



What are the top 10 algorithms every software engineer should know by heart?
As a software engineer, you’re expected to know a lot about algorithms. After all, they are the bread and butter of your trade. But with so many different algorithms out there, how can you possibly keep track of them all?
Never fear! We’ve compiled a list of the top 10 algorithms every software engineer should know by heart. From sorting and searching to graph theory and dynamic programming, these are the algorithms that will make you a master of your craft. So without further ado, let’s get started!
Sorting Algorithms
Sorting algorithms are some of the most fundamental and well-studied algorithms in computer science. They are used to order a list of elements in ascending or descending order. Some of the most popular sorting algorithms include quicksort, heapsort, and mergesort. However, there are many more out there for you to explore.
Searching Algorithms
Searching algorithms are used to find an element in a list of elements. The most famous search algorithm is probably binary search, which is used to find an element in a sorted list. However, there are many other search algorithms out there, such as linear search and interpolation search.

Graph Theory Algorithms
Graph theory is the study of graphs and their properties. Graph theory algorithms are used to solve problems on graphs, such as finding the shortest path between two nodes or finding the lowest cost path between two nodes. Some of the most famous graph theory algorithms include Dijkstra’s algorithm and Bellman-Ford algorithm.
This graph has six nodes (A-F) and eight arcs. It can be represented by the following Python data structure:
graph = {'A': ['B', 'C'],
'B': ['C', 'D'],
'C': ['D'],
'D': ['C'],
'E': ['F'],
'F': ['C']}
def find_all_paths(graph, start, end, path=[]):
path = path + [start]
if start == end:
return [path]
if not graph.has_key(start):
return []
paths = []
for node in graph[start]:
if node not in path:
newpaths = find_all_paths(graph, node, end, path)
for newpath in newpaths:
paths.append(newpath)
return paths
A sample run:
>>> find_all_paths(graph, 'A', 'D')
[['A', 'B', 'C', 'D'], ['A', 'B', 'D'], ['A', 'C', 'D']]
>>># Code by Eryk Kopczyński
def find_shortest_path(graph, start, end):
dist = {start: [start]}
q = deque(start)
while len(q):
at = q.popleft()
for next in graph[at]:
if next not in dist:
dist[next] = [dist[at], next]
q.append(next)
return dist.get(end)Dynamic Programming Algorithms
Dynamic programming is a technique for solving problems that can be divided into subproblems. Dynamic programming algorithms are used to find the optimal solution to a problem by breaking it down into smaller subproblems and solving each one optimally. Some of the most famous dynamic programming algorithms include Floyd-Warshall algorithm and Knapsack problem algorithm.

Number Theory Algorithms
Number theory is the study of integers and their properties. Number theory algorithms are used to solve problems on integers, such as factorization or primality testing. Some of the most famous number theory algorithms include Pollard’s rho algorithm and Miller-Rabin primality test algorithm.
Example: A school method based Python3 program to check if a number is prime
def isPrime(n):
# Corner case
if n <= 1:
return False
# Check from 2 to n-1
for i in range(2, n):
if n % i == 0:
return False
return TrueDriver Program to test above function
print(“true”) if isPrime(11) else print(“false”)
print(“true”) if isPrime(14) else print(“false”)
This code is contributed by Smitha Dinesh Semwal
Combinatorics Algorithms
Combinatorics is the study of combinatorial objects, such as permutations, combinations, and partitions. Combinatorics algorithms are used to solve problems on combinatorial objects, such as enumeration or generation problems. Some of the most famous combinatorics algorithms include Gray code algorithm and Lehmer code algorithm.
Example: A Python program to print all permutations using library function
from itertools import permutations

Get all permutations of [1, 2, 3]
perm = permutations([1, 2, 3])
Print the obtained permutations
for i in list(perm):
print (i)
Output:
(1, 2, 3) (1, 3, 2) (2, 1, 3) (2, 3, 1) (3, 1, 2) (3, 2, 1)
It generates n! permutations if the length of the input sequence is n.
If want to get permutations of length L then implement it in this way.

Geometry Algorithms
Geometry is the study of shapes and their properties. Geometry algorithms are used to solve problems on shapes, such as finding the area or volume of a shape or finding the intersection point of two lines. Some of the most famous geometry algorithms include Heron’s formula and Bresenham’s line drawing algorithm.
Cryptography Algorithms
Cryptography is the study of encryption and decryption techniques. Cryptography algorithms are used to encrypt or decrypt data. Some of the most famous cryptography algorithms include RSA algorithm and Diffie – Hellman key exchange algorithm.

String Matching Algorithm
String matching algorithms are used t o find incidences of one string within another string or text . Some of the most famous string matching algorithms include Knuth-Morris-Pratt algorithm and Boyer-Moore string search algorithm.
Data Compression Algorithms
Data compression algorithms are used t o reduce the size of data files without losing any information . Some of the most famous data compression algorithms include Lempel-Ziv-Welch (LZW) algorithm and run – length encoding (RLE) algorithm. These are just some of the many important algorithms every software engineer should know by heart ! Whether you’r e just starting out in your career or you’re looking to sharpen your skill set , learning these algorithms will certainly help you on your way!
According to Konstantinos Ameranis, here are also some of the top 10 algorithms every software engineer should know by heart:
I wouldn’t say so much specific algorithms, as groups of algorithms.
Advertise with us - Post Your Good Content Here
We are ranked in the Top 20 on Google
AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
Greedy algorithms.
If your problem can be solved with an algorithm that can make a decision now and at the end this decision will still be optimal, then you don’t need to look any further. Examples are Prim, Kruscal for Minimal Spanning Trees (MST) and the Fractional Knapsack problem.
Divide and Conquer.
Examples of this group are binary search and quicksort. Basically, you divide your problem into two distinct sub-problems, solve each one separately and at the end combine the solutions. Concerning complexity, you will probably get something recursive e.g. T(n) = 2T(n/2) + n, which you can solve using the Master theorem
Graph and search algorithms.
Other than the MST, Breadth First Search (BFS) and Depth First Search (DFS), Dijkstra and possibly A*. If you feel you want to go further in this, Bellman-Ford (for dense graphs), Branch and Bound, Iterative Deepening, Minimax, AB search.
Flows. Basically, Ford-Fulkerson.
Simulated Annealing.
This is a very easy, very powerful randomized optimization algorithm. It gobbles NP-hard problems like Travelling Salesman Problem (TSP) for breakfast.
Hashing. Properties of hashing, known hashing algorithms and how to use them to make a hashtable.
Dynamic Programming.
Examples are the Discrete Knapsack Problem and Longest Common Subsequence (LCS).
Randomized Algorithms.
Two great examples are given by Karger for the MST and Minimum Cut.
Approximation Algorithms.
There is a trade off sometimes between solution quality and time. Approximation algorithms can help with getting a not so good solution to a very hard problem at a good time.
Linear Programming.
Especially the simplex algorithm but also duality, rounding for integer programming etc.
These algorithms are the bread and butter of your trade and will serve you well in your career. Below, we will countdown another top 10 algorithms every software engineer should know by heart.
Binary Search Tree Insertion
Binary search trees are data structures that allow for fast data insertion, deletion, and retrieval. They are called binary trees because each node can have up to two children. Binary search trees are efficient because they are sorted; this means that when you search for an element in a binary search tree, you can eliminate half of the tree from your search space with each comparison.
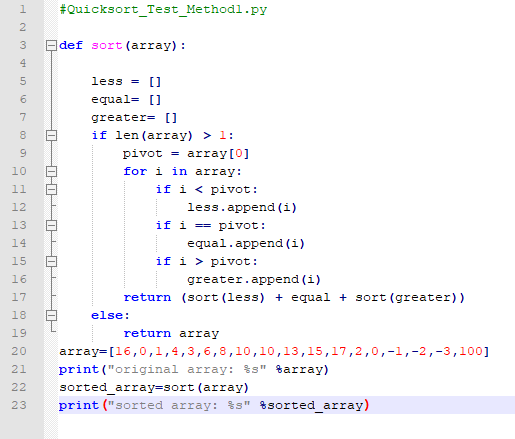
Quicksort
Quicksort is an efficient sorting algorithm that works by partitioning the array into two halves, then sorting each half recursively. Quicksort is a divide and conquer algorithm, which means it breaks down a problem into smaller subproblems, then solves each subproblem recursively. Quicksort is typically faster than other sorting algorithms, such as heapsort or mergesort.
Dijkstra’s Algorithm
Dijkstra’s algorithm is used to find the shortest path between two nodes in a graph. It is a greedy algorithm, meaning that it makes the locally optimal choice at each step in order to find the global optimum. Dijkstra’s algorithm is used in routing protocols and network design; it is also used in manufacturing to find the shortest path between machines on a factory floor.
Linear Regression
Linear regression is a statistical method used to predict future values based on past values. It is used in many fields, such as finance and economics, to forecast future trends. Linear regression is a simple yet powerful tool that can be used to make predictions about the future.
K-means Clustering

