



AWS Certification Exam Prep: DynamoDB facts and summaries, AWS DynamoDB Top 10 Questions and Answers Dump
Definition 1: Amazon DynamoDB is a fully managed proprietary NoSQL database service that supports key-value and document data structures and is offered by Amazon.com as part of the Amazon Web Services portfolio. DynamoDB exposes a similar data model to and derives its name from Dynamo, but has a different underlying implementation. Dynamo had a multi-master design requiring the client to resolve version conflicts and DynamoDB uses synchronous replication across multiple datacenters for high durability and availability.
Definition 2: DynamoDB is a fast and flexible non-relational database service for any scale. DynamoDB enables customers to offload the administrative burdens of operating and scaling distributed databases to AWS so that they don’t have to worry about hardware provisioning, setup and configuration, throughput capacity planning, replication, software patching, or cluster scaling.
Amazon DynamoDB explained
- Fully Managed
- Fast, consistent Performance
- Fine-grained access control
- Flexible




AWS DynamoDB Facts and Summaries
- Amazon DynamoDB is a low-latency NoSQL database.
- DynamoDB consists of Tables, Items, and Attributes
- DynamoDb supports both document and key-value data models
- DynamoDB Supported documents formats are JSON, HTML, XML
- DynamoDB has 2 types of Primary Keys: Partition Key and combination of Partition Key + Sort Key (Composite Key)
- DynamoDB has 2 consistency models: Strongly Consistent / Eventually Consistent
- DynamoDB Access is controlled using IAM policies.
- DynamoDB has fine grained access control using IAM Condition parameter dynamodb:LeadingKeys to allow users to access only the items where the partition key vakue matches their user ID.
- DynamoDB Indexes enable fast queries on specific data columns
- DynamoDB indexes give you a different view of your data based on alternative Partition / Sort Keys.
- DynamoDB Local Secondary indexes must be created when you create your table, they have same partition Key as your table, and they have a different Sort Key.
- DynamoDB Global Secondary Index Can be created at any time: at table creation or after. They have a different partition Key as your table and a different sort key as your table.
- A DynamoDB query operation finds items in a table using only the primary Key attribute: You provide the Primary Key name and a distinct value to search for.
- A DynamoDB Scan operation examines every item in the table. By default, it return data attributes.
- DynamoDB Query operation is generally more efficient than a Scan.
- With DynamoDB, you can reduce the impact of a query or scan by setting a smaller page size which uses fewer read operations.
- To optimize DynamoDB performance, isolate scan operations to specific tables and segregate them from your mission-critical traffic.
- To optimize DynamoDB performance, try Parallel scans rather than the default sequential scan.
- To optimize DynamoDB performance: Avoid using scan operations if you can: design tables in a way that you can use Query, Get, or BatchGetItems APIs.
- When you scan your table in Amazon DynamoDB, you should follow the DynamoDB best practices for avoiding sudden bursts of read activity.
- DynamoDb Provisioned Throughput is measured in Capacity Units.
- 1 Write Capacity Unit = 1 x 1KB Write per second.
- 1 Read Capacity Unit = 1 x 4KB Strongly Consistent Read Or 2 x 4KB Eventually Consistent Reads per second. Eventual consistent reads give us the maximum performance with the read operation.
- What is the maximum throughput that can be provisioned for a single DynamoDB table?
DynamoDB is designed to scale without limits. However, if you want to exceed throughput rates of 10,000 write capacity units or 10,000 read capacity units for an individual table, you must Contact AWS to increase it.
If you want to provision more than 20,000 write capacity units or 20,000 read capacity units from a single subscriber account, you must first contact AWS to request a limit increase. - Dynamo Db Performance: DAX is a DynamoDB-compatible caching service that enables you to benefit from fast in-memory performance for demanding applications.
- As an in-memory cache, DAX reduces the response times of eventually-consistent read workloads by an order of magnitude, from single-digit milliseconds to microseconds
- DAX improves response times for Eventually Consistent reads only.
- With DAX, you point your API calls to the DAX cluster instead of your table.
- If the item you are querying is on the cache, DAX will return it; otherwise, it will perform and Eventually Consistent GetItem operation to your DynamoDB table.
- DAX reduces operational and application complexity by providing a managed service that is API compatible with Amazon DynamoDB, and thus requires only minimal functional changes to use with an existing application.
- DAX is not suitable for write-intensive applications or applications that require Strongly Consistent reads.
- For read-heavy or bursty workloads, DAX provides increased throughput and potential operational cost savings by reducing the need to over-provision read capacity units. This is especially beneficial for applications that require repeated reads for individual keys.
- Dynamo Db Performance: ElastiCache
- In-memory cache sits between your application and database
- 2 different caching strategies: Lazy loading and Write Through: Lazy loading only caches the data when it is requested
- Elasticache Node failures are not fatal, just lots of cache misses
- Avoid stale data by implementing a TTL.
- Write-Through strategy writes data into cache whenever there is a change to the database. Data is never stale
- Write-Through penalty: Each write involves a write to the cache. Elasticache node failure means that data is missing until added or updated in the database.
- Elasticache is wasted resources if most of the data is never used.
- Time To Live (TTL) for DynamoDB allows you to define when items in a table expire so that they can be automatically deleted from the database. TTL is provided at no extra cost as a way to reduce storage usage and reduce the cost of storing irrelevant data without using provisioned throughput. With TTL enabled on a table, you can set a timestamp for deletion on a per-item basis, allowing you to limit storage usage to only those records that are relevant.
- DynamoDB Security: DynamoDB uses the CMK to generate and encrypt a unique data key for the table, known as the table key. With DynamoDB, AWS Owned, or AWS Managed CMK can be used to generate & encrypt keys. AWS Owned CMK is free of charge while AWS Managed CMK is chargeable. Customer managed CMK’s are not supported with encryption at rest.
- Amazon DynamoDB offers fully managed encryption at rest. DynamoDB encryption at rest provides enhanced security by encrypting your data at rest using an AWS Key Management Service (AWS KMS) managed encryption key for DynamoDB. This functionality eliminates the operational burden and complexity involved in protecting sensitive data.
- DynamoDB is a alternative solution which can be used for storage of session management. The latency of access to data is less , hence this can be used as a data store for session management
- DynamoDB Streams Use Cases and Design Patterns:
How do you set up a relationship across multiple tables in which, based on the value of an item from one table, you update the item in a second table?
How do you trigger an event based on a particular transaction?
How do you audit or archive transactions?
How do you replicate data across multiple tables (similar to that of materialized views/streams/replication in relational data stores)?
As a NoSQL database, DynamoDB is not designed to support transactions. Although client-side libraries are available to mimic the transaction capabilities, they are not scalable and cost-effective. For example, the Java Transaction Library for DynamoDB creates 7N+4 additional writes for every write operation. This is partly because the library holds metadata to manage the transactions to ensure that it’s consistent and can be rolled back before commit.You can use DynamoDB Streams to address all these use cases. DynamoDB Streams is a powerful service that you can combine with other AWS services to solve many similar problems. When enabled, DynamoDB Streams captures a time-ordered sequence of item-level modifications in a DynamoDB table and durably stores the information for up to 24 hours. Applications can access a series of stream records, which contain an item change, from a DynamoDB stream in near real time.
AWS maintains separate endpoints for DynamoDB and DynamoDB Streams. To work with database tables and indexes, your application must access a DynamoDB endpoint. To read and process DynamoDB Streams records, your application must access a DynamoDB Streams endpoint in the same Region
- 20 global secondary indexes are allowed per table? (by default)
- What is one key difference between a global secondary index and a local secondary index?
A local secondary index must have the same partition key as the main table - How many tables can an AWS account have per region? 256
- How many secondary indexes (global and local combined) are allowed per table? (by default): 25
You can define up to 5 local secondary indexes and 20 global secondary indexes per table (by default) – for a total of 25. - How can you increase your DynamoDB table limit in a region?
By contacting AWS and requesting a limit increase - For any AWS account, there is an initial limit of 256 tables per region.
- The minimum length of a partition key value is 1 byte. The maximum length is 2048 bytes.
- The minimum length of a sort key value is 1 byte. The maximum length is 1024 bytes.
- For tables with local secondary indexes, there is a 10 GB size limit per partition key value. A table with local secondary indexes can store any number of items, as long as the total size for any one partition key value does not exceed 10 GB.
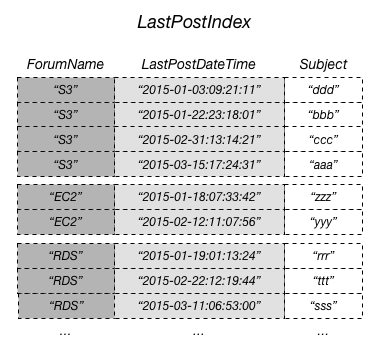
- The following diagram shows a local secondary index named LastPostIndex. Note that the partition key is the same as that of the Thread table, but the sort key is LastPostDateTime.


AWS DynamoDB secondary indexes example - Relational vs Non Relational (SQL vs NoSQL)



Top
Reference: AWS DynamoDB
AWS DynamoDB Questions and Answers Dumps
Q0: What should the Developer enable on the DynamoDB table to optimize performance and minimize costs?
- A. Amazon DynamoDB auto scaling
- B. Amazon DynamoDB cross-region replication
- C. Amazon DynamoDB Streams
- D. Amazon DynamoDB Accelerator

Top
Q2: A security system monitors 600 cameras, saving image metadata every 1 minute to an Amazon DynamoDb table. Each sample involves 1kb of data, and the data writes are evenly distributed over time. How much write throughput is required for the target table?
- A. 6000
- B. 10
- C. 3600
- D. 600
Q3: You are developing an application that will interact with a DynamoDB table. The table is going to take in a lot of read and write operations. Which of the following would be the ideal partition key for the DynamoDB table to ensure ideal performance?
- A. CustomerID
- B. CustomerName
- C. Location
- D. Age
Top
Q4: A DynamoDB table is set with a Read Throughput capacity of 5 RCU. Which of the following read configuration will provide us the maximum read throughput?
- A. Read capacity set to 5 for 4KB reads of data at strong consistency
- B. Read capacity set to 5 for 4KB reads of data at eventual consistency
- C. Read capacity set to 15 for 1KB reads of data at strong consistency
- D. Read capacity set to 5 for 1KB reads of data at eventual consistency

Q5: Your team is developing a solution that will make use of DynamoDB tables. Due to the nature of the application, the data is needed across a couple of regions across the world. Which of the following would help reduce the latency of requests to DynamoDB from different regions?
- A. Enable Multi-AZ for the DynamoDB table
- B. Enable global tables for DynamoDB
- C. Enable Indexes for the table
- D. Increase the read and write throughput for the tablez
Q6: An application is currently accessing a DynamoDB table. Currently the tables queries are performing well. Changes have been made to the application and now the performance of the application is starting to degrade. After looking at the changes , you see that the queries are making use of an attribute which is not the partition key? Which of the following would be the adequate change to make to resolve the issue?
- A. Add an index for the DynamoDB table
- B. Change all the queries to ensure they use the partition key
- C. Enable global tables for DynamoDB
- D. Change the read capacity on the table

Q7: Company B has created an e-commerce site using DynamoDB and is designing a products table that includes items purchased and the users who purchased the item.
When creating a primary key on a table which of the following would be the best attribute for the partition key? Select the BEST possible answer.
- A. None of these are correct.
- B. user_id where there are many users to few products
- C. category_id where there are few categories to many products
- D. product_id where there are few products to many users
Q8: Which API call can be used to retrieve up to 100 items at a time or 16 MB of data from a DynamoDB table?
- A. BatchItem
- B. GetItem
- C. BatchGetItem
- D. ChunkGetItem
Q9: Which DynamoDB limits can be raised by contacting AWS support?
- A. The number of hash keys per account
- B. The maximum storage used per account
- C. The number of tables per account
- D. The number of local secondary indexes per account
- E. The number of provisioned throughput units per account
Top
Q10: Which approach below provides the least impact to provisioned throughput on the “Product”
table?
- A. Create an “Images” DynamoDB table to store the Image with a foreign key constraint to
the “Product” table - B. Add an image data type to the “Product” table to store the images in binary format
- C. Serialize the image and store it in multiple DynamoDB tables
- D. Store the images in Amazon S3 and add an S3 URL pointer to the “Product” table item
for each image
Top
Q11: You’re creating a forum DynamoDB database for hosting forums. Your “thread” table contains the forum name and each “forum name” can have one or more “subjects”. What primary key type would you give the thread table in order to allow more than one subject to be tied to the forum primary key name?
- A. Hash
- B. Range and Hash
- C. Primary and Range
- D. Hash and Range
Amazon Aurora explained:
- High scalability
- High availability and durability
- High Performance
- Multi Region

Amazon ElastiCache Explained
- In-Memory data store
- High availability and reliability
- Fully managed
- Supports two pop
- Open source engine

Amazon Redshift explained
- Fast, fully managed, petabyte-scale data warehouse
- Supports wide range of open data formats
- Allows you to run SQL queries against large unstructured data in Amazon Simple Storage Service
- Integrates with popular Business Intelligence (BI) and extract, Transform, Load (ETL) solutions.

Amazon Neptune Explained
- Fully managed graph database
- Supports open graph APIs
- Used in Social Networking


Amazon Neptune Explained
Other AWS Facts and Summaries and Questions/Answers Dump
- AWS S3 facts and summaries and Q&A Dump
- AWS DynamoDB facts and summaries and Questions and Answers Dump
- AWS EC2 facts and summaries and Questions and Answers Dump
- AWS Serverless facts and summaries and Questions and Answers Dump
- AWS Developer and Deployment Theory facts and summaries and Questions and Answers Dump
- AWS IAM facts and summaries and Questions and Answers Dump
- AWS Lambda facts and summaries and Questions and Answers Dump
- AWS SQS facts and summaries and Questions and Answers Dump
- AWS RDS facts and summaries and Questions and Answers Dump
- AWS ECS facts and summaries and Questions and Answers Dump
- AWS CloudWatch facts and summaries and Questions and Answers Dump
- AWS SES facts and summaries and Questions and Answers Dump
- AWS EBS facts and summaries and Questions and Answers Dump
- AWS ELB facts and summaries and Questions and Answers Dump
- AWS Autoscaling facts and summaries and Questions and Answers Dump
- AWS VPC facts and summaries and Questions and Answers Dump
- AWS KMS facts and summaries and Questions and Answers Dump
- AWS Elastic Beanstalk facts and summaries and Questions and Answers Dump
- AWS CodeBuild facts and summaries and Questions and Answers Dump
- AWS CodeDeploy facts and summaries and Questions and Answers Dump
- AWS CodePipeline facts and summaries and Questions and Answers Dump
AWS Certification Exam Prep: S3 Facts, Summaries, Questions and Answers

AWS Certification Exam Prep: S3 Facts, Summaries, Questions and Answers
AWS S3 Facts and summaries, AWS S3 Top 10 Questions and Answers Dump
Definition 1: Amazon S3 or Amazon Simple Storage Service is a “simple storage service” offered by Amazon Web Services that provides object storage through a web service interface. Amazon S3 uses the same scalable storage infrastructure that Amazon.com uses to run its global e-commerce network.
Definition 2: Amazon Simple Storage Service (Amazon S3) is an object storage service that offers industry-leading scalability, data availability, security, and performance.
AWS S3 Explained graphically:










AWS S3 Facts and summaries
- S3 is a universal namespace, meaning each S3 bucket you create must have a unique name that is not being used by anyone else in the world.
- S3 is object based: i.e allows you to upload files.
- Files can be from 0 Bytes to 5 TB
- What is the maximum length, in bytes, of a DynamoDB range primary key attribute value?
The maximum length of a DynamoDB range primary key attribute value is 2048 bytes (NOT 256 bytes). - S3 has unlimited storage.
- Files are stored in Buckets.
- Read after write consistency for PUTS of new Objects
- Eventual Consistency for overwrite PUTS and DELETES (can take some time to propagate)
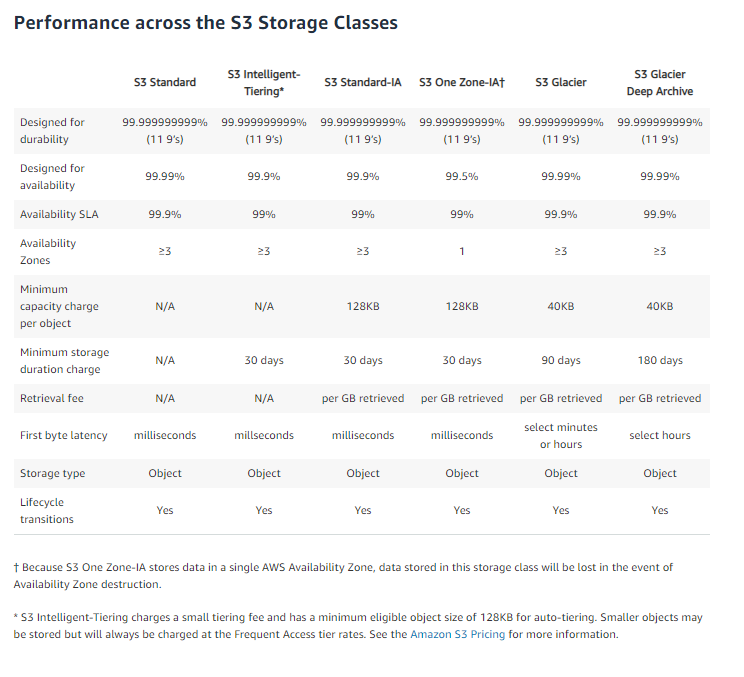
- S3 Storage Classes/Tiers:


- S3 Standard (durable, immediately available, frequently accesses)
- Amazon S3 Intelligent-Tiering (S3 Intelligent-Tiering): It works by storing objects in two access tiers: one tier that is optimized for frequent access and another lower-cost tier that is optimized for infrequent access.
- S3 Standard-Infrequent Access – S3 Standard-IA (durable, immediately available, infrequently accessed)
- S3 – One Zone-Infrequent Access – S3 One Zone IA: Same ad IA. However, data is stored in a single Availability Zone only
- S3 – Reduced Redundancy Storage (data that is easily reproducible, such as thumbnails, etc.)
- Glacier – Archived data, where you can wait 3-5 hours before accessing
You can have a bucket that has different objects stored in S3 Standard, S3 Intelligent-Tiering, S3 Standard-IA, and S3 One Zone-IA.
- The default URL for S3 hosted websites lists the bucket name first followed by s3-website-region.amazonaws.com . Example: enoumen.com.s3-website-us-east-1.amazonaws.com
- Core fundamentals of an S3 object
- Key (name)
- Value (data)
- Version (ID)
- Metadata
- Sub-resources (used to manage bucket-specific configuration)
- Bucket Policies, ACLs,
- CORS
- Transfer Acceleration
- Object-based storage only for files
- Not suitable to install OS on.
- Successful uploads will generate a HTTP 200 status code.
- S3 Security – Summary
- By default, all newly created buckets are PRIVATE.
- You can set up access control to your buckets using:
- Bucket Policies – Applied at the bucket level
- Access Control Lists – Applied at an object level.
- S3 buckets can be configured to create access logs, which log all requests made to the S3 bucket. These logs can be written to another bucket.
- S3 Encryption
- Encryption In-Transit (SSL/TLS)
- Encryption At Rest:
- Server side Encryption (SSE-S3, SSE-KMS, SSE-C)
- Client Side Encryption
- Remember that we can use a Bucket policy to prevent unencrypted files from being uploaded by creating a policy which only allows requests which include the x-amz-server-side-encryption parameter in the request header.
- S3 CORS (Cross Origin Resource Sharing):
CORS defines a way for client web applications that are loaded in one domain to interact with resources in a different domain.- Used to enable cross origin access for your AWS resources, e.g. S3 hosted website accessing javascript or image files located in another bucket. By default, resources in one bucket cannot access resources located in another. To allow this we need to configure CORS on the bucket being accessed and enable access for the origin (bucket) attempting to access.
- Always use the S3 website URL, not the regular bucket URL. E.g.: https://s3-eu-west-2.amazonaws.com/acloudguru
- S3 CloudFront:
- Edge locations are not just READ only – you can WRITE to them too (i.e put an object on to them.)
- Objects are cached for the life of the TTL (Time to Live)
- You can clear cached objects, but you will be charged. (Invalidation)
- S3 Performance optimization – 2 main approaches to Performance Optimization for S3:
- GET-Intensive Workloads – Use Cloudfront
- Mixed Workload – Avoid sequencial key names for your S3 objects. Instead, add a random prefix like a hex hash to the key name to prevent multiple objects from being stored on the same partition.
- mybucket/7eh4-2019-03-04-15-00-00/cust1234234/photo1.jpg
- mybucket/h35d-2019-03-04-15-00-00/cust1234234/photo2.jpg
- mybucket/o3n6-2019-03-04-15-00-00/cust1234234/photo3.jpg
- The best way to handle large objects uploads to the S3 service is to use the Multipart upload API. The Multipart upload API enables you to upload large objects in parts.
- You can enable versioning on a bucket, even if that bucket already has objects in it. The already existing objects, though, will show their versions as null. All new objects will have version IDs.
- Bucket names cannot start with a . or – characters. S3 bucket names can contain both the . and – characters. There can only be one . or one – between labels. E.G mybucket-com mybucket.com are valid names but mybucket–com and mybucket..com are not valid bucket names.
- What is the maximum number of S3 buckets allowed per AWS account (by default)? 100
- You successfully upload an item to the us-east-1 region. You then immediately make another API call and attempt to read the object. What will happen?
All AWS regions now have read-after-write consistency for PUT operations of new objects. Read-after-write consistency allows you to retrieve objects immediately after creation in Amazon S3. Other actions still follow the eventual consistency model (where you will sometimes get stale results if you have recently made changes) - S3 bucket policies require a Principal be defined. Review the access policy elements here
- What checksums does Amazon S3 employ to detect data corruption?
Amazon S3 uses a combination of Content-MD5 checksums and cyclic redundancy checks (CRCs) to detect data corruption. Amazon S3 performs these checksums on data at rest and repairs any corruption using redundant data. In addition, the service calculates checksums on all network traffic to detect corruption of data packets when storing or retrieving data.
AWS S3 Top 10 Questions and Answers Dump
Q0: You’ve written an application that uploads objects onto an S3 bucket. The size of the object varies between 200 – 500 MB. You’ve seen that the application sometimes takes a longer than expected time to upload the object. You want to improve the performance of the application. Which of the following would you consider?
- A. Create multiple threads and upload the objects in the multiple threads
- B. Write the items in batches for better performance
- C. Use the Multipart upload API
- D. Enable versioning on the Bucket
Top
Q2: You are using AWS SAM templates to deploy a serverless application. Which of the following resource will embed application from Amazon S3 buckets?
- A. AWS::Serverless::Api
- B. AWS::Serverless::Application
- C. AWS::Serverless::Layerversion
- D. AWS::Serverless::Function
Top
Q3: A static web site has been hosted on a bucket and is now being accessed by users. One of the web pages javascript section has been changed to access data which is hosted in another S3 bucket. Now that same web page is no longer loading in the browser. Which of the following can help alleviate the error?
- A. Enable versioning for the underlying S3 bucket.
- B. Enable Replication so that the objects get replicated to the other bucket
- C. Enable CORS for the bucket
- D. Change the Bucket policy for the bucket to allow access from the other bucket
Top
Advertise with us - Post Your Good Content Here
We are ranked in the Top 20 on Google
AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
Q4: Your mobile application includes a photo-sharing service that is expecting tens of thousands of users at launch. You will leverage Amazon Simple Storage Service (S3) for storage of the user Images, and you must decide how to authenticate and authorize your users for access to these images. You also need to manage the storage of these images. Which two of the following approaches should you use? Choose two answers from the options below
- A. Create an Amazon S3 bucket per user, and use your application to generate the S3 URL for the appropriate content.
- B. Use AWS Identity and Access Management (IAM) user accounts as your application-level user database, and offload the burden of authentication from your application code.
- C. Authenticate your users at the application level, and use AWS Security Token Service (STS)to grant token-based authorization to S3 objects.
- D. Authenticate your users at the application level, and send an SMS token message to the user. Create an Amazon S3 bucket with the same name as the SMS message token, and move the user’s objects to that bucket.
Top
Q5: Both ACLs and Bucket Policies can be used to grant access to S3 buckets. Which of the following statements is true about ACLs and Bucket policies?
- A. Bucket Policies are Written in JSON and ACLs are written in XML
- B. ACLs can be attached to S3 objects or S3 Buckets
- C. Bucket Policies and ACLs are written in JSON
- D. Bucket policies are only attached to s3 buckets, ACLs are only attached to s3 objects
Q6: What are good options to improve S3 performance when you have significantly high numbers of GET requests?
- A. Introduce random prefixes to S3 objects
- B. Introduce random suffixes to S3 objects
- C. Setup CloudFront for S3 objects
- D. Migrate commonly used objects to Amazon Glacier
Q7: If an application is storing hourly log files from thousands of instances from a high traffic
web site, which naming scheme would give optimal performance on S3?
- A. Sequential
- B. HH-DD-MM-YYYY-log_instanceID
- C. YYYY-MM-DD-HH-log_instanceID
- D. instanceID_log-HH-DD-MM-YYYY
- E. instanceID_log-YYYY-MM-DD-HH
Top

Q8: You are working with the S3 API and receive an error message: 409 Conflict. What is the possible cause of this error
- A. You’re attempting to remove a bucket without emptying the contents of the bucket first.
- B. You’re attempting to upload an object to the bucket that is greater than 5TB in size.
- C. Your request does not contain the proper metadata.
- D. Amazon S3 is having internal issues.
Q9: You created three S3 buckets – “mywebsite.com”, “downloads.mywebsite.com”, and “www.mywebsite.com”. You uploaded your files and enabled static website hosting. You specified both of the default documents under the “enable static website hosting” header. You also set the “Make Public” permission for the objects in each of the three buckets. You create the Route 53 Aliases for the three buckets. You are going to have your end users test your websites by browsing to http://mydomain.com/error.html, http://downloads.mydomain.com/index.html, and http://www.mydomain.com. What problems will your testers encounter?
- A. http://mydomain.com/error.html will not work because you did not set a value for the error.html file
- B. There will be no problems, all three sites should work.
- C. http://www.mywebsite.com will not work because the URL does not include a file name at the end of it.
- D. http://downloads.mywebsite.com/index.html will not work because the “downloads” prefix is not a supported prefix for S3 websites using Route 53 aliases
Q10: Which of the following is NOT a common S3 API call?
- A. UploadPart
- B. ReadObject
- C. PutObject
- D. DownloadBucket
Other AWS Facts and Summaries
- AWS S3 facts and summaries
- AWS DynamoDB facts and summaries
- AWS EC2 facts and summaries
- AWS Lambda facts and summaries
- AWS SQS facts and summaries
- AWS RDS facts and summaries
- AWS ECS facts and summaries
- AWS CloudWatch facts and summaries
- AWS SES facts and summaries
- AWS EBS facts and summaries
- AWS Serverless facts and summaries
- AWS ELB facts and summaries
- AWS Autoscaling facts and summaries
- AWS VPC facts and summaries
- AWS KMS facts and summaries
- AWS Elastic Beanstalk facts and summaries
- AWS CodeBuild facts and summaries
- AWS CodeDeploy facts and summaries
- AWS CodePipeline facts and summaries
2022 AWS Certified Developer Associate Exam Preparation: Questions and Answers Dump

2022 AWS Certified Developer Associate Exam Preparation: Questions and Answers Dump.
Welcome to AWS Certified Developer Associate Exam Preparation:
Definition and Objectives, Top 100 Questions and Answers dump, White papers, Courses, Labs and Training Materials, Exam info and details, References, Jobs, Others AWS Certificates

What is the AWS Certified Developer Associate Exam?
This AWS Certified Developer-Associate Examination is intended for individuals who perform a Developer role. It validates an examinee’s ability to:
- Demonstrate an understanding of core AWS services, uses, and basic AWS architecture best practices
- Demonstrate proficiency in developing, deploying, and debugging cloud-based applications by using AWS
Recommended general IT knowledge
The target candidate should have the following:
– In-depth knowledge of at least one high-level programming language
– Understanding of application lifecycle management
– The ability to write code for serverless applications
– Understanding of the use of containers in the development process
Recommended AWS knowledge
The target candidate should be able to do the following:
- Use the AWS service APIs, CLI, and software development kits (SDKs) to write applications
- Identify key features of AWS services
- Understand the AWS shared responsibility model
- Use a continuous integration and continuous delivery (CI/CD) pipeline to deploy applications on AWS
- Use and interact with AWS services
- Apply basic understanding of cloud-native applications to write code
- Write code by using AWS security best practices (for example, use IAM roles instead of secret and access keys in the code)
- Author, maintain, and debug code modules on AWS
What is considered out of scope for the target candidate?
The following is a non-exhaustive list of related job tasks that the target candidate is not expected to be able to perform. These items are considered out of scope for the exam:
– Design architectures (for example, distributed system, microservices)
– Design and implement CI/CD pipelines
- Administer IAM users and groups
- Administer Amazon Elastic Container Service (Amazon ECS)
- Design AWS networking infrastructure (for example, Amazon VPC, AWS Direct Connect)
- Understand compliance and licensing
Exam content
Response types
There are two types of questions on the exam:
– Multiple choice: Has one correct response and three incorrect responses (distractors)
– Multiple response: Has two or more correct responses out of five or more response options
Select one or more responses that best complete the statement or answer the question. Distractors, or incorrect answers, are response options that a candidate with incomplete knowledge or skill might choose.
Distractors are generally plausible responses that match the content area.
Unanswered questions are scored as incorrect; there is no penalty for guessing. The exam includes 50 questions that will affect your score.
Unscored content
The exam includes 15 unscored questions that do not affect your score. AWS collects information about candidate performance on these unscored questions to evaluate these questions for future use as scored questions. These unscored questions are not identified on the exam.
Exam results
The AWS Certified Developer – Associate (DVA-C01) exam is a pass or fail exam. The exam is scored against a minimum standard established by AWS professionals who follow certification industry best practices and guidelines.
Your results for the exam are reported as a scaled score of 100–1,000. The minimum passing score is 720.
Your score shows how you performed on the exam as a whole and whether you passed. Scaled scoring models help equate scores across multiple exam forms that might have slightly different difficulty levels.
Your score report could contain a table of classifications of your performance at each section level. This information is intended to provide general feedback about your exam performance. The exam uses a compensatory scoring model, which means that you do not need to achieve a passing score in each section. You need to pass only the overall exam.
Each section of the exam has a specific weighting, so some sections have more questions than other sections have. The table contains general information that highlights your strengths and weaknesses. Use caution when interpreting section-level feedback.
Content outline
This exam guide includes weightings, test domains, and objectives for the exam. It is not a comprehensive listing of the content on the exam. However, additional context for each of the objectives is available to help guide your preparation for the exam. The following table lists the main content domains and their weightings. The table precedes the complete exam content outline, which includes the additional context.
The percentage in each domain represents only scored content.
Domain 1: Deployment 22%
Domain 2: Security 26%
Domain 3: Development with AWS Services 30%
Domain 4: Refactoring 10%
Domain 5: Monitoring and Troubleshooting 12%
Domain 1: Deployment
1.1 Deploy written code in AWS using existing CI/CD pipelines, processes, and patterns.
– Commit code to a repository and invoke build, test and/or deployment actions
– Use labels and branches for version and release management
– Use AWS CodePipeline to orchestrate workflows against different environments
– Apply AWS CodeCommit, AWS CodeBuild, AWS CodePipeline, AWS CodeStar, and AWS
CodeDeploy for CI/CD purposes
– Perform a roll back plan based on application deployment policy
1.2 Deploy applications using AWS Elastic Beanstalk.
– Utilize existing supported environments to define a new application stack
– Package the application
– Introduce a new application version into the Elastic Beanstalk environment
– Utilize a deployment policy to deploy an application version (i.e., all at once, rolling, rolling with batch, immutable)
– Validate application health using Elastic Beanstalk dashboard
– Use Amazon CloudWatch Logs to instrument application logging
1.3 Prepare the application deployment package to be deployed to AWS.
– Manage the dependencies of the code module (like environment variables, config files and static image files) within the package
– Outline the package/container directory structure and organize files appropriately
– Translate application resource requirements to AWS infrastructure parameters (e.g., memory, cores)
1.4 Deploy serverless applications.
– Given a use case, implement and launch an AWS Serverless Application Model (AWS SAM) template
– Manage environments in individual AWS services (e.g., Differentiate between Development, Test, and Production in Amazon API Gateway)
Domain 2: Security
2.1 Make authenticated calls to AWS services.
– Communicate required policy based on least privileges required by application.
– Assume an IAM role to access a service
– Use the software development kit (SDK) credential provider on-premises or in the cloud to access AWS services (local credentials vs. instance roles)
2.2 Implement encryption using AWS services.
– Encrypt data at rest (client side; server side; envelope encryption) using AWS services
– Encrypt data in transit
Advertise with us - Post Your Good Content Here
We are ranked in the Top 20 on Google
AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
2.3 Implement application authentication and authorization.
– Add user sign-up and sign-in functionality for applications with Amazon Cognito identity or user pools
– Use Amazon Cognito-provided credentials to write code that access AWS services.
– Use Amazon Cognito sync to synchronize user profiles and data
– Use developer-authenticated identities to interact between end user devices, backend
authentication, and Amazon Cognito
Domain 3: Development with AWS Services
3.1 Write code for serverless applications.
– Compare and contrast server-based vs. serverless model (e.g., micro services, stateless nature of serverless applications, scaling serverless applications, and decoupling layers of serverless applications)
– Configure AWS Lambda functions by defining environment variables and parameters (e.g., memory, time out, runtime, handler)
– Create an API endpoint using Amazon API Gateway
– Create and test appropriate API actions like GET, POST using the API endpoint
– Apply Amazon DynamoDB concepts (e.g., tables, items, and attributes)
– Compute read/write capacity units for Amazon DynamoDB based on application requirements
– Associate an AWS Lambda function with an AWS event source (e.g., Amazon API Gateway, Amazon CloudWatch event, Amazon S3 events, Amazon Kinesis)
– Invoke an AWS Lambda function synchronously and asynchronously
3.2 Translate functional requirements into application design.
– Determine real-time vs. batch processing for a given use case
– Determine use of synchronous vs. asynchronous for a given use case
– Determine use of event vs. schedule/poll for a given use case
– Account for tradeoffs for consistency models in an application design
Domain 4: Refactoring
4.1 Optimize applications to best use AWS services and features.
Implement AWS caching services to optimize performance (e.g., Amazon ElastiCache, Amazon API Gateway cache)
Apply an Amazon S3 naming scheme for optimal read performance
4.2 Migrate existing application code to run on AWS.
– Isolate dependencies
– Run the application as one or more stateless processes
– Develop in order to enable horizontal scalability
– Externalize state
Domain 5: Monitoring and Troubleshooting
5.1 Write code that can be monitored.
– Create custom Amazon CloudWatch metrics
– Perform logging in a manner available to systems operators
– Instrument application source code to enable tracing in AWS X-Ray
5.2 Perform root cause analysis on faults found in testing or production.
– Interpret the outputs from the logging mechanism in AWS to identify errors in logs
– Check build and testing history in AWS services (e.g., AWS CodeBuild, AWS CodeDeploy, AWS CodePipeline) to identify issues
– Utilize AWS services (e.g., Amazon CloudWatch, VPC Flow Logs, and AWS X-Ray) to locate a specific faulty component
Which key tools, technologies, and concepts might be covered on the exam?
The following is a non-exhaustive list of the tools and technologies that could appear on the exam.
This list is subject to change and is provided to help you understand the general scope of services, features, or technologies on the exam.
The general tools and technologies in this list appear in no particular order.
AWS services are grouped according to their primary functions. While some of these technologies will likely be covered more than others on the exam, the order and placement of them in this list is no indication of relative weight or importance:
– Analytics
– Application Integration
– Containers
– Cost and Capacity Management
– Data Movement
– Developer Tools
– Instances (virtual machines)
– Management and Governance
– Networking and Content Delivery
– Security
– Serverless
AWS services and features
Analytics:
– Amazon Elasticsearch Service (Amazon ES)
– Amazon Kinesis
Application Integration:
– Amazon EventBridge (Amazon CloudWatch Events)
– Amazon Simple Notification Service (Amazon SNS)
– Amazon Simple Queue Service (Amazon SQS)
– AWS Step Functions
Compute:
– Amazon EC2
– AWS Elastic Beanstalk
– AWS Lambda
Containers:
– Amazon Elastic Container Registry (Amazon ECR)
– Amazon Elastic Container Service (Amazon ECS)
– Amazon Elastic Kubernetes Services (Amazon EKS)
Database:
– Amazon DynamoDB
– Amazon ElastiCache
– Amazon RDS
Developer Tools:
– AWS CodeArtifact
– AWS CodeBuild
– AWS CodeCommit
– AWS CodeDeploy
– Amazon CodeGuru
– AWS CodePipeline
– AWS CodeStar
– AWS Fault Injection Simulator
– AWS X-Ray
Management and Governance:
– AWS CloudFormation
– Amazon CloudWatch
Networking and Content Delivery:
– Amazon API Gateway
– Amazon CloudFront
– Elastic Load Balancing
Security, Identity, and Compliance:
– Amazon Cognito
– AWS Identity and Access Management (IAM)
– AWS Key Management Service (AWS KMS)
Storage:
– Amazon S3
Out-of-scope AWS services and features
The following is a non-exhaustive list of AWS services and features that are not covered on the exam.
These services and features do not represent every AWS offering that is excluded from the exam content.
Services or features that are entirely unrelated to the target job roles for the exam are excluded from this list because they are assumed to be irrelevant.
Out-of-scope AWS services and features include the following:
– AWS Application Discovery Service
– Amazon AppStream 2.0
– Amazon Chime
– Amazon Connect
– AWS Database Migration Service (AWS DMS)
– AWS Device Farm
– Amazon Elastic Transcoder
– Amazon GameLift
– Amazon Lex
– Amazon Machine Learning (Amazon ML)
– AWS Managed Services
– Amazon Mobile Analytics
– Amazon Polly
– Amazon QuickSight
– Amazon Rekognition
– AWS Server Migration Service (AWS SMS)
– AWS Service Catalog
– AWS Shield Advanced
– AWS Shield Standard
– AWS Snow Family
– AWS Storage Gateway
– AWS WAF
– Amazon WorkMail
– Amazon WorkSpaces
To succeed with the real exam, do not memorize the answers below. It is very important that you understand why a question is right or wrong and the concepts behind it by carefully reading the reference documents in the answers.
AWS Certified Developer – Associate Practice Questions And Answers Dump
Q0: Your application reads commands from an SQS queue and sends them to web services hosted by your
partners. When a partner’s endpoint goes down, your application continually returns their commands to the queue. The repeated attempts to deliver these commands use up resources. Commands that can’t be delivered must not be lost.
How can you accommodate the partners’ broken web services without wasting your resources?
- A. Create a delay queue and set DelaySeconds to 30 seconds
- B. Requeue the message with a VisibilityTimeout of 30 seconds.
- C. Create a dead letter queue and set the Maximum Receives to 3.
- D. Requeue the message with a DelaySeconds of 30 seconds.

Top

Q1: A developer is writing an application that will store data in a DynamoDB table. The ratio of reads operations to write operations will be 1000 to 1, with the same data being accessed frequently.
What should the Developer enable on the DynamoDB table to optimize performance and minimize costs?
- A. Amazon DynamoDB auto scaling
- B. Amazon DynamoDB cross-region replication
- C. Amazon DynamoDB Streams
- D. Amazon DynamoDB Accelerator
Top
Q2: You are creating a DynamoDB table with the following attributes:
- PurchaseOrderNumber (partition key)
- CustomerID
- PurchaseDate
- TotalPurchaseValue
One of your applications must retrieve items from the table to calculate the total value of purchases for a
particular customer over a date range. What secondary index do you need to add to the table?
- A. Local secondary index with a partition key of CustomerID and sort key of PurchaseDate; project the
TotalPurchaseValue attribute - B. Local secondary index with a partition key of PurchaseDate and sort key of CustomerID; project the
TotalPurchaseValue attribute - C. Global secondary index with a partition key of CustomerID and sort key of PurchaseDate; project the
TotalPurchaseValue attribute - D. Global secondary index with a partition key of PurchaseDate and sort key of CustomerID; project the
TotalPurchaseValue attribute

Top
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:

Q3: When referencing the remaining time left for a Lambda function to run within the function’s code you would use:
- A. The event object
- B. The timeLeft object
- C. The remains object
- D. The context object

Top
Q4: What two arguments does a Python Lambda handler function require?
- A. invocation, zone
- B. event, zone
- C. invocation, context
- D. event, context
Q5: Lambda allows you to upload code and dependencies for function packages:
- A. Only from a directly uploaded zip file
- B. Only via SFTP
- C. Only from a zip file in AWS S3
- D. From a zip file in AWS S3 or uploaded directly from elsewhere
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:

Q6: A Lambda deployment package contains:
- A. Function code, libraries, and runtime binaries
- B. Only function code
- C. Function code and libraries not included within the runtime
- D. Only libraries not included within the runtime
Q7: You are attempting to SSH into an EC2 instance that is located in a public subnet. However, you are currently receiving a timeout error trying to connect. What could be a possible cause of this connection issue?
- A. The security group associated with the EC2 instance has an inbound rule that allows SSH traffic, but does not have an outbound rule that allows SSH traffic.
- B. The security group associated with the EC2 instance has an inbound rule that allows SSH traffic AND has an outbound rule that explicitly denies SSH traffic.
- C. The security group associated with the EC2 instance has an inbound rule that allows SSH traffic AND the associated NACL has both an inbound and outbound rule that allows SSH traffic.
- D. The security group associated with the EC2 instance does not have an inbound rule that allows SSH traffic AND the associated NACL does not have an outbound rule that allows SSH traffic.
Top

