What are the Top 10 AWS jobs you can get with an AWS certification in 2022 plus AWS Interview Questions
AWS certifications are becoming increasingly popular as the demand for AWS-skilled workers continues to grow. AWS certifications show that an individual has the necessary skills to work with AWS technologies, which can be beneficial for both job seekers and employers. AWS-certified individuals can often command higher salaries and are more likely to be hired for AWS-related positions. So, what are the top 10 AWS jobs that you can get with an AWS certification?
AWS solutions architects are responsible for designing, implementing, and managing AWS solutions. They work closely with other teams to ensure that AWS solutions are designed and implemented correctly.
AWS Architects, AWS Cloud Architects, and AWS solutions architects spend their time architecting, building, and maintaining highly available, cost-efficient, and scalable AWS cloud environments. They also make recommendations regarding AWS toolsets and keep up with the latest in cloud computing.
Professional AWS cloud architects deliver technical architectures and lead implementation efforts, ensuring new technologies are successfully integrated into customer environments. This role works directly with customers and engineers, providing both technical leadership and an interface with client-side stakeholders.
AWS sysops administrators are responsible for managing and operating AWS systems. They work closely with AWS developers to ensure that systems are running smoothly and efficiently.
A Cloud Systems Administrator, or AWS SysOps administrator, is responsible for the effective provisioning, installation/configuration, operation, and maintenance of virtual systems, software, and related infrastructures. They also maintain analytics software and build dashboards for reporting.
AWS devops engineers are responsible for designing and implementing automated processes for Amazon Web Services. They work closely with other teams to ensure that processes are efficient and effective.
AWS DevOps engineers design AWS cloud solutions that impact and improve the business. They also perform server maintenance and implement any debugging or patching that may be necessary. Among other DevOps things!
AWS cloud engineers are responsible for designing, implementing, and managing cloud-based solutions using AWS technologies. They work closely with other teams to ensure that solutions are designed and implemented correctly.
5. AWS Network Engineer:
AWS network engineers are responsible for designing, implementing, and managing networking solutions using AWS technologies. They work closely with other teams to ensure that networking solutions are designed and implemented correctly.
Cloud network specialists, engineers, and architects help organizations successfully design, build, and maintain cloud-native and hybrid networking infrastructures, including integrating existing networks with AWS cloud resources.
AWS security engineers are responsible for ensuring the security of Amazon Web Services environments. They work closely with other teams to identify security risks and implement controls to mitigate those risks.
Cloud security engineers provide security for AWS systems, protect sensitive and confidential data, and ensure regulatory compliance by designing and implementing security controls according to the latest security best practices.
As a database administrator on Amazon Web Services (AWS), you’ll be responsible for setting up, maintaining, and securing databases hosted on the Amazon cloud platform. You’ll work closely with other teams to ensure that databases are properly configured and secured.
8. Cloud Support Engineer:
Support engineers are responsible for providing technical support to AWS customers. They work closely with customers to troubleshoot problems and provide resolution within agreed upon SLAs.
9. Sales Engineer:
Sales engineers are responsible for working with sales teams to generate new business opportunities through the use of AWS products and services .They must have a deep understanding of AWS products and how they can be used by potential customers to solve their business problems .
10. Cloud Developer
An AWS Developer builds software services and enterprise-level applications. Generally, previous experience working as a software developer and a working knowledge of the most common cloud orchestration tools is required to get and succeed at an AWS cloud developer job
Cloud consultants provide organizations with technical expertise and strategy in designing and deploying AWS cloud solutions or in consulting on specific issues such as performance, security, or data migration.
The field of cloud computing will continue to grow and even more different types of jobs will surface in the future.
AWS certified professionals are in high demand across a variety of industries. AWS certs can open the door to a number of AWS jobs, including cloud engineer, solutions architect, and DevOps engineer.
Through studying and practice, any of the listed jobs could becoming available to you if you pass your AWS certification exams. Educating yourself on AWS concepts plays a key role in furthering your career and receiving not only a higher salary, but a more engaging position.
What is Problem Formulation in Machine Learning and Top 4 examples of Problem Formulation in Machine Learning?
Machine Learning (ML) is a field of Artificial Intelligence (AI) that enables computers to learn from data, without being explicitly programmed. Machine learning algorithms build models based on sample data, known as “training data”, in order to make predictions or decisions, rather than following rules written by humans. Machine learning is closely related to and often overlaps with computational statistics; a discipline that also focuses on prediction-making through the use of computers. Machine learning can be applied in a wide variety of domains, such as medical diagnosis, stock trading, robot control, manufacturing and more.
What is Problem Formulation in Machine Learning and Top 4 examples of Problem Formulation in Machine Learning?
The process of machine learning consists of several steps: first, data is collected; then, a model is selected or created; finally, the model is trained on the collected data and then applied to new data. This process is often referred to as the “machine learning pipeline”. Problem formulation is the second step in this pipeline and it consists of selecting or creating a suitable model for the task at hand and determining how to represent the collected data so that it can be used by the selected model. In other words, problem formulation is the process of taking a real-world problem and translating it into a format that can be solved by a machine learning algorithm.
2023 AWS Certified Machine Learning Specialty (MLS-C01) Practice Exams
There are many different types of machine learning problems, such as classification, regression, prediction and so on. The choice of which type of problem to formulate depends on the nature of the task at hand and the type of data available. For example, if we want to build a system that can automatically detect fraudulent credit card transactions, we would formulate a classification problem. On the other hand, if our goal is to predict the sale price of houses given information about their size, location and age, we would formulate a regression problem. In general, it is best to start with a simple problem formulation and then move on to more complex ones if needed.
Some common examples of problem formulations in machine learning are: – Classification: given an input data point (e.g., an image), predict its category label (e.g., dog vs cat). – Regression: given an input data point (e.g., size and location of a house), predict a continuous output value (e.g., sale price). – Prediction: given an input sequence (e.g., a series of past stock prices), predict the next value in the sequence (e.g., future stock price). – Anomaly detection: given an input data point (e.g., transaction details), decide whether it is normal or anomalous (i.e., fraudulent). – Recommendation: given information about users (e.g., age and gender) and items (e.g., books and movies), recommend items to users (e.g., suggest books for someone who likes romance novels). – Optimization: given a set of constraints (e.g., budget) and objectives (e.g., maximize profit), find the best solution (e.g., product mix).
Problem Formulation: What this pipeline phase entails and why it’s important
The problem formulation phase of the ML Pipeline is critical, and it’s where everything begins. Typically, this phase is kicked off with a question of some kind. Examples of these kinds of questions include: Could cars really drive themselves? What additional product should we offer someone as they checkout? How much storage will clients need from a data center at a given time?
The problem formulation phase starts by seeing a problem and thinking “what question, if I could answer it, would provide the most value to my business?” If I knew the next product a customer was going to buy, is that most valuable? If I knew what was going to be popular over the holidays, is that most valuable? If I better understood who my customers are, is that most valuable?
However, some problems are not so obvious. When sales drop, new competitors emerge, or there’s a big change to a company/team/org, it can be easy to say, “I see the problem!” But sometimes the problem isn’t so clear. Consider self-driving cars. How many people think to themselves, “driving cars is a huge problem”? Probably not many. In fact, there isn’t a problem in the traditional sense of the word but there is an opportunity. Creating self-driving cars is a huge opportunity. That doesn’t mean there isn’t a problem or challenge connected to that opportunity. How do you design a self-driving system? What data would you look at to inform the decisions you make? Will people purchase self-driving cars?
Part of the problem formulation phase includes seeing where there are opportunities to use machine learning.
In the following practice examples, you are presented with four different business scenarios. For each scenario, consider the following questions:
Is machine learning appropriate for this problem, and why or why not?
What is the ML problem if there is one, and what would a success metric look like?
What kind of ML problem is this?
Is the data appropriate?’
The solutions given in this article are one of the many ways you can formulate a business problem.
I) Amazon recently began advertising to its customers when they visit the company website. The Director in charge of the initiative wants the advertisements to be as tailored to the customer as possible. You will have access to all the data from the retail webpage, as well as all the customer data.
ML is appropriate because of the scale, variety and speed required. There are potentially thousands of ads and millions of customers that need to be served customized ads immediately as they arrive to the site.
The problem is ads that are not useful to customers are a wasted opportunity and a nuisance to customers, yet not serving ads at all is a wasted opportunity. So how does Amazon serve the most relevant advertisements to its retail customers?
Success would be the purchase of a product that was advertised.
This is a supervised learning problem because we have a labeled data point, our success metric, which is the purchase of a product.
This data is appropriate because it is both the retail webpage data as well as the customer data.
II) You’re a Senior Business Analyst at a social media company that focuses on streaming. Streamers use a combination of hashtags and predefined categories to be discoverable by your platform’s consumers. You ran an analysis on unique streamer counts by hashtags and categories over the last month and found that out of tens of thousands of streamers, almost all use only 40 hashtags and 10 categories despite innumerable hashtags and hundreds of categories. You presume the predefined categories don’t represent all the possibilities very well, and that streamers are simply picking the closest fit. You figure there are likely many categories and groupings of streamers that are not accounted for. So you collect a dataset that consists of all streamer profile descriptions (all text), all the historical chat information for each streamer, and all their videos that have been streamed.
ML is appropriate because of the scale and variability.
The problem is the content of streamers is not being represented by the existing categories. Success would be naturally grouping the streamers into categories based on content and seeing if those align with the hashtags and categories that are being commonly used. If they do not, then the streamers are not being well represented and you can use these groupings to create new categories.
There isn’t a specific outcome variable. There’s no target or label. So this is an unsupervised problem.
The data is appropriate.
III) You’re a headphone manufacturer who sells directly to big and small electronic stores. As an attempt to increase competitive pricing, Store 1 and Store 2 decided to put together the pricing details for all headphone manufacturers and their products (about 350 products) and conduct daily releases of the data. You will have all the specs from each manufacturer and their product’s pricing. Your sales have recently been dropping so your first concern is whether there are competing products that are priced lower than your flagship product.
ML is probably not necessary for this. You can just search the dataset to see which headphones are priced lower than the flagship, then compare their features and build quality.
IV) You’re a Senior Product Manager at a leading ridesharing company. You did some market research, collected customer feedback, and discovered that both customers and drivers are not happy with an app feature. This feature allows customers to place a pin exactly where they want to be picked up. The customers say drivers rarely stop at the pin location. Drivers say customers most often put the pin in a place they can’t stop. Your company has a relationship with the most used maps app for the driver’s navigation so you leverage this existing relationship to get direct, backend access to their data. This includes latitude and longitude, visual photos of each lat/long, traffic delay details, and regulation data if available (ie- No Parking zones, 3 minute parking zones, fire hydrants, etc.).
ML is appropriate because of the scale and automation involved. It’s not feasible to drive everywhere and write down all the places that are ok for pickup. However, maybe we can predict whether a location is ok for pickup.
The problem is drivers and customers are having poor experiences connecting for pickup, which is pushing customers away from the platform.
Success would be properly identifying appropriate pickup locations so they can be integrated into the feature.
This is a supervised learning problem even though there aren’t any labels, yet. Someone will have to go through a sample of the data to label where there are ok places to park and not park, giving the algorithms some target information.
The data is appropriate once a sample of the dataset has been labeled. There may be some other data that could be included too. What about asking UPS for driver stop information? Where do they stop?
In conclusion, problem formulation is an important step in the machine learning pipeline that should not be overlooked or underestimated. It can make or break a machine learning project; therefore, it is important to take care when formulating machine learning problems.”
Step by Step Solution to a Machine Learning Problem – Feature Engineering
Feature Engineering is the act of reshaping and curating existing data to make patters more apparent. This process makes the data easier for an ML model to understand. Using knowledge of the data, features are engineered and tuned to make ML algorithms work more efficiently.
For this problem, imagine a scenario where you are running a real estate brokerage and you want to predict the selling price of a house. Using a specific county dataset and simple information (like the location, total square footage, and number of bedrooms), let’s practice training a baseline model, conducting feature engineering, and tuning a model to make a prediction.
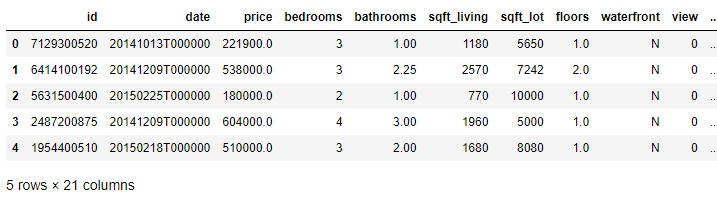
First, load the dataset and take a look at its basic properties.
# Load the dataset import pandas as pd import boto3
df = pd.read_csv(“xxxxx_data_2.csv”) df.head()
housing dataset example: xxxxx_data_2.csv
Output:
feature_engineering_dataset_example
This dataset has 21 columns:
id – Unique id number
date – Date of the house sale
price – Price the house sold for
bedrooms – Number of bedrooms
bathrooms – Number of bathrooms
sqft_living – Number of square feet of the living space
sqft_lot – Number of square feet of the lot
floors – Number of floors in the house
waterfront – Whether the home is on the waterfront
view – Number of lot sides with a view
condition – Condition of the house
grade – Classification by construction quality
sqft_above – Number of square feet above ground
sqft_basement – Number of square feet below ground
yr_built – Year built
yr_renovated – Year renovated
zipcode – ZIP code
lat – Latitude
long – Longitude
sqft_living15 – Number of square feet of living space in 2015 (can differ from sqft_living in the case of recent renovations)
sqrt_lot15 – Nnumber of square feet of lot space in 2015 (can differ from sqft_lot in the case of recent renovations)
This dataset is rich and provides a fantastic playground for the exploration of feature engineering. This exercise will focus on a small number of columns. If you are interested, you could return to this dataset later to practice feature engineering on the remaining columns.
A baseline model
Now, let’s train a baseline model.
People often look at square footage first when evaluating a home. We will do the same in the oflorur model and ask how well can the cost of the house be approximated based on this number alone. We will train a simple linear learner model (documentation). We will compare to this after finishing the feature engineering.
If you examine the quality metrics, you will see that the absolute loss is about $175,000.00. This tells us that the model is able to predict within an average of $175k of the true price. For a model based upon a single variable, this is not bad. Let’s try to do some feature engineering to improve on it.
Throughout the following work, we will constantly be adding to a dataframe called encoded. You will start by populating encoded with just the square footage you used previously.
encoded = df[[‘sqft_living’]].copy()
Categorical variables
Let’s start by including some categorical variables, beginning with simple binary variables.
The dataset has the waterfront feature, which is a binary variable. We should change the encoding from 'Y' and 'N' to 1 and 0. This can be done using the map function (documentation) provided by Pandas. It expects either a function to apply to that column or a dictionary to look up the correct transformation.
You can also encode many class categorical variables. Look at column condition, which gives a score of the quality of the house. Looking into the data source shows that the condition can be thought of as an ordinal categorical variable, so it makes sense to encode it with the order.
Ordinal categorical
Using the same method as in question 1, encode the ordinal categorical variable condition into the numerical range of 1 through 5.
A slightly more complex categorical variable is ZIP code. If you have worked with geospatial data, you may know that the full ZIP code is often too fine-grained to use as a feature on its own. However, there are only 7070 unique ZIP codes in this dataset, so we may use them.
However, we do not want to use unencoded ZIP codes. There is no reason that a larger ZIP code should correspond to a higher or lower price, but it is likely that particular ZIP codes would. This is the perfect case to perform one-hot encoding. You can use the get_dummies function (documentation) from Pandas to do this.
Nominal categorical
Using the Pandas get_dummies function, add columns to one-hot encode the ZIP code and add it to the dataset.
In this way, you may freely encode whatever categorical variables you wish. Be aware that for categorical variables with many categories, something will need to be done to reduce the number of columns created.
One additional technique, which is simple but can be highly successful, involves turning the ZIP code into a single numerical column by creating a single feature that is the average price of a home in that ZIP code. This is called target encoding.
To do this, use groupby (documentation) and mean (documentation) to first group the rows of the DataFrame by ZIP code and then take the mean of each group. The resulting object can be mapped over the ZIP code column to encode the feature.
Nominal categorical II
Complete the following code snippet to provide a target encoding for the ZIP code.
means = df.groupby(‘zipcode’)[‘price’].mean() encoded[‘zip_mean’] = df[‘zipcode’].map(means)
Normally, you only either one-hot encode or target encode. For this exercise, leave both in. In practice, you should try both, see which one performs better on a validation set, and then use that method.
Take a look at the dataset. Print a summary of the encoded dataset using describe (documentation).
encoded.describe()
Scaling – summary of the encoded dataset using describe
One column ranges from 290290 to 1354013540 (sqft_living), another column ranges from 11 to 55 (condition), 7171 columns are all either 00 or 11 (one-hot encoded ZIP code), and then the final column ranges from a few hundred thousand to a couple million (zip_mean).
In a linear model, these will not be on equal footing. The sqft_living column will be approximately 1300013000 times easier for the model to find a pattern in than the other columns. To solve this, you often want to scale features to a standardized range. In this case, you will scale sqft_living to lie within 00 and 11.
Feature scaling
Fill in the code skeleton below to scale the column of the DataFrame to be between 00 and 11.
Tech Jobs and Career at FAANG (now MAANGM): Facebook Meta Amazon Apple Netflix Google Microsoft
The FAANG companies (Facebook, Amazon, Apple, Netflix, Google, and Microsoft) are some of the most sought-after employers in the tech industry. They offer competitive salaries and benefits, and their employees are at the forefront of innovation.
The interview process for a job at a FAANG company is notoriously difficult. Candidates must be prepared to answer tough technical questions and demonstrate their problem-solving skills. The competition is fierce, but the rewards are worth it. Employees of FAANG companies enjoy perks like free food and transportation, and they often have the opportunity to work on cutting-edge projects.
If you’re interested in a career in tech, Google, Facebook, or Microsoft are great places to start your search. These companies are leaders in their field, and they offer endless opportunities for career growth.
FAANG stared as FANG circa 2013. The 2nd A became customary around 2016 as it wasn’t clear whether A referred to Apple or Amazon. Originally, FANG meant “large public, fast growing tech companies”. Now in 2021, the scope of what FANG referred to just doesn’t correspond to these 5 companies.
From an investment perspective (which is the origin of FANG) Facebook stock has grown the slowest of the 5 companies over the past 5 years. And they’re all dwarfed by Tesla.
From an employment desirability perspective (which is the context where FAANG is most used today). Microsoft is very similar to the group. It wasn’t “cool” around 2013 but its stock actually did better than Facebook or Alphabet over the past five years. Other companies like Airbnb, Twitter or Salesforce offer the same value proposition to employees, that is stability and tradable equity as part of the compensation.
FAANG refers to a category more than a specific list of companies.
As a side note, I expect people to routinely call the company Facebook, just like most people still say Google when they really mean Alphabet.
The technical interviews at FAANG companies, in the grand scheme, aren’t very difficult.
People frequently fail FAANG interviews because they choke — they experience anxiety and just forget their knowledge — or they don’t know the material to begin with.
Inverting a binary tree, matching up pairs of brackets, finding the duplicate in an array of distinct integers, etc., are all weeder-questions that should be solvable in 5–10 minutes, if you’re the type to suffer from interview jitters. You should know which data structures to use, intuitively, and you should be doing prep work to cover your knowledge gaps if you don’t.
Harder questions will take longer, but ultimately, you’ll have 45 minutes or so to solve 2–3 questions.
Technical interviews at FAANG companies are only difficult if you have shaky computer science fundamentals. Luckily, the process for cracking the code interview *cough* is very well-documented, hence, you only need to follow the already established strategies. If you’re interested in maximizing income while prioritizing career growth, it behooves you to spend a month or two studying these strategies.
In FAANG interview process, when you fail at the 1st (or 2nd stage), does it mean that single interviewer on the respective stage failed you, or is it still team collaboration /hiring manager decision?
If you were dropped after doing a single interview (usually called a “screen”) it means that this interviewer gave negative feedback. I would guess at some companies this feedback is reviewed by the hiring manager, but mostly I think a recruiter will just reject if the interviewer recommends no hire. Even if a hiring manager looks at it, they would probably reject almost always if the feedback is negative. The purpose of the screen is to quickly evaluate if a person is worth interviewing in depth.
If you were rejected after a whole interview panel, probably a hiring manager or similar did look at the entire feedback, and much of the time there was a discussion where interviewers looked at the entire feedback as well and shared their thoughts. However, if the feedback was clearly negative, it could’ve been just a snap decision by a manager without much discussion. Source.
What do you do after you absolutely flop a technical interview?
Take care of yourself / don’t beat yourself up.
It happens. It happened to me, it happened to smarter people. It’s ok.
Two thoughts to help here –
Getting to the interview stage is already a huge achievement. If you are interviewed, this means that in the expert opinion of the recruiters, people that did tech screens etc. you stand a chance to pass the interview. You earned your place in the interviewee seat. This is an accomplishment you can be proud of.
The consequences are probably* negligible in the long run. There’s at least 100 very desirable tech companies to work at at a given moment. You didn’t get in 1% of them at a moment in time. Big deal. You can probably retry in a few months. It’s very likely that you get an equivalent or even better opportunity, and there’s no use imagining what would have happened if you had had that job. (*“probably” because if you’re under time pressure to get a job rapidly… it may sting differently. But hey, there’s still the first thought).
As a bonus, you’ll probably remember very well the question on which you failed. Source: Jerome Cukier
If an interviewer says “we’re still interviewing other candidates at the moment”, and then walks you out into the lobby, does that mean they want to hire you potentially after or no?
Here’s a secret. I have been a recruiter for 24 years and when they walk you out after your interview and tell you that they are still interviewing other candidates at the moment, it really means they’re still interviewing other candidates at the moment. There’s no secret language here to try to interpret. It means what it means. You will have to wait for them to tell you what next steps are for you because, again, they have other people to interview. By Leah Roth
The difficulty of the interview is going to vary more interviewer to interviewer, than company to company. Also, how difficult the questions are is not directly related to how selective the process is; the latter being heavily influenced by business factors currently affecting these companies and what are their current hiring plans.
#1: So, how do know you this? You don’t. An affirmative answer to this question can only come from data.
#Answer #1: Fair question. I have been very involved in interviewing in a number of large tech cos. I have read, by now, thousands of interview debriefs. I have also interviewed a fair amount as a candidate, although I have not interviewed in each of the “FAANG” and I have definitely be more often on the interviewing side.
As such, I have seen for the same position, very easy questions and brutally difficult ones; I have seen very promising candidates not brought to onsite interviews because the hiring organization didn’t currently have resources to hire, but also ok-ish candidates given offers because the organization had trouble meeting their hiring targets. As a candidate I also experienced: easy interview exercises but no offer, very hard interview exercises and offer (with the caveat that I never know exactly how well I do, but I certainly can tell if a coding question or a system design question is easy or hard).
So. I am well aware that it’s still anecdotal evidence, but it’s still based on a fairly large sample of interviews and candidates.
#Reply to #1: Nope, you’re wrong. I have experience in the interview process at Amazon and Microsoft and have a different conclusion. Moreover, “experts” in lots of disparate fields make claims that are a bunch of bullcrap due to their own experiential biases. Additionally, you would need to be involved at all of the companies listed, not just some of the them, for that experience to be relevant in answering this question. We need to look at the data. If you don’t have data, I will not trust you just because of “your experience”. I don’t think it’s possible for Jerry C to have the necessary information to justify the confidence that is projected in this answer.
What you need is not so much a list of “incidents” but more generally some self-awareness on what you care about and how you’ve progressed and how you see your career.
The best source for this material is your performance reviews. Ideally you also kept some document about your career goals and/or conversation with your manager. (If you haven’t such documents, it’s never too late to start them!).
You should have 5–6 situations that are fairly recent and that you know on the back of your hand. These must include something difficult, and some of these situations must be focused on interpersonal relationships (or more generally, you should be aware of more situations that involved a difficult interpersonal relation). They may or may not have had a great outcome – it’s ok if you didn’t save the day. But you should always know the outcome both in terms of business and on your personal growth.
Once you have your set of situations and you can easily access these stories / effortlessly remember all details, you’ll find it much easier to answer any behavioural question.
In a software engineering interview, How should one answer the question, ‘Could you tell me about some of the technical challenges in your previous projects’?
To take a few steps back, there are 2 things that interviewers care about in behavioural interviews – whether the candidate has the right level, and whether they exhibit certain skillsets.
When you look at this question from the first angle, it’s important to be able to present hard problems on which it’s clear what the candidate’s personal contribution was. Typically, later projects are better for that than earlier ones.
Now, in terms of skillsets, this really depends company by company but typically, how well a candidate is able to describe a problem especially to someone with a different expertise, and whether they spontaneously go on to describe impact metrics, goes a long way.
So great answer: hard, recent, large scale project, that the candidate is able to contextualize (why was is important, why was it hard, what was at stake), where they are able to describe what they’ve done and what was the potential impact, and what were the actual consequences.
Not so great answer: a project that no one asked the candidate to do, but which they insisted on doing because they thought it was cool/interesting, on which they worked alone and which didn’t have any business impact. Source.
This question (like many other things in life) is much more complicated than it appears on the surface. That’s because it is conflating several very different issues, including:
What is retirement?
What is “early”?
At what age do most software engineers stop working in that role?
How long do employees stay on average at the FAANGs?
In the “old” days (let’s arbitrarily call that mid-20th century America), the typical worker was white, male and middle class, employed on location at a job for 40–50 hours a week. He began his working career at 18 (after high school) or 22 (after college), and worked continuously for a salary until the age of 65. At that time he retired (“stopped working”) and spent his remaining 5–10 years of life sitting at home watching tv or traveling to places that he had always wanted to visit.
That world has, to a large extent, been transmogrified over the past 50 years. People are working longer, changing employment more frequently, even changing careers and professions as technology and the economy change. The work force is increasingly diverse, and virtually all occupations are open to virtually all people. Over the past two years we have seen that an astonishing number of jobs can be done remotely, and on an asynchronous basis. And all of these changes have disproportionately affected software engineering.
So, let’s begin by laying out some facts:
When people plan to retire is a factor of their generation: Generation Y — ages 25 to 40 — plans to retire at an average age of 59. For Generation X — now 41 to 56 — the average age is 60. Baby boomers — who range from 57 to 75 — indicated they plan to work longer, with an average expected retirement age of 68.[1]
The average actual retirement age in the US is 62[2]
Most software engineers retire between the ages of 45 and 65, with less than 1% of developers working later than 65.[3]
But those numbers are misleading because many software engineers experience rapid career progression and move out of a pure development role long before they retire.
The average life expectancy in Silicon Valley is 85 years.[4]
The tenure of employment at the FAANGs is much shorter than than one might imagine. Unlike in the past, when a person might spend his or her entire career working for one or two employers, here are the average lengths of time that people work at the FAANGs: Facebook 2.5 years, Google 3.2 years, Apple 5 years.[5]
Therefore, if the question assumes that a software engineer gets hired at a FAANG company in his or her 20s, works there for 20 or 30 years as a coder, and then “retires early”, that is just not the way things work.
Much more likely is the scenario in which an engineer graduates from college at 21, gets a masters degree in computer science by 23, starts as a junior engineer at a small or large company for a few years, gets hired into a FAANG by their early 30s, spends 3–5 years coding there, is recruited to join a non-FAANG by their early 40s in a more senior role, and moves into management by their late 40s.
At that point things become a matter of personal preference: truly “retire”, start your own venture; invest in cryptocurrency; move up to senior management; begin a second career; etc.
The fact is that software engineering at a high level (such as would warrant employment at a FAANG in the first place) pays very well in relative terms, and with appropriate self-control and a moderate lifestyle would enable someone to “retire” at a relatively early age. But paradoxically, that same type of person is unlikely to do so.
Are companies like Google and Facebook heaven on earth in terms of workplaces?
No. In fact Google’s a really poor workplace by comparison with most others I’ve had in my career. Having a private office with a door you can close is a real boon to doing thoughtful, creative work, and having personal space so that you can feel psychologically safe is important too.
You don’t get any of that at Google, unless you’re a director or VP and your job function requires closed-door meetings. I have a very nice, state-of-the-art standing desk, with a state-of-the-art monitor, and the only way for me to avoid hearing my tech lead’s conversations is to put headphones on. (You can get very nice, state-of-the-art headphones, too.)
On the other hand, I also have regular access to great food, and an excellent gym, and all the La Croix water I can drink. I get to work on the most incredible technological platform on earth. And the money’s good. But heaven on earth? Nah. That’s one of the reasons the money’s good.
What is the starting salary of a software engineer at Google?
A new grad software engineer (L3) at Google makes a salary around $193,000 including stock compensation and bonus. The industry is getting a lot more competitive and top companies such as Google have to make offers with really generous stock packages. The below diagram shows a breakdown for the salary. View all the crowdsourced reports as well as other levels on Levels.fyi.
Hope that helps!
What is the best Google employee perk, and why?
Having recent left Google for a new startup I have to agree that the most-missed perk is the food. It’s not so much that it’s free — you can get lunch for about $10 per day so the cost is not a huge deal. There is simply nowhere you can go, even in a Silicon Valley city like Mountain View, that has healthy low-fat, varied choices that include features like edible fruits and vegetables. The food is even color-coded (red/yellow/green) based on how healthy it is (it always bothered me that the peanut-butter cups are red….).
Outside of Google you end up having muffins for breakfast and pizza for lunch. It tastes good but it’s not the same to your body.
But beyond just the food, the long term health impact of the set of perks at Google is huge. There is nothing better than being able to come in early, work out at the (free) gym by your office, shower (with towels provided as noted by others), then have eggs (or egg whites if you prefer) and toast (or one of a dozen other breakfasts). Source
Everyone has a study plan and list of resources they like to use. Different plans work for different people and there is no one size fits all.
This by no means is the only list of resources to join a larger technology company. But it is the list of resources I used myself to prepare for all my technology interviews.
Quick Background
I’m a current engineer at Microsoft who previously worked at Amazon for 1 year each respectively. I don’t have a master’s degree and I graduated from NYU, not an Ivy League. I’ll soon be joining Google and the following resources is how I got there.
Yes, the purchasable resources are affiliate links that help support this blog. Regardless, these are the resources I’ve used both purchasable and free.
This is the simplest book to get anyone started in studying for coding interviews.
If you’re an absolute beginner, I recommend you to start here. The questions have very details explanations that are easy to understand with basic knowledge of algorithms and data structures.
Elements of Programming Interviews (Python, Java, C++)
If you’re a little more experienced, every question in this book is at the interviewing level of all large technology companies.
If you’ve mastered the questions in this book, then you are more than ready for the average technology interview. The book is not as beginner friendly as CTCI but it does include a study plan depending on how much you need to prepare for your interviews. This is my personal favorite book I carried everywhere in university.
Blind has a list of 75 questions that is generally enough to solve most coding interviews. It’s a very curated and focused list for the most essential algorithms to leverage your time.
The playlist above is one of the clearest explanations I’ve ever seen and highly recommend if you need an explanation on any of the problems.
These problems are hard. Really hard for anyone who hasn’t practiced algorithms and is not beginner friendly. But if you are able to complete the sorting and searching section, you will be more capable than the average LeetCode user and be more than ready for your coding interview.
Consider this if you’re comfortable with LeetCode medium questions and find the questions in CTCI too easy.
This is the most common and best textbook anyone could use to learn algorithms. It’s also the textbook my university used personally to learn the core and essential algorithms to most coding problems.
The 4th edition was recently released and is still relevant to MIT students. If you need structure and a traditional classroom setting to study, follow MIT’s algorithm course here.
Graph theory does come up in interviews (and was a question I had at both Bloomberg and Google). Stay prepared and follow William Fiset’s graph theory explanation.
The diagrams are comprehensive and the step-by-step explanations are the best I’ve ever seen on the topic.
This handbook is for people who are strongly proficient with most Leetcode algorithms. It’s a free resource that strongly complements the CSES.fi curriculum.
For the most experienced algorithm enthusiasts, this book will cover every niche data structure and algorithm that could possibly be asked in any coding interview. This level of preparation is not generally needed for FAANG type companies but can show up if you’re considering hedge fund type companies.
In my opinion, you will be more than ready for any system design interview using these resources. The diagrams are clear and the explanations are as simple as possible in each book to help you learn system design concepts quickly.
I recommend the online course personally because yes the content from both books is great to own, it’s the online community discord you get access to that makes the yearly subscription worth it. The discord includes mock interview buddies, salary discussion, and over view on each system design topics to study with other users on.
The system design primer is the best free resource on all things system design. Dig deep into the Git repository and you will learn everything you need to know on system design. It’s all curated in a single repository and the clearly structured to give you a guided curriculum.
This quick overview on system design is great to review if you’re in a rush. The read typically takes users 45 minutes but you’ll be left knowing more system design than the average engineer.
Give it a read. If concepts are unclear or confusing, that might be a sign you’re not ready for interviews.
Regardless if you’re learning design patterns for the object-oriented programming interview, you will need to know design patterns as a software engineer at these large companies.
The book is the origin of the world’s most common design patterns today and showing proficiency in these for your object oriented interview is a requirement for certain large technology companies like Amazon.
The above resource is dense and written in language that’s hard to understand. While the original source material in design patterns is great, it doesn’t help much if it’s difficult to understand.
Consider Head First Design patterns to study a simplified explanation of those common design patterns. It might not be as in-depth as the original source material, but your understanding in design patterns will be more than enough to crack any object-oriented interview.
Closing Thoughts
Honestly, I did not go through all of these resources from cover to cover. If you do, I’m sure you wouldn’t need to study for another interview again. But likely we don’t have the time to do that so make sure that once you understand the core concepts in the any of the above categories that you invest your time moving on to the next.
Again, these are the resources I used and is not at all inclusive of anyone else’s study plan.
3 Years ago I applied to Google and was rejected immediately after the phone screen. Fast forward 2022 and was given another chance to re-interview. Here’s how the entire experience went.
Quick Background
I am currently a junior level software engineer at Microsoft (L60) with previous experience at Amazon (SDE I). My tenure is 1 year at Microsoft and 1 year at Amazon.
The first time I applied to Google was fall of my senior year of college at NYU. I failed the phone screen horribly and never thought I would join a company as competitive as Google. But I did not want to count myself out before even interviewing.
Recruiter Screen
I slowly built my LinkedIn to make sure recruiters would notice me whenever I wrote a LinkedIn post. With 15,000 followers at the time, it wasn’t too difficult to have one of them reach out with the chance to interview. A message came in my LinkedIn inbox and I responded promptly to schedule the initial recruiter call.
The chat was focused more on my previous experiences engineering and some of the projects I worked on. It was important to talk about what languages I was using and how much of my day was spent coding (70% of my day at Microsoft).
The recruiter was interested in having me follow through with a full-loop and asked when I would like to go through the process. It was important to me to ask what engineering level I was applying for. He shared it was L3/L4 role where the interviews would calibrate me depending on my performance. Knowing that, I mentioned I’d like to interview 1 month later and asked what the process looked like as explained to me.
