



What are the Top 200 AWS and Google Certified Machine Learning Specialty Questions and Answers Dumps?
This blog is the best way is the best way to prepare for your upcoming AWS Certified Machine Learning Specialty and Google Certified Professional Machine Learning Engineer exam. With over 100 questions and answers, this blog provides quizzes similar that are very similar to the real exam. It also includes the option to show and hide answers. Additionally, there are machine learning interview questions and detailed answers, as well as cheat sheets and illustrations. This blog is the best way to make sure you are well-prepared for your AWS Certified Machine Learning Specialty Exam.

The typical Google Machine Learning Engineer salary is $147,218. Machine Learning Engineer salaries at Google can range from $110,000 – $152,183.
Machine learning is an application of artificial intelligence (AI) that provides systems the ability to automatically learn and improve from experience without being explicitly programmed. Machine learning focuses on the development of computer programs that can access data and use it to learn for themselves.
- By the end of 2020, 85% of customer interactions will be handled without a human (Call Center, Chatbot, etc…)
- 61% of marketers say artificial intelligence is the most important aspect of their data strategy.
- 80% of business and tech leaders say AI already boosts productivity (Robotic Process Automation, Power Automate, etc..)
- Current AI technology can boost business productivity by up to 40%
AWS Machine Learning Certification Specialty Exam Prep for iOs Android Windows10/11

GCP Professional Machine Learning Engineer for iOs, Android, Windows 10/11
Quizzes, Practice Exams: Framing, Architecting, Designing, Developing ML Problems & Solutions, ML Jobs Interview Q&A

Azure AI Fundamentals AI-900 Exam Prep App for iOS, Android, Windows10/11
Basics and Advanced Machine Learning Quizzes on Azure, Azure Machine Learning Job Interviews Questions and Answer, ML Cheat Sheets

Machine Learning For Dummies App for iOs, Android, Windows10/11
Use this App to learn about Machine Learning and Elevate your Brain with Machine Learning Quizzes, Cheat Sheets, Ml Jobs Interview Questions and Answers updated daily.


What does a Professional Machine Learning Engineer do?
A Professional Machine Learning Engineer designs, builds, and productionizes ML models to solve business challenges using Google Cloud technologies and knowledge of proven ML models and techniques. The ML Engineer collaborates closely with other job roles to ensure long-term success of models. The ML Engineer should be proficient in all aspects of model architecture, data pipeline interaction, and metrics interpretation. The ML Engineer needs familiarity with application development, infrastructure management, data engineering, and security. Through an understanding of training, retraining, deploying, scheduling, monitoring, and improving models, they design and create scalable solutions for optimal performance.
The AWS Certified Machine Learning – Specialty certification is intended for individuals who perform a development or data science role. It validates a candidate’s ability to design, implement, deploy, and maintain machine learning (ML) solutions for given business problems.
This blog covers Machine Learning 101, Top 20 AWS Certified Machine Learning Specialty Questions and Answers, Top 20 Google Professional Machine Learning Engineer Sample Questions, Machine Learning Quizzes, Machine Learning Q&A, Top 10 Machine Learning Algorithms, Machine Learning Latest Hot News, Machine Learning Demos (Ex: Tensorflow Demos)
Question1: A machine learning team has several large CSV datasets in Amazon S3. Historically, models built with the Amazon SageMaker Linear Learner algorithm have taken hours to train on similar-sized datasets. The team’s leaders need to accelerate the training process. What can a machine learning specialist do to address this concern?

A) Use Amazon SageMaker Pipe mode.
B) Use Amazon Machine Learning to train the models.
C) Use Amazon Kinesis to stream the data to Amazon SageMaker.
D) Use AWS Glue to transform the CSV dataset to the JSON format.
ANSWER1:
Notes/Hint1:

Question 2) A local university wants to track cars in a parking lot to determine which students are parking in the lot. The university is wanting to ingest videos of the cars parking in near-real time, use machine learning to identify license plates, and store that data in an AWS data store. Which solution meets these requirements with the LEAST amount of development effort?
A) Use Amazon Kinesis Data Streams to ingest the video in near-real time, use the Kinesis Data Streams consumer integrated with Amazon Rekognition Video to process the license plate information, and then store results in DynamoDB.
B) Use Amazon Kinesis Video Streams to ingest the videos in near-real time, use the Kinesis Video Streams integration with Amazon Rekognition Video to identify the license plate information, and then store the results in DynamoDB.
C) Use Amazon Kinesis Data Streams to ingest videos in near-real time, call Amazon Rekognition to identify license plate information, and then store results in DynamoDB.
D) Use Amazon Kinesis Firehose to ingest the video in near-real time and outputs results onto S3. Set up a Lambda function that triggers when a new video is PUT onto S3 to send results to Amazon Rekognition to identify license plate information, and then store results in DynamoDB.

Answer 2)
Notes/Hint2)
Question 3) A term frequency–inverse document frequency (tf–idf) matrix using both unigrams and bigrams is built from a text corpus consisting of the following two sentences:
ANSWER3:
Notes/Hint3:
Question 4: A company is setting up a system to manage all of the datasets it stores in Amazon S3. The company would like to automate running transformation jobs on the data and maintaining a catalog of the metadata concerning the datasets. The solution should require the least amount of setup and maintenance. Which solution will allow the company to achieve its goals?
ANSWER4:
Notes/Hint4:
Question 5) Which service in the Kinesis family allows you to easily load streaming data into data stores and analytics tools?
ANSWER5:
Notes/Hint5:

Notes 6)
Notes/Hint 8)

Answer 9)
Notes 9)
Answer 10)
Answer 11)
Notes 11)

Notes 12)
Answer 13)

Notes 13)
Question 14) You have been tasked with capturing two different types of streaming events. The first event type includes mission-critical data that needs to immediately be processed before operations can continue. The second event type includes data of less importance, but operations can continue without immediately processing. What is the most appropriate solution to record these different types of events?
Answer 14)
Notes 14)

