



How does a database handle pagination?
It doesn’t. First, a database is a collection of related data, so I assume you mean DBMS or database language.
Second, pagination is generally a function of the front-end and/or middleware, not the database layer.
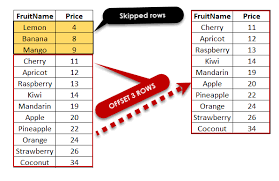
But some database languages provide helpful facilities that aide in implementing pagination. For example, many SQL dialects provide LIMIT and OFFSET clauses that can be used to emit up to n rows starting at a given row number. I.e., a “page” of rows. If the query results are sorted via ORDER BY and are generally unchanged between successive invocations, then that can be used to implement pagination.
That may not be the most efficient or effective implementation, though.
So how do you propose pagination should be done?
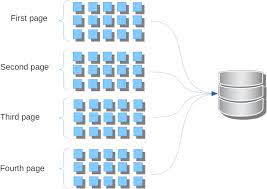
On context of web apps , let’s say there are 100 mn users. One cannot dump all the users in response.
Cache database query results in the middleware layer using Redis or similar and serve out pages of rows from that.

What if you have 30, 000 rows plus, do you fetch all of that from the database and cache in Redis?
I feel the most efficient solution is still offset and limit. It doesn’t make sense to use a database and then end up putting all of your data in Redis especially data that changes a lot. Redis is not for storing all of your data.
If you have large data set, you should use offset and limit, getting only what is needed from the database into main memory (and maybe caching those in Redis) at any point in time is very efficient.
With 30,000 rows in a table, if offset/limit is the only viable or appropriate restriction, then that’s sometimes the way to go.
More often, there’s a much better way of restricting 30,000 rows via some search criteria that significantly reduces the displayed volume of rows — ideally to a single page or a few pages (which are appropriate to cache in Redis.)
It’s unlikely (though it does happen) that users really want to casually browse 30,000 rows, page by page. More often, they want this one record, or these small number of records.

Question: This is a general question that applies to MySQL, Oracle DB or whatever else might be out there.
I know for MySQL there is LIMIT offset,size; and for Oracle there is ‘ROW_NUMBER’ or something like that.
But when such ‘paginated’ queries are called back to back, does the database engine actually do the entire ‘select’ all over again and then retrieve a different subset of results each time? Or does it do the overall fetching of results only once, keeps the results in memory or something, and then serves subsets of results from it for subsequent queries based on offset and size?
Advertise with us - Post Your Good Content Here
We are ranked in the Top 20 on Google
AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
If it does the full fetch every time, then it seems quite inefficient.
If it does full fetch only once, it must be ‘storing’ the query somewhere somehow, so that the next time that query comes in, it knows that it has already fetched all the data and just needs to extract next page from it. In that case, how will the database engine handle multiple threads? Two threads executing the same query?

something will be quick or slow without taking measurements, and complicate the code in advance to download 12 pages at once and cache them because “it seems to me that it will be faster”.
Answer: First of all, do not make assumptions in advance whether something will be quick or slow without taking measurements, and complicate the code in advance to download 12 pages at once and cache them because “it seems to me that it will be faster”.
YAGNI principle – the programmer should not add functionality until deemed necessary.
Do it in the simplest way (ordinary pagination of one page), measure how it works on production, if it is slow, then try a different method, if the speed is satisfactory, leave it as it is.
From my own practice – an application that retrieves data from a table containing about 80,000 records, the main table is joined with 4-5 additional lookup tables, the whole query is paginated, about 25-30 records per page, about 2500-3000 pages in total. Database is Oracle 12c, there are indexes on a few columns, queries are generated by Hibernate. Measurements on production system at the server side show that an average time (median – 50% percentile) of retrieving one page is about 300 ms. 95% percentile is less than 800 ms – this means that 95% of requests for retrieving a single page is less that 800ms, when we add a transfer time from the server to the user and a rendering time of about 0.5-1 seconds, the total time is less than 2 seconds. That’s enough, users are happy.