Q8: You have instances inside private subnets and a properly configured bastion host instance in a public subnet. None of the instances in the private subnets have a public or Elastic IP address. How can you connect an instance in the private subnet to the open internet to download system updates?
- A. Create and assign EIP to each instance
- B. Create and attach a second IGW to the VPC.
- C. Create and utilize a NAT Gateway
- D. Connect to a VPN
Top
Q9: What feature of VPC networking should you utilize if you want to create “elasticity” in your application’s architecture?
- A. Security Groups
- B. Route Tables
- C. Elastic Load Balancer
- D. Auto Scaling
Top
Q10: Lambda allows you to upload code and dependencies for function packages:
- A. Only from a directly uploaded zip file
- B. Only from a directly uploaded zip file
- C. Only from a zip file in AWS S3
- D. From a zip file in AWS S3 or uploaded directly from elsewhere
Q11: You’re writing a script with an AWS SDK that uses the AWS API Actions and want to create AMIs for non-EBS backed AMIs for you. Which API call should occurs in the final process of creating an AMI?
- A. RegisterImage
- B. CreateImage
- C. ami-register-image
- D. ami-create-image
Q12: When dealing with session state in EC2-based applications using Elastic load balancers which option is generally thought of as the best practice for managing user sessions?
- A. Having the ELB distribute traffic to all EC2 instances and then having the instance check a caching solution like ElastiCache running Redis or Memcached for session information
- B. Permenantly assigning users to specific instances and always routing their traffic to those instances
- C. Using Application-generated cookies to tie a user session to a particular instance for the cookie duration
- D. Using Elastic Load Balancer generated cookies to tie a user session to a particular instance
Q13: Which API call would best be used to describe an Amazon Machine Image?
- A. ami-describe-image
- B. ami-describe-images
- C. DescribeImage
- D. DescribeImages
Q14: What is one key difference between an Amazon EBS-backed and an instance-store backed instance?
- A. Autoscaling requires using Amazon EBS-backed instances
- B. Virtual Private Cloud requires EBS backed instances
- C. Amazon EBS-backed instances can be stopped and restarted without losing data
- D. Instance-store backed instances can be stopped and restarted without losing data
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q15: After having created a new Linux instance on Amazon EC2, and downloaded the .pem file (called Toto.pem) you try and SSH into your IP address (54.1.132.33) using the following command.
ssh -i my_key.pem ec2-user@52.2.222.22
However you receive the following error.
@@@@@@@@ WARNING: UNPROTECTED PRIVATE KEY FILE! @ @@@@@@@@@@@@@@@@@@@
What is the most probable reason for this and how can you fix it?
- A. You do not have root access on your terminal and need to use the sudo option for this to work.
- B. You do not have enough permissions to perform the operation.
- C. Your key file is encrypted. You need to use the -u option for unencrypted not the -i option.
- D. Your key file must not be publicly viewable for SSH to work. You need to modify your .pem file to limit permissions.
Q16: You have an EBS root device on /dev/sda1 on one of your EC2 instances. You are having trouble with this particular instance and you need to either Stop/Start, Reboot or Terminate the instance but you do NOT want to lose any data that you have stored on /dev/sda1. However, you are unsure if changing the instance state in any of the aforementioned ways will cause you to lose data stored on the EBS volume. Which of the below statements best describes the effect each change of instance state would have on the data you have stored on /dev/sda1?
- A. Whether you stop/start, reboot or terminate the instance it does not matter because data on an EBS volume is not ephemeral and the data will not be lost regardless of what method is used.
- B. If you stop/start the instance the data will not be lost. However if you either terminate or reboot the instance the data will be lost.
- C. Whether you stop/start, reboot or terminate the instance it does not matter because data on an EBS volume is ephemeral and it will be lost no matter what method is used.
- D. The data will be lost if you terminate the instance, however the data will remain on /dev/sda1 if you reboot or stop/start the instance because data on an EBS volume is not ephemeral.
Q17: EC2 instances are launched from Amazon Machine Images (AMIs). A given public AMI:
- A. Can only be used to launch EC2 instances in the same AWS availability zone as the AMI is stored
- B. Can only be used to launch EC2 instances in the same country as the AMI is stored
- C. Can only be used to launch EC2 instances in the same AWS region as the AMI is stored
- D. Can be used to launch EC2 instances in any AWS region
Q18: Which of the following statements is true about the Elastic File System (EFS)?
- A. EFS can scale out to meet capacity requirements and scale back down when no longer needed
- B. EFS can be used by multiple EC2 instances simultaneously
- C. EFS cannot be used by an instance using EBS
- D. EFS can be configured on an instance before launch just like an IAM role or EBS volumes
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q19: IAM Policies, at a minimum, contain what elements?
- A. ID
- B. Effects
- C. Resources
- D. Sid
- E. Principle
- F. Actions
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q20: What are the main benefits of IAM groups?
- A. The ability to create custom permission policies.
- B. Assigning IAM permission policies to more than one user at a time.
- C. Easier user/policy management.
- D. Allowing EC2 instances to gain access to S3.
Q21: What are benefits of using AWS STS?
- A. Grant access to AWS resources without having to create an IAM identity for them
- B. Since credentials are temporary, you don’t have to rotate or revoke them
- C. Temporary security credentials can be extended indefinitely
- D. Temporary security credentials can be restricted to a specific region
Q22: What should the Developer enable on the DynamoDB table to optimize performance and minimize costs?
- A. Amazon DynamoDB auto scaling
- B. Amazon DynamoDB cross-region replication
- C. Amazon DynamoDB Streams
- D. Amazon DynamoDB Accelerator
Top
Q23: A Developer has been asked to create an AWS Elastic Beanstalk environment for a production web application which needs to handle thousands of requests. Currently the dev environment is running on a t1 micro instance. How can the Developer change the EC2 instance type to m4.large?
- A. Use CloudFormation to migrate the Amazon EC2 instance type of the environment from t1 micro to m4.large.
- B. Create a saved configuration file in Amazon S3 with the instance type as m4.large and use the same during environment creation.
- C. Change the instance type to m4.large in the configuration details page of the Create New Environment page.
- D. Change the instance type value for the environment to m4.large by using update autoscaling group CLI command.
Q24: What statements are true about Availability Zones (AZs) and Regions?
- A. There is only one AZ in each AWS Region
- B. AZs are geographically separated inside a region to help protect against natural disasters affecting more than one at a time.
- C. AZs can be moved between AWS Regions based on your needs
- D. There are (almost always) two or more AZs in each AWS Region
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q25: An AWS Region contains:
- A. Edge Locations
- B. Data Centers
- C. AWS Services
- D. Availability Zones
Top
Q26: Which read request in DynamoDB returns a response with the most up-to-date data, reflecting the updates from all prior write operations that were successful?
- A. Eventual Consistent Reads
- B. Conditional reads for Consistency
- C. Strongly Consistent Reads
- D. Not possible
Top
Q27: You’ ve been asked to move an existing development environment on the AWS Cloud. This environment consists mainly of Docker based containers. You need to ensure that minimum effort is taken during the migration process. Which of the following step would you consider for this requirement?
- A. Create an Opswork stack and deploy the Docker containers
- B. Create an application and Environment for the Docker containers in the Elastic Beanstalk service
- C. Create an EC2 Instance. Install Docker and deploy the necessary containers.
- D. Create an EC2 Instance. Install Docker and deploy the necessary containers. Add an Autoscaling Group for scalability of the containers.
Top
Q28: You’ve written an application that uploads objects onto an S3 bucket. The size of the object varies between 200 – 500 MB. You’ve seen that the application sometimes takes a longer than expected time to upload the object. You want to improve the performance of the application. Which of the following would you consider?
- A. Create multiple threads and upload the objects in the multiple threads
- B. Write the items in batches for better performance
- C. Use the Multipart upload API
- D. Enable versioning on the Bucket
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Top
Q29: A security system monitors 600 cameras, saving image metadata every 1 minute to an Amazon DynamoDb table. Each sample involves 1kb of data, and the data writes are evenly distributed over time. How much write throughput is required for the target table?
- A. 6000
- B. 10
- C. 3600
- D. 600
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q30: What two arguments does a Python Lambda handler function require?
- A. invocation, zone
- B. event, zone
- C. invocation, context
- D. event, context
Top
Q31: Lambda allows you to upload code and dependencies for function packages:
- A. Only from a directly uploaded zip file
- B. Only via SFTP
- C. Only from a zip file in AWS S3
- D. From a zip file in AWS S3 or uploaded directly from elsewhere
Top
Q32: A Lambda deployment package contains:
- A. Function code, libraries, and runtime binaries
- B. Only function code
- C. Function code and libraries not included within the runtime
- D. Only libraries not included within the runtime
Top
Q33: You have instances inside private subnets and a properly configured bastion host instance in a public subnet. None of the instances in the private subnets have a public or Elastic IP address. How can you connect an instance in the private subnet to the open internet to download system updates?
- A. Create and assign EIP to each instance
- B. Create and attach a second IGW to the VPC.
- C. Create and utilize a NAT Gateway
- D. Connect to a VPN
Top
Q34: What feature of VPC networking should you utilize if you want to create “elasticity” in your application’s architecture?
- A. Security Groups
- B. Route Tables
- C. Elastic Load Balancer
- D. Auto Scaling
Top
Q30: Lambda allows you to upload code and dependencies for function packages:
- A. Only from a directly uploaded zip file
- B. Only from a directly uploaded zip file
- C. Only from a zip file in AWS S3
- D. From a zip file in AWS S3 or uploaded directly from elsewhere
Answer:
Top
Q31: An organization is using an Amazon ElastiCache cluster in front of their Amazon RDS instance. The organization would like the Developer to implement logic into the code so that the cluster only retrieves data from RDS when there is a cache miss. What strategy can the Developer implement to achieve this?
- A. Lazy loading
- B. Write-through
- C. Error retries
- D. Exponential backoff
Answer:
Top
Q32: A developer is writing an application that will run on Ec2 instances and read messages from SQS queue. The nessages will arrive every 15-60 seconds. How should the Developer efficiently query the queue for new messages?
- A. Use long polling
- B. Set a custom visibility timeout
- C. Use short polling
- D. Implement exponential backoff
Top
Q33: You are using AWS SAM to define a Lambda function and configure CodeDeploy to manage deployment patterns. With new Lambda function working as per expectation which of the following will shift traffic from original Lambda function to new Lambda function in the shortest time frame?
- A. Canary10Percent5Minutes
- B. Linear10PercentEvery10Minutes
- C. Canary10Percent15Minutes
- D. Linear10PercentEvery1Minute
Top
Q34: You are using AWS SAM templates to deploy a serverless application. Which of the following resource will embed application from Amazon S3 buckets?
- A. AWS::Serverless::Api
- B. AWS::Serverless::Application
- C. AWS::Serverless::Layerversion
- D. AWS::Serverless::Function
Top
Q35: You are using AWS Envelope Encryption for encrypting all sensitive data. Which of the followings is True with regards to Envelope Encryption?
- A. Data is encrypted be encrypting Data key which is further encrypted using encrypted Master Key.
- B. Data is encrypted by plaintext Data key which is further encrypted using encrypted Master Key.
- C. Data is encrypted by encrypted Data key which is further encrypted using plaintext Master Key.
- D. Data is encrypted by plaintext Data key which is further encrypted using plaintext Master Key.
Top
Q36: You are developing an application that will be comprised of the following architecture –
- A set of Ec2 instances to process the videos.
- These (Ec2 instances) will be spun up by an autoscaling group.
- SQS Queues to maintain the processing messages.
- There will be 2 pricing tiers.
How will you ensure that the premium customers videos are given more preference?
- A. Create 2 Autoscaling Groups, one for normal and one for premium customers
- B. Create 2 set of Ec2 Instances, one for normal and one for premium customers
- C. Create 2 SQS queus, one for normal and one for premium customers
- D. Create 2 Elastic Load Balancers, one for normal and one for premium customers.
Top
Q37: You are developing an application that will interact with a DynamoDB table. The table is going to take in a lot of read and write operations. Which of the following would be the ideal partition key for the DynamoDB table to ensure ideal performance?
- A. CustomerID
- B. CustomerName
- C. Location
- D. Age
Top
Q38: A developer is making use of AWS services to develop an application. He has been asked to develop the application in a manner to compensate any network delays. Which of the following two mechanisms should he implement in the application?
- A. Multiple SQS queues
- B. Exponential backoff algorithm
- C. Retries in your application code
- D. Consider using the Java sdk.
Top
Q39: An application is being developed that is going to write data to a DynamoDB table. You have to setup the read and write throughput for the table. Data is going to be read at the rate of 300 items every 30 seconds. Each item is of size 6KB. The reads can be eventual consistent reads. What should be the read capacity that needs to be set on the table?
- A. 10
- B. 20
- C. 6
- D. 30
Top
Q40: You are in charge of deploying an application that will be hosted on an EC2 Instance and sit behind an Elastic Load balancer. You have been requested to monitor the incoming connections to the Elastic Load Balancer. Which of the below options can suffice this requirement?
- A. Use AWS CloudTrail with your load balancer
- B. Enable access logs on the load balancer
- C. Use a CloudWatch Logs Agent
- D. Create a custom metric CloudWatch lter on your load balancer
Top
Q41: A static web site has been hosted on a bucket and is now being accessed by users. One of the web pages javascript section has been changed to access data which is hosted in another S3 bucket. Now that same web page is no longer loading in the browser. Which of the following can help alleviate the error?
- A. Enable versioning for the underlying S3 bucket.
- B. Enable Replication so that the objects get replicated to the other bucket
- C. Enable CORS for the bucket
- D. Change the Bucket policy for the bucket to allow access from the other bucket
Top
Q42: Your mobile application includes a photo-sharing service that is expecting tens of thousands of users at launch. You will leverage Amazon Simple Storage Service (S3) for storage of the user Images, and you must decide how to authenticate and authorize your users for access to these images. You also need to manage the storage of these images. Which two of the following approaches should you use? Choose two answers from the options below
- A. Create an Amazon S3 bucket per user, and use your application to generate the S3 URL for the appropriate content.
- B. Use AWS Identity and Access Management (IAM) user accounts as your application-level user database, and offload the burden of authentication from your application code.
- C. Authenticate your users at the application level, and use AWS Security Token Service (STS)to grant token-based authorization to S3 objects.
- D. Authenticate your users at the application level, and send an SMS token message to the user. Create an Amazon S3 bucket with the same name as the SMS message token, and move the user’s objects to that bucket.
Top
Q43: Your current log analysis application takes more than four hours to generate a report of the top 10 users of your web application. You have been asked to implement a system that can report this information in real time, ensure that the report is always up to date, and handle increases in the number of requests to your web application. Choose the option that is cost-effective and can fulfill the requirements.
- A. Publish your data to CloudWatch Logs, and congure your application to Autoscale to handle the load on demand.
- B. Publish your log data to an Amazon S3 bucket. Use AWS CloudFormation to create an Auto Scaling group to scale your post-processing application which is congured to pull down your log les stored an Amazon S3
- C. Post your log data to an Amazon Kinesis data stream, and subscribe your log-processing application so that is congured to process your logging data.
- D. Create a multi-AZ Amazon RDS MySQL cluster, post the logging data to MySQL, and run a map reduce job to retrieve the required information on user counts.
Answer:
Top
Q44: You’ve been instructed to develop a mobile application that will make use of AWS services. You need to decide on a data store to store the user sessions. Which of the following would be an ideal data store for session management?
- A. AWS Simple Storage Service
- B. AWS DynamoDB
- C. AWS RDS
- D. AWS Redshift
Answer:
Top
Q45: Your application currently interacts with a DynamoDB table. Records are inserted into the table via the application. There is now a requirement to ensure that whenever items are updated in the DynamoDB primary table , another record is inserted into a secondary table. Which of the below feature should be used when developing such a solution?
- A. AWS DynamoDB Encryption
- B. AWS DynamoDB Streams
- C. AWS DynamoDB Accelerator
- D. AWSTable Accelerator
Top
Q46: An application has been making use of AWS DynamoDB for its back-end data store. The size of the table has now grown to 20 GB , and the scans on the table are causing throttling errors. Which of the following should now be implemented to avoid such errors?
- A. Large Page size
- B. Reduced page size
- C. Parallel Scans
- D. Sequential scans
Top
Q47: Which of the following is correct way of passing a stage variable to an HTTP URL ? (Select TWO.)
- A. http://example.com/${}/prod
- B. http://example.com/${stageVariables.}/prod
- C. http://${stageVariables.}.example.com/dev/operation
- D. http://${stageVariables}.example.com/dev/operation
- E. http://${}.example.com/dev/operation
- F. http://example.com/${stageVariables}/prod
Top
Q48: Your company is planning on creating new development environments in AWS. They want to make use of their existing Chef recipes which they use for their on-premise configuration for servers in AWS. Which of the following service would be ideal to use in this regard?
- A. AWS Elastic Beanstalk
- B. AWS OpsWork
- C. AWS Cloudformation
- D. AWS SQS
Top
Q49: Your company has developed a web application and is hosting it in an Amazon S3 bucket configured for static website hosting. The users can log in to this app using their Google/Facebook login accounts. The application is using the AWS SDK for JavaScript in the browser to access data stored in an Amazon DynamoDB table. How can you ensure that API keys for access to your data in DynamoDB are kept secure?
- A. Create an Amazon S3 role in IAM with access to the specific DynamoDB tables, and assign it to the bucket hosting your website
- B. Configure S3 bucket tags with your AWS access keys for your bucket hosing your website so that the application can query them for access.
- C. Configure a web identity federation role within IAM to enable access to the correct DynamoDB resources and retrieve temporary credentials
- D. Store AWS keys in global variables within your application and configure the application to use these credentials when making requests.
Top
Q50: Your application currently makes use of AWS Cognito for managing user identities. You want to analyze the information that is stored in AWS Cognito for your application. Which of the following features of AWS Cognito should you use for this purpose?
- A. Cognito Data
- B. Cognito Events
- C. Cognito Streams
- D. Cognito Callbacks
Top
Q51: You’ve developed a set of scripts using AWS Lambda. These scripts need to access EC2 Instances in a VPC. Which of the following needs to be done to ensure that the AWS Lambda function can access the resources in the VPC. Choose 2 answers from the options given below
- A. Ensure that the subnet ID’s are mentioned when conguring the Lambda function
- B. Ensure that the NACL ID’s are mentioned when conguring the Lambda function
- C. Ensure that the Security Group ID’s are mentioned when conguring the Lambda function
- D. Ensure that the VPC Flow Log ID’s are mentioned when conguring the Lambda function
Top
Q52: You’ve currently been tasked to migrate an existing on-premise environment into Elastic Beanstalk. The application does not make use of Docker containers. You also can’t see any relevant environments in the beanstalk service that would be suitable to host your application. What should you consider doing in this case?
- A. Migrate your application to using Docker containers and then migrate the app to the Elastic Beanstalk environment.
- B. Consider using Cloudformation to deploy your environment to Elastic Beanstalk
- C. Consider using Packer to create a custom platform
- D. Consider deploying your application using the Elastic Container Service
Top
Q53: Company B is writing 10 items to the Dynamo DB table every second. Each item is 15.5Kb in size. What would be the required provisioned write throughput for best performance? Choose the correct answer from the options below.
- A. 10
- B. 160
- C. 155
- D. 16
Top
Q54: Which AWS Service can be used to automatically install your application code onto EC2, on premises systems and Lambda?
- A. CodeCommit
- B. X-Ray
- C. CodeBuild
- D. CodeDeploy
Top
Q55: Which AWS service can be used to compile source code, run tests and package code?
- A. CodePipeline
- B. CodeCommit
- C. CodeBuild
- D. CodeDeploy
Top
Q56: How can your prevent CloudFormation from deleting your entire stack on failure? (Choose 2)
- A. Set the Rollback on failure radio button to No in the CloudFormation console
- B. Set Termination Protection to Enabled in the CloudFormation console
- C. Use the –disable-rollback flag with the AWS CLI
- D. Use the –enable-termination-protection protection flag with the AWS CLI
Q57: Which of the following practices allows multiple developers working on the same application to merge code changes frequently, without impacting each other and enables the identification of bugs early on in the release process?
- A. Continuous Integration
- B. Continuous Deployment
- C. Continuous Delivery
- D. Continuous Development
Q58: When deploying application code to EC2, the AppSpec file can be written in which language?
- A. JSON
- B. JSON or YAML
- C. XML
- D. YAML
Q59: Part of your CloudFormation deployment fails due to a mis-configuration, by defaukt what will happen?
- A. CloudFormation will rollback only the failed components
- B. CloudFormation will rollback the entire stack
- C. Failed component will remain available for debugging purposes
- D. CloudFormation will ask you if you want to continue with the deployment
Top
Q60: You want to receive an email whenever a user pushes code to CodeCommit repository, how can you configure this?
- A. Create a new SNS topic and configure it to poll for CodeCommit eveents. Ask all users to subscribe to the topic to receive notifications
- B. Configure a CloudWatch Events rule to send a message to SES which will trigger an email to be sent whenever a user pushes code to the repository.
- C. Configure Notifications in the console, this will create a CloudWatch events rule to send a notification to a SNS topic which will trigger an email to be sent to the user.
- D. Configure a CloudWatch Events rule to send a message to SQS which will trigger an email to be sent whenever a user pushes code to the repository.
Top
Q61: Which AWS service can be used to centrally store and version control your application source code, binaries and libraries
- A. CodeCommit
- B. CodeBuild
- C. CodePipeline
- D. ElasticFileSystem
Top
Q62: You are using CloudFormation to create a new S3 bucket, which of the following sections would you use to define the properties of your bucket?
- A. Conditions
- B. Parameters
- C. Outputs
- D. Resources
Top
Q63: You are deploying a number of EC2 and RDS instances using CloudFormation. Which section of the CloudFormation template would you use to define these?
- A. Transforms
- B. Outputs
- C. Resources
- D. Instances
Top
Q64: Which AWS service can be used to fully automate your entire release process?
- A. CodeDeploy
- B. CodePipeline
- C. CodeCommit
- D. CodeBuild
Top
Q65: You want to use the output of your CloudFormation stack as input to another CloudFormation stack. Which sections of the CloudFormation template would you use to help you configure this?
- A. Outputs
- B. Transforms
- C. Resources
- D. Exports
Top
Q66: You have some code located in an S3 bucket that you want to reference in your CloudFormation template. Which section of the template can you use to define this?
- A. Inputs
- B. Resources
- C. Transforms
- D. Files
Top
Q67: You are deploying an application to a number of Ec2 instances using CodeDeploy. What is the name of the file
used to specify source files and lifecycle hooks?
- A. buildspec.yml
- B. appspec.json
- C. appspec.yml
- D. buildspec.json
Q68: Which of the following approaches allows you to re-use pieces of CloudFormation code in multiple templates, for common use cases like provisioning a load balancer or web server?
- A. Share the code using an EBS volume
- B. Copy and paste the code into the template each time you need to use it
- C. Use a cloudformation nested stack
- D. Store the code you want to re-use in an AMI and reference the AMI from within your CloudFormation template.
Q69: In the CodeDeploy AppSpec file, what are hooks used for?
- A. To reference AWS resources that will be used during the deployment
- B. Hooks are reserved for future use
- C. To specify files you want to copy during the deployment.
- D. To specify, scripts or function that you want to run at set points in the deployment lifecycle
Q70: Which command can you use to encrypt a plain text file using CMK?
- A. aws kms-encrypt
- B. aws iam encrypt
- C. aws kms encrypt
- D. aws encrypt
Q72: Which of the following is an encrypted key used by KMS to encrypt your data
- A. Custmoer Mamaged Key
- B. Encryption Key
- C. Envelope Key
- D. Customer Master Key
Q73: Which of the following statements are correct? (Choose 2)
- A. The Customer Master Key is used to encrypt and decrypt the Envelope Key or Data Key
- B. The Envelope Key or Data Key is used to encrypt and decrypt plain text files.
- C. The envelope Key or Data Key is used to encrypt and decrypt the Customer Master Key.
- D. The Customer MasterKey is used to encrypt and decrypt plain text files.
Q74: Which of the following statements is correct in relation to kMS/ (Choose 2)
- A. KMS Encryption keys are regional
- B. You cannot export your customer master key
- C. You can export your customer master key.
- D. KMS encryption Keys are global
Q75: A developer is preparing a deployment package for a Java implementation of an AWS Lambda function. What should the developer include in the deployment package? (Select TWO.)
A. Compiled application code
B. Java runtime environment
C. References to the event sources
D. Lambda execution role
E. Application dependencies
Q76: A developer uses AWS CodeDeploy to deploy a Python application to a fleet of Amazon EC2 instances that run behind an Application Load Balancer. The instances run in an Amazon EC2 Auto Scaling group across multiple Availability Zones. What should the developer include in the CodeDeploy deployment package?
A. A launch template for the Amazon EC2 Auto Scaling group
B. A CodeDeploy AppSpec file
C. An EC2 role that grants the application access to AWS services
D. An IAM policy that grants the application access to AWS services
Q76: A company is working on a project to enhance its serverless application development process. The company hosts applications on AWS Lambda. The development team regularly updates the Lambda code and wants to use stable code in production. Which combination of steps should the development team take to configure Lambda functions to meet both development and production requirements? (Select TWO.)
A. Create a new Lambda version every time a new code release needs testing.
B. Create two Lambda function aliases. Name one as Production and the other as Development. Point the Production alias to a production-ready unqualified Amazon Resource Name (ARN) version. Point the Development alias to the $LATEST version.
C. Create two Lambda function aliases. Name one as Production and the other as Development. Point the Production alias to the production-ready qualified Amazon Resource Name (ARN) version. Point the Development alias to the variable LAMBDA_TASK_ROOT.
D. Create a new Lambda layer every time a new code release needs testing.
E. Create two Lambda function aliases. Name one as Production and the other as Development. Point the Production alias to a production-ready Lambda layer Amazon Resource Name (ARN). Point the Development alias to the $LATEST layer ARN.
Q77: Each time a developer publishes a new version of an AWS Lambda function, all the dependent event source mappings need to be updated with the reference to the new version’s Amazon Resource Name (ARN). These updates are time consuming and error-prone. Which combination of actions should the developer take to avoid performing these updates when publishing a new Lambda version? (Select TWO.)
A. Update event source mappings with the ARN of the Lambda layer.
B. Point a Lambda alias to a new version of the Lambda function.
C. Create a Lambda alias for each published version of the Lambda function.
D. Point a Lambda alias to a new Lambda function alias.
E. Update the event source mappings with the Lambda alias ARN.
Q78: A company wants to store sensitive user data in Amazon S3 and encrypt this data at rest. The company must manage the encryption keys and use Amazon S3 to perform the encryption. How can a developer meet these requirements?
A. Enable default encryption for the S3 bucket by using the option for server-side encryption with customer-provided encryption keys (SSE-C).
B. Enable client-side encryption with an encryption key. Upload the encrypted object to the S3 bucket.
C. Enable server-side encryption with Amazon S3 managed encryption keys (SSE-S3). Upload an object to the S3 bucket.
D. Enable server-side encryption with customer-provided encryption keys (SSE-C). Upload an object to the S3 bucket.
Q79: A company is developing a Python application that submits data to an Amazon DynamoDB table. The company requires client-side encryption of specific data items and end-to-end protection for the encrypted data in transit and at rest. Which combination of steps will meet the requirement for the encryption of specific data items? (Select TWO.)
A. Generate symmetric encryption keys with AWS Key Management Service (AWS KMS).
B. Generate asymmetric encryption keys with AWS Key Management Service (AWS KMS).
C. Use generated keys with the DynamoDB Encryption Client.
D. Use generated keys to configure DynamoDB table encryption with AWS managed customer master keys (CMKs).
E. Use generated keys to configure DynamoDB table encryption with AWS owned customer master keys (CMKs).
Q80: A company is developing a REST API with Amazon API Gateway. Access to the API should be limited to users in the existing Amazon Cognito user pool. Which combination of steps should a developer perform to secure the API? (Select TWO.)
A. Create an AWS Lambda authorizer for the API.
B. Create an Amazon Cognito authorizer for the API.
C. Configure the authorizer for the API resource.
D. Configure the API methods to use the authorizer.
E. Configure the authorizer for the API stage.
Q81: A developer is implementing a mobile app to provide personalized services to app users. The application code makes calls to Amazon S3 and Amazon Simple Queue Service (Amazon SQS). Which options can the developer use to authenticate the app users? (Select TWO.)
A. Authenticate to the Amazon Cognito identity pool directly.
B. Authenticate to AWS Identity and Access Management (IAM) directly.
C. Authenticate to the Amazon Cognito user pool directly.
D. Federate authentication by using Login with Amazon with the users managed with AWS Security Token Service (AWS STS).
E. Federate authentication by using Login with Amazon with the users managed with the Amazon Cognito user pool.
Question: A company is implementing several order processing workflows. Each workflow is implemented by using AWS Lambda functions for each task. Which combination of steps should a developer follow to implement these workflows? (Select TWO.)
A. Define a AWS Step Functions task for each Lambda function.
B. Define a AWS Step Functions task for each workflow.
C. Write code that polls the AWS Step Functions invocation to coordinate each workflow.
D. Define an AWS Step Functions state machine for each workflow.
E. Define an AWS Step Functions state machine for each Lambda function.
Answer: A. D.
Notes: Step Functions is based on state machines and tasks. A state machine is a workflow. Tasks perform work by coordinating with other AWS services, such as Lambda. A state machine is a workflow. It can be used to express a workflow as a number of states, their relationships, and their input and output. You can coordinate individual tasks with Step Functions by expressing your workflow as a finite state machine, written in the Amazon States Language.
ReferenceText: Getting Started with AWS Step Functions.
ReferenceUrl: https://aws.amazon.com/step-functions/getting-started/
Category: Development
Welcome to AWS Certified Developer Associate Exam Preparation: Definition and Objectives, Top 100 Questions and Answers dump, White papers, Courses, Labs and Training Materials, Exam info and details, References, Jobs, Others AWS Certificates
What is the AWS Certified Developer Associate Exam?
This AWS Certified Developer-Associate Examination is intended for individuals who perform a Developer role. It validates an examinee’s ability to:
- Demonstrate an understanding of core AWS services, uses, and basic AWS architecture best practices
- Demonstrate proficiency in developing, deploying, and debugging cloud-based applications by using AWS
Recommended general IT knowledge
The target candidate should have the following:
– In-depth knowledge of at least one high-level programming language
– Understanding of application lifecycle management
– The ability to write code for serverless applications
– Understanding of the use of containers in the development process
Recommended AWS knowledge
The target candidate should be able to do the following:
- Use the AWS service APIs, CLI, and software development kits (SDKs) to write applications
- Identify key features of AWS services
- Understand the AWS shared responsibility model
- Use a continuous integration and continuous delivery (CI/CD) pipeline to deploy applications on AWS
- Use and interact with AWS services
- Apply basic understanding of cloud-native applications to write code
- Write code by using AWS security best practices (for example, use IAM roles instead of secret and access keys in the code)
- Author, maintain, and debug code modules on AWS
What is considered out of scope for the target candidate?
The following is a non-exhaustive list of related job tasks that the target candidate is not expected to be able to perform. These items are considered out of scope for the exam:
– Design architectures (for example, distributed system, microservices)
– Design and implement CI/CD pipelines
- Administer IAM users and groups
- Administer Amazon Elastic Container Service (Amazon ECS)
- Design AWS networking infrastructure (for example, Amazon VPC, AWS Direct Connect)
- Understand compliance and licensing
Exam content
Response types
There are two types of questions on the exam:
– Multiple choice: Has one correct response and three incorrect responses (distractors)
– Multiple response: Has two or more correct responses out of five or more response options
Select one or more responses that best complete the statement or answer the question. Distractors, or incorrect answers, are response options that a candidate with incomplete knowledge or skill might choose.
Distractors are generally plausible responses that match the content area.
Unanswered questions are scored as incorrect; there is no penalty for guessing. The exam includes 50 questions that will affect your score.
Unscored content
The exam includes 15 unscored questions that do not affect your score. AWS collects information about candidate performance on these unscored questions to evaluate these questions for future use as scored questions. These unscored questions are not identified on the exam.
Exam results
The AWS Certified Developer – Associate (DVA-C01) exam is a pass or fail exam. The exam is scored against a minimum standard established by AWS professionals who follow certification industry best practices and guidelines.
Your results for the exam are reported as a scaled score of 100–1,000. The minimum passing score is 720.
Your score shows how you performed on the exam as a whole and whether you passed. Scaled scoring models help equate scores across multiple exam forms that might have slightly different difficulty levels.
Your score report could contain a table of classifications of your performance at each section level. This information is intended to provide general feedback about your exam performance. The exam uses a compensatory scoring model, which means that you do not need to achieve a passing score in each section. You need to pass only the overall exam.
Each section of the exam has a specific weighting, so some sections have more questions than other sections have. The table contains general information that highlights your strengths and weaknesses. Use caution when interpreting section-level feedback.
Content outline
This exam guide includes weightings, test domains, and objectives for the exam. It is not a comprehensive listing of the content on the exam. However, additional context for each of the objectives is available to help guide your preparation for the exam. The following table lists the main content domains and their weightings. The table precedes the complete exam content outline, which includes the additional context.
The percentage in each domain represents only scored content.
Domain 1: Deployment 22%
Domain 2: Security 26%
Domain 3: Development with AWS Services 30%
Domain 4: Refactoring 10%
Domain 5: Monitoring and Troubleshooting 12%
Domain 1: Deployment
1.1 Deploy written code in AWS using existing CI/CD pipelines, processes, and patterns.
– Commit code to a repository and invoke build, test and/or deployment actions
– Use labels and branches for version and release management
– Use AWS CodePipeline to orchestrate workflows against different environments
– Apply AWS CodeCommit, AWS CodeBuild, AWS CodePipeline, AWS CodeStar, and AWS
CodeDeploy for CI/CD purposes
– Perform a roll back plan based on application deployment policy
1.2 Deploy applications using AWS Elastic Beanstalk.
– Utilize existing supported environments to define a new application stack
– Package the application
– Introduce a new application version into the Elastic Beanstalk environment
– Utilize a deployment policy to deploy an application version (i.e., all at once, rolling, rolling with batch, immutable)
– Validate application health using Elastic Beanstalk dashboard
– Use Amazon CloudWatch Logs to instrument application logging
1.3 Prepare the application deployment package to be deployed to AWS.
– Manage the dependencies of the code module (like environment variables, config files and static image files) within the package
– Outline the package/container directory structure and organize files appropriately
– Translate application resource requirements to AWS infrastructure parameters (e.g., memory, cores)
1.4 Deploy serverless applications.
– Given a use case, implement and launch an AWS Serverless Application Model (AWS SAM) template
– Manage environments in individual AWS services (e.g., Differentiate between Development, Test, and Production in Amazon API Gateway)
Domain 2: Security
2.1 Make authenticated calls to AWS services.
– Communicate required policy based on least privileges required by application.
– Assume an IAM role to access a service
– Use the software development kit (SDK) credential provider on-premises or in the cloud to access AWS services (local credentials vs. instance roles)
2.2 Implement encryption using AWS services.
– Encrypt data at rest (client side; server side; envelope encryption) using AWS services
– Encrypt data in transit
2.3 Implement application authentication and authorization.
– Add user sign-up and sign-in functionality for applications with Amazon Cognito identity or user pools
– Use Amazon Cognito-provided credentials to write code that access AWS services.
– Use Amazon Cognito sync to synchronize user profiles and data
– Use developer-authenticated identities to interact between end user devices, backend
authentication, and Amazon Cognito
Domain 3: Development with AWS Services
3.1 Write code for serverless applications.
– Compare and contrast server-based vs. serverless model (e.g., micro services, stateless nature of serverless applications, scaling serverless applications, and decoupling layers of serverless applications)
– Configure AWS Lambda functions by defining environment variables and parameters (e.g., memory, time out, runtime, handler)
– Create an API endpoint using Amazon API Gateway
– Create and test appropriate API actions like GET, POST using the API endpoint
– Apply Amazon DynamoDB concepts (e.g., tables, items, and attributes)
– Compute read/write capacity units for Amazon DynamoDB based on application requirements
– Associate an AWS Lambda function with an AWS event source (e.g., Amazon API Gateway, Amazon CloudWatch event, Amazon S3 events, Amazon Kinesis)
– Invoke an AWS Lambda function synchronously and asynchronously
3.2 Translate functional requirements into application design.
– Determine real-time vs. batch processing for a given use case
– Determine use of synchronous vs. asynchronous for a given use case
– Determine use of event vs. schedule/poll for a given use case
– Account for tradeoffs for consistency models in an application design
Domain 4: Refactoring
4.1 Optimize applications to best use AWS services and features.
Implement AWS caching services to optimize performance (e.g., Amazon ElastiCache, Amazon API Gateway cache)
Apply an Amazon S3 naming scheme for optimal read performance
4.2 Migrate existing application code to run on AWS.
– Isolate dependencies
– Run the application as one or more stateless processes
– Develop in order to enable horizontal scalability
– Externalize state
Domain 5: Monitoring and Troubleshooting
5.1 Write code that can be monitored.
– Create custom Amazon CloudWatch metrics
– Perform logging in a manner available to systems operators
– Instrument application source code to enable tracing in AWS X-Ray
5.2 Perform root cause analysis on faults found in testing or production.
– Interpret the outputs from the logging mechanism in AWS to identify errors in logs
– Check build and testing history in AWS services (e.g., AWS CodeBuild, AWS CodeDeploy, AWS CodePipeline) to identify issues
– Utilize AWS services (e.g., Amazon CloudWatch, VPC Flow Logs, and AWS X-Ray) to locate a specific faulty component
Which key tools, technologies, and concepts might be covered on the exam?
The following is a non-exhaustive list of the tools and technologies that could appear on the exam.
This list is subject to change and is provided to help you understand the general scope of services, features, or technologies on the exam.
The general tools and technologies in this list appear in no particular order.
AWS services are grouped according to their primary functions. While some of these technologies will likely be covered more than others on the exam, the order and placement of them in this list is no indication of relative weight or importance:
– Analytics
– Application Integration
– Containers
– Cost and Capacity Management
– Data Movement
– Developer Tools
– Instances (virtual machines)
– Management and Governance
– Networking and Content Delivery
– Security
– Serverless
AWS services and features
Analytics:
– Amazon Elasticsearch Service (Amazon ES)
– Amazon Kinesis
Application Integration:
– Amazon EventBridge (Amazon CloudWatch Events)
– Amazon Simple Notification Service (Amazon SNS)
– Amazon Simple Queue Service (Amazon SQS)
– AWS Step Functions
Compute:
– Amazon EC2
– AWS Elastic Beanstalk
– AWS Lambda
Containers:
– Amazon Elastic Container Registry (Amazon ECR)
– Amazon Elastic Container Service (Amazon ECS)
– Amazon Elastic Kubernetes Services (Amazon EKS)
Database:
– Amazon DynamoDB
– Amazon ElastiCache
– Amazon RDS
Developer Tools:
– AWS CodeArtifact
– AWS CodeBuild
– AWS CodeCommit
– AWS CodeDeploy
– Amazon CodeGuru
– AWS CodePipeline
– AWS CodeStar
– AWS Fault Injection Simulator
– AWS X-Ray
Management and Governance:
– AWS CloudFormation
– Amazon CloudWatch
Networking and Content Delivery:
– Amazon API Gateway
– Amazon CloudFront
– Elastic Load Balancing
Security, Identity, and Compliance:
– Amazon Cognito
– AWS Identity and Access Management (IAM)
– AWS Key Management Service (AWS KMS)
Storage:
– Amazon S3
Out-of-scope AWS services and features
The following is a non-exhaustive list of AWS services and features that are not covered on the exam.
These services and features do not represent every AWS offering that is excluded from the exam content.
Services or features that are entirely unrelated to the target job roles for the exam are excluded from this list because they are assumed to be irrelevant.
Out-of-scope AWS services and features include the following:
– AWS Application Discovery Service
– Amazon AppStream 2.0
– Amazon Chime
– Amazon Connect
– AWS Database Migration Service (AWS DMS)
– AWS Device Farm
– Amazon Elastic Transcoder
– Amazon GameLift
– Amazon Lex
– Amazon Machine Learning (Amazon ML)
– AWS Managed Services
– Amazon Mobile Analytics
– Amazon Polly
– Amazon QuickSight
– Amazon Rekognition
– AWS Server Migration Service (AWS SMS)
– AWS Service Catalog
– AWS Shield Advanced
– AWS Shield Standard
– AWS Snow Family
– AWS Storage Gateway
– AWS WAF
– Amazon WorkMail
– Amazon WorkSpaces
To succeed with the real exam, do not memorize the answers below. It is very important that you understand why a question is right or wrong and the concepts behind it by carefully reading the reference documents in the answers.
AWS Certified Developer – Associate Practice Questions And Answers Dump
Q0: Your application reads commands from an SQS queue and sends them to web services hosted by your
partners. When a partner’s endpoint goes down, your application continually returns their commands to the queue. The repeated attempts to deliver these commands use up resources. Commands that can’t be delivered must not be lost.
How can you accommodate the partners’ broken web services without wasting your resources?
- A. Create a delay queue and set DelaySeconds to 30 seconds
- B. Requeue the message with a VisibilityTimeout of 30 seconds.
- C. Create a dead letter queue and set the Maximum Receives to 3.
- D. Requeue the message with a DelaySeconds of 30 seconds.

