified 3 of them (which is 4-5% of total score, I think)
So in short – Put a lot of focus on making your foundations strong. Make sure you go through AWS Documentation and FAQs. Try and envision how all of the AWS components can fit together and provide an optimal solution. Keep calm.
This video gives outline about exam, must watch before or after Ryan’s course. #AWS Services
51
Walking you through how to best prepare for the AWS Certified Solutions Architect Associate SAA-C02 exam in 5 steps:
1. Understand the exam blueprint
2. Learn about the new topics included in the SAA-C02 version of the exam
3. Use the many FREE resources available to gain and deepen your knowledge
4. Enroll in our hands-on video course to learn AWS in depth
5. Use practice tests to fully prepare yourself for the exam and assess your exam readiness
AWS CERTIFIED SOLUTIONS ARCHITECT SAA-C02 : HOW TO BEST PREPARE IN 5 STEPS
52
Storage:
1. Know your different Amazon S3 storage tiers! You need to know the use cases, features and limitations, and relative costs; e.g. retrieval costs.
2. Amazon S3 lifecycle policies is also required knowledge — there are minimum storage times in certain tiers that you need to know.
3. For Glacier, you need to understand what it is, what it’s used for, and what the options are for retrieval times and fees.
4. For the Amazon Elastic File System (EFS), make sure you’re clear which operating systems you can use with it (just Linux).
5. For the Amazon Elastic Block Store (EBS), make sure you know when to use the different tiers including instance stores; e.g. what would you use for a datastore that requires the highest IO and the data is distributed across multiple instances? (Good instance store use case)
6. Learn about Amazon FSx. You’ll need to know about FSx for Windows and Lustre.
7. Know how to improve Amazon S3 performance including using CloudFront, and byte-range fetches — check out this whitepaper.
8. Make sure you understand about Amazon S3 object deletion protection options including versioning and MFA delete.
AWS CERTIFIED SOLUTIONS ARCHITECT SAA-C02 : HOW TO BEST PREPARE IN 5 STEPS
53
Compute:
1. You need to have a good understanding of the options for how to scale an Auto Scaling Group using metrics such as SQS queue depth, or numbers of SNS messages.
2. Know your different Auto Scaling policies including Target Tracking Policies.
3. Read up on High Performance Computing (HPC) with AWS. You’ll need to know about Amazon FSx with HPC use cases.
4. Know your placement groups. Make sure you can differentiate between spread, cluster and partition; e.g. what would you use for lowest latency? What about if you need to support an app that’s tightly coupled? Within an AZ or cross AZ?
5. Make sure you know the difference between Elastic Network Adapters (ENAs), Elastic Network Interfaces (ENIs) and Elastic Fabric Adapters (EFAs).
6. For the Amazon Elastic Container Service (ECS), make sure you understand how to assign IAM policies to ECS for providing S3 access. How can you decouple an ECS data processing process — Kinesis Firehose or SQS?
7. Make sure you’re clear on the different EC2 pricing models including Reserved Instances (RI) and the different RI options such as scheduled RIs.
8. Make sure you know the maximum execution time for AWS Lambda (it’s currently 900 seconds or 15 minutes).
AWS CERTIFIED SOLUTIONS ARCHITECT SAA-C02 : HOW TO BEST PREPARE IN 5 STEPS
54
Network
1. Understand what AWS Global Accelerator is and its use cases.
2. Understand when to use CloudFront and when to use AWS Global Accelerator.
3. Make sure you understand the different types of VPC endpoint and which require an Elastic Network Interface (ENI) and which require a route table entry.
4. You need to know how to connect multiple accounts; e.g. should you use VPC peering or a VPC endpoint?
5. Know the difference between PrivateLink and ClassicLink.
6. Know the patterns for extending a secure on-premises environment into AWS.
7. Know how to encrypt AWS Direct Connect (you can use a Virtual Private Gateway / AWS VPN).
8. Understand when to use Direct Connect vs Snowball to migrate data — lead time can be an issue with Direct Connect if you’re in a hurry.
9. Know how to prevent circumvention of Amazon CloudFront; e.g. Origin Access Identity (OAI) or signed URLs / signed cookies.
AWS CERTIFIED SOLUTIONS ARCHITECT SAA-C02 : HOW TO BEST PREPARE IN 5 STEPS
55
Databases
1. Make sure you understand Amazon Aurora and Amazon Aurora Serverless.
2. Know which RDS databases can have Read Replicas and whether you can read from a Multi-AZ standby.
3. Know the options for encrypting an existing RDS database; e.g. only at creation time otherwise you must encrypt a snapshot and create a new instance from the snapshot.
4. Know which databases are key-value stores; e.g. Amazon DynamoDB.
AWS CERTIFIED SOLUTIONS ARCHITECT SAA-C02 : HOW TO BEST PREPARE IN 5 STEPS
56
Application Integration
1. Make sure you know the use cases for the Amazon Simple Queue Service (SQS), and Simple Notification Service (SNS).
2. Understand the differences between Amazon Kinesis Firehose and SQS and when you would use each service.
3. Know how to use Amazon S3 event notifications to publish events to SQS — here’s a good “How To” article.
AWS CERTIFIED SOLUTIONS ARCHITECT SAA-C02 : HOW TO BEST PREPARE IN 5 STEPS
57
Management and Governance
1. You’ll need to know about AWS Organizations; e.g. how to migrate an account between organizations.
2. For AWS Organizations, you also need to know how to restrict actions using service control policies attached to OUs.
3. Understand what AWS Resource Access Manager is.
AWS CERTIFIED SOLUTIONS ARCHITECT SAA-C02 : HOW TO BEST PREPARE IN 5 STEPS
58
Jon Bonso list of helpful exam prep materials that you can use.
1. The official AWS SAA-C02 Certification Exam page.
2. The official AWS Exam Guide.
3. The official AWS Sample Questions
4. The official AWS Ramp-Up Guide: Architect PDF
5. Tutorials Dojo SAA-C02 Study Guide
6. Udemy Practice Exams
7. New AWS Services to prepare for:AWS Global Accelerator
8. New AWS Services to prepare for: Elastic Fabric Adapter — Amazon Web Services
9. New AWS Services to prepare for: AWS ParallelCluster – Amazon Web Services
10. New AWS Services to prepare for: Amazon FSx File Storage
Pass your SAA-C02 (AWS Solutions Architect Associate) exam with these Top 5 Resources
About this App
The AWS Certified Solution Architect Associate Examination reparation and Readiness Quiz App (SAA-C01, SAA-C01, SAA) Prep App helps you prepare and train for the AWS Certification Solution Architect Associate Exam with various questions and answers dumps.
This App provide updated Questions and Answers, an Intuitive Responsive Interface allowing to browse questions horizontally and browse tips and resources vertically after completing a quiz.
Features:
- 100+ Questions and Answers updated frequently to get you AWS certified.
- Quiz with score tracker, countdown timer, highest score saving. Vie Answers after completing the quiz for each category.
- Can only see answers after completing the quiz.
- Show/Hide button option for answers. Link to PRO Version to see all answers for each category
- Ability to navigate through questions for each category using next and previous button.
- Resource info page about the answer for each category and Top 60 Tips to succeed in the exam.
- Prominent Cloud Evangelist latest tweets and Technology Latest News Feed
- The app helps you study and practice from your mobile device with an intuitive interface.
- SAA-C01 and SAA-C02 compatible
- Resource info page about the answer for each category.
- Helps you study and practice from your mobile device with an intuitive interface.
The questions and Answers are divided in 4 categories:
