


AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
What are the top 10 Wonders of computing and software engineering?
Computer science and software engineering are fascinating fields that continue to evolve and surprise us. Computer science and software engineering are disciplines that are essential for the modern world. They have led to the development of many innovative products and services that have made our lives easier and more efficient. In this blog post, we’ll explore the top 10 wonders of computer science and software engineering.
The things Alan Keys found to be astonishing and amazing (and shocking) are:
- Turing’s notion of machines that can simulate machines completely by interpreting their descriptions (exhibiting the programmable computer as “a language machine” and a “meta-language machine” — along with this is the simplicity of what is required to do so (a great book is Marvin Minsky’s “Computation: Finite and Infinite Machines”). Turing’s approach is much more of a “real CS” approach compared to Goedel’s earlier methods, and soon led to a large number of important next steps.
- How simple (a) it is to design a whole computer from just one kind of logical element (e.g. “NOT-BOTH”), especially when compared (b) to how Russell and Whitehead struggled to “bootstrap mathematics, etc., from logic at the turn of the last century. (This is one of those “Point of View is Worth 80 IQ Points” …)
- Lisp, and McCarthy’s general approach to “mathematical theories of computation” and having languages that can act as their own metalanguage. One of the great cornucopias of our field.
- Sketchpad by Ivan Sutherland for so many reasons, including: the approach to interactive computer graphics and the simulations of the graphic relationships, the “object-oriented” approach to definition and deriving new kinds of things (including “masters” and making instances from masters), enormous virtual worlds that are windowed on the display, the use of goal-directed programming with the system solving the simultaneous goals in real-time, etc. And more, including the demonstration that a simulated computer on a computer need look nothing like the underlying hardware or any “normal” idea of “computer”.
- The big Shannon et al. ideas about how to have imperfect things be organized in systems that are much more perfectly behaved even if the organizational mechanisms are themselves noisy. Includes all forms of “noise”, “representations”, “communications”, “machines”, etc. and poking deeply into Biology and how living things work. Nice implications for “stochastic computing” of many kinds which are needed more and more as things scale.
- The deep implications of “symbolic computation” (now a very un-funded area) for being able to move from the trivialities of “data” (no matter how voluminous”) to the profundities and powers of “Meaning”. This used to be called “AI” and now has to be called “real AI” or “strong AI” (it would be much better under a less loaded term: how about “Flexible Competence”?)
- The Internet. Certainly the best thing done by my research community, and the first real essay into the kinds of scaling and stabilities that all computer science should be trying to understand and improve. This was a great invention and development process in all ways, and — by looking at Biology, which inspired but we really couldn’t use — it had a reasonable chance to work. That it was able to scale stably over more than 10 (maybe 11) orders of magnitude, as indeed planned, is still kind of amazing to me (even though it should have). Judging from most software systems today not being organized like the Internet, one is forced into the opinion that most computerists don’t understand it, why it is great (and maybe don’t even think of it as the fruits of “real computer science” because it just works so much better and more reliably than most other attempted artifacts in the field).
- Application: #1: Self-Driving Cars
Self-driving cars are one of the most hyped technologies of the past few years. And for good reason! These autonomous vehicles have the potential to drastically reduce accidents and improve traffic flow. While there are still some kinks to be ironed out, it’s only a matter of time until self-driving cars become the norm. - Application: #2: Artificial Intelligence
Artificial intelligence is another technology that is rapidly evolving. AI is being used in a variety of ways, from personal assistants like Siri to chatbots that can carry on a conversation. As AI gets more sophisticated, its capabilities will only continue to grow. - Application: #3: Virtual Reality
Virtual reality is another exciting technology with a lot of potential. VR has already been used in a number of different industries, from gaming to medicine. And as VR technology gets more advanced, we can only imagine the new and innovative ways it will be used in the future. - Application: #4: Blockchain
You’ve probably heard of Bitcoin, the digital currency that uses blockchain technology. But what exactly is blockchain? In short, it’s a decentralized database that can be used to store data securely. Blockchain is already being used in a number of different industries, and its applications are only growing. - Application: #5: Internet of Things
The internet of things refers to the growing trend of interconnected devices. From your phone to your fridge, more and more devices are being connected to the internet. This allows them to share data and makes them easier to control. The internet of things is changing the way we live and work, and there’s no doubt that its impact will only continue to grow in the years to come. - Application: #6: Data Science
Data science is a relatively new field that combines statistics, computer science, and domain expertise to extract knowledge from data. Data science is being used in a variety of industries, from healthcare to retail. And as data becomes increasingly abundant, data scientists will become even more important in helping organizations make sense of it all. - Application: #7: Machine Learning
Machine learning is a subset of artificial intelligence that allows computers to learn from data without being explicitly programmed. Machine learning is being used in a number of different ways, from fraud detection to object recognition. As machine learning algorithms get more sophisticated, they will continue to revolutionize the way we live and work. - Application: #8 Cybersecurity : Cybersecurity is a critical concern for businesses and individuals alike. With so much of our lives taking place online, it’s important to have measures in place to protect our information from hackers and cyber criminals.
These are just some of the many wonders of computer science and software engineering! Each one has the potential to change our world in amazing ways. We can’t wait to see what else these fields have in store for us!

Other notable wonders of computing:
#16 Mobile phones are handheld devices that allow us to make calls, send texts, and access the internet while on the go. They have become an indispensable part of our lives and have transformed the way we stay connected with others.
#17 Social Media
Social media platforms like Facebook, Twitter, and Instagram have changed the way we interact with each other. They provide us with a space to share our thoughts, feelings, and experiences with friends and family members who might be located anywhere in the world.
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6

 Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more codes)
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more codes)
#18 Cloud Computing
Cloud computing is a model of computing that allows users to access data and applications over the internet. It has made it possible for businesses to operate more efficiently by reducing their reliance on physical infrastructure.
#19 Big Data
Big data refers to large data sets that can be analyzed to reveal patterns and trends. It is being used by businesses in a variety of industries to make better decisions about everything from product development to marketing strategies.

#20 Augmented Reality Augmented reality is a type of technology that overlays digital information on real-world objects. It has many potential applications, including education, gaming, and navigation.

#21 3D Printing 3D printing is a process of creating three-dimensional objects from a digital file. It has revolutionized manufacturing by making it possible to create customized products quickly and easily. These are just some of the things that computer science and software engineering have made possible! As you can see, these disciplines have had a major impact on our world and will continue to shape the future as we move into the digital age.
Conclusion: So there you have it! These are the top 10 wonders of computer science and software engineering according to me. Do you agree with my list? What would you add or remove? Let me know in the comments below!
Addendum:
In the spirit of choosing artifacts over ideas, I would replace “symbolic computation “ with Unix.
I’ve mentioned elsewhere that one can praise in a sentence or two, but criticism ethically demands more careful substantiation.

All I’ll say here is that when Unix was being invented Xerox Parc was already successfully making systems with dynamic objects that required no separate OS layering or system builds. That said, Doug McIlroy did find the start of what could have been really fruitful ideas when he implemented “pipes” programming. If they had seen what could have been done if they had reduced the process overhead to zero bytes, and gone to a dynamic language, then something great could have resulted. By Alan Kay
What do you mean by organizing software systems like the internet?
Just to get you started: consider that the Internet’s (a) processes do not have to be stopped to fix, change, add to etc. (b) messages are not commands (c) units of computation are perfectly encapsulated (only the interior code code of a computer can decide to do anything or nothing) (d) units of transmission can be very badly damaged and messages will still get through, (e) scaling is more than 10 orders of magnitude (f) and on and on and on.
What SW systems to you know of that are remotely like this (that don’t depend intrinsically on what is wonderful about the Internet)?
This doesn’t mean the Internet is a perfect design at all. For example, the add-on of DNS was not nearly as good and lasting a scheme as the base semantics of TCP/IP. (It’s crazy that there are not unique IDs for every kind of entity manifested within the Internet system. Bob Kahn has been advocating this for several decades now — Joe Armstrong among others has pointed out that the modern hashing schemes (SHA256, etc.) are good enough to provide excellent unique IDs for Internet entities, etc.)

But the Internet did completely raise many bars qualitatively and astonishingly higher. It should be used as a starting point in thinking about how most SW systems can and should be organized.
Just a note about this big shift in thinking within the ARPA/Parc community — it is hard to pin down just when. But Wes Clark used to say that no computer is any good if it can’t work perfectly with 10% of its wires disconnected! Packet Switching (American version at RAND ARPA project in early 60s by Paul Baran) meant that you could do store and forward with a number of routes. If you made the protocol full-duplex, you could guarantee *eventually perfect* delivery of packets. At Parc the huge shift from “theoretical” to “punch in the face reality” came as we realized just how wonderfully well the extremely simple Ethernet was actually performing. This led to the articulated idea that no computation should ever require having to be stopped in order to improve/change/etc it.

In other words, make the systems design such that things will work “eventually as wished”, so you can spend your brain cells on (a) better designs, and (b) better optimizations. The Internet grew out of the whole community’s strong and emotional realizations around these ideas. By Alan Kay
What are the top 100 Free IQ Test Questions and Answers – Train and Elevate Your Brain

AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
What are the top 100 Free IQ Test Questions and Answers – Train and Elevate Your Brain
An Intelligence Quotient or “IQ” is a score derived from one of several standardized tests designed to assess human intelligence. The term “IQ” was coined by William Stern in 1912 as a proposed method of scoring children’s performance on the new Binet-Simon intelligence scale.
Ever since, there has been much debate over what exactly IQ tests measure, how accurate and reliable they are, and what purpose they serve. However, there is no denying that IQ scores can have major implications for an individual’s life chances, including their educational opportunities and career prospects.

IQ tests are often used for selecting students for gifted and talented programs or for entrance into schools for the intellectually gifted. They may also be used to identify individuals who are at risk of developmental delays or learning disabilities. In some cases, IQ scores are used to predict job performance or to screen job applicants.
- The first Mensa IQ test is called the Culture Fair Intelligence Test, or CFIT. This test is designed to minimize the influence of cultural biases on a person’s score. The CFIT is made up of four subtests, each of which measures a different type of cognitive ability.
- The second Mensa IQ test is called the Stanford-Binet Intelligence Scale, or SBIS. The SBIS is a revision of an earlier intelligence test that was used by the US military to screen recruits during World War I. Today, the SBIS is commonly used to diagnose learning disabilities in children.
- The third Mensa IQ test is called the Universal Nonverbal Intelligence Test, or UNIT. As its name suggests, the UNIT is a nonverbal intelligence test that can be administered to people of all ages, regardless of their native language.
- The fourth and final Mensa IQ test is called the Wright Scale of Human Ability, or WSHA. The WSHA was developed by William Herschel Wright, a British psychologist who also served as the first president of Mensa International. Like the other tests on this list, the WSHA consists of four subtests that measure different aspects of cognitive ability.
Below are the top 100 Free IQ Test Questions and Answers From Mensa:











What do IQ Tests Measure?
Broadly speaking, IQ tests measure an individual’s capacity for logical reasoning, problem-solving, and abstract thought. They usually involve a mixture of verbal and nonverbal questions and tasks. Standardized IQ tests often yield a bell-shaped distribution of scores with a mean of 100 and a standard deviation of 15. This means that the vast majority of people score between 85 and 115. Scores below 70 are generally considered to represent intellectual disability, while scores above 130 are considered to represent exceptional intelligence.
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more codes)
How Accurate and Reliable are IQ Tests?
The accuracy and reliability of IQ tests have long been debated by researchers and psychologists. Some argue that IQ tests are an unfair measure of intelligence because they often favor those with higher socioeconomic status or who speak English as their first language. Others argue that the test items on IQ tests often tap into culturally biased knowledge, such as knowledge of famous people or classical music.
IQ tests also tend to yield lower scores for certain groups, including women, ethnic minorities, and people from lower socio-economic backgrounds. This has led some to suggest that IQ tests may be biased against certain groups. However, it is important to keep in mind that all standardized tests have some degree of bias built into them. For example, a test designed to assess knowledge of American history will necessarily be biased against people from other countries who have not had the same exposure to American history. This does not mean that the test is invalid or unreliable; it simply means that the test is not measuring something that is equally important for everyone in the world.
Conclusion:
There is no denying that IQ scores can have major implications for an individual’s life chances, including their educational opportunities and career prospects. However, there is still much debate over what exactly IQ tests measure and how accurate and reliable they are. Because of this debate, it is important to consider IQ scores within the context of other factors when making decisions about someone’s ability or potential.
There are four main Mensa IQ tests: the Culture Fair Intelligence Test (CFIT), the Stanford-Binet Intelligence Scale (SBIS), the Universal Nonverbal Intelligence Test (UNIT), and the Wright Scale of Human Ability (WSHA). Each test assesses different aspects of cognitive ability, and all four tests are used to screen candidates for membership in Mensa International, an organization for people with high intelligence quotients. Thanks for reading!
What would be an example of an IQ question that only someone with an IQ of 135+ could answer?
The questions in the online tests seems to be more difficult close to the end. The question below is the last question in the online test from Mensa Norge that claims to measure up to IQ 145. Thus, the last question should only be possible to solve for people close to IQ 145, or that knows the logic of the question.
Do high IQ people find it hard to understand easy concepts somehow?
High IQ friend of mine: Makes a very high 6 figure salary coding
Also him: Doesn’t know how to open a milk carton

(The carton didn’t have the ‘lift n peel’ thing, it was plain transparent blue plastic)
He’s super smart, but the thing with the milk carton is that he’s not used to this kind of problem.
The solution is to look where to apply force and how to apply it.
But the kind of solution he’s used to making is: Find a way to make this super complicated massive piece of code work again.
Physical world problem vs hard logical problem (that you only ever envision in your head)
Another thing might be that he’s so used to complicated problems perhaps he thought there was more to it.
Or maybe he just never saw it before (but even then it’s not hard to figure out)
What are the most effective ways to improve emotional intelligence?
Emotional intelligence is about the ability to control, Recognize, express your emotions, and handle your interpersonal connections with empathy and sensibility. There are many ways to improve emotional intelligence such as.
- Increasing Self-Awareness
- Observing your feeling
- Pay attention to your behaviour
- Question your opinions
- Look at yourself objectively
- Know your emotional triggers
- Understand the links between people’s emotions and behaviour
- Read literature to improve Empathy
- Try Empathize with Yourself and Others
- Ask for feedback
- Dancing, Singing, Crying, Laughter, Listening, taking care of someone or something like the elderly or a pet , plant, gardening became a hobby of mine after house plants thrived, fairy gardens, rock gardens
What is a sign of high intelligence that not many people know about?
A sign of intelligence few people know about is having a tough time understanding a question you’re being asked.

