



What are some ways to increase precision or recall in machine learning?
What are some ways to Boost Precision and Recall in Machine Learning?
Sensitivity vs Specificity?
In machine learning, recall is the ability of the model to find all relevant instances in the data while precision is the ability of the model to correctly identify only the relevant instances. A high recall means that most relevant results are returned while a high precision means that most of the returned results are relevant. Ideally, you want a model with both high recall and high precision but often there is a trade-off between the two. In this blog post, we will explore some ways to increase recall or precision in machine learning.
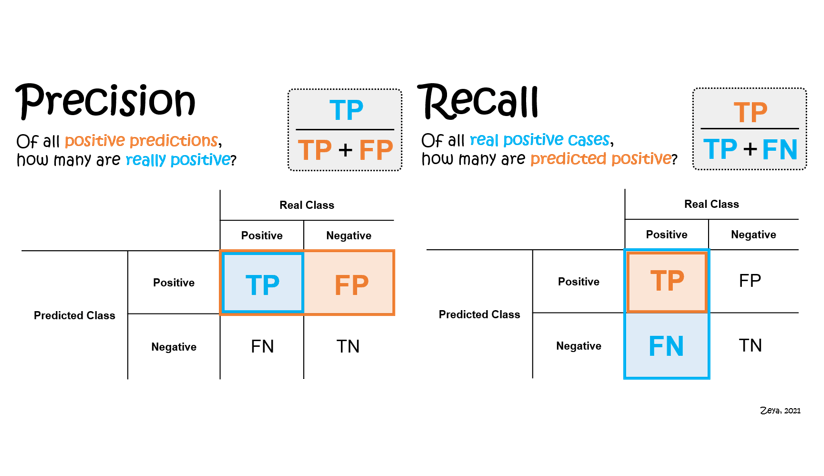
There are two main ways to increase recall:
by increasing the number of false positives or by decreasing the number of false negatives. To increase the number of false positives, you can lower your threshold for what constitutes a positive prediction. For example, if you are trying to predict whether or not an email is spam, you might lower the threshold for what constitutes spam so that more emails are classified as spam. This will result in more false positives (emails that are not actually spam being classified as spam) but will also increase recall (more actual spam emails being classified as spam).

To decrease the number of false negatives,
you can increase your threshold for what constitutes a positive prediction. For example, going back to the spam email prediction example, you might raise the threshold for what constitutes spam so that fewer emails are classified as spam. This will result in fewer false negatives (actual spam emails not being classified as spam) but will also decrease recall (fewer actual spam emails being classified as spam).

There are two main ways to increase precision:
by increasing the number of true positives or by decreasing the number of true negatives. To increase the number of true positives, you can raise your threshold for what constitutes a positive prediction. For example, using the spam email prediction example again, you might raise the threshold for what constitutes spam so that fewer emails are classified as spam. This will result in more true positives (emails that are actually spam being classified as spam) but will also decrease precision (more non-spam emails being classified as spam).