Question 15) You are collecting clickstream data from an e-commerce website to make near-real time product suggestions for users actively using the site. Which combination of tools can be used to achieve the quickest recommendations and meets all of the requirements?
Answer 15)
Notes 15)
Question 16) Which service built by AWS makes it easy to set up a retry mechanism, aggregate records to improve throughput, and automatically submits CloudWatch metrics?
Answer 16)
Notes 16)
[appbox appstore 1611045854-iphone screenshots]
[appbox microsoftstore 9n8rl80hvm4t-mobile screenshots]
Question 17) You have been tasked with capturing data from an online gaming platform to run analytics on and process through a machine learning pipeline. The data that you are ingesting is players controller inputs every 1 second (up to 10 players in a game) that is in JSON format. The data needs to be ingested through Kinesis Data Streams and the JSON data blob is 100 KB in size. What is the minimum number of shards you can use to successfully ingest this data?
Answer 17)
Notes 17)
Question 18) Which services in the Kinesis family allows you to analyze streaming data, gain actionable insights, and respond to your business and customer needs in real time?
Answer 18)
Notes 18)
Question 19) You are a ML specialist needing to collect data from Twitter tweets. Your goal is to collect tweets that include only the name of your company and the tweet body, and store it off into a data store in AWS. What set of tools can you use to stream, transform, and load the data into AWS with the LEAST amount of effort?
Answer 19)
Notes 19)
Question 20) Which service in the Kinesis family allows you to build custom applications that process or analyze streaming data for specialized needs?
Answer 20)
Notes 20)
Question21:
Answer21:
What are the Top 100 AWS and Google Certified Machine Learning Specialty Questions and Answers Dumps?
This blog is the best way is the best way to prepare for your upcoming AWS Certified Machine Learning Specialty and Google Certified Professional Machine Learning Engineer exam. With over 100 questions and answers, this blog provides quizzes similar that are very similar to the real exam. It also includes the option to show and hide answers. Additionally, there are machine learning interview questions and detailed answers, as well as cheat sheets and illustrations. This blog is the best way to make sure you are well-prepared for your AWS Certified Machine Learning Specialty Exam.
The typical Google Machine Learning Engineer salary is $147,218. Machine Learning Engineer salaries at Google can range from $110,000 – $152,183.
Machine learning is an application of artificial intelligence (AI) that provides systems the ability to automatically learn and improve from experience without being explicitly programmed. Machine learning focuses on the development of computer programs that can access data and use it to learn for themselves.
- By the end of 2020, 85% of customer interactions will be handled without a human (Call Center, Chatbot, etc…)
- 61% of marketers say artificial intelligence is the most important aspect of their data strategy.
- 80% of business and tech leaders say AI already boosts productivity (Robotic Process Automation, Power Automate, etc..)
- Current AI technology can boost business productivity by up to 40%
AWS Machine Learning Certification Specialty Exam Prep for iOs Android Windows10/11
GCP Professional Machine Learning Engineer for iOs, Android, Windows 10/11
Quizzes, Practice Exams: Framing, Architecting, Designing, Developing ML Problems & Solutions, ML Jobs Interview Q&A
Azure AI Fundamentals AI-900 Exam Prep App for iOS, Android, Windows10/11
Basics and Advanced Machine Learning Quizzes on Azure, Azure Machine Learning Job Interviews Questions and Answer, ML Cheat Sheets
Machine Learning For Dummies App for iOs, Android, Windows10/11
Use this App to learn about Machine Learning and Elevate your Brain with Machine Learning Quizzes, Cheat Sheets, Ml Jobs Interview Questions and Answers updated daily.
What does a Professional Machine Learning Engineer do?
A Professional Machine Learning Engineer designs, builds, and productionizes ML models to solve business challenges using Google Cloud technologies and knowledge of proven ML models and techniques. The ML Engineer collaborates closely with other job roles to ensure long-term success of models. The ML Engineer should be proficient in all aspects of model architecture, data pipeline interaction, and metrics interpretation. The ML Engineer needs familiarity with application development, infrastructure management, data engineering, and security. Through an understanding of training, retraining, deploying, scheduling, monitoring, and improving models, they design and create scalable solutions for optimal performance.
The AWS Certified Machine Learning – Specialty certification is intended for individuals who perform a development or data science role. It validates a candidate’s ability to design, implement, deploy, and maintain machine learning (ML) solutions for given business problems.
This blog covers Machine Learning 101, Top 20 AWS Certified Machine Learning Specialty Questions and Answers, Top 20 Google Professional Machine Learning Engineer Sample Questions, Machine Learning Quizzes, Machine Learning Q&A, Top 10 Machine Learning Algorithms, Machine Learning Latest Hot News, Machine Learning Demos (Ex: Tensorflow Demos)
Question1: A machine learning team has several large CSV datasets in Amazon S3. Historically, models built with the Amazon SageMaker Linear Learner algorithm have taken hours to train on similar-sized datasets. The team’s leaders need to accelerate the training process. What can a machine learning specialist do to address this concern?
A) Use Amazon SageMaker Pipe mode.
B) Use Amazon Machine Learning to train the models.
C) Use Amazon Kinesis to stream the data to Amazon SageMaker.
D) Use AWS Glue to transform the CSV dataset to the JSON format.
ANSWER1:
Notes/Hint1:
Question 2) A local university wants to track cars in a parking lot to determine which students are parking in the lot. The university is wanting to ingest videos of the cars parking in near-real time, use machine learning to identify license plates, and store that data in an AWS data store. Which solution meets these requirements with the LEAST amount of development effort?
A) Use Amazon Kinesis Data Streams to ingest the video in near-real time, use the Kinesis Data Streams consumer integrated with Amazon Rekognition Video to process the license plate information, and then store results in DynamoDB.
B) Use Amazon Kinesis Video Streams to ingest the videos in near-real time, use the Kinesis Video Streams integration with Amazon Rekognition Video to identify the license plate information, and then store the results in DynamoDB.
C) Use Amazon Kinesis Data Streams to ingest videos in near-real time, call Amazon Rekognition to identify license plate information, and then store results in DynamoDB.
D) Use Amazon Kinesis Firehose to ingest the video in near-real time and outputs results onto S3. Set up a Lambda function that triggers when a new video is PUT onto S3 to send results to Amazon Rekognition to identify license plate information, and then store results in DynamoDB.
Answer 2)
Notes/Hint2)
Question 3) A term frequency–inverse document frequency (tf–idf) matrix using both unigrams and bigrams is built from a text corpus consisting of the following two sentences:
ANSWER3:
Notes/Hint3:
Question 4: A company is setting up a system to manage all of the datasets it stores in Amazon S3. The company would like to automate running transformation jobs on the data and maintaining a catalog of the metadata concerning the datasets. The solution should require the least amount of setup and maintenance. Which solution will allow the company to achieve its goals?
ANSWER4:
Notes/Hint4:
Question 5) Which service in the Kinesis family allows you to easily load streaming data into data stores and analytics tools?
ANSWER5:
Notes/Hint5:
Notes 6)
Notes/Hint 8)
Answer 9)
Notes 9)
Answer 10)
Answer 11)
Notes 11)
Notes 12)
Answer 13)
Notes 13)
Question 14) You have been tasked with capturing two different types of streaming events. The first event type includes mission-critical data that needs to immediately be processed before operations can continue. The second event type includes data of less importance, but operations can continue without immediately processing. What is the most appropriate solution to record these different types of events?
Answer 14)
Notes 14)
Question 15) You are collecting clickstream data from an e-commerce website to make near-real time product suggestions for users actively using the site. Which combination of tools can be used to achieve the quickest recommendations and meets all of the requirements?
Answer 15)
Notes 15)
Question 16) Which service built by AWS makes it easy to set up a retry mechanism, aggregate records to improve throughput, and automatically submits CloudWatch metrics?
Answer 16)
Notes 16)
[appbox appstore 1611045854-iphone screenshots]
[appbox microsoftstore 9n8rl80hvm4t-mobile screenshots]
Question 17) You have been tasked with capturing data from an online gaming platform to run analytics on and process through a machine learning pipeline. The data that you are ingesting is players controller inputs every 1 second (up to 10 players in a game) that is in JSON format. The data needs to be ingested through Kinesis Data Streams and the JSON data blob is 100 KB in size. What is the minimum number of shards you can use to successfully ingest this data?
Answer 17)
Notes 17)
Question 18) Which services in the Kinesis family allows you to analyze streaming data, gain actionable insights, and respond to your business and customer needs in real time?
Answer 18)
Notes 18)
Question 19) You are a ML specialist needing to collect data from Twitter tweets. Your goal is to collect tweets that include only the name of your company and the tweet body, and store it off into a data store in AWS. What set of tools can you use to stream, transform, and load the data into AWS with the LEAST amount of effort?
Answer 19)
Notes 19)
Question 20) Which service in the Kinesis family allows you to build custom applications that process or analyze streaming data for specialized needs?
Answer 20)
Notes 20)
Question21:
Answer21:
Notes 21:
Question22:
Answer22:
Notes 22:
Question23:
Answer23:
Notes 23:
Question24:
Answer24:
Notes 24:
What are the Top 100 AWS and Google Certified Machine Learning Specialty Questions and Answers Dumps?
This blog is the best way is the best way to prepare for your upcoming AWS Certified Machine Learning Specialty and Google Certified Professional Machine Learning Engineer exam. With over 100 questions and answers, this blog provides quizzes similar that are very similar to the real exam. It also includes the option to show and hide answers. Additionally, there are machine learning interview questions and detailed answers, as well as cheat sheets and illustrations. This blog is the best way to make sure you are well-prepared for your AWS Certified Machine Learning Specialty Exam.
The typical Google Machine Learning Engineer salary is $147,218. Machine Learning Engineer salaries at Google can range from $110,000 – $152,183.
Machine learning is an application of artificial intelligence (AI) that provides systems the ability to automatically learn and improve from experience without being explicitly programmed. Machine learning focuses on the development of computer programs that can access data and use it to learn for themselves.
- By the end of 2020, 85% of customer interactions will be handled without a human (Call Center, Chatbot, etc…)
- 61% of marketers say artificial intelligence is the most important aspect of their data strategy.
- 80% of business and tech leaders say AI already boosts productivity (Robotic Process Automation, Power Automate, etc..)
- Current AI technology can boost business productivity by up to 40%
AWS Machine Learning Certification Specialty Exam Prep for iOs Android Windows10/11
GCP Professional Machine Learning Engineer for iOs, Android, Windows 10/11
Quizzes, Practice Exams: Framing, Architecting, Designing, Developing ML Problems & Solutions, ML Jobs Interview Q&A
Azure AI Fundamentals AI-900 Exam Prep App for iOS, Android, Windows10/11
Basics and Advanced Machine Learning Quizzes on Azure, Azure Machine Learning Job Interviews Questions and Answer, ML Cheat Sheets
Machine Learning For Dummies App for iOs, Android, Windows10/11
Use this App to learn about Machine Learning and Elevate your Brain with Machine Learning Quizzes, Cheat Sheets, Ml Jobs Interview Questions and Answers updated daily.
What does a Professional Machine Learning Engineer do?
A Professional Machine Learning Engineer designs, builds, and productionizes ML models to solve business challenges using Google Cloud technologies and knowledge of proven ML models and techniques. The ML Engineer collaborates closely with other job roles to ensure long-term success of models. The ML Engineer should be proficient in all aspects of model architecture, data pipeline interaction, and metrics interpretation. The ML Engineer needs familiarity with application development, infrastructure management, data engineering, and security. Through an understanding of training, retraining, deploying, scheduling, monitoring, and improving models, they design and create scalable solutions for optimal performance.
The AWS Certified Machine Learning – Specialty certification is intended for individuals who perform a development or data science role. It validates a candidate’s ability to design, implement, deploy, and maintain machine learning (ML) solutions for given business problems.
This blog covers Machine Learning 101, Top 20 AWS Certified Machine Learning Specialty Questions and Answers, Top 20 Google Professional Machine Learning Engineer Sample Questions, Machine Learning Quizzes, Machine Learning Q&A, Top 10 Machine Learning Algorithms, Machine Learning Latest Hot News, Machine Learning Demos (Ex: Tensorflow Demos)
Question1: A machine learning team has several large CSV datasets in Amazon S3. Historically, models built with the Amazon SageMaker Linear Learner algorithm have taken hours to train on similar-sized datasets. The team’s leaders need to accelerate the training process. What can a machine learning specialist do to address this concern?
A) Use Amazon SageMaker Pipe mode.
B) Use Amazon Machine Learning to train the models.
C) Use Amazon Kinesis to stream the data to Amazon SageMaker.
D) Use AWS Glue to transform the CSV dataset to the JSON format.
ANSWER1:
Notes/Hint1:
Question 2) A local university wants to track cars in a parking lot to determine which students are parking in the lot. The university is wanting to ingest videos of the cars parking in near-real time, use machine learning to identify license plates, and store that data in an AWS data store. Which solution meets these requirements with the LEAST amount of development effort?
A) Use Amazon Kinesis Data Streams to ingest the video in near-real time, use the Kinesis Data Streams consumer integrated with Amazon Rekognition Video to process the license plate information, and then store results in DynamoDB.
B) Use Amazon Kinesis Video Streams to ingest the videos in near-real time, use the Kinesis Video Streams integration with Amazon Rekognition Video to identify the license plate information, and then store the results in DynamoDB.
C) Use Amazon Kinesis Data Streams to ingest videos in near-real time, call Amazon Rekognition to identify license plate information, and then store results in DynamoDB.
D) Use Amazon Kinesis Firehose to ingest the video in near-real time and outputs results onto S3. Set up a Lambda function that triggers when a new video is PUT onto S3 to send results to Amazon Rekognition to identify license plate information, and then store results in DynamoDB.
Answer 2)
Notes/Hint2)
Question 3) A term frequency–inverse document frequency (tf–idf) matrix using both unigrams and bigrams is built from a text corpus consisting of the following two sentences:
ANSWER3:
Notes/Hint3:
Question 4: A company is setting up a system to manage all of the datasets it stores in Amazon S3. The company would like to automate running transformation jobs on the data and maintaining a catalog of the metadata concerning the datasets. The solution should require the least amount of setup and maintenance. Which solution will allow the company to achieve its goals?
ANSWER4:
Notes/Hint4:
Question 5) Which service in the Kinesis family allows you to easily load streaming data into data stores and analytics tools?
ANSWER5:
Notes/Hint5:
Notes 6)
Notes/Hint 8)
Answer 9)
Notes 9)
Answer 10)
Answer 11)
Notes 11)
Notes 12)
Answer 13)
Notes 13)
Question 14) You have been tasked with capturing two different types of streaming events. The first event type includes mission-critical data that needs to immediately be processed before operations can continue. The second event type includes data of less importance, but operations can continue without immediately processing. What is the most appropriate solution to record these different types of events?
Answer 14)
Notes 14)
Question 15) You are collecting clickstream data from an e-commerce website to make near-real time product suggestions for users actively using the site. Which combination of tools can be used to achieve the quickest recommendations and meets all of the requirements?
Answer 15)
Notes 15)
Question 16) Which service built by AWS makes it easy to set up a retry mechanism, aggregate records to improve throughput, and automatically submits CloudWatch metrics?
Answer 16)
Notes 16)
[appbox appstore 1611045854-iphone screenshots]
[appbox microsoftstore 9n8rl80hvm4t-mobile screenshots]
Question 17) You have been tasked with capturing data from an online gaming platform to run analytics on and process through a machine learning pipeline. The data that you are ingesting is players controller inputs every 1 second (up to 10 players in a game) that is in JSON format. The data needs to be ingested through Kinesis Data Streams and the JSON data blob is 100 KB in size. What is the minimum number of shards you can use to successfully ingest this data?
Answer 17)
Notes 17)
Question 18) Which services in the Kinesis family allows you to analyze streaming data, gain actionable insights, and respond to your business and customer needs in real time?
Answer 18)
Notes 18)
Question 19) You are a ML specialist needing to collect data from Twitter tweets. Your goal is to collect tweets that include only the name of your company and the tweet body, and store it off into a data store in AWS. What set of tools can you use to stream, transform, and load the data into AWS with the LEAST amount of effort?
Answer 19)
Notes 19)
Question 20) Which service in the Kinesis family allows you to build custom applications that process or analyze streaming data for specialized needs?
Answer 20)
Notes 20)
Question21:
Answer21:
What are the Top 100 AWS and Google Certified Machine Learning Specialty Questions and Answers Dumps?
This blog is the best way is the best way to prepare for your upcoming AWS Certified Machine Learning Specialty and Google Certified Professional Machine Learning Engineer exam. With over 100 questions and answers, this blog provides quizzes similar that are very similar to the real exam. It also includes the option to show and hide answers. Additionally, there are machine learning interview questions and detailed answers, as well as cheat sheets and illustrations. This blog is the best way to make sure you are well-prepared for your AWS Certified Machine Learning Specialty Exam.
The typical Google Machine Learning Engineer salary is $147,218. Machine Learning Engineer salaries at Google can range from $110,000 – $152,183.
Machine learning is an application of artificial intelligence (AI) that provides systems the ability to automatically learn and improve from experience without being explicitly programmed. Machine learning focuses on the development of computer programs that can access data and use it to learn for themselves.
- By the end of 2020, 85% of customer interactions will be handled without a human (Call Center, Chatbot, etc…)
- 61% of marketers say artificial intelligence is the most important aspect of their data strategy.
- 80% of business and tech leaders say AI already boosts productivity (Robotic Process Automation, Power Automate, etc..)
- Current AI technology can boost business productivity by up to 40%
AWS Machine Learning Certification Specialty Exam Prep for iOs Android Windows10/11
GCP Professional Machine Learning Engineer for iOs, Android, Windows 10/11
Quizzes, Practice Exams: Framing, Architecting, Designing, Developing ML Problems & Solutions, ML Jobs Interview Q&A
Azure AI Fundamentals AI-900 Exam Prep App for iOS, Android, Windows10/11
Basics and Advanced Machine Learning Quizzes on Azure, Azure Machine Learning Job Interviews Questions and Answer, ML Cheat Sheets
Machine Learning For Dummies App for iOs, Android, Windows10/11
Use this App to learn about Machine Learning and Elevate your Brain with Machine Learning Quizzes, Cheat Sheets, Ml Jobs Interview Questions and Answers updated daily.
What does a Professional Machine Learning Engineer do?
A Professional Machine Learning Engineer designs, builds, and productionizes ML models to solve business challenges using Google Cloud technologies and knowledge of proven ML models and techniques. The ML Engineer collaborates closely with other job roles to ensure long-term success of models. The ML Engineer should be proficient in all aspects of model architecture, data pipeline interaction, and metrics interpretation. The ML Engineer needs familiarity with application development, infrastructure management, data engineering, and security. Through an understanding of training, retraining, deploying, scheduling, monitoring, and improving models, they design and create scalable solutions for optimal performance.
The AWS Certified Machine Learning – Specialty certification is intended for individuals who perform a development or data science role. It validates a candidate’s ability to design, implement, deploy, and maintain machine learning (ML) solutions for given business problems.
This blog covers Machine Learning 101, Top 20 AWS Certified Machine Learning Specialty Questions and Answers, Top 20 Google Professional Machine Learning Engineer Sample Questions, Machine Learning Quizzes, Machine Learning Q&A, Top 10 Machine Learning Algorithms, Machine Learning Latest Hot News, Machine Learning Demos (Ex: Tensorflow Demos)
Question1: A machine learning team has several large CSV datasets in Amazon S3. Historically, models built with the Amazon SageMaker Linear Learner algorithm have taken hours to train on similar-sized datasets. The team’s leaders need to accelerate the training process. What can a machine learning specialist do to address this concern?
A) Use Amazon SageMaker Pipe mode.
B) Use Amazon Machine Learning to train the models.
C) Use Amazon Kinesis to stream the data to Amazon SageMaker.
D) Use AWS Glue to transform the CSV dataset to the JSON format.
ANSWER1:
Notes/Hint1:
Question 2) A local university wants to track cars in a parking lot to determine which students are parking in the lot. The university is wanting to ingest videos of the cars parking in near-real time, use machine learning to identify license plates, and store that data in an AWS data store. Which solution meets these requirements with the LEAST amount of development effort?
A) Use Amazon Kinesis Data Streams to ingest the video in near-real time, use the Kinesis Data Streams consumer integrated with Amazon Rekognition Video to process the license plate information, and then store results in DynamoDB.
B) Use Amazon Kinesis Video Streams to ingest the videos in near-real time, use the Kinesis Video Streams integration with Amazon Rekognition Video to identify the license plate information, and then store the results in DynamoDB.
C) Use Amazon Kinesis Data Streams to ingest videos in near-real time, call Amazon Rekognition to identify license plate information, and then store results in DynamoDB.
D) Use Amazon Kinesis Firehose to ingest the video in near-real time and outputs results onto S3. Set up a Lambda function that triggers when a new video is PUT onto S3 to send results to Amazon Rekognition to identify license plate information, and then store results in DynamoDB.
Answer 2)
Notes/Hint2)
Question 3) A term frequency–inverse document frequency (tf–idf) matrix using both unigrams and bigrams is built from a text corpus consisting of the following two sentences:
ANSWER3:
Notes/Hint3:
Question 4: A company is setting up a system to manage all of the datasets it stores in Amazon S3. The company would like to automate running transformation jobs on the data and maintaining a catalog of the metadata concerning the datasets. The solution should require the least amount of setup and maintenance. Which solution will allow the company to achieve its goals?
ANSWER4:
Notes/Hint4:
Question 5) Which service in the Kinesis family allows you to easily load streaming data into data stores and analytics tools?
ANSWER5:
Notes/Hint5:
Question 6) A data scientist is working on optimizing a model during the training process by varying multiple parameters. The data scientist observes that, during multiple runs with identical parameters, the loss function converges to different, yet stable, values. What should the data scientist do to improve the training process?
Notes 6)
Question 7) Your organization has a standalone Javascript (Node.js) application that streams data into AWS using Kinesis Data Streams. You notice that they are using the Kinesis API (AWS SDK) over the Kinesis Producer Library (KPL). What might be the reasoning behind this?
Question 8) A data scientist is evaluating different binary classification models. A false positive result is 5 times more expensive (from a business perspective) than a false negative result. The models should be evaluated based on the following criteria:
Notes/Hint 8)
Question 9) A data scientist uses logistic regression to build a fraud detection model. While the model accuracy is 99%, 90% of the fraud cases are not detected by the model. What action will definitely help the model detect more than 10% of fraud cases?
Answer 9)
Notes 9)
Question 10) A company is interested in building a fraud detection model. Currently, the data scientist does not have a sufficient amount of information due to the low number of fraud cases. Which method is MOST likely to detect the GREATEST number of valid fraud cases?
Answer 10)
Question 11) A machine learning engineer is preparing a data frame for a supervised learning task with the Amazon SageMaker Linear Learner algorithm. The ML engineer notices the target label classes are highly imbalanced and multiple feature columns contain missing values. The proportion of missing values across the entire data frame is less than 5%. What should the ML engineer do to minimize bias due to missing values?
Answer 11)
Notes 11)
Question 12) A company has collected customer comments on its products, rating them as safe or unsafe, using decision trees. The training dataset has the following features: id, date, full review, full review summary, and a binary safe/unsafe tag. During training, any data sample with missing features was dropped. In a few instances, the test set was found to be missing the full review text field. For this use case, which is the most effective course of action to address test data samples with missing features?
Notes 12)
Question 13) An insurance company needs to automate claim compliance reviews because human reviews are expensive and error-prone. The company has a large set of claims and a compliance label for each. Each claim consists of a few sentences in English, many of which contain complex related information. Management would like to use Amazon SageMaker built-in algorithms to design a machine learning supervised model that can be trained to read each claim and predict if the claim is compliant or not. Which approach should be used to extract features from the claims to be used as inputs for the downstream supervised task?
Answer 13)
Notes 13)
Question 14) You have been tasked with capturing two different types of streaming events. The first event type includes mission-critical data that needs to immediately be processed before operations can continue. The second event type includes data of less importance, but operations can continue without immediately processing. What is the most appropriate solution to record these different types of events?
Answer 14)
Notes 14)
Question 15) You are collecting clickstream data from an e-commerce website to make near-real time product suggestions for users actively using the site. Which combination of tools can be used to achieve the quickest recommendations and meets all of the requirements?
Answer 15)
Notes 15)
Question 16) Which service built by AWS makes it easy to set up a retry mechanism, aggregate records to improve throughput, and automatically submits CloudWatch metrics?
Answer 16)
Notes 16)
[appbox appstore 1611045854-iphone screenshots]
[appbox microsoftstore 9n8rl80hvm4t-mobile screenshots]
Question 17) You have been tasked with capturing data from an online gaming platform to run analytics on and process through a machine learning pipeline. The data that you are ingesting is players controller inputs every 1 second (up to 10 players in a game) that is in JSON format. The data needs to be ingested through Kinesis Data Streams and the JSON data blob is 100 KB in size. What is the minimum number of shards you can use to successfully ingest this data?
Answer 17)
Notes 17)
Question 18) Which services in the Kinesis family allows you to analyze streaming data, gain actionable insights, and respond to your business and customer needs in real time?
Answer 18)
Notes 18)
Question 19) You are a ML specialist needing to collect data from Twitter tweets. Your goal is to collect tweets that include only the name of your company and the tweet body, and store it off into a data store in AWS. What set of tools can you use to stream, transform, and load the data into AWS with the LEAST amount of effort?
Answer 19)
Notes 19)
Question 20) Which service in the Kinesis family allows you to build custom applications that process or analyze streaming data for specialized needs?
Answer 20)
Notes 20)
Question21: Of the following, which is an example of machine learning? (Select TWO.)
A) Calculating the shortest route from current location to the destination
B) Optimizing product pricing based on real-time sales data
C) Sentiment analysis of text on product reviews
D) A loan approval system that classifies applicants entirely based on credit score
Answer21:
Notes 21:
Question22:Which of the following is an appropriate use case for unsupervised learning?
A) Partitioning an image of a street scene into multiple segments
B) Finding an optimal path out of a maze
C) Identifying clusters of housing sales based on related data points
D) Analyzing sentiment of social media posts
Answer22:
Notes 22:
Question23:
Answer23:
Notes 23:
Question24: A Djamgatech retail company wants to deploy a machine learning model to predict the demand for a product using sales data from the past 5 years. What is the MOST efficient solution that the company should implement first?
A) Regression
B) Multi-class classification
C) Binary class classification
D) N/A
Answer24:
Notes 24:
Question25: In which phase of the ML pipeline do you analyze the business requirements and re-frame that information into a machine learning context.
A) Problem formulation
B) Model training
C) Deployment
D)
Answer25:
Notes 25:
iOs: https://apps.apple.com/
Android/Amazon: https://www.amazon.com/gp/product/B09TZ4H8V6
AWS MLS-C01 Machine Learning Exam Prep
Quizzes, Practice Exams: Modeling, Data Engineering, Vision, Exploratory Data Analysis, ML Ops, Cheat Sheets, ML Jobs Interview Q&A
Use this App to learn about Machine Learning on AWS and prepare for the AWS Machine Learning Specialty Certification MLS-C01.
Earning AWS Certified Machine Learning Specialty validates expertise in building, training, tuning, and deploying machine learning (ML) models on AWS.
The App provides hundreds of quizzes and practice exam about:
– Machine Learning Operation on AWS
– Modelling
– Data Engineering
– Computer Vision,
– Exploratory Data Analysis,
– ML implementation & Operations
– Machine Learning Basics Questions and Answers
– Machine Learning Advanced Questions and Answers
– Scorecard
– Countdown timer
– Machine Learning Cheat Sheets
– Machine Learning Interview Questions and Answers
– Machine Learning Latest News
The App covers Machine Learning Basics and Advanced topics including: NLP, Computer Vision, Python, linear regression, logistic regression, Sampling, dataset, statistical interaction, selection bias, non-Gaussian distribution, bias-variance trade-off, Normal Distribution, correlation and covariance, Point Estimates and Confidence Interval, A/B Testing, p-value, statistical power of sensitivity, over-fitting and under-fitting, regularization, Law of Large Numbers, Confounding Variables, Survivorship Bias, univariate, bivariate and multivariate, Resampling, ROC curve, TF/IDF vectorization, Cluster Sampling, etc.
Domain 1: Data Engineering
Create data repositories for machine learning.
Identify data sources (e.g., content and location, primary sources such as user data)
Determine storage mediums (e.g., DB, Data Lake, S3, EFS, EBS)
Identify and implement a data ingestion solution.
Data job styles/types (batch load, streaming)
Data ingestion pipelines (Batch-based ML workloads and streaming-based ML workloads), etc.
Domain 2: Exploratory Data Analysis
Sanitize and prepare data for modeling.
Perform feature engineering.
Analyze and visualize data for machine learning.
Domain 3: Modeling
Frame business problems as machine learning problems.
Select the appropriate model(s) for a given machine learning problem.
Train machine learning models.
Perform hyperparameter optimization.
Evaluate machine learning models.
Domain 4: Machine Learning Implementation and Operations
Build machine learning solutions for performance, availability, scalability, resiliency, and fault tolerance.
Recommend and implement the appropriate machine learning services and features for a given problem.
Apply basic AWS security practices to machine learning solutions.
Deploy and operationalize machine learning solutions.
Machine Learning Services covered:
Amazon Comprehend
AWS Deep Learning AMIs (DLAMI)
AWS DeepLens
Amazon Forecast
Amazon Fraud Detector
Amazon Lex
Amazon Polly
Amazon Rekognition
Amazon SageMaker
Amazon Textract
Amazon Transcribe
Amazon Translate
Other Services and topics covered are:
Ingestion/Collection
Processing/ETL
Data analysis/visualization
Model training
Model deployment/inference
Operational
AWS ML application services
Language relevant to ML (for example, Python, Java, Scala, R, SQL)
Notebooks and integrated development environments (IDEs),
S3, SageMaker, Kinesis, Lake Formation, Athena, Kibana, Redshift, Textract, EMR, Glue, SageMaker, CSV, JSON, IMG, parquet or databases, Amazon Athena
Amazon EC2, Amazon Elastic Container Registry (Amazon ECR), Amazon Elastic Container Service, Amazon Elastic Kubernetes Service , Amazon Redshift
Sagemaker API Explained:

AWS Certified Machine Learning Engineer Specialty Questions and Answers:
Question1: An advertising and analytics company uses machine learning to predict user response to online advertisements using a custom XGBoost model. The company wants to improve its ML pipeline by porting its training and inference code, written in R, to Amazon SageMaker, and do so with minimal changes to the existing code.
Answer1: Use the Build Your Own Container (BYOC) Amazon Sagemaker option.
Create a new docker container with the existing code. Register the container in Amazon Elastic Container registry. with the existing code. Register the container in Amazon Elastic Container Registry. Finally run the training and inference jobs using this container.
Question2: Which feature of Amazon SageMaker can you use for preprocessing the data?
Answer2: Amazon Sagemaker Notebook instances
Amazon SageMaker enables developers and data scientists to build, train, tune, and deploy machine learning (ML) models at scale. You can deploy trained ML models for real-time or batch predictions on unseen data, a process known as inference. However, in most cases, the raw input data must be preprocessed and can’t be used directly for making predictions. This is because most ML models expect the data in a predefined format, so the raw data needs to be first cleaned and formatted in order for the ML model to process the data. You can use the Amazon SageMaker built-in Scikit-learn library for preprocessing input data and then use the Amazon SageMaker built-in Linear Learner algorithm for predictions.
Question3: What setting, when creating an Amazon SageMaker notebook instance, can you use to install libraries and import data?
Answer3: LifeCycle Configuration
Question4: How to Choose the right Sagemaker built-in algorithm?