K-means clustering is a statistical technique used to group similar data points together. It is used in many fields, such as marketing and medicine, to group customers or patients with similar characteristics. K-means clustering is a simple yet powerful tool that can be used to group data points together for analysis.
Support Vector Machines
Support vector machines are supervised learning models used for classification and regression tasks. They are powerful machine learning models that can be used for data classification and prediction tasks. Support vector machines are widely used in many fields, such as computer vision and natural language processing.
Gradient Descent
Gradient descent is an optimization algorithm used to find the minimum of a function. It is a first-order optimization algorithm, meaning that it uses only first derivatives to find the minimum of a function. Gradient descent is widely used in many fields, such as machine learning and engineering design.
PageRank
PageRank is an algorithm used by Google Search to rank websites in their search engine results pages (SERP). It was developed by Google co-founder Larry Page and was named after him. PageRank is a link analysis algorithm that assigns a numerical weighting to each element of a hyperlinked set of documents, such as the World Wide Web (WWW), with the purpose of “measuring” its relative importance within the set.(Wikipedia)
RSA Encryption
RSA encryption is a public-key encryption algorithm that uses asymmetric key cryptography.(Wikipedia) It was developed by Ron Rivest, Adi Shamir, and Len Adleman in 1977 and has since been widely used in many different applications.(Wikipedia) RSA encryption is used to secure communications between parties and is often used in conjunction with digital signatures.(Wikipedia)
Fourier Transform
The Fourier transform is an integral transform that decomposes a function into its constituent frequencies.(Wikipedia) It was developed by Joseph Fourier in 1807 and has since been widely used in many different applications.(Wikipedia) The Fourier transform has many applications in physics and engineering, such as signal processing and image compression.(Wikipedia)
Conclusion:
These are the top 10 algorithms every software engineer should know by heart! Learning these algorithms will help you become a better software engineer and will give you a solid foundation on which to build your career!

Algorithm Breaking News 2022 – 2023
Instagram algorithm 2022 – 2023
Because the inception of 2010, Instagram has proved its price. The platform that was earlier generally known as a photo-sharing hub has step by step developed itself into aneCommerce platform with Instagram Procuring. Right now most companies use Instagram as a marketing tool to extend their attain throughout the platform. Within the earlier days of Instagram, hashtags grew to become a pattern for straightforward grouping and looking. In a while, a function of product tagging was launched. It made it simpler for folks to seek for the merchandise. In 2016, Instagram algorithms made a serious change. It launched Instagram tales, reside movies, and new enterprise instruments to show their merchandise and gain more followers to their profile.
Read More; How Instagram Algorithm Works In 2022: A Social Media Marketer’s Guide
Instagram uses “Read Path Models” to rank content. It’s an algorithm used by Developers to find the best outcome in a project or a basic filtering algorithm.
Here’s How the algorithm works to rank your content on explore page and home!
First your content is published after Instagram algorithm confirms its Community Guidelines.

After that, Algorithm classifies your content based on your Post Design and Captions.
Using Photo-recognition Instagram Scans your content finds similarities between your new piece of content and your audience’s previous interactions with your old content.
The same process occurs with your post captions. Your post instantly starts reaching your most followers and as engagement rises it gets on explore page.
In words of Instagram employee, This “Write Path Classifiers” algorithm didn’t tracked most important metrics to keep the explore page. That’s why they started building a new version of the algorithm that you can read below!
The new algorithm uses 3 Crucial ways to source content for Your Instagram Explore feed!
Instagram algorithm calculates real-time engagement and upload time signals to consider your post for Explore page.
In simple words, Instagram measures how much engagement creators at your level get and how much engagement your recent posts and how’s the engagement growing since the upload time.
Tip: Look at your insights and see what time your followers are highly active and post 40-70 minutes before the peak time.
This step constitutes search queries from Instagram users related to your post.
Instagram finds targeted users to show your post to them based on their search queries. Your post will show up on top of their explore page.
A Post on “Start Your Entrepreneurship Journey” will be shown to people searching for entrepreneurship to a small query about passive income.
From those queries Instagram source content for explore page.
How long you rank on Instagram page and to what audience depends on the engagement you get when you start ranking on explore page.
After the sourcing step is passed that means your content is eligible to rank on explore page.
And during this step, tracking engagement metrics and their growth algorithm keeps your Post on Explore Page.
Instagram announced Sensitivity control last year which impacted Instagram explore algorithm again!
What’s changed?
Instagram launched two new filters one High precision and low precision filters to maintain better content on Instagram for Different audiences.
Explore page changes every second with every refresh. So, do your content’s target audience.
With these two filters, Instagram tries to track engagement from different-different users and changes pieces of content.

In simple words, Instagram doesn’t want to show people bad content. That’s why these filters work to run explore page content through database to find if it’s suitable to run for another minute, hour or day on Instagram.
You get Hashtags reach because Instagram’s old algorithm “Write Path Classifier” is applicable to every single format of content.
Means your content ranks on hashtags based on relevancy with your Post Image and Caption.
If it’s relevant and getting enough engagement to rank on Hashtags size. You will rank on hashtags. It’s not hard to crack hashtags algorithm. The advice is don’t focus on hashtags that much, and keep your eyes on creating content for explore page.
“Instagram story views increase and decrease based on “navigation” and “interaction”.
What’s navigation?
In Instagram story insights, you will see a metric called “navigation” and below that you will see
Back- means the follower swiped back to see your last story or someone else’s story they saw before! Forward- means the follower clicked to see your next story Next story- the follower moved to see someone else’s story Exited- means the follower left the stories.
Founded: If your story have more forward and next stories. Then Instagram will push your stories to more followers as they want users to watch more stories and stay in stories tab.

Why?: After 2-3 stories they hit users with an ad!
Interactions: Polls/ Question stickers/ Quiz
When viewers interact with these story features. Instagram sees that followers are interacting more than before and that’s why they start pushing it more
How interactions like “profile visits” effect story views?
Yes, if your followers are visiting your profile through stories. Then that particular story (if its the first one) will receive more views than average as my story with 44 profile visits received the most views. So, you should do something worth a profile visit!
I didn’t get much out of the conversation about Instagram reels from employees at IG.
But the only tip was to maintain the highest quality of video while uploading because while content distribution through Instagram processors your video might lose some quality.
Acls algorithm 2022 – 2023,
Free copy/print of all the ACLS algorithms
Algorithms for Advanced Cardiac Life Support
algo-arrestTiktok algorithm 2022 – 2023,
Your first few hours on tiktok are crucial to your growth.
You gonna spend few hours on fyp, interacting with videos and creators about your niche. -After few hours, you can start to make your first video
The very first video plays a huge role in your future. -Quality content -Unique but similar to your niche
9-15 seconds maximum!!
After upload, wait about a few hours, before your second video
2nd video needs to have a hook
“You won,t believe this”
“ Nobody is talking about this, but”
“Did you know that..?”
“ X tips on how to ..”
Your hook needs to be on your first few seconds of the video
Your videos needs to be captivating or strange, this way users spends more time on it.
Your next 3 videos should be similar
Tiktok usually boosts your first videos, that’s their hook
Now you need to hook tiktok onto your account to keep boosting it.
You will lose views and engagement
Its normal, you are not shadow banned. you just have to do it on your own now.
Now its time to get more followers
Do duets/stiches/parts
this way you hook your new followers and cycle up your old videos
now you need to have schedule
3-4 posts /day works the best.
wait 3-4h before your next post
Followers >Views
If you have 10k followers then you need at least 10k views /post to keep growing fast -Don’t follow people who follow you.
How Does The Tiktok Algorithm Work? (+10 Viral Hacks To Go)

Youtube algorithm 2022 – 2023,
Google algorithm update 2022 – 2023,
https://developers.google.com/search/updates/ranking
This page lists the latest ranking updates made to Google Search that are relevant to website owners. To learn more about how Google makes improvements to Search and why we share updates, check out our blog post on How Google updates Search. You can also find more updates about Google Search on our blog.
https://blog.google/products/search/how-we-update-search-improve-results/
https://www.seroundtable.com/category/google-updates
Twitter algorithm 2022 – 2023,
Twitter, which was founded in 2006, is still one of the world’s most popular social networking sites. As of 2020, there are over 340 million active Twitter users, with over 500 million tweets posted each day.