Technical Phone Screen
6 Hour Virtual On-site a. 4 Technical Coding Interviews or 3 Technical Coding Interviews + 1 system design b. Behavioral “Googliness” interview
Phone Screen
Following the initial recruiter phone screen, I received an email from Google. It explained that I would be exempt from the Google Technical Phone Screen.
Why? I am personally not sure but it likely had to do with prior experience at large technology companies. I was personally surprised because to this day my first Google Phone Screen is still one of the toughest coding interviews I have ever been given.
It looked like that was as relevant as my current work experience and I didn’t have much to complain about moving quicker through the process and directly on-site.
Technical Onsite
Every coding question I had was a coding question that was either on LeetCode or could be solved with the patterns you find solving coding questions. Here’s what my experience for each of them looked like
Coding Interview #1
The interviewer looked like someone who was my age and likely joined Google directly after university. Maybe I wasn’t jealous. Maybe I was.
The question I was given was a string parsing Hash-Map question. Easily doable if you worked through a few medium questions regarding hash-maps and string parsing. But if you’re not careful, you may have fallen into a common trap.
Let me point it out for you. Abstract away the logic for tedious parsing logic by writing something like “parsingFunction()”. Otherwise 30 minutes may pass without you solving the question. I wrote a short “ToDo” mentioning I’d come back to it if the interviewer cared.
Spoiler: The interviewer didn’t care.
They lastly asked me to optimize with a heap and what the running time was. Unlike others who assert the running time, I solved for it and the interview concluded there.
Coding Interview #2
The interviewer who was more senior than the previous interviewer. I heard the coding question and thought the on-site was over.
The thing about some coding questions is whether you see the pattern for the algorithm or not. The recognizing the pattern for the algorithm can be much more difficult than actually writing the code for it. This was one of those interviews.
After hearing the questions I was thinking of ways to brute force the question or if there was a pattern I could see using smaller test cases. I wasn’t able to recognize it and eventually the interviewer told me what the pattern was.
I tried not to come off embarrassed but followed up with the algorithm to implement that pattern and the interviewer gave me the “go ahead” to code. I finished coding the pattern and answer the follow up by the interviewer on how to make my code modular to handle another requirement. This did not require implementation.
Afterwards was a discussion on time and space complexity and the interview was over.
Coding Interview #3
The interviewer was a mid-level engineer who was not as keen on chatting as much as the interviewers.
Some coding interviews are just one interview where you have to get the question correct or not. This one started off easy and iterated to be tougher.
My quick advice to anyone is to never come off arrogant for any coding question. You may know the question is easy and the interviewer likely does as well. Often times it’ll get harder and all that ego will go out the window. Go through the motions and communicate you always do for any other coding problem.
The problem given was directly on LeetCode and I felt more comfortable knowing I had solved this awhile ago before. If you’re familiar with “sliding window” then you more than likely would be able to solve it. But here’s where the challenge was.
After the warm-up question, the follow up had another requirement on top of the previous question. That follow up was more array manipulation. Finally the last iteration was shared.
I implemented the algorithm where Math.max was being called more than necessary. To me it didn’t affect the output of the algorithm and looked like it didn’t matter. But it mattered to the interviewer. I took that feedback and carefully implemented it the way the interviewer asked me to (whether it actually affected the algorithm or not).
Time and space complexity was solved and the interview was over.
Coding Interview #4
This was another interviewer who had joined Google after university and had the same work experience I did.
This prompt was not given to me and I expected I had to write down the details to the question myself. After asking some clarifying questions on what was and wasn’t in scope, I shared my algorithm.
The question was an object-oriented question to implement a graph. If you had taken any university course on graph theory, you would be more than prepared.
The interesting discussion was whether I had to implement the graph with BFS or DFS and explain the pro’s and con’s of each. Afterwards, I decided with BFS (because BFS is easier for me to implement) and the requirement followed up with taking K-most steps iterative.
I’m not sure if that’s the follow-up because I implemented it in BFS or if that was always the follow-up but I quickly adjusted the algorithm and solved for space and time complexity as always.
Googliness is just Google’s behavioral interview. Most questions were along the lines of
Tell me about yourself
What’s a project you worked on?
When was a time you implemented a change?
When was a time you dealt with a coworker who wasn’t pulling their weight?
To prepare for these, I’d recommend learning about the STAR format and outlining your work experiences if you can recall them before interviewing.
This seemed to go well but then I was given a question I didn’t expect. A product question and my thought process on how to work with teammates to answer the question.
My key point of advice: Nothing matters if the user doesn’t want it.
Emphasize how important user research is to build a product that a user will use otherwise everyone’s time could be better invested in other initiatives. Avoid jumping straight into designing the product and coordinating talks with product managers and UX designers.
Offer
2 weeks later, an informal offer was shared with me in my email.
Most of the interview didn’t not pertain to my previous experience directly. A systematic way of approaching, communicating, and implementing coding problems is enough without experience from Amazon/Microsoft.
That means you interviewed well. Someone else interviewed better for the first role, but the recruiter sees that there other roles for which you might be a better fit.
The eight interviews is a sign that someone in the process wanted you specifically for some role.
I think there may be two different things going on.
First, are you sure whether it’s a FAANG recruiter, or someone from an external sourcing firm which is retained by a FAANG company? I had this experience where someone reached out on LinkedIn and said they were recruiting for a Google role and passed along a job description. As I started asking them questions, it became clear that they just wanted me to fill out an application so that they can pass it to someone else. Now, as it happens, I am a former Google employee, so it quickly became clear that this person was not from Google at all, but just retained to source candidates. The role they wanted me to apply for was not in fact suitable, despite their claim that they reached out to me because I seemed like a good match.
If you are dealing with a case like this, probably what happens is that they source very broadly, basically spamming people, on the chance that some of the people they identify will in fact be a good fit. So they would solicit a resume, pass it to someone who is actually competent to judge, and that person would reject. And the sourcing firm will often ghost you at this point.
If you are dealing with an actual internal recruiter, I think it can be a similar situation. A recruiter often doesn’t really know if you are a fit or not, and it will often be some technical person who decides. That person may spend 30 seconds on your resume and say “no”. And positions get filled too, which would cause everyone in the pipeline to become irrelevant.
In such cases there is no advantage for the recruiter to further interact with you. Now, every place I worked with, I am pretty sure, had a policy that if a recruiter interacted with the candidate at all, they were supposed to formally reject them (via email or phone). But I imagine there’s very little incentive for a recruiter to do it, so they often don’t. And as a candidate, you don’t really have any way to complain about it to the company, unless you have a friend or colleague on the inside. If you do, I suggest you ask them, and it may do some good, if not to you (you are rejected either way), at least to the next applicant.
It’s not actually a line of code, so to speak, but lines of code.
I work in Salesforce, and for those who are not familiar with its cloud architecture, a component from QA could be moved to production only if the overall test coverage of the production is 75% or more. Meaning, if the total number of lines of code across all components, including the newly introduced ones, is 10000, enough test classes must be written with appropriate test scenarios so as to cover at least 7500 lines of the lump. This rule is enforced by Salesforce itself, so there’s no going around it. Asserts, on the other hand, could be done without.
If the movement of your components causes a shift in balance in production and tips its overall coverage to below 75%, you are supposed to work on the new components and raise their coverage before deployment. A nightmare of sorts, because there is a good chance your code is all clean and the issue occurs only because of a history of dirty code that had already gone in over years to drag the overall coverage to its teetering edges.
Someone in my previous company found out a sneaky way to smuggle in some code of his (or hers) without having to worry about this problem.
So this is simple math, right? If you have got 5000 lines of code, 3750 must be covered. But what if I have managed to cover only 2500 (50%) and my deadline is dangerously close?
Simple. I add 5000 lines of unnecessary code that I can surely cover by just one function call, so that the overall line number now is 10000 and covered lines are 7500, making my coverage percentage a sweet 75.
For this purpose they introduced a few full classes with a lone method in each of them. The method starts with,
Integer i = 0;
and continues with a repetition of the following line thousands of times.
i++;
And they had the audacity to copy and paste this repetitive ‘code’ throughout a bulky method and across classes in such a reckless manner that you could see a misplaced tab in first line replicated exactly in every 100th line or so.
Now all that is left for you to do is call this method in a test class, and you can cover scores of lines without breaking a sweat. All the code that actually matters may lie untested in automated coverage check, glaring red if one should care to take a look at, but you have effectively hoodwinked Salesforce deployment mechanism.
And the aftermath is even crazier. Seeing the way hoards of components could be moved in without having to embark on the tedious process of writing test classes, this technique acquired a status equivalent to ‘Salesforce best practices’ in our practice. In almost all the main orgs, if you search for it, you can find a class with streams of ‘i++;’ flowing along the screen for as far as you have the patience to scroll down.
Well, these cloaked dastards remained undetected for years before some of the untested scenarios started reeking. More sensible developers fished out the ‘i++;’ classes, raised the alarm and got down to clean up the mess. Just removing those classes drove the overall production coverage to abysmal low, preventing any form of interaction with production. What can I say, that kept many of us busy for at least a month.
I wouldn’t call the ‘developers’ that put this code in dumb. I would rather go for ‘wicked’. The higher heads and testers who didn’t care to look while this passed under their noses do qualify as dumb.
And the code… Man, that’s the dumbest thing I’ve ever seen.
If you are in the pipeline and you have interviews scheduled, then your recruiter will know exactly what loop will be set up for you and what kind of questions you may have. Recruiters try to get their candidates all the information they need to approach the interviews at the top of their potential, so ask the everything you need to know.
The actual answer depends on the candidate level and profile, the composition of the interviews is pretty much bespoke.
Dev: Alright, let the competition begin! Startup A: We will give you 50% of the revenue! Startup B: To hell with it, we will give you 100%! Startup A: Eh… we will give you 150%!
TL;DR: Nearly impossible. If you are a Google-sized company, of course. Totally impossible in other cases.
I run an outsourcing company. Our statistics so far:
500 CVs viewed per month
50 interview invitations sent per month
10 interviews conducted per month
1 job offer made (and usually refused) per month
And here we are looking for a mid-level developers in Russia.
Initially we wanted to hire some top-notch engineers and were ready to pay “any sum of money that would fit on the check”. We sent many invitations. Best people laughed at us and didn’t bother. Those who agreed – knew nothing. After that we had to shift our expectations greatly.
Still, we manage to find good developers from time to time. None of them can be considered super-expert, but as a team they cooperate extremely effectively, get the job done and all of them have that engineering spirit and innate curiosity that causes them to improve.
It takes constant human effort to keep sites like Google and Gmail online. Right now a Google engineer is fixing something that no one will ever know was broken. Some server somewhere is running out of memory, a fiber link has gone down, or a new release has a problem and needs to be rolled back. There are careful procedures, early warnings, and multiple layers of redundancy to ensure that problems never become visible to end users, but.
Sometimes problems do become visible but not in a way that an individual user can attribute to the site. A request might not get a prompt response, or any at all, but the user will probably blame the internet or their computer, not the site. Google itself is very rarely glitchy, but services like image search do sometimes have user visible problems.
And then of course, very rarely, a giant outage brings down something giant like YouTube or Google Cloud. But if it weren’t for an army of very smart, very diligent people, outages would happen much more often.
It’s what they don’t understand. 10x software engineers don’t really understand their job description.
They tend to think all these other things are their responsibility. And they don’t necessarily know why they’re doing all these other things. They just sense that it’s the right thing to do. If they spot something is wrong, they will just fix it. Sometimes it even seems like they’re not in control of what they do. It’s like a conscientiousness overdose.
10x engineers are often all over the code base. It is like they had no idea they were just part of one eng team.
I don’t think the premise behind the question is entirely true. These companies rely completely on programming problems with junior candidates that are not expected to have significant experience . Senior candidates do, in fact, get assessed based on their experience, although it might not always feel like it.
Let me illustrate this with an interview process I went through when interviewing for one of the aforementioned companies (AFAIK it’s typical for all the above). After the phone screen, there was a phone site interview with 5 consecutive interviews – 2 whiteboard coding + 2 whiteboard architecture problems + 1 behaviour interview. On the surface, it looks like experience doesn’t play a part, but, SURPRISE, experience and past projects play part in 3 interviews out of 5. A large part of the behavioural interview was actually discussing past projects and various decisions. As for the architecture problems – it’s true that the problem discussed is a new one, but those are essentially open ended questions, and the candidates experience (or lack thereof) clearly shines through. Unlike the coding exercises, these questions are almost impossible to solve without tackling something similar in the past.
Now, here a few reasons to why the emphasis is still on solving new problems and not diving into the candidates home territory, in no particular order:
Companies do not want to pass over strong candidates that just happen to be working on some boring stuff.
Most times companies do not want to clone a system that the candidate has worked on, so the ability to learn from experience, and apply it to new problems is much more valuable.
When the interviewer asks different candidates to design the same system, they can easily compare different candidates against one another. The interviewer is also guaranteed to have a deep understating of the problem they want the candidate to solve.
People can exaggerate (if not outright lie) their role in working on a particular project. This might be hard to catch-on in one hour, so it’s to avoid in the first place.
(This one is a minor concern, but still) Large companies hire by committee, where interviewers are gathered from the whole company. The fact that they shouldn’t discuss previous projects, removes the need to coordinate on questions, by preventing a situation where two interviewers accidentally end up talking about the same system, and essentially doing the interview twice.
Originally Answered: What can I, currently 17 years old, do to become an engineer/entrepreneur like Elon Musk?
This is a quick recap of my earlier response to a similar question on Quora:
I would recommend that you take a close look at the larger scheme of things in your life, by spending some time and effort to design your life blueprint, using Elon Musk as your inspiration and/or visual model.
By the way, here’s my quick snapshot of his beliefs and values:
1) Focus on something that has high value to someone else;
2) Go back to first principles, so as to understand things more deeply and widely, especially their implications;
3) Be very rigourous in your own self analysis; constantly question yourself, especially on the practicality of the idea(s) you have;
4) Be extremely tenacious in your pursuits;
5) Put in 100 hours or more every week, as sweat equity of intense efforts and focused execution count like hell;
6) Constantly think about how you could be doing better, faster, cheaper and smarter;
7) Relentlessly and ruthlessly think about how to make a better world;
Again, here’s my quick snapshot of his unique traits and characteristics:
ix) spiritual development (including contributions to society, volunteering, etc.);
2) Translate all your long-range goals and objectives in (1) into specific, prioritised and executable tasks that you need to accomplish daily, weekly, monthly, quarterly and even annually;
3) With the end in mind as formulated in (1) and (2), work out your start-point, endpoint and the developmental path of transition points in between;
4) Pinpoint specific tasks that you need to accomplish at each transition point till the endpoint;
5) Establish metrics to measure your progress, or milestone accomplishments;
6) Assign and allocate personal accountability, as some tasks may need to be shared, e.g. with team members, if any;
7) Identify and marshal resources that are required to get all the work done;
[I like to call them the 7 M’s: Money; Methods; Men; Machines; Materials; Metrics; and Mojo!]
8) Schedule a timetable for completion of each predefined task;
9) Highlight potential problems or challenges that may crop up along the Highway of Life, as you traverse on it;
10) Brainstorm a slew of possible strategies to deal with (9);
This is your contingency plan.
11) Institute some form of system, like a visual Pert Chart, to track, control and monitor your forward trajectory, as laid out in your systematic game plan, in conjunction with all the critical elements of (4) to (10);
12) Follow-up massively and follow-through consistently your systematic game plan;
13) Put in your sweat equity of intense effort and focused execution;
14) Stay focused on your strategic objectives, but remain flexible in your tactical execution;
You aren’t so stressed and nervous when you are practicing LeetCode, because your career doesn’t depend on how well you do while solving LeetCode.
When solving LeetCode, you aren’t expected to talk to the interviewer to get clarifications on the problem statement or input format. You aren’t expected to get hints and guidance from the interviewer, and to be able to pick them up. You aren’t expected to be able to communicate with other human beings in general, and to be able to talk about technical details of your solution in particular. You aren’t expected to be able to prove and explain your idea in clear, structured way. You aren’t expected to know how to test your solution, how to scale it, or how to adjust it to some unexpected additional constraints or changes. You may not be able to simply get constraints on input size and use them to figure out what is the complexity of expected solution. You have limited amount of time, so if you slowly got through most of the LeetCode, you may still struggle to get stuff done in 45 minutes. And many more… For all these things, you don’t need them to solve LeetCode, so you usually don’t practice them by solving LeetCode; you may not even know that you need to improve something there.
To sum it up: two main reasons are:
Higher stakes.
Lack of skills that are required at typical Google/Facebook interview, but not covered by solving LeetCode problems on your own.
You should also keep in mind that LeetCode isn’t the list of problems being asked at Google or Facebook interviews. If anything, it is more of a list of problems that you aren’t going to be asked, because companies ban leaked questions 🙂 You may get a question that is surprisingly different from what you did at LeetCode.
Originally Answered: I failed all technical interviews at Facebook, Google, Microsoft, Amazon and Apple. Should I give up the big companies and try some small startups?
Wanted to go Anonymous for obvious reasons.
Reality is stranger than Fiction.
In 2010: After graduation, I was interviewed by one of the companies mentioned above for an entry level Software Engineering Role. During the interview, the person tells me: ‘You can never be a Software Engineer’. Seriously? Of-course I didn’t get hired.
In 2013: I interviewed again with the same company but for a different department and got hired.
Fast Forward to 2016 Dec: I received 2 promotions since 2013 and now I am above the grade level of the guy who interviewed me. I remember the date, Dec 14 2016, I went to his desk and asked him to go out for a coffee. Initially he didn’t recognize me but later he did and we went out for a coffee. Needless to say, he was apologetic for his behavior.
For me, it felt REALLY GOOD. Its a story I’ll tell my Grandkids! 🙂
Big tech interviews at FAANG companies are intended to determine – as much as possible – whether you’ve got the knowledge and attributes to be a successful employee. A big part of that for software developers is familiarity with a good set of data structures and algorithms. Interview loops vary, but a good working knowledge of common algorithms will almost always come in handy for both interviews and the job.
Algorithm-related to questions I was asked in my first five years, or that I ask people with less than 5 years: sorting, searching, applying hashes correctly, mapping, medians and averages, trees, linked lists, traveling salesman (I was asked this a couple times, never asked it), and many more.
I never recommend an exhaustive months-long review before an interview, but it’s always a good idea to make sure you’re current on your basics: hash tables and sets, string operations, working with arrays and vectors and lists, binary trees, and linked lists.
Compared to other modern languages, python has two features that make it attractive, and then also make learning a second language difficult if you started with python. The first is that, despite some minor steps to allow annotation, python is loosely and dynamically typed. The second is that python provides a lot of syntactic sugar; this is shorthand, like a map function, where you can apply a function to each element in a data structure.
Do these features make it harder to switch to another language that is strongly and statically typed? For some people, yes, and for others, no.
Some programmers are naturally curious what’s happening under the hood. How are data being represented and manipulated? Why does an operation produce one type of result in one situation, and another type of result in another situation? If you are the kind of person who asks these questions, you are more likely to have an easier time transitioning. If you are a person who finds these questions uninteresting or even distasteful, transitioning to another language can be very painful.
I have excellent skills and experience on my resume, which makes it stand out.
Seriously, there is no magical spell that will make a crappy resume attractive to recruiters. Most people give up believing in magic after they are 5 or 6 years old. A software engineer who believes in magic is not a good candidate for hire.
All those complaints you have about their products? The people working there complain about the same exact things. Microsoft employees complain about how slow Outlook is. Google employees complain about everything changing all the time. Salesforce employees complain about how hard our products are to use.
So why don’t we do something about it? There are a few possible answers:
We are actively doing something about it right now and it will be fixed soon.
The problem is technically difficult to fix. For example, it’s currently beyond the state of the art to change the wake word (“Alexa”/”OK Google”) to a user-selected word. A variation of this is the problem that’s more expensive to fix than the amount of annoyance saved.
The team responsible for that functionality has problems. Maybe they have a bad manager or have been reorged a lot, and as a result they haven’t been doing a good job. Even once the problem is solved, it can take a long time to catch up.
The problem is related to making money. For example, Microsoft used to have a million different versions of Office, each including different programs and license restrictions. It was super confusing. But the bean counters knew how much extra money the company made from these bundles, compared to a simpler scheme, and it was a lot. So the confusion stayed.
The problem is cultural. For example, Google historically made its reputation by offering new features constantly. Everything about the culture was geared towards change and innovation. When they started making enterprise products, that cultural became baggage.
But none of that keeps the employees from complaining.
That’s perhaps the first stage of learning, recitation.
Using the four-stage model of learning that goes
Unconscious Incompetence
Conscious Incompetence
Conscious Competence
Unconscious Competence
that’s maybe a 2 to 2.5 there. You know you haven’t really understood why you are doing things that way and without detailed step-by-step, you don’t yet know how you would design those solutions.
You need to step back a bit, by reviewing some working solutions and then using those as examples of fundamentals. That might mean observing that there is a for() loop, for example – why? What is it there for? How does it work? What would happen if you changed it? If you wanted to use a for loop to write out “hello!” 8 times, how would you code that?
As you build up the knowledge of these fundamental steps, you’ll be able to see why they were strung together the way they were.
Next, practice solving smaller challenges. Use each of these tiny steps to create a solution – one where you understand why you chose the pieces you chose, what part of the problem it solves and how.
Early 2020 has been a very rough period for many companies who laid off tons of good people, many of which have bounced to a company who was not a good fit and eventually went to a third one. Forced remote work was also difficult for many folks. So in the current context, having changed 3 jobs in the last 4 years is really a non-event.
Now more generally, would my hiring recommendation be influenced by a candidate having changed jobs several times in a short period of time?
The assumption here is that if a candidate has switched jobs 3 times in 4 years, there must be something wrong.
I think this is a very dangerous assumption. There are lots of things that cause people to change jobs, sometimes choice, sometimes circumstances, and they don’t necessarily indicate anything wrong in the candidate. However, what could be wrong in a candidate can be assessed in the interview, such as:
is the candidate respectful? Is the candidate able to disagree consrtuctively?
does the candidate collaborate?
Does the candidate naturally support others?
Has the candidate experience navigating difficult human situations?
etc, etc.
There are a lot of signals we can detect in the interview and we can act upon them. Everything that comes outside of the interview / outside of reference check is just bias and should be ignored.
My IQ was around 145 the last time I checked (I’m 19).
I feel lots of gratitude for my ability to deeply understand and comprehend ideas and concepts, but it has definitely had its “downsides” throughout my life. I tend to think very deeply about things that I find interesting and this overwhelming desire to understand the world has led me to some dark places. When I was around 9 or 10, I discovered the feeling of existential panic. I had watched an astronomy documentary with my father (who is a geoscience professor) and was completely overwhelmed with the fact that I was living on an unprotected orb, orbiting around a star at speeds far faster than I could even comprehend. I don’t think anyone in my family expected me to really grasp what the documentary was saying so they were a bit alarmed when I spent that whole night and most of the next week panicking and hyperventilating in my bedroom.
I lost my mom to suicide when I was 11 which sent me into a deep depression for several years. I found myself thinking a lot about death and the meaning of human existence in my earlier teenage years. I was really unmotivated to do school work all throughout high school because I found no meaning in it. I didn’t understand why I was alive, or what being alive meant, or if there even was any true meaning to life. I constantly struggled to see how any of it truly mattered in the long run. What was the point of going to the grocery store or hanging out with my friends or getting a drivers license? I was an overdeveloped primate forced to live in and contribute to a social group that I didn’t ask to be in. I was living in a strange universe that made no sense and I was being expected to sit at a desk for 8 hours every day? Surrounded by people who didn’t care about anything except clothing and football games? No way man, count me out. I spent a lot of nights just sitting in my bedroom wondering if anything I did really mattered. Death is inevitable and the whole universe will one day end, what’s the point. I frequently wondered if non-existence was inherently better than existence because of all of the suffering that goes hand in hand with being a conscious being. I didn’t understand how anyone could enjoy playing along in this complex game if they knew they were all going to die eventually.
Heavy stuff, yeah.
When I was 18 I suddenly experienced what some people label as an “ego death” or a “spiritual awakening” in which it suddenly occurred to me that the inevitably of death doesn’t mean that life itself is inherently meaningless. I realized that all of my actions affect the universe and I have the ability to set off chain reactions that will continue to alter the world long after I’m gone. I also realized that even if life is inherently meaningless, then that is all the more reason to enjoy being alive and to experience the beauty and wonder of the world while I’m still around. After that day I began meditating daily to achieve a deeper awareness of myself and try to find inner peace. I began living for the experience of being alive and nothing else. All of this has brought me great peace and has allowed me to enjoy learning again. For so long learning was terrifying to me because it meant that I was going understand new information that could potentially terrify me. Information that I could not unlearn. I have become a very emotionally sensitive person after the death of my mother, so I simply could not handle the weight of learning about existential concepts for a while. Now that I’ve been able to find a state of peace within myself and radically accept the fact that I will die one day (and that I do not know what occurs after death) I have begun to enjoy learning again! I read a lot of nonfiction and fiction alike. I enjoy traveling and seeing the world from as many different perspectives as possible. Talking to new people and attempting to see my world through their eyes is very enjoyable for me. Picking up new skills is generally very easy for me and I spend a lot of my free time pondering philosophical issues, just because it’s fun for me. I’m not a very social person, I like having a few close friends, but I mostly enjoy being alone.
So all in all, I think having an IQ of 140+ is a very turbulent experience that can be very beautiful! When you are able to truly understand deep concepts, it can seriously freak you out, especially when you’re searching for meaning and answers to philosophical problems. If I hadn’t embraced a way of life that revolves around radically acceptance, I don’t think I would have the guts to look as deeply into some things as I do. However, since I do have that safety cushion, I’m able to shape my perception of the world with the knowledge that I learn. This allows me to see incredible beauty in our world and not take things too personally. When I have a rough day, all I need to do is sit on my roof for half an hour and look at the stars. It reminds me that I am a very small animal in a very big place that I know very little about. It really puts all of my silly human problems in perspective.
If you can explain to me how “no-code is the future”, maybe there’s a useful response to this.
As far as I can tell, “no-code” means that somebody already coded a generic solution and the “no-code” part is just adapting the generic solution for a specific problem.
Somebody had to code the generic solution.
As to the second part, “is a CS major even worth it?” I’ve had a 30+ year career in software engineering, and I didn’t major in CS. That hasn’t kept me from learning CS concepts, it hasn’t kept me from delivering good software, and it hasn’t stopped me from getting software jobs.
Is a CS major even worth it? Only the student knows the answer to that.
People have written no-English versions of many programming languages – but they aren’t used as much as you’d think because it’s just not that useful.
Consider the C language – there are no such English words as “int”, “bool”, ”enum”, “struct”, “typedef”, “extern”, or “const”. The words “auto”, “float” and “char” are English words – but with completely different meanings to how they are used in C.
This is the complete list of C “reserved words” – things you’d have to essentially memorize if you’re a non-English speaker…
…but very few of those words are used in their usual English meanings…and you have to just know what things like “union” mean – even if you’re a native english speaker.
But if you really think there is an advantage to this being your native language then:
#define changer switch
#define compteur register
#define raccord union
…and so on – and now all of your reserved words are in French.
I don’t think it’s going to help much.
IT”S ABOUT LIBRARIES AND DOCUMENTATION:
The problem isn’t something like the C language – we could easily provide translations for the 30 or so reserved words in 50 languages and have a #pragma or a command to the compiler to tell it which language to use.
No problem – easy stuff.
However, libraries are a much bigger problem.
Consider OpenGL – it has 250 named function, and hundreds of #defined tokens.
glBindVertexArray would be glLierTableauDeSommets or something. Making versions of OpenGL for 50 languages would be a hell of a lot more painful.
Then, someone has to write documentation for all of that in all of those languages.
But a program written and compiled against French OpenGL wouldn’t link to a library written in English – which would be a total nightmare.
Worse still, I’ve worked on teams where there were a dozen US programmers, two dozen Russians and a half dozen Ukrainians – spread over two continents – all using their own languages ON THE SAME PIECE OF SOFTWARE.
Without some kind of control – we’d have a random mix of variable and function names in the three languages.
So the rule was WE PROGRAM IN ENGLISH.
But that didn’t stop people from writing comments and documentation in Russian or Ukranian.
SO WHAT IS THE SOLUTION?
I don’t think there actually is a good solution for this…picking one human language for programmers to converse in seems to be the best solution – and the one we have.
There are 1.3 billion English speakers, 1.1 billion Mandarin speakers, 600 million Hindi speakers, 450 Spanish speakers…and no other language gets over half of that.
So if you have to pick a single language to standardize on – it’s going to be English.
Those who argue that Mandarin should be the choice need to understand that typing Mandarin on any reasonable kind of keyboard was essentially impossible until 1976 (!!) by which time using English-based programming languages was standard. Too late!
SO – ENGLISH IT IS…KINDA.
Even though we seem to have settled on English the problems are not yet over.
British English or US English – or some other dialect?
As a graphics engineer, it took me the best part of a decade to break the habit of spelling “colour” rather than “color” – and although the programming languages out there don’t use that particular word – the OpenGL and Direct3D libraries do – and they use the US English spelling rather than the one that people from England use in “English”.
ARE PROGRAMMERS UNIQUE IN THIS?
No – we have people like airline pilots, ships’ captains.
ICAO (International Civil Aviation Organization), require all pilots to have attained ICAO “Level 4” English ability. In effect, this means that all pilots that fly international routes must speak, read, write, and understand English fluently.
However, that’s not what happened for ships. In 1983 a group of linguists and shipping experts created “Seaspeak”. Most words are still in English – but the grammar is entirely synthetic. In 1988, the International Maritime Organization (IMO) made Seaspeak the official language of the seas.
Here’s the thing. The compensation will never be comparable.
When you join a big tech, public company, all of your compensation is public. Also it’s relatively easy to get a fair estimate of what comp looks like a few years down the road.
When you join a private company, the comp is a bet on a successful exit.
In 2015, Zenefits was a super hot company. Zoom had been around for.4 years and was very confidential.
In a now infamous Quora question[1] a user asked wether they should take an offer at Zenefits or Uber. As a result, The Zenefits CEO rescinded their offer. But most people would have chosen an offer at Zenefits or Uber, whose IPO was the most anticipated back then, over one at Zoom.
And yet Zenefits failed spectacularly, Uber’s IPO was lackluster, while Zoom went beyond all expectations.
So this is mostly about to risk aversion. Going to a large co means a “golden resume” that will always get you interviews, so it has a lot of long term value.
Working in a large company has other benefits. Processes are usually much better and there’s a lot to learn. This is also the opportunity to work on some problems at a huge scale. No one has billions of users outside of Google, Meta, Apple or Microsoft.
But working in a small private company whose valuation explodes is the only way for a software engineer to become very wealthy. The thing is though that it’s impossible for an aspiring employee to tell which company is going to experience that growth versus fail.
The pro’s and con’s really depend on the specific situation.
(1) When quitting for a new position…
Pros:
Better pay & benefits
More promotion opportunities
New location
New challenges (old job may have been boring)
New job aligned to your interests.
Cons:
New job/company was seriously misrepresented
“New boss same as the old boss” (no company is perfect!)
You might have wanted a new challenge, but you are now over your head.
Note: if you have a job and are not desperate, please do your homework and remember you are also interviewing them! You want a better job in most cases (unless that moving thing is going on).
(2) When quitting over a conflict…
Pros:
Can sleep at night (providing it was a ethical issue and you were in the right)
You showed them who is the boss!
Plus, you wont be on the local news if they get sued, or the IRS does a audit.
Again, if it was a toxic environment that you get to live as opposed to a stroke on the job! No job is worth it that is impacting your health, including mental health.
Cons:
No unemployment in most states if you just up and quit.
Job search with no income puts a lot of pressure at some point to take any job
the good news though, is you can continue looking while earning a paycheck (and hopefully still growing skills & experience)
The reason so many people are quitting now…
Note there is a third category, when you quit due to a lifestyle change. In this case, we are looking a women quitting to be a full-time mother, or someone going back to school. A spouse getting promoted but with a move might also place the other mate in this position…
Pro:
You get to live the life you want.
You are preparing for a better career
Con:
Loss of income
Reduced social interaction (for the full-time mom)
Note here that most couples that decide to do the stay at home mom generally plan ahead so one income will cover their expenses.
Second, I also don’t consider serious health issues when you leave the work force in general to fall under the scope of this discussion.
Originally Answered: Is practicing 500 programming questions on LeetCode, HackerEarth, etc enough to prepare for Google interview?
If you have 6 months to prepare for the interview I would definitely suggest the following things assuming that you have a formal CS degree and/or you have software development experience in some company:
Step 1 (Books/Courses for good understanding)
Go through a good data structure or algorithms book and revise all the topics like hash tables, arrays and strings, trees, graphs, tries, bit hacks, stacks, queues, sorting, recursion, and dynamic programming. Some good books according to me are:
The Stanford Coursera algorithms courses are also very good and you can look at them if you have time. It’s a bit more theoretical though.
Step 2 (Programming practice for algorithms and data structures)
Once you are done with Step 1 you need a lot of practice. It need not be a set number of problems like 500 or 1000. The best way to practice problems is to mimic an interview setting and time yourself for half an hour and solve a problem without any distraction. The steps here are to read a problem, think of a brute force solution that works very quickly, and then think of an optimized version that works and then write clean working code and come up with test cases within half an hour. Most of the top companies ask you 1 or 2 medium problems or 1 hard problem in 45 mts to 1 hour. Once you are done solving the problem you can compare your solution with the actual solution and see if there is scope to improve your solution or learn from the actual solution.
If you do the math it takes half an hour to solve a problem and at least 15 mts to look and compare with the correct solution. So 500 problems take 500 * 45 mts = 375 hours. Even if you spend 5 solid hours a day for problem-solving it comes to 75 days (2.5 months). If you are in a full-time job it’s hard to spend so much time every single day. Realistically if you spend 2–3 hours a day we are talking about 5 months just for practicing 500 problems. In my opinion, you don’t need to solve so many problems to crack the interview. All you need is a few problems in each topic and understand the fundamentals really well. The different topics for algo and ds are:
arrays and strings, bit hacks, dynamic programming, graphs, hash tables, linked lists, math problems, priority queues, queues, recursion, sorting, stacks, trees, and tries. As a starter try to solve 4–5 problems in each topic after you finish step 1 and then if you have time solve 2–3 problems a day for fun in each topic and you should be good. Also, it is far better to solve 5 problems than to read 50 problems. In fact, trying to cover problems by reading problems is not going to be of any use.
Step 3 (this can be done in parallel with step 1) (Systems Design)
Practice problems in systems, design (distributed systems, concurrency, OO design). These questions are common in Google and other top companies. The best way to crack this section is to actually do complex systems projects at work or school projects. There are lots of resources online which are very good for preparation for this topic.
Edit: Since I have received some request to point some resources I am listing some of my favorite ones:
Please know your resume in and out and make sure you can explain all the projects mentioned in the resume. You should be able to dive as deep as needed (technically) for the projects mentioned. Also do enough research about the company you are interviewing, the product, engineering culture and have good questions to ask them
Step 5 (mock interviews)
Last but not least please make sure you have some good friends working in a good company or your classmate mock interview you. You also have several resources online for this service. Also, work on the feedback you get from the mock interview. You can also interview a few companies you are not interested to work as a practice interview before your goal companies.
