


AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
AWS Certification Exam Prep: DynamoDB facts and summaries, AWS DynamoDB Top 10 Questions and Answers Dump
Definition 1: Amazon DynamoDB is a fully managed proprietary NoSQL database service that supports key-value and document data structures and is offered by Amazon.com as part of the Amazon Web Services portfolio. DynamoDB exposes a similar data model to and derives its name from Dynamo, but has a different underlying implementation. Dynamo had a multi-master design requiring the client to resolve version conflicts and DynamoDB uses synchronous replication across multiple datacenters for high durability and availability.
Definition 2: DynamoDB is a fast and flexible non-relational database service for any scale. DynamoDB enables customers to offload the administrative burdens of operating and scaling distributed databases to AWS so that they don’t have to worry about hardware provisioning, setup and configuration, throughput capacity planning, replication, software patching, or cluster scaling.
Amazon DynamoDB explained
- Fully Managed
- Fast, consistent Performance
- Fine-grained access control
- Flexible




AWS DynamoDB Facts and Summaries
- Amazon DynamoDB is a low-latency NoSQL database.
- DynamoDB consists of Tables, Items, and Attributes
- DynamoDb supports both document and key-value data models
- DynamoDB Supported documents formats are JSON, HTML, XML
- DynamoDB has 2 types of Primary Keys: Partition Key and combination of Partition Key + Sort Key (Composite Key)
- DynamoDB has 2 consistency models: Strongly Consistent / Eventually Consistent
- DynamoDB Access is controlled using IAM policies.
- DynamoDB has fine grained access control using IAM Condition parameter dynamodb:LeadingKeys to allow users to access only the items where the partition key vakue matches their user ID.
- DynamoDB Indexes enable fast queries on specific data columns
- DynamoDB indexes give you a different view of your data based on alternative Partition / Sort Keys.
- DynamoDB Local Secondary indexes must be created when you create your table, they have same partition Key as your table, and they have a different Sort Key.
- DynamoDB Global Secondary Index Can be created at any time: at table creation or after. They have a different partition Key as your table and a different sort key as your table.
- A DynamoDB query operation finds items in a table using only the primary Key attribute: You provide the Primary Key name and a distinct value to search for.
- A DynamoDB Scan operation examines every item in the table. By default, it return data attributes.
- DynamoDB Query operation is generally more efficient than a Scan.
- With DynamoDB, you can reduce the impact of a query or scan by setting a smaller page size which uses fewer read operations.
- To optimize DynamoDB performance, isolate scan operations to specific tables and segregate them from your mission-critical traffic.
- To optimize DynamoDB performance, try Parallel scans rather than the default sequential scan.
- To optimize DynamoDB performance: Avoid using scan operations if you can: design tables in a way that you can use Query, Get, or BatchGetItems APIs.
- When you scan your table in Amazon DynamoDB, you should follow the DynamoDB best practices for avoiding sudden bursts of read activity.
- DynamoDb Provisioned Throughput is measured in Capacity Units.
- 1 Write Capacity Unit = 1 x 1KB Write per second.
- 1 Read Capacity Unit = 1 x 4KB Strongly Consistent Read Or 2 x 4KB Eventually Consistent Reads per second. Eventual consistent reads give us the maximum performance with the read operation.
- What is the maximum throughput that can be provisioned for a single DynamoDB table?
DynamoDB is designed to scale without limits. However, if you want to exceed throughput rates of 10,000 write capacity units or 10,000 read capacity units for an individual table, you must Contact AWS to increase it.
If you want to provision more than 20,000 write capacity units or 20,000 read capacity units from a single subscriber account, you must first contact AWS to request a limit increase. - Dynamo Db Performance: DAX is a DynamoDB-compatible caching service that enables you to benefit from fast in-memory performance for demanding applications.
- As an in-memory cache, DAX reduces the response times of eventually-consistent read workloads by an order of magnitude, from single-digit milliseconds to microseconds
- DAX improves response times for Eventually Consistent reads only.
- With DAX, you point your API calls to the DAX cluster instead of your table.
- If the item you are querying is on the cache, DAX will return it; otherwise, it will perform and Eventually Consistent GetItem operation to your DynamoDB table.
- DAX reduces operational and application complexity by providing a managed service that is API compatible with Amazon DynamoDB, and thus requires only minimal functional changes to use with an existing application.
- DAX is not suitable for write-intensive applications or applications that require Strongly Consistent reads.
- For read-heavy or bursty workloads, DAX provides increased throughput and potential operational cost savings by reducing the need to over-provision read capacity units. This is especially beneficial for applications that require repeated reads for individual keys.
- Dynamo Db Performance: ElastiCache
- In-memory cache sits between your application and database
- 2 different caching strategies: Lazy loading and Write Through: Lazy loading only caches the data when it is requested
- Elasticache Node failures are not fatal, just lots of cache misses
- Avoid stale data by implementing a TTL.
- Write-Through strategy writes data into cache whenever there is a change to the database. Data is never stale
- Write-Through penalty: Each write involves a write to the cache. Elasticache node failure means that data is missing until added or updated in the database.
- Elasticache is wasted resources if most of the data is never used.
- Time To Live (TTL) for DynamoDB allows you to define when items in a table expire so that they can be automatically deleted from the database. TTL is provided at no extra cost as a way to reduce storage usage and reduce the cost of storing irrelevant data without using provisioned throughput. With TTL enabled on a table, you can set a timestamp for deletion on a per-item basis, allowing you to limit storage usage to only those records that are relevant.
- DynamoDB Security: DynamoDB uses the CMK to generate and encrypt a unique data key for the table, known as the table key. With DynamoDB, AWS Owned, or AWS Managed CMK can be used to generate & encrypt keys. AWS Owned CMK is free of charge while AWS Managed CMK is chargeable. Customer managed CMK’s are not supported with encryption at rest.
- Amazon DynamoDB offers fully managed encryption at rest. DynamoDB encryption at rest provides enhanced security by encrypting your data at rest using an AWS Key Management Service (AWS KMS) managed encryption key for DynamoDB. This functionality eliminates the operational burden and complexity involved in protecting sensitive data.
- DynamoDB is a alternative solution which can be used for storage of session management. The latency of access to data is less , hence this can be used as a data store for session management
- DynamoDB Streams Use Cases and Design Patterns:
How do you set up a relationship across multiple tables in which, based on the value of an item from one table, you update the item in a second table?
How do you trigger an event based on a particular transaction?
How do you audit or archive transactions?
How do you replicate data across multiple tables (similar to that of materialized views/streams/replication in relational data stores)?
As a NoSQL database, DynamoDB is not designed to support transactions. Although client-side libraries are available to mimic the transaction capabilities, they are not scalable and cost-effective. For example, the Java Transaction Library for DynamoDB creates 7N+4 additional writes for every write operation. This is partly because the library holds metadata to manage the transactions to ensure that it’s consistent and can be rolled back before commit.You can use DynamoDB Streams to address all these use cases. DynamoDB Streams is a powerful service that you can combine with other AWS services to solve many similar problems. When enabled, DynamoDB Streams captures a time-ordered sequence of item-level modifications in a DynamoDB table and durably stores the information for up to 24 hours. Applications can access a series of stream records, which contain an item change, from a DynamoDB stream in near real time.
AWS maintains separate endpoints for DynamoDB and DynamoDB Streams. To work with database tables and indexes, your application must access a DynamoDB endpoint. To read and process DynamoDB Streams records, your application must access a DynamoDB Streams endpoint in the same Region
- 20 global secondary indexes are allowed per table? (by default)
- What is one key difference between a global secondary index and a local secondary index?
A local secondary index must have the same partition key as the main table - How many tables can an AWS account have per region? 256
- How many secondary indexes (global and local combined) are allowed per table? (by default): 25
You can define up to 5 local secondary indexes and 20 global secondary indexes per table (by default) – for a total of 25. - How can you increase your DynamoDB table limit in a region?
By contacting AWS and requesting a limit increase - For any AWS account, there is an initial limit of 256 tables per region.
- The minimum length of a partition key value is 1 byte. The maximum length is 2048 bytes.
- The minimum length of a sort key value is 1 byte. The maximum length is 1024 bytes.
- For tables with local secondary indexes, there is a 10 GB size limit per partition key value. A table with local secondary indexes can store any number of items, as long as the total size for any one partition key value does not exceed 10 GB.
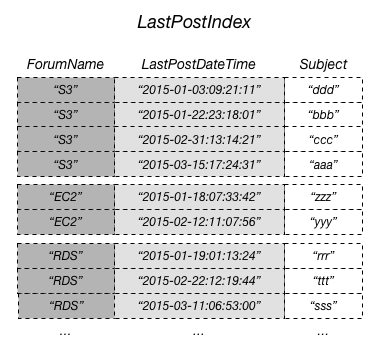
- The following diagram shows a local secondary index named LastPostIndex. Note that the partition key is the same as that of the Thread table, but the sort key is LastPostDateTime.