That’s a lot of information to sort through. And, if your company is going to utilize Twitter effectively, you must first grasp how Twitter’s timeline algorithm works and then learn the most dependable techniques of getting your information in front of your target audience.
Twitter Timeline Options: Top Tweets and Most Recent Tweets(Latest)
The Twitter Timeline may be configured to show tweets in two ways:
• Top Tweet
• Recent Tweets
These modes mays be switched by clicking the Stars icon in the upper right corner of your timeline feed.
The Most Popular Tweets
Top Tweets use an algorithm to display tweets in the order that a user is most likely to be interested in. The algorithm is based on how popular and relevant tweets are. Because of the large number of tweets sent at any given time, Twitter news feed algorithms like this one were developed to protect users from becoming overwhelmed and to keep them up to date on material that they genuinely care about.
Recent Tweets
The Latest Tweets section reorders your timeline in reverse chronological order, with the most recently Tweeted Tweets at the top. It displays tweets as they are sent in real time, so more information from more people will appear, but it will not display every tweet. The algorithm will still have some say in deciding which tweets to broadcast at the time.
Ranking Signals for the Twitter Timeline Algorithm:
The following are ranking indications for the Twitter timeline algorithm:
• How recent it is
• Use of rich media (pictures, gifs, video)
• Engagement (likes, responses, retweets)
• Author prominence
• User-author relationship
• User behavior
For example, a user is more likely to see a tweet in their timeline if it comes from a person with whom they frequently interact and has a large number of likes and responses.
What exactly are Twitter Topics?
Facebook Algorithm 2022 – 2023
Facebook can tend to feel like an uphill battle for businesses. The social media platform’s algorithm isn’t very clear about how your posts end up on users’ screens. When even the sponsored posts you’re investing in aren’t working, you know there has to be something you’re missing.
Paid or unpaid, the way you post on Facebook and reach the platform’s ever-expanding audience matters. Every time a user logs on to the website or app, Facebook is learning about what that user likes seeing and what they skip past.
The social media giant has tried a lot of different algorithms over the years, ranging from focusing on the video to simply asking users what they want to see more of. Today, things look a little different, and knowing how the Facebook algorithm works can be a game-changer for businesses.
So here’s what you need to know about Facebook’s Algorithm in 2021:
Facebook is concerned with three things when its algorithm learns about user activity and begins curating their feed to these behaviors.
Following these three elements to a great post can mean huge things for your engagement and reach on Facebook. Ignoring them ends up in things like these terrible Facebook ads we wish we never saw.
First up, the accounts with which the user interacts matter. If someone is always checking up on certain friends and family members, then that’s going to mean their posts will show up sooner on their feed.
The same goes for organizations and businesses that users interact with the most. That means it’s your job to post content that encourages users to not only follow and like you but also provide users the type of content that drives engagement.
What sort of posts do best on Facebook?
Users all have their own preferences for what they like to see. At the end of the day, a mix of videos, links to blogs and web pages, and photos are good to keep things diverse and dynamic.
That said, the sort of posts that do best on your business account will depend on the final element of the Facebook algorithm that matters most: user interactions.
From sharing a post to simply giving it a like or reaction, interactions matter most when it comes to the Facebook algorithm. The social media platform wants users active and logging in as often as possible. That’s why their machine learning algorithm sees interactions as a huge plus for your account.
Comments matter too! In fact, comments serve a dual purpose for your business account on Facebook. Not only do comments drive interactions on your page, but they also give you direct feedback from the audience.
If you listen to comments and take your user’s feedback seriously, you can avoid posting content that ends up falling flat. That doesn’t just hurt your reach and engagement but it’s also a blunder on your digital brand.
Can you beat the Facebook Algorithm once and for all?
We don’t like putting negative energy into the universe, but the Facebook algorithm is sort of like a villain you need to take down to achieve your goals as a business. Understanding the Facebook algorithm can feel like a battle sometimes.
How Does Amazon’s Search Algorithm Work to Find the Right Products?
The search algorithm of Amazon is sophisticated and has a key goal. It aims to connect online shoppers with the products they are looking for as soon as possible. If you reach the top of the Search Pages, your brand visibility will improve, and sales will go up.
Not an essay but here’s a summary:
Based on a Vickrey-Clarke-Groves (VCG) auction.
Total Value = Bid*(eCTR*eCVR)+Value (info)
This creates an oCPM environment (info)
The core of this according to the auction and engineering team has more or less been the same for years.
2018/2020 are different issues. The former affecting (mostly) those who don’t understand oCPM as FB prioritizes user experience and the latter causing issues for those still relying on attribution instead of lift (info).
Audio recognition software like Shazam – how does the algorithm work?
Have a read through this mate http://coding-geek.com/how-shazam-works/
It identifies the songs by creating a audio fingerprint by using a spectrogram. When a song is being played ,shazam creates an audio fingerprint of that song (provided the noise is not high) ,and then checks if it matches with the millions of other audio fingerprints in its database, if it finds a match it sends the info. Here is a really good blog : https://www.toptal.com/algorithms/shazam-it-music-processing-fingerprinting-and-recognition
How does the PALS algorithm in 2022 actually work?
What are some ways we can use machine learning and artificial intelligence for algorithmic trading in the stock market?
Machine Learning Engineer Interview Questions and Answers
- شماره خاله کرمانشاه
شماره کوص کرمانشاه
شماره جنده کرمانشاه
شماره داف کرمانشاه
شماره سکس کرمانشاهby شماره خاله نمک آبرود نوشهر چالوس (Programming on Medium) on July 25, 2024 at 7:45 pm
شماره خاله کرمانشاه شماره کوص کرمانشاه شماره جنده کرمانشاه شماره داف کرمانشاه شماره سکس کرمانشاهContinue reading on Medium »
- شماره خاله کرج
شماره کوص کرج
شماره جنده کرج
شماره داف کرج
شماره سکس کرجby شماره خاله نمک آبرود نوشهر چالوس (Programming on Medium) on July 25, 2024 at 7:43 pm
شماره خاله کرج شماره کوص کرج شماره جنده کرج شماره داف کرج شماره سکس کرجContinue reading on Medium »
- Simplifying Async Work with CombineLatest and Subjectsby Kirill Makharadze (Programming on Medium) on July 25, 2024 at 7:37 pm
When building a class that handles a lot of asynchronous work with the same entities, things can quickly get complicated.Continue reading on Medium »
- شماره خاله قوچان
شماره کوص قوچان
شماره جنده قوچان
شماره داف قوچان
شماره سکس قوچانby شماره خاله نمک آبرود نوشهر چالوس (Programming on Medium) on July 25, 2024 at 7:36 pm
شماره خاله قوچان شماره کوص قوچان شماره جنده قوچان شماره داف قوچان شماره سکس قوچانContinue reading on Medium »
- شماره خاله قم
شماره کوص قم
شماره جنده قم
شماره داف قم
شماره سکس قمby شماره خاله نمک آبرود نوشهر چالوس (Programming on Medium) on July 25, 2024 at 7:35 pm
شماره خاله قم شماره کوص قم شماره جنده قم شماره داف قم شماره سکس قمContinue reading on Medium »
- useEffect vs useLayoutEffect in Reactby AJ (Programming on Medium) on July 25, 2024 at 7:29 pm
useEffectContinue reading on Medium »
- شماره خاله قائن
شماره کوص قائن
شماره جنده قائن
شماره داف قائن
شماره سکس قائنby شماره خاله نمک آبرود نوشهر چالوس (Programming on Medium) on July 25, 2024 at 7:29 pm
شماره خاله قائن شماره کوص قائن شماره جنده قائن شماره داف قائن شماره سکس قائنContinue reading on Medium »
- More Evidence that Ternary LLMs Are Good Enoughby Benjamin Marie (Programming on Medium) on July 25, 2024 at 7:18 pm
-1, 0, and 1 are all you need to make good LLMsContinue reading on Medium »
- شماره کوس شماره خاله گرگان شماره خاله ملایر شماره خاله ملارد خاله صیغه کیس فراری شماره کون شماره…by سارا قنبری (Programming on Medium) on July 25, 2024 at 6:53 pm
Continue reading on Medium »
- Why choose React over Vanilla JavaScript?by Stefan (Programming on Medium) on July 25, 2024 at 6:52 pm
Here I will explain why I might choose React over Vanilla JavaScript. As a web developer, I once faced the decision of whether to build a…Continue reading on Medium »
- In C, how can I efficiently Write to multiple files based on name?by /u/uu3s (Algorithm) on October 7, 2023 at 12:10 am
submitted by /u/uu3s [link] [comments]
- How do I multiplying big numbers, using Karatsuba's method?by /u/uu3s (Algorithm) on October 7, 2023 at 12:08 am
submitted by /u/uu3s [link] [comments]
- How to test whether 2 languages are equal, when given in algebraic form?by /u/vv3st (Algorithm) on September 29, 2023 at 11:50 pm
submitted by /u/vv3st [link] [comments]
- How to find an st-path in a planar graph, which is adjacent to the fewest number of faces?by /u/vv3st (Algorithm) on September 29, 2023 at 11:50 pm
submitted by /u/vv3st [link] [comments]
- Please answer my questions on 2-chordless cycle extraction, from a failed comparability graph recognition?by /u/vv3st (Algorithm) on September 29, 2023 at 11:49 pm
submitted by /u/vv3st [link] [comments]
- Is it possible to boost the error probability of a Consensus protocol, over dynamic network?by /u/vv3st (Algorithm) on September 29, 2023 at 11:48 pm
submitted by /u/vv3st [link] [comments]
- How to incorporate custom Algorithm in SOLR-LUCENE, before Indexing?by /u/vv3st (Algorithm) on September 29, 2023 at 11:47 pm
submitted by /u/vv3st [link] [comments]
- Agglomerative Hierarchical Clustering complexityby /u/CompteDeMonteChristo (Algorithm) on April 11, 2023 at 4:19 pm
I wrote an algorithm for Agglomerative Hierarchical Clustering General agglomerative clustering methods have a time complexity of O(N³) and a memory complexity of O(N²) due to the need to calculate and recalculate full pairwise distance matrices. I'd like to calculate the complexity for it. The algorithm running on random data is empirically 60 times faster on 1000 points, 200 faster with 2000 points and 500 times faster with 3000 points. It is clearly not O(N³) I'd like to calculate or estimate the complexity of it. Could someone help me on this? You can test and get the source on this page: https://preview.redd.it/2bv8hmqj6ata1.png?width=1170&format=png&auto=webp&s=c213b338ae524f38fd3e0be9e38258d04b2b2bcc https://ganaye.com/ahc/?numberOfPoints=3000&wantedClusters=6&linkage=avg&canvasSize=500 submitted by /u/CompteDeMonteChristo [link] [comments]
- Finding Clique idsby /u/239847293847 (Algorithm) on August 31, 2020 at 2:06 pm
Hello I have the following problem: I have a few million tuples of the form (id1, id2). If I have the tuple (id1, id2) and (id2, id3), then of course id1, id2 and id3 are all in the same group, despite that the tuple (id1, id3) is missing. I do want to create an algorithm where I get a list of (id, groupid) tuples as a result. How do I do that fast? I've already implemented an algorithm, but it is way too slow, and it works the following (simplified): 1) increment groupid 2) move first element of the tuplelist into the toprocess-set 3) move first element of the toprocess-set into the processed set with the current groupid 4) find all elements in the tuplelist that are connected to that element and move them to the toprocess-set 5) if the toprocess-set isn't empty go back to 3 6) if the tuplelist is not empty go back to 1 submitted by /u/239847293847 [link] [comments]
- What is the relation of input arguments with Time Complexity?by /u/noobrunner6 (Algorithm) on July 4, 2020 at 1:35 am
Big O is about finding the growth rate with the respect of input size growing, but in all of the algorithms analysis we do how is the input size affecting the growth rate considered? From my experience, we just go through the code and see how long it will take to process based on the code written logic but how does input arguments play a factor in determining the time complexity, quite possible I do not fully understand time complexity yet. One thing I still do not get is how if you search up online about big O notation it mentions how it is a measure of growth of rate requirements in consideration of input size growing, but doesn’t worst case Big O consider up to the worst possible case? I guess my confusion is also how does the “input size growing” play a role or what do they mean by that? submitted by /u/noobrunner6 [link] [comments]
Jobs, Career, Salary, Total Compensation, Interview Tips at FAANGM: Facebook, Apple, Amazon, Netflix, Google, Microsoft