Why is that?
It’s because people with very high IQs have many meanings coming to their mind when their hear a word or a phrase.
For example, if someone asks “What do you do?” these high IQ people are likely to wonder whether they are being asked what kind of a job they do or what kind of hobbies they have, or how they would react under certain circumstances…
This need for constant precision is always present at a high IQ level, whereas for people of average IQs the most obvious and common meaning always comes to mind.
So, while not being able to understand a simple question is seen as a form of stupidity by many, it may actually be a sign of higher intelligence.
Lovecky, Deirdre V. (1994): Exceptionally Gifted Children: Different Minds. Roeper Review Vol.17 n°2.
What is a fake sign of intelligence?
I would say when a person feels the need to speak on every subject.
Or, just being overly talkative in general. I find that some people just like to hear themselves talk, and think that them blabbing non-stop makes them sound smart.
You generally know this is the case when they spend 20 minutes explaining something that should have only taken 30 seconds.
There were two competing awards in my high school yearbook.
- Talks most, says least.
- Talks least, says most.
It should be obvious which of those two you would want to be. There is virtue in knowing when not to talk, and just listen.
Is it possible to have a high IQ and score low on an IQ test?
I would say a person with a high IQ could have a bad day and score less than her best but it would still be far from a low score. Someone who scores low on an IQ test might have done better another day, but could never score high.
What do high IQ people think of normal IQ people?
Normal IQ people rely on the volume of ideas they can understand to arrive at their own opinions. It is much easier to evaluate an idea than it is coming up with one of equal value, as a result normal IQ people gain a significant benefit from making their opinions a collage of what they evaluated as best. This provides a series of practical advantages to the normal IQ person that no longer has to rely on his bad ideas but can supplant them for the good ones of somebody else, but also gives them a number of quirks. From the perspective of very high IQ people, normal IQ people are much more consistent performers than they are, as though their opinions in isolation are all average opinions of somebody 1.5 SD above them, but have a set of opinions that looks like the monstrous chimera of someone with multiple personalities. If an high IQ person has a standard distribution of quality for his opinions ranging around his IQ, the normal IQ person has a much smaller range of opinions all of higher quality than average but patched together in such a way as to appear incomprehensible how one could champion them all. This is the main reason of the communication range, we expect your opinions to have implications for your other opinions that quite simply aren’t there. From the perspective of high IQ people normal IQ people constantly try to have their cake and eat it too.
Which professions/fields of study can a person with an IQ between 130 and 140 (but average drive) be successful in? Which should he stay away from?
You will probably get an answer from one of the usual suspects posting his favorite career-to-IQ chart, which omits so much crucial data that it can only be surmised that those who promote usage of it are doing so to manipulate opinion.
The graphic I’m going to post under this text is much better because it shows a range of IQs that actual people doing actual jobs have. From it you can see that some janitors have the same IQ as some doctors. So you should seek a career in doing whatever you would like to do. You are much more likely to succeed in something you want to do than something you don’t want to do, regardless of your IQ.
Is there a connection between high IQ and low spatial intelligence?
Not necessarily. While there is some positive correlation with high spatial intelligence (the standard IQ test includes a number of questions related to spatial intelligence), it is far from absolute. My mother is quite likely the smartest person currently living in New York City and has virtually zero spatial intelligence. Conversely, there are loadmasters and packing experts who have unbelievable spatial intelligence but only average IQs.
Albert Einstein is gone, and Stephen Hawking is gone. Who is the next genius?
If we had to pick an existing genius who has a gravitational impact on any research project he (or she) touches, I would venture a guess that a lot of people would pick Terence Tao (mathematician), an Australian mathematician working out of UCLA. Not only has he been a prolific theorist, he also been a major public figure and communicator of math. He is considered an once in a generation type of talent and we won’t truly fully realize his impact for another few decades once people start applying his findings. That said, his work on compressed sensing is already having implications on sensor theory.
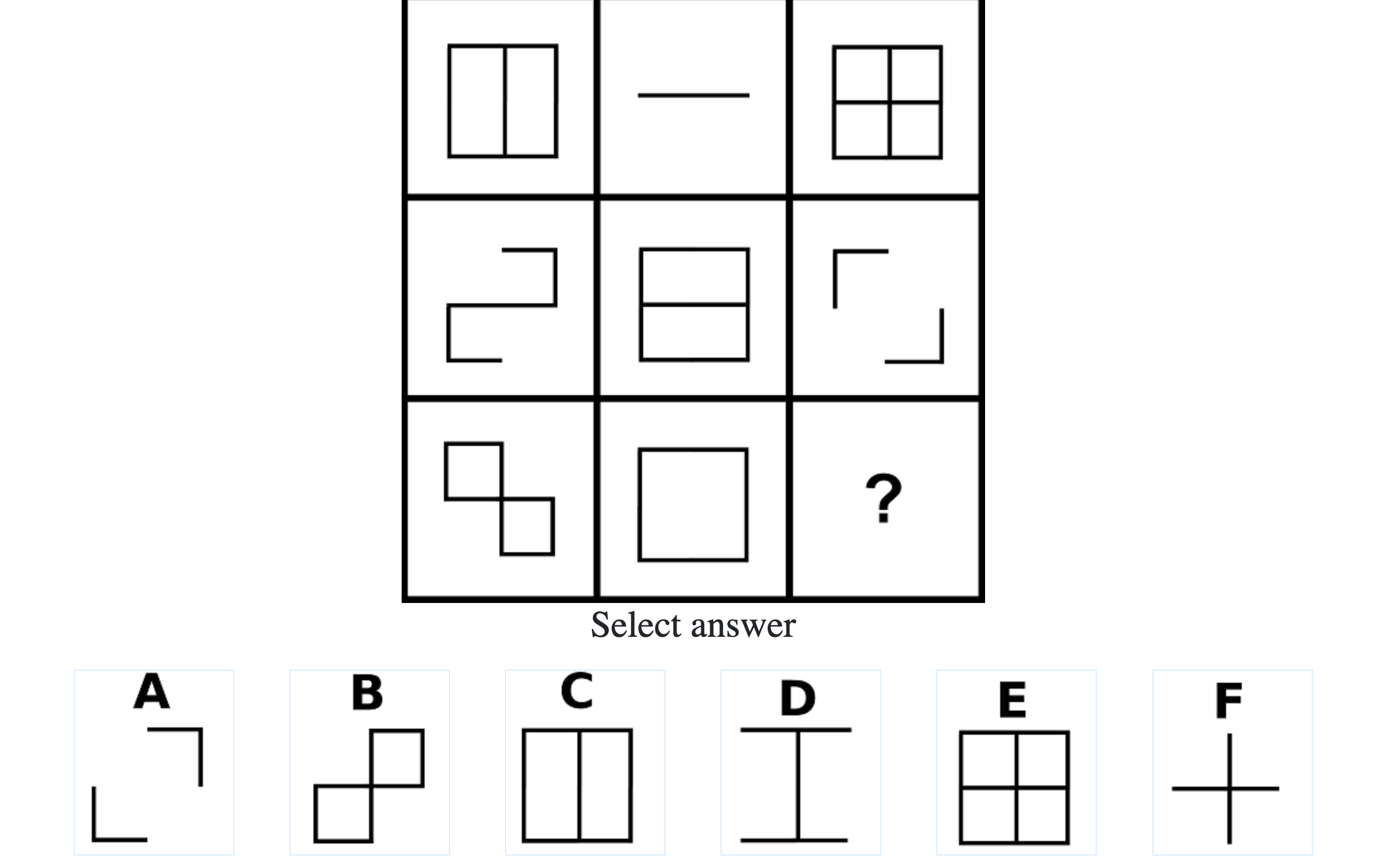
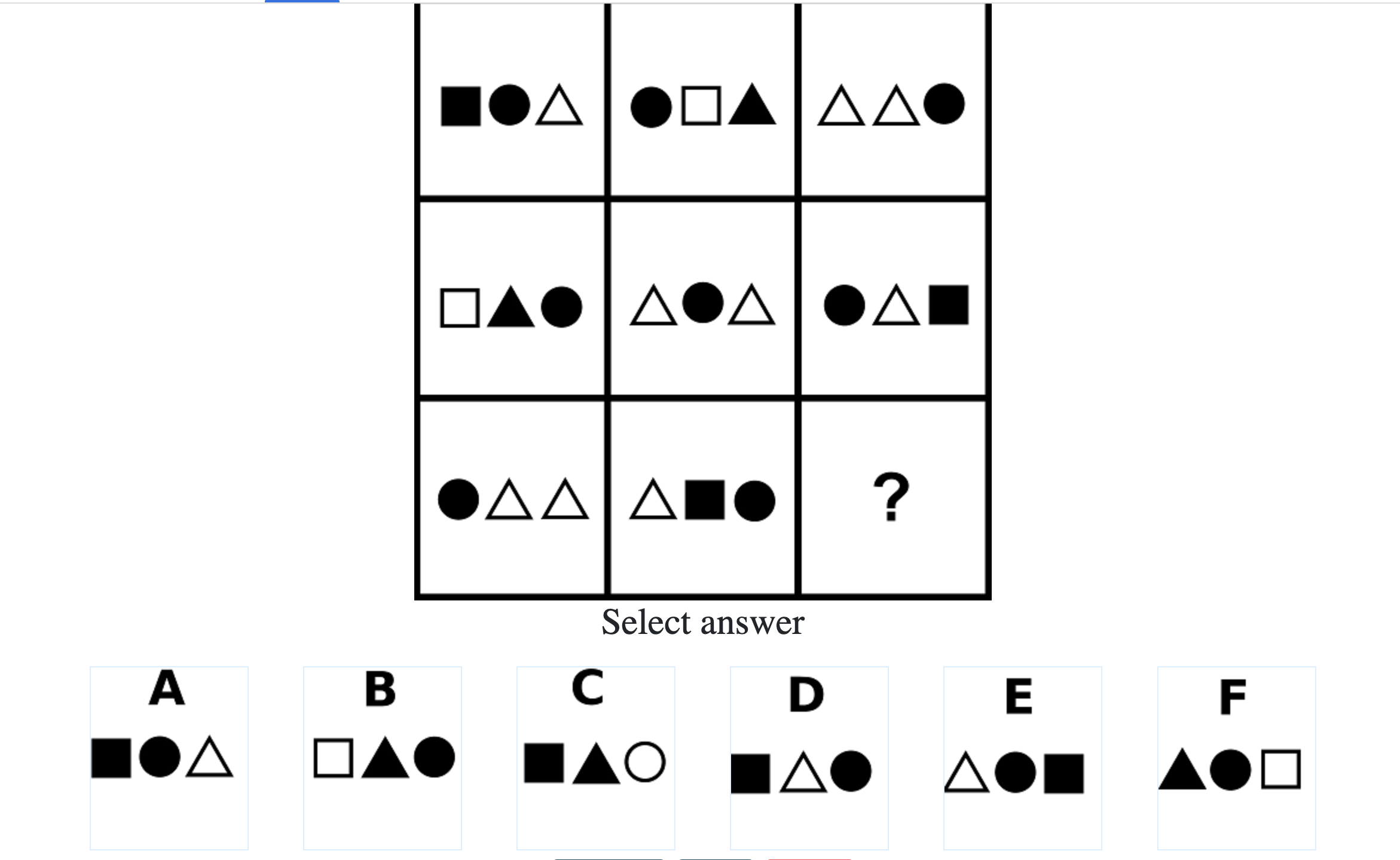
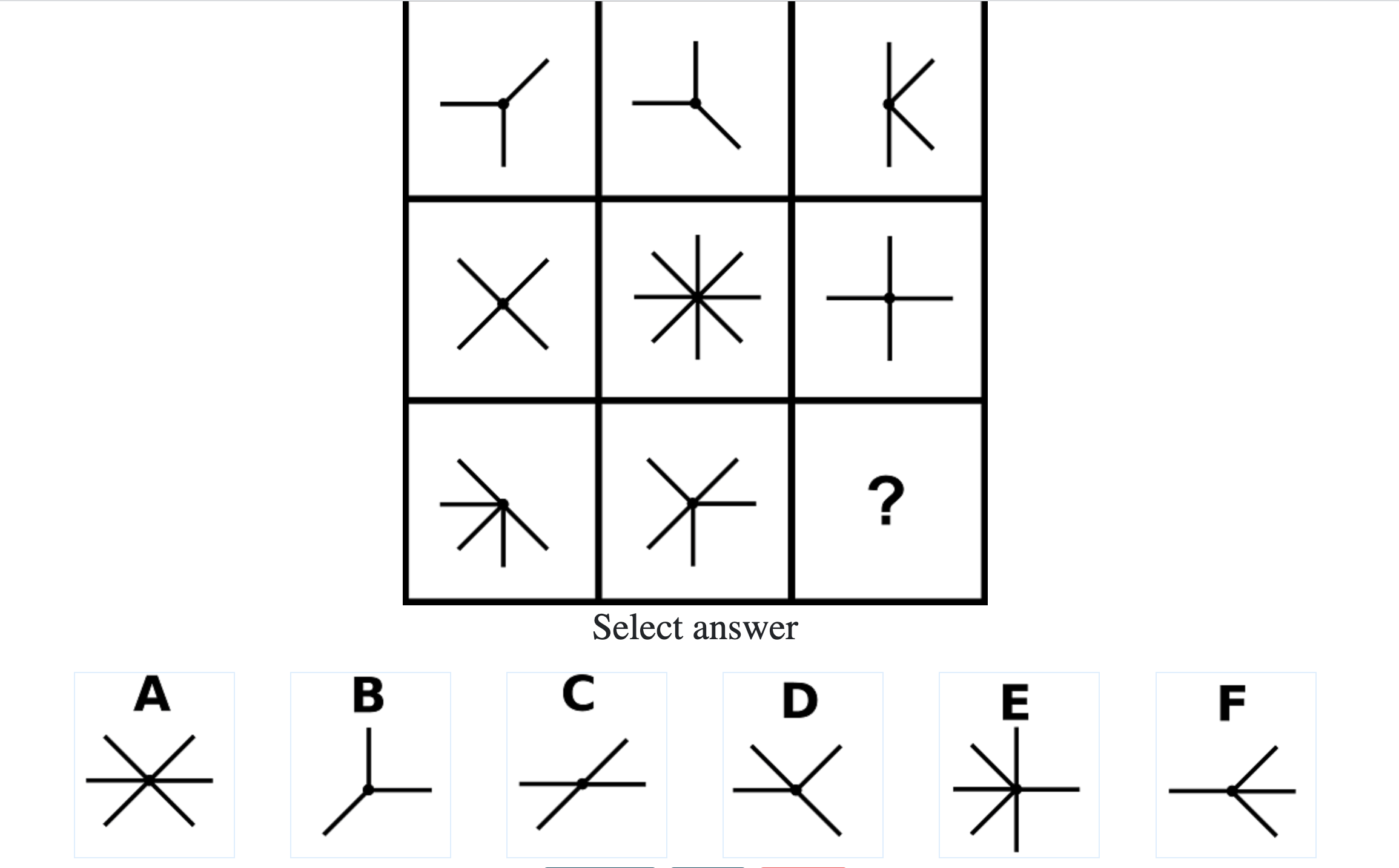
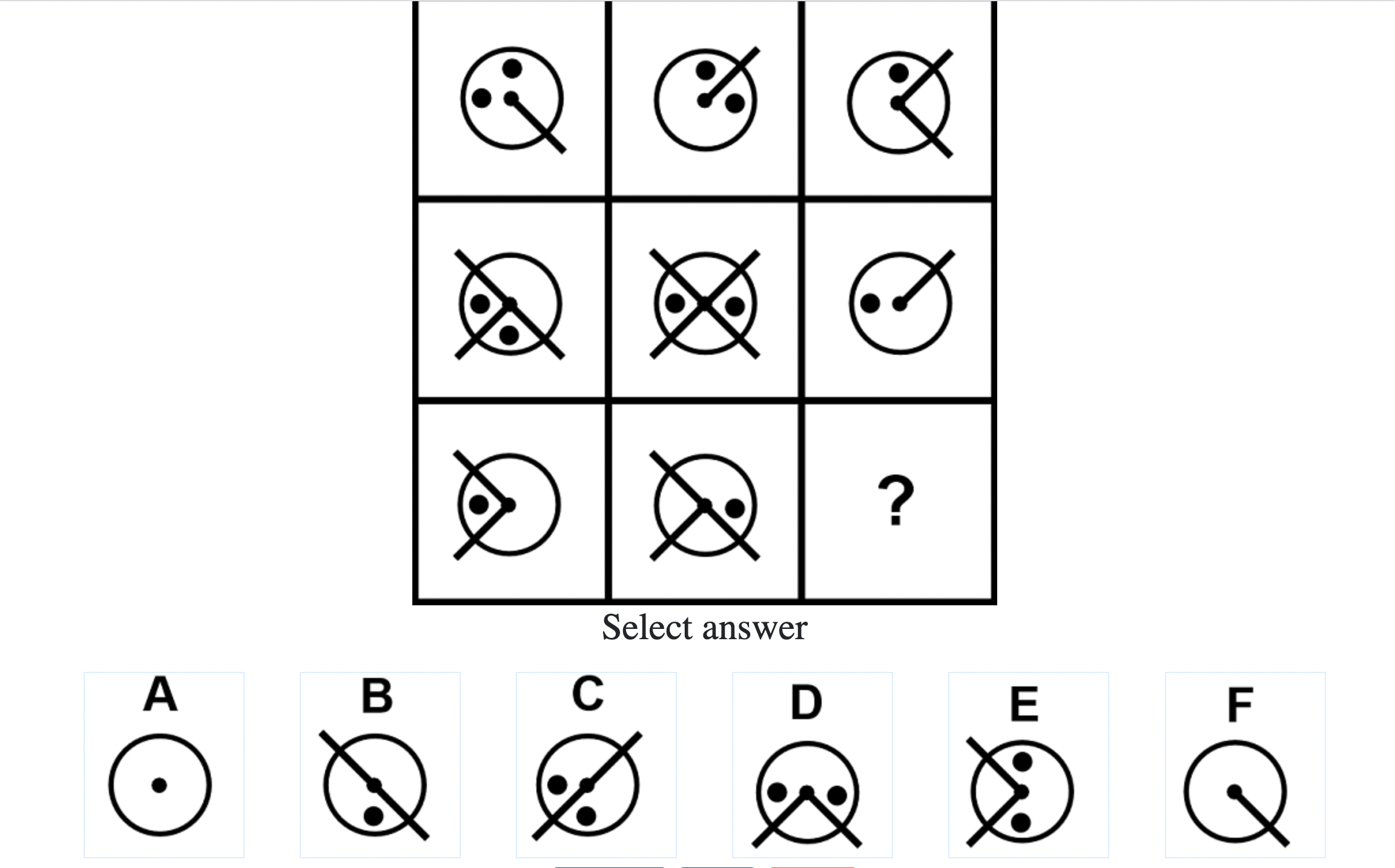
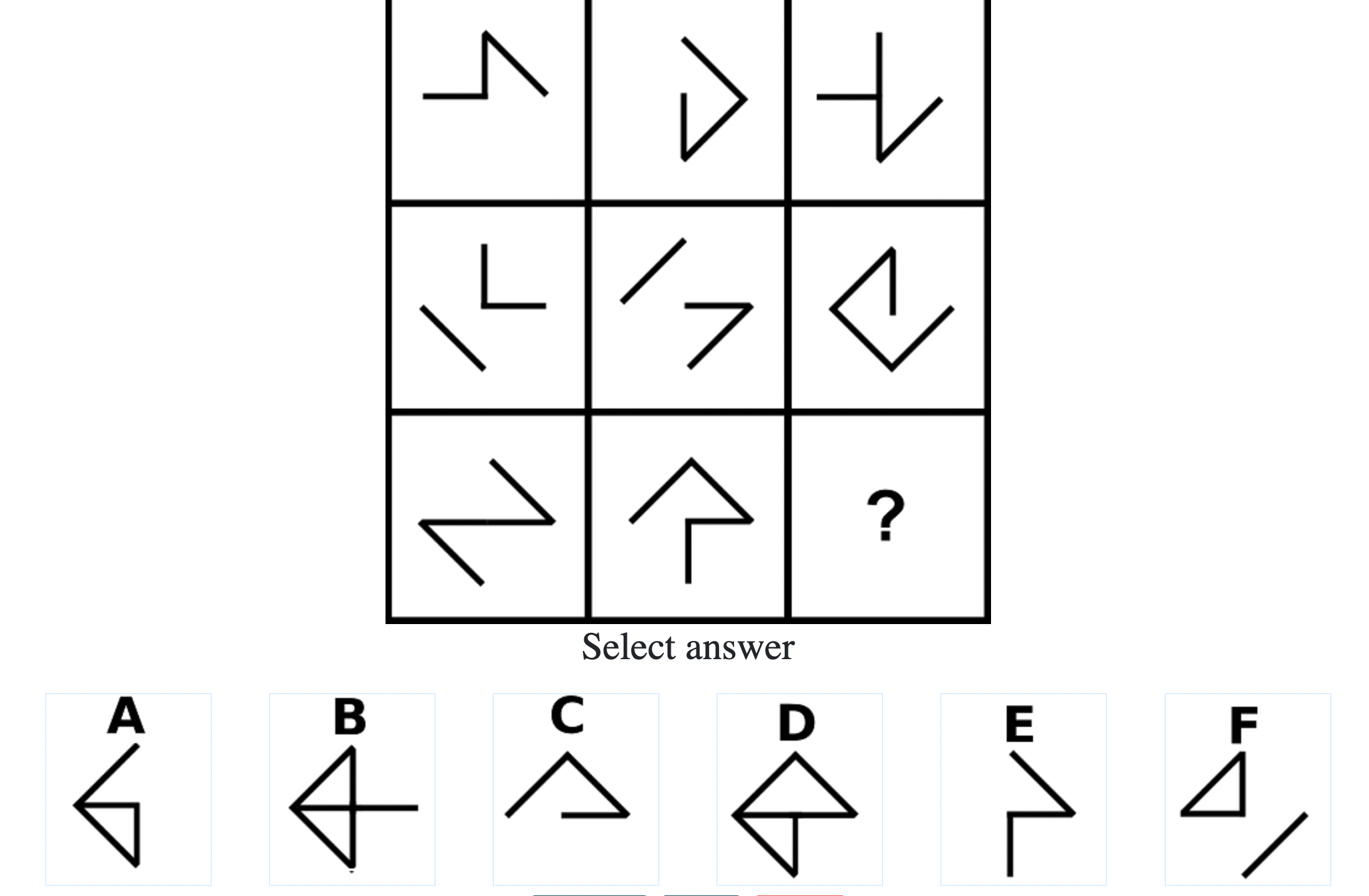
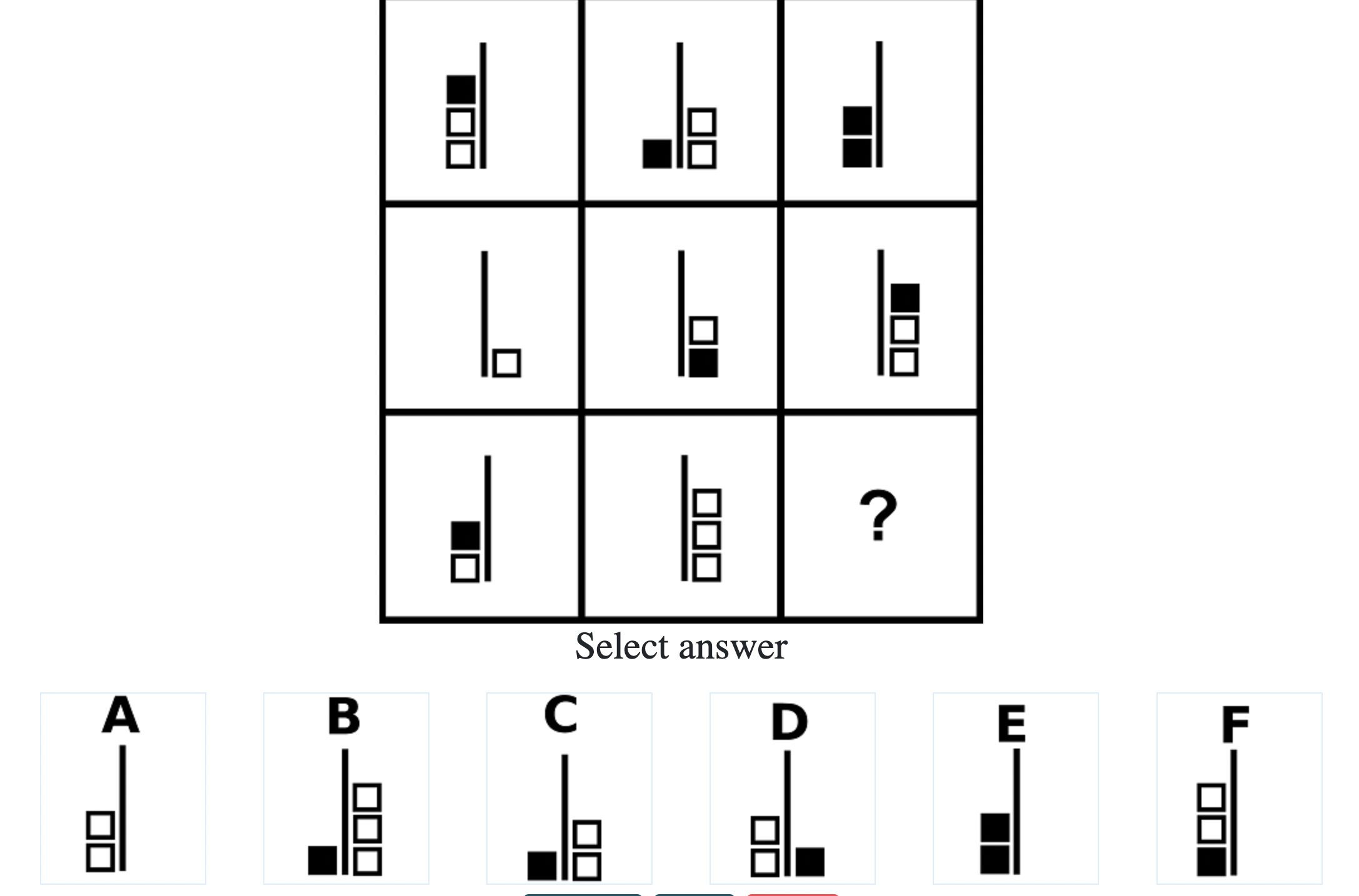
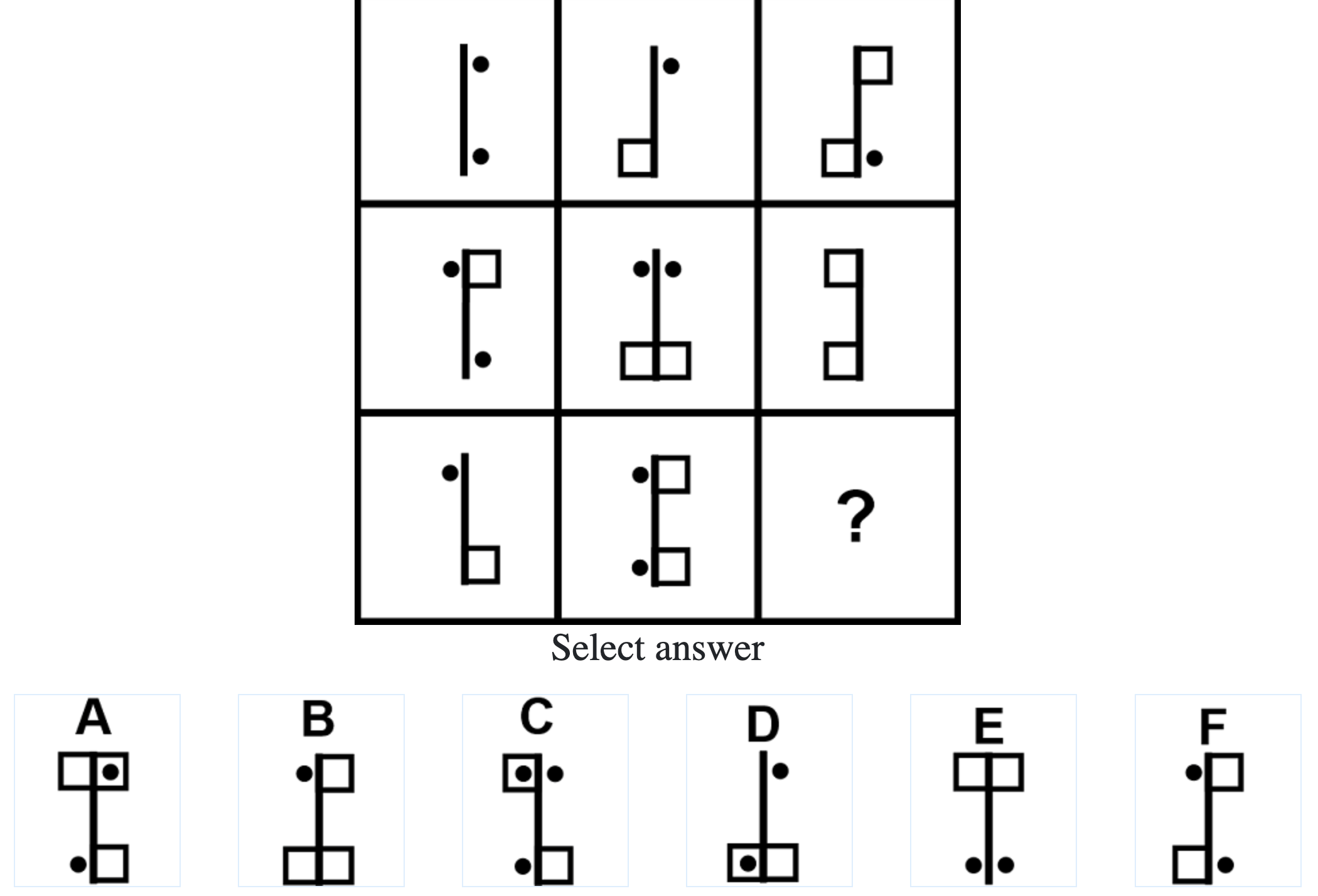
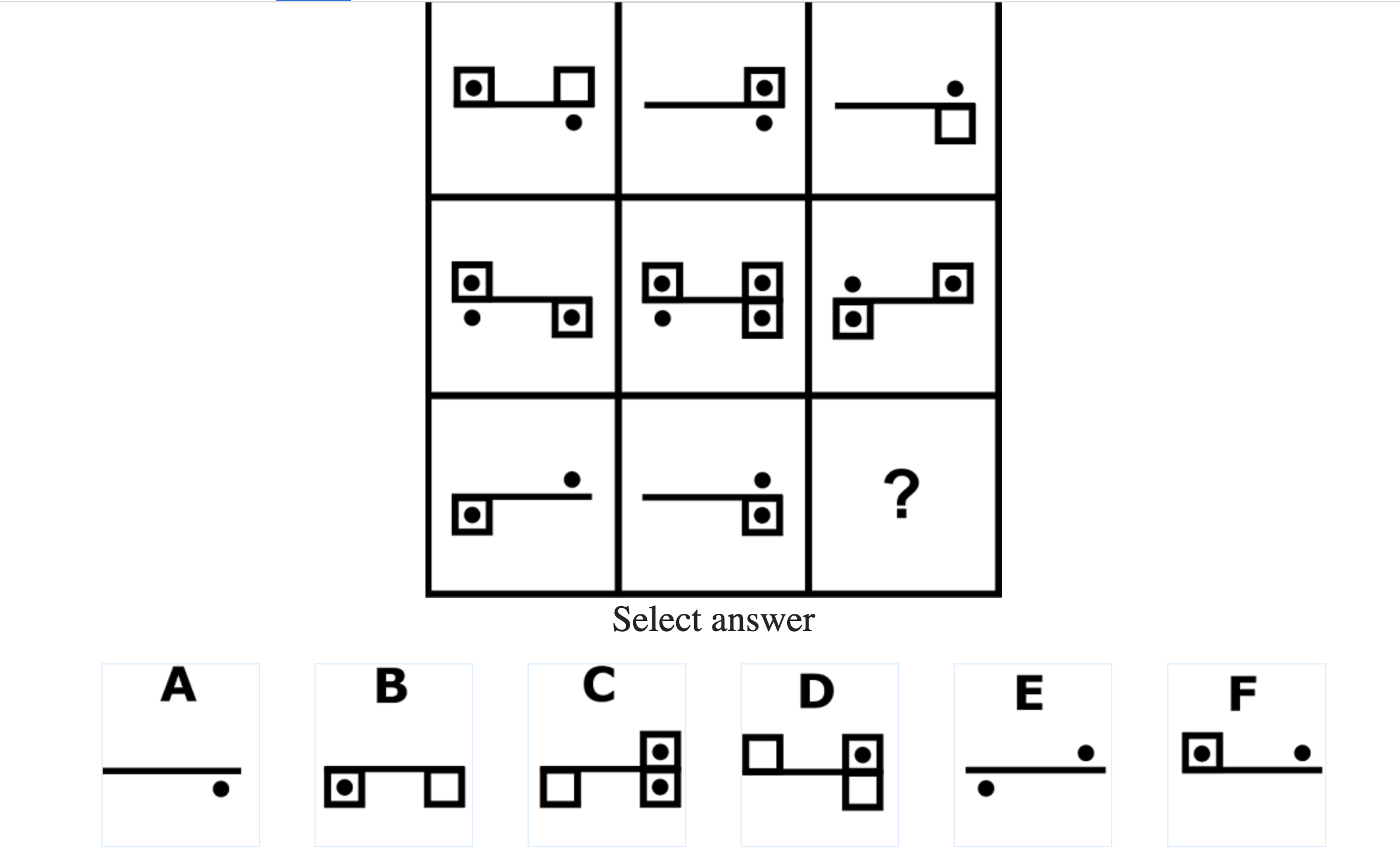
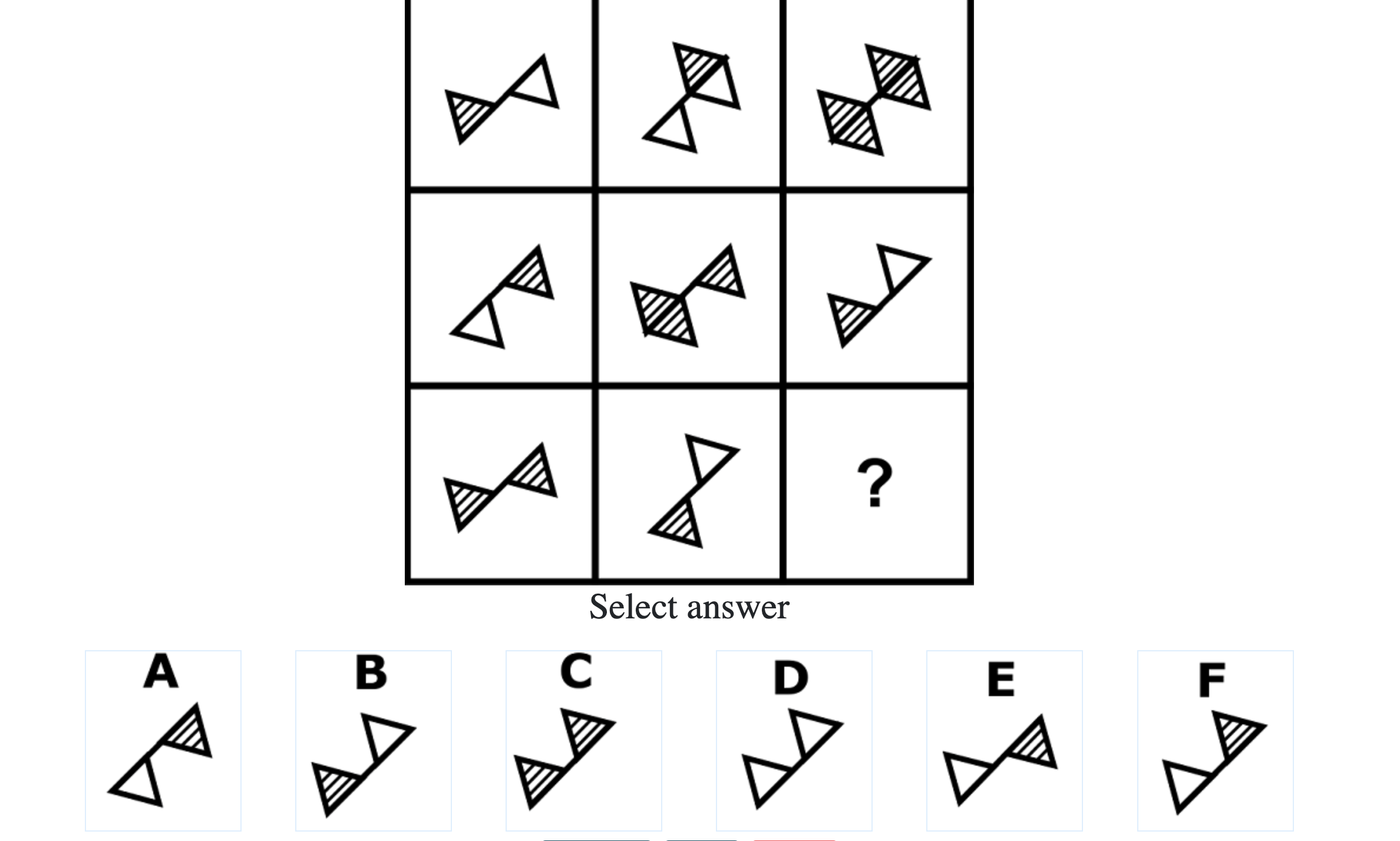
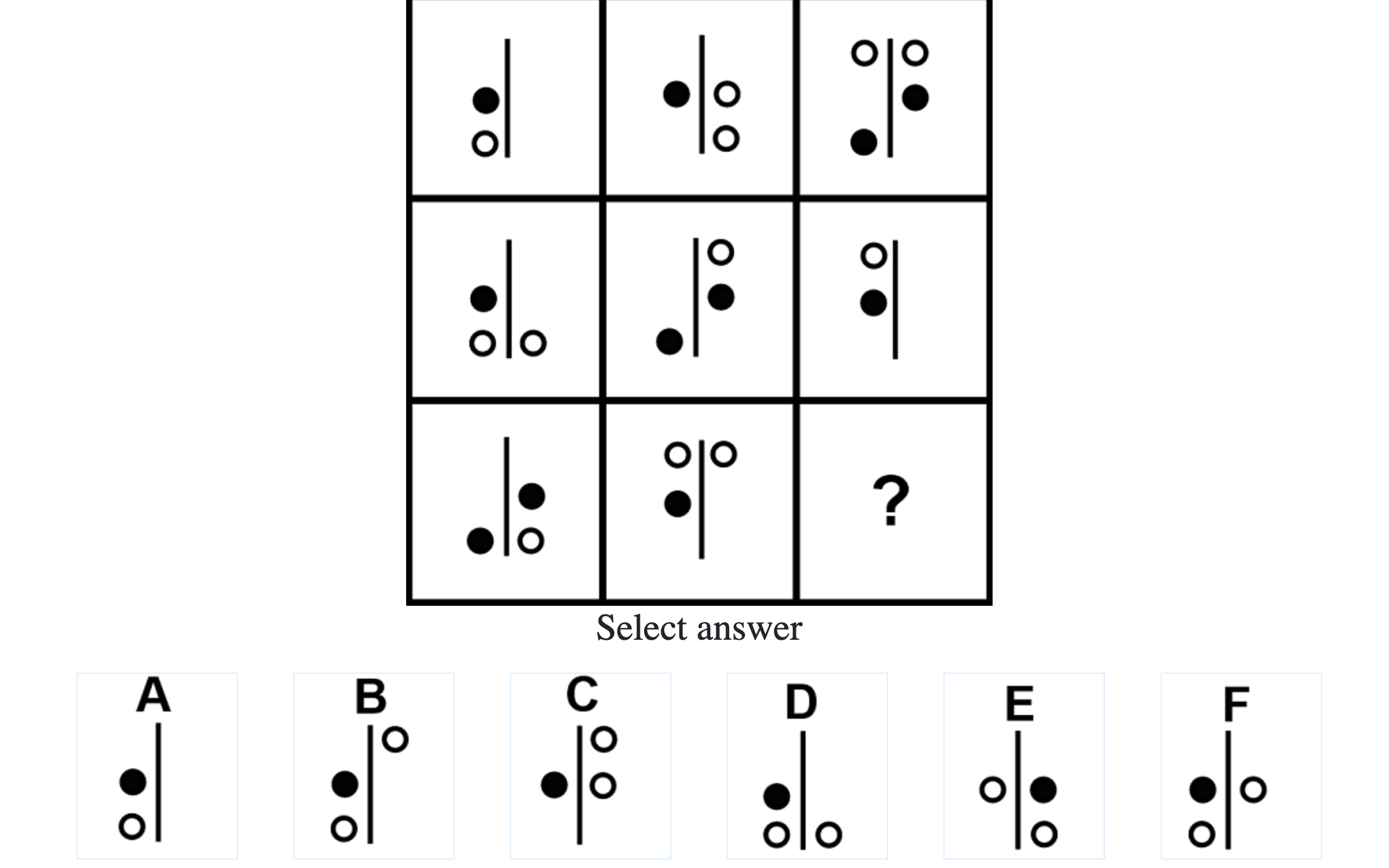
How difficult is the Mensa test?
Mensa Singapore uses the Raven’s Advanced Progressive Matrices (RAPM). I sat for the test around a year-and-a-half ago and was accepted into Mensa.
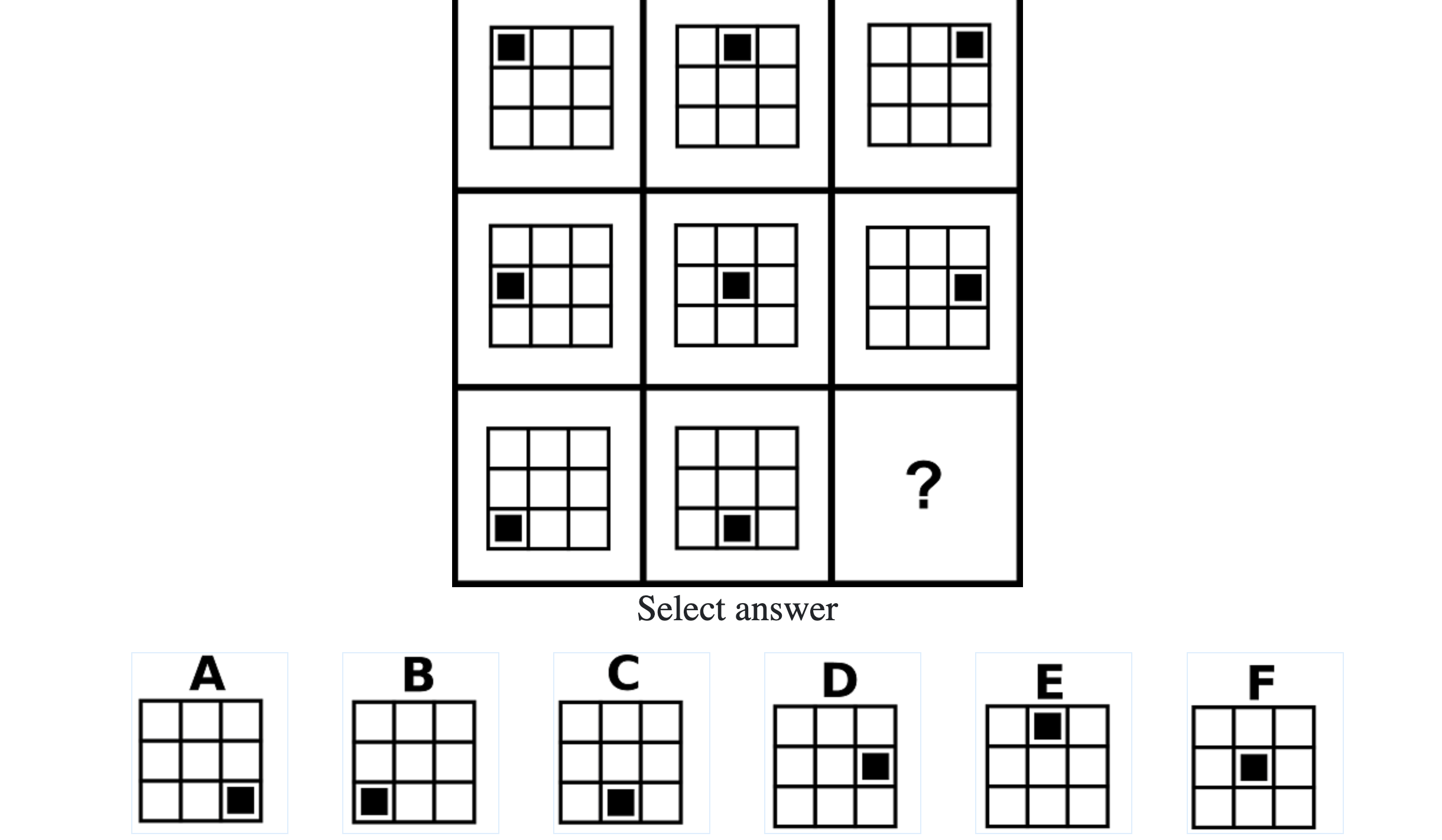
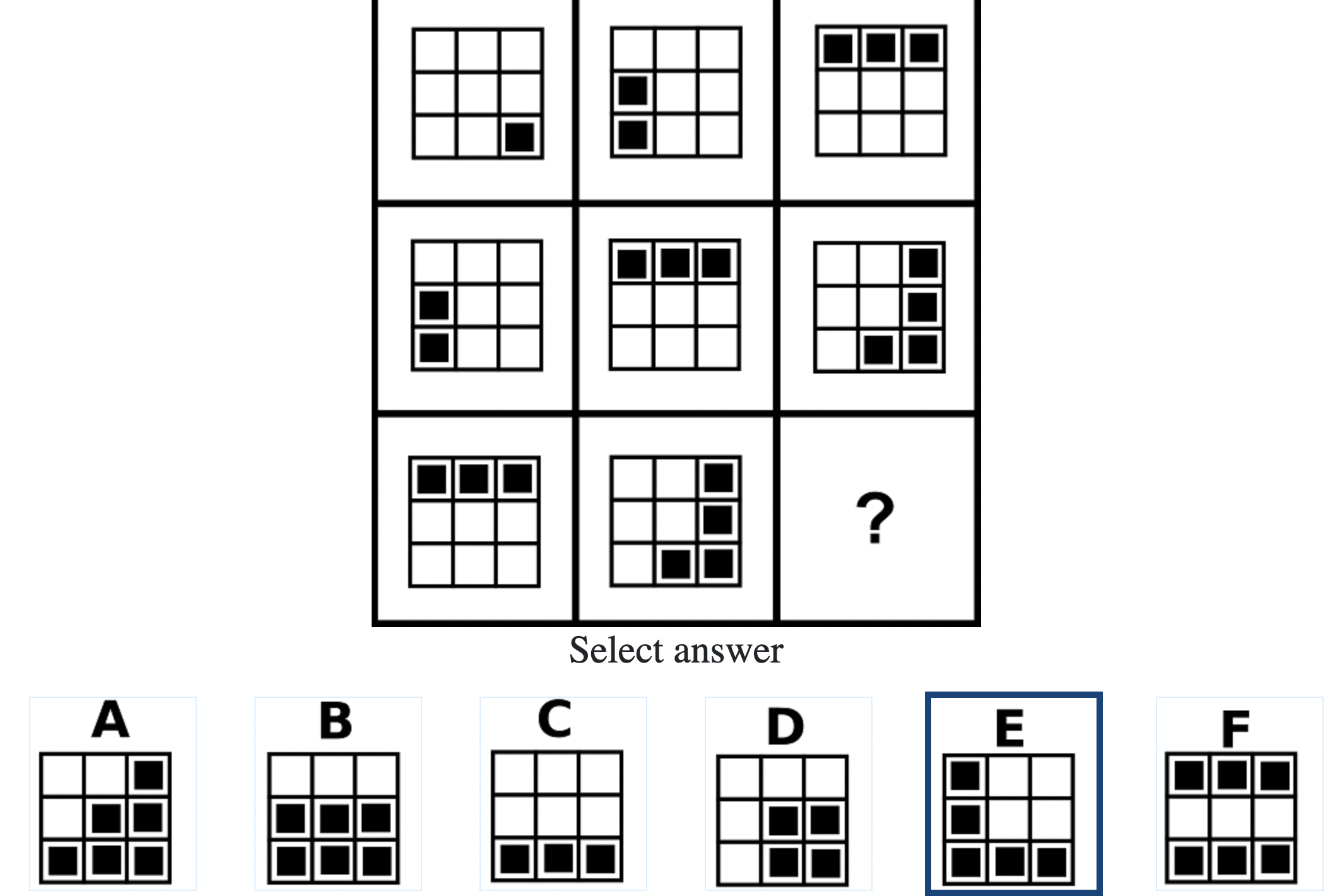
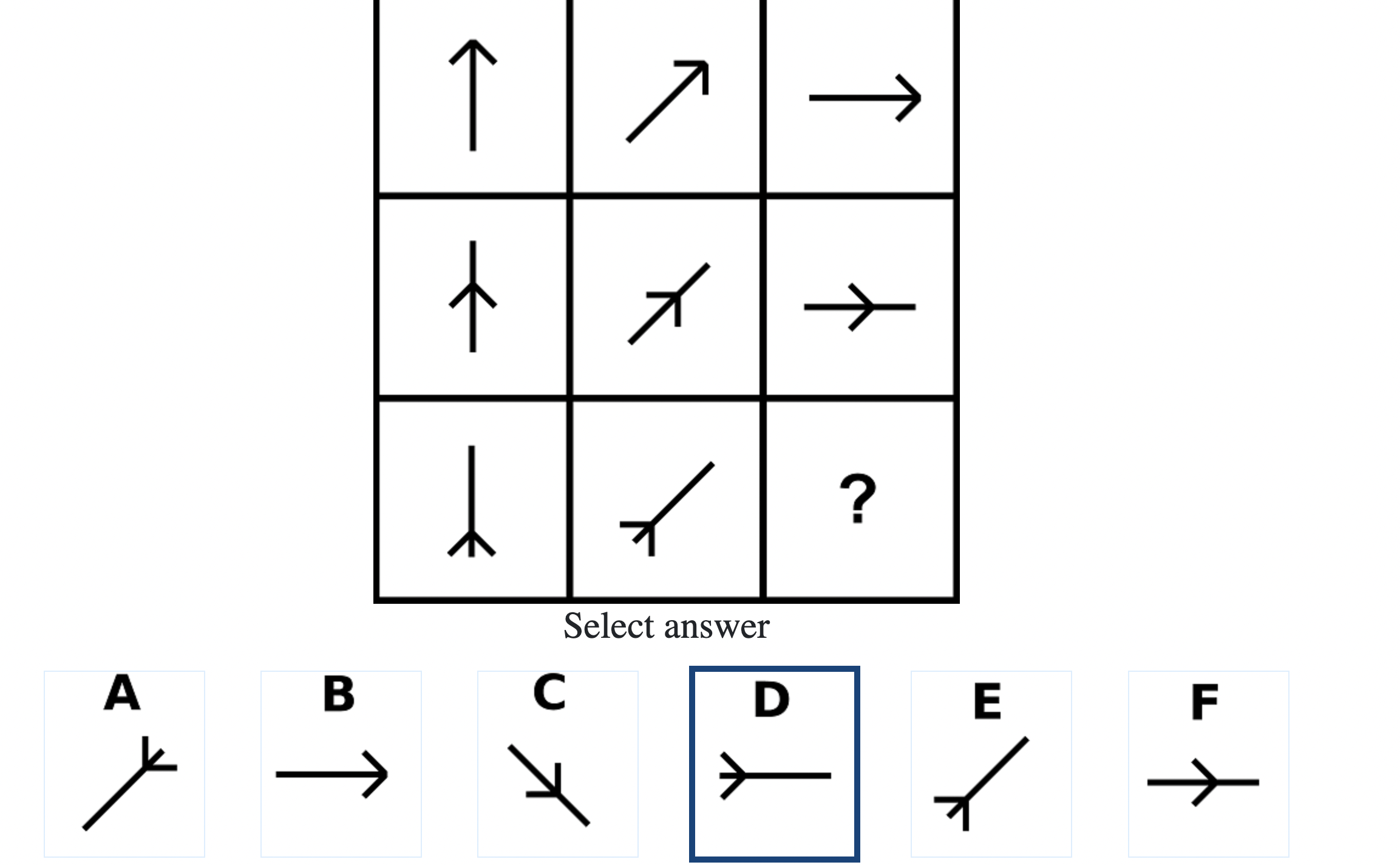
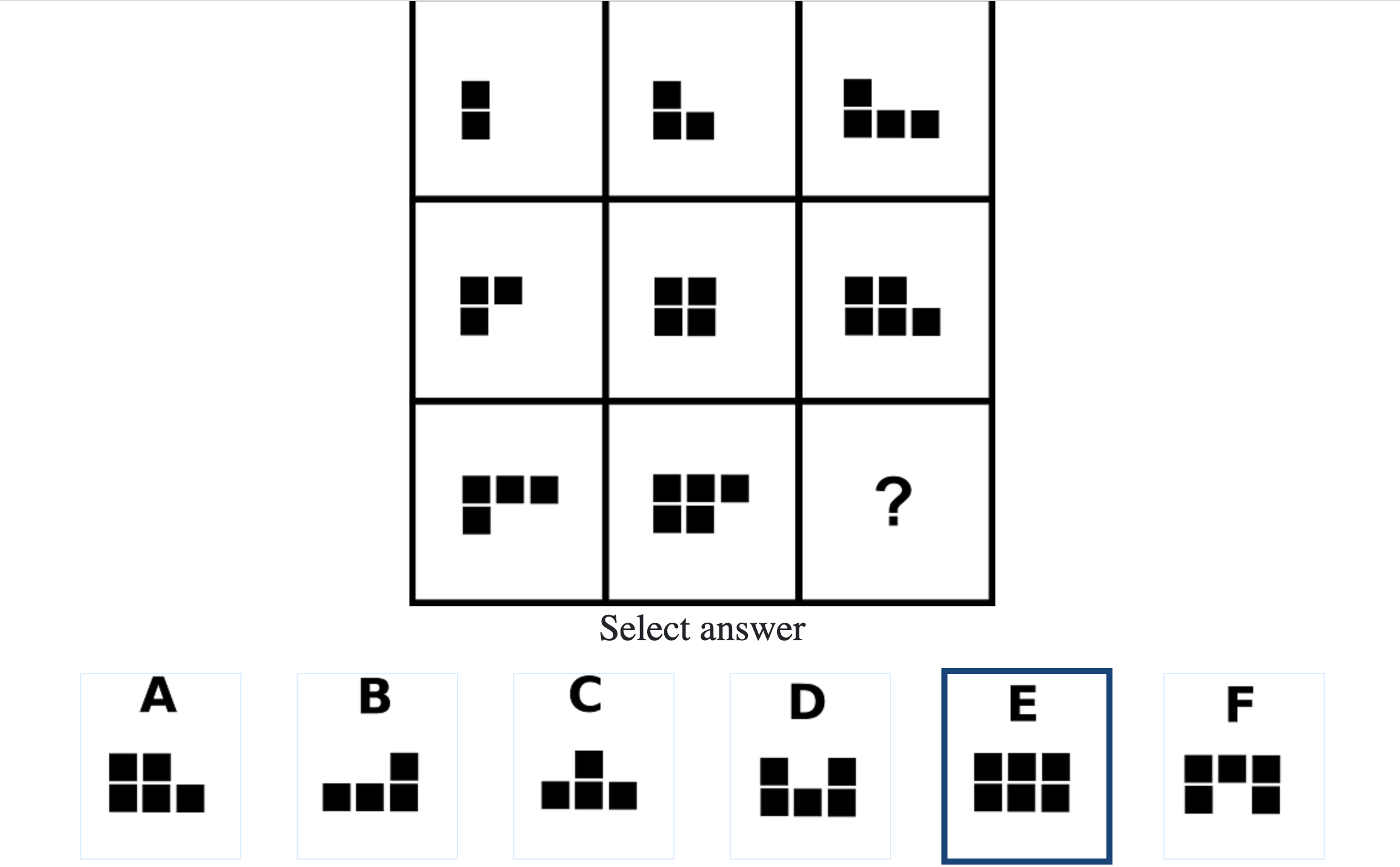
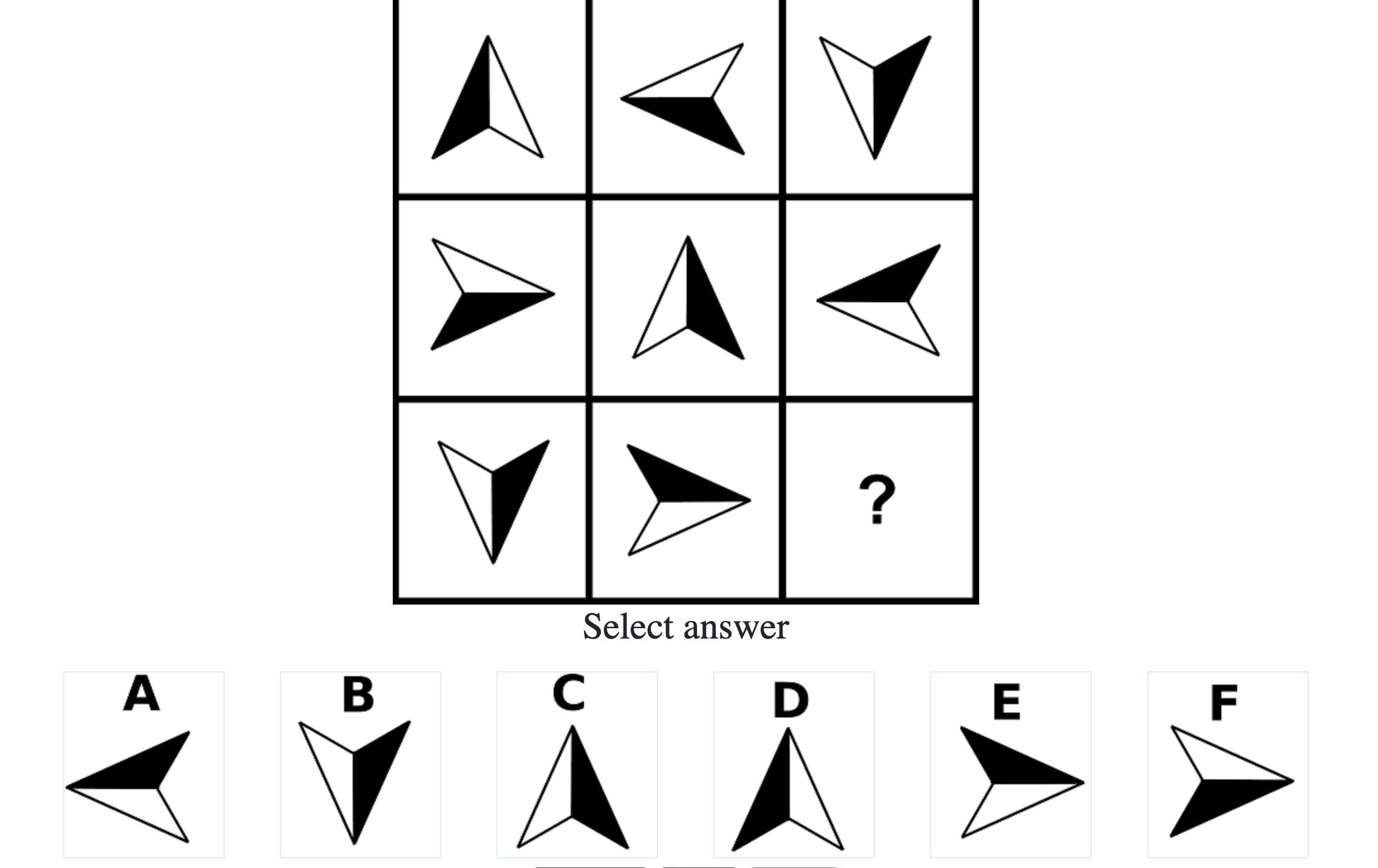
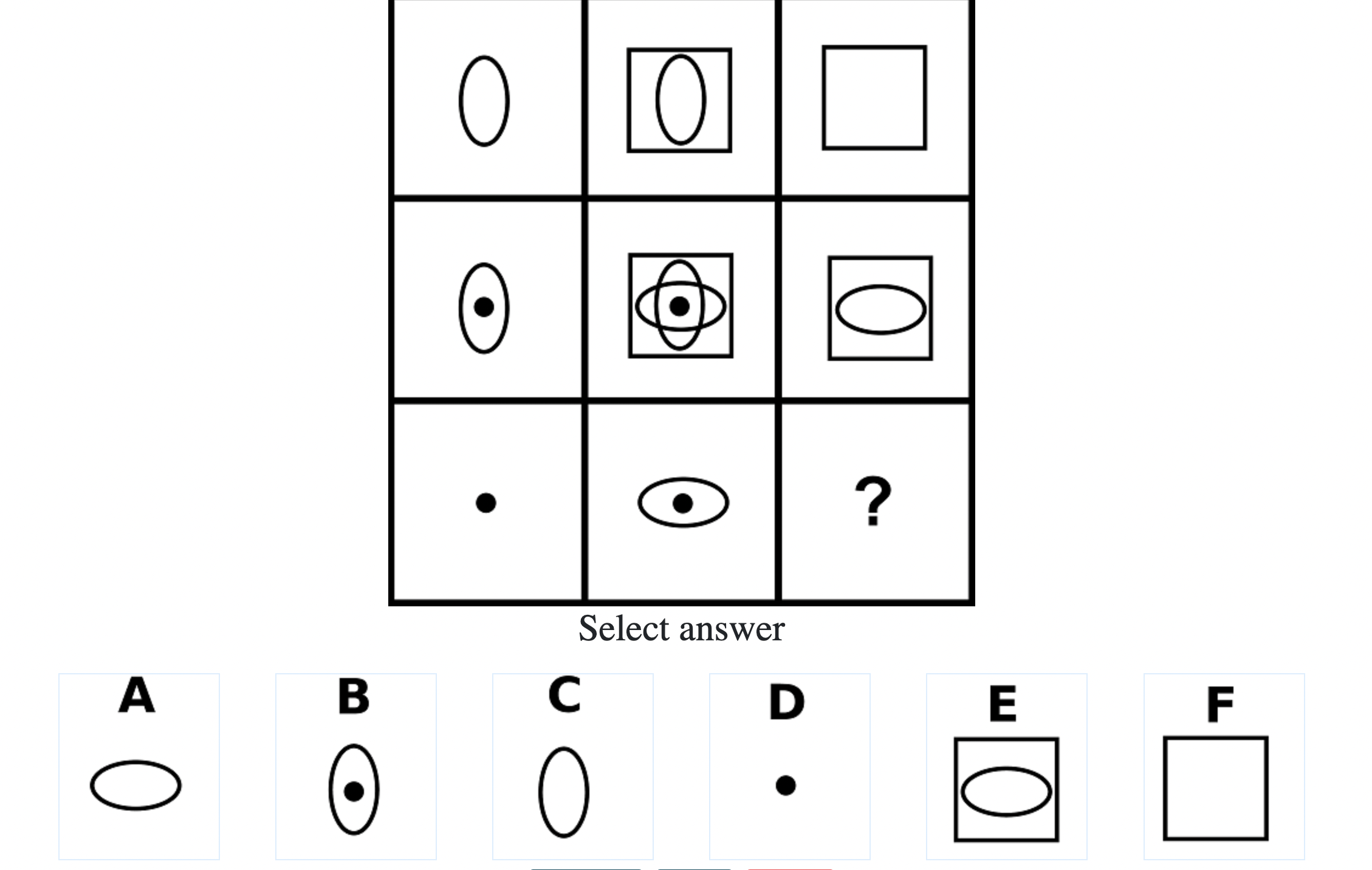
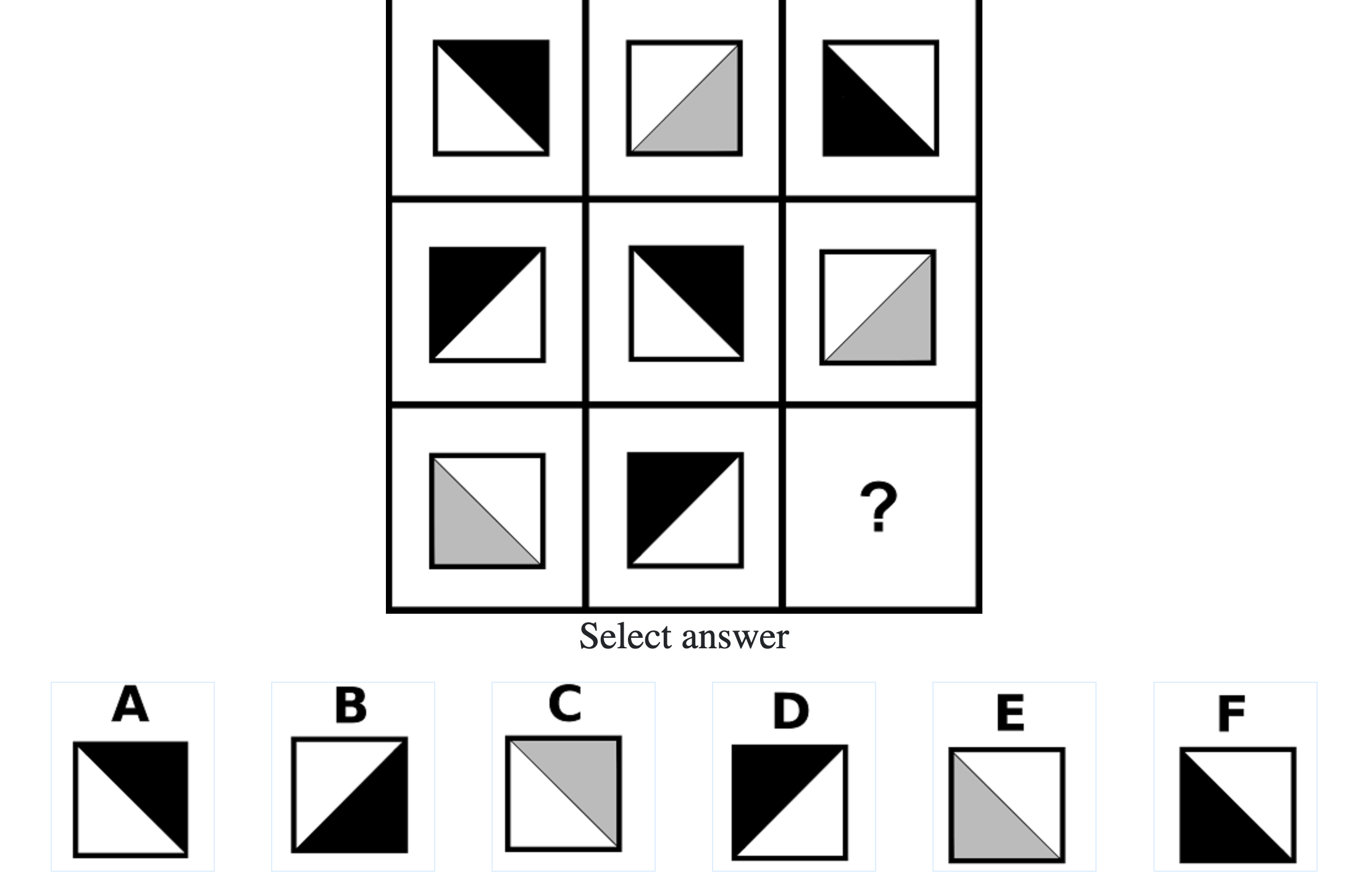
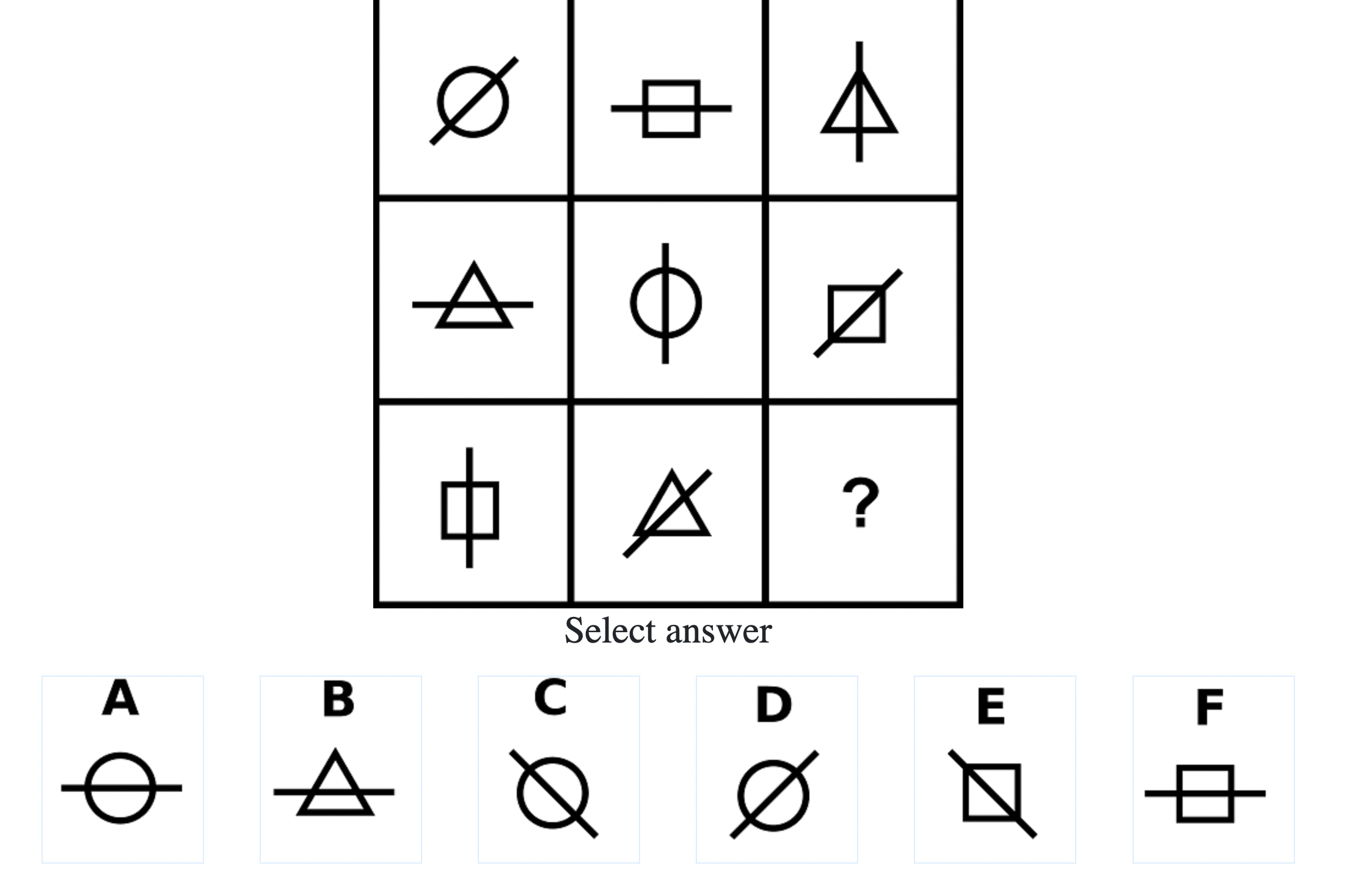
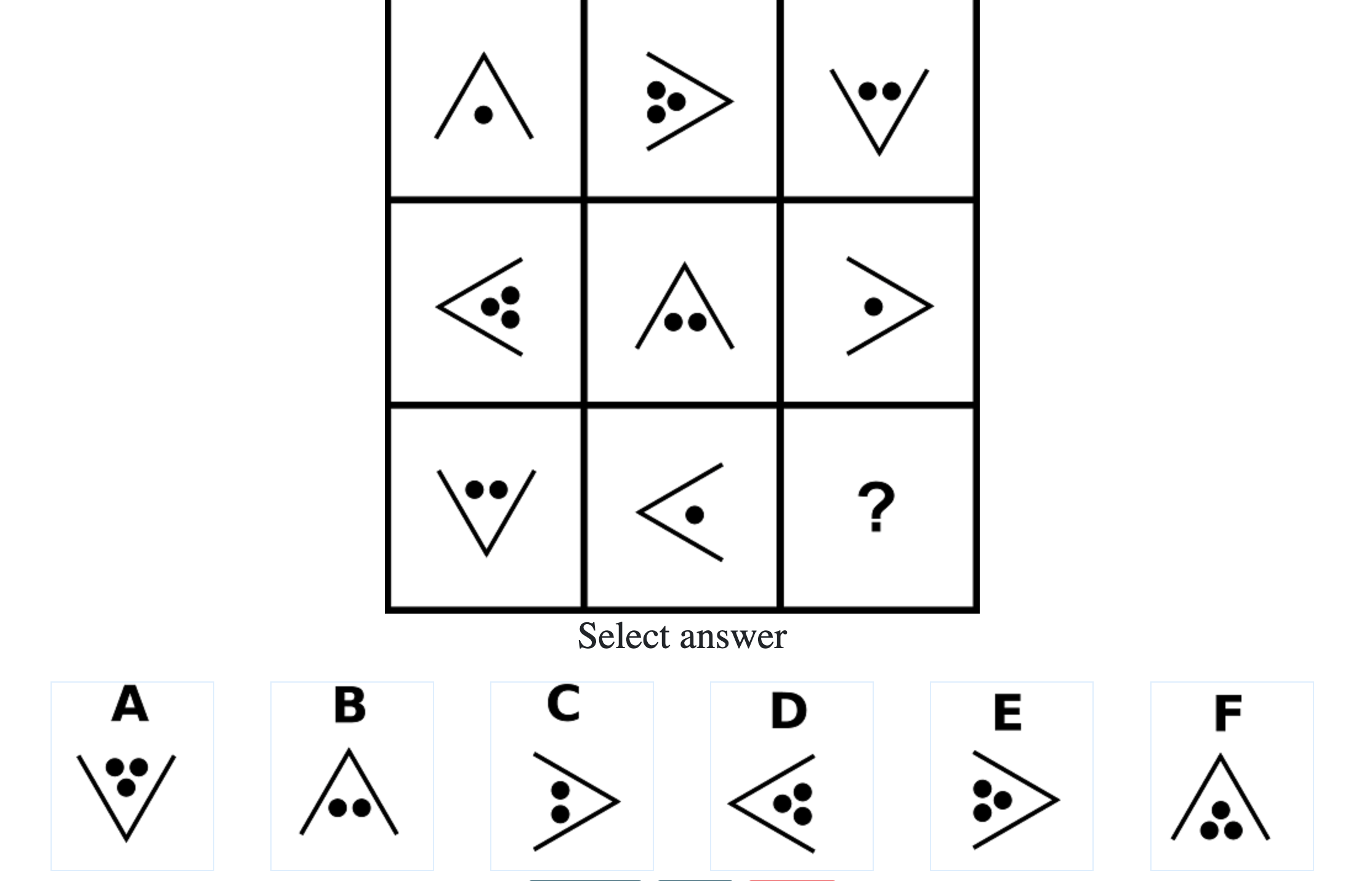
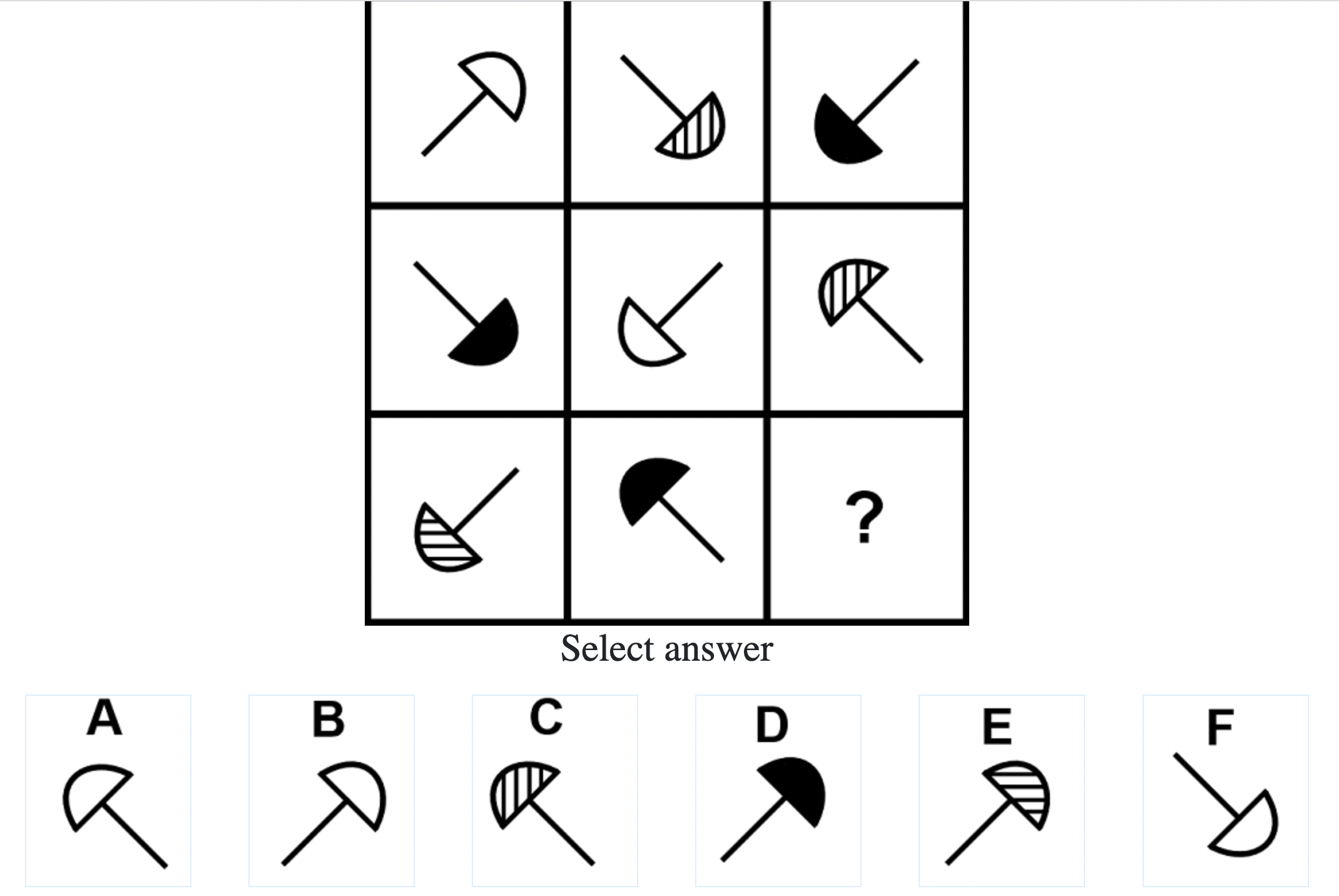
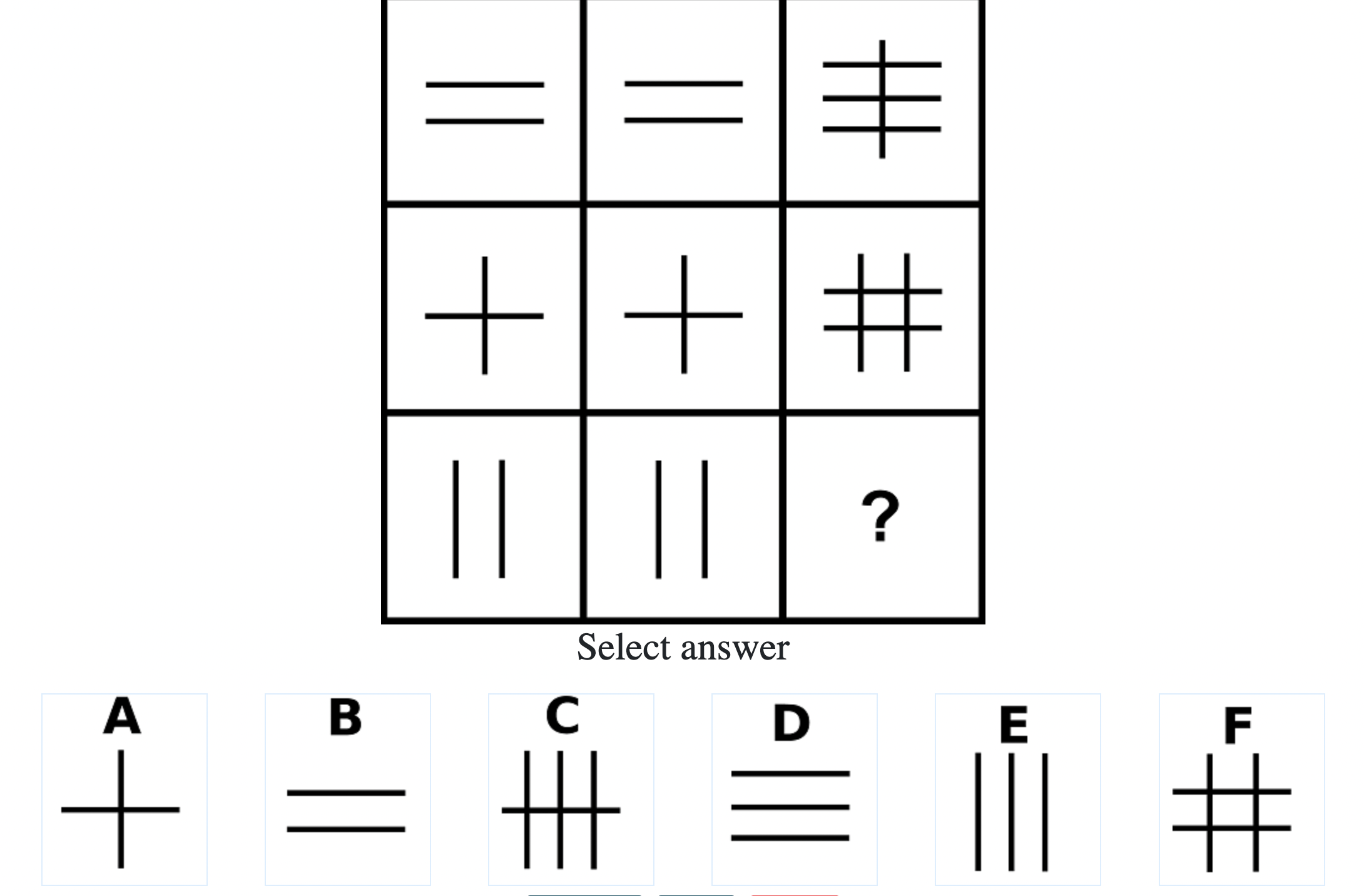
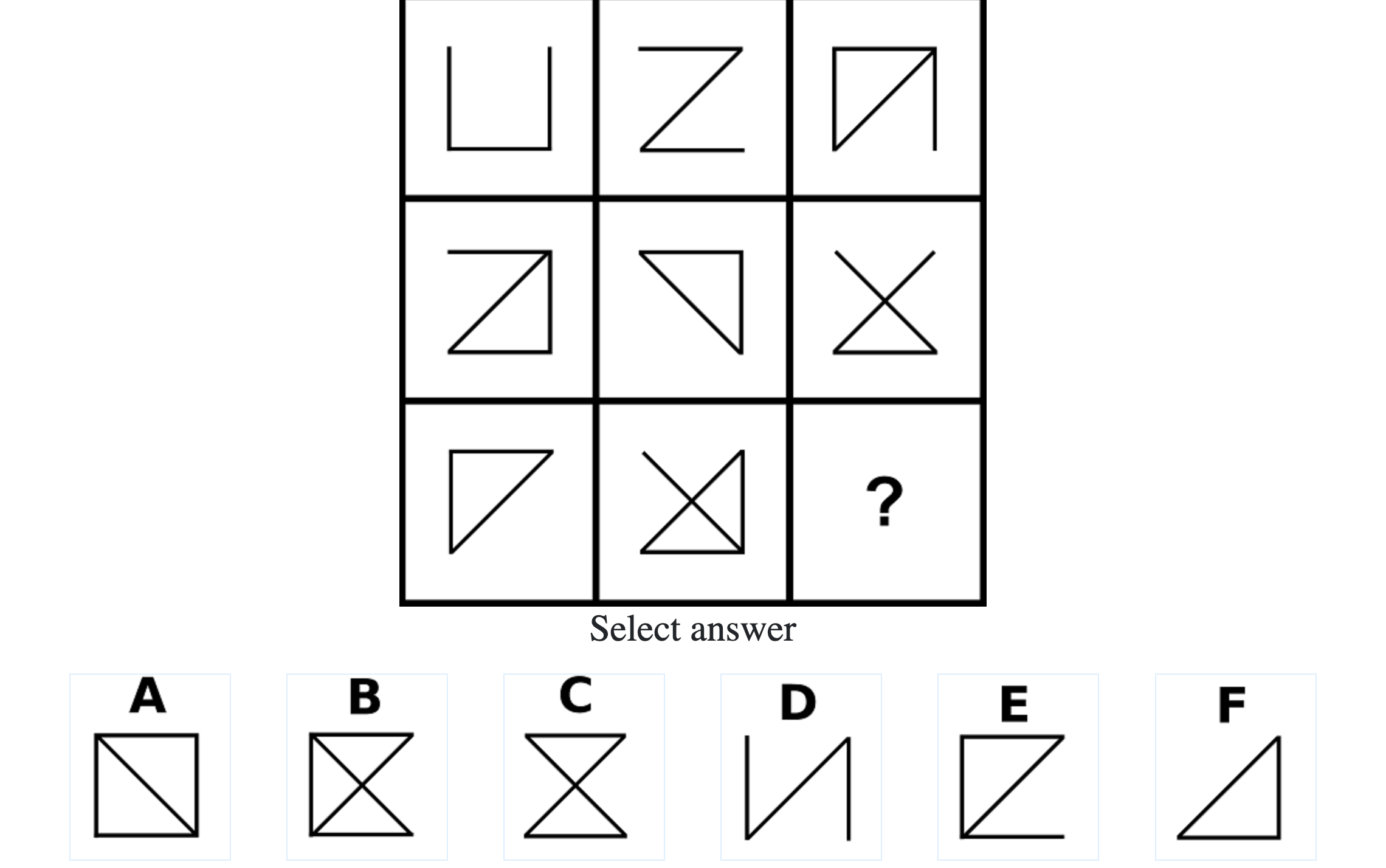
Each question consisted of a 3-by-3 matrix of some black-and-white figures with an underlying pattern. The space at the bottom left corner was blank and I had to choose one out of eight options to complete the pattern. Here’s a picture I found on Google which illustrates the question format:
Since the RAPM tests only non-verbal reasoning ability, you do not need to have any content knowledge to do the questions. However, you do need to have a good working memory, as we were not allowed to make any markings on the diagrams in the question paper.
I remember finishing the test 20 minutes early. There was only one particular question towards the end which I found difficult.
All in all, it’s nothing to worry about; I’m sure that even a sharp 12-year-old could do the test!
What is the difference between people with IQ 145 and people with an IQ of 190?
The usual caveat first, IQ is problematic and widely misunderstood. Almost everyone you ever meet has an IQ between about 80–120. Including the big CEOs and billionaires, politicians and teachers, leaders and successful people in general.
An IQ of 144 or so are borderline being too smart to actually function in society. They’re the serious nerds, the high functioning autistics, and can be the real problem solvers – if they are given a chance and not overlooked because they are socially inept or don’t think about the same things everyone around them does. They might have trouble just keeping a job or a relationship, or getting one that recognizes their intelligence and finds a way to put them to use.
This is already your crème de la crème, the top 1/6th of 1% or so. Honors students at national research universities, National Merit Scholars, and people whose college admissions were more competitive than Mensa, etc.
An IQ of 190 doesn’t practically exist. The occasional rare genius might get labelled with a number this high, but it’s meaningless at this point. This is the territory of DaVinci, Copernicus, Curie, Galileo, Einstein, Aquinas, etc.
What is the most interesting IQ study ever done?
In 1969, UCLA psychologist Dr. Robert Rosenthal did an IQ experiment.
He met with two grade-school teachers. He gave them a list of names from their new student body (20% of the class). He said that each person on that list had taken a special test and would emerge as highly intelligent within the next 12 months.
In reality, those students were chosen totally at random. As a group, they were of average intelligence.
The incredible finding is that, when they tested those children near the end of the year, each demonstrated significant increases in their IQ scores.
So what happened? Why?
The teacher’s own behavior towards those students affected the outcomes.
They gave the fake-talented students more attention. When one raised their hand to answer a question, the teacher often followed up to get better clarification. The teachers were more positive and encouraging to those students.
Meanwhile, the teacher was much shorter with students they deemed subpar. Rosenthal speculated the teacher figured the student might be dumb, so why go the extra mile?
Dr. Rosenthal said, “When we expect certain behaviors of others, we are likely to act in ways that make the expected behavior more likely to occur.”
The opposite of the Pygmalion effect is the Golem Effect; it occurs when our negative expectations generate negative results. This is partly why internalizing stereotypes is damaging.
What can we learn from these effects? Two things.
The first thing
The children in Rosenthal’s study began to internalize the belief that they were special. They bought into the idea, “I am smart so I can do this.”
Their self-efficacy grew and evolved and they stopped indulging in self-limiting beliefs.