To decrease the number of true negatives,
you can lower your threshold for what constitutes a positive prediction. For example, going back to the spam email prediction example once more, you might lower the threshold for what constitutes spam so that more emails are classified as spam. This will result in fewer true negatives (emails that are not actually spam not being classified as spam) but will also decrease precision (more non-spam emails being classified as spam).
To summarize,
there are a few ways to increase precision or recall in machine learning. One way is to use a different evaluation metric. For example, if you are trying to maximize precision, you can use the F1 score, which is a combination of precision and recall. Another way to increase precision or recall is to adjust the threshold for classification. This can be done by changing the decision boundary or by using a different algorithm altogether.
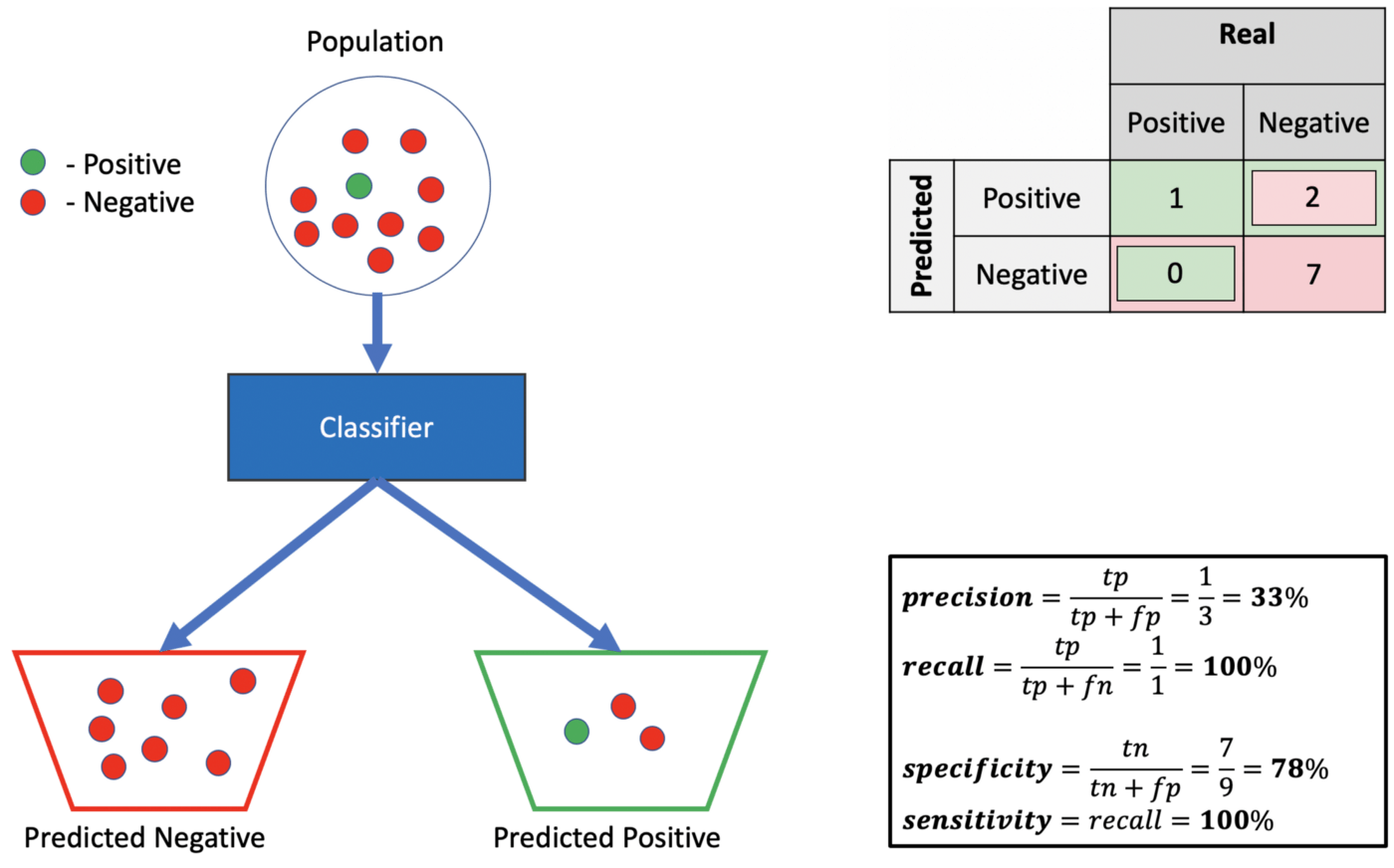
Sensitivity vs Specificity
In machine learning, sensitivity and specificity are two measures of the performance of a model. Sensitivity is the proportion of true positives that are correctly predicted by the model, while specificity is the proportion of true negatives that are correctly predicted by the model.
Google Colab For Machine Learning
State of the Google Colab for ML (October 2022)
Google introduced computing units, which you can purchase just like any other cloud computing unit you can from AWS or Azure etc. With Pro you get 100, and with Pro+ you get 500 computing units. GPU, TPU and option of High-RAM effects how much computing unit you use hourly. If you don’t have any computing units, you can’t use “Premium” tier gpus (A100, V100) and even P100 is non-viable.
Google Colab Pro+ comes with Premium tier GPU option, meanwhile in Pro if you have computing units you can randomly connect to P100 or T4. After you use all of your computing units, you can buy more or you can use T4 GPU for the half or most of the time (there can be a lot of times in the day that you can’t even use a T4 or any kinds of GPU). In free tier, offered gpus are most of the time K80 and P4, which performs similar to a 750ti (entry level gpu from 2014) with more VRAM.
For your consideration, T4 uses around 2, and A100 uses around 15 computing units hourly.
Based on the current knowledge, computing units costs for GPUs tend to fluctuate based on some unknown factor.

Considering those:
- For hobbyists and (under)graduate school duties, it will be better to use your own gpu if you have something with more than 4 gigs of VRAM and better than 750ti, or atleast purchase google pro to reach T4 even if you have no computing units remaining.
- For small research companies, and non-trivial research at universities, and probably for most of the people Colab now probably is not a good option.
- Colab Pro+ can be considered if you want Pro but you don’t sit in front of your computer, since it disconnects after 90 minutes of inactivity in your computer. But this can be overcomed with some scripts to some extend. So for most of the time Colab Pro+ is not a good option.
If you have anything more to say, please let me know so I can edit this post with them. Thanks!
Advertise with us - Post Your Good Content Here
We are ranked in the Top 20 on Google
AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
Conclusion:
In machine learning, precision and recall trade off against each other; increasing one often decreases the other. There is no single silver bullet solution for increasing either precision or recall; it depends on your specific use case which one is more important and which methods will work best for boosting whichever metric you choose. In this blog post, we explored some methods for increasing either precision or recall; hopefully this gives you a starting point for improving your own models!
What are some ways we can use machine learning and artificial intelligence for algorithmic trading in the stock market?