And some theory – see this answer to know what is purpose of Pagination pattern
- NestJS İle Veritabanı Seçimiby OĞUZHAN ÇART (Database on Medium) on July 26, 2024 at 1:47 pm
Herkese merhabalar, Bu yazımda nestJs ve veritabanlarını inceleyeceğiz.Continue reading on Medium »
- Database and SQL Languageby Yuvaraj (Database on Medium) on July 26, 2024 at 1:43 pm
Databases:Continue reading on Medium »
- Database Connection Poolby Nikita Sharma (Database on Medium) on July 26, 2024 at 12:48 pm
Hey! To dive into the concept of database connection pooling with SQLAlchemy lets take coffee shop analogy.. Imagine you’re at a busy…Continue reading on Medium »
- Transactions in Databasesby Clement Owireku-Bogyah (Database on Medium) on July 26, 2024 at 12:48 pm
Multiple users or processes frequently access the same data in databases simultaneously. This implies that we must ensure that these…Continue reading on Medium »
- Download Sage 50 2024 US Data using Sage 50 Database Repair Utilityby Thomaslane (Database on Medium) on July 26, 2024 at 12:25 pm
Introduction to Sage 50 and its database repair utilityContinue reading on Medium »
- GBase 8a Migration Plan Based on Netezza (1) — Migration Methods and Recommendationsby GBASE database (Database on Medium) on July 26, 2024 at 11:29 am
This article introduces the methods and recommendations for migrating from Netezza to GBase 8a MPP ClusterContinue reading on Medium »
- Canadian CTO CIO Email List, Lead and Directory Database 2024by Leads Datasets (Database on Medium) on July 26, 2024 at 10:48 am
Continue reading on Medium »
- CMO Email List, Lead and Directory Database 2024by Leads Datasets (Database on Medium) on July 26, 2024 at 10:45 am
Continue reading on Medium »
- COO Email List, Lead and Directory Database 2024by Leads Datasets (Database on Medium) on July 26, 2024 at 10:43 am
Continue reading on Medium »
- 100% Opt-in Founders Email List for a Detailed Database 2024by Leads Datasets (Database on Medium) on July 26, 2024 at 10:38 am
Continue reading on Medium »
- Hosted rdbms admin ?by /u/Ankar1n (Database) on July 26, 2024 at 8:51 am
Any solution where I can log in online to admin and do some staff with data, like delete some rows or insert etc. Like in supabase. I can do it locally via drizzle-kit studio or DataGrip, but I'm curious if there are any web-based versions. submitted by /u/Ankar1n [link] [comments]
- Comments that can contain imagesby /u/camperspro (Database) on July 26, 2024 at 6:07 am
Hello, I'm trying to think of how to design an SQL relationship for when a comment can contain multiple images. I was thinking of having a separate Image table that has an id and file path and a Comment table that has a foreign key to the Image table, but I'm wondering if there's a better way to approach this. Thanks! submitted by /u/camperspro [link] [comments]
- Stumped on how to set up a relationship between two tables for a school projectby /u/Oyyeee (Database) on July 25, 2024 at 9:31 pm
Hi everyone, I'm working on a relational database for a school project that evolves scheduling a basketball game between two teams. I've got a Teams table and a Schedule table. The primary key in the Teams table is TeamID. My schedule table's primary key is MatchupID and has fields for HomeTeamID and AwayTeamID. I'm stumped on how to schedule a one to many relationship given the home and away aspects of the fields in the Schedule table. Any advice would be appreciated! submitted by /u/Oyyeee [link] [comments]
- NoSQL Database comparisonby /u/basilyusuf1709 (Database) on July 25, 2024 at 8:35 pm
I feel like most of the comparative information for popular kev value stores were all over the place. I collected them all in one place and made a table for comparison. This took a lot of effort. Would appreciate the ⭐️ on this repository: https://github.com/basilysf1709/distributed-systems/databases submitted by /u/basilyusuf1709 [link] [comments]
- How to Implement Scheduled CDC to Capture 'Before' and 'After' Records of Changes Every 15 Minutes?by /u/goyalaman_ (Database) on July 25, 2024 at 6:07 am
I am relatively new to CDC and data intensive applications to be honest. Table on which CDC is implemented has very high rate of modification. I want change events to generated every 15 minutes or so in which 'before' is the original record and 'after' is the final record of all changes that happened during 15 minutes? I am wondering if members of this community have any insights in this or point me in any direction. PS: Do let me know if this is not the right place for this question. submitted by /u/goyalaman_ [link] [comments]
- [Job Alert] - Full Stack JavaScript Developerby /u/devloprr (Database) on July 25, 2024 at 5:13 am
Hi Guys, we have added a Full Stack JavaScript Developer job on our platform so if you are looking for a JavaScript Developer job please check the link Role - Full Stack JavaScript Developer 🧑💻 (Remote, Full-Time) 🚀 Description - This a Full Remote job, the offer is available from: United States Overview: The Full Stack JavaScript Developer is responsible for developing and maintaining web and software applications that deliver exceptional user experiences. This role will collaborate with cross-functional teams to create dynamic and responsive software application solutions. Link - http://devloprr.com/jobs submitted by /u/devloprr [link] [comments]