The act of believing something to be true can impact every aspect of our life. For example, OK Cupid’s founder, Christian Rudder, did a Pygmalion experiment with online dating.
Researchers lied to users. They reversed the matching algorithm on a select group of singles, pairing them with people who were objectively incompatible. And told them they were high probability matches.
Because the participants believed they had chemistry, they messaged each other and began flirting. They were friendlier and gave each other a shot. Some ended up together.
And now, somewhere out there, someone is banging their nemesis.
We position ourselves to thrive by surrounding ourselves with people who believe in us and hold us to a high standard.
This is why toxic people have such a devastating effect on your life.
The second: Become your own teacher or mentor
Think about a good boss versus a bad boss.
A good boss knows how to communicate and holds you to high but reasonable expectations. They give you useful feedback rather than waiting for you to make a mistake and scold you.
A bad boss does the opposite of those things.
Being an effective mentor to yourself comes down to having a growth mindset.
Someone with a fixed mindset thinks their identity is pre-determined.
They are often self-defeating.
“What’s the point. I’m stupid.”
“I’m too lazy to get in shape.”
“Nobody in my family is successful so I won’t be.”
People with a growth mindset dismiss these things. They are persistent.
They choose to march forward and keep fighting. They stay defiant in the face of difficult odds. They don’t seek out reasons they can’t win.
And they are often the most successful people in the world.
The good news? The fact that you are here reading this self-help article suggests you are likely of a growth mindset.
The takeaway is simple
- Surround yourself with great people who hold you to a high but reasonable standard.
- Treat yourself like another person who you are responsible for. Treat yourself like that student who is talented.
- Have the courage to believe in yourself even if nobody else does. Become a prophet of your own success.
For a person with an IQ of 140, is speaking to normal people (IQ 100) comparable to how normal people feel when speaking to someone w/ an IQ of 60?
Not even close. It doesn’t work that way.
A person with an intelligence quotient of 60 can barely function and complete everyday mundane tasks like using a smartphone to access Quora.
An IQ of 60 is found at the opposite end of 140 on the intelligence spectrum and is present in less than 1% of the population.
There are plenty of average IQ individuals that are well studied, well-spoken and quite interesting.
That said, filling your head with a plethora of information and factoids doesn’t make you knowledgeable. “Knowing” comes in degrees and varieties of quality and there’s quite a hop forward between “smart” and “brilliant.”
The major difference between normies and people in the high IQ range considered gifted/genius is their capacity to think. Not ability but, capacity. There’s a difference…
Your ability to think is more of a philosophical matter and intellectual skill—at least, fundamentally. You can be taught how to think by an intelligent and wise person. And hey, if you ever find such an opportunity, take it, because very few people walking around are privileged with this type of mentorship.
That said, the brain of a genius still has it easier when it comes to the ability to think as well. For instance, I didn’t need a PhD to develop the same ability for thought as say, your college professor.
The fundamental ability is innate. I was born with it and my capacity for it is greater.
Still, the major difference is capacity.
Chances are, if you find yourself listening to, or talking to someone with profound insight and, well, brilliant ideas, that person is likely in that top 1%.
But on both sides of that interaction, there’s a give and take that is enjoyable for both parties.
A normie trying to converse and partake in an exchange of ideas with the unfortunate soul that has a 60 IQ wouldn’t be much of an interaction. It would be pretty one sided.
A normie and a 140 plus is game on and pretty fun—especially if the normie is educated and smart.
What math, physics, or logic problems can I solve to make some quick prize money?
The Coin Toss Problem
Here’s the puzzle/problem:
Let’s presume we are best friends. I live in the house next to you. I make a gaming proposition along the following lines:
You throw a coin over and over again. So long as it comes up heads, you keep throwing. When it comes up tails you stop and I pay you $$$ — depending on how many heads you threw.
If you threw a tails to start, you get $0.
If you threw a heads then a tails, you get $1.
If you threw 2 heads then a tails, you get $2.
If you threw 3 heads, you get $4.
If you threw 4 heads, you get $8.
If you threw 5 heads, you get $16.
And on and on. The payoff doubles every time you add an extra heads.
Since this game consists entirely of me giving you money (from $0 to $??) — you will have to buy an “entry” —
How much will you pay me to play this game? — *Once.*
If you can solve this problem (and it has a solution) — you are well on your way to an early retirement.
This puzzle came up at the Physics Department Christmas Party at Stanford University in 1984.* I was the first to solve it. It took me about 24hours of passive playful pondering. I was 23.
But you were asking about money? Ok, I retired at age 33, only 37 months after I began work. Coincidence?? — Not entirely. (That story is here.)
This is a *difficult* puzzle.
Hopefully you will understand it.
Hopefully it will inspire you.
By w.w. Lenzo
Solution hints to Coin Toss Problem:
AFTER 765 DAYS: the question has been viewed 20,000 times inspiring only 71 answer attempts. We have SIX CORRECT RESPONSES! (see below)
Fifty-two answers were just guesses from people who clearly did not understand the problem. One person ran a test, collecting data. Only nineteen came from people who could perceive the infinity hidden within the puzzle — so let’s imagine they have an IQ>130.
Eleven of those nineteen made an effort to crack the paradox and six have so far done so correctly.
First Prize Goes To —
* * * Peter Barnett! * * *
* * * Nat Han! * * *
* * * Davide Checchia! * * *
* * * Io Scapula! * * *
* * * Angus Sullivan! * * *
* * * Erik Rådbo! * * *
The Turning Cards Problem:
I have a stack of 100 index cards. On each card is written a unique number. Each number can be positive or negative, whole or fractional, rational or irrational (like pi). Each number is real and unique.
These cards are placed in a huge bag and tumbled around until they are thoroughly randomized. Your job is to find the card with the highest number on it. The challenge is: You are only allowed to look at the cards one at a time. You must toss away the card in your hand before you can draw another card from the sack. In order to win you must say “stop!” at exactly the moment you are holding the highest card. You can never go back to an earlier card.
What is your optimum strategy?
What chance does that strategy give you to win this game?
What would your chance be if the stack had 1 million unique cards?
Finally (as though that weren’t enough) — suppose there were 1 million cards, but the winning condition is now to find either the highest card -or- the 2nd-highest card. How does that change your tactics? What now is your chance to win?
Clue: the answer to the last question is you have a 58% chance to end up with one of the two highest cards in a deck of 1 million cards!! (if you use optimal technique). Wow!!
Now, if that doesn’t inspire you, you’re not really alive to what’s going on here.
This second question/puzzle is interesting because it models a real-world problem that we face all the time — coming-to-terms with an unknown situation and making effective choices.
- How do we finally settle on a husband or wife?
- How do we choose which house to buy?
- How to pick a career? Or a philosophy?
Remember: 58% is possible on a million cards!! — Now think!! —
AFTER 650 DAYS: this question has been studied (approx) 24,000 times inspiring only 10 answer attempts. We have TWO ANSWERS which are 95% CORRECT!!—
First Prize (Almost) Goes To —
* * * Zijin Cui * * * — a college student —
* * * Bernard Cook * * * — an anesthesiologist —
Woo! Hoo! — Congratulations!!
Zijin solved the problem using good intuition and an unusual statistical approach. Yes, this is a stats problem disguising itself as a math puzzle.
Bernard solved my harder 58%-version by fearlessly applying combinatorics and Stirling’s approximation to zero-in on the correct answer. He took the bull by the horns and deftly flipped it belly-up. Kudos!!
Nonetheless, I am still hoping for somebody to solve both problems in closed-form (for an arbitrary number of cards).
Since nobody seems able, I will give a huge hint:
You have to use all the obvious variables PLUS you must invent a non-obvious variable to create an expression for the probability of winning. The calculation requires solving a double integral. One of these integrations is across the non-obvious variable, which then disappears entirely from the calculation & the solution.
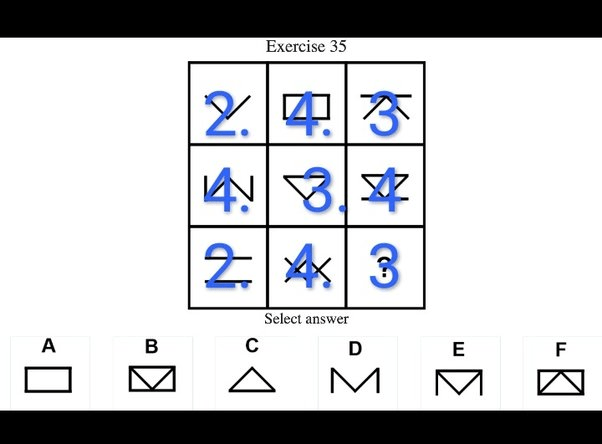
Haselbauer-Dickheiser Test
This test is known as the Haselbauer-Dickheiser test for exceptional intelligence.
The question source is: The Most Difficult IQ Test in the World
Source of 25 above images: The Most Difficult IQ Test in the World
Some possible answers:
- October 2018 – Dimitrios Kalemis
- November 2018 – Dimitrios Kalemis
- December 2018 – Dimitrios Kalemis
- January 2019 – Dimitrios Kalemis
- Sources: http://matrix67.com/iqtest/
BONUS QUESTION
Really stretch the ol’ brain a bit, loosen the cobwebs:
- What is existence made of, at the smallest scale?