- Design High Performing Architectures,
- Design Cost Optimized Architectures,
- Design Secure Applications And Architectures,
- Design Resilient Architecture,
The questions and answers cover the following topics: AWS VPC, S3, DynamoDB, EC2, ECS, Lambda, API Gateway, CloudWatch, CloudTrail, Code Pipeline, Code Deploy, TCO Calculator, AWS S3, AWS DynamoDB, CloudWatch , AWS SES, Amazon Lex, AWS EBS, AWS ELB, AWS Autoscaling , RDS, Aurora, Route 53, Amazon CodeGuru, Amazon Bracket, AWS Billing and Pricing, AWS Simply Monthly Calculator, AWS cost calculator, Ec2 pricing on-demand, AWS Pricing, AWS Pay As You Go, AWS No Upfront Cost, Cost Explorer, AWS Organizations, Consolidated billing, Instance Scheduler, on-demand instances, Reserved instances, Spot Instances, CloudFront, Web hosting on S3, S3 storage classes, AWS Regions, AWS Availability Zones, Trusted Advisor, Various architectural Questions and Answers about AWS, AWS SDK, AWS EBS Volumes, EC2, S3, Containers, KMS, AWS read replicas, Cloudfront, API Gateway, AWS Snapshots, Auto shutdown Ec2 instances, High Availability, RDS, DynamoDB, Elasticity, AWS Virtual Machines, AWS Caching, AWS Containers, AWS Architecture, AWS Ec2, AWS S3, AWS Security, AWS Lambda, Bastion Hosts, S3 lifecycle policy, kinesis sharing, AWS KMS, Design High Performing Architectures, Design Cost Optimized Architectures, Design Secure Applications And Architectures, Design Resilient Architecture, AWS vs Azure vs Google Cloud, Resources, Questions, AWS, AWS SDK, AWS EBS Volumes, AWS read replicas, Cloudfront, API Gateway, AWS Snapshots, Auto shutdown Ec2 instances, High Availability, RDS, DynamoDB, Elasticity, AWS Virtual Machines, AWS Caching, AWS Containers, AWS Architecture, AWS Ec2, AWS S3, AWS Security, AWS Lambda, Load Balancing, DynamoDB, EBS, Multi-AZ RDS, Aurora, EFS, DynamoDB, NLB, ALB, Aurora, Auto Scaling, DynamoDB(latency), Aurora(performance), Multi-AZ RDS(high availability), Throughput Optimized EBS (highly sequential), SAA-CO1, SAA-CO2, Cloudwatch, CloudTrail, KMS, ElasticBeanstalk, OpsWorks, RPO vs RTO, HA vs FT, Undifferentiated Heavy Lifting, Access Management Basics, Shared Responsibility Model, Cloud Service Models, etc…
The resources sections cover the following areas: Certification, AWS training, Mock Exam Preparation Tips, Cloud Architect Training, Cloud Architect Knowledge, Cloud Technology, cloud certification, cloud exam preparation tips, cloud solution architect associate exam, certification practice exam, learn aws free, amazon cloud solution architect, question dumps, acloud guru links, tutorial dojo links, linuxacademy links, latest aws certification tweets, and post from reddit, quota, linkedin, medium, cloud exam preparation tips, aws cloud solution architect associate exam, aws certification practice exam, cloud exam questions, learn aws free, amazon cloud solution architect, amazon cloud certified solution architect associate exam questions, as certification dumps, google cloud, azure cloud, acloud, learn google cloud, learn azure cloud, cloud comparison, etc.
Abilities Validated by the Certification:
- Effectively demonstrate knowledge of how to architect and deploy secure and robust applications on AWS technologies
- Define a solution using architectural design principles based on customer requirements
- Provide implementation guidance based on best practices to the organization throughout the life cycle of the project
Recommended Knowledge for the Certification:
- One year of hands-on experience designing available, cost-effective, fault-tolerant, and scalable distributed systems on AWS.
- Hands-on experience using compute, networking, storage, and database AWS services.
- Hands-on experience with AWS deployment and management services.
- Ability to identify and define technical requirements for an AWS-based application.
- bility to identify which AWS services meet a given technical requirement.
- Knowledge of recommended best practices for building secure and reliable applications on the AWS platform.
- An understanding of the basic architectural principles of building in the AWS Cloud.
- An understanding of the AWS global infrastructure.
- An understanding of network technologies as they relate to AWS.
- An understanding of security features and tools that AWS provides and how they relate to traditional services.
Note and disclaimer: We are not affiliated with AWS or Amazon or Microsoft or Google. The questions are put together based on the certification study guide and materials available online. We also receive questions and answers from anonymous users and we vet to make sure they are legitimate. The questions in this app should help you pass the exam but it is not guaranteed. We are not responsible for any exam you did not pass.
Important: To succeed with the real exam, do not memorize the answers in this app. It is very important that you understand why a question is right or wrong and the concepts behind it by carefully reading the reference documents in the answers.
What is the AWS Certified Solution Architect Associate Exam?
This exam validates an examinee’s ability to effectively demonstrate knowledge of how to architect and deploy secure and robust applications on AWS technologies. It validates an examinee’s ability to:
- Define a solution using architectural design principles based on customer requirements.
- Multiple-response: Has two correct responses out of five options.
There are two types of questions on the examination:
- Multiple-choice: Has one correct response and three incorrect responses (distractors).
- Provide implementation guidance based on best practices to the organization throughout the lifecycle of the project.
Select one or more responses that best complete the statement or answer the question. Distractors, or incorrect answers, are response options that an examinee with incomplete knowledge or skill would likely choose. However, they are generally plausible responses that fit in the content area defined by the test objective. Unanswered questions are scored as incorrect; there is no penalty for guessing.
To succeed with the real exam, do not memorize the answers below. It is very important that you understand why a question is right or wrong and the concepts behind it by carefully reading the reference documents in the answers.
AWS Certified Solution Architect Associate info and details
The AWS Certified Solution Architect Associate Exam is a multiple choice, multiple answer exam. Here is the Exam Overview:
- Certification Name: AWS Certified Solution Architect Associate.
- Prerequisites for the Exam: None.
- Exam Pattern: Multiple Choice Questions
- Duration: 130 mins
- Exam fees: US $150
- Exam Guide on AWS Website
- Available languages for tests: English, Japanese, Korean, Simplified Chinese
- Read AWS whitepapers
- Register for certification account here.
- Prepare for Certification Here
Other AWS Facts and Summaries and Questions/Answers Dump
- AWS S3 facts and summaries and Q&A Dump
- AWS DynamoDB facts and summaries and Questions and Answers Dump
- AWS EC2 facts and summaries and Questions and Answers Dump
- AWS Serverless facts and summaries and Questions and Answers Dump
- AWS Developer and Deployment Theory facts and summaries and Questions and Answers Dump
- AWS IAM facts and summaries and Questions and Answers Dump
- AWS vs Azure vs Google
- Pros and Cons of Cloud Computing
- Cloud Customer Insurance – Cloud Provider Insurance – Cyber Insurance
Additional Information for reference
Below are some useful reference links that would help you to learn about AWS Practitioner Exam.
- AWS certified cloud practitioner/
- certification faqs
- AWS Certified Solution Architect Associate Exam Prep Dumps
Other Relevant and Recommended AWS Certifications