- Understanding indexing, varchar vs. integerby /u/Lge24 (Database) on July 24, 2024 at 9:31 pm
Suppose the code will have an enum EmployeeStatus, which will be 1=hired, 2=fired, 3=interviewed, … Then in database, the table Employee will have a field named EmployeeStatus, containing 1 or 2 or 3. How will indexing EmployeeStatus increase performance upon querying the table such as “where employee_status = 1” ? And if the database had stored the string values (varchar) and not use any integer, how significant would the performance be upon querying “where employee_status = ‘hired’ “ (indexed, again) ? submitted by /u/Lge24 [link] [comments]
- GraphDBs Pitfalls and Why We Switched to Postgresby /u/rtalpaz (Database) on July 24, 2024 at 7:00 pm
I now think GraphDBs are definitely over used and engineers should mostly use RDBMS for most of their stuff. Would love to hear your thoughts 🙏🏻 submitted by /u/rtalpaz [link] [comments]
- Virtual Hackathon for TiDB Vector Search - More than $30k in total prizesby /u/rpaik (Database) on July 24, 2024 at 3:33 pm
We’re excited to announce another edition of TiDB Future App Hackathon! During this year’s Hackathon, participants will have an opportunity to develop new applications leveraging the new Vector Search feature on TiDB Serverless. We have over $US 30k in prizes, and beyond prizes, we want the Hackathon to provide opportunities for participants to expand your network and work with like-minded developers while working with the latest technologies. We hope you will join us! submitted by /u/rpaik [link] [comments]
- Tag based searchby /u/MajesticMistake2655 (Database) on July 24, 2024 at 3:21 pm
What is in your opinion the best way to write a database (tables) so that i can look up a user using a set of tags? I want the fastest search possible. I an trying this with mysql P.s. i do not want to use joints, it has to be fast in CRUD submitted by /u/MajesticMistake2655 [link] [comments]
- Is an online database a really powerful solution for small and large-scale businesses?by /u/edwardthomas__ (Database) on July 24, 2024 at 1:47 pm
I am trying to understand the difference in the need for online database solutions for small and large-scale firms. For instance, if small-scale business firms can still go without online database solutions, and large-scale firms need to regularly upgrade the solutions they use in the form of online databases. What are your findings? submitted by /u/edwardthomas__ [link] [comments]
- I’m brand new to this database stuff. Is this a server where I can store a database?by /u/FortSimYT_1 (Database) on July 24, 2024 at 10:22 am
I don’t know whether to use Azure, MySQL,Postgres lol submitted by /u/FortSimYT_1 [link] [comments]
- Choosing the right database(s)by /u/Secure-Economist-986 (Database) on July 24, 2024 at 12:43 am
Hi guys, we're currently planning migrating from SQL Server to another db engine because of the costs. Basically we're storing all data in SQL Server databases. One for system database which size is ~5GB. The data we store here, customers, users, settings etc.. like required to run the product. Another db, that we store the data have fixed schema. Besides the schema, the data is not changing either. Once created it stay same forever. We call it DATA db. We shard this DATA db annually. Every Jan 1st, we create a new db for that year with year suffix and redirect queries to this db for inserts. Annual size is ~2TB and ~3 billion rows. But this db frequently queried by customers. We have 18 DATA db for last 18 years. After short brief, we're planning to migrate another db engine to reduce costs and the first candidate for the system db is Postgres. Since our data is relational and team has experience on Postgres as well as SQL Server, we keen to pick Postgres. But for the DATA dBs, we have doubts about picking Postgres for that purpose, not because of problems but we're thinking if there's better option for that use case. Basically we're looking a database that can handle 100K+ writes/second and much more important it should serve 100K+ rows in seconds (under 5 seconds could be best if possible) Just letting you know, currently we're having 100K+ rows in 15 seconds min. Not going down. Our most used query has 4 where clauses and we have composite index which contains these 4 columns in the same order of the query and wee maintenanced. (Server: Xeon Premium, 16 cores, 128GB RAM and there's no disk performance issues. avg. disk queue len is ok, avg. disk read is ok) We're aware that Postgres can handle both of this workload but would love to hear some recommandations. Especially NoSQL databases look promising but I don't have enough experience to convince the team about them. submitted by /u/Secure-Economist-986 [link] [comments]
- Help finding MariaDB Columnstore Pentaho Pluginby /u/Konatokun (Database) on July 24, 2024 at 12:25 am