Top
Q1: A developer is writing an application that will store data in a DynamoDB table. The ratio of reads operations to write operations will be 1000 to 1, with the same data being accessed frequently.
What should the Developer enable on the DynamoDB table to optimize performance and minimize costs?
- A. Amazon DynamoDB auto scaling
- B. Amazon DynamoDB cross-region replication
- C. Amazon DynamoDB Streams
- D. Amazon DynamoDB Accelerator
Top
Q2: You are creating a DynamoDB table with the following attributes:
- PurchaseOrderNumber (partition key)
- CustomerID
- PurchaseDate
- TotalPurchaseValue
One of your applications must retrieve items from the table to calculate the total value of purchases for a
particular customer over a date range. What secondary index do you need to add to the table?
- A. Local secondary index with a partition key of CustomerID and sort key of PurchaseDate; project the
TotalPurchaseValue attribute - B. Local secondary index with a partition key of PurchaseDate and sort key of CustomerID; project the
TotalPurchaseValue attribute - C. Global secondary index with a partition key of CustomerID and sort key of PurchaseDate; project the
TotalPurchaseValue attribute - D. Global secondary index with a partition key of PurchaseDate and sort key of CustomerID; project the
TotalPurchaseValue attribute
Top
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q3: When referencing the remaining time left for a Lambda function to run within the function’s code you would use:
- A. The event object
- B. The timeLeft object
- C. The remains object
- D. The context object
Top
Q4: What two arguments does a Python Lambda handler function require?
- A. invocation, zone
- B. event, zone
- C. invocation, context
- D. event, context
Q5: Lambda allows you to upload code and dependencies for function packages:
- A. Only from a directly uploaded zip file
- B. Only via SFTP
- C. Only from a zip file in AWS S3
- D. From a zip file in AWS S3 or uploaded directly from elsewhere
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q6: A Lambda deployment package contains:
- A. Function code, libraries, and runtime binaries
- B. Only function code
- C. Function code and libraries not included within the runtime
- D. Only libraries not included within the runtime
Q7: You are attempting to SSH into an EC2 instance that is located in a public subnet. However, you are currently receiving a timeout error trying to connect. What could be a possible cause of this connection issue?
- A. The security group associated with the EC2 instance has an inbound rule that allows SSH traffic, but does not have an outbound rule that allows SSH traffic.
- B. The security group associated with the EC2 instance has an inbound rule that allows SSH traffic AND has an outbound rule that explicitly denies SSH traffic.
- C. The security group associated with the EC2 instance has an inbound rule that allows SSH traffic AND the associated NACL has both an inbound and outbound rule that allows SSH traffic.
- D. The security group associated with the EC2 instance does not have an inbound rule that allows SSH traffic AND the associated NACL does not have an outbound rule that allows SSH traffic.
Top
Q8: You have instances inside private subnets and a properly configured bastion host instance in a public subnet. None of the instances in the private subnets have a public or Elastic IP address. How can you connect an instance in the private subnet to the open internet to download system updates?
- A. Create and assign EIP to each instance
- B. Create and attach a second IGW to the VPC.
- C. Create and utilize a NAT Gateway
- D. Connect to a VPN
Top
Q9: What feature of VPC networking should you utilize if you want to create “elasticity” in your application’s architecture?
- A. Security Groups
- B. Route Tables
- C. Elastic Load Balancer
- D. Auto Scaling
Top
Q10: Lambda allows you to upload code and dependencies for function packages:
- A. Only from a directly uploaded zip file
- B. Only from a directly uploaded zip file
- C. Only from a zip file in AWS S3
- D. From a zip file in AWS S3 or uploaded directly from elsewhere
Q11: You’re writing a script with an AWS SDK that uses the AWS API Actions and want to create AMIs for non-EBS backed AMIs for you. Which API call should occurs in the final process of creating an AMI?
- A. RegisterImage
- B. CreateImage
- C. ami-register-image
- D. ami-create-image
Q12: When dealing with session state in EC2-based applications using Elastic load balancers which option is generally thought of as the best practice for managing user sessions?
- A. Having the ELB distribute traffic to all EC2 instances and then having the instance check a caching solution like ElastiCache running Redis or Memcached for session information
- B. Permenantly assigning users to specific instances and always routing their traffic to those instances
- C. Using Application-generated cookies to tie a user session to a particular instance for the cookie duration
- D. Using Elastic Load Balancer generated cookies to tie a user session to a particular instance
Q13: Which API call would best be used to describe an Amazon Machine Image?
- A. ami-describe-image
- B. ami-describe-images
- C. DescribeImage
- D. DescribeImages
Q14: What is one key difference between an Amazon EBS-backed and an instance-store backed instance?
- A. Autoscaling requires using Amazon EBS-backed instances
- B. Virtual Private Cloud requires EBS backed instances
- C. Amazon EBS-backed instances can be stopped and restarted without losing data
- D. Instance-store backed instances can be stopped and restarted without losing data
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q15: After having created a new Linux instance on Amazon EC2, and downloaded the .pem file (called Toto.pem) you try and SSH into your IP address (54.1.132.33) using the following command.
ssh -i my_key.pem ec2-user@52.2.222.22
However you receive the following error.
@@@@@@@@ WARNING: UNPROTECTED PRIVATE KEY FILE! @ @@@@@@@@@@@@@@@@@@@
What is the most probable reason for this and how can you fix it?
- A. You do not have root access on your terminal and need to use the sudo option for this to work.
- B. You do not have enough permissions to perform the operation.
- C. Your key file is encrypted. You need to use the -u option for unencrypted not the -i option.
- D. Your key file must not be publicly viewable for SSH to work. You need to modify your .pem file to limit permissions.
Q16: You have an EBS root device on /dev/sda1 on one of your EC2 instances. You are having trouble with this particular instance and you need to either Stop/Start, Reboot or Terminate the instance but you do NOT want to lose any data that you have stored on /dev/sda1. However, you are unsure if changing the instance state in any of the aforementioned ways will cause you to lose data stored on the EBS volume. Which of the below statements best describes the effect each change of instance state would have on the data you have stored on /dev/sda1?
- A. Whether you stop/start, reboot or terminate the instance it does not matter because data on an EBS volume is not ephemeral and the data will not be lost regardless of what method is used.
- B. If you stop/start the instance the data will not be lost. However if you either terminate or reboot the instance the data will be lost.
- C. Whether you stop/start, reboot or terminate the instance it does not matter because data on an EBS volume is ephemeral and it will be lost no matter what method is used.
- D. The data will be lost if you terminate the instance, however the data will remain on /dev/sda1 if you reboot or stop/start the instance because data on an EBS volume is not ephemeral.
Q17: EC2 instances are launched from Amazon Machine Images (AMIs). A given public AMI:
- A. Can only be used to launch EC2 instances in the same AWS availability zone as the AMI is stored
- B. Can only be used to launch EC2 instances in the same country as the AMI is stored
- C. Can only be used to launch EC2 instances in the same AWS region as the AMI is stored
- D. Can be used to launch EC2 instances in any AWS region
Q18: Which of the following statements is true about the Elastic File System (EFS)?
- A. EFS can scale out to meet capacity requirements and scale back down when no longer needed
- B. EFS can be used by multiple EC2 instances simultaneously
- C. EFS cannot be used by an instance using EBS
- D. EFS can be configured on an instance before launch just like an IAM role or EBS volumes
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q19: IAM Policies, at a minimum, contain what elements?
- A. ID
- B. Effects
- C. Resources
- D. Sid
- E. Principle
- F. Actions
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q20: What are the main benefits of IAM groups?
- A. The ability to create custom permission policies.
- B. Assigning IAM permission policies to more than one user at a time.
- C. Easier user/policy management.
- D. Allowing EC2 instances to gain access to S3.
Q21: What are benefits of using AWS STS?
- A. Grant access to AWS resources without having to create an IAM identity for them
- B. Since credentials are temporary, you don’t have to rotate or revoke them
- C. Temporary security credentials can be extended indefinitely
- D. Temporary security credentials can be restricted to a specific region
Q22: What should the Developer enable on the DynamoDB table to optimize performance and minimize costs?
- A. Amazon DynamoDB auto scaling
- B. Amazon DynamoDB cross-region replication
- C. Amazon DynamoDB Streams
- D. Amazon DynamoDB Accelerator
Top
Q23: A Developer has been asked to create an AWS Elastic Beanstalk environment for a production web application which needs to handle thousands of requests. Currently the dev environment is running on a t1 micro instance. How can the Developer change the EC2 instance type to m4.large?
- A. Use CloudFormation to migrate the Amazon EC2 instance type of the environment from t1 micro to m4.large.
- B. Create a saved configuration file in Amazon S3 with the instance type as m4.large and use the same during environment creation.
- C. Change the instance type to m4.large in the configuration details page of the Create New Environment page.
- D. Change the instance type value for the environment to m4.large by using update autoscaling group CLI command.
Q24: What statements are true about Availability Zones (AZs) and Regions?
- A. There is only one AZ in each AWS Region
- B. AZs are geographically separated inside a region to help protect against natural disasters affecting more than one at a time.
- C. AZs can be moved between AWS Regions based on your needs
- D. There are (almost always) two or more AZs in each AWS Region
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q25: An AWS Region contains:
- A. Edge Locations
- B. Data Centers
- C. AWS Services
- D. Availability Zones
Top
Q26: Which read request in DynamoDB returns a response with the most up-to-date data, reflecting the updates from all prior write operations that were successful?
- A. Eventual Consistent Reads
- B. Conditional reads for Consistency
- C. Strongly Consistent Reads
- D. Not possible
Top
Q27: You’ ve been asked to move an existing development environment on the AWS Cloud. This environment consists mainly of Docker based containers. You need to ensure that minimum effort is taken during the migration process. Which of the following step would you consider for this requirement?
- A. Create an Opswork stack and deploy the Docker containers
- B. Create an application and Environment for the Docker containers in the Elastic Beanstalk service
- C. Create an EC2 Instance. Install Docker and deploy the necessary containers.
- D. Create an EC2 Instance. Install Docker and deploy the necessary containers. Add an Autoscaling Group for scalability of the containers.
Top
Q28: You’ve written an application that uploads objects onto an S3 bucket. The size of the object varies between 200 – 500 MB. You’ve seen that the application sometimes takes a longer than expected time to upload the object. You want to improve the performance of the application. Which of the following would you consider?
- A. Create multiple threads and upload the objects in the multiple threads
- B. Write the items in batches for better performance
- C. Use the Multipart upload API
- D. Enable versioning on the Bucket
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Top
Q29: A security system monitors 600 cameras, saving image metadata every 1 minute to an Amazon DynamoDb table. Each sample involves 1kb of data, and the data writes are evenly distributed over time. How much write throughput is required for the target table?
- A. 6000
- B. 10
- C. 3600
- D. 600
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q30: What two arguments does a Python Lambda handler function require?
- A. invocation, zone
- B. event, zone
- C. invocation, context
- D. event, context
Top
Q31: Lambda allows you to upload code and dependencies for function packages:
- A. Only from a directly uploaded zip file
- B. Only via SFTP
- C. Only from a zip file in AWS S3
- D. From a zip file in AWS S3 or uploaded directly from elsewhere
Top
Q32: A Lambda deployment package contains:
- A. Function code, libraries, and runtime binaries
- B. Only function code
- C. Function code and libraries not included within the runtime
- D. Only libraries not included within the runtime
Top
Q33: You have instances inside private subnets and a properly configured bastion host instance in a public subnet. None of the instances in the private subnets have a public or Elastic IP address. How can you connect an instance in the private subnet to the open internet to download system updates?
- A. Create and assign EIP to each instance
- B. Create and attach a second IGW to the VPC.
- C. Create and utilize a NAT Gateway
- D. Connect to a VPN
Top
Q34: What feature of VPC networking should you utilize if you want to create “elasticity” in your application’s architecture?
- A. Security Groups
- B. Route Tables
- C. Elastic Load Balancer
- D. Auto Scaling
Top
Q30: Lambda allows you to upload code and dependencies for function packages:
- A. Only from a directly uploaded zip file
- B. Only from a directly uploaded zip file
- C. Only from a zip file in AWS S3
- D. From a zip file in AWS S3 or uploaded directly from elsewhere
Answer:
Top
Q31: An organization is using an Amazon ElastiCache cluster in front of their Amazon RDS instance. The organization would like the Developer to implement logic into the code so that the cluster only retrieves data from RDS when there is a cache miss. What strategy can the Developer implement to achieve this?
- A. Lazy loading
- B. Write-through
- C. Error retries
- D. Exponential backoff
Answer:
Top
Q32: A developer is writing an application that will run on Ec2 instances and read messages from SQS queue. The nessages will arrive every 15-60 seconds. How should the Developer efficiently query the queue for new messages?
- A. Use long polling
- B. Set a custom visibility timeout
- C. Use short polling
- D. Implement exponential backoff
Top
Q33: You are using AWS SAM to define a Lambda function and configure CodeDeploy to manage deployment patterns. With new Lambda function working as per expectation which of the following will shift traffic from original Lambda function to new Lambda function in the shortest time frame?
- A. Canary10Percent5Minutes
- B. Linear10PercentEvery10Minutes
- C. Canary10Percent15Minutes
- D. Linear10PercentEvery1Minute
Top
Q34: You are using AWS SAM templates to deploy a serverless application. Which of the following resource will embed application from Amazon S3 buckets?
- A. AWS::Serverless::Api
- B. AWS::Serverless::Application
- C. AWS::Serverless::Layerversion
- D. AWS::Serverless::Function
Top
Q35: You are using AWS Envelope Encryption for encrypting all sensitive data. Which of the followings is True with regards to Envelope Encryption?
- A. Data is encrypted be encrypting Data key which is further encrypted using encrypted Master Key.
- B. Data is encrypted by plaintext Data key which is further encrypted using encrypted Master Key.
- C. Data is encrypted by encrypted Data key which is further encrypted using plaintext Master Key.
- D. Data is encrypted by plaintext Data key which is further encrypted using plaintext Master Key.
Top
Q36: You are developing an application that will be comprised of the following architecture –
- A set of Ec2 instances to process the videos.
- These (Ec2 instances) will be spun up by an autoscaling group.
- SQS Queues to maintain the processing messages.
- There will be 2 pricing tiers.
How will you ensure that the premium customers videos are given more preference?
- A. Create 2 Autoscaling Groups, one for normal and one for premium customers
- B. Create 2 set of Ec2 Instances, one for normal and one for premium customers
- C. Create 2 SQS queus, one for normal and one for premium customers
- D. Create 2 Elastic Load Balancers, one for normal and one for premium customers.
Top
Q37: You are developing an application that will interact with a DynamoDB table. The table is going to take in a lot of read and write operations. Which of the following would be the ideal partition key for the DynamoDB table to ensure ideal performance?
- A. CustomerID
- B. CustomerName
- C. Location
- D. Age
Top
Q38: A developer is making use of AWS services to develop an application. He has been asked to develop the application in a manner to compensate any network delays. Which of the following two mechanisms should he implement in the application?
- A. Multiple SQS queues
- B. Exponential backoff algorithm
- C. Retries in your application code
- D. Consider using the Java sdk.
Top
Q39: An application is being developed that is going to write data to a DynamoDB table. You have to setup the read and write throughput for the table. Data is going to be read at the rate of 300 items every 30 seconds. Each item is of size 6KB. The reads can be eventual consistent reads. What should be the read capacity that needs to be set on the table?
- A. 10
- B. 20
- C. 6
- D. 30
Top
Q40: You are in charge of deploying an application that will be hosted on an EC2 Instance and sit behind an Elastic Load balancer. You have been requested to monitor the incoming connections to the Elastic Load Balancer. Which of the below options can suffice this requirement?
- A. Use AWS CloudTrail with your load balancer
- B. Enable access logs on the load balancer
- C. Use a CloudWatch Logs Agent
- D. Create a custom metric CloudWatch lter on your load balancer
Top
Q41: A static web site has been hosted on a bucket and is now being accessed by users. One of the web pages javascript section has been changed to access data which is hosted in another S3 bucket. Now that same web page is no longer loading in the browser. Which of the following can help alleviate the error?
- A. Enable versioning for the underlying S3 bucket.
- B. Enable Replication so that the objects get replicated to the other bucket
- C. Enable CORS for the bucket
- D. Change the Bucket policy for the bucket to allow access from the other bucket
Top
Q42: Your mobile application includes a photo-sharing service that is expecting tens of thousands of users at launch. You will leverage Amazon Simple Storage Service (S3) for storage of the user Images, and you must decide how to authenticate and authorize your users for access to these images. You also need to manage the storage of these images. Which two of the following approaches should you use? Choose two answers from the options below
- A. Create an Amazon S3 bucket per user, and use your application to generate the S3 URL for the appropriate content.
- B. Use AWS Identity and Access Management (IAM) user accounts as your application-level user database, and offload the burden of authentication from your application code.
- C. Authenticate your users at the application level, and use AWS Security Token Service (STS)to grant token-based authorization to S3 objects.
- D. Authenticate your users at the application level, and send an SMS token message to the user. Create an Amazon S3 bucket with the same name as the SMS message token, and move the user’s objects to that bucket.
Top
Q43: Your current log analysis application takes more than four hours to generate a report of the top 10 users of your web application. You have been asked to implement a system that can report this information in real time, ensure that the report is always up to date, and handle increases in the number of requests to your web application. Choose the option that is cost-effective and can fulfill the requirements.
- A. Publish your data to CloudWatch Logs, and congure your application to Autoscale to handle the load on demand.
- B. Publish your log data to an Amazon S3 bucket. Use AWS CloudFormation to create an Auto Scaling group to scale your post-processing application which is congured to pull down your log les stored an Amazon S3
- C. Post your log data to an Amazon Kinesis data stream, and subscribe your log-processing application so that is congured to process your logging data.
- D. Create a multi-AZ Amazon RDS MySQL cluster, post the logging data to MySQL, and run a map reduce job to retrieve the required information on user counts.
Answer:
Top
Q44: You’ve been instructed to develop a mobile application that will make use of AWS services. You need to decide on a data store to store the user sessions. Which of the following would be an ideal data store for session management?
- A. AWS Simple Storage Service
- B. AWS DynamoDB
- C. AWS RDS
- D. AWS Redshift
Answer:
Top
Q45: Your application currently interacts with a DynamoDB table. Records are inserted into the table via the application. There is now a requirement to ensure that whenever items are updated in the DynamoDB primary table , another record is inserted into a secondary table. Which of the below feature should be used when developing such a solution?
- A. AWS DynamoDB Encryption
- B. AWS DynamoDB Streams
- C. AWS DynamoDB Accelerator
- D. AWSTable Accelerator
Top
Q46: An application has been making use of AWS DynamoDB for its back-end data store. The size of the table has now grown to 20 GB , and the scans on the table are causing throttling errors. Which of the following should now be implemented to avoid such errors?
- A. Large Page size
- B. Reduced page size
- C. Parallel Scans
- D. Sequential scans
Top
Q47: Which of the following is correct way of passing a stage variable to an HTTP URL ? (Select TWO.)
- A. http://example.com/${}/prod
- B. http://example.com/${stageVariables.}/prod
- C. http://${stageVariables.}.example.com/dev/operation
- D. http://${stageVariables}.example.com/dev/operation
- E. http://${}.example.com/dev/operation
- F. http://example.com/${stageVariables}/prod
Top
Q48: Your company is planning on creating new development environments in AWS. They want to make use of their existing Chef recipes which they use for their on-premise configuration for servers in AWS. Which of the following service would be ideal to use in this regard?
- A. AWS Elastic Beanstalk
- B. AWS OpsWork
- C. AWS Cloudformation
- D. AWS SQS
Top
Q49: Your company has developed a web application and is hosting it in an Amazon S3 bucket configured for static website hosting. The users can log in to this app using their Google/Facebook login accounts. The application is using the AWS SDK for JavaScript in the browser to access data stored in an Amazon DynamoDB table. How can you ensure that API keys for access to your data in DynamoDB are kept secure?
- A. Create an Amazon S3 role in IAM with access to the specific DynamoDB tables, and assign it to the bucket hosting your website
- B. Configure S3 bucket tags with your AWS access keys for your bucket hosing your website so that the application can query them for access.
- C. Configure a web identity federation role within IAM to enable access to the correct DynamoDB resources and retrieve temporary credentials
- D. Store AWS keys in global variables within your application and configure the application to use these credentials when making requests.
Top
Q50: Your application currently makes use of AWS Cognito for managing user identities. You want to analyze the information that is stored in AWS Cognito for your application. Which of the following features of AWS Cognito should you use for this purpose?
- A. Cognito Data
- B. Cognito Events
- C. Cognito Streams
- D. Cognito Callbacks
Top
Q51: You’ve developed a set of scripts using AWS Lambda. These scripts need to access EC2 Instances in a VPC. Which of the following needs to be done to ensure that the AWS Lambda function can access the resources in the VPC. Choose 2 answers from the options given below
- A. Ensure that the subnet ID’s are mentioned when conguring the Lambda function
- B. Ensure that the NACL ID’s are mentioned when conguring the Lambda function
- C. Ensure that the Security Group ID’s are mentioned when conguring the Lambda function
- D. Ensure that the VPC Flow Log ID’s are mentioned when conguring the Lambda function
Top
Q52: You’ve currently been tasked to migrate an existing on-premise environment into Elastic Beanstalk. The application does not make use of Docker containers. You also can’t see any relevant environments in the beanstalk service that would be suitable to host your application. What should you consider doing in this case?
- A. Migrate your application to using Docker containers and then migrate the app to the Elastic Beanstalk environment.
- B. Consider using Cloudformation to deploy your environment to Elastic Beanstalk
- C. Consider using Packer to create a custom platform
- D. Consider deploying your application using the Elastic Container Service
Top
Q53: Company B is writing 10 items to the Dynamo DB table every second. Each item is 15.5Kb in size. What would be the required provisioned write throughput for best performance? Choose the correct answer from the options below.
- A. 10
- B. 160
- C. 155
- D. 16
Top
Q54: Which AWS Service can be used to automatically install your application code onto EC2, on premises systems and Lambda?
- A. CodeCommit
- B. X-Ray
- C. CodeBuild
- D. CodeDeploy
Top
Q55: Which AWS service can be used to compile source code, run tests and package code?
- A. CodePipeline
- B. CodeCommit
- C. CodeBuild
- D. CodeDeploy
Top
Q56: How can your prevent CloudFormation from deleting your entire stack on failure? (Choose 2)
- A. Set the Rollback on failure radio button to No in the CloudFormation console
- B. Set Termination Protection to Enabled in the CloudFormation console
- C. Use the –disable-rollback flag with the AWS CLI
- D. Use the –enable-termination-protection protection flag with the AWS CLI
Q57: Which of the following practices allows multiple developers working on the same application to merge code changes frequently, without impacting each other and enables the identification of bugs early on in the release process?
- A. Continuous Integration
- B. Continuous Deployment
- C. Continuous Delivery
- D. Continuous Development
Q58: When deploying application code to EC2, the AppSpec file can be written in which language?
- A. JSON
- B. JSON or YAML
- C. XML
- D. YAML
Q59: Part of your CloudFormation deployment fails due to a mis-configuration, by defaukt what will happen?
- A. CloudFormation will rollback only the failed components
- B. CloudFormation will rollback the entire stack
- C. Failed component will remain available for debugging purposes
- D. CloudFormation will ask you if you want to continue with the deployment
Top
Q60: You want to receive an email whenever a user pushes code to CodeCommit repository, how can you configure this?
- A. Create a new SNS topic and configure it to poll for CodeCommit eveents. Ask all users to subscribe to the topic to receive notifications
- B. Configure a CloudWatch Events rule to send a message to SES which will trigger an email to be sent whenever a user pushes code to the repository.
- C. Configure Notifications in the console, this will create a CloudWatch events rule to send a notification to a SNS topic which will trigger an email to be sent to the user.
- D. Configure a CloudWatch Events rule to send a message to SQS which will trigger an email to be sent whenever a user pushes code to the repository.
Top
Q61: Which AWS service can be used to centrally store and version control your application source code, binaries and libraries
- A. CodeCommit
- B. CodeBuild
- C. CodePipeline
- D. ElasticFileSystem
Top
Q62: You are using CloudFormation to create a new S3 bucket, which of the following sections would you use to define the properties of your bucket?
- A. Conditions
- B. Parameters
- C. Outputs
- D. Resources
Top
Q63: You are deploying a number of EC2 and RDS instances using CloudFormation. Which section of the CloudFormation template would you use to define these?
- A. Transforms
- B. Outputs
- C. Resources
- D. Instances
Top
Q64: Which AWS service can be used to fully automate your entire release process?
- A. CodeDeploy
- B. CodePipeline
- C. CodeCommit
- D. CodeBuild
Top
Q65: You want to use the output of your CloudFormation stack as input to another CloudFormation stack. Which sections of the CloudFormation template would you use to help you configure this?
- A. Outputs
- B. Transforms
- C. Resources
- D. Exports
Top
Q66: You have some code located in an S3 bucket that you want to reference in your CloudFormation template. Which section of the template can you use to define this?
- A. Inputs
- B. Resources
- C. Transforms
- D. Files
Top
Q67: You are deploying an application to a number of Ec2 instances using CodeDeploy. What is the name of the file
used to specify source files and lifecycle hooks?
- A. buildspec.yml
- B. appspec.json
- C. appspec.yml
- D. buildspec.json
Q68: Which of the following approaches allows you to re-use pieces of CloudFormation code in multiple templates, for common use cases like provisioning a load balancer or web server?
- A. Share the code using an EBS volume
- B. Copy and paste the code into the template each time you need to use it
- C. Use a cloudformation nested stack
- D. Store the code you want to re-use in an AMI and reference the AMI from within your CloudFormation template.
Q69: In the CodeDeploy AppSpec file, what are hooks used for?
- A. To reference AWS resources that will be used during the deployment
- B. Hooks are reserved for future use
- C. To specify files you want to copy during the deployment.
- D. To specify, scripts or function that you want to run at set points in the deployment lifecycle
Q70: Which command can you use to encrypt a plain text file using CMK?
- A. aws kms-encrypt
- B. aws iam encrypt
- C. aws kms encrypt
- D. aws encrypt
Q72: Which of the following is an encrypted key used by KMS to encrypt your data
- A. Custmoer Mamaged Key
- B. Encryption Key
- C. Envelope Key
- D. Customer Master Key
Q73: Which of the following statements are correct? (Choose 2)
- A. The Customer Master Key is used to encrypt and decrypt the Envelope Key or Data Key
- B. The Envelope Key or Data Key is used to encrypt and decrypt plain text files.
- C. The envelope Key or Data Key is used to encrypt and decrypt the Customer Master Key.
- D. The Customer MasterKey is used to encrypt and decrypt plain text files.
Q74: Which of the following statements is correct in relation to kMS/ (Choose 2)
- A. KMS Encryption keys are regional
- B. You cannot export your customer master key
- C. You can export your customer master key.
- D. KMS encryption Keys are global
Q75: A developer is preparing a deployment package for a Java implementation of an AWS Lambda function. What should the developer include in the deployment package? (Select TWO.)
A. Compiled application code
B. Java runtime environment
C. References to the event sources
D. Lambda execution role
E. Application dependencies
Q76: A developer uses AWS CodeDeploy to deploy a Python application to a fleet of Amazon EC2 instances that run behind an Application Load Balancer. The instances run in an Amazon EC2 Auto Scaling group across multiple Availability Zones. What should the developer include in the CodeDeploy deployment package?
A. A launch template for the Amazon EC2 Auto Scaling group
B. A CodeDeploy AppSpec file
C. An EC2 role that grants the application access to AWS services
D. An IAM policy that grants the application access to AWS services
Q76: A company is working on a project to enhance its serverless application development process. The company hosts applications on AWS Lambda. The development team regularly updates the Lambda code and wants to use stable code in production. Which combination of steps should the development team take to configure Lambda functions to meet both development and production requirements? (Select TWO.)
A. Create a new Lambda version every time a new code release needs testing.
B. Create two Lambda function aliases. Name one as Production and the other as Development. Point the Production alias to a production-ready unqualified Amazon Resource Name (ARN) version. Point the Development alias to the $LATEST version.
C. Create two Lambda function aliases. Name one as Production and the other as Development. Point the Production alias to the production-ready qualified Amazon Resource Name (ARN) version. Point the Development alias to the variable LAMBDA_TASK_ROOT.
D. Create a new Lambda layer every time a new code release needs testing.
E. Create two Lambda function aliases. Name one as Production and the other as Development. Point the Production alias to a production-ready Lambda layer Amazon Resource Name (ARN). Point the Development alias to the $LATEST layer ARN.
Q77: Each time a developer publishes a new version of an AWS Lambda function, all the dependent event source mappings need to be updated with the reference to the new version’s Amazon Resource Name (ARN). These updates are time consuming and error-prone. Which combination of actions should the developer take to avoid performing these updates when publishing a new Lambda version? (Select TWO.)
A. Update event source mappings with the ARN of the Lambda layer.
B. Point a Lambda alias to a new version of the Lambda function.
C. Create a Lambda alias for each published version of the Lambda function.
D. Point a Lambda alias to a new Lambda function alias.
E. Update the event source mappings with the Lambda alias ARN.
Q78: A company wants to store sensitive user data in Amazon S3 and encrypt this data at rest. The company must manage the encryption keys and use Amazon S3 to perform the encryption. How can a developer meet these requirements?
A. Enable default encryption for the S3 bucket by using the option for server-side encryption with customer-provided encryption keys (SSE-C).
B. Enable client-side encryption with an encryption key. Upload the encrypted object to the S3 bucket.
C. Enable server-side encryption with Amazon S3 managed encryption keys (SSE-S3). Upload an object to the S3 bucket.
D. Enable server-side encryption with customer-provided encryption keys (SSE-C). Upload an object to the S3 bucket.
Q79: A company is developing a Python application that submits data to an Amazon DynamoDB table. The company requires client-side encryption of specific data items and end-to-end protection for the encrypted data in transit and at rest. Which combination of steps will meet the requirement for the encryption of specific data items? (Select TWO.)
A. Generate symmetric encryption keys with AWS Key Management Service (AWS KMS).
B. Generate asymmetric encryption keys with AWS Key Management Service (AWS KMS).
C. Use generated keys with the DynamoDB Encryption Client.
D. Use generated keys to configure DynamoDB table encryption with AWS managed customer master keys (CMKs).
E. Use generated keys to configure DynamoDB table encryption with AWS owned customer master keys (CMKs).
Q80: A company is developing a REST API with Amazon API Gateway. Access to the API should be limited to users in the existing Amazon Cognito user pool. Which combination of steps should a developer perform to secure the API? (Select TWO.)
A. Create an AWS Lambda authorizer for the API.
B. Create an Amazon Cognito authorizer for the API.
C. Configure the authorizer for the API resource.
D. Configure the API methods to use the authorizer.
E. Configure the authorizer for the API stage.
Q81: A developer is implementing a mobile app to provide personalized services to app users. The application code makes calls to Amazon S3 and Amazon Simple Queue Service (Amazon SQS). Which options can the developer use to authenticate the app users? (Select TWO.)
A. Authenticate to the Amazon Cognito identity pool directly.
B. Authenticate to AWS Identity and Access Management (IAM) directly.
C. Authenticate to the Amazon Cognito user pool directly.
D. Federate authentication by using Login with Amazon with the users managed with AWS Security Token Service (AWS STS).
E. Federate authentication by using Login with Amazon with the users managed with the Amazon Cognito user pool.
Q82: A company is implementing several order processing workflows. Each workflow is implemented by using AWS Lambda functions for each task. Which combination of steps should a developer follow to implement these workflows? (Select TWO.)
A. Define a AWS Step Functions task for each Lambda function.
B. Define a AWS Step Functions task for each workflow.
C. Write code that polls the AWS Step Functions invocation to coordinate each workflow.
D. Define an AWS Step Functions state machine for each workflow.
E. Define an AWS Step Functions state machine for each Lambda function.
Q83: A company is migrating a web service to the AWS Cloud. The web service accepts requests by using HTTP (port 80). The company wants to use an AWS Lambda function to process HTTP requests. Which application design will satisfy these requirements?
A. Create an Amazon API Gateway API. Configure proxy integration with the Lambda function.
B. Create an Amazon API Gateway API. Configure non-proxy integration with the Lambda function.
C. Configure the Lambda function to listen to inbound network connections on port 80.
D. Configure the Lambda function as a target in the Application Load Balancer target group.
Q84: A company is developing an image processing application. When an image is uploaded to an Amazon S3 bucket, a number of independent and separate services must be invoked to process the image. The services do not have to be available immediately, but they must process every image. Which application design satisfies these requirements?
A. Configure an Amazon S3 event notification that publishes to an Amazon Simple Queue Service (Amazon SQS) queue. Each service pulls the message from the same queue.
B. Configure an Amazon S3 event notification that publishes to an Amazon Simple Notification Service (Amazon SNS) topic. Each service subscribes to the same topic.
C. Configure an Amazon S3 event notification that publishes to an Amazon Simple Queue Service (Amazon SQS) queue. Subscribe a separate Amazon Simple Notification Service (Amazon SNS) topic for each service to an Amazon SQS queue.
D. Configure an Amazon S3 event notification that publishes to an Amazon Simple Notification Service (Amazon SNS) topic. Subscribe a separate Simple Queue Service (Amazon SQS) queue for each service to the Amazon SNS topic.
Q85: A developer wants to implement Amazon EC2 Auto Scaling for a Multi-AZ web application. However, the developer is concerned that user sessions will be lost during scale-in events. How can the developer store the session state and share it across the EC2 instances?
A. Write the sessions to an Amazon Kinesis data stream. Configure the application to poll the stream.
B. Publish the sessions to an Amazon Simple Notification Service (Amazon SNS) topic. Subscribe each instance in the group to the topic.
C. Store the sessions in an Amazon ElastiCache for Memcached cluster. Configure the application to use the Memcached API.
D. Write the sessions to an Amazon Elastic Block Store (Amazon EBS) volume. Mount the volume to each instance in the group.
Q86: A developer is integrating a legacy web application that runs on a fleet of Amazon EC2 instances with an Amazon DynamoDB table. There is no AWS SDK for the programming language that was used to implement the web application. Which combination of steps should the developer perform to make an API call to Amazon DynamoDB from the instances? (Select TWO.)
A. Make an HTTPS POST request to the DynamoDB API endpoint for the AWS Region. In the request body, include an XML document that contains the request attributes.
B. Make an HTTPS POST request to the DynamoDB API endpoint for the AWS Region. In the request body, include a JSON document that contains the request attributes.
C. Sign the requests by using AWS access keys and Signature Version 4.
D. Use an EC2 SSH key to calculate Signature Version 4 of the request.
E. Provide the signature value through the HTTP X-API-Key header.
Q87: A developer has written several custom applications that read and write to the same Amazon DynamoDB table. Each time the data in the DynamoDB table is modified, this change should be sent to an external API. Which combination of steps should the developer perform to accomplish this task? (Select TWO.)
A. Configure an AWS Lambda function to poll the stream and call the external API.
B. Configure an event in Amazon EventBridge (Amazon CloudWatch Events) that publishes the change to an Amazon Managed Streaming for Apache Kafka (Amazon MSK) data stream.
C. Create a trigger in the DynamoDB table to publish the change to an Amazon Kinesis data stream.
D. Deliver the stream to an Amazon Simple Notification Service (Amazon SNS) topic and subscribe the API to the topic.
E. Enable DynamoDB Streams on the table.
Q88: A company is migrating the create, read, update, and delete (CRUD) functionality of an existing Java web application to AWS Lambda. Which minimal code refactoring is necessary for the CRUD operations to run in the Lambda function?
A. Implement a Lambda handler function.
B. Import an AWS X-Ray package.
C. Rewrite the application code in Python.
D. Add a reference to the Lambda execution role.
Q89: A company plans to use AWS log monitoring services to monitor an application that runs on premises. Currently, the application runs on a recent version of Ubuntu Server and outputs the logs to a local file. Which combination of steps should a developer perform to accomplish this goal? (Select TWO.)
A. Update the application code to include calls to the agent API for log collection.
B. Install the Amazon Elastic Container Service (Amazon ECS) container agent on the server.
C. Install the unified Amazon CloudWatch agent on the server.
D. Configure the long-term AWS credentials on the server to enable log collection by the agent.
E. Attach an IAM role to the server to enable log collection by the agent.
Q90: A developer wants to monitor invocations of an AWS Lambda function by using Amazon CloudWatch Logs. The developer added a number of print statements to the function code that write the logging information to the stdout stream. After running the function, the developer does not see any log data being generated. Why does the log data NOT appear in the CloudWatch logs?
A. The log data is not written to the stderr stream.
B. Lambda function logging is not automatically enabled.
C. The execution role for the Lambda function did not grant permissions to write log data to CloudWatch Logs.
D. The Lambda function outputs the logs to an Amazon S3 bucket.
Q91: Which of the following are best practices you should implement into ongoing deployments of your application? (Select THREE.)
A. Use stage variables to manage secrets across environments
B. Create account-specific AWS SAM templates for each environment
C. Use an AutoPublish alias
D. Use traffic shifting with pre- and post-deployment hooks
E. Test throughout the pipeline
Q92: You are handing off maintenance of your new serverless application to an incoming team lead. Which recommendations would you make? (Select THREE.)
A. Keep up to date with the quotas and payload sizes for each AWS service you are using
B. Analyze production access patterns to identify potential improvements
C. Design your services to extend their life as long as possible
D. Minimize changes to your production application
E. Compare the value of using the latest first-class integrations versus using Lambda between AWS services
Top
Q56: How can your prevent CloudFormation from deleting your entire stack on failure? (Choose 2)
- A. Set the Rollback on failure radio button to No in the CloudFormation console
- B. Set Termination Protection to Enabled in the CloudFormation console
- C. Use the –disable-rollback flag with the AWS CLI
- D. Use the –enable-termination-protection protection flag with the AWS CLI
Q57: Which of the following practices allows multiple developers working on the same application to merge code changes frequently, without impacting each other and enables the identification of bugs early on in the release process?
- A. Continuous Integration
- B. Continuous Deployment
- C. Continuous Delivery
- D. Continuous Development
Q58: When deploying application code to EC2, the AppSpec file can be written in which language?
- A. JSON
- B. JSON or YAML
- C. XML
- D. YAML
Q59: Part of your CloudFormation deployment fails due to a mis-configuration, by defaukt what will happen?
- A. CloudFormation will rollback only the failed components
- B. CloudFormation will rollback the entire stack
- C. Failed component will remain available for debugging purposes
- D. CloudFormation will ask you if you want to continue with the deployment
Top
Q60: You want to receive an email whenever a user pushes code to CodeCommit repository, how can you configure this?
- A. Create a new SNS topic and configure it to poll for CodeCommit eveents. Ask all users to subscribe to the topic to receive notifications
- B. Configure a CloudWatch Events rule to send a message to SES which will trigger an email to be sent whenever a user pushes code to the repository.
- C. Configure Notifications in the console, this will create a CloudWatch events rule to send a notification to a SNS topic which will trigger an email to be sent to the user.
- D. Configure a CloudWatch Events rule to send a message to SQS which will trigger an email to be sent whenever a user pushes code to the repository.
Top
Q61: Which AWS service can be used to centrally store and version control your application source code, binaries and libraries
- A. CodeCommit
- B. CodeBuild
- C. CodePipeline
- D. ElasticFileSystem
Top
Q62: You are using CloudFormation to create a new S3 bucket, which of the following sections would you use to define the properties of your bucket?
- A. Conditions
- B. Parameters
- C. Outputs
- D. Resources
Top
Q63: You are deploying a number of EC2 and RDS instances using CloudFormation. Which section of the CloudFormation template would you use to define these?
- A. Transforms
- B. Outputs
- C. Resources
- D. Instances
Top
Q64: Which AWS service can be used to fully automate your entire release process?
- A. CodeDeploy
- B. CodePipeline
- C. CodeCommit
- D. CodeBuild
Top
Q65: You want to use the output of your CloudFormation stack as input to another CloudFormation stack. Which sections of the CloudFormation template would you use to help you configure this?
- A. Outputs
- B. Transforms
- C. Resources
- D. Exports
Top
Q66: You have some code located in an S3 bucket that you want to reference in your CloudFormation template. Which section of the template can you use to define this?
- A. Inputs
- B. Resources
- C. Transforms
- D. Files
Top
Q67: You are deploying an application to a number of Ec2 instances using CodeDeploy. What is the name of the file
used to specify source files and lifecycle hooks?
- A. buildspec.yml
- B. appspec.json
- C. appspec.yml
- D. buildspec.json
Q68: Which of the following approaches allows you to re-use pieces of CloudFormation code in multiple templates, for common use cases like provisioning a load balancer or web server?
- A. Share the code using an EBS volume
- B. Copy and paste the code into the template each time you need to use it
- C. Use a cloudformation nested stack
- D. Store the code you want to re-use in an AMI and reference the AMI from within your CloudFormation template.
Q69: In the CodeDeploy AppSpec file, what are hooks used for?
- A. To reference AWS resources that will be used during the deployment
- B. Hooks are reserved for future use
- C. To specify files you want to copy during the deployment.
- D. To specify, scripts or function that you want to run at set points in the deployment lifecycle
Q70: Which command can you use to encrypt a plain text file using CMK?
- A. aws kms-encrypt
- B. aws iam encrypt
- C. aws kms encrypt
- D. aws encrypt
Q72: Which of the following is an encrypted key used by KMS to encrypt your data
- A. Custmoer Mamaged Key
- B. Encryption Key
- C. Envelope Key
- D. Customer Master Key
Q73: Which of the following statements are correct? (Choose 2)
- A. The Customer Master Key is used to encrypt and decrypt the Envelope Key or Data Key
- B. The Envelope Key or Data Key is used to encrypt and decrypt plain text files.
- C. The envelope Key or Data Key is used to encrypt and decrypt the Customer Master Key.
- D. The Customer MasterKey is used to encrypt and decrypt plain text files.
Q74: Which of the following statements is correct in relation to kMS/ (Choose 2)
- A. KMS Encryption keys are regional
- B. You cannot export your customer master key
- C. You can export your customer master key.
- D. KMS encryption Keys are global
Q75: A developer is preparing a deployment package for a Java implementation of an AWS Lambda function. What should the developer include in the deployment package? (Select TWO.)
A. Compiled application code
B. Java runtime environment
C. References to the event sources
D. Lambda execution role
E. Application dependencies
Q76: A developer uses AWS CodeDeploy to deploy a Python application to a fleet of Amazon EC2 instances that run behind an Application Load Balancer. The instances run in an Amazon EC2 Auto Scaling group across multiple Availability Zones. What should the developer include in the CodeDeploy deployment package?
A. A launch template for the Amazon EC2 Auto Scaling group
B. A CodeDeploy AppSpec file
C. An EC2 role that grants the application access to AWS services
D. An IAM policy that grants the application access to AWS services
Q76: A company is working on a project to enhance its serverless application development process. The company hosts applications on AWS Lambda. The development team regularly updates the Lambda code and wants to use stable code in production. Which combination of steps should the development team take to configure Lambda functions to meet both development and production requirements? (Select TWO.)
A. Create a new Lambda version every time a new code release needs testing.
B. Create two Lambda function aliases. Name one as Production and the other as Development. Point the Production alias to a production-ready unqualified Amazon Resource Name (ARN) version. Point the Development alias to the $LATEST version.
C. Create two Lambda function aliases. Name one as Production and the other as Development. Point the Production alias to the production-ready qualified Amazon Resource Name (ARN) version. Point the Development alias to the variable LAMBDA_TASK_ROOT.
D. Create a new Lambda layer every time a new code release needs testing.
E. Create two Lambda function aliases. Name one as Production and the other as Development. Point the Production alias to a production-ready Lambda layer Amazon Resource Name (ARN). Point the Development alias to the $LATEST layer ARN.
Q77: Each time a developer publishes a new version of an AWS Lambda function, all the dependent event source mappings need to be updated with the reference to the new version’s Amazon Resource Name (ARN). These updates are time consuming and error-prone. Which combination of actions should the developer take to avoid performing these updates when publishing a new Lambda version? (Select TWO.)
A. Update event source mappings with the ARN of the Lambda layer.
B. Point a Lambda alias to a new version of the Lambda function.
C. Create a Lambda alias for each published version of the Lambda function.
D. Point a Lambda alias to a new Lambda function alias.
E. Update the event source mappings with the Lambda alias ARN.
Q78: A company wants to store sensitive user data in Amazon S3 and encrypt this data at rest. The company must manage the encryption keys and use Amazon S3 to perform the encryption. How can a developer meet these requirements?
A. Enable default encryption for the S3 bucket by using the option for server-side encryption with customer-provided encryption keys (SSE-C).
B. Enable client-side encryption with an encryption key. Upload the encrypted object to the S3 bucket.
C. Enable server-side encryption with Amazon S3 managed encryption keys (SSE-S3). Upload an object to the S3 bucket.
D. Enable server-side encryption with customer-provided encryption keys (SSE-C). Upload an object to the S3 bucket.
Q79: A company is developing a Python application that submits data to an Amazon DynamoDB table. The company requires client-side encryption of specific data items and end-to-end protection for the encrypted data in transit and at rest. Which combination of steps will meet the requirement for the encryption of specific data items? (Select TWO.)
A. Generate symmetric encryption keys with AWS Key Management Service (AWS KMS).
B. Generate asymmetric encryption keys with AWS Key Management Service (AWS KMS).
C. Use generated keys with the DynamoDB Encryption Client.
D. Use generated keys to configure DynamoDB table encryption with AWS managed customer master keys (CMKs).
E. Use generated keys to configure DynamoDB table encryption with AWS owned customer master keys (CMKs).
Q80: A company is developing a REST API with Amazon API Gateway. Access to the API should be limited to users in the existing Amazon Cognito user pool. Which combination of steps should a developer perform to secure the API? (Select TWO.)
A. Create an AWS Lambda authorizer for the API.
B. Create an Amazon Cognito authorizer for the API.
C. Configure the authorizer for the API resource.
D. Configure the API methods to use the authorizer.
E. Configure the authorizer for the API stage.
Q81: A developer is implementing a mobile app to provide personalized services to app users. The application code makes calls to Amazon S3 and Amazon Simple Queue Service (Amazon SQS). Which options can the developer use to authenticate the app users? (Select TWO.)
A. Authenticate to the Amazon Cognito identity pool directly.
B. Authenticate to AWS Identity and Access Management (IAM) directly.
C. Authenticate to the Amazon Cognito user pool directly.
D. Federate authentication by using Login with Amazon with the users managed with AWS Security Token Service (AWS STS).
E. Federate authentication by using Login with Amazon with the users managed with the Amazon Cognito user pool.
Question: A company is implementing several order processing workflows. Each workflow is implemented by using AWS Lambda functions for each task. Which combination of steps should a developer follow to implement these workflows? (Select TWO.)
A. Define a AWS Step Functions task for each Lambda function.
B. Define a AWS Step Functions task for each workflow.
C. Write code that polls the AWS Step Functions invocation to coordinate each workflow.
D. Define an AWS Step Functions state machine for each workflow.
E. Define an AWS Step Functions state machine for each Lambda function.
Answer: A. D.
Notes: Step Functions is based on state machines and tasks. A state machine is a workflow. Tasks perform work by coordinating with other AWS services, such as Lambda. A state machine is a workflow. It can be used to express a workflow as a number of states, their relationships, and their input and output. You can coordinate individual tasks with Step Functions by expressing your workflow as a finite state machine, written in the Amazon States Language.
ReferenceText: Getting Started with AWS Step Functions.
ReferenceUrl: https://aws.amazon.com/step-functions/getting-started/
Category: Development
Welcome to AWS Certified Developer Associate Exam Preparation: Definition and Objectives, Top 100 Questions and Answers dump, White papers, Courses, Labs and Training Materials, Exam info and details, References, Jobs, Others AWS Certificates
What is the AWS Certified Developer Associate Exam?
This AWS Certified Developer-Associate Examination is intended for individuals who perform a Developer role. It validates an examinee’s ability to:
- Demonstrate an understanding of core AWS services, uses, and basic AWS architecture best practices
- Demonstrate proficiency in developing, deploying, and debugging cloud-based applications by using AWS
Recommended general IT knowledge
The target candidate should have the following:
– In-depth knowledge of at least one high-level programming language
– Understanding of application lifecycle management
– The ability to write code for serverless applications
– Understanding of the use of containers in the development process
Recommended AWS knowledge
The target candidate should be able to do the following:
- Use the AWS service APIs, CLI, and software development kits (SDKs) to write applications
- Identify key features of AWS services
- Understand the AWS shared responsibility model
- Use a continuous integration and continuous delivery (CI/CD) pipeline to deploy applications on AWS
- Use and interact with AWS services
- Apply basic understanding of cloud-native applications to write code
- Write code by using AWS security best practices (for example, use IAM roles instead of secret and access keys in the code)
- Author, maintain, and debug code modules on AWS
What is considered out of scope for the target candidate?
The following is a non-exhaustive list of related job tasks that the target candidate is not expected to be able to perform. These items are considered out of scope for the exam:
– Design architectures (for example, distributed system, microservices)
– Design and implement CI/CD pipelines
- Administer IAM users and groups
- Administer Amazon Elastic Container Service (Amazon ECS)
- Design AWS networking infrastructure (for example, Amazon VPC, AWS Direct Connect)
- Understand compliance and licensing
Exam content
Response types
There are two types of questions on the exam:
– Multiple choice: Has one correct response and three incorrect responses (distractors)
– Multiple response: Has two or more correct responses out of five or more response options
Select one or more responses that best complete the statement or answer the question. Distractors, or incorrect answers, are response options that a candidate with incomplete knowledge or skill might choose.
Distractors are generally plausible responses that match the content area.
Unanswered questions are scored as incorrect; there is no penalty for guessing. The exam includes 50 questions that will affect your score.
Unscored content
The exam includes 15 unscored questions that do not affect your score. AWS collects information about candidate performance on these unscored questions to evaluate these questions for future use as scored questions. These unscored questions are not identified on the exam.
Exam results
The AWS Certified Developer – Associate (DVA-C01) exam is a pass or fail exam. The exam is scored against a minimum standard established by AWS professionals who follow certification industry best practices and guidelines.
Your results for the exam are reported as a scaled score of 100–1,000. The minimum passing score is 720.
Your score shows how you performed on the exam as a whole and whether you passed. Scaled scoring models help equate scores across multiple exam forms that might have slightly different difficulty levels.
Your score report could contain a table of classifications of your performance at each section level. This information is intended to provide general feedback about your exam performance. The exam uses a compensatory scoring model, which means that you do not need to achieve a passing score in each section. You need to pass only the overall exam.
Each section of the exam has a specific weighting, so some sections have more questions than other sections have. The table contains general information that highlights your strengths and weaknesses. Use caution when interpreting section-level feedback.
Content outline
This exam guide includes weightings, test domains, and objectives for the exam. It is not a comprehensive listing of the content on the exam. However, additional context for each of the objectives is available to help guide your preparation for the exam. The following table lists the main content domains and their weightings. The table precedes the complete exam content outline, which includes the additional context.
The percentage in each domain represents only scored content.
Domain 1: Deployment 22%
Domain 2: Security 26%
Domain 3: Development with AWS Services 30%
Domain 4: Refactoring 10%
Domain 5: Monitoring and Troubleshooting 12%
Domain 1: Deployment
1.1 Deploy written code in AWS using existing CI/CD pipelines, processes, and patterns.
– Commit code to a repository and invoke build, test and/or deployment actions
– Use labels and branches for version and release management
– Use AWS CodePipeline to orchestrate workflows against different environments
– Apply AWS CodeCommit, AWS CodeBuild, AWS CodePipeline, AWS CodeStar, and AWS
CodeDeploy for CI/CD purposes
– Perform a roll back plan based on application deployment policy
1.2 Deploy applications using AWS Elastic Beanstalk.
– Utilize existing supported environments to define a new application stack
– Package the application
– Introduce a new application version into the Elastic Beanstalk environment
– Utilize a deployment policy to deploy an application version (i.e., all at once, rolling, rolling with batch, immutable)
– Validate application health using Elastic Beanstalk dashboard
– Use Amazon CloudWatch Logs to instrument application logging
1.3 Prepare the application deployment package to be deployed to AWS.
– Manage the dependencies of the code module (like environment variables, config files and static image files) within the package
– Outline the package/container directory structure and organize files appropriately
– Translate application resource requirements to AWS infrastructure parameters (e.g., memory, cores)
1.4 Deploy serverless applications.
– Given a use case, implement and launch an AWS Serverless Application Model (AWS SAM) template
– Manage environments in individual AWS services (e.g., Differentiate between Development, Test, and Production in Amazon API Gateway)
Domain 2: Security
2.1 Make authenticated calls to AWS services.
– Communicate required policy based on least privileges required by application.
– Assume an IAM role to access a service
– Use the software development kit (SDK) credential provider on-premises or in the cloud to access AWS services (local credentials vs. instance roles)
2.2 Implement encryption using AWS services.
– Encrypt data at rest (client side; server side; envelope encryption) using AWS services
– Encrypt data in transit
2.3 Implement application authentication and authorization.
– Add user sign-up and sign-in functionality for applications with Amazon Cognito identity or user pools
– Use Amazon Cognito-provided credentials to write code that access AWS services.
– Use Amazon Cognito sync to synchronize user profiles and data
– Use developer-authenticated identities to interact between end user devices, backend
authentication, and Amazon Cognito
Domain 3: Development with AWS Services
3.1 Write code for serverless applications.
– Compare and contrast server-based vs. serverless model (e.g., micro services, stateless nature of serverless applications, scaling serverless applications, and decoupling layers of serverless applications)
– Configure AWS Lambda functions by defining environment variables and parameters (e.g., memory, time out, runtime, handler)
– Create an API endpoint using Amazon API Gateway
– Create and test appropriate API actions like GET, POST using the API endpoint
– Apply Amazon DynamoDB concepts (e.g., tables, items, and attributes)
– Compute read/write capacity units for Amazon DynamoDB based on application requirements
– Associate an AWS Lambda function with an AWS event source (e.g., Amazon API Gateway, Amazon CloudWatch event, Amazon S3 events, Amazon Kinesis)
– Invoke an AWS Lambda function synchronously and asynchronously
3.2 Translate functional requirements into application design.
– Determine real-time vs. batch processing for a given use case
– Determine use of synchronous vs. asynchronous for a given use case
– Determine use of event vs. schedule/poll for a given use case
– Account for tradeoffs for consistency models in an application design
Domain 4: Refactoring
4.1 Optimize applications to best use AWS services and features.
Implement AWS caching services to optimize performance (e.g., Amazon ElastiCache, Amazon API Gateway cache)
Apply an Amazon S3 naming scheme for optimal read performance
4.2 Migrate existing application code to run on AWS.
– Isolate dependencies
– Run the application as one or more stateless processes
– Develop in order to enable horizontal scalability
– Externalize state
Domain 5: Monitoring and Troubleshooting
5.1 Write code that can be monitored.
– Create custom Amazon CloudWatch metrics
– Perform logging in a manner available to systems operators
– Instrument application source code to enable tracing in AWS X-Ray
5.2 Perform root cause analysis on faults found in testing or production.
– Interpret the outputs from the logging mechanism in AWS to identify errors in logs
– Check build and testing history in AWS services (e.g., AWS CodeBuild, AWS CodeDeploy, AWS CodePipeline) to identify issues
– Utilize AWS services (e.g., Amazon CloudWatch, VPC Flow Logs, and AWS X-Ray) to locate a specific faulty component
Which key tools, technologies, and concepts might be covered on the exam?
The following is a non-exhaustive list of the tools and technologies that could appear on the exam.
This list is subject to change and is provided to help you understand the general scope of services, features, or technologies on the exam.
The general tools and technologies in this list appear in no particular order.
AWS services are grouped according to their primary functions. While some of these technologies will likely be covered more than others on the exam, the order and placement of them in this list is no indication of relative weight or importance:
– Analytics
– Application Integration
– Containers
– Cost and Capacity Management
– Data Movement
– Developer Tools
– Instances (virtual machines)
– Management and Governance
– Networking and Content Delivery
– Security
– Serverless
AWS services and features
Analytics:
– Amazon Elasticsearch Service (Amazon ES)
– Amazon Kinesis
Application Integration:
– Amazon EventBridge (Amazon CloudWatch Events)
– Amazon Simple Notification Service (Amazon SNS)
– Amazon Simple Queue Service (Amazon SQS)
– AWS Step Functions
Compute:
– Amazon EC2
– AWS Elastic Beanstalk
– AWS Lambda
Containers:
– Amazon Elastic Container Registry (Amazon ECR)
– Amazon Elastic Container Service (Amazon ECS)
– Amazon Elastic Kubernetes Services (Amazon EKS)
Database:
– Amazon DynamoDB
– Amazon ElastiCache
– Amazon RDS
Developer Tools:
– AWS CodeArtifact
– AWS CodeBuild
– AWS CodeCommit
– AWS CodeDeploy
– Amazon CodeGuru
– AWS CodePipeline
– AWS CodeStar
– AWS Fault Injection Simulator
– AWS X-Ray
Management and Governance:
– AWS CloudFormation
– Amazon CloudWatch
Networking and Content Delivery:
– Amazon API Gateway
– Amazon CloudFront
– Elastic Load Balancing
Security, Identity, and Compliance:
– Amazon Cognito
– AWS Identity and Access Management (IAM)
– AWS Key Management Service (AWS KMS)
Storage:
– Amazon S3
Out-of-scope AWS services and features
The following is a non-exhaustive list of AWS services and features that are not covered on the exam.
These services and features do not represent every AWS offering that is excluded from the exam content.
Services or features that are entirely unrelated to the target job roles for the exam are excluded from this list because they are assumed to be irrelevant.
Out-of-scope AWS services and features include the following:
– AWS Application Discovery Service
– Amazon AppStream 2.0
– Amazon Chime
– Amazon Connect
– AWS Database Migration Service (AWS DMS)
– AWS Device Farm
– Amazon Elastic Transcoder
– Amazon GameLift
– Amazon Lex
– Amazon Machine Learning (Amazon ML)
– AWS Managed Services
– Amazon Mobile Analytics
– Amazon Polly
– Amazon QuickSight
– Amazon Rekognition
– AWS Server Migration Service (AWS SMS)
– AWS Service Catalog
– AWS Shield Advanced
– AWS Shield Standard
– AWS Snow Family
– AWS Storage Gateway
– AWS WAF
– Amazon WorkMail
– Amazon WorkSpaces
To succeed with the real exam, do not memorize the answers below. It is very important that you understand why a question is right or wrong and the concepts behind it by carefully reading the reference documents in the answers.
AWS Certified Developer – Associate Practice Questions And Answers Dump
Q0: Your application reads commands from an SQS queue and sends them to web services hosted by your
partners. When a partner’s endpoint goes down, your application continually returns their commands to the queue. The repeated attempts to deliver these commands use up resources. Commands that can’t be delivered must not be lost.
How can you accommodate the partners’ broken web services without wasting your resources?
- A. Create a delay queue and set DelaySeconds to 30 seconds
- B. Requeue the message with a VisibilityTimeout of 30 seconds.
- C. Create a dead letter queue and set the Maximum Receives to 3.
- D. Requeue the message with a DelaySeconds of 30 seconds.
Top
Q1: A developer is writing an application that will store data in a DynamoDB table. The ratio of reads operations to write operations will be 1000 to 1, with the same data being accessed frequently.
What should the Developer enable on the DynamoDB table to optimize performance and minimize costs?
- A. Amazon DynamoDB auto scaling
- B. Amazon DynamoDB cross-region replication
- C. Amazon DynamoDB Streams
- D. Amazon DynamoDB Accelerator
Top
Q2: You are creating a DynamoDB table with the following attributes:
- PurchaseOrderNumber (partition key)
- CustomerID
- PurchaseDate
- TotalPurchaseValue
One of your applications must retrieve items from the table to calculate the total value of purchases for a
particular customer over a date range. What secondary index do you need to add to the table?
- A. Local secondary index with a partition key of CustomerID and sort key of PurchaseDate; project the
TotalPurchaseValue attribute - B. Local secondary index with a partition key of PurchaseDate and sort key of CustomerID; project the
TotalPurchaseValue attribute - C. Global secondary index with a partition key of CustomerID and sort key of PurchaseDate; project the
TotalPurchaseValue attribute - D. Global secondary index with a partition key of PurchaseDate and sort key of CustomerID; project the
TotalPurchaseValue attribute
Top
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q3: When referencing the remaining time left for a Lambda function to run within the function’s code you would use:
- A. The event object
- B. The timeLeft object
- C. The remains object
- D. The context object
Top
Q4: What two arguments does a Python Lambda handler function require?
- A. invocation, zone
- B. event, zone
- C. invocation, context
- D. event, context
Q5: Lambda allows you to upload code and dependencies for function packages:
- A. Only from a directly uploaded zip file
- B. Only via SFTP
- C. Only from a zip file in AWS S3
- D. From a zip file in AWS S3 or uploaded directly from elsewhere
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q6: A Lambda deployment package contains:
- A. Function code, libraries, and runtime binaries
- B. Only function code
- C. Function code and libraries not included within the runtime
- D. Only libraries not included within the runtime
Q7: You are attempting to SSH into an EC2 instance that is located in a public subnet. However, you are currently receiving a timeout error trying to connect. What could be a possible cause of this connection issue?
- A. The security group associated with the EC2 instance has an inbound rule that allows SSH traffic, but does not have an outbound rule that allows SSH traffic.
- B. The security group associated with the EC2 instance has an inbound rule that allows SSH traffic AND has an outbound rule that explicitly denies SSH traffic.
- C. The security group associated with the EC2 instance has an inbound rule that allows SSH traffic AND the associated NACL has both an inbound and outbound rule that allows SSH traffic.
- D. The security group associated with the EC2 instance does not have an inbound rule that allows SSH traffic AND the associated NACL does not have an outbound rule that allows SSH traffic.
Top
Q8: You have instances inside private subnets and a properly configured bastion host instance in a public subnet. None of the instances in the private subnets have a public or Elastic IP address. How can you connect an instance in the private subnet to the open internet to download system updates?
- A. Create and assign EIP to each instance
- B. Create and attach a second IGW to the VPC.
- C. Create and utilize a NAT Gateway
- D. Connect to a VPN
Top
Q9: What feature of VPC networking should you utilize if you want to create “elasticity” in your application’s architecture?
- A. Security Groups
- B. Route Tables
- C. Elastic Load Balancer
- D. Auto Scaling
Top
Q10: Lambda allows you to upload code and dependencies for function packages:
- A. Only from a directly uploaded zip file
- B. Only from a directly uploaded zip file
- C. Only from a zip file in AWS S3
- D. From a zip file in AWS S3 or uploaded directly from elsewhere
Q11: You’re writing a script with an AWS SDK that uses the AWS API Actions and want to create AMIs for non-EBS backed AMIs for you. Which API call should occurs in the final process of creating an AMI?
- A. RegisterImage
- B. CreateImage
- C. ami-register-image
- D. ami-create-image
Q12: When dealing with session state in EC2-based applications using Elastic load balancers which option is generally thought of as the best practice for managing user sessions?
- A. Having the ELB distribute traffic to all EC2 instances and then having the instance check a caching solution like ElastiCache running Redis or Memcached for session information
- B. Permenantly assigning users to specific instances and always routing their traffic to those instances
- C. Using Application-generated cookies to tie a user session to a particular instance for the cookie duration
- D. Using Elastic Load Balancer generated cookies to tie a user session to a particular instance
Q13: Which API call would best be used to describe an Amazon Machine Image?
- A. ami-describe-image
- B. ami-describe-images
- C. DescribeImage
- D. DescribeImages
Q14: What is one key difference between an Amazon EBS-backed and an instance-store backed instance?
- A. Autoscaling requires using Amazon EBS-backed instances
- B. Virtual Private Cloud requires EBS backed instances
- C. Amazon EBS-backed instances can be stopped and restarted without losing data
- D. Instance-store backed instances can be stopped and restarted without losing data
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q15: After having created a new Linux instance on Amazon EC2, and downloaded the .pem file (called Toto.pem) you try and SSH into your IP address (54.1.132.33) using the following command.
ssh -i my_key.pem ec2-user@52.2.222.22
However you receive the following error.
@@@@@@@@ WARNING: UNPROTECTED PRIVATE KEY FILE! @ @@@@@@@@@@@@@@@@@@@
What is the most probable reason for this and how can you fix it?
- A. You do not have root access on your terminal and need to use the sudo option for this to work.
- B. You do not have enough permissions to perform the operation.
- C. Your key file is encrypted. You need to use the -u option for unencrypted not the -i option.
- D. Your key file must not be publicly viewable for SSH to work. You need to modify your .pem file to limit permissions.
Q16: You have an EBS root device on /dev/sda1 on one of your EC2 instances. You are having trouble with this particular instance and you need to either Stop/Start, Reboot or Terminate the instance but you do NOT want to lose any data that you have stored on /dev/sda1. However, you are unsure if changing the instance state in any of the aforementioned ways will cause you to lose data stored on the EBS volume. Which of the below statements best describes the effect each change of instance state would have on the data you have stored on /dev/sda1?
- A. Whether you stop/start, reboot or terminate the instance it does not matter because data on an EBS volume is not ephemeral and the data will not be lost regardless of what method is used.
- B. If you stop/start the instance the data will not be lost. However if you either terminate or reboot the instance the data will be lost.
- C. Whether you stop/start, reboot or terminate the instance it does not matter because data on an EBS volume is ephemeral and it will be lost no matter what method is used.
- D. The data will be lost if you terminate the instance, however the data will remain on /dev/sda1 if you reboot or stop/start the instance because data on an EBS volume is not ephemeral.
Q17: EC2 instances are launched from Amazon Machine Images (AMIs). A given public AMI:
- A. Can only be used to launch EC2 instances in the same AWS availability zone as the AMI is stored
- B. Can only be used to launch EC2 instances in the same country as the AMI is stored
- C. Can only be used to launch EC2 instances in the same AWS region as the AMI is stored
- D. Can be used to launch EC2 instances in any AWS region
Q18: Which of the following statements is true about the Elastic File System (EFS)?
- A. EFS can scale out to meet capacity requirements and scale back down when no longer needed
- B. EFS can be used by multiple EC2 instances simultaneously
- C. EFS cannot be used by an instance using EBS
- D. EFS can be configured on an instance before launch just like an IAM role or EBS volumes
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q19: IAM Policies, at a minimum, contain what elements?
- A. ID
- B. Effects
- C. Resources
- D. Sid
- E. Principle
- F. Actions
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q20: What are the main benefits of IAM groups?
- A. The ability to create custom permission policies.
- B. Assigning IAM permission policies to more than one user at a time.
- C. Easier user/policy management.
- D. Allowing EC2 instances to gain access to S3.
Q21: What are benefits of using AWS STS?
- A. Grant access to AWS resources without having to create an IAM identity for them
- B. Since credentials are temporary, you don’t have to rotate or revoke them
- C. Temporary security credentials can be extended indefinitely
- D. Temporary security credentials can be restricted to a specific region
Q22: What should the Developer enable on the DynamoDB table to optimize performance and minimize costs?
- A. Amazon DynamoDB auto scaling
- B. Amazon DynamoDB cross-region replication
- C. Amazon DynamoDB Streams
- D. Amazon DynamoDB Accelerator
Top
Q23: A Developer has been asked to create an AWS Elastic Beanstalk environment for a production web application which needs to handle thousands of requests. Currently the dev environment is running on a t1 micro instance. How can the Developer change the EC2 instance type to m4.large?
- A. Use CloudFormation to migrate the Amazon EC2 instance type of the environment from t1 micro to m4.large.
- B. Create a saved configuration file in Amazon S3 with the instance type as m4.large and use the same during environment creation.
- C. Change the instance type to m4.large in the configuration details page of the Create New Environment page.
- D. Change the instance type value for the environment to m4.large by using update autoscaling group CLI command.
Q24: What statements are true about Availability Zones (AZs) and Regions?
- A. There is only one AZ in each AWS Region
- B. AZs are geographically separated inside a region to help protect against natural disasters affecting more than one at a time.
- C. AZs can be moved between AWS Regions based on your needs
- D. There are (almost always) two or more AZs in each AWS Region
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q25: An AWS Region contains:
- A. Edge Locations
- B. Data Centers
- C. AWS Services
- D. Availability Zones
Top
Q26: Which read request in DynamoDB returns a response with the most up-to-date data, reflecting the updates from all prior write operations that were successful?
- A. Eventual Consistent Reads
- B. Conditional reads for Consistency
- C. Strongly Consistent Reads
- D. Not possible
Top
Q27: You’ ve been asked to move an existing development environment on the AWS Cloud. This environment consists mainly of Docker based containers. You need to ensure that minimum effort is taken during the migration process. Which of the following step would you consider for this requirement?
- A. Create an Opswork stack and deploy the Docker containers
- B. Create an application and Environment for the Docker containers in the Elastic Beanstalk service
- C. Create an EC2 Instance. Install Docker and deploy the necessary containers.
- D. Create an EC2 Instance. Install Docker and deploy the necessary containers. Add an Autoscaling Group for scalability of the containers.
Top
Q28: You’ve written an application that uploads objects onto an S3 bucket. The size of the object varies between 200 – 500 MB. You’ve seen that the application sometimes takes a longer than expected time to upload the object. You want to improve the performance of the application. Which of the following would you consider?
- A. Create multiple threads and upload the objects in the multiple threads
- B. Write the items in batches for better performance
- C. Use the Multipart upload API
- D. Enable versioning on the Bucket
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Top
Q29: A security system monitors 600 cameras, saving image metadata every 1 minute to an Amazon DynamoDb table. Each sample involves 1kb of data, and the data writes are evenly distributed over time. How much write throughput is required for the target table?
- A. 6000
- B. 10
- C. 3600
- D. 600
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Q30: What two arguments does a Python Lambda handler function require?
- A. invocation, zone
- B. event, zone
- C. invocation, context
- D. event, context
Top
Q31: Lambda allows you to upload code and dependencies for function packages:
- A. Only from a directly uploaded zip file
- B. Only via SFTP
- C. Only from a zip file in AWS S3
- D. From a zip file in AWS S3 or uploaded directly from elsewhere
Top
Q32: A Lambda deployment package contains:
- A. Function code, libraries, and runtime binaries
- B. Only function code
- C. Function code and libraries not included within the runtime
- D. Only libraries not included within the runtime
Top
Q33: You have instances inside private subnets and a properly configured bastion host instance in a public subnet. None of the instances in the private subnets have a public or Elastic IP address. How can you connect an instance in the private subnet to the open internet to download system updates?
- A. Create and assign EIP to each instance
- B. Create and attach a second IGW to the VPC.
- C. Create and utilize a NAT Gateway
- D. Connect to a VPN
Top
Q34: What feature of VPC networking should you utilize if you want to create “elasticity” in your application’s architecture?
- A. Security Groups
- B. Route Tables
- C. Elastic Load Balancer
- D. Auto Scaling
Top
Q30: Lambda allows you to upload code and dependencies for function packages:
- A. Only from a directly uploaded zip file
- B. Only from a directly uploaded zip file
- C. Only from a zip file in AWS S3
- D. From a zip file in AWS S3 or uploaded directly from elsewhere
Answer:
Top
Q31: An organization is using an Amazon ElastiCache cluster in front of their Amazon RDS instance. The organization would like the Developer to implement logic into the code so that the cluster only retrieves data from RDS when there is a cache miss. What strategy can the Developer implement to achieve this?
- A. Lazy loading
- B. Write-through
- C. Error retries
- D. Exponential backoff
Answer:
Top
Q32: A developer is writing an application that will run on Ec2 instances and read messages from SQS queue. The nessages will arrive every 15-60 seconds. How should the Developer efficiently query the queue for new messages?
- A. Use long polling
- B. Set a custom visibility timeout
- C. Use short polling
- D. Implement exponential backoff
Top
Q33: You are using AWS SAM to define a Lambda function and configure CodeDeploy to manage deployment patterns. With new Lambda function working as per expectation which of the following will shift traffic from original Lambda function to new Lambda function in the shortest time frame?
- A. Canary10Percent5Minutes
- B. Linear10PercentEvery10Minutes
- C. Canary10Percent15Minutes
- D. Linear10PercentEvery1Minute
Top
Q34: You are using AWS SAM templates to deploy a serverless application. Which of the following resource will embed application from Amazon S3 buckets?
- A. AWS::Serverless::Api
- B. AWS::Serverless::Application
- C. AWS::Serverless::Layerversion
- D. AWS::Serverless::Function
Top
Q35: You are using AWS Envelope Encryption for encrypting all sensitive data. Which of the followings is True with regards to Envelope Encryption?
- A. Data is encrypted be encrypting Data key which is further encrypted using encrypted Master Key.
- B. Data is encrypted by plaintext Data key which is further encrypted using encrypted Master Key.
- C. Data is encrypted by encrypted Data key which is further encrypted using plaintext Master Key.
- D. Data is encrypted by plaintext Data key which is further encrypted using plaintext Master Key.
Top
Q36: You are developing an application that will be comprised of the following architecture –
- A set of Ec2 instances to process the videos.
- These (Ec2 instances) will be spun up by an autoscaling group.
- SQS Queues to maintain the processing messages.
- There will be 2 pricing tiers.
How will you ensure that the premium customers videos are given more preference?
- A. Create 2 Autoscaling Groups, one for normal and one for premium customers
- B. Create 2 set of Ec2 Instances, one for normal and one for premium customers
- C. Create 2 SQS queus, one for normal and one for premium customers
- D. Create 2 Elastic Load Balancers, one for normal and one for premium customers.
Top
Q37: You are developing an application that will interact with a DynamoDB table. The table is going to take in a lot of read and write operations. Which of the following would be the ideal partition key for the DynamoDB table to ensure ideal performance?
- A. CustomerID
- B. CustomerName
- C. Location
- D. Age
Top
Q38: A developer is making use of AWS services to develop an application. He has been asked to develop the application in a manner to compensate any network delays. Which of the following two mechanisms should he implement in the application?
- A. Multiple SQS queues
- B. Exponential backoff algorithm
- C. Retries in your application code
- D. Consider using the Java sdk.
Top
Q39: An application is being developed that is going to write data to a DynamoDB table. You have to setup the read and write throughput for the table. Data is going to be read at the rate of 300 items every 30 seconds. Each item is of size 6KB. The reads can be eventual consistent reads. What should be the read capacity that needs to be set on the table?
- A. 10
- B. 20
- C. 6
- D. 30
Top
Q40: You are in charge of deploying an application that will be hosted on an EC2 Instance and sit behind an Elastic Load balancer. You have been requested to monitor the incoming connections to the Elastic Load Balancer. Which of the below options can suffice this requirement?
- A. Use AWS CloudTrail with your load balancer
- B. Enable access logs on the load balancer
- C. Use a CloudWatch Logs Agent
- D. Create a custom metric CloudWatch lter on your load balancer
Top
Q41: A static web site has been hosted on a bucket and is now being accessed by users. One of the web pages javascript section has been changed to access data which is hosted in another S3 bucket. Now that same web page is no longer loading in the browser. Which of the following can help alleviate the error?
- A. Enable versioning for the underlying S3 bucket.
- B. Enable Replication so that the objects get replicated to the other bucket
- C. Enable CORS for the bucket
- D. Change the Bucket policy for the bucket to allow access from the other bucket
Top
Q42: Your mobile application includes a photo-sharing service that is expecting tens of thousands of users at launch. You will leverage Amazon Simple Storage Service (S3) for storage of the user Images, and you must decide how to authenticate and authorize your users for access to these images. You also need to manage the storage of these images. Which two of the following approaches should you use? Choose two answers from the options below
- A. Create an Amazon S3 bucket per user, and use your application to generate the S3 URL for the appropriate content.
- B. Use AWS Identity and Access Management (IAM) user accounts as your application-level user database, and offload the burden of authentication from your application code.
- C. Authenticate your users at the application level, and use AWS Security Token Service (STS)to grant token-based authorization to S3 objects.
- D. Authenticate your users at the application level, and send an SMS token message to the user. Create an Amazon S3 bucket with the same name as the SMS message token, and move the user’s objects to that bucket.
Top
Q43: Your current log analysis application takes more than four hours to generate a report of the top 10 users of your web application. You have been asked to implement a system that can report this information in real time, ensure that the report is always up to date, and handle increases in the number of requests to your web application. Choose the option that is cost-effective and can fulfill the requirements.
- A. Publish your data to CloudWatch Logs, and congure your application to Autoscale to handle the load on demand.
- B. Publish your log data to an Amazon S3 bucket. Use AWS CloudFormation to create an Auto Scaling group to scale your post-processing application which is congured to pull down your log les stored an Amazon S3
- C. Post your log data to an Amazon Kinesis data stream, and subscribe your log-processing application so that is congured to process your logging data.
- D. Create a multi-AZ Amazon RDS MySQL cluster, post the logging data to MySQL, and run a map reduce job to retrieve the required information on user counts.
Answer:
Top
Q44: You’ve been instructed to develop a mobile application that will make use of AWS services. You need to decide on a data store to store the user sessions. Which of the following would be an ideal data store for session management?
- A. AWS Simple Storage Service
- B. AWS DynamoDB
- C. AWS RDS
- D. AWS Redshift
Answer:
Top
Q45: Your application currently interacts with a DynamoDB table. Records are inserted into the table via the application. There is now a requirement to ensure that whenever items are updated in the DynamoDB primary table , another record is inserted into a secondary table. Which of the below feature should be used when developing such a solution?
- A. AWS DynamoDB Encryption
- B. AWS DynamoDB Streams
- C. AWS DynamoDB Accelerator
- D. AWSTable Accelerator
Top
Q46: An application has been making use of AWS DynamoDB for its back-end data store. The size of the table has now grown to 20 GB , and the scans on the table are causing throttling errors. Which of the following should now be implemented to avoid such errors?
- A. Large Page size
- B. Reduced page size
- C. Parallel Scans
- D. Sequential scans
Top
Q47: Which of the following is correct way of passing a stage variable to an HTTP URL ? (Select TWO.)
- A. http://example.com/${}/prod
- B. http://example.com/${stageVariables.}/prod
- C. http://${stageVariables.}.example.com/dev/operation
- D. http://${stageVariables}.example.com/dev/operation
- E. http://${}.example.com/dev/operation
- F. http://example.com/${stageVariables}/prod
Top
Q48: Your company is planning on creating new development environments in AWS. They want to make use of their existing Chef recipes which they use for their on-premise configuration for servers in AWS. Which of the following service would be ideal to use in this regard?
- A. AWS Elastic Beanstalk
- B. AWS OpsWork
- C. AWS Cloudformation
- D. AWS SQS
Top
Q49: Your company has developed a web application and is hosting it in an Amazon S3 bucket configured for static website hosting. The users can log in to this app using their Google/Facebook login accounts. The application is using the AWS SDK for JavaScript in the browser to access data stored in an Amazon DynamoDB table. How can you ensure that API keys for access to your data in DynamoDB are kept secure?
- A. Create an Amazon S3 role in IAM with access to the specific DynamoDB tables, and assign it to the bucket hosting your website
- B. Configure S3 bucket tags with your AWS access keys for your bucket hosing your website so that the application can query them for access.
- C. Configure a web identity federation role within IAM to enable access to the correct DynamoDB resources and retrieve temporary credentials
- D. Store AWS keys in global variables within your application and configure the application to use these credentials when making requests.
Top
Q50: Your application currently makes use of AWS Cognito for managing user identities. You want to analyze the information that is stored in AWS Cognito for your application. Which of the following features of AWS Cognito should you use for this purpose?
- A. Cognito Data
- B. Cognito Events
- C. Cognito Streams
- D. Cognito Callbacks
Top
Q51: You’ve developed a set of scripts using AWS Lambda. These scripts need to access EC2 Instances in a VPC. Which of the following needs to be done to ensure that the AWS Lambda function can access the resources in the VPC. Choose 2 answers from the options given below
- A. Ensure that the subnet ID’s are mentioned when conguring the Lambda function
- B. Ensure that the NACL ID’s are mentioned when conguring the Lambda function
- C. Ensure that the Security Group ID’s are mentioned when conguring the Lambda function
- D. Ensure that the VPC Flow Log ID’s are mentioned when conguring the Lambda function
Top
Q52: You’ve currently been tasked to migrate an existing on-premise environment into Elastic Beanstalk. The application does not make use of Docker containers. You also can’t see any relevant environments in the beanstalk service that would be suitable to host your application. What should you consider doing in this case?
- A. Migrate your application to using Docker containers and then migrate the app to the Elastic Beanstalk environment.
- B. Consider using Cloudformation to deploy your environment to Elastic Beanstalk
- C. Consider using Packer to create a custom platform
- D. Consider deploying your application using the Elastic Container Service
Top
Q53: Company B is writing 10 items to the Dynamo DB table every second. Each item is 15.5Kb in size. What would be the required provisioned write throughput for best performance? Choose the correct answer from the options below.
- A. 10
- B. 160
- C. 155
- D. 16
Top
Q54: Which AWS Service can be used to automatically install your application code onto EC2, on premises systems and Lambda?
- A. CodeCommit
- B. X-Ray
- C. CodeBuild
- D. CodeDeploy
Top
Q55: Which AWS service can be used to compile source code, run tests and package code?
- A. CodePipeline
- B. CodeCommit
- C. CodeBuild
- D. CodeDeploy
Top
Q56: How can your prevent CloudFormation from deleting your entire stack on failure? (Choose 2)
- A. Set the Rollback on failure radio button to No in the CloudFormation console
- B. Set Termination Protection to Enabled in the CloudFormation console
- C. Use the –disable-rollback flag with the AWS CLI
- D. Use the –enable-termination-protection protection flag with the AWS CLI
Q57: Which of the following practices allows multiple developers working on the same application to merge code changes frequently, without impacting each other and enables the identification of bugs early on in the release process?
- A. Continuous Integration
- B. Continuous Deployment
- C. Continuous Delivery
- D. Continuous Development
Q58: When deploying application code to EC2, the AppSpec file can be written in which language?
- A. JSON
- B. JSON or YAML
- C. XML
- D. YAML
Q59: Part of your CloudFormation deployment fails due to a mis-configuration, by defaukt what will happen?
- A. CloudFormation will rollback only the failed components
- B. CloudFormation will rollback the entire stack
- C. Failed component will remain available for debugging purposes
- D. CloudFormation will ask you if you want to continue with the deployment
Top
Q60: You want to receive an email whenever a user pushes code to CodeCommit repository, how can you configure this?
- A. Create a new SNS topic and configure it to poll for CodeCommit eveents. Ask all users to subscribe to the topic to receive notifications
- B. Configure a CloudWatch Events rule to send a message to SES which will trigger an email to be sent whenever a user pushes code to the repository.
- C. Configure Notifications in the console, this will create a CloudWatch events rule to send a notification to a SNS topic which will trigger an email to be sent to the user.
- D. Configure a CloudWatch Events rule to send a message to SQS which will trigger an email to be sent whenever a user pushes code to the repository.
Top
Q61: Which AWS service can be used to centrally store and version control your application source code, binaries and libraries
- A. CodeCommit
- B. CodeBuild
- C. CodePipeline
- D. ElasticFileSystem
Top
Q62: You are using CloudFormation to create a new S3 bucket, which of the following sections would you use to define the properties of your bucket?
- A. Conditions
- B. Parameters
- C. Outputs
- D. Resources
Top
Q63: You are deploying a number of EC2 and RDS instances using CloudFormation. Which section of the CloudFormation template would you use to define these?
- A. Transforms
- B. Outputs
- C. Resources
- D. Instances
Top
Q64: Which AWS service can be used to fully automate your entire release process?
- A. CodeDeploy
- B. CodePipeline
- C. CodeCommit
- D. CodeBuild
Top
Q65: You want to use the output of your CloudFormation stack as input to another CloudFormation stack. Which sections of the CloudFormation template would you use to help you configure this?
- A. Outputs
- B. Transforms
- C. Resources
- D. Exports
Top
Q66: You have some code located in an S3 bucket that you want to reference in your CloudFormation template. Which section of the template can you use to define this?
- A. Inputs
- B. Resources
- C. Transforms
- D. Files
Top
Q67: You are deploying an application to a number of Ec2 instances using CodeDeploy. What is the name of the file
used to specify source files and lifecycle hooks?
- A. buildspec.yml
- B. appspec.json
- C. appspec.yml
- D. buildspec.json
Q68: Which of the following approaches allows you to re-use pieces of CloudFormation code in multiple templates, for common use cases like provisioning a load balancer or web server?
- A. Share the code using an EBS volume
- B. Copy and paste the code into the template each time you need to use it
- C. Use a cloudformation nested stack
- D. Store the code you want to re-use in an AMI and reference the AMI from within your CloudFormation template.
Q69: In the CodeDeploy AppSpec file, what are hooks used for?
- A. To reference AWS resources that will be used during the deployment
- B. Hooks are reserved for future use
- C. To specify files you want to copy during the deployment.
- D. To specify, scripts or function that you want to run at set points in the deployment lifecycle
Q70: Which command can you use to encrypt a plain text file using CMK?
- A. aws kms-encrypt
- B. aws iam encrypt
- C. aws kms encrypt
- D. aws encrypt
Q72: Which of the following is an encrypted key used by KMS to encrypt your data
- A. Custmoer Mamaged Key
- B. Encryption Key
- C. Envelope Key
- D. Customer Master Key
Q73: Which of the following statements are correct? (Choose 2)
- A. The Customer Master Key is used to encrypt and decrypt the Envelope Key or Data Key
- B. The Envelope Key or Data Key is used to encrypt and decrypt plain text files.
- C. The envelope Key or Data Key is used to encrypt and decrypt the Customer Master Key.
- D. The Customer MasterKey is used to encrypt and decrypt plain text files.
Q74: Which of the following statements is correct in relation to kMS/ (Choose 2)
- A. KMS Encryption keys are regional
- B. You cannot export your customer master key
- C. You can export your customer master key.
- D. KMS encryption Keys are global
Q75: A developer is preparing a deployment package for a Java implementation of an AWS Lambda function. What should the developer include in the deployment package? (Select TWO.)
A. Compiled application code
B. Java runtime environment
C. References to the event sources
D. Lambda execution role
E. Application dependencies
Q76: A developer uses AWS CodeDeploy to deploy a Python application to a fleet of Amazon EC2 instances that run behind an Application Load Balancer. The instances run in an Amazon EC2 Auto Scaling group across multiple Availability Zones. What should the developer include in the CodeDeploy deployment package?
A. A launch template for the Amazon EC2 Auto Scaling group
B. A CodeDeploy AppSpec file
C. An EC2 role that grants the application access to AWS services
D. An IAM policy that grants the application access to AWS services
Q76: A company is working on a project to enhance its serverless application development process. The company hosts applications on AWS Lambda. The development team regularly updates the Lambda code and wants to use stable code in production. Which combination of steps should the development team take to configure Lambda functions to meet both development and production requirements? (Select TWO.)
A. Create a new Lambda version every time a new code release needs testing.
B. Create two Lambda function aliases. Name one as Production and the other as Development. Point the Production alias to a production-ready unqualified Amazon Resource Name (ARN) version. Point the Development alias to the $LATEST version.
C. Create two Lambda function aliases. Name one as Production and the other as Development. Point the Production alias to the production-ready qualified Amazon Resource Name (ARN) version. Point the Development alias to the variable LAMBDA_TASK_ROOT.
D. Create a new Lambda layer every time a new code release needs testing.
E. Create two Lambda function aliases. Name one as Production and the other as Development. Point the Production alias to a production-ready Lambda layer Amazon Resource Name (ARN). Point the Development alias to the $LATEST layer ARN.
Q77: Each time a developer publishes a new version of an AWS Lambda function, all the dependent event source mappings need to be updated with the reference to the new version’s Amazon Resource Name (ARN). These updates are time consuming and error-prone. Which combination of actions should the developer take to avoid performing these updates when publishing a new Lambda version? (Select TWO.)
A. Update event source mappings with the ARN of the Lambda layer.
B. Point a Lambda alias to a new version of the Lambda function.
C. Create a Lambda alias for each published version of the Lambda function.
D. Point a Lambda alias to a new Lambda function alias.
E. Update the event source mappings with the Lambda alias ARN.
Q78: A company wants to store sensitive user data in Amazon S3 and encrypt this data at rest. The company must manage the encryption keys and use Amazon S3 to perform the encryption. How can a developer meet these requirements?
A. Enable default encryption for the S3 bucket by using the option for server-side encryption with customer-provided encryption keys (SSE-C).
B. Enable client-side encryption with an encryption key. Upload the encrypted object to the S3 bucket.
C. Enable server-side encryption with Amazon S3 managed encryption keys (SSE-S3). Upload an object to the S3 bucket.
D. Enable server-side encryption with customer-provided encryption keys (SSE-C). Upload an object to the S3 bucket.
Q79: A company is developing a Python application that submits data to an Amazon DynamoDB table. The company requires client-side encryption of specific data items and end-to-end protection for the encrypted data in transit and at rest. Which combination of steps will meet the requirement for the encryption of specific data items? (Select TWO.)
A. Generate symmetric encryption keys with AWS Key Management Service (AWS KMS).
B. Generate asymmetric encryption keys with AWS Key Management Service (AWS KMS).
C. Use generated keys with the DynamoDB Encryption Client.
D. Use generated keys to configure DynamoDB table encryption with AWS managed customer master keys (CMKs).
E. Use generated keys to configure DynamoDB table encryption with AWS owned customer master keys (CMKs).
Q80: A company is developing a REST API with Amazon API Gateway. Access to the API should be limited to users in the existing Amazon Cognito user pool. Which combination of steps should a developer perform to secure the API? (Select TWO.)
A. Create an AWS Lambda authorizer for the API.
B. Create an Amazon Cognito authorizer for the API.
C. Configure the authorizer for the API resource.
D. Configure the API methods to use the authorizer.
E. Configure the authorizer for the API stage.
Q81: A developer is implementing a mobile app to provide personalized services to app users. The application code makes calls to Amazon S3 and Amazon Simple Queue Service (Amazon SQS). Which options can the developer use to authenticate the app users? (Select TWO.)
A. Authenticate to the Amazon Cognito identity pool directly.
B. Authenticate to AWS Identity and Access Management (IAM) directly.
C. Authenticate to the Amazon Cognito user pool directly.
D. Federate authentication by using Login with Amazon with the users managed with AWS Security Token Service (AWS STS).
E. Federate authentication by using Login with Amazon with the users managed with the Amazon Cognito user pool.
Q82: A company is implementing several order processing workflows. Each workflow is implemented by using AWS Lambda functions for each task. Which combination of steps should a developer follow to implement these workflows? (Select TWO.)
A. Define a AWS Step Functions task for each Lambda function.
B. Define a AWS Step Functions task for each workflow.
C. Write code that polls the AWS Step Functions invocation to coordinate each workflow.
D. Define an AWS Step Functions state machine for each workflow.
E. Define an AWS Step Functions state machine for each Lambda function.
Q83: A company is migrating a web service to the AWS Cloud. The web service accepts requests by using HTTP (port 80). The company wants to use an AWS Lambda function to process HTTP requests. Which application design will satisfy these requirements?
A. Create an Amazon API Gateway API. Configure proxy integration with the Lambda function.
B. Create an Amazon API Gateway API. Configure non-proxy integration with the Lambda function.
C. Configure the Lambda function to listen to inbound network connections on port 80.
D. Configure the Lambda function as a target in the Application Load Balancer target group.
Q84: A company is developing an image processing application. When an image is uploaded to an Amazon S3 bucket, a number of independent and separate services must be invoked to process the image. The services do not have to be available immediately, but they must process every image. Which application design satisfies these requirements?
A. Configure an Amazon S3 event notification that publishes to an Amazon Simple Queue Service (Amazon SQS) queue. Each service pulls the message from the same queue.
B. Configure an Amazon S3 event notification that publishes to an Amazon Simple Notification Service (Amazon SNS) topic. Each service subscribes to the same topic.
C. Configure an Amazon S3 event notification that publishes to an Amazon Simple Queue Service (Amazon SQS) queue. Subscribe a separate Amazon Simple Notification Service (Amazon SNS) topic for each service to an Amazon SQS queue.
D. Configure an Amazon S3 event notification that publishes to an Amazon Simple Notification Service (Amazon SNS) topic. Subscribe a separate Simple Queue Service (Amazon SQS) queue for each service to the Amazon SNS topic.
Q85: A developer wants to implement Amazon EC2 Auto Scaling for a Multi-AZ web application. However, the developer is concerned that user sessions will be lost during scale-in events. How can the developer store the session state and share it across the EC2 instances?
A. Write the sessions to an Amazon Kinesis data stream. Configure the application to poll the stream.
B. Publish the sessions to an Amazon Simple Notification Service (Amazon SNS) topic. Subscribe each instance in the group to the topic.
C. Store the sessions in an Amazon ElastiCache for Memcached cluster. Configure the application to use the Memcached API.
D. Write the sessions to an Amazon Elastic Block Store (Amazon EBS) volume. Mount the volume to each instance in the group.
Q86: A developer is integrating a legacy web application that runs on a fleet of Amazon EC2 instances with an Amazon DynamoDB table. There is no AWS SDK for the programming language that was used to implement the web application. Which combination of steps should the developer perform to make an API call to Amazon DynamoDB from the instances? (Select TWO.)
A. Make an HTTPS POST request to the DynamoDB API endpoint for the AWS Region. In the request body, include an XML document that contains the request attributes.
B. Make an HTTPS POST request to the DynamoDB API endpoint for the AWS Region. In the request body, include a JSON document that contains the request attributes.
C. Sign the requests by using AWS access keys and Signature Version 4.
D. Use an EC2 SSH key to calculate Signature Version 4 of the request.
E. Provide the signature value through the HTTP X-API-Key header.
Q87: A developer has written several custom applications that read and write to the same Amazon DynamoDB table. Each time the data in the DynamoDB table is modified, this change should be sent to an external API. Which combination of steps should the developer perform to accomplish this task? (Select TWO.)
A. Configure an AWS Lambda function to poll the stream and call the external API.
B. Configure an event in Amazon EventBridge (Amazon CloudWatch Events) that publishes the change to an Amazon Managed Streaming for Apache Kafka (Amazon MSK) data stream.
C. Create a trigger in the DynamoDB table to publish the change to an Amazon Kinesis data stream.
D. Deliver the stream to an Amazon Simple Notification Service (Amazon SNS) topic and subscribe the API to the topic.
E. Enable DynamoDB Streams on the table.
Q88: A company is migrating the create, read, update, and delete (CRUD) functionality of an existing Java web application to AWS Lambda. Which minimal code refactoring is necessary for the CRUD operations to run in the Lambda function?
A. Implement a Lambda handler function.
B. Import an AWS X-Ray package.
C. Rewrite the application code in Python.
D. Add a reference to the Lambda execution role.
Q89: A company plans to use AWS log monitoring services to monitor an application that runs on premises. Currently, the application runs on a recent version of Ubuntu Server and outputs the logs to a local file. Which combination of steps should a developer perform to accomplish this goal? (Select TWO.)
A. Update the application code to include calls to the agent API for log collection.
B. Install the Amazon Elastic Container Service (Amazon ECS) container agent on the server.
C. Install the unified Amazon CloudWatch agent on the server.
D. Configure the long-term AWS credentials on the server to enable log collection by the agent.
E. Attach an IAM role to the server to enable log collection by the agent.
Q90: A developer wants to monitor invocations of an AWS Lambda function by using Amazon CloudWatch Logs. The developer added a number of print statements to the function code that write the logging information to the stdout stream. After running the function, the developer does not see any log data being generated. Why does the log data NOT appear in the CloudWatch logs?
A. The log data is not written to the stderr stream.
B. Lambda function logging is not automatically enabled.
C. The execution role for the Lambda function did not grant permissions to write log data to CloudWatch Logs.
D. The Lambda function outputs the logs to an Amazon S3 bucket.
Q91: Which of the following are best practices you should implement into ongoing deployments of your application? (Select THREE.)
A. Use stage variables to manage secrets across environments
B. Create account-specific AWS SAM templates for each environment
C. Use an AutoPublish alias
D. Use traffic shifting with pre- and post-deployment hooks
E. Test throughout the pipeline
Q92: You are handing off maintenance of your new serverless application to an incoming team lead. Which recommendations would you make? (Select THREE.)
A. Keep up to date with the quotas and payload sizes for each AWS service you are using
B. Analyze production access patterns to identify potential improvements
C. Design your services to extend their life as long as possible
D. Minimize changes to your production application
E. Compare the value of using the latest first-class integrations versus using Lambda between AWS services
Q93: You are handing off maintenance of your new serverless application to an incoming team lead. Which recommendations would you make? (Select THREE.)
A. Keep up to date with the quotas and payload sizes for each AWS service you are using
B. Analyze production access patterns to identify potential improvements
C. Design your services to extend their life as long as possible
D. Minimize changes to your production application
E. Compare the value of using the latest first-class integrations versus using Lambda between AWS services
Q94: Your application needs to connect to an Amazon RDS instance on the backend. What is the best recommendation to the developer whose function must read from and write to the Amazon RDS instance?
A. Initialize the number of connections you want outside of the handler
B. Use the database TTL setting to clean up connections
C. Use reserved concurrency to limit the number of concurrent functions that would try to write to the database
D. Use the database proxy feature to provide connection pooling for the functions
Question 95: A developer reports that a third-party library they need cannot be shared in the Lambda invocation environment. Which suggestion would you make?
A. Decrease the deployment package size
B. Set a provisioned concurrency of one so that the library doesn’t need to be shared across environments
C. Use reserved concurrency for the function that needs to use the library
D. Load the third-party library onto an Amazon EFS volume
AWS Certified Developer Associate exam: Whitepapers
AWS has provided whitepapers to help you understand the technical concepts. Below are the recommended whitepapers for the AWS Certified Developer – Associate Exam.
- Overview of Amazon Web Services
- Architecting for the Cloud: AWS Best Practices
- AWS Security Best Practices whitepaper, August 2016
- AWS Well-Architected Framework whitepaper, November 2017 Version 1.3 DVA-C01 Page |2
- Architecting for the Cloud AWS Best Practices whitepaper, February, 2016
- Practicing Continuous Integration and Continuous Delivery on AWS Accelerating Software Delivery with DevOps whitepaper, June 2017
- Microservices on AWS whitepaper, September 2017
- Serverless Architectures with AWS Lambda whitepaper, November 2017
- Optimizing Enterprise Economics with Serverless Architectures whitepaper, October 2017
- Running Containerized Microservices on AWS whitepaper, November 2017
- Blue/Green Deployments on AWS whitepaper, August 2016
Online Training and Labs for AWS Certified Developer Associates Exam
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
AWS Developer Associates Jobs
AWS Certified Developer-Associate Exam info and details, How To:
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
The AWS Certified Developer Associate exam is a multiple choice, multiple answer exam. Here is the Exam Overview:
- Certification Name: AWS Certified Developer Associate.
- Prerequisites for the Exam: None.
- Exam Pattern: Multiple Choice Questions
- The AWS Certified Developer-Associate Examination (DVA-C01) is a pass or fail exam. The examination is scored against a minimum standard established by AWS professionals guided by certification industry best practices and guidelines.
- Your results for the examination are reported as a score from 100 – 1000, with a minimum passing score of 720.
- Exam fees: US $150
- Exam Guide on AWS Website
- Available languages for tests: English, Japanese, Korean, Simplified Chinese
- Read AWS whitepapers
- Register for certification account here.
- Prepare for Certification Here
Exam Content Outline
Domain % of Examination Domain 1: Deployment (22%)
1.1 Deploy written code in AWS using existing CI/CD pipelines, processes, and patterns.
1.2 Deploy applications using Elastic Beanstalk.
1.3 Prepare the application deployment package to be deployed to AWS.
1.4 Deploy serverless applications22% Domain 2: Security (26%)
2.1 Make authenticated calls to AWS services.
2.2 Implement encryption using AWS services.
2.3 Implement application authentication and authorization.26% Domain 3: Development with AWS Services (30%)
3.1 Write code for serverless applications.
3.2 Translate functional requirements into application design.
3.3 Implement application design into application code.
3.4 Write code that interacts with AWS services by using APIs, SDKs, and AWS CLI.30% Domain 4: Refactoring
4.1 Optimize application to best use AWS services and features.
4.2 Migrate existing application code to run on AWS.10% Domain 5: Monitoring and Troubleshooting (10%)
5.1 Write code that can be monitored.
5.2 Perform root cause analysis on faults found in testing or production.10% TOTAL 100%
AWS Certified Developer Associate exam: Additional Information for reference
Below are some useful reference links that would help you to learn about AWS Certified Developer Associate Exam.
- Developing on AWS: An instructor-led live or virtual 3-day course
- https://aws.amazon.com/certification/faqs/
- AWS Digital Training: Application Services, Developer Tools, and other services covered on the exam
- Prepare for AWS Certification
- AWS EC2 Instance info
- AWS Certified Developer Associate Exam Guide
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Other Relevant and Recommended AWS Certifications