Machine Learning and Data Science Breaking News 2022 – 2023
- [P] Proportionately split dataframe with multiple target columnsby /u/Individual_Ad_1214 (Machine Learning) on July 26, 2024 at 10:24 pm
I have a dataframe with 30 rows and 10 columns. 5 of the columns are input features and the other 5 are output/target columns. The target columns contain classes represented as 0, 1, 2. I want to split the dataset into train and test such that, in the train set, for each output column, the proportion of class 1 is between 0.15 and 0.3. (I am not bothered about the distribution of classes in the test set). ADDITIONAL CONTEXT: I am trying to balance the output classes in a multi-class and multi-output dataset. My understanding is that this would be an optimization problem with 25 (?) degrees of freedom. So if I have any input dataset, I would be able to create a subset of that input dataset which is my training data and which has the desired class balance (i.e class 1 between 0.15 and 0.3 for each output column). I make the dataframe using this import pandas as pd import numpy as np from sklearn.model_selection import train_test_split np.random.seed(42) data = pd.DataFrame({ 'A': np.random.rand(30), 'B': np.random.rand(30), 'C': np.random.rand(30), 'D': np.random.rand(30), 'E': np.random.rand(30), 'F': np.random.choice([0, 1, 2], 30), 'G': np.random.choice([0, 1, 2], 30), 'H': np.random.choice([0, 1, 2], 30), 'I': np.random.choice([0, 1, 2], 30), 'J': np.random.choice([0, 1, 2], 30) }) My current silly/harebrained solution for this problem involves using two separate functions. I have a helper function that checks if the proportions of class 1 in each column is within my desired range def check_proportions(df, cols, min_prop = 0.15, max_prop = 0.3, class_category = 1): for col in cols: prop = (df[col] == class_category).mean() if not (min_prop <= prop <= max_prop): return False return True def proportionately_split_data(data, target_cols, min_prop = 0.15, max_prop = 0.3): while True: random_state = np.random.randint(100_000) train_df, test_df = train_test_split(data, test_size = 0.3, random_state = random_state) if check_proportions(train_df, target_cols, min_prop, max_prop): return train_df, test_df Finally, I run the code using target_cols = ["F", "G", "H", "I", "J"] train, test = proportionately_split_data(data, target_cols) My worry with this current "solution" is that it is probabilistic and not deterministic. I can see the proportionately_split_data getting stuck in an infinite loop if none of the random state I set in train_test_split can randomly generate data with the desired proportion. Any help would be much appreciated! I apologize for not providing this earlier, for a Minimal working example, the input (data) could be A B C D E OUTPUT_1 OUTPUT_2 OUTPUT_3 OUTPUT_4 OUTPUT_5 5.65 3.56 0.94 9.23 6.43 0 1 1 0 1 7.43 3.95 1.24 7.22 2.66 0 0 0 1 2 9.31 2.42 2.91 2.64 6.28 2 1 2 2 0 8.19 5.12 1.32 3.12 8.41 1 2 0 1 2 9.35 1.92 3.12 4.13 3.14 0 1 1 0 1 8.43 9.72 7.23 8.29 9.18 1 0 0 2 2 4.32 2.12 3.84 9.42 8.19 0 0 0 0 0 3.92 3.91 2.90 8.19 8.41 2 2 2 2 1 7.89 1.92 4.12 8.19 7.28 1 1 2 0 2 5.21 2.42 3.10 0.31 1.31 2 0 1 1 0 which has 10 rows and 10 columns, and an expected output (train set) could be A B C D E OUTPUT_1 OUTPUT_2 OUTPUT_3 OUTPUT_4 OUTPUT_5 5.65 3.56 0.94 9.23 6.43 0 1 1 0 1 7.43 3.95 1.24 7.22 2.66 0 0 0 1 2 9.31 2.42 2.91 2.64 6.28 2 1 2 2 0 8.19 5.12 1.32 3.12 8.41 1 2 0 1 2 8.43 9.72 7.23 8.29 9.18 1 0 0 2 2 3.92 3.91 2.90 8.19 8.41 2 2 2 2 1 5.21 2.42 3.10 0.31 1.31 2 0 1 1 0 Whereby each output column in the train set has at least 2 (>= 0.15 * number of rows in input data) instances of Class 1 and at most 3 (<= 0.3 * number of rows in input data). I guess I also didn't clarify that the proportion is in relation to the number of examples (or rows) in the input dataset. My test set would be the remaining rows in the input dataset. submitted by /u/Individual_Ad_1214 [link] [comments]
- [D] Is it possible to use Stable Diffusion v1 as a feature extractor by removing the text module and cross-attention layers?by /u/rustyelectron (Machine Learning) on July 26, 2024 at 7:28 pm
Hi, I'm interested in leveraging the Stable Diffusion v1 model as a feature extractor for a downstream task. Specifically, I want to do this without involving the text prompt mechanism. To achieve this, I'm considering: Eliminating the text encoder module Removing the cross-attention layers in the UNet Is this a feasible approach? Has anyone experimented with using Stable Diffusion in this way? What would be the challenges or limitations of such a modification? I can find papers that use SDv1 for downstream tasks along with a basic text prompt but none try to do it without involving the text prompt mechanism. Otherwise, I am considering to use DINOv2. submitted by /u/rustyelectron [link] [comments]
- [D] Epyc Siena 32c/64c with 265GB RAM Good for Starting Lab?by /u/Kltpzyxmm (Machine Learning) on July 26, 2024 at 6:37 pm
If I can get a good deal on a Siena Epyc CPU 32 or 64 core with say 256GB RAM is that a decent starting point to get into a local setup to run models? I need the lanes for the GPUs. submitted by /u/Kltpzyxmm [link] [comments]
- Minimum tenure at a companyby /u/ergodym (Data Science) on July 26, 2024 at 5:51 pm
What do you consider a minimum tenure to be at a company before deciding it's time to move on? When is too early as opposed to still try hard to change opinion. Specifically related to DS rols. submitted by /u/ergodym [link] [comments]