Good day, At this time I'm in need of Maria DB ColumnStore Kettle plugin because I'm moving some data to a ColumnStore based database for some reports. I tried compiling the github sources but I couldn't, and all prebuilt versions mentioned in the docs arent available. I'm using Pentaho Data Integration 9.4 submitted by /u/Konatokun [link] [comments]
- Database Design For Role Based Access Control With Admin For Specific Rolesby /u/silverparzival (Database) on July 23, 2024 at 7:09 pm
I am trying to build an application and I am trying to create role-based access control for my application. To explain I am going to use a basic scenario below. Assume I have 5 users for a blog, regular USER, SUPER ADMIN, ADMIN, EDITOR, REVIEW. A SUPER ADMIN has all the privileges. An ADMIN can have permissions specified by SUPER ADMIN. Scenario: A SUPER ADMIN can create an ADMIN and an ADMIN can for example create a REVIEWER ADMIN. A REVIEWER ADMIN can create more REVIEWERS and limit the permissions specific to reviewers. For example, the REVIEWER ADMIN creates 2 users, Reviewer A and Reviewer B and then gives them permissions. Reviewer A can only view blog posts and Reviewer B can view and delete posts. Note that the permissions will be specific to only reviewers. For example, the Reviewer ADMIN can only create users and then set permissions relating to review routes. I want to design the database in Postgres for the above but I am having a hard time understanding how to model the resources. Any sample database similar to the above or pointing me in the right direction will help as I have exhausted searching online and watching videos on YouTube. Thank you. submitted by /u/silverparzival [link] [comments]
- Database Design for Google Calendar: a tutorialby /u/BLochmann (Database) on July 23, 2024 at 5:55 pm
submitted by /u/BLochmann [link] [comments]
- Are one to many relationships truly one to many because of the constraints put on various fields?by /u/PersonalFigure8331 (Database) on July 23, 2024 at 1:30 pm
The primary key is forced to be unique. But is it the enforced uniqueneess of the entity column (the column the table is about) that actually makes the table perform as a one to many. If I were to allow duplicates on this field, they would essentially behave as a many to many table. Am I understanding this properly? Edit for clarity: I understand that one to many reflects business rules and real-world relationships: I'm asking, very specifically, to understand conceptually, whether it's constraints applied to the table on the many side that truly makes a table behave as a "many" side. Is that constraint what ensures that the one to many relationship actually works as expected. submitted by /u/PersonalFigure8331 [link] [comments]
- How can I find all unique sub graphs within a graph database such as memgraph?by /u/Montags25 (Database) on July 23, 2024 at 12:56 pm
I have a dataset of tens of thousands of directed subgraphs. The subgraphs are trees, they branch from the root node and never merge. I want to find all the unique subgraphs based on the event_type attribute of the nodes. Currently I have a solution that returns all subgraphs, converts the subgraph into a NetworkX DiGraph, before calling the weisfeiler_lehman_graph_hash to return a unique hash for the graph. This isn't efficient nor does it make use of the graph database. Is there a way I can do this with Cypher queries or within the graph database itself? submitted by /u/Montags25 [link] [comments]
- Certificate for database analysisby /u/ennezetaqu (Database) on July 23, 2024 at 8:11 am
Hello, I currently work as a ETL developer, but have no certificates. I was thinking about taking some certificates, but I'm not sure about which one is better. Do you have any advice? submitted by /u/ennezetaqu [link] [comments]
- Security advice needed regarding views (DB beginner)by /u/Desater_ (Database) on July 23, 2024 at 7:43 am
Hey there, I have a question that is about views in postgres. I have records that I want to be available to public/anon. Problem is, that userIDs are part of the record and I do not want to expose them. I created a security definer view, that hides the ids and only exposes the information I want. I am unexperienced with databases and can not really estimate the risks of this. I thought views are exactly for this use-case, but I am getting warned about this. I would be glad if you could provide information what a good practice would be, and what I have to ensure that my application is safe. Thank you! submitted by /u/Desater_ [link] [comments]
- Simple Laundry POS ERDby /u/Menihocbacc (Database) on July 23, 2024 at 6:48 am
Hello, we're trying to create a schema for our laundry POS project. Here is our initial representation of the schema. This project is a simple one, we would like to receive feedback from sources other than ourselves and our peers. We are still students and new to this, but we are mainly concerned about the one-to-many and many-to-one or many to many relationship. Please make an honest review on our laundry POS ERD roast it if you have to. https://preview.redd.it/iybphc0ft7ed1.jpg?width=3669&format=pjpg&auto=webp&s=cefdc2119bfa0b183e0d0986967c0b967d0d9faf submitted by /u/Menihocbacc [link] [comments]