This is a general guide for choosing which algorithm to use depending on what business problem you have and what data you have.
Top 10 Google Professional Machine Learning Engineer Sample Questions
Question 1: You work for a textile manufacturer and have been asked to build a model to detect and classify fabric defects. You trained a machine learning model with high recall based on high resolution images taken at the end of the production line. You want quality control inspectors to gain trust in your model. Which technique should you use to understand the rationale of your classifier?
A. Use K-fold cross validation to understand how the model performs on different test datasets.
B. Use the Integrated Gradients method to efficiently compute feature attributions for each predicted image.
C. Use PCA (Principal Component Analysis) to reduce the original feature set to a smaller set of easily understood features.
D. Use k-means clustering to group similar images together, and calculate the Davies-Bouldin index to evaluate the separation between clusters.
Answer 1)
Notes 1)
Question 2: You need to write a generic test to verify whether Dense Neural Network (DNN) models automatically released by your team have a sufficient number of parameters to learn the task for which they were built. What should you do?
Answer 2)
Notes 2)
[appbox appstore 1560083470-iphone screenshots]
[appbox googleplay com.awssolutionarchitectassociateexampreppro.app]
Answer 3)
Notes 3)
Question 4: You work on a team where the process for deploying a model into production starts with data scientists training different versions of models in a Kubeflow pipeline. The workflow then stores the new model artifact into the corresponding Cloud Storage bucket. You need to build the next steps of the pipeline after the submitted model is ready to be tested and deployed in production on AI Platform. How should you configure the architecture before deploying the model to production?
Question 10) You work for a large financial institution that is planning to use Dialogflow to create a chatbot for the company’s mobile app. You have reviewed old chat logs and tagged each conversation for intent based on each customer’s stated intention for contacting customer service. About 70% of customer inquiries are simple requests that are solved within 10 intents. The remaining 30% of inquiries require much longer and more complicated requests. Which intents should you automate first?
[appbox appstore 1611045854-iphone screenshots]
[appbox microsoftstore 9n8rl80hvm4t-mobile screenshots]
Machine Learning Q&A Part I:
Google.
Azure and AWS are second class citizens in this area.
Sure, AWS has 70% of the market.
Sure, Azure is the easiest turn key and super user friendly.
But, the king of machine learning in the cloud is GCP.
GCP = Google Cloud Platform
Google has the largest data science team in the world, not mention they have Hinton.
Let’s forgot for a minute they created TensorFlow and give it away.
Let’s just talk about building a real world model with data that doesn’t fit into a excel spreadsheet.
The vast majority of applied machine learning is supervised and that means we need data.
Not just normal data, we need very clean highly structured data.
Where’s the easiest place in the world to upload and model a Petabyte of structured data? BigQuery of course.
Why BigQuery? I don’t have to do anything but upload my data. No spinning up RedShit clusters or whatever I have to do in Azure, just upload and massage data with my familiar SQL. If I do have to wrangle my data it won’t take my six months to update 5 rows here, minutes usually.
Then, you’ll need a front end. Cloud datalab is a Jupyter notebook, which is good because I don’t want nor do I need anything else.
Then, with a single line of code I connect by datalab (Jupyter) notebook to my data in BigQuery and build away.
I’ve worked in all three and the only thing I care about is getting to my job the fastest and right now that means I build my models in GCP.
If you’re new to machine learning don’t start in GCP or any cloud vendor for that matter. Start learning Python from the comfort of your laptop.
The course below is free to the first 20.
The Complete Python Course for Machine Learning Engineers
Here, I want to share the best research paper on Machine Learning classification methods, titled ‘Do we Need Hundreds of Classifiers to Solve Real World Classification Problems?’, published in the ‘Journal of Machine Learning Research’.
This paper nicely explained 179 classification techniques and applied them on 121 data sets thus sharing small summary of the paper:
Do we Need Hundreds of Classifiers to Solve Real World Classification Problems?
The paper evaluated 179 classifiers arising from 17 ML families (discriminant analysis, Bayesian, neural networks, support vector machines, decision trees, rule-based classifiers, boosting, bagging, stacking, random forests and other ensembles, generalized linear models, nearest neighbours, partial least squares and principal component regression, logistic and multinomial regression, multiple adaptive regression splines and other methods), implemented in Weka, R ( with and without the caret package), C and Matlab, including all the relevant classifiers available today.
Experiments used total 121 data sets , which represent the whole UCI data base (excluding the large-scale problems) and other own real problems, in order to achieve significant conclusions about the classifier behaviour, not dependent on the data set collection.
The whole data set and partitions are available from: http://persoal.citius.usc.es/manuel.fernandez.delgado/papers/jmlr/data.tar.gz
The classifiers most likely to be the bests are the random forest (RF) versions, the best of which (implemented in R and accessed via caret) achieves 94.1% of the maximum accuracy overcoming 90% in the 84.3% of the data sets. However, the difference is not statistically significant with the second best, the SVM with Gaussian kernel implemented in C using LibSVM, which achieves 92.3% of the maximum accuracy. A few models are clearly better than the remaining ones: random forest, SVM with Gaussian and polynomial kernels, extreme learning machine with Gaussian kernel, C5.0 and avNNet (a committee of multi-layer perceptrons implemented in R with the caret package).
The random forest is clearly the best family of classifiers (3 out of 5 bests classifiers are RF), followed by SVM (4 classifiers in the top-10), neural networks and boosting ensembles (5 and 3 members in the top-20, respectively).
You can see the table with the complete results: http://persoal.citius.usc.es/manuel.fernandez.delgado/papers/jmlr/results.txt
I hope it will be helpful for Statistic and Machine Leaning aspirants!
Thank you!
These basic questions should help:
1. Is the classification going to be supervised or unsupervised? Several well defined techniques likes SVM (Support Vector Machines), trained neural net,etc. are applicable for supervised classification. For unsupervised classification, GMMs (Gaussian Mixture Models), HMMs (Hidden Markov models) with Baye’s techniques could be used. (Several other techniques could of course be used as well)
2.How much training data do you have in case it is supervised ? A small number of training data may yield discouraging classification accuracy even if the chosen classifier is the most suitable one for the problem. In such a case, try to obtain more number of samples. There’s also generally a correlation (for practical purposes at least) between the feature dimensionality and the number of samples for given technique. For example, while using SVM, the linear kernel tends to yield better results when the number of training samples are less than or equal to or only slightly more than the number of feature dimensions as compared to RBF or any other kernel.
3. If the feature vector dimensionality is small enough (1/2/3 -D) then it makes sense to plot and visually inspect if techniques like clustering could be more useful. With very high number of feature dimensions, methods like clustering are generally not advisable(Refer : “The Curse Of Dimensionality”).
4. Are you doing classification in real time ? Some techniques ,e.g. “Template Match” in image classification may lead to a higher number of errors but is generally faster than most other techniques if the number of templates to be evaluated are not excessively high.
5. Depending upon the problem domain, you can decide if you can choose the underlying model in such a way that it can use certain temporal/spatial correlations that may be inherent in the data. For example, HMMs use the temporal continuity of speech samples for enhancing classification results in speech recognition problems.
Another point, slightly off the topic perhaps, but the classification performance is as much a function of choosing the correct feature vectors, the pre-processing of the feature vectors as much as the classifier itself. It’s generally a good idea to give reserve some initial part of the project to try out various classifiers on the same data-set. It may at least help you reject the ones which are highly inaccurate.
At a high level, these skills are a combination of software and data engineering.
The persons that are more appropriate to do this job are a data engineer and/or a machine learning engineer.
That being said, if you work at a startup or happen to be in a small company and need to put the models into production yourself, here are the top skills you need to get:
- Well structured code: it doesn’t need to be perfect but at least can be understood and updated by other team members. Avoid spaghetti code[1] as the plague.
- Add logs: if you are a Python user, the logging[2] module is your friend. Avoid print statements at any cost.
- Model versioning: add a hash key to your different models. You will thank me later.
- Metadata everywhere: save as much data about your models and ML experiments as you can (running time, hyperparameters, used features, CV scores, and so on). You will thank me later, again.
- Monitor performances: execution time and statistical scores of your models.
- Data and models management: store the necessary data and models somewhere that is available to everyone (S3[3] for example). Avoid uploading these to your VCS[4] system. Don’t share them using Slack or Drive. I won’t judge you though, I do it sometimes (read often). Read more here …..
Some of the mistakes that might involve during building a machine learning model (I can think of) are listed here:
- Not understanding the structure of the dataset
- Not giving proper care during features selection
- Leaving out categorical features and considering just numerical variables
- Falling into dummy variable trap
- Selection of inefficient machine learning algorithm
- Not trying out various ML algorithms for building the model based on structure of data.
- Improper tuning of model parameters
- Most importantly: Building an idiotstic imperfect model i.e. suppose we have a classification problem with 99% chances of falling into class1 and remaining to class2. The built model may develop a mapping function which all the time for all data inputs, may predict the result to be class1. Well, one might say his/her model has 99% accuracy. But in reality the 1% class2 case hasn’t been included in the model. So this must be taken into consideration.
- Read more here…
[appbox appstore 1560083470-iphone screenshots]
[appbox googleplay com.awssolutionarchitectassociateexampreppro.app]