It is possible for some people; I don’t know whether it is possible for you.
You’re solving 50% of easy problems. Reality check: that’s…cute. Your target success rate, to have a good chance, should be near-100% on Easy, 75% on Medium, and 50% on Hard. On top of that, non-Leetcode rounds like system design should be solid, too.
You can see there’s a big gap between where you are and where you need to be.
The good news is that despite how large that gap is, without a doubt, there have been cases of people being able to learn fast enough to cover that gap in 90 days. These cases are not at all common, and I will warn you that the vast majority of people who are where you are now cannot get to where you need to be in 90 days. So, the odds are against you, but you might be better than the odds would say.
What is special about the situations of the people who can get there that fast? Off the top of my head, the key factors are:
A strong previous background in CS and algorithms
Being able to spend a significant amount of time daily to study
High aptitude / talent / intelligence for learning these sorts of concepts
Having an effective methodology for learning. The fact that you’re actively solving problems on Leetcode is a decent start here.
If the above factors describe you, you might be better off than the odds would suggest. It is at least possible that you could achieve your goal.
(Note: I’ve interviewed hundreds of developers in my time at Facebook, Microsoft and now as the co-founder and CEO of Educative. I’ve also failed several coding interviews because I wasn’t prepared. At Educative, we’ve helped thousands of developers level up their careers with hands-on courses on programming languages, system design, and interview prep.)
Is Interview Prep a Full-time Job?
Let’s break it down. A full-time job – 40 hours per week, 52 weeks per year – encompasses 2080 hours. If you take two weeks of vacation, you’re actually working 2,000 hours. The 1,000 hours recommendation is saying you need six months of full-time work to prepare for your interview at a top tech company. Really?
I think three months is a reasonable timeframe to fully prepare. And if you’ve interviewed more recently, studying the specific process of the company where you’re applying can cut that time down to 4-6 weeks of dedicated prep.
I’ve written more about the ideal interview prep roadmap for DEV Community, but I’ll give you the breakdown here.
The “Secret” to a Successful Interview Prep Plan
First of all, I want to be clear that there’s no silver bullet to interview prep. But during my time interviewing candidates at Facebook and Microsoft, I noticed there was one trait that all the best candidates shared: they understood why companies asked the questions they did.
The key to a successful interview prep program is to understand what each question is actually trying to accomplish. Understanding the intent behind every step of the interview process helps you prepare in the right way.
A lot of younger developers think they need to be experts in a few programming languages, or even just one language in order to crack the developer interview. Writing efficient code is a crucial skill, but what software companies are actually looking for (especially the big ones with custom libraries and technology stacks that you will be expected to learn anyway) is an understanding of the various components of engineering, as well as your creative problem-solving ability.
That breaks down into five key areas that “Big Tech” companies are focused on in the interview process:
1. Coding
Interviewers are testing the basics of your ability to code. What language should you be using? Start with the language you know best. Especially in larger companies, new syntaxes can be taught or libraries used if you establish you can execute well. I have interviewed people that used programming languages that I barely know myself. I know C++ inside and out, so even though Python is a more efficient language, I would always personally choose to interview using C++. The most important thing is just to brush up on the basics of your favorite programming language.
The questions in coding interviews focus on generic problem-solving, data structures (Mastering Data Structures: An interview refresher), and algorithms. So revisit concepts that you haven’t touched since undergrad to have a fresh, foundational understanding of topics like complexity analysis (Algorithms and Complexity Analysis: An interview refresher), arrays, queues, trees, tries, hash tables, sorting, and searching. Then practice solving problems using these concepts in the programming language you have chosen.
Whether you’re building a mobile app or web-scale systems, it’s important to understand threads, locks, synchronization, and multi-threading. These concepts are some of the most challenging and factor heavily into your “hiring level” at many organizations. The more expert you are at concurrency, the higher your level, and the better the pay.
Since you’ve already determined the language you’re using in (1), study up on process handling using that same language. Prepare for an interview – Concurrency
3. System Design
Like concurrency problems, system design is now key to the hiring process at most companies, and has an impact on your hiring level.
There isn’t a clear-cut answer to an open-ended question where a candidate must work their way to an efficient, meaningful solution to a general problem with multiple parts.
Most candidates don’t have a background designing large-scale systems in the first place, as reaching that level is several years into a career path and most systems are designed collaboratively anyway.
For this reason, it is important to spend time clarifying the product and system scope, a quick back-of-the-envelop estimation, defining APIs to address each feature in the system scope and defining the data model. Once this foundational work is done, you can take the data model and features to actually design the system.
In Object-Oriented Design questions, interviewers are looking for your understanding of design patterns and your ability to transform the requirements into comprehensible classes. You spend most of your time explaining the various components, their interfaces and how different components interact with each other using the interfaces. Interviewers are looking for your ability to identify patterns and to apply effective, time-tested solutions rather than re-inventing the wheel. In a way, it is the partner of the system design interview.
This is the one that doesn’t have a clear cut learning path, and because of that, it is often overlooked by developers. But for established companies like Google and Amazon, culture is one of the biggest factors. The skills you demonstrate in coding and design interviews prove that you know programming. But without the right attitude, are you open to learning? Are you passionate about the product and want to build things with the team? If not, companies can think you’re not worth hiring. No organization wants to create a toxic work environment.
Since every company has a few different distinguishing features in their culture, it’s important to read up on what their values and products are (Coding Interview Preparation | Codinginterview has information on many top tech companies, including Google and Facebook). Then enter the interview track ready to answer these basics:
Interest in the product, and demonstrate understanding of the business. (Don’t mistake Facebook’s business model, which relies on big data, for AWS or Azure, which facilitate big data as a service. If you’re going into Google, know how user data and personalization is the core of Google’s monetization for its various products and services, while knowing what makes Android unique compared to iOS. Be an advocate.)
Be prepared to talk about disagreements in the workplace. If you’ve been working for more than a few years, you’ve had disagreements. Even if you’re coming out of school, group projects apply. Companies want to know how you work on a team and navigate conflict.
Talk about how the company helps you build and execute your own goals both as a technologist and in your career. What are you passionate about?
Talk about significant engineering accomplishments – what have you built; what crazy/difficult bugs have you solved?
Conclusion
Strategic interview prep is essential if you want to present yourself as the best candidate for an engineering role.
It doesn’t have to take 1,000 hours, nor should it – but at big companies like Google and Facebook where the interview process is so intentional, it will absolutely benefit you to study that process and fully understand the why behind each step.
There are plenty of battle-tested resources linked in my answer that will guide you throughout the prep process, and I hope they can be helpful to you on your career journey.
Originally Answered: I have practiced over 300 algorithms questions on LintCode and LeetCode but still can’t get any offer, what should I do?
I have interviewed and been interviewed a number of times, and I have found out that most of the time people (including myself) flunk an interview due to the following reasons:
Failing to come up with a solution to a problem: If you can’t come up with even one single solution to a problem, then it’s definitely a red flag since that reflects poorly on your problem solving skills. Also, don’t be afraid to provide a non-optimal solution initially. A non-optimal solution is better than no solution at all.
Coming up with solutions but can’t implement them: That means you need to work more on your implementation skills. Write lots and lots of code, and make sure you use a whiteboard or pen and paper to mimic the interview experience as much as possible. In an interview you won’t have an IDE with autocomplete and syntax highlighting to help you. Also make sure that you’re very comfortable in your programming language of choice.
Solving the problem but not optimally: That could mean that you’re missing some fundamental knowledge of data structures and algorithms, so make sure that you know your basics well.
Solving the problem but after a long time, or after receiving too many hints: Again, you need more problem solving practice.
Solving the problem but with many bugs: You need to properly test your code after writing it. Don’t wait for the interviewer to point out the bugs for you. You wouldn’t want to hire someone who doesn’t test their code, right?
Failing to ask the interviewer enough questions before diving into the code: Diving right into the code without asking the interviewer enough questions is definitely a red flag, even if you came up with a good solution. It tells the interviewer that either you’re arrogant, or that you’re reckless. It’s also not in your favor, because you may end up solving the wrong problem. Discussing the problem and asking questions to the interviewer is important because it ensures that both of you are on the same page. The interviewer’s answers to your questions may also provide with some very useful hints that may greatly simplify the problem.
Being arrogant: If you’re perceived as arrogant, no one will want to hire you no matter how good you are.
Lying on the resume: Falsely claiming knowledge of something, or lying about employment history is a huge red flag. It shows dishonesty, and no one wants to work with someone who is dishonest.
I hope this helps, and good luck with your future interviews.
Unless we’re talking about Google, which has problems that are unique to them in comparison to the rest, you can be sure that big tech companies ask LeetCode-style questions quite often. Seeing LeetCode Hard problems specifically, however, is not that common in these interviews, and it’s more likely that you’ll be facing LeetCode Medium questions and one or two Hard questions at best. This is because having a time limit to solve them as well as an interviewer right beside you already adds enough pressure to make these questions feel harder than they normally would be; increasing their difficulty would simply be detrimental to the interviewing process.
I suggest that you avoid using the difficulty of LeetCode questions that you can solve as a way of telling if you’re prepared for your interviews as well because it can be pretty misleading. One reason this is the case is that LeetCode’s environment is different from an interviewing environment; LeetCode cares more about running time and the optimal solution to a problem, while an interviewer cares more about your approach to the question (an intuitive solution can always be optimized further with a discussion between you and the interviewer).
Another reason you should avoid worrying too much about LeetCode-style questions is that FAANG companies are starting to refrain from asking them, as they’re noticing that many candidates come to their interviews already knowing the answer to some of their questions; currently, if your interviewer notices that you already know the answer to the question you’re given, they won’t take it into account and instead will move on to another question, as already knowing how to solve the problem tells them nothing about the way you approach challenging situations in the first place.
Also, you should consider that LeetCode only lets you practice what you already know in coding; if you don’t have a good knowledge of data structures & algorithms beforehand, LeetCode will be a difficult resource to use efficiently, and it also won’t teach you anything about important non-technical skills like communication skills, which is a crucial aspect that interviewers also evaluate. Therefore, I also suggest that you avoid using LeetCode as your only resource to prepare for your technical interviews, as it doesn’t cover everything that you need to learn on its own.
For example, you may want to enroll in a program like Tech Interview Proas you use LeetCode. TIP is a program that was created by an ex-Google software engineer and was designed to be a “how to get into big tech” course, with over 20 hours of instructional video content on data structures & algorithms and system design.
Another good resource that you could use, this time to cover the behavioral aspect of interviews, is Interviewing.io. With it, you can engage in mock interviews with other software engineers that have worked with Facebook and Google before and also receive feedback on your performance.
You could also read a book like Cracking the Coding Interview, which offers plenty of programming questions that are very similar to what you can expect from FAANG companies, as well as valuable insight into the interviewing process.
Harvard is seen in popular culture as being very selective, and so any funnel which has a conversion rate lower than 5% is going to describe itself as “more selective than Harvard”. “More selective than Harvard” has 70m hits on Google. When Walmart opened a DC store, it hired about 2.5% of the people that sent applications, and ran a story that it was “twice as selective as Harvard”. Tech internships, somewhat unsurprisingly, are harder to get as jobs at Walmart.
Generally speaking, the more LeetCode problems you solve, the better your odds of getting an offer will be. Be careful, however, as using the number of problems you solve on LeetCode as a reference for how ready you are for your technical interviews is misleading, especially if it’s for Google and Facebook. Even if you solve every problem on LeetCode (please don’t try this), there’s still a chance you won’t get an offer, and there are several reasons why.
First of all, coding is not the only thing taken into consideration by interviewers from big tech companies. One of the main things they look for in a candidate is the presence of strong soft skills like teamwork, leadership, and communication. If you’re raising red flags in that department—if the interviewer doesn’t think you have the leadership skills to lead a team down the road, for example—odds are that you’re going to get overlooked. They also expect you’ll be able to clearly explain your thought process before solving a given coding problem, which is something a surprising number of developers have trouble with.
The second problem with using LeetCode alone is that it can only help you practice data structures & algorithms and system design, but not exactly teach you about them. This might not be an issue if you’re solving questions from the Easy section of LeetCode, but once you get to the Medium and Hard problem sets, you’ll need more theoretical knowledge to properly handle these problems.
So, ideally, you’ll want to prepare using resources that help you learn more about DS&A and systems design before you start practicing on LeetCode, and you’ll also want to work on your behavioral skills to ensure you do well there, too. Here are some tools that can help:
Interviewing.io: A site where you can engage in mock interviews with other software engineers—some of whom have worked at Google and Facebook—and receive immediate, objective feedback on your performance.
Tech Interview Pro: An interview prep program designed by a former Google software engineer that includes 150+ instructional video lessons on data structures & algorithms, systems design, and the interview process as a whole. TIP members also get access to a private Facebook group of 1,500+ course graduates who’ve used what they learned in the course to land jobs at Google, Facebook, and other big tech companies.
So, using LeetCode on its own would prepare you well for questions about data structures & algorithms, but may leave you unprepared for questions related to systems design and the behavioral aspect of your interviews. But by complementing LeetCode with other resources, you’ll put yourself in a much better position to receive an offer from Google, Facebook, or anyone else. Best of luck.
Dmitry Aliev is correct that this was introduced into the language before references.
I’ll take this question as an excuse to add a bit more color to this.
C++ evolved from C via an early dialect called “C with Classes”, which was initially implemented with Cpre, a fancy “preprocessor” targeting C that didn’t fully parse the “C with Classes” language. What it did was add an implicit this pointer parameter to member functions. E.g.:
struct S {
int f();
};
was translated to something like:
int f__1S(S *this);
(the funny name f__1S is just an example of a possible “mangling” of the name of S::f, which allows traditional linkers to deal with the richer naming environment of C++).
What might comes as a surprise to the modern C++ programmer is that in that model this is an ordinary parameter variable and therefore it can be assigned to! Indeed, in the early implementations that was possible:
struct S {
int n;
S(S *other) {
this = other; // Possible in C with Classes.
this->n = 42; // Same as: other->n = 42;
}
};
Interestingly, an idiom arose around this ability: Constructors could manage class-specific memory allocation by “assigning to this” before doing anything else in the constructor. E.g.:
struct S {
S() {
this = my_allocator(sizeof(S));
…
}
~S() {
my_deallocator(this);
this = 0; // Disabled normal destructor post-processing.
}
…
};
That technique (brittle as it was, particularly when dealing with derived classes) became so widespread that when C with Classes was re-implemented with a “real” compiler (Cfront), assignment to this remained valid in constructors and destructors even though this had otherwise evolved into an immutable expression. The C++ front end I maintain still has modes that accept that anachronism. See also section 17 of the old Cfront manual found here, for some fun reminiscing.
When standardization of C++ began, the core language work was handled by three working groups: Core I dealt with declarative stuff, Core II dealt with expression stuff, and Core III dealt with “new stuff” (templates and exception handling, mostly). In this context, Core II had to (among many other tasks) formalize the rules for overload resolution and the binding of this. Over time, they realized that that name binding should in fact be mostly like reference binding. Hence, in standard C++ the binding of something like:
struct S {
int n;
int f() const {
return this->n;
}
} s = { 42 };
int r = s.f();
is specified to be approximately like:
struct S { int n; } s = { 42 };
int f__1S(S const &__this) {
return (&__this)->n;
}
int r = f__1S(s);
In other words, the expression this is now effectively a kind of alias for &__this, where __this is just a name I made up for an unnamable implicit reference parameter.
C++11 further tweaked this by introducing syntax to control the kind of reference that this is bound from. E.g.,
struct S {
int f() const &;
int g() &&;
};
can be thought of as introducing hidden parameters as follows:
int f__1S(S const &__this);
int g__1S(S &&__this);
That model was relatively well-understood by the mid-to-late 1990s… but then unfortunately we forgot about it when we introduced lambda expression. Indeed, in C++11 we allowed lambda expressions to “capture” this:
struct S {
int n;
int f() {
auto lm = [this]{ return this->n; };
return lm();
}
};
After that language feature was released, we started getting many reports of buggy programs that “captured” this thinking they captured the class value, when instead they really wanted to capture __this (or *this). So we scrambled to try to rectify that in C++17, but because lambdas had gotten tremendously popular we had to make a compromise. Specifically:
we introduced the ability to capture *this
we allowed [=, this] since now [this] is really a “by reference” capture of *this
even though [this] was now a “by reference” capture, we left in the ability to write [&, this], despite it being redundant (compatibility with earlier standards)
Our tale is not done, however. Once you write much generic C++ code you’ll probably find out that it’s really frustrating that the __this parameter cannot be made generic because it’s implicitly declared. So we (the C++ standardization committee) decided to allow that parameter to be made explicit in C++23. For example, you can write (example from the linked paper):
struct less_than {
template <typename T, typename U>
bool operator()(this less_than self,
T const& lhs, U const& rhs) {
return lhs < rhs;
}
};
In that example, the “object parameter” (i.e., the previously hidden reference parameter __this) is now an explicit parameter and it is no longer a reference!
Here is another example (also from the paper):
struct X {
template <typename Self>
void foo(this Self&&, int);
};
struct D: X {};
void ex(X& x, D& d) {
x.foo(1); // Self=X&
move(x).foo(2); // Self=X
d.foo(3); // Self=D&
}
Here:
the type of the object parameter is a deducible template-dependent type
the deduction actually allows a derived type to be found
This feature is tremendously powerful, and may well be the most significant addition by C++23 to the core language. If you’re reasonably well-versed in modern C++, I highly recommend reading that paper (P0847) — it’s fairly accessible.
When an employee is hired, there is a step in the process where they are given a stack of documents to sign that (anecdotally) I’ll venture maybe 1 in 1,000 actually read. One of the least understood (or read) is the notice that the company controls, collects and analyzes all communications, internet activity and data stored on company-owned or -managed devices and systems.
This includes network traffic that flows across their servers. It’s safe to assume that mid-to-large employers are fully aware of the amount of on-the-clock time employees spend shopping, tweeting or watching YouTube, and know which employees are spending inordinate amounts of ‘company time’ shopping on Amazon rather than tackling assignments.
This also include Bring Your Own Device policies— where employees are allowed to use their personal smartphone, tablet or laptop for business purposes. Companies don’t always ‘exploit’ the policy for nefarious surveillance purposes, but employers are within their rights to collect information like location data from your BYOD smartphone both on and off the clock.
An example of where this can hurt employees is when they start to look for another job.
If you email/Slack/message your supervisor and ask for a personal day off to attend to a family matter, but your device logs show you are accessing job-search sites and your location data suggests your aren’t at home or even within the radius of a competitor’s office, they know. This tends to make your boss cranky, and can adversely impact your employment to the point of losing your job.
I disagree with this kind of intrusive surveillance, and the presumption of guilt employees face when they take steps to protect themselves by using encrypted tools like Signal, proxy servers or switching devices to Airplane Mode intrudes on the employee’s legitimate rights to privacy: you may not want your employer to know that you’re seeing a psychiatrist on your lunch hour, and they really have no reasonable expectation for you to disclose this (or not take steps to conceal it.)
I think so. I remember there was a noticeable number of people going to Facebook, and some discussion of it among the employees. And then there was an explicit event where Google rearranged its compensation strategy. Everyone got a huge raise just at that moment, and from that point on the salaries and stock grants became close to the top of the market, as they need to be for a company that hires top talent.
If you can’t get FAANG to pay attention to you, you probably need to get another job first. Perhaps one of the companies that are considered to be pretty good would be interested.
It is actually quite hard to get an entry-level role at a top tech company, because where you went to college (and internships, which you don’t have) plays a disproportionate role. It’s not surprising, because what else can they go on? Interviewing is expensive, and there are hundreds of applicants per opening, so they want to pre-filter candidates somehow.
Once you have a few years of experience, things look a little better, especially if you climb up the prestige pole. For instance, Microsoft (or Twitter where I work today) isn’t FAANG, but you can be sure that recruiters would take applicants from there seriously, and you would have a good chance to get an interview. But the main factor is what you manage to do in your time at work. If you do well, get promoted, demonstrate clear impact (that you can articulate externally), build your professional network, that would improve your chances to both get your foot in the door, and also to pass the interviews.
There are also other things you can do, but I think they depend on luck too much. Slowly improving your portfolio is the way to go, I think.
All of these companies assume that if you know the front-end domain, you can learn whatever technology du jour to become a front-end developer, and besides, if you don’t know anything about front-end, you can still grow into a front-end developer if that’s the path you’re interested in.
That being said, TypeScript is increasingly becoming the standard way to write client-side web code. Both Microsoft and Google are very committed to TS, while Facebook uses JavaScript with Flow. Google also uses Dart for some of its front end.
Likewise, there are a number of technologies on which the larger companies have taken diverging choices. Google is very committed to gRPC, I mean, g stands for Google; while Facebook is behind graphQL. (graph being, originally. the “social graph” of Facebook). AFAIK, Microsoft uses both.
Neither Google nor Facebook have ever really embraced node.js. This would have seemed odd a few years ago but now the web ecosystem is generally turning away from tools and web servers written in node.js. I don’t know for sure what Microsoft uses for its web servers.
Facebook is unsurprisingly very committed to React and React Native. Google though uses a number of web frameworks, including non-open sourced ones, and among others Angular and Flutter. Microsoft, AFAIK, uses React and React Native and Angular.
But all these skills are transferable. If you understand React, it’s easy to learn Angular and conversely; TypeScript and Flow have similarities, etc.
One common denominator is HTML, CSS, web APIs and web standards, which are always relevant.
Your goal, in an interview, is not to impress your interviewer, but to demonstrate that you have the necessary skill set to be hired.
In a large tech company, the threshold to be considered “impressive” is pretty high… you have people that had superlative achievements in their field (or outside of tech), and in their day to day they’re just treated like normal people. I never interviewed for Amazon, but I interviewed (and got hired) at both Facebook and Google, and both of my interviewer brackets included folks who had their own Wikipedia entry (and since then, all of my Facebook interviewers had amazing careers and most got their own Wikipedia page). So that’s the caliber of folks that your interviewers work with on a daily basis.
So your interviewer is not going to be impressed by your interview performance. That said, I’ve observed that many tech employees treat others as if they could be the next Ada Lovelace or the next Steve Jobs no matter their current achievements. This is not forced, but it’s an attitude that comes naturally because we’ve observed so many people achieve greatness. Interviewers would love nothing more than to give the highest recommendation for the candidate that they are seeing right now, it’s very fulfilling (conversely, having to reject a candidate is always a bit frustrating). So I think it’s fair that your interviewer is hoping you can become a superstar, but that hope is the same as for every other candidate and not directly linked to how well you are doing right now.
Google’s interview process leans towards making sure that an unsuitable candidate is not hired, they are ok if a few suitable candidates are missed in the process.
There is also a factor of chance involved in the process. Here is a story to prove that:
I have personally asked at least 5 engineers at Google if they would be willing to interview again assuming they would be offered 1.5 times their current compensation. Obviously they loose the job if they don’t clear the interview. I am yet to meet somebody willing to take this bargain , I wont take it either.
Btw google also offers anybody who leaves google to comeback and join at the same level without an interview if they comeback within 2 years. My guess is that they also realize the chance involved.
Not clearing an interview at google is an indicator of only one thing, that you did not clear a google interview. Don’t draw conclusions about your ability based on this.
At Google there’s a selection of laptops you can choose from: a couple of Macs, a couple of Chromebooks, a couple of Linux laptops and a couple of windows laptops. Usually there’s a smaller, lighter version, for people who favor portability, and a larger version if you prefer a larger screen.
I’ve seen developers use all. I’d guess that Macs are most common (but under 50%} and Windows machines are least common.
I use a Chromebook (well, two Chromebooks). You turn it on, you log in and it looks exactly the same as your other Chromebook. This saves me carrying a laptop between work and home. If you work from another office, you don’t need to carry your laptop, you just grab one off the shelf, log in, and it looks the same as the computer you left at home.
(I tried using a Mac, I couldn’t get used to it, I didn’t know how to do anything, the keyboard shortcuts drove me crazy and so I gave it back and got a Chromebook).
Google and Meta (formerly Facebook) have a long-standing culture where employees believe that they’re hot stuff and that the company has to keep them happy because the company needs them as much as they need the company. Amazon doesn’t have that, probably because they fire people pretty often, making many of the remaining employees feel disposable.
Google and Meta have different concepts of culture fit—or at least they did historically. At Google, culture fit means “don’t be a person who’s hard to work with”. At Meta, culture fit means “be a person who believes that we are doing great things here and who will be excited to work hard on those great things”. As a result, it tends to be easy for Meta to keep convincing their existing employees that the company is doing the right thing. Google, on the other hand, ends up with a significant proportion of employees who are not easily convinced, and demand change.
Though it’s been so long since I’ve actually worked in the tech industry that I’m not sure if Meta still fits the description I gave above, and there are signs that Google has been trending away from the description I gave above.
The question was:
Why is employee activism seen more in Google but not in other companies like Facebook and Amazon?
Just to add a small note to Dimitriy’s great answer, computer science PhDs tend to be analytical and hyperrational. Working for Google is probably the single best “pass” to choosing whatever the hell you want for the rest of your career, or at least for the next step or two. I think some CS PhDs work for Google not because it’s what they want, but because they don’t know what they want, and if you don’t know what you want and you can get a job there, it would be hard to do better than Google. Why not make $250,000 a year while figuring out your next step? The other companies in this so-called “top-tier” have issues; they are potentially great employers, but their issues make them anywhere from slightly to dramatically less attractive.
The main factor why top prop trading firms and hedge funds are difficult to get into compared to tech companies is their size.
According to Wikipedia Two Sigma has about 1600 employees[1] and Jane Street has about 1900 employees .[2] Even the largest hedge fund, Bridgewater, only has 1500[3] and the third largest hedge fund, Renaissance Technology manages $130 billion with 310 employees.
Maybe these numbers on Wikipedia aren’t exact but I’d bet they’re well within the ballpark of being accurate.
Facebook has nearly 60,000 employees ,[4] Amazon has 160,000 ,[5] Apple has 154,000,[6] Netflix has around 12,000[7], and Google has 140,000[8]. Again, maybe these number aren’t precise but I don’t feel like doing more in depth research.
However, it’s pretty obvious to see that the big tech companies employ multiples of what those finance firms do and quite simply there are far more opportunities at those tech companies. More seats mean it’s going to be less competitive to be hired.
Second, those top hedge funds and prop trading firms pay well. Like really well.
And Jane Street’s 2020 graduate hires straight from college were paid a $200k annual base salary, plus a $100k sign-on bonus, plus a $100k-$150k guaranteed performance bonus. Junior bankers’ high salaries look a little paltry by comparison.[9]
So a new college grad makes $400-$450k. That’s a 22–23 year old making that. That same article found documents that said the average per employee in their London office was $1.3 million. Some make more and some make less, but that’s an eye wateringly high number when you consider all of the admin and support aren’t making close to that.
A friend’s younger brother worked at Jane Street about 10 years ago. He may still but I haven’t talked to her much since we moved. He was a rock star at Jane Street, and while I’m relying on my memory of a 10 year old conversation so I may not be totally accurate, he was in his late 20’s or early 30’s and made $4 million (and it may actually have been $8M) that year.
I know tech people are paid well but I doubt many, if any, make $400-$450k in year one and are making millions by their late 20’s is unheard of unless they founded or join a startup at the right time.
In addition, the interview processes at those firms is insanely difficult. I’ve never worked or interviewed at them but I’ve heard war stories. Just to get your foot in the door is nearly impossible then getting an offer to work there is basically impossible
My friend’s brother was half way through an absolutely top PhD program in Physics when he was recruited by them. I don’t consider myself a slouch and I’ve met a ton of highly intelligent people, but this guy was like his brain was plugged into a computer and the internet. And he was a dynamic personality.
They hire the absolute best of the best and because they’re small and privately held they don’t actually ever need to hire or grow because the public markets can’t punish their stock price because they don’t have one. If some of those top investment firms can’t find the right fit they may simply not need to make a hire right then and can wait. They’re not big banks like Goldman that need to hire X number of analysts and associates because they need to replace the people who left.
So the main reasons that it’s tougher to get into a top hedge fund or prop trading firm than big tech is because they’re much smaller, they pay more, they are even more diligent in their hiring practices, and they hire very intelligent people.
If that were to happen, we’ll have bigger problems to deal with. The Google monorepo exists on tens of thousands of machines. That would mean: every data center, every workstation used by Google would suddenly be out of commission – not just turned off, but so that storage isn’t even available. This is only possible in a complete doomsday scenario.
It’s generally possible to find better compensated jobs for people with experience in big tech cos. This experience is very desirable for companies in fast growth mode – not just the technical expertise but also knowledge of processes of world-class engineering organizations. Smaller but fast-growing companies can offer better packages but with an element of risk – if the company ends up failing, the employee will only get their salary.
To Conclude:
The tech industry is booming, and there are a lot of great opportunities for those with the skills and experience to land a job at one of the FAANG companies. Google, Facebook, Amazon, Apple, Netflix, and Microsoft are all leaders in the tech industry, and they offer competitive salaries and benefits. The interview process for these companies can be intense, but if you’re prepared and knowledgeable about the company’s culture and values, you’ll have a good chance of landing the job. Perks at these companies can include free food and transportation, stock options, and generous vacation time. If you’re looking for a challenging and rewarding career in the tech industry, consider applying for a job at one of the FAANGM companies.
