



Your home’s safety can hinge on the subtlest of electronics. It’s an electric world out there, and with great home convenience comes the somewhat daunting task of managing power efficiently and safely. But here’s an electric truth you might not have plugged into yet—there’s a world of difference between a power strip and its more resilient sibling, the surge protector. Read on to learn more.
Power Strips: Not All Outlets Are Equal
A power strip is the standard go-to when you need a few extra outlets in a pinch. Picture the power strip as an adaptable traffic cop for your electrical items—it directs power traffic and keeps all your devices organized.
The run-of-the-mill strip comes with multiple outlets, possibly with a fuse to avoid overloading, but when it comes to sudden voltage spikes, they’re just as shocked as your electronics. While power strips are handy for plugging in your everyday devices like lamps, laptops, and toasters, they’re not fit for the challenges of more sensitive electronics.
Surge Protectors: Grounded Defense for Electronics
Surge protectors take the defensive line against unexpected jolts of power. Beyond the quintessential role of offering additional outlets, these bruisers can detect and suppress voltage spikes, ensuring that your electronics remain unscathed.
What might seem like a flicker in your lights can wreak havoc on a computer, TV, or home entertainment system, but a good surge protector stands in the way like a protective barrier. This level of protection is one of the top reasons to use surge protectors at home as opposed to typical power strips.
Making the Switch
Choosing between power strips and surge protectors isn’t just about preference—it’s a judgment call for safeguarding your home’s tech and electronics. A decent surge protector might be pricier than a simple power strip, but the investment pales next to the potential cost of replacing your fried laptop or smart home hub. When in doubt, opt for the surge—it’s the wise route to powering up your gadgets safely and securely.
Electrical safety isn’t a lightning-quick decision; it’s a current of constants, small choices that spark a larger assurance in your home. By recognizing the stark differences between power strips and surge protectors, you’re not just playing it safe but conducting a symphony of safeguarded living.

Benefits and Drawbacks of Working Remotely in Africa: Has Africa fully embraced hybrid teams, digital workspace and the use of remote workers?

What are The Benefits and Drawbacks of Working Remotely in Africa?
Has Africa fully embraced hybrid teams, digital workspace and the use of remote workers?

The COVID-19 pandemic has forced many businesses to reevaluate the way they operate. For some, this has meant a shift to hybrid teams, with employees working remotely part of the time. For others, it’s meant a move to digital workspaces and an embrace of remote workers. But what does this mean for Africa? Has the continent fully embraced these changes? Let’s take a look.
Listen to Top 1000 Africa Quiz and Trivia Audible

The Pros of Working Remotely in Africa
There are a number of advantages to working remotely in Africa. First, it allows businesses to tap into a larger pool of talent. With more people working remotely, businesses can hire the best employees, regardless of location. Second, it can help reduce costs. With no need for office space or equipment, businesses can save money by having employees work remotely. Finally, it can promote a better work-life balance. With no need to commute, employees can have more time for family and hobbies.

The Cons of Working Remotely in Africa
However, there are also some drawbacks to working remotely in Africa. First, there is the issue of internet connectivity. While most African countries have access to high-speed internet, there are still some areas that do not. This can make it difficult for remote workers to stay connected and productive. Second, there is the issue of time zones. With workers in different time zones, it can be difficult to schedule meetings and conference calls. Finally, there is the issue of culture.
Working remotely can be isolating, and it can be difficult to build relationships with coworkers when you’re not in the same place.
The Benefits of Hybrid Teams
A hybrid team is a mix of full-time employees and freelancers or contractors who work together to achieve a common goal. This model offers a number of benefits for businesses, including increased flexibility, reduced costs, and improved access to skills and talent.
One of the biggest advantages of hybrid teams is that they offer businesses increased flexibility. With a hybrid team, businesses can scale up or down as needed, which is ideal in today’s ever-changing business landscape. Additionally, hybrid teams allow businesses to tap into a wider pool of skills and talent. And because freelancers and contractors are typically paid by the project, businesses can save money by only paying for the work that is completed.
The Digital Workspace
The digital workspace is a new way of working that enables employees to be productive from anywhere at any time. It includes cloud-based applications and services that allow employees to access their files and applications from any device with an internet connection.
The digital workspace offers a number of benefits for businesses, including increased productivity, reduced costs, and improved collaboration. Perhaps most importantly, it gives employees the freedom to work from anywhere at any time. This is especially beneficial for employees in Africa who may not have reliable access to electricity or internet connectivity.
Remote Workers in Africa
The COVID-19 pandemic has forced many businesses around the world to embrace remote work. In Africa, we are seeing a similar trend, with more and more businesses allowing employees to work from home or other remote locations. There are many reasons for this, but chief among them are increased productivity and reduced costs.
When done correctly, remote work can lead to increased productivity as employees are free to design their own schedules and work in environments that suit their needs. Additionally, remote work can help reduce costs by eliminating the need for office space and associated overhead costs.
The benefits of hybrid teams are well-documented. A study by Harvard Business Review found that companies with diverse teams are 35% more likely to outperform their peers. Another study by McKinsey & Company found that businesses with gender-diverse leadership teams are 21% more likely to generate above-average profits. In Africa, the benefits of hybrid teams are especially pronounced.
The African continent is home to a wide variety of cultures and languages. This diversity is an asset that can be leveraged by businesses to gain a competitive edge. By tapping into the talents of people from all corners of the continent, businesses can create products and services that appeal to a global market.
In addition, the use of remote workers allows businesses to tap into a wider pool of talent. By eliminating the need for employees to be physically present in an office, businesses can hire the best person for the job regardless of location. This has led to increased productivity and efficiency in the workplace.
Overall, working remotely in Africa has its pros and cons. However, with the right infrastructure and support in place, remote work can be a great option for businesses and employees alike.
The rise of hybrid teams has had a positive impact on Africa. By bringing together people with different skillsets and backgrounds, businesses have been able to create products and services that appeal to a global market. In addition, the use of remote workers has allowed businesses to tap into a wider pool of talent. This has led to increased productivity and efficiency in the workplace.
The COVID-19 pandemic has changed the way we live and work. In Africa, we are seeing a trend towards hybrid teams, the digital workspace, and remote workers. This new way of working offers a number of benefits for businesses, including increased flexibility, reduced costs, and improved access to skills and talent. As we continue to adapt to the new normal brought on by the pandemic, it is clear that these trends are here to stay.
Globle Wordle Africa: Wordle For Geography Africa
https://inRealTimeNow.com/Africa
Best Work From Home Job in Africa 2022 – 2023

HISTORY – GEOGRAPHY – CULTURE – PEOPLE – CUISINE – ECONOMICS – LANGUAGES – MUSIC – WILDLIFE – FOOTBALL – POLITICS – ANIMALS – TOURISM – SCIENCE – ENVIRONMENT
How well do you know Africa? Test your knowledge with this Africa history and geography quiz. Africa is the world’s second largest continent, and it is home to a stunning diversity of cultures, languages, and landscapes. From the Sahara Desert to the rainforests of the Congo Basin, Africa boasts a huge variety of geography. And its history is just as rich, from ancient civilizations like Egypt and Ethiopia to European colonization and the struggle for independence. So whether you’re an Africa expert or just getting started, this quiz will help you test your knowledge of this amazing continent.
Africa is a vast and fascinating continent with a rich history and diverse culture. To test your knowledge of Africa, take this Africa History and Geography Quiz. See how much you know about the people, places, and events that have shaped Africa over the centuries.
This book contains hundreds of quizzes with illustrations and answers about African History, Geography, Wildlife, Economics, Culture, Cuisine, Wildlife, Languages, Music and People and a lot more…
#africa #wakandaforever #quiz #africatourism #africageography #discoverafrica

https://play.google.com/store/
Advertise with us - Post Your Good Content Here
We are ranked in the Top 20 on Google
AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
http://books.apple.com/us/

- Mount Cameroon 🇨🇲by /u/HolySenzu (Africa) on July 26, 2024 at 8:08 pm
submitted by /u/HolySenzu [link] [comments]
- Haiti Gang Leader Barbecue Signs Peace Agreement as Kenyan Police Intensify Missionby /u/elementalist001 (Africa) on July 26, 2024 at 7:50 pm
submitted by /u/elementalist001 [link] [comments]
- What. A. Story!by /u/Austie33 (Africa) on July 26, 2024 at 12:37 pm
Never knew Rangers existed. Has anyone seen? submitted by /u/Austie33 [link] [comments]
- The Strategic Imperative: Why Africa is the Next Battleground in Global Influenceby Ben Wilson (Africa on Medium) on July 26, 2024 at 11:48 am
In the global chess game for power, Africa is becoming the board on which superpowers are vying for supremacy. A year ago, the Biden…Continue reading on Medium »
- Crash Course in Financial Leverage: How Credit Boosts Your Path to Financial Independence in…by Ohere (Africa on Medium) on July 26, 2024 at 11:34 am
Imagine growing a giant tree from a tiny seed. That’s the power of financial leverage, and in Nigeria, a credit card can be that seed.Continue reading on Medium »
- ...He used that night to practice how to walk with shoes.by DOO Reviews (Africa on Medium) on July 26, 2024 at 11:20 am
The Beauty of African Heritage by Essien Okoko (2016) No-body-asked-me-but-I-will-say-it-anyway Note: Before I start eating this book…Continue reading on Medium »
- Nigeria’s Hope PSB Targets ₦6.5 Billion Fraud Recoveryby From Lagos To The World Powered By TTT Media (Africa on Medium) on July 26, 2024 at 9:02 am
Hope Payment Service Bank (Hope PSB), one of Nigeria's prominent digital banks, is currently facing a significant challenge as it seeks to…Continue reading on Medium »
- THE POWER OF TALENT: Nurturing Young Voices for a Brighter Futureby Penner Ministries (Africa on Medium) on July 26, 2024 at 8:21 am
Amidst the challenges faced by many children, the power of talent offers a beacon of hope. At Penner Ministries, we believe that music is…Continue reading on Medium »
- Building a Python Workshop: You Won't Get There Aloneby Kudzayi Bamhare (Africa on Medium) on July 26, 2024 at 8:13 am
In May 2023, I said goodbye to the group of students I had been mentoring through Stanford's Code In Place Program. Initially, my decision…Continue reading on Medium »
- Comment Daredare a amélioré son temps de livraison en s’inspirant de la méthode de Pep Guardiolaby Hénock Emporio (Africa on Medium) on July 26, 2024 at 7:40 am
Chez Daredare, nous cherchons constamment à améliorer notre service de livraison pour satisfaire nos clients.Continue reading on Medium »
- CoinW Africa Trading Fiesta | Deposit, Trade, and Refer to Get Up to $300 Future Bonus for Eachby CoinWAfrica (Africa on Medium) on July 26, 2024 at 7:38 am
Engage in derivatives trading and reach volume milestones to unlock rewards up to $300 future bonus.Continue reading on Medium »
- WSPN and Canza Finance Partner to Revolutionize Financial Services in Africa and Emerging Marketsby WSPN (Africa on Medium) on July 26, 2024 at 3:53 am
July 26, 2024 — WSPN, a leading global digital payments company, is thrilled to announce its strategic collaboration with Canza Finance, a…Continue reading on Medium »
- The Escalating Food Crisis in Africa: A Call for Urgent Actionby Ebenezer Sarfo (Africa on Medium) on July 26, 2024 at 1:10 am
Africa, a continent renowned for its rich cultures, diverse landscapes, and abundant resources, is currently facing a severe food crisis…Continue reading on Medium »
- Dangote, Africa's richest man, is scrambling to calm a crisis with the Nigerian government over his $20 billion refinery | Semaforby /u/rogerram1 (Africa) on July 25, 2024 at 8:16 pm
submitted by /u/rogerram1 [link] [comments]
- Tripartite Free Trade Area (TFTA) - Common Market Of EAC - COMESA - SADCby /u/elementalist001 (Africa) on July 25, 2024 at 3:04 pm
submitted by /u/elementalist001 [link] [comments]
- North African Campaign Part 1 🎙️ The Italian Invasion of Egyptby /u/HistorianBirb (Africa) on July 25, 2024 at 1:09 pm
submitted by /u/HistorianBirb [link] [comments]
- 730 Million People—Including 20% of Africans—Faced Hunger Last Yearby /u/crustose_lichen (Africa) on July 25, 2024 at 9:27 am
submitted by /u/crustose_lichen [link] [comments]
- Women behind the lens: 'I Want to Be Like Her is my way of paying tribute to 10 exceptional Africans'by /u/sheLiving (Africa) on July 25, 2024 at 8:58 am
submitted by /u/sheLiving [link] [comments]
- Read how Kenyan activists & lawyers are fighting IMF's draconian & oppressive austerity measures.by /u/krisdyabe (Africa) on July 25, 2024 at 8:04 am
https://preview.redd.it/t4y3ya7ugmed1.jpg?width=675&format=pjpg&auto=webp&s=26c1ceb64c5585840ff0537ac8f55f2eb27143eb Business Daily - Lawyers, activists sue to block Ruto from signing Finance Bill - Business Daily (businessdailyafrica.com) submitted by /u/krisdyabe [link] [comments]
- Against sentimental pessimist narratives of Africaby /u/Feisty-Mongoose-5146 (Africa) on July 25, 2024 at 1:03 am
This is a long dump of some thoughts I’ve been having for a while. Once when i was a 19-year old college student in the US, a white schoolmate sneered at me when i told him where i was from. “No offense, Africa has never been great”, he said. I didn’t have the knowledge to respond to him at the time, something which has bothered me in the time since then. That’s what is post is about. Africa is discussed as a scapegoated as a “dark continent”, associated in the imagination of many as a place to do with suffering, poverty, war, disease etc. Obviously this is an image that arose because of its domination by foreign powers, and the continued political and economic problems of the states that came out of that era of political domination. The facts of this reality as well as the ideological discourse of racism that arose along with European domination has solidified this image of Africa in the popular conscious. It is propagated and perpetuated not just by non-Africans but also by many Africans as well especially outside of Africa. And yet, i would like to offer the additional context that is necessary to cure oneself of this image. That context is as follows: The negative conditions that are uniquely associated with Africa today have belonged to humans everywhere for the vast majority of the history of human civilization. Poverty, war, disease, superstition, exploitation and domination is the history of the entire planet. History books about anywhere on earth will tell you this. When Julius Caesar wrote about England, he wrote of savages who painted themselves blue before they fought. Europe was full of warring tribes that were called barbarians and stigmatized by Romans and that fought and were dominated by them for 300 years. The same goes for Asian Minor. When the Roman Empire collapsed and the relative political and economic stability it provided, Europe fell into war and constant turmoil for the next 1500 years. These processes are what provided the modern nation states that we know of today, many of which would go on to dominate the whole world after they came up with capitalism, an invention that enabled them to project power in a way no one else could compete with. That’s the only thing that made northwestern Europe special. And it only began 500 years ago. That’s all “white supremacy” is. The ideology that came up to explain this accident of history. And anywhere in the world, wherever people have developed an innovation that gives them an advantage and allows them to project power at the expense of other groups, they come up with a narrative about how they are better smarter stronger more moral etc etc. that’s all it is. And yet, guess the percentage of French people that could read and write in 1800. Less than 20%. The streets of Paris and London flowed with shit and they had no idea it had anything to do with disease. The best doctors at the time literally believed bad blood were what caused diseases and would bleed their patients, hastening their deaths. They believed witches were responsible for bad fortunes. And yet their propaganda would have you believe they were always above such folly. Poverty and exploitation has been the lot of more than 99% of humans that lived anywhere. Anyone that thinks white peoole were just living like kings while African slaves were working in the fields of Virginia should read about indentured servitude. All the colonists of Virginia were 12 year old beggar boys and girls on the streets of London and Bristol who would have had an ear cut off for stealing a loaf of bread but instead were shipped off against their will to Virginia. Their average life span was less than 10 years because they were worked to death and could be traded and bartered. All the sailors and soldiers of the British empire were press ganged and forced into service and whipped to ensure their diligence, executed when they tried to run away, which they did plenty. The death rate of the sailors who went on slaving expeditions was something like 50%. Africa was a death sentence and some of those slavers literally had to be kidnapped after being tricked into getting drunk. It was misery all the way down. All of this only started to change in the 19th century. Even then, read Charles dickens. Oliver Twist was just how the average Englishman lived until the next senseless war was declared by their inbred queen. The proud “masters of the world” that northwest europe thought itself to be was something that only happened in a brief spell of time compared to human history. The traders who went to Africa and Asia were half-starved and were at the mercy of the kings of Africa and Asia, not cold calculating imperialists of the late 19th century. War - Africa has been racked by civil war and the way it’s talked about you would think that’s the only place that happens. How did the nation of France come to be? Through everyone agreeing and having a party? Hell no. What about Germany? Italy? Mexico? China? Colombia? Japan? The United States? Russia? Rome? Persia? Turkey? Vietnam? Cambodia? India, Pakistan and Bangladesh? It was always bloody. Genocide, war, massacres, drownings. Read the history of the French Revolution. Read about the wars in China you’ve never heard about which had a casual body count of 150 million people. The processes of political centralization and state formation in Africa may have been artificially started by European colonization and are still ongoing, but guess what it happened elsewhere too. It’s only a matter of when they happened. So enough with the woe-is-us were the only victims narratives. It’s one thing for the racists to perpetuate time, it’s another thing for us to do so. Yes, the slave trade was a unique evil. Yet the history of the world has been full of barbarism, this one just ended up touching Africans uniquely. What it gave us also uniquely is the lie of racial ideology and the attendant belief by some people that they are better. But that’s all it is - a belief helped by convenient ignorance or all I’ve said above. The history of the world is long. Civilizations come and go. Empires rise and fall. Turks, mongols, Mughals, Romans, Han Chinese, the Portuguese, the British were whose empire never saw the sun set (who have now ended up as Americas poor little b**ch) Egypt, Alexander’s Greece, the Zulu, all came, all faded into oblivion except for people who study these things.knowledge of this and a zen attitude is required if we will resist this disempowering narratives about ourselves. Our time will come, and it will go again. The random ebbs and flows of history, even with the attendant pain and suffering says absolutely nothing about our inherent worth as human beings. Thanks for coming to my Ted talk. submitted by /u/Feisty-Mongoose-5146 [link] [comments]
What are the Top 5 things that can say a lot about a software engineer or programmer’s quality?

What are the Top 5 things that can say a lot about a software engineer or programmer’s quality?
When it comes to the quality of a software engineer or programmer, there are a few key things that can give you a good indication. First, take a look at their code quality. A good software engineer will take pride in their work and produce clean, well-organized code. They will also be able to explain their code concisely and confidently. Another thing to look for is whether they are up-to-date on the latest coding technologies and trends. A good programmer will always be learning and keeping up with the latest industry developments. Finally, pay attention to how they handle difficult problems. A good software engineer will be able to think creatively and come up with innovative solutions to complex issues. If you see these qualities in a software engineer or programmer, chances are they are of high quality.
Below are the top 5 things can say a lot about a software engineer/ programmer’s quality?
- The number of possible paths through the code (branch points) is minimized. Top quality code tends to be much more straight line than poor code. As a result, the author can design, code and test very quickly and is often looked at as a programming guru. In addition this code is far more resilient in Production.
- The code clearly matches the underlying business requirements and can therefore be understood very quickly by new resources. As a result there is much less tendency for a maintenance programmer to break the basic design as opposed to spaghetti code where small changes can have catastrophic effects.
- There is an overall sense of pride in the source code itself. If the enterprise has clear written standards, these are followed to the letter. If not, the code is internally consistent in terms of procedure/object, function/method or variable/attribute naming. Also indentation and continuations are universally consistent throughout. Last but not least, the majority of code blocks are self-evident to the requirements and where not the case, adequate purpose focused documentation is provided.
In general, I have seen two types of programs provided for initial Production deployment. One looks like it was just written moments ago and the other looks like it has had 20 years of maintenance performed on it. Unfortunately, the authors of the second type cannot generally see the difference so it is a lost cause and we just have to continue to deal with the problems. - In today’s programming environment, a project may span many platforms, languages etc. A simple web page may invoke an API which in turn accesses a database. For this example lets say JavaScript – Rest API – C# – SQL – RDBMS. The programmer can basically embed logic anywhere in this chain, but needs to be aware of reuse, performance and maintenance issues. For instance, if a part of the process requires access to three database tables, it is both faster and clearer to allow the DBMS engine return a single query than compare the tables in the API code. Similarly every business rule coded in the client side reduces re-usability potential.
Top quality developers understand these issues and can optimize their designs to take advantages of the strengths of the component technologies. - The ability to stay current with new trends and technologies. Technology is constantly evolving, and a good software engineer or programmer should be able to stay up-to-date on the latest trends and technologies in order to be able to create the best possible products.
To conclude:
Below are other things to consider when hiring good software engineers or programmers:
- The ability to write clean, well-organized code. This is a key indicator of a good software engineer or programmer. The ability to write code that is easy to read and understand is essential for creating high-quality software.
- The ability to test and debug code. A good coder should be able to test their code thoroughly and identify and fix any errors that may exist.
- The ability to write efficient code. Software engineering is all about creating efficient solutions to problems. A good software engineer or programmer will be able to write code that is efficient and effective.
- The ability to work well with others. Software engineering is typically a team-based effort. A good software engineer or programmer should be able to work well with others in order to create the best possible product.
- The ability to stay current with new trends and technologies.
Why is there a lack of diversity among software engineers in tech companies in USA and Canada?

Why is there a lack of diversity among software engineers in tech companies in USA and Canada?
One of the most significant problems facing the tech industry is a lack of diversity among software engineers. In the United States and Canada, women and visible minorities are grossly underrepresented in the field. This problem is often attributed to the pipelines that feed into the industry. For example, women are less likely than men to study computer science in college. However, this does not fully explain the disparity. Hiring practices at tech companies are also to blame. Studies have shown that companies are biased against female and minority candidates. They are more likely to hire white men with similar educational backgrounds and work experience. This lack of diversity has negative consequences for both the individuals affected and the companies themselves. Immersive technologies, such as virtual reality, are being designed and developed primarily by white men. This creates a product that does not reflect the needs or perspectives of a diverse population. In addition, companies with diverse teams have been shown to perform better than those without diversity. They are more innovative and adaptable to change. The lack of diversity among software engineers is a problem that needs to be addressed by both educators and tech companies if the industry is to thrive in the future.