Basically, data mining is a key aspect of data analytics. Some even consider the former as essential to execute before the latter. While data analytics is the complete package and involves most components needed to examine a data set and extract valuable information, data mining focuses specifically on identifying hidden patterns.
That’s just the surface-level comparison though. The image above gives an overview of how the two differ.
One such difference is the presence of a hypothesis. Data analytics usually requires coming up with one, as it aims to find specific answers. Data mining, on the other hand, generally doesn’t need one to test or prove. The expected output are patterns or trends, which doesn’t require coming up with a statement or fact to test.
However, that doesn’t mean you mine data blindly. You still have a goal, whether it’s to come up with a recommender system or identify predictors of a certain dimension. Ultimately though, you strive to come up with data patterns or trends. For data analysis on the other hand, you’re expected to come up with valuable and actionable insights, usually in relation to a predetermined hypothesis. Read more here ….
The data science life cycle is not something well-defined like the software development life-cycle, and there is no ‘one-size-fits-all’ solution for data science projects. Every step in the life-cycle of a data science project depends on various data scientist skills and data science tools. The typical life-cycle of a data science project involves jumping back and forth among various interdependent science tasks using a variety of tools, techniques, programming, etc.
Thus, the data science life-cycle can include the following steps:
- Business requirement understanding.
- Data collection.
- Data cleaning.
- Data analysis.
- Modeling.
- Performance evaluation.
- Communicating with stakeholders.
- Deployment.
- Real-world testing.
- Business buy-in.
- Support and maintenance.
Looks neat, but here is the scheme to visualize how it is happening in reality:
Agile development processes, especially continuous delivery lends itself well to the data science project life-cycle. The early comparison helps the data science team to change approaches, refine hypotheses and even discard the project if the business case is nonviable or the benefits from the predictive models are not worth the effort to build it.
[appbox appstore 1611045854-iphone screenshots]
[appbox microsoftstore 9n8rl80hvm4t-mobile screenshots]
Machine Learning Q&A -Part II:
At a high level, these skills are a combination of software and data engineering.
The persons that are more appropriate to do this job are a data engineer and/or a machine learning engineer.
That being said, if you work at a startup or happen to be in a small company and need to put the models into production yourself, here are the top skills you need to get:
- Well structured code: it doesn’t need to be perfect but at least can be understood and updated by other team members. Avoid spaghetti code[1] as the plague.
- Add logs: if you are a Python user, the logging[2] module is your friend. Avoid print statements at any cost.
- Model versioning: add a hash key to your different models. You will thank me later.
- Metadata everywhere: save as much data about your models and ML experiments as you can (running time, hyperparameters, used features, CV scores, and so on). You will thank me later, again.
- Monitor performances: execution time and statistical scores of your models.
- Data and models management: store the necessary data and models somewhere that is available to everyone (S3[3] for example). Avoid uploading these to your VCS[4] system. Don’t share them using Slack or Drive. I won’t judge you though, I do it sometimes (read often). Read more here …..
Some of the mistakes that might involve during building a machine learning model (I can think of) are listed here:
- Not understanding the structure of the dataset
- Not giving proper care during features selection
- Leaving out categorical features and considering just numerical variables
- Falling into dummy variable trap
- Selection of inefficient machine learning algorithm
- Not trying out various ML algorithms for building the model based on structure of data.
- Improper tuning of model parameters
- Most importantly: Building an idiotstic imperfect model i.e. suppose we have a classification problem with 99% chances of falling into class1 and remaining to class2. The built model may develop a mapping function which all the time for all data inputs, may predict the result to be class1. Well, one might say his/her model has 99% accuracy. But in reality the 1% class2 case hasn’t been included in the model. So this must be taken into consideration.
- Read more here…
Basically, data mining is a key aspect of data analytics. Some even consider the former as essential to execute before the latter. While data analytics is the complete package and involves most components needed to examine a data set and extract valuable information, data mining focuses specifically on identifying hidden patterns.
That’s just the surface-level comparison though. The image above gives an overview of how the two differ.
One such difference is the presence of a hypothesis. Data analytics usually requires coming up with one, as it aims to find specific answers. Data mining, on the other hand, generally doesn’t need one to test or prove. The expected output are patterns or trends, which doesn’t require coming up with a statement or fact to test.
However, that doesn’t mean you mine data blindly. You still have a goal, whether it’s to come up with a recommender system or identify predictors of a certain dimension. Ultimately though, you strive to come up with data patterns or trends. For data analysis on the other hand, you’re expected to come up with valuable and actionable insights, usually in relation to a predetermined hypothesis. Read more here ….
The data science life cycle is not something well-defined like the software development life-cycle, and there is no ‘one-size-fits-all’ solution for data science projects. Every step in the life-cycle of a data science project depends on various data scientist skills and data science tools. The typical life-cycle of a data science project involves jumping back and forth among various interdependent science tasks using a variety of tools, techniques, programming, etc.
Thus, the data science life-cycle can include the following steps:
- Business requirement understanding.
- Data collection.
- Data cleaning.
- Data analysis.
- Modeling.
- Performance evaluation.
- Communicating with stakeholders.
- Deployment.
- Real-world testing.
- Business buy-in.
- Support and maintenance.
Looks neat, but here is the scheme to visualize how it is happening in reality:
Agile development processes, especially continuous delivery lends itself well to the data science project life-cycle. The early comparison helps the data science team to change approaches, refine hypotheses and even discard the project if the business case is nonviable or the benefits from the predictive models are not worth the effort to build it.
iOs: https://apps.apple.com/ca/app/aws-machine-learning-prep-pro/id1611045854
Android/Amazon: https://www.amazon.com/gp/product/B09TZ4H8V6
AWS MLS-C01 Machine Learning Exam Prep
Quizzes, Practice Exams: Modeling, Data Engineering, Vision, Exploratory Data Analysis, ML Ops, Cheat Sheets, ML Jobs Interview Q&A
Use this App to learn about Machine Learning on AWS and prepare for the AWS Machine Learning Specialty Certification MLS-C01.
Earning AWS Certified Machine Learning Specialty validates expertise in building, training, tuning, and deploying machine learning (ML) models on AWS.
The App provides hundreds of quizzes and practice exam about:
– Machine Learning Operation on AWS
– Modelling
– Data Engineering
– Computer Vision,
– Exploratory Data Analysis,
– ML implementation & Operations
– Machine Learning Basics Questions and Answers
– Machine Learning Advanced Questions and Answers
– Scorecard
– Countdown timer
– Machine Learning Cheat Sheets
– Machine Learning Interview Questions and Answers
– Machine Learning Latest News
The App covers Machine Learning Basics and Advanced topics including: NLP, Computer Vision, Python, linear regression, logistic regression, Sampling, dataset, statistical interaction, selection bias, non-Gaussian distribution, bias-variance trade-off, Normal Distribution, correlation and covariance, Point Estimates and Confidence Interval, A/B Testing, p-value, statistical power of sensitivity, over-fitting and under-fitting, regularization, Law of Large Numbers, Confounding Variables, Survivorship Bias, univariate, bivariate and multivariate, Resampling, ROC curve, TF/IDF vectorization, Cluster Sampling, etc.
Domain 1: Data Engineering
Create data repositories for machine learning.
Identify data sources (e.g., content and location, primary sources such as user data)
Determine storage mediums (e.g., DB, Data Lake, S3, EFS, EBS)
Identify and implement a data ingestion solution.
Data job styles/types (batch load, streaming)
Data ingestion pipelines (Batch-based ML workloads and streaming-based ML workloads), etc.
Domain 2: Exploratory Data Analysis
Sanitize and prepare data for modeling.
Perform feature engineering.
Analyze and visualize data for machine learning.
Domain 3: Modeling
Frame business problems as machine learning problems.
Select the appropriate model(s) for a given machine learning problem.
Train machine learning models.
Perform hyperparameter optimization.
Evaluate machine learning models.
Domain 4: Machine Learning Implementation and Operations
Build machine learning solutions for performance, availability, scalability, resiliency, and fault tolerance.
Recommend and implement the appropriate machine learning services and features for a given problem.
Apply basic AWS security practices to machine learning solutions.
Deploy and operationalize machine learning solutions.
Machine Learning Services covered:
Amazon Comprehend
AWS Deep Learning AMIs (DLAMI)
AWS DeepLens
Amazon Forecast
Amazon Fraud Detector
Amazon Lex
Amazon Polly
Amazon Rekognition
Amazon SageMaker
Amazon Textract
Amazon Transcribe
Amazon Translate
Other Services and topics covered are:
Ingestion/Collection
Processing/ETL
Data analysis/visualization
Model training
Model deployment/inference
Operational
AWS ML application services
Language relevant to ML (for example, Python, Java, Scala, R, SQL)
Notebooks and integrated development environments (IDEs),
S3, SageMaker, Kinesis, Lake Formation, Athena, Kibana, Redshift, Textract, EMR, Glue, SageMaker, CSV, JSON, IMG, parquet or databases, Amazon Athena
Amazon EC2, Amazon Elastic Container Registry (Amazon ECR), Amazon Elastic Container Service, Amazon Elastic Kubernetes Service , Amazon Redshift
Sagemaker API Explained:
AWS Certified Machine Learning Engineer Specialty Questions and Answers:
Question1: An advertising and analytics company uses machine learning to predict user response to online advertisements using a custom XGBoost model. The company wants to improve its ML pipeline by porting its training and inference code, written in R, to Amazon SageMaker, and do so with minimal changes to the existing code.
Answer1: Use the Build Your Own Container (BYOC) Amazon Sagemaker option.
Create a new docker container with the existing code. Register the container in Amazon Elastic Container registry. with the existing code. Register the container in Amazon Elastic Container Registry. Finally run the training and inference jobs using this container.
Question2: Which feature of Amazon SageMaker can you use for preprocessing the data?
Answer2: Amazon Sagemaker Notebook instances
Amazon SageMaker enables developers and data scientists to build, train, tune, and deploy machine learning (ML) models at scale. You can deploy trained ML models for real-time or batch predictions on unseen data, a process known as inference. However, in most cases, the raw input data must be preprocessed and can’t be used directly for making predictions. This is because most ML models expect the data in a predefined format, so the raw data needs to be first cleaned and formatted in order for the ML model to process the data. You can use the Amazon SageMaker built-in Scikit-learn library for preprocessing input data and then use the Amazon SageMaker built-in Linear Learner algorithm for predictions.
Question3: What setting, when creating an Amazon SageMaker notebook instance, can you use to install libraries and import data?
Answer3: LifeCycle Configuration
Question4: How to Choose the right Sagemaker built-in algorithm?
This is a general guide for choosing which algorithm to use depending on what business problem you have and what data you have.
Top 10 Google Professional Machine Learning Engineer Sample Questions
Question 1: You work for a textile manufacturer and have been asked to build a model to detect and classify fabric defects. You trained a machine learning model with high recall based on high resolution images taken at the end of the production line. You want quality control inspectors to gain trust in your model. Which technique should you use to understand the rationale of your classifier?
A. Use K-fold cross validation to understand how the model performs on different test datasets.
B. Use the Integrated Gradients method to efficiently compute feature attributions for each predicted image.
C. Use PCA (Principal Component Analysis) to reduce the original feature set to a smaller set of easily understood features.
D. Use k-means clustering to group similar images together, and calculate the Davies-Bouldin index to evaluate the separation between clusters.
Answer 1)
BNotes 1)
Question 2: You need to write a generic test to verify whether Dense Neural Network (DNN) models automatically released by your team have a sufficient number of parameters to learn the task for which they were built. What should you do?
Answer 2)
Notes 2)
[appbox appstore 1560083470-iphone screenshots]
[appbox googleplay com.awssolutionarchitectassociateexampreppro.app]
Answer 3)
Notes 3)
Question 4: You work on a team where the process for deploying a model into production starts with data scientists training different versions of models in a Kubeflow pipeline. The workflow then stores the new model artifact into the corresponding Cloud Storage bucket. You need to build the next steps of the pipeline after the submitted model is ready to be tested and deployed in production on AI Platform. How should you configure the architecture before deploying the model to production?
Question 10) You work for a large financial institution that is planning to use Dialogflow to create a chatbot for the company’s mobile app. You have reviewed old chat logs and tagged each conversation for intent based on each customer’s stated intention for contacting customer service. About 70% of customer inquiries are simple requests that are solved within 10 intents. The remaining 30% of inquiries require much longer and more complicated requests. Which intents should you automate first?
[appbox appstore 1611045854-iphone screenshots]
[appbox microsoftstore 9n8rl80hvm4t-mobile screenshots]
Machine Learning Q&A Part I:
Google.
Azure and AWS are second class citizens in this area.
Sure, AWS has 70% of the market.
Sure, Azure is the easiest turn key and super user friendly.
But, the king of machine learning in the cloud is GCP.
GCP = Google Cloud Platform
Google has the largest data science team in the world, not mention they have Hinton.
Let’s forgot for a minute they created TensorFlow and give it away.
Let’s just talk about building a real world model with data that doesn’t fit into a excel spreadsheet.
The vast majority of applied machine learning is supervised and that means we need data.
Not just normal data, we need very clean highly structured data.
Where’s the easiest place in the world to upload and model a Petabyte of structured data? BigQuery of course.
Why BigQuery? I don’t have to do anything but upload my data. No spinning up RedShit clusters or whatever I have to do in Azure, just upload and massage data with my familiar SQL. If I do have to wrangle my data it won’t take my six months to update 5 rows here, minutes usually.
Then, you’ll need a front end. Cloud datalab is a Jupyter notebook, which is good because I don’t want nor do I need anything else.
Then, with a single line of code I connect by datalab (Jupyter) notebook to my data in BigQuery and build away.
I’ve worked in all three and the only thing I care about is getting to my job the fastest and right now that means I build my models in GCP.
If you’re new to machine learning don’t start in GCP or any cloud vendor for that matter. Start learning Python from the comfort of your laptop.
The course below is free to the first 20.
The Complete Python Course for Machine Learning Engineers
Here, I want to share the best research paper on Machine Learning classification methods, titled ‘Do we Need Hundreds of Classifiers to Solve Real World Classification Problems?’, published in the ‘Journal of Machine Learning Research’.
This paper nicely explained 179 classification techniques and applied them on 121 data sets thus sharing small summary of the paper:
Do we Need Hundreds of Classifiers to Solve Real World Classification Problems?
The paper evaluated 179 classifiers arising from 17 ML families (discriminant analysis, Bayesian, neural networks, support vector machines, decision trees, rule-based classifiers, boosting, bagging, stacking, random forests and other ensembles, generalized linear models, nearest neighbours, partial least squares and principal component regression, logistic and multinomial regression, multiple adaptive regression splines and other methods), implemented in Weka, R ( with and without the caret package), C and Matlab, including all the relevant classifiers available today.
Experiments used total 121 data sets , which represent the whole UCI data base (excluding the large-scale problems) and other own real problems, in order to achieve significant conclusions about the classifier behaviour, not dependent on the data set collection.
The whole data set and partitions are available from: http://persoal.citius.usc.es/manuel.fernandez.delgado/papers/jmlr/data.tar.gz
The classifiers most likely to be the bests are the random forest (RF) versions, the best of which (implemented in R and accessed via caret) achieves 94.1% of the maximum accuracy overcoming 90% in the 84.3% of the data sets. However, the difference is not statistically significant with the second best, the SVM with Gaussian kernel implemented in C using LibSVM, which achieves 92.3% of the maximum accuracy. A few models are clearly better than the remaining ones: random forest, SVM with Gaussian and polynomial kernels, extreme learning machine with Gaussian kernel, C5.0 and avNNet (a committee of multi-layer perceptrons implemented in R with the caret package).
The random forest is clearly the best family of classifiers (3 out of 5 bests classifiers are RF), followed by SVM (4 classifiers in the top-10), neural networks and boosting ensembles (5 and 3 members in the top-20, respectively).
You can see the table with the complete results: http://persoal.citius.usc.es/manuel.fernandez.delgado/papers/jmlr/results.txt
I hope it will be helpful for Statistic and Machine Leaning aspirants!
Thank you!
These basic questions should help:
1. Is the classification going to be supervised or unsupervised? Several well defined techniques likes SVM (Support Vector Machines), trained neural net,etc. are applicable for supervised classification. For unsupervised classification, GMMs (Gaussian Mixture Models), HMMs (Hidden Markov models) with Baye’s techniques could be used. (Several other techniques could of course be used as well)
2.How much training data do you have in case it is supervised ? A small number of training data may yield discouraging classification accuracy even if the chosen classifier is the most suitable one for the problem. In such a case, try to obtain more number of samples. There’s also generally a correlation (for practical purposes at least) between the feature dimensionality and the number of samples for given technique. For example, while using SVM, the linear kernel tends to yield better results when the number of training samples are less than or equal to or only slightly more than the number of feature dimensions as compared to RBF or any other kernel.
3. If the feature vector dimensionality is small enough (1/2/3 -D) then it makes sense to plot and visually inspect if techniques like clustering could be more useful. With very high number of feature dimensions, methods like clustering are generally not advisable(Refer : “The Curse Of Dimensionality”).
4. Are you doing classification in real time ? Some techniques ,e.g. “Template Match” in image classification may lead to a higher number of errors but is generally faster than most other techniques if the number of templates to be evaluated are not excessively high.
5. Depending upon the problem domain, you can decide if you can choose the underlying model in such a way that it can use certain temporal/spatial correlations that may be inherent in the data. For example, HMMs use the temporal continuity of speech samples for enhancing classification results in speech recognition problems.
Another point, slightly off the topic perhaps, but the classification performance is as much a function of choosing the correct feature vectors, the pre-processing of the feature vectors as much as the classifier itself. It’s generally a good idea to give reserve some initial part of the project to try out various classifiers on the same data-set. It may at least help you reject the ones which are highly inaccurate.
At a high level, these skills are a combination of software and data engineering.
The persons that are more appropriate to do this job are a data engineer and/or a machine learning engineer.
That being said, if you work at a startup or happen to be in a small company and need to put the models into production yourself, here are the top skills you need to get:
- Well structured code: it doesn’t need to be perfect but at least can be understood and updated by other team members. Avoid spaghetti code[1] as the plague.
- Add logs: if you are a Python user, the logging[2] module is your friend. Avoid print statements at any cost.
- Model versioning: add a hash key to your different models. You will thank me later.
- Metadata everywhere: save as much data about your models and ML experiments as you can (running time, hyperparameters, used features, CV scores, and so on). You will thank me later, again.
- Monitor performances: execution time and statistical scores of your models.
- Data and models management: store the necessary data and models somewhere that is available to everyone (S3[3] for example). Avoid uploading these to your VCS[4] system. Don’t share them using Slack or Drive. I won’t judge you though, I do it sometimes (read often). Read more here …..
Some of the mistakes that might involve during building a machine learning model (I can think of) are listed here:
- Not understanding the structure of the dataset
- Not giving proper care during features selection
- Leaving out categorical features and considering just numerical variables
- Falling into dummy variable trap
- Selection of inefficient machine learning algorithm
- Not trying out various ML algorithms for building the model based on structure of data.
- Improper tuning of model parameters
- Most importantly: Building an idiotstic imperfect model i.e. suppose we have a classification problem with 99% chances of falling into class1 and remaining to class2. The built model may develop a mapping function which all the time for all data inputs, may predict the result to be class1. Well, one might say his/her model has 99% accuracy. But in reality the 1% class2 case hasn’t been included in the model. So this must be taken into consideration.
- Read more here…
[appbox appstore 1560083470-iphone screenshots]
[appbox googleplay com.awssolutionarchitectassociateexampreppro.app]
Basically, data mining is a key aspect of data analytics. Some even consider the former as essential to execute before the latter. While data analytics is the complete package and involves most components needed to examine a data set and extract valuable information, data mining focuses specifically on identifying hidden patterns.
That’s just the surface-level comparison though. The image above gives an overview of how the two differ.
One such difference is the presence of a hypothesis. Data analytics usually requires coming up with one, as it aims to find specific answers. Data mining, on the other hand, generally doesn’t need one to test or prove. The expected output are patterns or trends, which doesn’t require coming up with a statement or fact to test.
However, that doesn’t mean you mine data blindly. You still have a goal, whether it’s to come up with a recommender system or identify predictors of a certain dimension. Ultimately though, you strive to come up with data patterns or trends. For data analysis on the other hand, you’re expected to come up with valuable and actionable insights, usually in relation to a predetermined hypothesis. Read more here ….
The data science life cycle is not something well-defined like the software development life-cycle, and there is no ‘one-size-fits-all’ solution for data science projects. Every step in the life-cycle of a data science project depends on various data scientist skills and data science tools. The typical life-cycle of a data science project involves jumping back and forth among various interdependent science tasks using a variety of tools, techniques, programming, etc.
Thus, the data science life-cycle can include the following steps:
- Business requirement understanding.
- Data collection.
- Data cleaning.
- Data analysis.
- Modeling.
- Performance evaluation.
- Communicating with stakeholders.
- Deployment.
- Real-world testing.
- Business buy-in.
- Support and maintenance.
Looks neat, but here is the scheme to visualize how it is happening in reality:
Agile development processes, especially continuous delivery lends itself well to the data science project life-cycle. The early comparison helps the data science team to change approaches, refine hypotheses and even discard the project if the business case is nonviable or the benefits from the predictive models are not worth the effort to build it.
[appbox appstore 1611045854-iphone screenshots]
[appbox microsoftstore 9n8rl80hvm4t-mobile screenshots]
Machine Learning Q&A -Part II:
At a high level, these skills are a combination of software and data engineering.
The persons that are more appropriate to do this job are a data engineer and/or a machine learning engineer.
That being said, if you work at a startup or happen to be in a small company and need to put the models into production yourself, here are the top skills you need to get:
- Well structured code: it doesn’t need to be perfect but at least can be understood and updated by other team members. Avoid spaghetti code[1] as the plague.
- Add logs: if you are a Python user, the logging[2] module is your friend. Avoid print statements at any cost.
- Model versioning: add a hash key to your different models. You will thank me later.
- Metadata everywhere: save as much data about your models and ML experiments as you can (running time, hyperparameters, used features, CV scores, and so on). You will thank me later, again.
- Monitor performances: execution time and statistical scores of your models.
- Data and models management: store the necessary data and models somewhere that is available to everyone (S3[3] for example). Avoid uploading these to your VCS[4] system. Don’t share them using Slack or Drive. I won’t judge you though, I do it sometimes (read often). Read more here …..
Some of the mistakes that might involve during building a machine learning model (I can think of) are listed here:
- Not understanding the structure of the dataset
- Not giving proper care during features selection
- Leaving out categorical features and considering just numerical variables
- Falling into dummy variable trap
- Selection of inefficient machine learning algorithm
- Not trying out various ML algorithms for building the model based on structure of data.
- Improper tuning of model parameters
- Most importantly: Building an idiotstic imperfect model i.e. suppose we have a classification problem with 99% chances of falling into class1 and remaining to class2. The built model may develop a mapping function which all the time for all data inputs, may predict the result to be class1. Well, one might say his/her model has 99% accuracy. But in reality the 1% class2 case hasn’t been included in the model. So this must be taken into consideration.
- Read more here…
Basically, data mining is a key aspect of data analytics. Some even consider the former as essential to execute before the latter. While data analytics is the complete package and involves most components needed to examine a data set and extract valuable information, data mining focuses specifically on identifying hidden patterns.
That’s just the surface-level comparison though. The image above gives an overview of how the two differ.
One such difference is the presence of a hypothesis. Data analytics usually requires coming up with one, as it aims to find specific answers. Data mining, on the other hand, generally doesn’t need one to test or prove. The expected output are patterns or trends, which doesn’t require coming up with a statement or fact to test.
However, that doesn’t mean you mine data blindly. You still have a goal, whether it’s to come up with a recommender system or identify predictors of a certain dimension. Ultimately though, you strive to come up with data patterns or trends. For data analysis on the other hand, you’re expected to come up with valuable and actionable insights, usually in relation to a predetermined hypothesis. Read more here ….
The data science life cycle is not something well-defined like the software development life-cycle, and there is no ‘one-size-fits-all’ solution for data science projects. Every step in the life-cycle of a data science project depends on various data scientist skills and data science tools. The typical life-cycle of a data science project involves jumping back and forth among various interdependent science tasks using a variety of tools, techniques, programming, etc.
Thus, the data science life-cycle can include the following steps:
- Business requirement understanding.
- Data collection.
- Data cleaning.
- Data analysis.
- Modeling.
- Performance evaluation.
- Communicating with stakeholders.
- Deployment.
- Real-world testing.
- Business buy-in.
- Support and maintenance.
Looks neat, but here is the scheme to visualize how it is happening in reality:
Agile development processes, especially continuous delivery lends itself well to the data science project life-cycle. The early comparison helps the data science team to change approaches, refine hypotheses and even discard the project if the business case is nonviable or the benefits from the predictive models are not worth the effort to build it.
iOs: https://apps.apple.com/ca/app/aws-machine-learning-prep-pro/id1611045854
Android/Amazon: https://www.amazon.com/gp/product/B09TZ4H8V6
AWS MLS-C01 Machine Learning Exam Prep
Quizzes, Practice Exams: Modeling, Data Engineering, Vision, Exploratory Data Analysis, ML Ops, Cheat Sheets, ML Jobs Interview Q&A
Use this App to learn about Machine Learning on AWS and prepare for the AWS Machine Learning Specialty Certification MLS-C01.
Earning AWS Certified Machine Learning Specialty validates expertise in building, training, tuning, and deploying machine learning (ML) models on AWS.
The App provides hundreds of quizzes and practice exam about:
– Machine Learning Operation on AWS
– Modelling
– Data Engineering
– Computer Vision,
– Exploratory Data Analysis,
– ML implementation & Operations
– Machine Learning Basics Questions and Answers
– Machine Learning Advanced Questions and Answers
– Scorecard
– Countdown timer
– Machine Learning Cheat Sheets
– Machine Learning Interview Questions and Answers
– Machine Learning Latest News
The App covers Machine Learning Basics and Advanced topics including: NLP, Computer Vision, Python, linear regression, logistic regression, Sampling, dataset, statistical interaction, selection bias, non-Gaussian distribution, bias-variance trade-off, Normal Distribution, correlation and covariance, Point Estimates and Confidence Interval, A/B Testing, p-value, statistical power of sensitivity, over-fitting and under-fitting, regularization, Law of Large Numbers, Confounding Variables, Survivorship Bias, univariate, bivariate and multivariate, Resampling, ROC curve, TF/IDF vectorization, Cluster Sampling, etc.
Domain 1: Data Engineering
Create data repositories for machine learning.
Identify data sources (e.g., content and location, primary sources such as user data)
Determine storage mediums (e.g., DB, Data Lake, S3, EFS, EBS)
Identify and implement a data ingestion solution.
Data job styles/types (batch load, streaming)
Data ingestion pipelines (Batch-based ML workloads and streaming-based ML workloads), etc.
Domain 2: Exploratory Data Analysis
Sanitize and prepare data for modeling.
Perform feature engineering.
Analyze and visualize data for machine learning.
Domain 3: Modeling
Frame business problems as machine learning problems.
Select the appropriate model(s) for a given machine learning problem.
Train machine learning models.
Perform hyperparameter optimization.
Evaluate machine learning models.
Domain 4: Machine Learning Implementation and Operations
Build machine learning solutions for performance, availability, scalability, resiliency, and fault tolerance.
Recommend and implement the appropriate machine learning services and features for a given problem.
Apply basic AWS security practices to machine learning solutions.
Deploy and operationalize machine learning solutions.
Machine Learning Services covered:
Amazon Comprehend
AWS Deep Learning AMIs (DLAMI)
AWS DeepLens
Amazon Forecast
Amazon Fraud Detector
Amazon Lex
Amazon Polly
Amazon Rekognition
Amazon SageMaker
Amazon Textract
Amazon Transcribe
Amazon Translate
Other Services and topics covered are:
Ingestion/Collection
Processing/ETL
Data analysis/visualization
Model training
Model deployment/inference
Operational
AWS ML application services
Language relevant to ML (for example, Python, Java, Scala, R, SQL)
Notebooks and integrated development environments (IDEs),
S3, SageMaker, Kinesis, Lake Formation, Athena, Kibana, Redshift, Textract, EMR, Glue, SageMaker, CSV, JSON, IMG, parquet or databases, Amazon Athena
Amazon EC2, Amazon Elastic Container Registry (Amazon ECR), Amazon Elastic Container Service, Amazon Elastic Kubernetes Service , Amazon Redshift
Sagemaker API Explained:
AWS Certified Machine Learning Engineer Specialty Questions and Answers:
Question1: An advertising and analytics company uses machine learning to predict user response to online advertisements using a custom XGBoost model. The company wants to improve its ML pipeline by porting its training and inference code, written in R, to Amazon SageMaker, and do so with minimal changes to the existing code.
Answer1: Use the Build Your Own Container (BYOC) Amazon Sagemaker option.
Create a new docker container with the existing code. Register the container in Amazon Elastic Container registry. with the existing code. Register the container in Amazon Elastic Container Registry. Finally run the training and inference jobs using this container.
Question2: Which feature of Amazon SageMaker can you use for preprocessing the data?
Answer2: Amazon Sagemaker Notebook instances
Amazon SageMaker enables developers and data scientists to build, train, tune, and deploy machine learning (ML) models at scale. You can deploy trained ML models for real-time or batch predictions on unseen data, a process known as inference. However, in most cases, the raw input data must be preprocessed and can’t be used directly for making predictions. This is because most ML models expect the data in a predefined format, so the raw data needs to be first cleaned and formatted in order for the ML model to process the data. You can use the Amazon SageMaker built-in Scikit-learn library for preprocessing input data and then use the Amazon SageMaker built-in Linear Learner algorithm for predictions.
Question3: What setting, when creating an Amazon SageMaker notebook instance, can you use to install libraries and import data?
Answer3: LifeCycle Configuration
Question4: How to Choose the right Sagemaker built-in algorithm?
This is a general guide for choosing which algorithm to use depending on what business problem you have and what data you have.
Top 10 Google Professional Machine Learning Engineer Sample Questions
Question 1: You work for a textile manufacturer and have been asked to build a model to detect and classify fabric defects. You trained a machine learning model with high recall based on high resolution images taken at the end of the production line. You want quality control inspectors to gain trust in your model. Which technique should you use to understand the rationale of your classifier?
A. Use K-fold cross validation to understand how the model performs on different test datasets.
B. Use the Integrated Gradients method to efficiently compute feature attributions for each predicted image.
C. Use PCA (Principal Component Analysis) to reduce the original feature set to a smaller set of easily understood features.
D. Use k-means clustering to group similar images together, and calculate the Davies-Bouldin index to evaluate the separation between clusters.
Answer 1)
BNotes 1)
Question 2: You need to write a generic test to verify whether Dense Neural Network (DNN) models automatically released by your team have a sufficient number of parameters to learn the task for which they were built. What should you do?
Answer 2)
Notes 2)
[appbox appstore 1560083470-iphone screenshots]
[appbox googleplay com.awssolutionarchitectassociateexampreppro.app]
Answer 3)
Notes 3)
Question 4: You work on a team where the process for deploying a model into production starts with data scientists training different versions of models in a Kubeflow pipeline. The workflow then stores the new model artifact into the corresponding Cloud Storage bucket. You need to build the next steps of the pipeline after the submitted model is ready to be tested and deployed in production on AI Platform. How should you configure the architecture before deploying the model to production?
Question 10) You work for a large financial institution that is planning to use Dialogflow to create a chatbot for the company’s mobile app. You have reviewed old chat logs and tagged each conversation for intent based on each customer’s stated intention for contacting customer service. About 70% of customer inquiries are simple requests that are solved within 10 intents. The remaining 30% of inquiries require much longer and more complicated requests. Which intents should you automate first?
[appbox appstore 1611045854-iphone screenshots]
[appbox microsoftstore 9n8rl80hvm4t-mobile screenshots]
Machine Learning Q&A Part I:
Google.
Azure and AWS are second class citizens in this area.
Sure, AWS has 70% of the market.
Sure, Azure is the easiest turn key and super user friendly.
But, the king of machine learning in the cloud is GCP.
GCP = Google Cloud Platform
Google has the largest data science team in the world, not mention they have Hinton.
Let’s forgot for a minute they created TensorFlow and give it away.
Let’s just talk about building a real world model with data that doesn’t fit into a excel spreadsheet.
The vast majority of applied machine learning is supervised and that means we need data.
Not just normal data, we need very clean highly structured data.
Where’s the easiest place in the world to upload and model a Petabyte of structured data? BigQuery of course.
Why BigQuery? I don’t have to do anything but upload my data. No spinning up RedShit clusters or whatever I have to do in Azure, just upload and massage data with my familiar SQL. If I do have to wrangle my data it won’t take my six months to update 5 rows here, minutes usually.
Then, you’ll need a front end. Cloud datalab is a Jupyter notebook, which is good because I don’t want nor do I need anything else.
Then, with a single line of code I connect by datalab (Jupyter) notebook to my data in BigQuery and build away.
I’ve worked in all three and the only thing I care about is getting to my job the fastest and right now that means I build my models in GCP.
If you’re new to machine learning don’t start in GCP or any cloud vendor for that matter. Start learning Python from the comfort of your laptop.
The course below is free to the first 20.
The Complete Python Course for Machine Learning Engineers
Here, I want to share the best research paper on Machine Learning classification methods, titled ‘Do we Need Hundreds of Classifiers to Solve Real World Classification Problems?’, published in the ‘Journal of Machine Learning Research’.
This paper nicely explained 179 classification techniques and applied them on 121 data sets thus sharing small summary of the paper:
Do we Need Hundreds of Classifiers to Solve Real World Classification Problems?
The paper evaluated 179 classifiers arising from 17 ML families (discriminant analysis, Bayesian, neural networks, support vector machines, decision trees, rule-based classifiers, boosting, bagging, stacking, random forests and other ensembles, generalized linear models, nearest neighbours, partial least squares and principal component regression, logistic and multinomial regression, multiple adaptive regression splines and other methods), implemented in Weka, R ( with and without the caret package), C and Matlab, including all the relevant classifiers available today.
Experiments used total 121 data sets , which represent the whole UCI data base (excluding the large-scale problems) and other own real problems, in order to achieve significant conclusions about the classifier behaviour, not dependent on the data set collection.
The whole data set and partitions are available from: http://persoal.citius.usc.es/manuel.fernandez.delgado/papers/jmlr/data.tar.gz
The classifiers most likely to be the bests are the random forest (RF) versions, the best of which (implemented in R and accessed via caret) achieves 94.1% of the maximum accuracy overcoming 90% in the 84.3% of the data sets. However, the difference is not statistically significant with the second best, the SVM with Gaussian kernel implemented in C using LibSVM, which achieves 92.3% of the maximum accuracy. A few models are clearly better than the remaining ones: random forest, SVM with Gaussian and polynomial kernels, extreme learning machine with Gaussian kernel, C5.0 and avNNet (a committee of multi-layer perceptrons implemented in R with the caret package).
The random forest is clearly the best family of classifiers (3 out of 5 bests classifiers are RF), followed by SVM (4 classifiers in the top-10), neural networks and boosting ensembles (5 and 3 members in the top-20, respectively).
You can see the table with the complete results: http://persoal.citius.usc.es/manuel.fernandez.delgado/papers/jmlr/results.txt
I hope it will be helpful for Statistic and Machine Leaning aspirants!
Thank you!
These basic questions should help:
1. Is the classification going to be supervised or unsupervised? Several well defined techniques likes SVM (Support Vector Machines), trained neural net,etc. are applicable for supervised classification. For unsupervised classification, GMMs (Gaussian Mixture Models), HMMs (Hidden Markov models) with Baye’s techniques could be used. (Several other techniques could of course be used as well)
2.How much training data do you have in case it is supervised ? A small number of training data may yield discouraging classification accuracy even if the chosen classifier is the most suitable one for the problem. In such a case, try to obtain more number of samples. There’s also generally a correlation (for practical purposes at least) between the feature dimensionality and the number of samples for given technique. For example, while using SVM, the linear kernel tends to yield better results when the number of training samples are less than or equal to or only slightly more than the number of feature dimensions as compared to RBF or any other kernel.
3. If the feature vector dimensionality is small enough (1/2/3 -D) then it makes sense to plot and visually inspect if techniques like clustering could be more useful. With very high number of feature dimensions, methods like clustering are generally not advisable(Refer : “The Curse Of Dimensionality”).
4. Are you doing classification in real time ? Some techniques ,e.g. “Template Match” in image classification may lead to a higher number of errors but is generally faster than most other techniques if the number of templates to be evaluated are not excessively high.
5. Depending upon the problem domain, you can decide if you can choose the underlying model in such a way that it can use certain temporal/spatial correlations that may be inherent in the data. For example, HMMs use the temporal continuity of speech samples for enhancing classification results in speech recognition problems.
Another point, slightly off the topic perhaps, but the classification performance is as much a function of choosing the correct feature vectors, the pre-processing of the feature vectors as much as the classifier itself. It’s generally a good idea to give reserve some initial part of the project to try out various classifiers on the same data-set. It may at least help you reject the ones which are highly inaccurate.
At a high level, these skills are a combination of software and data engineering.
The persons that are more appropriate to do this job are a data engineer and/or a machine learning engineer.
That being said, if you work at a startup or happen to be in a small company and need to put the models into production yourself, here are the top skills you need to get:
- Well structured code: it doesn’t need to be perfect but at least can be understood and updated by other team members. Avoid spaghetti code[1] as the plague.
- Add logs: if you are a Python user, the logging[2] module is your friend. Avoid print statements at any cost.
- Model versioning: add a hash key to your different models. You will thank me later.
- Metadata everywhere: save as much data about your models and ML experiments as you can (running time, hyperparameters, used features, CV scores, and so on). You will thank me later, again.
- Monitor performances: execution time and statistical scores of your models.