Seeking series based on my favorites! I'm looking for some new TV series to watch and would love your recommendations. Here are some of my top favorites: The Americans La Casa de Papel Berlin Breaking Bad (not so much Better Call Saul) The Diplomat Tokyo Vice Boardwalk Empire Ozark Mosquito Coast Narcos Peaky Blinders Black Sails For All Mankind Dark The Gentlemen Weeds Ted Lasso Happy Valley The Wire I also really enjoy documentaries by Mads Brügger. As you can see, I enjoy a mix of thrillers, crime dramas, historical series, and some lighter comedies. I love documentaries that adress contemporary societal issues. I’d really appreciate any suggestions that align with these interests! Thanks in advance for your recommendations! submitted by /u/emillindstrom [link] [comments]
In this technical blog post, we will explore how to implement AWS CloudFront with multiple origin cache behavior using Terraform…Continue reading on Medium »
A criação de conteúdo é um elemento fundamental para o sucesso de qualquer negócio online. Estudos indicam que a produção de conteúdo de…Continue reading on Medium »
In a landmark move for India’s tech industry, Ola’s AI subsidiary, Krutrim, has launched Ola Maps, a highly competitive alternative to…Continue reading on Medium »
Blazing-fast performance:The Google Tensor G2 chip delivers smooth multitasking and exceptional speed, whether you’re gaming, editing…Continue reading on Medium »
Neste projeto abrangente, enfrentei o desafio de implantar a aplicação HumanGov SaaS usando a plataforma Amazon Web Services (AWS)…Continue reading on Medium »
Hey there, tech folks and business leaders! Are you scratching your head over VMware’s pricing changes? Don’t worry, you’re not alone…Continue reading on Medium »
In another project grounded in a real-world scenario, I assumed the role of a Cloud Specialist tasked with overseeing the migration of a…Continue reading on Medium »
In my organization we keep getting spammed by a certain email address, having the sender name "xavid garcia.” This person was sending emails to multiple users as well as distribution lists, which ends up in hundreds of employees’ inboxes. We have since blocked this email address and everything was fine for a while. Recently we started receiving again hundreds of emails from "xavid garcia"m however this time from many different email addresses. The name however is always the same "xavid garcia". I'm fairly new to this and would reall yappreciate if someone could shine some light on how larger organization would deal with blocking such emails. I can't imagine that an admin would have to spend hours upon hours and integrating this task into their normal daily work, since this xavid guy can just create new email addresses and keep spamming our users. He sends everything from malicious links, phishing attempts, attachments etc. We also have MDO365P2 in place, and since manually blocking some of his email addresses in the anti-spam as well as in the Tenant Allow/Block lists, , the policy works and those are moved to quarantine. but he keeps making new ones on a daily basis. I was thinking about making a powershell script which would look at the email sender name, since it's always the same" and react to them that way, but this is not idea as the email would land in the user mailbox anyway... How can I remediate this? THANK YOU SO MUCH!! submitted by /u/Party_Crab_8877 [link] [comments]
Amazon ElastiCache is a crucial service for architects aiming to optimize database performance through in-memory caching. By integrating…Continue reading on Medium »
They’ve forced me to use Outlook for Windows and I hate it. How can I get the old mail app back? I’ll literally pay for it. Kind regards, throwaway_aagghh submitted by /u/throwaway_aagghh [link] [comments]
AppData\roaming\secure transaction systems.exe Windows 11 Window keeps popping up, sometimes multiple times per minute. It shows very quickly (less than a second) and then disappears. I had to screen record to get the name of it. Thoughts?? submitted by /u/Time-Cobbler-4062 [link] [comments]
For years, kids raised the issue of predation on Roblox. They’ve filmed To Catch A Predator-style YouTube videos, mass-reported sex games and complained–loudly–to Roblox about creepy characters on the multibillion-dollar childrens’ gaming platform. In one instance, kids called out a well-known Roblox developer–who went by DoctorRofatnik–for sending predatory messages to a 12-year-old. Months later, he kidnapped and raped a 15-year-old he met on Roblox. We've been reporting on the intersection of child safety and the digital world for years. So we took the complaints seriously. For the last eight months, we filed dozens of Freedom of Information Act requests for police reports linked to Roblox for this story. We found at least 24 men have been accused of abducting or abusing minors they either met or groomed through Roblox since 2018. Roblox has 78 million daily users and more than 40% are under the age of 13. The platform is so popular with children it's started to appeal to an unwelcome user base: predators and registered sex offenders. We both made Roblox avatars to test the company's safety features for kids, and we were shocked by what we found. It took less than a couple minutes for a stranger to try and groom Cecilia–after she said she was 4. Meanwhile, Olivia flew around the country to piece together the story behind DoctorRofatnik–whom the FBI would later discover is actually a man named Arnold Castillo. Do you want to learn more about predators on Roblox? Drop your questions in the comments and our reporters, Olivia and u/cecianasta, will respond in our AMA today from 1 - 2pm ET. STORY LINK: https://www.bloomberg.com/features/2024-roblox-pedophile-problem/ submitted by /u/bloomberg [link] [comments]
I am debating getting 365 but idk if it’s worth it since I have Microsoft Office 2021 pro plus, is it worth almost 80 bucks a year or is what I have good for now. I don’t feel like I’m lacking on any features with the one I have rn but idk maybe there’s something that will furthermore help me at what i’m doing submitted by /u/Ashen_hunt3r [link] [comments]
In this article, we delve into two unique AWS services in the desktop and app streaming category. These services extend beyond the…Continue reading on Medium »
Welcome to “Google Business Profile with AI: Training Guide,” a comprehensive resource crafted to help businesses thrive in the digital…Continue reading on Medium »
India, navigating its labyrinthine streets and adapting to its unique travel needs can often be as challenging as it is essential. Google…Continue reading on Medium »
Consultant SEO à Casablanca : Expert en référencement naturel offrant des services d’optimisation SEO pour améliorer votre visibilité en…Continue reading on Medium »
https://preview.redd.it/basf8w9fdoed1.jpg?width=1280&format=pjpg&auto=webp&s=a13f045d479fdd664db82a5f31e92cebaf1b7585 The fourth season of Netflix’s The Witcher entered production in April 2024. Now, a few months on, it’s time to check in with how production is going, what we know so far about season 5, and cover a new face we’ll be seeing next season. Liam Hemsworth Debuts as Geralt of Rivia Replacing Henry Cavill The new season will debut Liam Hemsworth as Geralt of Rivia, replacing Henry Cavill. It will also see the return of the previous main cast: Anya Chalotra, Freya Allan, Joey Batey, Graham McTavish, Cassie Clare, Meng’er Zhang, and many more. First Look at Liam Hemsworth as Geralt Liam Hemsworth was cast in The Witcher in late 2022, following Henry Cavill’s sudden exit. Netflix finally released the official first look at Liam Hemsworth as Geralt of Rivia earlier this year. The picture comes from a short shoot made for promotional purposes. Entertainment Weekly was given the exclusive. Early Pap Photos Before the official release, there were paparazzi photos from Metro and Redanian Intelligence. These showed Liam Hemsworth in full costume while filming The Witcher Season 4. There’s a full gallery of photos, including Anya Chalotra’s Yennefer at the same location. The scene reenacted the previous season’s iconic fight between Geralt and Vilgefortz. They reshot it to make it part of Liam’s introduction as Geralt. Season 4 will possibly be the “true” version of how that happened. Introducing Laurence Fishburne as Regis A Beloved Character Next up, we have the first look at Laurence Fishburne as Regis, the fan-favorite barber-surgeon who is also a vampire. For many, Regis is known from the acclaimed The Witcher 3 expansion Blood & Wine. On-Set Photos Fishburne was photographed at Waverley Abbey, England. The Witcher was filming a large sequence from the books where Geralt, Regis, and the rest of the group are at a refugee camp. Religious fanatics threatened to burn a woman at the stake, and Regis steps in and has one of his big moments. Ciri’s New Outfit and The Rats Freya Allan as Ciri Another set of photos obtained by Redanian Intelligence shows Freya Allan as Ciri along with her companions, The Rats. They are played by Ben Radcliffe, Christelle Elwin, Aggy K. Adams, Fabian McCallum, Juliette Alexandra, and Connor Crawford. At the end of Season 3, Ciri meets these six teenage bandits and introduces herself to them as Falka. In Season 4, she becomes a member of their team, involved in armed robbery. Robbery Scene Freya Allan was photographed filming Ciri and the Rats robbing a carriage of a baron’s daughter, which is a scene from the books. Another photo from a previous filming day shows The Rats themselves. New Nilfgaardian Armor Costume Changes Back at Waverley Abbey, we have a new set of Nilfgaardian armor again. First, they were all black in Season 1 but sparked controversy. For Seasons 2 and 3, The Witcher introduced different versions, looking more medieval, albeit more golden than black. Now, they are all black again. Chaos at the Refugee Camp This is part of the same sequence mentioned above, with Geralt, Regis, Jaskier, and the rest of Geralt’s Hansa. Shortly after Regis has his big moment, Nilfgaard attacks the refugee camp, resulting in our heroes losing track of each other. Jack Myers Joins The Cast New Faces We can confirm that Jack Myers has joined The Witcher Season 4 in a role we believe is codenamed River. Myers was most recently seen in Masters of the Air for Apple TV+ and previously appeared in Netflix Originals The Crown, White Lines, and The Dark Crystal: Age of Resistance. Myers is also cast in an upcoming untitled Marvel film. New Cast Members Here are the new cast members of The Witcher Season 4, both revealed officially and those uncovered by Redanian Intelligence: Laurence Fishburne as Regis Sharlto Copley as Leo Bonhart Danny Woodburn as Zoltan Chivay Linden Porco as Percival Schuttenbach James Purefoy as Stefan Skellen Clive Russell as Stribog Eve Ridley as Nimue Audrey Kattan as Beata Miles Jovian in an unknown role Edmund Kingsley in an unknown role Production Timeline Filming Schedule Season 4 of The Witcher is filming until late October 2024. We’re told it’ll be wrapped up on October 31st, with Season 5’s production following shortly after. Conclusion With a new Geralt, fresh characters, and gripping storylines, Season 4 of The Witcher promises to be a thrilling addition to the series. Keep an eye out for the official release and more exciting updates as we get closer to the premiere. FAQs 1. When will The Witcher Season 4 wrap up filming? Season 4 of The Witcher is scheduled to wrap up filming by October 31, 2024. 2. Who is replacing Henry Cavill as Geralt of Rivia? Liam Hemsworth is replacing Henry Cavill as Geralt of Rivia in Season 4. 3. What role does Laurence Fishburne play in Season 4? Laurence Fishburne plays Regis, a fan-favorite vampire character from the books. 4. Who are The Rats in Season 4? The Rats are a group of teenage bandits that Ciri joins. They are played by Ben Radcliffe, Christelle Elwin, Aggy K. Adams, Fabian McCallum, Juliette Alexandra, and Connor Crawford. 5. When will Season 5 of The Witcher start production? Season 5’s production is set to begin shortly after the wrap of Season 4 in late October 2024. submitted by /u/Movieeebird [link] [comments]
The speed of audio technology advancement is high, thus having the right pair of headphones does alter the experience that one will have…Continue reading on Medium »
Nomad, known for its high-quality cell phone cases, chargers and watchbands, recently gained attention by offering special editions such…Continue reading on Medium »
¿Cansado de buscar enchufes para cargar tu celular? ¡Tenemos la solución perfecta para ti! Nuestro nuevo banco de carga inalámbrico…Continue reading on Medium »
I'm trying to decide whether to get the Office Professional Plus 2021 or subscribe to Office 365 because I've used both in different work settings, but now, as I'm getting a more permanent workspace, I just want something that makes sense financially and functionally in the long term. So, afaik, Office 2021 is a one-time purchase, which means no recurring subscription fees, which does sound fair, but would I be missing out on any features and updates compared to 365? And does it handle security updates properly? We've had issues with that in the past. With Office 365, updates are automatic, but with Office 2021, do I have more control over when and if I install them? So, yeah, I'm hoping to hear what the advantages of getting the standalone Office 2021 over the subscription model, especially in terms of features. Because, price-wise, I'd certainly go for it. submitted by /u/Xanf3rr [link] [comments]
Scorpionfix is the trusted Apple mac repair Dubai service center. It is well-known for providing excellent repair services and ensuring…Continue reading on Medium »
So I discovered the Reba series and have literally fallen in love with her. But.. at season 4 (currently on) something feels off ... like her spark is gone. Did something seem off to anyone else? [link] [comments]
Welcome to the Daily Advice Thread for /r/Apple. This thread can be used to ask for technical advice regarding Apple software and hardware, to ask questions regarding the buying or selling of Apple products or to post other short questions. Have a question you need answered? Ask away! Please remember to adhere to our rules, which can be found in the sidebar. Join our Discord and IRC chat rooms for support: Discord IRC Note: Comments are sorted by /new for your convenience. Here is an archive of all previous Daily Advice Threads. This is best viewed on a browser. If on mobile, type in the search bar [author:"AutoModerator" title:"Daily Advice Thread" or title:"Daily Tech Support Thread"] (without the brackets, and including the quotation marks around the titles and author.) The Daily Advice Thread is posted each day at 06:00 AM EST (Click HERE for other timezones) and then the old one is archived. It is advised to wait for the new thread to post your question if this time is nearing for quickest answer time. submitted by /u/AutoModerator [link] [comments]
Is there any place to see upcoming shows on the new interface? The only tabs are home, series, movies and my netflix, and if you scroll down you will eventually find a new section but upcoming (as in this week, next week, worth the wait) is nowhere to be seen. If they decided to get rid of it that would be one thing, but clearly it must be somewhere as there is a whole banner in "my netflix" for reminders, which can only be set by selecting upcoming things. Am I missing something? submitted by /u/Mxyzptly [link] [comments]
Hey there, I searched to find if someone has asked this before and could not find anything. Is there a way, to automatically trigger an flow that shrotens a file's path that's producing a "Path is too long" error by renaming it? submitted by /u/GeilesTender [link] [comments]
I have the standard plan of Netflix. Around 9 devices are already logged in at 2 different locations (3 different profiles). If I log in on a new device at a third different location, will my account get blocked? The standard plan only states that the downloads and simultaneous streaming is allowed on only two devices. So if there is no download or simultaneous streaming, is adding the 10th device okay? submitted by /u/_anonymous_acc [link] [comments]
Give me some movies or series I should watch These are some movies/ series that I have watched that I enjoyed. stranger things The tall grass raising Deon Megan a series of unfortunate events submitted by /u/Ichigo_daisy [link] [comments]
I only paid for netflix to use 5.1 surround on my computer is a chargeback valid now that netflix is useless a few days after paying for the next month. submitted by /u/hundredlives [link] [comments]
My (now EX) wife set up Netflix some years ago and I've always been the one paying the monthly fees. Now I get the notice "Your device isn't part of the netflix household for this account" and can't watch anything. I assume it thinks she is the account holder, and I can't have access because I'm in a different household now. Since I'm paying the subscription, I would like to be the one who has access. Is there a way to transfer the account to my name? If I create a new account I'll lose all of my watch history, preferences, etc. The info I read online isn't clear about what should happen in this situation. I found a similar post from someone here on this Reddit sub so I figured I could ask here to see if anyone else knows. submitted by /u/fgennari [link] [comments]
I’m boarding a plane soon and I get this notification when I try and download shows to watch. If I remove some films and shows I just downloaded, can I download other things instead? I’ve already undownloaded a few but it’s still not letting me download this one film, and I’m worried if I undownload everything it just won’t let me download anything at all submitted by /u/pm_me_picsxx [link] [comments]
I’m looking for a action-packed netflix series with a overpowered protagonist that’s finished airing and won’t be getting anymore seasons the reason why I want the netflix series to be finished, is because for some reason I can remember the faces of the characters in the show submitted by /u/Thin-Addition6101 [link] [comments]
The Netflix Series, “Night Stalker: The Hunt For A Serial Killer,” says March 17, 1985 is Day 1 and August 31, 1985 is Day 167. Shouldn’t August 31, 1985 be day 168? submitted by /u/pairuno1d [link] [comments]
I came on to watch a show and noticed that I nolonger have an option for picture in picture from the website or the stand alone app. anyone else noticed this yet? Is it gone forever? submitted by /u/External-Camera9114 [link] [comments]
Hey guys, In my workplace, I have a three PC setup with four monitors. Two monitors are on the bottom row while the other two are located above these bottom row monitors. Mouse without borders is excellent, however, I wish that there were more options in organizing the computer monitor matrix. Ideally, I would centre the bottom two monitors to act as a single screen so that I could easily move up diagonally and reach the other monitor on the top left or top right. The current setup is okay but since you can only create two rows that snap into a 2x2 matrix, once I get to the top right monitor, I need to come back through the top left monitor to get to the bottom row of monitors, this just feels a bit unnatural. Perhaps, there is an option that I am not aware of. In any case, I guess my situation is fairly specific but I was curious if anyone else had a work around for this as it can cause some confusion. Cheers! submitted by /u/TicklezPanda [link] [comments]
I got a google play gift card from my teacher today, and when I back home and try to redeem it. it shows [we need more info] Obviously, i don't have the details of the gift card. How could I do submitted by /u/Molly_Mianbao [link] [comments]
She has a Sony TV and got a message from netflix saying her tv was too old. It is a 1080p bravia and she doesn’t have the 4k subscription. What the hell? Netflix can just decide what TV is ‘too old?’ Edit: thank you for your replies! i’ve ordered a roku. 🙂 submitted by /u/dudeosm [link] [comments]
Looking for advice from people within MS, ideally hiring managers I've been waiting for weeks for a result from my final interview. The recruiter said they're working on making a decision. So I've got pretty low hopes at this point. There's other Microsoft jobs I'm interested in, but would applying to them look bad? Would it jeopardize my (slim) chances for this job I've already interviewed for? Edit to add: I've applied to several MS jobs, but once this interview process started, I stopped applying to others. Just wondering if applying to others while waiting for this one's result would look bad submitted by /u/Formal-Ferret-953 [link] [comments]
I have been offered a surface Go 3 tablet with keyboard and pen for 200€ It is the 6500 pentium version but with 8gb ram. Is it a good buy of should I look for something more recent, and, obviously more expensive? I need it principally for work, online apps and Excel spreadsheets and Word docs. submitted by /u/Secure-Advertising10 [link] [comments]
I really love insane plot twist movies/shows like the two I mentioned in the title. Please recommend movies/shows similar to "Black Mirror" or "Behind Her Eyes" or a movie/show that has an insane plot twist that no one can ever anticipate until the end. Thanks! submitted by /u/Redditsyic [link] [comments]
First, I'm a pretty big fan. It wasn't the writing, that was okay. It wasn't the special effects, those were pretty mid. It wasn't even the characters, because we didn't get to see any growth yet. They came together but not out of an evolution, rather a necessity. I don't even follow some of the criticism on here so far regarding things like Michael's approach to.. well... Everything. I am more of an apologist in that matter because he was a delivery driver we know next to nothing about prior to this. He led a simple life with simple morals and was not just flung into leadership, but having to save the love of his life from an existential, supernatural threat while figuring out his own identify through all of this incredible change. He didn't know how to "lead" Dionne away from the danger because they've never faced danger and isn't the foundation of their long relationship of mutual respect. (I do have one critique at the end) What really sold me though was the charisma and talent of the actors, an often unpredictable story, and fairly good pacing that I think could mature in season 2. Season 2 will be a gamble though because having them together means a very different structure for the remainder of the series. With that said, I have some observations in no particular order: How did Michael and Dionne afford their lifestyle doing social work and deliveries? I know multiple things can be true but is that real life overseas? I know America is a sort of pseudo third world country with the power of our dollars but they're in London, one of, if not the most expensive cities IN THE WORLD. HOW?? (Nice cars, house, third party high end medical services for Mom) Is Kraze supposed to be Skylar or Peter from Heroes? If it's by touching then he would have stolen Michael's power and likely done something to get out of his death, no? But then if you have two characters able to bounce through time and space things will get narratively messy quite quickly. You could maybe argue he didn't figure out the time portion and just teleported, fucked up the guard, and got out of there and absorbed the next power before he understood what he had since we didn't see his final moments but I have the feeling they're gonna try the same move they did with Michael when he first got his at death. Why do the powers fritz out at the worst possible times? At first I thought maybe one of them was a power nullifier but there was no indication of that. I guess we could say maybe different emotions effect them in different ways but most of their origins came from trauma anyway. Taze couldn't go invisible around Kraze pretty early on. Speaking of Taze, he killed or tried to kill half the group so why are they so tolerant of him? Out of everyone he's the biggest liability with the least to offer. He was also the most reckless with his powers exposing them to all friends/foes with no discretion. Michael tried to save the love of his life essentially once and said "guess it's just meant to be?" I get not being ready for an incredible role thrown onto him but to shrug off any potential when he's already managed to alter time once and his more mature future self even thought it was possible seemed like a bit of a plot convenience to move things along. While Dionne shouldn't be in the fight she could have been the Lois Lane to his Superman and worked behind the scenes. Odds and ends: Sabrina just randomly confesses to murder at a police station and gets to walk out? Andre is getting fired because they do background checks AFTER someone starts a job? Taze is stabbed in a gang fight and just gets patched up and released? Taze is invisible and doesn't stay near his crew and hide the other drugs when they're busted? He kind of just runs off.. I get Michael not being ready for this but Taze was raised in the streets and has to have better instincts for this stuff. They said it has only been a couple days when Michael is about to jump to the future again, how is Rodney's friend just suddenly up and healed when he was in a possibly permanent coma? Also why did the hospital just tell his crew his room when he was stabbed? Shouldn't there be some degree of security or an allowed list of visitors? Again, I'm hoping for a season 2 for sure but hope with the renewal they can put more time and thought into a tighter script. The actors can carry the series through but there's a lot of missed potential left on the floor here. submitted by /u/HateMakinSNs [link] [comments]
Originally Answered: What can I improve on for my next FAANG Sr SWE interview?
I’m going to read between the lines and assume that you are working at a grade below senior at a company which is not a FAANG. I’m also assuming that you feel that you are ready and that you’ve already done the obvious, read the books, practiced questions etc.
Your senior eng interview has 3 facets, coding, system design and behavioral.
Your levers to do better at each are:
To get better at coding interviews, interview more candidates. Seeing what others do well and less well is very helpful. This really applies to all sorts of interviews but IMO is most helpful for coding interviews.
To get better at system design interviews, read more design docs at your existing company, attend more design reviews, and force yourself to participate. Comment, ask questions. It doesn’t matter if you’re off the mark. See what doesn’t make sense to you and challenge it.
To get better at behavioral interviews, read your perf packets and the feedback from your coworkers. Read the docs that you wrote on your career plans (If you don’t have any, ask yourself why and start one). Reflect, regularly, on what has been hardest in your career, what you have done very well, where you struggled, what you would do differently.
I’d like to answer first in general — about attrition rates in the tech sector — and then about Amazon specifically.
Industry-Wide Retention
Retention in the US high-tech industry is very challenging. I believe there are two main reasons for that.
First, there is an acute shortage of qualified workers, which means companies are desperate to get employees anywhere they can, including — sometimes mainly — by poaching them from other companies. This is why so many companies moved into the Seattle East Side in the ’90s or South Lake Union in the last five years, for example: to poach from Microsoft and Amazon, respectively.
I remember the crazy late-90’s in the Israel high-tech industry. People would come in, work for 6–12 months, then jump ship for a fancier title and a bump in pay. It was insane; it was disgusting (I mean that literally: I would sometimes feel physically sick thinking about how stupid it all was.)
The second reason — which I’m not as certain about — is that the high-tech industry is so incredibly dynamic. Things change constantly: new companies spring up and grow like crazy (Uber anyone?); “old” companies that were considered the cream of the crop a couple of years ago are suddenly untouchable (Yahoo!). New technologies explode onto the scene and old ones stagnate.
Not only does that create a lot of churn as companies keep growing and shrinking; it also creates incredible pressure on tech workers to stay on top of their game. We’re always looking for the next big technology, the next big field, then next big product… The sad part is that a lot of it is just hype, but the psychological pressure is real enough, and it makes people move around always looking for the next great opportunity.
Amazon
The reason I want to talk about Amazon — which generally suffers from the same problems I’ve described above — is that there’s a perception in the public that Amazon is somehow worse than the rest of the industry; that it has awful attrition, because it’s a terrible place to work. I’ve tackled that in a couple of other answers (e.g. this one and this one), but it’s a very persistent myth.
Much of the fault is in reports like this one from PayScale, which then get regurgitated in hundreds of stories like this one (from BuzzFeed). The basic story seems very simple: the average tenure of an Amazon employee is about a year, which is — undoubtedly — really low, even in tech-industry terms.
That’s a great example of (supposedly) Benjamin Disraeli’s famous quote, “lies, damned lies and statistics”. There are at least two reasons why this number is completely meaningless:
Short tenure does not mean high attrition: in the last 6–7 years the number of employees at Amazon has grown exponentially, and I mean this literally:
This means that at any time, pretty much, about 20–40% of all Amazon employees have joined less than a year ago. It’s no really surprising that they have a short tenure, is it?
Measuring retention is not trivial, but this methodology is just plain dumb (or maybe intentionally misleading).
Amazon is not (only) a tech company: sure, if you compare Amazon to Google and Facebook it comes out bad. But unlike those companies, the majority of Amazon employees are not tech workers. They’re warehouse workers, drivers, customer-service people, etc. Many of them are temp workers, and many others are not considering the job as a career.
There is a good discussion to be had about how Amazon treats these workers and whether it can do better, but it makes no sense to compare it with Microsoft or Apple; Walmart and Target would be much better comparisons.
Use AWS Cheatsheets – I also found the cheatsheets provided by Tutorials Dojo very helpful. In my opinion, it is better than Jayendrapatil Patil’s blog since it contains more updated information that complements your review notes. #AWS Cheat Sheet
26
Watch this exam readiness 3hr video, it very recent webinar this provides what is expected in the exam. #AWS Exam Prep Video
27
Start off watching Ryan’s videos. Try and completely focus on the hands on. Take your time to understand what you are trying to learn and achieve in those LAB Sessions. #AWS Exam Prep Video
28
Do not rush into completing the videos. Take your time and hone the basics. Focus and spend a lot of time for the back bone of AWS infrastructure – Compute/EC2 section, Storage (S3/EBS/EFS), Networking (Route 53/Load Balancers), RDS, VPC, Route 3. These sections are vast, with lot of concepts to go over and have loads to learn. Trust me you will need to thoroughly understand each one of them to ensure you pass the certification comfortably. #AWS Exam Prep Video
29
Make sure you go through resources section and also AWS documentation for each components. Go over FAQs. If you have a question, please post it in the community. Trust me, each answer here helps you understand more about AWS. #AWS Faqs
30
Like any other product/service, each AWS offering has a different flavor. I will take an example of EC2 (Spot/Reserved/Dedicated/On Demand etc.). Make sure you understand what they are, what are the pros/cons of each of these flavors. Applies for all other offerings too. #AWS Services
31
Follow Neal K Davis on Linkedin and Read his updates about DVA-C01 #AWS Services
What is the AWS Certified Developer Associate Exam?
The AWS Certified Developer – Associate examination is intended for individuals who perform a development role and have one or more years of hands-on experience developing and maintaining an AWS-based application. It validates an examinee’s ability to:
Demonstrate an understanding of core AWS services, uses, and basic AWS architecture best practices
Demonstrate proficiency in developing, deploying, and debugging cloud-based applications using AWS
There are two types of questions on the examination:
Multiple-choice: Has one correct response and three incorrect responses (distractors).
Provide implementation guidance based on best practices to the organization throughout the lifecycle of the project.
Select one or more responses that best complete the statement or answer the question. Distractors, or incorrect answers, are response options that an examinee with incomplete knowledge or skill would likely choose. However, they are generally plausible responses that fit in the content area defined by the test objective. Unanswered questions are scored as incorrect; there is no penalty for guessing.
To succeed with the real exam, do not memorize the answers below. It is very important that you understand why a question is right or wrong and the concepts behind it by carefully reading the reference documents in the answers.
Understand bastion hosts, and which subnet one might live on. Bastion hosts are instances that sit within your public subnet and are typically accessed using SSH or RDP. Once remote connectivity has been established with the bastion host, it then acts as a ‘jump’ server, allowing you to use SSH or RDP to login to other instances (within private subnets) deeper within your network. When properly configured through the use of security groups and Network ACLs, the bastion essentially acts as a bridge to your private instances via the Internet.” Bastion Hosts
3
Know the difference between Directory Service’s AD Connector and Simple AD. Use Simple AD if you need an inexpensive Active Directory–compatible service with the common directory features. AD Connector lets you simply connect your existing on-premises Active Directory to AWS. AD Connector and Simple AD
4
Know how to enable cross-account access with IAM: To delegate permission to access a resource, you create an IAM role that has two policies attached. The permissions policy grants the user of the role the needed permissions to carry out the desired tasks on the resource. The trust policy specifies which trusted accounts are allowed to grant its users permissions to assume the role. The trust policy on the role in the trusting account is one-half of the permissions. The other half is a permissions policy attached to the user in the trusted account that allows that user to switch to, or assume the role. Enable cross-account access with IAM
Know which services allow you to retain full admin privileges of the underlying EC2 instances EC2 Full admin privilege
8
Know When Elastic IPs are free or not: If you associate additional EIPs with that instance, you will be charged for each additional EIP associated with that instance per hour on a pro rata basis. Additional EIPs are only available in Amazon VPC. To ensure efficient use of Elastic IP addresses, we impose a small hourly charge when these IP addresses are not associated with a running instance or when they are associated with a stopped instance or unattached network interface. When are AWS Elastic IPs Free or not?
9
Know what are the four high level categories of information Trusted Advisor supplies. #AWS Trusted advisor
10
Know how to troubleshoot a connection time out error when trying to connect to an instance in your VPC. You need a security group rule that allows inbound traffic from your public IP address on the proper port, you need a route that sends all traffic destined outside the VPC (0.0.0.0/0) to the Internet gateway for the VPC, the network ACLs must allow inbound and outbound traffic from your public IP address on the proper port, etc. #AWS Connection time out error
11
Be able to identify multiple possible use cases and eliminate non-use cases for SWF. #AWS
Understand how you might set up consolidated billing and cross-account access such that individual divisions resources are isolated from each other, but corporate IT can oversee all of it. #AWS Set up consolidated billing
Know how you would go about making changes to an Auto Scaling group, fully understanding what you can and can’t change. “You can only specify one launch configuration for an Auto Scaling group at a time, and you can’t modify a launch configuration after you’ve created it. Therefore, if you want to change the launch configuration for your Auto Scaling group, you must create a launch configuration and then update your Auto Scaling group with the new launch configuration. When you change the launch configuration for your Auto Scaling group, any new instances are launched using the new configuration parameters, but existing instances are not affected. #AWS Make Change to Auto Scaling group
14
Know how you would go about making changes to an Auto Scaling group, fully understanding what you can and can’t change. “You can only specify one launch configuration for an Auto Scaling group at a time, and you can’t modify a launch configuration after you’ve created it. Therefore, if you want to change the launch configuration for your Auto Scaling group, you must create a launch configuration and then update your Auto Scaling group with the new launch configuration. When you change the launch configuration for your Auto Scaling group, any new instances are launched using the new configuration parameters, but existing instances are not affected. #AWS Make Change to Auto Scaling group
15
Know which field you use to run a script upon launching your instance. #AWS User data script
16
Know how DynamoDB (durable, and you can pay for strong consistency), Elasticache (great for speed, not so durable), and S3 (eventual consistency results in lower latency) compare to each other in terms of durability and low latency. #AWS DynamoDB consistency
Know the difference between bucket policies, IAM policies, and ACLs for use with S3, and examples of when you would use each. “With IAM policies, companies can grant IAM users fine-grained control to their Amazon S3 bucket or objects while also retaining full control over everything the users do. With bucket policies, companies can define rules which apply broadly across all requests to their Amazon S3 resources, such as granting write privileges to a subset of Amazon S3 resources. Customers can also restrict access based on an aspect of the request, such as HTTP referrer and IP address. With ACLs, customers can grant specific permissions (i.e. READ, WRITE, FULL_CONTROL) to specific users for an individual bucket or object. #AWS Difference between bucket policies
Understand how you can use ELB cross-zone load balancing to ensure even distribution of traffic to EC2 instances in multiple AZs registered with a load balancer. #AWS ELB cross-zone load balancing
Spot instances are good for cost optimization, even if it seems you might need to fall back to On-Demand instances if you wind up getting kicked off them and the timeline grows tighter. The primary (but still not only) factor seems to be whether you can gracefully handle instances that die on you–which is pretty much how you should always design everything, anyway! #AWS Spot instances
22
The term “use case” is not the same as “function” or “capability”. A use case is something that your app/system will need to accomplish, not just behaviour that you will get from that service. In particular, a use case doesn’t require that the service be a 100% turnkey solution for that situation, just that the service plays a valuable role in enabling it. #AWS use case
23
There might be extra, unnecessary information in some of the questions (red herrings), so try not to get thrown off by them. Understand what services can and can’t do, but don’t ignore “obvious”-but-still-correct answers in favour of super-tricky ones. #AWS Exam Answers: Distractors
24
If you don’t know what they’re trying to ask, in a question, just move on and come back to it later (by using the helpful “mark this question” feature in the exam tool). You could easily spend way more time than you should on a single confusing question if you don’t triage and move on. #AWS Exa: Skip Questions that are vague and come back to them later
25
Some exam questions required you to understand features and use cases of: VPC peering, cross-account access, DirectConnect, snapshotting EBS RAID arrays, DynamoDB, spot instances, Glacier, AWS/user security responsibilities, etc. #AWS
26
The 30 Day constraint in the S3 Lifecycle Policy before transitioning to S3-IA and S3-One Zone IA storage classes #AWS S3 lifecycle policy
Watch Acloud Guru Videos Lectures while commuting / lunch break – Reschedule the exam if you are not yet ready #AWS ACloud Guru
36
Watch Linux Academy Videos Lectures while commuting / lunch break – Reschedule the exam if you are not yet ready #AWS Linux Academy
37
Watch Udemy Videos Lectures while commuting / lunch break – Reschedule the exam if you are not yet ready #AWS Linux Academy
38
The Udemy practice test interface is good that it pinpoints your weak areas, so what I did was to re-watch all the videos that I got the wrong answers. Since I was able to gauge my exam readiness, I decided to reschedule my exam for 2 more weeks, to help me focus on completing the practice tests. #AWS Udemy
39
Use AWS Cheatsheets – I also found the cheatsheets provided by Tutorials Dojo very helpful. In my opinion, it is better than Jayendrapatil Patil’s blog since it contains more updated information that complements your review notes. #AWS Cheat Sheet
40
Watch this exam readiness 3hr video, it very recent webinar this provides what is expected in the exam. #AWS Exam Prep Video
41
Start off watching Ryan’s videos. Try and completely focus on the hands on. Take your time to understand what you are trying to learn and achieve in those LAB Sessions. #AWS Exam Prep Video
42
Do not rush into completing the videos. Take your time and hone the basics. Focus and spend a lot of time for the back bone of AWS infrastructure – Compute/EC2 section, Storage (S3/EBS/EFS), Networking (Route 53/Load Balancers), RDS, VPC, Route 3. These sections are vast, with lot of concepts to go over and have loads to learn. Trust me you will need to thoroughly understand each one of them to ensure you pass the certification comfortably. #AWS Exam Prep Video
43
Make sure you go through resources section and also AWS documentation for each components. Go over FAQs. If you have a question, please post it in the community. Trust me, each answer here helps you understand more about AWS. #AWS Faqs
44
Like any other product/service, each AWS offering has a different flavor. I will take an example of EC2 (Spot/Reserved/Dedicated/On Demand etc.). Make sure you understand what they are, what are the pros/cons of each of these flavors. Applies for all other offerings too. #AWS Services
45
Ensure to attend all quizzes after each section. Please do not treat these quizzes as your practice exams. These quizzes are designed to mostly test your knowledge on the section you just finished. The exam itself is designed to test you with scenarios and questions, where in you will need to recall and apply your knowledge of different AWS technologies/services you learn over multiple lectures. #AWS Services
46
I, personally, do not recommend to attempt a practice exam or simulator exam until you have done all of the above. It was a little overwhelming for me. I had thoroughly gone over the videos. And understood the concepts pretty well, but once I opened exam simulator I felt the questions were pretty difficult. I also had a feeling that videos do not cover lot of topics. But later I realized, given the vastness of AWS Services and offerings it is really difficult to encompass all these services and their details in the course content. The fact that these services keep changing so often, does not help #AWS Services
47
Go back and make a note of all topics, that you felt were unfamiliar for you. Go through the resources section and fiund links to AWS documentation. After going over them, you shoud gain at least 5-10% more knowledge on AWS. Have expectations from the online courses as a way to get thorough understanding of basics and strong foundations for your AWS knowledge. But once you are done with videos. Make sure you spend a lot of time on AWS documentation and FAQs. There are many many topics/sub topics which may not be covered in the course and you would need to know, atleast their basic functionalities, to do well in the exam. #AWS Services
48
Once you start taking practice exams, it may seem really difficult at the beginning. So, please do not panic if you find the questions complicated or difficult. IMO they are designed or put in a way to sound complicated but they are not. Be calm and read questions very carefully. In my observation, many questions have lot of information which sometimes is not relevant to the solution you are expected to provide. Read the question slowly and read it again until you understand what is expected out of it. #AWS Services
49
With each practice exam you will come across topics that you may need to scale your knowledge on or learn them from scratch. #AWS Services
50
With each test and the subsequent revision, you will surely feel more confident. There are 130 mins for questions. 2 mins for each question which is plenty of time. At least take 8-10 practice tests. The ones on udemy/tutorialdojo are really good. If you are a acloudguru member. The exam simulator is really good. Manage your time well. Keep patience. I saw someone mention in one of the discussions that do not under estimate the mental focus/strength needed to sit through 130 mins solving these questions. And it is really true. Do not give away or waste any of those precious 130 mins. While answering flag/mark questions you think you are not completely sure. My advice is, even if you finish early, spend your time reviewing the answers. I could review 40 of my answers at the end of test. And I at least rectified 3 of them (which is 4-5% of total score, I think) So in short – Put a lot of focus on making your foundations strong. Make sure you go through AWS Documentation and FAQs. Try and envision how all of the AWS components can fit together and provide an optimal solution. Keep calm. This video gives outline about exam, must watch before or after Ryan’s course.#AWS Services
51
Walking you through how to best prepare for the AWS Certified Solutions Architect Associate SAA-C02 exam in 5 steps: 1. Understand the exam blueprint 2. Learn about the new topics included in the SAA-C02 version of the exam 3. Use the many FREE resources available to gain and deepen your knowledge 4. Enroll in our hands-on video course to learn AWS in depth 5. Use practice tests to fully prepare yourself for the exam and assess your exam readiness AWS CERTIFIED SOLUTIONS ARCHITECT SAA-C02 : HOW TO BEST PREPARE IN 5 STEPS
52
Storage: 1. Know your different Amazon S3 storage tiers! You need to know the use cases, features and limitations, and relative costs; e.g. retrieval costs. 2. Amazon S3 lifecycle policies is also required knowledge — there are minimum storage times in certain tiers that you need to know. 3. For Glacier, you need to understand what it is, what it’s used for, and what the options are for retrieval times and fees. 4. For the Amazon Elastic File System (EFS), make sure you’re clear which operating systems you can use with it (just Linux). 5. For the Amazon Elastic Block Store (EBS), make sure you know when to use the different tiers including instance stores; e.g. what would you use for a datastore that requires the highest IO and the data is distributed across multiple instances? (Good instance store use case) 6. Learn about Amazon FSx. You’ll need to know about FSx for Windows and Lustre. 7. Know how to improve Amazon S3 performance including using CloudFront, and byte-range fetches — check out this whitepaper. 8. Make sure you understand about Amazon S3 object deletion protection options including versioning and MFA delete. AWS CERTIFIED SOLUTIONS ARCHITECT SAA-C02 : HOW TO BEST PREPARE IN 5 STEPS
53
Compute: 1. You need to have a good understanding of the options for how to scale an Auto Scaling Group using metrics such as SQS queue depth, or numbers of SNS messages. 2. Know your different Auto Scaling policies including Target Tracking Policies. 3. Read up on High Performance Computing (HPC) with AWS. You’ll need to know about Amazon FSx with HPC use cases. 4. Know your placement groups. Make sure you can differentiate between spread, cluster and partition; e.g. what would you use for lowest latency? What about if you need to support an app that’s tightly coupled? Within an AZ or cross AZ? 5. Make sure you know the difference between Elastic Network Adapters (ENAs), Elastic Network Interfaces (ENIs) and Elastic Fabric Adapters (EFAs). 6. For the Amazon Elastic Container Service (ECS), make sure you understand how to assign IAM policies to ECS for providing S3 access. How can you decouple an ECS data processing process — Kinesis Firehose or SQS? 7. Make sure you’re clear on the different EC2 pricing models including Reserved Instances (RI) and the different RI options such as scheduled RIs. 8. Make sure you know the maximum execution time for AWS Lambda (it’s currently 900 seconds or 15 minutes). AWS CERTIFIED SOLUTIONS ARCHITECT SAA-C02 : HOW TO BEST PREPARE IN 5 STEPS
54
Network 1. Understand what AWS Global Accelerator is and its use cases. 2. Understand when to use CloudFront and when to use AWS Global Accelerator. 3. Make sure you understand the different types of VPC endpoint and which require an Elastic Network Interface (ENI) and which require a route table entry. 4. You need to know how to connect multiple accounts; e.g. should you use VPC peering or a VPC endpoint? 5. Know the difference between PrivateLink and ClassicLink. 6. Know the patterns for extending a secure on-premises environment into AWS. 7. Know how to encrypt AWS Direct Connect (you can use a Virtual Private Gateway / AWS VPN). 8. Understand when to use Direct Connect vs Snowball to migrate data — lead time can be an issue with Direct Connect if you’re in a hurry. 9. Know how to prevent circumvention of Amazon CloudFront; e.g. Origin Access Identity (OAI) or signed URLs / signed cookies. AWS CERTIFIED SOLUTIONS ARCHITECT SAA-C02 : HOW TO BEST PREPARE IN 5 STEPS
55
Databases 1. Make sure you understand Amazon Aurora and Amazon Aurora Serverless. 2. Know which RDS databases can have Read Replicas and whether you can read from a Multi-AZ standby. 3. Know the options for encrypting an existing RDS database; e.g. only at creation time otherwise you must encrypt a snapshot and create a new instance from the snapshot. 4. Know which databases are key-value stores; e.g. Amazon DynamoDB. AWS CERTIFIED SOLUTIONS ARCHITECT SAA-C02 : HOW TO BEST PREPARE IN 5 STEPS
56
Application Integration 1. Make sure you know the use cases for the Amazon Simple Queue Service (SQS), and Simple Notification Service (SNS). 2. Understand the differences between Amazon Kinesis Firehose and SQS and when you would use each service. 3. Know how to use Amazon S3 event notifications to publish events to SQS — here’s a good “How To” article. AWS CERTIFIED SOLUTIONS ARCHITECT SAA-C02 : HOW TO BEST PREPARE IN 5 STEPS
57
Management and Governance 1. You’ll need to know about AWS Organizations; e.g. how to migrate an account between organizations. 2. For AWS Organizations, you also need to know how to restrict actions using service control policies attached to OUs. 3. Understand what AWS Resource Access Manager is. AWS CERTIFIED SOLUTIONS ARCHITECT SAA-C02 : HOW TO BEST PREPARE IN 5 STEPS
The AWS Certified Solution Architect Associate Examination reparation and Readiness Quiz App (SAA-C01, SAA-C01, SAA) Prep App helps you prepare and train for the AWS Certification Solution Architect Associate Exam with various questions and answers dumps.