AWS Certification Exams Roadmap[/caption]
- AWS Certified Cloud Practitioner
- AWS Certified Solutions Architect – Associate
- AWS Certified Developer – Associate
- AWS Certified SysOps Administrator – Associate
- AWS Certified Solutions Architect – Professional
- AWS Certified DevOps Engineer – Professional
- AWS Certified Big Data Specialty
- AWS Certified Advanced Networking.
- AWS Certified Security – Specialty
AWS Solution Architect Associate Exam Whitepapers:
AWS has provided whitepapers to help you understand the technical concepts. Below are the recommended whitepapers.
Online Training and Labs for AWS Certified Solution Architect Associate Exam
AWS Certified Solution Architect Associate Jobs


AWS Certification and Training Apps for all platforms:
AWS Cloud practitioner FREE version:
AWS Certified Cloud practitioner for the web:pwa
AWS Certified Cloud practitioner Exam Prep App for iOS
AWS Certified Cloud practitioner Exam Prep App for Microsoft/Windows10
AWS Certified Cloud practitioner Exam Prep App for Android (Google Play Store)
AWS Certified Cloud practitioner Exam Prep App for Android (Amazon App Store)
AWS Certified Cloud practitioner Exam Prep App for Android (Huawei App Gallery)
AWS Solution Architect FREE version:
AWS Certified Solution Architect Associate Exam Prep App for iOS: https://apps.apple.com/ca/app/solution-architect-assoc-quiz/id1501225766
Solution Architect Associate for Android Google Play
AWS Certified Solution Architect Associate Exam Prep App for the eb: Pwa
AWS Certified Solution Architect Associate Exam Prep App for Amazon android
AWS Certified Cloud practitioner Exam Prep App for Microsoft/Windows10
AWS Certified Cloud practitioner Exam Prep App for Huawei App Gallery
AWS Cloud Practitioner PRO Versions:
AWS Certified Cloud practitioner PRO Exam Prep App for iOS
AWS Certified Cloud Practitioner PRO Associate Exam Prep App for android google
AWS Certified Cloud practitioner Exam Prep App for Amazon android
AWS Certified Cloud practitioner Exam Prep App for Windows 10
AWS Certified Cloud practitioner Exam Prep PRO App for Android (Huawei App Gallery) Coming soon
AWS Solution Architect PRO
AWS Certified Solution Architect Associate PRO versions for iOS
AWS Certified Solution Architect Associate PRO Exam Prep App for Android google
AWS Certified Solution Architect Associate PRO Exam Prep App for Windows10
AWS Certified Solution Architect Associate PRO Exam Prep App for Amazon android
Huawei App Gallery: Coming soon
AWS Certified Developer Associates Free version:
AWS Certified Developer Associates for Android (Google Play)
AWS Certified Developer Associates Web/PWA
AWS Certified Developer Associates for iOs
AWS Certified Developer Associates for Android (Huawei App Gallery)
AWS Certified Developer Associates for windows 10 (Microsoft App store)
Amazon App Store: Coming soon
AWS Developer Associates PRO version
PRO version with mock exam for android (Google Play)
PRO version with mock exam ios
AWS Certified Developer Associates PRO for Android (Amazon App Store): Coming Soon
AWS Certified Developer Associates PRO for Android (Huawei App Gallery): Coming soon
AWS Certification Exam Prep: DynamoDB Facts, Summaries and Questions/Answers.

AWS Certification Exam Prep: DynamoDB facts and summaries, AWS DynamoDB Top 10 Questions and Answers Dump
Definition 1: Amazon DynamoDB is a fully managed proprietary NoSQL database service that supports key-value and document data structures and is offered by Amazon.com as part of the Amazon Web Services portfolio. DynamoDB exposes a similar data model to and derives its name from Dynamo, but has a different underlying implementation. Dynamo had a multi-master design requiring the client to resolve version conflicts and DynamoDB uses synchronous replication across multiple datacenters for high durability and availability.
Definition 2: DynamoDB is a fast and flexible non-relational database service for any scale. DynamoDB enables customers to offload the administrative burdens of operating and scaling distributed databases to AWS so that they don’t have to worry about hardware provisioning, setup and configuration, throughput capacity planning, replication, software patching, or cluster scaling.
Amazon DynamoDB explained
- Fully Managed
- Fast, consistent Performance
- Fine-grained access control
- Flexible