AWS DynamoDB secondary indexes example - Relational vs Non Relational (SQL vs NoSQL)



Top
Reference: AWS DynamoDB
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6

 Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more codes)
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more codes)
Active Anti-Aging Eye Gel, Reduces Dark Circles, Puffy Eyes, Crow's Feet and Fine Lines & Wrinkles, Packed with Hyaluronic Acid & Age Defying Botanicals

AWS DynamoDB Questions and Answers Dumps
Q0: What should the Developer enable on the DynamoDB table to optimize performance and minimize costs?
- A. Amazon DynamoDB auto scaling
- B. Amazon DynamoDB cross-region replication
- C. Amazon DynamoDB Streams
- D. Amazon DynamoDB Accelerator

Top

Q2: A security system monitors 600 cameras, saving image metadata every 1 minute to an Amazon DynamoDb table. Each sample involves 1kb of data, and the data writes are evenly distributed over time. How much write throughput is required for the target table?
- A. 6000
- B. 10
- C. 3600
- D. 600
Q3: You are developing an application that will interact with a DynamoDB table. The table is going to take in a lot of read and write operations. Which of the following would be the ideal partition key for the DynamoDB table to ensure ideal performance?
- A. CustomerID
- B. CustomerName
- C. Location
- D. Age
Top
Q4: A DynamoDB table is set with a Read Throughput capacity of 5 RCU. Which of the following read configuration will provide us the maximum read throughput?
- A. Read capacity set to 5 for 4KB reads of data at strong consistency
- B. Read capacity set to 5 for 4KB reads of data at eventual consistency
- C. Read capacity set to 15 for 1KB reads of data at strong consistency
- D. Read capacity set to 5 for 1KB reads of data at eventual consistency
Q5: Your team is developing a solution that will make use of DynamoDB tables. Due to the nature of the application, the data is needed across a couple of regions across the world. Which of the following would help reduce the latency of requests to DynamoDB from different regions?
- A. Enable Multi-AZ for the DynamoDB table
- B. Enable global tables for DynamoDB
- C. Enable Indexes for the table
- D. Increase the read and write throughput for the tablez
Q6: An application is currently accessing a DynamoDB table. Currently the tables queries are performing well. Changes have been made to the application and now the performance of the application is starting to degrade. After looking at the changes , you see that the queries are making use of an attribute which is not the partition key? Which of the following would be the adequate change to make to resolve the issue?
- A. Add an index for the DynamoDB table
- B. Change all the queries to ensure they use the partition key
- C. Enable global tables for DynamoDB
- D. Change the read capacity on the table