This App provide updated Questions and Answers, an Intuitive Responsive Interface allowing to browse questions horizontally and browse tips and resources vertically after completing a quiz.
Features:
100+ Questions and Answers updated frequently to get you AWS certified.
Quiz with score tracker, countdown timer, highest score saving. Vie Answers after completing the quiz for each category.
Ability to navigate through questions for each category using next and previous button.
Resource info page about the answer for each category and Top 60 Tips to succeed in the exam.
Prominent Cloud Evangelist latest tweets and Technology Latest News Feed
The app helps you study and practice from your mobile device with an intuitive interface.
SAA-C01 and SAA-C02 compatible
Resource info page about the answer for each category.
Helps you study and practice from your mobile device with an intuitive interface.
The questions and Answers are divided in 4 categories:
Design High Performing Architectures,
Design Cost Optimized Architectures,
Design Secure Applications And Architectures,
Design Resilient Architecture,
The questions and answers cover the following topics: AWS VPC, S3, DynamoDB, EC2, ECS, Lambda, API Gateway, CloudWatch, CloudTrail, Code Pipeline, Code Deploy, TCO Calculator, AWS S3, AWS DynamoDB, CloudWatch , AWS SES, Amazon Lex, AWS EBS, AWS ELB, AWS Autoscaling , RDS, Aurora, Route 53, Amazon CodeGuru, Amazon Bracket, AWS Billing and Pricing, AWS Simply Monthly Calculator, AWS cost calculator, Ec2 pricing on-demand, AWS Pricing, AWS Pay As You Go, AWS No Upfront Cost, Cost Explorer, AWS Organizations, Consolidated billing, Instance Scheduler, on-demand instances, Reserved instances, Spot Instances, CloudFront, Web hosting on S3, S3 storage classes, AWS Regions, AWS Availability Zones, Trusted Advisor, Various architectural Questions and Answers about AWS, AWS SDK, AWS EBS Volumes, EC2, S3, Containers, KMS, AWS read replicas, Cloudfront, API Gateway, AWS Snapshots, Auto shutdown Ec2 instances, High Availability, RDS, DynamoDB, Elasticity, AWS Virtual Machines, AWS Caching, AWS Containers, AWS Architecture, AWS Ec2, AWS S3, AWS Security, AWS Lambda, Bastion Hosts, S3 lifecycle policy, kinesis sharing, AWS KMS, Design High Performing Architectures, Design Cost Optimized Architectures, Design Secure Applications And Architectures, Design Resilient Architecture, AWS vs Azure vs Google Cloud, Resources, Questions, AWS, AWS SDK, AWS EBS Volumes, AWS read replicas, Cloudfront, API Gateway, AWS Snapshots, Auto shutdown Ec2 instances, High Availability, RDS, DynamoDB, Elasticity, AWS Virtual Machines, AWS Caching, AWS Containers, AWS Architecture, AWS Ec2, AWS S3, AWS Security, AWS Lambda, Load Balancing, DynamoDB, EBS, Multi-AZ RDS, Aurora, EFS, DynamoDB, NLB, ALB, Aurora, Auto Scaling, DynamoDB(latency), Aurora(performance), Multi-AZ RDS(high availability), Throughput Optimized EBS (highly sequential), SAA-CO1, SAA-CO2, Cloudwatch, CloudTrail, KMS, ElasticBeanstalk, OpsWorks, RPO vs RTO, HA vs FT, Undifferentiated Heavy Lifting, Access Management Basics, Shared Responsibility Model, Cloud Service Models, etc…
The resources sections cover the following areas: Certification, AWS training, Mock Exam Preparation Tips, Cloud Architect Training, Cloud Architect Knowledge, Cloud Technology, cloud certification, cloud exam preparation tips, cloud solution architect associate exam, certification practice exam, learn aws free, amazon cloud solution architect, question dumps, acloud guru links, tutorial dojo links, linuxacademy links, latest aws certification tweets, and post from reddit, quota, linkedin, medium, cloud exam preparation tips, aws cloud solution architect associate exam, aws certification practice exam, cloud exam questions, learn aws free, amazon cloud solution architect, amazon cloud certified solution architect associate exam questions, as certification dumps, google cloud, azure cloud, acloud, learn google cloud, learn azure cloud, cloud comparison, etc.
Abilities Validated by the Certification:
Effectively demonstrate knowledge of how to architect and deploy secure and robust applications on AWS technologies
Define a solution using architectural design principles based on customer requirements
Provide implementation guidance based on best practices to the organization throughout the life cycle of the project
Recommended Knowledge for the Certification:
One year of hands-on experience designing available, cost-effective, fault-tolerant, and scalable distributed systems on AWS.
Hands-on experience using compute, networking, storage, and database AWS services.
Hands-on experience with AWS deployment and management services.
Ability to identify and define technical requirements for an AWS-based application.
bility to identify which AWS services meet a given technical requirement.
Knowledge of recommended best practices for building secure and reliable applications on the AWS platform.
An understanding of the basic architectural principles of building in the AWS Cloud.
An understanding of the AWS global infrastructure.
An understanding of network technologies as they relate to AWS.
An understanding of security features and tools that AWS provides and how they relate to traditional services.
Note and disclaimer: We are not affiliated with AWS or Amazon or Microsoft or Google. The questions are put together based on the certification study guide and materials available online. We also receive questions and answers from anonymous users and we vet to make sure they are legitimate. The questions in this app should help you pass the exam but it is not guaranteed. We are not responsible for any exam you did not pass.
Important: To succeed with the real exam, do not memorize the answers in this app. It is very important that you understand why a question is right or wrong and the concepts behind it by carefully reading the reference documents in the answers.
What is the AWS Certified Solution Architect Associate Exam?
This exam validates an examinee’s ability to effectively demonstrate knowledge of how to architect and deploy secure and robust applications on AWS technologies. It validates an examinee’s ability to:
Define a solution using architectural design principles based on customer requirements.
Multiple-response: Has two correct responses out of five options.
There are two types of questions on the examination:
Multiple-choice: Has one correct response and three incorrect responses (distractors).
Provide implementation guidance based on best practices to the organization throughout the lifecycle of the project.
Select one or more responses that best complete the statement or answer the question. Distractors, or incorrect answers, are response options that an examinee with incomplete knowledge or skill would likely choose. However, they are generally plausible responses that fit in the content area defined by the test objective. Unanswered questions are scored as incorrect; there is no penalty for guessing.
To succeed with the real exam, do not memorize the answers below. It is very important that you understand why a question is right or wrong and the concepts behind it by carefully reading the reference documents in the answers.
Cloud computing is the new big thing in Information Technology. Everyone, every business will sooner or later adopt it, because of hosting cost benefits, scalability and more.
This blog outlines the Pros and Cons of Cloud Computing, Pros and Cons of Cloud Technology, Faqs, Facts, Questions and Answers Dump about cloud computing.
Cloud Practitioner Exam Prep AWS vs Azure vs Google
What is cloud computing?
Cloud computing is an information technology paradigm that enables ubiquitous access to shared pools of configurable system resources and higher-level services that can be rapidly provisioned with minimal management effort, often over the Internet. Cloud computing relies on sharing of resources to achieve coherence and economies of scale, similar to a public utility. Simply put, cloud computing is the delivery of computing services including servers, storage, databases, networking, software, analytics, and intelligence—over the Internet (“the cloud”) to offer faster innovation, flexible resources, and economies of scale. You typically pay only for cloud services you use, helping you lower your operating costs, run your infrastructure more efficiently, and scale as your business needs change.
Stop spending money on running and maintaining data centers
Go global in minutes
Benefits of AWS Cloud Computing
Cost effective & Time saving: Cloud computing eliminates the capital expense of buying hardware and software and setting up and running on-site datacenters; the racks of servers, the round-the-clock electricity for power and cooling, and the IT experts for managing the infrastructure.
The ability to pay only for cloud services you use, helping you lower your operating costs.
Powerful server capabilities and Performance: The biggest cloud computing services run on a worldwide network of secure datacenters, which are regularly upgraded to the latest generation of fast and efficient computing hardware. This offers several benefits over a single corporate datacenter, including reduced network latency for applications and greater economies of scale.
Powerful and scalable server capabilities: The ability to scale elastically; That means delivering the right amount of IT resources—for example, more or less computing power, storage, bandwidth—right when they’re needed, and from the right geographic location.
SaaS ( Software as a service). Software as a service is a method for delivering software applications over the Internet, on demand and typically on a subscription basis. With SaaS, cloud providers host and manage the software application and underlying infrastructure, and handle any maintenance, like software upgrades and security patching. Users connect to the application over the Internet, usually with a web browser on their phone, tablet, or PC.
PaaS ( Platform as a service). Platform as a service refers to cloud computing services that supply an on-demand environment for developing, testing, delivering, and managing software applications. PaaS is designed to make it easier for developers to quickly create web or mobile apps, without worrying about setting up or managing the underlying infrastructure of servers, storage, network, and databases needed for development.
IaaS ( Infrastructure as a service). The most basic category of cloud computing services. With IaaS, you rent IT infrastructure—servers and virtual machines (VMs), storage, networks, operating systems—from a cloud provider on a pay-as-you-go basis
Serverless: Running complex Applications without a single server. Overlapping with PaaS, serverless computing focuses on building app functionality without spending time continually managing the servers and infrastructure required to do so. The cloud provider handles the setup, capacity planning, and server management for you. Serverless architectures are highly scalable and event-driven, only using resources when a specific function or trigger occurs.
Infrastructure provisioning as code, helps recreating same infrastructure by re-running the same code in a few click.
Automatic and Reliable Data backup and storage of data: Cloud computing makes data backup, disaster recovery, and business continuity easier and less expensive because data can be mirrored at multiple redundant sites on the cloud provider’s network.
Increase Productivity: On-site datacenters typically require a lot of “racking and stacking”—hardware setup, software patching, and other time-consuming IT management chores. Cloud computing removes the need for many of these tasks, so IT teams can spend time on achieving more important business goals.
Security: Many cloud providers offer a broad set of policies, technologies, and controls that strengthen your security posture overall, helping protect your data, apps, and infrastructure from potential threats.
Speed: Most cloud computing services are provided self service and on demand, so even vast amounts of computing resources can be provisioned in minutes, typically with just a few mouse clicks, giving businesses a lot of flexibility and taking the pressure off capacity planning. In a cloud computing environment, new IT resources are only a click away. This means that the time those resources are available to your developers is reduced from weeks to minutes. As a result, the organization experiences a dramatic increase in agility because the cost and time it takes to experiment and develop is lower
Go global in minutes Easily deploy your application in multiple regions around the world with just a few clicks. This means that you can provide a lower latency and better experience for your customers simply and at minimal cost.
Privacy: Cloud computing poses privacy concerns because the service provider can access the data that is in the cloud at any time. It could accidentally or deliberately alter or delete information.Many cloud providers can share information with third parties if necessary for purposes of law and order without a warrant. That is permitted in their privacy policies, which users must agree to before they start using cloud services.
Security: According to the Cloud Security Alliance, the top three threats in the cloud are Insecure Interfaces and API’s, Data Loss & Leakage, and Hardware Failure—which accounted for 29%, 25% and 10% of all cloud security outages respectively. Together, these form shared technology vulnerabilities.
Ownership of Data: There is the problem of legal ownership of the data (If a user stores some data in the cloud, can the cloud provider profit from it?). Many Terms of Service agreements are silent on the question of ownership.
Limited Customization Options: Cloud computing is cheaper because of economics of scale, and—like any outsourced task—you tend to get what you get. A restaurant with a limited menu is cheaper than a personal chef who can cook anything you want.
Downtime: Technical outages are inevitable and occur sometimes when cloud service providers (CSPs) become overwhelmed in the process of serving their clients. This may result to temporary business suspension.
Security of stored data and data in transit may be a concern when storing sensitive data at a cloud storage provider[10]
Users with specific records-keeping requirements, such as public agencies that must retain electronic records according to statute, may encounter complications with using cloud computing and storage. For instance, the U.S. Department of Defense designated the Defense Information Systems Agency (DISA) to maintain a list of records management products that meet all of the records retention, personally identifiable information (PII), and security (Information Assurance; IA) requirements
Cloud storage is a rich resource for both hackers and national security agencies. Because the cloud holds data from many different users and organizations, hackers see it as a very valuable target.
Piracy and copyright infringement may be enabled by sites that permit filesharing. For example, the CodexCloud ebook storage site has faced litigation from the owners of the intellectual property uploaded and shared there, as have the GrooveShark and YouTube sites it has been compared to.
Public clouds: A cloud is called a “public cloud” when the services are rendered over a network that is open for public use. They are owned and operated by a third-party cloud service providers, which deliver their computing resources, like servers and storage, over the Internet. Microsoft Azure is an example of a public cloud. With a public cloud, all hardware, software, and other supporting infrastructure is owned and managed by the cloud provider. You access these services and manage your account using a web browser. For infrastructure as a service (IaaS) and platform as a service (PaaS), Amazon Web Services (AWS), Microsoft Azure and Google Cloud Platform (GCP) hold a commanding position among the many cloud companies.
Private cloud is cloud infrastructure operated solely for a single organization, whether managed internally or by a third party, and hosted either internally or externally. A private cloud refers to cloud computing resources used exclusively by a single business or organization. A private cloud can be physically located on the company’s on-site datacenter. Some companies also pay third-party service providers to host their private cloud. A private cloud is one in which the services and infrastructure are maintained on a private network.
Hybrid cloud is a composition of a public cloud and a private environment, such as a private cloud or on-premise resources, that remain distinct entities but are bound together, offering the benefits of multiple deployment models. Hybrid cloud can also mean the ability to connect collocation, managed and/or dedicated services with cloud resources. Hybrid clouds combine public and private clouds, bound together by technology that allows data and applications to be shared between them. By allowing data and applications to move between private and public clouds, a hybrid cloud gives your business greater flexibility, more deployment options, and helps optimize your existing infrastructure, security, and compliance.
Community Cloud: A community cloud in computing is a collaborative effort in which infrastructure is shared between several organizations from a specific community with common concerns, whether managed internally or by a third-party and hosted internally or externally. This is controlled and used by a group of organizations that have shared interest. The costs are spread over fewer users than a public cloud, so only some of the cost savings potential of cloud computing are realized.
Definition 1:Amazon DynamoDB is a fully managed proprietary NoSQL database service that supports key-value and document data structures and is offered by Amazon.com as part of the Amazon Web Services portfolio. DynamoDB exposes a similar data model to and derives its name from Dynamo, but has a different underlying implementation. Dynamo had a multi-master design requiring the client to resolve version conflicts and DynamoDB uses synchronous replication across multiple datacenters for high durability and availability.
Definition 2:DynamoDB is a fast and flexible non-relational database service for any scale. DynamoDB enables customers to offload the administrative burdens of operating and scaling distributed databases to AWS so that they don’t have to worry about hardware provisioning, setup and configuration, throughput capacity planning, replication, software patching, or cluster scaling.
Amazon DynamoDB explained
Fully Managed
Fast, consistent Performance
Fine-grained access control
Flexible
Amazon DynamoDB explained
AWS DynamoDB Facts and Summaries
Amazon DynamoDB is a low-latency NoSQL database.
DynamoDB consists of Tables, Items, and Attributes
DynamoDb supports both document and key-value data models
DynamoDB Supported documents formats are JSON, HTML, XML
DynamoDB has 2 types of Primary Keys: Partition Key and combination of Partition Key + Sort Key (Composite Key)
DynamoDB has 2 consistency models: Strongly Consistent / Eventually Consistent
DynamoDB Access is controlled using IAM policies.
DynamoDB has fine grained access control using IAM Condition parameter dynamodb:LeadingKeys to allow users to access only the items where the partition key vakue matches their user ID.
DynamoDB Indexes enable fast queries on specific data columns
DynamoDB indexes give you a different view of your data based on alternative Partition / Sort Keys.
DynamoDB Local Secondary indexes must be created when you create your table, they have same partition Key as your table, and they have a different Sort Key.
DynamoDB Global Secondary Index Can be created at any time: at table creation or after. They have a different partition Key as your table and a different sort key as your table.
A DynamoDB query operation finds items in a table using only the primary Key attribute: You provide the Primary Key name and a distinct value to search for.
A DynamoDB Scan operation examines every item in the table. By default, it return data attributes.
DynamoDB Query operation is generally more efficient than a Scan.
With DynamoDB, you can reduce the impact of a query or scan by setting a smaller page size which uses fewer read operations.
To optimize DynamoDB performance, isolate scan operations to specific tables and segregate them from your mission-critical traffic.
To optimize DynamoDB performance, try Parallel scans rather than the default sequential scan.
To optimize DynamoDB performance: Avoid using scan operations if you can: design tables in a way that you can use Query, Get, or BatchGetItems APIs.
When you scan your table in Amazon DynamoDB, you should follow the DynamoDB best practices for avoiding sudden bursts of read activity.
DynamoDb Provisioned Throughput is measured in Capacity Units.
1 Write Capacity Unit = 1 x 1KB Write per second.
1 Read Capacity Unit = 1 x 4KB Strongly Consistent Read Or 2 x 4KB Eventually Consistent Reads per second. Eventual consistent reads give us the maximum performance with the read operation.
What is the maximum throughput that can be provisioned for a single DynamoDB table? DynamoDB is designed to scale without limits. However, if you want to exceed throughput rates of 10,000 write capacity units or 10,000 read capacity units for an individual table, you must Contact AWS to increase it. If you want to provision more than 20,000 write capacity units or 20,000 read capacity units from a single subscriber account, you must first contact AWS to request a limit increase.
Dynamo Db Performance: DAX is a DynamoDB-compatible caching service that enables you to benefit from fast in-memory performance for demanding applications.
As an in-memory cache, DAX reduces the response times of eventually-consistent read workloads by an order of magnitude, from single-digit milliseconds to microseconds
DAX improves response times for Eventually Consistent reads only.
With DAX, you point your API calls to the DAX cluster instead of your table.
If the item you are querying is on the cache, DAX will return it; otherwise, it will perform and Eventually Consistent GetItem operation to your DynamoDB table.
DAX reduces operational and application complexity by providing a managed service that is API compatible with Amazon DynamoDB, and thus requires only minimal functional changes to use with an existing application.
DAX is not suitable for write-intensive applications or applications that require Strongly Consistent reads.
For read-heavy or bursty workloads, DAX provides increased throughput and potential operational cost savings by reducing the need to over-provision read capacity units. This is especially beneficial for applications that require repeated reads for individual keys.
Dynamo Db Performance: ElastiCache
In-memory cache sits between your application and database
2 different caching strategies: Lazy loading and Write Through: Lazy loading only caches the data when it is requested
Elasticache Node failures are not fatal, just lots of cache misses
Avoid stale data by implementing a TTL.
Write-Through strategy writes data into cache whenever there is a change to the database. Data is never stale
Write-Through penalty: Each write involves a write to the cache. Elasticache node failure means that data is missing until added or updated in the database.
Elasticache is wasted resources if most of the data is never used.
Time To Live (TTL) for DynamoDB allows you to define when items in a table expire so that they can be automatically deleted from the database. TTL is provided at no extra cost as a way to reduce storage usage and reduce the cost of storing irrelevant data without using provisioned throughput. With TTL enabled on a table, you can set a timestamp for deletion on a per-item basis, allowing you to limit storage usage to only those records that are relevant.
DynamoDB Security: DynamoDB uses the CMK to generate and encrypt a unique data key for the table, known as the table key. With DynamoDB, AWS Owned, or AWS Managed CMK can be used to generate & encrypt keys. AWS Owned CMK is free of charge while AWS Managed CMK is chargeable. Customer managed CMK’s are not supported with encryption at rest.
Amazon DynamoDB offers fully managed encryption at rest. DynamoDB encryption at rest provides enhanced security by encrypting your data at rest using an AWS Key Management Service (AWS KMS) managed encryption key for DynamoDB. This functionality eliminates the operational burden and complexity involved in protecting sensitive data.
DynamoDB is a alternative solution which can be used for storage of session management. The latency of access to data is less , hence this can be used as a data store for session management
DynamoDB Streams Use Cases and Design Patterns: How do you set up a relationship across multiple tables in which, based on the value of an item from one table, you update the item in a second table? How do you trigger an event based on a particular transaction? How do you audit or archive transactions? How do you replicate data across multiple tables (similar to that of materialized views/streams/replication in relational data stores)? As a NoSQL database, DynamoDB is not designed to support transactions. Although client-side libraries are available to mimic the transaction capabilities, they are not scalable and cost-effective. For example, the Java Transaction Library for DynamoDB creates 7N+4 additional writes for every write operation. This is partly because the library holds metadata to manage the transactions to ensure that it’s consistent and can be rolled back before commit.
You can use DynamoDB Streams to address all these use cases. DynamoDB Streams is a powerful service that you can combine with other AWS services to solve many similar problems. When enabled, DynamoDB Streams captures a time-ordered sequence of item-level modifications in a DynamoDB table and durably stores the information for up to 24 hours. Applications can access a series of stream records, which contain an item change, from a DynamoDB stream in near real time.
AWS maintains separate endpoints for DynamoDB and DynamoDB Streams. To work with database tables and indexes, your application must access a DynamoDB endpoint. To read and process DynamoDB Streams records, your application must access a DynamoDB Streams endpoint in the same Region
20 global secondary indexes are allowed per table? (by default)
What is one key difference between a global secondary index and a local secondary index? A local secondary index must have the same partition key as the main table
How many tables can an AWS account have per region? 256
How many secondary indexes (global and local combined) are allowed per table? (by default): 25 You can define up to 5 local secondary indexes and 20 global secondary indexes per table (by default) – for a total of 25.
How can you increase your DynamoDB table limit in a region? By contacting AWS and requesting a limit increase
For any AWS account, there is an initial limit of 256 tables per region.
The minimum length of a partition key value is 1 byte. The maximum length is 2048 bytes.
The minimum length of a sort key value is 1 byte. The maximum length is 1024 bytes.
For tables with local secondary indexes, there is a 10 GB size limit per partition key value. A table with local secondary indexes can store any number of items, as long as the total size for any one partition key value does not exceed 10 GB.
The following diagram shows a local secondary index named LastPostIndex. Note that the partition key is the same as that of the Thread table, but the sort key is LastPostDateTime.
Q0: What should the Developer enable on the DynamoDB table to optimize performance and minimize costs?
A. Amazon DynamoDB auto scaling
B. Amazon DynamoDB cross-region replication
C. Amazon DynamoDB Streams
D. Amazon DynamoDB Accelerator
D. DAX is a DynamoDB-compatible caching service that enables you to benefit from fast in-memory performance for demanding applications. DAX addresses three core scenarios:
As an in-memory cache, DAX reduces the response times of eventually-consistent read workloads by an order of magnitude, from single-digit milliseconds to microseconds.
DAX reduces operational and application complexity by providing a managed service that is API-compatible with Amazon DynamoDB, and thus requires only minimal functional changes to use with an existing application.
For read-heavy or bursty workloads, DAX provides increased throughput and potential operational cost savings by reducing the need to over-provision read capacity units. This is especially beneficial for applications that require repeated reads for individual keys.
Q2: A security system monitors 600 cameras, saving image metadata every 1 minute to an Amazon DynamoDb table. Each sample involves 1kb of data, and the data writes are evenly distributed over time. How much write throughput is required for the target table?
A. 6000
B. 10
C. 3600
D. 600
B. When you mention the write capacity of a table in Dynamo DB, you mention it as the number of 1KB writes per second. So in the above question, since the write is happening every minute, we need to divide the value of 600 by 60, to get the number of KB writes per second. This gives a value of 10.
You can specify the Write capacity in the Capacity tab of the DynamoDB table.
Q3: You are developing an application that will interact with a DynamoDB table. The table is going to take in a lot of read and write operations. Which of the following would be the ideal partition key for the DynamoDB table to ensure ideal performance?
A. CustomerID
B. CustomerName
C. Location
D. Age
Answer- A Use high-cardinality attributes. These are attributes that have distinct values for each item, like e-mailid, employee_no, customerid, sessionid, orderid, and so on.. Use composite attributes. Try to combine more than one attribute to form a unique key. Reference: Choosing the right DynamoDB Partition Key
Q4: A DynamoDB table is set with a Read Throughput capacity of 5 RCU. Which of the following read configuration will provide us the maximum read throughput?
A. Read capacity set to 5 for 4KB reads of data at strong consistency
B. Read capacity set to 5 for 4KB reads of data at eventual consistency
C. Read capacity set to 15 for 1KB reads of data at strong consistency
D. Read capacity set to 5 for 1KB reads of data at eventual consistency
Answer: B. The calculation of throughput capacity for option B would be: Read capacity(5) * Amount of data(4) = 20. Since its required at eventual consistency , we can double the read throughput to 20*2=40
Q5: Your team is developing a solution that will make use of DynamoDB tables. Due to the nature of the application, the data is needed across a couple of regions across the world. Which of the following would help reduce the latency of requests to DynamoDB from different regions?
A. Enable Multi-AZ for the DynamoDB table
B. Enable global tables for DynamoDB
C. Enable Indexes for the table
D. Increase the read and write throughput for the tablez
Answer: B Amazon DynamoDB global tables provide a fully managed solution for deploying a multi-region, multimaster database, without having to build and maintain your own replication solution. When you create a global table, you specify the AWS regions where you want the table to be available. DynamoDB performs all of the necessary tasks to create identical tables in these regions, and propagate ongoing data changes to all of them. Reference: Global Tables
Q6: An application is currently accessing a DynamoDB table. Currently the tables queries are performing well. Changes have been made to the application and now the performance of the application is starting to degrade. After looking at the changes , you see that the queries are making use of an attribute which is not the partition key? Which of the following would be the adequate change to make to resolve the issue?
A. Add an index for the DynamoDB table
B. Change all the queries to ensure they use the partition key
C. Enable global tables for DynamoDB
D. Change the read capacity on the table
Answer: A Amazon DynamoDB provides fast access to items in a table by specifying primary key values. However, many applications might benefit from having one or more secondary (or alternate) keys available, to allow efficient access to data with attributes other than the primary key. To address this, you can create one or more secondary indexes on a table, and issue Query or Scan requests against these indexes.
A secondary index is a data structure that contains a subset of attributes from a table, along with an alternate key to support Query operations. You can retrieve data from the index using a Query, in much the same way as you use Query with a table. A table can have multiple secondary indexes, which gives your applications access to many different query patterns.
Q7: Company B has created an e-commerce site using DynamoDB and is designing a products table that includes items purchased and the users who purchased the item. When creating a primary key on a table which of the following would be the best attribute for the partition key? Select the BEST possible answer.
A. None of these are correct.
B. user_id where there are many users to few products
C. category_id where there are few categories to many products
D. product_id where there are few products to many users
Answer: B. When designing tables it is important for the data to be distributed evenly across the entire table. It is best practice for performance to set your primary key where there are many primary keys to few rows. An example would be many users to few products. An example of bad design would be a primary key of product_id where there are few products but many users. When designing tables it is important for the data to be distributed evenly across the entire table. It is best practice for performance to set your primary key where there are many primary keys to few rows. An example would be many users to few products. An example of bad design would be a primary key of product_id where there are few products but many users. Reference: Partition Keys and Sort Keys
The BatchGetItem operation returns the attributes of one or more items from one or more tables. You identify requested items by primary key.
A single operation can retrieve up to 16 MB of data, which can contain as many as 100 items. BatchGetItem will return a partial result if the response size limit is exceeded, the table’s provisioned throughput is exceeded, or an internal processing failure occurs. If a partial result is returned, the operation returns a value for UnprocessedKeys. You can use this value to retry the operation starting with the next item to get.Reference: API-Specific Limits
Q9: Which DynamoDB limits can be raised by contacting AWS support?
A. The number of hash keys per account
B. The maximum storage used per account
C. The number of tables per account
D. The number of local secondary indexes per account
E. The number of provisioned throughput units per account
Answer: C. and E.
For any AWS account, there is an initial limit of 256 tables per region. AWS places some default limits on the throughput you can provision. These are the limits unless you request a higher amount. To request a service limit increase see https://aws.amazon.com/support.
Q10: Which approach below provides the least impact to provisioned throughput on the “Product” table?
A. Create an “Images” DynamoDB table to store the Image with a foreign key constraint to the “Product” table
B. Add an image data type to the “Product” table to store the images in binary format
C. Serialize the image and store it in multiple DynamoDB tables
D. Store the images in Amazon S3 and add an S3 URL pointer to the “Product” table item for each image
Answer: D.
Amazon DynamoDB currently limits the size of each item that you store in a table (see Limits in DynamoDB). If your application needs to store more data in an item than the DynamoDB size limit permits, you can try compressing one or more large attributes, or you can store them as an object in Amazon Simple Storage Service (Amazon S3) and store the Amazon S3 object identifier in your DynamoDB item. Compressing large attribute values can let them fit within item limits in DynamoDB and reduce your storage costs. Compression algorithms such as GZIP or LZO produce binary output that you can then store in a Binary attribute type. Reference: Best Practices for Storing Large Items and Attributes
Q11: You’re creating a forum DynamoDB database for hosting forums. Your “thread” table contains the forum name and each “forum name” can have one or more “subjects”. What primary key type would you give the thread table in order to allow more than one subject to be tied to the forum primary key name?
A. Hash
B. Range and Hash
C. Primary and Range
D. Hash and Range
Answer: D. Each forum name can have one or more subjects. In this case, ForumName is the hash attribute and Subject is the range attribute.
Definition 1: Amazon S3 or Amazon Simple Storage Service is a “simple storage service” offered by Amazon Web Services that provides object storage through a web service interface. Amazon S3 uses the same scalable storage infrastructure that Amazon.com uses to run its global e-commerce network.
Definition 2: Amazon Simple Storage Service (Amazon S3) is an object storage service that offers industry-leading scalability, data availability, security, and performance.
S3 is a universal namespace, meaning each S3 bucket you create must have a unique name that is not being used by anyone else in the world.
S3 is object based: i.e allows you to upload files.
Files can be from 0 Bytes to 5 TB
What is the maximum length, in bytes, of a DynamoDB range primary key attribute value? The maximum length of a DynamoDB range primary key attribute value is 2048 bytes (NOT 256 bytes).
S3 has unlimited storage.
Files are stored in Buckets.
Read after write consistency for PUTS of new Objects
Eventual Consistency for overwrite PUTS and DELETES (can take some time to propagate)
S3 Standard (durable, immediately available, frequently accesses)
Amazon S3 Intelligent-Tiering (S3 Intelligent-Tiering): It works by storing objects in two access tiers: one tier that is optimized for frequent access and another lower-cost tier that is optimized for infrequent access.
S3 – One Zone-Infrequent Access – S3 One Zone IA: Same ad IA. However, data is stored in a single Availability Zone only
S3 – Reduced Redundancy Storage (data that is easily reproducible, such as thumbnails, etc.)
Glacier – Archived data, where you can wait 3-5 hours before accessing
You can have a bucket that has different objects stored in S3 Standard, S3 Intelligent-Tiering, S3 Standard-IA, and S3 One Zone-IA.
The default URL for S3 hosted websites lists the bucket name first followed by s3-website-region.amazonaws.com . Example: enoumen.com.s3-website-us-east-1.amazonaws.com
Core fundamentals of an S3 object
Key (name)
Value (data)
Version (ID)
Metadata
Sub-resources (used to manage bucket-specific configuration)
Bucket Policies, ACLs,
CORS
Transfer Acceleration
Object-based storage only for files
Not suitable to install OS on.
Successful uploads will generate a HTTP 200 status code.
S3 Security – Summary
By default, all newly created buckets are PRIVATE.
You can set up access control to your buckets using:
Bucket Policies – Applied at the bucket level
Access Control Lists – Applied at an object level.
S3 buckets can be configured to create access logs, which log all requests made to the S3 bucket. These logs can be written to another bucket.
S3 Encryption
Encryption In-Transit (SSL/TLS)
Encryption At Rest:
Server side Encryption (SSE-S3, SSE-KMS, SSE-C)
Client Side Encryption
Remember that we can use a Bucket policy to prevent unencrypted files from being uploaded by creating a policy which only allows requests which include the x-amz-server-side-encryption parameter in the request header.