A prominent Engineer from Silicon Valley said this about the topic: Women and minorities are systematically discouraged from taking STEM subjects starting around the third grade. Fewer of them excel in math and science in high school. Fewer go to college. Women and minorities don’t see women and minorities in tech roles in the media. Some hiring managers are racist, misogynist scumbags. Some co-workers are dismissive of them. They have trouble finding mentors. The women, at least, are encouraged continuously to drop out and make fat babies.
This all forms a pretty effective filter. By Kurt Guntheroth.
Find Local and Remote Real Time Jobs at https://inRealtimeJobs.com
Software industry has mostly adopted and promoted conformist culture, thanks to its leaders who mostly have been power mongers and Machiavellian by approach, with few exceptions here and there in few organizations. Conforming culture will inherently repel diversity since one is more assured of conforming staff in a known culture rather than more diverse culture. Most of these so called pseudo leaders don’t really seek diverse ideas which inherently stem from diverse cultures. And so such organizations never end up becoming diverse.
There aren’t enough women in the industry — in individual contributor roles and in leadership roles. There also aren’t enough African-Americans and Latinos.
Why does this matter? Many reasons. One big one is that exclusion leads to more exclusion. When one gender/ethnic group is significantly underrepresented in a workforce, strong biases bake in -> the people in the affected group think they don’t belong at the compan(ies) and the people at the companies have an insular bias to pick people from their networks/people who share their backgrounds.
Silicon Valley is the hottest growth sector in the US and will continue to create the best career and wealth opportunities over the next 20–30 years. It’s really not good that the industry isn’t absorbing more women, African-Americans, and Latinos.
To conclude:
Technology is a rapidly growing industry with a huge demand for qualified software engineers. However, there is a lack of diversity among software engineers in tech companies in the USA and Canada. Women and minorities are greatly underrepresented in the field of software engineering. This is due to several factors, including the misogynistic and racist culture of many tech companies. The lack of diversity among software engineers has a negative impact on the quality of products and services offered by tech companies. It also limits the ability of these companies to innovate and serve a wide range of customers. In order to increase diversity among software engineers, tech companies need to change their hiring practices and create an inclusive environment that values all types of people.
Find local and Remote Real Time Jobs at https://inRealtimeJobs.com
Examining the Fragmented Data on Black Entrepreneurship in North America
Financing Black Businesses in Canada and USA: Challenges and Opportunities
What is the single most influential book every Programmers should read

What is the single most influential book every Programmers should read
There are a lot of books that can be influential to programmers. But, what is the one book that every programmer should read? This is a question that has been asked by many, and it is still up for debate. However, there are some great contenders for this title. In this blog post, we will discuss three possible books that could be called the most influential book for programmers. So, what are you waiting for? Keep reading to find out more!

- Bjarne Stroustrup – The C++ Programming Language,
- Brian W. Kernighan, Rob Pike – The Practice of Programming,
- Donald Knuth – The Art of Computer Programming,
- Ellen Ullman – Close to the Machine,
- Ellis Horowitz – Fundamentals of Computer Algorithms,
- Eric Raymond – The Art of Unix Programming,
- Gerald M. Weinberg – The Psychology of Computer Programming,
- James Gosling – The Java Programming Language,
- Joel Spolsky – The Best Software Writing I,
- Keith Curtis – After the Software Wars,
- Richard M. Stallman – Free Software, Free Society,
- Richard P. Gabriel – Patterns of Software,
- Richard P. Gabriel – Innovation Happens Elsewhere,
- Code Complete (2nd edition) by Steve McConnell,
- The Pragmatic Programmer,
- Structure and Interpretation of Computer Programs,
- The C Programming Language by Kernighan and Ritchie,
- Introduction to Algorithms by Cormen, Leiserson, Rivest & Stein,
- Design Patterns by the Gang of Four,
- Refactoring: Improving the Design of Existing Code,
- The Mythical Man Month,
- The Art of Computer Programming by Donald Knuth,
- Compilers: Principles, Techniques and Tools by Alfred V. Aho, Ravi Sethi and Jeffrey D. Ullman,
- Gödel, Escher, Bach by Douglas Hofstadter,
- Clean Code: A Handbook of Agile Software Craftsmanship by Robert C. Martin,
- Effective C++,
- More Effective C++,
- CODE by Charles Petzold,
- Programming Pearls by Jon Bentley,
- Working Effectively with Legacy Code by Michael C. Feathers,
- Peopleware by Demarco and Lister
- Coders at Work by Peter Seibel,
- Surely You’re Joking, Mr. Feynman!,
- Effective Java 2nd edition,
- Patterns of Enterprise Application Architecture by Martin Fowler,
- The Little Schemer,
- The Seasoned Schemer,
- Why’s (Poignant) Guide to Ruby,
- The Inmates Are Running The Asylum: Why High Tech Products Drive Us Crazy and How to Restore the Sanity,
- The Art of Unix Programming,
- Test-Driven Development: By Example by Kent Beck,
- Practices of an Agile Developer,
- Don’t Make Me Think,
- Agile Software Development, Principles, Patterns, and Practices by Robert C. Martin,
- Domain Driven Designs by Eric Evans,
- The Design of Everyday Things by Donald Norman,
- Modern C++ Design by Andrei Alexandrescu,
- Best Software Writing I by Joel Spolsky,
- The Practice of Programming by Kernighan and Pike,
- Pragmatic Thinking and Learning: Refactor Your Wetware by Andy Hunt,
- Software Estimation: Demystifying the Black Art by Steve McConnel,
- The Passionate Programmer (My Job Went To India) by Chad Fowler,
- Hackers: Heroes of the Computer Revolution,
- Algorithms + Data Structures = Programs,
- Writing Solid Code,
- JavaScript – The Good Parts,
- Getting Real by 37 Signals,
- Foundations of Programming by Karl Seguin,
- Computer Graphics: Principles and Practice in C (2nd Edition),
- Thinking in Java by Bruce Eckel,
- The Elements of Computing Systems,
- Refactoring to Patterns by Joshua Kerievsky,
- Modern Operating Systems by Andrew S. Tanenbaum,
- The Annotated Turing,
- Things That Make Us Smart by Donald Norman,
- The Timeless Way of Building by Christopher Alexander,
- The Deadline: A Novel About Project Management by Tom DeMarco,
- The C++ Programming Language (3rd edition) by Stroustrup,
- Patterns of Enterprise Application Architecture,
- Computer Systems – A Programmer’s Perspective,
- Agile Principles, Patterns, and Practices in C# by Robert C. Martin,
- Growing Object-Oriented Software, Guided by Tests,
- Framework Design Guidelines by Brad Abrams,
- Object Thinking by Dr. David West,
- Advanced Programming in the UNIX Environment by W. Richard Stevens,
- Hackers and Painters: Big Ideas from the Computer Age,
- The Soul of a New Machine by Tracy Kidder,
- CLR via C# by Jeffrey Richter,
- The Timeless Way of Building by Christopher Alexander,
- Design Patterns in C# by Steve Metsker,
- Alice in Wonderland by Lewis Carol,
- Zen and the Art of Motorcycle Maintenance by Robert M. Pirsig,
- About Face – The Essentials of Interaction Design,
- Here Comes Everybody: The Power of Organizing Without Organizations by Clay Shirky,
- The Tao of Programming,
- Computational Beauty of Nature,
- Writing Solid Code by Steve Maguire,
- Philip and Alex’s Guide to Web Publishing,
- Object-Oriented Analysis and Design with Applications by Grady Booch,
- Effective Java by Joshua Bloch,
- Computability by N. J. Cutland,
- Masterminds of Programming,
- The Tao Te Ching,
- The Productive Programmer,
- The Art of Deception by Kevin Mitnick,
- The Career Programmer: Guerilla Tactics for an Imperfect World by Christopher Duncan,
- Paradigms of Artificial Intelligence Programming: Case studies in Common Lisp,
- Masters of Doom,
- Pragmatic Unit Testing in C# with NUnit by Andy Hunt and Dave Thomas with Matt Hargett,
- How To Solve It by George Polya,
- The Alchemist by Paulo Coelho,
- Smalltalk-80: The Language and its Implementation,
- Writing Secure Code (2nd Edition) by Michael Howard,
- Introduction to Functional Programming by Philip Wadler and Richard Bird,
- No Bugs! by David Thielen,
- Rework by Jason Freid and DHH,
- JUnit in Action
Source: Wikipedia

What are the concepts every Java C# C++ Python Rust programmer must know?
Ok…I think this is one of the most important questions to answer. According to the my personal experience as a Programmer, I would say you must learn following 5 universal core concepts of programming to become a successful Java programmer.
(1) Mastering the fundamentals of Java programming Language – This is the most important skill that you must learn to become successful java programmer. You must master the fundamentals of the language, specially the areas like OOP, Collections, Generics, Concurrency, I/O, Stings, Exception handling, Inner Classes and JVM architecture.
Recommended readings are OCA Java SE 8 Programmer by by Kathy Sierra and Bert Bates (First read Head First Java if you are a new comer ) and Effective Java by Joshua Bloch.
(2) Data Structures and Algorithms – Programming languages are basically just a tool to solve problems. Problems generally has data to process on to make some decisions and we have to build a procedure to solve that specific problem domain. In any real life complexity of the problem domain and the data we have to handle would be very large. That’s why it is essential to knowing basic data structures like Arrays, Linked Lists, Stacks, Queues, Trees, Heap, Dictionaries ,Hash Tables and Graphs and also basic algorithms like Searching, Sorting, Hashing, Graph algorithms, Greedy algorithms and Dynamic Programming.
Recommended readings are Data Structures & Algorithms in Java by Robert Lafore (Beginner) , Algorithms Robert Sedgewick (intermediate) and Introduction to Algorithms-MIT press by CLRS (Advanced).
(3) Design Patterns – Design patterns are general reusable solution to a commonly occurring problem within a given context in software design and they are absolutely crucial as hard core Java Programmer. If you don’t use design patterns you will write much more code, it will be buggy and hard to understand and refactor, not to mention untestable and they are really great way for communicating your intent very quickly with other programmers.
Recommended readings are Head First Design Patterns Elisabeth Freeman and Kathy Sierra and Design Patterns: Elements of Reusable by Gang of four.
(4) Programming Best Practices – Programming is not only about learning and writing code. Code readability is a universal subject in the world of computer programming. It helps standardize products and help reduce future maintenance cost. Best practices helps you, as a programmer to think differently and improves problem solving attitude within you. A simple program can be written in many ways if given to multiple developers. Thus the need to best practices come into picture and every programmer must aware about these things.
Recommended readings are Clean Code by Robert Cecil Martin and Code Complete by Steve McConnell.
(5) Testing and Debugging (T&D) – As you know about the writing the code for specific problem domain, you have to learn how to test that code snippet and debug it when it is needed. Some programmers skip their unit testing or other testing methodology part and leave it to QA guys. That will lead to delivering 80% bugs hiding in your code to the QA team and reduce the productivity and risking and pushing your project boundaries to failure. When a miss behavior or bug occurred within your code when the testing phase. It is essential to know about the debugging techniques to identify that bug and its root cause.
Recommended readings are Debugging by David Agans and A Friendly Introduction to Software Testing by Bill Laboon.
I hope these instructions will help you to become a successful Java Programmer. Here i am explain only the universal core concepts that you must learn as successful programmer. I am not mentioning any technologies that Java programmer must know such as Spring, Hibernate, Micro-Servicers and Build tools, because that can be change according to the problem domain or environment that you are currently working on…..Happy Coding!
Summary: There’s no doubt that books have had a profound influence on society and the advancement of human knowledge. But which book is the most influential for programmers? Some might say it’s The Art of Computer Programming, or The Pragmatic Programmer. But I would argue that the most influential book for programmers is CODE: The Hidden Language of Computer Hardware and Software. In CODE, author Charles Petzold takes you on a journey from the basics of computer hardware to the intricate workings of software. Along the way, you learn how to write code in Assembly language, and gain an understanding of how computers work at a fundamental level. If you’re serious about becoming a programmer, then CODE should be at the top of your reading list!
Advertise with us - Post Your Good Content Here
We are ranked in the Top 20 on Google
AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
Programming Breaking News
- Simple terminal chat application - open for testingby /u/gosuwachu (programming) on July 26, 2024 at 10:42 pm
submitted by /u/gosuwachu [link] [comments]
- Haskell Nuggets: k-means · in Codeby /u/mstksg (programming) on July 26, 2024 at 9:28 pm
submitted by /u/mstksg [link] [comments]
- JSNation 2024 Sessions Now Available Onlineby /u/pmz (programming) on July 26, 2024 at 6:53 pm
submitted by /u/pmz [link] [comments]
- Why Postgres and DuckDB for Analyticsby /u/craig081785 (programming) on July 26, 2024 at 6:31 pm
submitted by /u/craig081785 [link] [comments]
- Crafting Interpreters with Rust: On Garbage Collectionby /u/UnclHoe (programming) on July 26, 2024 at 6:04 pm
submitted by /u/UnclHoe [link] [comments]
- Connection avalanche safety tips and prepping for real-time applicationsby /u/alexeyr (programming) on July 26, 2024 at 4:54 pm
submitted by /u/alexeyr [link] [comments]
- Recapping the first Local‑First conferenceby /u/alexeyr (programming) on July 26, 2024 at 4:35 pm
submitted by /u/alexeyr [link] [comments]
- Applied Machine Learning for Tabular Databy /u/BrewedDoritos (programming) on July 26, 2024 at 4:31 pm
submitted by /u/BrewedDoritos [link] [comments]
- What is Response Mapping in API Integration?by /u/itsrorymurphy (programming) on July 26, 2024 at 4:02 pm
submitted by /u/itsrorymurphy [link] [comments]
- Organizations shift away from Oracle Java as pricing changes biteby /u/Franco1875 (programming) on July 26, 2024 at 3:44 pm
submitted by /u/Franco1875 [link] [comments]
- Node.js adds experimental TypeScript support, as it 'simply cannot be ignored' • DEVCLASSby /u/stronghup (programming) on July 26, 2024 at 3:42 pm
submitted by /u/stronghup [link] [comments]
- Announcing TypeScript 5.6 Betaby /u/DanielRosenwasser (programming) on July 26, 2024 at 2:11 pm
submitted by /u/DanielRosenwasser [link] [comments]
- Approximate nearest neighbor search with DiskANN in libSQLby /u/avinassh (programming) on July 26, 2024 at 1:48 pm
submitted by /u/avinassh [link] [comments]
- Web-Check - A free All-in-one OSINT tool for analysing any website.by /u/brucebaird (programming) on July 26, 2024 at 1:10 pm
submitted by /u/brucebaird [link] [comments]
- Laxman loan app Customer Care Helpline Number➕%7569714050 ➕7569714050➕7569714050 Call Now Me.Laxmanby Hhghg (Coding on Medium) on July 26, 2024 at 12:50 pm
Continue reading on Medium »
- How to Start Your First AI Project with Python and OpenAI API.by Kris Ograbek (Python on Medium) on July 26, 2024 at 12:49 pm
The step-by-step guide for beginners (with the full setup).Continue reading on AI Advances »
- Laxman loan app Customer Care Helpline Number➕%7569714050 ➕7569714050➕7569714050 Call Now Me.Laxmanby Hhghg (Coding on Medium) on July 26, 2024 at 12:48 pm
Continue reading on Medium »
- The Sorting Algorithm Cup: Round 2by Batu Senturk (Coding on Medium) on July 26, 2024 at 12:48 pm
Join us for the second round of the Sorting Algorithm Cup. Today we will see Gnome Sort, Heap Sort, Insertion Sort and Merge Sort.Continue reading on Medium »
- Create a Currency Converter with Python from Scratchby Rahul Patodi (Python on Medium) on July 26, 2024 at 12:47 pm
The currency converter project is a Python application that utilizes the Tkinter library for its graphical user interface (GUI). It allows…Continue reading on Wiki Flood »
- Create a Currency Converter with Python from Scratchby Rahul Patodi (Coding on Medium) on July 26, 2024 at 12:47 pm
The currency converter project is a Python application that utilizes the Tkinter library for its graphical user interface (GUI). It allows…Continue reading on Wiki Flood »
- Mpokket loan customer care number✍️//* 8144933033/**/8144933033 Just Call nowby hotagi (Programming on Medium) on July 26, 2024 at 12:46 pm
Mpokket loan customer care number✍️//* 8144933033/**/8144933033 Just Call now Continue reading on Medium »
- Laxman loan app Customer Care Helpline Number➕%7569714050 ➕7569714050➕7569714050 Call Now Me.Laxmanby Hhghg (Programming on Medium) on July 26, 2024 at 12:46 pm
Continue reading on Medium »
- Fin8z[Telegram]Mandy Morris – EME Integration Practitionerby Wian Roberts (Python on Medium) on July 26, 2024 at 12:45 pm
Continue reading on Medium »
- Fin8z[Telegram]David Lion – Soul Medicineby Wian Roberts (Python on Medium) on July 26, 2024 at 12:44 pm
Continue reading on Medium »
- Fin8z[Telegram]Mina Irfan – Feminine Magic, Miracles & Abundanceby Wian Roberts (Python on Medium) on July 26, 2024 at 12:43 pm
Continue reading on Medium »
- Fin8z[Telegram]Marie Forleo – Copy Cure 2023by Wian Roberts (Python on Medium) on July 26, 2024 at 12:42 pm
Continue reading on Medium »
- Fin8z[Telegram]Jack Hopkins – 10K Accelerator Programby Wian Roberts (Python on Medium) on July 26, 2024 at 12:42 pm
Continue reading on Medium »
- Fin8z[Telegram]Owen Cook – Blueprint Reloaded Diamondby Wian Roberts (Python on Medium) on July 26, 2024 at 12:41 pm
Continue reading on Medium »
- A Python Epoch Timestamp Timezone Trapby /u/stackoverflooooooow (programming) on July 26, 2024 at 12:41 pm
submitted by /u/stackoverflooooooow [link] [comments]
- RB 'loan.app customer care helpline number-/* 7569714050/*-*7569714050//*all call.RBby Rhjiigd (Programming on Medium) on July 26, 2024 at 12:41 pm
Continue reading on Medium »
- Fin8z[Telegram]Whitney Uland – The Self-Made Celebrityby Wian Roberts (Python on Medium) on July 26, 2024 at 12:41 pm
Continue reading on Medium »
- Fin8z[Telegram]Chase Chappell – Ecommerce Accelerator Course 2024by Wian Roberts (Python on Medium) on July 26, 2024 at 12:40 pm
Continue reading on Medium »
- RB 'loan.app customer care helpline number-/* 7569714050/*-*7569714050//*all call.RBby Rhjiigd (Programming on Medium) on July 26, 2024 at 12:40 pm
Continue reading on Medium »
- What’s the difference between monolithic and microservices architecture?by Gantasofttraining (Programming on Medium) on July 26, 2024 at 12:36 pm
Continue reading on Medium »
- What’s the difference between monolithic and microservices architecture?by Gantasofttraining (Coding on Medium) on July 26, 2024 at 12:36 pm
Continue reading on Medium »
- RB 'loan.app customer care helpline number-/* 7569714050/*-*7569714050//*all call.RBby BG Hui (Programming on Medium) on July 26, 2024 at 12:32 pm
Continue reading on Medium »
- How do I contact mPokket customer care?8144933033//*814-4933-033by dagesi (Programming on Medium) on July 26, 2024 at 12:32 pm
How do I contact mPokket customer care?8144933033//*814-4933-033Continue reading on Medium »
- شماره خاله تبریز 09037735073by ماساژ وبرنامه حضوری09037735073 (Programming on Medium) on July 26, 2024 at 12:32 pm
Continue reading on Medium »
- How do I contact mPokket customer care?8144933033//*814-4933-033by dagesi (Programming on Medium) on July 26, 2024 at 12:31 pm
How do I contact mPokket customer care?8144933033//*814-4933-033Continue reading on Medium »
- How do I contact mPokket customer care?8144933033//*814-4933-033by dagesi (Programming on Medium) on July 26, 2024 at 12:31 pm
How do I contact mPokket customer care?8144933033//*814-4933-033Continue reading on Medium »
- What is a closure in Python?by Gantasofttraining (Coding on Medium) on July 26, 2024 at 12:29 pm
Continue reading on Medium »
- When You Might Not Need Redis: Tuning PostgreSQL for Cachingby Tomer Ben David (Coding on Medium) on July 26, 2024 at 12:25 pm
While Redis is often the go-to choice for high-performance caching, there are scenarios where optimizing PostgreSQL can yield acceptable…Continue reading on Medium »
- 12 seed phrase okx walletby Anna Ly (Coding on Medium) on July 26, 2024 at 12:07 pm
Continue reading on Medium »
- AI-Driven Development: The Role of AI in Modern IDEs [2023–10–15]by Jett Black (Coding on Medium) on July 26, 2024 at 12:00 pm
Continue reading on Medium »
- How to Self-Learn Coding?by Shariq Ahmed (Coding on Medium) on July 26, 2024 at 11:51 am
Tips by self-taught full-stack developerContinue reading on Medium »
- Creating a Fallout-Style UI Using Modern CSSby /u/sadyetfly11 (programming) on July 26, 2024 at 10:06 am
submitted by /u/sadyetfly11 [link] [comments]
- How To Build A Movie Recommendation System Powered By Knowledge Graph FalkorDBby /u/carbatgym (programming) on July 26, 2024 at 8:19 am
submitted by /u/carbatgym [link] [comments]
- Defense of Lisp macros: an automotive tragedyby /u/molteanu (programming) on July 26, 2024 at 7:51 am
submitted by /u/molteanu [link] [comments]
- When Objects Are Not Enoughby /u/lelanthran (programming) on July 26, 2024 at 6:42 am
submitted by /u/lelanthran [link] [comments]
- I made a TUI Text Editor in C++by /u/OnlyOneBrian (programming) on July 26, 2024 at 4:41 am
submitted by /u/OnlyOneBrian [link] [comments]
- Splitting and Merging Partitions in PostgreSQL 17by /u/jmswlms (programming) on July 26, 2024 at 3:18 am
submitted by /u/jmswlms [link] [comments]
- Rewriting completely the GameSpy support from 2000 to 2004 using Reverse Engineering on EA and Bungie Gamesby /u/r_retrohacking_mod2 (programming) on July 25, 2024 at 9:39 pm
submitted by /u/r_retrohacking_mod2 [link] [comments]
- AI Didn't Take My Jobby /u/bob-the-bicycle (programming) on July 25, 2024 at 3:27 pm
submitted by /u/bob-the-bicycle [link] [comments]
- Node.js adds experimental support for TypeScriptby /u/donutloop (programming) on July 25, 2024 at 12:37 pm
submitted by /u/donutloop [link] [comments]
- StackExchange is changing the data dump process, potentially violating the CC BY-SA licenseby /u/Resident-Trouble-574 (programming) on July 25, 2024 at 10:43 am
submitted by /u/Resident-Trouble-574 [link] [comments]
- The State of the Subreddit (May 2024)by /u/ketralnis (programming) on May 1, 2024 at 5:37 pm
Hello fellow programs! tl;dr some revisions to the rules to reduce low quality blogspam. The most notable are: banning listicles ("7 cool things I copy-pasted from somebody else!"), extreme beginner articles ("how to use a for loop"), and some limitations on career posts (they must be related to programming careers). Lastly, I want feedback on these changes and the subreddit in general and invite you to vote and use the report button when you see posts that violate the rules because they'll help us get to it faster. r/programming's mission is to be the place with the highest quality programming content, where I can go to read something interesting and learn something new every day. Last time we spoke I introduced the rules that we've been moderating by to accomplish that. Subjectively, quality on the subreddit while not perfect is much improved since then. Since it's still mainly just me moderating it's hard to tell what's objectively bad vs what just annoys me personally, and to do that I've been keeping an eye on a few forms of content to see how they perform (using mostly votes and comment quantity & health). Based on that the notable changes are: 🚫 Listicles. "7 cool python functions", "14 ways to get promoted". These are usually spammy content farms. If you found 15 amazing open source projects that will blow my mind, post those projects instead. 🚫 Extreme beginner content ("how to write a for loop"). This is difficult to identify objectively (how can you tell it from good articles like "how does kafka work?" or "getting started with linear algebra for ML"?) so there will be some back and forth on calibrating, but there has been a swath of very low quality "tutorials" if you can even call them that, that I very much doubt anybody is actually learning anything from and they sit at 0 points. Since "what is a variable?" is probably not useful to anybody already reading r/programming this is a quick painless way to boost the average quality on the subreddit. ⚠️ Career posts must be related to software engineering careers. To be honest I'm personally not a fan of career posts on r/programming at all (but shout out to cscareerquestions!) but during the last rules revision they were doing pretty well so I know there is an audience for it that I don't want to get in the way of. Since then there has been growth in this category all across the quality spectrum (with an accompanying rise in product management methodology like "agile vs waterfall", also across the quality spectrum). Going forward these posts must be distinctly related to software engineering careers rather than just generic working. This isn't a huge problem yet but I predict that it will be as the percentage of career content is growing. In all of these cases the category is more of a tell that the quality is probably low, so exceptions will be made where that's not the case. These are difficult categories to moderate by so I'll probably make some mistakes on the boundaries and that's okay, let me know and we'll figure it out. Some other categories that I'm keeping an eye on but not ruling on today are: Corporate blogs simply describing their product in the guise of "what is an authorisation framework?" (I'm looking at you Auth0 and others like it). Pretty much anything with a rocket ship emoji in it. Companies use their blogs as marketing, branding, and recruiting tools and that's okay when it's "writing a good article will make people think of us" but it doesn't go here if it's just a literal advert. Usually they are titled in a way that I don't spot them until somebody reports it or mentions it in the comments. Generic AI content that isn't technical in content. "Does Devin mean that programming is over?", "Will AI put farmers out of work?", "Is AI art?". For a few weeks these were the titles of about 20 articles per day, some scoring high and some low. Fashions like this come and go but I'm keeping an eye on it. Newsletters: There are a few people that post every edition of their newsletter to reddit, where that newsletter is really just aggregating content from elsewhere. It's clear that they are trying to grow a monetised audience using reddit, but that's okay if it's providing valuable curation or if the content is good and people like it. So we'll see. Career posts. Personally I'd like r/programming to be a deeply technical place but as mentioned there's clearly an audience for career advice. That said, the posts that are scoring the highest in this category are mostly people upvoting to agree with a statement in the title, not something that anybody is learning from. ("Don't make your engineers context-switch." "Everybody should get private offices." "Micromanaging sucks.") The ones that one could actually learn from with an instructive lean mostly don't do well; people seem to not really be interested in how to have the best 1:1s with their managers or how you went from Junior to Senior in 18 hours (though sometimes they are). That tells me that there's some subtlety to why these posts are scoring well and I'm keeping an eye on the category. What I don't want is for "vote up if you want free snacks" to push out the good stuff or to be a farm for the other 90% of content that's really just personal brand builders. I'm sure you're as annoyed as I am about these but they're fuzzy lines and difficult to come up with objective criteria around. As always I'm looking for feedback on these and if I'm missing any and any other points regarding the subreddit and moderation so let me know what you think. The rules! With all of that, here is the current set of the rules with the above changes included so I can link to them all in one place. ✅ means that it's currently allowed, 🚫 means that it's not currently allowed, ⚠️ means that we leave it up if it is already popular but if we catch it young in its life we do try to remove it early. ✅ Actual programming content. They probably have actual code in them. Language or library writeups, papers, technology descriptions. How an allocator works. How my new fancy allocator I just wrote works. How our startup built our Frobnicator. For many years this was the only category of allowed content. ✅ Academic CS or programming papers ✅ Programming news. ChatGPT can write code. A big new CVE just dropped. Curl 8.01 released now with Coffee over IP support. ✅ Programmer career content. How to become a Staff engineer in 30 days. Habits of the best engineering managers. These must be related or specific to programming/software engineering careers in some way ✅ Articles/news interesting to programmers but not about programming. Work from home is bullshit. Return to office is bullshit. There's a Steam sale on programming games. Terry Davis has died. How to SCRUMM. App Store commissions are going up. How to hire a more diverse development team. Interviewing programmers is broken. ⚠️ General technology news. Google buys its last competitor. A self driving car hit a pedestrian. Twitter is collapsing. Oculus accidentally showed your grandmother a penis. Github sued when Copilot produces the complete works of Harry Potter in a code comment. Meta cancels work from home. Gnome dropped a feature I like. How to run Stable Diffusion to generate pictures of, uh, cats, yeah it's definitely just for cats. A bitcoin VR metaversed my AI and now my app store is mobile social local. 🚫 Politics. The Pirate Party is winning in Sweden. Please vote for net neutrality. Big Tech is being sued in Europe for gestures broadly. Grace Hopper Conference is now 60% male. 🚫 Gossip. Richard Stallman switches to Windows. Elon Musk farted. Linus Torvalds was a poopy-head on a mailing list. The People's Rust Foundation is arguing with the Rust Foundation For The People. Terraform has been forked into Terra and Form. Stack Overflow sucks now. Stack Overflow is good actually. ✅ Demos with code. I wrote a game, here it is on GitHub 🚫 Demos without code. I wrote a game, come buy it! Please give me feedback on my startup (totally not an ad nosirree). I stayed up all night writing a commercial text editor, here's the pricing page. I made a DALL-E image generator. I made the fifteenth animation of A* this week, here's a GIF. 🚫 AskReddit type forum questions. What's your favourite programming language? Tabs or spaces? Does anyone else hate it when. 🚫 Support questions. How do I write a web crawler? How do I get into programming? Where's my missing semicolon? Please do this obvious homework problem for me. Personally I feel very strongly about not allowing these because they'd quickly drown out all of the actual content I come to see, and there are already much more effective places to get them answered anyway. In real life the quality of the ones that we see is also universally very low. 🚫 Surveys and 🚫 Job postings and anything else that is looking to extract value from a place a lot of programmers hang out without contributing anything itself. 🚫 Meta posts. DAE think r/programming sucks? Why did you remove my post? Why did you ban this user that is totes not me I swear I'm just asking questions. Except this meta post. This one is okay because I'm a tyrant that the rules don't apply to (I assume you are saying about me to yourself right now). 🚫 Images, memes, anything low-effort or low-content. Thankfully we very rarely see any of this so there's not much to remove but like support questions once you have a few of these they tend to totally take over because it's easier to make a meme than to write a paper and also easier to vote on a meme than to read a paper. ⚠️ Posts that we'd normally allow but that are obviously, unquestioningly super low quality like blogspam copy-pasted onto a site with a bazillion ads. It has to be pretty bad before we remove it and even then sometimes these are the first post to get traction about a news event so we leave them up if they're the best discussion going on about the news event. There's a lot of grey area here with CVE announcements in particular: there are a lot of spammy security "blogs" that syndicate stories like this. Pretty much all listicles are disallowed under this rule. 7 cool python functions. 14 ways to get promoted. If you found 15 amazing open source projects that will blow my mind, post those projects instead. ⚠️ Extreme beginner content. What is a variable. What is a for loop. Making an HTPT request using curl. Like listicles this is disallowed because of the quality typical to them, but high quality tutorials are still allowed and actively encouraged. ⚠️ Posts that are duplicates of other posts or the same news event. We leave up either the first one or the healthiest discussion. ⚠️ Posts where the title editorialises too heavily or especially is a lie or conspiracy theory. Comments are only very loosely moderated and it's mostly 🚫 Bots of any kind (Beep boop you misspelled misspelled!) and 🚫 Incivility (You idiot, everybody knows that my favourite toy is better than your favourite toy.) However the number of obvious GPT comment bots is rising and will quickly become untenable for the number of active moderators we have. submitted by /u/ketralnis [link] [comments]