Jobs Career Salary Total Compensation Interview Tips at FAANGM: Facebook Apple, Amazon Netflix Google Microsoft
This blog is about Clever Questions, Answers, Resources, Links, Discussions, Tips about jobs and careers at FAANGM companies: Facebook, Apple, Amazon, AWS, Netflix, Google, Microsoft, Linkedin.
How to prepare for FAANGM jobs interviews
You must be able to write code. It is as simple as that. Prepare for the interview by practicing coding exercises in different categories. You’ll solve one or more coding problems focused on CS fundamentals like algorithms, data structures, recursions, and binary trees.
Coding Interview Tips
These tips from FAANGM engineers can help you do your best.
Make sure you understand the question. Read it back to your interviewer. Be sure to ask any clarifying questions.
An interview is a two-way conversation; feel free to be the one to ask questions, too.
Don’t rush. Take some time to consider your approach. For example, on a tree question, you’ll need to choose between an iterative or a recursive approach. It’s OK to first use a working, unoptimized solution that you can iterate on later.
Talk through your thinking and processes out loud. This can feel unnatural; be sure to practice it before the interview.
Test your code by running through your problem with a few test and edge cases. Again, talk through your logic out loud when you walk through your test cases.
Think of how your solution could be better, and try to improve it. When you’ve finished, your interviewer will ask you to analyze the complexity of the code in Big O notation.
Walk through your code line by line and assign a complexity to each line.
Remember how to analyze how “good” your solution is: how long does it take for your solution to complete? Watch this video to get familiar with Big O Notation.
https://www.youtube.com/watch?v=v4cd1O4zkGw
How to Approach Problems During Your Interview
Before you code
• Ask clarifying questions. Talk through the problem and ask follow-up questions to make sure you understand the exact problem you’re trying to solve before you jump into building
the solution.
• Let the interviewer know if you’ve seen the problem previously. That will help us understand your context.
• Present multiple potential solutions, if possible. Talk through which solution you’re choosing and why.
Advertise with us - Post Your Good Content Here
We are ranked in the Top 20 on Google
AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
While you code
• Don’t forget to talk! While your tech screen will focus heavily on coding, the engineer you’re interviewing with will also be evaluating your thought process. Explaining your decisions and actions as you go will help the interviewer understand your choices.
• Be flexible. Some problems have elegant solutions, and some must be brute forced.
If you get stuck, just describe your best approach and ask the interviewer if you should go that route. It’s much better to have non-optimal but working code than just an idea with nothing written down.
• Iterate rather than immediately trying to jump to the clever solution. If you can’t explain your concept clearly in five minutes, it’s probably too complex.
• Consider (and be prepared to talk about):
• Different algorithms and algorithmic techniques, such as sorting, divide-and-conquer, recursion, etc.
• Data structures, particularly those used most often (array, stack/queue, hashset/hashmap/hashtable/dictionary, tree/binary tree, heap, graph, etc.)
• O memory constraints on the complexity of the algorithm you’re writing and its running time as expressed by big-O notation.
• Generally, avoid solutions with lots of edge cases or huge if/else if/else blocks, in most cases. Deciding between iteration and recursion can be an important step
- After you code
• Expect questions. The interviewer may tweak the problem a bit to test your knowledge and see if you can come up with another answer and/or further optimize your solution.
• Take the interviewer’s hints to improve your code. If the interviewer makes a suggestion or asks a question, listen fully so you can incorporate any hints they may provide.
• Ask yourself if you would approve your solution as part of your codebase. Explain your answer to your interviewer. Make sure your solution is correct and efficient, that you’ve taken into account edge cases, and that it clearly reflects the ideas you’re trying to express in your code.
FAANGM Screening/Phone Interview Examples:
Arrays
Reverse to Make Equal: Given two arrays A and B of length N, determine if there is a way to make A equal to B by reversing any subarrays from array B any number of times. Solution here
Contiguous Subarrays: You are given an array arr of N integers. For each index i, you are required to determine the number of contiguous subarrays that fulfills the following conditions:
The value at index i must be the maximum element in the contiguous subarrays, and
These contiguous subarrays must either start from or end on index i. Solution here
Add 2 long integer (Example: “1001202033933333093737373737” + “934019393939122727099000000”) Solution here
# Python3 program to find sum of
# two large numbers. # Function for finding sum of
# larger numbers
def findSum(str1, str2):
# Before proceeding further,
# make sure length of str2 is larger.
if (len(str1) > len(str2)):
t = str1;
str1 = str2;
str2 = t; # Take an empty string for
# storing result
str = ""; # Calculate length of both string
n1 = len(str1);
n2 = len(str2); # Reverse both of strings
str1 = str1[::-1];
str2 = str2[::-1]; carry = 0;
for i in range(n1):
# Do school mathematics, compute
# sum of current digits and carry
sum = ((ord(str1[i]) - 48) +
((ord(str2[i]) - 48) + carry));
str += chr(sum % 10 + 48); # Calculate carry for next step
carry = int(sum / 10); # Add remaining digits of larger number
for i in range(n1, n2):
sum = ((ord(str2[i]) - 48) + carry);
str += chr(sum % 10 + 48);
carry = (int)(sum / 10); # Add remaining carry
if (carry):
str += chr(carry + 48); # reverse resultant string
str = str[::-1]; return str; # Driver code
str1 = "12";
str2 = "198111";
print(findSum(str1, str2)); # This code is contributed by mits Optimized version below
# python 3 program to find sum of two large numbers. # Function for finding sum of larger numbers
def findSum(str1, str2): # Before proceeding further, make sure length
# of str2 is larger.
if len(str1)> len(str2):
temp = str1
str1 = str2
str2 = temp # Take an empty string for storing result
str3 = "" # Calculate length of both string
n1 = len(str1)
n2 = len(str2)
diff = n2 - n1 # Initially take carry zero
carry = 0 # Traverse from end of both strings
for i in range(n1-1,-1,-1):
# Do school mathematics, compute sum of
# current digits and carry
sum = ((ord(str1[i])-ord('0')) +
int((ord(str2[i+diff])-ord('0'))) + carry)
str3 = str3+str(sum%10 )
carry = sum//10 # Add remaining digits of str2[]
for i in range(n2-n1-1,-1,-1):
sum = ((ord(str2[i])-ord('0'))+carry)
str3 = str3+str(sum%10 )
carry = sum//10 # Add remaining carry
if (carry):
str3+str(carry+'0') # reverse resultant string
str3 = str3[::-1] return str3 # Driver code
if __name__ == "__main__":
str1 = "12"
str2 = "198111"
print(findSum(str1, str2)) # This code is contributed by ChitraNayal Strings
Rotational Cipher: One simple way to encrypt a string is to “rotate” every alphanumeric character by a certain amount.
Rotating a character means replacing it with another character that is a certain number of steps away in normal alphabetic or numerical order. For example, if the string “Zebra-493?” is rotated 3 places, the resulting string is “Cheud-726?”. Every alphabetic character is replaced with the character 3 letters higher (wrapping around from Z to A), and every numeric character replaced with the character 3 digits higher (wrapping around from 9 to 0). Note that the non-alphanumeric characters remain unchanged. Given a string and a rotation factor, return an encrypted string. Solution here
Matching Pairs: Given two strings s and t of length N, find the maximum number of possible matching pairs in strings s and t after swapping exactly two characters within s. A swap is switching s[i] and s[j], where s[i] and s[j] denotes the character that is present at the ith and jth index of s, respectively. The matching pairs of the two strings are defined as the number of indices for which s[i] and t[i] are equal. Note: This means you must swap two characters at different indices. Solution here
Minimum Length Substrings: You are given two strings s and t. You can select any substring of string s and rearrange the characters of the selected substring.
Determine the minimum length of the substring of s such that string t is a substring of the selected substring. Solution here
Recursion
Encrypted Words: You’ve devised a simple encryption method for alphabetic strings that shuffles the characters in such a way that the resulting string is hard to quickly read, but is easy to convert back into the original string.
When you encrypt a string S, you start with an initially-empty resulting string R and append characters to it as follows:
Append the middle character of S (if S has even length, then we define the middle character as the left-most of the two central characters)
Append the encrypted version of the substring of S that’s to the left of the middle character (if non-empty)
Append the encrypted version of the substring of S that’s to the right of the middle character (if non-empty)
For example, to encrypt the string “abc”, we first take “b”, and then append the encrypted version of “a” (which is just “a”) and the encrypted version of “c” (which is just “c”) to get “bac”.
If we encrypt “abcxcba” we’ll get “xbacbca”. That is, we take “x” and then append the encrypted version “abc” and then append the encrypted version of “cba”.
Greedy Algorithms
Slow Sums: Suppose we have a list of N numbers, and repeat the following operation until we’re left with only a single number: Choose any two numbers and replace them with their sum. Moreover, we associate a penalty with each operation equal to the value of the new number, and call the penalty for the entire list as the sum of the penalties of each operation.For example, given the list [1, 2, 3, 4, 5], we could choose 2 and 3 for the first operation, which would transform the list into [1, 5, 4, 5] and incur a penalty of 5. The goal in this problem is to find the worst possible penalty for a given input.
Linked Lists
Reverse Operations: You are given a singly-linked list that contains N integers. A subpart of the list is a contiguous set of even elements, bordered either by either end of the list or an odd element. For example, if the list is [1, 2, 8, 9, 12, 16], the subparts of the list are [2, 8] and [12, 16].Then, for each subpart, the order of the elements is reversed. In the example, this would result in the new list, [1, 8, 2, 9, 16, 12].The goal of this question is: given a resulting list, determine the original order of the elements. Solution Here.
Hash Tables
Pair Sums: Given a list of n integers arr[0..(n-1)], determine the number of different pairs of elements within it which sum to k. If an integer appears in the list multiple times, each copy is considered to be different; that is, two pairs are considered different if one pair includes at least one array index which the other doesn’t, even if they include the same values. Solution here.
Note: These exercises assume you have knowledge in coding but not necessarily knowledge of binary trees, sorting algorithms, or related concepts.
• Topic 1 | Arrays & Strings
• A Very Big Sum
• Designer PDF Viewer
• Left Rotation
A very big Sum in Java
import java.io.*;
import java.util.*;
import java.text.*;
import java.math.*;
import java.util.regex.*;
public class Solution {
/**
* Your solution in here. Just need to add the number in a variable type long so you
* don't face overflow.
*/
static long aVeryBigSum(int n, long[] ar) {
long sum = 0;
for (int i = 0; i < n; i++) {
sum += ar[i];
}
return sum;
}
/**
* HackerRank provides this code.
*/
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
int n = in.nextInt();
long[] ar = new long[n];
for(int ar_i = 0; ar_i < n; ar_i++){
ar[ar_i] = in.nextLong();
}
long result = aVeryBigSum(n, ar);
System.out.println(result);
}
}
Left Rotation in Java
import java.io.*;
import java.util.*;
import java.text.*;
import java.math.*;
import java.util.regex.*;
public class Solution {
static int[] leftRotation(int[] a, int d) {
// They say in requirements that these inputs should not be considered.
// However, noting that we should prevent against those.
if (d == 0 || a.length == 0) {
return a;
}
int rotation = d % a.length;
if (rotation == 0) return a;
// Please note that there is an implementation, circular arrays that could be considered here,
// but that one has an edge case (Test#1)
// As, we don't need to optimize for memory, let's keep it simple.
int [] b = new int[a.length];
for (int i = 0; i < a.length; i++) {
b[i] = a[indexHelper(i + rotation, a.length)];
}
return b;
}
/**
* Takes care of the case where the rotation index. You have to take into account
* how it is rotated towards the left. To compute index of B, we rotate towards the right.
* If we were to do a[i] in the loop, then these method would need to be slightly chnaged
* to compute index of b.
*/
private static int indexHelper(int index, int length) {
if (index >= length) {
return index - length;
} else {
return index;
}
}
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
int n = in.nextInt();
int d = in.nextInt();
int[] a = new int[n];
for(int a_i = 0; a_i < n; a_i++){
a[a_i] = in.nextInt();
}
int[] result = leftRotation(a, d);
for (int i = 0; i < result.length; i++) {
System.out.print(result[i] + (i != result.length - 1 ? " " : ""));
}
System.out.println("");
in.close();
}
}
Sparse Array in Java
import java.io.*;
import java.util.*;
public class Solution {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
final int totalN = Integer.parseInt(scanner.nextLine());
final Map<String, Integer> mapWords = buildCollectionOfStrings(scanner, totalN);
final int numberQueries = Integer.parseInt(scanner.nextLine());
printOcurrenceOfQueries(scanner, numberQueries, mapWords);
}