S3 CORS (Cross Origin Resource Sharing): CORS defines a way for client web applications that are loaded in one domain to interact with resources in a different domain.
Used to enable cross origin access for your AWS resources, e.g. S3 hosted website accessing javascript or image files located in another bucket. By default, resources in one bucket cannot access resources located in another. To allow this we need to configure CORS on the bucket being accessed and enable access for the origin (bucket) attempting to access.
Always use the S3 website URL, not the regular bucket URL. E.g.: https://s3-eu-west-2.amazonaws.com/acloudguru
S3 CloudFront:
Edge locations are not just READ only – you can WRITE to them too (i.e put an object on to them.)
Objects are cached for the life of the TTL (Time to Live)
You can clear cached objects, but you will be charged. (Invalidation)
S3 Performance optimization – 2 main approaches to Performance Optimization for S3:
GET-Intensive Workloads – Use Cloudfront
Mixed Workload – Avoid sequencial key names for your S3 objects. Instead, add a random prefix like a hex hash to the key name to prevent multiple objects from being stored on the same partition.
The best way to handle large objects uploads to the S3 service is to use the Multipart upload API. The Multipart upload API enables you to upload large objects in parts.
You can enable versioning on a bucket, even if that bucket already has objects in it. The already existing objects, though, will show their versions as null. All new objects will have version IDs.
Bucket names cannot start with a . or – characters. S3 bucket names can contain both the . and – characters. There can only be one . or one – between labels. E.G mybucket-com mybucket.com are valid names but mybucket–com and mybucket..com are not valid bucket names.
What is the maximum number of S3 buckets allowed per AWS account (by default)? 100
You successfully upload an item to the us-east-1 region. You then immediately make another API call and attempt to read the object. What will happen? All AWS regions now have read-after-write consistency for PUT operations of new objects. Read-after-write consistency allows you to retrieve objects immediately after creation in Amazon S3. Other actions still follow the eventual consistency model (where you will sometimes get stale results if you have recently made changes)
S3 bucket policies require a Principal be defined. Review the access policy elements here
What checksums does Amazon S3 employ to detect data corruption? Amazon S3 uses a combination of Content-MD5 checksums and cyclic redundancy checks (CRCs) to detect data corruption. Amazon S3 performs these checksums on data at rest and repairs any corruption using redundant data. In addition, the service calculates checksums on all network traffic to detect corruption of data packets when storing or retrieving data.
Q0: You’ve written an application that uploads objects onto an S3 bucket. The size of the object varies between 200 – 500 MB. You’ve seen that the application sometimes takes a longer than expected time to upload the object. You want to improve the performance of the application. Which of the following would you consider?
A. Create multiple threads and upload the objects in the multiple threads
B. Write the items in batches for better performance
C. Use the Multipart upload API
D. Enable versioning on the Bucket
C. All other options are invalid since the best way to handle large object uploads to the S3 service is to use the Multipart upload API. The Multipart upload API enables you to upload large objects in parts. You can use this API to upload new large objects or make a copy of an existing object. Multipart uploading is a three-step process: You initiate the upload, you upload the object parts, and after you have uploaded all the parts, you complete the multipart upload. Upon receiving the complete multipart upload request, Amazon S3 constructs the object from the uploaded parts, and you can then access the object just as you would any other object in your bucket.
Q2: You are using AWS SAM templates to deploy a serverless application. Which of the following resource will embed application from Amazon S3 buckets?
A. AWS::Serverless::Api
B. AWS::Serverless::Application
C. AWS::Serverless::Layerversion
D. AWS::Serverless::Function
Answer – B AWS::Serverless::Application resource in AWS SAm template is used to embed application frm Amazon S3 buckets. Reference: Declaring Serverless Resources
Q3: A static web site has been hosted on a bucket and is now being accessed by users. One of the web pages javascript section has been changed to access data which is hosted in another S3 bucket. Now that same web page is no longer loading in the browser. Which of the following can help alleviate the error?
A. Enable versioning for the underlying S3 bucket.
B. Enable Replication so that the objects get replicated to the other bucket
C. Enable CORS for the bucket
D. Change the Bucket policy for the bucket to allow access from the other bucket
Answer – C
Cross-origin resource sharing (CORS) defines a way for client web applications that are loaded in one domain to interact with resources in a different domain. With CORS support, you can build rich client-side web applications with Amazon S3 and selectively allow cross-origin access to your Amazon S3 resources.
Cross-Origin Resource Sharing: Use-case Scenarios The following are example scenarios for using CORS:
Scenario 1: Suppose that you are hosting a website in an Amazon S3 bucket named website as described in Hosting a Static Website on Amazon S3. Your users load the website endpoint http://website.s3-website-us-east-1.amazonaws.com. Now you want to use JavaScript on the webpages that are stored in this bucket to be able to make authenticated GET and PUT requests against the same bucket by using the Amazon S3 API endpoint for the bucket, website.s3.amazonaws.com. A browser would normally block JavaScript from allowing those requests, but with CORS you can congure your bucket to explicitly enable cross-origin requests from website.s3-website-us-east-1.amazonaws.com.
Scenario 2: Suppose that you want to host a web font from your S3 bucket. Again, browsers require a CORS check (also called a preight check) for loading web fonts. You would congure the bucket that is hosting the web font to allow any origin to make these requests.
Q4: Your mobile application includes a photo-sharing service that is expecting tens of thousands of users at launch. You will leverage Amazon Simple Storage Service (S3) for storage of the user Images, and you must decide how to authenticate and authorize your users for access to these images. You also need to manage the storage of these images. Which two of the following approaches should you use? Choose two answers from the options below
A. Create an Amazon S3 bucket per user, and use your application to generate the S3 URL for the appropriate content.
B. Use AWS Identity and Access Management (IAM) user accounts as your application-level user database, and offload the burden of authentication from your application code.
C. Authenticate your users at the application level, and use AWS Security Token Service (STS)to grant token-based authorization to S3 objects.
D. Authenticate your users at the application level, and send an SMS token message to the user. Create an Amazon S3 bucket with the same name as the SMS message token, and move the user’s objects to that bucket.
Answer- C The AWS Security Token Service (STS) is a web service that enables you to request temporary, limited-privilege credentials for AWS Identity and Access Management (IAM) users or for users that you authenticate (federated users). The token can then be used to grant access to the objects in S3. You can then provides access to the objects based on the key values generated via the user id.
Q5: Both ACLs and Bucket Policies can be used to grant access to S3 buckets. Which of the following statements is true about ACLs and Bucket policies?
A. Bucket Policies are Written in JSON and ACLs are written in XML
B. ACLs can be attached to S3 objects or S3 Buckets
C. Bucket Policies and ACLs are written in JSON
D. Bucket policies are only attached to s3 buckets, ACLs are only attached to s3 objects
Answer: A. and B. Only Bucket Policies are written in JSON, ACLs are written in XML. While Bucket policies are indeed only attached to S3 buckets, ACLs can be attached to S3 Buckets OR S3 Objects. Reference:
Q6: What are good options to improve S3 performance when you have significantly high numbers of GET requests?
A. Introduce random prefixes to S3 objects
B. Introduce random suffixes to S3 objects
C. Setup CloudFront for S3 objects
D. Migrate commonly used objects to Amazon Glacier
Answer: C CloudFront caching is an excellent way to avoid putting extra strain on the S3 service and to improve the response times of reqeusts by caching data closer to users at CloudFront locations. S3 Transfer Acceleration optimizes the TCP protocol and adds additional intelligence between the client and the S3 bucket, making S3 Transfer Acceleration a better choice if a higher throughput is desired. If you have objects that are smaller than 1GB or if the data set is less than 1GB in size, you should consider using Amazon CloudFront’s PUT/POST commands for optimal performance. Reference: Amazon S3 Transfer Acceleration
Q7: If an application is storing hourly log files from thousands of instances from a high traffic web site, which naming scheme would give optimal performance on S3?
A. Sequential
B. HH-DD-MM-YYYY-log_instanceID
C. YYYY-MM-DD-HH-log_instanceID
D. instanceID_log-HH-DD-MM-YYYY
E. instanceID_log-YYYY-MM-DD-HH
Answer: A. B. C. D. and E. Amazon S3 now provides increased performance to support at least 3,500 requests per second to add data and 5,500 requests per second to retrieve data, which can save significant processing time for no additional charge. Each S3 prefix can support these request rates, making it simple to increase performance significantly. This S3 request rate performance increase removes any previous guidance to randomize object prefixes to achieve faster performance. That means you can now use logical or sequential naming patterns in S3 object naming without any performance implications.
Q9: You created three S3 buckets – “mywebsite.com”, “downloads.mywebsite.com”, and “www.mywebsite.com”. You uploaded your files and enabled static website hosting. You specified both of the default documents under the “enable static website hosting” header. You also set the “Make Public” permission for the objects in each of the three buckets. You create the Route 53 Aliases for the three buckets. You are going to have your end users test your websites by browsing to http://mydomain.com/error.html, http://downloads.mydomain.com/index.html, and http://www.mydomain.com. What problems will your testers encounter?
A. http://mydomain.com/error.html will not work because you did not set a value for the error.html file
B. There will be no problems, all three sites should work.
C. http://www.mywebsite.com will not work because the URL does not include a file name at the end of it.
D. http://downloads.mywebsite.com/index.html will not work because the “downloads” prefix is not a supported prefix for S3 websites using Route 53 aliases
Answer: B. It used to be that the only allowed domain prefix when creating Route 53 Aliases for S3 static websites was the “www” prefix. However, this is no longer the case. You can now use other subdomain.
The AWS Certified Cloud Practitioner Exam (CLF-C02) is an introduction to AWS services and the intention is to examine the candidates ability to define what the AWS cloud is and its global infrastructure. It provides an overview of AWS core services security aspects, pricing and support services. The main objective is to provide an overall understanding about the Amazon Web Services Cloud platform. The course helps you get the conceptual understanding of the AWS and can help you know about the basics of AWS and cloud computing, including the services, cases and benefits [Get AWS CCP Practice Exam PDF Dumps here]
Prepare and Ace the AWS Cloud Practitioner Certification CCP CLF-C02: Practice Exam, Quizzes for each Exam Category, Detailed Answers, FAQs, I Passed AWS CCP Testimonials, Top 10 Tips and Tricks to help you ace the AWS CCP exam
To succeed with the real exam, do not memorize the answers below. It is very important that you understand why a question is right or wrong and the concepts behind it by carefully reading the reference documents in the answers.
aws cloud practitioner practice questions and answers
aws cloud practitioner practice exam questions and references
Q1:For auditing purposes, your company now wants to monitor all API activity for all regions in your AWS environment. What can you use to fulfill this new requirement?
A. For each region, enable CloudTrail and send all logs to a bucket in each region.
B. Enable CloudTrail for all regions.
C. Ensure one CloudTrail is enabled for all regions.
D. Use AWS Config to enable the trail for all regions.
Ensure one CloudTrail is enabled for all regions. Turn on CloudTrail for all regions in your environment and CloudTrail will deliver log files from all regions to one S3 bucket. AWS CloudTrail is a service that enables governance, compliance, operational auditing, and risk auditing of your AWS account. With CloudTrail, you can log, continuously monitor, and retain account activity related to actions across your AWS infrastructure. CloudTrail provides event history of your AWS account activity, including actions taken through the AWS Management Console, AWS SDKs, command line tools, and other AWS services. This event history simplifies security analysis, resource change tracking, and troubleshooting.
Use a VPC Endpoint to access S3. A VPC endpoint enables you to privately connect your VPC to supported AWS services and VPC endpoint services powered by PrivateLink without requiring an internet gateway, NAT device, VPN connection, or AWS Direct Connect connection. Instances in your VPC do not require public IP addresses to communicate with resources in the service. Traffic between your VPC and the other service does not leave the Amazon network.
AWS PrivateLink simplifies the security of data shared with cloud-based applications by eliminating the exposure of data to the public Internet.
[Get AWS CCP Practice Exam PDF Dumps here] It is AWS responsibility to secure Edge locations and decommission the data. AWS responsibility “Security of the Cloud” – AWS is responsible for protecting the infrastructure that runs all of the services offered in the AWS Cloud. This infrastructure is composed of the hardware, software, networking, and facilities that run AWS Cloud services.
Q4:You have EC2 instances running at 90% utilization and you expect this to continue for at least a year. What type of EC2 instance would you choose to ensure your cost stay at a minimum?
[Get AWS CCP Practice Exam PDF Dumps here] Reserved instances are the best choice for instances with continuous usage and offer a reduced cost because you purchase the instance for the entire year. Amazon EC2 Reserved Instances (RI) provide a significant discount (up to 75%) compared to On-Demand pricing and provide a capacity reservation when used in a specific Availability Zone.
The AWS Simple Monthly Calculator helps customers and prospects estimate their monthly AWS bill more efficiently. Using this tool, they can add, modify and remove services from their ‘bill’ and it will recalculate their estimated monthly charges automatically.
A. Sign up for the free alert under filing preferences in the AWS Management Console.
B. Set a schedule to regularly review the Billing an Cost Management dashboard each month.
C. Create an email alert in AWS Budget
D. In CloudWatch, create an alarm that triggers each time the limit is exceeded.
Answer:
Answer: iOS – Android (C) [Get AWS CCP Practice Exam PDF Dumps here] AWS Budgets gives you the ability to set custom budgets that alert you when your costs or usage exceed (or are forecasted to exceed) your budgeted amount. You can also use AWS Budgets to set reservation utilization or coverage targets and receive alerts when your utilization drops below the threshold you define. Reservation alerts are supported for Amazon EC2, Amazon RDS, Amazon Redshift, Amazon ElastiCache, and Amazon Elasticsearch reservations.
Q7:An Edge Location is a specialization AWS data centre that works with which services?
A. Lambda
B. CloudWatch
C. CloudFront
D. Route 53
Answer:
Answer: Get AWS Certified Cloud Practitioner Practice Exam CCP CLF-C02 eBook Print Book here Lambda@Edge lets you run Lambda functions to customize the content that CloudFront delivers, executing the functions in AWS locations closer to the viewer. Amazon CloudFront is a web service that speeds up distribution of your static and dynamic web content, such as .html, .css, .js, and image files, to your users. CloudFront delivers your content through a worldwide network of data centers called edge locations. When a user requests content that you’re serving with CloudFront, the user is routed to the edge location that provides the lowest latency (time delay), so that content is delivered with the best possible performance.
CloudFront speeds up the distribution of your content by routing each user request through the AWS backbone network to the edge location that can best serve your content. Typically, this is a CloudFront edge server that provides the fastest delivery to the viewer. Using the AWS network dramatically reduces the number of networks that your users’ requests must pass through, which improves performance. Users get lower latency—the time it takes to load the first byte of the file—and higher data transfer rates.
You also get increased reliability and availability because copies of your files (also known as objects) are now held (or cached) in multiple edge locations around the world.
Anser: A. Route 53 is a domain name system service by AWS. When a Disaster does occur , it can be easy to switch to secondary sites using the Route53 service. Amazon Route 53 is a highly available and scalable cloud Domain Name System (DNS) web service. It is designed to give developers and businesses an extremely reliable and cost effective way to route end users to Internet applications by translating names like www.example.com into the numeric IP addresses like 192.0.2.1 that computers use to connect to each other. Amazon Route 53 is fully compliant with IPv6 as well.
Answer: D. The below snapshot from the AWS Documentation shows the spectrum of the Disaster recovery methods. If you go to the further end of the spectrum you have the least time for downtime for the users.
Q11:Your company is planning to host resources in the AWS Cloud. They want to use services which can be used to decouple resources hosted on the cloud. Which of the following services can help fulfil this requirement?
A. AWS EBS Volumes
B. AWS EBS Snapshots
C. AWS Glacier
D. AWS SQS
Answer:
D. AWS SQS: Amazon Simple Queue Service (Amazon SQS) offers a reliable, highly-scalable hosted queue for storing messages as they travel between applications or microservices. It moves data between distributed application components and helps you decouple these components.
A. 99.999999999% Durability and 99.99% Availability S3 Standard Storage class has a rating of 99.999999999% durability (referred to as 11 nines) and 99.99% availability.
A. Redshift is a database offering that is fully-managed and used for data warehousing and analytics, including compatibility with existing business intelligence tools.
B. and C. CENTRALLY MANAGE POLICIES ACROSS MULTIPLE AWS ACCOUNTS AUTOMATE AWS ACCOUNT CREATION AND MANAGEMENT CONTROL ACCESS TO AWS SERVICES CONSOLIDATE BILLING ACROSS MULTIPLE AWS ACCOUNTS
Q17:There is a requirement hosting a set of servers in the Cloud for a short period of 3 months. Which of the following types of instances should be chosen to be cost effective.
A. Spot Instances
B. On-Demand
C. No Upfront costs Reserved
D. Partial Upfront costs Reserved
Answer:
B. Since the requirement is just for 3 months, then the best cost effective option is to use On-Demand Instances.
You can use Amazon CloudWatch Logs to monitor, store, and access your log files from Amazon Elastic Compute Cloud (Amazon EC2) instances, AWS CloudTrail, and other sources. You can then retrieve the associated log data from CloudWatch Log.
Q22:A company is deploying a new two-tier web application in AWS. The company wants to store their most frequently used data so that the response time for the application is improved. Which AWS service provides the solution for the company’s requirements?
A. MySQL Installed on two Amazon EC2 Instances in a single Availability Zone
Amazon ElastiCache is a web service that makes it easy to deploy, operate, and scale an in-memory data store or cache in the cloud. The service improves the performance of web applications by allowing you to retrieve information from fast, managed, in-memory data stores, instead of relying entirely on slower disk-based databases.
Q23:You have a distributed application that periodically processes large volumes of data across multiple Amazon EC2 Instances. The application is designed to recover gracefully from Amazon EC2 instance failures. You are required to accomplish this task in the most cost-effective way. Which of the following will meetyour requirements?
When you think of cost effectiveness, you can either have to choose Spot or Reserved instances. Now when you have a regular processing job, the best is to use spot instances and since your application is designed recover gracefully from Amazon EC2 instance failures, then even if you lose the Spot instance , there is no issue because your application can recover.
A network access control list (ACL) is an optional layer of security for your VPC that acts as a firewall for controlling traffic in and out of one or more subnets. You might set up network ACLs with rules similar to your security groups in order to add an additional layer of security to your VPC.
Q25:A company is deploying a two-tier, highly available web application to AWS. Which service provides durable storage for static content while utilizing Overall CPU resources for the web tier?
A. Amazon EBC volume.
B. Amazon S3
C. Amazon EC2 instance store
D. Amazon RDS instance
Answer:
B. Amazon S3 is the default storage service that should be considered for companies. It provides durable storage for all static content.
Q26:When working on the costing for on-demand EC2 instances , which are the following are attributes which determine the costing of the EC2 Instance. Choose 3 answers from the options given below
Q27:You have a mission-critical application which must be globally available at all times. If this is the case, which of the below deployment mechanisms would you employ
Always build components which are loosely coupled. This is so that even if one component does fail, the entire system does not fail. Also if you build with the assumption that everything will fail, then you will ensure that the right measures are taken to build a highly available and fault tolerant system.
Q29: You have 2 accounts in your AWS account. One for the Dev and the other for QA. All are part ofconsolidated billing. The master account has purchase 3 reserved instances. The Dev department is currently using 2 reserved instances. The QA team is planning on using 3 instances which of the same instance type. What is the pricing tier of the instances that can be used by the QA Team?
Since all are a part of consolidating billing, the pricing of reserved instances can be shared by All. And since 2 are already used by the Dev team , another one can be used by the QA team. The rest of the instances can be on-demand instances.
Amazon Simple Queue Service (Amazon SQS) offers a reliable, highly-scalable hosted queue for storing messages as they travel between applications or microservices. It moves data between distributed application components and helps you decouple these components.
Q32:You are exploring what services AWS has off-hand. You have a large number of data sets that need to be processed. Which of the following services can help fulfil this requirement.
A. EMR
B. S3
C. Glacier
D. Storage Gateway
Answer:
A. Amazon EMR helps you analyze and process vast amounts of data by distributing the computational work across a cluster of virtual servers running in the AWS Cloud. The cluster is managed using an open-source framework called Hadoop. Amazon EMR lets you focus on crunching or analyzing your data without having to worry about time-consuming setup, management, and tuning of Hadoop clusters or the compute capacity they rely on.
Amazon Inspector enables you to analyze the behaviour of your AWS resources and helps you to identify potential security issues. Using Amazon Inspector, you can define a collection of AWS resources that you want to include in an assessment target. You can then create an assessment template and launch a security assessment run of this target.
Q34:Your company is planning to offload some of the batch processing workloads on to AWS. These jobs can be interrupted and resumed at any time. Which of the following instance types would be the most cost effective to use for this purpose.
A. On-Demand
B. Spot
C. Full Upfront Reserved
D. Partial Upfront Reserved
Answer:
B. Spot Instances are a cost-effective choice if you can be flexible about when your applications run and if your applications can be interrupted. For example, Spot Instances are well-suited for data analysis, batch jobs, background processing, and optional tasks
Note that the AWS Console cannot be used to upload data onto Glacier. The console can only be used to create a Glacier vault which can be used to upload the data.
Snowball is a petabyte-scale data transport solution that uses secure appliances to transfer large amounts of data& into and out of the AWS cloud. Using Snowball addresses common challenges with large-scale data transfers including high network costs, long transfer times, and security concerns. Transferring data with Snowball is simple, fast, secure, and can be as little as one-fifth the cost of high-speed Internet.
Amazon Inspector enables you to analyze the behavior of your AWS resources and helps you to identify potential security issues. Using Amazon Inspector, you can define a collection of AWS resources that you want to include in an assessment target. You can then create an assessment template and launch a security assessment run of this target.
AWS Database Migration Service helps you migrate databases to AWS quickly and securely. The source database remains fully operational during the migration, minimizing downtime to applications that rely on the database. The AWS Database Migration Service can migrate your data to and from most widely used commercial and open source databases.
You can reduce the load on your source DB Instance by routing read queries from your applications to the read replica. Read replicas allow you to elastically scale out beyond the capacity constraints of a single DB instance for read-heavy database workloads.
When you create an EBS volume in an Availability Zone, it is automatically replicated within that zone to prevent data loss due to failure of any single hardware component
Q42:Your company is planning to host a large e-commerce application on the AWS Cloud. One of their major concerns is Internet attacks such as DDos attacks.
Which of the following services can help mitigate this concern. Choose 2 answers from the options given below
One of the first techniques to mitigate DDoS attacks is to minimize the surface area that can be attacked thereby limiting the options for attackers and allowing you to build protections in a single place. We want to ensure that we do not expose our application or resources to ports, protocols or applications from where they do not expect any communication. Thus, minimizing the possible points of attack and letting us concentrate our mitigation efforts. In some cases, you can do this by placing your computation resources behind Content Distribution Networks (CDNs), Load Balancers and restricting direct Internet traffic to certain parts of your infrastructure like your database servers. In other cases, you can use firewalls or Access Control Lists (ACLs) to control what traffic reaches your applications.
You can use the consolidated billing feature in AWS Organizations to consolidate payment for multiple AWS accounts or multiple AISPL accounts. With consolidated billing, you can see a combined view of AWS charges incurred by all of your accounts. You also can get a cost report for each member account that is associated with your master account. Consolidated billing is offered at no additional charge.
One of the first techniques to mitigate DDoS attacks is to minimize the surface area that can be attacked thereby limiting the options for attackers and allowing you to build protections in a single place. We want to ensure that we do not expose our application or resources to ports, protocols or applications from where they do not expect any communication. Thus, minimizing the possible points of attack and letting us concentrate our mitigation efforts. In some cases, you can do this by placing your computation resources behind; Content Distribution Networks (CDNs), Load Balancers and restricting direct Internet traffic to certain parts of your infrastructure like your database servers. In other cases, you can use firewalls or Access Control Lists (ACLs) to control what traffic reaches your applications.
If you want a self-managed database, that means you want complete control over the database engine and the underlying infrastructure. In such a case you need to host the database on an EC2 Instance
If the database is going to be used for a minimum of one year at least , then it is better to get Reserved Instances. You can save on costs , and if you use a partial upfront options , you can get a better discount
The AWS Console cannot be used to upload data onto Glacier. The console can only be used to create a Glacier vault which can be used to upload the data.
Security groups acts as a virtual firewall for your instance to control inbound and outbound traffic. Network access control list (ACL) is an optional layer of security for your VPC that acts as a firewall for controlling traffic in and out of one or more subnets.
Q52:You plan to deploy an application on AWS. This application needs to be PCI Compliant. Which of the below steps are needed to ensure the compliance? Choose 2 answers from the below list:
A. Choose AWS services which are PCI Compliant
B. Ensure the right steps are taken during application development for PCI Compliance
C. Encure the AWS Services are made PCI Compliant
D. Do an audit after the deployment of the application for PCI Compliance.
Q57:Which of the following is a factor when calculating Total Cost of Ownership (TCO) for the AWS Cloud?
A. The number of servers migrated to AWS
B. The number of users migrated to AWS
C. The number of passwords migrated to AWS
D. The number of keys migrated to AWS
Answer:
A. Running servers will incur costs. The number of running servers is one factor of Server Costs; a key component of AWS’s Total Cost of Ownership (TCO). Reference: AWS cost calculator
Q58:Which AWS Services can be used to store files? Choose 2 answers from the options given below:
A. Amazon CloudWatch
B. Amazon Simple Storage Service (Amazon S3)
C. Amazon Elastic Block Store (Amazon EBS)
D. AWS COnfig
D. AWS Amazon Athena
B. and C. Amazon S3 is a Object storage built to store and retrieve any amount of data from anywhere. Amazon Elastic Block Store is a Persistent block storage for Amazon EC2.
C: AWS is defined as a cloud services provider. They provide hundreds of services of which compute and storage are included (not not limited to). Reference: AWS
Q60: Which AWS service can be used as a global content delivery network (CDN) service?
A. Amazon SES
B. Amazon CouldTrail
C. Amazon CloudFront
D. Amazon S3
Answer:
C: Amazon CloudFront is a web service that gives businesses and web application developers an easy and cost effective way to distribute content with low latency and high data transfer speeds. Like other AWS services, Amazon CloudFront is a self-service, pay-per-use offering, requiring no long term commitments or minimum fees. With CloudFront, your files are delivered to end-users using a global network of edge locations.Reference: AWS cloudfront
Q61:What best describes the concept of fault tolerance?
Choose the correct answer:
A. The ability for a system to withstand a certain amount of failure and still remain functional.
B. The ability for a system to grow in size, capacity, and/or scope.
C. The ability for a system to be accessible when you attempt to access it.
D. The ability for a system to grow and shrink based on demand.
Answer:
A: Fault tolerance describes the concept of a system (in our case a web application) to have failure in some of its components and still remain accessible (highly available). Fault tolerant web applications will have at least two web servers (in case one fails).
Q62: The firm you work for is considering migrating to AWS. They are concerned about cost and the initial investment needed. Which of the following features of AWS pricing helps lower the initial investment amount needed?
Choose 2 answers from the options given below:
A. The ability to choose the lowest cost vendor.
B. The ability to pay as you go
C. No upfront costs
D. Discounts for upfront payments
Answer:
B and C: The best features of moving to the AWS Cloud is: No upfront cost and The ability to pay as you go where the customer only pays for the resources needed. Reference: AWS pricing
Q64: Your company has started using AWS. Your IT Security team is concerned with the security of hosting resources in the Cloud. Which AWS service provides security optimization recommendations that could help the IT Security team secure resources using AWS?
An online resource to help you reduce cost, increase performance, and improve security by optimizing your AWS environment, Trusted Advisor provides real time guidance to help you provision your resources following AWS best practices. Reference: AWS trusted advisor
Q65:What is the relationship between AWS global infrastructure and the concept of high availability?
Choose the correct answer:
A. AWS is centrally located in one location and is subject to widespread outages if something happens at that one location.
B. AWS regions and Availability Zones allow for redundant architecture to be placed in isolated parts of the world.
C. Each AWS region handles a different AWS services, and you must use all regions to fully use AWS.
As an AWS user, you can create your applications infrastructure and duplicate it. By placing duplicate infrastructure in multiple regions, high availability is created because if one region fails you have a backup (in a another region) to use.
Q66: You are hosting a number of EC2 Instances on AWS. You are looking to monitor CPU Utilization on the Instance. Which service would you use to collect and track performance metrics for AWS services?
Answer: iOS – Android C: Amazon CloudWatch is a monitoring service for AWS cloud resources and the applications you run on AWS. You can use Amazon CloudWatch to collect and track metrics, collect and monitor log files, set alarms, and automatically react to changes in your AWS resources. Reference: AWS cloudwatch
Q67: Which of the following support plans give access to all the checks in the Trusted Advisor service.
Q68: Which of the following in AWS maps to a separate geographic location?
A. AWS Region B. AWS Data Centers C. AWS Availability Zone
Answer:
Answer: iOS – Android A: Amazon cloud computing resources are hosted in multiple locations world-wide. These locations are composed of AWS Regions and Availability Zones. Each AWS Region is a separate geographic area. Reference: AWS Regions And Availability Zone
Q69:What best describes the concept of scalability?
Choose the correct answer:
A. The ability for a system to grow and shrink based on demand.
B. The ability for a system to grow in size, capacity, and/or scope.
C. The ability for a system be be accessible when you attempt to access it.
D. The ability for a system to withstand a certain amount of failure and still remain functional.
Answer
Answer: iOS – Android B: Scalability refers to the concept of a system being able to easily (and cost-effectively) scale UP. For web applications, this means the ability to easily add server capacity when demand requires.
Q70: If you wanted to monitor all events in your AWS account, which of the below services would you use?
A. AWS CloudWatch
B. AWS CloudWatch logs
C. AWS Config
D. AWS CloudTrail
Answer:
D: AWS CloudTrail is a service that enables governance, compliance, operational auditing, and risk auditing of your AWS account. With CloudTrail, you can log, continuously monitor, and retain account activity related to actions across your AWS infrastructure. CloudTrail provides event history of your AWS account activity, including actions taken through the AWS Management Console, AWS SDKs, command line tools, and other AWS services. This event history simplifies security analysis, resource change tracking, and troubleshooting. Reference: Cloudtrail
Q71:What are the four primary benefits of using the cloud/AWS?
Choose the correct answer:
A. Fault tolerance, scalability, elasticity, and high availability.
B. Elasticity, scalability, easy access, limited storage.
C. Fault tolerance, scalability, sometimes available, unlimited storage
D. Unlimited storage, limited compute capacity, fault tolerance, and high availability.
Answer:
Answer: iOS – Android Fault tolerance, scalability, elasticity, and high availability are the four primary benefits of AWS/the cloud.
Q72:What best describes a simplified definition of the “cloud”?
Choose the correct answer:
A. All the computers in your local home network.
B. Your internet service provider
C. A computer located somewhere else that you are utilizing in some capacity.
D. An on-premise data center that your company owns.
Answer
Answer: iOS – Android (D) The simplest definition of the cloud is a computer that is located somewhere else that you are utilizing in some capacity. AWS is a cloud services provider, as the provide access to computers they own (located at AWS data centers), that you use for various purposes.
Q73: Your development team is planning to host a development environment on the cloud. This consists of EC2 and RDS instances. This environment will probably only be required for 2 months.
Which types of instances would you use for this purpose?
A. On-Demand
B. Spot
C. Reserved
D. Dedicated
Answer:
Answer: iOS – Android (A) The best and cost effective option would be to use On-Demand Instances. The AWS documentation gives the following additional information on On-Demand EC2 Instances. With On-Demand instances you only pay for EC2 instances you use. The use of On-Demand instances frees you from the costs and complexities of planning, purchasing, and maintaining hardware and transforms what are commonly large fixed costs into much smaller variable costs. Reference: AWS ec2 pricing on-demand
Q74: Which of the following can be used to secure EC2 Instances?
Answer: iOS – Android security groups acts as a virtual firewall for your instance to control inbound and outbound traffic. When you launch an instance in a VPC, you can assign up to five security groups to the instance. Security groups act at the instance level, not the subnet level. Therefore, each instance in a subnet in your VPC could be assigned to a different set of security groups. If you don’t specify a particular group at launch time, the instance is automatically assigned to the default security group for the VPC. Reference: VPC Security Groups
Q75: What is the purpose of a DNS server?
Choose the correct answer:
A. To act as an internet search engine.
B. To protect you from hacking attacks.
C. To convert common language domain names to IP addresses.
Domain name system servers act as a “third party” that provides the service of converting common language domain names to IP addresses (which are required for a web browser to properly make a request for web content).
High availability refers to the concept that something will be accessible when you try to access it. An object or web application is “highly available” when it is accessible a vast majority of the time.
RDS is a SQL database service (that offers several database engine options), and DynamoDB is a NoSQL database option that only offers one NoSQL engine.
Reference:
Q78: What are two open source in-memory engines supported by ElastiCache?
Q85:If you want to have SMS or email notifications sent to various members of your department with status updates on resources in your AWS account, what service should you choose?
Choose the correct answer:
A. SNS
B. GetSMS
C. RDS
D. STS
Answer:
Answer: iOS – Android (A) Simple Notification Service (SNS) is what publishes messages to SMS and/or email endpoints.
Amazon WorkSpaces is a managed, secure Desktop-as-a-Service (DaaS) solution. You can use Amazon WorkSpaces to provision either Windows or Linux desktops in just a few minutes and quickly scale to provide thousands of desktops to workers across the globe
Q87: Your company has recently migrated large amounts of data to the AWS cloud in S3 buckets. But it is necessary to discover and protect the sensitive data in these buckets. Which AWS service can do that?
Notes:Amazon Macie is a fully managed data security and data privacy service that uses machine learning and pattern matching to discover and protect your sensitive data in AWS.
Q88: Your Finance Department has instructed you to save costs wherever possible when using the AWS Cloud. You notice that using reserved EC2 instances on a 1year contract will save money. What payment method will save the most money?
A: Deferred
B: Partial Upfront
C: All Upfront
D: No Upfront
Answer: C
Notes: With the All Upfront option, you pay for the entire Reserved Instance term with one upfront payment. This option provides you with the largest discount compared to On Demand Instance pricing.
Q89: A fantasy sports company needs to run an application for the length of a football season (5 months). They will run the application on an EC2 instance and there can be no interruption. Which purchasing option best suits this use case?
Notes: This is not a long enough term to make reserved instances the better option. Plus, the application can’t be interrupted, which rules out spot instances. Dedicated instances provide the option to bring along existing software licenses.
The scenario does not indicate a need to do this.
Q90:Your company is considering migrating its data center to the cloud. What are the advantages of the AWS cloud over an on-premises data center?
A. Replace upfront operational expenses with low variable operational expenses.
B. Maintain physical access to the new data center, but share responsibility with AWS.
C. Replace low variable costs with upfront capital expenses.
D. Replace upfront capital expenses with low variable costs.
Q91:You are leading a pilot program to try the AWS Cloud for one of your applications. You have been instructed to provide an estimate of your AWS bill. Which service will allow you to do this by manually entering your planned resources by service?