Top 30 AWS Certified Developer Associate Exam Tips

Top 30 AWS Certified Developer Associate Exam Tips
AWS Certified Developer Associate Exam Prep Urls
Get the free app at: android: https://play.google.com/store/apps/details?id=com.awscertdevassociateexampreppro.enoumen
iOs: https://apps.apple.com/ca/app/aws-certified-developer-assoc/id1511211095
PRO version with mock exam android: https://play.google.com/store/apps/details?id=com.awscertdevassociateexampreppro.enoumen
PRO version with mock exam ios: https://apps.apple.com/ca/app/aws-certified-dev-ass-dva-c01/id1506519319t

0
Understand some basic code samples such as JSON code, config files, and IAM policy documents: Amazon EC2, Amazon Elastic Load Balancing, Amazon EC2 Auto Scaling, Amazon Simple Notification Service (SNS), AWS KMS, Amazon CloudTrail, AWS Organizations, Amazon Simple Workflow Service (SWF), and Amazon Virtual Private Cloud (VPC), Load Balancing, DynamoDB, EBS, Multi-AZ RDS, Aurora, EFS, DynamoDB, NLB, ALB, Aurora, Auto Scalling, DynamoDB(latency), Aurora(performance), Multi-AZ RDS(high availability), Throughput Optimized EBS (highly sequential), Read the quizlet note cards here
AWS topics for DVA-C01
1
What to study: LAMBDA [10-15% of Exam]Invocation types, Using notifications and event source mappings, Concurrency and throttling, X-Ray and Amazon SQS DLQs, Versions and aliases, Blue/green deployment, Packaging and deployment, VPC connections (with Internet/NAT GW), Lambda as ELB target, Dependencies, Environment variables (inc. encrypting them)
AWS topics for DVA-C01
2
What to study: DYNAMODB [10-12% of Exam]Scans vs queries (and the APIs, parameters you can use), Local and Global Secondary indexes, Calculating Read Capacity Units (RCUs) and Write, Capacity Units (WCUs), Performance / optimization best practices, Use cases (e.g. session state, key/value data store, scalability), DynamoDB Streams, Use in serverless app with Lambda and API Gateway, DynamoDB Accelerator (DAX) use cases
AWS topics for DVA-C01: DynamoDB
3
What to study: API Gateway [8-10% of Exam] Lambda / IAM / Cognito authorizers, Invalidation of cache, Integration types: proxy vs custom / AWS vs HTTP, Caching, Import / export OpenAPI Swagger specifications, Stage variables, Performance metrics,
AWS topics for DVA-C01: API Gateway
4
Advertise with us - Post Your Good Content Here
We are ranked in the Top 20 on Google
AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
What to study: COGNITO [7-8% of Exam] User pools vs Identity pools, Unauthenticated identities, AWS Cognito Sync, Using MFA with Cognito, Web identity federation,
AWS topics for DVA-C01: COGNITO
5
What to study: S3 [7-8% of Exam]Encryption – make sure you understand S3 encryption very well for the exam, S3 Transfer Acceleration, Versioning, Copying data, Lifecycle rules,
AWS topics for DVA-C01
6
What to study: IAM IAM policies and roles, Cross account access, Multi-factor authentication (MFA), API calls, IAM Roles with EC2 (instance profiles), Access keys vs roles, IAM best practices, Federation,
AWS topics for DVA-C01: IAM
7
What to study: ECS Shared storage between containers, Single vs multi-docker environments, Uploading / downloading images with ECR, Placement strategies (e.g. spread, binpack, random etc.), Port mappings, Defining task definitions, IAM Roles for Tasks,
AWS topics for DVA-C01: ECS

8
What to study: ELASTIC BEANSTALK Deployment policies and blue/green, .ebextensions and config file usage, Updating deployments, Worker vs web tier, Deployment, packaging and files, code, commands used, Use cases,
AWS topics for DVA-C01: AMAZON ELASTIC BEANSTALK
9
What to study: CLOUDFORMATIONS CloudFormation template anatomy (e.g. mappings, outputs, parameters, etc.), Packaging and deployment including commands used, AWS Serverless Application Model (SAM),
AWS topics for DVA-C01
10
What to study: AMAZON CLOUDWATCH Monitoring application logs, Trigger scheduled Lambda invocation, Custom metrics, Metric resolution,
AWS topics for DVA-C01: AMAZON CLOUDWATCH
11
What to study: CODECOMMIT, CODEBUILD, CODEDEPLOY, CODEPIPELINE, CODESTAR Know how each tool fits into the CI/CD pipeline, Various files used such as appspec.yml, buildspec.yml etc., Process for packaging and deployment, Deployment types with CodeDeploy including different , destination services (e.g. Lambda, ECS, EC2), Manual approvals with CodePipeline,
AWS topics for DVA-C01: CODECOMMIT, CODEBUILD, CODEDEPLOY, CODEPIPELINE, CODESTAR
12
What to study: AMAZON CLOUDFRONT
AWS topics for DVA-C01: AMAZON CLOUDFRONT
13
What to study: X-RAYS X-Ray daemon, installing and configuring, Lambda with X-Ray, Use cases / benefits, Inclusion in Elastic Beanstalk environment, Annotations vs segments vs subsegments vs metadata, API calls, Port used (UDP 2000),
AWS topics for DVA-C01: X-RAYS
14
What to study: SQS Standard queues, FIFO, DLQ, delay queue, Decoupling applications use cases, Event source mapping to Lambda, Visibility timeout, Short polling vs long polling,
AWS topics for DVA-C01: SQS
15
What to study: ELASTICACHE Use cases (caching and session state), In-memory data store, Services it sits in front of (e.g. Amazon RDS), Comparison against DynamoDB DAX, Lazy loading vs Write Through Caching, Memcached vs Redis,
AWS topics for DVA-C01: ELASTICACHE
16
What to study: STEP FUNCTIONS Step Functions state machines, Using to coordinate multiple Lambda function invocations
AWS topics for DVA-C01: STEP FUNCTIONS
17
What to study: SSM PARAMETER STORE Storing credentials, Rotation (application needs to do it) – comparison with secrets manager (which handles rotation automatically),
SSM PARAMETER STORE

18
Know what instance types can be launched from which types of AMIs, and which instance types require an HVM AMI
AWS HVM AMI
19
Have a good understanding of how Route53 supports all of the different DNS record types, and when you would use certain ones over others.
Route 53 supports all of the different DNS record types
20
Know which services have native encryption at rest within the region, and which do not.
AWS Services with native Encryption at rest
21
Kinesis Sharding:
#AWS Kinesis Sharding
22

Handling SSL Certificates in ELB ( Wildcard certificate vs SNI )
#AWS Handling SSL Certificates in ELB ( Wildcard certificate vs SNI )
23
Different types of Aurora Endpoints
#AWS Different types of Aurora Endpoints
24
The Default Termination Policy for Auto Scaling Group (Oldest launch configuration vs Instance Protection)
#AWS Default Termination Policy for Auto Scaling Group
25

Use AWS Cheatsheets – I also found the cheatsheets provided by Tutorials Dojo very helpful. In my opinion, it is better than Jayendrapatil Patil’s blog since it contains more updated information that complements your review notes.
#AWS Cheat Sheet
26
Watch this exam readiness 3hr video, it very recent webinar this provides what is expected in the exam.
#AWS Exam Prep Video
27
Start off watching Ryan’s videos. Try and completely focus on the hands on. Take your time to understand what you are trying to learn and achieve in those LAB Sessions.
#AWS Exam Prep Video

28
Do not rush into completing the videos. Take your time and hone the basics. Focus and spend a lot of time for the back bone of AWS infrastructure – Compute/EC2 section, Storage (S3/EBS/EFS), Networking (Route 53/Load Balancers), RDS, VPC, Route 3. These sections are vast, with lot of concepts to go over and have loads to learn. Trust me you will need to thoroughly understand each one of them to ensure you pass the certification comfortably.
#AWS Exam Prep Video
29
Make sure you go through resources section and also AWS documentation for each components. Go over FAQs. If you have a question, please post it in the community. Trust me, each answer here helps you understand more about AWS.
#AWS Faqs
30
Like any other product/service, each AWS offering has a different flavor. I will take an example of EC2 (Spot/Reserved/Dedicated/On Demand etc.). Make sure you understand what they are, what are the pros/cons of each of these flavors. Applies for all other offerings too.
#AWS Services
31
Follow Neal K Davis on Linkedin and Read his updates about DVA-C01
#AWS Services
What is the AWS Certified Developer Associate Exam?
The AWS Certified Developer – Associate examination is intended for individuals who perform a development role and have one or more years of hands-on experience developing and maintaining an AWS-based application. It validates an examinee’s ability to:
- Demonstrate an understanding of core AWS services, uses, and basic AWS architecture best practices
- Demonstrate proficiency in developing, deploying, and debugging cloud-based applications using AWS
There are two types of questions on the examination:
- Multiple-choice: Has one correct response and three incorrect responses (distractors).
- Provide implementation guidance based on best practices to the organization throughout the lifecycle of the project.
Select one or more responses that best complete the statement or answer the question. Distractors, or incorrect answers, are response options that an examinee with incomplete knowledge or skill would likely choose. However, they are generally plausible responses that fit in the content area defined by the test objective. Unanswered questions are scored as incorrect; there is no penalty for guessing.
To succeed with the real exam, do not memorize the answers below. It is very important that you understand why a question is right or wrong and the concepts behind it by carefully reading the reference documents in the answers.
AWS Certified Developer Associate info and details
The AWS Certified Developer Associate Exam is a multiple choice, multiple answer exam. Here is the Exam Overview:
- Certification Name: AWS Certified Developer Associate.
- Prerequisites for the Exam: None.
- Exam Pattern: Multiple Choice Questions
- Number of Questions: 65
- Duration: 130 mins
- Exam fees: US $150
- Exam Guide on AWS Website
- Available languages for tests: English, Japanese, Korean, Simplified Chinese
- Read AWS whitepapers
- Register for certification account here.
- Prepare for Certification Here
Other AWS Facts and Summaries and Questions/Answers Dump
- AWS S3 facts and summaries and Q&A Dump
- AWS DynamoDB facts and summaries and Questions and Answers Dump
- AWS EC2 facts and summaries and Questions and Answers Dump
- AWS Serverless facts and summaries and Questions and Answers Dump
- AWS Developer and Deployment Theory facts and summaries and Questions and Answers Dump
- AWS IAM facts and summaries and Questions and Answers Dump
- AWS vs Azure vs Google
- Pros and Cons of Cloud Computing
- Cloud Customer Insurance – Cloud Provider Insurance – Cyber Insurance
Additional Information for reference
Below are some useful reference links that would help you to learn about AWS Practitioner Exam.
- AWS certified cloud practitioner/
- certification faqs
- AWS Certified Developer Associate Exam Prep Dumps
Other Relevant and Recommended AWS Certifications
 AWS Certification Exams Roadmap[/caption]
AWS Certification Exams Roadmap[/caption]
- AWS Certified Cloud Practitioner
- AWS Certified Solution Architect – Associate
- AWS Certified Developer – Associate
- AWS Certified SysOps Administrator – Associate
- AWS Certified Developer – Professional
- AWS Certified DevOps Engineer – Professional
- AWS Certified Big Data Specialty
- AWS Certified Advanced Networking.
- AWS Certified Security – Specialty
AWS Developer Associate Exam Whitepapers:
AWS has provided whitepapers to help you understand the technical concepts. Below are the recommended whitepapers.
Online Training and Labs for AWS Certified Developer Associate Exam
AWS Certified Developer Associate Jobs
Top 60 AWS Solution Architect Associate Exam Tips