- Data and models management: store the necessary data and models somewhere that is available to everyone (S3[3] for example). Avoid uploading these to your VCS[4] system. Don’t share them using Slack or Drive. I won’t judge you though, I do it sometimes (read often). Read more here …..
Some of the mistakes that might involve during building a machine learning model (I can think of) are listed here:
- Not understanding the structure of the dataset
- Not giving proper care during features selection
- Leaving out categorical features and considering just numerical variables
- Falling into dummy variable trap
- Selection of inefficient machine learning algorithm
- Not trying out various ML algorithms for building the model based on structure of data.
- Improper tuning of model parameters
- Most importantly: Building an idiotstic imperfect model i.e. suppose we have a classification problem with 99% chances of falling into class1 and remaining to class2. The built model may develop a mapping function which all the time for all data inputs, may predict the result to be class1. Well, one might say his/her model has 99% accuracy. But in reality the 1% class2 case hasn’t been included in the model. So this must be taken into consideration.
- Read more here…
[appbox appstore 1560083470-iphone screenshots]
[appbox googleplay com.awssolutionarchitectassociateexampreppro.app]
Basically, data mining is a key aspect of data analytics. Some even consider the former as essential to execute before the latter. While data analytics is the complete package and involves most components needed to examine a data set and extract valuable information, data mining focuses specifically on identifying hidden patterns.
That’s just the surface-level comparison though. The image above gives an overview of how the two differ.
One such difference is the presence of a hypothesis. Data analytics usually requires coming up with one, as it aims to find specific answers. Data mining, on the other hand, generally doesn’t need one to test or prove. The expected output are patterns or trends, which doesn’t require coming up with a statement or fact to test.
However, that doesn’t mean you mine data blindly. You still have a goal, whether it’s to come up with a recommender system or identify predictors of a certain dimension. Ultimately though, you strive to come up with data patterns or trends. For data analysis on the other hand, you’re expected to come up with valuable and actionable insights, usually in relation to a predetermined hypothesis. Read more here ….
The data science life cycle is not something well-defined like the software development life-cycle, and there is no ‘one-size-fits-all’ solution for data science projects. Every step in the life-cycle of a data science project depends on various data scientist skills and data science tools. The typical life-cycle of a data science project involves jumping back and forth among various interdependent science tasks using a variety of tools, techniques, programming, etc.
Thus, the data science life-cycle can include the following steps:
- Business requirement understanding.
- Data collection.
- Data cleaning.
- Data analysis.
- Modeling.
- Performance evaluation.
- Communicating with stakeholders.
- Deployment.
- Real-world testing.
- Business buy-in.
- Support and maintenance.
Looks neat, but here is the scheme to visualize how it is happening in reality:
Agile development processes, especially continuous delivery lends itself well to the data science project life-cycle. The early comparison helps the data science team to change approaches, refine hypotheses and even discard the project if the business case is nonviable or the benefits from the predictive models are not worth the effort to build it.
[appbox appstore 1611045854-iphone screenshots]
[appbox microsoftstore 9n8rl80hvm4t-mobile screenshots]
Machine Learning Q&A -Part II:
At a high level, these skills are a combination of software and data engineering.
The persons that are more appropriate to do this job are a data engineer and/or a machine learning engineer.
That being said, if you work at a startup or happen to be in a small company and need to put the models into production yourself, here are the top skills you need to get:
- Well structured code: it doesn’t need to be perfect but at least can be understood and updated by other team members. Avoid spaghetti code[1] as the plague.
- Add logs: if you are a Python user, the logging[2] module is your friend. Avoid print statements at any cost.
- Model versioning: add a hash key to your different models. You will thank me later.
- Metadata everywhere: save as much data about your models and ML experiments as you can (running time, hyperparameters, used features, CV scores, and so on). You will thank me later, again.
- Monitor performances: execution time and statistical scores of your models.
- Data and models management: store the necessary data and models somewhere that is available to everyone (S3[3] for example). Avoid uploading these to your VCS[4] system. Don’t share them using Slack or Drive. I won’t judge you though, I do it sometimes (read often). Read more here …..
Some of the mistakes that might involve during building a machine learning model (I can think of) are listed here:
- Not understanding the structure of the dataset
- Not giving proper care during features selection
- Leaving out categorical features and considering just numerical variables
- Falling into dummy variable trap
- Selection of inefficient machine learning algorithm
- Not trying out various ML algorithms for building the model based on structure of data.
- Improper tuning of model parameters
- Most importantly: Building an idiotstic imperfect model i.e. suppose we have a classification problem with 99% chances of falling into class1 and remaining to class2. The built model may develop a mapping function which all the time for all data inputs, may predict the result to be class1. Well, one might say his/her model has 99% accuracy. But in reality the 1% class2 case hasn’t been included in the model. So this must be taken into consideration.
- Read more here…
Basically, data mining is a key aspect of data analytics. Some even consider the former as essential to execute before the latter. While data analytics is the complete package and involves most components needed to examine a data set and extract valuable information, data mining focuses specifically on identifying hidden patterns.
That’s just the surface-level comparison though. The image above gives an overview of how the two differ.
One such difference is the presence of a hypothesis. Data analytics usually requires coming up with one, as it aims to find specific answers. Data mining, on the other hand, generally doesn’t need one to test or prove. The expected output are patterns or trends, which doesn’t require coming up with a statement or fact to test.
However, that doesn’t mean you mine data blindly. You still have a goal, whether it’s to come up with a recommender system or identify predictors of a certain dimension. Ultimately though, you strive to come up with data patterns or trends. For data analysis on the other hand, you’re expected to come up with valuable and actionable insights, usually in relation to a predetermined hypothesis. Read more here ….
The data science life cycle is not something well-defined like the software development life-cycle, and there is no ‘one-size-fits-all’ solution for data science projects. Every step in the life-cycle of a data science project depends on various data scientist skills and data science tools. The typical life-cycle of a data science project involves jumping back and forth among various interdependent science tasks using a variety of tools, techniques, programming, etc.
Thus, the data science life-cycle can include the following steps:
- Business requirement understanding.
- Data collection.
- Data cleaning.
- Data analysis.
- Modeling.
- Performance evaluation.
- Communicating with stakeholders.
- Deployment.
- Real-world testing.
- Business buy-in.
- Support and maintenance.
Looks neat, but here is the scheme to visualize how it is happening in reality:
Agile development processes, especially continuous delivery lends itself well to the data science project life-cycle. The early comparison helps the data science team to change approaches, refine hypotheses and even discard the project if the business case is nonviable or the benefits from the predictive models are not worth the effort to build it.
iOs: https://apps.apple.com/ca/app/aws-machine-learning-prep-pro/id1611045854
Android/Amazon: https://www.amazon.com/gp/product/B09TZ4H8V6
AWS MLS-C01 Machine Learning Exam Prep
Quizzes, Practice Exams: Modeling, Data Engineering, Vision, Exploratory Data Analysis, ML Ops, Cheat Sheets, ML Jobs Interview Q&A
Use this App to learn about Machine Learning on AWS and prepare for the AWS Machine Learning Specialty Certification MLS-C01.
Earning AWS Certified Machine Learning Specialty validates expertise in building, training, tuning, and deploying machine learning (ML) models on AWS.
The App provides hundreds of quizzes and practice exam about:
– Machine Learning Operation on AWS
– Modelling
– Data Engineering
– Computer Vision,
– Exploratory Data Analysis,
– ML implementation & Operations
– Machine Learning Basics Questions and Answers
– Machine Learning Advanced Questions and Answers
– Scorecard
– Countdown timer
– Machine Learning Cheat Sheets
– Machine Learning Interview Questions and Answers
– Machine Learning Latest News
The App covers Machine Learning Basics and Advanced topics including: NLP, Computer Vision, Python, linear regression, logistic regression, Sampling, dataset, statistical interaction, selection bias, non-Gaussian distribution, bias-variance trade-off, Normal Distribution, correlation and covariance, Point Estimates and Confidence Interval, A/B Testing, p-value, statistical power of sensitivity, over-fitting and under-fitting, regularization, Law of Large Numbers, Confounding Variables, Survivorship Bias, univariate, bivariate and multivariate, Resampling, ROC curve, TF/IDF vectorization, Cluster Sampling, etc.
Domain 1: Data Engineering
Create data repositories for machine learning.
Identify data sources (e.g., content and location, primary sources such as user data)
Determine storage mediums (e.g., DB, Data Lake, S3, EFS, EBS)
Identify and implement a data ingestion solution.
Data job styles/types (batch load, streaming)
Data ingestion pipelines (Batch-based ML workloads and streaming-based ML workloads), etc.
Domain 2: Exploratory Data Analysis
Sanitize and prepare data for modeling.
Perform feature engineering.
Analyze and visualize data for machine learning.
Domain 3: Modeling
Frame business problems as machine learning problems.
Select the appropriate model(s) for a given machine learning problem.
Train machine learning models.
Perform hyperparameter optimization.
Evaluate machine learning models.
Domain 4: Machine Learning Implementation and Operations
Build machine learning solutions for performance, availability, scalability, resiliency, and fault tolerance.
Recommend and implement the appropriate machine learning services and features for a given problem.
Apply basic AWS security practices to machine learning solutions.
Deploy and operationalize machine learning solutions.
Machine Learning Services covered:
Amazon Comprehend
AWS Deep Learning AMIs (DLAMI)
AWS DeepLens
Amazon Forecast
Amazon Fraud Detector
Amazon Lex
Amazon Polly
Amazon Rekognition
Amazon SageMaker
Amazon Textract
Amazon Transcribe
Amazon Translate
Other Services and topics covered are:
Ingestion/Collection
Processing/ETL
Data analysis/visualization
Model training
Model deployment/inference
Operational
AWS ML application services
Language relevant to ML (for example, Python, Java, Scala, R, SQL)
Notebooks and integrated development environments (IDEs),
S3, SageMaker, Kinesis, Lake Formation, Athena, Kibana, Redshift, Textract, EMR, Glue, SageMaker, CSV, JSON, IMG, parquet or databases, Amazon Athena
Amazon EC2, Amazon Elastic Container Registry (Amazon ECR), Amazon Elastic Container Service, Amazon Elastic Kubernetes Service , Amazon Redshift
Sagemaker API Explained:
AWS Certified Machine Learning Engineer Specialty Questions and Answers:
Question1: An advertising and analytics company uses machine learning to predict user response to online advertisements using a custom XGBoost model. The company wants to improve its ML pipeline by porting its training and inference code, written in R, to Amazon SageMaker, and do so with minimal changes to the existing code.
Answer1: Use the Build Your Own Container (BYOC) Amazon Sagemaker option.
Create a new docker container with the existing code. Register the container in Amazon Elastic Container registry. with the existing code. Register the container in Amazon Elastic Container Registry. Finally run the training and inference jobs using this container.
Question2: Which feature of Amazon SageMaker can you use for preprocessing the data?
Answer2: Amazon Sagemaker Notebook instances
Amazon SageMaker enables developers and data scientists to build, train, tune, and deploy machine learning (ML) models at scale. You can deploy trained ML models for real-time or batch predictions on unseen data, a process known as inference. However, in most cases, the raw input data must be preprocessed and can’t be used directly for making predictions. This is because most ML models expect the data in a predefined format, so the raw data needs to be first cleaned and formatted in order for the ML model to process the data. You can use the Amazon SageMaker built-in Scikit-learn library for preprocessing input data and then use the Amazon SageMaker built-in Linear Learner algorithm for predictions.
Question3: What setting, when creating an Amazon SageMaker notebook instance, can you use to install libraries and import data?
Answer3: LifeCycle Configuration
Question4: How to Choose the right Sagemaker built-in algorithm?
This is a general guide for choosing which algorithm to use depending on what business problem you have and what data you have.
Top 10 Google Professional Machine Learning Engineer Sample Questions
Question 1: You work for a textile manufacturer and have been asked to build a model to detect and classify fabric defects. You trained a machine learning model with high recall based on high resolution images taken at the end of the production line. You want quality control inspectors to gain trust in your model. Which technique should you use to understand the rationale of your classifier?
A. Use K-fold cross validation to understand how the model performs on different test datasets.
B. Use the Integrated Gradients method to efficiently compute feature attributions for each predicted image.
C. Use PCA (Principal Component Analysis) to reduce the original feature set to a smaller set of easily understood features.
D. Use k-means clustering to group similar images together, and calculate the Davies-Bouldin index to evaluate the separation between clusters.
Answer 1)
BNotes 1)
Question 2: You need to write a generic test to verify whether Dense Neural Network (DNN) models automatically released by your team have a sufficient number of parameters to learn the task for which they were built. What should you do?
Answer 2)
Notes 2)
[appbox appstore 1560083470-iphone screenshots]
[appbox googleplay com.awssolutionarchitectassociateexampreppro.app]
Answer 3)
Notes 3)
Question 4: You work on a team where the process for deploying a model into production starts with data scientists training different versions of models in a Kubeflow pipeline. The workflow then stores the new model artifact into the corresponding Cloud Storage bucket. You need to build the next steps of the pipeline after the submitted model is ready to be tested and deployed in production on AI Platform. How should you configure the architecture before deploying the model to production?
Question 10) You work for a large financial institution that is planning to use Dialogflow to create a chatbot for the company’s mobile app. You have reviewed old chat logs and tagged each conversation for intent based on each customer’s stated intention for contacting customer service. About 70% of customer inquiries are simple requests that are solved within 10 intents. The remaining 30% of inquiries require much longer and more complicated requests. Which intents should you automate first?
[appbox appstore 1611045854-iphone screenshots]
[appbox microsoftstore 9n8rl80hvm4t-mobile screenshots]
Machine Learning Q&A Part I:
Google.
Azure and AWS are second class citizens in this area.
Sure, AWS has 70% of the market.
Sure, Azure is the easiest turn key and super user friendly.
But, the king of machine learning in the cloud is GCP.
GCP = Google Cloud Platform
Google has the largest data science team in the world, not mention they have Hinton.
Let’s forgot for a minute they created TensorFlow and give it away.
Let’s just talk about building a real world model with data that doesn’t fit into a excel spreadsheet.
The vast majority of applied machine learning is supervised and that means we need data.
Not just normal data, we need very clean highly structured data.
Where’s the easiest place in the world to upload and model a Petabyte of structured data? BigQuery of course.
Why BigQuery? I don’t have to do anything but upload my data. No spinning up RedShit clusters or whatever I have to do in Azure, just upload and massage data with my familiar SQL. If I do have to wrangle my data it won’t take my six months to update 5 rows here, minutes usually.
Then, you’ll need a front end. Cloud datalab is a Jupyter notebook, which is good because I don’t want nor do I need anything else.
Then, with a single line of code I connect by datalab (Jupyter) notebook to my data in BigQuery and build away.
I’ve worked in all three and the only thing I care about is getting to my job the fastest and right now that means I build my models in GCP.
If you’re new to machine learning don’t start in GCP or any cloud vendor for that matter. Start learning Python from the comfort of your laptop.
The course below is free to the first 20.
The Complete Python Course for Machine Learning Engineers
Here, I want to share the best research paper on Machine Learning classification methods, titled ‘Do we Need Hundreds of Classifiers to Solve Real World Classification Problems?’, published in the ‘Journal of Machine Learning Research’.
This paper nicely explained 179 classification techniques and applied them on 121 data sets thus sharing small summary of the paper:
Do we Need Hundreds of Classifiers to Solve Real World Classification Problems?
The paper evaluated 179 classifiers arising from 17 ML families (discriminant analysis, Bayesian, neural networks, support vector machines, decision trees, rule-based classifiers, boosting, bagging, stacking, random forests and other ensembles, generalized linear models, nearest neighbours, partial least squares and principal component regression, logistic and multinomial regression, multiple adaptive regression splines and other methods), implemented in Weka, R ( with and without the caret package), C and Matlab, including all the relevant classifiers available today.
Experiments used total 121 data sets , which represent the whole UCI data base (excluding the large-scale problems) and other own real problems, in order to achieve significant conclusions about the classifier behaviour, not dependent on the data set collection.
The whole data set and partitions are available from: http://persoal.citius.usc.es/manuel.fernandez.delgado/papers/jmlr/data.tar.gz
The classifiers most likely to be the bests are the random forest (RF) versions, the best of which (implemented in R and accessed via caret) achieves 94.1% of the maximum accuracy overcoming 90% in the 84.3% of the data sets. However, the difference is not statistically significant with the second best, the SVM with Gaussian kernel implemented in C using LibSVM, which achieves 92.3% of the maximum accuracy. A few models are clearly better than the remaining ones: random forest, SVM with Gaussian and polynomial kernels, extreme learning machine with Gaussian kernel, C5.0 and avNNet (a committee of multi-layer perceptrons implemented in R with the caret package).
The random forest is clearly the best family of classifiers (3 out of 5 bests classifiers are RF), followed by SVM (4 classifiers in the top-10), neural networks and boosting ensembles (5 and 3 members in the top-20, respectively).
You can see the table with the complete results: http://persoal.citius.usc.es/manuel.fernandez.delgado/papers/jmlr/results.txt
I hope it will be helpful for Statistic and Machine Leaning aspirants!
Thank you!
These basic questions should help:
1. Is the classification going to be supervised or unsupervised? Several well defined techniques likes SVM (Support Vector Machines), trained neural net,etc. are applicable for supervised classification. For unsupervised classification, GMMs (Gaussian Mixture Models), HMMs (Hidden Markov models) with Baye’s techniques could be used. (Several other techniques could of course be used as well)
2.How much training data do you have in case it is supervised ? A small number of training data may yield discouraging classification accuracy even if the chosen classifier is the most suitable one for the problem. In such a case, try to obtain more number of samples. There’s also generally a correlation (for practical purposes at least) between the feature dimensionality and the number of samples for given technique. For example, while using SVM, the linear kernel tends to yield better results when the number of training samples are less than or equal to or only slightly more than the number of feature dimensions as compared to RBF or any other kernel.
3. If the feature vector dimensionality is small enough (1/2/3 -D) then it makes sense to plot and visually inspect if techniques like clustering could be more useful. With very high number of feature dimensions, methods like clustering are generally not advisable(Refer : “The Curse Of Dimensionality”).
4. Are you doing classification in real time ? Some techniques ,e.g. “Template Match” in image classification may lead to a higher number of errors but is generally faster than most other techniques if the number of templates to be evaluated are not excessively high.
5. Depending upon the problem domain, you can decide if you can choose the underlying model in such a way that it can use certain temporal/spatial correlations that may be inherent in the data. For example, HMMs use the temporal continuity of speech samples for enhancing classification results in speech recognition problems.
Another point, slightly off the topic perhaps, but the classification performance is as much a function of choosing the correct feature vectors, the pre-processing of the feature vectors as much as the classifier itself. It’s generally a good idea to give reserve some initial part of the project to try out various classifiers on the same data-set. It may at least help you reject the ones which are highly inaccurate.
At a high level, these skills are a combination of software and data engineering.
The persons that are more appropriate to do this job are a data engineer and/or a machine learning engineer.
That being said, if you work at a startup or happen to be in a small company and need to put the models into production yourself, here are the top skills you need to get:
- Well structured code: it doesn’t need to be perfect but at least can be understood and updated by other team members. Avoid spaghetti code[1] as the plague.
- Add logs: if you are a Python user, the logging[2] module is your friend. Avoid print statements at any cost.
- Model versioning: add a hash key to your different models. You will thank me later.
- Metadata everywhere: save as much data about your models and ML experiments as you can (running time, hyperparameters, used features, CV scores, and so on). You will thank me later, again.
- Monitor performances: execution time and statistical scores of your models.
- Data and models management: store the necessary data and models somewhere that is available to everyone (S3[3] for example). Avoid uploading these to your VCS[4] system. Don’t share them using Slack or Drive. I won’t judge you though, I do it sometimes (read often). Read more here …..
Some of the mistakes that might involve during building a machine learning model (I can think of) are listed here:
- Not understanding the structure of the dataset
- Not giving proper care during features selection
- Leaving out categorical features and considering just numerical variables
- Falling into dummy variable trap
- Selection of inefficient machine learning algorithm
- Not trying out various ML algorithms for building the model based on structure of data.
- Improper tuning of model parameters
- Most importantly: Building an idiotstic imperfect model i.e. suppose we have a classification problem with 99% chances of falling into class1 and remaining to class2. The built model may develop a mapping function which all the time for all data inputs, may predict the result to be class1. Well, one might say his/her model has 99% accuracy. But in reality the 1% class2 case hasn’t been included in the model. So this must be taken into consideration.
- Read more here…
[appbox appstore 1560083470-iphone screenshots]
[appbox googleplay com.awssolutionarchitectassociateexampreppro.app]
Basically, data mining is a key aspect of data analytics. Some even consider the former as essential to execute before the latter. While data analytics is the complete package and involves most components needed to examine a data set and extract valuable information, data mining focuses specifically on identifying hidden patterns.
That’s just the surface-level comparison though. The image above gives an overview of how the two differ.
One such difference is the presence of a hypothesis. Data analytics usually requires coming up with one, as it aims to find specific answers. Data mining, on the other hand, generally doesn’t need one to test or prove. The expected output are patterns or trends, which doesn’t require coming up with a statement or fact to test.
However, that doesn’t mean you mine data blindly. You still have a goal, whether it’s to come up with a recommender system or identify predictors of a certain dimension. Ultimately though, you strive to come up with data patterns or trends. For data analysis on the other hand, you’re expected to come up with valuable and actionable insights, usually in relation to a predetermined hypothesis. Read more here ….
The data science life cycle is not something well-defined like the software development life-cycle, and there is no ‘one-size-fits-all’ solution for data science projects. Every step in the life-cycle of a data science project depends on various data scientist skills and data science tools. The typical life-cycle of a data science project involves jumping back and forth among various interdependent science tasks using a variety of tools, techniques, programming, etc.
Thus, the data science life-cycle can include the following steps:
- Business requirement understanding.
- Data collection.
- Data cleaning.
- Data analysis.
- Modeling.
- Performance evaluation.
- Communicating with stakeholders.
- Deployment.
- Real-world testing.
- Business buy-in.
- Support and maintenance.
Looks neat, but here is the scheme to visualize how it is happening in reality:
Agile development processes, especially continuous delivery lends itself well to the data science project life-cycle. The early comparison helps the data science team to change approaches, refine hypotheses and even discard the project if the business case is nonviable or the benefits from the predictive models are not worth the effort to build it.
[appbox appstore 1611045854-iphone screenshots]
[appbox microsoftstore 9n8rl80hvm4t-mobile screenshots]
Machine Learning Q&A -Part II:
At a high level, these skills are a combination of software and data engineering.
The persons that are more appropriate to do this job are a data engineer and/or a machine learning engineer.
That being said, if you work at a startup or happen to be in a small company and need to put the models into production yourself, here are the top skills you need to get:
- Well structured code: it doesn’t need to be perfect but at least can be understood and updated by other team members. Avoid spaghetti code[1] as the plague.
- Add logs: if you are a Python user, the logging[2] module is your friend. Avoid print statements at any cost.
- Model versioning: add a hash key to your different models. You will thank me later.
- Metadata everywhere: save as much data about your models and ML experiments as you can (running time, hyperparameters, used features, CV scores, and so on). You will thank me later, again.
- Monitor performances: execution time and statistical scores of your models.
- Data and models management: store the necessary data and models somewhere that is available to everyone (S3[3] for example). Avoid uploading these to your VCS[4] system. Don’t share them using Slack or Drive. I won’t judge you though, I do it sometimes (read often). Read more here …..
Some of the mistakes that might involve during building a machine learning model (I can think of) are listed here:
- Not understanding the structure of the dataset
- Not giving proper care during features selection
- Leaving out categorical features and considering just numerical variables
- Falling into dummy variable trap
- Selection of inefficient machine learning algorithm
- Not trying out various ML algorithms for building the model based on structure of data.
- Improper tuning of model parameters
- Most importantly: Building an idiotstic imperfect model i.e. suppose we have a classification problem with 99% chances of falling into class1 and remaining to class2. The built model may develop a mapping function which all the time for all data inputs, may predict the result to be class1. Well, one might say his/her model has 99% accuracy. But in reality the 1% class2 case hasn’t been included in the model. So this must be taken into consideration.
- Read more here…
Basically, data mining is a key aspect of data analytics. Some even consider the former as essential to execute before the latter. While data analytics is the complete package and involves most components needed to examine a data set and extract valuable information, data mining focuses specifically on identifying hidden patterns.
That’s just the surface-level comparison though. The image above gives an overview of how the two differ.
One such difference is the presence of a hypothesis. Data analytics usually requires coming up with one, as it aims to find specific answers. Data mining, on the other hand, generally doesn’t need one to test or prove. The expected output are patterns or trends, which doesn’t require coming up with a statement or fact to test.
However, that doesn’t mean you mine data blindly. You still have a goal, whether it’s to come up with a recommender system or identify predictors of a certain dimension. Ultimately though, you strive to come up with data patterns or trends. For data analysis on the other hand, you’re expected to come up with valuable and actionable insights, usually in relation to a predetermined hypothesis. Read more here ….
The data science life cycle is not something well-defined like the software development life-cycle, and there is no ‘one-size-fits-all’ solution for data science projects. Every step in the life-cycle of a data science project depends on various data scientist skills and data science tools. The typical life-cycle of a data science project involves jumping back and forth among various interdependent science tasks using a variety of tools, techniques, programming, etc.
Thus, the data science life-cycle can include the following steps:
- Business requirement understanding.
- Data collection.
- Data cleaning.
- Data analysis.
- Modeling.
- Performance evaluation.
- Communicating with stakeholders.
- Deployment.
- Real-world testing.
- Business buy-in.
- Support and maintenance.
Looks neat, but here is the scheme to visualize how it is happening in reality:
Agile development processes, especially continuous delivery lends itself well to the data science project life-cycle. The early comparison helps the data science team to change approaches, refine hypotheses and even discard the project if the business case is nonviable or the benefits from the predictive models are not worth the effort to build it.
Machine Learning Latest News
Top 10 Machine Learning Algorithms
What are the simplest examples of machine learning algorithms?
Source: Top 10 Machine Learning Algorithms for Data Scientist
In machine learning, there’s something called the “No Free Lunch” theorem. In a nutshell, it states that no one algorithm works best for every problem. It’s especially relevant for supervised learning. For example, you can’t say that neural networks are always better than decision trees or vice-versa. Furthermore, there are many factors at play, such as the size and structure of your dataset. As a result, you should try many different algorithms for your problem!
Top ML Algorithms
1. Linear Regression
Regression is a technique for numerical prediction. Additionally, regression is a statistical measure that attempts to determine the strength of the relationship between two variables. One is a dependent variable. Other is from a series of other changing variables which are our independent variables. Moreover, just like Classification is for predicting categorical labels, Regression is for predicting a continuous value. For example, we may wish to predict the salary of university graduates with 5 years of work experience. We use regression to determine how much specific factors or sectors influence the dependent variable.
Linear regression attempts to model the relationship between a scalar variable and explanatory variables by fitting a linear equation. For example, one might want to relate the weights of individuals to their heights using a linear regression model.
Additionally, this operator calculates a linear regression model. It uses the Akaike criterion for model selection. Furthermore, the Akaike information criterion is a measure of the relative goodness of a fit of a statistical model.
2. Logistic Regression
Logistic regression is a classification model. It uses input variables to predict a categorical outcome variable. The variable can take on one of a limited set of class values. A binomial logistic regression relates to two binary output categories. A multinomial logistic regression allows for more than two classes. Examples of logistic regression include classifying a binary condition as “healthy” / “not healthy”. Logistic regression applies the logistic sigmoid function to weighted input values to generate a prediction of the data class.
A logistic regression model estimates the probability of a dependent variable as a function of independent variables. The dependent variable is the output that we are trying to predict. The independent variables or explanatory variables are the factors that we feel could influence the output. Multiple regression refers to regression analysis with two or more independent variables. Multivariate regression, on the other hand, refers to regression analysis with two or more dependent variables.
3. Linear Discriminant Analysis
Logistic Regression is a classification algorithm traditionally for two-class classification problems. If you have more than two classes then the Linear Discriminant Analysis algorithm is the preferred linear classification technique.
The representation of LDA is pretty straight forward. It consists of statistical properties of your data, calculated for each class. For a single input variable this includes:
- The mean value for each class.
- The variance calculated across all classes.
We make predictions by calculating a discriminate value for each class. After that we make a prediction for the class with the largest value. The technique assumes that the data has a Gaussian distribution. Hence, it is a good idea to remove outliers from your data beforehand. It’s a simple and powerful method for classification predictive modelling problems.
4. Classification and Regression Trees
Prediction Trees are for predicting response or class YY from input X1, X2,…,XnX1,X2,…,Xn. If it is a continuous response it is a regression tree, if it is categorical, it is a classification tree. At each node of the tree, we check the value of one the input XiXi. Depending on the (binary) answer we continue to the left or to the right subbranch. When we reach a leaf we will find the prediction.
Contrary to linear or polynomial regression which are global models, trees try to partition the data space into small enough parts where we can apply a simple different model on each part. The non-leaf part of the tree is just the procedure to determine for each data xx what is the model we will use to classify it.
5. Naive Bayes
A Naive Bayes Classifier is a supervised machine-learning algorithm that uses the Bayes’ Theorem, which assumes that features are statistically independent. The theorem relies on the naive assumption that input variables are independent of each other, i.e. there is no way to know anything about other variables when given an additional variable. Regardless of this assumption, it has proven itself to be a classifier with good results.
Naive Bayes Classifiers rely on the Bayes’ Theorem, which is based on conditional probability or in simple terms, the likelihood that an event (A) will happen given that another event (B) has already happened. Essentially, the theorem allows a hypothesis to be updated each time new evidence is introduced. The equation below expresses Bayes’ Theorem in the language of probability:
Let’s explain what each of these terms means.
- “P” is the symbol to denote probability.
- P(A | B) = The probability of event A (hypothesis) occurring given that B (evidence) has occurred.
- P(B | A) = The probability of the event B (evidence) occurring given that A (hypothesis) has occurred.
- P(A) = The probability of event B (hypothesis) occurring.
- P(B) = The probability of event A (evidence) occurring.
6. K-Nearest Neighbors
k-nearest neighbours (or k-NN for short) is a simple machine learning algorithm that categorizes an input by using its k nearest neighbours.
For example, suppose a k-NN algorithm has an input of data points of specific men and women’s weight and height, as plotted below. To determine the gender of an unknown input (green point), k-NN can look at the nearest k neighbours (suppose ) and will determine that the input’s gender is male. This method is a very simple and logical way of marking unknown inputs, with a high rate of success.
Also, we can k-NN in a variety of machine learning tasks; for example, in computer vision, k-NN can help identify handwritten letters and in gene expression analysis, the algorithm can determine which genes contribute to a certain characteristic. Overall, k-nearest neighbours provide a combination of simplicity and effectiveness that makes it an attractive algorithm to use for many machine learning tasks.
7. Learning Vector Quantization
A downside of K-Nearest Neighbors is that you need to hang on to your entire training dataset. The Learning Vector Quantization algorithm (or LVQ for short) is an artificial neural network algorithm that allows you to choose how many training instances to hang onto and learns exactly what those instances should look like.
Additionally, the representation for LVQ is a collection of codebook vectors. We select them randomly in the beginning and adapted to best summarize the training dataset over a number of iterations of the learning algorithm. After learned, the codebook vectors can make predictions just like K-Nearest Neighbors. Also, we find the most similar neighbour (best matching codebook vector) by calculating the distance between each codebook vector and the new data instance. The class value or (real value in the case of regression) for the best matching unit is then returned as the prediction. Moreover, you can get the best results if you rescale your data to have the same range, such as between 0 and 1.
If you discover that KNN gives good results on your dataset try using LVQ to reduce the memory requirements of storing the entire training dataset.
8. Bagging and Random Forest
A Random Forest consists of a collection or ensemble of simple tree predictors, each capable of producing a response when presented with a set of predictor values. For classification problems, this response takes the form of a class membership, which associates, or classifies, a set of independent predictor values with one of the categories present in the dependent variable. Alternatively, for regression problems, the tree response is an estimate of the dependent variable given the predictors.e
A Random Forest consists of an arbitrary number of simple trees, which determine the final outcome. For classification problems, the ensemble of simple trees votes for the most popular class. In the regression problem, we average responses to obtain an estimate of the dependent variable. Using tree ensembles can lead to significant improvement in prediction accuracy (i.e., better ability to predict new data cases).
9. SVM
A Support Vector Machine (SVM) is a supervised machine learning algorithm that can be employed for both classification and regression purposes. Also, SVMs have more common usage in classification problems and as such, this is what we will focus on in this post.
SVMs are based on the idea of finding a hyperplane that best divides a dataset into two classes, as shown in the image below.
Also, you can think of a hyperplane as a line that linearly separates and classifies a set of data.
Intuitively, the further from the hyperplane our data points lie, the more confident we are that they have been correctly classified. We, therefore, want our data points to be as far away from the hyperplane as possible, while still being on the correct side of it.
So when we add a new testing data , whatever side of the hyperplane it lands will decide the class that we assign to it.
The distance between the hyperplane and the nearest data point from either set is the margin. Furthermore, the goal is to choose a hyperplane with the greatest possible margin between the hyperplane and any point within the training set, giving a greater chance of correct classification of data.
But the data is rarely ever as clean as our simple example above. A dataset will often look more like the jumbled balls below which represent a linearly non-separable dataset.
10. Boosting and AdaBoost
Boosting is an ensemble technique that attempts to create a strong classifier from a number of weak classifiers. We do this by building a model from the training data, then creating a second model that attempts to correct the errors from the first model. We can add models until the training set is predicted perfectly or a maximum number of models are added.
AdaBoost was the first really successful boosting algorithm developed for binary classification. It is the best starting point for understanding boosting. Modern boosting methods build on AdaBoost, most notably stochastic gradient boosting machines.
AdaBoost is used with short decision trees. After the first tree is created, the performance of the tree on each training instance is used to weight how much attention the next tree that is created should pay attention to each training instance. Training data that is hard to predict is given more weight, whereas easy to predict instances are given less weight. Models are created sequentially one after the other, each updating the weights on the training instances that affect the learning performed by the next tree in the sequence. After all the trees are built, predictions are made for new data, and the performance of each tree is weighted by how accurate it was on training data.
Because so much attention is put on correcting mistakes by the algorithm it is important that you have clean data with outliers removed.
Summary
A typical question asked by a beginner, when facing a wide variety of machine learning algorithms, is “which algorithm should I use?” The answer to the question varies depending on many factors, including: (1) The size, quality, and nature of data; (2) The available computational time; (3) The urgency of the task; and (4) What you want to do with the data.
Even an experienced data scientist cannot tell which algorithm will perform the best before trying different algorithms. Although there are many other Machine Learning algorithms, these are the most popular ones. If you’re a newbie to Machine Learning, these would be a good starting point to learn.
Follow this link, if you are looking to learn Data Science Course Online!
Additionally, if you are having an interest in learning Data Science, Learn online Data Science Course to boost your career in Data Science.
Also, learn AWS Big Data Course click here, AWS Online Course
Furthermore, if you want to read more about data science, read this Data Science blogs
The foundations of most algorithms lie in linear algebra, multivariable calculus, and optimization methods. Most algorithms use a sequence of combinations to estimate an objective function given a set of data, and the sequence order and included methods distinguish one algorithm from another. It’s helpful to learn enough math to read the development papers associated with key algorithms in the field, as many other methods (or one’s own innovations) include pieces of those algorithms. It’s like learning the language of machine learning. Once you are fluent in it, it’s pretty easy to modify algorithms as needed and create new ones likely to improve on a problem in a short period of time.
Matrix factorization: a simple, beautiful way to do dimensionality reduction —and dimensionality reduction is the essence of cognition. Recommender systems would be a big application of matrix factorization. Another application I’ve been using over the years (starting in 2010 with video data) is factorizing a matrix of pairwise mutual information (or pointwise mutual information, which is more common) between features, which can be used for feature extraction, computing word embeddings, computing label embeddings (that was the topic of a recent paper of mine [1]), etc.
Used in a convolutional settings, this acts as an excellent unsupervised feature extractor for images and videos. There’s one big issue though: it is fundamentally a shallow algorithm. Deep neural networks will quickly outperform it if any kind of supervision labels are available.
[1] [1607.05691] Information-theoretical label embeddings for large-scale image classification
Machine Learning Demos:

See how well you synchronize to the lyrics of the popular hit “Dance Monkey.” This in-browser experience uses the Facemesh model for estimating key points around the lips to score lip-syncing accuracy.Explore demo View code

Use your phone’s camera to identify emojis in the real world. Can you find all the emojis before time expires?Explore demo View code
Play Pac-Man using images trained in your browser.Explore demo View code
No coding required! Teach a machine to recognize images and play sounds.Explore demo View code

Explore pictures in a fun new way, just by moving around.Explore demo View code

Enjoy a real-time piano performance by a neural network.Explore demo View code
Train a server-side model to classify baseball pitch types using Node.js.View code
See how to visualize in-browser training and model behaviour and training using tfjs-vis.Explore demo View code
Community demos
Get started with official templates and explore top picks from the community for inspiration.Glitch
Check out community Glitches and make your own TensorFlow.js-powered projects.Explore Glitch Codepen
Fork boilerplate templates and check out working examples from the community.Explore CodePen GitHub Community Projects
See what the community has created and submitted to the TensorFlow.js gallery page.Explore GitHub
 https://cdpn.io/jasonmayes/fullcpgrid/QWbNeJdOpen in Editor
https://cdpn.io/jasonmayes/fullcpgrid/QWbNeJdOpen in Editor
Real time body segmentation using TensorFlow.js
Load in a pre-trained Body-Pix model from the TensorFlow.js team so that you can locate all pixels in an image that are part of a body, and what part of the body they belong to. Clone this to make your own TensorFlow.js powered projects to recognize body parts in images from your webcam and more!
New Pen from Template https://cdpn.io/jasonmayes/fullcpgrid/qBEJxggOpen in Editor
https://cdpn.io/jasonmayes/fullcpgrid/qBEJxggOpen in Editor
Multiple object detection using pre trained model in TensorFlow.js
This demo shows how we can use a pre made machine learning solution to recognize objects (yes, more than one at a time!) on any image you wish to present to it. Even better, not only do we know that the image contains an object, but we can also get the co-ordinates of the bounding box for each object it finds, which allows you to highlight the found object in the image.
For this demo we are loading a model using the ImageNet-SSD architecture, to recognize 90 common objects it has already been taught to find from the COCO dataset.
If what you want to recognize is in that list of things it knows about (for example a cat, dog, etc), this may be useful to you as is in your own projects, or just to experiment with Machine Learning in the browser and get familiar with the possibilities of machine learning.
If you are feeling particularly confident you can check out our GitHub documentation (https://github.com/tensorflow/tfjs-models/tree/master/coco-ssd) which goes into much more detail for customizing various parameters to tailor performance to your needs.
New Pen from Template https://cdpn.io/jasonmayes/fullcpgrid/JjompwwOpen in Editor
https://cdpn.io/jasonmayes/fullcpgrid/JjompwwOpen in Editor
Classifying images using a pre trained model in TensorFlow.js
This demo shows how we can use a pre made machine learning solution to classify images (aka a binary image classifier). It should be noted that this model works best when a single item is in the image at a time. Busy images may not work so well. You may want to try our demo for Multiple Object Detection (https://codepen.io/jasonmayes/pen/qBEJxgg) for that.
For this demo we are loading a model using the MobileNet architecture, to recognize 1000 common objects it has already been taught to find from the ImageNet data set (http://image-net.org/).
If what you want to recognize is in that list of things it knows about (for example a cat, dog, etc), this may be useful to you as is in your own projects, or just to experiment with Machine Learning in the browser and get familiar with the possibilities of machine learning.
Please note: This demo loads an easy to use JavaScript class made by the TensorFlow.js team to do the hardwork for you so no machine learning knowledge is needed to use it.
If you were looking to learn how to load in a TensorFlow.js saved model directly yourself then please see our tutorial on loading TensorFlow.js models directly.
If you want to train a system to recognize your own objects, using your own data, then check out our tutorials on “transfer learning”.
New Pen from Template Open in Editor
Open in Editor
Tensorflow.js Boilerplate
The hello world for TensorFlow.js 🙂 Absolute minimum needed to import into your website and simply prints the loaded TensorFlow.js version. From here we can do great things. Clone this to make your own TensorFlow.js powered projects or if you are following a tutorial that needs TensorFlow.js to work.
Examples
tfjs-examples provides small code examples that implement various ML tasks using TensorFlow.js.MNIST Digit Recognizer
Train a model to recognize handwritten digits from the MNIST database.Explore example View code Addition RNN
Train a model to learn addition from text examples.Explore example View code
TensorFlow.js Layers: Iris Demo
More TensorFlow examples
Top-paying Cloud certifications:
[appbox appstore 1611045854-iphone screenshots]
[appbox microsoftstore 9n8rl80hvm4t-mobile screenshots]
- Google Certified Professional Cloud Architect — $175,761/year
- AWS Certified Solutions Architect – Associate — $149,446/year
- Azure/Microsoft Cloud Solution Architect – $141,748/yr
- Google Cloud Associate Engineer – $145,769/yr
- AWS Certified Cloud Practitioner — $131,465/year
- Microsoft Certified: Azure Fundamentals — $126,653/year
- Microsoft Certified: Azure Administrator Associate — $125,993/year
Supervised Learning
Linear Regression
Logistic Regression
Naive Bayes
Support Vector Machines
Decision Trees
K-Nearest Neighbors
Machine Learning in Practice
Bias-Variance Tradeoff
How to Select a Model
How to Select Features
Regularizing Your Model
Ensembling: How to Combine Your Models
Evaluation Metrics
Unsupervised Learning
Market Basket Analysis
K-Means Clustering
Principal Components Analysis
Deep Learning
Feedforward Neural Networks
Grab Bag of Neural Network Practices
Convolutional Neural Networks
Recurrent Neural Networks
Test Your Knowledge
Best Subset Features Feature
Selection Examples
Adding Features Example
Activation Practice I
Activation Practice II
Activation Practice III
Weight Initialization
Batch vs. Stochastic
Convolutional Application
Convolutional Layer Advantages
Are you interested in becoming an AWS Certified Machine Learning Specialist? If so, then this exam preparation blog is for you! The blog contains over 100 quiz and practice exam questions, as well as detailed answers. The questions are very similar to those you will encounter on the actual exam, so this is a great way to prepare. In addition, the blog also includes cheat sheets and illustrations to help you understand the concepts better.
Bring your own algorithm to an MLOps Pipeline: Architecture