- How do you find use cases for data science in an organization?by /u/cptsanderzz (Data Science) on July 26, 2024 at 3:15 pm
I know most people say “find a problem then use data science to solve it” but my question is how do people find these problems? Throughout my minimal career of 3 years as a data scientist the vast majority of problems can be solved using data analysis, how do you find opportunities to utilize more sophisticated data science techniques? submitted by /u/cptsanderzz [link] [comments]
- DS in product analytics, what are your low hanging fruits when entering a new job or project that brought the most impactby /u/LibiSC (Data Science) on July 26, 2024 at 3:13 pm
If you are no in product analytics more industry agnostic recommendations are welcome submitted by /u/LibiSC [link] [comments]
- [D] Every annotator has a guidebook, but the reviewers don'tby /u/Spico197 (Machine Learning) on July 26, 2024 at 1:20 pm
I submitted to the ACL rolling review in June and found the reviewers' evaluation scores very subjective. Although the ACL committee has an instruction on some basic reviewing guidelines, there lacks of a preliminary test for the reviewers to explicitly show the evaluation standards. Maybe we should provide some paper-score examples to prompt the reviewers for more objective reviews? Or build a test before they make reviews to make sure they fully understand the meaning of soundness and overall assessment, rather than giving some random scores based on their personal interests. submitted by /u/Spico197 [link] [comments]
- [D] How OpenAI JSON mode implemented?by /u/Financial_Air5256 (Machine Learning) on July 26, 2024 at 11:15 am
I assume that all the training data is in JSON format, but higher temperature or other randomness during generation doesn’t guarantee that the outputs will always be in JSON. What other methods do you think could ensure that the outputs are consistently in JSON? Perhaps some rule-based methods during decoding could help? submitted by /u/Financial_Air5256 [link] [comments]
- [D] Do only some hardware support int4 quantization? If so why?by /u/Abs0lute_Jeer0 (Machine Learning) on July 26, 2024 at 7:56 am
I tried quantizing my finetuned mT5 model using the optimum’s openvino wrapper to int8 and int4. There was very little difference in the inference time, close to 5%. This makes me wonder if it’s an issue with hardware. I’m using intel sapphire rapids and it has an avx512_vnni instruction set. How did I figure out if it supports int4? And why and why not? submitted by /u/Abs0lute_Jeer0 [link] [comments]
- [D] Normalization in transformersby /u/lostn4d (Machine Learning) on July 26, 2024 at 7:44 am
After the first theoretical issue with my transformer, I now see another. The original paper uses normalization after residual addition (Post-LN), which led to training difficulties and later got replaced by normalization at the beginning of each attention or mlp block/branch (Pre-LN). This is known to work better in practice (trainable without warmup, restores highway effect), but it still doesn't seem completely ok theoretically. First consider things without normalization. Assuming attention and mlp blocks are properly set up and mostly keep norms, each residual addition would sum two similar norm signals, potentially scaling up by something like 1.4 (depending on correlation, but it starts at sqrt(2) after random init). So the norms after the blocks could look like this: [1(main)+1(residual)=1.4] -> [1.4+1.4=2] -> [2+2=2.8] etc. This would cause various problems (like changing the softmax temp in later attention blocks), so adjustment is needed. Pre-LN ensures each block works on normalized values (thus with constant - if slightly arbitrary - softmax temperature). But since it doesn't affect the norm of the main signal (as forwarded by the skip connection) but only the residual, the norms can still grow, albeit slower. The expectation is now roughly: [1+1=1.4] -> [1.4+1=1.7] -> [1.7+1=2] -> [2+1=2.2] etc - with a final normalization correcting the signal near output (Pre-LN paper). One possible issue with this is that later attention blocks may have reduced effect, as they add unit norm residuals to a potentially larger and larger main signal. What is the usual take on this problem? Can it be ignored in practice? Does Pre-LN work acceptably despite it, even for deep models (where the main norm discrepancy can grow larger)? There are lots of alternative normalization papers, but what is the practical consensus? Btw attention is extremely norm-sensitive (or, equivalently, the hidden temperature of softmax is critical). This is a sharp contrast to fc or convolution which are mostly scale-oblivious. For anybody interested: consider what happens when most raw attention dot products come out 0 (= query and key is orthogonal, no info from this context slot) with only one slot giving 1 (= positive affinity, after downscaled by sqrt(qk_siz) ). I for one got surprised by this during debug. submitted by /u/lostn4d [link] [comments]
- What's the most interesting Data Science interview question you've encountered?by /u/NickSinghTechCareers (Data Science) on July 26, 2024 at 12:42 am