AWS DynamoDB Facts and Summaries
- Amazon DynamoDB is a low-latency NoSQL database.
- DynamoDB consists of Tables, Items, and Attributes
- DynamoDb supports both document and key-value data models
- DynamoDB Supported documents formats are JSON, HTML, XML
- DynamoDB has 2 types of Primary Keys: Partition Key and combination of Partition Key + Sort Key (Composite Key)
- DynamoDB has 2 consistency models: Strongly Consistent / Eventually Consistent
- DynamoDB Access is controlled using IAM policies.
- DynamoDB has fine grained access control using IAM Condition parameter dynamodb:LeadingKeys to allow users to access only the items where the partition key vakue matches their user ID.
- DynamoDB Indexes enable fast queries on specific data columns
- DynamoDB indexes give you a different view of your data based on alternative Partition / Sort Keys.
- DynamoDB Local Secondary indexes must be created when you create your table, they have same partition Key as your table, and they have a different Sort Key.
- DynamoDB Global Secondary Index Can be created at any time: at table creation or after. They have a different partition Key as your table and a different sort key as your table.
- A DynamoDB query operation finds items in a table using only the primary Key attribute: You provide the Primary Key name and a distinct value to search for.
- A DynamoDB Scan operation examines every item in the table. By default, it return data attributes.
- DynamoDB Query operation is generally more efficient than a Scan.
- With DynamoDB, you can reduce the impact of a query or scan by setting a smaller page size which uses fewer read operations.
- To optimize DynamoDB performance, isolate scan operations to specific tables and segregate them from your mission-critical traffic.
- To optimize DynamoDB performance, try Parallel scans rather than the default sequential scan.
- To optimize DynamoDB performance: Avoid using scan operations if you can: design tables in a way that you can use Query, Get, or BatchGetItems APIs.
- When you scan your table in Amazon DynamoDB, you should follow the DynamoDB best practices for avoiding sudden bursts of read activity.
- DynamoDb Provisioned Throughput is measured in Capacity Units.
- 1 Write Capacity Unit = 1 x 1KB Write per second.
- 1 Read Capacity Unit = 1 x 4KB Strongly Consistent Read Or 2 x 4KB Eventually Consistent Reads per second. Eventual consistent reads give us the maximum performance with the read operation.
- What is the maximum throughput that can be provisioned for a single DynamoDB table?
DynamoDB is designed to scale without limits. However, if you want to exceed throughput rates of 10,000 write capacity units or 10,000 read capacity units for an individual table, you must Contact AWS to increase it.
If you want to provision more than 20,000 write capacity units or 20,000 read capacity units from a single subscriber account, you must first contact AWS to request a limit increase. - Dynamo Db Performance: DAX is a DynamoDB-compatible caching service that enables you to benefit from fast in-memory performance for demanding applications.
- As an in-memory cache, DAX reduces the response times of eventually-consistent read workloads by an order of magnitude, from single-digit milliseconds to microseconds
- DAX improves response times for Eventually Consistent reads only.
- With DAX, you point your API calls to the DAX cluster instead of your table.
- If the item you are querying is on the cache, DAX will return it; otherwise, it will perform and Eventually Consistent GetItem operation to your DynamoDB table.
- DAX reduces operational and application complexity by providing a managed service that is API compatible with Amazon DynamoDB, and thus requires only minimal functional changes to use with an existing application.
- DAX is not suitable for write-intensive applications or applications that require Strongly Consistent reads.
- For read-heavy or bursty workloads, DAX provides increased throughput and potential operational cost savings by reducing the need to over-provision read capacity units. This is especially beneficial for applications that require repeated reads for individual keys.
- Dynamo Db Performance: ElastiCache
- In-memory cache sits between your application and database
- 2 different caching strategies: Lazy loading and Write Through: Lazy loading only caches the data when it is requested
- Elasticache Node failures are not fatal, just lots of cache misses
- Avoid stale data by implementing a TTL.
- Write-Through strategy writes data into cache whenever there is a change to the database. Data is never stale
- Write-Through penalty: Each write involves a write to the cache. Elasticache node failure means that data is missing until added or updated in the database.
- Elasticache is wasted resources if most of the data is never used.
- Time To Live (TTL) for DynamoDB allows you to define when items in a table expire so that they can be automatically deleted from the database. TTL is provided at no extra cost as a way to reduce storage usage and reduce the cost of storing irrelevant data without using provisioned throughput. With TTL enabled on a table, you can set a timestamp for deletion on a per-item basis, allowing you to limit storage usage to only those records that are relevant.
- DynamoDB Security: DynamoDB uses the CMK to generate and encrypt a unique data key for the table, known as the table key. With DynamoDB, AWS Owned, or AWS Managed CMK can be used to generate & encrypt keys. AWS Owned CMK is free of charge while AWS Managed CMK is chargeable. Customer managed CMK’s are not supported with encryption at rest.
- Amazon DynamoDB offers fully managed encryption at rest. DynamoDB encryption at rest provides enhanced security by encrypting your data at rest using an AWS Key Management Service (AWS KMS) managed encryption key for DynamoDB. This functionality eliminates the operational burden and complexity involved in protecting sensitive data.
- DynamoDB is a alternative solution which can be used for storage of session management. The latency of access to data is less , hence this can be used as a data store for session management
- DynamoDB Streams Use Cases and Design Patterns:
How do you set up a relationship across multiple tables in which, based on the value of an item from one table, you update the item in a second table?
How do you trigger an event based on a particular transaction?
How do you audit or archive transactions?
How do you replicate data across multiple tables (similar to that of materialized views/streams/replication in relational data stores)?
As a NoSQL database, DynamoDB is not designed to support transactions. Although client-side libraries are available to mimic the transaction capabilities, they are not scalable and cost-effective. For example, the Java Transaction Library for DynamoDB creates 7N+4 additional writes for every write operation. This is partly because the library holds metadata to manage the transactions to ensure that it’s consistent and can be rolled back before commit.You can use DynamoDB Streams to address all these use cases. DynamoDB Streams is a powerful service that you can combine with other AWS services to solve many similar problems. When enabled, DynamoDB Streams captures a time-ordered sequence of item-level modifications in a DynamoDB table and durably stores the information for up to 24 hours. Applications can access a series of stream records, which contain an item change, from a DynamoDB stream in near real time.
AWS maintains separate endpoints for DynamoDB and DynamoDB Streams. To work with database tables and indexes, your application must access a DynamoDB endpoint. To read and process DynamoDB Streams records, your application must access a DynamoDB Streams endpoint in the same Region
- 20 global secondary indexes are allowed per table? (by default)
- What is one key difference between a global secondary index and a local secondary index?
A local secondary index must have the same partition key as the main table - How many tables can an AWS account have per region? 256
- How many secondary indexes (global and local combined) are allowed per table? (by default): 25
You can define up to 5 local secondary indexes and 20 global secondary indexes per table (by default) – for a total of 25. - How can you increase your DynamoDB table limit in a region?
By contacting AWS and requesting a limit increase - For any AWS account, there is an initial limit of 256 tables per region.
- The minimum length of a partition key value is 1 byte. The maximum length is 2048 bytes.
- The minimum length of a sort key value is 1 byte. The maximum length is 1024 bytes.
- For tables with local secondary indexes, there is a 10 GB size limit per partition key value. A table with local secondary indexes can store any number of items, as long as the total size for any one partition key value does not exceed 10 GB.
- The following diagram shows a local secondary index named LastPostIndex. Note that the partition key is the same as that of the Thread table, but the sort key is LastPostDateTime.


AWS DynamoDB secondary indexes example - Relational vs Non Relational (SQL vs NoSQL)
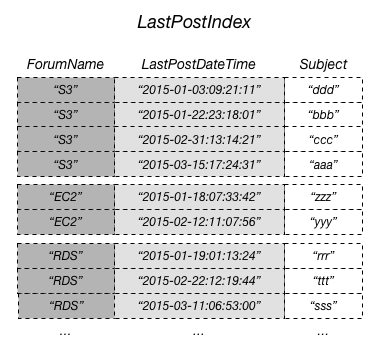



Top
Reference: AWS DynamoDB
AWS DynamoDB Questions and Answers Dumps
Q0: What should the Developer enable on the DynamoDB table to optimize performance and minimize costs?
- A. Amazon DynamoDB auto scaling
- B. Amazon DynamoDB cross-region replication
- C. Amazon DynamoDB Streams
- D. Amazon DynamoDB Accelerator
Top
Q2: A security system monitors 600 cameras, saving image metadata every 1 minute to an Amazon DynamoDb table. Each sample involves 1kb of data, and the data writes are evenly distributed over time. How much write throughput is required for the target table?
- A. 6000
- B. 10
- C. 3600
- D. 600
Q3: You are developing an application that will interact with a DynamoDB table. The table is going to take in a lot of read and write operations. Which of the following would be the ideal partition key for the DynamoDB table to ensure ideal performance?
- A. CustomerID
- B. CustomerName
- C. Location
- D. Age
Top
Q4: A DynamoDB table is set with a Read Throughput capacity of 5 RCU. Which of the following read configuration will provide us the maximum read throughput?
- A. Read capacity set to 5 for 4KB reads of data at strong consistency
- B. Read capacity set to 5 for 4KB reads of data at eventual consistency
- C. Read capacity set to 15 for 1KB reads of data at strong consistency
- D. Read capacity set to 5 for 1KB reads of data at eventual consistency
Q5: Your team is developing a solution that will make use of DynamoDB tables. Due to the nature of the application, the data is needed across a couple of regions across the world. Which of the following would help reduce the latency of requests to DynamoDB from different regions?
- A. Enable Multi-AZ for the DynamoDB table
- B. Enable global tables for DynamoDB
- C. Enable Indexes for the table
- D. Increase the read and write throughput for the tablez
Q6: An application is currently accessing a DynamoDB table. Currently the tables queries are performing well. Changes have been made to the application and now the performance of the application is starting to degrade. After looking at the changes , you see that the queries are making use of an attribute which is not the partition key? Which of the following would be the adequate change to make to resolve the issue?
- A. Add an index for the DynamoDB table
- B. Change all the queries to ensure they use the partition key
- C. Enable global tables for DynamoDB
- D. Change the read capacity on the table
Q7: Company B has created an e-commerce site using DynamoDB and is designing a products table that includes items purchased and the users who purchased the item.
When creating a primary key on a table which of the following would be the best attribute for the partition key? Select the BEST possible answer.
- A. None of these are correct.
- B. user_id where there are many users to few products
- C. category_id where there are few categories to many products
- D. product_id where there are few products to many users
Q8: Which API call can be used to retrieve up to 100 items at a time or 16 MB of data from a DynamoDB table?
- A. BatchItem
- B. GetItem
- C. BatchGetItem
- D. ChunkGetItem
Q9: Which DynamoDB limits can be raised by contacting AWS support?
- A. The number of hash keys per account
- B. The maximum storage used per account
- C. The number of tables per account
- D. The number of local secondary indexes per account
- E. The number of provisioned throughput units per account
Top
Q10: Which approach below provides the least impact to provisioned throughput on the “Product”
table?
- A. Create an “Images” DynamoDB table to store the Image with a foreign key constraint to
the “Product” table - B. Add an image data type to the “Product” table to store the images in binary format
- C. Serialize the image and store it in multiple DynamoDB tables
- D. Store the images in Amazon S3 and add an S3 URL pointer to the “Product” table item
for each image
Top
Q11: You’re creating a forum DynamoDB database for hosting forums. Your “thread” table contains the forum name and each “forum name” can have one or more “subjects”. What primary key type would you give the thread table in order to allow more than one subject to be tied to the forum primary key name?
- A. Hash
- B. Range and Hash
- C. Primary and Range
- D. Hash and Range
Amazon Aurora explained:
- High scalability
- High availability and durability
- High Performance
- Multi Region