Code and Serve Your ML Model with AWS CodeBuild
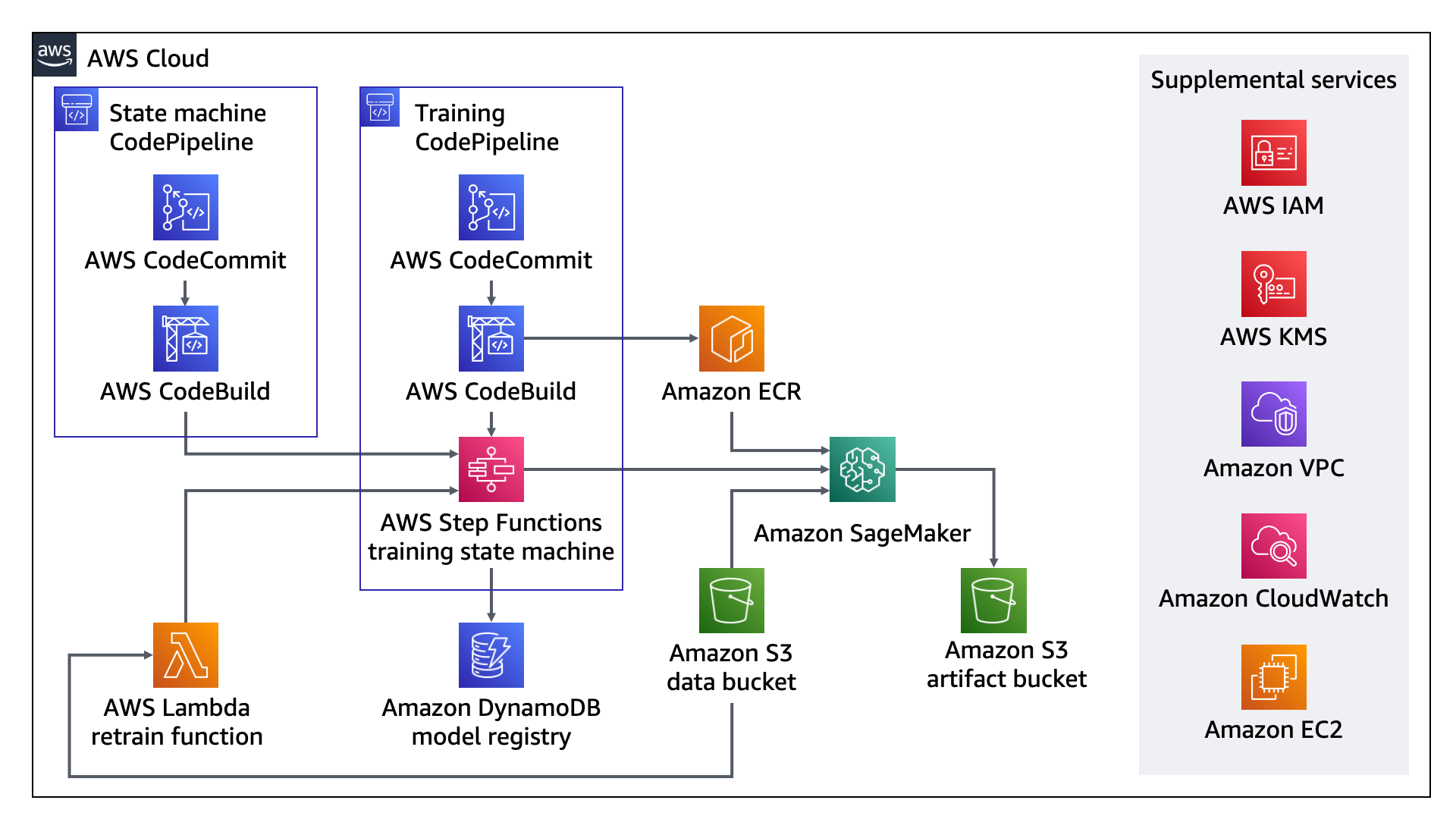
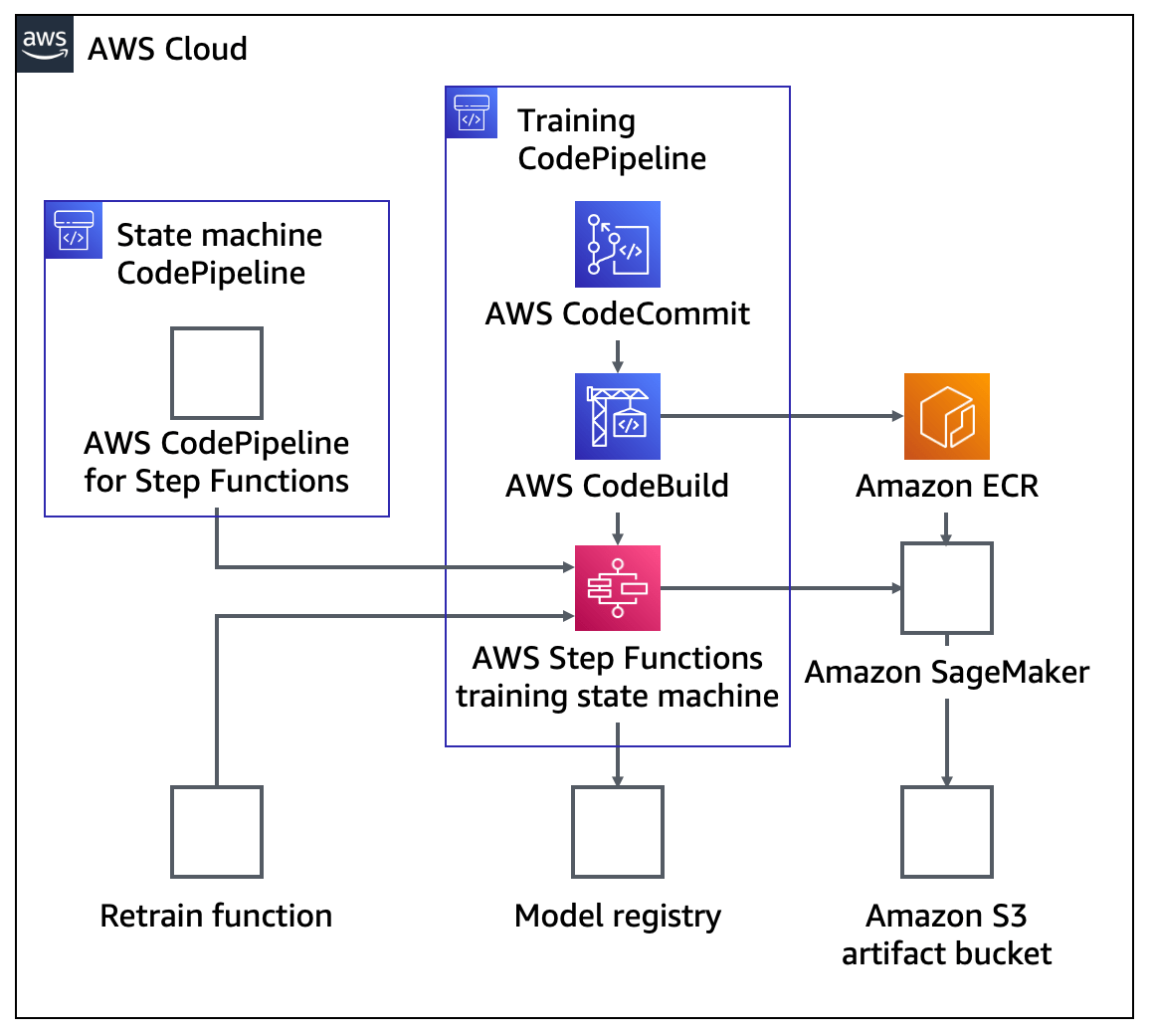
What are some ways we can use machine learning and artificial intelligence for algorithmic trading in the stock market?
How do we know that the Top 3 Voice Recognition Devices like Siri Alexa and Ok Google are not spying on us?
What are some good datasets for Data Science and Machine Learning?
Machine Learning Engineer Interview Questions and Answers
- [R] How do you search for implementations of Mixture of Expert models that can be trained locally in a laptop or desktop without ultra-high end GPUs?by /u/Furiousguy79 (Machine Learning) on July 25, 2024 at 11:12 pm
Hi, I am a 2nd year PhD student in CS. My supervisor just got this idea about MoEs and fairness and asked me to implement it ( work on a toy classification problem on tabular data and NOT language data). However as it is not their area of expertise, they did not give any guidelines on how to approach it. My main question is: How do I search for or proceed with implementing a mixture of expert models? The ones that I find are for chatting and such but I mainly work with tabular EHR data. This is my first foray into this area (LLMs and MoEs) and I am kind of lost with all these Mixtral, openMoE, etc. As we do not have access to Google Collab or have powerful GPUs I have to rely on local training (My lab PC has 2080ti and my laptop has 4070). Any guideline or starting point on how to proceed would be greatly appreciated. submitted by /u/Furiousguy79 [link] [comments]
- [D] What do you use LLMs for?by /u/RND_RandoM (Machine Learning) on July 25, 2024 at 10:31 pm
Just wanted to start a small discussion about why you use LLMs and which model works best for your use case. I am asking because I am concerned that there is little use for LLMs apart from doing role play, helping with coding, and answering general questions submitted by /u/RND_RandoM [link] [comments]
- [R] Moderating LLM Inputs with PromptGuardby /u/Different-General700 (Machine Learning) on July 25, 2024 at 10:12 pm
Meta's release of its latest Llama language model family this week, including the massive Llama-3 405B model, has generated a great deal of excitement among AI developers. These open-weights frontier models, which have been updated with a new license that allows unrestricted use of outputs, will enable significant improvements to AI-powered applications, and enable widespread commercial use of synthetic data. Less discussed, but no less important, are Meta's latest open moderation tools, including a new model called PromptGuard. PromptGuard is a small, lightweight classification model trained to detect malicious prompts, including jailbreaks and prompt injections. These attacks can be used to manipulate language models to produce harmful outputs or extract sensitive information. Companies building enterprise-ready applications must be able to detect and mitigate these attacks to ensure their models are safe to use, especially in sensitive and highly-regulated domains like healthcare, finance, and law. PromptGuard is a text classification model based on mDeBERTa-v3-base, a small transformer model with multilingual capabilities. Meta trained this model to output probabilities for 3 classes: BENIGN, INJECTION, and JAILBREAK. The JAILBREAK class is designed to identify malicious user prompts (such as the "Do Anything Now(opens in a new tab)" or DAN prompt, which instructs a language model to ignore previous instructions and enter an unrestricted mode). On the other hand, the INJECTION class is designed to identify retrieved contexts, such as a webpage or document, which have been poisoned with malicious content to influence the model's output. In our tests, we find that the model is able to identify common jailbreaks like DAN, but also labels benign prompts as injections. This likely happens because the model is trained to handle both prompts and retrieved contexts (such as web searches and news articles), and a benign prompt may appear similar to a malicious context. As stated in the model card: Application developers typically want to allow users flexibility in how they interact with an application, and to only filter explicitly violating prompts (what the ‘jailbreak’ label detects). Third-party content has a different expected distribution of inputs (we don’t expect any “prompt-like” content in this part of the input) This indicates that when applying the model to user prompts, you may want to ignore the INJECTION label, and only filter JAILBREAK inputs. On the other hand, when filtering third-party context to show to the model, such as a news article, you'd want to remove both JAILBREAK and INJECTION labels. We wrote a quick blog post about how you can use PromptGuard to protect your language models from malicious inputs. You can read more here: https://www.trytaylor.ai/blog/promptguard submitted by /u/Different-General700 [link] [comments]
- [P] How to make "Out-of-sample" Predictionsby /u/Individual_Ad_1214 (Machine Learning) on July 25, 2024 at 7:47 pm
My data is a bit complicated to describe so I'm going try to describe something analogous. Each example is randomly generated, but you can group them based on a specific but latent (by latent I mean this isn't added into the features used to develop a model, but I have access to it) feature (in this example we'll call this number of bedrooms). Feature x1 Feature x2 Feature x3 ... Output (Rent) Row 1 Row 2 Row 3 Row 4 Row 5 Row 6 Row 7 2 Row 8 1 Row 9 0 So I can group Row 1, Row 2, and Row 3 based on a latent feature called number of bedrooms (which in this case is 0 bedroom). Similarly, Row 4, Row 5, & Row 6 have 2 Bedrooms, and Row 7, Row 8, & Row 9 have 4 Bedrooms. Furthermore, these groups also have an optimum price which is used to create output classes (output here is Rent; increase, keep constant, or decrease). So say the optimum price for the 4 bedrooms group is $3mil, and row 7 has a price of $4mil (=> 3 - 4 = -1 mil, i.e a -ve value so convert this to class 2, or above optimum or increase rent), row 8 has a price of $3mil (=> 3 - 3 = 0, convert this to class 1, or at optimum), and row 9 has a price of $2mil (3 - 2 = 1, i.e +ve value, so convert this to class 0, or below optimum, or decrease rent). I use this method to create an output class for each example in the dataset (essentially, if example x has y number of bedrooms, I get the known optimum price for that number of bedrooms and I subtract the example's price from the optimum price). Say I have 10 features (e.g. square footage, number of bathrooms, parking spaces etc.) in the dataset, these 10 features provide the model with enough information to figure out the "number of bedrooms". So when I am evaluating the model, feature x1 feature x2 feature x3 ... Row 10 e.g. I pass into the model a test example (Row 10) which I know has 4 bedrooms and is priced at $6mil, the model can accurately predict class 2 (i.e increase rent) for this example. Because the model was developed using data with a representative number of bedrooms in my dataset. Features.... Output (Rent) Row 1 0 Row 2 0 Row 3 0 However, my problem arises at examples with a low number of bedrooms (i.e. 0 bedrooms). The input features doesn't have enough information to determine the number of bedrooms for examples with a low number of bedrooms (which is fine because we assume that within this group, we will always decrease the rent, so we set the optimum price to say $2000. So row 1 price could be $8000, (8000 - 2000 = 6000, +ve value thus convert to class 0 or below optimum/decrease rent). And within this group we rely on the class balance to help the model learn to make predictions because the proportion is heavily skewed towards class 0 (say 95% = class 0 or decrease rent, and 5 % = class 1 or class 2). We do this based the domain knowledge of the data (so in this case, we would always decrease the rent because no one wants to live in a house with 0 bedrooms). MAIN QUESTION: We now want to predict (or undertake inference) for examples with number of bedrooms in between 0 bedrooms and 2 bedrooms (e.g 1 bedroom NOTE: our training data has no example with 1 bedroom). What I notice is that the model's predictions on examples with 1 bedroom act as if these examples had 0 bedrooms and it mostly predicts class 0. My question is, apart from specifically including examples with 1 bedroom in my input data, is there any other way (more statistics or ML related way) for me to improve the ability of my model to generalise on unseen data? submitted by /u/Individual_Ad_1214 [link] [comments]
- [D] Will An Unsupervised FSD Eventually Be Efficient Enough Run on Tesla's HW3?by /u/ZeApelido (Machine Learning) on July 25, 2024 at 7:32 pm
Tesla has a version (V12.5) of their supervised "Full Self Driving" that potential showing signficant improvements, though we will wait to see how much miles per critical disengagment have gone up. (Maybe 600-1000. Previous versions at 100-200 miles per critical disengagement). In order to make this improvement, they upped the parameter count by 5x the previous models. They are just barely making it function on HW3 (works on HW4). These models are already taking advantage of distillation and compression techniques. Considering that the miles per critical disengagement still needs to go up another 100x, I would think model parameter count will have to go up signficantly, maybe 10x-100x? While there are continuing advances in model distillation and compression, I find it hard to fathom that much larger models needed to achieve unsupervised driving will be compressed even further. Tweets like this imply (presumably from advances like LLAMA 2 to LLAMA 3) that these compression ratios will continue at a massive pace. https://x.com/wintonARK/status/1816537413206048915 What do you think? To me, the likely needed increase in model size to get to robotaxi level fidelity will outweigh any advances in distillation so that HW3 will unlikely be able to handle the model. submitted by /u/ZeApelido [link] [comments]
- [R] EMNLP Paper review scoresby /u/Immediate-Hour-8466 (Machine Learning) on July 25, 2024 at 7:06 pm
EMNLP paper review scores Overall assessment for my paper is 2, 2.5 and 3. Is there any chance that it may still be selected? The confidence is 2, 2.5 and 3. The soundness is 2, 2.5, 3.5. I am not sure how soundness and confidence may affect my paper's selection. Pls explain how this works. Which metrics should I consider important. Thank you! submitted by /u/Immediate-Hour-8466 [link] [comments]
- [N] OpenAI announces SearchGPTby /u/we_are_mammals (Machine Learning) on July 25, 2024 at 6:41 pm
https://openai.com/index/searchgpt-prototype/ We’re testing SearchGPT, a temporary prototype of new AI search features that give you fast and timely answers with clear and relevant sources. submitted by /u/we_are_mammals [link] [comments]
- Compute is on Output. Not input. [D]by /u/juliannorton (Machine Learning) on July 25, 2024 at 5:34 pm
Transformer-based LLMs like GPT, Gemini, LLaMa, are decoder-only architectures. This means that the compute utilized and the time it takes for an output is directly related to the size of the output, NOT the size of the input. Meaning you could feed it 100 pages, but if the output is 1 page, that's what matters for compute. It’s notoriously tricky to get an LLM to output text that’s short and concise, and many practitioners give up trying to get it to be concise after some tinkering with prompt engineering. However, fine-tuning deals with the problem at the source, retraining the model to prefer outputting shorter outputs. submitted by /u/juliannorton [link] [comments]
- [P] Local Llama 3.1 and Marqo Retrieval Augmented Generationby /u/elliesleight (Machine Learning) on July 25, 2024 at 4:45 pm
I built a simple starter demo of a Knowledge Question and Answering System using Llama 3.1 (8B GGUF) and Marqo. Feel free to experiment and build on top of this yourselves! GitHub: https://github.com/ellie-sleightholm/marqo-llama3_1 submitted by /u/elliesleight [link] [comments]
- [N] AI achieves silver-medal standard solving International Mathematical Olympiad problemsby /u/we_are_mammals (Machine Learning) on July 25, 2024 at 4:16 pm
https://deepmind.google/discover/blog/ai-solves-imo-problems-at-silver-medal-level/ They solved 4 of the 6 IMO problems (although it took days to solve some of them). This would have gotten them a score of 28/42, just one point below the gold-medal level. submitted by /u/we_are_mammals [link] [comments]
- [R] Explainability of HuggingFace Models (LLMs) for Text Summarization/Generation Tasksby /u/PhoenixHeadshot25 (Machine Learning) on July 25, 2024 at 3:19 pm
Hi community, I am exploring the Responsible AI domain where I have started reading about methods and tools to make Deep Learning Models explainable. I have already used SHAP and LIMe for ML model explainability. However, I am unsure about their use in explaining LLMs. I know that these methods are model agnostic but can we use these methods for Text Generation or Summarization tasks? I got reference docs from Shap explaining GPT2 for text generation tasks, but I am unsure about using it for other newer LLMs. Additionally, I would like to know, are there any better ways for Explainable AI for LLMs? submitted by /u/PhoenixHeadshot25 [link] [comments]
- Worth it to take a pay cut for the data scientist title?by /u/son_of_tv_c (Data Science) on July 25, 2024 at 3:17 pm
I have an MS in stats and 7 years as an analyst under my belt. I've been looking for a data scientist jb ever since I got the MS 4 years ago (got it part time while I started as an analyst) and have been having a hell of a time at it. I get plenty of interest in analyst positoins, but little interest in data scientist positoins. As I'm sure you all know, there is considerable overlap between the titles but HR drones and ATS doesn't necessarily know this. All they care about is key words. I've been offered a data scientist positoin at a company that I am ready to accept. The positoin is a little underpaid for a DS but about enough for me right now, but I'm thinking it could be a great stepping stone. I work that for 2-3 years then I'm competitive for higher compensated DS positoins. However I just got off the phone with a recriuter for a DA positoin that would pay between 25-40k more than the DS positoin (it's just a band at this point). The responsibilities are similar, it's just that this place has more money and is located in a HCOL are (both are remote though so COL and relocating are not a factor for me). More money now would be great, but I don't really know if this is going to leave me in a better position in a few years. Obviously, we're talking an offer vs just one phone screen, the higher DA positoin isn't a sure thing right now. But I'm just wondering if you guys would even keep pursing the DA positoin or just take the DS positoin and make up the difference in a few years with a higher paid DS positoin? Also I hate that this is a factor but I've done 12 interveiws just this month, I really REALLY don't want to do anymore, so it's a huge factor in me wanting to just drop out of the DA interveiw process and take the DS. submitted by /u/son_of_tv_c [link] [comments]
- [D] High-Dimensional Probabilistic Modelsby /u/smorad (Machine Learning) on July 25, 2024 at 2:58 pm
What is the standard way to model high-dimensional stochastic processes today? I have some process defined over images x, and I would like to compute P(x' | x, z) for all x'. I know there are Normalizing Flows, Gaussian Processes, etc, but I do not know which to get started with. I specifically want to compute the probabilities, not just sample some x' ~ P(x, z). submitted by /u/smorad [link] [comments]
- [R] Shared Imagination: LLMs Hallucinate Alikeby /u/zyl1024 (Machine Learning) on July 25, 2024 at 1:49 pm
Happy to share our recent paper, where we demonstrate that LLMs exhibit surprising agreement on purely imaginary and hallucinated contents -- what we call a "shared imagination space". To arrive at this conclusion, we ask LLMs to generate questions on hypothetical contents (e.g., a made-up concept in physics) and then find that they can answer each other's (unanswerable and nonsensical) questions with much higher accuracy than random chance. From this, we investigate in multiple directions on its emergence, generality and possible reasons, and given such consistent hallucination and imagination behavior across modern LLMs, discuss implications to hallucination detection and computational creativity. Link to the paper: https://arxiv.org/abs/2407.16604 Link to the tweet with result summary and highlight: https://x.com/YilunZhou/status/1816371178501476473 Please feel free to ask any questions! The main experiment setup and finding. submitted by /u/zyl1024 [link] [comments]
- Forecast time series modelby /u/uraz5432 (Data Science) on July 25, 2024 at 1:00 pm
Hello, I am new to forecasting, looking for suggestions on what model/ models to use for my use case. I have time series data on free trial signups for users to our product. Mainly two categories of users: US users and non US users. The users have unlimited free trial. They can convert to full paid customers anytime if they want to get all the features. We have 50% of the users convert to paid within the first month of the trial, 10% in month 2, and so on. By 4th month of free trial sign up, the conversion to paid is around 1%, and this is then a non zero value for as far as the data goes back ( let’s say 15 months from trial sign up). I have last two years of data for the free trial by each segment. I am using a simple linear model with seasonally for the month to forecast 12 months out for the free trial orders. How can I use the above to forecast the conversion to paid by month for next 12 months? Like mentioned above, the conversions can happen between month 1 to month 15 from the trial sign up date. I would need to forecast US and non US separately. What would be some models to try? Any suggestions on forecasting trials and paid conversions are appreciated. Thanks in advance. submitted by /u/uraz5432 [link] [comments]
- How do you describe your job to others who don’t know?by /u/Rare_Art_9541 (Data Science) on July 25, 2024 at 12:53 pm
I always struggle with describing what I do without overcomplicating it. Especially with my parents. They speak Spanish and what I try to describe in Spanish I can’t communicate it. submitted by /u/Rare_Art_9541 [link] [comments]
- [R] Paper NAACL 2024: "Reliability Estimation of News Media Sources: Birds of a Feather Flock Together"by /u/sergbur (Machine Learning) on July 25, 2024 at 9:10 am
For people working on information verification in general, for instance, working on fact checking, fake news detection or even using RAG from news articles this paper may be useful. Authors use different reinforcement learning techniques to estimate reliability values of news media outlets based on how they interact on the web. The method is easy to scale since the source code is available to build larger hyperlink-based interaction graphs from Common Crawl News. Authors also released the computed values and dataset with news media reliability annotation: Github repo: https://github.com/idiap/News-Media-Reliability Paper: https://aclanthology.org/2024.naacl-long.383/ Live Demo Example: https://lab.idiap.ch/criteria/ In the demo, the retrieved news articles will be order not only by the match to the query but also by the estimated reliability for each sources (URL domains are color coded from green to red, for instance, scrolling down will show results coming from less reliable sources marked with red-ish colors). Alternatively, if a news URL or a news outlet domain (e.g. apnews.com) is given as a query, information about the estimated values are detailed (e.g. showing the neighboring sources interacting with the media, etc.) Have a nice day, everyone! 🙂 submitted by /u/sergbur [link] [comments]
- [D] ACL ARR June (EMNLP) Review Discussionby /u/always_been_a_toy (Machine Learning) on July 25, 2024 at 4:45 am
Too anxious about reviews as they didn’t arrive yet! Wanted to share with the community and see the reactions to the reviews! Rant and stuff! Be polite in comments. submitted by /u/always_been_a_toy [link] [comments]
- "[Discussion]" Where do you get your updates on latest research in video generation and computer vision?by /u/Sobieski526 (Machine Learning) on July 24, 2024 at 9:20 pm
As the title says, looking for some tips on how you keep track of the latest research in video generation and CV. I have been reading through https://cvpr.thecvf.com/ and it's a great source, are there any simiar ones? submitted by /u/Sobieski526 [link] [comments]
- [R] Pre-prompting your LLM increases performanceby /u/CalendarVarious3992 (Machine Learning) on July 24, 2024 at 8:33 pm
Research done at UoW shows that pre-prompting your LLM, or providing context prior to asking your question leads to better results. Even when the context is self generated. https://arxiv.org/pdf/2110.08387 For example asking, "What should I do while in Rome?" is less effective than a series of prompts, "What are the top restaraunts in Rome?" "What are the top sight seeing locations in Rome?" "Best things to do in Rome" "What should I do in Rome?" I always figured this was the case from anecdotal evidence but good to see people who are way starter than me explain it in this paper. And while chain prompting is a little more time consuming there's chrome extensions like ChatGPT Queue that ease up the process. Are their any other "hacks" to squeeze out better performance ? submitted by /u/CalendarVarious3992 [link] [comments]
Active Hydrating Toner, Anti-Aging Replenishing Advanced Face Moisturizer, with Vitamins A, C, E & Natural Botanicals to Promote Skin Balance & Collagen Production, 6.7 Fl Oz