What's the most interesting Data Science Interview question you've been asked? Bonus points if it: appears to be hard, but is actually easy appears to be simple, but is actually nuanced I'll go first – at a geospatial analytics startup, I was asked about how we could use location data to help McDonalds open up their next store location in an optimal spot. It was fun to riff about what features I'd use in my analysis, and potential downsides off each feature. I also got to show off my domain knowledge by mentioning some interesting retail analytics / credit-card spend datasets I'd also incorporate. This impressed the interviewer since the companies I mentioned were all potential customers/partners/competitors (it's a complicated ecosystem!). How about you – what's the most interesting Data Science interview question you've encountered? submitted by /u/NickSinghTechCareers [link] [comments]
- [R] How do you search for implementations of Mixture of Expert models that can be trained locally in a laptop or desktop without ultra-high end GPUs?by /u/Furiousguy79 (Machine Learning) on July 25, 2024 at 11:12 pm
Hi, I am a 2nd year PhD student in CS. My supervisor just got this idea about MoEs and fairness and asked me to implement it ( work on a toy classification problem on tabular data and NOT language data). However as it is not their area of expertise, they did not give any guidelines on how to approach it. My main question is: How do I search for or proceed with implementing a mixture of expert models? The ones that I find are for chatting and such but I mainly work with tabular EHR data. This is my first foray into this area (LLMs and MoEs) and I am kind of lost with all these Mixtral, openMoE, etc. As we do not have access to Google Collab or have powerful GPUs I have to rely on local training (My lab PC has 2080ti and my laptop has 4070). Any guideline or starting point on how to proceed would be greatly appreciated. submitted by /u/Furiousguy79 [link] [comments]
- Seeking ML Solutions for Analyzing Player Movement in Field Sportsby /u/vaalenz (Data Science) on July 25, 2024 at 10:40 pm
Hi everyone! I'm working on a project where I have detailed information on player movements in field sports such as Soccer, Rugby, and Field Hockey. The dataset includes second-by-second data on player positions (latitude and longitude), speed, and heart rate. I’m looking for help with two specific objectives using machine learning: Detecting and Classifying Game Phases: I want to develop a system that can identify and classify different game phases like attacking, defending, counter-attacks, rest periods, etc. Automatically Splitting the Game into Quarters or Halves: Additionally, I need to automatically segment the game into quarters or halves, and determine the exact times these segments occur. I’d appreciate any suggestions on how to approach these problems. What algorithms or models would be best suited for these tasks? Are there any existing frameworks or tools that could be particularly useful?Thanks for your help!! submitted by /u/vaalenz [link] [comments]
- What is it with jobs requiring a master’s AND a PhD?by /u/Rare_Art_9541 (Data Science) on July 25, 2024 at 8:11 pm
I was looking through some postings On indeed. And I noticed that there are several data science postings that require both a master’s and a PhD. You’re telling me if you decide to skip a master’s and go straight for the PhD, you’re not considered qualified? submitted by /u/Rare_Art_9541 [link] [comments]
- [P] How to make "Out-of-sample" Predictionsby /u/Individual_Ad_1214 (Machine Learning) on July 25, 2024 at 7:47 pm
My data is a bit complicated to describe so I'm going try to describe something analogous. Each example is randomly generated, but you can group them based on a specific but latent (by latent I mean this isn't added into the features used to develop a model, but I have access to it) feature (in this example we'll call this number of bedrooms). Feature x1 Feature x2 Feature x3 ... Output (Rent) Row 1 Row 2 Row 3 Row 4 Row 5 Row 6 Row 7 2 Row 8 1 Row 9 0 So I can group Row 1, Row 2, and Row 3 based on a latent feature called number of bedrooms (which in this case is 0 bedroom). Similarly, Row 4, Row 5, & Row 6 have 2 Bedrooms, and Row 7, Row 8, & Row 9 have 4 Bedrooms. Furthermore, these groups also have an optimum price which is used to create output classes (output here is Rent; increase, keep constant, or decrease). So say the optimum price for the 4 bedrooms group is $3mil, and row 7 has a price of $4mil (=> 3 - 4 = -1 mil, i.e a -ve value so convert this to class 2, or above optimum or increase rent), row 8 has a price of $3mil (=> 3 - 3 = 0, convert this to class 1, or at optimum), and row 9 has a price of $2mil (3 - 2 = 1, i.e +ve value, so convert this to class 0, or below optimum, or decrease rent). I use this method to create an output class for each example in the dataset (essentially, if example x has y number of bedrooms, I get the known optimum price for that number of bedrooms and I subtract the example's price from the optimum price). Say I have 10 features (e.g. square footage, number of bathrooms, parking spaces etc.) in the dataset, these 10 features provide the model with enough information to figure out the "number of bedrooms". So when I am evaluating the model, feature x1 feature x2 feature x3 ... Row 10 e.g. I pass into the model a test example (Row 10) which I know has 4 bedrooms and is priced at $6mil, the model can accurately predict class 2 (i.e increase rent) for this example. Because the model was developed using data