- How would you architect this?by /u/bishop491 (Database) on July 22, 2024 at 8:53 pm
Background: this is an annual PITA that I'm told will never change. I have greater hopes. It works as follows... Committee decides on what laptop specifications are acceptable this year for vendors to sell to us They send the specs in a spreadsheet We update a template in Excel that has validations for all options (OS, RAM, Storage, etc) That template goes out to vendors, they select options and send back to us We upload to a database via Java web app This whole thing seems incredibly complicated and clunky. The committee decides the minimum specs, but our developers (not our database people or me) decide what "other" values can be in there. For example, if 32G of memory is minimum, they will put in 32G, 64G, etc, etc. This also means that if a vendor has a config that we don't have in the list but meets the minimum, the validations still think that is wrong. Sometime back, they allowed free text in all fields but then complained about cleaning the data that came in. That's why the validations were done. But that's the opposite end of the spectrum because now we are shooting in the dark at options that may or may not be there. And then they will free-text options like graphics and put in proprietary language that doesn't even tell if it meets minimum spec. I want to re-architect this but am told it's been this way and always will be. What makes sense in my head is to have the vendors put in the models of the laptops they sell and then behind the scenes we go to CDW or somewhere similar to grab the specs on those machines. That would then pull in the specs and the vendors can validate from there. We spend so many hours propping up a bad process. I mean, honestly the spreadsheet is pretty useless in terms of "validating." How would you redesign this? submitted by /u/bishop491 [link] [comments]
- 1.5TB Databaseby /u/nikola_0020 (Database) on July 22, 2024 at 3:30 pm
Hello everyone! I have 700 .gz files, each around 200MB compressed, which expand to 2GB each (totaling 1.5TB). I want to avoid making a huge 1.5TB database. Is there a good way to store this compressed data so it’s queryable? Also, how can I efficiently load these 700 files? I use Postgresql for the DB. Thanks in advance! You're awesome! submitted by /u/nikola_0020 [link] [comments]
- Need advice on a Database Management Systemby /u/Fxguy1 (Database) on July 22, 2024 at 2:26 pm
I'm somewhat new to database development but know enough to be dangerous. I'm trying to build a relational database that has 3 tables - a table containing a list of medications, a table with a list of health problems, and a link table that links a medication to a health problem. I'm looking for something that has more of a GUI and the ability to manually enter data like you would with Microsoft Access. Unfortunately I'm on a Mac and so Access isnt really an option. The ultimate goal is a web application so a web page frontend with php and mysql on the backend. The only reason I am inclined to use mysql is it is all I know. Perhaps PostgreSQL or MongoDB would be easier? Are there other options that are easier to use than MySQL? Ideally I could build and test self-hosting and then move to a hosted site / server to deploy. submitted by /u/Fxguy1 [link] [comments]
- Database design for storing image metadataby /u/kevinfat2 (Database) on July 22, 2024 at 5:01 am
I'm trying to understand what are typical designs for storing image metadata. Imagine you might have scans of drawings, scans of documents, photos, etc. A scan of a multipage document represented as a sequence of images might lead to something like the below tables such as the following as a super basic starting point. Here a scanned document would be represented by a images_groups and the multiple images point back to that with group_id. Now for the various one off photos would these also need an entry in images_groups even if there is only a single image. Is paying the cost of a row in images_groups a typical design here? I'm trying to learn what are the various options that have been tried in the past and thought of even for something nit picky like having to store an extra row for each image. images - id - group_id - filepath images_groups - id submitted by /u/kevinfat2 [link] [comments]
Active Hydrating Toner, Anti-Aging Replenishing Advanced Face Moisturizer, with Vitamins A, C, E & Natural Botanicals to Promote Skin Balance & Collagen Production, 6.7 Fl Oz



Age Defying 0.3% Retinol Serum, Anti-Aging Dark Spot Remover for Face, Fine Lines & Wrinkle Pore Minimizer, with Vitamin E & Natural Botanicals


Firming Moisturizer, Advanced Hydrating Facial Replenishing Cream, with Hyaluronic Acid, Resveratrol & Natural Botanicals to Restore Skin's Strength, Radiance, and Resilience, 1.75 Oz

Skin Stem Cell Serum


Smartphone 101 - Pick a smartphone for me - android or iOS - Apple iPhone or Samsung Galaxy or Huawei or Xaomi or Google Pixel
Can AI Really Predict Lottery Results? We Asked an Expert.