Age Defying 0.3% Retinol Serum, Anti-Aging Dark Spot Remover for Face, Fine Lines & Wrinkle Pore Minimizer, with Vitamin E & Natural Botanicals


Firming Moisturizer, Advanced Hydrating Facial Replenishing Cream, with Hyaluronic Acid, Resveratrol & Natural Botanicals to Restore Skin's Strength, Radiance, and Resilience, 1.75 Oz

Skin Stem Cell Serum


Smartphone 101 - Pick a smartphone for me - android or iOS - Apple iPhone or Samsung Galaxy or Huawei or Xaomi or Google Pixel
Can AI Really Predict Lottery Results? We Asked an Expert.




Djamgatech

Read Photos and PDFs Aloud for me iOS
Read Photos and PDFs Aloud for me android
Read Photos and PDFs Aloud For me Windows 10/11
Read Photos and PDFs Aloud For Amazon
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more)
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6(Email us for more)



FREE 10000+ Quiz Trivia and and Brain Teasers for All Topics including Cloud Computing, General Knowledge, History, Television, Music, Art, Science, Movies, Films, US History, Soccer Football, World Cup, Data Science, Machine Learning, Geography, etc....

List of Freely available programming books - What is the single most influential book every Programmers should read
- Bjarne Stroustrup - The C++ Programming Language
- Brian W. Kernighan, Rob Pike - The Practice of Programming
- Donald Knuth - The Art of Computer Programming
- Ellen Ullman - Close to the Machine
- Ellis Horowitz - Fundamentals of Computer Algorithms
- Eric Raymond - The Art of Unix Programming
- Gerald M. Weinberg - The Psychology of Computer Programming
- James Gosling - The Java Programming Language
- Joel Spolsky - The Best Software Writing I
- Keith Curtis - After the Software Wars
- Richard M. Stallman - Free Software, Free Society
- Richard P. Gabriel - Patterns of Software
- Richard P. Gabriel - Innovation Happens Elsewhere
- Code Complete (2nd edition) by Steve McConnell
- The Pragmatic Programmer
- Structure and Interpretation of Computer Programs
- The C Programming Language by Kernighan and Ritchie
- Introduction to Algorithms by Cormen, Leiserson, Rivest & Stein
- Design Patterns by the Gang of Four
- Refactoring: Improving the Design of Existing Code
- The Mythical Man Month
- The Art of Computer Programming by Donald Knuth
- Compilers: Principles, Techniques and Tools by Alfred V. Aho, Ravi Sethi and Jeffrey D. Ullman
- Gödel, Escher, Bach by Douglas Hofstadter
- Clean Code: A Handbook of Agile Software Craftsmanship by Robert C. Martin
- Effective C++
- More Effective C++
- CODE by Charles Petzold
- Programming Pearls by Jon Bentley
- Working Effectively with Legacy Code by Michael C. Feathers
- Peopleware by Demarco and Lister
- Coders at Work by Peter Seibel
- Surely You're Joking, Mr. Feynman!
- Effective Java 2nd edition
- Patterns of Enterprise Application Architecture by Martin Fowler
- The Little Schemer
- The Seasoned Schemer
- Why's (Poignant) Guide to Ruby
- The Inmates Are Running The Asylum: Why High Tech Products Drive Us Crazy and How to Restore the Sanity
- The Art of Unix Programming
- Test-Driven Development: By Example by Kent Beck
- Practices of an Agile Developer
- Don't Make Me Think
- Agile Software Development, Principles, Patterns, and Practices by Robert C. Martin
- Domain Driven Designs by Eric Evans
- The Design of Everyday Things by Donald Norman
- Modern C++ Design by Andrei Alexandrescu
- Best Software Writing I by Joel Spolsky
- The Practice of Programming by Kernighan and Pike
- Pragmatic Thinking and Learning: Refactor Your Wetware by Andy Hunt
- Software Estimation: Demystifying the Black Art by Steve McConnel
- The Passionate Programmer (My Job Went To India) by Chad Fowler
- Hackers: Heroes of the Computer Revolution
- Algorithms + Data Structures = Programs
- Writing Solid Code
- JavaScript - The Good Parts
- Getting Real by 37 Signals
- Foundations of Programming by Karl Seguin
- Computer Graphics: Principles and Practice in C (2nd Edition)
- Thinking in Java by Bruce Eckel
- The Elements of Computing Systems
- Refactoring to Patterns by Joshua Kerievsky
- Modern Operating Systems by Andrew S. Tanenbaum
- The Annotated Turing
- Things That Make Us Smart by Donald Norman
- The Timeless Way of Building by Christopher Alexander
- The Deadline: A Novel About Project Management by Tom DeMarco
- The C++ Programming Language (3rd edition) by Stroustrup
- Patterns of Enterprise Application Architecture
- Computer Systems - A Programmer's Perspective
- Agile Principles, Patterns, and Practices in C# by Robert C. Martin
- Growing Object-Oriented Software, Guided by Tests
- Framework Design Guidelines by Brad Abrams
- Object Thinking by Dr. David West
- Advanced Programming in the UNIX Environment by W. Richard Stevens
- Hackers and Painters: Big Ideas from the Computer Age
- The Soul of a New Machine by Tracy Kidder
- CLR via C# by Jeffrey Richter
- The Timeless Way of Building by Christopher Alexander
- Design Patterns in C# by Steve Metsker
- Alice in Wonderland by Lewis Carol
- Zen and the Art of Motorcycle Maintenance by Robert M. Pirsig
- About Face - The Essentials of Interaction Design
- Here Comes Everybody: The Power of Organizing Without Organizations by Clay Shirky
- The Tao of Programming
- Computational Beauty of Nature
- Writing Solid Code by Steve Maguire
- Philip and Alex's Guide to Web Publishing
- Object-Oriented Analysis and Design with Applications by Grady Booch
- Effective Java by Joshua Bloch
- Computability by N. J. Cutland
- Masterminds of Programming
- The Tao Te Ching
- The Productive Programmer
- The Art of Deception by Kevin Mitnick
- The Career Programmer: Guerilla Tactics for an Imperfect World by Christopher Duncan
- Paradigms of Artificial Intelligence Programming: Case studies in Common Lisp
- Masters of Doom
- Pragmatic Unit Testing in C# with NUnit by Andy Hunt and Dave Thomas with Matt Hargett
- How To Solve It by George Polya
- The Alchemist by Paulo Coelho
- Smalltalk-80: The Language and its Implementation
- Writing Secure Code (2nd Edition) by Michael Howard
- Introduction to Functional Programming by Philip Wadler and Richard Bird
- No Bugs! by David Thielen
- Rework by Jason Freid and DHH
- JUnit in Action
#BlackOwned #BlackEntrepreneurs #BlackBuniness #AWSCertified #AWSCloudPractitioner #AWSCertification #AWSCLFC02 #CloudComputing #AWSStudyGuide #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AWSBasics #AWSCertified #AWSMachineLearning #AWSCertification #AWSSpecialty #MachineLearning #AWSStudyGuide #CloudComputing #DataScience #AWSCertified #AWSSolutionsArchitect #AWSArchitectAssociate #AWSCertification #AWSStudyGuide #CloudComputing #AWSArchitecture #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AzureFundamentals #AZ900 #MicrosoftAzure #ITCertification #CertificationPrep #StudyMaterials #TechLearning #MicrosoftCertified #AzureCertification #TechBooks
Top 1000 Canada Quiz and trivia: CANADA CITIZENSHIP TEST- HISTORY - GEOGRAPHY - GOVERNMENT- CULTURE - PEOPLE - LANGUAGES - TRAVEL - WILDLIFE - HOCKEY - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Top 1000 Africa Quiz and trivia: HISTORY - GEOGRAPHY - WILDLIFE - CULTURE - PEOPLE - LANGUAGES - TRAVEL - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Exploring the Pros and Cons of Visiting All Provinces and Territories in Canada.


Exploring the Advantages and Disadvantages of Visiting All 50 States in the USA

Health Health, a science-based community to discuss health news and the coronavirus (COVID-19) pandemic
- US infant mortality increased in 2022 for the first time in decades, CDC report showsby /u/cnn on July 25, 2024 at 6:37 pm
submitted by /u/cnn [link] [comments]
- Study raises hopes that shingles vaccine may delay onset of dementia | Dementia | The Guardianby /u/chilladipa on July 25, 2024 at 3:38 pm
submitted by /u/chilladipa [link] [comments]
- How fit is your city? New rankings by the American College of Sports Medicineby /u/idc2011 on July 25, 2024 at 3:35 pm
submitted by /u/idc2011 [link] [comments]
- Twice-Yearly Lenacapavir or Daily F/TAF for HIV Prevention in Cisgender Women | New England Journal of Medicineby /u/chilladipa on July 25, 2024 at 3:30 pm
submitted by /u/chilladipa [link] [comments]
- Biden Made a Healthy Decisionby /u/theatlantic on July 25, 2024 at 3:15 pm
submitted by /u/theatlantic [link] [comments]
Today I Learned (TIL) You learn something new every day; what did you learn today? Submit interesting and specific facts about something that you just found out here.
- TIL actor John Larroquette was the uncredited narrator of the prologue to the 1974 horror movie Texas Chainsaw Massacre. In lieu of cash, he was paid by the Director Tobe Hooper in Marijuana.by /u/openletter8 on July 25, 2024 at 6:56 pm
submitted by /u/openletter8 [link] [comments]
- TIL that the every Shakopee Mdewakanton Sioux indian receives a payout of around $1 million per year from casino profits.by /u/friendlystranger4u on July 25, 2024 at 6:22 pm
submitted by /u/friendlystranger4u [link] [comments]
- TIL Motorcycles in China are dictated by law to be decommissioned and destroyed in 13 years after registration regardless of the conditionsby /u/Easy_Piece_592 on July 25, 2024 at 5:56 pm
submitted by /u/Easy_Piece_592 [link] [comments]
- TIL a man named Jonathan Riches has filed more than 2,600 lawsuits since 2006. He even sued Guinness World Records to try to stop them from titling him as "the most litigious man in history".by /u/doopityWoop22 on July 25, 2024 at 5:03 pm
submitted by /u/doopityWoop22 [link] [comments]
- TIL that in 2018, an American half-pipe skier qualified for the Olympics despite minimal experience. Olympic requirements stated that an athlete needed to place in the top 30 at multiple events. She simply sought out events with fewer than 30 participants, showed up, and skied down without falling.by /u/ctdca on July 25, 2024 at 4:28 pm
submitted by /u/ctdca [link] [comments]
Reddit Science This community is a place to share and discuss new scientific research. Read about the latest advances in astronomy, biology, medicine, physics, social science, and more. Find and submit new publications and popular science coverage of current research.
- Abstinence-only sex education linked to higher pornography use among women | This finding adds to the ongoing conversation about the effectiveness and impacts of different sexuality education approaches.by /u/chrisdh79 on July 25, 2024 at 6:49 pm
submitted by /u/chrisdh79 [link] [comments]
- AlphaProof and AlphaGeometry 2 AI models achieve silver medal standard in solving International Mathematical Olympiad problemsby /u/Big_Profit9076 on July 25, 2024 at 5:59 pm
submitted by /u/Big_Profit9076 [link] [comments]
- Scientists have described a new species of chordate, Nuucichthys rhynchocephalus, the first soft-bodied vertebrate from the Drumian Marjum Formation of the American Great Basin.by /u/grimisgreedy on July 25, 2024 at 5:55 pm
submitted by /u/grimisgreedy [link] [comments]
- Secularists revealed as a unique political force in America, with an intriguing divergence from liberals. Unlike nonreligiosity, which denotes a lack of religious affiliation or belief, secularism involves an active identification with principles grounded in empirical evidence and rational thought.by /u/mvea on July 25, 2024 at 5:40 pm
submitted by /u/mvea [link] [comments]
- New shingles vaccine could reduce risk of dementia. The study found at least a 17% reduction in dementia diagnoses in the six years after the new recombinant shingles vaccination, equating to 164 or more additional days lived without dementia.by /u/Wagamaga on July 25, 2024 at 4:48 pm
submitted by /u/Wagamaga [link] [comments]
Reddit Sports Sports News and Highlights from the NFL, NBA, NHL, MLB, MLS, and leagues around the world.
- A's place their lone all-star, Mason Miller, on IL with fractured finger after hitting training tableby /u/Oldtimer_2 on July 25, 2024 at 8:15 pm
submitted by /u/Oldtimer_2 [link] [comments]
- Flyers sign All-Star Travis Konecny to an 8-year extension worth $70 millionby /u/Oldtimer_2 on July 25, 2024 at 7:45 pm
submitted by /u/Oldtimer_2 [link] [comments]
- Bills’ Von Miller says he believes domestic assault case to be closed, with no charges filedby /u/Oldtimer_2 on July 25, 2024 at 7:43 pm
submitted by /u/Oldtimer_2 [link] [comments]
- Padres' Dylan Cease throws no-hitter vs. Nationalsby /u/Oldtimer_2 on July 25, 2024 at 7:41 pm
submitted by /u/Oldtimer_2 [link] [comments]
- Appeal denied in Valieva case; U.S. skaters to get gold in Parisby /u/PrincessBananas85 on July 25, 2024 at 6:18 pm
submitted by /u/PrincessBananas85 [link] [comments]