with a representative number of bedrooms in my dataset. Features.... Output (Rent) Row 1 0 Row 2 0 Row 3 0 However, my problem arises at examples with a low number of bedrooms (i.e. 0 bedrooms). The input features doesn't have enough information to determine the number of bedrooms for examples with a low number of bedrooms (which is fine because we assume that within this group, we will always decrease the rent, so we set the optimum price to say $2000. So row 1 price could be $8000, (8000 - 2000 = 6000, +ve value thus convert to class 0 or below optimum/decrease rent). And within this group we rely on the class balance to help the model learn to make predictions because the proportion is heavily skewed towards class 0 (say 95% = class 0 or decrease rent, and 5 % = class 1 or class 2). We do this based the domain knowledge of the data (so in this case, we would always decrease the rent because no one wants to live in a house with 0 bedrooms). MAIN QUESTION: We now want to predict (or undertake inference) for examples with number of bedrooms in between 0 bedrooms and 2 bedrooms (e.g 1 bedroom NOTE: our training data has no example with 1 bedroom). What I notice is that the model's predictions on examples with 1 bedroom act as if these examples had 0 bedrooms and it mostly predicts class 0. My question is, apart from specifically including examples with 1 bedroom in my input data, is there any other way (more statistics or ML related way) for me to improve the ability of my model to generalise on unseen data? submitted by /u/Individual_Ad_1214 [link] [comments]
- Does every new data science job get boring after a couple years?by /u/Lamp_Shade_Head (Data Science) on July 25, 2024 at 7:26 pm
I am in my second job after grad school and am noticing a pattern in how I feel about my job as time goes on. In my first job, I felt bored and restless around the 1.5-year mark and eventually left. Now, after 2.5 years at my current job, I find myself feeling bored and disinterested again. I fulfill my responsibilities and do them well, but I no longer go above and beyond as I did in the first year. Is it unusual to feel this way, or is it normal? submitted by /u/Lamp_Shade_Head [link] [comments]
- [R] EMNLP Paper review scoresby /u/Immediate-Hour-8466 (Machine Learning) on July 25, 2024 at 7:06 pm
EMNLP paper review scores Overall assessment for my paper is 2, 2.5 and 3. Is there any chance that it may still be selected? The confidence is 2, 2.5 and 3. The soundness is 2, 2.5, 3.5. I am not sure how soundness and confidence may affect my paper's selection. Pls explain how this works. Which metrics should I consider important. Thank you! submitted by /u/Immediate-Hour-8466 [link] [comments]
- Using Kriging interpolation on 2D slices of 3D databy /u/RandomFactChecker_ (Data Science) on July 25, 2024 at 6:52 pm
Edit: Added image of the dataset I am working on which can be seen on the top left where the kriging perdiction is on the top right. I'm working on interpolating 2D data slices from a 3D grid at a specific point. If I take slices around that point in various directions, can I average the kriging values from these different slices to obtain a single overall 3D kriging value for that point? Would doing this ruin the values outputted by the Kinging interpolation and make them have greater error? If I can take this approach what would be the best approach to ensure accuracy in this interpolation process? The dataset I am working on which can be seen on the top left where the kriging prediction is on the top right. To be more specific the database I am using is one I created myself which is filled with wind speed, direction and variance at each lat lon point at 0.25 resolution. I am doing this for alts 15 000 - 30 000 meters however as seen there is gaps in the data. I am trying to use kriging to fill in these gaps. In the photo below I am only doing one slice of data at lon = -179 so I can use 2D kriging but I am wondering if I can do the averaging around each point to something closer to a 3D kring. I am also doing this because I have a working 2D kriging add on for MATLAB that has good documentation but cant find a good one for 3D. The https://preview.redd.it/3rwti6ip4wed1.png?width=1038&format=png&auto=webp&s=a0cbce4a84d551f03f9b2c657f4153987661f4a2 submitted by /u/RandomFactChecker_ [link] [comments]
- [N] OpenAI announces SearchGPTby /u/we_are_mammals (Machine Learning) on July 25, 2024 at 6:41 pm
https://openai.com/index/searchgpt-prototype/ We’re testing SearchGPT, a temporary prototype of new AI search features that give you fast and timely answers with clear and relevant sources. submitted by /u/we_are_mammals [link] [comments]
- [P] Local Llama 3.1 and Marqo Retrieval Augmented Generationby /u/elliesleight (Machine Learning) on July 25, 2024 at 4:45 pm
I built a simple starter demo of a Knowledge Question and Answering System using Llama 3.1 (8B GGUF) and Marqo. Feel free to experiment and build on top of this yourselves! GitHub: https://github.com/ellie-sleightholm/marqo-llama3_1 submitted by /u/elliesleight [link] [comments]
Top 100 Data Science and Data Analytics and Data Engineering Interview Questions and Answers
What are some good datasets for Data Science and Machine Learning?
Active Hydrating Toner, Anti-Aging Replenishing Advanced Face Moisturizer, with Vitamins A, C, E & Natural Botanicals to Promote Skin Balance & Collagen Production, 6.7 Fl Oz