Q7: Company B has created an e-commerce site using DynamoDB and is designing a products table that includes items purchased and the users who purchased the item.
When creating a primary key on a table which of the following would be the best attribute for the partition key? Select the BEST possible answer.
- A. None of these are correct.
- B. user_id where there are many users to few products
- C. category_id where there are few categories to many products
- D. product_id where there are few products to many users
Q8: Which API call can be used to retrieve up to 100 items at a time or 16 MB of data from a DynamoDB table?
- A. BatchItem
- B. GetItem
- C. BatchGetItem
- D. ChunkGetItem

Q9: Which DynamoDB limits can be raised by contacting AWS support?
- A. The number of hash keys per account
- B. The maximum storage used per account
- C. The number of tables per account
- D. The number of local secondary indexes per account
- E. The number of provisioned throughput units per account
Top
Q10: Which approach below provides the least impact to provisioned throughput on the “Product”
table?
- A. Create an “Images” DynamoDB table to store the Image with a foreign key constraint to
the “Product” table - B. Add an image data type to the “Product” table to store the images in binary format
- C. Serialize the image and store it in multiple DynamoDB tables
- D. Store the images in Amazon S3 and add an S3 URL pointer to the “Product” table item
for each image
Top
Q11: You’re creating a forum DynamoDB database for hosting forums. Your “thread” table contains the forum name and each “forum name” can have one or more “subjects”. What primary key type would you give the thread table in order to allow more than one subject to be tied to the forum primary key name?
- A. Hash
- B. Range and Hash
- C. Primary and Range
- D. Hash and Range

Amazon Aurora explained:
- High scalability
- High availability and durability
- High Performance
- Multi Region

Amazon ElastiCache Explained
- In-Memory data store
- High availability and reliability
- Fully managed
- Supports two pop
- Open source engine

Amazon Redshift explained
- Fast, fully managed, petabyte-scale data warehouse
- Supports wide range of open data formats
- Allows you to run SQL queries against large unstructured data in Amazon Simple Storage Service
- Integrates with popular Business Intelligence (BI) and extract, Transform, Load (ETL) solutions.

Amazon Neptune Explained
Unlock the Secrets of Africa: Master African History, Geography, Culture, People, Cuisine, Economics, Languages, Music, Wildlife, Football, Politics, Animals, Tourism, Science and Environment with the Top 1000 Africa Quiz and Trivia. Get Yours Now!
"Become a Canada Expert: Ace the Citizenship Test and Impress Everyone with Your Knowledge of Canadian History, Geography, Government, Culture, People, Languages, Travel, Wildlife, Hockey, Tourism, Sceneries, Arts, and Data Visualization. Get the Top 1000 Canada Quiz Now!"
- Fully managed graph database
- Supports open graph APIs
- Used in Social Networking


Amazon Neptune Explained
Other AWS Facts and Summaries and Questions/Answers Dump
- AWS S3 facts and summaries and Q&A Dump
- AWS DynamoDB facts and summaries and Questions and Answers Dump
- AWS EC2 facts and summaries and Questions and Answers Dump
- AWS Serverless facts and summaries and Questions and Answers Dump
- AWS Developer and Deployment Theory facts and summaries and Questions and Answers Dump
- AWS IAM facts and summaries and Questions and Answers Dump
- AWS Lambda facts and summaries and Questions and Answers Dump
- AWS SQS facts and summaries and Questions and Answers Dump
- AWS RDS facts and summaries and Questions and Answers Dump
- AWS ECS facts and summaries and Questions and Answers Dump
- AWS CloudWatch facts and summaries and Questions and Answers Dump
- AWS SES facts and summaries and Questions and Answers Dump
- AWS EBS facts and summaries and Questions and Answers Dump
- AWS ELB facts and summaries and Questions and Answers Dump
- AWS Autoscaling facts and summaries and Questions and Answers Dump
- AWS VPC facts and summaries and Questions and Answers Dump
- AWS KMS facts and summaries and Questions and Answers Dump
- AWS Elastic Beanstalk facts and summaries and Questions and Answers Dump
- AWS CodeBuild facts and summaries and Questions and Answers Dump
- AWS CodeDeploy facts and summaries and Questions and Answers Dump
- AWS CodePipeline facts and summaries and Questions and Answers Dump
AWS Certification Exam Prep: S3 Facts, Summaries, Questions and Answers

AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
AWS Certification Exam Prep: S3 Facts, Summaries, Questions and Answers
AWS S3 Facts and summaries, AWS S3 Top 10 Questions and Answers Dump
Definition 1: Amazon S3 or Amazon Simple Storage Service is a “simple storage service” offered by Amazon Web Services that provides object storage through a web service interface. Amazon S3 uses the same scalable storage infrastructure that Amazon.com uses to run its global e-commerce network.
Definition 2: Amazon Simple Storage Service (Amazon S3) is an object storage service that offers industry-leading scalability, data availability, security, and performance.
AWS S3 Explained graphically:










Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more codes)
Active Anti-Aging Eye Gel, Reduces Dark Circles, Puffy Eyes, Crow's Feet and Fine Lines & Wrinkles, Packed with Hyaluronic Acid & Age Defying Botanicals
AWS S3 Facts and summaries
- S3 is a universal namespace, meaning each S3 bucket you create must have a unique name that is not being used by anyone else in the world.
- S3 is object based: i.e allows you to upload files.
- Files can be from 0 Bytes to 5 TB
- What is the maximum length, in bytes, of a DynamoDB range primary key attribute value?
The maximum length of a DynamoDB range primary key attribute value is 2048 bytes (NOT 256 bytes). - S3 has unlimited storage.
- Files are stored in Buckets.
- Read after write consistency for PUTS of new Objects
- Eventual Consistency for overwrite PUTS and DELETES (can take some time to propagate)
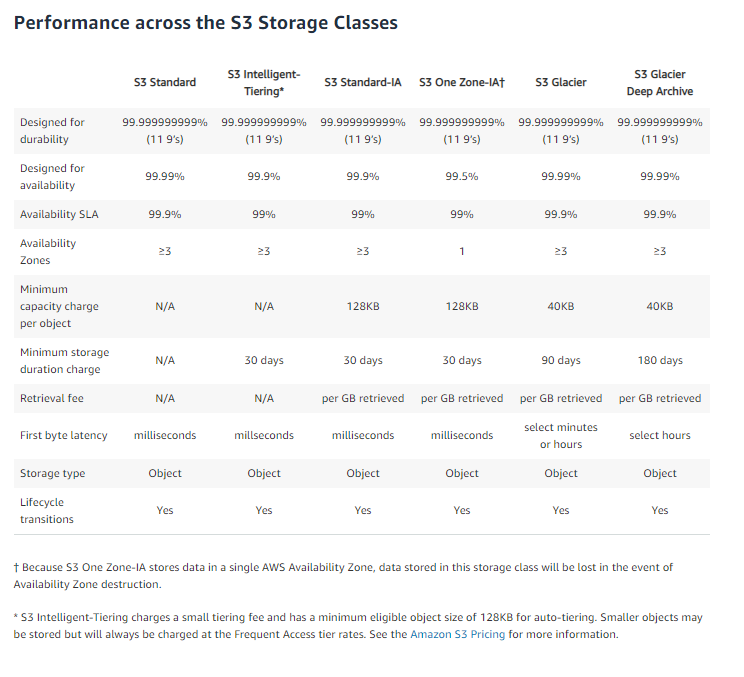
- S3 Storage Classes/Tiers:


- S3 Standard (durable, immediately available, frequently accesses)
- Amazon S3 Intelligent-Tiering (S3 Intelligent-Tiering): It works by storing objects in two access tiers: one tier that is optimized for frequent access and another lower-cost tier that is optimized for infrequent access.
- S3 Standard-Infrequent Access – S3 Standard-IA (durable, immediately available, infrequently accessed)
- S3 – One Zone-Infrequent Access – S3 One Zone IA: Same ad IA. However, data is stored in a single Availability Zone only
- S3 – Reduced Redundancy Storage (data that is easily reproducible, such as thumbnails, etc.)
- Glacier – Archived data, where you can wait 3-5 hours before accessing
You can have a bucket that has different objects stored in S3 Standard, S3 Intelligent-Tiering, S3 Standard-IA, and S3 One Zone-IA.
- The default URL for S3 hosted websites lists the bucket name first followed by s3-website-region.amazonaws.com . Example: enoumen.com.s3-website-us-east-1.amazonaws.com
- Core fundamentals of an S3 object
- Key (name)
- Value (data)
- Version (ID)
- Metadata
- Sub-resources (used to manage bucket-specific configuration)
- Bucket Policies, ACLs,
- CORS
- Transfer Acceleration
- Object-based storage only for files
- Not suitable to install OS on.
- Successful uploads will generate a HTTP 200 status code.
- S3 Security – Summary
- By default, all newly created buckets are PRIVATE.
- You can set up access control to your buckets using:
- Bucket Policies – Applied at the bucket level
- Access Control Lists – Applied at an object level.
- S3 buckets can be configured to create access logs, which log all requests made to the S3 bucket. These logs can be written to another bucket.
- S3 Encryption
- Encryption In-Transit (SSL/TLS)
- Encryption At Rest:
- Server side Encryption (SSE-S3, SSE-KMS, SSE-C)
- Client Side Encryption
- Remember that we can use a Bucket policy to prevent unencrypted files from being uploaded by creating a policy which only allows requests which include the x-amz-server-side-encryption parameter in the request header.
- S3 CORS (Cross Origin Resource Sharing):
CORS defines a way for client web applications that are loaded in one domain to interact with resources in a different domain.- Used to enable cross origin access for your AWS resources, e.g. S3 hosted website accessing javascript or image files located in another bucket. By default, resources in one bucket cannot access resources located in another. To allow this we need to configure CORS on the bucket being accessed and enable access for the origin (bucket) attempting to access.
- Always use the S3 website URL, not the regular bucket URL. E.g.: https://s3-eu-west-2.amazonaws.com/acloudguru
- S3 CloudFront:
- Edge locations are not just READ only – you can WRITE to them too (i.e put an object on to them.)
- Objects are cached for the life of the TTL (Time to Live)
- You can clear cached objects, but you will be charged. (Invalidation)
- S3 Performance optimization – 2 main approaches to Performance Optimization for S3:
- GET-Intensive Workloads – Use Cloudfront
- Mixed Workload – Avoid sequencial key names for your S3 objects. Instead, add a random prefix like a hex hash to the key name to prevent multiple objects from being stored on the same partition.
- mybucket/7eh4-2019-03-04-15-00-00/cust1234234/photo1.jpg
- mybucket/h35d-2019-03-04-15-00-00/cust1234234/photo2.jpg
- mybucket/o3n6-2019-03-04-15-00-00/cust1234234/photo3.jpg
- The best way to handle large objects uploads to the S3 service is to use the Multipart upload API. The Multipart upload API enables you to upload large objects in parts.
- You can enable versioning on a bucket, even if that bucket already has objects in it. The already existing objects, though, will show their versions as null. All new objects will have version IDs.
- Bucket names cannot start with a . or – characters. S3 bucket names can contain both the . and – characters. There can only be one . or one – between labels. E.G mybucket-com mybucket.com are valid names but mybucket–com and mybucket..com are not valid bucket names.
- What is the maximum number of S3 buckets allowed per AWS account (by default)? 100
- You successfully upload an item to the us-east-1 region. You then immediately make another API call and attempt to read the object. What will happen?
All AWS regions now have read-after-write consistency for PUT operations of new objects. Read-after-write consistency allows you to retrieve objects immediately after creation in Amazon S3. Other actions still follow the eventual consistency model (where you will sometimes get stale results if you have recently made changes) - S3 bucket policies require a Principal be defined. Review the access policy elements here
- What checksums does Amazon S3 employ to detect data corruption?
Amazon S3 uses a combination of Content-MD5 checksums and cyclic redundancy checks (CRCs) to detect data corruption. Amazon S3 performs these checksums on data at rest and repairs any corruption using redundant data. In addition, the service calculates checksums on all network traffic to detect corruption of data packets when storing or retrieving data.
AWS S3 Top 10 Questions and Answers Dump
Q0: You’ve written an application that uploads objects onto an S3 bucket. The size of the object varies between 200 – 500 MB. You’ve seen that the application sometimes takes a longer than expected time to upload the object. You want to improve the performance of the application. Which of the following would you consider?