/**
* This method construcs a map with the collection of Strings and occurrence.
*/
private static Map<String, Integer> buildCollectionOfStrings(Scanner scanner, int n) {
final Map<String, Integer> map = new HashMap<String, Integer>();
for (int i = 0; i < n; i++) {
final String line = scanner.nextLine();
if (map.containsKey(line)) {
map.put(line, map.get(line) + 1);
} else {
map.put(line, 1);
}
}
return map;
}
private static void printOcurrenceOfQueries(Scanner scanner, int numberQueries, Map<String, Integer> mapWords) {
for (int i = 0; i < numberQueries; i++) {
// for each query, we look for how many times it occurs and we print on screen the value.
final String line = scanner.nextLine();
if (mapWords.containsKey(line)) {
System.out.println(mapWords.get(line));
} else {
System.out.println(0);
}
}
}
}
• Topic 2 | Lists
Insert a Node at a Position Given in a List
Cycle Detection
Topic 3 | Stacks & Queues
Balanced Brackets
Queue Using Two Stacks
Topic 4 | Hash & Maps
Ice Cream Parlor
Colorful Number
Topic 5 | Sorting Algorithms
Insertion Sort part 2
Quicksort part 2
• Topic 6 | Trees
Binary Tree Insertion
Height of a Binary Tree
Qheap1
Topic 7 | Graphs (BFS & DFS)
Breath First Search
Snakes and Ladders
Solution here
• Topic 8 | Recursion
Fibonacci Numbers
Solutions: All solutions are available in this public repository:
FAANGM Interview Tips
What they usually look for:
The interviewer will be thinking about how your skills and experience might help their teams.
Help them understand the value you could bring by focusing on these traits and abilities.
• Communication: Are you asking for requirements and clarity when necessary, or are you
just diving into the code? Your initial tech screen should be a conversation, so don’t forget
to ask questions.
• Problem solving: They are evaluating how you comprehend and explain complex ideas. Are you providing the reasoning behind a particular solution? Developing and comparing multiple solutions? Using appropriate data structures? Speaking about space and time complexity? Optimizing your solution?
• Coding. Can you convert solutions to executable code? Is the code organized and does it
capture the right logical structure?
• Verification. Are you considering a reasonable number of test cases or coming up with a
good argument for why your code is correct? If your solution has bugs, are you able to walk
through your own logic to find them and explain what the code is doing?
– Please review Amazon Leadership Principles, to help you understand Amazon’s culture and assess if it’s the right environment for you (For Amazon)
– Review the STAR interview technique (All)
FAANGM Compensation
Legend – Base / Stocks (Total over 4 years) / Sign On
– 105/180/22.5 (2016, L3)
– 105/280/58 (2016, L3)
– 105/330/22.5 (2016, L3)
– 110/180/25 (2016, L3)
– 110/270/30 (2016, L3)
– 110/250/20 (2016, L3)
– 110/160/70 (2016, L3)
– 112/180/50 (2016, L3)
– 115/180/50 (2016, L3)
– 140/430/50 (2016, L3)
– 110/90/0 (2017, L3)
– 145/415/100 (2017, L3)
– 120/220/25 (2018, L3)
– 145/270/30 (2017, L4)
– 150/400/30 (2018, L4)
– 155/315/50 (2017, L4)
– 155/650/50 (2017, L4)
– 170/350/50 (2017, L4)
– 170/400/75 (2017, L4)
*Google’s target annual bonus is 15%. Vesting is monthly and has no cliff.
– 105/120/120 (2016, E3)
– 105/150/75 (2016, E3)
– 105/100/50 (2016, E3)
– 105/240/105 (2016, E3)
– 107/150/75 (2016, E3)
– 110/150/75 (2016, E3)
– 110/235/75 (2016, E3)
– 115/150/75 (2016, E3)
– 110/150/110 (2017, E3)
– 115/160/100 (2017, E3)
– 160/300/70 (2017, E4)
– 145/220/0 (2017, E4)
– 160/300/100 (2017, E4)
– 160/300/100 (2017, E4)
– 150/250/25 (2017, E4)
– 150/250/60 (2017, E4)
– 175/250/0 (2017, E5)
– 160/250/100 (2018, E4)
– 170/450/65 (2015, E5)
– 180/600/50 (2016, E5)
– 180/625/50 (2016, E5)
– 170/500/100 (2017, E5)
– 175/450/50 (2017, E5)
– 175/480/75 (2017, E5)
– 190/600/70 (2017, E5)
– 185/600/100 (2017, E5)
– 185/1000/100 (2017, E5)
– 190/500/120 (2017, E5)
– 200/550/50 (2018, E5)
– 210/1000/100 (2017, E6)
*Facebook’s target annual bonus is 10% for E3 and E4. 15% for E5 and 20% for E6. Vesting is quarterly and has no cliff.
LinkedIn (Microsoft)
– 125/150/25 (2016, SE)
– 120/150/10 (2016, SE)
– 170/300/30 (2016, Senior SE)
– 140/250/50 (2017, Senior SE)
Apple
– 110/60/40 (2016, ICT2)
– 140/99/8 (2016, ICT3)
– 140/100/20 (2016, ICT3)
– 155/130/65 (2017, ICT3)
– 120/100/21 (2017, ICT3)
– 135/105/20 (2017, ICT3)
– 160/105/30 (2017, ICT4)
Amazon
– 95/52/47 (2016, SDE I)
– 95/53/47 (2016, SDE I)
– 95/53/47 (2016, SDE I)
– 100/70/59 (2016, SDE I)
– 103/65/52 (2016, SDE I)
– 103/65/40 (2016, SDE I)
– 103/65/52 (2016, SDE I)
– 110/200/50 (2016, SDE I)
– 135/70/45 (2016, SDE I)
– 106/60/65 (2017, SDE I)
– 130/88/62 (2016, SDE II)
– 127/94/55 (2017, SDE II)
– 152/115/72 (2017, SDE II)
– 160/160/125 (2017, SDE II)
– 178/175/100 (2017, SDE II)
– 145/120/100 (2018, SDE II)
– 160/320/185 (2018, SDE III)
*Amazon stocks have a 5/15/40/40 vesting schedule and sign on is split almost evenly over the first two years*
Microsoft
– 100/25/25 (2016, SDE)
– 106/120/20 (2016, SDE)
– 106/60/20 (2016, SDE)
– 106/60/10 (2016, SDE)
– 106/60/15 (2016, SDE)
– 106/60/15 (2016, SDE)
– 106/120/15 (2016, SDE)
– 107/90/35 (2016, SDE)
– 107/120/30 (2017, SDE)
– 110/50/20 (2016, SDE)
– 119/25/15 (2017, SDE)
– 130/200/20 (2016, SWE1)
– 120/150/18.5 (2016, SWE1)
– 145/125/15 (2017, SWE1)
– 160/600/50 (2017, SWE II)
Uber
– 110/180/0 (2016, L3)
– 110/150/0 (2016, L3)
– 140/590/0 (2017, L4)
Lyft
– 135/260/60 (2017, L3)
– 170/720/20 (2017, L4)
– 152/327/0 (2017, L4)
– 175/480/0 (2017, L4)
Dropbox
– 167/464/10 (2017, IC2)
– 160/250/10 (2017, IC2)
– 160/300/50 (2017, IC2)
Top-paying Cloud certifications for FAANGM:
- Google Certified Professional Cloud Architect — $175,761/year
- AWS Certified Solutions Architect – Associate — $149,446/year
- Azure/Microsoft Cloud Solution Architect – $141,748/yr
- Google Cloud Associate Engineer – $145,769/yr
- AWS Certified Cloud Practitioner — $131,465/year
- Microsoft Certified: Azure Fundamentals — $126,653/year
- Microsoft Certified: Azure Administrator Associate — $125,993/year
According to the 2020 Global Knowledge report, the top-paying cloud certifications for the year are (drumroll, please):
FAANGM FAQ (Frequently Asked Questions and Answers)
Does any of the FANG offer internship to self taught programmers?
I am not a lawyer, but I believe there is some sort of legal restrictions on what an internship can be (in California, at least). In my previous company, we had discussed cases on whether or not someone who was out of school can be an intern, and we got an unequivocal verdict that you have to be in school, or about to start school (usually college or graduate school, but high school can work too), in order to be considered for an internship.
I suspect the reason for this is to protect a potential intern from exploitation by companies who would offer temporary jobs to people while labeling them as learning opportunities in order to pay less.
Personally, I feel for people like you, in an ideal world you should be allowed to have the same opportunities as the formally schooled people, and occasionally there are. For example, some companies offer residency programs which are a bit similar to internships. In many cases, though, these are designed to help underrepresented groups. Some examples include:
Facebook’s The Artificial Intelligence (AI) Residency Program
Google’s Eng Residency
Microsoft AI Residency Program
How can I get an intership as a product manager at faang or any other tech company?
What questions to expect in cloud support engineer deployment roles at AWS?
Recipes to succeed in corporate, how to navigate the job world.
Ever wonder how the FAANGM big tech make their money?