Age Defying 0.3% Retinol Serum, Anti-Aging Dark Spot Remover for Face, Fine Lines & Wrinkle Pore Minimizer, with Vitamin E & Natural Botanicals


Firming Moisturizer, Advanced Hydrating Facial Replenishing Cream, with Hyaluronic Acid, Resveratrol & Natural Botanicals to Restore Skin's Strength, Radiance, and Resilience, 1.75 Oz

Skin Stem Cell Serum


Smartphone 101 - Pick a smartphone for me - android or iOS - Apple iPhone or Samsung Galaxy or Huawei or Xaomi or Google Pixel
Can AI Really Predict Lottery Results? We Asked an Expert.




Djamgatech

Read Photos and PDFs Aloud for me iOS
Read Photos and PDFs Aloud for me android
Read Photos and PDFs Aloud For me Windows 10/11
Read Photos and PDFs Aloud For Amazon
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more)
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6(Email us for more)



FREE 10000+ Quiz Trivia and and Brain Teasers for All Topics including Cloud Computing, General Knowledge, History, Television, Music, Art, Science, Movies, Films, US History, Soccer Football, World Cup, Data Science, Machine Learning, Geography, etc....


List of Freely available programming books - What is the single most influential book every Programmers should read
- Bjarne Stroustrup - The C++ Programming Language
- Brian W. Kernighan, Rob Pike - The Practice of Programming
- Donald Knuth - The Art of Computer Programming
- Ellen Ullman - Close to the Machine
- Ellis Horowitz - Fundamentals of Computer Algorithms
- Eric Raymond - The Art of Unix Programming
- Gerald M. Weinberg - The Psychology of Computer Programming
- James Gosling - The Java Programming Language
- Joel Spolsky - The Best Software Writing I
- Keith Curtis - After the Software Wars
- Richard M. Stallman - Free Software, Free Society
- Richard P. Gabriel - Patterns of Software
- Richard P. Gabriel - Innovation Happens Elsewhere
- Code Complete (2nd edition) by Steve McConnell
- The Pragmatic Programmer
- Structure and Interpretation of Computer Programs
- The C Programming Language by Kernighan and Ritchie
- Introduction to Algorithms by Cormen, Leiserson, Rivest & Stein
- Design Patterns by the Gang of Four
- Refactoring: Improving the Design of Existing Code
- The Mythical Man Month
- The Art of Computer Programming by Donald Knuth
- Compilers: Principles, Techniques and Tools by Alfred V. Aho, Ravi Sethi and Jeffrey D. Ullman
- Gödel, Escher, Bach by Douglas Hofstadter
- Clean Code: A Handbook of Agile Software Craftsmanship by Robert C. Martin
- Effective C++
- More Effective C++
- CODE by Charles Petzold
- Programming Pearls by Jon Bentley
- Working Effectively with Legacy Code by Michael C. Feathers
- Peopleware by Demarco and Lister
- Coders at Work by Peter Seibel
- Surely You're Joking, Mr. Feynman!
- Effective Java 2nd edition
- Patterns of Enterprise Application Architecture by Martin Fowler
- The Little Schemer
- The Seasoned Schemer
- Why's (Poignant) Guide to Ruby
- The Inmates Are Running The Asylum: Why High Tech Products Drive Us Crazy and How to Restore the Sanity
- The Art of Unix Programming
- Test-Driven Development: By Example by Kent Beck
- Practices of an Agile Developer
- Don't Make Me Think
- Agile Software Development, Principles, Patterns, and Practices by Robert C. Martin
- Domain Driven Designs by Eric Evans
- The Design of Everyday Things by Donald Norman
- Modern C++ Design by Andrei Alexandrescu
- Best Software Writing I by Joel Spolsky
- The Practice of Programming by Kernighan and Pike
- Pragmatic Thinking and Learning: Refactor Your Wetware by Andy Hunt
- Software Estimation: Demystifying the Black Art by Steve McConnel
- The Passionate Programmer (My Job Went To India) by Chad Fowler
- Hackers: Heroes of the Computer Revolution
- Algorithms + Data Structures = Programs
- Writing Solid Code
- JavaScript - The Good Parts
- Getting Real by 37 Signals
- Foundations of Programming by Karl Seguin
- Computer Graphics: Principles and Practice in C (2nd Edition)
- Thinking in Java by Bruce Eckel
- The Elements of Computing Systems
- Refactoring to Patterns by Joshua Kerievsky
- Modern Operating Systems by Andrew S. Tanenbaum
- The Annotated Turing
- Things That Make Us Smart by Donald Norman
- The Timeless Way of Building by Christopher Alexander
- The Deadline: A Novel About Project Management by Tom DeMarco
- The C++ Programming Language (3rd edition) by Stroustrup
- Patterns of Enterprise Application Architecture
- Computer Systems - A Programmer's Perspective
- Agile Principles, Patterns, and Practices in C# by Robert C. Martin
- Growing Object-Oriented Software, Guided by Tests
- Framework Design Guidelines by Brad Abrams
- Object Thinking by Dr. David West
- Advanced Programming in the UNIX Environment by W. Richard Stevens
- Hackers and Painters: Big Ideas from the Computer Age
- The Soul of a New Machine by Tracy Kidder
- CLR via C# by Jeffrey Richter
- The Timeless Way of Building by Christopher Alexander
- Design Patterns in C# by Steve Metsker
- Alice in Wonderland by Lewis Carol
- Zen and the Art of Motorcycle Maintenance by Robert M. Pirsig
- About Face - The Essentials of Interaction Design
- Here Comes Everybody: The Power of Organizing Without Organizations by Clay Shirky
- The Tao of Programming
- Computational Beauty of Nature
- Writing Solid Code by Steve Maguire
- Philip and Alex's Guide to Web Publishing
- Object-Oriented Analysis and Design with Applications by Grady Booch
- Effective Java by Joshua Bloch
- Computability by N. J. Cutland
- Masterminds of Programming
- The Tao Te Ching
- The Productive Programmer
- The Art of Deception by Kevin Mitnick
- The Career Programmer: Guerilla Tactics for an Imperfect World by Christopher Duncan
- Paradigms of Artificial Intelligence Programming: Case studies in Common Lisp
- Masters of Doom
- Pragmatic Unit Testing in C# with NUnit by Andy Hunt and Dave Thomas with Matt Hargett
- How To Solve It by George Polya
- The Alchemist by Paulo Coelho
- Smalltalk-80: The Language and its Implementation
- Writing Secure Code (2nd Edition) by Michael Howard
- Introduction to Functional Programming by Philip Wadler and Richard Bird
- No Bugs! by David Thielen
- Rework by Jason Freid and DHH
- JUnit in Action
#BlackOwned #BlackEntrepreneurs #BlackBuniness #AWSCertified #AWSCloudPractitioner #AWSCertification #AWSCLFC02 #CloudComputing #AWSStudyGuide #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AWSBasics #AWSCertified #AWSMachineLearning #AWSCertification #AWSSpecialty #MachineLearning #AWSStudyGuide #CloudComputing #DataScience #AWSCertified #AWSSolutionsArchitect #AWSArchitectAssociate #AWSCertification #AWSStudyGuide #CloudComputing #AWSArchitecture #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AzureFundamentals #AZ900 #MicrosoftAzure #ITCertification #CertificationPrep #StudyMaterials #TechLearning #MicrosoftCertified #AzureCertification #TechBooks
Top 1000 Canada Quiz and trivia: CANADA CITIZENSHIP TEST- HISTORY - GEOGRAPHY - GOVERNMENT- CULTURE - PEOPLE - LANGUAGES - TRAVEL - WILDLIFE - HOCKEY - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Top 1000 Africa Quiz and trivia: HISTORY - GEOGRAPHY - WILDLIFE - CULTURE - PEOPLE - LANGUAGES - TRAVEL - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Exploring the Pros and Cons of Visiting All Provinces and Territories in Canada.