Djamgatech

Read Photos and PDFs Aloud for me iOS
Read Photos and PDFs Aloud for me android
Read Photos and PDFs Aloud For me Windows 10/11
Read Photos and PDFs Aloud For Amazon
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more)
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6(Email us for more)



FREE 10000+ Quiz Trivia and and Brain Teasers for All Topics including Cloud Computing, General Knowledge, History, Television, Music, Art, Science, Movies, Films, US History, Soccer Football, World Cup, Data Science, Machine Learning, Geography, etc....


List of Freely available programming books - What is the single most influential book every Programmers should read
- Bjarne Stroustrup - The C++ Programming Language
- Brian W. Kernighan, Rob Pike - The Practice of Programming
- Donald Knuth - The Art of Computer Programming
- Ellen Ullman - Close to the Machine
- Ellis Horowitz - Fundamentals of Computer Algorithms
- Eric Raymond - The Art of Unix Programming
- Gerald M. Weinberg - The Psychology of Computer Programming
- James Gosling - The Java Programming Language
- Joel Spolsky - The Best Software Writing I
- Keith Curtis - After the Software Wars
- Richard M. Stallman - Free Software, Free Society
- Richard P. Gabriel - Patterns of Software
- Richard P. Gabriel - Innovation Happens Elsewhere
- Code Complete (2nd edition) by Steve McConnell
- The Pragmatic Programmer
- Structure and Interpretation of Computer Programs
- The C Programming Language by Kernighan and Ritchie
- Introduction to Algorithms by Cormen, Leiserson, Rivest & Stein
- Design Patterns by the Gang of Four
- Refactoring: Improving the Design of Existing Code
- The Mythical Man Month
- The Art of Computer Programming by Donald Knuth
- Compilers: Principles, Techniques and Tools by Alfred V. Aho, Ravi Sethi and Jeffrey D. Ullman
- Gödel, Escher, Bach by Douglas Hofstadter
- Clean Code: A Handbook of Agile Software Craftsmanship by Robert C. Martin
- Effective C++
- More Effective C++
- CODE by Charles Petzold
- Programming Pearls by Jon Bentley
- Working Effectively with Legacy Code by Michael C. Feathers
- Peopleware by Demarco and Lister
- Coders at Work by Peter Seibel
- Surely You're Joking, Mr. Feynman!
- Effective Java 2nd edition
- Patterns of Enterprise Application Architecture by Martin Fowler
- The Little Schemer
- The Seasoned Schemer
- Why's (Poignant) Guide to Ruby
- The Inmates Are Running The Asylum: Why High Tech Products Drive Us Crazy and How to Restore the Sanity
- The Art of Unix Programming
- Test-Driven Development: By Example by Kent Beck
- Practices of an Agile Developer
- Don't Make Me Think
- Agile Software Development, Principles, Patterns, and Practices by Robert C. Martin
- Domain Driven Designs by Eric Evans
- The Design of Everyday Things by Donald Norman
- Modern C++ Design by Andrei Alexandrescu
- Best Software Writing I by Joel Spolsky
- The Practice of Programming by Kernighan and Pike
- Pragmatic Thinking and Learning: Refactor Your Wetware by Andy Hunt
- Software Estimation: Demystifying the Black Art by Steve McConnel
- The Passionate Programmer (My Job Went To India) by Chad Fowler
- Hackers: Heroes of the Computer Revolution
- Algorithms + Data Structures = Programs
- Writing Solid Code
- JavaScript - The Good Parts
- Getting Real by 37 Signals
- Foundations of Programming by Karl Seguin
- Computer Graphics: Principles and Practice in C (2nd Edition)
- Thinking in Java by Bruce Eckel
- The Elements of Computing Systems
- Refactoring to Patterns by Joshua Kerievsky
- Modern Operating Systems by Andrew S. Tanenbaum
- The Annotated Turing
- Things That Make Us Smart by Donald Norman
- The Timeless Way of Building by Christopher Alexander
- The Deadline: A Novel About Project Management by Tom DeMarco
- The C++ Programming Language (3rd edition) by Stroustrup
- Patterns of Enterprise Application Architecture
- Computer Systems - A Programmer's Perspective
- Agile Principles, Patterns, and Practices in C# by Robert C. Martin