This is a common bug in the thinking of people, doing the wrong thing harder in the hope that it works this time. Asking tough questions is like hitting a key harder when the broken search function in LinkedIn fails. No matter how hard you hit the key, it won’t work.
Given the low quality of the LinkedIn platform from a technical perspective it seems hard to imagine that they hire the best or even the mediocre. But it may be that because their interviews are too tough to hire good programmers.
Just because so few people can get a question right, does not mean it is a good question, merely that it is tough. I am also a professional software developer and know a bunch of algorithms, but also am wholly ignorant of many others. Thus it is easy to ask me (or anyone else) questions they can’t answer. I am (for instance) an expert on sort/merging, and partial text matching, really useful for big data, wholly useless for UX.
So if you ask about an obscure algorithm or brain teaser that is too hard you don’t measure their ability, but their luck in happening to know that algo or having seen the answer to a puzzle. More importantly how likely are they to need it ?
This is a tricky problem for interviewers, if you know that a certain class of algorithms are necessary for a job, then if you’re a competent s/w dev manager then odds are that you’ve already put them in and they just have to integrate or debug them. Ah, so I’ve now given away one of my interview techniques. We both know that debugging is more of our development effort than writing code. Quicksort (for instance) is conceptually quite easy being taught to 16 year old Brits or undergraduate Americans, but it turns out that some implementations can go quadratic in space and/or time complexity and that comparison of floating point numbers is a sometimes thing and of course some idiot may have put = where he should have put == or >= when > is appropriate.
Resolving that is a better test, not complete of course, but better.
For instance I know more about integrating C++ with Excel than 99.9% of programmers. I can ask you why there are a whole bunch of INT 3’s laying around a disassembly of Excel, yes I have disassembled Excel, and yes my team was at one point asked to debug the damned thing for Microsoft. I can ask about LSTRs, and why SafeArrays are in fact really dangerous. I can even ask you how to template them. That’s not easy, trust me on this.
Are you impressed by my knowledge of this ?
I sincerely hope not.
Do you think it would help me build a competent search engine, something that the coders at LinkedIn are simply unable to do ?
No.
I also know a whole bunch of numerical methods for solving PDEs. Do you know what a PDE even is ? This can be really hard as well. Do you care if you can’t do this ? Again not relevant to fixing the formless hell of LI code. fire up the developer mode of your browser and see what it thinks of Linkedin’s HTML, I’ve never seen a debugger actually vomit in my face before.
A good interview is a measure not just of ability but of the precise set of skills you bring to the team. A good interviewer is not looking for the best, but the best fit.
Sadly some interviewers see it as an ego thing that they can ask hard questions. So can I, but it’s not my job. My job is identfying those that can deliver most, hard questions that you can’t answer are far less illuminating that questions you struggle with because I get to see the quality of your thinking in terms of complexity, insight, working with incomplete and misleading information and determination not to give up because it is going badly.
Do you as a candidate ask questions well ? If I say something wrong, do you a) notice, b) have the soft skills to put it to me politely, c) have the courage to do so ?
Courage is an under-rated attribute that superior programmers have and failed projects have too little of.
Yes, some people have too much courage, which is a deeper point, where for many things there is an optimum amount and the right mix for your team at this time. I once had to make real time un-reversible changes to a really important database whilst something very very bad happened on TV news screens above my head. Too much or too little bravery would have had consequences. Most coding ain’t that dramatic, but the superior programmer has judgement, when to try the cool new language/framework feature in production code, when to optimise for speed, or for space and when for never ever crashes even when memory is corrupted by external effects. When does portability matter or not ? Some code will only be used once and we both know some of it will literally never be executed in live, do we obsess about it’s quality in terms of performance and maintainability .
The right answer is it depends, and that is a lot more important to hiring the best than curious problems in number theory or O(N Log(N)) for very specific code paths that rarely execute.
Also programming is a marathon, not a sprint, or perhaps more like a long distance obstacle course, stretches of plodding along with occasional walls. Writing a better search engine than LinkedIn “programmers” manage is a wall, I know this because my (then) 15 year old son took several weeks, at 15, he was only 2 or 3 times better than the best at LinkedIn, but he’s 18 now and as a professional grade programmer, him working for LinkedIn would be like putting the head of the Vulcan Science Academy in among a room of Gwyneth Paltrow clones.
And that ultimately may be the problem.
Good people have more options and if you have a bad recruitment process then they often will reject your offer. We spend more of our lives with the people we work with than sleep with and if at interview management is seen as pompous or arrogant then they won’t get the best people.
There’s now a Careers advice space on Quora, you might find it interesting.
8- Resources:
– Cracking the Coding Interview: 189 Programming Questions and Solutions
Top sites for practice problems:
• Facebook Sample Interview Problems and Solutions
• InterviewBit
• LeetCode
• HackerRank
Video prep guides for tech interviews:
• Cracking the Facebook Coding Interview: The Approach (The password is FB_IPS)
• Cracking the Facebook Coding Interview: Problem Walk-through (The password is FB_IPS)
Additional resources*:
• I Interviewed at Five Top Companies in Silicon Valley in Five Days, and Luckily Got
Five Job Offers
Active Hydrating Toner, Anti-Aging Replenishing Advanced Face Moisturizer, with Vitamins A, C, E & Natural Botanicals to Promote Skin Balance & Collagen Production, 6.7 Fl Oz