Exploring the Advantages and Disadvantages of Visiting All 50 States in the USA

Health Health, a science-based community to discuss health news and the coronavirus (COVID-19) pandemic
- The pull-out method: Why this common contraceptive fails to deliverby /u/Kampala_Dispatch on July 26, 2024 at 7:51 pm
submitted by /u/Kampala_Dispatch [link] [comments]
- Health Canada data reveals surprising number of adverse cannabis reactions (spoiler: it's small)by /u/carajuana_readit on July 26, 2024 at 5:49 pm
submitted by /u/carajuana_readit [link] [comments]
- Online portals deliver scary health news before doctors can weigh inby /u/washingtonpost on July 26, 2024 at 4:37 pm
submitted by /u/washingtonpost [link] [comments]
- Vaccine 'sharply cuts risk of dementia' new study findsby /u/SubstantialSnow7114 on July 26, 2024 at 1:53 pm
submitted by /u/SubstantialSnow7114 [link] [comments]
- Calls to limit sexual partners as mpox makes a resurgence in Australiaby /u/boppinmule on July 26, 2024 at 12:31 pm
submitted by /u/boppinmule [link] [comments]
Today I Learned (TIL) You learn something new every day; what did you learn today? Submit interesting and specific facts about something that you just found out here.
- TIL that in Thailand, if your spouse cheats on you, you can legally sue their lover for damages and can receive up to 5,000,000 THB ($140,000 USD) or more under Section 1523 of the Thai Civil and Commercial Codeby /u/Mavrokordato on July 26, 2024 at 6:57 pm
submitted by /u/Mavrokordato [link] [comments]
- TIL that with a population of 170 million people, Bangladesh is the most populous country to have never won a medal at the Olympic Games.by /u/Blackraven2007 on July 26, 2024 at 6:49 pm
submitted by /u/Blackraven2007 [link] [comments]
- TIL a psychologist got himself admitted to a mental hospital by claiming he heard the words "empty", "hollow" and "thud" in his head. Then, it took him two months to convince them he was sane, after agreeing he was insane and accepting medication.by /u/Hadeverse-050 on July 26, 2024 at 6:44 pm
submitted by /u/Hadeverse-050 [link] [comments]
- TIL Senator John Edwards of NC, USA cheated on his wife and had a child with another woman. He tried to deny it but eventually caved and admitted his mistake. He used campaign funds and was indicted by a grand jury. His life story inspired the show "The Good Wife" by Robert & Michelle Kingby /u/AdvisorPast637 on July 26, 2024 at 6:09 pm
submitted by /u/AdvisorPast637 [link] [comments]
- TIL Zhang Shuhong was a Chinese businessman who committed suicide after toys made at his factory for Fisher-Price (a division of Mattel) were found to contain lead paintby /u/Hopeful-Candle-4884 on July 26, 2024 at 4:43 pm
submitted by /u/Hopeful-Candle-4884 [link] [comments]
Reddit Science This community is a place to share and discuss new scientific research. Read about the latest advances in astronomy, biology, medicine, physics, social science, and more. Find and submit new publications and popular science coverage of current research.
- Human decision makers who possess the authority to override ML predictions may impede the self-correction of discriminatory models and even induce initially unbiased models to become discriminatory with timeby /u/f1u82ypd on July 26, 2024 at 6:29 pm
submitted by /u/f1u82ypd [link] [comments]
- Study uses Game of Thrones (GOT) to advance understanding of face blindness: Psychologists have used the TV series GOT to understand how the brain enables us to recognise faces. Their findings provide new insights into prosopagnosia or face blindness, a condition that impairs facial recognition.by /u/AnnaMouse247 on July 26, 2024 at 5:14 pm
submitted by /u/AnnaMouse247 [link] [comments]
- Specific genes may be related to the trajectory of recovery for stroke survivors, study finds. Researchers say genetic variants were strongly associated with depression, PTSD and cognitive health outcomes. Findings may provide useful insights for developing targeted therapies.by /u/AnnaMouse247 on July 26, 2024 at 5:08 pm
submitted by /u/AnnaMouse247 [link] [comments]
- New experimental drug shows promise in clearing HIV from brain: originally developed to treat cancer, study finds that by targeting infected cells in the brain, drug may clear virus from hidden areas that have been a major challenge in HIV treatment.by /u/AnnaMouse247 on July 26, 2024 at 4:57 pm
submitted by /u/AnnaMouse247 [link] [comments]
- Rapid diagnosis sepsis tests could decrease result wait times from days to hours, researchers report in Natureby /u/Science_News on July 26, 2024 at 3:50 pm
submitted by /u/Science_News [link] [comments]
Reddit Sports Sports News and Highlights from the NFL, NBA, NHL, MLB, MLS, and leagues around the world.
- Charles Barkley leaves door open to post-TNT job optionsby /u/PrincessBananas85 on July 26, 2024 at 8:47 pm
submitted by /u/PrincessBananas85 [link] [comments]
- Report: Nuggets sign Westbrook to 2-year, $6.8M dealby /u/Oldtimer_2 on July 26, 2024 at 8:13 pm
submitted by /u/Oldtimer_2 [link] [comments]
- Dolphins signing Tua to 4-year, $212.4M extensionby /u/Oldtimer_2 on July 26, 2024 at 8:09 pm
submitted by /u/Oldtimer_2 [link] [comments]
- Rams cornerback Derion Kendrick suffers season-ending torn ACLby /u/Oldtimer_2 on July 26, 2024 at 8:06 pm
submitted by /u/Oldtimer_2 [link] [comments]
- Hosting the Olympics has become financially untenable, economists sayby /u/toaster_strudel_ on July 26, 2024 at 7:34 pm
submitted by /u/toaster_strudel_ [link] [comments]