- A. Create multiple threads and upload the objects in the multiple threads
- B. Write the items in batches for better performance
- C. Use the Multipart upload API
- D. Enable versioning on the Bucket
Top
Q2: You are using AWS SAM templates to deploy a serverless application. Which of the following resource will embed application from Amazon S3 buckets?
- A. AWS::Serverless::Api
- B. AWS::Serverless::Application
- C. AWS::Serverless::Layerversion
- D. AWS::Serverless::Function
Top
Q3: A static web site has been hosted on a bucket and is now being accessed by users. One of the web pages javascript section has been changed to access data which is hosted in another S3 bucket. Now that same web page is no longer loading in the browser. Which of the following can help alleviate the error?
- A. Enable versioning for the underlying S3 bucket.
- B. Enable Replication so that the objects get replicated to the other bucket
- C. Enable CORS for the bucket
- D. Change the Bucket policy for the bucket to allow access from the other bucket
Top
Q4: Your mobile application includes a photo-sharing service that is expecting tens of thousands of users at launch. You will leverage Amazon Simple Storage Service (S3) for storage of the user Images, and you must decide how to authenticate and authorize your users for access to these images. You also need to manage the storage of these images. Which two of the following approaches should you use? Choose two answers from the options below
- A. Create an Amazon S3 bucket per user, and use your application to generate the S3 URL for the appropriate content.
- B. Use AWS Identity and Access Management (IAM) user accounts as your application-level user database, and offload the burden of authentication from your application code.
- C. Authenticate your users at the application level, and use AWS Security Token Service (STS)to grant token-based authorization to S3 objects.
- D. Authenticate your users at the application level, and send an SMS token message to the user. Create an Amazon S3 bucket with the same name as the SMS message token, and move the user’s objects to that bucket.
Top
Q5: Both ACLs and Bucket Policies can be used to grant access to S3 buckets. Which of the following statements is true about ACLs and Bucket policies?
- A. Bucket Policies are Written in JSON and ACLs are written in XML
- B. ACLs can be attached to S3 objects or S3 Buckets
- C. Bucket Policies and ACLs are written in JSON
- D. Bucket policies are only attached to s3 buckets, ACLs are only attached to s3 objects
Q6: What are good options to improve S3 performance when you have significantly high numbers of GET requests?
- A. Introduce random prefixes to S3 objects
- B. Introduce random suffixes to S3 objects
- C. Setup CloudFront for S3 objects
- D. Migrate commonly used objects to Amazon Glacier
Q7: If an application is storing hourly log files from thousands of instances from a high traffic
web site, which naming scheme would give optimal performance on S3?
- A. Sequential
- B. HH-DD-MM-YYYY-log_instanceID
- C. YYYY-MM-DD-HH-log_instanceID
- D. instanceID_log-HH-DD-MM-YYYY
- E. instanceID_log-YYYY-MM-DD-HH
Top
Q8: You are working with the S3 API and receive an error message: 409 Conflict. What is the possible cause of this error
- A. You’re attempting to remove a bucket without emptying the contents of the bucket first.
- B. You’re attempting to upload an object to the bucket that is greater than 5TB in size.
- C. Your request does not contain the proper metadata.
- D. Amazon S3 is having internal issues.
Q9: You created three S3 buckets – “mywebsite.com”, “downloads.mywebsite.com”, and “www.mywebsite.com”. You uploaded your files and enabled static website hosting. You specified both of the default documents under the “enable static website hosting” header. You also set the “Make Public” permission for the objects in each of the three buckets. You create the Route 53 Aliases for the three buckets. You are going to have your end users test your websites by browsing to http://mydomain.com/error.html, http://downloads.mydomain.com/index.html, and http://www.mydomain.com. What problems will your testers encounter?
- A. http://mydomain.com/error.html will not work because you did not set a value for the error.html file
- B. There will be no problems, all three sites should work.
- C. http://www.mywebsite.com will not work because the URL does not include a file name at the end of it.
- D. http://downloads.mywebsite.com/index.html will not work because the “downloads” prefix is not a supported prefix for S3 websites using Route 53 aliases
Q10: Which of the following is NOT a common S3 API call?
- A. UploadPart
- B. ReadObject
- C. PutObject
- D. DownloadBucket
Other AWS Facts and Summaries
- AWS S3 facts and summaries
- AWS DynamoDB facts and summaries
- AWS EC2 facts and summaries
- AWS Lambda facts and summaries
- AWS SQS facts and summaries
- AWS RDS facts and summaries
- AWS ECS facts and summaries
- AWS CloudWatch facts and summaries
- AWS SES facts and summaries
- AWS EBS facts and summaries
- AWS Serverless facts and summaries
- AWS ELB facts and summaries
- AWS Autoscaling facts and summaries
- AWS VPC facts and summaries
- AWS KMS facts and summaries
- AWS Elastic Beanstalk facts and summaries
- AWS CodeBuild facts and summaries
- AWS CodeDeploy facts and summaries
- AWS CodePipeline facts and summaries
Active Hydrating Toner, Anti-Aging Replenishing Advanced Face Moisturizer, with Vitamins A, C, E & Natural Botanicals to Promote Skin Balance & Collagen Production, 6.7 Fl Oz