The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
- AWS Certified Cloud Practitioner
- AWS Certified Solutions Architect – Associate
- AAWS Certified Developer – Associate
- AWS Certified SysOps Administrator – Associate
- AWS Certified Solutions Architect – Professional
- AWS Certified DevOps Engineer – Professional
- AWS Certified Big Data Specialty
- AWS Certified Advanced Networking.
- AWS Certified Security – Specialty
Other AWS Facts and Summaries and Questions/Answers Dump
- AWS S3 facts and summaries and Q&A Dump
- AWS DynamoDB facts and summaries and Questions and Answers Dump
- AWS EC2 facts and summaries and Questions and Answers Dump
- AWS Serverless facts and summaries and Questions and Answers Dump
- AWS Developer and Deployment Theory facts and summaries and Questions and Answers Dump
- AWS IAM facts and summaries and Questions and Answers Dump
- AWS Lambda facts and summaries and Questions and Answers Dump
- AWS SQS facts and summaries and Questions and Answers Dump
- AWS RDS facts and summaries and Questions and Answers Dump
- AWS ECS facts and summaries and Questions and Answers Dump
- AWS CloudWatch facts and summaries and Questions and Answers Dump
- AWS SES facts and summaries and Questions and Answers Dump
- AWS EBS facts and summaries and Questions and Answers Dump
- AWS ELB facts and summaries and Questions and Answers Dump
- AWS Autoscaling facts and summaries and Questions and Answers Dump
- AWS VPC facts and summaries and Questions and Answers Dump
- AWS KMS facts and summaries and Questions and Answers Dump
- AWS Elastic Beanstalk facts and summaries and Questions and Answers Dump
- AWS CodeBuild facts and summaries and Questions and Answers Dump
- AWS CodeDeploy facts and summaries and Questions and Answers Dump
- AWS CodePipeline facts and summaries and Questions and Answers Dump
AWS Certified Developer Associate exam: Whitepapers
AWS has provided whitepapers to help you understand the technical concepts. Below are the recommended whitepapers for the AWS Certified Developer – Associate Exam.
- Overview of Amazon Web Services
- Architecting for the Cloud: AWS Best Practices
- AWS Security Best Practices whitepaper, August 2016
- AWS Well-Architected Framework whitepaper, November 2017 Version 1.3 DVA-C01 Page |2
- Architecting for the Cloud AWS Best Practices whitepaper, February, 2016
- Practicing Continuous Integration and Continuous Delivery on AWS Accelerating Software Delivery with DevOps whitepaper, June 2017
- Microservices on AWS whitepaper, September 2017
- Serverless Architectures with AWS Lambda whitepaper, November 2017
- Optimizing Enterprise Economics with Serverless Architectures whitepaper, October 2017
- Running Containerized Microservices on AWS whitepaper, November 2017
- Blue/Green Deployments on AWS whitepaper, August 2016
Online Training and Labs for AWS Certified Developer Associates Exam
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
AWS Developer Associates Jobs
AWS Certified Developer-Associate Exam info and details, How To:
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
The AWS Certified Developer Associate exam is a multiple choice, multiple answer exam. Here is the Exam Overview:
- Certification Name: AWS Certified Developer Associate.
- Prerequisites for the Exam: None.
- Exam Pattern: Multiple Choice Questions
- The AWS Certified Developer-Associate Examination (DVA-C01) is a pass or fail exam. The examination is scored against a minimum standard established by AWS professionals guided by certification industry best practices and guidelines.
- Your results for the examination are reported as a score from 100 – 1000, with a minimum passing score of 720.
- Exam fees: US $150
- Exam Guide on AWS Website
- Available languages for tests: English, Japanese, Korean, Simplified Chinese
- Read AWS whitepapers
- Register for certification account here.
- Prepare for Certification Here
Exam Content Outline
Domain % of Examination Domain 1: Deployment (22%)
1.1 Deploy written code in AWS using existing CI/CD pipelines, processes, and patterns.
1.2 Deploy applications using Elastic Beanstalk.
1.3 Prepare the application deployment package to be deployed to AWS.
1.4 Deploy serverless applications22% Domain 2: Security (26%)
2.1 Make authenticated calls to AWS services.
2.2 Implement encryption using AWS services.
2.3 Implement application authentication and authorization.26% Domain 3: Development with AWS Services (30%)
3.1 Write code for serverless applications.
3.2 Translate functional requirements into application design.
3.3 Implement application design into application code.
3.4 Write code that interacts with AWS services by using APIs, SDKs, and AWS CLI.30% Domain 4: Refactoring
4.1 Optimize application to best use AWS services and features.
4.2 Migrate existing application code to run on AWS.10% Domain 5: Monitoring and Troubleshooting (10%)
5.1 Write code that can be monitored.
5.2 Perform root cause analysis on faults found in testing or production.10% TOTAL 100%
In this AWS tutorial, we are going to discuss how we can make the best use of AWS services to build a highly scalable, and fault tolerant configuration of EC2 instances. The use of Load Balancers and Auto Scaling Groups falls under a number of best practices in AWS, including Performance Efficiency, Reliability and high availability.
Before we dive into this hands-on tutorial on how exactly we can build this solution, let’s have a brief recap on what an Auto Scaling group is, and what a Load balancer is.
Autoscaling group (ASG)
An Autoscaling group (ASG) is a logical grouping of instances which can scale up and scale down depending on pre-configured settings. By setting Scaling policies of your ASG, you can choose how many EC2 instances are launched and terminated based on your application’s load. You can do this based on manual, dynamic, scheduled or predictive scaling.
Elastic Load Balancer (ELB)
An Elastic Load Balancer (ELB) is a name describing a number of services within AWS designed to distribute traffic across multiple EC2 instances in order to provide enhanced scalability, availability, security and more. The particular type of Load Balancer we will be using today is an Application Load Balancer (ALB). The ALB is a Layer 7 Load Balancer designed to distribute HTTP/HTTPS traffic across multiple nodes – with added features such as TLS termination, Sticky Sessions and Complex routing configurations.
Getting Started
First of all, we open our AWS management console and head to the EC2 management console.
We scroll down on the left-hand side and select ‘Launch Templates’. A Launch Template is a configuration template which defines the settings for EC2 instances launched by the ASG.
Under Launch Templates, we will select “Create launch template”.
We specify the name ‘MyTestTemplate’ and use the same text in the description.
Under the ‘Auto Scaling guidance’ box, tick the box which says ‘Provide guidance to help me set up a template that I can use with EC2 Auto Scaling’ and scroll down to launch template contents.
When it comes to choosing our AMI (Amazon Machine Image) we can choose the Amazon Linux 2 under ‘Quick Start’.
The Amazon Linux 2 AMI is free tier eligible, and easy to use for our demonstration purposes.
Next, we select the ‘t2.micro’ under instance types, as this is also free tier eligible.
Under Network Settings, we create a new Security Group called ExampleSG in our default VPC, allowing HTTP access to everyone. It should look like this.
AWS Certified Developer Associate exam: Additional Information for reference
Below are some useful reference links that would help you to learn about AWS Certified Developer Associate Exam.
- Developing on AWS: An instructor-led live or virtual 3-day course
- https://aws.amazon.com/certification/faqs/
- AWS Digital Training: Application Services, Developer Tools, and other services covered on the exam
- Prepare for AWS Certification
- AWS EC2 Instance info
- AWS Certified Developer Associate Exam Guide
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Other Relevant and Recommended AWS Certifications
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
- AWS Certified Cloud Practitioner
- AWS Certified Solutions Architect – Associate
- AAWS Certified Developer – Associate
- AWS Certified SysOps Administrator – Associate
- AWS Certified Solutions Architect – Professional
- AWS Certified DevOps Engineer – Professional
- AWS Certified Big Data Specialty
- AWS Certified Advanced Networking.
- AWS Certified Security – Specialty
Other AWS Facts and Summaries and Questions/Answers Dump
- AWS S3 facts and summaries and Q&A Dump
- AWS DynamoDB facts and summaries and Questions and Answers Dump
- AWS EC2 facts and summaries and Questions and Answers Dump
- AWS Serverless facts and summaries and Questions and Answers Dump
- AWS Developer and Deployment Theory facts and summaries and Questions and Answers Dump
- AWS IAM facts and summaries and Questions and Answers Dump
- AWS Lambda facts and summaries and Questions and Answers Dump
- AWS SQS facts and summaries and Questions and Answers Dump
- AWS RDS facts and summaries and Questions and Answers Dump
- AWS ECS facts and summaries and Questions and Answers Dump
- AWS CloudWatch facts and summaries and Questions and Answers Dump
- AWS SES facts and summaries and Questions and Answers Dump
- AWS EBS facts and summaries and Questions and Answers Dump
- AWS ELB facts and summaries and Questions and Answers Dump
- AWS Autoscaling facts and summaries and Questions and Answers Dump
- AWS VPC facts and summaries and Questions and Answers Dump
- AWS KMS facts and summaries and Questions and Answers Dump
- AWS Elastic Beanstalk facts and summaries and Questions and Answers Dump
- AWS CodeBuild facts and summaries and Questions and Answers Dump
- AWS CodeDeploy facts and summaries and Questions and Answers Dump
- AWS CodePipeline facts and summaries and Questions and Answers Dump
AWS Certifications Breaking News and Top Stories
- How much deep dive do you need to pass AWS Solution Architect Professional? Is Cantrill exam enough for content wise?by /u/IamOkei
I have the SAA, DVA, Security Specialty and SysOps certs from AWS. Currently, I am preparing my exam with Cantrill and TD. Can I know Cantrill videos are deep enough to pass the exam? submitted by /u/IamOkei [link] [comments]
- Release: A Discord Server With Free a Learning Method!by /u/IdoPIdo
Hello everyone, I am currently releasing (more as a beta test) my server and my bot. The bot which is called study bot can give you random questions from a pool of over 900 questions, create mock tests and track your stats. The usage of the bot is free, and due to the nature of discord you can do it anytime, anywhere. For example, you can use !question eks to get a question which includes EKS, !test sns sqs to get a mock test which contains primarily (if not exclusively!) questions regarding SNS and SQS. Give it a try, and feedback is always welcome. Invite link: https://discord.gg/tP6S8YbjJ8 submitted by /u/IdoPIdo [link] [comments]
- Passed SysOps Administrator. Associate (SOA-C02)by /u/TX_Wander
Took the exam Tuesday morning and had the results emailed a few hours later. This is my third AWS certification. I have: Solutions Architect Associate and Developer Associate. I’ve worked with AWS professionally for about 4 yrs. I used the Udemy course by Stephane Maarek, and the practice exams by Stephane Maarek and Abhishek Singh as the primary training. Studied for 2 weeks. The test was a lot more difficult than both the solutions architect and developer associate tests. If you want to pursue the SysOps Administrator cert, I’d definitely recommend doing at least solutions architect first to get some foundational knowledge. submitted by /u/TX_Wander [link] [comments]
- Should I cancel my associate data engineering test?by /u/Apart-Plankton9951
I have my test on August 31. I believe I can get a full refund as long as its 24 hour or further from the exam time from Pearson (correct me if I am wrong). I have no prior AWS experience, I have some azure experience from my associates degree and an Azure fundamentals cert I did 2 year ago. I have 2 years of experience as a python dev and I have worked with SQL as well. I have access to Stephen Maarek's course and 4 practice exams for free. My concern is that the amount of material is massive. I sat through Maarek's CCP course but this data engineering one is much heavier. How would you prepare if you were me? I can dedicate about 3-5 hours per day. At this point, is it even worth trying or should I save my money and cancel it? submitted by /u/Apart-Plankton9951 [link] [comments]
- If you are about to purchase any monthly subscription, a news for you. 50% off on Coursera Plus Subscription until 9th August 2024.by /u/ewan_m
submitted by /u/ewan_m [link] [comments]
- AWS Certified Machine Learning Engineer - Associateby /u/B_Copeland
Hello Everyone, I wanted to get your thoughts on this newest cert from Amazon. The website mentioned that more details are coming on the 13th of August, but in your experience, would 2 to 3 months be sufficient to train for this exam? Also, does anyone know of resources for this cert other than skill builder and tutorialsdojo? Thanks in advance for any advice. submitted by /u/B_Copeland [link] [comments]
- TDJ Changesby /u/pablobhz
Did anyone noticed that TDJ questions have been updated? I took a test there yesterday and I’ve noticed some questions about some stuff I’ve never studied / read about. Anyway, got 70% on this “new” test. Three questions I missed because I was sleepy. Most tests I’m doing there I’m getting 68% or more. I believe I’m almost ready to take the test next month 😀 submitted by /u/pablobhz [link] [comments]
- AWS and Azureby /u/quanta777
In case of multiple environments, in AWS we deploy them into each account and each account will have its own unique email which be its own root account. All the accounts will be managed by the Control tower/Organizations. In case of Azure we will have one account in which we will create multiple resource groups and deploy the environments. Is it technically correct to say AWS approach is more isolated while Azure is more integrated? submitted by /u/quanta777 [link] [comments]
- hosting a python teams bot on lambda?by /u/FlyingCatOfLol
how would I go about hosting a microsoft teams bot on lambda using an api gateway? I've already set up an app and bot on dev framework for the teams part, but unsure about what to do/use for this. submitted by /u/FlyingCatOfLol [link] [comments]
- Using DynamoDB as substitute for QLDBby /u/bjernie
Since QLDB is closing down in a year my company is looking at different ledger alternatives. We have talked about using DynamoDB as a replacement. It supports transactions, we can make our own optimistic locking to handle concurrent request, we can use DynamoDB streams to make our own history by creating a new item in another table every time an item is updated. So although DynamoDB isn't immutable, by saving the item every time its updated that kinda solves that issue. What would the downsides be of using DynamoDB as a replacement for QLDB? submitted by /u/bjernie [link] [comments]
- How to save LightSail Website back up to Laptop Local storageby /u/PreetKanwal
Hi Everyone, I have two back up of wordpress websites on lightsail server which are not being used anymore. I am looking for ways by which I can save them on my laptop so I wont have to pay fees every month. https://imgur.com/a/6x4SyDn submitted by /u/PreetKanwal [link] [comments]
- Failed AWS Advanced Networking part deuxby /u/newbietofx
This time got worst. 665 All domains I sucked. Less on dx and bgp. More on lb with EKS, cloud formation with pam, on premise dns but resource is using ip address from on premise so I can't tell if this is supposed to be inbound or outbound endpoint. Macsec. There is one on data flow. Like which one comes first. Gateway endpoint or gateway load balancer. I've setup an endpoint which comes before load balancer since I have to reference it via route table. Something about 7300 and 7100. I nvr quite understand why we use them. Many choose 2 or three. I'll make sure I max my time before I call it quits. Fk. This is harder than cissp or I never force myself. submitted by /u/newbietofx [link] [comments]
- Is Cantril SAP course + Tutorial Dojo enough to pass the exam? I don't wanna do extra courses from Davis or Maarekby /u/IamOkei
Can someone let me know if the Cantril course and ebook from TD enough to pass? submitted by /u/IamOkei [link] [comments]
- Serverless Architecture: Simplifying Web App Developmentby /u/anujtomar_17
submitted by /u/anujtomar_17 [link] [comments]
- Serverless Architecture: Simplifying Web App Developmentby /u/anujtomar_17
submitted by /u/anujtomar_17 [link] [comments]
- Microsoft SQL server and Lambdaby /u/HK_0066
I want to access my Microsoft SQL server database from a lambda to create apis for frontend i am facing driver issues have gone through multiple articles and documentation nothing is working let me know somthing which can help me, any resource any video link will be helpfull thanks <3 submitted by /u/HK_0066 [link] [comments]
- Passed AWS SAA-C03!by /u/Rocket_Job
I just want to thank this community for all the tips and tricks. I took the exam this morning, finished by 11 AM, and received the results by 6 PM. The exam was more difficult than I expected (which scared me, I thought I might fail). The resources I used included Stephane Maarek's course on Udemy, as well as his practice exam and TD's practice exams. Here's a breakdown of my practice exam scores, listed in the order I took them: Stephane Maarek's Practice Exams: Practice Test 1: 72% Practice Test 2: 69% Practice Test 3: 70% Practice Test 4: 76% Practice Test 5: 78% Practice Test 6: 55% (I'm not sure how this happened, lol) TD's Practice Exams: Timed Mode Set 1: 81.54% Timed Mode Set 2: 69.23% Timed Mode Set 3: 75.38% Timed Mode Set 4: 72.31% Review Mode Set 1: 83.08% Timed Mode Set 5: 66.15% Timed Mode Set 6: 67.69% Timed Mode Set 7: 63.08% Bonus Timed Mode Set 8: 77.78% I found that TD's questions were closer to the real exam. My final score was 810. I started Studying last May for 1-2 hrs everyday(on and off due to fulltime work) The explanations for each question in the practice tests really helped me understand and learn the services. submitted by /u/Rocket_Job [link] [comments]
- AWS RDS MariaDB : Do Queries Get Slower As DB Size Grows?by /u/kkatdare
I'm a solo developer who's not expert in databases. I've an application that has its database running on EC2 instance. The database gets few hundred - thousand inserts every day. It's a pure text database with no blobs. I have the indexing in place. My question is - do the database queries get slower as the DB size / row-count increases? At what point would this actually be a concern? submitted by /u/kkatdare [link] [comments]
- IAM role or IAM service role for EC2 instanceby /u/jesuisapprenant
I always thought that we have to use IAM roles for anything related to a service in AWS, but in my study guide, it says: INCORRECT: "Set up an IAM service role with permissions to list and write objects to the S3 bucket. Attach the IAM role to the EC2 instance which will enable it to retrieve temporary security credentials from the instance userdata and use that access to upload the photos to the S3 bucket" is incorrect because although it uses an IAM Role, the temporary security credentials should be retrieved from the instance metadata and not from the user data CORRECT: "Set up an IAM role with permissions to list and write objects to the S3 bucket. Attach the IAM role to the EC2 instance which will enable it to retrieve temporary security credentials from the instance metadata and use that access to upload the photos to the S3 bucket" is correct as it uses an IAM Role and fetches the temporary security credentials from the instance metadata. Is it correct to be using an IAM role for an EC2 instance? Thanks in advance! submitted by /u/jesuisapprenant [link] [comments]
- how to resolve this issue can anyone help ?by /u/InsideOwl5683
https://preview.redd.it/s6e94em9qmed1.png?width=969&format=png&auto=webp&s=2984f8bf48537bba9d9c8df6419caca5c4815bd7 submitted by /u/InsideOwl5683 [link] [comments]
- The most comprehensive guide on How to host WordPress on AWS using EC2, RDS & Caddyby /u/ShivamJoker
submitted by /u/ShivamJoker [link] [comments]
- AWS for interviewby /u/Mr-Robot-2022
Hello! Not sure if this is the right place to post this question. I have an interview coming up where I am required to have basic knowledge about AWS. I am completely clueless as to where to begin in order to learn. AWS seems to have a lot of services. What are the most important ones? How do I learn them? Can anyone help? submitted by /u/Mr-Robot-2022 [link] [comments]
- Hub and spoke architecture tipsby /u/DiFettoso
Hi, in my hub and spoke infrastructure (in separate accounts with transit gateway), I need to target from a balancer in the hub account, the workload machines that are in the spoke accounts. Now I create a balancer on the hub and associate to it a target group type ip address (of the machine in the spoke account) and this works. However I was told that the private addresses of the ec2 could change, is this true? in what case? do you know if there is any way the machines could lose their private ip address? submitted by /u/DiFettoso [link] [comments]
- CodeDeploy and CodeBuild are confusing the hell out of meby /u/SharMarvellous
so i was trying to deploy my static app code from commit to codebuild and then codedeploy. did the commit part, did the codebuild with artifact in s3, and also, did the deployment. but once i go to my ec2's public IPv4, all i could see was default apache 'It works', not my webapp. later, even the 'it works' page wasn't visible. and yeah i know the buildspec and appspec are important, i'll share them as well. buildspec.yml: version: 0.2 phases: install: runtime-versions: nodejs: 14 commands: - echo Installing dependencies... - yum update -y - yum install -y nodejs npm - npm install -g html-minifier-terser - npm install -g clean-css-cli - npm install -g uglify-js build: commands: - echo Build started on `date` - echo Minifying HTML files... - find . -name "*.html" -type f -exec html-minifier-terser --collapse-whitespace --remove-comments --minify-css true --minify-js true {} -o ./dist/{} \; - echo Minifying CSS... - cleancss -o ./dist/styles.min.css styles.css - echo Minifying JavaScript... - uglifyjs app.js -o ./dist/app.min.js post_build: commands: - echo Build completed on `date` - echo Copying appspec.yml and scripts... - cp appspec.yml ./dist/ - mkdir -p ./dist/scripts - cp scripts/* ./dist/scripts/ artifacts: files: - '**/*' base-directory: 'dist' appspec.yml: version: 0.0 os: linux files: - source: / destination: /var/www/html/ hooks: BeforeInstall: - location: scripts/before_install.sh timeout: 300 runas: root AfterInstall: - location: scripts/after_install.sh timeout: 300 runas: root ApplicationStart: - location: scripts/start_application.sh timeout: 300 runas: root ValidateService: - location: scripts/validate_service.sh timeout: 300 runas: root note: if i create the zip file and upload it in s3, it loads but public ipv4 shows apache default 'it works' (i was doing static app), but if i just create the build artifact, i am not getting any .zip file, only a folder and files inside that whole directory created. can you please help me out here. even if i try build process by choosing 'Artifacts packaging' as 'Zip', go to s3, copy its URL, and then create deployment, the publlic IPv4 is still showing the apache default 'it works'. Any kind of help would be highly appreciated here submitted by /u/SharMarvellous [link] [comments]
- AWS Resource Explorerby /u/VJeroen
How do I manage and organize resources in AWS. In my resource explorer I have over 500 resources not related to anything I have created in AWS like Redis caches, DataCatalog, security groups, subnets, etc. What if I create a resource and forget to add a tag. It's going to end up in this sea of garbage resources I have no control over. This is just agonising and depressing. I already tried to use a CLI tool like Cloud-Nuke to delete al this crap, but it is still there. Is it possible to have an overview of your resources in AWS like in Azure where everything is in resource groups even the resources that are created automatically because the main resource you actually want to use depends on them. And how do I then delete it when I have already deleted the main resource. submitted by /u/VJeroen [link] [comments]
- Federation: How to learn it without getting panic attacksby /u/jesuisapprenant
I always get these questions about different ways to federate: there are AssumeRolesWithSAML, AssumeRolesWithWebIdentity, SAML 2.0, IdP, Active Directories, LDAP, etc and etc., and even though I reviewed it a million times, I still can't get the questions right. Adding to this complexity is whether or not we need to create IAM roles or policies, if we need ARNs, and mapping IdP to IAM roles. I really just want to master it once and for all, all of this federation stuff. How to learn this? submitted by /u/jesuisapprenant [link] [comments]
- Database size restrictionby /u/Upper-Lifeguard-8478
Hi, Has anybody ever encountered a situation in which, if the database growing very close to the max storage limit of aurora postgres(which is ~128TB) and the growth rate suggests it will breach that limit soon. What are the possible options at hand? We have the big tables partitioned but , as I understand it doesn't have any out of the box partition compression strategy. There exists toast compression but that only kicks in when the row size becomes >2KB. But if the row size stays within 2KB and the table keep growing then there appears to be no option for compression. Some people saying to move historical data to S3 in parquet or avro and use athena to query the data, but i believe this only works if we have historical readonly data. Also not sure how effectively it will work for complex queries with joins, partitions etc. Is this a viable option? Or any other possible option exists which we should opt? submitted by /u/Upper-Lifeguard-8478 [link] [comments]
- How to use calculated fields in AWS QuickSight?by /u/LengthinessNo5837
I am using AWS QuickSight to create dashboards. In my dataset there is a "bmi" column. I want it to be in range like 0-10, 10-20 so on. I found a way to implement this using calculated fields in quicksight that creates another column that will have the range. ifelse( {bmi} >= 0 and {bmi} <= 14, '0-14', {bmi} >= 15 and {bmi} <= 19, '15-19', {bmi} >= 20 and {bmi} <= 24, '20-24', {bmi} >= 25 and {bmi} <= 29, '25-29', {bmi} >= 30 and {bmi} <= 34, '30-34', {bmi} >= 35 and {bmi} <= 39, '35-39', {bmi} >= 40 and {bmi} <= 44, '40-44', {bmi} >= 45 and {bmi} <= 49, '45-49', {bmi} >= 50, '50+', 'Unknown' ) But it says "The syntax of the calculated field expression is incorrect. Correct the syntax and choose Create again." It doesn't give more details about the errors. submitted by /u/LengthinessNo5837 [link] [comments]
- Why would someone choose AssumeRoleWithSAML over AssumeRoleWithWebIdentity?by /u/jesuisapprenant
For these two (AssumeRoleWithWebIdentity vs AssumeRoleWithSAML), if we are using an enterprise solution LDAP/Active Directory etc, we will be using AssumeRoleWithSAML right, and then if we are using social media, like Facebook, Google, via Cognito, it would be AssumeRoleWithWebIdentity? The thing is Cognito supports SAML as well, so why would someone choose AssumeRoleWithSAML over AssumeRoleWithWebIdentity? Thanks in advance PS: I'm having a lot of trouble with IAM federation and SAML and all these different "AssumeRole"s . What is the best way forward to understand all of this? Should I just memorize the below steps? 1. The user browses to your organization’s portal and selects the option to go to the AWS Management Console. In your organization, the portal is typically a function of your IdP that handles the exchange of trust between your organization and AWS. 2. The portal verifies the user’s identity in your organization. 3. The portal generates a SAML authentication response that includes assertions that identify the user and include attributes about the user. The portal sends this response to the client browser. 4. The client browser is redirected to the AWS single sign-on endpoint and posts the SAML assertion. 5. The endpoint requests temporary security credentials on behalf of the user and creates a console sign-in URL that uses those credentials. 6. AWS sends the sign-in URL back to the client as a redirect. 7. The client browser is redirected to the AWS Management Console. If the SAML authentication response includes attributes that map to multiple IAM roles, the user is first prompted to select the role for accessing the console submitted by /u/jesuisapprenant [link] [comments]
- Taking the Cloud Practitioner Exam in 3 monthsby /u/Ready_Manager2538
Hi, just wanted to hear some thoughts. I plan to take the AWS Cloud Practitioner in 3 months and I plan to study for it for a couple of hours per day around 2-3 hours and 5 days a week on top of my full-time job. I’m completely new to cloud and was wondering if it’s enough time for me to study? I’ve been hearing from some people that they studied for much longer for the exam and I’m worried because I want to pass it because the money i’ll spend is sponsored. Thank you in advance! submitted by /u/Ready_Manager2538 [link] [comments]
- The email specified is already associated with an AWS accountby /u/Big_Selection1004
submitted by /u/Big_Selection1004 [link] [comments]
- Constantly getting Error while fetching Metadata or CheckpointMetaData for AWS Glue + PySpark streaming jobby /u/ohoian
I have my checkpoint directory set to my s3 bucket, and it doesn’t change. The job itself is meant to start, read a kinesis stream and grab the past hour of data, divide it into 15 min segments, do some aggregating on each of them, and write the results to another s3 bucket of mine. I have no idea why this error is happening submitted by /u/ohoian [link] [comments]
- Need help with Cloud Practitioner CLF-C02by /u/keeponpushin1986
I've been through stephen maarke's course as well as a two practice tests from TD and I still failed my test. After looking at my weak areas for the exam, it seems to be centered around billing. How can I learn more on this topic without having to go through Maareks course again. Does anyone have any note cards by chance? Thanks in advance submitted by /u/keeponpushin1986 [link] [comments]
- Elastic beanstalk initial deployment works; NGINX errors after being deployed for sometimeby /u/angsous
Seeking some help on where to start on this issue. When I deploy my Elastic Beanstalk Django webserver, everything works great. Without changing anything, I come back the next day and trying to call the API results in 500 NGINX error: 172.31.8.174 - - [25/Jul/2024:00:44:58 +0000] "POST /admin/login/?next=/admin/ HTTP/1.1" 500 145 "https://[url]/admin/login/?next=/admin/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36" "76.93.92.197" I don't see any other logs related to this 500 error and Elastic beanstalk is supposed to handle the NGINX part for you, so I don't really know what setup to debug here. Anyone ever have a similar issue and have some advice on where to start? submitted by /u/angsous [link] [comments]
- Best AWS Certification For Skill Growthby /u/ASAP_Beet
I am searching for a way to boost my AWS skills, and am trying to decide between attending AWS ReInvent or starting a certification. As a disclaimer, I am not doing this in an attempt to get a job or resume build. I am already somewhere between intermediate and advanced with a decent amount of AWS tools and searching for a way to get closer to an expert in at least a few of these topics. For people here who have done some of the more advanced certifications, do you feel like they are a good tool to increase your skills, or are they more of a way to prove/quantify the skills you already have? Also, any recommendations for which certifications are best for advanced data engineering / DevOps would be much appreciated! submitted by /u/ASAP_Beet [link] [comments]
- Implementing Multi-Account AWS Management using Terraform, AWS Identity Center, and Okta SSOby /u/Famous_Tell
I am seeking advice on utilizing Terraform in conjunction with AWS Identity Center and AWS Organizations to administer over 20 separate AWS accounts. The primary focus is on managing AWS roles. Additionally, we intend to implement Okta as our Single Sign-On (SSO) solution. submitted by /u/Famous_Tell [link] [comments]
- Glue vs spark clusters on EC2 for distributed spark jobsby /u/naughty_thanos
I have a distributed workflow that is triggered when a notification is received in an SQS queue. The step function has a parallel state with 13 branches. Essentially, wash message triggers 13 runs of the same glue job with different job arguments. The glue jobs read data from different tables. The glue job config is as follows - Worker type - G.4X Number of workers - 12 So each job run uses 48 DPUs My glue script is as optimised as possible with parallelism, push down predicates and filtering where needed to reduce long data loads from catalog source. 11 out of the 13 job runs complete within 6-7 mins while the other 2 complete in 11-13 mins, roughly double (due to the large data load and transformations) One day would have 22 executions of the step function which means 22x13 glue job runs Estimated glue job runs are costing $500-600 per day based on DPU-hours Would it be cheaper to use spark clusters setup on an EC2 instance (maybe even if a higher compute) and run spark jobs instead of using glue? The whole idea to use glue was because of the serverless capabilities to avoid overpaying for EC2 instances. Using the setup with glue is costing roughly $15-16k per month. Surely EC2 computer would be cheaper (in the long run as the cost can be estimated and constant irrespective of compute load) Using EMR is not an option as it is not whitelisted in my organisation yet. EC2 and glue are my options. submitted by /u/naughty_thanos [link] [comments]
- Migration of 25 static websites to AWSby /u/TheFantasticFuture
Hi all, I want to migrate my static websites, some are also WordPress to AWS. Now I'm wondering which service to choose, Lightsail, EC2 or just S3? So far for me Lightsail with Plesk installation is leading, or just VPS Amazon Linux 2023 and ISPCongig control panel installation. Which option do you recommend, or a completely different combination of services at a reasonable price, I want to use AWS. Thanks for the ideas! submitted by /u/TheFantasticFuture [link] [comments]
- Best Way to prepare for This ?by /u/Bippity_Boppity69
I am planning to start the AWS cloud practitioner certificate, what are some resources available for free , to practice and get good idea of my potential result? Also, I have no cloud background but I am a Computer science student doing bachelors, how much time will it take for me to prepare ? submitted by /u/Bippity_Boppity69 [link] [comments]
- My AWS Cloud Practitioner Certificationby /u/Commercial-Suit-7693
https://preview.redd.it/lhm8f52dnied1.png?width=2000&format=png&auto=webp&s=8ba557a06b2eba22741f2f324e1bd07cd017704f I passed my exam Cloud Practitioner CLF-C02 exam 3 months ago. I was very excited and now I'm preparing for my other AWS Certification. All thanks to my youtube guides and to itexamshub for their source guide. submitted by /u/Commercial-Suit-7693 [link] [comments]
- AWS SSO Azure - It's not you, it's usby /u/RafikiYAh
Hi All, I`ve been trying to add AWS IAM Identity Center (successor to AWS Single Sign-On) to Entra ID to use SSO. The integration works (from EntraID`s part, all good, at least that is what is showing while hitting test connection). However connecting and logging in to AWS, it always gives "It's not you, it's us" page error and does not login. I`ve tried many online tutorials they all work out of the box for them, but for me it just does not work. what I`ve done so far: 1.add enterprise app to Entra 2.uploaded metadata from AWS to Entra uploaded Federation Metadata XML from Entra do AWS added same users created in aws into entra id+added users to Entra Enterprise app. In short, all these steps are all over the internet, videos and blogs, however, after multiple tries, I feel like I`m missing something, I checked the attributes and claims and tried many online variations and still no luck. Does someone have any info regarding this? I would greatly appreciate it, thanks! submitted by /u/RafikiYAh [link] [comments]
- How to stop EC2 and S3 resources after a budget alertby /u/PBerit
https://preview.redd.it/2c9q9fmcrged1.png?width=1706&format=png&auto=webp&s=c267a5f6b82d8ec28bbbc81da64c85abb262f0b0 Hi all, I have configured a budget limit for AWS. I noticed, that there is also the possibility to configure an action that stops resources when a budget alert is triggered. However, I have 2 problems as you can see on the screenshot of the budget alarm configuration menu in AWS: 1) There is only the possibility in my budget menu to stop EC2 instances. I also would like to stop S3 storage after a budget alarm. How can I do that? 2) Strangely, I can't choose and EC2 instances. When I click on it, there is a message "No instances found in this region"? Why do I get this message and how can I choose the EC2 resources? submitted by /u/PBerit [link] [comments]
- AWS Course For jobby /u/WhatsMueenUpto
Hey Cloud Guys Recommend me best course for AWS foundation and solution architecture for job I have 2 months to complete these courses submitted by /u/WhatsMueenUpto [link] [comments]
- AWS Certified AI Practitioner (AIF) resourcesby /u/madrasi2021
Note : This certification exam was just recently announced and is entering "BETA" in August. Last updated : 24-July-2024 Here is a master list of resources to help those who are interested in the new AWS Certified AI Practitioner exam. All my Exam Resource Posts : [CCP/CLF](https://www.reddit.com/r/AWSCertifications/comments/1d1xg1p/aws\_certified\_cloud\_practitioner\_clfc02\_ccp/) [SAA](https://www.reddit.com/r/AWSCertifications/comments/1d5kkuw/aws\_certified\_solutions\_architect\_associate/) [DVA](https://www.reddit.com/r/AWSCertifications/comments/1db1vhf/aws\_certified\_developer\_associate\_dvac02\_resources/) [DEA](https://www.reddit.com/r/AWSCertifications/comments/195sbcj/aws\_certified\_data\_engineer\_associate\_dea\_deac01/) [AIF] (this one!) If you find this post useful - upvote. This post is written for benefit of this community and hence I am happy to take feedback / suggestions / changes etc - please comment! tl;dr The exam was just announced and is not even live right now. It will open up in BETA from August 13. The official material behind the exam is yet to be published in detail. Even the "Exam Guide" (aka "Curriculum") is not yet out there and this means any training material is bound to change when its announced. However there are a lot of useful pointers / material we can generally get started on / watch out for and this post will be in "beta" mode itself till the exams are Generally Available. Exam Details The exam code is AIF-C01. AWS page with all the details : [https://aws.amazon.com/certification/certified-ai-practitioner/\](https://aws.amazon.com/certification/certified-ai-practitioner/) The first resource to usually read is the Exam Guide (tells you whats in / out of scope) : Yet to be published. Minimum Viable Path to Certification Most people usually need 2 things to pass the exam A single video based course introducing the exam curriculum Typically these are courses where someone reads from some slides, shows you the AWS console and how to use it and then gives you tips on what to remember. One good quality practice exam Note : do not fall for some random "dump" found on internet or any resource offerring you a Guarantee to pass. 1. Video Courses There aren't any video courses yet. Stephane Maarek and Andrew Brown have indicated they are preparing material. I will link to these when I hear of their release. There is an "Exam Prep" course from Skillbuilder but note that this just covers the high level domains but is not a comprehensive deep dive. [https://explore.skillbuilder.aws/learn/public/learning\_plan/view/2193/standard-exam-prep-plan-aws-certified-ai-practitioner-aif-c01\](https://explore.skillbuilder.aws/learn/public/learning\_plan/view/2193/standard-exam-prep-plan-aws-certified-ai-practitioner-aif-c01) Optional : There is a slightly extended version of this in the paid tier. Right now it seems to be identical to the free one but should be updated on 13th August with more (paid tier only) material. [https://explore.skillbuilder.aws/learn/public/learning\_plan/view/2194/enhanced-exam-prep-plan-aws-certified-ai-practitioner-aif-c01\](https://explore.skillbuilder.aws/learn/public/learning\_plan/view/2194/enhanced-exam-prep-plan-aws-certified-ai-practitioner-aif-c01) Please note that this course may not enough on its own to pass and you may want to try additional material below. 2. Practice Exams Official Practice exam : not yet published [Tutorialsdojo.com](http://Tutorialsdojo.com) seem to be working on some material here (as per threads where they broke the platform and said its because they are doing deployment to support the new question types) Alternative Gen AI learning material FREE courses on SkillBuilder Generative AI Learning Plan for Developers Amazon Bedrock - Getting Started Building Generative AI Applications using Amazon Bedrock AI Language Service Learning Plan Foundations of Prompt Engineering Subscription tier (paid) on Skillbuilder Cloud Quest - Gen AI is a game based learning platform - provides a digital badge on completion. You can follow the Twitch.tv video series aligned with this Quest for free here : https://pages.awscloud.com/GLOBAL-other-T2-Traincert-AWS-Cloud-Quest-Gen-AI-Season1-2024-reg.html [Simulearn - Gen AI](https://explore.skillbuilder.aws/learn/course/external/view/elearning/19378/aws-cloud-quest-generative-ai) is a Gen AI / Gamified learning platform that's new - its not free and does not provide a digital badge. FAQ What does BETA exams mean? BETA exams are actual certification exams but are discounted as they are new and may not be as polished as the final generally available exams. In return for the small discount and early access - test takers are basically providing feedback on the exam / exam questions in a way that allows AWS to then make it generally available for the public. This also allows content providers to take the exam and tailor their training / test material. Where can I find vouchers for the exam? The BETA exams are discounted by 33% during Beta phase. If you have a voucher for 50% off from passing another AWS exam or other source - you could try to see if that stacks on top - we would not for sure till someone has attempted this. When will I get my exam results. Unlike previous beta exams - these new one's are Does this exam format differ to the Cloud Practitioner exam? Yes - please see this post on new types of questions that you can expect on this exam https://www.reddit.com/r/AWSCertifications/comments/1ea16sa/new_question_types_for_new_exams Good Luck folks! submitted by /u/madrasi2021 [link] [comments]
- How long to pass AWS CLOUD PRACTITIONER?by /u/Theravrauli
I've been studying & it's relatively new to me, I was thinking when to book it. I've just learnt up to Amazon S3 on Stepehen Mareek's course but I really want to get my exam booked in & have a goal to focus to, any thoughts? submitted by /u/Theravrauli [link] [comments]
- Tutorial Dojo - SAA-C03by /u/jaron1978
We have a corporate Udemy account and I have seen a lot of people recommending the TD Practice Tests. Are they the Jon Bonso tests? Thanks submitted by /u/jaron1978 [link] [comments]
- Passed SAA-C03 yesterday!by /u/Pudge4tw
I used Kodekloud AWS Solutions Architect Associate Certification course for video och and hands-on training then I bought the practice tests at Tuturialsdojo. If anyone have questions regarding any of those just ask along! submitted by /u/Pudge4tw [link] [comments]
- Passed SAA-C03 yesterdayby /u/escape00000
Someone said there aren’t enough posts like this so… Barely passed. Don’t feel like the resources I used adequately prepared me for the exam, and I probably should have studied way harder. I’m a part of an AWS study group that is down to 2 members now. We’re deciding between data engineer or developer next. submitted by /u/escape00000 [link] [comments]
- Passed DEA-C01by /u/proliphery
This is my official “I passed DEA-C01” post. I was not planning to post, but it was requested by u/madrasi2021. His posts and comments have been very helpful, so I decided to post per his request. I found there were not as many resources available for DEA as for other certifications. I’m assuming this is because the cert is so new. I used a video course (Udemy - Maarek/Kane) that was pretty good but not as hands-on as Cantrill’s courses. (Unfortunately I don’t see DEA moving ahead on Cantrill’s roadmap. Maybe we can encourage him…) I also used practice tests from TutorialsDojo. There were only 3 practice test sets in TD for DEA (compared to 7 sets for SAA). The tests were still helpful, even though there were fewer questions to study. Now, I was able to pass the exam with these resources, but I didn’t think they covered the material as fully as other exams. Also, I have some background in data engineering, data analysis, and especially SQL going back several years, but only about a year experience with AWS services. Good luck to everyone who tackles this exam! submitted by /u/proliphery [link] [comments]
- Passed SAA-C03!by /u/Parking-Tomorrow-600
Hey Everyone! First off, super thankful for this community. I was browsing different posts here nonstop to find the best way to study and there were some super helpful posts. I only gave myself one month to study and take the exam. I just used TD and watched all their videos and did all their practice exams. I did it for a month every day and was able to pass the exam on my first try! I also heard back within a couple of hours after taking the exam that I passed. More than happy to answer any questions anyone has! submitted by /u/Parking-Tomorrow-600 [link] [comments]
Reference: https://enoumen.com/2019/06/23/aws-solution-architect-associate-exam-prep-facts-and-summaries-questions-and-answers-dump/
AWS Certified Developer Associate exam: Whitepapers
AWS has provided whitepapers to help you understand the technical concepts. Below are the recommended whitepapers for the AWS Certified Developer – Associate Exam.
- Overview of Amazon Web Services
- Architecting for the Cloud: AWS Best Practices
- AWS Security Best Practices whitepaper, August 2016
- AWS Well-Architected Framework whitepaper, November 2017 Version 1.3 DVA-C01 Page |2
- Architecting for the Cloud AWS Best Practices whitepaper, February, 2016
- Practicing Continuous Integration and Continuous Delivery on AWS Accelerating Software Delivery with DevOps whitepaper, June 2017
- Microservices on AWS whitepaper, September 2017
- Serverless Architectures with AWS Lambda whitepaper, November 2017
- Optimizing Enterprise Economics with Serverless Architectures whitepaper, October 2017
- Running Containerized Microservices on AWS whitepaper, November 2017
- Blue/Green Deployments on AWS whitepaper, August 2016
Online Training and Labs for AWS Certified Developer Associates Exam
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
AWS Developer Associates Jobs
AWS Certified Developer-Associate Exam info and details, How To:
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
The AWS Certified Developer Associate exam is a multiple choice, multiple answer exam. Here is the Exam Overview:
- Certification Name: AWS Certified Developer Associate.
- Prerequisites for the Exam: None.
- Exam Pattern: Multiple Choice Questions
- The AWS Certified Developer-Associate Examination (DVA-C01) is a pass or fail exam. The examination is scored against a minimum standard established by AWS professionals guided by certification industry best practices and guidelines.
- Your results for the examination are reported as a score from 100 – 1000, with a minimum passing score of 720.
- Exam fees: US $150
- Exam Guide on AWS Website
- Available languages for tests: English, Japanese, Korean, Simplified Chinese
- Read AWS whitepapers
- Register for certification account here.
- Prepare for Certification Here
Exam Content Outline
Domain % of Examination Domain 1: Deployment (22%)
1.1 Deploy written code in AWS using existing CI/CD pipelines, processes, and patterns.
1.2 Deploy applications using Elastic Beanstalk.
1.3 Prepare the application deployment package to be deployed to AWS.
1.4 Deploy serverless applications22% Domain 2: Security (26%)
2.1 Make authenticated calls to AWS services.
2.2 Implement encryption using AWS services.
2.3 Implement application authentication and authorization.26% Domain 3: Development with AWS Services (30%)
3.1 Write code for serverless applications.
3.2 Translate functional requirements into application design.
3.3 Implement application design into application code.
3.4 Write code that interacts with AWS services by using APIs, SDKs, and AWS CLI.30% Domain 4: Refactoring
4.1 Optimize application to best use AWS services and features.
4.2 Migrate existing application code to run on AWS.10% Domain 5: Monitoring and Troubleshooting (10%)
5.1 Write code that can be monitored.
5.2 Perform root cause analysis on faults found in testing or production.10% TOTAL 100%
AWS Certified Developer Associate exam: Additional Information for reference
Below are some useful reference links that would help you to learn about AWS Certified Developer Associate Exam.
- Developing on AWS: An instructor-led live or virtual 3-day course
- https://aws.amazon.com/certification/faqs/
- AWS Digital Training: Application Services, Developer Tools, and other services covered on the exam
- Prepare for AWS Certification
- AWS EC2 Instance info
- AWS Certified Developer Associate Exam Guide
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Other Relevant and Recommended AWS Certifications
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
- AWS Certified Cloud Practitioner
- AWS Certified Solutions Architect – Associate
- AAWS Certified Developer – Associate
- AWS Certified SysOps Administrator – Associate
- AWS Certified Solutions Architect – Professional
- AWS Certified DevOps Engineer – Professional
- AWS Certified Big Data Specialty
- AWS Certified Advanced Networking.
- AWS Certified Security – Specialty
Other AWS Facts and Summaries and Questions/Answers Dump
- AWS S3 facts and summaries and Q&A Dump
- AWS DynamoDB facts and summaries and Questions and Answers Dump
- AWS EC2 facts and summaries and Questions and Answers Dump
- AWS Serverless facts and summaries and Questions and Answers Dump
- AWS Developer and Deployment Theory facts and summaries and Questions and Answers Dump
- AWS IAM facts and summaries and Questions and Answers Dump
- AWS Lambda facts and summaries and Questions and Answers Dump
- AWS SQS facts and summaries and Questions and Answers Dump
- AWS RDS facts and summaries and Questions and Answers Dump
- AWS ECS facts and summaries and Questions and Answers Dump
- AWS CloudWatch facts and summaries and Questions and Answers Dump
- AWS SES facts and summaries and Questions and Answers Dump
- AWS EBS facts and summaries and Questions and Answers Dump
- AWS ELB facts and summaries and Questions and Answers Dump
- AWS Autoscaling facts and summaries and Questions and Answers Dump
- AWS VPC facts and summaries and Questions and Answers Dump
- AWS KMS facts and summaries and Questions and Answers Dump
- AWS Elastic Beanstalk facts and summaries and Questions and Answers Dump
- AWS CodeBuild facts and summaries and Questions and Answers Dump
- AWS CodeDeploy facts and summaries and Questions and Answers Dump
- AWS CodePipeline facts and summaries and Questions and Answers Dump
AWS Certified Developer Associate exam: Whitepapers
AWS has provided whitepapers to help you understand the technical concepts. Below are the recommended whitepapers for the AWS Certified Developer – Associate Exam.
- Overview of Amazon Web Services
- Architecting for the Cloud: AWS Best Practices
- AWS Security Best Practices whitepaper, August 2016
- AWS Well-Architected Framework whitepaper, November 2017 Version 1.3 DVA-C01 Page |2
- Architecting for the Cloud AWS Best Practices whitepaper, February, 2016
- Practicing Continuous Integration and Continuous Delivery on AWS Accelerating Software Delivery with DevOps whitepaper, June 2017
- Microservices on AWS whitepaper, September 2017
- Serverless Architectures with AWS Lambda whitepaper, November 2017
- Optimizing Enterprise Economics with Serverless Architectures whitepaper, October 2017
- Running Containerized Microservices on AWS whitepaper, November 2017
- Blue/Green Deployments on AWS whitepaper, August 2016
Online Training and Labs for AWS Certified Developer Associates Exam
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
AWS Developer Associates Jobs
AWS Certified Developer-Associate Exam info and details, How To:
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
The AWS Certified Developer Associate exam is a multiple choice, multiple answer exam. Here is the Exam Overview:
- Certification Name: AWS Certified Developer Associate.
- Prerequisites for the Exam: None.
- Exam Pattern: Multiple Choice Questions
- The AWS Certified Developer-Associate Examination (DVA-C01) is a pass or fail exam. The examination is scored against a minimum standard established by AWS professionals guided by certification industry best practices and guidelines.
- Your results for the examination are reported as a score from 100 – 1000, with a minimum passing score of 720.
- Exam fees: US $150
- Exam Guide on AWS Website
- Available languages for tests: English, Japanese, Korean, Simplified Chinese
- Read AWS whitepapers
- Register for certification account here.
- Prepare for Certification Here
Exam Content Outline
Domain % of Examination Domain 1: Deployment (22%)
1.1 Deploy written code in AWS using existing CI/CD pipelines, processes, and patterns.
1.2 Deploy applications using Elastic Beanstalk.
1.3 Prepare the application deployment package to be deployed to AWS.
1.4 Deploy serverless applications22% Domain 2: Security (26%)
2.1 Make authenticated calls to AWS services.
2.2 Implement encryption using AWS services.
2.3 Implement application authentication and authorization.26% Domain 3: Development with AWS Services (30%)
3.1 Write code for serverless applications.
3.2 Translate functional requirements into application design.
3.3 Implement application design into application code.
3.4 Write code that interacts with AWS services by using APIs, SDKs, and AWS CLI.30% Domain 4: Refactoring
4.1 Optimize application to best use AWS services and features.
4.2 Migrate existing application code to run on AWS.10% Domain 5: Monitoring and Troubleshooting (10%)
5.1 Write code that can be monitored.
5.2 Perform root cause analysis on faults found in testing or production.10% TOTAL 100%
In this AWS tutorial, we are going to discuss how we can make the best use of AWS services to build a highly scalable, and fault tolerant configuration of EC2 instances. The use of Load Balancers and Auto Scaling Groups falls under a number of best practices in AWS, including Performance Efficiency, Reliability and high availability.
Before we dive into this hands-on tutorial on how exactly we can build this solution, let’s have a brief recap on what an Auto Scaling group is, and what a Load balancer is.
Autoscaling group (ASG)
An Autoscaling group (ASG) is a logical grouping of instances which can scale up and scale down depending on pre-configured settings. By setting Scaling policies of your ASG, you can choose how many EC2 instances are launched and terminated based on your application’s load. You can do this based on manual, dynamic, scheduled or predictive scaling.
Elastic Load Balancer (ELB)
An Elastic Load Balancer (ELB) is a name describing a number of services within AWS designed to distribute traffic across multiple EC2 instances in order to provide enhanced scalability, availability, security and more. The particular type of Load Balancer we will be using today is an Application Load Balancer (ALB). The ALB is a Layer 7 Load Balancer designed to distribute HTTP/HTTPS traffic across multiple nodes – with added features such as TLS termination, Sticky Sessions and Complex routing configurations.
Getting Started
First of all, we open our AWS management console and head to the EC2 management console.
We scroll down on the left-hand side and select ‘Launch Templates’. A Launch Template is a configuration template which defines the settings for EC2 instances launched by the ASG.
Under Launch Templates, we will select “Create launch template”.
We specify the name ‘MyTestTemplate’ and use the same text in the description.
Under the ‘Auto Scaling guidance’ box, tick the box which says ‘Provide guidance to help me set up a template that I can use with EC2 Auto Scaling’ and scroll down to launch template contents.
When it comes to choosing our AMI (Amazon Machine Image) we can choose the Amazon Linux 2 under ‘Quick Start’.
The Amazon Linux 2 AMI is free tier eligible, and easy to use for our demonstration purposes.
Next, we select the ‘t2.micro’ under instance types, as this is also free tier eligible.
Under Network Settings, we create a new Security Group called ExampleSG in our default VPC, allowing HTTP access to everyone. It should look like this.
AWS Certified Developer Associate exam: Additional Information for reference
Below are some useful reference links that would help you to learn about AWS Certified Developer Associate Exam.
- Developing on AWS: An instructor-led live or virtual 3-day course
- https://aws.amazon.com/certification/faqs/
- AWS Digital Training: Application Services, Developer Tools, and other services covered on the exam
- Prepare for AWS Certification
- AWS EC2 Instance info
- AWS Certified Developer Associate Exam Guide
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
Other Relevant and Recommended AWS Certifications
The Cloud is the future: Get Certified now.
The AWS Certified Solution Architect Average Salary is: US $149,446/year. Get Certified with the App below:
- AWS Certified Cloud Practitioner
- AWS Certified Solutions Architect – Associate
- AAWS Certified Developer – Associate
- AWS Certified SysOps Administrator – Associate
- AWS Certified Solutions Architect – Professional
- AWS Certified DevOps Engineer – Professional
- AWS Certified Big Data Specialty
- AWS Certified Advanced Networking.
- AWS Certified Security – Specialty
Other AWS Facts and Summaries and Questions/Answers Dump
- AWS S3 facts and summaries and Q&A Dump
- AWS DynamoDB facts and summaries and Questions and Answers Dump
- AWS EC2 facts and summaries and Questions and Answers Dump
- AWS Serverless facts and summaries and Questions and Answers Dump
- AWS Developer and Deployment Theory facts and summaries and Questions and Answers Dump
- AWS IAM facts and summaries and Questions and Answers Dump
- AWS Lambda facts and summaries and Questions and Answers Dump
- AWS SQS facts and summaries and Questions and Answers Dump
- AWS RDS facts and summaries and Questions and Answers Dump
- AWS ECS facts and summaries and Questions and Answers Dump
- AWS CloudWatch facts and summaries and Questions and Answers Dump
- AWS SES facts and summaries and Questions and Answers Dump
- AWS EBS facts and summaries and Questions and Answers Dump
- AWS ELB facts and summaries and Questions and Answers Dump
- AWS Autoscaling facts and summaries and Questions and Answers Dump
- AWS VPC facts and summaries and Questions and Answers Dump
- AWS KMS facts and summaries and Questions and Answers Dump
- AWS Elastic Beanstalk facts and summaries and Questions and Answers Dump
- AWS CodeBuild facts and summaries and Questions and Answers Dump
- AWS CodeDeploy facts and summaries and Questions and Answers Dump
- AWS CodePipeline facts and summaries and Questions and Answers Dump
AWS Certifications Breaking News and Top Stories
- How much deep dive do you need to pass AWS Solution Architect Professional? Is Cantrill exam enough for content wise?by /u/IamOkei
I have the SAA, DVA, Security Specialty and SysOps certs from AWS. Currently, I am preparing my exam with Cantrill and TD. Can I know Cantrill videos are deep enough to pass the exam? submitted by /u/IamOkei [link] [comments]
- Release: A Discord Server With Free a Learning Method!by /u/IdoPIdo
Hello everyone, I am currently releasing (more as a beta test) my server and my bot. The bot which is called study bot can give you random questions from a pool of over 900 questions, create mock tests and track your stats. The usage of the bot is free, and due to the nature of discord you can do it anytime, anywhere. For example, you can use !question eks to get a question which includes EKS, !test sns sqs to get a mock test which contains primarily (if not exclusively!) questions regarding SNS and SQS. Give it a try, and feedback is always welcome. Invite link: https://discord.gg/tP6S8YbjJ8 submitted by /u/IdoPIdo [link] [comments]
- Passed SysOps Administrator. Associate (SOA-C02)by /u/TX_Wander
Took the exam Tuesday morning and had the results emailed a few hours later. This is my third AWS certification. I have: Solutions Architect Associate and Developer Associate. I’ve worked with AWS professionally for about 4 yrs. I used the Udemy course by Stephane Maarek, and the practice exams by Stephane Maarek and Abhishek Singh as the primary training. Studied for 2 weeks. The test was a lot more difficult than both the solutions architect and developer associate tests. If you want to pursue the SysOps Administrator cert, I’d definitely recommend doing at least solutions architect first to get some foundational knowledge. submitted by /u/TX_Wander [link] [comments]
- Should I cancel my associate data engineering test?by /u/Apart-Plankton9951
I have my test on August 31. I believe I can get a full refund as long as its 24 hour or further from the exam time from Pearson (correct me if I am wrong). I have no prior AWS experience, I have some azure experience from my associates degree and an Azure fundamentals cert I did 2 year ago. I have 2 years of experience as a python dev and I have worked with SQL as well. I have access to Stephen Maarek's course and 4 practice exams for free. My concern is that the amount of material is massive. I sat through Maarek's CCP course but this data engineering one is much heavier. How would you prepare if you were me? I can dedicate about 3-5 hours per day. At this point, is it even worth trying or should I save my money and cancel it? submitted by /u/Apart-Plankton9951 [link] [comments]
- If you are about to purchase any monthly subscription, a news for you. 50% off on Coursera Plus Subscription until 9th August 2024.by /u/ewan_m
submitted by /u/ewan_m [link] [comments]
- AWS Certified Machine Learning Engineer - Associateby /u/B_Copeland
Hello Everyone, I wanted to get your thoughts on this newest cert from Amazon. The website mentioned that more details are coming on the 13th of August, but in your experience, would 2 to 3 months be sufficient to train for this exam? Also, does anyone know of resources for this cert other than skill builder and tutorialsdojo? Thanks in advance for any advice. submitted by /u/B_Copeland [link] [comments]
- TDJ Changesby /u/pablobhz
Did anyone noticed that TDJ questions have been updated? I took a test there yesterday and I’ve noticed some questions about some stuff I’ve never studied / read about. Anyway, got 70% on this “new” test. Three questions I missed because I was sleepy. Most tests I’m doing there I’m getting 68% or more. I believe I’m almost ready to take the test next month 😀 submitted by /u/pablobhz [link] [comments]
- AWS and Azureby /u/quanta777
In case of multiple environments, in AWS we deploy them into each account and each account will have its own unique email which be its own root account. All the accounts will be managed by the Control tower/Organizations. In case of Azure we will have one account in which we will create multiple resource groups and deploy the environments. Is it technically correct to say AWS approach is more isolated while Azure is more integrated? submitted by /u/quanta777 [link] [comments]
- hosting a python teams bot on lambda?by /u/FlyingCatOfLol
how would I go about hosting a microsoft teams bot on lambda using an api gateway? I've already set up an app and bot on dev framework for the teams part, but unsure about what to do/use for this. submitted by /u/FlyingCatOfLol [link] [comments]
- Using DynamoDB as substitute for QLDBby /u/bjernie
Since QLDB is closing down in a year my company is looking at different ledger alternatives. We have talked about using DynamoDB as a replacement. It supports transactions, we can make our own optimistic locking to handle concurrent request, we can use DynamoDB streams to make our own history by creating a new item in another table every time an item is updated. So although DynamoDB isn't immutable, by saving the item every time its updated that kinda solves that issue. What would the downsides be of using DynamoDB as a replacement for QLDB? submitted by /u/bjernie [link] [comments]
I Passed AWS Developer Associate Certification DVA-C01 Testimonials
Passed DVA-C01
Passed the certified developer associate this week.
Primary study was Stephane Maarek’s course on Udemy.
I also used the Practice Exams by Stephane Maarek and Abhishek Singh.
I used Stephane’s course and practice exams for the Solutions Architect Associate as well, and find his course does a good job preparing you to pass the exams.
The practice exams were more challenging than the actual exam, so they are a good gauge to see if you are ready for the exam.
Haven’t decided if I’ll do another associate level certification next or try for the solutions architect professional.
Cleared AWS Certified Developer – Associate (DVA-C01)
I cleared Developer associate exam yesterday. I scored 873.
Actual Exam Exp: More questions were focused on mainly on Lambda, API, Dynamodb, cloudfront, cognito(must know proper difference between user pool and identity pool)
3 questions I found were just for redis vs memecached (so maybe you can focus more here also to know exact use case& difference.) other topic were cloudformation, beanstalk, sts, ec2. Exam was mix of too easy and too tough for me. some questions were one liner and somewhere too long.
Resources: The main resources I used was udemy. Course of Stéphane Maarek and practice exams of Neal Davis and Stéphane Maarek. These exams proved really good and they even helped me in focusing the area which I lacked. And they are up to the level to actual exam, I found 3-4 exact same questions in actual exam(This might be just luck ! ). so I feel, the course of stephane is more than sufficient and you can trust it. I have achieved solution architect associate previously so I knew basic things, so I took around 2 weeks for preparation and revised the Stephen’s course as much as possible. Parallelly I gave the mentioned exams as well, which guided me where to focus more.
Thanks to all of you and feel free to comment/DM me, if you think I can help you in anyway for achieving the same.
Passed the Developer Associate. My Notes.
There was more SNS “fan out” options. None of the Udemy or Tutorial Dojo tests had that.
They aren’t joking about the 30 min check I and expiring your exam if you don’t check in at least 15 mins before hand.
When you finish do a pass over review for multi select questions and check the number required.
Review again and look for gotcha phrases like “least operational cost”, “fastest solution”, “most secure”, and “least expensive”. Change your answers of you put on what “you” would do.
Watch out for questions that mention services that don’t really have anything to do with the problem.
Look at every service mentioned in the question. You can probably think of a better stack for the solution but just adhere to what the present.
If you are clueless of an answer start by ruling out the ones you KNOW are wrong and then guess.
Take as many practice exams like tutorial dojo as you can. On review filter out the review for “incorrect”. Open another tab on the subject and read up or book mark it.
I would get 50-60% first pass at each exam. Then 85-95% after reading the answer and the open tabs and book marks.
If taking the Pearson proctored online test down load the OnVue App as soon as you can. Installing that thing made me miss the 15 min window and I had to rebook and pay. Their checkin is confusing between all the cert portals and their own site. Just use the “Manage Pearson Exams” from the aws cert portal to force auth to theirs.
New versions of the Developer (Associate) and DevOps Engineer (Professional) exams in Feb/March 2023
AWS Certified Developer – Associate
Current version: DVA-C01
New version: DVA-C02
Last day to take the current exam: 2023-02-27
Registration open for the updated exam: 2023-01-31
First day to take the updated exam: 2023-02-28
AWS Certified DevOps Engineer – Professional
Current version: DOP-C01
New version: DOP-C02
Last day to take the current exam: 2023-03-06
Registration open for the updated exam: 2023-01-31
First day to take the updated exam: 2023-03-07
Both updates were posted on 2022-10-04 on https://aws.amazon.com/certification/coming-soon/. The exam guides and practice questions are also available there.
Passed DVA-C01 scored 910
Past January as usual I chose some goals to achieve during 2022, including to obtain an AWS certification. In February I started studying using the Pluralsight platform. The course for developers is a good introduction but is messy sometimes. At the end of the course I had a big picture of the main AWS services but I was really confused by all the different topics. Pluralsight offers alsl some labs that allowed me to practice with AWS services because I my work wasn’t related to cloud.
Then a senior engineer suggested me to study using ACloudGuru platform and I loved their contents. They focus only on the details necessary for the exam. During the videos they show useful list to summarize services and tables to compare them. Moreover they offer a quite unrestricted playground where to put your hands. So i could try their labs but also try my first cloudformation scripts and lambdas. There are also 4 practice exams that are very similar to real questions. Even though their platform is buggy sometimes, the subscription was worth it.
At the same time I purchased the pack of practice questions from Jon Bonso on Udemy and indeed the answer explainations are very detailed and very useful.
For practicing more, I was adding wrong questions to the Anki desktop application but I was revising them on my phone whenever I could. I ended up with 150 different questions on Anki.
In the meantime, in August I left my software engineer job because my boss told me that I was not able to work with cloud technologies. In september I started a new job as cloud engineer in a new company. Finally, in October I passed the Developer Associate exam and I scored 910.
I put a lot of effort into prepare the exam and eventually i got it! However I believe this is just my first step and I want to keep studying. My next objective is the Solutions Architect Associate certification.