- Growing Object-Oriented Software, Guided by Tests
- Framework Design Guidelines by Brad Abrams
- Object Thinking by Dr. David West
- Advanced Programming in the UNIX Environment by W. Richard Stevens
- Hackers and Painters: Big Ideas from the Computer Age
- The Soul of a New Machine by Tracy Kidder
- CLR via C# by Jeffrey Richter
- The Timeless Way of Building by Christopher Alexander
- Design Patterns in C# by Steve Metsker
- Alice in Wonderland by Lewis Carol
- Zen and the Art of Motorcycle Maintenance by Robert M. Pirsig
- About Face - The Essentials of Interaction Design
- Here Comes Everybody: The Power of Organizing Without Organizations by Clay Shirky
- The Tao of Programming
- Computational Beauty of Nature
- Writing Solid Code by Steve Maguire
- Philip and Alex's Guide to Web Publishing
- Object-Oriented Analysis and Design with Applications by Grady Booch
- Effective Java by Joshua Bloch
- Computability by N. J. Cutland
- Masterminds of Programming
- The Tao Te Ching
- The Productive Programmer
- The Art of Deception by Kevin Mitnick
- The Career Programmer: Guerilla Tactics for an Imperfect World by Christopher Duncan
- Paradigms of Artificial Intelligence Programming: Case studies in Common Lisp
- Masters of Doom
- Pragmatic Unit Testing in C# with NUnit by Andy Hunt and Dave Thomas with Matt Hargett
- How To Solve It by George Polya
- The Alchemist by Paulo Coelho
- Smalltalk-80: The Language and its Implementation
- Writing Secure Code (2nd Edition) by Michael Howard
- Introduction to Functional Programming by Philip Wadler and Richard Bird
- No Bugs! by David Thielen
- Rework by Jason Freid and DHH
- JUnit in Action
#BlackOwned #BlackEntrepreneurs #BlackBuniness #AWSCertified #AWSCloudPractitioner #AWSCertification #AWSCLFC02 #CloudComputing #AWSStudyGuide #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AWSBasics #AWSCertified #AWSMachineLearning #AWSCertification #AWSSpecialty #MachineLearning #AWSStudyGuide #CloudComputing #DataScience #AWSCertified #AWSSolutionsArchitect #AWSArchitectAssociate #AWSCertification #AWSStudyGuide #CloudComputing #AWSArchitecture #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AzureFundamentals #AZ900 #MicrosoftAzure #ITCertification #CertificationPrep #StudyMaterials #TechLearning #MicrosoftCertified #AzureCertification #TechBooks
Top 1000 Canada Quiz and trivia: CANADA CITIZENSHIP TEST- HISTORY - GEOGRAPHY - GOVERNMENT- CULTURE - PEOPLE - LANGUAGES - TRAVEL - WILDLIFE - HOCKEY - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Top 1000 Africa Quiz and trivia: HISTORY - GEOGRAPHY - WILDLIFE - CULTURE - PEOPLE - LANGUAGES - TRAVEL - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Exploring the Pros and Cons of Visiting All Provinces and Territories in Canada.


Exploring the Advantages and Disadvantages of Visiting All 50 States in the USA

Health Health, a science-based community to discuss health news and the coronavirus (COVID-19) pandemic
- Fentanyl’s deadly chemistry: How criminals make illicit opioidsby /u/Maxcactus on July 26, 2024 at 8:14 am
submitted by /u/Maxcactus [link] [comments]
- A New Artificial Heart in Houston Might Save Millionsby /u/zsreport on July 25, 2024 at 11:13 pm
submitted by /u/zsreport [link] [comments]
- Medical boards punished these doctors and nurses. South Carolina prisons hired them anyway.by /u/jms1225 on July 25, 2024 at 8:06 pm
submitted by /u/jms1225 [link] [comments]
- US infant mortality increased in 2022 for the first time in decades, CDC report showsby /u/cnn on July 25, 2024 at 6:37 pm
submitted by /u/cnn [link] [comments]
- Study raises hopes that shingles vaccine may delay onset of dementia | Dementia | The Guardianby /u/chilladipa on July 25, 2024 at 3:38 pm
submitted by /u/chilladipa [link] [comments]
Today I Learned (TIL) You learn something new every day; what did you learn today? Submit interesting and specific facts about something that you just found out here.