Notes: With the AWS Pricing Calculator, you can input the services you will use, and the configuration of those services, and get an estimate of the costs these services will accrue. AWS Pricing Calculator lets you explore AWS services, and create an estimate for the cost of your use cases on AWS.
Q92:Which AWS service would enable you to view the spending distribution in one of your AWS accounts?
Notes: AWS Cost Explorer is a free tool that you can use to view your costs and usage. You can view data up to the last 13 months, forecast how much you are likely to spend for the next three months, and get recommendations for what Reserved Instances to purchase. You can use AWS Cost Explorer to see patterns in how much you spend on AWS resources over time, identify areas that need further inquiry, and see trends that you can use to understand your costs. You can also specify time ranges for the data, and view time data by day or by month.
Q93:You are managing the company’s AWS account. The current support plan is Basic, but you would like to begin using Infrastructure Event Management. What support plan (that already includes Infrastructure Event Management without an additional fee) should you upgrade to?
A. Upgrade to Enterprise plan.
B. Do nothing. It is included in the Basic plan.
C. Upgrade to Developer plan.
D. Upgrade to the Business plan. No other steps are necessary.
Notes:AWS Infrastructure Event Management is a structured program available to Enterprise support customers (and Business Support customers for an additional fee) that helps you plan for large-scale events, such as product or application launches, infrastructure migrations, and marketing events.
With Infrastructure Event Management, you get strategic planning assistance before your event, as well as real-time support during these moments that matter most for your business.
Q94:You have decided to use the AWS Cost and Usage Report to track your EC2 Reserved Instance costs. To where can these reports be published?
A. Trusted Advisor
B. An S3 Bucket that you own.
C. CloudWatch
D. An AWS owned S3 Bucket.
Answer: B
Notes: The AWS Cost and Usage Reports (AWS CUR) contains the most comprehensive set of cost and usage data available. You can use Cost and Usage Reports to publish your AWS billing reports to an Amazon Simple Storage Service (Amazon S3) bucket that you own. You can receive reports that break down your costs by the hour or day, by product or product resource, or by tags that you define yourself. AWS updates the report in your bucket once a day in comma-separated value (CSV) format. You can view the reports using spreadsheet software such as Microsoft Excel or Apache OpenOffice Calc, or access them from an application using the Amazon S3 API.
Q95:What can we do in AWS to receive the benefits of volume pricing for your multiple AWS accounts?
A. Use consolidated billing in AWS Organizations.
B. Purchase services in bulk from AWS Marketplace.
Notes: You can use the consolidated billing feature in AWS Organizations to consolidate billing and payment for multiple AWS accounts or multiple Amazon Internet Services Pvt. Ltd (AISPL) accounts. You can combine the usage across all accounts in the organization to share the volume pricing discounts, Reserved Instance discounts, and Savings Plans. This can result in a lower charge for your project, department, or company than with individual standalone accounts.
Q96:A gaming company is using the AWS Developer Tool Suite to develop, build, and deploy their applications. Which AWS service can be used to trace user requests from end-to-end through the application?
Notes:AWS X-Ray helps developers analyze and debug production, distributed applications, such as those built using a microservices architecture. With X-Ray, you can understand how your application and its underlying services are performing to identify and troubleshoot the root cause of performance issues and errors. X-Ray provides an end-to-end view of requests as they travel through your application, and shows a map of your application’s underlying components.
Q97:A company needs to use a Load Balancer which can serve traffic at the TCP, and UDP layers. Additionally, it needs to handle millions of requests per second at very low latencies. Which Load Balancer should they use?
Notes:Network Load Balancer is best suited for load balancing of Transmission Control Protocol (TCP), User Datagram Protocol (UDP) and Transport Layer Security (TLS) traffic where extreme performance is required. Operating at the connection level (Layer 4), Network Load Balancer routes traffic to targets within Amazon Virtual Private Cloud (Amazon VPC) and is capable of handling millions of requests per second while maintaining ultra-low latencies.
Q98:Your company is migrating its services to the AWS cloud. The DevOps team has heard about infrastructure as code, and wants to investigate this concept. Which AWS service would they investigate?
Notes:AWS CloudFormation is a service that helps you model and set up your Amazon Web Services resources so that you can spend less time managing those resources and more time focusing on your applications that run in AWS.
Q99:You have a MySQL database that you want to migrate to the cloud, and you need it to be significantly faster there. You are looking for a speed increase up to 5 times the current performance. Which AWS offering could you use?
Notes:Amazon Aurora is a MySQL and PostgreSQL-compatible relational database built for the cloud, that combines the performance and availability of traditional enterprise databases with the simplicity and cost-effectiveness of open source databases. Amazon Aurora is up to five times faster than standard MySQL databases and three times faster than standard PostgreSQL databases.
Q100:A developer is trying to programmatically retrieve information from an EC2 instance such as public keys, ip address, and instance id. From where can this information be retrieved?
Notes: This type of data is stored in Instance metadata. Instance userdata does not retrieve the information mentioned, but can be used to help configure a new instance.
Q101: Why is AWS more economical than traditional data centers for applications with varying compute workloads?
A) Amazon EC2 costs are billed on a monthly basis. B) Users retain full administrative access to their Amazon EC2 instances. C) Amazon EC2 instances can be launched on demand when needed. D) Users can permanently run enough instances to handle peak workloads.
Answer: C Notes: The ability to launch instances on demand when needed allows users to launch and terminate instances in response to a varying workload. This is a more economical practice than purchasing enough on-premises servers to handle the peak load. Reference: Advantage of cloud computing
Q102: Which AWS service would simplify the migration of a database to AWS?
A) AWS Storage Gateway B) AWS Database Migration Service (AWS DMS) C) Amazon EC2 D) Amazon AppStream 2.0
Answer: B Notes: AWS DMS helps users migrate databases to AWS quickly and securely. The source database remains fully operational during the migration, minimizing downtime to applications that rely on the database. AWS DMS can migrate data to and from most widely used commercial and open-source databases. Reference: AWS DMS
Q103: Which AWS offering enables users to find, buy, and immediately start using software solutions in their AWS environment?
A) AWS Config B) AWS OpsWorks C) AWS SDK D) AWS Marketplace
Answer: D Notes: AWS Marketplace is a digital catalog with thousands of software listings from independent software vendors that makes it easy to find, test, buy, and deploy software that runs on AWS. Reference: AWS Markerplace
Q104: Which AWS networking service enables a company to create a virtual network within AWS?
A) AWS Config B) Amazon Route 53 C) AWS Direct Connect D) Amazon Virtual Private Cloud (Amazon VPC)
Answer: D Notes: Amazon VPC lets users provision a logically isolated section of the AWS Cloud where users can launch AWS resources in a virtual network that they define. Reference: VPC https://aws.amazon.com/vpc/
Q105: Which component of the AWS global infrastructure does Amazon CloudFront use to ensure low-latency delivery?
A) AWS Regions B) Edge locations C) Availability Zones D) Virtual Private Cloud (VPC)
Answer: B Notes: – To deliver content to users with lower latency, Amazon CloudFront uses a global network of points of presence (edge locations and regional edge caches) worldwide. Reference: Cloudfront – https://aws.amazon.com/cloudfront/
Q106: How would a system administrator add an additional layer of login security to a user’s AWS Management Console?
A) Use Amazon Cloud Directory B) Audit AWS Identity and Access Management (IAM) roles C) Enable multi-factor authentication D) Enable AWS CloudTrail
Answer: C Notes: – Multi-factor authentication (MFA) is a simple best practice that adds an extra layer of protection on top of a username and password. With MFA enabled, when a user signs in to an AWS Management Console, they will be prompted for their username and password (the first factor—what they know), as well as for an authentication code from their MFA device (the second factor—what they have). Taken together, these multiple factors provide increased security for AWS account settings and resources. Reference: MFA – https://aws.amazon.com/iam/features/mfa/
Q107: Which service can identify the user that made the API call when an Amazon EC2 instance is terminated?
A) AWS Trusted Advisor B) AWS CloudTrail C) AWS X-Ray D) AWS Identity and Access Management (AWS IAM)
Answer: B Notes: – AWS CloudTrail helps users enable governance, compliance, and operational and risk auditing of their AWS accounts. Actions taken by a user, role, or an AWS service are recorded as events in CloudTrail. Events include actions taken in the AWS Management Console, AWS Command Line Interface (CLI), and AWS SDKs and APIs. Reference: AWS CloudTrail https://docs.aws.amazon.com/awscloudtrail/latest/userguide/cloudtrail-user-guide.html
Q108: Which service would be used to send alerts based on Amazon CloudWatch alarms?
A) Amazon Simple Notification Service (Amazon SNS) B) AWS CloudTrail C) AWS Trusted Advisor D) Amazon Route 53
Answer: A Notes: Amazon SNS and Amazon CloudWatch are integrated so users can collect, view, and analyze metrics for every active SNS. Once users have configured CloudWatch for Amazon SNS, they can gain better insight into the performance of their Amazon SNS topics, push notifications, and SMS deliveries. Reference: CloudWatch for Amazon SNS https://docs.aws.amazon.com/sns/latest/dg/sns-monitoring-using-cloudwatch.html
Q109: Where can a user find information about prohibited actions on the AWS infrastructure?
A) AWS Trusted Advisor B) AWS Identity and Access Management (IAM) C) AWS Billing Console D) AWS Acceptable Use Policy
Answer: D Notes: – The AWS Acceptable Use Policy provides information regarding prohibited actions on the AWS infrastructure. Reference: AWS Acceptable Use Policy – https://aws.amazon.com/aup/
Q110: Which of the following is an AWS responsibility under the AWS shared responsibility model?
A) Configuring third-party applications B) Maintaining physical hardware C) Securing application access and data D) Managing guest operating systems
Answer: B Notes: – Maintaining physical hardware is an AWS responsibility under the AWS shared responsibility model. Reference: AWS shared responsibility model https://aws.amazon.com/compliance/shared-responsibility-model/
Q111: Which recommendations are included in the AWS Trusted Advisor checks? (Select TWO.)
A) Amazon S3 bucket permissions
B) AWS service outages for services
C) Multi-factor authentication (MFA) use on the AWS account root user
D) Available software patches for Amazon EC2 instances
Answer: A and C
Notes: Trusted Advisor checks for S3 bucket permissions in Amazon S3 with open access permissions. Bucket permissions that grant list access to everyone can result in higher than expected charges if objects in the bucket are listed by unintended users at a high frequency. Bucket permissions that grant upload and delete access to all users create potential security vulnerabilities by allowing anyone to add, modify, or remove items in a bucket. This Trusted Advisor check examines explicit bucket permissions and associated bucket policies that might override the bucket permissions.
Trusted Advisor does not provide notifications for service outages. You can use the AWS Personal Health Dashboard to learn about AWS Health events that can affect your AWS services or account.
Trusted Advisor checks the root account and warns if MFA is not enabled.
Trusted Advisor does not provide information about the number of users in an AWS account.
What is the difference between Amazon EC2 Savings Plans and Spot Instances?
Amazon EC2 Savings Plans are ideal for workloads that involve a consistent amount of compute usage over a 1-year or 3-year term. With Amazon EC2 Savings Plans, you can reduce your compute costs by up to 72% over On-Demand costs.
Spot Instances are ideal for workloads with flexible start and end times, or that can withstand interruptions. With Spot Instances, you can reduce your compute costs by up to 90% over On-Demand costs. Unlike Amazon EC2 Savings Plans, Spot Instances do not require contracts or a commitment to a consistent amount of compute usage.
Amazon EBS vs Amazon EFS
An Amazon EBS volume stores data in a single Availability Zone. To attach an Amazon EC2 instance to an EBS volume, both the Amazon EC2 instance and the EBS volume must reside within the same Availability Zone.
Amazon EFS is a regional service. It stores data in and across multiple Availability Zones. The duplicate storage enables you to access data concurrently from all the Availability Zones in the Region where a file system is located. Additionally, on-premises servers can access Amazon EFS using AWS Direct Connect.
Which cloud deployment model allows you to connect public cloud resources to on-premises infrastructure?
Applications made available through hybrid deployments connect cloud resources to on-premises infrastructure and applications. For example, you might have an application that runs in the cloud but accesses data stored in your on-premises data center.
What is the difference between Amazon EC2 Savings Plans and Spot Instances?
Amazon EC2 Savings Plans are ideal for workloads that involve a consistent amount of compute usage over a 1-year or 3-year term. With Amazon EC2 Savings Plans, you can reduce your compute costs by up to 72% over On-Demand costs.
Spot Instances are ideal for workloads with flexible start and end times, or that can withstand interruptions. With Spot Instances, you can reduce your compute costs by up to 90% over On-Demand costs. Unlike Amazon EC2 Savings Plans, Spot Instances do not require contracts or a commitment to a consistent amount of compute usage.
Which benefit of cloud computing helps you innovate and build faster?
Agility: The cloud gives you quick access to resources and services that help you build and deploy your applications faster.
Which developer tool allows you to write code within your web browser?
Cloud9 is an integrated development environment (IDE) that allows you to write code within your web browser.
Which method of accessing an EC2 instance requires both a private key and a public key?
SSH allows you to access an EC2 instance from your local laptop using a key pair, which consists of a private key and a public key.
Which service allows you to track the name of the user making changes in your AWS account?
CloudTrail tracks user activity and API calls in your account, which includes identity information (the user’s name, source IP address, etc.) about the API caller.
Which analytics service allows you to query data in Amazon S3 using Structured Query Language (SQL)?
Athena is a query service that makes it easy to analyze data in Amazon S3 using SQL.
Which machine learning service helps you build, train, and deploy models quickly?
SageMaker helps you build, train, and deploy machine learning models quickly.
Which EC2 storage mechanism is recommended when running a database on an EC2 instance?
EBS is a storage device you can attach to your instances and is a recommended storage option when you run databases on an instance.
Which storage service is a scalable file system that only works with Linux-based workloads?
EFS is an elastic file system for Linux-based workloads.
Djamgatech: AI Driven Certification Preparation: Azure AI, AWS Machine Learning Specialty, AWS Data Analytics, GCP ML, GCP PDE,
Which AWS service provides a secure and resizable compute platform with choice of processor, storage, networking, operating system, and purchase model?
Amazon Elastic Compute Cloud (Amazon EC2) is a web service that provides secure, resizable compute capacity in the cloud. Amazon EC2 offers the broadest and deepest compute platform with choice of processor, storage, networking, operating system, and purchase model. Amazon EC2.
Which services allow you to build hybrid environments by connecting on-premises infrastructure to AWS?
Site-to-site VPN allows you to establish a secure connection between your on-premises equipment and the VPCs in your AWS account.
Direct Connect allows you to establish a dedicated network connection between your on-premises network and AWS.
What service could you recommend to a developer to automate the software release process?
CodePipeline is a developer tool that allows you to continuously automate the software release process.
Which service allows you to practice infrastructure as code by provisioning your AWS resources via scripted templates?
CloudFormation allows you to provision your AWS resources via scripted templates.
Which machine learning service allows you to add image analysis to your applications?
Rekognition is a service that makes it easy to add image analysis to your applications.
Which services allow you to run containerized applications without having to manage servers or clusters?
Fargate removes the need for you to interact with servers or clusters as it provisions, configures, and scales clusters of virtual machines to run containers for you.
ECS lets you run your containerized Docker applications on both Amazon EC2 and AWS Fargate.
EKS lets you run your containerized Kubernetes applications on both Amazon EC2 and AWS Fargate.
Amazon S3 offers multiple storage classes. Which storage class is best for archiving data when you want the cheapest cost and don’t mind long retrieval times?
S3 Glacier Deep Archive offers the lowest cost and is used to archive data. You can retrieve objects within 12 hours.
In the shared responsibility model, what is the customer responsible for?
You are responsible for patching the guest OS, including updates and security patches.
You are responsible for firewall configuration and securing your application.
A company needs phone, email, and chat access 24 hours a day, 7 days a week. The response time must be less than 1 hour if a production system has a service interruption. Which AWS Support plan meets these requirements at the LOWEST cost?
The Business Support plan provides phone, email, and chat access 24 hours a day, 7 days a week. The Business Support plan has a response time of less than 1 hour if a production system has a service interruption.
Which of the following is an advantage of consolidated billing on AWS?
Consolidated billing is a feature of AWS Organizations. You can combine the usage across all accounts in your organization to share volume pricing discounts, Reserved Instance discounts, and Savings Plans. This solution can result in a lower charge compared to the use of individual standalone accounts.
A company requires physical isolation of its Amazon EC2 instances from the instances of other customers. Which instance purchasing option meets this requirement?
With Dedicated Hosts, a physical server is dedicated for your use. Dedicated Hosts provide visibility and the option to control how you place your instances on an isolated, physical server. For more information about Dedicated Hosts, see Amazon EC2 Dedicated Hosts.
A company is hosting a static website from a single Amazon S3 bucket. Which AWS service will achieve lower latency and high transfer speeds?
CloudFront is a web service that speeds up the distribution of your static and dynamic web content, such as .html, .css, .js, and image files, to your users. Content is cached in edge locations. Content that is repeatedly accessed can be served from the edge locations instead of the source S3 bucket. For more information about CloudFront, see Accelerate static website content delivery.
Which AWS service provides a simple and scalable shared file storage solution for use with Linux-based Amazon EC2 instances and on-premises servers?
Amazon EFS provides an elastic file system that lets you share file data without the need to provision and manage storage. It can be used with AWS Cloud services and on-premises resources, and is built to scale on demand to petabytes without disrupting applications. With Amazon EFS, you can grow and shrink your file systems automatically as you add and remove files, eliminating the need to provision and manage capacity to accommodate growth.
Which service allows you to generate encryption keys managed by AWS?
KMS allows you to generate and manage encryption keys. The keys generated by KMS are managed by AWS.
Which service can integrate with a Lambda function to automatically take remediation steps when it uncovers suspicious network activity when monitoring logs in your AWS account?
GuardDuty can perform automated remediation actions by leveraging Amazon CloudWatch Events and AWS Lambda. GuardDuty continuously monitors for threats and unauthorized behavior to protect your AWS accounts, workloads, and data stored in Amazon S3. GuardDuty analyzes multiple AWS data sources, such as AWS CloudTrail event logs, Amazon VPC Flow Logs, and DNS logs.
Which service allows you to create access keys for someone needing to access AWS via the command line interface (CLI)?
IAM allows you to create users and generate access keys for users needing to access AWS via the CLI.
Which service allows you to record software configuration changes within your Amazon EC2 instances over time?
Config helps with recording compliance and configuration changes over time for your AWS resources.
Which service assists with compliance and auditing by offering a downloadable report that provides the status of passwords and MFA devices in your account?
IAM provides a downloadable credential report that lists all users in your account and the status of their various credentials, including passwords, access keys, and MFA devices.
Which service allows you to locate credit card numbers stored in Amazon S3?
Macie is a data privacy service that helps you uncover and protect your sensitive data, such as personally identifiable information (PII) like credit card numbers, passport numbers, social security numbers, and more.
How do you manage permissions for multiple users at once using AWS Identity and Access Management (IAM)?
An IAM group is a collection of IAM users. When you assign an IAM policy to a group, all users in the group are granted permissions specified by the policy.
Which service protects your web application from cross-site scripting attacks?
WAF helps protect your web applications from common web attacks, like SQL injection or cross-site scripting.
Which AWS Trusted Advisor real-time guidance recommendations are available for AWS Basic Support and AWS Developer Support customers?
Basic and Developer Support customers get 50 service limit checks.
Basic and Developer Support customers get security checks for “Specific Ports Unrestricted” on Security Groups.
Basic and Developer Support customers get security checks on S3 Bucket Permissions.
Which service allows you to simplify billing by using a single payment method for all your accounts?
Organizations offers consolidated billing that provides 1 bill for all your AWS accounts. This also gives you access to volume discounts.
Which AWS service usage will always be free even after the 12-month free tier plan has expired?
One million Lambda requests are always free each month.
What is the easiest way for a customer on the AWS Basic Support plan to increase service limits?
The Basic Support plan allows 24/7 access to Customer Service via email and the ability to open service limit increase support cases.
Which types of issues are covered by AWS Support?
“How to” questions about AWS service and features
Problems detected by health checks
Djamgatech: AI Driven Certification Preparation: Azure AI, AWS Machine Learning Specialty, AWS Data Analytics, GCP ML, GCP PDE,
Which features of AWS reduce your total cost of ownership (TCO)?
Sharing servers with others allows you to save money.
Elastic computing allows you to trade capital expense for variable expense.
You pay only for the computing resources you use with no long-term commitments.
Which service allows you to select and deploy operating system and software patches automatically across large groups of Amazon EC2 instances?
Systems Manager allows you to automate operational tasks across your AWS resources.
Which service provides the easiest way to set up and govern a secure, multi-account AWS environment?
Control Tower allows you to centrally govern and enforce the best use of AWS services across your accounts.
Which cost management tool gives you the ability to be alerted when the actual or forecasted cost and usage exceed your desired threshold?
Budgets allow you to improve planning and cost control with flexible budgeting and forecasting. You can choose to be alerted when your budget threshold is exceeded.
Which tool allows you to compare your estimated service costs per Region?
The Pricing Calculator allows you to get an estimate for the cost of AWS services. Comparing service costs per Region is a common use case.
Who can assist with accelerating the migration of legacy contact center infrastructure to AWS?
Professional Services is a global team of experts that can help you realize your desired business outcomes with AWS.
The AWS Partner Network (APN) is a global community of partners that helps companies build successful solutions with AWS.
Which cost management tool allows you to view costs from the past 12 months, current detailed costs, and forecasts costs for up to 3 months?
Cost Explorer allows you to visualize, understand, and manage your AWS costs and usage over time.
Which service reduces the operational overhead of your IT organization?
Managed Services implements best practices to maintain your infrastructure and helps reduce your operational overhead and risk.
I assume it is your subscription where the VPCs are located, otherwise you can’t really discover the information you are looking for. On the EC2 server you could use AWS CLI or Powershell based scripts that query the IP information. Based on IP you can find out what instance uses the network interface, what security groups are tied to it and in which VPC the instance is hosted. Read more here…
When using AWS Lambda inside your VPC, your Lambda function will be allocated private IP addresses, and only private IP addresses, from your specified subnets. This means that you must ensure that your specified subnets have enough free address space for your Lambda function to scale up to. Each simultaneous invocation needs its own IP. Read more here…
When a Lambda “is in a VPC”, it really means that its attached Elastic Network Interface is the customer’s VPC and not the hidden VPC that AWS manages for Lambda.
The ENI is not related to the AWS Lambda management system that does the invocation (the data plane mentioned here). The AWS Step Function system can go ahead and invoke the Lambda through the API, and the network request for that can pass through the underlying VPC and host infrastructure.
Those Lambdas in turn can invoke other Lambda directly through the API, or more commonly by decoupling them, such as through Amazon SQS used as a trigger. Read more ….
How do I invoke an AWS Lambda function programmatically?
Invokes a Lambda function. You can invoke a function synchronously (and wait for the response), or asynchronously. To invoke a function asynchronously, set InvocationType to Event.
For synchronous invocation, details about the function response, including errors, are included in the response body and headers. For either invocation type, you can find more information in the execution log and trace.
When an error occurs, your function may be invoked multiple times. Retry behavior varies by error type, client, event source, and invocation type. For example, if you invoke a function asynchronously and it returns an error, Lambda executes the function up to two more times. For more information, see Retry Behavior.
For asynchronous invocation, Lambda adds events to a queue before sending them to your function. If your function does not have enough capacity to keep up with the queue, events may be lost. Occasionally, your function may receive the same event multiple times, even if no error occurs. To retain events that were not processed, configure your function with a dead-letter queue.
The status code in the API response doesn’t reflect function errors. Error codes are reserved for errors that prevent your function from executing, such as permissions errors, limit errors, or issues with your function’s code and configuration. For example, Lambda returns TooManyRequestsException if executing the function would cause you to exceed a concurrency limit at either the account level ( Concurrent Invocation Limit Exceeded) or function level ( Reserved Function Concurrent Invocation LimitExceeded).
For functions with a long timeout, your client might be disconnected during synchronous invocation while it waits for a response. Configure your HTTP client, SDK, firewall, proxy, or operating system to allow for long connections with timeout or keep-alive settings.
The subnet mask determines how many bits of the network address are relevant (and thus indirectly the size of the network block in terms of how many host addresses are available) –
192.0.2.0, subnet mask 255.255.255.0 means that 192.0.2 is the significant portion of the network number, and that there 8 bits left for host addresses (i.e. 192.0.2.0 thru 192.0.2.255)
192.0.2.0, subnet mask 255.255.255.128 means that 192.0.2.0 is the significant portion of the network number (first three octets and the most significant bit of the last octet), and that there 7 bits left for host addresses (i.e. 192.0.2.0 thru 192.0.2.127)
When in doubt, envision the network number and subnet mask in base 2 (i.e. binary) and it will become much clearer. Read more here…
Separate out the roles needed to do each job. (Assuming this is a corporate environment)
Have a role for EC2, another for Networking, another for IAM.
Everyone should not be admin. Everyone should not be able to add/remove IGW’s, NAT gateways, alter security groups and NACLS, or setup peering connections.
Also, another thing… lock down full internet access. Limit to what is needed and that’s it. Read more here….
How can we setup AWS public-private subnet in VPC without NAT server?
Within a single VPC, the subnets’ route tables need to point to each other. This will already work without additional routes because VPC sets up the local target to point to the VPC subnet.
Security groups are not used here since they are attached to instances, and not networks.
The NAT EC2 instance (server), or AWS-provided NAT gateway is necessary only if the private subnet internal addresses need to make outbound connections. The NAT will translate the private subnet internal addresses to the public subnet internal addresses, and the AWS VPC Internet Gateway will translate these to external IP addresses, which can then go out to the Internet. Read more here ….
What are the applications (or workloads) that cannot be migrated on to cloud (AWS or Azure or GCP)?
A good example of workloads that currently are not in public clouds are mobile and fixed core telecom networks for tier 1 service providers. This is despite the fact that these core networks are increasingly software based and have largely been decoupled from the hardware. There are a number of reasons for this such as the public cloud providers such as Azure and AWS do not offer the guaranteed availability required by telecom networks. These networks require 99.999% availability and is typically referred to as telecom grade.
The regulatory environment frequently restricts hosting of subscriber data outside the of the operators data centers or in another country and key network functions such as lawful interception cannot contractually be hosted off-prem. Read more here….
How many CIDRs can we add to my own created VPC?
You can add up to 5 IPv4 CIDR blocks, or 1 IPv6 block per VPC. You can further segment the network by utilizing up to 200 subnets per VPC. Amazon VPC Limits. Read more …
Why can’t a subnet’s CIDR be changed once it has been assigned?
Sure it can, but you’ll need to coordinate with the neighbors. You can merge two /25’s into a single /24 quite effortlessly if you control the entire range it covers. In practice you’ll see many tiny allocations in public IPv4 space, like /29’s and even smaller. Those are all assigned to different people. If you want to do a big shuffle there, you have a lot of coordinating to do.. or accept the fallout from the breakage you cause. Read more…
Can one VPC talk to another VPC?
Yes, but a Virtual Private Cloud is usually built for the express purpose of being isolated from unwanted external traffic. I can think of several good reasons to encourage that sort of communication, so the idea is not without merit. Read more..
Good knowledge about the AWS services, and how to leverage them to solve simple to complex problems.
As your question is related to the deployment Pod, you will probably be asked about deployment methods (A/B testing like blue-green deployment) as well as pipelining strategies. You might be asked during this interview to reason about a simple task and to code it (like parsing a log file). Also review the TCP/IP stack in-depth as well as the tools to troubleshoot it for the networking round. You will eventually have some Linux questions, the range of questions can vary from common CLI tools to Linux internals like signals / syscalls / file descriptors and so on.
Last but not least the Leadership principles, I can only suggest you to prepare a story for each of them. You will quickly find what LP they are looking for and would be able to give the right signal to your interviewer.
Finally, remember that theres a debrief after the (usually 5) stages of your on site interview, and more senior and convincing interviewers tend to defend their vote so don’t screw up with them.
Be natural, focus on the question details and ask for confirmation, be cool but not too much. At the end of the day, remember that your job will be to understand customer issues and provide a solution, so treat your interviewers as if they were customers and they will see a successful CSE in you, be reassured and give you the job.
Expect questions on cloudformations, Teraform, Aws ec2/rds and stack related questions.
It also depends on the support team you are being hired for. Networking or compute teams (Ec2) have different interview patterns vs database or big data support.
In any case, basics of OS, networking are critical to the interview. If you have a phone screen, we will be looking for basic/semi advance skills of these and your speciality. For example if you mention Oracle in your resume and you are interviewing for the database team, expect a flurry of those questions.
Other important aspect is the Amazon leadership principles. Half of your interview is based on LPs. If you fail to have scenarios where you do not demonstrate our LPs, you cannot expect to work here even though your technical skills are above average (Having extraordinary skills is a different thing).
The overall interview itself will have 1 phone screen if you are interviewing in the US and 1–2 if outside US. The onsite loop will be 4 rounds , 2 of which are technical (again divided into OS and networking and the specific speciality of the team you are interviewing for ) and 2 of them are leadership principles where we test your soft skills and management skills as they are very important in this job. You need to have a strong view point, disagree if it seems valid to do so, empathy and be a team player while showing the ability to pull off things individually as well. These skills will be critical for cracking LP interviews.
You will NOT be asked to code or write queries as its not part of the job, so you can concentrate on the theoretical part of the subject and also your resume. We will grill you on topics mentioned on your resume to start with.
Monolithic architecture is something that build from single piece of material, historically from rock. Monolith term normally use for object made from single large piece of material.” – Non-Technical Definition. “Monolithic application has single code base with multiple modules.
Large Monolithic code-base (often spaghetti code) puts immense cognitive complexity on the developer’s head. As a result, the development velocity is poor. Granular scaling (i.e., scaling part of the application) is not possible. Polyglot programming or polyglot database is challenging.
Drawbacks of Monolithic Architecture
This simple approach has a limitation in size and complexity. Application is too large and complex to fully understand and made changes fast and correctly. The size of the application can slow down the start-up time. You must redeploy the entire application on each update.
Sticky sessions, also known as session affinity, allow you to route a site user to the particular web server that is managing that individual user’s session. The session’s validity can be determined by a number of methods, including a client-side cookies or via configurable duration parameters that can be set at the load balancer which routes requests to the web servers.
Some advantages with utilizing sticky sessions are that it’s cost effective due to the fact you are storing sessions on the same web servers running your applications and that retrieval of those sessions is generally fast because it eliminates network latency. A drawback for using storing sessions on an individual node is that in the event of a failure, you are likely to lose the sessions that were resident on the failed node. In addition, in the event the number of your web servers change, for example a scale-up scenario, it’s possible that the traffic may be unequally spread across the web servers as active sessions may exist on particular servers. If not mitigated properly, this can hinder the scalability of your applications. Read more here …
After you terminate an instance, it remains visible in the console for a short while, and then the entry is automatically deleted. You cannot delete the terminated instance entry yourself. After an instance is terminated, resources such as tags and volumes are gradually disassociated from the instance, therefore may no longer be visible on the terminated instance after a short while.
When an instance terminates, the data on any instance store volumes associated with that instance is deleted.
By default, Amazon EBS root device volumes are automatically deleted when the instance terminates. However, by default, any additional EBS volumes that you attach at launch, or any EBS volumes that you attach to an existing instance persist even after the instance terminates. This behavior is controlled by the volume’s DeleteOnTermination attribute, which you can modify
When you first launch an instance with gp2 volumes attached, you get an initial burst credit allowing for up to 30 minutes of 3,000 iops/sec.
After the first 30 minutes, your volume will accrue credits as follows (taken directly from AWS documentation):
Within the General Purpose (SSD) implementation is a Token Bucket model that works as follows
Each token represents an “I/O credit” that pays for one read or one write.
A bucket is associated with each General Purpose (SSD) volume, and can hold up to 5.4 million tokens.
Tokens accumulate at a rate of 3 per configured GB per second, up to the capacity of the bucket.
Tokens can be spent at up to 3000 per second per volume.
The baseline performance of the volume is equal to the rate at which tokens are accumulated — 3 IOPS per GB per second.
In addition to this, gp2 volumes provide baseline performance of 3 iops per Gb, up to 1Tb (3000 iops). Volumes larger than 1Tb no longer work on the credit system, as they already provide a baseline of 3000 iops. Gp2 volumes have a cap of 10,000 iops regardless of the volume size (so the iops max out for volumes larger than 3.3Tb)
Elastic IP addresses are free when you have them assigned to an instance, feel free to use one! Elastic IPs get disassociated when you stop an instance, so you will get charged in the mean time. The benefit is that you get to keep that IP allocated to your account though, instead of losing it like any other. Once you start the instance you just re-associate it back and you have your old IP again.
Here are the changes associated with the use of Elastic IP addresses
No cost for Elastic IP addresses while in use
* $0.01 per non-attached Elastic IP address per complete hour
* $0.00 per Elastic IP address remap – first 100 remaps / month
* $0.10 per Elastic IP address remap – additional remap / month over 100
If you require any additional information about pricing please reference the link below
The short answer to reducing your AWS EC2 costs – turn off your instances when you don’t need them.
Your AWS bill is just like any other utility bill, you get charged for however much you used that month. Don’t make the mistake of leaving your instances on 24/7 if you’re only using them during certain days and times (ex. Monday – Friday, 9 to 5).
To automatically start and stop your instances, AWS offers an “EC2 scheduler” solution. A better option would be a cloud cost management tool that not only stops and starts your instances automatically, but also tracks your usage and makes sizing recommendations to optimize your cloud costs and maximize your time and savings.
You could potentially save money using Reserved Instances. But, in non-production environments such as dev, test, QA, and training, Reserved Instances are not your best bet. Why is this the case? These environments are less predictable; you may not know how many instances you need and when you will need them, so it’s better to not waste spend on these usage charges. Instead, schedule such instances (preferably using ParkMyCloud). Scheduling instances to be only up 12 hours per day on weekdays will save you 65% – better than all but the most restrictive 3-year RIs!
Well AWS is a web service provider which offers a set of services related to compute, storage, database, network and more to help the business scale and grow
All your concerns are related to AWS EC2 instance, so let me start with an instance
Instance:
An EC2 instance is similar to a server where you can host your websites or applications to make it available Globally
It is highly scalable and works on the pay-as-you-go model
You can increase or decrease the capacity of these instances as per the requirement
AMI:
AMI provides the information required to launch the EC2 instance
AMI includes the pre-configured templates of the operating system that runs on the AWS
Users can launch multiple instances with the same configuration from a single AMI
Snapshot:
Snapshots are the incremental backups for the Amazon EBS
Data in the EBS are stored in S3 by taking point-to-time snapshots
Unique data are only deleted when a snapshot is deleted
They are definitely all chalk and cheese to one another.
A VPN (Virtual Private Network) is essentially an encrypted “channel” connecting two networks, or a machine to a network, generally over the public internet.
A VPS (Virtual Private Server) is a rented virtual machine running on someone else’s hardware. AWS EC2 can be thought of as a VPS, but the term is usually used to describe low-cost products offered by lots of other hosting companies.