Top 100 AWS Solutions Architect Associate Certification Exam Questions and Answers Dump SAA-C03
Top 60 AWS Solution Architect Associate Exam Tips
Top 100 AWS Certified Cloud Practitioner Exam Preparation Questions and Answers Dumps

Welcome to the Top 100 AWS Certified Cloud Practitioner Exam Preparation Questions and Answers Dumps :
Table of Content:
Top 100 Questions and Answers Dumps,
Courses, Labs and Training Materials,
Jobs,
AWS Cloud Support Engineer Job Interview Prep,
Top 20 AWS Training and Certification Q&A ,
Latest Products & Services at AWS RE:INVENT


The AWS Certified Cloud Practitioner average salary is — $131,465/year
What is the AWS Certified Cloud Practitioner Exam?
The AWS Certified Cloud Practitioner Exam (CLF-C02) is an introduction to AWS services and the intention is to examine the candidates ability to define what the AWS cloud is and its global infrastructure. It provides an overview of AWS core services security aspects, pricing and support services. The main objective is to provide an overall understanding about the Amazon Web Services Cloud platform. The course helps you get the conceptual understanding of the AWS and can help you know about the basics of AWS and cloud computing, including the services, cases and benefits [Get AWS CCP Practice Exam PDF Dumps here]
Advertise with us - Post Your Good Content Here
We are ranked in the Top 20 on Google
AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
2023 AWS CCP CLF-C02 Practice Exam Course on – Top 250+ Questions and Detailed Answers – Success Guaranteed – Save 50% with this link

AWS CCP CLF-C02 on Android – AWS CCP CLF-C02 on iOS – AWS CCP CLF-C02 on Windows 10/11


To succeed with the real exam, do not memorize the answers below. It is very important that you understand why a question is right or wrong and the concepts behind it by carefully reading the reference documents in the answers.
AWS Certified Cloud Practitioner Exam Prep (CLF-C02) Questions and Answers
AWS Certified Cloud Practitioner Exam Certification Prep Quiz App
Download AWS Cloud Practitioner Exam Prep Pro App (No Ads, Full Version with Answers) for:
AWS CCP CLF-C02 on Android – AWS CCP CLF-C02 on iOS – AWS CCP CLF-C02 on Windows 10/11
Below we are providing you with:
- aws cloud practitioner exam questions
- aws cloud practitioner sample questions
- aws cloud practitioner exam dumps
- aws cloud practitioner practice questions and answers
- aws cloud practitioner practice exam questions and references
Q1: For auditing purposes, your company now wants to monitor all API activity for all regions in your AWS environment. What can you use to fulfill this new requirement?
- A. For each region, enable CloudTrail and send all logs to a bucket in each region.
- B. Enable CloudTrail for all regions.
- C. Ensure one CloudTrail is enabled for all regions.
- D. Use AWS Config to enable the trail for all regions.
Answer:
Top
Q2: What is the best solution to provide secure access to an S3 bucket not using the internet?
- A. Use a VPN connection.
- B. Use an Internet Gateway.
- C. Use a VPC Endpoint to access S3.
- D. Use a NAT Gateway.
Answer:
Top
Q3: In the AWS Shared Responsibility Model, which of the following are the responsibility of AWS?
- A. Securing Edge Locations
- B. Encrypting data
- C. Password policies
- D. Decomissioning data
Answer:
Top
Q4: You have EC2 instances running at 90% utilization and you expect this to continue for at least a year. What type of EC2 instance would you choose to ensure your cost stay at a minimum?
- A. Dedicated host instances
- B. On-demand instances
- C. Spot instances
- D. Reserved instances
Answer:
Top
Q5: What tool would you use to get an estimated monthly cost for your environment?
- A. TCO Calculator
- B. Simply Monthly Calculator
- C. Cost Explorer
- D. Consolidated Billing
Answer:
Top
Q6: How do you make sure your organization does not exceed its monthly budget?

AWS CCP CLF-C01 on Android – AWS CCP CLF-C01 on iOS – AWS CCP CLF-C01 on Windows 10/11
Get AWS Certified Cloud Practitioner Practice Exam CCP CLF-C02 eBook Print Book here
- A. Sign up for the free alert under filing preferences in the AWS Management Console.
- B. Set a schedule to regularly review the Billing an Cost Management dashboard each month.
- C. Create an email alert in AWS Budget
- D. In CloudWatch, create an alarm that triggers each time the limit is exceeded.
Answer:
Top
Q7: An Edge Location is a specialization AWS data centre that works with which services?
- A. Lambda
- B. CloudWatch
- C. CloudFront
- D. Route 53
Answer:
Top
Q8: What is the preferred method of linking 2 AWS accounts?
- A. AWS Organizations
- B. Cost Explorer
- C. VPC Peering
- D. Consolidated billing
Answer:

Top
Q9: Which of the following service is most useful when a Disaster Recovery method is triggered in AWS.
- A. Amazon Route 53
- B. Amazon SNS
- C. Amazon SQS
- D. Amazon Inspector
Answer:
Q10: Which of the following disaster recovery deployment mechanisms that has the highest downtime
- A. Pilot light
- B. Warm standby
- C. Multi Site
- D. Backup and Restore
Answer: iOS – Android [Get AWS Certified Cloud Practitioner Exam Practice CCP CLF-C01 eBook Print Book here]
AWS CCP CLF-C01 on Android – AWS CCP CLF-C01 on iOS – AWS CCP CLF-C01 on Windows 10/11 [Get AWS CCP Practice Exam PDF Dumps here]
Q11: Your company is planning to host resources in the AWS Cloud. They want to use services which can be used to decouple resources hosted on the cloud. Which of the following services can help fulfil this requirement?
- A. AWS EBS Volumes
- B. AWS EBS Snapshots
- C. AWS Glacier
- D. AWS SQS
Answer:
Q12: If you have a set of frequently accessed files that are used on a daily basis, what S3 storage class should you store them in?
- A. Infrequent Access
- B. Fast Access
- C. Reduced Redundancy
- D. Standard
Answer:
AWS CCP CLF-C01 on Android – AWS CCP CLF-C01 on iOS – AWS CCP CLF-C01 on Windows 10/11 [Get AWS CCP Practice Exam PDF Dumps here]
Q13: What is the availability and durability rating of S3 Standard Storage Class?
Choose the correct answer:
- A. 99.999999999% Durability and 99.99% Availability
- B. 99.999999999% Availability and 99.90% Durability
- C. 99.999999999% Durability and 99.00% Availability
- D. 99.999999999% Availability and 99.99% Durability
Answer:
Q14: What AWS database is primarily used to analyze data using standard SQL formatting with compatibility for your existing business intelligence tools
- A. Redshift
- B. RDS
- C. DynamoDB
- D. ElastiCache
Answer:
Q15: What are the benefits of DynamoDB?
Choose the 3 correct answers:
- A. Single-digit millisecond latency.
- B. Supports multiple known NoSQL database engines like MariaDB and Oracle NoSQL.
- C. Supports both document and key-value store data models.
- D. Automatic scaling of throughput capacity.
Answer:
AWS CCP CLF-C01 on Android – AWS CCP CLF-C01 on iOS – AWS CCP CLF-C01 on Windows 10/11
[Get AWS CCP Practice Exam PDF Dumps here]
Q16: Which of the following are the benefits of AWS Organizations?
Choose the 2 correct answers:
- A. Analyze cost before migrating to AWS.
- B. Centrally manage access polices across multiple AWS accounts.
- C. Automate AWS account creation and management.
- D. Provide technical help (by AWS) for issues in your AWS account.
Answer: iOS – Android [Get AWS CCP Practice Exam PDF Dumps here]
Q17: There is a requirement hosting a set of servers in the Cloud for a short period of 3 months. Which of the following types of instances should be chosen to be cost effective.
- A. Spot Instances
- B. On-Demand
- C. No Upfront costs Reserved
- D. Partial Upfront costs Reserved
Answer:
Q18: Which of the following is not a disaster recovery deployment technique.
- A. Pilot light
- B. Warm standby
- C. Single Site
- D. Multi-Site
Answer:
Top
Q19: Which of the following are attributes to the costing for using the Simple Storage Service. Choose 2 answers from the options given below
- A. The storage class used for the objects stored.
- B. Number of S3 buckets.
- C. The total size in gigabytes of all objects stored.
- D. Using encryption in S3
Answer:
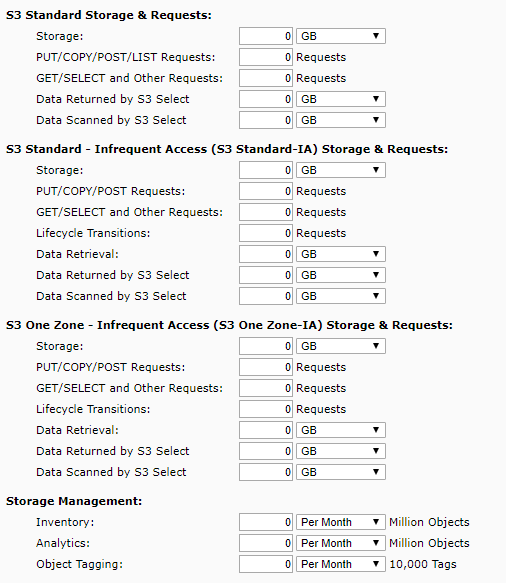
Q20: What endpoints are possible to send messages to with Simple Notification Service?
Choose the 3 correct answers:
- A. SQS
- B. SMS
- C. FTP
- D. Lambda
Answer:
Top
AWS CCP CLF-C01 on Android – AWS CCP CLF-C01 on iOS – AWS CCP CLF-C01 on Windows 10/11
Q21: What service helps you to aggregate logs from your EC2 instance? Choose one answer from the options below:
- A. SQS
- B. S3
- C. Cloudtrail
- D. Cloudwatch Logs
Answer:
Q22: A company is deploying a new two-tier web application in AWS. The company wants to store their most frequently used data so that the response time for the application is improved. Which AWS service provides the solution for the company’s requirements?
- A. MySQL Installed on two Amazon EC2 Instances in a single Availability Zone
- B. Amazon RDS for MySQL with Multi-AZ
- C. Amazon ElastiCache
- D. Amazon DynamoDB
Answer:
Top
Q23: You have a distributed application that periodically processes large volumes of data across multiple Amazon EC2 Instances. The application is designed to recover gracefully from Amazon EC2 instance failures. You are required to accomplish this task in the most cost-effective way. Which of the following will meet your requirements?
- A. Spot Instances
- B. Reserved Instances
- C. Dedicated Instances
On-Demand Instances
Answer:
Top
AWS CCP CLF-C01 on Android – AWS CCP CLF-C01 on iOS – AWS CCP CLF-C01 on Windows 10/11
Q24: Which of the following features is associated with a Subnet in a VPC to protect against Incoming traffic requests?
- A. AWS Inspector
- B. Subnet Groups
- C. Security Groups
- D. NACL
Answer:
Top
Q25: A company is deploying a two-tier, highly available web application to AWS. Which service provides durable storage for static content while utilizing Overall CPU resources for the web tier?
- A. Amazon EBC volume.
- B. Amazon S3
- C. Amazon EC2 instance store
- D. Amazon RDS instance
Answer:
Top
Q26: What are characteristics of Amazon S3?
Choose 2 answers from the options given below.
- A. S3 allows you to store objects of virtually unlimited size.
- B. S3 allows you to store unlimited amounts of data.
- C. S3 should be used to host relational database.
- D. Objects are directly accessible via a URL.
Answer:
Q26: When working on the costing for on-demand EC2 instances , which are the following are attributes which determine the costing of the EC2 Instance. Choose 3 answers from the options given below
- A. Instance Type
- B. AMI Type
- C. Region
- D. Edge location
Answer:
Q27: You have a mission-critical application which must be globally available at all times. If this is the case, which of the below deployment mechanisms would you employ
- A. Deployment to multiple edge locations
- B. Deployment to multiple Availability Zones
- D. Deployment to multiple Data Centers
- D. Deployment to multiple Regions
Answer:
Q28: Which of the following are right principles when designing cloud based systems. Choose 2 answers from the options below
- A. Build Tightly-coupled components
- B. Build loosely-coupled components
- C. Assume everything will fail
- D. Use as many services as possible
Answer:
Q29: You have 2 accounts in your AWS account. One for the Dev and the other for QA. All are part of consolidated billing. The master account has purchase 3 reserved instances. The Dev department is currently using 2 reserved instances. The QA team is planning on using 3 instances which of the same instance type. What is the pricing tier of the instances that can be used by the QA Team?
- A. No Reserved and 3 on-demand
- B. One Reserved and 2 on-demand
- C. Two Reserved and 1 on-demand
- D. Three Reserved and no on-demand
Answer:
Q30: Which one of the following features is normally present in all of AWS Support plans
- A. 24/7 access to Customer Service
- B. Access to all features in the Trusted Advisor
- C. A technical Account Manager
- D. A dedicated support person
Answer:

Q31: Which of the following storage mechanisms can be used to store messages effectively which can be used across distributed systems?
- A. Amazon Glacier
- B. Amazon EBS Volumes
- C. Amazon EBS Snapshots
- D. Amazon SQS
Answer:
Q32: You are exploring what services AWS has off-hand. You have a large number of data sets that need to be processed. Which of the following services can help fulfil this requirement.
- A. EMR
- B. S3
- C. Glacier
- D. Storage Gateway
Answer:
Q33: Which of the following services allows you to analyze EC2 Instances against pre-defined security templates to check for vulnerabilities
- A. AWS Trusted Advisor
- B. AWS Inspector
- C. AWS WAF
- D. AWS Shield
Answer:
Top
Q34: Your company is planning to offload some of the batch processing workloads on to AWS. These jobs can be interrupted and resumed at any time. Which of the following instance types would be the most cost effective to use for this purpose.
- A. On-Demand
- B. Spot
- C. Full Upfront Reserved
- D. Partial Upfront Reserved
Answer:
AWS CCP CLF-C01 on Android – AWS CCP CLF-C01 on iOS – AWS CCP CLF-C01 on Windows 10/11
Q35: Which of the following is not a category recommendation given by the AWS Trusted Advisor?
- A. Security
- B. High Availability
- C. Performance
- D. Fault tolerance
Answer:

Q36: Which of the below cannot be used to get data onto Amazon Glacier.
- A. AWS Glacier API
- B. AWS Console
- C. AWS Glacier SDK
- D. AWS S3 Lifecycle policies
Answer:
Q37: Which of the following from AWS can be used to transfer petabytes of data from on-premise locations to the AWS Cloud.
- A. AWS Import/Export
- B. AWS EC2
- C. AWS Snowball
- D. AWS Transfer
Answer:
Q38: Which of the following services allows you to analyze EC2 Instances against pre-defined security templates to check for vulnerabilities
- A. AWS Trusted Advisor
- B. AWS Inspector
- C. AWS WAF
- D. AWS Shield
Answer:
Top
Q39: Your company wants to move an existing Oracle database to the AWS Cloud. Which of the following services can help facilitate this move.
- A. AWS Database Migration Service
- B. AWS VM Migration Service
- C. AWS Inspector
- D. AWS Trusted Advisor
Answer:
Top
AWS CCP CLF-C01 on Android – AWS CCP CLF-C01 on iOS – AWS CCP CLF-C01 on Windows 10/11
Q40: Which of the following features of AWS RDS allows for offloading reads of the database.
- A. Cross region replication
- B. Creating Read Replica’s
- C. Using snapshots
- D. Using Multi-AZ feature
Answer:
Top
Q41: Which of the following does AWS perform on its behalf for EBS volumes to make it less prone to failure?
- A. Replication of the volume across Availability Zones
- B. Replication of the volume in the same Availability Zone
- C. Replication of the volume across Regions
- D. Replication of the volume across Edge locations
Answer:
Q42: Your company is planning to host a large e-commerce application on the AWS Cloud. One of their major concerns is Internet attacks such as DDos attacks.
Which of the following services can help mitigate this concern. Choose 2 answers from the options given below
- A. A. Cloudfront
- B. AWS Shield
- C. C. AWS EC2
- D. AWS Config
Answer:
Q43: Which of the following are 2 ways that AWS allows to link accounts
- A. Consolidating billing
- B. AWS Organizations
- C. Cost Explorer
- D. IAM
Answer:
Q44: Which of the following helps in DDos protection. Choose 2 answers from the options given below
- A. Cloudfront
- B. AWS Shield
- C. AWS EC2
- D. AWS Config
Answer:
Q45: Which of the following can be used to call AWS services from programming languages
- A. AWS SDK
- B. AWS Console
- C. AWS CLI
- D. AWS IAM
Answer:
Q46: A company wants to host a self-managed database in AWS. How would you ideally implement this solution?
- A. Using the AWS DynamoDB service
- B. Using the AWS RDS service
- C. Hosting a database on an EC2 Instance
- D. Using the Amazon Aurora service
Answer:
Q47: When creating security groups, which of the following is a responsibility of the customer. Choose 2 answers from the options given below.
- A. Giving a name and description for the security group
- B. Defining the rules as per the customer requirements.
- C. Ensure the rules are applied immediately
- D. Ensure the security groups are linked to the Elastic Network interface
Answer:
Q48: There is a requirement to host a database server for a minimum period of one year. Which of the following would result in the least cost?
- A. Spot Instances
- B. On-Demand
- C. No Upfront costs Reserved
- D. Partial Upfront costs Reserved
Answer:
Q49: Which of the below can be used to import data into Amazon Glacier?
Choose 3 answers from the options given below:
- A. AWS Glacier API
- B. AWS Console
- C. AWS Glacier SDK
- D. AWS S3 Lifecycle policies
Answer:
Q50: Which of the following can be used to secure EC2 Instances hosted in AWS. Choose 2 answers
- A. Usage of Security Groups
- B. Usage of AMI’s
- C. Usage of Network Access Control Lists
- D. Usage of the Internet gateway
Answer:
Q51: Which of the following can be used to host virtual servers on AWS
- A. AWS IAM
- B. AWS Server
- C. AWS EC2
- D. AWS Regions
Answer:
Q52: You plan to deploy an application on AWS. This application needs to be PCI Compliant. Which of the below steps are needed to ensure the compliance? Choose 2 answers from the below list:
- A. Choose AWS services which are PCI Compliant
- B. Ensure the right steps are taken during application development for PCI Compliance
- C. Encure the AWS Services are made PCI Compliant
- D. Do an audit after the deployment of the application for PCI Compliance.
Answer:
Q54: The Trusted Advisor service provides insight regarding which four categories of an AWS account?
- A. Security, fault tolerance, high availability, performance and Service Limits
- B. Security, access control, high availability, performance and Service Limits
- C. Performance, cost optimization, Security, fault tolerance and Service Limits
- D. Performance, cost optimization, Access Control, Connectivity, and Service Limits
Answer:
Top
Q55: As per the AWS Acceptable Use Policy, penetration testing of EC2 instances
- A. May be performed by AWS, and will be performed by AWS upon customer request
- B. May be performed by AWS, and is periodically performed by AWS
- C. Are expressly prohibited under all circumtances
- D. May be performed by the customer on their own instances with prior authorization from AWS
- E. May be performed by the customer on their own instances, only if performed from EC2 instances
Answer:
Top
Q56: What is the AWS feature that enables fast, easy, and secure transfers of files over long distances between your client and your Amazon S3 bucket
- A. File Transfer
- B. HTTP Transfer
- C. Transfer Acceleration
- D. S3 Acceleration
Answer:
Top
Q56: What best describes an AWS region?
Choose the correct answer:
- A. The physical networking connections between Availability Zones.
- B. A specific location where an AWS data center is located.
- C. A collection of DNS servers.
- D. An isolated collection of AWS Availability Zones, of which there are many placed all around the world.
Answer:
Top
Q57: Which of the following is a factor when calculating Total Cost of Ownership (TCO) for the AWS Cloud?
- A. The number of servers migrated to AWS
- B. The number of users migrated to AWS
- C. The number of passwords migrated to AWS
- D. The number of keys migrated to AWS
Answer:
Q58: Which AWS Services can be used to store files? Choose 2 answers from the options given below:
- A. Amazon CloudWatch
- B. Amazon Simple Storage Service (Amazon S3)
- C. Amazon Elastic Block Store (Amazon EBS)
- D. AWS COnfig
- D. AWS Amazon Athena
Q59: What best describes Amazon Web Services (AWS)?
Choose the correct answer:
- A. AWS is the cloud.
- B. AWS only provides compute and storage services.
- C. AWS is a cloud services provider.
- D. None of the above.
Answer:
Q60: Which AWS service can be used as a global content delivery network (CDN) service?
- A. Amazon SES
- B. Amazon CouldTrail
- C. Amazon CloudFront
- D. Amazon S3
Answer:
Q61: What best describes the concept of fault tolerance?
Choose the correct answer:
- A. The ability for a system to withstand a certain amount of failure and still remain functional.
- B. The ability for a system to grow in size, capacity, and/or scope.
- C. The ability for a system to be accessible when you attempt to access it.
- D. The ability for a system to grow and shrink based on demand.
Answer:
AWS CCP CLF-C01 on Android – AWS CCP CLF-C01 on iOS – AWS CCP CLF-C01 on Windows 10/11
Q62: The firm you work for is considering migrating to AWS. They are concerned about cost and the initial investment needed. Which of the following features of AWS pricing helps lower the initial investment amount needed?
Choose 2 answers from the options given below:
- A. The ability to choose the lowest cost vendor.
- B. The ability to pay as you go
- C. No upfront costs
- D. Discounts for upfront payments
Answer:
Q63: What best describes the concept of elasticity?
Choose the correct answer:
- A. The ability for a system to grow in size, capacity, and/or scope.
- B. The ability for a system to grow and shrink based on demand.
- C. The ability for a system to withstand a certain amount of failure and still remain functional.
- D. ability for a system to be accessible when you attempt to access it.
Answer:
Q64: Your company has started using AWS. Your IT Security team is concerned with the security of hosting resources in the Cloud. Which AWS service provides security optimization recommendations that could help the IT Security team secure resources using AWS?
- A. AWS API Gateway
- B. Reserved Instances
- C. AWS Trusted Advisor
- D. AWS Spot Instances
Answer:
Q65: What is the relationship between AWS global infrastructure and the concept of high availability?
Choose the correct answer:
- A. AWS is centrally located in one location and is subject to widespread outages if something happens at that one location.
- B. AWS regions and Availability Zones allow for redundant architecture to be placed in isolated parts of the world.
- C. Each AWS region handles a different AWS services, and you must use all regions to fully use AWS.
- D. None of the above
Answer
Q66: You are hosting a number of EC2 Instances on AWS. You are looking to monitor CPU Utilization on the Instance. Which service would you use to collect and track performance metrics for AWS services?
- A. Amazon CloudFront
- B. Amazon CloudSearch
- C. Amazon CloudWatch
- D. AWS Managed Services
AWS CCP CLF-C01 on Android – AWS CCP CLF-C01 on iOS – AWS CCP CLF-C01 on Windows 10/11
Answer:
Q67: Which of the following support plans give access to all the checks in the Trusted Advisor service.
Choose 2 answers from the options given below:
- A. Basic
- B. Business
- C. Enterprise
- D. None
Answer:
Q68: Which of the following in AWS maps to a separate geographic location?
A. AWS Region
B. AWS Data Centers
C. AWS Availability Zone
Answer:
Q69: What best describes the concept of scalability?
Choose the correct answer:
- A. The ability for a system to grow and shrink based on demand.
- B. The ability for a system to grow in size, capacity, and/or scope.
- C. The ability for a system be be accessible when you attempt to access it.
- D. The ability for a system to withstand a certain amount of failure and still remain functional.
Answer
Q70: If you wanted to monitor all events in your AWS account, which of the below services would you use?
- A. AWS CloudWatch
- B. AWS CloudWatch logs
- C. AWS Config
- D. AWS CloudTrail
Answer:
Q71: What are the four primary benefits of using the cloud/AWS?
Choose the correct answer:
- A. Fault tolerance, scalability, elasticity, and high availability.
- B. Elasticity, scalability, easy access, limited storage.
- C. Fault tolerance, scalability, sometimes available, unlimited storage
- D. Unlimited storage, limited compute capacity, fault tolerance, and high availability.
Answer:
Q72: What best describes a simplified definition of the “cloud”?
Choose the correct answer:
- A. All the computers in your local home network.
- B. Your internet service provider
- C. A computer located somewhere else that you are utilizing in some capacity.
- D. An on-premise data center that your company owns.
Answer
Top
Q73: Your development team is planning to host a development environment on the cloud. This consists of EC2 and RDS instances. This environment will probably only be required for 2 months.
Which types of instances would you use for this purpose?
- A. On-Demand
- B. Spot
- C. Reserved
- D. Dedicated
Answer:
Q74: Which of the following can be used to secure EC2 Instances?
- A. Security Groups
- B. EC2 Lists
- C. AWS Configs
- D. AWS CloudWatch
AWS CCP CLF-C01 on Android – AWS CCP CLF-C01 on iOS – AWS CCP CLF-C01 on Windows 10/11
Answer:
Q75: What is the purpose of a DNS server?
Choose the correct answer:
- A. To act as an internet search engine.
- B. To protect you from hacking attacks.
- C. To convert common language domain names to IP addresses.
- D. To serve web application content.
Answer:
Q76:What best describes the concept of high availability?
Choose the correct answer:
- A. The ability for a system to grow in size, capacity, and/or scope.
- B. The ability for a system to withstand a certain amount of failure and still remain functional.
- C. The ability for a system to grow and shrink based on demand.
- D. The ability for a system to be accessible when you attempt to access it.
Answer:
Top
AWS CCP CLF-C01 on Android – AWS CCP CLF-C01 on iOS – AWS CCP CLF-C01 on Windows 10/11
Q77: What is the major difference between AWS’s RDS and DynamoDB database services?
Choose the correct answer:
- A. RDS offers NoSQL database options, and DynamoDB offers SQL database options.
- B. RDS offers one SQL database option, and DynamoDB offers many NoSQL database options.
- C. RDS offers SQL database options, and DynamoDB offers a NoSQL database option.
- D. None of the above
Answer:
Q78: What are two open source in-memory engines supported by ElastiCache?
Choose the 2 correct answers:
- A. CacheIt
- B. Aurora
- C. MemcacheD
- D. Redis
Answer:
Q79: What AWS database service is used for data warehousing of petabytes of data?
Choose the correct answer:
- A. RDS
- B. Elasticache
- C. Redshift
- D. DynamoDB
Answer:
Q80: Which AWS service uses a combination of publishers and subscribers?
Choose the correct answer:
- A. Lambda
- B. RDS
- C. EC2
- D. SNS
Answer:
Q81: What SQL database engine options are available in RDS?
Choose the 3 correct answers:
- A. MySQL
- B. MongoDB
- C. PostgreSQL
- D. MariaDB
Answer:
Q81: What is the name of AWS’s RDS SQL database engine?
Choose the correct answer:
- A. Lightsail
- B. Aurora
- C. MySQL
- D. SNS
Answer:
Q82: Under what circumstances would you choose to use the AWS service CloudTrail?
Choose the correct answer:
- A. When you want to log what actions various IAM users are taking in your AWS account.
- B. When you want a serverless compute platform.
- C. When you want to collect and view resource metrics.
- D. When you want to send SMS notifications based on events that occur in your account.
Answer:
Q83: If you want to monitor the average CPU usage of your EC2 instances, which AWS service should you use?
Choose the correct answer:
- A. CloudMonitor
- B. CloudTrail
- C. CloudWatch
- D. None of the above
Answer:
Q84: What is AWS’s relational database service?
Choose the correct answer:
- A. ElastiCache
- B. DymamoDB
- C. RDS
- D. Redshift
Answer:
Q85: If you want to have SMS or email notifications sent to various members of your department with status updates on resources in your AWS account, what service should you choose?
Choose the correct answer:
- A. SNS
- B. GetSMS
- C. RDS
- D. STS
Answer:
AWS CCP CLF-C01 on Android – AWS CCP CLF-C01 on iOS – AWS CCP CLF-C01 on Windows 10/11
Q86: Which AWS service can provide a Desktop as a Service (DaaS) solution?
A. EC2
B. AWS Systems Manager
C. Amazon WorkSpaces
D. Elastic Beanstalk
Q87: Your company has recently migrated large amounts of data to the AWS cloud in S3 buckets. But it is necessary to discover and protect the sensitive data in these buckets. Which AWS service can do that?
A. GuardDuty
B. Amazon Macie
C. CloudTrail
D. AWS Inspector
Q88: Your Finance Department has instructed you to save costs wherever possible when using the AWS Cloud. You notice that using reserved EC2 instances on a 1year contract will save money. What payment method will save the most money?
A: Deferred
B: Partial Upfront
C: All Upfront
D: No Upfront
Q89: A fantasy sports company needs to run an application for the length of a football season (5 months). They will run the application on an EC2 instance and there can be no interruption. Which purchasing option best suits this use case?
A. On-Demand
B. Reserved
C. Dedicated
D. Spot
Q90: Your company is considering migrating its data center to the cloud. What are the advantages of the AWS cloud over an on-premises data center?
A. Replace upfront operational expenses with low variable operational expenses.
B. Maintain physical access to the new data center, but share responsibility with AWS.
C. Replace low variable costs with upfront capital expenses.
D. Replace upfront capital expenses with low variable costs.
Q91: You are leading a pilot program to try the AWS Cloud for one of your applications. You have been instructed to provide an estimate of your AWS bill. Which service will allow you to do this by manually entering your planned resources by service?
A. AWS CloudTrail
B. AWS Cost and Usage Report
C. AWS Pricing Calculator
D. AWS Cost Explorer
Q92: Which AWS service would enable you to view the spending distribution in one of your AWS accounts?
A. AWS Spending Explorer
B. Billing Advisor
C. AWS Organizations
D. AWS Cost Explorer
Q93: You are managing the company’s AWS account. The current support plan is Basic, but you would like to begin using Infrastructure Event Management. What support plan (that already includes Infrastructure Event Management without an additional fee) should you upgrade to?
A. Upgrade to Enterprise plan.
B. Do nothing. It is included in the Basic plan.
C. Upgrade to Developer plan.
D. Upgrade to the Business plan. No other steps are necessary.
Q94: You have decided to use the AWS Cost and Usage Report to track your EC2 Reserved Instance costs. To where can these reports be published?
A. Trusted Advisor
B. An S3 Bucket that you own.
C. CloudWatch
D. An AWS owned S3 Bucket.
Q95: What can we do in AWS to receive the benefits of volume pricing for your multiple AWS accounts?
A. Use consolidated billing in AWS Organizations.
B. Purchase services in bulk from AWS Marketplace.
C. Use AWS Trusted Advisor
D. You will receive volume pricing by default.
Q96: A gaming company is using the AWS Developer Tool Suite to develop, build, and deploy their applications. Which AWS service can be used to trace user requests from end-to-end through the application?
A. AWS X-Ray
B. CloudWatch
C. AWS Inspector
D. CloudTrail
Q97: A company needs to use a Load Balancer which can serve traffic at the TCP, and UDP layers. Additionally, it needs to handle millions of requests per second at very low latencies. Which Load Balancer should they use?
A. TCP Load Balancer
B. Application Load Balancer
C. Classic Load Balancer
D. Network Load Balancer
Q98: Your company is migrating its services to the AWS cloud. The DevOps team has heard about infrastructure as code, and wants to investigate this concept. Which AWS service would they investigate?
A. AWS CloudFormation
B. AWS Lambda
C. CodeCommit
D. Elastic Beanstalk
Q99: You have a MySQL database that you want to migrate to the cloud, and you need it to be significantly faster there. You are looking for a speed increase up to 5 times the current performance. Which AWS offering could you use?
A. Elasticache
B. Amazon Aurora
C. DynamoDB
D. Amazon RDS MySQL
Q100:A developer is trying to programmatically retrieve information from an EC2 instance such as public keys, ip address, and instance id. From where can this information be retrieved?
A. Instance metadata
B. Instance Snapshot
C. CloudWatch Logs
D. Instance userdata
Q101: Why is AWS more economical than traditional data centers for applications with varying compute workloads?
A) Amazon EC2 costs are billed on a monthly basis.
B) Users retain full administrative access to their Amazon EC2 instances.
C) Amazon EC2 instances can be launched on demand when needed.
D) Users can permanently run enough instances to handle peak workloads.
Q102: Which AWS service would simplify the migration of a database to AWS?
A) AWS Storage Gateway
B) AWS Database Migration Service (AWS DMS)
C) Amazon EC2
D) Amazon AppStream 2.0
Q103: Which AWS offering enables users to find, buy, and immediately start using software solutions in their AWS environment?
A) AWS Config
B) AWS OpsWorks
C) AWS SDK
D) AWS Marketplace
Q104: Which AWS networking service enables a company to create a virtual network within AWS?
A) AWS Config
B) Amazon Route 53
C) AWS Direct Connect
D) Amazon Virtual Private Cloud (Amazon VPC)
Q105: Which component of the AWS global infrastructure does Amazon CloudFront use to ensure low-latency delivery?
A) AWS Regions
B) Edge locations
C) Availability Zones
D) Virtual Private Cloud (VPC)
Q106: How would a system administrator add an additional layer of login security to a user’s AWS Management Console?
A) Use Amazon Cloud Directory
B) Audit AWS Identity and Access Management (IAM) roles
C) Enable multi-factor authentication
D) Enable AWS CloudTrail
Q107: Which service can identify the user that made the API call when an Amazon EC2 instance is terminated?
A) AWS Trusted Advisor
B) AWS CloudTrail
C) AWS X-Ray
D) AWS Identity and Access Management (AWS IAM)
Q108: Which service would be used to send alerts based on Amazon CloudWatch alarms?
A) Amazon Simple Notification Service (Amazon SNS)
B) AWS CloudTrail
C) AWS Trusted Advisor
D) Amazon Route 53
Q109: Where can a user find information about prohibited actions on the AWS infrastructure?
A) AWS Trusted Advisor
B) AWS Identity and Access Management (IAM)
C) AWS Billing Console
D) AWS Acceptable Use Policy
Q110: Which of the following is an AWS responsibility under the AWS shared responsibility model?
A) Configuring third-party applications
B) Maintaining physical hardware
C) Securing application access and data
D) Managing guest operating systems
Q111: Which recommendations are included in the AWS Trusted Advisor checks? (Select TWO.)
AWS CCP Exam Topics:
The AWS Cloud Practitioner exam is broken down into 4 domains
- Cloud Concepts
- Security and Compliance
- Technology
- Billing and Pricing.
AWS Certified Cloud Practitioner Exam Whitepapers:
AWS has provided whitepapers to help you understand the technical concepts. Below are the recommended whitepapers.
- Overview of Amazon Web Services
- Architecting for the Cloud: AWS Best Practices
- How AWS Pricing works whitepaper.
- The Total Cost of (Non) Ownership of Web Application in the Cloud
- Compare AWS Support Plans
Online Training and Labs for AWS Cloud Certified Practitioner Exam
AWS Cloud Practitioners Jobs
AWS Certified Cloud Practitioner Exam info and details, How To:
The AWS Certified Cloud Practitioner Exam is a multiple choice, multiple answer exam. Here is the Exam Overview:
- Certification Name: AWS Certified Cloud Practitioner.
- Prerequisites for the Exam: None.
- Exam Pattern: Multiple Choice Questions
- Number of Questions: 65
- Duration: 90 mins
- Exam fees: US $100
- Exam Guide on AWS Website
- Available languages for tests: English, Japanese, Korean, Simplified Chinese
- Read AWS whitepapers
- Register for certification account here.
- Prepare for Certification Here
Additional Information for reference
Below are some useful reference links that would help you to learn about AWS Practitioner Exam.
- AWS certified cloud practitioner/
- certification faqs
- AWS Cloud Practitioner Certification Exam on Quora
Other Relevant and Recommended AWS Certifications
AWS Certified Cloud Practitioner
AWS Certified Solutions Architect – Associate
AWS Certified Solution Architect Exam Prep App: Free
AAWS Certified Developer – Associate
AWS Certified SysOps Administrator – Associate
AWS Certified Solutions Architect – Professional
AWS Certified DevOps Engineer – Professional
AWS Certified Big Data Specialty
AWS Certified Advanced Networking.
AWS Certified Security – Specialty
Other AWS Certification Exams Questions and Answers Dumps:
Top 20 AWS Certified Associate SysOps Administrator Practice Quiz – Questions and Answers Dumps
Big Data and Data Analytics 101 – Top 100 AWS Certified Data Analytics Specialty Certification Questions and Answers Dumps
CyberSecurity 101 and Top 25 AWS Certified Security Specialty Questions and Answers Dumps
Networking 101 and Top 20 AWS Certified Advanced Networking Specialty Questions and Answers Dumps
Other AWS Facts and Summaries and Questions/Answers Dump
- AWS S3 facts and summaries and Q&A Dump
- AWS DynamoDB facts and summaries and Questions and Answers Dump
- AWS EC2 facts and summaries and Questions and Answers Dump
- AWS Serverless facts and summaries and Questions and Answers Dump
- AWS Developer and Deployment Theory facts and summaries and Questions and Answers Dump
- AWS IAM facts and summaries and Questions and Answers Dump
- AWS Lambda facts and summaries and Questions and Answers Dump
- AWS SQS facts and summaries and Questions and Answers Dump
- AWS RDS facts and summaries and Questions and Answers Dump
- AWS ECS facts and summaries and Questions and Answers Dump
- AWS CloudWatch facts and summaries and Questions and Answers Dump
- AWS SES facts and summaries and Questions and Answers Dump
- AWS EBS facts and summaries and Questions and Answers Dump
- AWS ELB facts and summaries and Questions and Answers Dump
- AWS Autoscaling facts and summaries and Questions and Answers Dump
- AWS VPC facts and summaries and Questions and Answers Dump
- AWS KMS facts and summaries and Questions and Answers Dump
- AWS Elastic Beanstalk facts and summaries and Questions and Answers Dump
- AWS CodeBuild facts and summaries and Questions and Answers Dump
- AWS CodeDeploy facts and summaries and Questions and Answers Dump
- AWS CodePipeline facts and summaries and Questions and Answers Dump
- Pros and Cons of Cloud Computing
- Cloud Customer Insurance – Cloud Provider Insurance – Cyber Insurance
Below is a listing of AWS certification exam quiz apps for all platforms:
AWS CCP CLF-C01 on Android – AWS CCP CLF-C01 on iOS – AWS CCP CLF-C01 on Windows 10/11
AWS Certified Cloud practitioner Exam Prep FREE version: CCP, CLF-C01
Online Training and Labs for AWS Certified Solution Architect Associate Exam
AWS Certified Solution Architect Associate Jobs

AWS Certification and Training Apps for all platforms:
AWS Cloud practitioner FREE version:
AWS Certified Cloud practitioner for the web:pwa
AWS Certified Cloud practitioner Exam Prep App for iOS
AWS Certified Cloud practitioner Exam Prep App for Microsoft/Windows10
AWS Certified Cloud practitioner Exam Prep App for Android (Google Play Store)
AWS Certified Cloud practitioner Exam Prep App for Android (Amazon App Store)
AWS Certified Cloud practitioner Exam Prep App for Android (Huawei App Gallery)
AWS Solution Architect FREE version:
AWS Certified Solution Architect Associate Exam Prep App for iOS:
Solution Architect Associate for Android Google Play
AWS Certified Solution Architect Associate Exam Prep App :Pwa
AWS Certified Solution Architect Associate Exam Prep App for Amazon android
AWS Certified Cloud practitioner Exam Prep App for Microsoft/Windows10
AWS Certified Cloud practitioner Exam Prep App for Huawei App Gallery
AWS Cloud Practitioner PRO Versions:
AWS Certified Cloud practitioner PRO Exam Prep App for iOS
AWS Certified Cloud Practitioner PRO Associate Exam Prep App for android google
AWS Certified Cloud practitioner Exam Prep App for Amazon android
AWS Certified Cloud practitioner Exam Prep App for Windows 10
AWS Certified Cloud practitioner Exam Prep PRO App for Android (Huawei App Gallery)
AWS Solution Architect PRO
AWS Certified Solution Architect Associate PRO versions for iOS
AWS Certified Solution Architect Associate PRO Exam Prep App for Android google
AWS Certified Solution Architect Associate PRO Exam Prep App for Windows10
AWS Certified Solution Architect Associate PRO Exam Prep App for Amazon android
Huawei App Gallery: Coming soon
AWS Certified Developer Associates Free version:
AWS Certified Developer Associates for Android (Google Play)
AWS Certified Developer Associates Web/PWA
AWS Certified Developer Associates for iOs
AWS Certified Developer Associates for Android (Huawei App Gallery)
AWS Certified Developer Associates for windows 10 (Microsoft App store)
Amazon App Store: Coming soon
AWS Developer Associates PRO version
PRO version with mock exam for android (Google Play)
PRO version with mock exam ios
AWS Certified Developer Associates PRO for Android (Microsoft App Store)
AWS Certified Developer Associates PRO for Android (Huawei App Gallery): Coming soon
Latest Cloud AWS Cloud Training Questions and Answers from around the Web:
Jon Bonso vs Stephane Maarek CCP Practice Exam Differences
Tutorialsdojo.com are the best in the market IMO
They have a long standing reputation for quality.
I’ve used them, I’ve recommended them to friends and family and I recommend them to students of my AWS courses also.
And last but not least, the Djamgatech Apps for iOs and and android.
Practice on the web directly here via the AWS Cloud Practitioner Exam Perp App
I would also recommend checking: Exam Digest

What is the difference between Amazon EC2 Savings Plans and Spot Instances?
Amazon EC2 Savings Plans are ideal for workloads that involve a consistent amount of compute usage over a 1-year or 3-year term.
With Amazon EC2 Savings Plans, you can reduce your compute costs by up to 72% over On-Demand costs.
Spot Instances are ideal for workloads with flexible start and end times, or that can withstand interruptions. With Spot Instances, you can reduce your compute costs by up to 90% over On-Demand costs.
Unlike Amazon EC2 Savings Plans, Spot Instances do not require contracts or a commitment to a consistent amount of compute usage.
Amazon EBS vs Amazon EFS
An Amazon EBS volume stores data in a single Availability Zone.
To attach an Amazon EC2 instance to an EBS volume, both the Amazon EC2 instance and the EBS volume must reside within the same Availability Zone.
Amazon EFS is a regional service. It stores data in and across multiple Availability Zones.
The duplicate storage enables you to access data concurrently from all the Availability Zones in the Region where a file system is located. Additionally, on-premises servers can access Amazon EFS using AWS Direct Connect.
Which cloud deployment model allows you to connect public cloud resources to on-premises infrastructure?
Applications made available through hybrid deployments connect cloud resources to on-premises infrastructure and applications. For example, you might have an application that runs in the cloud but accesses data stored in your on-premises data center.
What is the difference between Amazon EC2 Savings Plans and Spot Instances?
Amazon EC2 Savings Plans are ideal for workloads that involve a consistent amount of compute usage over a 1-year or 3-year term.
With Amazon EC2 Savings Plans, you can reduce your compute costs by up to 72% over On-Demand costs.
Spot Instances are ideal for workloads with flexible start and end times, or that can withstand interruptions. With Spot Instances, you can reduce your compute costs by up to 90% over On-Demand costs.
Unlike Amazon EC2 Savings Plans, Spot Instances do not require contracts or a commitment to a consistent amount of compute usage.
Which benefit of cloud computing helps you innovate and build faster?
Agility: The cloud gives you quick access to resources and services that help you build and deploy your applications faster.
Which developer tool allows you to write code within your web browser?
Cloud9 is an integrated development environment (IDE) that allows you to write code within your web browser.
Which method of accessing an EC2 instance requires both a private key and a public key?
SSH allows you to access an EC2 instance from your local laptop using a key pair, which consists of a private key and a public key.
Which service allows you to track the name of the user making changes in your AWS account?
CloudTrail tracks user activity and API calls in your account, which includes identity information (the user’s name, source IP address, etc.) about the API caller.
Which analytics service allows you to query data in Amazon S3 using Structured Query Language (SQL)?
Athena is a query service that makes it easy to analyze data in Amazon S3 using SQL.
Which machine learning service helps you build, train, and deploy models quickly?
SageMaker helps you build, train, and deploy machine learning models quickly.
Which EC2 storage mechanism is recommended when running a database on an EC2 instance?
EBS is a storage device you can attach to your instances and is a recommended storage option when you run databases on an instance.
Which storage service is a scalable file system that only works with Linux-based workloads?
EFS is an elastic file system for Linux-based workloads.

Which AWS service provides a secure and resizable compute platform with choice of processor, storage, networking, operating system, and purchase model?
Amazon Elastic Compute Cloud (Amazon EC2) is a web service that provides secure, resizable compute capacity in the cloud. Amazon EC2 offers the broadest and deepest compute platform with choice of processor, storage, networking, operating system, and purchase model. Amazon EC2.
Which services allow you to build hybrid environments by connecting on-premises infrastructure to AWS?
Site-to-site VPN allows you to establish a secure connection between your on-premises equipment and the VPCs in your AWS account.
Direct Connect allows you to establish a dedicated network connection between your on-premises network and AWS.
What service could you recommend to a developer to automate the software release process?
CodePipeline is a developer tool that allows you to continuously automate the software release process.
Which service allows you to practice infrastructure as code by provisioning your AWS resources via scripted templates?
CloudFormation allows you to provision your AWS resources via scripted templates.
Which machine learning service allows you to add image analysis to your applications?
Rekognition is a service that makes it easy to add image analysis to your applications.
Which services allow you to run containerized applications without having to manage servers or clusters?
Fargate removes the need for you to interact with servers or clusters as it provisions, configures, and scales clusters of virtual machines to run containers for you.
ECS lets you run your containerized Docker applications on both Amazon EC2 and AWS Fargate.
EKS lets you run your containerized Kubernetes applications on both Amazon EC2 and AWS Fargate.
Amazon S3 offers multiple storage classes. Which storage class is best for archiving data when you want the cheapest cost and don’t mind long retrieval times?
S3 Glacier Deep Archive offers the lowest cost and is used to archive data. You can retrieve objects within 12 hours.

In the shared responsibility model, what is the customer responsible for?
You are responsible for patching the guest OS, including updates and security patches.
You are responsible for firewall configuration and securing your application.
A company needs phone, email, and chat access 24 hours a day, 7 days a week. The response time must be less than 1 hour if a production system has a service interruption. Which AWS Support plan meets these requirements at the LOWEST cost?
The Business Support plan provides phone, email, and chat access 24 hours a day, 7 days a week. The Business Support plan has a response time of less than 1 hour if a production system has a service interruption.
For more information about AWS Support plans, see Compare AWS Support Plans.
Which Amazon EC2 pricing model adjusts based on supply and demand of EC2 instances?
Spot Instances are discounted more heavily when there is more capacity available in the Availability Zones.
For more information about Spot Instances, see Amazon EC2 Spot Instances.
Which of the following is an advantage of consolidated billing on AWS?
Consolidated billing is a feature of AWS Organizations. You can combine the usage across all accounts in your organization to share volume pricing discounts, Reserved Instance discounts, and Savings Plans. This solution can result in a lower charge compared to the use of individual standalone accounts.
For more information about consolidated billing, see Consolidated billing for AWS Organizations.
A company requires physical isolation of its Amazon EC2 instances from the instances of other customers. Which instance purchasing option meets this requirement?
With Dedicated Hosts, a physical server is dedicated for your use. Dedicated Hosts provide visibility and the option to control how you place your instances on an isolated, physical server. For more information about Dedicated Hosts, see Amazon EC2 Dedicated Hosts.
A company is hosting a static website from a single Amazon S3 bucket. Which AWS service will achieve lower latency and high transfer speeds?
CloudFront is a web service that speeds up the distribution of your static and dynamic web content, such as .html, .css, .js, and image files, to your users. Content is cached in edge locations. Content that is repeatedly accessed can be served from the edge locations instead of the source S3 bucket. For more information about CloudFront, see Accelerate static website content delivery.
Which AWS service provides a simple and scalable shared file storage solution for use with Linux-based Amazon EC2 instances and on-premises servers?
Amazon EFS provides an elastic file system that lets you share file data without the need to provision and manage storage. It can be used with AWS Cloud services and on-premises resources, and is built to scale on demand to petabytes without disrupting applications. With Amazon EFS, you can grow and shrink your file systems automatically as you add and remove files, eliminating the need to provision and manage capacity to accommodate growth.
For more information about using Amazon EFS, see Walkthrough: Create and mount a file system on premises with AWS Direct Connect and VPN.
Which service allows you to generate encryption keys managed by AWS?
KMS allows you to generate and manage encryption keys. The keys generated by KMS are managed by AWS.
Which service can integrate with a Lambda function to automatically take remediation steps when it uncovers suspicious network activity when monitoring logs in your AWS account?
GuardDuty can perform automated remediation actions by leveraging Amazon CloudWatch Events and AWS Lambda. GuardDuty continuously monitors for threats and unauthorized behavior to protect your AWS accounts, workloads, and data stored in Amazon S3. GuardDuty analyzes multiple AWS data sources, such as AWS CloudTrail event logs, Amazon VPC Flow Logs, and DNS logs.
Which service allows you to create access keys for someone needing to access AWS via the command line interface (CLI)?
IAM allows you to create users and generate access keys for users needing to access AWS via the CLI.
Which service allows you to record software configuration changes within your Amazon EC2 instances over time?
Config helps with recording compliance and configuration changes over time for your AWS resources.
Which service assists with compliance and auditing by offering a downloadable report that provides the status of passwords and MFA devices in your account?
IAM provides a downloadable credential report that lists all users in your account and the status of their various credentials, including passwords, access keys, and MFA devices.
Which service allows you to locate credit card numbers stored in Amazon S3?
Macie is a data privacy service that helps you uncover and protect your sensitive data, such as personally identifiable information (PII) like credit card numbers, passport numbers, social security numbers, and more.
How do you manage permissions for multiple users at once using AWS Identity and Access Management (IAM)?
An IAM group is a collection of IAM users. When you assign an IAM policy to a group, all users in the group are granted permissions specified by the policy.
Which service protects your web application from cross-site scripting attacks?
Which AWS Trusted Advisor real-time guidance recommendations are available for AWS Basic Support and AWS Developer Support customers?
Basic and Developer Support customers get 50 service limit checks.
Basic and Developer Support customers get security checks for “Specific Ports Unrestricted” on Security Groups.
Basic and Developer Support customers get security checks on S3 Bucket Permissions.
Which service allows you to simplify billing by using a single payment method for all your accounts?
Organizations offers consolidated billing that provides 1 bill for all your AWS accounts. This also gives you access to volume discounts.
Which AWS service usage will always be free even after the 12-month free tier plan has expired?
One million Lambda requests are always free each month.
What is the easiest way for a customer on the AWS Basic Support plan to increase service limits?
The Basic Support plan allows 24/7 access to Customer Service via email and the ability to open service limit increase support cases.
Which types of issues are covered by AWS Support?
“How to” questions about AWS service and features
Problems detected by health checks
Which features of AWS reduce your total cost of ownership (TCO)?
Sharing servers with others allows you to save money.
Elastic computing allows you to trade capital expense for variable expense.
You pay only for the computing resources you use with no long-term commitments.
Which service allows you to select and deploy operating system and software patches automatically across large groups of Amazon EC2 instances?
Systems Manager allows you to automate operational tasks across your AWS resources.
Which service provides the easiest way to set up and govern a secure, multi-account AWS environment?
Control Tower allows you to centrally govern and enforce the best use of AWS services across your accounts.
Which cost management tool gives you the ability to be alerted when the actual or forecasted cost and usage exceed your desired threshold?
Budgets allow you to improve planning and cost control with flexible budgeting and forecasting. You can choose to be alerted when your budget threshold is exceeded.
Which tool allows you to compare your estimated service costs per Region?
The Pricing Calculator allows you to get an estimate for the cost of AWS services. Comparing service costs per Region is a common use case.
Who can assist with accelerating the migration of legacy contact center infrastructure to AWS?
Professional Services is a global team of experts that can help you realize your desired business outcomes with AWS.
The AWS Partner Network (APN) is a global community of partners that helps companies build successful solutions with AWS.
Which cost management tool allows you to view costs from the past 12 months, current detailed costs, and forecasts costs for up to 3 months?
Cost Explorer allows you to visualize, understand, and manage your AWS costs and usage over time.
Which service reduces the operational overhead of your IT organization?
Managed Services implements best practices to maintain your infrastructure and helps reduce your operational overhead and risk.
How do I set up Failover on Amazon AWS Route53?
How can a program running inside AWS EC2 determine which VPC and security group an incoming IP address or TCP connection belongs to, for application-layer firewalling?
I assume it is your subscription where the VPCs are located, otherwise you can’t really discover the information you are looking for. On the EC2 server you could use AWS CLI or Powershell based scripts that query the IP information. Based on IP you can find out what instance uses the network interface, what security groups are tied to it and in which VPC the instance is hosted. Read more here…What are some tips, tricks and gotchas when using AWS Lambda to connect to a VPC?
When using AWS Lambda inside your VPC, your Lambda function will be allocated private IP addresses, and only private IP addresses, from your specified subnets. This means that you must ensure that your specified subnets have enough free address space for your Lambda function to scale up to. Each simultaneous invocation needs its own IP. Read more here…
How do AWS step functions communicate with lambda functions which are in a VPC?
When a Lambda “is in a VPC”, it really means that its attached Elastic Network Interface is the customer’s VPC and not the hidden VPC that AWS manages for Lambda.
The ENI is not related to the AWS Lambda management system that does the invocation (the data plane mentioned here). The AWS Step Function system can go ahead and invoke the Lambda through the API, and the network request for that can pass through the underlying VPC and host infrastructure.
Those Lambdas in turn can invoke other Lambda directly through the API, or more commonly by decoupling them, such as through Amazon SQS used as a trigger. Read more ….
How do I invoke an AWS Lambda function programmatically?
public InvokeResult invoke(InvokeRequest request)
Invokes a Lambda function. You can invoke a function synchronously (and wait for the response), or asynchronously. To invoke a function asynchronously, set InvocationType to Event.
For synchronous invocation, details about the function response, including errors, are included in the response body and headers. For either invocation type, you can find more information in the execution log and trace.
When an error occurs, your function may be invoked multiple times. Retry behavior varies by error type, client, event source, and invocation type. For example, if you invoke a function asynchronously and it returns an error, Lambda executes the function up to two more times. For more information, see Retry Behavior.
For asynchronous invocation, Lambda adds events to a queue before sending them to your function. If your function does not have enough capacity to keep up with the queue, events may be lost. Occasionally, your function may receive the same event multiple times, even if no error occurs. To retain events that were not processed, configure your function with a dead-letter queue.
The status code in the API response doesn’t reflect function errors. Error codes are reserved for errors that prevent your function from executing, such as permissions errors, limit errors, or issues with your function’s code and configuration. For example, Lambda returns TooManyRequestsException if executing the function would cause you to exceed a concurrency limit at either the account level ( Concurrent Invocation Limit Exceeded) or function level ( Reserved Function Concurrent Invocation LimitExceeded).
For functions with a long timeout, your client might be disconnected during synchronous invocation while it waits for a response. Configure your HTTP client, SDK, firewall, proxy, or operating system to allow for long connections with timeout or keep-alive settings.
This operation requires permission for the lambda:InvokeFunction action. Read more…
What are the differences between default and non-default AWS VPCs?
Default VPC
- 1 per region
- a set VPC CIDR range … you can’t changed it
- has everything configured by default .. 1 subnet per AZ, an internet gateway, routes and subnets set to allocate IPv4 by default.
Custom VPCs
- As any as you want per region (within limits)
- Customisable CIDR range
- Customisable subnet structure
- Nothing configured by default, you have to configure everything
The subnet mask determines how many bits of the network address are relevant (and thus indirectly the size of the network block in terms of how many host addresses are available) –
192.0.2.0, subnet mask 255.255.255.0 means that 192.0.2 is the significant portion of the network number, and that there 8 bits left for host addresses (i.e. 192.0.2.0 thru 192.0.2.255)
192.0.2.0, subnet mask 255.255.255.128 means that 192.0.2.0 is the significant portion of the network number (first three octets and the most significant bit of the last octet), and that there 7 bits left for host addresses (i.e. 192.0.2.0 thru 192.0.2.127)
When in doubt, envision the network number and subnet mask in base 2 (i.e. binary) and it will become much clearer. Read more here…
What are some best practices securing my Amazon Virtual Private Cloud (VPC)?
IAM is the new perimeter.
Separate out the roles needed to do each job. (Assuming this is a corporate environment)
Have a role for EC2, another for Networking, another for IAM.
Everyone should not be admin. Everyone should not be able to add/remove IGW’s, NAT gateways, alter security groups and NACLS, or setup peering connections.
Also, another thing… lock down full internet access. Limit to what is needed and that’s it. Read more here….
Within a single VPC, the subnets’ route tables need to point to each other. This will already work without additional routes because VPC sets up the local target to point to the VPC subnet.
Security groups are not used here since they are attached to instances, and not networks.
See: Amazon Virtual Private Cloud
The NAT EC2 instance (server), or AWS-provided NAT gateway is necessary only if the private subnet internal addresses need to make outbound connections. The NAT will translate the private subnet internal addresses to the public subnet internal addresses, and the AWS VPC Internet Gateway will translate these to external IP addresses, which can then go out to the Internet. Read more here ….
What are the applications (or workloads) that cannot be migrated on to cloud (AWS or Azure or GCP)?
A good example of workloads that currently are not in public clouds are mobile and fixed core telecom networks for tier 1 service providers. This is despite the fact that these core networks are increasingly software based and have largely been decoupled from the hardware. There are a number of reasons for this such as the public cloud providers such as Azure and AWS do not offer the guaranteed availability required by telecom networks. These networks require 99.999% availability and is typically referred to as telecom grade.
The regulatory environment frequently restricts hosting of subscriber data outside the of the operators data centers or in another country and key network functions such as lawful interception cannot contractually be hosted off-prem. Read more here….
How many CIDRs can we add to my own created VPC?
You can add up to 5 IPv4 CIDR blocks, or 1 IPv6 block per VPC. You can further segment the network by utilizing up to 200 subnets per VPC. Amazon VPC Limits. Read more …
Why can’t a subnet’s CIDR be changed once it has been assigned?
Sure it can, but you’ll need to coordinate with the neighbors. You can merge two /25’s into a single /24 quite effortlessly if you control the entire range it covers. In practice you’ll see many tiny allocations in public IPv4 space, like /29’s and even smaller. Those are all assigned to different people. If you want to do a big shuffle there, you have a lot of coordinating to do.. or accept the fallout from the breakage you cause. Read more…
Can one VPC talk to another VPC?
AWS CCP CLF-C01 on Android – AWS CCP CLF-C01 on iOS – AWS CCP CLF-C01 on Windows 10/11
What questions to expect in cloud support engineer deployment roles at AWS?
Cloud Support Engineer (CSE) is a role which requires the following abilities:
- Wide range of technical skills
- Good communication and time management
- Good knowledge about the AWS services, and how to leverage them to solve simple to complex problems.
As your question is related to the deployment Pod, you will probably be asked about deployment methods (A/B testing like blue-green deployment) as well as pipelining strategies. You might be asked during this interview to reason about a simple task and to code it (like parsing a log file). Also review the TCP/IP stack in-depth as well as the tools to troubleshoot it for the networking round. You will eventually have some Linux questions, the range of questions can vary from common CLI tools to Linux internals like signals / syscalls / file descriptors and so on.
Last but not least the Leadership principles, I can only suggest you to prepare a story for each of them. You will quickly find what LP they are looking for and would be able to give the right signal to your interviewer.
Finally, remember that theres a debrief after the (usually 5) stages of your on site interview, and more senior and convincing interviewers tend to defend their vote so don’t screw up with them.
Be natural, focus on the question details and ask for confirmation, be cool but not too much. At the end of the day, remember that your job will be to understand customer issues and provide a solution, so treat your interviewers as if they were customers and they will see a successful CSE in you, be reassured and give you the job.
Expect questions on cloudformations, Teraform, Aws ec2/rds and stack related questions.
Its a high tech call center. You are expected to take calls, chats of customers and give them technical advice. You will not be doing any of the cool stuff you did earlier (if you are coming from engineering job or DBA). You will surely gain a very good knowledge of multiple AWS services and the one that you will be hired in, however most of the knowledge will be theoretical and nothing practical in day-to-day life.
It also depends on the support team you are being hired for. Networking or compute teams (Ec2) have different interview patterns vs database or big data support.
In any case, basics of OS, networking are critical to the interview. If you have a phone screen, we will be looking for basic/semi advance skills of these and your speciality. For example if you mention Oracle in your resume and you are interviewing for the database team, expect a flurry of those questions.
Other important aspect is the Amazon leadership principles. Half of your interview is based on LPs. If you fail to have scenarios where you do not demonstrate our LPs, you cannot expect to work here even though your technical skills are above average (Having extraordinary skills is a different thing).
The overall interview itself will have 1 phone screen if you are interviewing in the US and 1–2 if outside US. The onsite loop will be 4 rounds , 2 of which are technical (again divided into OS and networking and the specific speciality of the team you are interviewing for ) and 2 of them are leadership principles where we test your soft skills and management skills as they are very important in this job. You need to have a strong view point, disagree if it seems valid to do so, empathy and be a team player while showing the ability to pull off things individually as well. These skills will be critical for cracking LP interviews.
You will NOT be asked to code or write queries as its not part of the job, so you can concentrate on the theoretical part of the subject and also your resume. We will grill you on topics mentioned on your resume to start with.
Traditional monolithic architectures are hard to scale: TRUE
Monolithic architecture is something that build from single piece of material, historically from rock. Monolith term normally use for object made from single large piece of material.” – Non-Technical Definition. “Monolithic application has single code base with multiple modules.
Large Monolithic code-base (often spaghetti code) puts immense cognitive complexity on the developer’s head. As a result, the development velocity is poor. Granular scaling (i.e., scaling part of the application) is not possible. Polyglot programming or polyglot database is challenging.
Drawbacks of Monolithic Architecture
This simple approach has a limitation in size and complexity. Application is too large and complex to fully understand and made changes fast and correctly. The size of the application can slow down the start-up time. You must redeploy the entire application on each update.
18. Sticky Sessions help increase your application’s scability: FALSE
Sticky sessions, also known as session affinity, allow you to route a site user to the particular web server that is managing that individual user’s session. The session’s validity can be determined by a number of methods, including a client-side cookies or via configurable duration parameters that can be set at the load balancer which routes requests to the web servers.
Some advantages with utilizing sticky sessions are that it’s cost effective due to the fact you are storing sessions on the same web servers running your applications and that retrieval of those sessions is generally fast because it eliminates network latency. A drawback for using storing sessions on an individual node is that in the event of a failure, you are likely to lose the sessions that were resident on the failed node. In addition, in the event the number of your web servers change, for example a scale-up scenario, it’s possible that the traffic may be unequally spread across the web servers as active sessions may exist on particular servers. If not mitigated properly, this can hinder the scalability of your applications. Read more here …
AWS recommends replicating across Availability Zones for resiliency: TRUE
If you need to replicate your data or applications in an AWS Local Zone, AWS recommends that you use one of the following zones as the failover zone:
Another Local Zone
An Availability Zone in the Region that is not the parent zone. You can use the describe-availability-zones command to view the parent zone.
For more information about AWS Regions and Availability Zones, see AWS Global Infrastructure.
What are the benefits of AWS Cloud Computing?
- Trade Capital expenses for variable expenses
- Increase speed and agility
- Benefit from massive economies at scale
- Stop spending money on running and maintaining data centers
- Stop guessing capacity
- Go global in minutes
What is the default behavior for an EC2 instance when terminated?
After you terminate an instance, it remains visible in the console for a short while, and then the entry is automatically deleted. You cannot delete the terminated instance entry yourself. After an instance is terminated, resources such as tags and volumes are gradually disassociated from the instance, therefore may no longer be visible on the terminated instance after a short while.
When an instance terminates, the data on any instance store volumes associated with that instance is deleted.
By default, Amazon EBS root device volumes are automatically deleted when the instance terminates. However, by default, any additional EBS volumes that you attach at launch, or any EBS volumes that you attach to an existing instance persist even after the instance terminates. This behavior is controlled by the volume’s DeleteOnTermination attribute, which you can modify
For more information, please visit: Terminate Your Instance
How do Amazon EC2 EBS burst credits work?
The documentation on General Purpose SSD (gp2) EBS volumes can be found at this page: New SSD-Backed Elastic Block Storage
When you first launch an instance with gp2 volumes attached, you get an initial burst credit allowing for up to 30 minutes of 3,000 iops/sec.
After the first 30 minutes, your volume will accrue credits as follows (taken directly from AWS documentation):
Within the General Purpose (SSD) implementation is a Token Bucket model that works as follows
- Each token represents an “I/O credit” that pays for one read or one write.
- A bucket is associated with each General Purpose (SSD) volume, and can hold up to 5.4 million tokens.
- Tokens accumulate at a rate of 3 per configured GB per second, up to the capacity of the bucket.
- Tokens can be spent at up to 3000 per second per volume.
- The baseline performance of the volume is equal to the rate at which tokens are accumulated — 3 IOPS per GB per second.
In addition to this, gp2 volumes provide baseline performance of 3 iops per Gb, up to 1Tb (3000 iops). Volumes larger than 1Tb no longer work on the credit system, as they already provide a baseline of 3000 iops. Gp2 volumes have a cap of 10,000 iops regardless of the volume size (so the iops max out for volumes larger than 3.3Tb)
Is elastic IP service free if we associate it with any VM (EC2 server)?
Elastic IP addresses are free when you have them assigned to an instance, feel free to use one! Elastic IPs get disassociated when you stop an instance, so you will get charged in the mean time. The benefit is that you get to keep that IP allocated to your account though, instead of losing it like any other. Once you start the instance you just re-associate it back and you have your old IP again.
Here are the changes associated with the use of Elastic IP addresses
No cost for Elastic IP addresses while in use
* $0.01 per non-attached Elastic IP address per complete hour
* $0.00 per Elastic IP address remap – first 100 remaps / month
* $0.10 per Elastic IP address remap – additional remap / month over 100
If you require any additional information about pricing please reference the link below
Amazon EC2 Pricing – Amazon Web Services
The other cost are as outlined in the paragraph you have quoted.
How do I reduce my AWS EC2 cost? My AWS EC2 expenditure comprises 80% of my AWS bill.
The short answer to reducing your AWS EC2 costs – turn off your instances when you don’t need them.
Your AWS bill is just like any other utility bill, you get charged for however much you used that month. Don’t make the mistake of leaving your instances on 24/7 if you’re only using them during certain days and times (ex. Monday – Friday, 9 to 5).
To automatically start and stop your instances, AWS offers an “EC2 scheduler” solution. A better option would be a cloud cost management tool that not only stops and starts your instances automatically, but also tracks your usage and makes sizing recommendations to optimize your cloud costs and maximize your time and savings.
You could potentially save money using Reserved Instances. But, in non-production environments such as dev, test, QA, and training, Reserved Instances are not your best bet. Why is this the case? These environments are less predictable; you may not know how many instances you need and when you will need them, so it’s better to not waste spend on these usage charges. Instead, schedule such instances (preferably using ParkMyCloud). Scheduling instances to be only up 12 hours per day on weekdays will save you 65% – better than all but the most restrictive 3-year RIs!
You can also save money with:
- Spot Instances
- AWS Dedicated Hosts & Dedicated Instances
- Auto Scaling Groups
- Rightsizing
What is the difference between an Instance, AMI and Snaphots in AWS? What are they used for?
Well AWS is a web service provider which offers a set of services related to compute, storage, database, network and more to help the business scale and grow
All your concerns are related to AWS EC2 instance, so let me start with an instance
Instance:
- An EC2 instance is similar to a server where you can host your websites or applications to make it available Globally
- It is highly scalable and works on the pay-as-you-go model
- You can increase or decrease the capacity of these instances as per the requirement
AMI:
- AMI provides the information required to launch the EC2 instance
- AMI includes the pre-configured templates of the operating system that runs on the AWS
- Users can launch multiple instances with the same configuration from a single AMI
Snapshot:
- Snapshots are the incremental backups for the Amazon EBS
- Data in the EBS are stored in S3 by taking point-to-time snapshots
- Unique data are only deleted when a snapshot is deleted
- Multiple EBS can be created using these snapshots
What are the main differences between a VPNs, VPS and VPC?
They are definitely all chalk and cheese to one another.
A VPN (Virtual Private Network) is essentially an encrypted “channel” connecting two networks, or a machine to a network, generally over the public internet.
A VPS (Virtual Private Server) is a rented virtual machine running on someone else’s hardware. AWS EC2 can be thought of as a VPS, but the term is usually used to describe low-cost products offered by lots of other hosting companies.
A VPC (Virtual Private Cloud) is a virtual network in AWS (Amazon Web Services). It can be divided into private and public subnets, have custom routing rules, have internal connections to other VPCs, etc. EC2 instances and other resources are placed in VPCs similarly to how physical data centers have operated for a very long time.
AWS CCP CLF-C01 on Android – AWS CCP CLF-C01 on iOS – AWS CCP CLF-C01 on Windows 10/11
What is the use of elastic IP in AWS?
Elastic IP address is basically the static IP (IPv4) address that you can allocate to your resources.
Now, in case that you allocate IP to the resource (and the resource is running), you are not charged anything. On the other hand, if you create Elastic IP, but you do not allocate it to the resource (or the resource is not running), then you are charged some amount (should be around $0.005 per hour if I remember correctly)
Additional info about these:
You are limited to 5 Elastic IP addresses per region. If you require more than that, you can contact AWS support with a request for additional addresses. You need to have a good reason in order to be approved because IPv4 addresses are becoming a scarce resource.
In general, you should be good without Elastic IPs for most of the use-cases (as every EC2 instance has its own public IP, and you can use load balancers, as well as map most of the resources via Route 53).
One of the use-cases that I’ve seen where my client is using Elastic IP is to make it easier for him to access specific EC2 instance via RDP, as well as do deployment through Visual Studio, as he targets the Elastic IP, and thus does not have to watch for any changes in public IP (in case of stopping or rebooting).
Why would you choose not to use AWS Transit Gateway instead of VPC peering?
At this time, AWS Transit Gateway does not support inter region attachments. The transit gateway and the attached VPCs must be in the same region. VPC peering supports inter region peering.
Difference between AWS Workspace and AWS Ec2 VM?
- The EC2 instance is server instance whilst a Workspace is windows desktop instance
Both Windows Server and Windows workstation editions have desktops. Windows Server Core doesn’t not (and AWS doesn’t have an AMI for Windows Server Core that I could find).
It is possible to SSH into a Windows instance – this is done on port 22. You would not see a desktop when using SSH if you had enabled it. It is not enabled by default.
If you are seeing a desktop, I believe you’re “RDPing” to the Windows instance. This is done with the RDP protocol on port 3389.
- Two different protocols and two different ports.
- Workspaces doesn’t allow terminal or ssh services by default. You need to use Workspace client. You still can enable RDP or/and SSH but this is not recommended.
- Workspaces is a managed desktop service. AWS is taking care of pre-build AMIs, software licenses, joining to domain, scaling etc.
- What is Amazon EC2? Scalable, pay-as-you-go compute capacity in the cloud. Amazon Elastic Compute Cloud (Amazon EC2) is a web service that provides resizable compute capacity in the cloud. It is designed to make web-scale computing easier for developers.
- What is Amazon WorkSpaces? Easily provision cloud-based desktops that allow end-users to access applications and resources. With a few clicks in the AWS Management Console, customers can provision a high-quality desktop experience for any number of users at a cost that is highly competitive with traditional desktops and half the cost of most virtual desktop infrastructure (VDI) solutions. End-users can access the documents, applications and resources they need with the device of their choice, including laptops, iPad, Kindle Fire, or Android tablets.
- Amazon EC2 can be classified as a tool in the “Cloud Hosting” category, while Amazon WorkSpaces is grouped under “Virtual Desktop”.
Some of the features offered by Amazon EC2 are:
- Elastic – Amazon EC2 enables you to increase or decrease capacity within minutes, not hours or days. You can commission one, hundreds or even thousands of server instances simultaneously.
- Completely Controlled – You have complete control of your instances. You have root access to each one, and you can interact with them as you would any machine.
- Flexible – You have the choice of multiple instance types, operating systems, and software packages. Amazon EC2 allows you to select a configuration of memory, CPU, instance storage, and the boot partition size that is optimal for your choice of operating system and application.
On the other hand, Amazon WorkSpaces provides the following key features:
- Support Multiple Devices- Users can access their Amazon WorkSpaces using their choice of device, such as a laptop computer (Mac OS or Windows), iPad, Kindle Fire, or Android tablet.
- Keep Your Data Secure and Available- Amazon WorkSpaces provides each user with access to persistent storage in the AWS cloud. When users access their desktops using Amazon WorkSpaces, you control whether your corporate data is stored on multiple client devices, helping you keep your data secure.
- Choose the Hardware and Software you need- Amazon WorkSpaces offers a choice of bundles providing different amounts of CPU, memory, and storage so you can match your Amazon WorkSpaces to your requirements. Amazon WorkSpaces offers preinstalled applications (including Microsoft Office) or you can bring your own licensed software.
Amazon EBS vs Amazon EFS
An Amazon EBS volume stores data in a single Availability Zone.
To attach an Amazon EC2 instance to an EBS volume, both the Amazon EC2 instance and the EBS volume must reside within the same Availability Zone.
Amazon EFS is a regional service. It stores data in and across multiple Availability Zones.
The duplicate storage enables you to access data concurrently from all the Availability Zones in the Region where a file system is located. Additionally, on-premises servers can access Amazon EFS using AWS Direct Connect.
AWS CCP CLF-C01 on Android – AWS CCP CLF-C01 on iOS – AWS CCP CLF-C01 on Windows 10/11
AWS Services Cheat Sheet:
Compute
| Category | Service | Description |
| Instances (Virtual machines) | EC2 | Provides secure, resizable compute capacity in the cloud. It makes web-scale cloud computing easier for developers. EC2 |
| EC2 Spot | Run fault-tolerant workloads for up to 90% off. EC2Spot | |
| EC2 Autoscaling | Automatically add or remove compute capacity to meet changes in demand. EC2_AustoScaling | |
| Lightsail | Designed to be the easiest way to launch & manage a virtual private server with AWS. An easy-to-use cloud platform that offers everything need to build an application or website. Lightsail | |
| Batch | Enables developers, scientists, & engineers to easily & efficiently run hundreds of thousands of batch computing jobs on AWS. Fully managed batch processing at any scale. Batch | |
| Containers | Elastic Container Service (ECS) | Highly secure, reliable, & scalable way to run containers. ECS |
| Elastic Container Registry (ECR) | Easily store, manage, & deploy container images. ECR | |
| Elastic Kubernetes Service (EKS) | Fully managed Kubernetes service. EKS | |
| Fargate | Serverless compute for containers. Fargate | |
| Serverless | Lambda | Run code without thinking about servers. Pay only for the compute time you consume. Lamda |
| Edge and hybrid | Outposts | Run AWS infrastructure & services on premises for a truly consistent hybrid experience. Outposts |
| Snow Family | Collect and process data in rugged or disconnected edge environments. SnowFamily | |
| Wavelength | Deliver ultra-low latency application for 5G devices. Wavelenth | |
| VMware Cloud on AWS | Innovate faster, rapidly transition to the cloud, & work securely from any location. VMware_On_AWS | |
| Local Zones | Run latency sensitive applications closer to end-users. LocalZones |
Networking and Content Delivery
| Use cases | Functionality | Service | Description |
| Build a cloud network | Define and provision a logically isolated network for your AWS resources | VPC | VPC lets you provision a logically isolated section of the AWS Cloud where you can launch AWS resources in a virtual network that you define. VPC |
| Connect VPCs and on-premises networks through a central hub | Transit Gateway | Transit Gateway connects VPCs & on-premises networks through a central hub. This simplifies network & puts an end to complex peering relationships. TransitGateway | |
| Provide private connectivity between VPCs, services, and on-premises applications | PrivateLink | PrivateLink provides private connectivity between VPCs & services hosted on AWS or on-premises, securely on the Amazon network. PrivateLink | |
| Route users to Internet applications with a managed DNS service | Route 53 | Route 53 is a highly available & scalable cloud DNS web service. Route53 | |
| Scale your network design | Automatically distribute traffic across a pool of resources, such as instances, containers, IP addresses, and Lambda functions | Elastic Load Balancing | Elastic Load Balancing automatically distributes incoming application traffic across multiple targets, such as EC2’s, containers, IP addresses, & Lambda functions. ElasticLoadBalancing |
| Direct traffic through the AWS Global network to improve global application performance | Global Accelerator | Global Accelerator is a networking service that sends user’s traffic through AWS’s global network infrastructure, improving internet user performance by up to 60%. GlobalAccelerator | |
| Secure your network traffic | Safeguard applications running on AWS against DDoS attacks | Shield | Shield is a managed Distributed Denial of Service (DDoS) protection service that safeguards applications running on AWS. Shield |
| Protect your web applications from common web exploits | WAF | WAF is a web application firewall that helps protect your web applications or APIs against common web exploits that may affect availability, compromise security, or consume excessive resources. WAF | |
| Centrally configure and manage firewall rules | Firewall Manager | Firewall Manager is a security management service which allows to centrally configure & manage firewall rules across accounts & apps in AWS Organization. link text | |
| Build a hybrid IT network | Connect your users to AWS or on-premises resources using a Virtual Private Network | (VPN) – Client | VPN solutions establish secure connections between on-premises networks, remote offices, client devices, & the AWS global network. VPN |
| Create an encrypted connection between your network and your Amazon VPCs or AWS Transit Gateways | (VPN) – Site to Site | Site-to-Site VPN creates a secure connection between data center or branch office & AWS cloud resources. site_to_site | |
| Establish a private, dedicated connection between AWS and your datacenter, office, or colocation environment | Direct Connect | Direct Connect is a cloud service solution that makes it easy to establish a dedicated network connection from your premises to AWS. DirectConnect | |
| Content delivery networks | Securely deliver data, videos, applications, and APIs to customers globally with low latency, and high transfer speeds | CloudFront | CloudFront expedites distribution of static & dynamic web content. CloudFront |
| Build a network for microservices architectures | Provide application-level networking for containers and microservices | App Mesh | App Mesh makes it accessible to guide & control microservices operating on AWS. AppMesh |
| Create, maintain, and secure APIs at any scale | API Gateway | API Gateway allows the user to design & expand their own REST and WebSocket APIs at any scale. APIGateway | |
| Discover AWS services connected to your applications | Cloud Map | Cloud Map permits the name & handles the cloud resources. CloudMap |
AWS CCP CLF-C01 on Android – AWS CCP CLF-C01 on iOS – AWS CCP CLF-C01 on Windows 10/11
Storage
| Service | Description |
| AWS S3 | S3 is the storehouse for the internet i.e. object storage built to store & retrieve any amount of data from anywhere S3 |
| AWS Backup | AWS Backup is an externally-accessible backup provider that makes it easier to align & optimize the backup of data across AWS services in the cloud. AWS_Backup |
| Amazon EBS | Amazon Elastic Block Store is a web service that provides block-level storage volumes. EBS |
| Amazon EFS Storage | EFS offers file storage for the user’s Amazon EC2 instances. It’s kind of blob Storage. EFS |
| Amazon FSx | FSx supply fully managed 3rd-party file systems with the native compatibility & characteristic sets for workloads. It’s available as FSx for Windows server (Fully managed file storage built on Windows Server) & Lustre (Fully managed high-performance file system integrated with S3). FSx_Windows FSx_Lustre |
| AWS Storage Gateway | Storage Gateway is a service which connects an on-premises software appliance with cloud-based storage. Storage_Gateway |
| AWS DataSync | DataSync makes it simple & fast to move large amounts of data online between on-premises storage & S3, EFS, or FSx for Windows File Server. DataSync |
| AWS Transfer Family | The Transfer Family provides fully managed support for file transfers directly into & out of S3. Transfer_Family |
| AWS Snow Family | Highly-secure, portable devices to collect & process data at the edge, and migrate data into and out of AWS. Snow_Family |
Classification:
Object storage: S3
File storage services: Elastic File System, FSx for Windows Servers & FSx for Lustre
Block storage: EBS
Backup: AWS Backup
Data transfer:
Storage gateway –> 3 types: Tape, File, Volume.
Transfer Family –> SFTP, FTPS, FTP.
Edge computing and storage and Snow Family –> Snowcone, Snowball, Snowmobile
Databases
| Database type | Use cases | Service | Description |
| Relational | Traditional applications, ERP, CRM, e-commerce | Aurora, RDS, Redshift | RDS is a web service that makes it easier to set up, control, and scale a relational database in the cloud. Aurora RDS Redshift |
| Key-value | High-traffic web apps, e-commerce systems, gaming applications | DynamoDB | DynamoDB is a fully administered NoSQL database service that offers quick and reliable performance with integrated scalability. DynamoDB |
| In-memory | Caching, session management, gaming leaderboards, geospatial applications | ElastiCache for Memcached & Redis | ElastiCache helps in setting up, managing, and scaling in-memory cache conditions. Memcached Redis |
| Document | Content management, catalogs, user profiles | DocumentDB | DocumentDB (with MongoDB compatibility) is a quick, dependable, and fully-managed database service that makes it easy for you to set up, operate, and scale MongoDB-compatible databases.DocumentDB |
| Wide column | High scale industrial apps for equipment maintenance, fleet management, and route optimization | Keyspaces (for Apache Cassandra) | Keyspaces is a scalable, highly available, and managed Apache Cassandra–compatible database service. Keyspaces |
| Graph | Fraud detection, social networking, recommendation engines | Neptune | Neptune is a fast, reliable, fully managed graph database service that makes it easy to build and run applications that work with highly connected datasets. Neptune |
| Time series | IoT applications, DevOps, industrial telemetry | Timestream | Timestream is a fast, scalable, and serverless time series database service for IoT and operational applications that makes it easy to store and analyze trillions of events per day. Timestream |
| Ledger | Systems of record, supply chain, registrations, banking transactions | Quantum Ledger Database (QLDB) | QLDB is a fully managed ledger database that provides a transparent, immutable, and cryptographically verifiable transaction log owned by a central trusted authority. QLDB |
Developer Tools
| Service | Description |
| Cloud9 | Cloud9 is a cloud-based IDE that enables the user to write, run, and debug code. Cloud9 |
| CodeArtifact | CodeArtifact is a fully managed artifact repository service that makes it easy for organizations of any size to securely store, publish, & share software packages used in their software development process. CodeArtifact |
| CodeBuild | CodeBuild is a fully managed service that assembles source code, runs unit tests, & also generates artefacts ready to deploy. CodeBuild |
| CodeGuru | CodeGuru is a developer tool powered by machine learning that provides intelligent recommendations for improving code quality & identifying an application’s most expensive lines of code. CodeGuru |
| Cloud Development Kit | Cloud Development Kit (AWS CDK) is an open source software development framework to define cloud application resources using familiar programming languages. CDK |
| CodeCommit | CodeCommit is a version control service that enables the user to personally store & manage Git archives in the AWS cloud. CodeCommit |
| CodeDeploy | CodeDeploy is a fully managed deployment service that automates software deployments to a variety of compute services such as EC2, Fargate, Lambda, & on-premises servers. CodeDeploy |
| CodePipeline | CodePipeline is a fully managed continuous delivery service that helps automate release pipelines for fast & reliable app & infra updates. CodePipeline |
| CodeStar | CodeStar enables to quickly develop, build, & deploy applications on AWS. CodeStar |
| CLI | AWS CLI is a unified tool to manage AWS services & control multiple services from the command line & automate them through scripts. CLI |
| X-Ray | X-Ray helps developers analyze & debug production, distributed applications, such as those built using a microservices architecture. X-Ray |
Migration & Transfer services
| Service | Description |
| Migration Evaluator | Build a data-driven business case for AWS. ME |
| Migration Hub | Migration Hub provides a single location to track the progress of app migrations across multiple AWS & partner solutions. MigrationHub |
| Application Discovery Service | Application Discovery Service helps enterprise customers plan migration projects by gathering information about their on-premises data centers. ADS |
| Server Migration Service (SMS) | SMS is an agentless service which makes it easier & faster to migrate thousands of on-premises workloads to AWS. SMS |
| Database Migration Service (DMS) | DMS helps migrate databases to AWS quickly & securely. DMS |
| CloudEndure Migration | CloudEndure Migration simplifies, expedites, & reduces the cost of cloud migration by offering a highly automated lift-&-shift solution. CloudEndure |
| VMware Cloud on AWS | Refer compute section. |
| DataSync | Refer storage section. |
| Transfer Family | Refer storage section. |
| Snow Family | Refer storage section. |
AWS CCP CLF-C01 on Android – AWS CCP CLF-C01 on iOS – AWS CCP CLF-C01 on Windows 10/11
SDKs & Toolkits
| Service | Description |
| CDK | CDK uses the familiarity & expressive power of programming languages for modeling apps. CDK |
| Corretto | Corretto is a no-cost, multiplatform, production-ready distribution of the OpenJDK. Corretto |
| Crypto Tools | Cryptography is hard to do safely & correctly. The AWS Crypto Tools libraries are designed to help everyone do cryptography right, even without special expertise. Crypto Tools |
| Serverless Application Model (SAM) | SAM is an open-source framework for building serverless applications. It provides shorthand syntax to express functions, APIs, databases, & event source mappings. SAM |
| Tools for developing and managing applications on AWS |
Security, Identity, & Compliance
| Category | Use cases | Service | Description |
| Identity & access management | Securely manage access to services and resources | Identity & Access Management (IAM) | IAM is a web service for safely controlling access to AWS services. IAM |
| Securely manage access to services and resources | Single Sign-On | SSO helps in simplifying, managing SSO access to AWS accounts & business applications. SSO | |
| Identity management for apps | Cognito | Cognito lets you add user sign-up, sign-in, & access control to web & mobile apps quickly and easily. Cognito | |
| Managed Microsoft Active Directory | Directory Service | AWS Managed Microsoft Active Directory (AD) enables your directory-aware workloads & AWS resources to use managed Active Directory (AD) in AWS. DirectoryService | |
| Simple, secure service to share AWS resources | Resource Access Manager | Resource Access Manager (RAM) is a service that enables you to easily & securely share AWS resources with any AWS account or within AWS Organization. RAM | |
| Central governance and management across AWS accounts | Organizations | Organizations helps you centrally govern your environment as you grow and scale your workloads on AWS. Orgs | |
| Detection | Unified security and compliance center | Security Hub | Security Hub gives a comprehensive view of security alerts & security posture across AWS accounts. SecurityHub |
| Managed threat detection service | GuardDuty | GuardDuty is a threat detection service that continuously monitors for malicious activity & unauthorized behavior to protect AWS accounts, workloads, & data stored in S3. GuardDuty | |
| Analyze application security | Inspector | Inspector is a security vulnerability assessment service improves the security & compliance of the AWS resources. Inspector | |
| Record and evaluate configurations of your AWS resources | Config | Config is a service that enables to assess, audit, & evaluate the configurations of AWS resources. Config | |
| Track user activity and API usage | CloudTrail | CloudTrail is a service that enables governance, compliance, operational auditing, & risk auditing of AWS account. CloudTrail | |
| Security management for IoT devices | IoT Device Defender | IoT Device Defender is a fully managed service that helps secure fleet of IoT devices. IoTDD | |
| Infrastructure protection | DDoS protection | Shield | Shield is a managed DDoS protection service that safeguards apps running. It provides always-on detection & automatic inline mitigations that minimize application downtime & latency. Shield |
| Filter malicious web traffic | Web Application Firewall (WAF) | WAF is a web application firewall that helps protect web apps or APIs against common web exploits that may affect availability, compromise security, or consume excessive resources. WAF | |
| Central management of firewall rules | Firewall Manager | Firewall Manager eases the user AWS WAF administration & maintenance activities over multiple accounts & resources. FirewallManager | |
| Data protection | Discover and protect your sensitive data at scale | Macie | Macie is a fully managed data (security & privacy) service that uses ML & pattern matching to discover & protect sensitive data. Macie |
| Key storage and management | Key Management Service (KMS) | KMS makes it easy for to create & manage cryptographic keys & control their use across a wide range of AWS services & in your applications. KMS | |
| Hardware based key storage for regulatory compliance | CloudHSM | CloudHSM is a cloud-based hardware security module (HSM) that enables you to easily generate & use your own encryption keys. CloudHSM | |
| Provision, manage, and deploy public and private SSL/TLS certificates | Certificate Manager | Certificate Manager is a service that easily provision, manage, & deploy public and private SSL/TLS certs for use with AWS services & internal connected resources. ACM | |
| Rotate, manage, and retrieve secrets | Secrets Manager | Secrets Manager assist the user to safely encode, store, & recover credentials for any user’s database & other services. SecretsManager | |
| Incident response | Investigate potential security issues | Detective | Detective makes it easy to analyze, investigate, & quickly identify the root cause of potential security issues or suspicious activities. Detective |
| Fast, automated, cost- effective disaster recovery | CloudEndure Disaster Recovery | Provides scalable, cost-effective business continuity for physical, virtual, & cloud servers. CloudEndure | |
| Compliance | No cost, self-service portal for on-demand access to AWS’ compliance reports | Artifact | Artifact is a web service that enables the user to download AWS security & compliance records. Artifact |
Data Lakes & Analytics
| Category | Use cases | Service | Description |
| Analytics | Interactive analytics | Athena | Athena is an interactive query service that makes it easy to analyze data in S3 using standard SQL. Athena |
| Big data processing | EMR | EMR is the industry-leading cloud big data platform for processing vast amounts of data using open source tools such as Apache Spark, Hive, HBase,Flink, Hudi, & Presto. EMR | |
| Data warehousing | Redshift | The most popular & fastest cloud data warehouse. Redshift | |
| Real-time analytics | Kinesis | Kinesis makes it easy to collect, process, & analyze real-time, streaming data so one can get timely insights. Kinesis | |
| Operational analytics | Elasticsearch Service | Elasticsearch Service is a fully managed service that makes it easy to deploy, secure, & run Elasticsearch cost effectively at scale. ES | |
| Dashboards & visualizations | Quicksight | QuickSight is a fast, cloud-powered business intelligence service that makes it easy to deliver insights to everyone in organization. QuickSight | |
| Data movement | Real-time data movement | 1) Amazon Managed Streaming for Apache Kafka (MSK) 2) Kinesis Data Streams 3) Kinesis Data Firehose 4) Kinesis Data Analytics 5) Kinesis Video Streams 6) Glue | MSK is a fully managed service that makes it easy to build & run applications that use Apache Kafka to process streaming data. MSK KDS KDF KDA KVS Glue |
| Data lake | Object storage | 1) S3 2) Lake Formation | Lake Formation is a service that makes it easy to set up a secure data lake in days. A data lake is a centralized, curated, & secured repository that stores all data, both in its original form & prepared for analysis. S3 LakeFormation |
| Backup & archive | 1) S3 Glacier 2) Backup | S3 Glacier & S3 Glacier Deep Archive are a secure, durable, & extremely low-cost S3 cloud storage classes for data archiving & long-term backup. S3Glacier | |
| Data catalog | 1) Glue 2)) Lake Formation | Refer as above. | |
| Third-party data | Data Exchange | Data Exchange makes it easy to find, subscribe to, & use third-party data in the cloud. DataExchange | |
| Predictive analytics && machine learning | Frameworks & interfaces | Deep Learning AMIs | Deep Learning AMIs provide machine learning practitioners & researchers with the infrastructure & tools to accelerate deep learning in the cloud, at any scale. DeepLearningAMIs |
| Platform services | SageMaker | SageMaker is a fully managed service that provides every developer & data scientist with the ability to build, train, & deploy machine learning (ML) models quickly. SageMaker |
Containers
| Use cases | Service | Description |
| Store, encrypt, and manage container images | ECR | Refer compute section |
| Run containerized applications or build microservices | ECS | Refer compute section |
| Manage containers with Kubernetes | EKS | Refer compute section |
| Run containers without managing servers | Fargate | Fargate is a serverless compute engine for containers that works with both ECS & EKS. Fargate |
| Run containers with server-level control | EC2 | Refer compute section |
| Containerize and migrate existing applications | App2Container | App2Container (A2C) is a command-line tool for modernizing .NET & Java applications into containerized applications. App2Container |
| Quickly launch and manage containerized applications | Copilot | Copilot is a command line interface (CLI) that enables customers to quickly launch & easily manage containerized applications on AWS. Copilot |
Serverless
| Category | Service | Description |
| Compute | Lambda | Lambda lets you run code without provisioning or managing servers. You pay only for the compute time you consume. |
| Lambda@Edge | Lambda@Edge is a feature of Amazon CloudFront that lets you run code closer to users of your application, which improves performance & reduces latency. | |
| Fargate | Refer containers section | |
| Storage | S3 | Refer storage section |
| EFS | Refer storage section | |
| Data stores | DynamoDB | DynamoDB is a key-value & document database that delivers single-digit millisecond performance at any scale. |
| Aurora Serverless | Aurora Serverless is an on-demand, auto-scaling configuration for Amazon Aurora (MySQL & PostgreSQL-compatible editions), where the database will automatically start up, shut down, & scale capacity up or down based on your application’s needs. | |
| RDS Proxy | RDS Proxy is a fully managed, highly available database proxy for RDS that makes applications more scalable, resilient to database failures, & more secure. | |
| API Proxy | API Gateway | API Gateway is a fully managed service that makes it easy for developers to create, publish, maintain, monitor, & secure APIs at any scale. |
| Application integration | SNS | SNS is a fully managed messaging service for both system-to-system & app-to-person (A2P) communication. |
| SQS | SQS is a fully managed message queuing service that enables to decouple & scale microservices, distributed systems, & serverless applications. | |
| AppSync | AppSync is a fully managed service that makes it easy to develop GraphQL APIs by handling the heavy lifting of securely connecting to data sources like AWS DynamoDB, Lambda. | |
| EventBridge | EventBridge is a serverless event bus that makes it easy to connect applications together using data from apps, integrated SaaS apps, & AWS services. | |
| Orchestration | Step Functions | Step Functions is a serverless function orchestrator that makes it easy to sequence Lambda functions & multiple AWS services into business-critical applications. |
| Analytics | Kinesis | Kinesis makes it easy to collect, process, & analyze real-time, streaming data so one can get timely insights. |
| Athena | Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. |
AWS CCP CLF-C01 on Android – AWS CCP CLF-C01 on iOS – AWS CCP CLF-C01 on Windows 10/11
Application Integration
| Category | Service | Description |
| Messaging | SNS | Reliable high throughput pub/sub, SMS, email, and mobile push notifications |
| SQS | Message queue that sends, stores, and receives messages between application components at any volume | |
| MQ | Message broker for Apache ActiveMQ that makes migration easy and enables hybrid architectures | |
| Workflows | Step Functions | Coordinate multiple AWS services into serverless workflows so you can build and update apps quickly |
| API management | API Gateway | Create, publish, maintain, monitor, & secure APIs at any scale for serverless workloads & web apps |
| AppSync | Create a flexible API to securely access, manipulate, & combine data from one or more data sources | |
| Event bus | EventBridge | Build an event-driven architecture that connects application data from your own apps, SaaS, & AWS services |
| AppFlow | Automate the flow of data between SaaS applications & AWS services at nearly any scale, without code. |
AWS CCP CLF-C01 on Android – AWS CCP CLF-C01 on iOS – AWS CCP CLF-C01 on Windows 10/11
Management & Governance Services
| Category | Service | Description |
| Enable | Control Tower | The easiest way to set up and govern a new, secure multi-account AWS environment. ControlTower |
| Organizations | Organizations helps centrally govern environment as you grow & scale workloads on AWS Organizations | |
| Well-Architected Tool | Well-Architected Tool helps review the state of workloads & compares them to the latest AWS architectural best practices. WATool | |
| Budgets | Budgets allows to set custom budgets to track cost & usage from the simplest to the most complex use cases. Budgets | |
| License Manager | License Manager makes it easier to manage software licenses from software vendors such as Microsoft, SAP, Oracle, & IBM across AWS & on-premises environments. LicenseManager | |
| Provision | CloudFormation | CloudFormation enables the user to design & provision AWS infrastructure deployments predictably & repeatedly. CloudFormation |
| Service Catalog | Service Catalog allows organizations to create & manage catalogs of IT services that are approved for use on AWS. ServiceCatalog | |
| OpsWorks | OpsWorks presents a simple and flexible way to create and maintain stacks and applications. OpsWorks | |
| Marketplace | Marketplace is a digital catalog with thousands of software listings from independent software vendors that make it easy to find, test, buy, & deploy software that runs on AWS. Marketplace | |
| Operate | CloudWatch | CloudWatch offers a reliable, scalable, & flexible monitoring solution that can easily start. CloudWatch |
| CloudTrail | CloudTrail is a service that enables governance, compliance, operational auditing, & risk auditing of AWS account. CloudTrail | |
| Config | Config | |
| Systems Manager | Systems Manager to plan, proctor, & automate administration tasks on the AWS resources. SystemsManager | |
| Cost & usage report | Refer cost management section | |
| Cost explorer | Refer cost management section | |
| Managed Services | Operate your AWS infrastructure on your behalf. ManagedServices | |
| X Ray | X-Ray |
AWS CCP CLF-C01 on Android – AWS CCP CLF-C01 on iOS – AWS CCP CLF-C01 on Windows 10/11
AWS Recommended security best practices
| Turn on multifactor authentication for the “root” account |
| Turn on CloudTrail log file validation. |
| Enable CloudTrail multi-region logging. |
| Integrate CloudTrail with CloudWatch. |
| Enable access logging for CloudTrail S3 buckets. |
| Enable access logging for Elastic Load Balancer (ELB). |
| Enable Redshift audit logging. |
| Enable Virtual Private Cloud (VPC) flow logging. |
| Require multifactor authentication (MFA) to delete CloudTrail buckets |
| Enable CloudTrail logging across all AWS. |
| Turn on multi-factor authentication for IAM users. |
| Enable IAM users for multi-mode access. |
| Attach IAM policies to groups or roles |
| Rotate IAM access keys regularly, and standardize on the selected number of days |
| Set up a strict password policy. |
| Set the password expiration period to 90 days and prevent reuseCustomer Visualforce pages with standard headers |
| Don’t use expired SSL/TLS certificates |
| User HTTPS for CloudFront distributions |
| Restrict access to CloudTrail bucket. |
| Encrypt CloudTrail log files at rest |
| Encrypt Elastic Block Store (EBS) database. |
| Provision access to resources using IAM roles. |
| Ensure EC2 security groups don’t have large ranges of ports open |
| Configure EC2 security groups to restrict inbound access to EC2. |
| Avoid using root user accounts. |
| Use secure SSL ciphers when connecting between the client and ELB. |
| Use secure SSL versions when connecting between client and ELB. |
| Use a standard naming (tagging) convention for EC2. |
| Encrypt RDS. |
| Ensure access keys are not being used with root accounts. |
| Use secure CloudFront SSL versions. |
| Enable the require_ssl parameter in all Redshift clusters. |
| Rotate SSH keys periodically. |
| Minimize the number of discrete security groups. |
| Reduce number of IAM groups. |
| Terminate unused access keys |
| Disable access for inactive or unused IAM users |
| Remove unused IAM access keys |
| Delete unused SSH Public Keys |
| Restrict access to AMIs. |
| Restrict access to EC2 security groups. |
| Restrict access to RDS instances. |
| Restrict access to Redshift clusters. |
| Restrict outbound access. |
| Disallow unrestricted ingress access on uncommon ports. |
| Restrict access to well-known ports such as CIFS, FTP, ICMP, SMTP, SSH, Remote desktop |
| Inventory & categorize all existing custom apps by the types of data stored, compliance requirements & possible threats they face. |
| Involve IT security throughout the development process. |
| Grant the fewest privileges as possible for application users |
| Enforce a single set of data loss prevention policies across custom applications and all other cloud services. |
| Encrypt highly sensitive data such as protected health information (PHI) or personally identifiable information (PII). |
AWS RE:INVENT 2021 – LATEST PRODUCTS AND SERVICES ANNOUNCED:
1- Read For Me
Read For Me launched at the 2021 AWS re:Invent Builders’ Fair in Las Vegas. A web application which helps the visually impaired ‘hear documents. With the help of AI services such as Amazon Textract, Amazon Comprehend, Amazon Translate and Amazon Polly utilizing an event-driven architecture and serverless technology, users upload a picture of a document, or anything with text, and within a few seconds “hear” that document in their chosen language.