Top 60 AWS Solution Architect Associate Exam Tips
SAA Exam Prep App urls

Solution Architect FREE version:
Google Play Store (Android)
Apple Store (iOS)
Pwa: Web
Amazon android: Amazon App Store (Android)
Microsoft/Windows10:
0 In a nutshell, below are the resources and apps that you need for SAA-C03 Exam Prep:
- Study material by Adrian Cantrill ($40) or Joyjeet Banerjee ($50)
- PRO Quiz and Practice Exams by Djamgatech ($9.99) [iOS – Android]
- Quiz and Practice Exams by Djamgatech [Web – android – iOS – windows] (FREE or $5)
- Practice tests by Tutorial Dojo ($15)
- AWS labs and practices at AWS Qwiklabs ($25-50)
- Extra: $30 for Marek’s course on Udemy
- Extra: You can check out Practice exams by Ken Adams for solutions architect. (SAA-C02 – Updated June 2021)
Read FAQs and learn more about the following topics in details: Load Balancing, DynamoDB, EBS, Multi-AZ RDS, Aurora, EFS, DynamoDB, NLB, ALB, Aurora, Auto Scalling, DynamoDB(latency), Aurora(performance), Multi-AZ RDS(high availability), Throughput Optimized EBS (highly sequential), Read the quizlet note cards about Cloudwatch, CloudTrail, KMS, ElasticBeanstalk, OpsWorks here. Read Dexter’s Barely passed AWS Cram Notes about RPO vs RTO, HA vs FT, Undifferentiated Heavy Lifting, Access Management Basics, Shared Responsibility Model, Cloud Service Models
AWS topics for SAA-CO1 and SAA-CO2
1
Know what instance types can be launched from which types of AMIs, and which instance types require an HVM AMI
AWS HVM AMI
2
Understand bastion hosts, and which subnet one might live on. Bastion hosts are instances that sit within your public subnet and are typically accessed using SSH or RDP. Once remote connectivity has been established with the bastion host, it then acts as a ‘jump’ server, allowing you to use SSH or RDP to login to other instances (within private subnets) deeper within your network. When properly configured through the use of security groups and Network ACLs, the bastion essentially acts as a bridge to your private instances via the Internet.”
Bastion Hosts
3
Know the difference between Directory Service’s AD Connector and Simple AD. Use Simple AD if you need an inexpensive Active Directory–compatible service with the common directory features. AD Connector lets you simply connect your existing on-premises Active Directory to AWS.
AD Connector and Simple AD
4
Know how to enable cross-account access with IAM: To delegate permission to access a resource, you create an IAM role that has two policies attached. The permissions policy grants the user of the role the needed permissions to carry out the desired tasks on the resource. The trust policy specifies which trusted accounts are allowed to grant its users permissions to assume the role. The trust policy on the role in the trusting account is one-half of the permissions. The other half is a permissions policy attached to the user in the trusted account that allows that user to switch to, or assume the role.
Enable cross-account access with IAM
5
Have a good understanding of how Route53 supports all of the different DNS record types, and when you would use certain ones over others.
Route 53 supports all of the different DNS record types
Advertise with us - Post Your Good Content Here
We are ranked in the Top 20 on Google
AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
6
Know which services have native encryption at rest within the region, and which do not.
AWS Services with native Encryption at rest
7
Know which services allow you to retain full admin privileges of the underlying EC2 instances
EC2 Full admin privilege
8
Know When Elastic IPs are free or not: If you associate additional EIPs with that instance, you will be charged for each additional EIP associated with that instance per hour on a pro rata basis. Additional EIPs are only available in Amazon VPC. To ensure efficient use of Elastic IP addresses, we impose a small hourly charge when these IP addresses are not associated with a running instance or when they are associated with a stopped instance or unattached network interface.
When are AWS Elastic IPs Free or not?
9
Know what are the four high level categories of information Trusted Advisor supplies.
#AWS Trusted advisor
10
Know how to troubleshoot a connection time out error when trying to connect to an instance in your VPC. You need a security group rule that allows inbound traffic from your public IP address on the proper port, you need a route that sends all traffic destined outside the VPC (0.0.0.0/0) to the Internet gateway for the VPC, the network ACLs must allow inbound and outbound traffic from your public IP address on the proper port, etc.
#AWS Connection time out error
11
Be able to identify multiple possible use cases and eliminate non-use cases for SWF.
#AWS
12
Understand how you might set up consolidated billing and cross-account access such that individual divisions resources are isolated from each other, but corporate IT can oversee all of it.
#AWS Set up consolidated billing
13
Know how you would go about making changes to an Auto Scaling group, fully understanding what you can and can’t change. “You can only specify one launch configuration for an Auto Scaling group at a time, and you can’t modify a launch configuration after you’ve created it. Therefore, if you want to change the launch configuration for your Auto Scaling group, you must create a launch configuration and then update your Auto Scaling group with the new launch configuration. When you change the launch configuration for your Auto Scaling group, any new instances are launched using the new configuration parameters, but existing instances are not affected.
#AWS Make Change to Auto Scaling group
14
Know how you would go about making changes to an Auto Scaling group, fully understanding what you can and can’t change. “You can only specify one launch configuration for an Auto Scaling group at a time, and you can’t modify a launch configuration after you’ve created it. Therefore, if you want to change the launch configuration for your Auto Scaling group, you must create a launch configuration and then update your Auto Scaling group with the new launch configuration. When you change the launch configuration for your Auto Scaling group, any new instances are launched using the new configuration parameters, but existing instances are not affected.
#AWS Make Change to Auto Scaling group
15
Know which field you use to run a script upon launching your instance.
#AWS User data script
16
Know how DynamoDB (durable, and you can pay for strong consistency), Elasticache (great for speed, not so durable), and S3 (eventual consistency results in lower latency) compare to each other in terms of durability and low latency.
#AWS DynamoDB consistency
17
Know the difference between bucket policies, IAM policies, and ACLs for use with S3, and examples of when you would use each. “With IAM policies, companies can grant IAM users fine-grained control to their Amazon S3 bucket or objects while also retaining full control over everything the users do. With bucket policies, companies can define rules which apply broadly across all requests to their Amazon S3 resources, such as granting write privileges to a subset of Amazon S3 resources. Customers can also restrict access based on an aspect of the request, such as HTTP referrer and IP address. With ACLs, customers can grant specific permissions (i.e. READ, WRITE, FULL_CONTROL) to specific users for an individual bucket or object.
#AWS Difference between bucket policies
18
Know when and how you can encrypt snapshots.
#AWS EBS Encryption
19
Understand how you can use ELB cross-zone load balancing to ensure even distribution of traffic to EC2 instances in multiple AZs registered with a load balancer.
#AWS ELB cross-zone load balancing
20
How would you allow users to log into the AWS console using active directory integration. Here is a link to some good reference material.
#AWS og into the AWS console using active directory integration
21
Spot instances are good for cost optimization, even if it seems you might need to fall back to On-Demand instances if you wind up getting kicked off them and the timeline grows tighter. The primary (but still not only) factor seems to be whether you can gracefully handle instances that die on you–which is pretty much how you should always design everything, anyway!
#AWS Spot instances
22
The term “use case” is not the same as “function” or “capability”. A use case is something that your app/system will need to accomplish, not just behaviour that you will get from that service. In particular, a use case doesn’t require that the service be a 100% turnkey solution for that situation, just that the service plays a valuable role in enabling it.
#AWS use case
23
There might be extra, unnecessary information in some of the questions (red herrings), so try not to get thrown off by them. Understand what services can and can’t do, but don’t ignore “obvious”-but-still-correct answers in favour of super-tricky ones.
#AWS Exam Answers: Distractors
24
If you don’t know what they’re trying to ask, in a question, just move on and come back to it later (by using the helpful “mark this question” feature in the exam tool). You could easily spend way more time than you should on a single confusing question if you don’t triage and move on.
#AWS Exa: Skip Questions that are vague and come back to them later
25
Some exam questions required you to understand features and use cases of: VPC peering, cross-account access, DirectConnect, snapshotting EBS RAID arrays, DynamoDB, spot instances, Glacier, AWS/user security responsibilities, etc.
#AWS
26
The 30 Day constraint in the S3 Lifecycle Policy before transitioning to S3-IA and S3-One Zone IA storage classes
#AWS S3 lifecycle policy
27
Enabling Cross-region snapshot copy for an AWS KMS-encrypted cluster
Redis Auth / Amazon MQ / IAM DB Authentication
#AWS Cross-region snapshot copy for an AWS KMS-encrypted cluster
28
Know that FTP is using TCP and not UDP (Helpful for questions where you are asked to troubleshoot the network flow)
TCP and UDP
30
Kinesis Sharding:
#AWS Kinesis Sharding
31
Handling SSL Certificates in ELB ( Wildcard certificate vs SNI )
#AWS Handling SSL Certificates in ELB ( Wildcard certificate vs SNI )
32
Difference between OAI, Signed URL (CloudFront) and Pre-signed URL (S3)
#AWS Difference between OAI, Signed URL (CloudFront) and Pre-signed URL (S3)
33
Different types of Aurora Endpoints
#AWS Different types of Aurora Endpoints
34
The Default Termination Policy for Auto Scaling Group (Oldest launch configuration vs Instance Protection)
#AWS Default Termination Policy for Auto Scaling Group
35
Watch Acloud Guru Videos Lectures while commuting / lunch break – Reschedule the exam if you are not yet ready
#AWS ACloud Guru
36
Watch Linux Academy Videos Lectures while commuting / lunch break – Reschedule the exam if you are not yet ready
#AWS Linux Academy
37
Watch Udemy Videos Lectures while commuting / lunch break – Reschedule the exam if you are not yet ready
#AWS Linux Academy
38
The Udemy practice test interface is good that it pinpoints your weak areas, so what I did was to re-watch all the videos that I got the wrong answers. Since I was able to gauge my exam readiness, I decided to reschedule my exam for 2 more weeks, to help me focus on completing the practice tests.
#AWS Udemy
39
Use AWS Cheatsheets – I also found the cheatsheets provided by Tutorials Dojo very helpful. In my opinion, it is better than Jayendrapatil Patil’s blog since it contains more updated information that complements your review notes.
#AWS Cheat Sheet
40
Watch this exam readiness 3hr video, it very recent webinar this provides what is expected in the exam.
#AWS Exam Prep Video
41
Start off watching Ryan’s videos. Try and completely focus on the hands on. Take your time to understand what you are trying to learn and achieve in those LAB Sessions.
#AWS Exam Prep Video
42
Do not rush into completing the videos. Take your time and hone the basics. Focus and spend a lot of time for the back bone of AWS infrastructure – Compute/EC2 section, Storage (S3/EBS/EFS), Networking (Route 53/Load Balancers), RDS, VPC, Route 3. These sections are vast, with lot of concepts to go over and have loads to learn. Trust me you will need to thoroughly understand each one of them to ensure you pass the certification comfortably.
#AWS Exam Prep Video
43
Make sure you go through resources section and also AWS documentation for each components. Go over FAQs. If you have a question, please post it in the community. Trust me, each answer here helps you understand more about AWS.
#AWS Faqs
44
Like any other product/service, each AWS offering has a different flavor. I will take an example of EC2 (Spot/Reserved/Dedicated/On Demand etc.). Make sure you understand what they are, what are the pros/cons of each of these flavors. Applies for all other offerings too.
#AWS Services
45
Ensure to attend all quizzes after each section. Please do not treat these quizzes as your practice exams. These quizzes are designed to mostly test your knowledge on the section you just finished. The exam itself is designed to test you with scenarios and questions, where in you will need to recall and apply your knowledge of different AWS technologies/services you learn over multiple lectures.
#AWS Services
46
I, personally, do not recommend to attempt a practice exam or simulator exam until you have done all of the above. It was a little overwhelming for me. I had thoroughly gone over the videos. And understood the concepts pretty well, but once I opened exam simulator I felt the questions were pretty difficult. I also had a feeling that videos do not cover lot of topics. But later I realized, given the vastness of AWS Services and offerings it is really difficult to encompass all these services and their details in the course content. The fact that these services keep changing so often, does not help
#AWS Services
47
Go back and make a note of all topics, that you felt were unfamiliar for you. Go through the resources section and fiund links to AWS documentation. After going over them, you shoud gain at least 5-10% more knowledge on AWS. Have expectations from the online courses as a way to get thorough understanding of basics and strong foundations for your AWS knowledge. But once you are done with videos. Make sure you spend a lot of time on AWS documentation and FAQs. There are many many topics/sub topics which may not be covered in the course and you would need to know, atleast their basic functionalities, to do well in the exam.
#AWS Services
48
Once you start taking practice exams, it may seem really difficult at the beginning. So, please do not panic if you find the questions complicated or difficult. IMO they are designed or put in a way to sound complicated but they are not. Be calm and read questions very carefully. In my observation, many questions have lot of information which sometimes is not relevant to the solution you are expected to provide. Read the question slowly and read it again until you understand what is expected out of it.
#AWS Services
49
With each practice exam you will come across topics that you may need to scale your knowledge on or learn them from scratch.
#AWS Services
50
With each test and the subsequent revision, you will surely feel more confident.
There are 130 mins for questions. 2 mins for each question which is plenty of time.
At least take 8-10 practice tests. The ones on udemy/tutorialdojo are really good. If you are a acloudguru member. The exam simulator is really good.
Manage your time well. Keep patience. I saw someone mention in one of the discussions that do not under estimate the mental focus/strength needed to sit through 130 mins solving these questions. And it is really true.
Do not give away or waste any of those precious 130 mins. While answering flag/mark questions you think you are not completely sure. My advice is, even if you finish early, spend your time reviewing the answers. I could review 40 of my answers at the end of test. And I at least rectified 3 of them (which is 4-5% of total score, I think)
So in short – Put a lot of focus on making your foundations strong. Make sure you go through AWS Documentation and FAQs. Try and envision how all of the AWS components can fit together and provide an optimal solution. Keep calm.
This video gives outline about exam, must watch before or after Ryan’s course. #AWS Services
51
Walking you through how to best prepare for the AWS Certified Solutions Architect Associate SAA-C02 exam in 5 steps:
1. Understand the exam blueprint
2. Learn about the new topics included in the SAA-C02 version of the exam
3. Use the many FREE resources available to gain and deepen your knowledge
4. Enroll in our hands-on video course to learn AWS in depth
5. Use practice tests to fully prepare yourself for the exam and assess your exam readiness
AWS CERTIFIED SOLUTIONS ARCHITECT SAA-C02 : HOW TO BEST PREPARE IN 5 STEPS
52
Storage:
1. Know your different Amazon S3 storage tiers! You need to know the use cases, features and limitations, and relative costs; e.g. retrieval costs.
2. Amazon S3 lifecycle policies is also required knowledge — there are minimum storage times in certain tiers that you need to know.
3. For Glacier, you need to understand what it is, what it’s used for, and what the options are for retrieval times and fees.
4. For the Amazon Elastic File System (EFS), make sure you’re clear which operating systems you can use with it (just Linux).
5. For the Amazon Elastic Block Store (EBS), make sure you know when to use the different tiers including instance stores; e.g. what would you use for a datastore that requires the highest IO and the data is distributed across multiple instances? (Good instance store use case)
6. Learn about Amazon FSx. You’ll need to know about FSx for Windows and Lustre.
7. Know how to improve Amazon S3 performance including using CloudFront, and byte-range fetches — check out this whitepaper.
8. Make sure you understand about Amazon S3 object deletion protection options including versioning and MFA delete.
AWS CERTIFIED SOLUTIONS ARCHITECT SAA-C02 : HOW TO BEST PREPARE IN 5 STEPS
53
Compute:
1. You need to have a good understanding of the options for how to scale an Auto Scaling Group using metrics such as SQS queue depth, or numbers of SNS messages.
2. Know your different Auto Scaling policies including Target Tracking Policies.
3. Read up on High Performance Computing (HPC) with AWS. You’ll need to know about Amazon FSx with HPC use cases.
4. Know your placement groups. Make sure you can differentiate between spread, cluster and partition; e.g. what would you use for lowest latency? What about if you need to support an app that’s tightly coupled? Within an AZ or cross AZ?
5. Make sure you know the difference between Elastic Network Adapters (ENAs), Elastic Network Interfaces (ENIs) and Elastic Fabric Adapters (EFAs).
6. For the Amazon Elastic Container Service (ECS), make sure you understand how to assign IAM policies to ECS for providing S3 access. How can you decouple an ECS data processing process — Kinesis Firehose or SQS?
7. Make sure you’re clear on the different EC2 pricing models including Reserved Instances (RI) and the different RI options such as scheduled RIs.
8. Make sure you know the maximum execution time for AWS Lambda (it’s currently 900 seconds or 15 minutes).
AWS CERTIFIED SOLUTIONS ARCHITECT SAA-C02 : HOW TO BEST PREPARE IN 5 STEPS
54
Network
1. Understand what AWS Global Accelerator is and its use cases.
2. Understand when to use CloudFront and when to use AWS Global Accelerator.
3. Make sure you understand the different types of VPC endpoint and which require an Elastic Network Interface (ENI) and which require a route table entry.
4. You need to know how to connect multiple accounts; e.g. should you use VPC peering or a VPC endpoint?
5. Know the difference between PrivateLink and ClassicLink.
6. Know the patterns for extending a secure on-premises environment into AWS.
7. Know how to encrypt AWS Direct Connect (you can use a Virtual Private Gateway / AWS VPN).
8. Understand when to use Direct Connect vs Snowball to migrate data — lead time can be an issue with Direct Connect if you’re in a hurry.
9. Know how to prevent circumvention of Amazon CloudFront; e.g. Origin Access Identity (OAI) or signed URLs / signed cookies.
AWS CERTIFIED SOLUTIONS ARCHITECT SAA-C02 : HOW TO BEST PREPARE IN 5 STEPS
55
Databases
1. Make sure you understand Amazon Aurora and Amazon Aurora Serverless.
2. Know which RDS databases can have Read Replicas and whether you can read from a Multi-AZ standby.
3. Know the options for encrypting an existing RDS database; e.g. only at creation time otherwise you must encrypt a snapshot and create a new instance from the snapshot.
4. Know which databases are key-value stores; e.g. Amazon DynamoDB.
AWS CERTIFIED SOLUTIONS ARCHITECT SAA-C02 : HOW TO BEST PREPARE IN 5 STEPS
56
Application Integration
1. Make sure you know the use cases for the Amazon Simple Queue Service (SQS), and Simple Notification Service (SNS).
2. Understand the differences between Amazon Kinesis Firehose and SQS and when you would use each service.
3. Know how to use Amazon S3 event notifications to publish events to SQS — here’s a good “How To” article.
AWS CERTIFIED SOLUTIONS ARCHITECT SAA-C02 : HOW TO BEST PREPARE IN 5 STEPS
57
Management and Governance
1. You’ll need to know about AWS Organizations; e.g. how to migrate an account between organizations.
2. For AWS Organizations, you also need to know how to restrict actions using service control policies attached to OUs.
3. Understand what AWS Resource Access Manager is.
AWS CERTIFIED SOLUTIONS ARCHITECT SAA-C02 : HOW TO BEST PREPARE IN 5 STEPS
58
Jon Bonso list of helpful exam prep materials that you can use.
1. The official AWS SAA-C02 Certification Exam page.
2. The official AWS Exam Guide.
3. The official AWS Sample Questions
4. The official AWS Ramp-Up Guide: Architect PDF
5. Tutorials Dojo SAA-C02 Study Guide
6. Udemy Practice Exams
7. New AWS Services to prepare for:AWS Global Accelerator
8. New AWS Services to prepare for: Elastic Fabric Adapter — Amazon Web Services
9. New AWS Services to prepare for: AWS ParallelCluster – Amazon Web Services
10. New AWS Services to prepare for: Amazon FSx File Storage
Pass your SAA-C02 (AWS Solutions Architect Associate) exam with these Top 5 Resources
About this App
The AWS Certified Solution Architect Associate Examination reparation and Readiness Quiz App (SAA-C01, SAA-C01, SAA) Prep App helps you prepare and train for the AWS Certification Solution Architect Associate Exam with various questions and answers dumps.
This App provide updated Questions and Answers, an Intuitive Responsive Interface allowing to browse questions horizontally and browse tips and resources vertically after completing a quiz.
Features:
- 100+ Questions and Answers updated frequently to get you AWS certified.
- Quiz with score tracker, countdown timer, highest score saving. Vie Answers after completing the quiz for each category.
- Can only see answers after completing the quiz.
- Show/Hide button option for answers. Link to PRO Version to see all answers for each category
- Ability to navigate through questions for each category using next and previous button.
- Resource info page about the answer for each category and Top 60 Tips to succeed in the exam.
- Prominent Cloud Evangelist latest tweets and Technology Latest News Feed
- The app helps you study and practice from your mobile device with an intuitive interface.
- SAA-C01 and SAA-C02 compatible
- Resource info page about the answer for each category.
- Helps you study and practice from your mobile device with an intuitive interface.
The questions and Answers are divided in 4 categories:
- Design High Performing Architectures,
- Design Cost Optimized Architectures,
- Design Secure Applications And Architectures,
- Design Resilient Architecture,
The questions and answers cover the following topics: AWS VPC, S3, DynamoDB, EC2, ECS, Lambda, API Gateway, CloudWatch, CloudTrail, Code Pipeline, Code Deploy, TCO Calculator, AWS S3, AWS DynamoDB, CloudWatch , AWS SES, Amazon Lex, AWS EBS, AWS ELB, AWS Autoscaling , RDS, Aurora, Route 53, Amazon CodeGuru, Amazon Bracket, AWS Billing and Pricing, AWS Simply Monthly Calculator, AWS cost calculator, Ec2 pricing on-demand, AWS Pricing, AWS Pay As You Go, AWS No Upfront Cost, Cost Explorer, AWS Organizations, Consolidated billing, Instance Scheduler, on-demand instances, Reserved instances, Spot Instances, CloudFront, Web hosting on S3, S3 storage classes, AWS Regions, AWS Availability Zones, Trusted Advisor, Various architectural Questions and Answers about AWS, AWS SDK, AWS EBS Volumes, EC2, S3, Containers, KMS, AWS read replicas, Cloudfront, API Gateway, AWS Snapshots, Auto shutdown Ec2 instances, High Availability, RDS, DynamoDB, Elasticity, AWS Virtual Machines, AWS Caching, AWS Containers, AWS Architecture, AWS Ec2, AWS S3, AWS Security, AWS Lambda, Bastion Hosts, S3 lifecycle policy, kinesis sharing, AWS KMS, Design High Performing Architectures, Design Cost Optimized Architectures, Design Secure Applications And Architectures, Design Resilient Architecture, AWS vs Azure vs Google Cloud, Resources, Questions, AWS, AWS SDK, AWS EBS Volumes, AWS read replicas, Cloudfront, API Gateway, AWS Snapshots, Auto shutdown Ec2 instances, High Availability, RDS, DynamoDB, Elasticity, AWS Virtual Machines, AWS Caching, AWS Containers, AWS Architecture, AWS Ec2, AWS S3, AWS Security, AWS Lambda, Load Balancing, DynamoDB, EBS, Multi-AZ RDS, Aurora, EFS, DynamoDB, NLB, ALB, Aurora, Auto Scaling, DynamoDB(latency), Aurora(performance), Multi-AZ RDS(high availability), Throughput Optimized EBS (highly sequential), SAA-CO1, SAA-CO2, Cloudwatch, CloudTrail, KMS, ElasticBeanstalk, OpsWorks, RPO vs RTO, HA vs FT, Undifferentiated Heavy Lifting, Access Management Basics, Shared Responsibility Model, Cloud Service Models, etc…
The resources sections cover the following areas: Certification, AWS training, Mock Exam Preparation Tips, Cloud Architect Training, Cloud Architect Knowledge, Cloud Technology, cloud certification, cloud exam preparation tips, cloud solution architect associate exam, certification practice exam, learn aws free, amazon cloud solution architect, question dumps, acloud guru links, tutorial dojo links, linuxacademy links, latest aws certification tweets, and post from reddit, quota, linkedin, medium, cloud exam preparation tips, aws cloud solution architect associate exam, aws certification practice exam, cloud exam questions, learn aws free, amazon cloud solution architect, amazon cloud certified solution architect associate exam questions, as certification dumps, google cloud, azure cloud, acloud, learn google cloud, learn azure cloud, cloud comparison, etc.
Abilities Validated by the Certification:
- Effectively demonstrate knowledge of how to architect and deploy secure and robust applications on AWS technologies
- Define a solution using architectural design principles based on customer requirements
- Provide implementation guidance based on best practices to the organization throughout the life cycle of the project
Recommended Knowledge for the Certification:
- One year of hands-on experience designing available, cost-effective, fault-tolerant, and scalable distributed systems on AWS.
- Hands-on experience using compute, networking, storage, and database AWS services.
- Hands-on experience with AWS deployment and management services.
- Ability to identify and define technical requirements for an AWS-based application.
- bility to identify which AWS services meet a given technical requirement.
- Knowledge of recommended best practices for building secure and reliable applications on the AWS platform.
- An understanding of the basic architectural principles of building in the AWS Cloud.
- An understanding of the AWS global infrastructure.
- An understanding of network technologies as they relate to AWS.
- An understanding of security features and tools that AWS provides and how they relate to traditional services.
Note and disclaimer: We are not affiliated with AWS or Amazon or Microsoft or Google. The questions are put together based on the certification study guide and materials available online. We also receive questions and answers from anonymous users and we vet to make sure they are legitimate. The questions in this app should help you pass the exam but it is not guaranteed. We are not responsible for any exam you did not pass.
Important: To succeed with the real exam, do not memorize the answers in this app. It is very important that you understand why a question is right or wrong and the concepts behind it by carefully reading the reference documents in the answers.
What is the AWS Certified Solution Architect Associate Exam?
This exam validates an examinee’s ability to effectively demonstrate knowledge of how to architect and deploy secure and robust applications on AWS technologies. It validates an examinee’s ability to:
- Define a solution using architectural design principles based on customer requirements.
- Multiple-response: Has two correct responses out of five options.
There are two types of questions on the examination:
- Multiple-choice: Has one correct response and three incorrect responses (distractors).
- Provide implementation guidance based on best practices to the organization throughout the lifecycle of the project.
Select one or more responses that best complete the statement or answer the question. Distractors, or incorrect answers, are response options that an examinee with incomplete knowledge or skill would likely choose. However, they are generally plausible responses that fit in the content area defined by the test objective. Unanswered questions are scored as incorrect; there is no penalty for guessing.
To succeed with the real exam, do not memorize the answers below. It is very important that you understand why a question is right or wrong and the concepts behind it by carefully reading the reference documents in the answers.
AWS Certified Solution Architect Associate info and details
The AWS Certified Solution Architect Associate Exam is a multiple choice, multiple answer exam. Here is the Exam Overview:
- Certification Name: AWS Certified Solution Architect Associate.
- Prerequisites for the Exam: None.
- Exam Pattern: Multiple Choice Questions
- Duration: 130 mins
- Exam fees: US $150
- Exam Guide on AWS Website
- Available languages for tests: English, Japanese, Korean, Simplified Chinese
- Read AWS whitepapers
- Register for certification account here.
- Prepare for Certification Here
Other AWS Facts and Summaries and Questions/Answers Dump
- AWS S3 facts and summaries and Q&A Dump
- AWS DynamoDB facts and summaries and Questions and Answers Dump
- AWS EC2 facts and summaries and Questions and Answers Dump
- AWS Serverless facts and summaries and Questions and Answers Dump
- AWS Developer and Deployment Theory facts and summaries and Questions and Answers Dump
- AWS IAM facts and summaries and Questions and Answers Dump
- AWS vs Azure vs Google
- Pros and Cons of Cloud Computing
- Cloud Customer Insurance – Cloud Provider Insurance – Cyber Insurance
Additional Information for reference
Below are some useful reference links that would help you to learn about AWS Practitioner Exam.
- AWS certified cloud practitioner/
- certification faqs
- AWS Certified Solution Architect Associate Exam Prep Dumps
Other Relevant and Recommended AWS Certifications
AWS Certification Exams Roadmap[/caption]
- AWS Certified Cloud Practitioner
- AWS Certified Solutions Architect – Associate
- AWS Certified Developer – Associate
- AWS Certified SysOps Administrator – Associate
- AWS Certified Solutions Architect – Professional
- AWS Certified DevOps Engineer – Professional
- AWS Certified Big Data Specialty
- AWS Certified Advanced Networking.
- AWS Certified Security – Specialty
AWS Solution Architect Associate Exam Whitepapers:
AWS has provided whitepapers to help you understand the technical concepts. Below are the recommended whitepapers.
Online Training and Labs for AWS Certified Solution Architect Associate Exam
AWS Certified Solution Architect Associate Jobs