- TIL that George Takei respectfully declined an offer to voice himself in the Simpsons episode Marge vs. the Monorail because he didn't want to ridicule public transportationby /u/Lucy_loveebby on July 26, 2024 at 7:08 am
submitted by /u/Lucy_loveebby [link] [comments]
- TIL about Shizo Kanakuri, a Japanese runner who dropped out of the 1912 Olympic race (he fell asleep during his rest mid-race), but returned 54 years later to officially finish it. Kanakuri joked: “It was a long trip. Along the way, I got married, had six children and 10 grandchildren.”by /u/EnigmaticScience on July 26, 2024 at 6:57 am
submitted by /u/EnigmaticScience [link] [comments]
- TIL Gerhard Domagk’s discovery of the antibacterial properties of Prontosil won him the 1939 Nobel Prize in Medicine but German citizens were forbidden to accept the prize under Hitler. Domagk was forced to reject it by the Gespato before receiving it in 1947 but without the prize moneyby /u/ubcstaffer123 on July 26, 2024 at 3:56 am
submitted by /u/ubcstaffer123 [link] [comments]
- Today I learned that the actor Keegan-Michael Key had two biological half-siblings (one of whom was comic book writer Dwayne McDuffie) and Key didn't know about either of them until after both of them had died.by /u/wimpykidfan37 on July 26, 2024 at 3:31 am
submitted by /u/wimpykidfan37 [link] [comments]
- TIL that average human height went down from 5'10" (178 cm) for men and 5'6" (168 cm) for women to 5'5" (165 cm) and 5'1" (155 cm) 10,000 years ago and it took until the 20th century for average human height to match pre-Neolithic Revolution levels.by /u/quadrahex on July 26, 2024 at 2:04 am
submitted by /u/quadrahex [link] [comments]
Reddit Science This community is a place to share and discuss new scientific research. Read about the latest advances in astronomy, biology, medicine, physics, social science, and more. Find and submit new publications and popular science coverage of current research.
- New study uses Game of Thrones to advance understanding of face blindness. In people with prosopagnosia, the effect of familiarity was not found in the same regions of the brain as it was in neurotypical participants while watching the TV show. Face blindness affects approximately 1 in 50 people.by /u/mvea on July 26, 2024 at 7:45 am
submitted by /u/mvea [link] [comments]
- MIT scientists have discovered an intriguing new way to produce hydrogen fuel, using just soda cans, seawater and coffee grounds. The team says the chemical reaction could be put to work powering engines or fuel cells in marine vehicles like submarines that suck in seawater.by /u/mvea on July 26, 2024 at 7:37 am
submitted by /u/mvea [link] [comments]
- Science Impact: Experimental Warn-On-Forecast System Yields 75-Minute Lead Time on Violent Tornado {NOAA Press Release}by /u/Elijah-Joyce-Weather on July 26, 2024 at 4:55 am
submitted by /u/Elijah-Joyce-Weather [link] [comments]
- 65 million Americans now own firearms for protection, suggests the results of a nationally representative survey carried out in 2023by /u/FunnyGamer97 on July 26, 2024 at 2:16 am
submitted by /u/FunnyGamer97 [link] [comments]
- Examining tornado exposure, post-tornado distress, and gender following the March 2020 tornado in Nashville, Tennesseeby /u/Elijah-Joyce-Weather on July 25, 2024 at 11:49 pm
submitted by /u/Elijah-Joyce-Weather [link] [comments]
Reddit Sports Sports News and Highlights from the NFL, NBA, NHL, MLB, MLS, and leagues around the world.
- Canada's men's and women's soccer teams have relied on drones and spying for years, sources sayby /u/FireLychee on July 26, 2024 at 3:37 am
submitted by /u/FireLychee [link] [comments]
- After a grueling Tour de France, top riders are racing to recover for Paris Olympics time trialby /u/Oldtimer_2 on July 26, 2024 at 12:54 am
submitted by /u/Oldtimer_2 [link] [comments]
- Canada WNT coach Bev Priestman suspended, sent home from Olympics amid spying scandalby /u/Oldtimer_2 on July 26, 2024 at 12:49 am
submitted by /u/Oldtimer_2 [link] [comments]
- 'End of an Era': TNT's 'Inside the NBA' Ending After NBA Chooses Amazonby /u/lame_building14 on July 26, 2024 at 12:36 am
submitted by /u/lame_building14 [link] [comments]
- Canada axes coach from Olympics over drone useby /u/chief_sitass on July 26, 2024 at 12:31 am
submitted by /u/chief_sitass [link] [comments]