Mathematic/Arithmetic Problems:
What is ‘epicness’ in artistic mediums?
“A feeling of ‘epicness’ occurs when someone who has been habituated to perceive a piece of art at one scale suddenly must perceive that piece of art at a different scale, and realizes that they had the option to perceive it in that way the entire time. ‘Scale’ refers to effective size of interactions; for example: ‘nano’, ‘human’, or ‘planetary’ scales.” Given this is true, explain how the concept of “sometimes what you were looking for was right under your nose the whole time” can result in a feeling of ‘epicness’. Describe a situation where that concept would not result in a feeling of epicness. Describe an addition to that situation that makes it feel epic. By Elliott Kelley (IQ: 190)https://www.quora.com/profile/Elliott-Kelley
How do geniuses and people with high IQ (above 180) solve problems in real life and very hard questions in an IQ test?
A few traits of the profoundly gifted include divergent thinking (different ways of considering the problem and its possible solutions–think back to spontaneous challenges in Odyssey of the Mind from grade school), thinking in analogies such that information is interconnected (so, math and music and sociology concepts may be linked in memory), and projection into the problem (such that someone literally is walking through a mental representation of the problem as if he/she were the problem). Complex material is quite simple because of these traits, but simple problems become a bit of an overload, as the question-makers aren’t anticipating interconnection of material or divergent solutions. Combining multiple steps into a single step is also common (holistic learning).
This allows profoundly gifted individuals to intuit solutions to material they may not explicitly know or have seen before (such as math included on the SAT taken prior to junior high). For references on this, see here: https://www.slideshare.net/ColleenFarrelly/understanding-the-profoundly-gifted
As an example, take a writer who is imaging a scene with several characters. She might close her eyes and imagine the scene involving those characters and then imagine herself as that particular character. Doing this for each step of the scene allows her to intuit how each character would respond to the situation and to each other, along with allowing her to mentally visualize the scene unfolding. In this manner, she simply records what she sees in her mind’s eye.
What is a person with IQ between 150 & 160 like?
I’m going to go anonymous on this because I don’t usually talk about my IQ to anyone.
- Finding meaningful conversation is seriously hard since I feel that people don’t always understand what I’m saying unless they happen to be an expert on said subject.
- Thus, I find it hard to symphatize with other people since their worldview is vastly different.
- I have been clinically depressed when I was younger since I couldn’t adapt to norms.
- I have never cared and never will care about societal norms.
- I’m social and have huge social circles but only few friends.
- School was never hard for me but I never got great grades since I got bored and lazy about school. It never gave me anything new or exiting to research.
- I often got in trouble at school for talking against teachers because I knew they were wrong and got offended when corrected.
- I have always absolutely loved all science and I’m fascinated about almost any subject you can humanly think of.
- I hate people who feel superior solely based on their IQ. Critical thinking, expertise and hard work will earn my respect, not your IQ. This is why I’m not part of Mensa.
- I would really like to meet someone with substantially higher IQ than mine.
- When people challenge in constructive way and argument their points very well I feel like I’m in heaven. It’s truly great though rare.
- Short fuse has always been my problem and I’m learning to control it.
- I despise irrational thinking.
- But love facts.
- Find it funny when people try to “teach” me things that aren’t true or at least largely untrue as facts.
- I’m blunt and don’t usually sugarcoat things.
- I find dating extremely hard since I get easily bored (my current partner is an exception to this rule).
Bottom line is that I try to get by and help people as much as I can and be understanding. Slowing down for others is often frustrating but I feel like I’m getting so much out of this that I wouldn’t trade my life for anyone else. By the Author
Who has the highest recorded IQ of all time?
Top 10 highest recorded IQs of all time
10. Stephen Hawking IQ-154
9. Albert Einstein IQ 160–190
8. Judit Polgar IQ-170