AWS Certification and Training Apps for all platforms:
AWS Cloud practitioner FREE version:
AWS Certified Cloud practitioner for the web:pwa
AWS Certified Cloud practitioner Exam Prep App for iOS
AWS Certified Cloud practitioner Exam Prep App for Microsoft/Windows10
AWS Certified Cloud practitioner Exam Prep App for Android (Google Play Store)
AWS Certified Cloud practitioner Exam Prep App for Android (Amazon App Store)
AWS Certified Cloud practitioner Exam Prep App for Android (Huawei App Gallery)
AWS Solution Architect FREE version:
AWS Certified Solution Architect Associate Exam Prep App for iOS: https://apps.apple.com/ca/app/solution-architect-assoc-quiz/id1501225766
Solution Architect Associate for Android Google Play
AWS Certified Solution Architect Associate Exam Prep App for the eb: Pwa
AWS Certified Solution Architect Associate Exam Prep App for Amazon android
AWS Certified Cloud practitioner Exam Prep App for Microsoft/Windows10
AWS Certified Cloud practitioner Exam Prep App for Huawei App Gallery
AWS Cloud Practitioner PRO Versions:
AWS Certified Cloud practitioner PRO Exam Prep App for iOS
AWS Certified Cloud Practitioner PRO Associate Exam Prep App for android google
AWS Certified Cloud practitioner Exam Prep App for Amazon android
AWS Certified Cloud practitioner Exam Prep App for Windows 10
AWS Certified Cloud practitioner Exam Prep PRO App for Android (Huawei App Gallery) Coming soon
AWS Solution Architect PRO
AWS Certified Solution Architect Associate PRO versions for iOS
AWS Certified Solution Architect Associate PRO Exam Prep App for Android google
AWS Certified Solution Architect Associate PRO Exam Prep App for Windows10
AWS Certified Solution Architect Associate PRO Exam Prep App for Amazon android
Huawei App Gallery: Coming soon
AWS Certified Developer Associates Free version:
AWS Certified Developer Associates for Android (Google Play)
AWS Certified Developer Associates Web/PWA
AWS Certified Developer Associates for iOs
AWS Certified Developer Associates for Android (Huawei App Gallery)
AWS Certified Developer Associates for windows 10 (Microsoft App store)
Amazon App Store: Coming soon
AWS Developer Associates PRO version
PRO version with mock exam for android (Google Play)
PRO version with mock exam ios
AWS Certified Developer Associates PRO for Android (Amazon App Store): Coming Soon
AWS Certified Developer Associates PRO for Android (Huawei App Gallery): Coming soon
How does using a VPN or Proxy or TOR or private browsing protects your online activity?

How does using a VPN or Proxy or TOR or private browsing protects your online activity?
There are several ways that using a virtual private network (VPN), proxy, TOR, or private browsing can protect your online activity:
- VPN: A VPN encrypts your internet connection and routes your traffic through a secure server, making it harder for others to track your online activity. This can protect you from hackers, government surveillance, and other types of online threats.
- Proxy: A proxy acts as an intermediary between your device and the internet. When you use a proxy, your internet traffic is routed through the proxy server, which can mask your IP address and make it harder for others to track your online activity.
- TOR: The TOR network is a decentralized network of servers that routes your internet traffic through multiple servers to obscure your IP address and location. This can make it more difficult for others to track your online activity.
- Private browsing: Private browsing mode, also known as “incognito mode,” is a feature that is available in most modern web browsers. When you use private browsing, your web browser does not store any information about your browsing activity, including cookies, history, or cache. This can make it harder for others to track your online activity.
Overall, using a VPN, proxy, TOR, or private browsing can help protect your online activity by making it harder for others to track your internet usage and by providing an additional layer of security. However, it is important to note that these tools are not foolproof and cannot completely guarantee your online privacy. It is always a good idea to be aware of your online activity and take steps to protect your personal information.
VPNs are used to provide remote corporate employees, gig economy freelance workers and business travelers with access to software applications hosted on proprietary networks. To gain access to a restricted resource through a VPN, the user must be authorized to use the VPN app and provide one or more authentication factors, such as a password, security token or biometric data.

A VPN extends a private network across a public network, and enables users to send and receive data across shared or public networks as if their computing devices were directly connected to the private network. Applications running on a computing device, e.g. a laptop, desktop, smartphone, across a VPN may therefore benefit from the functionality, security, and management of the private network. Encryption is a common though not an inherent part of a VPN connection.
To ensure security, the private network connection is established using an encrypted layered tunneling protocol and VPN users use authentication methods, including passwords or certificates, to gain access to the VPN. In other applications, Internet users may secure their connections with a VPN, to circumvent geo restrictions and censorship, or to connect to proxy servers to protect personal identity and location to stay anonymous on the Internet. However, some websites block access to known VPN technology to prevent the circumvention of their geo-restrictions, and many VPN providers have been developing strategies to get around these roadblocks.
Private browsing on incognito window or inPrivate window a privacy feature in some web browsers (Chrome, Firefox, Explorer, Edge). When operating in such a mode, the browser creates a temporary session that is isolated from the browser’s main session and user data. Browsing history is not saved, and local data associated with the session, such as cookies, are cleared when the session is closed.
These modes are designed primarily to prevent data and history associated with a particular browsing session from persisting on the device, or being discovered by another user of the same device. Private browsing modes do not necessarily protect users from being tracked by other websites or their internet service provider (ISP). Furthermore, there is a possibility that identifiable traces of activity could be leaked from private browsing sessions by means of the operating system, security flaws in the browser, or via malicious browser extensions, and it has been found that certain HTML5APIs can be used to detect the presence of private browsing modes due to differences in behaviour.
The question is:
How does using a VPN or Proxy or TOR or private browsing protects your online activity?
What are the pros and cons of VPN vs Proxy?
How can VPN, Proxy, TOR, private browsing, incognito windows How does using a VPN, Proxy, TOR, private browsing, incognito windows protects your online activity? protects your online activity?
- VPN masks your real IP address by hiding it with one of its servers. As a result, no third party will be able to link your online activity to your physical location. To top it off, you avoid annoying ads and stay off the marketer’s radars.
- VPN encrypts your internet traffic in order to make it impossible for anybody to decode your sensitive information and steal your identity. You can also learn more what a development team tells about how they protect their users against data theft.
If your VPN doesn’t protect your online activities, it means there are some problems with the aforementioned protection measures. This could be:
- VPN connection disruption. Unfortunately, a sudden disruption of your connection can deanonymize you, if at this moment your device is sending or receiving IP-related requests. In order to avoid such a situation, the kill switch option should be always ON.
- DNS/IP address leakage. This problem can be caused by various reasons from configuration mistakes to a conflict between the app under discussion and some other installed software. Regardless of the reason, you will end up with otherwise perfectly working security app, which, in fact, is leaking your IP address.
- Outdated protocol. In a nutshell, it is the technology that manages the сreation of your secured connection. If your current protocol becomes obsolete, the app will not work perfectly.
- Free apps. This is about free software that makes money on your privacy. The actions of such applications are also considered as unethical and illegal. Stealing your private data and selling of it to third parties is one of them.
- User carelessness. For instance, turn on your virtual private network when you visit any website or enter your credentials. Don’t use the app sporadically.
How is a VPN different from a proxy server?
On top of serving as a proxy server, VPN provides encryption. A proxy server only hides your IP address.
Proxies are good for the low-stakes task like: watching regionally restricted videos on YouTube, creating another Gmail account when your IP limit ran out, accessing region restricted websites, bypassing content filters, request restrictions on IP.
On the other hand, proxies are not so great for the high-stakes task. As we know, proxies only act as a middleman in our Internet traffic, they only serve a webpage which we are requesting them to serve.
Advertise with us - Post Your Good Content Here
We are ranked in the Top 20 on Google
AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
Just like the proxy service, a VPN makes your traffic to have appeared from the remote IP address that is not yours. But, that’s when all the similarities end.
Unlike a proxy, VPN is set at the operating system level, it captures all the traffic coming from the device it is set up on. Whether it is your web traffic, BitTorrent client, game, or a Windows Update, it captures traffic from all the applications from your device.
Another difference between proxy and VPN is – VPN tunnels all your traffic through heavily encrypted and secure connection to the VPN server.
This makes VPN an ideal solution high-stakes tasks where security and privacy are of paramount of importance. With VPN, neither your ISP, Government, or a guy snooping over open Wi-Fi connection can access your traffic.
What are daily use of VPN for?
There are many uses of Virtual Private Network (VPN) for normal users and company employees. Here are the list of the most common usages:
Accessing Business Networks From Any Places in the World :
This is one of the best use of VPN. It is very much helpful when you are travelling and have to complete some work. You can connect any computer to your business network from anywhere and set up your work easily. Local resources need some security so they have to be kept in VPN-only to ensure their safety.
To Hide Your Browsing Data From ISP & Local Users :
All Internet Service Providers (ISP) will log the data of your IP address. If you use the VPN then they can only see the connection of your VPN. It won’t let anyone spy on your website history.
Moreover, it secures your connection when you use a public Wi-Fi network. As you may or may not know, users on these networks can spy on your browsing history, even if you are surfing HTTPS websites. Virtual Private Networks protect your privacy on public unsecured Wi-Fi connection.
To Access Geographically Blocked Sites :
Have you ever faced a problem like “This content is not available in your country”? VPNs are the best solution to bypass these restrictions.
Some videos on YouTube will also show this restriction. VPNs are a quick fix for all these restrictions.
What about TOR and VPN? What are the Pros and Cons?
The Tor network is similar to a VPN. Messages to and from your computer pass through the Tor network rather than connecting directly to resources on the Internet. But where VPNs provide privacy, Tor provides anonymity.
Tor is free and open-source software for enabling anonymous communication. The name is derived from an acronym for the original software project name “The Onion Router”. Tor directs Internet traffic through a free, worldwide, volunteer overlay network consisting of more than seven thousand relays to conceal a user’s location and usage from anyone conducting network surveillance or traffic analysis. Using Tor makes it more difficult to trace Internet activity to the user: this includes “visits to Web sites, online posts, instant messages, and other communication forms”.[ Tor’s intended use is to protect the personal privacy of its users, as well as their freedom and ability to conduct confidential communication by keeping their Internet activities from being monitored.
Tor does not prevent an online service from determining when it is being accessed through Tor. Tor protects a user’s privacy, but does not hide the fact that someone is using Tor. Some websites restrict allowances through Tor. For example, Wikipedia blocks attempts by Tor users to edit articles unless special permission is sought. Although a VPN is generally faster than Tor, using them together will slow down your internet connection and should be avoided. More is not necessarily better in this situation.
Is VPN necessary when using the deep web?
The deep web is the part of the web that can not be indexed by search machines: internal company login pages, or a school portal (the internal portal) private google sites or government pages.
The dark web is the more sinister form of the Deep Web. The dark web is more associated with illegal activity (i.e child pornography, drug dealing, hitmen etc).
A VPN is not necessary when connecting to the DEEP WEB. Please do not confuse the DEEP WEB with the DARK WEB.
Are there any good free VPN services?
It is not recommended to use free VPN for following reasons:
1- Security: Free VPNs don’t necessarily have to ensure your privacy is protected.
2- Tracking – Free VPNs have no obligation to keep your details safe, so at any point, your details could be passed on.
3- Speed / bandwidth – Some free VPN services are capped at a lower bandwidth that is you will receive less browsing or download speed to that of paid VPN.
4- Protocols supported – A free VPN may not support all necessary protocols. PPTP, OpenVPN and L2TP are generally provided only on paid VPN services.
If you are ok with the risks of using Free VPN, here are some you can try:
- TunnelBear: Secure VPN Service
- Hide.me VPN
- SurfEasy | Ultra fast, no-log private network VPN for Android, iOS, Mac & Windows
- CyberGhost Fast and Secure VPN Service
- Windscibe Free VPN and Ad Block
- OpenVPN – Open Source VPN
- SoftEther VPN Open Source
- Zenmate
- HotSpot Shield
Paid VPNs are better and give you:
- great customer support
- lighting internet speed
- user friendly design
- minimum 256-bit security
- advanced features such as P2P, double encryption, VPN over Onion etc.
Below are the top paid VPNs:
1- NordVPN – cost-effective, provides Netflix in 5 countries (US, CAN, UK, JP, NL) and does not log your info.
2- ExpressVPN – nearly 3x NordVPN’s price but guarantees Netflix in the US. Excellent customer service and claims to not log your info.
3- Private Internet Access – a U.S. based VPN that has proven its no log policy in the court of law. This is a unique selling point that 99.99% VPNs don’t have.
4- OpenVPN provides flexible VPN solutions to secure your data communications, whether it’s for Internet privacy, remote access for employees, securing IoT, or for networking Cloud data centers.
Other Questions about VPN and security:
Why might certain web sites not load with VPN?
For security, some corporations like Banks often block IP addresses used by major VPN companies, because it is thought to improve security.
Can a VPN bypass being flagged as a suspicious log-in on Facebook & Instagram?
You probably need a VPN that allow you to use dedicated IP address, otherwise the server ips are constantly switching every time you reconnect to your vpn and shared ip usually raised as suspicious logins due to many people logging in from the same ip address (which make the site thinks it might be bots or mass-hacked accounts).
How is a hacker traced when server logs show his or her IP is from a VPN?
- Start looking for IP address leaks. Even hackers are terrible at not leaking their IPs.
- Look for times the attacker forgot to enable their VPN. It happens all the time.
- Look at other things related to the attcke like domains for example. They might have registered a domain using something you can trace or they left a string in the malware that can help identify them.
- Silently take control of the command and control server legally.
What is the most secure VPN protocol?
- OpenVPN technology uses the highest levels (military standards) of encryption algorithms i.e. 256bit keys to secure your data transfers.
- OpenVPN is also known to have the fastest speeds even in the case of long distance connections that have latency. The protocol is highly recommended for streaming, downloading files and watching live TV. In addition to speeds, the protocol is stable and known to have fewer disconnections compared to its many counterparts.
- OpenVPN comes equipped with solid military grade encryption and is way better, security wise, than PPTP, L2TP/IPSec and SSTP.
What are some alternatives for VPN?
- Tor network, it is anonymous, free and well, rather slow, certainly fast enough to access your private email, but not fast enough to stream a movie.
- Proxies are remote computers that individuals or organizations use to restrict Internet access, filter content, and make Internet browsing more secure. It acts as a middleman between the end user and the web server, since all connection requests pass through it. It filters the request first then sends it to the web server. Once the web server responds, the proxy filters the response then sends it to the end user.
- IPSec (Cisco, Netgear, etc.): secure network protocol suite that authenticates and encrypts the packets of data sent over an Internet Protocol network.
- SSL (Full) like OpenVPN
- SSL (Partial) like SSL-Explorer and most appliances
- SSH Tunneling is a method of transporting arbitrary networking data over an encrypted SSH connection. It can be used to add encryption to legacy applications. It also provides a way to secure the data traffic of any given application using port forwarding, basically tunneling any TCP/IP port over SSH.
- PPTP
- L2TP (old Cisco, pre IPSec)
- DirectAccess
- Hamachi
- You can create you own VPN as well using any encryption or simple tunneling technology.
How does private browsing or incognito window work?
When you are in private browsing mode, your browser doesn’t store any of this information at all. It functions as a completely isolated browser session.
For most web browsers, their optional private mode, often also called InPrivate or incognito, is like normal browsing except for a few things.
- it uses separate temporary cookies that are deleted once the browser is closed (leaving your existing cookies unaffected)
- no private activity is logged to the browser’s history
- it often uses a separate temporary cache
What are the advantages of Google Chrome’s private browsing?
- simultaneously log into a website using different account names
- access websites without extensions (all extensions are disabled by default when in Incognito)
- Shield you from being tracked by Google, Facebook and other online advertising companies
- Allow you to be anonymous visitor to a website, or see how a personalized webpage will look like from a third-party perspective
Firefox private browsing or chrome incognito?
Mozilla doesn’t really have an incentive to spy on their users. It’s not really going to get them anything because they’re not a data broker and don’t sell ads. Couple this with the fact that Firefox is open-source and I would argue that Firefox is the clear winner here.
Chrome now prevents sites from checking for private browsing mode
Mozilla Private Network VPN gives Firefox another privacy boost
Adding a VPN to Firefox is clever because it means the privacy protection is integrated into one application rather than being spread across different services. That integration probably makes it more likely to be used by people who wouldn’t otherwise use one.
Pros and Cons of Adding VPN to browsers like Firefox and Opera:
Turning on the VPN will give users a secure connection to a trusted server when using a device connected to public Wi-Fi (and running the gamut of rogue Wi-Fi hotspots and unknown intermediaries). Many travellers use subscription VPNs when away from a home network – the Mozilla Private Network is just a simpler, zero-cost alternative.
However, like Opera’s offering, it’s not a true VPN – that is, it only encrypts traffic while using one browser, Firefox. Traffic from all other applications on the same computer won’t be secured in the same way.
As with any VPN, it won’t keep you completely anonymous. Websites you visit will see a Cloudflare IP address instead of your own, but you will still get advertising cookies and if you log in to a website your identity will be known to that site.
Additional reading:
Resources:
1- Wikipedia
2- Quora
4- Reddit
AWS Developer and Deployment Theory: Facts and Summaries and Questions/Answers