Age Defying 0.3% Retinol Serum, Anti-Aging Dark Spot Remover for Face, Fine Lines & Wrinkle Pore Minimizer, with Vitamin E & Natural Botanicals


Firming Moisturizer, Advanced Hydrating Facial Replenishing Cream, with Hyaluronic Acid, Resveratrol & Natural Botanicals to Restore Skin's Strength, Radiance, and Resilience, 1.75 Oz

Skin Stem Cell Serum


Smartphone 101 - Pick a smartphone for me - android or iOS - Apple iPhone or Samsung Galaxy or Huawei or Xaomi or Google Pixel
Can AI Really Predict Lottery Results? We Asked an Expert.




Djamgatech

Read Photos and PDFs Aloud for me iOS
Read Photos and PDFs Aloud for me android
Read Photos and PDFs Aloud For me Windows 10/11
Read Photos and PDFs Aloud For Amazon
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more)
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6(Email us for more)



FREE 10000+ Quiz Trivia and and Brain Teasers for All Topics including Cloud Computing, General Knowledge, History, Television, Music, Art, Science, Movies, Films, US History, Soccer Football, World Cup, Data Science, Machine Learning, Geography, etc....

List of Freely available programming books - What is the single most influential book every Programmers should read
- Bjarne Stroustrup - The C++ Programming Language
- Brian W. Kernighan, Rob Pike - The Practice of Programming
- Donald Knuth - The Art of Computer Programming
- Ellen Ullman - Close to the Machine
- Ellis Horowitz - Fundamentals of Computer Algorithms
- Eric Raymond - The Art of Unix Programming
- Gerald M. Weinberg - The Psychology of Computer Programming
- James Gosling - The Java Programming Language
- Joel Spolsky - The Best Software Writing I
- Keith Curtis - After the Software Wars
- Richard M. Stallman - Free Software, Free Society
- Richard P. Gabriel - Patterns of Software
- Richard P. Gabriel - Innovation Happens Elsewhere
- Code Complete (2nd edition) by Steve McConnell
- The Pragmatic Programmer
- Structure and Interpretation of Computer Programs
- The C Programming Language by Kernighan and Ritchie
- Introduction to Algorithms by Cormen, Leiserson, Rivest & Stein
- Design Patterns by the Gang of Four
- Refactoring: Improving the Design of Existing Code
- The Mythical Man Month
- The Art of Computer Programming by Donald Knuth
- Compilers: Principles, Techniques and Tools by Alfred V. Aho, Ravi Sethi and Jeffrey D. Ullman
- Gödel, Escher, Bach by Douglas Hofstadter
- Clean Code: A Handbook of Agile Software Craftsmanship by Robert C. Martin
- Effective C++
- More Effective C++
- CODE by Charles Petzold
- Programming Pearls by Jon Bentley
- Working Effectively with Legacy Code by Michael C. Feathers
- Peopleware by Demarco and Lister
- Coders at Work by Peter Seibel
- Surely You're Joking, Mr. Feynman!
- Effective Java 2nd edition
- Patterns of Enterprise Application Architecture by Martin Fowler
- The Little Schemer
- The Seasoned Schemer
- Why's (Poignant) Guide to Ruby
- The Inmates Are Running The Asylum: Why High Tech Products Drive Us Crazy and How to Restore the Sanity
- The Art of Unix Programming
- Test-Driven Development: By Example by Kent Beck
- Practices of an Agile Developer
- Don't Make Me Think
- Agile Software Development, Principles, Patterns, and Practices by Robert C. Martin
- Domain Driven Designs by Eric Evans
- The Design of Everyday Things by Donald Norman
- Modern C++ Design by Andrei Alexandrescu
- Best Software Writing I by Joel Spolsky
- The Practice of Programming by Kernighan and Pike
- Pragmatic Thinking and Learning: Refactor Your Wetware by Andy Hunt
- Software Estimation: Demystifying the Black Art by Steve McConnel
- The Passionate Programmer (My Job Went To India) by Chad Fowler
- Hackers: Heroes of the Computer Revolution
- Algorithms + Data Structures = Programs
- Writing Solid Code
- JavaScript - The Good Parts
- Getting Real by 37 Signals
- Foundations of Programming by Karl Seguin
- Computer Graphics: Principles and Practice in C (2nd Edition)
- Thinking in Java by Bruce Eckel
- The Elements of Computing Systems
- Refactoring to Patterns by Joshua Kerievsky
- Modern Operating Systems by Andrew S. Tanenbaum
- The Annotated Turing
- Things That Make Us Smart by Donald Norman
- The Timeless Way of Building by Christopher Alexander
- The Deadline: A Novel About Project Management by Tom DeMarco
- The C++ Programming Language (3rd edition) by Stroustrup
- Patterns of Enterprise Application Architecture
- Computer Systems - A Programmer's Perspective
- Agile Principles, Patterns, and Practices in C# by Robert C. Martin
- Growing Object-Oriented Software, Guided by Tests
- Framework Design Guidelines by Brad Abrams
- Object Thinking by Dr. David West
- Advanced Programming in the UNIX Environment by W. Richard Stevens
- Hackers and Painters: Big Ideas from the Computer Age
- The Soul of a New Machine by Tracy Kidder
- CLR via C# by Jeffrey Richter
- The Timeless Way of Building by Christopher Alexander
- Design Patterns in C# by Steve Metsker
- Alice in Wonderland by Lewis Carol
- Zen and the Art of Motorcycle Maintenance by Robert M. Pirsig
- About Face - The Essentials of Interaction Design
- Here Comes Everybody: The Power of Organizing Without Organizations by Clay Shirky
- The Tao of Programming
- Computational Beauty of Nature
- Writing Solid Code by Steve Maguire
- Philip and Alex's Guide to Web Publishing
- Object-Oriented Analysis and Design with Applications by Grady Booch
- Effective Java by Joshua Bloch
- Computability by N. J. Cutland
- Masterminds of Programming
- The Tao Te Ching
- The Productive Programmer
- The Art of Deception by Kevin Mitnick
- The Career Programmer: Guerilla Tactics for an Imperfect World by Christopher Duncan
- Paradigms of Artificial Intelligence Programming: Case studies in Common Lisp
- Masters of Doom
- Pragmatic Unit Testing in C# with NUnit by Andy Hunt and Dave Thomas with Matt Hargett
- How To Solve It by George Polya
- The Alchemist by Paulo Coelho
- Smalltalk-80: The Language and its Implementation
- Writing Secure Code (2nd Edition) by Michael Howard
- Introduction to Functional Programming by Philip Wadler and Richard Bird
- No Bugs! by David Thielen
- Rework by Jason Freid and DHH
- JUnit in Action
#BlackOwned #BlackEntrepreneurs #BlackBuniness #AWSCertified #AWSCloudPractitioner #AWSCertification #AWSCLFC02 #CloudComputing #AWSStudyGuide #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AWSBasics #AWSCertified #AWSMachineLearning #AWSCertification #AWSSpecialty #MachineLearning #AWSStudyGuide #CloudComputing #DataScience #AWSCertified #AWSSolutionsArchitect #AWSArchitectAssociate #AWSCertification #AWSStudyGuide #CloudComputing #AWSArchitecture #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AzureFundamentals #AZ900 #MicrosoftAzure #ITCertification #CertificationPrep #StudyMaterials #TechLearning #MicrosoftCertified #AzureCertification #TechBooks
Top 1000 Canada Quiz and trivia: CANADA CITIZENSHIP TEST- HISTORY - GEOGRAPHY - GOVERNMENT- CULTURE - PEOPLE - LANGUAGES - TRAVEL - WILDLIFE - HOCKEY - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Top 1000 Africa Quiz and trivia: HISTORY - GEOGRAPHY - WILDLIFE - CULTURE - PEOPLE - LANGUAGES - TRAVEL - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Exploring the Pros and Cons of Visiting All Provinces and Territories in Canada.