Amazon ElastiCache Explained
- In-Memory data store
- High availability and reliability
- Fully managed
- Supports two pop
- Open source engine

Amazon Redshift explained
- Fast, fully managed, petabyte-scale data warehouse
- Supports wide range of open data formats
- Allows you to run SQL queries against large unstructured data in Amazon Simple Storage Service
- Integrates with popular Business Intelligence (BI) and extract, Transform, Load (ETL) solutions.

Amazon Neptune Explained
- Fully managed graph database
- Supports open graph APIs
- Used in Social Networking


Amazon Neptune Explained
Other AWS Facts and Summaries and Questions/Answers Dump
- AWS S3 facts and summaries and Q&A Dump
- AWS DynamoDB facts and summaries and Questions and Answers Dump
- AWS EC2 facts and summaries and Questions and Answers Dump
- AWS Serverless facts and summaries and Questions and Answers Dump
- AWS Developer and Deployment Theory facts and summaries and Questions and Answers Dump
- AWS IAM facts and summaries and Questions and Answers Dump
- AWS Lambda facts and summaries and Questions and Answers Dump
- AWS SQS facts and summaries and Questions and Answers Dump
- AWS RDS facts and summaries and Questions and Answers Dump
- AWS ECS facts and summaries and Questions and Answers Dump
- AWS CloudWatch facts and summaries and Questions and Answers Dump
- AWS SES facts and summaries and Questions and Answers Dump
- AWS EBS facts and summaries and Questions and Answers Dump
- AWS ELB facts and summaries and Questions and Answers Dump
- AWS Autoscaling facts and summaries and Questions and Answers Dump
- AWS VPC facts and summaries and Questions and Answers Dump
- AWS KMS facts and summaries and Questions and Answers Dump
- AWS Elastic Beanstalk facts and summaries and Questions and Answers Dump
- AWS CodeBuild facts and summaries and Questions and Answers Dump
- AWS CodeDeploy facts and summaries and Questions and Answers Dump
- AWS CodePipeline facts and summaries and Questions and Answers Dump
AWS Certification Exam Prep: S3 Facts, Summaries, Questions and Answers

AWS Certification Exam Prep: S3 Facts, Summaries, Questions and Answers
AWS S3 Facts and summaries, AWS S3 Top 10 Questions and Answers Dump
Definition 1: Amazon S3 or Amazon Simple Storage Service is a “simple storage service” offered by Amazon Web Services that provides object storage through a web service interface. Amazon S3 uses the same scalable storage infrastructure that Amazon.com uses to run its global e-commerce network.
Definition 2: Amazon Simple Storage Service (Amazon S3) is an object storage service that offers industry-leading scalability, data availability, security, and performance.
AWS S3 Explained graphically:










AWS S3 Facts and summaries
- S3 is a universal namespace, meaning each S3 bucket you create must have a unique name that is not being used by anyone else in the world.
- S3 is object based: i.e allows you to upload files.
- Files can be from 0 Bytes to 5 TB
- What is the maximum length, in bytes, of a DynamoDB range primary key attribute value?
The maximum length of a DynamoDB range primary key attribute value is 2048 bytes (NOT 256 bytes). - S3 has unlimited storage.
- Files are stored in Buckets.
- Read after write consistency for PUTS of new Objects
- Eventual Consistency for overwrite PUTS and DELETES (can take some time to propagate)
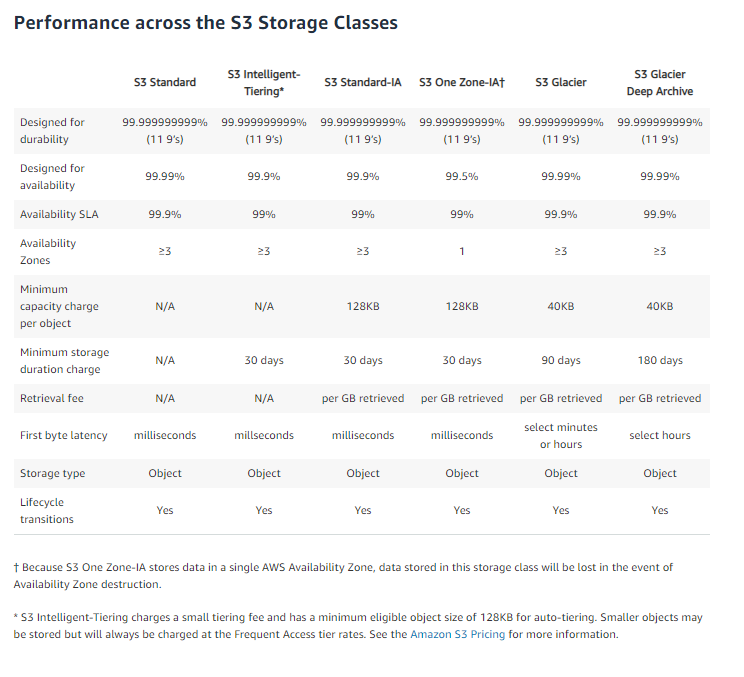
- S3 Storage Classes/Tiers:


- S3 Standard (durable, immediately available, frequently accesses)
- Amazon S3 Intelligent-Tiering (S3 Intelligent-Tiering): It works by storing objects in two access tiers: one tier that is optimized for frequent access and another lower-cost tier that is optimized for infrequent access.
- S3 Standard-Infrequent Access – S3 Standard-IA (durable, immediately available, infrequently accessed)
- S3 – One Zone-Infrequent Access – S3 One Zone IA: Same ad IA. However, data is stored in a single Availability Zone only
- S3 – Reduced Redundancy Storage (data that is easily reproducible, such as thumbnails, etc.)
- Glacier – Archived data, where you can wait 3-5 hours before accessing
You can have a bucket that has different objects stored in S3 Standard, S3 Intelligent-Tiering, S3 Standard-IA, and S3 One Zone-IA.
- The default URL for S3 hosted websites lists the bucket name first followed by s3-website-region.amazonaws.com . Example: enoumen.com.s3-website-us-east-1.amazonaws.com
- Core fundamentals of an S3 object
- Key (name)
- Value (data)
- Version (ID)
- Metadata
- Sub-resources (used to manage bucket-specific configuration)
- Bucket Policies, ACLs,
- CORS
- Transfer Acceleration
- Object-based storage only for files
- Not suitable to install OS on.
- Successful uploads will generate a HTTP 200 status code.
- S3 Security – Summary
- By default, all newly created buckets are PRIVATE.
- You can set up access control to your buckets using:
- Bucket Policies – Applied at the bucket level
- Access Control Lists – Applied at an object level.
- S3 buckets can be configured to create access logs, which log all requests made to the S3 bucket. These logs can be written to another bucket.
- S3 Encryption
- Encryption In-Transit (SSL/TLS)
- Encryption At Rest:
- Server side Encryption (SSE-S3, SSE-KMS, SSE-C)
- Client Side Encryption
- Remember that we can use a Bucket policy to prevent unencrypted files from being uploaded by creating a policy which only allows requests which include the x-amz-server-side-encryption parameter in the request header.
- S3 CORS (Cross Origin Resource Sharing):
CORS defines a way for client web applications that are loaded in one domain to interact with resources in a different domain.- Used to enable cross origin access for your AWS resources, e.g. S3 hosted website accessing javascript or image files located in another bucket. By default, resources in one bucket cannot access resources located in another. To allow this we need to configure CORS on the bucket being accessed and enable access for the origin (bucket) attempting to access.
- Always use the S3 website URL, not the regular bucket URL. E.g.: https://s3-eu-west-2.amazonaws.com/acloudguru
- S3 CloudFront:
- Edge locations are not just READ only – you can WRITE to them too (i.e put an object on to them.)
- Objects are cached for the life of the TTL (Time to Live)
- You can clear cached objects, but you will be charged. (Invalidation)
- S3 Performance optimization – 2 main approaches to Performance Optimization for S3:
- GET-Intensive Workloads – Use Cloudfront
- Mixed Workload – Avoid sequencial key names for your S3 objects. Instead, add a random prefix like a hex hash to the key name to prevent multiple objects from being stored on the same partition.
- mybucket/7eh4-2019-03-04-15-00-00/cust1234234/photo1.jpg
- mybucket/h35d-2019-03-04-15-00-00/cust1234234/photo2.jpg
- mybucket/o3n6-2019-03-04-15-00-00/cust1234234/photo3.jpg
- The best way to handle large objects uploads to the S3 service is to use the Multipart upload API. The Multipart upload API enables you to upload large objects in parts.
- You can enable versioning on a bucket, even if that bucket already has objects in it. The already existing objects, though, will show their versions as null. All new objects will have version IDs.
- Bucket names cannot start with a . or – characters. S3 bucket names can contain both the . and – characters. There can only be one . or one – between labels. E.G mybucket-com mybucket.com are valid names but mybucket–com and mybucket..com are not valid bucket names.
- What is the maximum number of S3 buckets allowed per AWS account (by default)? 100
- You successfully upload an item to the us-east-1 region. You then immediately make another API call and attempt to read the object. What will happen?
All AWS regions now have read-after-write consistency for PUT operations of new objects. Read-after-write consistency allows you to retrieve objects immediately after creation in Amazon S3. Other actions still follow the eventual consistency model (where you will sometimes get stale results if you have recently made changes) - S3 bucket policies require a Principal be defined. Review the access policy elements here
- What checksums does Amazon S3 employ to detect data corruption?
Amazon S3 uses a combination of Content-MD5 checksums and cyclic redundancy checks (CRCs) to detect data corruption. Amazon S3 performs these checksums on data at rest and repairs any corruption using redundant data. In addition, the service calculates checksums on all network traffic to detect corruption of data packets when storing or retrieving data.
AWS S3 Top 10 Questions and Answers Dump
Q0: You’ve written an application that uploads objects onto an S3 bucket. The size of the object varies between 200 – 500 MB. You’ve seen that the application sometimes takes a longer than expected time to upload the object. You want to improve the performance of the application. Which of the following would you consider?
- A. Create multiple threads and upload the objects in the multiple threads
- B. Write the items in batches for better performance
- C. Use the Multipart upload API
- D. Enable versioning on the Bucket
Top
Q2: You are using AWS SAM templates to deploy a serverless application. Which of the following resource will embed application from Amazon S3 buckets?
- A. AWS::Serverless::Api
- B. AWS::Serverless::Application
- C. AWS::Serverless::Layerversion
- D. AWS::Serverless::Function
Top
Q3: A static web site has been hosted on a bucket and is now being accessed by users. One of the web pages javascript section has been changed to access data which is hosted in another S3 bucket. Now that same web page is no longer loading in the browser. Which of the following can help alleviate the error?
- A. Enable versioning for the underlying S3 bucket.
- B. Enable Replication so that the objects get replicated to the other bucket
- C. Enable CORS for the bucket
- D. Change the Bucket policy for the bucket to allow access from the other bucket
Top
Advertise with us - Post Your Good Content Here
We are ranked in the Top 20 on Google
AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
Q4: Your mobile application includes a photo-sharing service that is expecting tens of thousands of users at launch. You will leverage Amazon Simple Storage Service (S3) for storage of the user Images, and you must decide how to authenticate and authorize your users for access to these images. You also need to manage the storage of these images. Which two of the following approaches should you use? Choose two answers from the options below
- A. Create an Amazon S3 bucket per user, and use your application to generate the S3 URL for the appropriate content.
- B. Use AWS Identity and Access Management (IAM) user accounts as your application-level user database, and offload the burden of authentication from your application code.
- C. Authenticate your users at the application level, and use AWS Security Token Service (STS)to grant token-based authorization to S3 objects.
- D. Authenticate your users at the application level, and send an SMS token message to the user. Create an Amazon S3 bucket with the same name as the SMS message token, and move the user’s objects to that bucket.
Top
Q5: Both ACLs and Bucket Policies can be used to grant access to S3 buckets. Which of the following statements is true about ACLs and Bucket policies?
- A. Bucket Policies are Written in JSON and ACLs are written in XML
- B. ACLs can be attached to S3 objects or S3 Buckets
- C. Bucket Policies and ACLs are written in JSON
- D. Bucket policies are only attached to s3 buckets, ACLs are only attached to s3 objects
Q6: What are good options to improve S3 performance when you have significantly high numbers of GET requests?
- A. Introduce random prefixes to S3 objects
- B. Introduce random suffixes to S3 objects
- C. Setup CloudFront for S3 objects
- D. Migrate commonly used objects to Amazon Glacier
Q7: If an application is storing hourly log files from thousands of instances from a high traffic
web site, which naming scheme would give optimal performance on S3?
- A. Sequential
- B. HH-DD-MM-YYYY-log_instanceID
- C. YYYY-MM-DD-HH-log_instanceID
- D. instanceID_log-HH-DD-MM-YYYY
- E. instanceID_log-YYYY-MM-DD-HH
Top
Q8: You are working with the S3 API and receive an error message: 409 Conflict. What is the possible cause of this error
- A. You’re attempting to remove a bucket without emptying the contents of the bucket first.
- B. You’re attempting to upload an object to the bucket that is greater than 5TB in size.
- C. Your request does not contain the proper metadata.
- D. Amazon S3 is having internal issues.
Q9: You created three S3 buckets – “mywebsite.com”, “downloads.mywebsite.com”, and “www.mywebsite.com”. You uploaded your files and enabled static website hosting. You specified both of the default documents under the “enable static website hosting” header. You also set the “Make Public” permission for the objects in each of the three buckets. You create the Route 53 Aliases for the three buckets. You are going to have your end users test your websites by browsing to http://mydomain.com/error.html, http://downloads.mydomain.com/index.html, and http://www.mydomain.com. What problems will your testers encounter?
- A. http://mydomain.com/error.html will not work because you did not set a value for the error.html file
- B. There will be no problems, all three sites should work.
- C. http://www.mywebsite.com will not work because the URL does not include a file name at the end of it.
- D. http://downloads.mywebsite.com/index.html will not work because the “downloads” prefix is not a supported prefix for S3 websites using Route 53 aliases
Q10: Which of the following is NOT a common S3 API call?
- A. UploadPart
- B. ReadObject
- C. PutObject
- D. DownloadBucket
Other AWS Facts and Summaries
- AWS S3 facts and summaries
- AWS DynamoDB facts and summaries
- AWS EC2 facts and summaries
- AWS Lambda facts and summaries
- AWS SQS facts and summaries
- AWS RDS facts and summaries
- AWS ECS facts and summaries
- AWS CloudWatch facts and summaries
- AWS SES facts and summaries
- AWS EBS facts and summaries
- AWS Serverless facts and summaries
- AWS ELB facts and summaries
- AWS Autoscaling facts and summaries
- AWS VPC facts and summaries
- AWS KMS facts and summaries
- AWS Elastic Beanstalk facts and summaries
- AWS CodeBuild facts and summaries
- AWS CodeDeploy facts and summaries
- AWS CodePipeline facts and summaries
Active Hydrating Toner, Anti-Aging Replenishing Advanced Face Moisturizer, with Vitamins A, C, E & Natural Botanicals to Promote Skin Balance & Collagen Production, 6.7 Fl Oz