Age Defying 0.3% Retinol Serum, Anti-Aging Dark Spot Remover for Face, Fine Lines & Wrinkle Pore Minimizer, with Vitamin E & Natural Botanicals


Firming Moisturizer, Advanced Hydrating Facial Replenishing Cream, with Hyaluronic Acid, Resveratrol & Natural Botanicals to Restore Skin's Strength, Radiance, and Resilience, 1.75 Oz

Skin Stem Cell Serum


Smartphone 101 - Pick a smartphone for me - android or iOS - Apple iPhone or Samsung Galaxy or Huawei or Xaomi or Google Pixel
Can AI Really Predict Lottery Results? We Asked an Expert.





Djamgatech

Read Photos and PDFs Aloud for me iOS
Read Photos and PDFs Aloud for me android
Read Photos and PDFs Aloud For me Windows 10/11
Read Photos and PDFs Aloud For Amazon
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more)
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6(Email us for more)



FREE 10000+ Quiz Trivia and and Brain Teasers for All Topics including Cloud Computing, General Knowledge, History, Television, Music, Art, Science, Movies, Films, US History, Soccer Football, World Cup, Data Science, Machine Learning, Geography, etc....

List of Freely available programming books - What is the single most influential book every Programmers should read
- Bjarne Stroustrup - The C++ Programming Language
- Brian W. Kernighan, Rob Pike - The Practice of Programming
- Donald Knuth - The Art of Computer Programming
- Ellen Ullman - Close to the Machine
- Ellis Horowitz - Fundamentals of Computer Algorithms
- Eric Raymond - The Art of Unix Programming
- Gerald M. Weinberg - The Psychology of Computer Programming
- James Gosling - The Java Programming Language
- Joel Spolsky - The Best Software Writing I
- Keith Curtis - After the Software Wars
- Richard M. Stallman - Free Software, Free Society
- Richard P. Gabriel - Patterns of Software
- Richard P. Gabriel - Innovation Happens Elsewhere
- Code Complete (2nd edition) by Steve McConnell
- The Pragmatic Programmer
- Structure and Interpretation of Computer Programs
- The C Programming Language by Kernighan and Ritchie
- Introduction to Algorithms by Cormen, Leiserson, Rivest & Stein
- Design Patterns by the Gang of Four
- Refactoring: Improving the Design of Existing Code
- The Mythical Man Month
- The Art of Computer Programming by Donald Knuth
- Compilers: Principles, Techniques and Tools by Alfred V. Aho, Ravi Sethi and Jeffrey D. Ullman
- Gödel, Escher, Bach by Douglas Hofstadter
- Clean Code: A Handbook of Agile Software Craftsmanship by Robert C. Martin
- Effective C++
- More Effective C++
- CODE by Charles Petzold
- Programming Pearls by Jon Bentley
- Working Effectively with Legacy Code by Michael C. Feathers
- Peopleware by Demarco and Lister
- Coders at Work by Peter Seibel
- Surely You're Joking, Mr. Feynman!
- Effective Java 2nd edition
- Patterns of Enterprise Application Architecture by Martin Fowler
- The Little Schemer
- The Seasoned Schemer
- Why's (Poignant) Guide to Ruby
- The Inmates Are Running The Asylum: Why High Tech Products Drive Us Crazy and How to Restore the Sanity
- The Art of Unix Programming
- Test-Driven Development: By Example by Kent Beck
- Practices of an Agile Developer
- Don't Make Me Think
- Agile Software Development, Principles, Patterns, and Practices by Robert C. Martin
- Domain Driven Designs by Eric Evans
- The Design of Everyday Things by Donald Norman
- Modern C++ Design by Andrei Alexandrescu
- Best Software Writing I by Joel Spolsky
- The Practice of Programming by Kernighan and Pike
- Pragmatic Thinking and Learning: Refactor Your Wetware by Andy Hunt
- Software Estimation: Demystifying the Black Art by Steve McConnel
- The Passionate Programmer (My Job Went To India) by Chad Fowler
- Hackers: Heroes of the Computer Revolution
- Algorithms + Data Structures = Programs
- Writing Solid Code
- JavaScript - The Good Parts
- Getting Real by 37 Signals
- Foundations of Programming by Karl Seguin
- Computer Graphics: Principles and Practice in C (2nd Edition)
- Thinking in Java by Bruce Eckel
- The Elements of Computing Systems
- Refactoring to Patterns by Joshua Kerievsky
- Modern Operating Systems by Andrew S. Tanenbaum
- The Annotated Turing
- Things That Make Us Smart by Donald Norman
- The Timeless Way of Building by Christopher Alexander
- The Deadline: A Novel About Project Management by Tom DeMarco
- The C++ Programming Language (3rd edition) by Stroustrup
- Patterns of Enterprise Application Architecture
- Computer Systems - A Programmer's Perspective
- Agile Principles, Patterns, and Practices in C# by Robert C. Martin
- Growing Object-Oriented Software, Guided by Tests
- Framework Design Guidelines by Brad Abrams
- Object Thinking by Dr. David West
- Advanced Programming in the UNIX Environment by W. Richard Stevens
- Hackers and Painters: Big Ideas from the Computer Age
- The Soul of a New Machine by Tracy Kidder
- CLR via C# by Jeffrey Richter
- The Timeless Way of Building by Christopher Alexander
- Design Patterns in C# by Steve Metsker
- Alice in Wonderland by Lewis Carol
- Zen and the Art of Motorcycle Maintenance by Robert M. Pirsig
- About Face - The Essentials of Interaction Design
- Here Comes Everybody: The Power of Organizing Without Organizations by Clay Shirky
- The Tao of Programming
- Computational Beauty of Nature
- Writing Solid Code by Steve Maguire
- Philip and Alex's Guide to Web Publishing
- Object-Oriented Analysis and Design with Applications by Grady Booch
- Effective Java by Joshua Bloch
- Computability by N. J. Cutland
- Masterminds of Programming
- The Tao Te Ching
- The Productive Programmer
- The Art of Deception by Kevin Mitnick
- The Career Programmer: Guerilla Tactics for an Imperfect World by Christopher Duncan
- Paradigms of Artificial Intelligence Programming: Case studies in Common Lisp
- Masters of Doom
- Pragmatic Unit Testing in C# with NUnit by Andy Hunt and Dave Thomas with Matt Hargett
- How To Solve It by George Polya
- The Alchemist by Paulo Coelho
- Smalltalk-80: The Language and its Implementation
- Writing Secure Code (2nd Edition) by Michael Howard
- Introduction to Functional Programming by Philip Wadler and Richard Bird
- No Bugs! by David Thielen
- Rework by Jason Freid and DHH
- JUnit in Action
#BlackOwned #BlackEntrepreneurs #BlackBuniness #AWSCertified #AWSCloudPractitioner #AWSCertification #AWSCLFC02 #CloudComputing #AWSStudyGuide #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AWSBasics #AWSCertified #AWSMachineLearning #AWSCertification #AWSSpecialty #MachineLearning #AWSStudyGuide #CloudComputing #DataScience #AWSCertified #AWSSolutionsArchitect #AWSArchitectAssociate #AWSCertification #AWSStudyGuide #CloudComputing #AWSArchitecture #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AzureFundamentals #AZ900 #MicrosoftAzure #ITCertification #CertificationPrep #StudyMaterials #TechLearning #MicrosoftCertified #AzureCertification #TechBooks
Top 1000 Canada Quiz and trivia: CANADA CITIZENSHIP TEST- HISTORY - GEOGRAPHY - GOVERNMENT- CULTURE - PEOPLE - LANGUAGES - TRAVEL - WILDLIFE - HOCKEY - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Top 1000 Africa Quiz and trivia: HISTORY - GEOGRAPHY - WILDLIFE - CULTURE - PEOPLE - LANGUAGES - TRAVEL - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Exploring the Pros and Cons of Visiting All Provinces and Territories in Canada.