7. Leonardo Da Vinci IQ 180–190

6. Richard Rosner IQ-192

5. Gary Kasparov IQ-194

4. Kim Ung Yong IQ-210
3. Christopher Hirata IQ-225

2. Terence Tao IQ 225–230

1.William James Sidis IQ 250–300

In 1899, at age one, Sidis could already confidently read The New York Times by himself. At age eight, he was fluent in eight different languages (Armenian, French, German, Greek, Hebrew, Latin, Russian and Turkish) and had invented one for himself called ‘Vendergood’.
Sidis set the world record in 1909 for the youngest enrolment in Harvard University—he was 11 years old—studying advanced mathematics.
Yet Sidis’ memories of this time were far from happy. His biographer, Amy Wallace, claimed that,
“He had been made a laughing stock [. . .] he admitted he had never kissed a girl. He was teased and chased [. . .] and all he wanted was to be away from academia [and] be a regular working man.” [1]
If that wasn’t already enough, news reporters frequently followed Sidis around campus, seeking to sensationalise his story.
It is considered that Sidis’ IQ fell somewhere between 250 and 300 (Einstein’s IQ was estimated at 160). [2]
After graduating Harvard at 16, Sidis worked a brief stint as a mathematics professor at Rice University (Houston, TX). He resigned shortly after, however, because he was harassed by journalists everywhere he went. He claimed,
“I want to live a perfect life. The only way to live a perfect life is to live in isolation.” [3]
And that he did. Following his resignation, Sidis went into hiding, moving from city to city, working minimum wage jobs to earn his keep. During this time, he wrote a vast number of books in subjects ranging from modern history to mathematics.
In 1919, he was arrested for his coordination of a number of communist rallies and sentenced to 18 months in prison. After his release from prison, he isolated himself in his apartment in Boston. He was determined to finally live an independent and private life, becoming estranged from his own parents in the process.
It was there that he lived out the rest of his days. Isolated and, for the most part, completely alone until his death in 1944.
It seems all Sidis ever wanted was to lead a ‘normal life’. And he was, most certainly, cursed with one incredibly remarkable mind.
Edit: I think it’s absolutely hilarious you guys have all this information worth contesting about this guy, and all you care about is the brief mention of “communist rallies”.
Footnotes
Reference: Mensa Norway
IQ Q&A:
How will the world look like when AI GPT models reach 1600 IQ?
Mo Gawdat, former Chief Business Officer of Google [X] predicts that AI will evolve from this year’s 155 IQ to 1600 IQ within the next decade.
Gawdat describes that this will be equal to the relative difference between Einstein’s IQ to of a fly.
What kind of problems do you think AI will be able to solve then? How will humans decode or translate the results?
Some notable comments:
Things will be similar to industrial revolution, first the society will disrupt(average human economic value will fall) and revolution or war will come. Than, we will have a new historic era. New economic approaches new type of working, education and social structure.
Industrial revolution happened 1760 – 1840 => https://www.britannica.com/summary/Industrial-Revolution-Timeline
and first war started 1914 (fast economic transformation triggered total war).
And lets look when computer revolution started: 1971
https://en.wikipedia.org/wiki/History_of_personal_computers
when it enters the workspace and start doing your job, we can call it economically revolutional. So, we are expecting till 2040’s nearly all of jobs right now will be useless, and it already started:
By looking the history, when society economically disrupted we see big crisis than war. Now, our economy is not doing great, for young person its impossible to buy a home by just working at job. This will definitely cause economic crisis and war in the end. So, things already started, 2024 will be awful year economically i believe. And after next year or inside 2024? Good luck everybody
What are some extremely difficult genius level (160+) IQ questions?
Genius-level IQ is typically considered to be 160 or above. Questions for individuals at this level would likely involve complex problem-solving, advanced mathematical concepts, pattern recognition, and critical thinking. Here are some types of questions that might be challenging:
1. Advanced Pattern Recognition:
Identify the next figure in a complex sequence, or determine the underlying rule of a series of shapes, numbers, or symbols.
2. Cryptic Crossword Puzzles:
These require a deep understanding of the language, wordplay, cultural references, and the ability to think outside the box.
3. Abstract Logical Puzzles:
Solve puzzles that require advanced logic and the ability to see multiple steps ahead, similar to high-level chess problems.
4. Mathematical Problem Solving:
Solve complex mathematical problems that require a deep understanding of various mathematical concepts and theories.
5. Memory Challenges:
Remember long strings of numbers, letters, or symbols, and then manipulate or recall them in specific ways.
6. Spatial Visualization:
Visualize complex three-dimensional shapes in your mind and solve problems related to them.
7. Philosophical and Theoretical Questions:
Engage with deep philosophical questions that require critical thinking, extensive knowledge, and the ability to articulate and defend a position.
8. Creative Problem-Solving:
Generate innovative solutions to complex problems that may not have a single correct answer.

How do intelligent people recognize each other?
You can see it in a person’s eyes where they stand mentally. If you don’t believe me, go to a pre-school (ages 4-5) with average kids and speak to one. Look them in the eye. Then go to a pre-school for gifted kids and look them in the eye. You can see it within, that there is something… “more”. You can see their effortless focus and attention on you, and you feel that they are “there” listening and processing what you’re doing, saying, etc. It’s as if you can see their little gears effortlessly turning away, figuring you out. It never goes away and stays with them throughout their life. They may be able to hide it, but it’s there if you look.
Young ones haven’t learned to hide it yet, and most don’t even realize they have it, but you can see it, plain as day and night.
If you’re interested in learning more about the secret signs of intellectual brilliance and how intelligent individuals identify each other, check out this fascinating article: The Secret Signs of Intellectual Brilliance: How Intelligent Individuals Identify Each Other. It delves deeper into the unique qualities and behaviors that set intellectually gifted individuals apart from the average population.
Is the difference between IQ 190 and 130 as big as between 130 and 70?
Is the Sigma test the hardest IQ test? The last problem is finally solved. People with an IQ between 180-200 could never solve it.
Can a 130 IQ correctly answer a question from a 160+ IQ test?
Is it okay if I assert myself as “smarter than everyone else in the room” if my IQ is 126?
What are some things only a person with 160 IQ+ could solve within a reasonable amount of time?
How does a person with an IQ of 170+ think?
What would be an example of an IQ question that only someone with an IQ of 135+ could answer?
What are the most difficult IQ questions?
What is a person with IQ between 150 & 160 like?
Do you think 140-160 IQs are mostly where “average geniuses” and polymaths are?
How much different between a person with IQ 180 vs IQ 90 in their way of thinking? Please provide some example
Can you solve this IQ-test question? -168 IQ requires
aptilink iq test
What are some ways we can use machine learning and artificial intelligence for algorithmic trading in the stock market
AI Revolution in October 2023: The Latest Innovations Reshaping the Tech Landscape
How to find common elements in two unsorted arrays with sizes n and m avoiding double for loop?

AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
How to find common elements in two unsorted arrays with sizes n and m avoiding double for loop?
Programmers, software engineers, coders, IT professionals, and software architects all face the common challenge of needing to find common elements in two unsorted arrays with sizes n and m. This can be a difficult task, especially if you don’t want to use a double for loop.
In this blog post, we will be discussing how to find common elements in two unsorted arrays with sizes n and m avoiding double for loop. We will be discussing various methods that can be used to solve this problem and comparing the time complexity of each method.
There are several ways that you can find common elements in two unsorted arrays with sizes n and m avoiding double for loop. One way is by using the hashing technique. With this technique, you can create a hash table for one of the arrays. Then, you can traverse through the second array and check if the element is present in the hash table or not. If the element is present in the hash table, then it is a common element. Another way that you can find common elements in two unsorted arrays with sizes n and m avoiding double for loop is by using the sorting technique. With this technique, you can sort both of the arrays first. Then, you can traverse through both of the arrays simultaneously and compare the elements. If the elements are equal, then it is a common element.
Method 1: Linear Search
The first method we will discuss is linear search. This method involves iterating through both arrays and comparing each element. If the element is found in both arrays, it is added to the result array. The time complexity of this method is O(nm), where n is the size of the first array and m is the size of the second array.
Method 2: HashMap Method
The second method we will discuss is the HashMap method. This method involves creating a HashMap of all the elements in the first array. Then, we iterate through the second array and check if the elements are present in the HashMap. If they are, we add them to the result array. The time complexity of this method is O(n+m), where n is the size of the first array and m is the size of the second array.
Method 3: Sort and Compare Method
The third method we will discuss is the Sort and Compare Method. This method involves sorting both arrays using any sorting algorithm like merge sort or quick sort. Once both arrays are sorted, we compare each element of both arrays one by one until we find a match. If a match is found, we add it to our result array. The time complexity of this method is O(nlogn+mlogm), where n is the size of the first array and m is the size of the second array.
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more codes)
The naïve algorithm for finding common elements in two unsorted arrays with sizes nn and mm is O(nm)O(nm), i.e. quadratic.
The algorithm for sorting an array is O(nlogn)O(nlogn), and you can find common elements in two sorted arrays in O(n+m)O(n+m). In other words, for large enough arrays, it is significantly faster to first sort them, then look for the common elements, because the sorting algorithm will dominate the complexity, so your final algorithm ends up at O(nlogn)O(nlogn) as well.
Conclusion:
In this blog post, we discussed how to find common elements in two unsorted arrays with sizes n and m avoiding double for loop. We discussed three different methods that can be used to solve this problem and compared their time complexities. We hope that this blog post was helpful in understanding how to solve this problem.
There are many different ways to find common elements in two unsorted arrays with sizes n and m avoiding double for loop. The most straight forward way is by using a double for loop but this approach is not very efficient. A more efficient way is by using a hash table which has a time complexity of O(n+m). This algorithm is faster because we only need to loop through one of the arrays. We can then use the values from that array to check if there are any duplicates in the second array. This approach also uses less memory because we are not creating a new list to store the common elements.
Simple Linear Regression vs. Multiple Linear Regression vs. MANOVA: A Data Scientist’s Guide

AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
Simple Linear Regression vs. Multiple Linear Regression vs. MANOVA: A Data Scientist’s Guide
As a data scientist, it’s important to understand the difference between simple linear regression, multiple linear regression, and MANOVA. This will come in handy when you’re working with different datasets and trying to figure out which one to use. Here’s a quick overview of each method:
A Short Overview of Simple Linear Regression, Multiple Linear Regression, and MANOVA
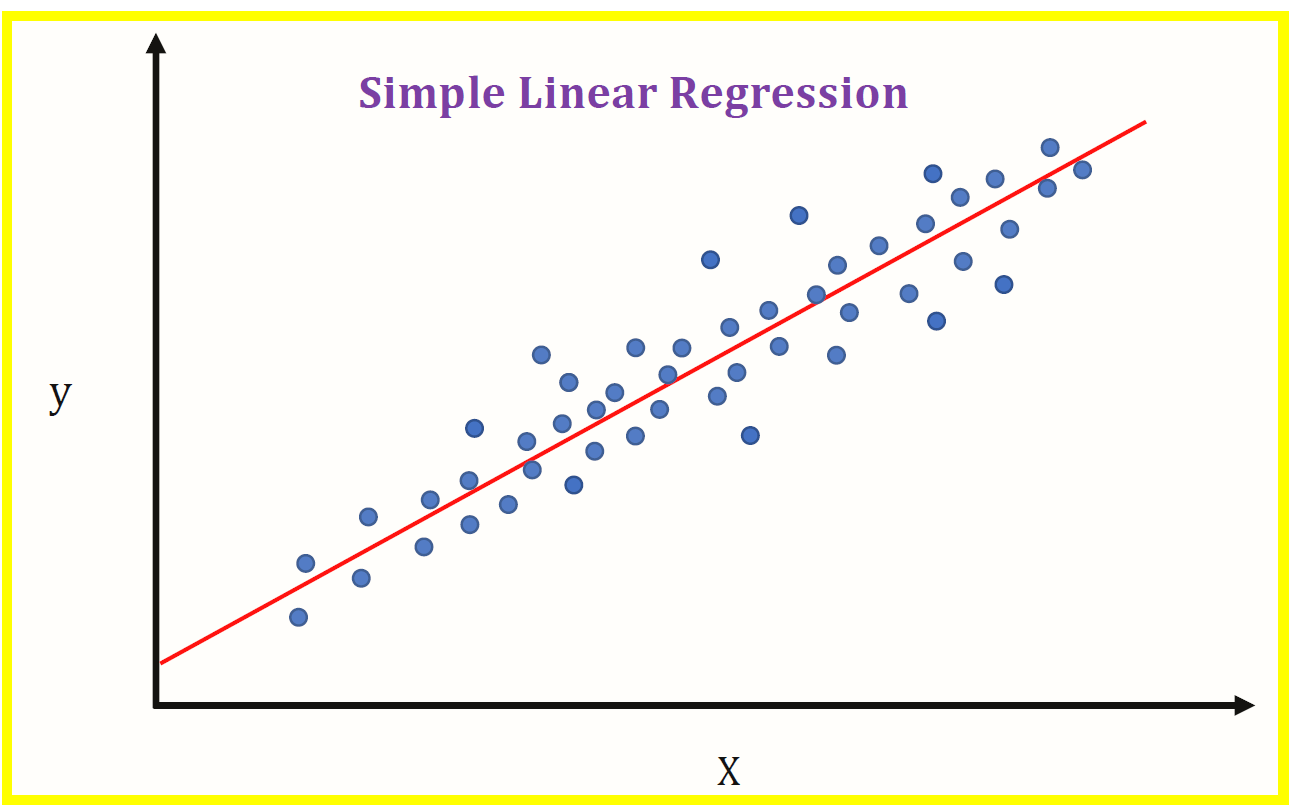
Simple linear regression is used to predict the value of a dependent variable (y) based on the value of one independent variable (x). This is the most basic form of regression analysis.
Multiple linear regression is used to predict the value of a dependent variable (y) based on the values of two or more independent variables (x1, x2, x3, etc.). This is more complex than simple linear regression but can provide more accurate predictions.
MANOVA is used to predict the value of a dependent variable (y) based on the values of two or more independent variables (x1, x2, x3, etc.), while also taking into account the relationships between those variables. This is the most complex form of regression analysis but can provide the most accurate predictions.
So, which one should you use? It depends on your dataset and what you’re trying to predict. If you have a small dataset with only one independent variable, then simple linear regression will suffice. If you have a larger dataset with multiple independent variables, then multiple linear regression will be more appropriate. And if you need to take into account the relationships between your independent variables, then MANOVA is the way to go.
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more codes)
In data science, there are a variety of techniques that can be used to model relationships between variables. Three of the most common techniques are simple linear regression, multiple linear regression, and MANOVA. Although these techniques may appear to be similar at first glance, there are actually some key differences that set them apart. Let’s take a closer look at each technique to see how they differ.
Simple Linear Regression
Simple linear regression is a statistical technique that can be used to model the relationship between a dependent variable and a single independent variable. The dependent variable is the variable that is being predicted, while the independent variable is the variable that is being used to make predictions.
Multiple Linear Regression
Multiple linear regression is a statistical technique that can be used to model the relationship between a dependent variable and two or more independent variables. As with simple linear regression, the dependent variable is the variable that is being predicted. However, in multiple linear regression, there can be multiple independent variables that are being used to make predictions.
MANOVA
MANOVA (multivariate analysis of variance) is a statistical technique that can be used to model the relationship between a dependent variable and two or more independent variables. Unlike simple linear regression or multiple linear regression, MANOVA can only be used when the dependent variable is continuous. Additionally, MANOVA can only be used when there are two or more dependent variables.

When it comes to data modeling, there are a variety of different techniques that can be used. Simple linear regression, multiple linear regression, and MANOVA are three of the most common techniques. Each technique has its own set of benefits and drawbacks that should be considered before deciding which technique to use for a particular project.We often encounter data points that are correlated. For example, the number of hours studied is correlated with the grades achieved. In such cases, we can use regression analysis to study the relationships between the variables.
Simple linear regression is a statistical method that allows us to predict the value of a dependent variable (y) based on the value of an independent variable (x). In other words, we can use simple linear regression to find out how much y will change when x changes.
Multiple linear regression is a statistical method that allows us to predict the value of a dependent variable (y) based on the values of multiple independent variables (x1, x2, …, xn). In other words, we can use multiple linear regression to find out how much y will change when any of the independent variables changes.
Multivariate analysis of variance (MANOVA) is a statistical method that allows us to compare multiple dependent variables (y1, y2, …, yn) simultaneously. In other words, MANOVA can help us understand how multiple dependent variables vary together.
Simple Linear Regression vs Multiple Linear Regression vs MANOVA: A Comparative Study
The main difference between simple linear regression and multiple linear regression is that simple linear regression can be used to predict the value of a dependent variable based on the value of only one independent variable whereas multiple linear regression can be used to predict the value of a dependent variable based on the values of two or more independent variables. Another difference between simple linear regression and multiple linear regression is that simple linear regression is less likely to produce Type I and Type II errors than multiple linear regression.
Both simple linear regression and multiple linear regression are used to predict future values. However, MANOVA is used to understand how present values vary.
Conclusion:
In this article, we have seen the key differences between simple linear regression vs multiple linear regression vs MANOVA along with their applications. Simple linear regression should be used when there is only one predictor variable whereas multiple linear regressions should be used when there are two or more predictor variables. MANOVA should be used when there are two or more response variables. Hope you found this article helpful!
Get Certified with the AWS Data analytics DAS-C01 Exam Prep PRO App:
Very Similar to real exam, Countdown timer, Score card, Show/Hide Answers, Cheat Sheets, FlashCards, Detailed Answers and References
No ADS, Access All Quiz Detailed Answers, Reference and Score Card
Hundreds of Quizzes covering Quiz and Brain Teaser for AWS Data analytics DAS-C01, Data Science, Various Practice Exams covering Data Collection, Data Security, Data processing, Data Analysis, Data Visualization, Data Storage and Management,
Data Lakes, S3, Kinesis, Lake Formation, Athena, Kibana, Redshift, EMR, Glue, Kafka, Apache Spark, SQl, NoSQL, Python,DynamoDB, DocumentDB, linear regression, logistic regression, Sampling, dataset, statistical interaction, selection bias, non-Gaussian distribution, bias-variance trade-off, Normal Distribution, correlation and covariance, Point Estimates and Confidence Interval, A/B Testing, p-value, statistical power of sensitivity, over-fitting and under-fitting, regularization, Law of Large Numbers, Confounding Variables, Survivorship Bias, univariate, bivariate and multivariate, Resampling, ROC curve, TF/IDF vectorization, Cluster Sampling, Data cleansing, ETL, Data Science and Analytics Cheat Sheets
What are some good datasets for Data Science and Machine Learning?
Top 100 Data Science and Data Analytics and Data Engineering Interview Questions and Answers
Simple Linear Regression vs. Multiple Linear Regression vs. MANOVA: A Data Scientist’s Guide
As a data scientist, it’s important to understand the difference between simple linear regression, multiple linear regression, and MANOVA. This will come in handy when you’re working with different datasets and trying to figure out which one to use. Here’s a quick overview of each method:
A Short Overview of Simple Linear Regression, Multiple Linear Regression, and MANOVA
Simple linear regression is used to predict the value of a dependent variable (y) based on the value of one independent variable (x). This is the most basic form of regression analysis.
Multiple linear regression is used to predict the value of a dependent variable (y) based on the values of two or more independent variables (x1, x2, x3, etc.). This is more complex than simple linear regression but can provide more accurate predictions.
MANOVA is used to predict the value of a dependent variable (y) based on the values of two or more independent variables (x1, x2, x3, etc.), while also taking into account the relationships between those variables. This is the most complex form of regression analysis but can provide the most accurate predictions.
So, which one should you use? It depends on your dataset and what you’re trying to predict. If you have a small dataset with only one independent variable, then simple linear regression will suffice. If you have a larger dataset with multiple independent variables, then multiple linear regression will be more appropriate. And if you need to take into account the relationships between your independent variables, then MANOVA is the way to go.
In data science, there are a variety of techniques that can be used to model relationships between variables. Three of the most common techniques are simple linear regression, multiple linear regression, and MANOVA. Although these techniques may appear to be similar at first glance, there are actually some key differences that set them apart. Let’s take a closer look at each technique to see how they differ.
Simple Linear Regression
Simple linear regression is a statistical technique that can be used to model the relationship between a dependent variable and a single independent variable. The dependent variable is the variable that is being predicted, while the independent variable is the variable that is being used to make predictions.
Multiple Linear Regression
Multiple linear regression is a statistical technique that can be used to model the relationship between a dependent variable and two or more independent variables. As with simple linear regression, the dependent variable is the variable that is being predicted. However, in multiple linear regression, there can be multiple independent variables that are being used to make predictions.
MANOVA
MANOVA (multivariate analysis of variance) is a statistical technique that can be used to model the relationship between a dependent variable and two or more independent variables. Unlike simple linear regression or multiple linear regression, MANOVA can only be used when the dependent variable is continuous. Additionally, MANOVA can only be used when there are two or more dependent variables.
When it comes to data modeling, there are a variety of different techniques that can be used. Simple linear regression, multiple linear regression, and MANOVA are three of the most common techniques. Each technique has its own set of benefits and drawbacks that should be considered before deciding which technique to use for a particular project.We often encounter data points that are correlated. For example, the number of hours studied is correlated with the grades achieved. In such cases, we can use regression analysis to study the relationships between the variables.
Simple linear regression is a statistical method that allows us to predict the value of a dependent variable (y) based on the value of an independent variable (x). In other words, we can use simple linear regression to find out how much y will change when x changes.
Multiple linear regression is a statistical method that allows us to predict the value of a dependent variable (y) based on the values of multiple independent variables (x1, x2, …, xn). In other words, we can use multiple linear regression to find out how much y will change when any of the independent variables changes.
Multivariate analysis of variance (MANOVA) is a statistical method that allows us to compare multiple dependent variables (y1, y2, …, yn) simultaneously. In other words, MANOVA can help us understand how multiple dependent variables vary together.
Simple Linear Regression vs Multiple Linear Regression vs MANOVA: A Comparative Study
The main difference between simple linear regression and multiple linear regression is that simple linear regression can be used to predict the value of a dependent variable based on the value of only one independent variable whereas multiple linear regression can be used to predict the value of a dependent variable based on the values of two or more independent variables. Another difference between simple linear regression and multiple linear regression is that simple linear regression is less likely to produce Type I and Type II errors than multiple linear regression.
Both simple linear regression and multiple linear regression are used to predict future values. However, MANOVA is used to understand how present values vary.
Conclusion:
In this article, we have seen the key differences between simple linear regression vs multiple linear regression vs MANOVA along with their applications. Simple linear regression should be used when there is only one predictor variable whereas multiple linear regressions should be used when there are two or more predictor variables. MANOVA should be used when there are two or more response variables. Hope you found this article helpful!
Get Certified with the AWS Data analytics DAS-C01 Exam Prep PRO App:
Very Similar to real exam, Countdown timer, Score card, Show/Hide Answers, Cheat Sheets, FlashCards, Detailed Answers and References
No ADS, Access All Quiz Detailed Answers, Reference and Score Card
Hundreds of Quizzes covering Quiz and Brain Teaser for AWS Data analytics DAS-C01, Data Science, Various Practice Exams covering Data Collection, Data Security, Data processing, Data Analysis, Data Visualization, Data Storage and Management,
Data Lakes, S3, Kinesis, Lake Formation, Athena, Kibana, Redshift, EMR, Glue, Kafka, Apache Spark, SQl, NoSQL, Python,DynamoDB, DocumentDB, linear regression, logistic regression, Sampling, dataset, statistical interaction, selection bias, non-Gaussian distribution, bias-variance trade-off, Normal Distribution, correlation and covariance, Point Estimates and Confidence Interval, A/B Testing, p-value, statistical power of sensitivity, over-fitting and under-fitting, regularization, Law of Large Numbers, Confounding Variables, Survivorship Bias, univariate, bivariate and multivariate, Resampling, ROC curve, TF/IDF vectorization, Cluster Sampling, Data cleansing, ETL, Data Science and Analytics Cheat Sheets
What’s the difference between a proxy and a VPN and why is one security stronger than the other? Which security feature is stronger and why?

AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
What’s the difference between a proxy and a VPN, and why is one security stronger than the other? Which security feature is stronger and why?
When it comes to online security, there are a number of different factors to consider. Two of the most popular methods for protecting your identity and data are proxy servers and VPNs. Both proxy servers and VPNs can help to mask your IP address and encrypt your traffic, but there are some key differences between the two. One major difference is that proxy servers only encrypt traffic going through the server, while VPNs encrypt all traffic from your device. This means that proxy servers are only effective if you’re using specific apps or visiting specific websites. VPNs, on the other hand, provide a more comprehensive solution as they can encrypt all traffic from your device, no matter where you’re accessing the internet from. Another key difference is that proxy servers tend to be less expensive than VPNs, but they also offer less privacy and security. When it comes to online security, proxy servers and VPNs both have their pros and cons. It’s important to weigh these factors carefully before decide which option is right for you.
VPN is virtual private network connects your incoming traffic and outgoing traffic to another network.
A proxy just relays your internet traffic. To websites you visit, your IP appears to be that of the proxy server.
A VPN is a type of proxy for which all the communication between your computer and the proxy server is encrypted. With a VPN, no one snooping your internet connection (e.g., your ISP) can see what websites you are visiting or what you are doing there. Security is much better.
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more codes)
VPN PROS:
What is a Proxy Server?
A proxy server is a computer system that performs as an intermediary in the request made by users. This type of server helps prevent an attacker from attacking the network and serves as a tool used to create a firewall.
The etymology of the word proxy means “a figure that can be used to represent the value of something”, this means that a proxy server represents or acts on behalf of the user. The fundamental purpose of proxy servers is to safeguard the direct connection of internet users and resources.
All requests made by the users from the internet go to the proxy server. The responses of the request return back to the proxy server for evaluation and then to the user. Proxy servers serve as an intermediary between the local network and the world wide web. Proxy servers are used for several reasons, such as to filter web content, to avert restrictions like parental blocks, to screen downloads and uploads, and to provide privacy when browsing the internet. The proxy server also prevents and protects the identity of the users.
There are different types of proxy servers used according to the different purposes of a request made by the clients and users. Proxies provide a valuable layer of security for your network and computers. It can be set up as web filters or firewalls which can protect computers from threats such as malware or ransomware. This extra security is also significant when linked with a secured gateway or attached security products. This way, network administrators can filter traffic according to its level of safety or traffic consumption of the network.
Are Proxies and VPNs the same?
Proxies are not the same as VPNs. The only similarity between Proxies and VPNs is that they both connect you to the internet via an intermediary server. An online proxy forwards your traffic to its destination, while a VPN, on the other hand, encrypts all traffic between the VPN server and your device. Here are some more differences between proxies and VPNs:
- VPNs help you encrypt your traffic while proxy servers don’t do that.
- Proxies don’t protect you from government surveillance, ISP tracking, and hackers, which is why they are never used to handle sensitive information. VPN protects you from the same.
- VPNs function on the operating system level while proxies work on the application level.
- Proxies only reroute the traffic of a specific app or browser while VPNs reroute it through a VPN server.
- Since VPNs need to encrypt your sensitive data, they can be slower than proxies.
- Most proxy servers are free while most VPNs are paid. Don’t trust free VPN services as they can compromise your data.
- A VPN connection is found to be more reliable than proxy server connections that can drop more frequently.
Why Is a VPN Considered to be More Secure Than a Proxy Server?
By now, you might have already noticed the reason since we have discussed it. The question is: Is a VPN better than a proxy? The simple answer is “Yes.”
How? A VPN provides privacy and security by routing your traffic through a secure VPN server and encrypting your traffic while a proxy, on the other hand, simply passes that traffic through a mediating server. It doesn’t necessarily offer any extra protection unless you use some extra features.
Proxy PROS:
However, when the motivation is to avoid geo-blocking, a proxy is more likely to be successful. Websites that need to do geo-blocking can normally tell that your IP is that of a VPN server. They don’t account for all the possible proxy servers.
But the problem here is they use datacenter IP (the server IP),
Also VPNs save logs and save EVERYTHING you do.
In the other hand, there are many types of proxy: datacenter proxy (worst one), Residential proxy, Mobile proxy 4G, and Mobile Proxy 5G.
If you use residential proxy or mobile proxy it might be much better and safer for many reasons:
- Residential IP means that the Proxy use a regular ISP like comcast, Charter, Sprint, etc.
- They don’t save logs.
- The connection is not even direct, it goes to their server first and then to a a real device in another place.
- Websites like facebook and shopping sites won’t block you, because you use residential or mobile proxy, so they won’t know that you use a proxy to hide your real IP, while VPN will be easily detected.
Now people would say that the problem with socks5 residential and mobile proxy is the cost, because most of websites sells it on very expensive price.
I use a good cheap and very high quality socks5 residential proxy costs only 3 USD a month per dedicated residential proxy, and the traffic is unlimited.
And it is very fast because it is dedicated and also virgin with fraud score 0.
The website name is Liber8Proxy.com
Moreover socks5 residential proxy uses socks5 connection port with promixitron so it would cover your entire PC traffic.
Also their customers support are nice and they always online.
Source: https://qr.ae/pvWauF
What are the Top 10 AWS jobs you can get with an AWS certification in 2022 plus AWS Interview Questions

AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
What are the Top 10 AWS jobs you can get with an AWS certification in 2022 plus AWS Interview Questions
AWS certifications are becoming increasingly popular as the demand for AWS-skilled workers continues to grow. AWS certifications show that an individual has the necessary skills to work with AWS technologies, which can be beneficial for both job seekers and employers. AWS-certified individuals can often command higher salaries and are more likely to be hired for AWS-related positions. So, what are the top 10 AWS jobs that you can get with an AWS certification?
1. AWS Solutions Architect / Cloud Architect:
AWS solutions architects are responsible for designing, implementing, and managing AWS solutions. They work closely with other teams to ensure that AWS solutions are designed and implemented correctly.
AWS Architects, AWS Cloud Architects, and AWS solutions architects spend their time architecting, building, and maintaining highly available, cost-efficient, and scalable AWS cloud environments. They also make recommendations regarding AWS toolsets and keep up with the latest in cloud computing.
Professional AWS cloud architects deliver technical architectures and lead implementation efforts, ensuring new technologies are successfully integrated into customer environments. This role works directly with customers and engineers, providing both technical leadership and an interface with client-side stakeholders.