Age Defying 0.3% Retinol Serum, Anti-Aging Dark Spot Remover for Face, Fine Lines & Wrinkle Pore Minimizer, with Vitamin E & Natural Botanicals


Firming Moisturizer, Advanced Hydrating Facial Replenishing Cream, with Hyaluronic Acid, Resveratrol & Natural Botanicals to Restore Skin's Strength, Radiance, and Resilience, 1.75 Oz

Skin Stem Cell Serum


Smartphone 101 - Pick a smartphone for me - android or iOS - Apple iPhone or Samsung Galaxy or Huawei or Xaomi or Google Pixel
Can AI Really Predict Lottery Results? We Asked an Expert.




Djamgatech

Read Photos and PDFs Aloud for me iOS
Read Photos and PDFs Aloud for me android
Read Photos and PDFs Aloud For me Windows 10/11
Read Photos and PDFs Aloud For Amazon
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more)
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6(Email us for more)



FREE 10000+ Quiz Trivia and and Brain Teasers for All Topics including Cloud Computing, General Knowledge, History, Television, Music, Art, Science, Movies, Films, US History, Soccer Football, World Cup, Data Science, Machine Learning, Geography, etc....


List of Freely available programming books - What is the single most influential book every Programmers should read
- Bjarne Stroustrup - The C++ Programming Language
- Brian W. Kernighan, Rob Pike - The Practice of Programming
- Donald Knuth - The Art of Computer Programming
- Ellen Ullman - Close to the Machine
- Ellis Horowitz - Fundamentals of Computer Algorithms
- Eric Raymond - The Art of Unix Programming
- Gerald M. Weinberg - The Psychology of Computer Programming
- James Gosling - The Java Programming Language
- Joel Spolsky - The Best Software Writing I
- Keith Curtis - After the Software Wars
- Richard M. Stallman - Free Software, Free Society
- Richard P. Gabriel - Patterns of Software
- Richard P. Gabriel - Innovation Happens Elsewhere
- Code Complete (2nd edition) by Steve McConnell
- The Pragmatic Programmer
- Structure and Interpretation of Computer Programs
- The C Programming Language by Kernighan and Ritchie
- Introduction to Algorithms by Cormen, Leiserson, Rivest & Stein
- Design Patterns by the Gang of Four
- Refactoring: Improving the Design of Existing Code
- The Mythical Man Month
- The Art of Computer Programming by Donald Knuth
- Compilers: Principles, Techniques and Tools by Alfred V. Aho, Ravi Sethi and Jeffrey D. Ullman
- Gödel, Escher, Bach by Douglas Hofstadter
- Clean Code: A Handbook of Agile Software Craftsmanship by Robert C. Martin
- Effective C++
- More Effective C++
- CODE by Charles Petzold
- Programming Pearls by Jon Bentley
- Working Effectively with Legacy Code by Michael C. Feathers
- Peopleware by Demarco and Lister
- Coders at Work by Peter Seibel
- Surely You're Joking, Mr. Feynman!
- Effective Java 2nd edition
- Patterns of Enterprise Application Architecture by Martin Fowler
- The Little Schemer
- The Seasoned Schemer
- Why's (Poignant) Guide to Ruby
- The Inmates Are Running The Asylum: Why High Tech Products Drive Us Crazy and How to Restore the Sanity
- The Art of Unix Programming
- Test-Driven Development: By Example by Kent Beck
- Practices of an Agile Developer
- Don't Make Me Think
- Agile Software Development, Principles, Patterns, and Practices by Robert C. Martin
- Domain Driven Designs by Eric Evans
- The Design of Everyday Things by Donald Norman
- Modern C++ Design by Andrei Alexandrescu
- Best Software Writing I by Joel Spolsky
- The Practice of Programming by Kernighan and Pike
- Pragmatic Thinking and Learning: Refactor Your Wetware by Andy Hunt
- Software Estimation: Demystifying the Black Art by Steve McConnel
- The Passionate Programmer (My Job Went To India) by Chad Fowler
- Hackers: Heroes of the Computer Revolution
- Algorithms + Data Structures = Programs
- Writing Solid Code
- JavaScript - The Good Parts
- Getting Real by 37 Signals
- Foundations of Programming by Karl Seguin
- Computer Graphics: Principles and Practice in C (2nd Edition)
- Thinking in Java by Bruce Eckel
- The Elements of Computing Systems
- Refactoring to Patterns by Joshua Kerievsky
- Modern Operating Systems by Andrew S. Tanenbaum
- The Annotated Turing
- Things That Make Us Smart by Donald Norman
- The Timeless Way of Building by Christopher Alexander
- The Deadline: A Novel About Project Management by Tom DeMarco
- The C++ Programming Language (3rd edition) by Stroustrup
- Patterns of Enterprise Application Architecture
- Computer Systems - A Programmer's Perspective
- Agile Principles, Patterns, and Practices in C# by Robert C. Martin
- Growing Object-Oriented Software, Guided by Tests
- Framework Design Guidelines by Brad Abrams
- Object Thinking by Dr. David West
- Advanced Programming in the UNIX Environment by W. Richard Stevens
- Hackers and Painters: Big Ideas from the Computer Age
- The Soul of a New Machine by Tracy Kidder
- CLR via C# by Jeffrey Richter
- The Timeless Way of Building by Christopher Alexander
- Design Patterns in C# by Steve Metsker
- Alice in Wonderland by Lewis Carol
- Zen and the Art of Motorcycle Maintenance by Robert M. Pirsig
- About Face - The Essentials of Interaction Design
- Here Comes Everybody: The Power of Organizing Without Organizations by Clay Shirky
- The Tao of Programming
- Computational Beauty of Nature
- Writing Solid Code by Steve Maguire
- Philip and Alex's Guide to Web Publishing
- Object-Oriented Analysis and Design with Applications by Grady Booch
- Effective Java by Joshua Bloch
- Computability by N. J. Cutland
- Masterminds of Programming
- The Tao Te Ching
- The Productive Programmer
- The Art of Deception by Kevin Mitnick
- The Career Programmer: Guerilla Tactics for an Imperfect World by Christopher Duncan
- Paradigms of Artificial Intelligence Programming: Case studies in Common Lisp
- Masters of Doom
- Pragmatic Unit Testing in C# with NUnit by Andy Hunt and Dave Thomas with Matt Hargett
- How To Solve It by George Polya
- The Alchemist by Paulo Coelho
- Smalltalk-80: The Language and its Implementation
- Writing Secure Code (2nd Edition) by Michael Howard
- Introduction to Functional Programming by Philip Wadler and Richard Bird
- No Bugs! by David Thielen
- Rework by Jason Freid and DHH
- JUnit in Action
#BlackOwned #BlackEntrepreneurs #BlackBuniness #AWSCertified #AWSCloudPractitioner #AWSCertification #AWSCLFC02 #CloudComputing #AWSStudyGuide #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AWSBasics #AWSCertified #AWSMachineLearning #AWSCertification #AWSSpecialty #MachineLearning #AWSStudyGuide #CloudComputing #DataScience #AWSCertified #AWSSolutionsArchitect #AWSArchitectAssociate #AWSCertification #AWSStudyGuide #CloudComputing #AWSArchitecture #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AzureFundamentals #AZ900 #MicrosoftAzure #ITCertification #CertificationPrep #StudyMaterials #TechLearning #MicrosoftCertified #AzureCertification #TechBooks
Top 1000 Canada Quiz and trivia: CANADA CITIZENSHIP TEST- HISTORY - GEOGRAPHY - GOVERNMENT- CULTURE - PEOPLE - LANGUAGES - TRAVEL - WILDLIFE - HOCKEY - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Top 1000 Africa Quiz and trivia: HISTORY - GEOGRAPHY - WILDLIFE - CULTURE - PEOPLE - LANGUAGES - TRAVEL - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Exploring the Pros and Cons of Visiting All Provinces and Territories in Canada.