Exploring the Advantages and Disadvantages of Visiting All 50 States in the USA

Health Health, a science-based community to discuss health news and the coronavirus (COVID-19) pandemic
- Circadian rhythms can influence drugs’ effectivenessby /u/Sariel007 on April 24, 2024 at 10:33 pm
submitted by /u/Sariel007 [link] [comments]
- Does eating too much sugar really make kids hyper? We asked researchers.by /u/newzee1 on April 24, 2024 at 9:45 pm
submitted by /u/newzee1 [link] [comments]
- Why dentists say you shouldn’t rinse after brushingby /u/newzee1 on April 24, 2024 at 9:35 pm
submitted by /u/newzee1 [link] [comments]
- Partnering for a Healthier Detroit: Gilbert Family Foundation & Henry Ford Health's Visionby /u/sbgroup65 on April 24, 2024 at 7:50 pm
submitted by /u/sbgroup65 [link] [comments]
- First patient receives combined pig kidney transplant, heart pumpby /u/VirtualNecromancer on April 24, 2024 at 6:45 pm
submitted by /u/VirtualNecromancer [link] [comments]
Today I Learned (TIL) You learn something new every day; what did you learn today? Submit interesting and specific facts about something that you just found out here.
- TIL that John Rock, one of the creators of the contraceptive pill, was a devout Catholicby /u/trashconverters on April 25, 2024 at 2:46 am
submitted by /u/trashconverters [link] [comments]
- TIL that the Chicago area has more hot dog restaurants than McDonald's, Wendy's, and Burger King restaurants combinedby /u/Brix001 on April 25, 2024 at 1:32 am
submitted by /u/Brix001 [link] [comments]
- TIL of the Glasgow effect, a term which refers to the lower life expectancy of residents of the Scottish city compared to the rest of the UK and Europe. Some hypotheses for this effect include stress, especially in childhood, leading to ill health; violent gang culture; and rate of premature births.by /u/pukkapaddington on April 25, 2024 at 1:32 am
submitted by /u/pukkapaddington [link] [comments]
- TIL of the mummy of Takabuti, a young ancient Egyptian woman who died from an axe blow to her back. A study of the proteins in her leg muscles allowed researchers to hypothesise that she had been running for some time before she was killed.by /u/roughvandyke on April 24, 2024 at 11:55 pm
submitted by /u/roughvandyke [link] [comments]
- TIL that it took Boeing less than 3 years from starting the 747 project to first flight. The first commercial flight occurred 11 months later.by /u/getthedudesdanny on April 24, 2024 at 11:19 pm
submitted by /u/getthedudesdanny [link] [comments]
Reddit Science This community is a place to share and discuss new scientific research. Read about the latest advances in astronomy, biology, medicine, physics, social science, and more. Find and submit new publications and popular science coverage of current research.
- James Webb Space Telescope takes its first images of forming planetary systemsby /u/UVicScience on April 25, 2024 at 1:05 am
submitted by /u/UVicScience [link] [comments]
- Tiny rubber spheres used to make a programmable fluid: “We can [now] make hydraulic actuators soft and self-controlled. The fluid itself is doing all the control for us, so we don’t have to control the robot from the outside”by /u/TurretLauncher on April 25, 2024 at 12:33 am
submitted by /u/TurretLauncher [link] [comments]
- A sweetener used in cakes, soft drinks and chewing gum - neotame (sugar substitute E961), used to replace aspartame - can affect people’s health by weakening the gut wall as it damages intestinal bacteria, which may lead to irritable bowel syndrome or insulin resistance, a new study has found.by /u/mvea on April 24, 2024 at 9:29 pm
submitted by /u/mvea [link] [comments]
- A Florida man with migraines had a CT scan which showed that his brain was infested with tapeworm cysts. A new study hypothesised that he ate undercooked infected pork that contained tapeworm cysts, known as cysticercus, and re-infected himself with eggs passed in his faeces through poor hygiene.by /u/mvea on April 24, 2024 at 9:13 pm
submitted by /u/mvea [link] [comments]
- Early warning sign of extinction. Research found before an extinction pulse 34 million years ago, marine communities became highly specialized everywhere but in the southern high latitudes, implying that these micro-plankton migrated en masse to higher latitudes and away from the tropicsby /u/Wagamaga on April 24, 2024 at 9:04 pm
submitted by /u/Wagamaga [link] [comments]
Reddit Sports Sports News and Highlights from the NFL, NBA, NHL, MLB, MLS, and leagues around the world.
- Heat catch fire from deep, steal Game 2 from Celticsby /u/Oldtimer_2 on April 25, 2024 at 2:54 am
submitted by /u/Oldtimer_2 [link] [comments]
- 'Invest in these women': WNBA champion A'ja Wilson hopes Caitlin Clark's popularity helps the league growby /u/kundu123 on April 25, 2024 at 1:28 am
submitted by /u/kundu123 [link] [comments]
- Tiger Woods, Rory McIlroy to receive massive loyalty payouts from PGA Tour after equity investment, per reportby /u/Oldtimer_2 on April 25, 2024 at 12:50 am
submitted by /u/Oldtimer_2 [link] [comments]
- Hiltzik: The folly of public financing for stadiums - Los Angeles Timesby /u/davster39 on April 24, 2024 at 10:12 pm
submitted by /u/davster39 [link] [comments]
- Chicago Bears give new stadium update, say they will provide over $2B for lakefront domed projectby /u/Oldtimer_2 on April 24, 2024 at 10:02 pm
submitted by /u/Oldtimer_2 [link] [comments]