AWS Developer and Deployment Theory: Facts and Summaries and Questions/Answers
AWS Developer – Deployment Theory Facts and summaries, Top 80 AWS Developer DVA-C02 Theory Questions and Answers Dump
Definition 1: The AWS Developer is responsible for designing, deploying, and developing cloud applications on AWS platform
Definition 2: The AWS Developer Tools is a set of services designed to enable developers and IT operations professionals practicing DevOps to rapidly and safely deliver software.
The AWS Certified Developer Associate certification is a widely recognized certification that validates a candidate’s expertise in developing and maintaining applications on the Amazon Web Services (AWS) platform.
The certification is about to undergo a major change with the introduction of the new exam version DVA-C02, replacing the current DVA-C01. In this article, we will discuss the differences between the two exams and what candidates should consider in terms of preparation for the new DVA-C02 exam.
Quick facts
- What’s happening?
- The DVA-C01 exam is being replaced by the DVA-C02 exam.
- When is this taking place?
- The last day to take the current exam is February 27th, 2023 and the first day to take the new exam is February 28th, 2023.
- What’s the difference?
- The new exam features some new AWS services and features.
Main differences between DVA-C01 and DVA-C02
The table below details the differences between the DVA-C01 and DVA-C02 exams domains and weightings:

In terms of the exam content weightings, the DVA-C02 exam places a greater emphasis on deployment and management, with a slightly reduced emphasis on development and refactoring. This shift reflects the increased importance of operations and management in cloud computing, as well as the need for developers to have a strong understanding of how to deploy and maintain applications on the AWS platform.
One major difference between the two exams is the focus on the latest AWS services and features. The DVA-C02 exam covers around 57 services vs only 33 services in the DVA-C01. This reflects the rapidly evolving AWS ecosystem and the need for developers to be up-to-date with the latest services and features in order to effectively build and maintain applications on the platform.
Click the image above to watch our video about the NEW AWS Developer Associate Exam DVA-C02 from our youtube channel
Training resources for the AWS Developer Associate
In terms of preparation for the DVA-C02 exam, we strongly recommend enrolling in our on-demand training courses for the AWS Developer Associate certification. It is important for candidates to familiarize themselves with the latest AWS services and features, as well as the updated exam content weightings. Practical experience working with AWS services and hands-on experimentation with new services and features will be key to success on the exam. Candidates should also focus on their understanding of security best practices, access control, and compliance, as these topics will carry a greater weight in the new exam.
Frequently asked questions – FAQs:
In conclusion, the change from the DVA-C01 to the DVA-C02 exam represents a major shift in the focus and content of the AWS Certified Developer Associate certification. Candidates preparing for the new exam should focus on familiarizing themselves with the latest AWS services and features, as well as the updated exam content weightings, and placing a strong emphasis on security, governance, and compliance.
With the right preparation and focus, candidates can successfully navigate the changes in the DVA-C02 exam and maintain their status as a certified AWS Developer Associate.
Advertise with us - Post Your Good Content Here
We are ranked in the Top 20 on Google
AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
Download AWS Certified Developer Associate Mock Exam Pro App for:

All Platforms (PWA) – Android – iOS – Windows 10 –
AWS Developer and Deployment Theory Facts and summaries

- Continuous Integration is about integrating or merging the code changes frequently, at least once per day. It enables multiple devs to work on the same application.
- Continuous delivery is all about automating the build, test, and deployment functions.
- Continuous Deployment fully automates the entire release process, code is deployed into Production as soon as it has successfully passed through the release pipeline.
- AWS CodePipeline is a continuous integration/Continuous delivery service:
- It automates your end-to-end software release process based on user defines workflow
- It can be configured to automatically trigger your pipeline as soon as a change is detected in your source code repository
- It integrates with other services from AWS like CodeBuild and CodeDeploy, as well as third party custom plug-ins.
- AWS CodeBuild is a fully managed build service. It can build source code, run tests and produce software packages based on commands that you define yourself.
- Dy default the buildspec.yml defines the build commands and settings used by CodeBuild to run your build.
- AWS CodeDeploy is a fully managed automated deployment service and can be used as part of a Continuous Delivery or Continuous Deployment process.
- There are 2 types of deployment approach:
- In-place or Rolling update- you stop the application on each host and deploy the latest code. EC2 and on premise systems only. To roll back, you must re-deploy the previous version of the application.
- Blue/Green : New instances are provisioned and the new application is deployed to these new instances. Traffic is routed to the new instances according to your own schedule. Supported for EC2, on-premise systems and Lambda functions. Rollback is easy, just route the traffic back to the original instances. Blue is active deployment, green is new release.
- Docker allows you to package your software into Containers which you can run in Elastic Container Service (ECS)
- A docker Container includes everything the software needs to run including code, libraries, runtime and environment variables etc..
- A special file called Dockerfile is used to specify the instructions needed to assemble your Docker image.
- Once built, Docker images can be stored in Elastic Container Registry (ECR) and ECS can then use the image to launch Docker Containers.
- AWS CodeCommit is based on Git. It provides centralized repositories for all your code, binaries, images, and libraries.
- CodeCommit tracks and manages code changes. It maintains version history.
- CodeCommit manages updates from multiple sources and enables collaboration.
- To support CORS, API resource needs to implement an OPTIONS method that can respond to the OPTIONS preflight request with following headers:
- You have a legacy application that works via XML messages. You need to place the application behind the API gateway in order for customers to make API calls. Which of the following would you need to configure?
You will need to work with the Request and Response Data mapping. - Your application currently points to several Lambda functions in AWS. A change is being made to one of the Lambda functions. You need to ensure that application traffic is shifted slowly from one Lambda function to the other. Which of the following steps would you carry out?
- Create an ALIAS with the –routing-config parameter
- Update the ALIAS with the –routing-config parameter
- AWS CodeDeploy: The AppSpec file defines all the parameters needed for the deployment e.g. location of application files and pre/post deployment validation tests to run.
- For Ec2 / On Premise systems, the appspec.yml file must be placed in the root directory of your revision (the same folder that contains your application code). Written in YAML.
- For Lambda and ECS deployment, the AppSpec file can be YAML or JSON
- Visual workflows are automatically created when working with which Step Functions
- API Gateway stages store configuration for deployment. An API Gateway Stage refers to A snapshot of your API
- AWS SWF Services SWF guarantees delivery order of messages/tasks
- Blue/Green Deployments with CodeDeploy on AWS Lambda can happen in multiple ways. Which of these is a potential option? Linear, All at once, Canary
- X-Ray Filter Expressions allow you to search through request information using characteristics like URL Paths, Trace ID, Annotations
- S3 has eventual consistency for overwrite PUTS and DELETES.
- What can you do to ensure the most recent version of your Lambda functions is in CodeDeploy?
Specify the version to be deployed in AppSpec file.
Top
Reference: AWS Developer Tools
AWS Developer and Deployment Theory: Top 80 Questions and Answers Dump
Q0: Which AWS service can be used to compile source code, run tests and package code?
- A. CodePipeline
- B. CodeCommit
- C. CodeBuild
- D. CodeDeploy
TopQ1: How can your prevent CloudFormation from deleting your entire stack on failure? (Choose 2)
- A. Set the Rollback on failure radio button to No in the CloudFormation console
- B. Set Termination Protection to Enabled in the CloudFormation console
- C. Use the –disable-rollback flag with the AWS CLI
- D. Use the –enable-termination-protection protection flag with the AWS CLI
Q2: Which of the following practices allows multiple developers working on the same application to merge code changes frequently, without impacting each other and enables the identification of bugs early on in the release process?
- A. Continuous Integration
- B. Continuous Deployment
- C. Continuous Delivery
- D. Continuous Development
Q3: When deploying application code to EC2, the AppSpec file can be written in which language?
- A. JSON
- B. JSON or YAML
- C. XML
- D. YAML
Q4: Part of your CloudFormation deployment fails due to a mis-configuration, by defaukt what will happen?
- A. CloudFormation will rollback only the failed components
- B. CloudFormation will rollback the entire stack
- C. Failed component will remain available for debugging purposes
- D. CloudFormation will ask you if you want to continue with the deployment
Q5: You want to receive an email whenever a user pushes code to CodeCommit repository, how can you configure this?
- A. Create a new SNS topic and configure it to poll for CodeCommit eveents. Ask all users to subscribe to the topic to receive notifications
- B. Configure a CloudWatch Events rule to send a message to SES which will trigger an email to be sent whenever a user pushes code to the repository.
- C. Configure Notifications in the console, this will create a CloudWatch events rule to send a notification to a SNS topic which will trigger an email to be sent to the user.
- D. Configure a CloudWatch Events rule to send a message to SQS which will trigger an email to be sent whenever a user pushes code to the repository.
Q6: Which AWS service can be used to centrally store and version control your application source code, binaries and libraries
- A. CodeCommit
- B. CodeBuild
- C. CodePipeline
- D. ElasticFileSystem
Q7: You are using CloudFormation to create a new S3 bucket,
which of the following sections would you use to define the properties of your bucket?- A. Conditions
- B. Parameters
- C. Outputs
- D. Resources
Q8: You are deploying a number of EC2 and RDS instances using CloudFormation. Which section of the CloudFormation template
would you use to define these?
- A. Transforms
- B. Outputs
- C. Resources
- D. Instances
Q9: Which AWS service can be used to fully automate your entire release process?
- A. CodeDeploy
- B. CodePipeline
- C. CodeCommit
- D. CodeBuild
Q10: You want to use the output of your CloudFormation stack as input to another CloudFormation stack. Which sections of the CloudFormation template would you use to help you configure this?
- A. Outputs
- B. Transforms
- C. Resources
- D. Exports
Q11: You have some code located in an S3 bucket that you want to reference in your CloudFormation template. Which section of the template can you use to define this?
- A. Inputs
- B. Resources
- C. Transforms
- D. Files
Q12: You are deploying an application to a number of Ec2 instances using CodeDeploy. What is the name of the file
used to specify source files and lifecycle hooks?
- A. buildspec.yml
- B. appspec.json
- C. appspec.yml
- D. buildspec.json
Q13: Which of the following approaches allows you to re-use pieces of CloudFormation code in multiple templates, for common use cases like provisioning a load balancer or web server?
- A. Share the code using an EBS volume
- B. Copy and paste the code into the template each time you need to use it
- C. Use a cloudformation nested stack
- D. Store the code you want to re-use in an AMI and reference the AMI from within your CloudFormation template.
Q14: In the CodeDeploy AppSpec file, what are hooks used for?
- A. To reference AWS resources that will be used during the deployment
- B. Hooks are reserved for future use
- C. To specify files you want to copy during the deployment.
- D. To specify, scripts or function that you want to run at set points in the deployment lifecycle
Q15:You need to setup a RESTful API service in AWS that would be serviced via the following url https://democompany.com/customers Which of the following combination of services can be used for development and hosting of the RESTful service? Choose 2 answers from the options below
- A. AWS Lambda and AWS API gateway
- B. AWS S3 and Cloudfront
- C. AWS EC2 and AWS Elastic Load Balancer
- D. AWS SQS and Cloudfront
Q16: As a developer, you have created a Lambda function that is used to work with a bucket in Amazon S3. The Lambda function is not working as expected. You need to debug the issue and understand what’s the underlying issue. How can you accomplish this in an easily understandable way?
- A. Use AWS Cloudwatch metrics
- B. Put logging statements in your code
- C. Set the Lambda function debugging level to verbose
- D. Use AWS Cloudtrail logs
Q17: You have a lambda function that is processed asynchronously. You need a way to check and debug issues if the function fails? How could you accomplish this?
- A. Use AWS Cloudwatch metrics
- B. Assign a dead letter queue
- C. Congure SNS notications
- D. Use AWS Cloudtrail logs
Q18: You are developing an application that is going to make use of Amazon Kinesis. Due to the high throughput , you decide to have multiple shards for the streams. Which of the following is TRUE when it comes to processing data across multiple shards?
- A. You cannot guarantee the order of data across multiple shards. Its possible only within a shard
- B. Order of data is possible across all shards in a streams
- C. Order of data is not possible at all in Kinesis streams
- D. You need to use Kinesis firehose to guarantee the order of data
Q19: You’ve developed a Lambda function and are now in the process of debugging it. You add the necessary print statements in the code to assist in the debugging. You go to Cloudwatch logs , but you see no logs for the lambda function. Which of the following could be the underlying issue for this?
- A. You’ve not enabled versioning for the Lambda function
- B. The IAM Role assigned to the Lambda function does not have the necessary permission to create Logs
- C. There is not enough memory assigned to the function
- D. There is not enough time assigned to the function
Q20: Your application is developed to pick up metrics from several servers and push them off to Cloudwatch. At times , the application gets client 429 errors. Which of the following can be done from the programming side to resolve such errors?
- A. Use the AWS CLI instead of the SDK to push the metrics
- B. Ensure that all metrics have a timestamp before sending them across
- C. Use exponential backoff in your request
- D. Enable encryption for the requests
Q21: You have been instructed to use the CodePipeline service for the CI/CD automation in your company. Due to security reasons , the resources that would be part of the deployment are placed in another account. Which of the following steps need to be carried out to accomplish this deployment? Choose 2 answers from the options given below
- A. Dene a customer master key in KMS
- B. Create a reference Code Pipeline instance in the other account
- C. Add a cross account role
- D. Embed the access keys in the codepipeline process
Q22: You are planning on deploying an application to the worker role in Elastic Beanstalk. Moreover, this worker application is going to run the periodic tasks. Which of the following is a must have as part of the deployment?
- A. An appspec.yaml file
- B. A cron.yaml file
- C. A cron.cong file
- D. An appspec.json file
Q23: An application needs to make use of an SQS queue for working with messages. An SQS queue has been created with the default settings. The application needs 60 seconds to process each message. Which of the following step need to be carried out by the application.
- A. Change the VisibilityTimeout for each message and then delete the message after processing is completed
- B. Delete the message and change the visibility timeout.
- C. Process the message , change the visibility timeout. Delete the message
- D. Process the message and delete the message
Q24: AWS CodeDeploy deployment fails to start & generate following error code, ”HEALTH_CONSTRAINTS_INVALID”, Which of the following can be used to eliminate this error?
- A. Make sure the minimum number of healthy instances is equal to the total number of instances in the deployment group.
- B. Increase the number of healthy instances required during deployment
- C. Reduce number of healthy instances required during deployment
- D. Make sure the number of healthy instances is equal to the specified minimum number of healthy instances.
Q25: How are the state machines in AWS Step Functions defined?
- A. SAML
- B. XML
- C. YAML
- D. JSON
Q26:How can API Gateway methods be configured to respond to requests?
- A. Forwarded to method handlers
- B. AWS Lambda
- C. Integrated with other AWS Services
- D. Existing HTTP endpoints
Q27: Which of the following could be an example of an API Gateway Resource URL for a trucks resource?
- A. https://1a2sb3c4.execute-api.us-east-1.awsapigateway.com/trucks
- B. https://trucks.1a2sb3c4.execute-api.us-east-1.amazonaws.com
- C. https://1a2sb3c4.execute-api.amazonaws.com/trucks
- D. https://1a2sb3c4.execute-api.us-east-1.amazonaws.com/cars
Q28: API Gateway Deployments are:
- A. A specific snapshot of your API’s methods
- B. A specific snapshot of all of your API’s settings, resources, and methods
- C. A specific snapshot of your API’s resources
- D. A specific snapshot of your API’s resources and methods
Q29: A SWF workflow task or task execution can live up to how long?
- A. 1 Year
- B. 14 days
- C. 24 hours
- D. 3 days
Q30: With AWS Step Functions, all the work in your state machine is done by tasks. These tasks performs work by using what types of things? (Choose the best 3 answers)
- A. An AWS Lambda Function Integration
- B. Passing parameters to API actions of other services
- C. Activities
- D. An EC2 Integration
Q31: How does SWF make decisions?
- A. A decider program that is written in the language of the developer’s choice
- B. A visual workflow created in the SWF visual workflow editor
- C. A JSON-defined state machine that contains states within it to select the next step to take
- D. SWF outsources all decisions to human deciders through the AWS Mechanical Turk service.
Q32: In order to effectively build and test your code, AWS CodeBuild allows you to:
- A. Select and use some 3rd party providers to run tests against your code
- B. Select a pre-configured environment
- C. Provide your own custom AMI
- D. Provide your own custom container image
Q33: X-Ray Filter Expressions allow you to search through request information using characteristics like:
- A. URL Paths
- B. Metadata
- C. Trace ID
- D. Annotations
Q34: CodePipeline pipelines are workflows that deal with stages, actions, transitions, and artifacts. Which of the following statements is true about these concepts?
- A. Stages contain at least two actions
- B. Artifacts are never modified or iterated on when used inside of CodePipeline
- C. Stages contain at least one action
- D. Actions will have a deployment artifact as either an input an output or both
Q35: When deploying a simple Python web application with Elastic Beanstalk which of the following AWS resources will be created and managed for you by Elastic Beanstalk?
- A. An Elastic Load Balancer
- B. An S3 Bucket
- C. A Lambda Function
- D. An EC2 instance
Q36: Elastic Beanstalk is used to:
- A. Deploy and scale web applications and services developed with a supported platform
- B. Deploy and scale serverless applications
- C. Deploy and scale applications based purely on EC2 instances
- D. Manage the deployment of all AWS infrastructure resources of your AWS applications
Q35: How can AWS X-Ray determine what data to collect?
- A. X-Ray applies a sampling algorithm by default
- B. X-Ray collects data on all requests by default
- C. You can implement your own sampling frequencies for data collection
- D. X-Ray collects data on all requests for services enabled with it
Q37: Which API call is used to list all resources that belong to a CloudFormation Stack?
- A. DescribeStacks
- B. GetTemplate
- C. DescribeStackResources
- D. ListStackResources
Q38: What is the default behaviour of a CloudFormation stack if the creation of one resource fails?
- A. Rollback
- B. The stack continues creating and the failed resource is ignored
- C. Delete
- D. Undo
Q39: Which AWS CLI command lists all current stacks in your CloudFormation service?
- A. aws cloudformation describe-stacks
- B. aws cloudformation list-stacks
- C. aws cloudformation create-stack
- D. aws cloudformation describe-stack-resources
Q40:
Which API call is used to list all resources that belong to a CloudFormation Stack?
- A. DescribeStacks
- B. GetTemplate
- C. ListStackResources
- D. DescribeStackResources
Q41: How does using ElastiCache help to improve database performance?
- A. It can store petabytes of data
- B. It provides faster internet speeds
- C. It can store the results of frequent or highly-taxing queries
- D. It uses read replicas
Q42: Which of the following best describes the Lazy Loading caching strategy?
- A. Every time the underlying database is written to or updated the cache is updated with the new information.
- B. Every miss to the cache is counted and when a specific number is reached a full copy of the database is migrated to the cache
- C. A specific amount of time is set before the data in the cache is marked as expired. After expiration, a request for expired data will be made through to the backing database.
- D. Data is added to the cache when a cache miss occurs (when there is no data in the cache and the request must go to the database for that data)
Q43: What are two benefits of using RDS read replicas?
- A. You can add/remove read replicas based on demand, so it creates elasticity for RDS.
- B. Improves performance of the primary database by taking workload from it
- C. Automatic failover in the case of Availability Zone service failures
- D. Allows both reads and writes
Q44: What is the simplest way to enable an S3 bucket to be able to send messages to your SNS topic?
- A. Attach an IAM role to the S3 bucket to send messages to SNS.
- B. Activate the S3 pipeline feature to send notifications to another AWS service – in this case select SNS.
- C. Add a resource-based access control policy on the SNS topic.
- D. Use AWS Lambda to receive events from the S3 bucket and then use the Publish API action to send them to the SNS topic.
Q45: You have just set up a push notification service to send a message to an app installed on a device with the Apple Push Notification Service. It seems to work fine. You now want to send a message to an app installed on devices for multiple platforms, those being the Apple Push Notification Service(APNS) and Google Cloud Messaging for Android (GCM). What do you need to do first for this to be successful?
- A. Request Credentials from Mobile Platforms, so that each device has the correct access control policies to access the SNS publisher
- B. Create a Platform Application Object which will connect all of the mobile devices with your app to the correct SNS topic.
- C. Request a Token from Mobile Platforms, so that each device has the correct access control policies to access the SNS publisher.
- D. Get a set of credentials in order to be able to connect to the push notification service you are trying to setup.
Q46: SNS message can be sent to different kinds of endpoints. Which of these is NOT currently a supported endpoint?
- A. Slack Messages
- B. SMS (text message)
- C. HTTP/HTTPS
- D. AWS Lambda
Q47: Company B provides an online image recognition service and utilizes SQS to decouple system components for scalability. The SQS consumers poll the imaging queue as often as possible to keep end-to-end throughput as high as possible. However, Company B is realizing that polling in tight loops is burning CPU cycles and increasing costs with empty responses. How can Company B reduce the number empty responses?
- A. Set the imaging queue VisibilityTimeout attribute to 20 seconds
- B. Set the imaging queue MessageRetentionPeriod attribute to 20 seconds
- C. Set the imaging queue ReceiveMessageWaitTimeSeconds Attribute to 20 seconds
- D. Set the DelaySeconds parameter of a message to 20 seconds
Q48: Which of the following statements about SQS standard queues are true?
- A. Message order can be indeterminate – you’re not guaranteed to get messages in the same order they were sent in
- B. Messages will be delivered exactly once and messages will be delivered in First in, First out order
- C. Messages will be delivered exactly once and message delivery order is indeterminate
- D. Messages can be delivered one or more times
Q49: Which of the following is true if long polling is enabled?
- A. If long polling is enabled, then each poll only polls a subset of SQS servers; in order for all messages to be received, polling must continuously occur
- B. The reader will listen to the queue until timeout
- C. Increases costs because each request lasts longer
- D. The reader will listen to the queue until a message is available or until timeout
Q50: When dealing with session state in EC2-based applications using Elastic load balancers which option is generally thought of as the best practice for managing user sessions?
- A. Having the ELB distribute traffic to all EC2 instances and then having the instance check a caching solution like ElastiCache running Redis or Memcached for session information
- B. Permanently assigning users to specific instances and always routing their traffic to those instances
- C. Using Application-generated cookies to tie a user session to a particular instance for the cookie duration
- D. Using Elastic Load Balancer generated cookies to tie a user session to a particular instance
Q51: When requested through an STS API call, credentials are returned with what three components?
- A. Security Token, Access Key ID, Signed URL
- B. Security Token, Access Key ID, Secret Access Key
- C. Signed URL, Security Token, Username
- D. Security Token, Secret Access Key, Personal Pin Code
Q52: Your application must write to an SQS queue. Your corporate security policies require that AWS credentials are always encrypted and are rotated at least once a week.
How can you securely provide credentials that allow your application to write to the queue?- A. Have the application fetch an access key from an Amazon S3 bucket at run time.
- B. Launch the application’s Amazon EC2 instance with an IAM role.
- C. Encrypt an access key in the application source code.
- D. Enroll the instance in an Active Directory domain and use AD authentication.
TopQ53: Your web application reads an item from your DynamoDB table, changes an attribute, and then writes the item back to the table. You need to ensure that one process doesn’t overwrite a simultaneous change from another process.
How can you ensure concurrency?- A. Implement optimistic concurrency by using a conditional write.
- B. Implement pessimistic concurrency by using a conditional write.
- C. Implement optimistic concurrency by locking the item upon read.
- D. Implement pessimistic concurrency by locking the item upon read.
TopQ54: Which statements about DynamoDB are true? Choose 2 answers
- A. DynamoDB uses optimistic concurrency control
- B. DynamoDB restricts item access during writes
- C. DynamoDB uses a pessimistic locking model
- D. DynamoDB restricts item access during reads
- E. DynamoDB uses conditional writes for consistency
TopQ55: Your CloudFormation template has the following Mappings section:


Which JSON snippet will result in the value “ami-6411e20d” when a stack is launched in us-east-1?
- A. { “Fn::FindInMap” : [ “Mappings”, { “RegionMap” : [“us-east-1”, “us-west-1”] }, “32”]}
- B. { “Fn::FindInMap” : [ “Mappings”, { “Ref” : “AWS::Region” }, “32”]}
- C. { “Fn::FindInMap” : [ “RegionMap”, { “Ref” : “AWS::Region” }, “32”]}
- D. { “Fn::FindInMap” : [ “RegionMap”, { “RegionMap” : “AWS::Region” }, “32”]}
TopQ56: Your application triggers events that must be delivered to all your partners. The exact partner list is constantly changing: some partners run a highly available endpoint, and other partners’ endpoints are online only a few hours each night. Your application is mission-critical, and communication with your partners must not introduce delay in its operation. A delay in delivering the event to one partner cannot delay delivery to other partners.
What is an appropriate way to code this?
- A. Implement an Amazon SWF task to deliver the message to each partner. Initiate an Amazon SWF workflow execution.
- B. Send the event as an Amazon SNS message. Instruct your partners to create an HTTP. Subscribe their HTTP endpoint to the Amazon SNS topic.
- C. Create one SQS queue per partner. Iterate through the queues and write the event to each one. Partners retrieve messages from their queue.
- D. Send the event as an Amazon SNS message. Create one SQS queue per partner that subscribes to the Amazon SNS topic. Partners retrieve messages from their queue.
Q57: You have a three-tier web application (web, app, and data) in a single Amazon VPC. The web and app tiers each span two Availability Zones, are in separate subnets, and sit behind ELB Classic Load Balancers. The data tier is a Multi-AZ Amazon RDS MySQL database instance in database subnets.
When you call the database tier from your app tier instances, you receive a timeout error. What could be causing this?- A. The IAM role associated with the app tier instances does not have rights to the MySQL database.
- B. The security group for the Amazon RDS instance does not allow traffic on port 3306 from the app
instances. - C. The Amazon RDS database instance does not have a public IP address.
- D. There is no route defined between the app tier and the database tier in the Amazon VPC.
Q58: What type of block cipher does Amazon S3 offer for server side encryption?
- A. RC5
- B. Blowfish
- C. Triple DES
- D. Advanced Encryption Standard
Q59: You have written an application that uses the Elastic Load Balancing service to spread
traffic to several web servers Your users complain that they are sometimes forced to login
again in the middle of using your application, after they have already togged in. This is not
behaviour you have designed. What is a possible solution to prevent this happening?- A. Use instance memory to save session state.
- B. Use instance storage to save session state.
- C. Use EBS to save session state
- D. Use ElastiCache to save session state.
- E. Use Glacier to save session slate.
Q60: You are writing to a DynamoDB table and receive the following exception:”
ProvisionedThroughputExceededException”. though according to your Cloudwatch metrics
for the table, you are not exceeding your provisioned throughput. What could be an
explanation for this?- A. You haven’t provisioned enough DynamoDB storage instances
- B. You’re exceeding your capacity on a particular Range Key
- C. You’re exceeding your capacity on a particular Hash Key
- D. You’re exceeding your capacity on a particular Sort Key
- E. You haven’t configured DynamoDB Auto Scaling triggers
Q61: Which DynamoDB limits can be raised by contacting AWS support?
- A. The number of hash keys per account
- B. The maximum storage used per account
- C. The number of tables per account
- D. The number of local secondary indexes per account
- E. The number of provisioned throughput units per account
TopQ62: AWS CodeBuild allows you to compile your source code, run unit tests, and produce deployment artifacts by:
- A. Allowing you to provide an Amazon Machine Image to take these actions within
- B. Allowing you to select an Amazon Machine Image and provide a User Data bootstrapping script to prepare an instance to take these actions within
- C. Allowing you to provide a container image to take these actions within
- D. Allowing you to select from pre-configured environments to take these actions within
TopQ63: Which of the following will not cause a CloudFormation stack deployment to rollback?
- A. The template contains invalid JSON syntax
- B. An AMI specified in the template exists in a different region than the one in which the stack is being deployed.
- C. A subnet specified in the template does not exist
- D. The template specifies an instance-store backed AMI and an incompatible EC2 instance type.
TopQ64: Your team is using CodeDeploy to deploy an application which uses secure parameters that are stored in the AWS System Mangers Parameter Store. What two options below must be completed so CodeDeploy can deploy the application?
- A. Use ssm get-parameters with –with-decryption option
- B. Add permissions using AWS access keys
- C. Add permissions using AWS IAM role
- D. Use ssm get-parameters with –with-no-decryption option
TopQ65: A corporate web application is deployed within an Amazon VPC, and is connected to the corporate data center via IPSec VPN. The application must authenticate against the on-premise LDAP server. Once authenticated, logged-in users can only access an S3 keyspace specific to the user. Which of the solutions below meet these requirements? Choose two answers How would you authenticate to the application given these details? (Choose 2)
- A. The application authenticates against LDAP, and retrieves the name of an IAM role associated with the user. The application then calls the IAM Security Token Service to assume that IAM Role. The application can use the temporary credentials to access the S3 keyspace.
- B. Develop an identity broker which authenticates against LDAP, and then calls IAM Security Token Service to get IAM federated user credentials. The application calls the identity broker to get IAM federated user credentials with access to the appropriate S3 keyspace
- C. Develop an identity broker which authenticates against IAM Security Token Service to assume an IAM Role to get temporary AWS security credentials. The application calls the identity broker to get AWS temporary security credentials with access to the app
- D. The application authenticates against LDAP. The application then calls the IAM Security Service to login to IAM using the LDAP credentials. The application can use the IAM temporary credentials to access the appropriate S3 bucket.
TopQ66:
A corporate web application is deployed within an Amazon VPC, and is connected to the corporate data center via IPSec VPN. The application must authenticate against the on-premise LDAP server. Once authenticated, logged-in users can only access an S3 keyspace specific to the user. Which of the solutions below meet these requirements? Choose two answers
How would you authenticate to the application given these details? (Choose 2)- A. The application authenticates against LDAP, and retrieves the name of an IAM role associated with the user. The application then calls the IAM Security Token Service to assume that IAM Role. The application can use the temporary credentials to access the S3 keyspace.
- B. Develop an identity broker which authenticates against LDAP, and then calls IAM Security Token Service to get IAM federated user credentials. The application calls the identity broker to get IAM federated user credentials with access to the appropriate S3 keyspace
- C. Develop an identity broker which authenticates against IAM Security Token Service to assume an IAM Role to get temporary AWS security credentials. The application calls the identity broker to get AWS temporary security credentials with access to the app
- D. The application authenticates against LDAP. The application then calls the IAM Security Service to login to IAM using the LDAP credentials. The application can use the IAM temporary credentials to access the appropriate S3 bucket.
TopQ67: When users are signing in to your application using Cognito, what do you need to do to make sure if the user has compromised credentials, they must enter a new password?
- A. Create a user pool in Cognito
- B. Block use for “Compromised credential” in the Basic security section
- C. Block use for “Compromised credential” in the Advanced security section
- D. Use secure remote password
Q68: You work in a large enterprise that is currently evaluating options to migrate your 27 GB Subversion code base. Which of the following options is the best choice for your organization?
- A. AWS CodeHost
- B. AWS CodeCommit
- C. AWS CodeStart
- D. None of these
Q69: You are on a development team and you need to migrate your Spring Application over to AWS. Your team is looking to build, modify, and test new versions of the application. What AWS services could help you migrate your app?
- A. Elastic Beanstalk
- B. SQS
- C. Ec2
- D. AWS CodeDeploy
Q70:
You are a developer responsible for managing a high volume API running in your company’s datacenter. You have been asked to implement a similar API, but one that has potentially higher volume. And you must do it in the most cost effective way, using as few services and components as possible. The API stores and fetches data from a key value store. Which services could you utilize in AWS?- A. DynamoDB
- B. Lambda
- C. API Gateway
- D. EC2
Q71: By default, what event occurs if your CloudFormation receives an error during creation?
- A. DELETE_IN_PROGRESS
- B. CREATION_IN_PROGRESS
- C. DELETE_COMPLETE
- D. ROLLBACK_IN_PROGRESS
TopQ72:
AWS X-Ray was recently implemented inside of a service that you work on. Several weeks later, after a new marketing push, that service started seeing a large spike in traffic and you’ve been tasked with investigating a few issues that have started coming up but when you review the X-Ray data you can’t find enough information to draw conclusions so you decide to:- A. Start passing in the X-Amzn-Trace-Id: True HTTP header from your upstream requests
- B. Refactor the service to include additional calls to the X-Ray API using an AWS SDK
- C. Update the sampling algorithm to increase the sample rate and instrument X-Ray to collect more pertinent information
- D. Update your application to use the custom API Gateway TRACE method to send in data
Q74: X-Ray metadata:
- A. Associates request data with a particular Trace-ID
- B. Stores key-value pairs of any type that are not searchable
- C. Collects at the service layer to provide information on the overall health of the system
- D. Stores key-value pairs of searchable information
TopQ75: Which of the following is the right sequence that gets called in CodeDeploy when you use Lambda hooks in an EC2/On-Premise Deployment?
- A. Before Install-AfterInstall-Validate Service-Application Start
- B. Before Install-After-Install-Application Stop-Application Start
- C. Before Install-Application Stop-Validate Service-Application Start
- D. Application Stop-Before Install-After Install-Application Start
Q76:
Describe the process of registering a mobile device with SNS push notification service using GCM.- A. Receive Registration ID and token for each mobile device. Then, register the mobile application with Amazon SNS, and pass the GCM token credentials to Amazon SNS
- B. Pass device token to SNS to create mobile subscription endpoint for each mobile device, then request the device token from each mobile device. SNS then communicates on your behalf to the GCM service
- C. None of these are correct
- D. Submit GCM notification credentials to Amazon SNS, then receive the Registration ID for each mobile device. After that, pass the device token to SNS, and SNS then creates a mobile subscription endpoint for each device and communicates with the GCM service on your behalf
Q77:
You run an ad-supported photo sharing website using S3 to serve photos to visitors of your site. At some point you find out that other sites have been linking to the photos on your site, causing loss to your business. What is an effective method to mitigate this?- A. Store photos on an EBS volume of the web server.
- B. Block the IPs of the offending websites in Security Groups.
- C. Remove public read access and use signed URLs with expiry dates.
- D. Use CloudFront distributions for static content.
Q78: How can you control access to the API Gateway in your environment?
- A. Cognito User Pools
- B. Lambda Authorizers
- C. API Methods
- D. API Stages
Q79: What kind of message does SNS send to endpoints?
- A. An XML document with parameters like Message, Source, Destination, Type
- B. A JSON document with parameters like Message, Signature, Subject, Type.
- C. An XML document with parameters like Message, Signature, Subject, Type
- D. A JSON document with parameters like Message, Source, Destination, Type
Q80: Company B provides an online image recognition service and utilizes SQS to decouple system components for scalability. The SQS consumers poll the imaging queue as often as possible to keep end-to-end throughput as high as possible. However, Company B is realizing that polling in tight loops is burning CPU cycles and increasing costs with empty responses. How can Company B reduce the number of empty responses?
- A. Set the imaging queue MessageRetentionPeriod attribute to 20 seconds.
- B. Set the imaging queue ReceiveMessageWaitTimeSeconds attribute to 20 seconds.
- C. Set the imaging queue VisibilityTimeout attribute to 20 seconds.
- D. Set the DelaySeconds parameter of a message to 20 seconds.
Top81: You’re using CloudFormation templates to build out staging environments. What section of the CloudFormation would you edit in order to allow the user to specify the PEM key-name at start time?
- A. Resources Section
- B. Parameters Section
- C. Mappings Section
- D. Declaration Section
TopQ82: You are writing an AWS CloudFormation template and you want to assign values to properties that will not be available until runtime. You know that you can use intrinsic functions to do this but are unsure as to which part of the template they can be used in. Which of the following is correct in describing how you can currently use intrinsic functions in an AWS CloudFormation template?
- A. You can use intrinsic functions in any part of a template, except AWSTemplateFormatVersion and Description
- B. You can use intrinsic functions in any part of a template.
- C. You can use intrinsic functions only in the resource properties part of a template.
- D. You can only use intrinsic functions in specific parts of a template. You can use intrinsic functions in resource properties, metadata attributes, and update policy attributes.
Top
Other AWS Facts and Summaries and Questions/Answers Dump
- AWS S3 facts and summaries and Q&A Dump
- AWS DynamoDB facts and summaries and Questions and Answers Dump
- AWS EC2 facts and summaries and Questions and Answers Dump
- AWS Serverless facts and summaries and Questions and Answers Dump
- AWS Developer and Deployment Theory facts and summaries and Questions and Answers Dump
- AWS IAM facts and summaries and Questions and Answers Dump
- AWS Lambda facts and summaries and Questions and Answers Dump
- AWS SQS facts and summaries and Questions and Answers Dump
- AWS RDS facts and summaries and Questions and Answers Dump
- AWS ECS facts and summaries and Questions and Answers Dump
- AWS CloudWatch facts and summaries and Questions and Answers Dump
- AWS SES facts and summaries and Questions and Answers Dump
- AWS EBS facts and summaries and Questions and Answers Dump
- AWS ELB facts and summaries and Questions and Answers Dump
- AWS Autoscaling facts and summaries and Questions and Answers Dump
- AWS VPC facts and summaries and Questions and Answers Dump
- AWS KMS facts and summaries and Questions and Answers Dump
- AWS Elastic Beanstalk facts and summaries and Questions and Answers Dump
- AWS CodeBuild facts and summaries and Questions and Answers Dump
- AWS CodeDeploy facts and summaries and Questions and Answers Dump
- AWS CodePipeline facts and summaries and Questions and Answers Dump

AWS Certification Exam Prep: S3 Facts, Summaries, Questions and Answers

AWS Certification Exam Prep: S3 Facts, Summaries, Questions and Answers
AWS S3 Facts and summaries, AWS S3 Top 10 Questions and Answers Dump
Definition 1: Amazon S3 or Amazon Simple Storage Service is a “simple storage service” offered by Amazon Web Services that provides object storage through a web service interface. Amazon S3 uses the same scalable storage infrastructure that Amazon.com uses to run its global e-commerce network.
Definition 2: Amazon Simple Storage Service (Amazon S3) is an object storage service that offers industry-leading scalability, data availability, security, and performance.
AWS S3 Explained graphically:










AWS S3 Facts and summaries
- S3 is a universal namespace, meaning each S3 bucket you create must have a unique name that is not being used by anyone else in the world.
- S3 is object based: i.e allows you to upload files.
- Files can be from 0 Bytes to 5 TB
- What is the maximum length, in bytes, of a DynamoDB range primary key attribute value?
The maximum length of a DynamoDB range primary key attribute value is 2048 bytes (NOT 256 bytes). - S3 has unlimited storage.
- Files are stored in Buckets.
- Read after write consistency for PUTS of new Objects
- Eventual Consistency for overwrite PUTS and DELETES (can take some time to propagate)
- S3 Storage Classes/Tiers:


- S3 Standard (durable, immediately available, frequently accesses)
- Amazon S3 Intelligent-Tiering (S3 Intelligent-Tiering): It works by storing objects in two access tiers: one tier that is optimized for frequent access and another lower-cost tier that is optimized for infrequent access.
- S3 Standard-Infrequent Access – S3 Standard-IA (durable, immediately available, infrequently accessed)
- S3 – One Zone-Infrequent Access – S3 One Zone IA: Same ad IA. However, data is stored in a single Availability Zone only
- S3 – Reduced Redundancy Storage (data that is easily reproducible, such as thumbnails, etc.)
- Glacier – Archived data, where you can wait 3-5 hours before accessing
You can have a bucket that has different objects stored in S3 Standard, S3 Intelligent-Tiering, S3 Standard-IA, and S3 One Zone-IA.
- The default URL for S3 hosted websites lists the bucket name first followed by s3-website-region.amazonaws.com . Example: enoumen.com.s3-website-us-east-1.amazonaws.com
- Core fundamentals of an S3 object
- Key (name)
- Value (data)
- Version (ID)
- Metadata
- Sub-resources (used to manage bucket-specific configuration)
- Bucket Policies, ACLs,
- CORS
- Transfer Acceleration
- Object-based storage only for files
- Not suitable to install OS on.
- Successful uploads will generate a HTTP 200 status code.
- S3 Security – Summary
- By default, all newly created buckets are PRIVATE.
- You can set up access control to your buckets using:
- Bucket Policies – Applied at the bucket level
- Access Control Lists – Applied at an object level.
- S3 buckets can be configured to create access logs, which log all requests made to the S3 bucket. These logs can be written to another bucket.
- S3 Encryption
- Encryption In-Transit (SSL/TLS)
- Encryption At Rest:
- Server side Encryption (SSE-S3, SSE-KMS, SSE-C)
- Client Side Encryption
- Remember that we can use a Bucket policy to prevent unencrypted files from being uploaded by creating a policy which only allows requests which include the x-amz-server-side-encryption parameter in the request header.
- S3 CORS (Cross Origin Resource Sharing):
CORS defines a way for client web applications that are loaded in one domain to interact with resources in a different domain.- Used to enable cross origin access for your AWS resources, e.g. S3 hosted website accessing javascript or image files located in another bucket. By default, resources in one bucket cannot access resources located in another. To allow this we need to configure CORS on the bucket being accessed and enable access for the origin (bucket) attempting to access.
- Always use the S3 website URL, not the regular bucket URL. E.g.: https://s3-eu-west-2.amazonaws.com/acloudguru
- S3 CloudFront:
- Edge locations are not just READ only – you can WRITE to them too (i.e put an object on to them.)
- Objects are cached for the life of the TTL (Time to Live)
- You can clear cached objects, but you will be charged. (Invalidation)
- S3 Performance optimization – 2 main approaches to Performance Optimization for S3:
- GET-Intensive Workloads – Use Cloudfront
- Mixed Workload – Avoid sequencial key names for your S3 objects. Instead, add a random prefix like a hex hash to the key name to prevent multiple objects from being stored on the same partition.
- mybucket/7eh4-2019-03-04-15-00-00/cust1234234/photo1.jpg
- mybucket/h35d-2019-03-04-15-00-00/cust1234234/photo2.jpg
- mybucket/o3n6-2019-03-04-15-00-00/cust1234234/photo3.jpg
- The best way to handle large objects uploads to the S3 service is to use the Multipart upload API. The Multipart upload API enables you to upload large objects in parts.
- You can enable versioning on a bucket, even if that bucket already has objects in it. The already existing objects, though, will show their versions as null. All new objects will have version IDs.
- Bucket names cannot start with a . or – characters. S3 bucket names can contain both the . and – characters. There can only be one . or one – between labels. E.G mybucket-com mybucket.com are valid names but mybucket–com and mybucket..com are not valid bucket names.
- What is the maximum number of S3 buckets allowed per AWS account (by default)? 100
- You successfully upload an item to the us-east-1 region. You then immediately make another API call and attempt to read the object. What will happen?
All AWS regions now have read-after-write consistency for PUT operations of new objects. Read-after-write consistency allows you to retrieve objects immediately after creation in Amazon S3. Other actions still follow the eventual consistency model (where you will sometimes get stale results if you have recently made changes) - S3 bucket policies require a Principal be defined. Review the access policy elements here
- What checksums does Amazon S3 employ to detect data corruption?
Amazon S3 uses a combination of Content-MD5 checksums and cyclic redundancy checks (CRCs) to detect data corruption. Amazon S3 performs these checksums on data at rest and repairs any corruption using redundant data. In addition, the service calculates checksums on all network traffic to detect corruption of data packets when storing or retrieving data.
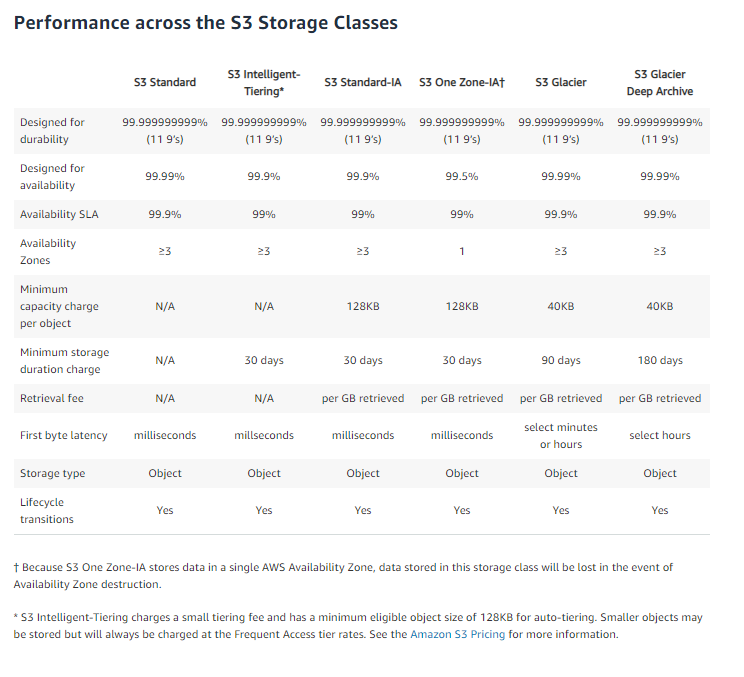
AWS S3 Top 10 Questions and Answers Dump
Q0: You’ve written an application that uploads objects onto an S3 bucket. The size of the object varies between 200 – 500 MB. You’ve seen that the application sometimes takes a longer than expected time to upload the object. You want to improve the performance of the application. Which of the following would you consider?
- A. Create multiple threads and upload the objects in the multiple threads
- B. Write the items in batches for better performance
- C. Use the Multipart upload API
- D. Enable versioning on the Bucket
Top
Q2: You are using AWS SAM templates to deploy a serverless application. Which of the following resource will embed application from Amazon S3 buckets?
- A. AWS::Serverless::Api
- B. AWS::Serverless::Application
- C. AWS::Serverless::Layerversion
- D. AWS::Serverless::Function
Top
Q3: A static web site has been hosted on a bucket and is now being accessed by users. One of the web pages javascript section has been changed to access data which is hosted in another S3 bucket. Now that same web page is no longer loading in the browser. Which of the following can help alleviate the error?
- A. Enable versioning for the underlying S3 bucket.
- B. Enable Replication so that the objects get replicated to the other bucket
- C. Enable CORS for the bucket
- D. Change the Bucket policy for the bucket to allow access from the other bucket
Top
Q4: Your mobile application includes a photo-sharing service that is expecting tens of thousands of users at launch. You will leverage Amazon Simple Storage Service (S3) for storage of the user Images, and you must decide how to authenticate and authorize your users for access to these images. You also need to manage the storage of these images. Which two of the following approaches should you use? Choose two answers from the options below
- A. Create an Amazon S3 bucket per user, and use your application to generate the S3 URL for the appropriate content.
- B. Use AWS Identity and Access Management (IAM) user accounts as your application-level user database, and offload the burden of authentication from your application code.
- C. Authenticate your users at the application level, and use AWS Security Token Service (STS)to grant token-based authorization to S3 objects.
- D. Authenticate your users at the application level, and send an SMS token message to the user. Create an Amazon S3 bucket with the same name as the SMS message token, and move the user’s objects to that bucket.
Top
Q5: Both ACLs and Bucket Policies can be used to grant access to S3 buckets. Which of the following statements is true about ACLs and Bucket policies?
- A. Bucket Policies are Written in JSON and ACLs are written in XML
- B. ACLs can be attached to S3 objects or S3 Buckets
- C. Bucket Policies and ACLs are written in JSON
- D. Bucket policies are only attached to s3 buckets, ACLs are only attached to s3 objects
Q6: What are good options to improve S3 performance when you have significantly high numbers of GET requests?
- A. Introduce random prefixes to S3 objects
- B. Introduce random suffixes to S3 objects
- C. Setup CloudFront for S3 objects
- D. Migrate commonly used objects to Amazon Glacier
Q7: If an application is storing hourly log files from thousands of instances from a high traffic
web site, which naming scheme would give optimal performance on S3?
- A. Sequential
- B. HH-DD-MM-YYYY-log_instanceID
- C. YYYY-MM-DD-HH-log_instanceID
- D. instanceID_log-HH-DD-MM-YYYY
- E. instanceID_log-YYYY-MM-DD-HH
Top
Q8: You are working with the S3 API and receive an error message: 409 Conflict. What is the possible cause of this error
- A. You’re attempting to remove a bucket without emptying the contents of the bucket first.
- B. You’re attempting to upload an object to the bucket that is greater than 5TB in size.
- C. Your request does not contain the proper metadata.
- D. Amazon S3 is having internal issues.
Q9: You created three S3 buckets – “mywebsite.com”, “downloads.mywebsite.com”, and “www.mywebsite.com”. You uploaded your files and enabled static website hosting. You specified both of the default documents under the “enable static website hosting” header. You also set the “Make Public” permission for the objects in each of the three buckets. You create the Route 53 Aliases for the three buckets. You are going to have your end users test your websites by browsing to http://mydomain.com/error.html, http://downloads.mydomain.com/index.html, and http://www.mydomain.com. What problems will your testers encounter?
- A. http://mydomain.com/error.html will not work because you did not set a value for the error.html file
- B. There will be no problems, all three sites should work.
- C. http://www.mywebsite.com will not work because the URL does not include a file name at the end of it.
- D. http://downloads.mywebsite.com/index.html will not work because the “downloads” prefix is not a supported prefix for S3 websites using Route 53 aliases
Q10: Which of the following is NOT a common S3 API call?
- A. UploadPart
- B. ReadObject
- C. PutObject
- D. DownloadBucket
Other AWS Facts and Summaries
- AWS S3 facts and summaries
- AWS DynamoDB facts and summaries
- AWS EC2 facts and summaries
- AWS Lambda facts and summaries
- AWS SQS facts and summaries
- AWS RDS facts and summaries
- AWS ECS facts and summaries
- AWS CloudWatch facts and summaries
- AWS SES facts and summaries
- AWS EBS facts and summaries
- AWS Serverless facts and summaries
- AWS ELB facts and summaries
- AWS Autoscaling facts and summaries
- AWS VPC facts and summaries
- AWS KMS facts and summaries
- AWS Elastic Beanstalk facts and summaries
- AWS CodeBuild facts and summaries
- AWS CodeDeploy facts and summaries
- AWS CodePipeline facts and summaries
Active Hydrating Toner, Anti-Aging Replenishing Advanced Face Moisturizer, with Vitamins A, C, E & Natural Botanicals to Promote Skin Balance & Collagen Production, 6.7 Fl Oz



Age Defying 0.3% Retinol Serum, Anti-Aging Dark Spot Remover for Face, Fine Lines & Wrinkle Pore Minimizer, with Vitamin E & Natural Botanicals


Firming Moisturizer, Advanced Hydrating Facial Replenishing Cream, with Hyaluronic Acid, Resveratrol & Natural Botanicals to Restore Skin's Strength, Radiance, and Resilience, 1.75 Oz

Skin Stem Cell Serum


Smartphone 101 - Pick a smartphone for me - android or iOS - Apple iPhone or Samsung Galaxy or Huawei or Xaomi or Google Pixel
Can AI Really Predict Lottery Results? We Asked an Expert.




Djamgatech

Read Photos and PDFs Aloud for me iOS
Read Photos and PDFs Aloud for me android
Read Photos and PDFs Aloud For me Windows 10/11
Read Photos and PDFs Aloud For Amazon
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more)
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6(Email us for more)



FREE 10000+ Quiz Trivia and and Brain Teasers for All Topics including Cloud Computing, General Knowledge, History, Television, Music, Art, Science, Movies, Films, US History, Soccer Football, World Cup, Data Science, Machine Learning, Geography, etc....

List of Freely available programming books - What is the single most influential book every Programmers should read
- Bjarne Stroustrup - The C++ Programming Language
- Brian W. Kernighan, Rob Pike - The Practice of Programming
- Donald Knuth - The Art of Computer Programming
- Ellen Ullman - Close to the Machine
- Ellis Horowitz - Fundamentals of Computer Algorithms
- Eric Raymond - The Art of Unix Programming
- Gerald M. Weinberg - The Psychology of Computer Programming
- James Gosling - The Java Programming Language
- Joel Spolsky - The Best Software Writing I
- Keith Curtis - After the Software Wars
- Richard M. Stallman - Free Software, Free Society
- Richard P. Gabriel - Patterns of Software
- Richard P. Gabriel - Innovation Happens Elsewhere
- Code Complete (2nd edition) by Steve McConnell
- The Pragmatic Programmer
- Structure and Interpretation of Computer Programs
- The C Programming Language by Kernighan and Ritchie
- Introduction to Algorithms by Cormen, Leiserson, Rivest & Stein
- Design Patterns by the Gang of Four
- Refactoring: Improving the Design of Existing Code
- The Mythical Man Month
- The Art of Computer Programming by Donald Knuth
- Compilers: Principles, Techniques and Tools by Alfred V. Aho, Ravi Sethi and Jeffrey D. Ullman
- Gödel, Escher, Bach by Douglas Hofstadter
- Clean Code: A Handbook of Agile Software Craftsmanship by Robert C. Martin
- Effective C++
- More Effective C++
- CODE by Charles Petzold
- Programming Pearls by Jon Bentley
- Working Effectively with Legacy Code by Michael C. Feathers
- Peopleware by Demarco and Lister
- Coders at Work by Peter Seibel
- Surely You're Joking, Mr. Feynman!
- Effective Java 2nd edition
- Patterns of Enterprise Application Architecture by Martin Fowler
- The Little Schemer
- The Seasoned Schemer
- Why's (Poignant) Guide to Ruby
- The Inmates Are Running The Asylum: Why High Tech Products Drive Us Crazy and How to Restore the Sanity
- The Art of Unix Programming
- Test-Driven Development: By Example by Kent Beck
- Practices of an Agile Developer
- Don't Make Me Think
- Agile Software Development, Principles, Patterns, and Practices by Robert C. Martin
- Domain Driven Designs by Eric Evans
- The Design of Everyday Things by Donald Norman
- Modern C++ Design by Andrei Alexandrescu
- Best Software Writing I by Joel Spolsky
- The Practice of Programming by Kernighan and Pike
- Pragmatic Thinking and Learning: Refactor Your Wetware by Andy Hunt
- Software Estimation: Demystifying the Black Art by Steve McConnel
- The Passionate Programmer (My Job Went To India) by Chad Fowler
- Hackers: Heroes of the Computer Revolution
- Algorithms + Data Structures = Programs
- Writing Solid Code
- JavaScript - The Good Parts
- Getting Real by 37 Signals
- Foundations of Programming by Karl Seguin
- Computer Graphics: Principles and Practice in C (2nd Edition)
- Thinking in Java by Bruce Eckel
- The Elements of Computing Systems
- Refactoring to Patterns by Joshua Kerievsky
- Modern Operating Systems by Andrew S. Tanenbaum
- The Annotated Turing
- Things That Make Us Smart by Donald Norman
- The Timeless Way of Building by Christopher Alexander
- The Deadline: A Novel About Project Management by Tom DeMarco
- The C++ Programming Language (3rd edition) by Stroustrup
- Patterns of Enterprise Application Architecture
- Computer Systems - A Programmer's Perspective
- Agile Principles, Patterns, and Practices in C# by Robert C. Martin
- Growing Object-Oriented Software, Guided by Tests
- Framework Design Guidelines by Brad Abrams
- Object Thinking by Dr. David West
- Advanced Programming in the UNIX Environment by W. Richard Stevens
- Hackers and Painters: Big Ideas from the Computer Age
- The Soul of a New Machine by Tracy Kidder
- CLR via C# by Jeffrey Richter
- The Timeless Way of Building by Christopher Alexander
- Design Patterns in C# by Steve Metsker
- Alice in Wonderland by Lewis Carol
- Zen and the Art of Motorcycle Maintenance by Robert M. Pirsig
- About Face - The Essentials of Interaction Design
- Here Comes Everybody: The Power of Organizing Without Organizations by Clay Shirky
- The Tao of Programming
- Computational Beauty of Nature
- Writing Solid Code by Steve Maguire
- Philip and Alex's Guide to Web Publishing
- Object-Oriented Analysis and Design with Applications by Grady Booch
- Effective Java by Joshua Bloch
- Computability by N. J. Cutland
- Masterminds of Programming
- The Tao Te Ching
- The Productive Programmer
- The Art of Deception by Kevin Mitnick
- The Career Programmer: Guerilla Tactics for an Imperfect World by Christopher Duncan
- Paradigms of Artificial Intelligence Programming: Case studies in Common Lisp
- Masters of Doom
- Pragmatic Unit Testing in C# with NUnit by Andy Hunt and Dave Thomas with Matt Hargett
- How To Solve It by George Polya
- The Alchemist by Paulo Coelho
- Smalltalk-80: The Language and its Implementation
- Writing Secure Code (2nd Edition) by Michael Howard
- Introduction to Functional Programming by Philip Wadler and Richard Bird
- No Bugs! by David Thielen
- Rework by Jason Freid and DHH
- JUnit in Action
#BlackOwned #BlackEntrepreneurs #BlackBuniness #AWSCertified #AWSCloudPractitioner #AWSCertification #AWSCLFC02 #CloudComputing #AWSStudyGuide #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AWSBasics #AWSCertified #AWSMachineLearning #AWSCertification #AWSSpecialty #MachineLearning #AWSStudyGuide #CloudComputing #DataScience #AWSCertified #AWSSolutionsArchitect #AWSArchitectAssociate #AWSCertification #AWSStudyGuide #CloudComputing #AWSArchitecture #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AzureFundamentals #AZ900 #MicrosoftAzure #ITCertification #CertificationPrep #StudyMaterials #TechLearning #MicrosoftCertified #AzureCertification #TechBooks
Top 1000 Canada Quiz and trivia: CANADA CITIZENSHIP TEST- HISTORY - GEOGRAPHY - GOVERNMENT- CULTURE - PEOPLE - LANGUAGES - TRAVEL - WILDLIFE - HOCKEY - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Top 1000 Africa Quiz and trivia: HISTORY - GEOGRAPHY - WILDLIFE - CULTURE - PEOPLE - LANGUAGES - TRAVEL - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Exploring the Pros and Cons of Visiting All Provinces and Territories in Canada.


Exploring the Advantages and Disadvantages of Visiting All 50 States in the USA

Health Health, a science-based community to discuss health news and the coronavirus (COVID-19) pandemic
- The pull-out method: Why this common contraceptive fails to deliverby /u/Kampala_Dispatch on July 26, 2024 at 7:51 pm
submitted by /u/Kampala_Dispatch [link] [comments]
- Health Canada data reveals surprising number of adverse cannabis reactions (spoiler: it's small)by /u/carajuana_readit on July 26, 2024 at 5:49 pm
submitted by /u/carajuana_readit [link] [comments]
- Online portals deliver scary health news before doctors can weigh inby /u/washingtonpost on July 26, 2024 at 4:37 pm
submitted by /u/washingtonpost [link] [comments]
- Vaccine 'sharply cuts risk of dementia' new study findsby /u/SubstantialSnow7114 on July 26, 2024 at 1:53 pm
submitted by /u/SubstantialSnow7114 [link] [comments]
- Calls to limit sexual partners as mpox makes a resurgence in Australiaby /u/boppinmule on July 26, 2024 at 12:31 pm
submitted by /u/boppinmule [link] [comments]
Today I Learned (TIL) You learn something new every day; what did you learn today? Submit interesting and specific facts about something that you just found out here.
- TIL that in Thailand, if your spouse cheats on you, you can legally sue their lover for damages and can receive up to 5,000,000 THB ($140,000 USD) or more under Section 1523 of the Thai Civil and Commercial Codeby /u/Mavrokordato on July 26, 2024 at 6:57 pm
submitted by /u/Mavrokordato [link] [comments]
- TIL that with a population of 170 million people, Bangladesh is the most populous country to have never won a medal at the Olympic Games.by /u/Blackraven2007 on July 26, 2024 at 6:49 pm
submitted by /u/Blackraven2007 [link] [comments]
- TIL a psychologist got himself admitted to a mental hospital by claiming he heard the words "empty", "hollow" and "thud" in his head. Then, it took him two months to convince them he was sane, after agreeing he was insane and accepting medication.by /u/Hadeverse-050 on July 26, 2024 at 6:44 pm
submitted by /u/Hadeverse-050 [link] [comments]
- TIL Senator John Edwards of NC, USA cheated on his wife and had a child with another woman. He tried to deny it but eventually caved and admitted his mistake. He used campaign funds and was indicted by a grand jury. His life story inspired the show "The Good Wife" by Robert & Michelle Kingby /u/AdvisorPast637 on July 26, 2024 at 6:09 pm
submitted by /u/AdvisorPast637 [link] [comments]
- TIL Zhang Shuhong was a Chinese businessman who committed suicide after toys made at his factory for Fisher-Price (a division of Mattel) were found to contain lead paintby /u/Hopeful-Candle-4884 on July 26, 2024 at 4:43 pm
submitted by /u/Hopeful-Candle-4884 [link] [comments]
Reddit Science This community is a place to share and discuss new scientific research. Read about the latest advances in astronomy, biology, medicine, physics, social science, and more. Find and submit new publications and popular science coverage of current research.
- Human decision makers who possess the authority to override ML predictions may impede the self-correction of discriminatory models and even induce initially unbiased models to become discriminatory with timeby /u/f1u82ypd on July 26, 2024 at 6:29 pm
submitted by /u/f1u82ypd [link] [comments]
- Study uses Game of Thrones (GOT) to advance understanding of face blindness: Psychologists have used the TV series GOT to understand how the brain enables us to recognise faces. Their findings provide new insights into prosopagnosia or face blindness, a condition that impairs facial recognition.by /u/AnnaMouse247 on July 26, 2024 at 5:14 pm
submitted by /u/AnnaMouse247 [link] [comments]
- Specific genes may be related to the trajectory of recovery for stroke survivors, study finds. Researchers say genetic variants were strongly associated with depression, PTSD and cognitive health outcomes. Findings may provide useful insights for developing targeted therapies.by /u/AnnaMouse247 on July 26, 2024 at 5:08 pm
submitted by /u/AnnaMouse247 [link] [comments]
- New experimental drug shows promise in clearing HIV from brain: originally developed to treat cancer, study finds that by targeting infected cells in the brain, drug may clear virus from hidden areas that have been a major challenge in HIV treatment.by /u/AnnaMouse247 on July 26, 2024 at 4:57 pm
submitted by /u/AnnaMouse247 [link] [comments]
- Rapid diagnosis sepsis tests could decrease result wait times from days to hours, researchers report in Natureby /u/Science_News on July 26, 2024 at 3:50 pm
submitted by /u/Science_News [link] [comments]
Reddit Sports Sports News and Highlights from the NFL, NBA, NHL, MLB, MLS, and leagues around the world.
- Charles Barkley leaves door open to post-TNT job optionsby /u/PrincessBananas85 on July 26, 2024 at 8:47 pm
submitted by /u/PrincessBananas85 [link] [comments]
- Report: Nuggets sign Westbrook to 2-year, $6.8M dealby /u/Oldtimer_2 on July 26, 2024 at 8:13 pm
submitted by /u/Oldtimer_2 [link] [comments]
- Dolphins signing Tua to 4-year, $212.4M extensionby /u/Oldtimer_2 on July 26, 2024 at 8:09 pm
submitted by /u/Oldtimer_2 [link] [comments]
- Rams cornerback Derion Kendrick suffers season-ending torn ACLby /u/Oldtimer_2 on July 26, 2024 at 8:06 pm
submitted by /u/Oldtimer_2 [link] [comments]
- Hosting the Olympics has become financially untenable, economists sayby /u/toaster_strudel_ on July 26, 2024 at 7:34 pm
submitted by /u/toaster_strudel_ [link] [comments]