Exploring the Advantages and Disadvantages of Visiting All 50 States in the USA

Health Health, a science-based community to discuss health news and the coronavirus (COVID-19) pandemic
- US infant mortality increased in 2022 for the first time in decades, CDC report showsby /u/cnn on July 25, 2024 at 6:37 pm
submitted by /u/cnn [link] [comments]
- Study raises hopes that shingles vaccine may delay onset of dementia | Dementia | The Guardianby /u/chilladipa on July 25, 2024 at 3:38 pm
submitted by /u/chilladipa [link] [comments]
- How fit is your city? New rankings by the American College of Sports Medicineby /u/idc2011 on July 25, 2024 at 3:35 pm
submitted by /u/idc2011 [link] [comments]
- Twice-Yearly Lenacapavir or Daily F/TAF for HIV Prevention in Cisgender Women | New England Journal of Medicineby /u/chilladipa on July 25, 2024 at 3:30 pm
submitted by /u/chilladipa [link] [comments]
- Biden Made a Healthy Decisionby /u/theatlantic on July 25, 2024 at 3:15 pm
submitted by /u/theatlantic [link] [comments]
Today I Learned (TIL) You learn something new every day; what did you learn today? Submit interesting and specific facts about something that you just found out here.
- TIL actor John Larroquette was the uncredited narrator of the prologue to the 1974 horror movie Texas Chainsaw Massacre. In lieu of cash, he was paid by the Director Tobe Hooper in Marijuana.by /u/openletter8 on July 25, 2024 at 6:56 pm
submitted by /u/openletter8 [link] [comments]
- TIL that the every Shakopee Mdewakanton Sioux indian receives a payout of around $1 million per year from casino profits.by /u/friendlystranger4u on July 25, 2024 at 6:22 pm
submitted by /u/friendlystranger4u [link] [comments]
- TIL Motorcycles in China are dictated by law to be decommissioned and destroyed in 13 years after registration regardless of the conditionsby /u/Easy_Piece_592 on July 25, 2024 at 5:56 pm
submitted by /u/Easy_Piece_592 [link] [comments]
- TIL a man named Jonathan Riches has filed more than 2,600 lawsuits since 2006. He even sued Guinness World Records to try to stop them from titling him as "the most litigious man in history".by /u/doopityWoop22 on July 25, 2024 at 5:03 pm
submitted by /u/doopityWoop22 [link] [comments]
- TIL that in 2018, an American half-pipe skier qualified for the Olympics despite minimal experience. Olympic requirements stated that an athlete needed to place in the top 30 at multiple events. She simply sought out events with fewer than 30 participants, showed up, and skied down without falling.by /u/ctdca on July 25, 2024 at 4:28 pm
submitted by /u/ctdca [link] [comments]
Reddit Science This community is a place to share and discuss new scientific research. Read about the latest advances in astronomy, biology, medicine, physics, social science, and more. Find and submit new publications and popular science coverage of current research.
- Abstinence-only sex education linked to higher pornography use among women | This finding adds to the ongoing conversation about the effectiveness and impacts of different sexuality education approaches.by /u/chrisdh79 on July 25, 2024 at 6:49 pm
submitted by /u/chrisdh79 [link] [comments]
- AlphaProof and AlphaGeometry 2 AI models achieve silver medal standard in solving International Mathematical Olympiad problemsby /u/Big_Profit9076 on July 25, 2024 at 5:59 pm
submitted by /u/Big_Profit9076 [link] [comments]
- Scientists have described a new species of chordate, Nuucichthys rhynchocephalus, the first soft-bodied vertebrate from the Drumian Marjum Formation of the American Great Basin.by /u/grimisgreedy on July 25, 2024 at 5:55 pm
submitted by /u/grimisgreedy [link] [comments]
- Secularists revealed as a unique political force in America, with an intriguing divergence from liberals. Unlike nonreligiosity, which denotes a lack of religious affiliation or belief, secularism involves an active identification with principles grounded in empirical evidence and rational thought.by /u/mvea on July 25, 2024 at 5:40 pm
submitted by /u/mvea [link] [comments]
- New shingles vaccine could reduce risk of dementia. The study found at least a 17% reduction in dementia diagnoses in the six years after the new recombinant shingles vaccination, equating to 164 or more additional days lived without dementia.by /u/Wagamaga on July 25, 2024 at 4:48 pm
submitted by /u/Wagamaga [link] [comments]
Reddit Sports Sports News and Highlights from the NFL, NBA, NHL, MLB, MLS, and leagues around the world.
- A's place their lone all-star, Mason Miller, on IL with fractured finger after hitting training tableby /u/Oldtimer_2 on July 25, 2024 at 8:15 pm
submitted by /u/Oldtimer_2 [link] [comments]
- Flyers sign All-Star Travis Konecny to an 8-year extension worth $70 millionby /u/Oldtimer_2 on July 25, 2024 at 7:45 pm
submitted by /u/Oldtimer_2 [link] [comments]
- Bills’ Von Miller says he believes domestic assault case to be closed, with no charges filedby /u/Oldtimer_2 on July 25, 2024 at 7:43 pm
submitted by /u/Oldtimer_2 [link] [comments]
- Padres' Dylan Cease throws no-hitter vs. Nationalsby /u/Oldtimer_2 on July 25, 2024 at 7:41 pm
submitted by /u/Oldtimer_2 [link] [comments]
- Appeal denied in Valieva case; U.S. skaters to get gold in Parisby /u/PrincessBananas85 on July 25, 2024 at 6:18 pm
submitted by /u/PrincessBananas85 [link] [comments]