2- Delivering code and architectures through AWS Proton and Git
Infrastructure operators are looking for ways to centrally define and manage the architecture of their services, while developers need to find a way to quickly and safely deploy their code. In this session, learn how to use AWS Proton to define architectural templates and make them available to development teams in a collaborative manner. Also, learn how to enable development teams to customize their templates so that they fit the needs of their services.
3- Accelerate front-end web and mobile development with AWS Amplify
User-facing web and mobile applications are the primary touchpoint between organizations and their customers. To meet the ever-rising bar for customer experience, developers must deliver high-quality apps with both foundational and differentiating features. AWS Amplify helps front-end web and mobile developers build faster front to back. In this session, review Amplify’s core capabilities like authentication, data, and file storage and explore new capabilities, such as Amplify Geo and extensibility features for easier app customization with AWS services and better integration with existing deployment pipelines. Also learn how customers have been successful using Amplify to innovate in their businesses.
3- Train ML models at scale with Amazon SageMaker, featuring Aurora
Today, AWS customers use Amazon SageMaker to train and tune millions of machine learning (ML) models with billions of parameters. In this session, learn about advanced SageMaker capabilities that can help you manage large-scale model training and tuning, such as distributed training, automatic model tuning, optimizations for deep learning algorithms, debugging, profiling, and model checkpointing, so that even the largest ML models can be trained in record time for the lowest cost. Then, hear from Aurora, a self-driving vehicle technology company, on how they use SageMaker training capabilities to train large perception models for autonomous driving using massive amounts of images, video, and 3D point cloud data.
AWS RE:INVENT 2020 – LATEST PRODUCTS AND SERVICES ANNOUNCED:
1-Modernize log analytics with Amazon Elasticsearch Service
4- Amazon Location Service: Enable apps with location features
5- Automate, track, and manage tasks with Amazon Connect Tasks
6- Solve customer issues quickly with Amazon Connect Wisdom
7- Introducing Amazon Managed Service for Grafana:
Prometheus is a popular open-source monitoring and alerting solution optimized for container environments. Customers love Prometheus for its active open-source community and flexible query language, using it to monitor containers across AWS and on-premises environments. Amazon Managed Service for Prometheus is a fully managed Prometheus-compatible monitoring service. In this session, learn how you can use the same open-source Prometheus data model, existing instrumentation, and query language to monitor performance with improved scalability, availability, and security without having to manage the underlying infrastructure.
AWS CloudShell is a free, browser-based shell available from the AWS console that provides a simple way to interact with AWS resources through the AWS command-line interface (CLI). In this session, see an overview of both AWS CloudShell and the AWS CLI, which when used together are the fastest and easiest ways to automate tasks, write scripts, and explore new AWS services. Also, see a demo of both services and how to quickly and easily get started with each.
12-AWS Fault Injection Simulator: Fully managed chaos engineering service
Increase availability with AWS observability solutions
To provide access to critical resources when needed and also limit the potential financial impact of an application outage, a highly available application design is critical. In this session, learn how you can use Amazon CloudWatch and AWS X-Ray to increase the availability of your applications. Join this session to learn how AWS observability solutions can help you proactively detect, efficiently investigate, and quickly resolve operational issues. All of which help you manage and improve your application’s availability.
AWS CCP CLF-C01 on Android – AWS CCP CLF-C01 on iOS – AWS CCP CLF-C01 on Windows 10/11
Securing your Amazon EKS applications: Best practices
Security is critical for your Kubernetes-based applications. Join this session to learn about the security features and best practices for Amazon EKS. This session covers encryption and other configurations and policies to keep your containers safe.
Join Dr. Werner Vogels at 8:00AM (PST) as he goes behind the scenes to show how Amazon is solving today’s hardest technology problems. Based on his experience working with some of the largest and most successful applications in the world, Dr. Vogels shares his insights on building truly resilient architectures and what that means for the future of software development.
Containers
Getting an insight into your Kubernetes applications
Do you need to know what’s happening with your applications that run on Amazon EKS? In this session, learn how you can combine open-source tools, such as Prometheus and Grafana, with Amazon CloudWatch using CloudWatch Container Insights. Come to this session for a demo of Prometheus metrics with Container Insights.
AWS Copilot: Simplifying container development
The hard part is done. You and your team have spent weeks poring over pull requests, building microservices and containerizing them. Congrats! But what do you do now? How do you get those services on AWS? How do you manage multiple environments? How do you automate deployments? AWS Copilot is a new command line tool that makes building, developing, and operating containerized applications on AWS a breeze. In this session, learn how AWS Copilot can help you and your team manage your services and deploy them to production, safely and delightfully.
Securing your Amazon EKS applications: Best practices
Security is critical for your Kubernetes-based applications. Join this session to learn about the security features and best practices for Amazon EKS. This session covers encryption and other configurations and policies to keep your containers safe.
GitOps compliant: How CommBank multiplied Amazon EKS clusters
In this session, learn how the Commonwealth Bank of Australia (CommBank) built a platform to run containerized applications in a regulated environment and then replicated it across multiple departments using Amazon EKS, AWS CDK, and GitOps. This session covers how to manage multiple multi-team Amazon EKS clusters across multiple AWS accounts while ensuring compliance and observability requirements and integrating Amazon EKS with AWS Identity and Access Management, Amazon CloudWatch, AWS Secrets Manager, Application Load Balancer, Amazon Route 53, and AWS Certificate Manager.
Getting up and running with Amazon EKS
Amazon EKS is a fully managed service that makes it easy to deploy, manage, and scale containerized applications using Kubernetes on AWS. Join this session to learn about how Verizon runs its core applications on Amazon EKS at scale. Verizon also discusses how it worked with AWS to overcome several post-Amazon EKS migration challenges and ensured that the platform was robust.
Developing CI/CD pipelines with Amazon ECS and AWS Fargate
Containers have helped revolutionize modern application architecture. While managed container services have enabled greater agility in application development, coordinating safe deployments and maintainable infrastructure has become more important than ever. This session outlines how to integrate CI/CD best practices into deployments of your Amazon ECS and AWS Fargate services using pipelines and the latest in AWS developer tooling.
Securing your Amazon ECS applications: Best practices
With Amazon ECS, you can run your containerized workloads securely and with ease. In this session, learn how to utilize the full spectrum of Amazon ECS security features and its tight integrations with AWS security features to help you build highly secure applications.
Optimize costs and manage spend for containerized applications
Do you have to budget your spend for container workloads? Do you need to be able to optimize your spend in multiple services to reduce waste? If so, this session is for you. It walks you through how you can use AWS services and configurations to improve your cost visibility. You learn how you can select the best compute options for your containers to maximize utilization and reduce duplication. This combined with various AWS purchase options helps you ensure that you’re using the best options for your services and your budget.
AWS Fargate: Are serverless containers right for you?
You have a choice of approach when it comes to provisioning compute for your containers. Some users prefer to have more direct control of their instances, while others could do away with the operational heavy lifting. AWS Fargate removes the need to provision and manage servers, lets you specify and pay for resources per application, and improves security through application isolation by design. This session explores the benefits and considerations of running on Fargate or directly on Amazon EC2 instances. You hear about new and upcoming features and learn how Amenity Analytics benefits from the serverless operational model.
Containers at AWS: More options and power than ever before
Are you confused by the many choices of containers services that you can run on AWS? This session explores all your options and the advantages of each. Whether you are just beginning to learn Docker or are an expert with Kubernetes, join this session to learn how to pick the right services that would work best for you.
AWS CCP CLF-C01 on Android – AWS CCP CLF-C01 on iOS – AWS CCP CLF-C01 on Windows 10/11
Modernizing with containers
Leading containers migration and modernization initiatives can be daunting, but AWS is making it easier. This session explores architectural choices and common patterns, and it provides real-world customer examples. Learn about core technologies to help you build and operate container environments at scale. Discover how abstractions can reduce the pain for infrastructure teams, operators, and developers. Finally, hear the AWS vision for how to bring it all together with improved usability for more business agility.
Improving observability with AWS App Mesh and Amazon ECS
As the number of services grow within an application, it becomes difficult to pinpoint the exact location of errors, reroute traffic after failures, and safely deploy code changes. In this session, learn how to integrate AWS App Mesh with Amazon ECS to export monitoring data and implement consistent communications control logic across your application. This makes it easy to quickly pinpoint the exact locations of errors and automatically reroute network traffic, keeping your container applications highly available and performing well.
Best practices for containerizing legacy applications
Enterprises are continually looking to develop new applications using container technologies and leveraging modern CI/CD tools to automate their software delivery lifecycles. This session highlights the types of applications and associated factors that make a candidate suitable to be containerized. It also covers best practices that can be considered as you embark on your modernization journey.
Looking at Amazon EKS through a networking lens
Because of its security, reliability, and scalability capabilities, Amazon Elastic Kubernetes Service (Amazon EKS) is used by organization in their most sensitive and mission-critical applications. This session focuses on how Amazon EKS networking works with an Amazon VPC and how to expose your Kubernetes application using Elastic Load Balancing load balancers. It also looks at options for more efficient IP address utilization.
AWS networking best practices in large-scale migrations
Network design is a critical component in your large-scale migration journey. This session covers some of the real-world networking challenges faced when migrating to the cloud. You learn how to overcome these challenges by diving deep into topics such as establishing private connectivity to your on-premises data center and accelerating data migrations using AWS Direct Connect/Direct Connect gateway, centralizing and simplifying your networking with AWS Transit Gateway, and extending your private DNS into the cloud. The session also includes a discussion of related best practices.
Innovating on AWS in a 5G world
5G will be the catalyst for the next industrial revolution. In this session, come learn about key technical use cases for different industry segments that will be enabled by 5G and related technologies, and hear about the architectural patterns that will support these use cases. You also learn about AWS-enabled 5G reference architectures that incorporate AWS services.
AWS CCP CLF-C01 on Android – AWS CCP CLF-C01 on iOS – AWS CCP CLF-C01 on Windows 10/11
How to choose the right instance type for ML inference
AWS offers a breadth and depth of machine learning (ML) infrastructure you can use through either a do-it-yourself approach or a fully managed approach with Amazon SageMaker. In this session, explore how to choose the proper instance for ML inference based on latency and throughput requirements, model size and complexity, framework choice, and portability. Join this session to compare and contrast compute-optimized CPU-only instances, such as Amazon EC2 C4 and C5; high-performance GPU instances, such as Amazon EC2 G4 and P3; cost-effective variable-size GPU acceleration with Amazon Elastic Inference; and highest performance/cost with Amazon EC2 Inf1 instances powered by custom-designed AWS Inferentia chips.
Architectural patterns & best practices for workloads on VMware Cloud on AWS
When it comes to architecting your workloads on VMware Cloud on AWS, it is important to understand design patterns and best practices. Come join this session to learn how you can build well-architected cloud-based solutions for your VMware workloads. This session covers infrastructure designs with native AWS service integrations across compute, networking, storage, security, and operations. It also covers the latest announcements for VMware Cloud on AWS and how you can use these new features in your current architecture.
The cutover: Moving your traffic to the cloud
One of the most critical phases of executing a migration is moving traffic from your existing endpoints to your newly deployed resources in the cloud. This session discusses practices and patterns that can be leveraged to ensure a successful cutover to the cloud. The session covers preparation, tools and services, cutover techniques, rollback strategies, and engagement mechanisms to ensure a successful cutover.
AWS CCP CLF-C01 on Android – AWS CCP CLF-C01 on iOS – AWS CCP CLF-C01 on Windows 10/11
AWS DeepRacer is the fastest way to get rolling with machine learning. Developers of all skill levels can get hands-on, learning how to train reinforcement learning models in a cloud based 3D racing simulator. Attend a session to get started, and then test your skills by competing for prizes and glory in an exciting autonomous car racing experience throughout re:Invent!
AWS DeepRacer gives you an interesting and fun way to get started with reinforcement learning (RL). RL is an advanced machine learning (ML) technique that takes a very different approach to training models than other ML methods. Its super power is that it learns very complex behaviors without requiring any labeled training data, and it can make short-term decisions while optimizing for a longer-term goal. AWS DeepRacer makes it fast and easy to build models in Amazon SageMaker and train, test, and iterate quickly and easily on the track in the AWS DeepRacer 3D racing simulator.
Decoupling serverless workloads with Amazon EventBridge
Event-driven architecture can help you decouple services and simplify dependencies as your applications grow. In this session, you learn how Amazon EventBridge provides new options for developers who are looking to gain the benefits of this approach.
AWS CCP CLF-C01 on Android – AWS CCP CLF-C01 on iOS – AWS CCP CLF-C01 on Windows 10/11
Deep dive on Amazon Timestream
Amazon Timestream is a fast, scalable, and serverless time series database service for IoT and operational applications that makes it easy to store and analyze trillions of events per day at as little as one-tenth the cost of relational databases. In this session, dive deep on Amazon Timestream features and capabilities, including its serverless automatic scaling architecture, its storage tiering that simplifies your data lifecycle management, its purpose-built query engine that lets you access and analyze recent and historical data together, and its built-in time series analytics functions that help you identify trends and patterns in your data in near-real time.
Accelerating outcomes and migrations with Savings Plans
Savings Plans is a flexible pricing model that allows you to save up to 72 percent on Amazon EC2, AWS Fargate, and AWS Lambda. Many AWS users have adopted Savings Plans since its launch in November 2019 for the simplicity, savings, ease of use, and flexibility. In this session, learn how many organizations use Savings Plans to drive more migrations and business outcomes. Hear from Comcast on their compute transformation journey to the cloud and how it started with RIs. As their cloud usage evolved, they adopted Savings Plans to drive business outcomes such as new architecture patterns.
Learn how teams at Amazon rapidly release features at scale
The ability to deploy only configuration changes, separate from code, means you do not have to restart the applications or services that use the configuration and changes take effect immediately. In this session, learn best practices used by teams within Amazon to rapidly release features at scale. Learn about a pattern that uses AWS CodePipeline and AWS AppConfig that will allow you to roll out application configurations without taking applications out of service. This will help you ship features faster across complex environments or regions.
Top-paying Cloud certifications:
- Google Certified Professional Cloud Architect — $175,761/year
- AWS Certified Solutions Architect – Associate — $149,446/year
- Azure/Microsoft Cloud Solution Architect – $141,748/yr
- Google Cloud Associate Engineer – $145,769/yr
- AWS Certified Cloud Practitioner — $131,465/year
- Microsoft Certified: Azure Fundamentals — $126,653/year
- Microsoft Certified: Azure Administrator Associate — $125,993/year


AWS CCP CLF-C01 on Android – AWS CCP CLF-C01 on iOS – AWS CCP CLF-C01 on Windows 10/11