Average yearly salary: $148,000-$158,000 USD
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more codes)
2. AWS SysOps Administrator / Cloud System Administrators:
AWS sysops administrators are responsible for managing and operating AWS systems. They work closely with AWS developers to ensure that systems are running smoothly and efficiently.
A Cloud Systems Administrator, or AWS SysOps administrator, is responsible for the effective provisioning, installation/configuration, operation, and maintenance of virtual systems, software, and related infrastructures. They also maintain analytics software and build dashboards for reporting.
Average yearly salary: $97,000-$107,000 USD
3. AWS DevOps Engineer:
AWS devops engineers are responsible for designing and implementing automated processes for Amazon Web Services. They work closely with other teams to ensure that processes are efficient and effective.
AWS DevOps engineers design AWS cloud solutions that impact and improve the business. They also perform server maintenance and implement any debugging or patching that may be necessary. Among other DevOps things!
Average yearly salary: $118,000-$138,000 USD

4. AWS Cloud Engineer:
AWS cloud engineers are responsible for designing, implementing, and managing cloud-based solutions using AWS technologies. They work closely with other teams to ensure that solutions are designed and implemented correctly.
5. AWS Network Engineer:
AWS network engineers are responsible for designing, implementing, and managing networking solutions using AWS technologies. They work closely with other teams to ensure that networking solutions are designed and implemented correctly.
Cloud network specialists, engineers, and architects help organizations successfully design, build, and maintain cloud-native and hybrid networking infrastructures, including integrating existing networks with AWS cloud resources.
Average yearly salary: $107,000-$127,000 USD
6. AWS Security Engineer:
AWS security engineers are responsible for ensuring the security of Amazon Web Services environments. They work closely with other teams to identify security risks and implement controls to mitigate those risks.
Cloud security engineers provide security for AWS systems, protect sensitive and confidential data, and ensure regulatory compliance by designing and implementing security controls according to the latest security best practices.
Average yearly salary: $132,000-$152,000 USD

7. AWS Database administrator:
As a database administrator on Amazon Web Services (AWS), you’ll be responsible for setting up, maintaining, and securing databases hosted on the Amazon cloud platform. You’ll work closely with other teams to ensure that databases are properly configured and secured.
8. Cloud Support Engineer:
Support engineers are responsible for providing technical support to AWS customers. They work closely with customers to troubleshoot problems and provide resolution within agreed upon SLAs.
9. Sales Engineer:
Sales engineers are responsible for working with sales teams to generate new business opportunities through the use of AWS products and services .They must have a deep understanding of AWS products and how they can be used by potential customers to solve their business problems .
10. Cloud Developer
An AWS Developer builds software services and enterprise-level applications. Generally, previous experience working as a software developer and a working knowledge of the most common cloud orchestration tools is required to get and succeed at an AWS cloud developer job
Average yearly salary: $132,000 USD
11. Cloud Consultant
Cloud consultants provide organizations with technical expertise and strategy in designing and deploying AWS cloud solutions or in consulting on specific issues such as performance, security, or data migration.
Average yearly salary: $104,000-$124,000
12. Cloud Data Architect
Cloud data architects and data engineers may be cloud database administrators or data analytics professionals who know how to leverage AWS database resources, technologies, and services to unlock the value of enterprise data.
Average yearly salary: $130,000-$140,000 USD
Getting a job after getting an AWS certification
The field of cloud computing will continue to grow and even more different types of jobs will surface in the future.
AWS certified professionals are in high demand across a variety of industries. AWS certs can open the door to a number of AWS jobs, including cloud engineer, solutions architect, and DevOps engineer.
Through studying and practice, any of the listed jobs could becoming available to you if you pass your AWS certification exams. Educating yourself on AWS concepts plays a key role in furthering your career and receiving not only a higher salary, but a more engaging position.
Source: 8 AWS jobs you can get with an AWS certification
AWS Tech Jobs Interview Questions in 2022
Graphs
1) Process Ordering – LeetCode link…
2) Number of Islands – LeetCode link…
3) k Jumps on Grid – Loading…)
Sort
1) Finding Prefix in Dictionary – LeetCode Link…
Tree
1) Binary Tree Top Down View – LeetCode link…
2) Traversing binary tree in an outward manner.
3) Diameter of a binary tree [Path is needed] – Diameter of a Binary Tree – GeeksforGeeks
Sliding window
1) Contains Duplicates III – LeetCode link…
2) Minimum Window Substring [Variation of this question] – LeetCode link..
Linked List
1) Reverse a Linked List II – LeetCode link…
2) Remove Loop From Linked List – Remove Loop in Linked List
3) Reverse a Linked List in k-groups – LeetCode link…
Binary Search
1) Search In rotate sorted Array – LeetCode link…
Solution:
def pivotedBinarySearch(arr, n, key): pivot = findPivot(arr, 0, n-1) # If we didn't find a pivot, # then array is not rotated at all if pivot == -1: return binarySearch(arr, 0, n-1, key) # If we found a pivot, then first # compare with pivot and then # search in two subarrays around pivot if arr[pivot] == key: return pivot if arr[0] <= key: return binarySearch(arr, 0, pivot-1, key) return binarySearch(arr, pivot + 1, n-1, key)# Function to get pivot. For array# 3, 4, 5, 6, 1, 2 it returns 3# (index of 6)def findPivot(arr, low, high): # base cases if high < low: return -1 if high == low: return low # low + (high - low)/2; mid = int((low + high)/2) if mid < high and arr[mid] > arr[mid + 1]: return mid if mid > low and arr[mid] < arr[mid - 1]: return (mid-1) if arr[low] >= arr[mid]: return findPivot(arr, low, mid-1) return findPivot(arr, mid + 1, high)# Standard Binary Search functiondef binarySearch(arr, low, high, key): if high < low: return -1 # low + (high - low)/2; mid = int((low + high)/2) if key == arr[mid]: return mid if key > arr[mid]: return binarySearch(arr, (mid + 1), high, key) return binarySearch(arr, low, (mid - 1), key)# Driver program to check above functions# Let us search 3 in below arrayif __name__ == '__main__': arr1 = [5, 6, 7, 8, 9, 10, 1, 2, 3] n = len(arr1) key = 3 print("Index of the element is : ", \ pivotedBinarySearch(arr1, n, key))# This is contributed by Smitha Dinesh SemwalArrays
1) Max bandWidth [Priority Queue, Sorting] – Loading…
2) Next permutation – Loading…
3) Largest Rectangle in Histogram – Loading…
Content by – Sandeep Kumar
#AWS #interviews #leetcode #questions #array #sorting #queue #loop #tree #graphs #amazon #sde —-#interviewpreparation #coding #computerscience #softwareengineer
AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
What are the Top 5 things that can say a lot about a software engineer or programmer’s quality?
When it comes to the quality of a software engineer or programmer, there are a few key things that can give you a good indication. First, take a look at their code quality. A good software engineer will take pride in their work and produce clean, well-organized code. They will also be able to explain their code concisely and confidently. Another thing to look for is whether they are up-to-date on the latest coding technologies and trends. A good programmer will always be learning and keeping up with the latest industry developments. Finally, pay attention to how they handle difficult problems. A good software engineer will be able to think creatively and come up with innovative solutions to complex issues. If you see these qualities in a software engineer or programmer, chances are they are of high quality.
Below are the top 5 things can say a lot about a software engineer/ programmer’s quality?
- The number of possible paths through the code (branch points) is minimized. Top quality code tends to be much more straight line than poor code. As a result, the author can design, code and test very quickly and is often looked at as a programming guru. In addition this code is far more resilient in Production.
- The code clearly matches the underlying business requirements and can therefore be understood very quickly by new resources. As a result there is much less tendency for a maintenance programmer to break the basic design as opposed to spaghetti code where small changes can have catastrophic effects.
- There is an overall sense of pride in the source code itself. If the enterprise has clear written standards, these are followed to the letter. If not, the code is internally consistent in terms of procedure/object, function/method or variable/attribute naming. Also indentation and continuations are universally consistent throughout. Last but not least, the majority of code blocks are self-evident to the requirements and where not the case, adequate purpose focused documentation is provided.
In general, I have seen two types of programs provided for initial Production deployment. One looks like it was just written moments ago and the other looks like it has had 20 years of maintenance performed on it. Unfortunately, the authors of the second type cannot generally see the difference so it is a lost cause and we just have to continue to deal with the problems. - In today’s programming environment, a project may span many platforms, languages etc. A simple web page may invoke an API which in turn accesses a database. For this example lets say JavaScript – Rest API – C# – SQL – RDBMS. The programmer can basically embed logic anywhere in this chain, but needs to be aware of reuse, performance and maintenance issues. For instance, if a part of the process requires access to three database tables, it is both faster and clearer to allow the DBMS engine return a single query than compare the tables in the API code. Similarly every business rule coded in the client side reduces re-usability potential.
Top quality developers understand these issues and can optimize their designs to take advantages of the strengths of the component technologies. - The ability to stay current with new trends and technologies. Technology is constantly evolving, and a good software engineer or programmer should be able to stay up-to-date on the latest trends and technologies in order to be able to create the best possible products.
To conclude:
Below are other things to consider when hiring good software engineers or programmers:
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more codes)
- The ability to write clean, well-organized code. This is a key indicator of a good software engineer or programmer. The ability to write code that is easy to read and understand is essential for creating high-quality software.
- The ability to test and debug code. A good coder should be able to test their code thoroughly and identify and fix any errors that may exist.
- The ability to write efficient code. Software engineering is all about creating efficient solutions to problems. A good software engineer or programmer will be able to write code that is efficient and effective.
- The ability to work well with others. Software engineering is typically a team-based effort. A good software engineer or programmer should be able to work well with others in order to create the best possible product.
- The ability to stay current with new trends and technologies.
How to Protect Yourself from Man-in-the-Middle Attacks: Tips for Safer Communication

AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
How to Protect Yourself from Man-in-the-Middle Attacks: Tips for Safer Communication
Man-in-the-middle (MITM) attacks are a type of cyberattack where a malicious actor intercepts communications between two parties in order to secretly access sensitive data or inject false information. While MITM attacks can be difficult to detect, there are some steps you can take to protect yourself.
For example, always verifying the identity of the person you’re communicating with and using encrypted communication tools whenever possible. Additionally, it’s important to be aware of common signs that an attack may be happening, such as unexpected messages or requests for sensitive information.
Man-in-the-middle attacks are one of the most common types of cyberattacks. MITM attacks can allow the attacker to gain access to sensitive information, such as passwords or financial data. Man-in-the-middle attacks can be very difficult to detect, but there are some steps you can take to protect yourself. First, be aware of the warning signs of a man-in-the-middle attack. These include:
– unexpected changes in login pages,
– unexpected requests for personal information,
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more codes)
– and unusual account activity.
If you see any of these warning signs, do not enter any sensitive information and contact the company or individual involved immediately. Second, use strong security measures, such as two-factor authentication, to protect your accounts. This will make it more difficult for attackers to gain access to your information. Finally, keep your software and operating system up to date with the latest security patches. This will help to close any potential vulnerabilities that could be exploited by attackers.
Man-in-the-middle attacks can be devastating for individuals and businesses alike. By intercepting communications between two parties, attackers can gain access to sensitive information or even impersonate one of the parties involved. Fortunately, there are a number of steps you can take to protect yourself from man-in-the-middle attacks.
- First, avoid using public Wi-Fi networks for sensitive transactions. Attackers can easily set up their own rogue networks, and it can be difficult to tell the difference between a legitimate network and a malicious one. If you must use public Wi-Fi, be sure to use a VPN to encrypt your traffic.
- Second, be cautious about the links you click on. When in doubt, hover over a link to see where it will actually take you. And always be suspicious of links that come from untrustworthy sources.
- Finally, keep your software and security tools up to date. Man-in-the-middle attacks are constantly evolving, so it’s important to have the latest defenses in place.
By following these simple tips, you can help keep yourself safe from man-in-the-middle attacks.
Is MITM attack possible when on HTTPS?
HTTPS (or really, SSL) is specifically designed to thwart MITM attacks.
Web browsers validate that both the certificate presented by the server is labeled correctly with the website’s domain name and that it has a chain of trust back to a well-known certificate authority. Under normal circumstances, this is enough to prevent anyone from impersonating the website.
As the question points out, you can thwart this by somehow acquiring the secret key for the existing website’s certificate.
You can also launch a MITM attack by getting one of the well-known certificate authorities to issue you a certificate with the domain name of the website you wish to impersonate. This can be (and has been) accomplished by social engineering and hacking into the registrars.
Outside of those two main methods, you would have to rely upon bugs in the SSL protocol or its implementations (of which a few have been discovered over the years).
What are the countermeasures of MITM?
1- Certificates.
For the web, we use a similar principle. A certificate is a specific document issued by a third party that validate the identity of a website. Your PC can ask the third party if the certificate is correct, and only if it is allow the traffic. This is what HTTPs does.
2- Simple…encryption!
Man In The Middle attacks are carried out because an attacker is in between both communicators (let’s say two clients or a client and a server). If he is able to see the communication in clear text, he can do a whole lot ranging from stealing login credentials to snooping on conversations. If encryption is implemented, the attacker would see gibberish and “un-understandable” text instead.
In terms of web communication, digital certificates would do a great job of encrypting communication stream (any website using HTTPS encrypts communication stream by default). For social media apps like whats app and Skype, it is the responsibility of the vendor to implement encryption.
MitM Attack Techniques and Types
- ARP Cache Poisoning. Address Resolution Protocol (ARP) is a low-level process that translates the machine address (MAC) to the IP address on the local network. …
- DNS Cache Poisoning. …
- Wi-Fi Eavesdropping. …
- Session Hijacking.
- IP Spoofing
- DNS Spoofing
- HTTPS Spoofing
- SSL Hijacking
- Email Hijacking
- Wifi Eavesdropping
- Cookie Stealing and so on.
Can MITM attacks steal credit card information?
When you enter your sensitive information on an HTTP website and press that “Send” button, all your private details travel in plain text from your web browser to the destination server.
A cyber-attacker can employ a man-in-the-middle attack and intercept your information. Since it’s not encrypted, the hacker can see everything: your name, physical address, card numbers, and anything else you entered.
To avoid MITM attacks, don’t share your info on HTTP sites. More on SSL certificates and man-in-the-middle attacks in this detailed medium article
How common are MITM attacks in public places with free WIFI?
Not common by people, but common by malware and other software that are designed to do that.
How do you ensure your RDP is secure from MITM attacks?
- Make sure all of your workstations and remote servers are patched.
- On highly sensitive devices, use two-factor authentication.
- Reduce the number of remote account users with elevated privileges on the server.
- Make a safe password.
- Your credentials should not be saved in your RDP register.
- Remove the RDP file from your computer.
What is Problem Formulation in Machine Learning and Top 4 examples of Problem Formulation in Machine Learning?

AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
What is Problem Formulation in Machine Learning and Top 4 examples of Problem Formulation in Machine Learning?
Machine Learning (ML) is a field of Artificial Intelligence (AI) that enables computers to learn from data, without being explicitly programmed. Machine learning algorithms build models based on sample data, known as “training data”, in order to make predictions or decisions, rather than following rules written by humans. Machine learning is closely related to and often overlaps with computational statistics; a discipline that also focuses on prediction-making through the use of computers. Machine learning can be applied in a wide variety of domains, such as medical diagnosis, stock trading, robot control, manufacturing and more.

The process of machine learning consists of several steps: first, data is collected; then, a model is selected or created; finally, the model is trained on the collected data and then applied to new data. This process is often referred to as the “machine learning pipeline”. Problem formulation is the second step in this pipeline and it consists of selecting or creating a suitable model for the task at hand and determining how to represent the collected data so that it can be used by the selected model. In other words, problem formulation is the process of taking a real-world problem and translating it into a format that can be solved by a machine learning algorithm.

There are many different types of machine learning problems, such as classification, regression, prediction and so on. The choice of which type of problem to formulate depends on the nature of the task at hand and the type of data available. For example, if we want to build a system that can automatically detect fraudulent credit card transactions, we would formulate a classification problem. On the other hand, if our goal is to predict the sale price of houses given information about their size, location and age, we would formulate a regression problem. In general, it is best to start with a simple problem formulation and then move on to more complex ones if needed.
Some common examples of problem formulations in machine learning are:
– Classification: given an input data point (e.g., an image), predict its category label (e.g., dog vs cat).
– Regression: given an input data point (e.g., size and location of a house), predict a continuous output value (e.g., sale price).
– Prediction: given an input sequence (e.g., a series of past stock prices), predict the next value in the sequence (e.g., future stock price).
– Anomaly detection: given an input data point (e.g., transaction details), decide whether it is normal or anomalous (i.e., fraudulent).
– Recommendation: given information about users (e.g., age and gender) and items (e.g., books and movies), recommend items to users (e.g., suggest books for someone who likes romance novels).
– Optimization: given a set of constraints (e.g., budget) and objectives (e.g., maximize profit), find the best solution (e.g., product mix).

Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more codes)
ML PRO without ADS on iOs [No Ads]
ML PRO without ADS on Windows [No Ads]
ML PRO For Web/Android on Amazon [No Ads]
Problem Formulation: What this pipeline phase entails and why it’s important
The problem formulation phase of the ML Pipeline is critical, and it’s where everything begins. Typically, this phase is kicked off with a question of some kind. Examples of these kinds of questions include: Could cars really drive themselves? What additional product should we offer someone as they checkout? How much storage will clients need from a data center at a given time?
The problem formulation phase starts by seeing a problem and thinking “what question, if I could answer it, would provide the most value to my business?” If I knew the next product a customer was going to buy, is that most valuable? If I knew what was going to be popular over the holidays, is that most valuable? If I better understood who my customers are, is that most valuable?
However, some problems are not so obvious. When sales drop, new competitors emerge, or there’s a big change to a company/team/org, it can be easy to say, “I see the problem!” But sometimes the problem isn’t so clear. Consider self-driving cars. How many people think to themselves, “driving cars is a huge problem”? Probably not many. In fact, there isn’t a problem in the traditional sense of the word but there is an opportunity. Creating self-driving cars is a huge opportunity. That doesn’t mean there isn’t a problem or challenge connected to that opportunity. How do you design a self-driving system? What data would you look at to inform the decisions you make? Will people purchase self-driving cars?
Part of the problem formulation phase includes seeing where there are opportunities to use machine learning.
In the following practice examples, you are presented with four different business scenarios. For each scenario, consider the following questions:
- Is machine learning appropriate for this problem, and why or why not?
- What is the ML problem if there is one, and what would a success metric look like?
- What kind of ML problem is this?
- Is the data appropriate?’
The solutions given in this article are one of the many ways you can formulate a business problem.
I) Amazon recently began advertising to its customers when they visit the company website. The Director in charge of the initiative wants the advertisements to be as tailored to the customer as possible. You will have access to all the data from the retail webpage, as well as all the customer data.
- ML is appropriate because of the scale, variety and speed required. There are potentially thousands of ads and millions of customers that need to be served customized ads immediately as they arrive to the site.
- The problem is ads that are not useful to customers are a wasted opportunity and a nuisance to customers, yet not serving ads at all is a wasted opportunity. So how does Amazon serve the most relevant advertisements to its retail customers?
- Success would be the purchase of a product that was advertised.
- This is a supervised learning problem because we have a labeled data point, our success metric, which is the purchase of a product.
- This data is appropriate because it is both the retail webpage data as well as the customer data.
II) You’re a Senior Business Analyst at a social media company that focuses on streaming. Streamers use a combination of hashtags and predefined categories to be discoverable by your platform’s consumers. You ran an analysis on unique streamer counts by hashtags and categories over the last month and found that out of tens of thousands of streamers, almost all use only 40 hashtags and 10 categories despite innumerable hashtags and hundreds of categories. You presume the predefined categories don’t represent all the possibilities very well, and that streamers are simply picking the closest fit. You figure there are likely many categories and groupings of streamers that are not accounted for. So you collect a dataset that consists of all streamer profile descriptions (all text), all the historical chat information for each streamer, and all their videos that have been streamed.
- ML is appropriate because of the scale and variability.
- The problem is the content of streamers is not being represented by the existing categories. Success would be naturally grouping the streamers into categories based on content and seeing if those align with the hashtags and categories that are being commonly used. If they do not, then the streamers are not being well represented and you can use these groupings to create new categories.
- There isn’t a specific outcome variable. There’s no target or label. So this is an unsupervised problem.
- The data is appropriate.
III) You’re a headphone manufacturer who sells directly to big and small electronic stores. As an attempt to increase competitive pricing, Store 1 and Store 2 decided to put together the pricing details for all headphone manufacturers and their products (about 350 products) and conduct daily releases of the data. You will have all the specs from each manufacturer and their product’s pricing. Your sales have recently been dropping so your first concern is whether there are competing products that are priced lower than your flagship product.
- ML is probably not necessary for this. You can just search the dataset to see which headphones are priced lower than the flagship, then compare their features and build quality.
IV) You’re a Senior Product Manager at a leading ridesharing company. You did some market research, collected customer feedback, and discovered that both customers and drivers are not happy with an app feature. This feature allows customers to place a pin exactly where they want to be picked up. The customers say drivers rarely stop at the pin location. Drivers say customers most often put the pin in a place they can’t stop. Your company has a relationship with the most used maps app for the driver’s navigation so you leverage this existing relationship to get direct, backend access to their data. This includes latitude and longitude, visual photos of each lat/long, traffic delay details, and regulation data if available (ie- No Parking zones, 3 minute parking zones, fire hydrants, etc.).
- ML is appropriate because of the scale and automation involved. It’s not feasible to drive everywhere and write down all the places that are ok for pickup. However, maybe we can predict whether a location is ok for pickup.
- The problem is drivers and customers are having poor experiences connecting for pickup, which is pushing customers away from the platform.
- Success would be properly identifying appropriate pickup locations so they can be integrated into the feature.
- This is a supervised learning problem even though there aren’t any labels, yet. Someone will have to go through a sample of the data to label where there are ok places to park and not park, giving the algorithms some target information.
- The data is appropriate once a sample of the dataset has been labeled. There may be some other data that could be included too. What about asking UPS for driver stop information? Where do they stop?
In conclusion, problem formulation is an important step in the machine learning pipeline that should not be overlooked or underestimated. It can make or break a machine learning project; therefore, it is important to take care when formulating machine learning problems.”