Exploring the Advantages and Disadvantages of Visiting All 50 States in the USA

Health Health, a science-based community to discuss health news and the coronavirus (COVID-19) pandemic
- US infant mortality increased in 2022 for the first time in decades, CDC report showsby /u/cnn on July 25, 2024 at 6:37 pm
submitted by /u/cnn [link] [comments]
- Study raises hopes that shingles vaccine may delay onset of dementia | Dementia | The Guardianby /u/chilladipa on July 25, 2024 at 3:38 pm
submitted by /u/chilladipa [link] [comments]
- How fit is your city? New rankings by the American College of Sports Medicineby /u/idc2011 on July 25, 2024 at 3:35 pm
submitted by /u/idc2011 [link] [comments]
- Twice-Yearly Lenacapavir or Daily F/TAF for HIV Prevention in Cisgender Women | New England Journal of Medicineby /u/chilladipa on July 25, 2024 at 3:30 pm
submitted by /u/chilladipa [link] [comments]
- Biden Made a Healthy Decisionby /u/theatlantic on July 25, 2024 at 3:15 pm
submitted by /u/theatlantic [link] [comments]
Today I Learned (TIL) You learn something new every day; what did you learn today? Submit interesting and specific facts about something that you just found out here.
- TIL actor John Larroquette was the uncredited narrator of the prologue to the 1974 horror movie Texas Chainsaw Massacre. In lieu of cash, he was paid by the Director Tobe Hooper in Marijuana.by /u/openletter8 on July 25, 2024 at 6:56 pm
submitted by /u/openletter8 [link] [comments]
- TIL that the every Shakopee Mdewakanton Sioux indian receives a payout of around $1 million per year from casino profits.by /u/friendlystranger4u on July 25, 2024 at 6:22 pm
submitted by /u/friendlystranger4u [link] [comments]
- TIL Motorcycles in China are dictated by law to be decommissioned and destroyed in 13 years after registration regardless of the conditionsby /u/Easy_Piece_592 on July 25, 2024 at 5:56 pm
submitted by /u/Easy_Piece_592 [link] [comments]
- TIL a man named Jonathan Riches has filed more than 2,600 lawsuits since 2006. He even sued Guinness World Records to try to stop them from titling him as "the most litigious man in history".by /u/doopityWoop22 on July 25, 2024 at 5:03 pm
submitted by /u/doopityWoop22 [link] [comments]
- TIL that in 2018, an American half-pipe skier qualified for the Olympics despite minimal experience. Olympic requirements stated that an athlete needed to place in the top 30 at multiple events. She simply sought out events with fewer than 30 participants, showed up, and skied down without falling.by /u/ctdca on July 25, 2024 at 4:28 pm
submitted by /u/ctdca [link] [comments]
Reddit Science This community is a place to share and discuss new scientific research. Read about the latest advances in astronomy, biology, medicine, physics, social science, and more. Find and submit new publications and popular science coverage of current research.
- Abstinence-only sex education linked to higher pornography use among women | This finding adds to the ongoing conversation about the effectiveness and impacts of different sexuality education approaches.by /u/chrisdh79 on July 25, 2024 at 6:49 pm
submitted by /u/chrisdh79 [link] [comments]
- AlphaProof and AlphaGeometry 2 AI models achieve silver medal standard in solving International Mathematical Olympiad problemsby /u/Big_Profit9076 on July 25, 2024 at 5:59 pm
submitted by /u/Big_Profit9076 [link] [comments]
- Scientists have described a new species of chordate, Nuucichthys rhynchocephalus, the first soft-bodied vertebrate from the Drumian Marjum Formation of the American Great Basin.by /u/grimisgreedy on July 25, 2024 at 5:55 pm
submitted by /u/grimisgreedy [link] [comments]
- Secularists revealed as a unique political force in America, with an intriguing divergence from liberals. Unlike nonreligiosity, which denotes a lack of religious affiliation or belief, secularism involves an active identification with principles grounded in empirical evidence and rational thought.by /u/mvea on July 25, 2024 at 5:40 pm
submitted by /u/mvea [link] [comments]
- New shingles vaccine could reduce risk of dementia. The study found at least a 17% reduction in dementia diagnoses in the six years after the new recombinant shingles vaccination, equating to 164 or more additional days lived without dementia.by /u/Wagamaga on July 25, 2024 at 4:48 pm
submitted by /u/Wagamaga [link] [comments]
Reddit Sports Sports News and Highlights from the NFL, NBA, NHL, MLB, MLS, and leagues around the world.
- A's place their lone all-star, Mason Miller, on IL with fractured finger after hitting training tableby /u/Oldtimer_2 on July 25, 2024 at 8:15 pm
submitted by /u/Oldtimer_2 [link] [comments]
- Flyers sign All-Star Travis Konecny to an 8-year extension worth $70 millionby /u/Oldtimer_2 on July 25, 2024 at 7:45 pm
submitted by /u/Oldtimer_2 [link] [comments]
- Bills’ Von Miller says he believes domestic assault case to be closed, with no charges filedby /u/Oldtimer_2 on July 25, 2024 at 7:43 pm
submitted by /u/Oldtimer_2 [link] [comments]
- Padres' Dylan Cease throws no-hitter vs. Nationalsby /u/Oldtimer_2 on July 25, 2024 at 7:41 pm
submitted by /u/Oldtimer_2 [link] [comments]
- Appeal denied in Valieva case; U.S. skaters to get gold in Parisby /u/PrincessBananas85 on July 25, 2024 at 6:18 pm
submitted by /u/PrincessBananas85 [link] [comments]