AWS Cloud Practitioner Breaking News – AWS CCP CLF-C01 Testimonials – AWS Top Stories
 A Twitter List by enoumen
A Twitter List by enoumen I Passed AWS CCP Testimonials
I just passed my AWS CCP!!!
(Source: r/AWSCertifications)
Study Materials and Timeline:
I watched (binged) the A Cloud Guru course in two days and did the 6 practice exams over a week. I originally was only getting 70%’s on the exams, but continued doing them on my free time (to the point where I’d have 15 minutes and knock one out on my phone lol) and started getting 90%’s. – A mix of knowledge vs memorization tbh. Just make sure you read why your answers are wrong.
I don’t really have a huge IT background, although will note I work in a DevOps (1 1/2 years) environment; so I do use AWS to host our infrastructure. However, the exam is very high level compared to what I do/services I use. I’m fairly certain with zero knowledge/experience, someone could pass this within two weeks. AWS is also currently promoting a “get certified” challenge and is offering 50% off.
Best!
Resources:
A Cloud Guru Course:
AWS – Get AWS Certified: Cloud Practitioner Challenge:
AWS CCP CLF-C01 on Android – AWS CCP CLF-C01 on iOS – AWS CCP CLF-C01 on Windows 10/11
Good Tool For AWS Certified Cloud Practitioner Exam Preparation
Went through the entire CloudAcademy course. Most of the info went out the other ear. Got a 67% on their final exam. Took the ExamPro free exam, got 69%.
Was going to take it last Saturday, but I bought TutorialDojo’s exams on Udemy. Did one Friday night, got a 50% and rescheduled it a week later to today Sunday.
Took 4 total TD exams. Got a 50%, 54%, 67%, and 64%. Even up until last night I hated the TD exams with a passion, I thought they were covering way too much stuff that didn’t even pop up in study guides I read. Their wording for some problems were also atrocious. But looking back, the bulk of my “studying” was going through their pretty well written explanations, and their links to the white papers allowed me to know what and where to read.
Not sure what score I got yet on the exam. As someone who always hated testing, I’m pretty proud of myself. I also had to take a dump really bad starting at around question 25. Thanks to TutorialsDojo Jon Bonso for completely destroying my confidence before the exam, forcing me to up my game. It’s better to walk in way over prepared than underprepared.
I would like to thank this community for recommendations about exam preparation. It was wayyyy easier than I expected (also way easier than TD practice exams scenario-based questions-a lot less wordy on real exam). I felt so unready before the exam that I rescheduled the exam twice. Quick tip: if you have limited time to prepare for this exam, I would recommend scheduling the exam beforehand so that you don’t procrastinate fully.
Resources:
-Stephane’s course on Udemy (I have seen people saying to skip hands-on videos but I found them extremely helpful to understand most of the concepts-so try to not skip those hands-on)
-Tutorials Dojo practice exams (I did only 3.5 practice tests out of 5 and already got 8-10 EXACTLY worded questions on my real exam)
Previous Aws knowledge:
-Very little to no experience (deployed my group’s app to cloud via Elastic beanstalk in college-had 0 clue at the time about what I was doing-had clear guidelines)
Preparation duration: -2 weeks (honestly watched videos for 12 days and then went over summary and practice tests on the last two days)
Links to resources:
https://www.udemy.com/course/aws-certified-cloud-practitioner-new/
https://tutorialsdojo.com/courses/aws-certified-cloud-practitioner-practice-exams/
I used Stephane Maarek on Udemy. Purchased his course and the 6 Practice Exams. Also got Neal Davis’ 500 practice questions on Udemy. I took Stephane’s class over 2 days, then spent the next 2 weeks going over the tests (3~4 per day) till I was constantly getting over 80% – passed my exam with a 882.
What an adventure, I’ve never really gieven though to getting a cert until one day it just dawned on me that it’s one of the few resources that are globally accepted. So you can approach any company and basically prove you know what’s up on AWS 😀
Passed with two weeks of prep (after work and weekends)
Resources Used:
This was just a nice structured presentation that also gives you the powerpoint slides plus cheatsheets and a nice overview of what is said in each video lecture.
Udemy – AWS Certified Cloud Practitioner Practice Exams, created by Jon Bonso**, Tutorials Dojo**
These are some good prep exams, they ask the questions in a way that actually make you think about the related AWS Service. With only a few “Bullshit! That was asked in a confusing way” questions that popped up.
I took CCP 2 days ago and got the pass notification right after submitting the answers. In about the next 3 hours I got an email from Credly for the badge. This morning I got an official email from AWS congratulating me on passing, the score is much higher than I expected. I took Stephane Maarek’s CCP course and his 6 demo exams, then Neal Davis’ 500 questions also. On all the demo exams, I took 1 fail and all passes with about 700-800. But in the real exam, I got 860. The questions in the real exam are kind of less verbose IMO, but I don’t truly agree with some people I see on this sub saying that they are easier.
Just a little bit of sharing, now I’ll find something to continue ^^
Good luck with your own exams.
Passed the exam! Spent 25 minutes answering all the questions. Another 10 to review. I might come back and update this post with my actual score.
Background
– A year of experience working with AWS (e.g., EC2, Elastic Beanstalk, Route 53, and Amplify).
– Cloud development on AWS is not my strong suit. I just Google everything, so my knowledge is very spotty. Less so now since I studied for this exam.
Study stats
– Spent three weeks studying for the exam.
– Studied an hour to two every day.
– Solved 800-1000 practice questions.
– Took 450 screenshots of practice questions and technology/service descriptions as reference notes to quickly swift through on my phone and computer for review. Screenshots were of questions that I either didn’t know, knew but was iffy on, or those I believed I’d easily forget.
– Made 15-20 pages of notes. Chill. Nothing crazy. This is on A4 paper. Free-form note taking. With big diagrams. Around 60-80 words per page.
– I was getting low-to-mid 70%s on Neal Davis’s and Stephane Maarek’s practice exams. Highest score I got was an 80%.
– I got a 67(?)% on one of Stephane Maarek’s exams. The only sub-70% I ever got on any practice test. I got slightly anxious. But given how much harder Maarek’s exams are compared to the actual exam, the anxiety was undue.
– Finishing the practice exams on time was never a problem for me. I would finish all of them comfortably within 35 minutes.
Resources used
– AWS Cloud Practitioner Essentials on the AWS Training and Certification Portal
– AWS Certified Cloud Practitioner Practice Tests (Book) by Neal Davis
– 6 Practice Exams | AWS Certified Cloud Practitioner CLF-C01 by Stephane Maarek*
– Certified Cloud Practitioner Course by Exam Pro (Paid Version)**
– One or two free practice exams found by a quick Google search
*Regarding Exam Pro: I went through about 40% of the video lectures. I went through all the videos in the first few sections but felt that watching the lectures was too slow and laborious even at 1.5-2x speed. (The creator, for the most part, reads off of the slides, adding brief comments here and there.) So, I decided to only watch the video lectures for sections I didn’t have a good grasp on. (I believe the video lectures provided in the course are just split versions of the full length course available for free on YouTube under the freeCodeCamp channel, here.) The online course provides five practice exams. I did not take any of them.
**Regarding Stephane Maarek: I only took his practice exams. I did not take his study guide course.
Notes
– My study regimen (i.e., an hour to two every day for three weeks) was overkill.
– The questions on the practice exams created by Neal Davis and Stephane Maarek were significantly harder than those on the actual exam. I believe I could’ve passed without touching any of these resources.
– I retook one or two practice exams out of the 10+ I’ve taken. I don’t think there’s a need to retake the exams as long as you are diligent about studying the questions and underlying concepts you got wrong. I reviewed all the questions I missed on every practice exam the day before.
What would I do differently?
– Focus on practice tests only. No video lectures.
– Focus on the technologies domain. You can intuit your way through questions in the other domains.
– Chill
I thank you all for helping me through this process! Couldn’t have done it without all of the recommendations and guidance on this page.
Background: I am a back-end developer that works 12 hours a day for corporate America, so no time to study (or do anything) but I made it work.
Could I have probably gone for SAA first? Yeah, but I wanted to prove to myself that I could do it. I studied for about a month. I used Maarek’s Udemy course at 1.5x speed and I couldn’t recommend it more. I also used his practice exams. I’ll be honest, I took 5 practice exams and got somehow managed to fail every single one in the mid 60’s lol. Cleared the exam with an 800. Practice exams WAY harder.
My 2 cents on must knows:
AWS Shared Security Model (who owns what)
Everything Billing (EC2 instance, S3, different support plans)
I had a few ML questions that caught me off guard
VPC concepts – i.e. subnets, NACL, Transit Gateway
I studied solidly for two weeks, starting with Tutorials Dojo (which was recommended somewhere on here). I turned all of their vocabulary words and end of module questions into note cards. I did the same with their final assessment and one free exam.
During my second week, I studied the cards for anywhere from one to two hours a day, and I’d randomly watch videos on common exam questions.
The last thing I did was watch a 3 hr long video this morning that walks you through setting up AWS Instances. The visual of setting things up filled in a lot of holes.
I had some PSI software problems, and ended up getting started late. I was pretty dejected towards the end of the exam, and was honestly (and pleasantly) surprised to see that I passed.
Hopefully this helps someone. Keep studying and pushing through – if you know it, you know it. Even if you have a bad start. Cheers 🍻
- Failed AWS Advanced Networking part deuxby /u/newbietofx (AWS Certifications) on July 25, 2024 at 1:58 pm
This time got worst. 665 All domains I sucked. Less on dx and bgp. More on lb with EKS, cloud formation with pam, on premise dns but resource is using ip address from on premise so I can't tell if this is supposed to be inbound or outbound endpoint. Macsec. There is one on data flow. Like which one comes first. Gateway endpoint or gateway load balancer. I've setup an endpoint which comes before load balancer since I have to reference it via route table. Something about 7300 and 7100. I nvr quite understand why we use them. Many choose 2 or three. I'll make sure I max my time before I call it quits. Fk. This is harder than cissp or I never force myself. submitted by /u/newbietofx [link] [comments]
- Is Cantril SAP course + Tutorial Dojo enough to pass the exam? I don't wanna do extra courses from Davis or Maarekby /u/IamOkei (AWS Certifications) on July 25, 2024 at 1:00 pm
Can someone let me know if the Cantril course and ebook from TD enough to pass? submitted by /u/IamOkei [link] [comments]
- Serverless Architecture: Simplifying Web App Developmentby /u/anujtomar_17 (AWS Certifications) on July 25, 2024 at 12:48 pm
submitted by /u/anujtomar_17 [link] [comments]
- Passed AWS SAA-C03!by /u/Rocket_Job (AWS Certifications) on July 25, 2024 at 11:58 am
I just want to thank this community for all the tips and tricks. I took the exam this morning, finished by 11 AM, and received the results by 6 PM. The exam was more difficult than I expected (which scared me, I thought I might fail). The resources I used included Stephane Maarek's course on Udemy, as well as his practice exam and TD's practice exams. Here's a breakdown of my practice exam scores, listed in the order I took them: Stephane Maarek's Practice Exams: Practice Test 1: 72% Practice Test 2: 69% Practice Test 3: 70% Practice Test 4: 76% Practice Test 5: 78% Practice Test 6: 55% (I'm not sure how this happened, lol) TD's Practice Exams: Timed Mode Set 1: 81.54% Timed Mode Set 2: 69.23% Timed Mode Set 3: 75.38% Timed Mode Set 4: 72.31% Review Mode Set 1: 83.08% Timed Mode Set 5: 66.15% Timed Mode Set 6: 67.69% Timed Mode Set 7: 63.08% Bonus Timed Mode Set 8: 77.78% I found that TD's questions were closer to the real exam. My final score was 810. I started Studying last May for 1-2 hrs everyday(on and off due to fulltime work) The explanations for each question in the practice tests really helped me understand and learn the services. submitted by /u/Rocket_Job [link] [comments]
- Federation: How to learn it without getting panic attacksby /u/jesuisapprenant (AWS Certifications) on July 25, 2024 at 5:35 am
I always get these questions about different ways to federate: there are AssumeRolesWithSAML, AssumeRolesWithWebIdentity, SAML 2.0, IdP, Active Directories, LDAP, etc and etc., and even though I reviewed it a million times, I still can't get the questions right. Adding to this complexity is whether or not we need to create IAM roles or policies, if we need ARNs, and mapping IdP to IAM roles. I really just want to master it once and for all, all of this federation stuff. How to learn this? submitted by /u/jesuisapprenant [link] [comments]
- Taking the Cloud Practitioner Exam in 3 monthsby /u/Ready_Manager2538 (AWS Certifications) on July 25, 2024 at 3:42 am
Hi, just wanted to hear some thoughts. I plan to take the AWS Cloud Practitioner in 3 months and I plan to study for it for a couple of hours per day around 2-3 hours and 5 days a week on top of my full-time job. I’m completely new to cloud and was wondering if it’s enough time for me to study? I’ve been hearing from some people that they studied for much longer for the exam and I’m worried because I want to pass it because the money i’ll spend is sponsored. Thank you in advance! submitted by /u/Ready_Manager2538 [link] [comments]
- Need help with Cloud Practitioner CLF-C02by /u/keeponpushin1986 (AWS Certifications) on July 25, 2024 at 2:16 am
I've been through stephen maarke's course as well as a two practice tests from TD and I still failed my test. After looking at my weak areas for the exam, it seems to be centered around billing. How can I learn more on this topic without having to go through Maareks course again. Does anyone have any note cards by chance? Thanks in advance submitted by /u/keeponpushin1986 [link] [comments]
- Best AWS Certification For Skill Growthby /u/ASAP_Beet (AWS Certifications) on July 24, 2024 at 11:10 pm
I am searching for a way to boost my AWS skills, and am trying to decide between attending AWS ReInvent or starting a certification. As a disclaimer, I am not doing this in an attempt to get a job or resume build. I am already somewhere between intermediate and advanced with a decent amount of AWS tools and searching for a way to get closer to an expert in at least a few of these topics. For people here who have done some of the more advanced certifications, do you feel like they are a good tool to increase your skills, or are they more of a way to prove/quantify the skills you already have? Also, any recommendations for which certifications are best for advanced data engineering / DevOps would be much appreciated! submitted by /u/ASAP_Beet [link] [comments]
- Best Way to prepare for This ?by /u/Bippity_Boppity69 (AWS Certifications) on July 24, 2024 at 7:28 pm
I am planning to start the AWS cloud practitioner certificate, what are some resources available for free , to practice and get good idea of my potential result? Also, I have no cloud background but I am a Computer science student doing bachelors, how much time will it take for me to prepare ? submitted by /u/Bippity_Boppity69 [link] [comments]
- My AWS Cloud Practitioner Certificationby /u/Commercial-Suit-7693 (AWS Certifications) on July 24, 2024 at 7:16 pm
https://preview.redd.it/lhm8f52dnied1.png?width=2000&format=png&auto=webp&s=8ba557a06b2eba22741f2f324e1bd07cd017704f I passed my exam Cloud Practitioner CLF-C02 exam 3 months ago. I was very excited and now I'm preparing for my other AWS Certification. All thanks to my youtube guides and to itexamshub for their source guide. submitted by /u/Commercial-Suit-7693 [link] [comments]
- Mistral Large 2 foundation model now available in Amazon Bedrockby aws@amazon.com (Recent Announcements) on July 24, 2024 at 5:00 pm
Mistral AI’s Mistral Large 2 (24.07) foundation model is now generally available in Amazon Bedrock. This model is the latest version of Mistral AI's flagship large language model, Mistral Large (24.02), with significant improvements on multilingual accuracy, conversational behavior, coding capabilities, reasoning and instruction-following behavior. With this new release of Mistral Large, you can leverage its multi-lingual proficiency to seamlessly communicate and process information in dozens of languages, including English, French, German, Spanish, Italian, Chinese, Japanese, Korean, Portuguese, Dutch, Polish, Arabic, and Hindi. It has an increased context window of 128k (compared to 32k in the original version), making it able to process more information in order to generate accurate responses. Its advanced coding capabilities enable you to develop software across various programming languages, such as Python, Java, C, C++, JavaScript, and Bash, as well as specialized languages like Swift and Fortran. The model also has best-in-class agentic capabilities with native function calling and JSON outputting allowing it to interact with external systems, APIs, and tools. Mistral AI’s Mistral Large 2 foundation model is now available on Amazon Bedrock in the US West (Oregon) region. To learn more read the Machine Learning blog, visit the Mistral AI on Amazon Bedrock product page, and read the documentation. To get started with Mistral Large on Amazon Bedrock, visit the Amazon Bedrock console.
- AWS DataSync expands support for agentless cross-region data transfers to include opt-in regionsby aws@amazon.com (Recent Announcements) on July 24, 2024 at 5:00 pm
AWS DataSync now supports agentless cross-region data transfers between all regions in the commercial AWS partition, including opt-in regions. With this update, you can now transfer millions of files or objects between AWS Storage services such as Amazon S3, Amazon EFS, and Amazon FSx in different regions without deploying or managing a DataSync agent. AWS DataSync is an online data movement service that simplifies, automates, and accelerates the transfer of files and objects. It uses a purpose-built network protocol and scale-out architecture to move data quickly and securely between AWS Storage services, on-premises storage, edge locations, or other clouds. DataSync uses an agent to access storage systems that are located on premises or in other clouds while providing fully-managed access to storage in AWS. With this release, you can now transfer data between AWS Storage services in any region in the commercial partition, including opt-in regions, without deploying a DataSync agent. This enables you to easily replicate data between managed file systems for business continuity, as well as copy portions of your data to different buckets or file systems to meet evolving application requirements. Agentless cross-region transfers are now available in all AWS regions where AWS DataSync is available. To get started, visit the AWS DataSync console. To learn more, view the AWS DataSync documentation.
- AWS Signer open sources Notation plugin for container image signingby aws@amazon.com (Recent Announcements) on July 24, 2024 at 5:00 pm
Today, AWS open-sourced the AWS Signer plugin for Notation, giving customers flexibility and transparency in how they sign and verify container images with AWS Signer, a managed signing service. Notation is an open source tool developed by the Notary Project, an industry standard for securing software supply chains by authenticating container images and other OCI artifacts. The plugin extends Notation with Signer managed secrets and revocation capabilities. Customers can now incorporate the Signer plugin as a library inside their native tools to generate and verify container artifacts signatures. Notation can be used as a CLI executable or as a Golang library. With the open sourced Signer Plugin, you can now seamlessly incorporate signing and verification activities into your existing applications and tooling by adding a go-library. This removes the need for installing and invoking the plugin as an executable. Additionally, you get transparency in how AWS Signer APIs are used for signature generation and verification. If you prefer a CLI integration with Signer, you can now also build your own version of the Signer Plugin executable or continue downloading pre-built executables from AWS Signer documentation. AWS Signer Plugin is released as an open-source project under the Apache 2.0 license. You can access the source code and instructions to build the Signer plugin in the GitHub repository here. To learn more about container image signing refer this blog.
- Not getting response to our Q&A in Udemy from Stephaneby /u/Low-Tale-3532 (AWS Certifications) on July 24, 2024 at 2:28 pm
Hi Community, I bought Stephane Mareeks DEA-C01 practice exam course and posted 8 to 10 questions from last 3 weeks but not getting any response and posted the request in his another hands on course still no response. Exam is scheduled in 7 days. Not only for me for others as well same . How I can get him to respond to our queries? Shall I raise a udemy support ticket? Or request for a refund submitted by /u/Low-Tale-3532 [link] [comments]
- AWS Course For jobby /u/WhatsMueenUpto (AWS Certifications) on July 24, 2024 at 12:08 pm
Hey Cloud Guys Recommend me best course for AWS foundation and solution architecture for job I have 2 months to complete these courses submitted by /u/WhatsMueenUpto [link] [comments]
- AWS Certified AI Practitioner (AIF) resourcesby /u/madrasi2021 (AWS Certifications) on July 24, 2024 at 11:50 am
Note : This certification exam was just recently announced and is entering "BETA" in August. Last updated : 24-July-2024 Here is a master list of resources to help those who are interested in the new AWS Certified AI Practitioner exam. All my Exam Resource Posts : [CCP/CLF](https://www.reddit.com/r/AWSCertifications/comments/1d1xg1p/aws\_certified\_cloud\_practitioner\_clfc02\_ccp/) [SAA](https://www.reddit.com/r/AWSCertifications/comments/1d5kkuw/aws\_certified\_solutions\_architect\_associate/) [DVA](https://www.reddit.com/r/AWSCertifications/comments/1db1vhf/aws\_certified\_developer\_associate\_dvac02\_resources/) [DEA](https://www.reddit.com/r/AWSCertifications/comments/195sbcj/aws\_certified\_data\_engineer\_associate\_dea\_deac01/) [AIF] (this one!) If you find this post useful - upvote. This post is written for benefit of this community and hence I am happy to take feedback / suggestions / changes etc - please comment! tl;dr The exam was just announced and is not even live right now. It will open up in BETA from August 13. The official material behind the exam is yet to be published in detail. Even the "Exam Guide" (aka "Curriculum") is not yet out there and this means any training material is bound to change when its announced. However there are a lot of useful pointers / material we can generally get started on / watch out for and this post will be in "beta" mode itself till the exams are Generally Available. Exam Details The exam code is AIF-C01. AWS page with all the details : [https://aws.amazon.com/certification/certified-ai-practitioner/\](https://aws.amazon.com/certification/certified-ai-practitioner/) The first resource to usually read is the Exam Guide (tells you whats in / out of scope) : Yet to be published. Minimum Viable Path to Certification Most people usually need 2 things to pass the exam A single video based course introducing the exam curriculum Typically these are courses where someone reads from some slides, shows you the AWS console and how to use it and then gives you tips on what to remember. One good quality practice exam Note : do not fall for some random "dump" found on internet or any resource offerring you a Guarantee to pass. 1. Video Courses There aren't any video courses yet. Stephane Maarek and Andrew Brown have indicated they are preparing material. I will link to these when I hear of their release. There is an "Exam Prep" course from Skillbuilder but note that this just covers the high level domains but is not a comprehensive deep dive. [https://explore.skillbuilder.aws/learn/public/learning\_plan/view/2193/standard-exam-prep-plan-aws-certified-ai-practitioner-aif-c01\](https://explore.skillbuilder.aws/learn/public/learning\_plan/view/2193/standard-exam-prep-plan-aws-certified-ai-practitioner-aif-c01) Optional : There is a slightly extended version of this in the paid tier. Right now it seems to be identical to the free one but should be updated on 13th August with more (paid tier only) material. [https://explore.skillbuilder.aws/learn/public/learning\_plan/view/2194/enhanced-exam-prep-plan-aws-certified-ai-practitioner-aif-c01\](https://explore.skillbuilder.aws/learn/public/learning\_plan/view/2194/enhanced-exam-prep-plan-aws-certified-ai-practitioner-aif-c01) Please note that this course may not enough on its own to pass and you may want to try additional material below. 2. Practice Exams Official Practice exam : not yet published [Tutorialsdojo.com](http://Tutorialsdojo.com) seem to be working on some material here (as per threads where they broke the platform and said its because they are doing deployment to support the new question types) Alternative Gen AI learning material FREE courses on SkillBuilder Generative AI Learning Plan for Developers Amazon Bedrock - Getting Started Building Generative AI Applications using Amazon Bedrock AI Language Service Learning Plan Foundations of Prompt Engineering Subscription tier (paid) on Skillbuilder Cloud Quest - Gen AI is a game based learning platform - provides a digital badge on completion. You can follow the Twitch.tv video series aligned with this Quest for free here : https://pages.awscloud.com/GLOBAL-other-T2-Traincert-AWS-Cloud-Quest-Gen-AI-Season1-2024-reg.html [Simulearn - Gen AI](https://explore.skillbuilder.aws/learn/course/external/view/elearning/19378/aws-cloud-quest-generative-ai) is a Gen AI / Gamified learning platform that's new - its not free and does not provide a digital badge. FAQ What does BETA exams mean? BETA exams are actual certification exams but are discounted as they are new and may not be as polished as the final generally available exams. In return for the small discount and early access - test takers are basically providing feedback on the exam / exam questions in a way that allows AWS to then make it generally available for the public. This also allows content providers to take the exam and tailor their training / test material. Where can I find vouchers for the exam? The BETA exams are discounted by 33% during Beta phase. If you have a voucher for 50% off from passing another AWS exam or other source - you could try to see if that stacks on top - we would not for sure till someone has attempted this. When will I get my exam results. Unlike previous beta exams - these new one's are Does this exam format differ to the Cloud Practitioner exam? Yes - please see this post on new types of questions that you can expect on this exam https://www.reddit.com/r/AWSCertifications/comments/1ea16sa/new_question_types_for_new_exams Good Luck folks! submitted by /u/madrasi2021 [link] [comments]
- How long to pass AWS CLOUD PRACTITIONER?by /u/Theravrauli (AWS Certifications) on July 24, 2024 at 11:23 am
I've been studying & it's relatively new to me, I was thinking when to book it. I've just learnt up to Amazon S3 on Stepehen Mareek's course but I really want to get my exam booked in & have a goal to focus to, any thoughts? submitted by /u/Theravrauli [link] [comments]
- Tutorial Dojo - SAA-C03by /u/jaron1978 (AWS Certifications) on July 24, 2024 at 10:20 am
We have a corporate Udemy account and I have seen a lot of people recommending the TD Practice Tests. Are they the Jon Bonso tests? Thanks submitted by /u/jaron1978 [link] [comments]
- Passed SAA-C03 yesterday!by /u/Pudge4tw (AWS Certifications) on July 24, 2024 at 7:51 am
I used Kodekloud AWS Solutions Architect Associate Certification course for video och and hands-on training then I bought the practice tests at Tuturialsdojo. If anyone have questions regarding any of those just ask along! submitted by /u/Pudge4tw [link] [comments]
- Why would someone choose AssumeRoleWithSAML over AssumeRoleWithWebIdentity?by /u/jesuisapprenant (AWS Certifications) on July 24, 2024 at 5:53 am
For these two (AssumeRoleWithWebIdentity vs AssumeRoleWithSAML), if we are using an enterprise solution LDAP/Active Directory etc, we will be using AssumeRoleWithSAML right, and then if we are using social media, like Facebook, Google, via Cognito, it would be AssumeRoleWithWebIdentity? The thing is Cognito supports SAML as well, so why would someone choose AssumeRoleWithSAML over AssumeRoleWithWebIdentity? Thanks in advance submitted by /u/jesuisapprenant [link] [comments]
- Do I really need the SAA?by /u/logan9053 (AWS Certifications) on July 24, 2024 at 3:47 am
My job requires SysOps assc cert, after getting my ccp do I really need the SAA before getting SysOps? Is there any benefit there? I was always made to believe Solitions Architect is basically for ppl in sales. TIA submitted by /u/logan9053 [link] [comments]
- Passed SAA-C03 yesterdayby /u/escape00000 (AWS Certifications) on July 24, 2024 at 12:37 am
Someone said there aren’t enough posts like this so… Barely passed. Don’t feel like the resources I used adequately prepared me for the exam, and I probably should have studied way harder. I’m a part of an AWS study group that is down to 2 members now. We’re deciding between data engineer or developer next. submitted by /u/escape00000 [link] [comments]
- Cloud practitionerby /u/gbrot (AWS Certifications) on July 23, 2024 at 11:58 pm
Welp taking the test next week at the testing center. I used Stefan on udemy and TD and I feel I have a good grasp on the material and went over CAF and well architect framework. submitted by /u/gbrot [link] [comments]
- Nervous as hellby /u/Competitive_Gift_539 (AWS Certifications) on July 23, 2024 at 11:39 pm
I write my exams in the next hour and I’m not so confident about it. Kinda thinking about rescheduling. submitted by /u/Competitive_Gift_539 [link] [comments]
- AWS Cost Categories now supports “Billing Entity” dimensionby aws@amazon.com (Recent Announcements) on July 23, 2024 at 9:00 pm
AWS Cost Categories has added a new dimension “Billing Entity” to its rules. You can now use eight types of dimensions: “Linked Account”, “Charge Type”, “Service”, "Usage Type", “Cost Allocation Tags”, “Region”, “Billing Entity” and other “Cost Category” while creating cost categories rules. AWS Cost Categories is a feature within the AWS Cost Management product suite that enables you to group cost and usage information into meaningful categories based on your needs. You can create custom categories and map your cost and usage information into these categories based on the rules defined by you using various dimensions. Once cost categories are set up and enabled, you will be able to view and manage your AWS cost and usage information by these categories in AWS cost management services, e.g. understanding the ownership of your spend at the Cost Categories level in AWS Cost Explorer and AWS Cost and Usage Report (CUR). Cost categories can be applied to your AWS cost and usage at the beginning of the month or retroactively for up to 12 months. Adding Billing Entity gives customers more granular control over their cost categories. Billing Entity is the unit to identify whether customers’ invoices or transactions are for AWS Marketplace or for purchases of other AWS services. Cost categories is provided free of charge and this feature is available in all Commercial Regions. To get started with cost categories, please visit AWS Cost Categories product details page, AWS Cost Categories FAQs - Amazon Web Services.
- Passed DEA-C01by /u/proliphery (AWS Certifications) on July 23, 2024 at 8:52 pm
This is my official “I passed DEA-C01” post. I was not planning to post, but it was requested by u/madrasi2021. His posts and comments have been very helpful, so I decided to post per his request. I found there were not as many resources available for DEA as for other certifications. I’m assuming this is because the cert is so new. I used a video course (Udemy - Maarek/Kane) that was pretty good but not as hands-on as Cantrill’s courses. (Unfortunately I don’t see DEA moving ahead on Cantrill’s roadmap. Maybe we can encourage him…) I also used practice tests from TutorialsDojo. There were only 3 practice test sets in TD for DEA (compared to 7 sets for SAA). The tests were still helpful, even though there were fewer questions to study. Now, I was able to pass the exam with these resources, but I didn’t think they covered the material as fully as other exams. Also, I have some background in data engineering, data analysis, and especially SQL going back several years, but only about a year experience with AWS services. Good luck to everyone who tackles this exam! submitted by /u/proliphery [link] [comments]
- Passed DVA-C02 !!.. What next?by /u/mayur2797 (AWS Certifications) on July 23, 2024 at 7:51 pm
First, let me share my 4-week experience with those who are still undecisive on whether to go for it, or how. Just for context, this is my first experience with AWS ever, and my first AWS certification ever (I skipped Cloud Practitioner and Solutions Architect). 1. Stephane Maarek's course on Udemy. It contains 34-35 hours of contents. I truly appreciated how he touched base with the basic knowledge of AWS and common abbreviations that you should have already known. After each/most theory lecture or explanation, he will show a hands-on of how it would be applied in real life, and you are welcome to practice alongside. He also makes sure that you are always within the free tier wherever possible so that there are no charges to be paid. If there are, he will warn you before starting the hands-on. IMO, this course is super helpful to go through "quickly" to get a first glance at the wordings, contents, understanding of the workflows, what connects to what, order of execution etc. 2. TutorialDojo's Practice Exams. After quickly going through and understanding Stephane's course, practicing is ABSOLUTELY CRUCIAL to pass the exam. Practicing question papers or answering questions before the exams is always a prime rule of succeeding in any exam! Always remember! TD provides a detailed explanation and ref. links for every question, regardless if you answered it right or wrong. You can filter the explanations per topic, or filter only the questions that were wrongly answered. TD has 3 modes: a. Time-based -> You have 5 practice exams which are time-based, with the intention of simulating a real exam. You get your score at the end, and the explanations as well. b. Review mode -> You get 5 review mode exam question sets. This is a more "relaxed" exam simulation, where your answer is evaluated immediately after answering each question, and gives you the explanation for it. c. Topic-based -> You get 4 sets, one for each of the main topics that are evaluated in the exam. You will be receiving questions pertaining only to the topic which you selected, and it runs the same as in review mode (getting the explanation immediately after answering each question) Feel free to ask anything, I will try to help whenever and however I can! Question I just have a quick question for my fellow AWS certification holders. What next? Re-write your CV? Apply for DevOps jobs? Any advice on how to make the switch from IT Support to DevOps (with experience in SE)? submitted by /u/mayur2797 [link] [comments]
- Meta Llama 3.1 generative AI models now available in Amazon SageMaker JumpStartby aws@amazon.com (Recent Announcements) on July 23, 2024 at 5:20 pm
The most advanced and capable Meta Llama models to date, Llama 3.1, are now available in Amazon SageMaker JumpStart, a machine learning (ML) hub that offers pretrained models and built-in algorithms to help you quickly get started with ML. You can deploy and use Llama 3.1 models with a few clicks in SageMaker Studio or programmatically through the SageMaker Python SDK. Llama 3.1 models demonstrate significant improvements over previous versions due to increased training data and scale. The models support a 128K context length, an increase of 120K tokens from Llama 3. Llama 3.1 models have 16 times the capacity of Llama 3 models and improved reasoning for multilingual dialogue use cases in eight languages. The models can access more information from lengthy text passages to make more informed decisions and leverage richer contextual data to generate more refined responses. According to Meta, Llama 3.1 405B is one of the largest publicly available foundation models and is well suited for synthetic data generation and model distillation, both of which can improve smaller Llama models. For use of synthetic data to fine tune models, you must comply with Meta's license. Read the EULA for additional information. All Llama 3.1 models provide state-of-the-art capabilities in general knowledge, math, tool use, and multilingual translation. Llama 3.1 models are available today in SageMaker JumpStart in US East (Ohio), US West (Oregon), and US East (N. Virginia) AWS regions. To get started with Llama 3.1 models in SageMaker JumpStart, see documentation and blog.
- Meta Llama 3.1 generative AI models now available in Amazon Bedrockby aws@amazon.com (Recent Announcements) on July 23, 2024 at 5:00 pm
The most advanced Meta Llama models to date, Llama 3.1, are now available in Amazon Bedrock. Amazon Bedrock offers a turnkey way to build generative AI applications with Llama. Llama 3.1 models are a collection of 8B, 70B, and 405B parameter size models offering new capabilities for your generative AI applications. All Llama 3.1 models demonstrate significant improvements over previous versions. The models support a 128K context length, have 16 times the capacity of Llama 3, and exhibit improved reasoning for multilingual dialogue use cases in eight languages. The models access more information from lengthy text to make more informed decisions and leverage richer contextual data to generate more subtle and refined responses. According to Meta, Llama 3.1 405B is one of the best and largest publicly available foundation models and is well suited for synthetic data generation and model distillation. Llama 3.1 models also provide state-of-the-art capabilities in general knowledge, math, tool use, and multilingual translation. Meta’s Llama 3.1 models are available in Amazon Bedrock in the US West (Oregon) Region. To learn more, read the AWS News launch blog, Llama in Amazon Bedrock product page, and documentation. To get started with Llama 3.1 in Amazon Bedrock, visit the Amazon Bedrock console. To request to be considered for access to the preview of Llama 3.1 405B in Amazon Bedrock, contact your AWS account team or submit a support ticket via the AWS Management Console. When creating the support ticket, select Bedrock as the Service and Models as the Category.
- AWS AppConfig announces feature flag targets, variants, and splitsby aws@amazon.com (Recent Announcements) on July 23, 2024 at 5:00 pm
Today, AWS announces advanced targeting capabilities for AWS AppConfig feature flags. Customers can set up multiple values within flag data, and target those values to fine-grained and high-cardinality user segments. A common use-case for feature flag targets include allow lists, where a customer can specify user IDs or customer tiers, and only enable a new or premium feature for those segments. Another use-case is to split traffic to 15% of your user-base, and experiment with a user experience optimization for a limited cohort of users before rolling the feature out to all users. Customers can start using this powerful feature by creating an AWS AppConfig feature flag, set its value, and then create one or more variants of that flag with different variations of data. Customers then create rules to determine which variant should be targeted to specific segments. Once the flag, variants, and rules are created, customers use the latest version of the AWS AppConfig Agent running in EC2, Lambda, ECS, EKS, or on-premises to retrieve the flag data. When requesting flag data, customers pass in context, like user IDs or other user metadata, which are evaluated client-side against the flag rules to return the appropriate and specific data. AWS AppConfig’s feature flag targets, variants, and splits are available in all AWS Regions, including the AWS GovCloud (US) Regions. To get started, use the AWS AppConfig Getting Started Guide.
- Amazon ECS now supports Amazon Linux 2023 and more for on-premises container workloadsby aws@amazon.com (Recent Announcements) on July 23, 2024 at 5:00 pm
Amazon Elastic Container Service (Amazon ECS) now supports managing on-premises workloads running on Amazon Linux 2023, Fedora 40, Debian 11, Debian 12, Ubuntu 24, and CentOS Stream 9. Amazon ECS Anywhere is a feature of Amazon ECS that enables you to run and manage container-based applications on-premises, including on your own virtual machines (VMs) and bare metal servers. Amazon ECS Anywhere is available in all AWS Regions globally. To learn more visit the ECS Anywhere user guide.
- Amazon EKS introduces new controls for Kubernetes version support policyby aws@amazon.com (Recent Announcements) on July 23, 2024 at 5:00 pm
Today, Amazon EKS announces new controls for Kubernetes version policy, allowing cluster administrators to configure end of standard support behavior for EKS clusters. This behavior can easily be set through the EKS Console and CLI. Kubernetes version policy control is available for Kubernetes versions in standard support. Controls for Kubernetes version policy makes it easier for you to choose which clusters should enter extended support and which clusters can be automatically upgraded at the end of standard support. This control provides the flexibility for you to balance version upgrades against business requirements depending on the environment or applications running per cluster. Controls for Kubernetes version policy is available in all AWS regions. To learn more about the controls for Kubernetes version policy, refer to the EKS documentation.
- AWS Mainframe Modernization Code Conversion with mLogica is now generally availableby aws@amazon.com (Recent Announcements) on July 23, 2024 at 5:00 pm
We are excited to announce public availability of Mainframe Modernization Code Conversion with mLogica. This new capability enables automated conversion of legacy code written in Assembler language to COBOL. The majority of mainframe environments include Assembler code that is expensive to maintain. Modernization of the code unblocks modernization projects to enable refactor projects, replatform projects, on-mainframe modernization initiatives, within AWS Mainframe Modernization toolchains, or to use alongside third-party modernization toolchains. AWS Mainframe Modernization service allows you to modernize and migrate on-premises mainframe applications to AWS. It offers automated refactor and replatform patterns, as well as augmentation patterns via data replication and file transfer. AWS Mainframe Modernization Code Conversion is available through the AWS Mainframe Modernization service console. To learn more, visit AWS Mainframe Modernization service product and documentation pages.
- Passed SAA-C03!by /u/Parking-Tomorrow-600 (AWS Certifications) on July 23, 2024 at 4:06 pm
Hey Everyone! First off, super thankful for this community. I was browsing different posts here nonstop to find the best way to study and there were some super helpful posts. I only gave myself one month to study and take the exam. I just used TD and watched all their videos and did all their practice exams. I did it for a month every day and was able to pass the exam on my first try! I also heard back within a couple of hours after taking the exam that I passed. More than happy to answer any questions anyone has! submitted by /u/Parking-Tomorrow-600 [link] [comments]
- TutorialsDojo is unusableby /u/dubai-dweller (AWS Certifications) on July 23, 2024 at 3:04 pm
https://preview.redd.it/orozyj4x9aed1.png?width=1768&format=png&auto=webp&s=39f08133f600688d4f5a41e2418aa4b0a45775e6 I keep getting redirected out of a Timed Mode exam and now I am seeing this. I know everyone praises them here but my experience has not been good so far. I still can't use the service I paid for. edit: Apologies for the harsh words but I was in the middle of a Timed Exam and was frustrated when I had to re-answer the questions again and again and then got this page. submitted by /u/dubai-dweller [link] [comments]
- Amazon Connect Contact Lens launches a new dashboard for outbound campaign analyticsby aws@amazon.com (Recent Announcements) on July 22, 2024 at 8:30 pm
Amazon Connect Contact Lens now offers a new dashboard for outbound campaign analytics. You can now easily visualize and monitor campaign performance, track efficiency, measure compliance, and understand campaign outcomes for your voice workloads. You can view real-time and historical reports using custom time periods and benchmarks, track campaign progress and delivery status, and drill down into call classification outcomes (e.g., human answered, voicemail). You can also quickly identify trends and patterns across key metrics, such as dials attempted or abandonment rate, to monitor and enhance campaign performance. Additionally, these metrics are now available via API for custom reporting or integrations with other data sources. Outbound campaign analytics is available in Amazon Connect Contact Lens reports and the GetMetricDataV2 API in all AWS regions where Amazon Connect outbound campaigns is available. This includes US East (N. Virginia), US West (Oregon), Asia Pacific (Sydney), Canada (Central), Europe (Frankfurt), and Europe (London). For more information about outbound campaign analytics, consult the Amazon Connect Administrator Guide and Amazon Connect API Reference. To learn more about Amazon Connect Outbound Campaigns, please visit the outbound campaigns webpage.
- Amazon DocumentDB announces improvements to document compressionby aws@amazon.com (Recent Announcements) on July 22, 2024 at 5:00 pm
Amazon DocumentDB (with MongoDB compatibility) now supports the ability to enable compression on existing collections, set a compression threshold for each collection, and enable compression on all new collections using a cluster-wide setting. Compressed documents in Amazon DocumentDB can be up to 7 times smaller than uncompressed documents, leading to lower storage costs, I/O costs, and improved query performance. Customers can enable document compression across their entire cluster using a single cluster-wide parameter group setting. With the compression setting enabled, all new collections created during a database migration or after upgrading the cluster will be compressed by default. The compression parameter also applies to collections created through insert operations or $out aggregation stage. Moreover, customers can now modify compression settings on existing collections using the new CollMod settings, without migrating its documents to a new compressed collection. CollMod now supports enabling compression on existing collection and setting a minimum compression threshold on document size. These compression settings will apply to both new and updated documents in the modified collections. These compression benefits are now supported in Amazon DocumentDB 5.0 instance-based clusters in all regions where Amazon DocumentDB is available. Please refer to document compression page in the developer guide for more details.
- Amazon DocumentDB now supports change streams on reader instancesby aws@amazon.com (Recent Announcements) on July 22, 2024 at 5:00 pm
Amazon DocumentDB (with MongoDB compatibility) now supports change streams on reader instances. With change stream on reader instances, customers can now isolate change stream workloads to specific reader instances, which reduces the load on cluster’s writer instance. Change stream tokens can be shared across writer and reader instances, enabling customers to resume change streams from a specific document or time from any Amazon DocumentDB instance during a cluster failover or maintenance event. This functionality is also available in Amazon DocumentDB global clusters – customers can now read change streams from reader instances from the secondary global cluster. These change stream enhancements are available in Amazon DocumentDB 5.0 instance-based clusters and global clusters in all regions where Amazon DocumentDB is supported. Amazon DocumentDB is a fully managed, native JSON database that makes it simple and cost-effective to operate critical document workloads at virtually any scale without managing infrastructure. To learn more, please visit the documentation, and get started by creating Amazon DocumentDB cluster from the AWS Management Console. For pricing and region availability, visit the pricing page.
- Amazon VPC IPAM now supports BYOIP for IPs registered with any Internet Registryby aws@amazon.com (Recent Announcements) on July 22, 2024 at 5:00 pm
Starting today, Amazon Virtual Private Cloud (VPC) IP Address Manager (IPAM) supports Bring-Your-Own-IP (BYOIP) for IP addresses registered with any Internet Registry. Internet registries manage the allocation and registration of IP addresses within specific geographical regions. BYOIP allows you to bring IP addresses allocated to you by these registries, to AWS, and use them for your workloads. This new feature extends BYOIP support to previously unsupported Internet Registries, including JPNIC, LACNIC, and AFRINIC. When setting up BYOIP, AWS validates that you control the IP address space that you are bringing to AWS. This validation ensures that users cannot use IP ranges belonging to others, preventing routing and security issues. Previously, IPAM only supported validation via the Registration Data Access Protocol (RDAP), which not all internet registries supported. Now, you can use DNS records for validating that the IP addresses belong to you, and process does not rely on any internet registries. Once you have set up BYOIP, you can create Elastic IP addresses (IPv4) from your BYOIP address range and use them with AWS resources such as Amazon Elastic Compute Cloud (Amazon EC2) instances and NAT gateways. If you have BYOIPv6 addresses, you can associate them with subnets, Elastic Network Interfaces (ENI), and Amazon EC2 instances within your VPCs. This feature is currently available in all AWS Regions, except China (Beijing, operated by Sinnet), and China (Ningxia, operated by NWCD). For more information, review IPAM’s technical documentation.
- Amazon Connect Contact Lens now provides generative AI-powered summaries within seconds after a contact endsby aws@amazon.com (Recent Announcements) on July 22, 2024 at 5:00 pm
Amazon Connect Contact Lens now provides generative AI-powered post-contact summaries within seconds after a contact ends, versus minutes previously, helping you get faster insights when reviewing contacts, save time on after-contact work, and more quickly identifying opportunities to improve contact quality and agent performance. These faster summaries are available via API and Kinesis data streams, enabling integrations with third-party agent workspace or CRM systems. You can also access these summaries natively within Amazon Connect through contact details and contact control panel (CCP). Generative AI-powered post-contact summaries are available in the US West (Oregon), and US East (Northern Virginia) regions. To learn more, please visit our documentation and our webpage. This feature is included with Contact Lens conversational analytics at no additional charge. For information about Contact Lens pricing, please visit our pricing page.
- Amazon RDS now supports M6i, R6i, M6g, R6g, and T4g database instances in Israel (Tel Aviv) Regionby aws@amazon.com (Recent Announcements) on July 22, 2024 at 5:00 pm
Amazon Relational Database Service (Amazon RDS) for PostgreSQL, MySQL, and MariaDB now supports M6i, R6i, M6g, R6g, and T4g database instances in Israel (Tel Aviv) Region. With this expansion, customers of RDS for open source engines in Israel (Tel Aviv) Region have more than double the number of available instance types to choose from. M6i and R6i database instance types offer a new maximum instance size for the region of 32xlarge. 32xlarge supports 128 vCPU, which is 33% more than the maximum size of M5 and R5 database instance types. For complete information on pricing and regional availability, please refer to the Amazon RDS pricing page. Get started by creating any of these fully managed database instance using the Amazon RDS Management Console. For more details, refer to the Amazon RDS User Guide.
- AWS KMS increases default service quotas for cryptographic operationsby aws@amazon.com (Recent Announcements) on July 22, 2024 at 5:00 pm
AWS KMS has doubled default service quotas for cryptographic operations in all AWS Regions, including raising the symmetric cryptographic operation request rate from 50,000 to 100,000 in US East (N. Virginia), US West (Oregon), and Europe (Ireland). The request rate for cryptographic operations involving RSA and ECC KMS keys has also been increased from 500 to 1,000 in all AWS Regions. These default service quotas have been increased in all AWS Regions, including the AWS GovCloud (US) Regions. To learn more, see Request quotas section in the AWS KMS Developer Guide.
- Amazon MQ now supports quorum queues for RabbitMQ 3.13by aws@amazon.com (Recent Announcements) on July 22, 2024 at 5:00 pm
Amazon MQ now provides support for quorum queues, a replicated FIFO queue type offered by open-source RabbitMQ that uses the Raft consensus algorithm to maintain data consistency. Quorum queues are the replicated queue type recommended by open-source RabbitMQ maintainers. With quorum queues, developers can design highly available messaging systems with higher data consistency and fault tolerance. Quorum queues can detect network failures faster and recover more quickly, improving the resiliency of the message broker as a whole. Quorum queues also provide poison message handling which helps developers manage unprocessed messages more efficiently. Amazon MQ benchmarks show that quorum queues offer an increased throughput (up to 2 times higher) compared to classic mirrored queues on RabbitMQ brokers. Amazon MQ supports quorum queues only on RabbitMQ 3.13 and above. You can easily get started with quorum queues by declaring a new queue with queue type as ‘quorum’. To learn more about using quorum queues, see the Amazon MQ developer guide and the Amazon MQ release notes. Quorum queues are available in all the regions Amazon MQ is available in. For a full list of available regions see the AWS Region Table.
- Productionize Fine-tuned Foundation Models from SageMaker Canvasby aws@amazon.com (Recent Announcements) on July 19, 2024 at 5:20 pm
Amazon SageMaker Canvas now supports deploying fine-tuned Foundation Models (FMs) to SageMaker real-time inference endpoints, allowing you to bring generative AI capabilities into production and consume outside the Canvas workspace. SageMaker Canvas is a no-code workspace that enables analysts and citizen data scientists to generate accurate ML predictions and use generative AI capabilities. SageMaker Canvas provides access to fine-tuning FMs powered by Amazon Bedrock and SageMaker JumpStart such as Amazon Titan Express, Falcon-7B-Instruct, Falcon-40B-Instruct, and Flan-T5 variants. You can upload a dataset, select a FM to fine-tune, and SageMaker Canvas automatically creates and tunes the model to adapt the FMs to the patterns and nuances of your specific use-case enhancing the performance of the model’s responses. Starting today, you can deploy fine-tuned FMs to SageMaker endpoints making it easier to integrate generative AI capabilities into your applications outside the SageMaker Canvas workspace. To get started, log in to SageMaker Canvas to access the fine-tuned FMs Select the desired model and deploy it with the appropriate endpoint configurations such as indefinitely or for a specific duration of time. SageMaker Inferencing charges will apply to deployed models. A new user can access the latest version by directly launching SageMaker Canvas from their AWS console. An existing user can access the latest version of SageMaker Canvas by clicking “Log Out” and logging back in. The expanded feature is now available in all AWS regions where SageMaker Canvas is supported. To learn more, refer to the SageMaker Canvas product documentation.
- Amazon Connect launches search API for agent statusby aws@amazon.com (Recent Announcements) on July 19, 2024 at 5:20 pm
Amazon Connect now provides an API to search an agent status by name, ID, tag, or other criteria. Agent statuses are used in the Contact Control Panel (CCP) to indicate if an agent is available to handle contacts or not, for example because they are away for lunch or in training. With this new API, you can now answer questions such as, “How many of our statuses are disabled?”, and, “What statuses have ‘break’ in their description?”, and see a response with details like name, description, display order, and ARN. The SearchAgentStatuses API is supported in all AWS regions where Amazon Connect is offered. To learn more about Amazon Connect, the AWS cloud-based contact center, please visit the Amazon Connect website. To learn more about the new search APIs, see the API documentation. To learn more about agent statuses, see the Amazon Connect Administrator Guide.
- Amazon Connect launches search API for hierarchy groupsby aws@amazon.com (Recent Announcements) on July 19, 2024 at 5:20 pm
Amazon Connect now provides an API to search for hierarchy groups by name, group ID, tag, or other criteria. Hierarchy groups describe your organization’s structure, and are used for reporting and access control. With this new API, you can now answer questions such as, “How many teams operate in the northwest region?” and, “What groups have a tag indicating they can access performance reviews?” and see a response with details like name, description, hierarchy level, ARN, and when a record was last updated. The SearchUserHierarchyGroups API is supported in all AWS regions where Amazon Connect is offered. To learn more about Amazon Connect, the AWS cloud-based contact center, please visit the Amazon Connect website. To learn more about the new search APIs, see the API documentation. To learn more about hierarchy groups, see the Amazon Connect Administrator Guide.
- Simplify Your AWS Marketplace Catalog API (CAPI) Integration with Strongly-Typed API Schemasby aws@amazon.com (Recent Announcements) on July 19, 2024 at 5:00 pm
We're excited to announce the introduction of a GitHub library that will host the schemas for the DetailsDocument used in StartChangeSet, DescribeChangeSet, and DescribeEntity APIs in Catalog API (CAPI). This new feature aims to simplify the integration process for developers working with the Catalog API. Today, as a developer in seller/partner organizations, you need to construct the API request structure manually when integrating with Catalog API for operations such adding pricing dimensions. This involves reviewing the API documentation and experimenting to understand the schema of the "DetailsDocument" for the request. With the new schema library, you can directly import the Java and Python libraries to create a strongly-typed response, without having to refer to the documentation or experiment with the JSON structure. This will save time and reduce the risk of errors during both integration testing and implementation. Additionally, if there are changes to the DetailsDocument schema, you can simply download the new version of the library, review the changes, and make the necessary updates to your code. This new functionality will exist alongside sending and receiving a string object in the "Details" attribute of the StartChangeSet, DescribeChangeSet, and DescribeEntity APIs. If you've already integrated with these APIs, you can continue using the "Details" attribute. However, newly onboarding sellers and sellers onboarding new API actions are advised to use the schema library to make integration with Catalog API faster. For information on how to download the shape library and use it, refer to StartChangeSet API, DescribeChangeSet API and DescribeEntity API.
- Amazon CloudWatch Logs Infrequent Access log class available in GovCloud Regionsby aws@amazon.com (Recent Announcements) on July 19, 2024 at 5:00 pm
Amazon CloudWatch Logs Infrequent Access (Logs IA), a log class for cost-effectively consolidating all your logs natively on AWS, is now available in all GovCloud regions. Logs IA helps improve visibility into your overall application health with a subset of CloudWatch Logs' capabilities including managed ingestion, cross-account log analytics, and encryption with a lower per GB ingestion price. This makes Logs IA ideal for ad-hoc querying and after-the-fact forensic analysis on infrequently accessed logs. With Logs IA, you can choose the log class that best aligns with your use case. While you can use CloudWatch Logs Standard for logs requiring real-time operational visibility, anomaly detection, or real-time logs analysis, Logs IA is best suited for logs that require infrequent querying. By consolidating your logs natively in CloudWatch, you can eliminate the operational overhead of managing multiple solutions and reduce your Mean Time to Resolution (MTTR) by analyzing all your logs in one place. CloudWatch Logs IA is now available in all AWS GovCloud (US) regions. With a few clicks in the AWS Management Console, you can start using CloudWatch Logs IA to send logs to CloudWatch. Alternatively, you can use AWS Command Line Interface (AWS CLI), AWS CloudFormation, AWS Cloud Development Kit (AWS CDK), and AWS SDKs. Learn more about CloudWatch Logs IA pricing and read the user guide here.
- AWS Lambda now supports Amazon MQ for ActiveMQ and RabbitMQ in five new regionsby aws@amazon.com (Recent Announcements) on July 19, 2024 at 5:00 pm
AWS Lambda now supports Amazon MQ for ActiveMQ and RabbitMQ in the Asia Pacific (Hyderabad), Asia Pacific (Melbourne), Europe (Spain), Europe (Zurich), and Israel (Tel Aviv) regions, enabling you to build serverless applications with Lambda functions that are invoked based on messages posted to Amazon MQ message brokers. Amazon MQ is a managed message broker service for Apache ActiveMQ Classic and RabbitMQ that makes it easy to migrate to a message broker in the cloud. Lambda makes it easy to read from Amazon MQ message brokers and process messages without needing to create and manage a consumer application that monitors Amazon MQ queues for updates. Your Lambda function is invoked when the messages exceed the batch size or batch window, or when the payload exceeds 6MB. Lambda manages connectivity with your Amazon MQ message brokers on your behalf. This feature incurs no additional charge. You pay for the Lambda function invocations triggered by the event source mapping connected to Amazon MQ message brokers. To learn more, see the Lambda developer Guide for Amazon MQ.
- Amazon EC2 C7i-flex instances are now available in Asia Pacific (Sydney) and Asia Pacific (Tokyo) Regionsby aws@amazon.com (Recent Announcements) on July 18, 2024 at 9:40 pm
Starting today, Amazon Elastic Compute Cloud (Amazon EC2) C7i-flex instances that deliver up to 19% better price performance compared to C6i instances, are available in Asia Pacific (Sydney) and Asia Pacific (Tokyo) regions. C7i-flex instances expand the EC2 Flex instances portfolio to provide the easiest way for you to get price performance benefits for a majority of compute intensive workloads. The new instances are powered by the 4th generation Intel Xeon Scalable custom processors (Sapphire Rapids) that are available only on AWS, and offer 5% lower prices compared to C7i. C7i-flex instances offer the most common sizes, from large to 8xlarge, and are a great first choice for applications that don't fully utilize all compute resources. With C7i-flex instances, you can seamlessly run web and application servers, databases, caches, Apache Kafka, and Elasticsearch, and more. For compute-intensive workloads that need larger instance sizes (up to 192 vCPUs and 384 GiB memory) or continuous high CPU usage, you can leverage C7i instances. C7i-flex instances are available in the following AWS Regions: US East (Ohio), US West (N. California), Europe (Ireland, London, Paris, Spain, Stockholm), Canada (Central), Asia Pacific (Mumbai, Singapore, Sydney, Tokyo), and South America (São Paulo). To learn more, visit Amazon EC2 C7i-flex instances.
Top 60 AWS Solution Architect Associate Exam Tips
Top 100 AWS Solutions Architect Associate Certification Exam Questions and Answers Dump SAA-C03
Active Hydrating Toner, Anti-Aging Replenishing Advanced Face Moisturizer, with Vitamins A, C, E & Natural Botanicals to Promote Skin Balance & Collagen Production, 6.7 Fl Oz



Age Defying 0.3% Retinol Serum, Anti-Aging Dark Spot Remover for Face, Fine Lines & Wrinkle Pore Minimizer, with Vitamin E & Natural Botanicals


Firming Moisturizer, Advanced Hydrating Facial Replenishing Cream, with Hyaluronic Acid, Resveratrol & Natural Botanicals to Restore Skin's Strength, Radiance, and Resilience, 1.75 Oz

Skin Stem Cell Serum


Smartphone 101 - Pick a smartphone for me - android or iOS - Apple iPhone or Samsung Galaxy or Huawei or Xaomi or Google Pixel
Can AI Really Predict Lottery Results? We Asked an Expert.




Djamgatech

Read Photos and PDFs Aloud for me iOS
Read Photos and PDFs Aloud for me android
Read Photos and PDFs Aloud For me Windows 10/11
Read Photos and PDFs Aloud For Amazon
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more)
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6(Email us for more)



FREE 10000+ Quiz Trivia and and Brain Teasers for All Topics including Cloud Computing, General Knowledge, History, Television, Music, Art, Science, Movies, Films, US History, Soccer Football, World Cup, Data Science, Machine Learning, Geography, etc....


List of Freely available programming books - What is the single most influential book every Programmers should read
- Bjarne Stroustrup - The C++ Programming Language
- Brian W. Kernighan, Rob Pike - The Practice of Programming
- Donald Knuth - The Art of Computer Programming
- Ellen Ullman - Close to the Machine
- Ellis Horowitz - Fundamentals of Computer Algorithms
- Eric Raymond - The Art of Unix Programming
- Gerald M. Weinberg - The Psychology of Computer Programming
- James Gosling - The Java Programming Language
- Joel Spolsky - The Best Software Writing I
- Keith Curtis - After the Software Wars
- Richard M. Stallman - Free Software, Free Society
- Richard P. Gabriel - Patterns of Software
- Richard P. Gabriel - Innovation Happens Elsewhere
- Code Complete (2nd edition) by Steve McConnell
- The Pragmatic Programmer
- Structure and Interpretation of Computer Programs
- The C Programming Language by Kernighan and Ritchie
- Introduction to Algorithms by Cormen, Leiserson, Rivest & Stein
- Design Patterns by the Gang of Four
- Refactoring: Improving the Design of Existing Code
- The Mythical Man Month
- The Art of Computer Programming by Donald Knuth
- Compilers: Principles, Techniques and Tools by Alfred V. Aho, Ravi Sethi and Jeffrey D. Ullman
- Gödel, Escher, Bach by Douglas Hofstadter
- Clean Code: A Handbook of Agile Software Craftsmanship by Robert C. Martin
- Effective C++
- More Effective C++
- CODE by Charles Petzold
- Programming Pearls by Jon Bentley
- Working Effectively with Legacy Code by Michael C. Feathers
- Peopleware by Demarco and Lister
- Coders at Work by Peter Seibel
- Surely You're Joking, Mr. Feynman!
- Effective Java 2nd edition
- Patterns of Enterprise Application Architecture by Martin Fowler
- The Little Schemer
- The Seasoned Schemer
- Why's (Poignant) Guide to Ruby
- The Inmates Are Running The Asylum: Why High Tech Products Drive Us Crazy and How to Restore the Sanity
- The Art of Unix Programming
- Test-Driven Development: By Example by Kent Beck
- Practices of an Agile Developer
- Don't Make Me Think
- Agile Software Development, Principles, Patterns, and Practices by Robert C. Martin
- Domain Driven Designs by Eric Evans
- The Design of Everyday Things by Donald Norman
- Modern C++ Design by Andrei Alexandrescu
- Best Software Writing I by Joel Spolsky
- The Practice of Programming by Kernighan and Pike
- Pragmatic Thinking and Learning: Refactor Your Wetware by Andy Hunt
- Software Estimation: Demystifying the Black Art by Steve McConnel
- The Passionate Programmer (My Job Went To India) by Chad Fowler
- Hackers: Heroes of the Computer Revolution
- Algorithms + Data Structures = Programs
- Writing Solid Code
- JavaScript - The Good Parts
- Getting Real by 37 Signals
- Foundations of Programming by Karl Seguin
- Computer Graphics: Principles and Practice in C (2nd Edition)
- Thinking in Java by Bruce Eckel
- The Elements of Computing Systems
- Refactoring to Patterns by Joshua Kerievsky
- Modern Operating Systems by Andrew S. Tanenbaum
- The Annotated Turing
- Things That Make Us Smart by Donald Norman
- The Timeless Way of Building by Christopher Alexander
- The Deadline: A Novel About Project Management by Tom DeMarco
- The C++ Programming Language (3rd edition) by Stroustrup
- Patterns of Enterprise Application Architecture
- Computer Systems - A Programmer's Perspective
- Agile Principles, Patterns, and Practices in C# by Robert C. Martin
- Growing Object-Oriented Software, Guided by Tests
- Framework Design Guidelines by Brad Abrams
- Object Thinking by Dr. David West
- Advanced Programming in the UNIX Environment by W. Richard Stevens
- Hackers and Painters: Big Ideas from the Computer Age
- The Soul of a New Machine by Tracy Kidder
- CLR via C# by Jeffrey Richter
- The Timeless Way of Building by Christopher Alexander
- Design Patterns in C# by Steve Metsker
- Alice in Wonderland by Lewis Carol
- Zen and the Art of Motorcycle Maintenance by Robert M. Pirsig
- About Face - The Essentials of Interaction Design
- Here Comes Everybody: The Power of Organizing Without Organizations by Clay Shirky
- The Tao of Programming
- Computational Beauty of Nature
- Writing Solid Code by Steve Maguire
- Philip and Alex's Guide to Web Publishing
- Object-Oriented Analysis and Design with Applications by Grady Booch
- Effective Java by Joshua Bloch
- Computability by N. J. Cutland
- Masterminds of Programming
- The Tao Te Ching
- The Productive Programmer
- The Art of Deception by Kevin Mitnick
- The Career Programmer: Guerilla Tactics for an Imperfect World by Christopher Duncan
- Paradigms of Artificial Intelligence Programming: Case studies in Common Lisp
- Masters of Doom
- Pragmatic Unit Testing in C# with NUnit by Andy Hunt and Dave Thomas with Matt Hargett
- How To Solve It by George Polya
- The Alchemist by Paulo Coelho
- Smalltalk-80: The Language and its Implementation
- Writing Secure Code (2nd Edition) by Michael Howard
- Introduction to Functional Programming by Philip Wadler and Richard Bird
- No Bugs! by David Thielen
- Rework by Jason Freid and DHH
- JUnit in Action
#BlackOwned #BlackEntrepreneurs #BlackBuniness #AWSCertified #AWSCloudPractitioner #AWSCertification #AWSCLFC02 #CloudComputing #AWSStudyGuide #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AWSBasics #AWSCertified #AWSMachineLearning #AWSCertification #AWSSpecialty #MachineLearning #AWSStudyGuide #CloudComputing #DataScience #AWSCertified #AWSSolutionsArchitect #AWSArchitectAssociate #AWSCertification #AWSStudyGuide #CloudComputing #AWSArchitecture #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AzureFundamentals #AZ900 #MicrosoftAzure #ITCertification #CertificationPrep #StudyMaterials #TechLearning #MicrosoftCertified #AzureCertification #TechBooks
Top 1000 Canada Quiz and trivia: CANADA CITIZENSHIP TEST- HISTORY - GEOGRAPHY - GOVERNMENT- CULTURE - PEOPLE - LANGUAGES - TRAVEL - WILDLIFE - HOCKEY - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Top 1000 Africa Quiz and trivia: HISTORY - GEOGRAPHY - WILDLIFE - CULTURE - PEOPLE - LANGUAGES - TRAVEL - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Exploring the Pros and Cons of Visiting All Provinces and Territories in Canada.


Exploring the Advantages and Disadvantages of Visiting All 50 States in the USA

Health Health, a science-based community to discuss health news and the coronavirus (COVID-19) pandemic
- US infant mortality increased in 2022 for the first time in decades, CDC report showsby /u/cnn on July 25, 2024 at 6:37 pm
submitted by /u/cnn [link] [comments]
- Study raises hopes that shingles vaccine may delay onset of dementia | Dementia | The Guardianby /u/chilladipa on July 25, 2024 at 3:38 pm
submitted by /u/chilladipa [link] [comments]
- How fit is your city? New rankings by the American College of Sports Medicineby /u/idc2011 on July 25, 2024 at 3:35 pm
submitted by /u/idc2011 [link] [comments]
- Twice-Yearly Lenacapavir or Daily F/TAF for HIV Prevention in Cisgender Women | New England Journal of Medicineby /u/chilladipa on July 25, 2024 at 3:30 pm
submitted by /u/chilladipa [link] [comments]
- Biden Made a Healthy Decisionby /u/theatlantic on July 25, 2024 at 3:15 pm
submitted by /u/theatlantic [link] [comments]
Today I Learned (TIL) You learn something new every day; what did you learn today? Submit interesting and specific facts about something that you just found out here.
- TIL actor John Larroquette was the uncredited narrator of the prologue to the 1974 horror movie Texas Chainsaw Massacre. In lieu of cash, he was paid by the Director Tobe Hooper in Marijuana.by /u/openletter8 on July 25, 2024 at 6:56 pm
submitted by /u/openletter8 [link] [comments]
- TIL that the every Shakopee Mdewakanton Sioux indian receives a payout of around $1 million per year from casino profits.by /u/friendlystranger4u on July 25, 2024 at 6:22 pm
submitted by /u/friendlystranger4u [link] [comments]
- TIL Motorcycles in China are dictated by law to be decommissioned and destroyed in 13 years after registration regardless of the conditionsby /u/Easy_Piece_592 on July 25, 2024 at 5:56 pm
submitted by /u/Easy_Piece_592 [link] [comments]
- TIL a man named Jonathan Riches has filed more than 2,600 lawsuits since 2006. He even sued Guinness World Records to try to stop them from titling him as "the most litigious man in history".by /u/doopityWoop22 on July 25, 2024 at 5:03 pm
submitted by /u/doopityWoop22 [link] [comments]
- TIL that in 2018, an American half-pipe skier qualified for the Olympics despite minimal experience. Olympic requirements stated that an athlete needed to place in the top 30 at multiple events. She simply sought out events with fewer than 30 participants, showed up, and skied down without falling.by /u/ctdca on July 25, 2024 at 4:28 pm
submitted by /u/ctdca [link] [comments]
Reddit Science This community is a place to share and discuss new scientific research. Read about the latest advances in astronomy, biology, medicine, physics, social science, and more. Find and submit new publications and popular science coverage of current research.
- Abstinence-only sex education linked to higher pornography use among women | This finding adds to the ongoing conversation about the effectiveness and impacts of different sexuality education approaches.by /u/chrisdh79 on July 25, 2024 at 6:49 pm
submitted by /u/chrisdh79 [link] [comments]
- AlphaProof and AlphaGeometry 2 AI models achieve silver medal standard in solving International Mathematical Olympiad problemsby /u/Big_Profit9076 on July 25, 2024 at 5:59 pm
submitted by /u/Big_Profit9076 [link] [comments]
- Scientists have described a new species of chordate, Nuucichthys rhynchocephalus, the first soft-bodied vertebrate from the Drumian Marjum Formation of the American Great Basin.by /u/grimisgreedy on July 25, 2024 at 5:55 pm
submitted by /u/grimisgreedy [link] [comments]
- Secularists revealed as a unique political force in America, with an intriguing divergence from liberals. Unlike nonreligiosity, which denotes a lack of religious affiliation or belief, secularism involves an active identification with principles grounded in empirical evidence and rational thought.by /u/mvea on July 25, 2024 at 5:40 pm
submitted by /u/mvea [link] [comments]
- New shingles vaccine could reduce risk of dementia. The study found at least a 17% reduction in dementia diagnoses in the six years after the new recombinant shingles vaccination, equating to 164 or more additional days lived without dementia.by /u/Wagamaga on July 25, 2024 at 4:48 pm
submitted by /u/Wagamaga [link] [comments]
Reddit Sports Sports News and Highlights from the NFL, NBA, NHL, MLB, MLS, and leagues around the world.
- A's place their lone all-star, Mason Miller, on IL with fractured finger after hitting training tableby /u/Oldtimer_2 on July 25, 2024 at 8:15 pm
submitted by /u/Oldtimer_2 [link] [comments]
- Flyers sign All-Star Travis Konecny to an 8-year extension worth $70 millionby /u/Oldtimer_2 on July 25, 2024 at 7:45 pm
submitted by /u/Oldtimer_2 [link] [comments]
- Bills’ Von Miller says he believes domestic assault case to be closed, with no charges filedby /u/Oldtimer_2 on July 25, 2024 at 7:43 pm
submitted by /u/Oldtimer_2 [link] [comments]
- Padres' Dylan Cease throws no-hitter vs. Nationalsby /u/Oldtimer_2 on July 25, 2024 at 7:41 pm
submitted by /u/Oldtimer_2 [link] [comments]
- Appeal denied in Valieva case; U.S. skaters to get gold in Parisby /u/PrincessBananas85 on July 25, 2024 at 6:18 pm
submitted by /u/PrincessBananas85 [link] [comments]