Step by Step Solution to a Machine Learning Problem – Feature Engineering
Feature Engineering is the act of reshaping and curating existing data to make patters more apparent. This process makes the data easier for an ML model to understand. Using knowledge of the data, features are engineered and tuned to make ML algorithms work more efficiently.
For this problem, imagine a scenario where you are running a real estate brokerage and you want to predict the selling price of a house. Using a specific county dataset and simple information (like the location, total square footage, and number of bedrooms), let’s practice training a baseline model, conducting feature engineering, and tuning a model to make a prediction.
First, load the dataset and take a look at its basic properties.
# Load the dataset
import pandas as pd
import boto3
df = pd.read_csv(“xxxxx_data_2.csv”)
df.head()

Output:
This dataset has 21 columns:
id– Unique id numberdate– Date of the house saleprice– Price the house sold forbedrooms– Number of bedroomsbathrooms– Number of bathroomssqft_living– Number of square feet of the living spacesqft_lot– Number of square feet of the lotfloors– Number of floors in the housewaterfront– Whether the home is on the waterfrontview– Number of lot sides with a viewcondition– Condition of the housegrade– Classification by construction qualitysqft_above– Number of square feet above groundsqft_basement– Number of square feet below groundyr_built– Year builtyr_renovated– Year renovatedzipcode– ZIP codelat– Latitudelong– Longitudesqft_living15– Number of square feet of living space in 2015 (can differ fromsqft_livingin the case of recent renovations)sqrt_lot15– Nnumber of square feet of lot space in 2015 (can differ fromsqft_lotin the case of recent renovations)
This dataset is rich and provides a fantastic playground for the exploration of feature engineering. This exercise will focus on a small number of columns. If you are interested, you could return to this dataset later to practice feature engineering on the remaining columns.
A baseline model
Now, let’s train a baseline model.
People often look at square footage first when evaluating a home. We will do the same in the oflorur model and ask how well can the cost of the house be approximated based on this number alone. We will train a simple linear learner model (documentation). We will compare to this after finishing the feature engineering.
import sagemaker
import numpy as np
from sklearn.model_selection import train_test_split
import time
t1 = time.time()
# Split training, validation, and test
ys = np.array(df[‘price’]).astype(“float32”)
xs = np.array(df[‘sqft_living’]).astype(“float32”).reshape(-1,1)
np.random.seed(8675309)
train_features, test_features, train_labels, test_labels = train_test_split(xs, ys, test_size=0.2)
val_features, test_features, val_labels, test_labels = train_test_split(test_features, test_labels, test_size=0.5)
# Train model
linear_model = sagemaker.LinearLearner(role=sagemaker.get_execution_role(),
instance_count=1,
instance_type=’ml.m4.xlarge’,
predictor_type=’regressor’)
train_records = linear_model.record_set(train_features, train_labels, channel=’train’)
val_records = linear_model.record_set(val_features, val_labels, channel=’validation’)
test_records = linear_model.record_set(test_features, test_labels, channel=’test’)
linear_model.fit([train_records, val_records, test_records], logs=False)
sagemaker.analytics.TrainingJobAnalytics(linear_model._current_job_name, metric_names = [‘test:mse’, ‘test:absolute_loss’]).dataframe()
If you examine the quality metrics, you will see that the absolute loss is about $175,000.00. This tells us that the model is able to predict within an average of $175k of the true price. For a model based upon a single variable, this is not bad. Let’s try to do some feature engineering to improve on it.
Throughout the following work, we will constantly be adding to a dataframe called encoded. You will start by populating encoded with just the square footage you used previously.
encoded = df[[‘sqft_living’]].copy()
Categorical variables
Let’s start by including some categorical variables, beginning with simple binary variables.
The dataset has the waterfront feature, which is a binary variable. We should change the encoding from 'Y' and 'N' to 1 and 0. This can be done using the map function (documentation) provided by Pandas. It expects either a function to apply to that column or a dictionary to look up the correct transformation.
Binary categorical
Let’s write code to transform the waterfront variable into binary values. The skeleton has been provided below.
encoded[‘waterfront’] = df[‘waterfront’].map({‘Y’:1, ‘N’:0})
You can also encode many class categorical variables. Look at column condition, which gives a score of the quality of the house. Looking into the data source shows that the condition can be thought of as an ordinal categorical variable, so it makes sense to encode it with the order.
Ordinal categorical
Using the same method as in question 1, encode the ordinal categorical variable condition into the numerical range of 1 through 5.
encoded[‘condition’] = df[‘condition’].map({‘Poor’:1, ‘Fair’:2, ‘Average’:3, ‘Good’:4, ‘Very Good’:5})
A slightly more complex categorical variable is ZIP code. If you have worked with geospatial data, you may know that the full ZIP code is often too fine-grained to use as a feature on its own. However, there are only 7070 unique ZIP codes in this dataset, so we may use them.
However, we do not want to use unencoded ZIP codes. There is no reason that a larger ZIP code should correspond to a higher or lower price, but it is likely that particular ZIP codes would. This is the perfect case to perform one-hot encoding. You can use the get_dummies function (documentation) from Pandas to do this.
Nominal categorical
Using the Pandas get_dummies function, add columns to one-hot encode the ZIP code and add it to the dataset.
encoded = pd.concat([encoded, pd.get_dummies(df[‘zipcode’])], axis=1)
In this way, you may freely encode whatever categorical variables you wish. Be aware that for categorical variables with many categories, something will need to be done to reduce the number of columns created.
One additional technique, which is simple but can be highly successful, involves turning the ZIP code into a single numerical column by creating a single feature that is the average price of a home in that ZIP code. This is called target encoding.
To do this, use groupby (documentation) and mean (documentation) to first group the rows of the DataFrame by ZIP code and then take the mean of each group. The resulting object can be mapped over the ZIP code column to encode the feature.
Nominal categorical II
Complete the following code snippet to provide a target encoding for the ZIP code.
means = df.groupby(‘zipcode’)[‘price’].mean()
encoded[‘zip_mean’] = df[‘zipcode’].map(means)
Normally, you only either one-hot encode or target encode. For this exercise, leave both in. In practice, you should try both, see which one performs better on a validation set, and then use that method.
Scaling
Take a look at the dataset. Print a summary of the encoded dataset using describe (documentation).
encoded.describe()

One column ranges from 290290 to 1354013540 (sqft_living), another column ranges from 11 to 55 (condition), 7171 columns are all either 00 or 11 (one-hot encoded ZIP code), and then the final column ranges from a few hundred thousand to a couple million (zip_mean).
In a linear model, these will not be on equal footing. The sqft_living column will be approximately 1300013000 times easier for the model to find a pattern in than the other columns. To solve this, you often want to scale features to a standardized range. In this case, you will scale sqft_living to lie within 00 and 11.
Feature scaling
Fill in the code skeleton below to scale the column of the DataFrame to be between 00 and 11.
sqft_min = encoded[‘sqft_living’].min()
sqft_max = encoded[‘sqft_living’].max()
encoded[‘sqft_living’] = encoded[‘sqft_living’].map(lambda x : (x-sqft_min)/(sqft_max – sqft_min))
cond_min = encoded[‘condition’].min()
cond_max = encoded[‘condition’].max()
encoded[‘condition’] = encoded[‘condition’].map(lambda x : (x-cond_min)/(cond_max – cond_min))]
Predicting Credit Card Fraud Solution
Predicting Airplane Delays Solution
Data Processing for Machine Learning Example
Model Training and Evaluation Examples
Targeting Direct Marketing Solution
What are the Greenest or Least Environmentally Friendly Programming Languages?
AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
What are the Greenest or Least Environmentally Friendly Programming Languages?
Technology has revolutionized the way we live, work, and play. It has also had a profound impact on the world of programming languages. In recent years, there has been a growing trend towards green, energy-efficient languages such as C and C++. C++ and Rust are two of the most popular languages in this category. Both are designed to be more efficient than traditional languages like Java and JavaScript. And both have been shown to be highly effective at reducing greenhouse gas emissions. So if you’re looking for a language that’s good for the environment, these two are definitely worth considering.
The study below runs 10 benchmark problems in 28 languages [1]. It measures the runtime, memory usage, and energy consumption of each language. The abstract of the paper is shown below.
“This paper presents a study of the runtime, memory usage and energy consumption of twenty seven well-known software languages. We monitor the performance of such languages using ten different programming problems, expressed in each of the languages. Our results show interesting findings, such as, slower/faster languages consuming less/more energy, and how memory usage influences energy consumption. We show how to use our results to provide software engineers support to decide which language to use when energy efficiency is a concern”. [2]
According to the “paper,” in this study, they monitored the performance of these languages using different programming problems for which they used different algorithms compiled by the “Computer Language Benchmarks Game” project, dedicated to implementing algorithms in different languages.
The team used Intel’s Running Average Power Limit (RAPL) tool to measure power consumption, which can provide very accurate power consumption estimates.
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more codes)
The research shows that several factors influence energy consumption, as expected. The speed at which they are executed in the energy consumption is usually decisive, but not always the one that runs the fastest is the one that consumes the least energy as other factors enter into the power consumption equation besides speed, as the memory usage.
Energy
From this table, it is worth noting that C, C++and Java are among the languages that consume the least energy. On the other hand, JavaScript consumes almost twice as much as Java and four times what C consumes. As an interpreted language, Python needs more time to execute and is, therefore, one of the least “green” languages, occupying the position of those that consume the most energy.
Time:
The results are similar to the energy expenditure; the faster a programming language is, the less energy it expends.
Memory
In terms of memory consumption, we see how Java has become one of the most memory-consuming languages along with JavaScript.
Ranking
In this ranking, we can see the “greenest” and most efficient languages are: C, C+, Rust, and Java, although this last one shoots the memory usage.
From the Paper: Normalized global results for Energy, Time, and Memory.

To conclude:
Most Environmentally Friendly Languages: C, Rust, and C++
Least Environmentally Friendly Languages: Ruby, Python, Perl
Although this study may seem curious and without much practical application, it may help design better and more efficient programming languages. Also, we can use this new parameter in our equation when choosing a programing language.
This parameter can no longer be ignored in the future or almost the present; besides, the fastest languages are generally also the most environmentally friendly.
If you’re interested in something that is both green and energy efficient, you might want to consider the Groeningen Programming Language (GPL). Developed by a team of researchers at the University of Groningen in the Netherlands, GPL is a relatively new language that is based on the C and C++ programming languages. Python and Rust are also used in its development. GPL is designed to be used for developing energy efficient applications. Its syntax is similar to other popular programming languages, so it should be relatively easy for experienced programmers to learn. And since it’s open source, you can download and use it for free. So why not give GPL a try? It just might be the perfect language for your next project.
Top 10 Caveats – Counter arguments:
#1 C++ will perform better than Python to solve some simple algorithmic problems. C++ is a fairly bare-bone language with a medium level of abstraction, while Python is a high-level languages that relies on many external components, some of which have actually been written in C++. And of course C++ will be efficient than C# to solve some basic problem. But let’s see what happens if you build a complete web application back-end in C++.
#2: This isn’t much useful. I can imagine that the fastest (performance-wise) programming languages are greenest, and vice versa. However, running time is not only the factor here. An engineer may spend 5 minutes writing a Python script that does the job pretty well, and spends hours on debugging C++ code that does the same thing. And the performance difference on the final code may not differ much!
#3: Has anyone actually taken a look at the winning C and Rust solutions? Most of them are hand-written assembly code masked as SSE intrinsic. That is the kind of code that only a handful of people are able to maintain, not to mention come up with. On the other hand, the Python solutions are pure Python code without a trace of accelerated (read: written in Fortran, C, C++, and/or Rust) libraries like NumPy used in all sane Python projects.
#4: I used C++ years ago and now use Python, for saving energy consumption, I turn off my laptop when I got off work, I don’t use extra monitors, my AC is always set to 28 Celsius degree, I plan to change my car to electrical one, and I use Python.
#5: I disagree. We should consider the energy saved by the products created in those languages. For example, a C# – based Microsoft Teams allows people to work remotely. How much CO2 do we save that way? 😉
Now, try to do the same in C.
#6 Also, some Python programs, such as anything using NumPy, spend a considerable fraction of their cycles outside the Python interpreter in a C or C++ library..
I would love to see a scatterplot of execution time vs. energy usage as well. Given that modern CPUs can turbo and then go to a low-power state, a modest increase of energy usage during execution can pay dividends in letting the processor go to sleep quicker.
An application that vectorized heavily may end up having very high peak power and moderately higher energy usage that’s repaid by going to sleep much sooner. In the cell phone application processor business, we called that “race to sleep.” By Joe Zbiciak
#7 By Tim Mensch : It’s almost complete garbage.
If you look at the TypeScript numbers, they are more than 5x worse than JavaScript.
This has to mean they were running the TypeScript compiler every time they ran their benchmark. That’s not how TypeScript works. TypeScript should be identical to JavaScript. It is JavaScript once it’s running, after all.
Given that glaring mistake, the rest of their numbers are suspect.
I suspect Python and Ruby really are pretty bad given better written benchmarks I’ve seen, but given their testing issues, not as bad as they imply. Python at least has a “compile” phase as well, so if they were running a benchmark repeatedly, they were measuring the startup energy usage along with the actual energy usage, which may have swamped the benchmark itself.
PHP similarly has a compile step, but PHP may actually run that compile step every time a script is run. So of all of the benchmarks, it might be the closest.
I do wonder if they also compiled the C and C++ code as part of the benchmarks as well. C++ should be as optimized or more so than C, and as such should use the same or less power, unless you’re counting the compile phase. And if they’re also measuring the compile phase, then they are being intentionally deceptive. Or stupid. But I’ll go with deceptive to be polite. (You usually compile a program in C or C++ once and then you can run it millions or billions of times—or more. The energy cost of compiling is miniscule compared to the run time cost of almost any program.)
I’ve read that 80% of all studies are garbage. This is one of those garbage studies.
#8 By Chaim Solomon: This is nonsense
This is nonsense as it runs low-level benchmarks that benchmark basic algorithms in high-level languages. You don’t do that for anything more than theoretical work.
Do a comparison of real-world tasks and you should find less of a spread.
Do a comparison of web-server work or something like that – I guess you may find a factor of maybe 5 or 10 – if it’s done right.
Don’t do low-level algorithms in a high-level language for anything more than teaching. If you need such an algorithm – the way to do it is to implement it in a library as a native module. And then it’s compiled to machine code and runs as fast as any other implementation.
#9 By Tim Mensch
It’s worse than nonsense. TypeScript complies directly to JavaScript, but gets a crazy worse rating somehow?!
#10 By Tim Mensch
For NumPy and machine learning applications, most of the calculations are going to be in C.
The world I’ve found myself in is server code, though. Servers that run 24/7/365.
And in that case, a server written in C or C++ will be able to saturate its network interface at a much lower continuous CPU load than a Python or Ruby server can. So in that respect, the latter languages’ performance issues really do make a difference in ongoing energy usage.
But as you point out, in mobile there could be an even greater difference due to the CPU being put to sleep or into a low power mode if it finishes its work more quickly.
Active Hydrating Toner, Anti-Aging Replenishing Advanced Face Moisturizer, with Vitamins A, C, E & Natural Botanicals to Promote Skin Balance & Collagen Production, 6.7 Fl Oz



Age Defying 0.3% Retinol Serum, Anti-Aging Dark Spot Remover for Face, Fine Lines & Wrinkle Pore Minimizer, with Vitamin E & Natural Botanicals


Firming Moisturizer, Advanced Hydrating Facial Replenishing Cream, with Hyaluronic Acid, Resveratrol & Natural Botanicals to Restore Skin's Strength, Radiance, and Resilience, 1.75 Oz

Skin Stem Cell Serum


Smartphone 101 - Pick a smartphone for me - android or iOS - Apple iPhone or Samsung Galaxy or Huawei or Xaomi or Google Pixel
Can AI Really Predict Lottery Results? We Asked an Expert.




Djamgatech

Read Photos and PDFs Aloud for me iOS
Read Photos and PDFs Aloud for me android
Read Photos and PDFs Aloud For me Windows 10/11
Read Photos and PDFs Aloud For Amazon
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more)
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6(Email us for more)



FREE 10000+ Quiz Trivia and and Brain Teasers for All Topics including Cloud Computing, General Knowledge, History, Television, Music, Art, Science, Movies, Films, US History, Soccer Football, World Cup, Data Science, Machine Learning, Geography, etc....

List of Freely available programming books - What is the single most influential book every Programmers should read
- Bjarne Stroustrup - The C++ Programming Language
- Brian W. Kernighan, Rob Pike - The Practice of Programming
- Donald Knuth - The Art of Computer Programming
- Ellen Ullman - Close to the Machine
- Ellis Horowitz - Fundamentals of Computer Algorithms
- Eric Raymond - The Art of Unix Programming
- Gerald M. Weinberg - The Psychology of Computer Programming
- James Gosling - The Java Programming Language
- Joel Spolsky - The Best Software Writing I
- Keith Curtis - After the Software Wars
- Richard M. Stallman - Free Software, Free Society
- Richard P. Gabriel - Patterns of Software
- Richard P. Gabriel - Innovation Happens Elsewhere
- Code Complete (2nd edition) by Steve McConnell
- The Pragmatic Programmer
- Structure and Interpretation of Computer Programs
- The C Programming Language by Kernighan and Ritchie
- Introduction to Algorithms by Cormen, Leiserson, Rivest & Stein
- Design Patterns by the Gang of Four
- Refactoring: Improving the Design of Existing Code
- The Mythical Man Month
- The Art of Computer Programming by Donald Knuth
- Compilers: Principles, Techniques and Tools by Alfred V. Aho, Ravi Sethi and Jeffrey D. Ullman
- Gödel, Escher, Bach by Douglas Hofstadter
- Clean Code: A Handbook of Agile Software Craftsmanship by Robert C. Martin
- Effective C++
- More Effective C++
- CODE by Charles Petzold
- Programming Pearls by Jon Bentley
- Working Effectively with Legacy Code by Michael C. Feathers
- Peopleware by Demarco and Lister
- Coders at Work by Peter Seibel
- Surely You're Joking, Mr. Feynman!
- Effective Java 2nd edition
- Patterns of Enterprise Application Architecture by Martin Fowler
- The Little Schemer
- The Seasoned Schemer
- Why's (Poignant) Guide to Ruby
- The Inmates Are Running The Asylum: Why High Tech Products Drive Us Crazy and How to Restore the Sanity
- The Art of Unix Programming
- Test-Driven Development: By Example by Kent Beck
- Practices of an Agile Developer
- Don't Make Me Think
- Agile Software Development, Principles, Patterns, and Practices by Robert C. Martin
- Domain Driven Designs by Eric Evans
- The Design of Everyday Things by Donald Norman
- Modern C++ Design by Andrei Alexandrescu
- Best Software Writing I by Joel Spolsky
- The Practice of Programming by Kernighan and Pike
- Pragmatic Thinking and Learning: Refactor Your Wetware by Andy Hunt
- Software Estimation: Demystifying the Black Art by Steve McConnel
- The Passionate Programmer (My Job Went To India) by Chad Fowler
- Hackers: Heroes of the Computer Revolution
- Algorithms + Data Structures = Programs
- Writing Solid Code
- JavaScript - The Good Parts
- Getting Real by 37 Signals
- Foundations of Programming by Karl Seguin
- Computer Graphics: Principles and Practice in C (2nd Edition)
- Thinking in Java by Bruce Eckel
- The Elements of Computing Systems
- Refactoring to Patterns by Joshua Kerievsky
- Modern Operating Systems by Andrew S. Tanenbaum
- The Annotated Turing
- Things That Make Us Smart by Donald Norman
- The Timeless Way of Building by Christopher Alexander
- The Deadline: A Novel About Project Management by Tom DeMarco
- The C++ Programming Language (3rd edition) by Stroustrup
- Patterns of Enterprise Application Architecture
- Computer Systems - A Programmer's Perspective
- Agile Principles, Patterns, and Practices in C# by Robert C. Martin
- Growing Object-Oriented Software, Guided by Tests
- Framework Design Guidelines by Brad Abrams
- Object Thinking by Dr. David West
- Advanced Programming in the UNIX Environment by W. Richard Stevens
- Hackers and Painters: Big Ideas from the Computer Age
- The Soul of a New Machine by Tracy Kidder
- CLR via C# by Jeffrey Richter
- The Timeless Way of Building by Christopher Alexander
- Design Patterns in C# by Steve Metsker
- Alice in Wonderland by Lewis Carol
- Zen and the Art of Motorcycle Maintenance by Robert M. Pirsig
- About Face - The Essentials of Interaction Design
- Here Comes Everybody: The Power of Organizing Without Organizations by Clay Shirky
- The Tao of Programming
- Computational Beauty of Nature
- Writing Solid Code by Steve Maguire
- Philip and Alex's Guide to Web Publishing
- Object-Oriented Analysis and Design with Applications by Grady Booch
- Effective Java by Joshua Bloch
- Computability by N. J. Cutland
- Masterminds of Programming
- The Tao Te Ching
- The Productive Programmer
- The Art of Deception by Kevin Mitnick
- The Career Programmer: Guerilla Tactics for an Imperfect World by Christopher Duncan
- Paradigms of Artificial Intelligence Programming: Case studies in Common Lisp
- Masters of Doom
- Pragmatic Unit Testing in C# with NUnit by Andy Hunt and Dave Thomas with Matt Hargett
- How To Solve It by George Polya
- The Alchemist by Paulo Coelho
- Smalltalk-80: The Language and its Implementation
- Writing Secure Code (2nd Edition) by Michael Howard
- Introduction to Functional Programming by Philip Wadler and Richard Bird
- No Bugs! by David Thielen
- Rework by Jason Freid and DHH
- JUnit in Action
#BlackOwned #BlackEntrepreneurs #BlackBuniness #AWSCertified #AWSCloudPractitioner #AWSCertification #AWSCLFC02 #CloudComputing #AWSStudyGuide #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AWSBasics #AWSCertified #AWSMachineLearning #AWSCertification #AWSSpecialty #MachineLearning #AWSStudyGuide #CloudComputing #DataScience #AWSCertified #AWSSolutionsArchitect #AWSArchitectAssociate #AWSCertification #AWSStudyGuide #CloudComputing #AWSArchitecture #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AzureFundamentals #AZ900 #MicrosoftAzure #ITCertification #CertificationPrep #StudyMaterials #TechLearning #MicrosoftCertified #AzureCertification #TechBooks
Top 1000 Canada Quiz and trivia: CANADA CITIZENSHIP TEST- HISTORY - GEOGRAPHY - GOVERNMENT- CULTURE - PEOPLE - LANGUAGES - TRAVEL - WILDLIFE - HOCKEY - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Top 1000 Africa Quiz and trivia: HISTORY - GEOGRAPHY - WILDLIFE - CULTURE - PEOPLE - LANGUAGES - TRAVEL - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Exploring the Pros and Cons of Visiting All Provinces and Territories in Canada.


Exploring the Advantages and Disadvantages of Visiting All 50 States in the USA

Health Health, a science-based community to discuss health news and the coronavirus (COVID-19) pandemic
- Louisiana may reclassify drugs used in abortion as controlled dangerous substancesby /u/rustyseapants on May 18, 2024 at 12:51 am
submitted by /u/rustyseapants [link] [comments]
- Keto diet may accelerate organ ageingby /u/dead_planets_society on May 17, 2024 at 7:14 pm
submitted by /u/dead_planets_society [link] [comments]
- Transboundary Pollution is Creating a Public Health Emergency in San Diego, Californiaby /u/thinkB4WeSpeak on May 17, 2024 at 5:38 pm
submitted by /u/thinkB4WeSpeak [link] [comments]
- Burning the stomach lining reduces the ‘hunger hormone’ and cuts weightby /u/Science_News on May 17, 2024 at 5:36 pm
submitted by /u/Science_News [link] [comments]
- Discovery of new biological law may explain aging and evolutionby /u/newsweek on May 17, 2024 at 2:40 pm
submitted by /u/newsweek [link] [comments]
Today I Learned (TIL) You learn something new every day; what did you learn today? Submit interesting and specific facts about something that you just found out here.
- TIL that Captain Planet (1990-1996) was created by media mogul Ted Turner along with executive producer Barbara Pyleby /u/Business-Secret-4392 on May 18, 2024 at 3:24 am
submitted by /u/Business-Secret-4392 [link] [comments]
- TIL: Gravity on the ISS is ~90% of the Earth's. It looks like they're on zero-G because both the astronauts and the ISS are in a continual state of freefall (orbiting the Earth).by /u/SauloJr on May 18, 2024 at 2:32 am
submitted by /u/SauloJr [link] [comments]
- TIL Not only did the YMCA use to offer dormitory housing at most of it's US locations, it boasted over 100,000 rooms in the 1940's. This was more than any hotel chain at the time.by /u/UndyingCorn on May 18, 2024 at 1:19 am
submitted by /u/UndyingCorn [link] [comments]
- TIL Rachel McAdams who plays 17 year old Regina George was 25 years old at the time. Her mother on film Amy Poehler was was only 8 years older at 33.by /u/Sal21G on May 18, 2024 at 1:09 am
submitted by /u/Sal21G [link] [comments]
- TIL that NASA lost a $330m Mars Orbiter in 1999, immediately before mars orbit was achieved, because one of the contracted US companies used imperial units instead of metric.by /u/FrogsEverywhere on May 18, 2024 at 12:11 am
submitted by /u/FrogsEverywhere [link] [comments]
Reddit Science This community is a place to share and discuss new scientific research. Read about the latest advances in astronomy, biology, medicine, physics, social science, and more. Find and submit new publications and popular science coverage of current research.
- Benign nail condition linked to rare syndrome that greatly increases cancer risk | National Institutes of Health (NIH)by /u/Leo_nardo on May 18, 2024 at 3:30 am
submitted by /u/Leo_nardo [link] [comments]
- Global life expectancy to increase by nearly 5 years by 2050 despite geopolitical, metabolic, and environmental threats, study finds: Life expectancy will increase by 4.9 years in males and 4.2 years in females between 2022 and 2050by /u/FunnyGamer97 on May 18, 2024 at 1:41 am
submitted by /u/FunnyGamer97 [link] [comments]
- T cell activation and deficits in T regulatory cells are associated with major depressive disorder and severity of depressionby /u/fatsug on May 18, 2024 at 12:59 am
submitted by /u/fatsug [link] [comments]
- A new study provides insights into the origin of avian endothermy, suggesting its evolution in theropod and ornithiscian dinosaurs starting in the Early Jurassic.by /u/grimisgreedy on May 18, 2024 at 12:59 am
submitted by /u/grimisgreedy [link] [comments]
- Inga Bischoff, a doctoral student in Dr. André Schäfer’s research team at Saarland University, has synthesized in the laboratory the world’s first ‘heterobimetallic’ sandwich complex – a dimetallocene that contains two different metal atomsby /u/TurretLauncher on May 17, 2024 at 10:30 pm
submitted by /u/TurretLauncher [link] [comments]
Reddit Sports Sports News and Highlights from the NFL, NBA, NHL, MLB, MLS, and leagues around the world.
- Pacers pull past Knicks to force Game 7by /u/Oldtimer_2 on May 18, 2024 at 3:20 am
submitted by /u/Oldtimer_2 [link] [comments]
- Florida Panthers clinch series win over Boston Bruins - Will face New York Rangers in Eastern Conference Finalby /u/SkepticalZebra on May 18, 2024 at 2:06 am
submitted by /u/SkepticalZebra [link] [comments]
- Report: Braves' Fletcher bet with bookie tied to Mizuhara scandalby /u/Oldtimer_2 on May 18, 2024 at 1:42 am
submitted by /u/Oldtimer_2 [link] [comments]
- Tiger Woods misses cut at 2024 PGA Championshipby /u/PrincessBananas85 on May 18, 2024 at 12:55 am
submitted by /u/PrincessBananas85 [link] [comments]
- Woods gets stuck in sand, makes two early triples en route to a 77 and will miss the cut at PGAby /u/Oldtimer_2 on May 18, 2024 at 12:47 am
submitted by /u/Oldtimer_2 [link] [comments]