A VPC (Virtual Private Cloud) is a virtual network in AWS (Amazon Web Services). It can be divided into private and public subnets, have custom routing rules, have internal connections to other VPCs, etc. EC2 instances and other resources are placed in VPCs similarly to how physical data centers have operated for a very long time.
Elastic IP address is basically the static IP (IPv4) address that you can allocate to your resources.
Now, in case that you allocate IP to the resource (and the resource is running), you are not charged anything. On the other hand, if you create Elastic IP, but you do not allocate it to the resource (or the resource is not running), then you are charged some amount (should be around $0.005 per hour if I remember correctly)
Additional info about these:
You are limited to 5 Elastic IP addresses per region. If you require more than that, you can contact AWS support with a request for additional addresses. You need to have a good reason in order to be approved because IPv4 addresses are becoming a scarce resource.
In general, you should be good without Elastic IPs for most of the use-cases (as every EC2 instance has its own public IP, and you can use load balancers, as well as map most of the resources via Route 53).
One of the use-cases that I’ve seen where my client is using Elastic IP is to make it easier for him to access specific EC2 instance via RDP, as well as do deployment through Visual Studio, as he targets the Elastic IP, and thus does not have to watch for any changes in public IP (in case of stopping or rebooting).
At this time, AWS Transit Gateway does not support inter region attachments. The transit gateway and the attached VPCs must be in the same region. VPC peering supports inter region peering.
The EC2 instance is server instance whilst a Workspace is windows desktop instance
Both Windows Server and Windows workstation editions have desktops. Windows Server Core doesn’t not (and AWS doesn’t have an AMI for Windows Server Core that I could find).
It is possible to SSH into a Windows instance – this is done on port 22. You would not see a desktop when using SSH if you had enabled it. It is not enabled by default.
If you are seeing a desktop, I believe you’re “RDPing” to the Windows instance. This is done with the RDP protocol on port 3389.
Two different protocols and two different ports.
Workspaces doesn’t allow terminal or ssh services by default. You need to use Workspace client. You still can enable RDP or/and SSH but this is not recommended.
Workspaces is a managed desktop service. AWS is taking care of pre-build AMIs, software licenses, joining to domain, scaling etc.
What is Amazon EC2?Scalable, pay-as-you-go compute capacity in the cloud. Amazon Elastic Compute Cloud (Amazon EC2) is a web service that provides resizable compute capacity in the cloud. It is designed to make web-scale computing easier for developers.
What is Amazon WorkSpaces?Easily provision cloud-based desktops that allow end-users to access applications and resources. With a few clicks in the AWS Management Console, customers can provision a high-quality desktop experience for any number of users at a cost that is highly competitive with traditional desktops and half the cost of most virtual desktop infrastructure (VDI) solutions. End-users can access the documents, applications and resources they need with the device of their choice, including laptops, iPad, Kindle Fire, or Android tablets.
Elastic – Amazon EC2 enables you to increase or decrease capacity within minutes, not hours or days. You can commission one, hundreds or even thousands of server instances simultaneously.
Completely Controlled – You have complete control of your instances. You have root access to each one, and you can interact with them as you would any machine.
Flexible – You have the choice of multiple instance types, operating systems, and software packages. Amazon EC2 allows you to select a configuration of memory, CPU, instance storage, and the boot partition size that is optimal for your choice of operating system and application.
On the other hand, Amazon WorkSpaces provides the following key features:
Support Multiple Devices- Users can access their Amazon WorkSpaces using their choice of device, such as a laptop computer (Mac OS or Windows), iPad, Kindle Fire, or Android tablet.
Keep Your Data Secure and Available- Amazon WorkSpaces provides each user with access to persistent storage in the AWS cloud. When users access their desktops using Amazon WorkSpaces, you control whether your corporate data is stored on multiple client devices, helping you keep your data secure.
Choose the Hardware and Software you need- Amazon WorkSpaces offers a choice of bundles providing different amounts of CPU, memory, and storage so you can match your Amazon WorkSpaces to your requirements. Amazon WorkSpaces offers preinstalled applications (including Microsoft Office) or you can bring your own licensed software.
Amazon EBS vs Amazon EFS
An Amazon EBS volume stores data in a single Availability Zone. To attach an Amazon EC2 instance to an EBS volume, both the Amazon EC2 instance and the EBS volume must reside within the same Availability Zone.
Amazon EFS is a regional service. It stores data in and across multiple Availability Zones. The duplicate storage enables you to access data concurrently from all the Availability Zones in the Region where a file system is located. Additionally, on-premises servers can access Amazon EFS using AWS Direct Connect.
Provides secure, resizable compute capacity in the cloud. It makes web-scale cloud computing easier for developers. EC2
EC2 Spot
Run fault-tolerant workloads for up to 90% off. EC2Spot
EC2 Autoscaling
Automatically add or remove compute capacity to meet changes in demand. EC2_AustoScaling
Lightsail
Designed to be the easiest way to launch & manage a virtual private server with AWS. An easy-to-use cloud platform that offers everything need to build an application or website. Lightsail
Batch
Enables developers, scientists, & engineers to easily & efficiently run hundreds of thousands of batch computing jobs on AWS. Fully managed batch processing at any scale. Batch
Containers
Elastic Container Service (ECS)
Highly secure, reliable, & scalable way to run containers. ECS
Run code without thinking about servers. Pay only for the compute time you consume. Lamda
Edge and hybrid
Outposts
Run AWS infrastructure & services on premises for a truly consistent hybrid experience. Outposts
Snow Family
Collect and process data in rugged or disconnected edge environments. SnowFamily
Wavelength
Deliver ultra-low latency application for 5G devices. Wavelenth
VMware Cloud on AWS
Innovate faster, rapidly transition to the cloud, & work securely from any location. VMware_On_AWS
Local Zones
Run latency sensitive applications closer to end-users. LocalZones
Networking and Content Delivery
Use cases
Functionality
Service
Description
Build a cloud network
Define and provision a logically isolated network for your AWS resources
VPC
VPC lets you provision a logically isolated section of the AWS Cloud where you can launch AWS resources in a virtual network that you define. VPC
Connect VPCs and on-premises networks through a central hub
Transit Gateway
Transit Gateway connects VPCs & on-premises networks through a central hub. This simplifies network & puts an end to complex peering relationships. TransitGateway
Provide private connectivity between VPCs, services, and on-premises applications
PrivateLink
PrivateLink provides private connectivity between VPCs & services hosted on AWS or on-premises, securely on the Amazon network. PrivateLink
Route users to Internet applications with a managed DNS service
Route 53
Route 53 is a highly available & scalable cloud DNS web service. Route53
Scale your network design
Automatically distribute traffic across a pool of resources, such as instances, containers, IP addresses, and Lambda functions
Elastic Load Balancing
Elastic Load Balancing automatically distributes incoming application traffic across multiple targets, such as EC2’s, containers, IP addresses, & Lambda functions. ElasticLoadBalancing
Direct traffic through the AWS Global network to improve global application performance
Global Accelerator
Global Accelerator is a networking service that sends user’s traffic through AWS’s global network infrastructure, improving internet user performance by up to 60%. GlobalAccelerator
Secure your network traffic
Safeguard applications running on AWS against DDoS attacks
Shield
Shield is a managed Distributed Denial of Service (DDoS) protection service that safeguards applications running on AWS. Shield
Protect your web applications from common web exploits
WAF
WAF is a web application firewall that helps protect your web applications or APIs against common web exploits that may affect availability, compromise security, or consume excessive resources. WAF
Centrally configure and manage firewall rules
Firewall Manager
Firewall Manager is a security management service which allows to centrally configure & manage firewall rules across accounts & apps in AWS Organization. link text
Build a hybrid IT network
Connect your users to AWS or on-premises resources using a Virtual Private Network
(VPN) – Client
VPN solutions establish secure connections between on-premises networks, remote offices, client devices, & the AWS global network. VPN
Create an encrypted connection between your network and your Amazon VPCs or AWS Transit Gateways
(VPN) – Site to Site
Site-to-Site VPN creates a secure connection between data center or branch office & AWS cloud resources. site_to_site
Establish a private, dedicated connection between AWS and your datacenter, office, or colocation environment
Direct Connect
Direct Connect is a cloud service solution that makes it easy to establish a dedicated network connection from your premises to AWS. DirectConnect
Content delivery networks
Securely deliver data, videos, applications, and APIs to customers globally with low latency, and high transfer speeds
CloudFront
CloudFront expedites distribution of static & dynamic web content. CloudFront
Build a network for microservices architectures
Provide application-level networking for containers and microservices
App Mesh
App Mesh makes it accessible to guide & control microservices operating on AWS. AppMesh
Create, maintain, and secure APIs at any scale
API Gateway
API Gateway allows the user to design & expand their own REST and WebSocket APIs at any scale. APIGateway
Discover AWS services connected to your applications
Cloud Map
Cloud Map permits the name & handles the cloud resources. CloudMap
S3 is the storehouse for the internet i.e. object storage built to store & retrieve any amount of data from anywhere S3
AWS Backup
AWS Backup is an externally-accessible backup provider that makes it easier to align & optimize the backup of data across AWS services in the cloud. AWS_Backup
Amazon EBS
Amazon Elastic Block Store is a web service that provides block-level storage volumes. EBS
Amazon EFS Storage
EFS offers file storage for the user’s Amazon EC2 instances. It’s kind of blob Storage. EFS
Amazon FSx
FSx supply fully managed 3rd-party file systems with the native compatibility & characteristic sets for workloads. It’s available as FSx for Windows server (Fully managed file storage built on Windows Server) & Lustre (Fully managed high-performance file system integrated with S3). FSx_WindowsFSx_Lustre
AWS Storage Gateway
Storage Gateway is a service which connects an on-premises software appliance with cloud-based storage. Storage_Gateway
AWS DataSync
DataSync makes it simple & fast to move large amounts of data online between on-premises storage & S3, EFS, or FSx for Windows File Server. DataSync
AWS Transfer Family
The Transfer Family provides fully managed support for file transfers directly into & out of S3. Transfer_Family
AWS Snow Family
Highly-secure, portable devices to collect & process data at the edge, and migrate data into and out of AWS. Snow_Family
Classification: Object storage: S3 File storage services: Elastic File System, FSx for Windows Servers & FSx for Lustre Block storage: EBS Backup: AWS Backup Data transfer: Storage gateway –> 3 types: Tape, File, Volume. Transfer Family –> SFTP, FTPS, FTP. Edge computing and storage and Snow Family –> Snowcone, Snowball, Snowmobile
Databases
Database type
Use cases
Service
Description
Relational
Traditional applications, ERP, CRM, e-commerce
Aurora, RDS, Redshift
RDS is a web service that makes it easier to set up, control, and scale a relational database in the cloud. AuroraRDSRedshift
Key-value
High-traffic web apps, e-commerce systems, gaming applications
DynamoDB
DynamoDB is a fully administered NoSQL database service that offers quick and reliable performance with integrated scalability. DynamoDB
ElastiCache helps in setting up, managing, and scaling in-memory cache conditions. MemcachedRedis
Document
Content management, catalogs, user profiles
DocumentDB
DocumentDB (with MongoDB compatibility) is a quick, dependable, and fully-managed database service that makes it easy for you to set up, operate, and scale MongoDB-compatible databases.DocumentDB
Wide column
High scale industrial apps for equipment maintenance, fleet management, and route optimization
Keyspaces (for Apache Cassandra)
Keyspaces is a scalable, highly available, and managed Apache Cassandra–compatible database service. Keyspaces
Graph
Fraud detection, social networking, recommendation engines
Neptune
Neptune is a fast, reliable, fully managed graph database service that makes it easy to build and run applications that work with highly connected datasets. Neptune
Time series
IoT applications, DevOps, industrial telemetry
Timestream
Timestream is a fast, scalable, and serverless time series database service for IoT and operational applications that makes it easy to store and analyze trillions of events per day. Timestream
Ledger
Systems of record, supply chain, registrations, banking transactions
Quantum Ledger Database (QLDB)
QLDB is a fully managed ledger database that provides a transparent, immutable, and cryptographically verifiable transaction log owned by a central trusted authority. QLDB
Developer Tools
Service
Description
Cloud9
Cloud9 is a cloud-based IDE that enables the user to write, run, and debug code. Cloud9
CodeArtifact
CodeArtifact is a fully managed artifact repository service that makes it easy for organizations of any size to securely store, publish, & share software packages used in their software development process. CodeArtifact
CodeBuild
CodeBuild is a fully managed service that assembles source code, runs unit tests, & also generates artefacts ready to deploy. CodeBuild
CodeGuru
CodeGuru is a developer tool powered by machine learning that provides intelligent recommendations for improving code quality & identifying an application’s most expensive lines of code. CodeGuru
Cloud Development Kit
Cloud Development Kit (AWS CDK) is an open source software development framework to define cloud application resources using familiar programming languages. CDK
CodeCommit
CodeCommit is a version control service that enables the user to personally store & manage Git archives in the AWS cloud. CodeCommit
CodeDeploy
CodeDeploy is a fully managed deployment service that automates software deployments to a variety of compute services such as EC2, Fargate, Lambda, & on-premises servers. CodeDeploy
CodePipeline
CodePipeline is a fully managed continuous delivery service that helps automate release pipelines for fast & reliable app & infra updates. CodePipeline
CodeStar
CodeStar enables to quickly develop, build, & deploy applications on AWS. CodeStar
CLI
AWS CLI is a unified tool to manage AWS services & control multiple services from the command line & automate them through scripts. CLI
X-Ray
X-Ray helps developers analyze & debug production, distributed applications, such as those built using a microservices architecture. X-Ray
CDK uses the familiarity & expressive power of programming languages for modeling apps. CDK
Corretto
Corretto is a no-cost, multiplatform, production-ready distribution of the OpenJDK. Corretto
Crypto Tools
Cryptography is hard to do safely & correctly. The AWS Crypto Tools libraries are designed to help everyone do cryptography right, even without special expertise. Crypto Tools
Serverless Application Model (SAM)
SAM is an open-source framework for building serverless applications. It provides shorthand syntax to express functions, APIs, databases, & event source mappings. SAM
Tools for developing and managing applications on AWS
Security, Identity, & Compliance
Category
Use cases
Service
Description
Identity & access management
Securely manage access to services and resources
Identity & Access Management (IAM)
IAM is a web service for safely controlling access to AWS services. IAM
Securely manage access to services and resources
Single Sign-On
SSO helps in simplifying, managing SSO access to AWS accounts & business applications. SSO
Identity management for apps
Cognito
Cognito lets you add user sign-up, sign-in, & access control to web & mobile apps quickly and easily. Cognito
Managed Microsoft Active Directory
Directory Service
AWS Managed Microsoft Active Directory (AD) enables your directory-aware workloads & AWS resources to use managed Active Directory (AD) in AWS. DirectoryService
Simple, secure service to share AWS resources
Resource Access Manager
Resource Access Manager (RAM) is a service that enables you to easily & securely share AWS resources with any AWS account or within AWS Organization. RAM
Central governance and management across AWS accounts
Organizations
Organizations helps you centrally govern your environment as you grow and scale your workloads on AWS. Orgs
Detection
Unified security and compliance center
Security Hub
Security Hub gives a comprehensive view of security alerts & security posture across AWS accounts. SecurityHub
Managed threat detection service
GuardDuty
GuardDuty is a threat detection service that continuously monitors for malicious activity & unauthorized behavior to protect AWS accounts, workloads, & data stored in S3. GuardDuty
Analyze application security
Inspector
Inspector is a security vulnerability assessment service improves the security & compliance of the AWS resources. Inspector
Record and evaluate configurations of your AWS resources
Config
Config is a service that enables to assess, audit, & evaluate the configurations of AWS resources. Config
Track user activity and API usage
CloudTrail
CloudTrail is a service that enables governance, compliance, operational auditing, & risk auditing of AWS account. CloudTrail
Security management for IoT devices
IoT Device Defender
IoT Device Defender is a fully managed service that helps secure fleet of IoT devices. IoTDD
Infrastructure protection
DDoS protection
Shield
Shield is a managed DDoS protection service that safeguards apps running. It provides always-on detection & automatic inline mitigations that minimize application downtime & latency. Shield
Filter malicious web traffic
Web Application Firewall (WAF)
WAF is a web application firewall that helps protect web apps or APIs against common web exploits that may affect availability, compromise security, or consume excessive resources. WAF
Central management of firewall rules
Firewall Manager
Firewall Manager eases the user AWS WAF administration & maintenance activities over multiple accounts & resources. FirewallManager
Data protection
Discover and protect your sensitive data at scale
Macie
Macie is a fully managed data (security & privacy) service that uses ML & pattern matching to discover & protect sensitive data. Macie
Key storage and management
Key Management Service (KMS)
KMS makes it easy for to create & manage cryptographic keys & control their use across a wide range of AWS services & in your applications. KMS
Hardware based key storage for regulatory compliance
CloudHSM
CloudHSM is a cloud-based hardware security module (HSM) that enables you to easily generate & use your own encryption keys. CloudHSM
Provision, manage, and deploy public and private SSL/TLS certificates
Certificate Manager
Certificate Manager is a service that easily provision, manage, & deploy public and private SSL/TLS certs for use with AWS services & internal connected resources. ACM
Rotate, manage, and retrieve secrets
Secrets Manager
Secrets Manager assist the user to safely encode, store, & recover credentials for any user’s database & other services. SecretsManager
Incident response
Investigate potential security issues
Detective
Detective makes it easy to analyze, investigate, & quickly identify the root cause of potential security issues or suspicious activities. Detective
Provides scalable, cost-effective business continuity for physical, virtual, & cloud servers. CloudEndure
Compliance
No cost, self-service portal for on-demand access to AWS’ compliance reports
Artifact
Artifact is a web service that enables the user to download AWS security & compliance records. Artifact
Data Lakes & Analytics
Category
Use cases
Service
Description
Analytics
Interactive analytics
Athena
Athena is an interactive query service that makes it easy to analyze data in S3 using standard SQL. Athena
Big data processing
EMR
EMR is the industry-leading cloud big data platform for processing vast amounts of data using open source tools such as Apache Spark, Hive, HBase,Flink, Hudi, & Presto. EMR
Data warehousing
Redshift
The most popular & fastest cloud data warehouse. Redshift
Real-time analytics
Kinesis
Kinesis makes it easy to collect, process, & analyze real-time, streaming data so one can get timely insights. Kinesis
Operational analytics
Elasticsearch Service
Elasticsearch Service is a fully managed service that makes it easy to deploy, secure, & run Elasticsearch cost effectively at scale. ES
Dashboards & visualizations
Quicksight
QuickSight is a fast, cloud-powered business intelligence service that makes it easy to deliver insights to everyone in organization. QuickSight
Data movement
Real-time data movement
1) Amazon Managed Streaming for Apache Kafka (MSK) 2) Kinesis Data Streams 3) Kinesis Data Firehose 4) Kinesis Data Analytics 5) Kinesis Video Streams 6) Glue
MSK is a fully managed service that makes it easy to build & run applications that use Apache Kafka to process streaming data. MSKKDSKDFKDAKVSGlue
Data lake
Object storage
1) S3 2) Lake Formation
Lake Formation is a service that makes it easy to set up a secure data lake in days. A data lake is a centralized, curated, & secured repository that stores all data, both in its original form & prepared for analysis. S3LakeFormation
Backup & archive
1) S3 Glacier 2) Backup
S3 Glacier & S3 Glacier Deep Archive are a secure, durable, & extremely low-cost S3 cloud storage classes for data archiving & long-term backup. S3Glacier
Data catalog
1) Glue 2)) Lake Formation
Refer as above.
Third-party data
Data Exchange
Data Exchange makes it easy to find, subscribe to, & use third-party data in the cloud. DataExchange
Predictive analytics && machine learning
Frameworks & interfaces
Deep Learning AMIs
Deep Learning AMIs provide machine learning practitioners & researchers with the infrastructure & tools to accelerate deep learning in the cloud, at any scale. DeepLearningAMIs
Platform services
SageMaker
SageMaker is a fully managed service that provides every developer & data scientist with the ability to build, train, & deploy machine learning (ML) models quickly. SageMaker
Containers
Use cases
Service
Description
Store, encrypt, and manage container images
ECR
Refer compute section
Run containerized applications or build microservices
ECS
Refer compute section
Manage containers with Kubernetes
EKS
Refer compute section
Run containers without managing servers
Fargate
Fargate is a serverless compute engine for containers that works with both ECS & EKS. Fargate
Run containers with server-level control
EC2
Refer compute section
Containerize and migrate existing applications
App2Container
App2Container (A2C) is a command-line tool for modernizing .NET & Java applications into containerized applications. App2Container
Quickly launch and manage containerized applications
Copilot
Copilot is a command line interface (CLI) that enables customers to quickly launch & easily manage containerized applications on AWS. Copilot
Lambda@Edge is a feature of Amazon CloudFront that lets you run code closer to users of your application, which improves performance & reduces latency.
Aurora Serverless is an on-demand, auto-scaling configuration for Amazon Aurora (MySQL & PostgreSQL-compatible editions), where the database will automatically start up, shut down, & scale capacity up or down based on your application’s needs.
RDS Proxy is a fully managed, highly available database proxy for RDS that makes applications more scalable, resilient to database failures, & more secure.
AppSync is a fully managed service that makes it easy to develop GraphQL APIs by handling the heavy lifting of securely connecting to data sources like AWS DynamoDB, Lambda.
EventBridge is a serverless event bus that makes it easy to connect applications together using data from apps, integrated SaaS apps, & AWS services.
Step Functions is a serverless function orchestrator that makes it easy to sequence Lambda functions & multiple AWS services into business-critical applications.
The easiest way to set up and govern a new, secure multi-account AWS environment. ControlTower
Organizations
Organizations helps centrally govern environment as you grow & scale workloads on AWS Organizations
Well-Architected Tool
Well-Architected Tool helps review the state of workloads & compares them to the latest AWS architectural best practices. WATool
Budgets
Budgets allows to set custom budgets to track cost & usage from the simplest to the most complex use cases. Budgets
License Manager
License Manager makes it easier to manage software licenses from software vendors such as Microsoft, SAP, Oracle, & IBM across AWS & on-premises environments. LicenseManager
Provision
CloudFormation
CloudFormation enables the user to design & provision AWS infrastructure deployments predictably & repeatedly. CloudFormation
Service Catalog
Service Catalog allows organizations to create & manage catalogs of IT services that are approved for use on AWS. ServiceCatalog
OpsWorks
OpsWorks presents a simple and flexible way to create and maintain stacks and applications. OpsWorks
Marketplace
Marketplace is a digital catalog with thousands of software listings from independent software vendors that make it easy to find, test, buy, & deploy software that runs on AWS. Marketplace
Operate
CloudWatch
CloudWatch offers a reliable, scalable, & flexible monitoring solution that can easily start. CloudWatch
CloudTrail
CloudTrail is a service that enables governance, compliance, operational auditing, & risk auditing of AWS account. CloudTrail
Read For Me launched at the 2021 AWS re:Invent Builders’ Fair in Las Vegas. A web application which helps the visually impaired ‘hear documents. With the help of AI services such as Amazon Textract, Amazon Comprehend, Amazon Translate and Amazon Polly utilizing an event-driven architecture and serverless technology, users upload a picture of a document, or anything with text, and within a few seconds “hear” that document in their chosen language.
AWS read for me
2- Delivering code and architectures through AWS Proton and Git
Infrastructure operators are looking for ways to centrally define and manage the architecture of their services, while developers need to find a way to quickly and safely deploy their code. In this session, learn how to use AWS Proton to define architectural templates and make them available to development teams in a collaborative manner. Also, learn how to enable development teams to customize their templates so that they fit the needs of their services.
3- Accelerate front-end web and mobile development with AWS Amplify
User-facing web and mobile applications are the primary touchpoint between organizations and their customers. To meet the ever-rising bar for customer experience, developers must deliver high-quality apps with both foundational and differentiating features. AWS Amplify helps front-end web and mobile developers build faster front to back. In this session, review Amplify’s core capabilities like authentication, data, and file storage and explore new capabilities, such as Amplify Geo and extensibility features for easier app customization with AWS services and better integration with existing deployment pipelines. Also learn how customers have been successful using Amplify to innovate in their businesses.
3- Train ML models at scale with Amazon SageMaker, featuring Aurora
Today, AWS customers use Amazon SageMaker to train and tune millions of machine learning (ML) models with billions of parameters. In this session, learn about advanced SageMaker capabilities that can help you manage large-scale model training and tuning, such as distributed training, automatic model tuning, optimizations for deep learning algorithms, debugging, profiling, and model checkpointing, so that even the largest ML models can be trained in record time for the lowest cost. Then, hear from Aurora, a self-driving vehicle technology company, on how they use SageMaker training capabilities to train large perception models for autonomous driving using massive amounts of images, video, and 3D point cloud data.
AWS RE:INVENT 2020 – LATEST PRODUCTS AND SERVICES ANNOUNCED:
Amazon Elasticsearch Service is uniquely positioned to handle log analytics workloads. With a multitude of open-source and AWS-native service options, users can assemble effective log data ingestion pipelines and couple these with Amazon Elasticsearch Service to build a robust, cost-effective log analytics solution. This session reviews patterns and frameworks leveraged by companies such as Capital One to build an end-to-end log analytics solution using Amazon Elasticsearch Service.
Many companies in regulated industries have achieved compliance requirements using AWS Config. They also need a record of the incidents generated by AWS Config in tools such as ServiceNow for audits and remediation. In this session, learn how you can achieve compliance as code using AWS Config. Through the creation of a noncompliant Amazon EC2 machine, this demo shows how AWS Config triggers an incident into a governance, risk, and compliance system for audit recording and remediation. The session also covers best practices for how to automate the setup process with AWS CloudFormation to support many teams.
3- Cost-optimize your enterprise workloads with Amazon EBS – Compute
Recent times have underscored the need to enable agility while maintaining the lowest total cost of ownership (TCO). In this session, learn about the latest volume types that further optimize your performance and cost, while enabling you to run newer applications on AWS with high availability. Dive deep into the latest AWS volume launches and cost-optimization strategies for workloads such as databases, virtual desktop infrastructure, and low-latency interactive applications.
Location data is a vital ingredient in today’s applications, enabling use cases from asset tracking to geomarketing. Now, developers can use the new Amazon Location Service to add maps, tracking, places, geocoding, and geofences to applications, easily, securely, and affordably. Join this session to see how to get started with the service and integrate high-quality location data from geospatial data providers Esri and HERE. Learn how to move from experimentation to production quickly with location capabilities. This session can help developers who require simple location data and those building sophisticated asset tracking, customer engagement, fleet management, and delivery applications.
In this session, learn how Amazon Connect Tasks makes it easy for you to prioritize, assign, and track all the tasks that agents need to complete, including work in external applications needed to resolve customer issues (such as emails, cases, and social posts). Tasks provides a single place for agents to be assigned calls, chats, and tasks, ensuring agents are focused on the highest-priority work. Also, learn how you can also use Tasks with Amazon Connect’s workflow capabilities to automate task-related actions that don’t require agent interaction. Come see how you can use Amazon Connect Tasks to increase customer satisfaction while improving agent productivity.
New agent-assist capabilities from Amazon Connect Wisdom make it easier and faster for agents to find the information they need to solve customer issues in real time. In this session, see how agents can use simple ML-powered search to find information stored across knowledge bases, wikis, and FAQs, like Salesforce and ServiceNow. Join the session to hear Traeger Pellet Grills discuss how it’s using these new features, along with Contact Lens for Amazon Connect, to deliver real-time recommendations to agents based on issues automatically detected during calls.
Grafana is a popular, open-source data visualization tool that enables you to centrally query and analyze observability data across multiple data sources. Learn how the new Amazon Managed Service for Grafana, announced with Grafana’s parent company Grafana Labs, solves common observability challenges. With the new fully managed service, you can monitor, analyze, and alarm on metrics, logs, and traces while offloading the operational management of security patching, upgrading, and resource scaling to AWS. This session also covers new Grafana capabilities such as advanced security features and native AWS service integrations to simplify configuration and onboarding of data sources.
Prometheus is a popular open-source monitoring and alerting solution optimized for container environments. Customers love Prometheus for its active open-source community and flexible query language, using it to monitor containers across AWS and on-premises environments. Amazon Managed Service for Prometheus is a fully managed Prometheus-compatible monitoring service. In this session, learn how you can use the same open-source Prometheus data model, existing instrumentation, and query language to monitor performance with improved scalability, availability, and security without having to manage the underlying infrastructure.
Today, enterprises use low-power, long-range wide-area network (LoRaWAN) connectivity to transmit data over long ranges, through walls and floors of buildings, and in commercial and industrial use cases. However, this requires companies to operate their own LoRa network server (LNS). In this session, learn how you can use LoRaWAN for AWS IoT Core to avoid time-consuming and undifferentiated development work, operational overhead of managing infrastructure, or commitment to costly subscription-based pricing from third-party service providers.
10-AWS CloudShell: The fastest way to get started with AWS CLI
AWS CloudShell is a free, browser-based shell available from the AWS console that provides a simple way to interact with AWS resources through the AWS command-line interface (CLI). In this session, see an overview of both AWS CloudShell and the AWS CLI, which when used together are the fastest and easiest ways to automate tasks, write scripts, and explore new AWS services. Also, see a demo of both services and how to quickly and easily get started with each.
Industrial organizations use AWS IoT SiteWise to liberate their industrial equipment data in order to make data-driven decisions. Now with AWS IoT SiteWise Edge, you can collect, organize, process, and monitor your equipment data on premises before sending it to local or AWS Cloud destinations—all while using the same asset models, APIs, and functionality. Learn how you can extend the capabilities of AWS IoT SiteWise to the edge with AWS IoT SiteWise Edge.
AWS Fault Injection Simulator is a fully managed chaos engineering service that helps you improve application resiliency by making it easy and safe to perform controlled chaos engineering experiments on AWS. In this session, see an overview of chaos engineering and AWS Fault Injection Simulator, and then see a demo of how to use AWS Fault Injection Simulator to make applications more resilient to failure.
Organizations are breaking down data silos and building petabyte-scale data lakes on AWS to democratize access to thousands of end users. Since its launch, AWS Lake Formation has accelerated data lake adoption by making it easy to build and secure data lakes. In this session, AWS Lake Formation GM Mehul A. Shah showcases recent innovations enabling modern data lake use cases. He also introduces a new capability of AWS Lake Formation that enables fine-grained, row-level security and near-real-time analytics in data lakes.
Machine learning (ML) models may generate predictions that are not fair, whether because of biased data, a model that contains bias, or bias that emerges over time as real-world conditions change. Likewise, closed-box ML models are opaque, making it difficult to explain to internal stakeholders, auditors, external regulators, and customers alike why models make predictions both overall and for individual inferences. In this session, learn how Amazon SageMaker Clarify is providing built-in tools to detect bias across the ML workflow including during data prep, after training, and over time in your deployed model.
Amazon EMR on Amazon EKS introduces a new deployment option in Amazon EMR that allows you to run open-source big data frameworks on Amazon EKS. This session digs into the technical details of Amazon EMR on Amazon EKS, helps you understand benefits for customers using Amazon EMR or running open-source Spark on Amazon EKS, and discusses performance considerations.
Finding unexpected anomalies in metrics can be challenging. Some organizations look for data that falls outside of arbitrary ranges; if the range is too narrow, they miss important alerts, and if it is too broad, they receive too many false alerts. In this session, learn about Amazon Lookout for Metrics, a fully managed anomaly detection service that is powered by machine learning and over 20 years of anomaly detection expertise at Amazon to quickly help organizations detect anomalies and understand what caused them. This session guides you through setting up your own solution to monitor for anomalies and showcases how to deliver notifications via various integrations with the service.
17- Improve application availability with ML-powered insights using Amazon DevOps Guru
As applications become increasingly distributed and complex, developers and IT operations teams need more automated practices to maintain application availability and reduce the time and effort spent detecting, debugging, and resolving operational issues manually. In this session, discover Amazon DevOps Guru, an ML-powered cloud operations service, informed by years of Amazon.com and AWS operational excellence, that provides an easy and automated way to improve an application’s operational performance and availability. See how you can transform your IT operations and reduce mean time to recovery (MTTR) with contextual insights.
Amazon Connect Voice ID provides real-time caller authentication that makes voice interactions in contact centers more secure and efficient. Voice ID uses machine learning to verify the identity of genuine customers by analyzing a caller’s unique voice characteristics. This allows contact centers to use an additional security layer that doesn’t rely on the caller answering multiple security questions, and it makes it easy to enroll and verify customers without disrupting the natural flow of the conversation. Join this session to see how fast and secure ML-based voice authentication can power your contact center.
G4ad instances feature the latest AMD Radeon Pro V520 GPUs and second-generation AMD EPYC processors. These new instances deliver the best price performance in Amazon EC2 for graphics-intensive applications such as virtual workstations, game streaming, and graphics rendering. This session dives deep into these instances, ideal use cases, and performance benchmarks, and it provides a demo.
new capability that enables deployment of Amazon ECS tasks on customer-managed infrastructure. This session covers the evolution of Amazon ECS over time, including new on-premises capabilities to manage your hybrid footprint using a common fully managed control plane and API. You learn some foundational technical details and important tenets that AWS is using to design these capabilities, and the session ends with a short demo of Amazon ECS Anywhere.
Amazon Aurora Serverless is an on-demand, auto scaling configuration of Amazon Aurora that automatically adjusts database capacity based on application demand. With Amazon Aurora Serverless v2, you can now scale database workloads instantly from hundreds to hundreds of thousands of transactions per second and adjust capacity in fine-grained increments to provide just the right amount of database resources. This session dives deep into Aurora Serverless v2 and shows how it can help you operate even the most demanding database workloads worry-free.
Apple delights its customers with stunning devices like iPhones, iPads, MacBooks, Apple Watches, and Apple TVs, and developers want to create applications that run on iOS, macOS, iPadOS, tvOS, watchOS, and Safari. In this session, learn how Amazon is innovating to improve the development experience for Apple applications. Come learn how AWS now enables you to develop, build, test, and sign Apple applications with the flexibility, scalability, reliability, and cost benefits of Amazon EC2.
When industrial equipment breaks down, this means costly downtime. To avoid this, you perform maintenance at regular intervals, which is inefficient and increases your maintenance costs. Predictive maintenance allows you to plan the required repair at an optimal time before a breakdown occurs. However, predictive maintenance solutions can be challenging and costly to implement given the high costs and complexity of sensors and infrastructure. You also have to deal with the challenges of interpreting sensor data and accurately detecting faults in order to send alerts. Come learn how Amazon Monitron helps you solve these challenges by offering an out-of-the-box, end-to-end, cost-effective system.
As data grows, we need innovative approaches to get insight from all the information at scale and speed. AQUA is a new hardware-accelerated cache that uses purpose-built analytics processors to deliver up to 10 times better query performance than other cloud data warehouses by automatically boosting certain types of queries. It’s available in preview on Amazon Redshift RA3 nodes in select regions at no extra cost and without any code changes. Attend this session to understand how AQUA works and which analytic workloads will benefit the most from AQUA.
Figuring out if a part has been manufactured correctly, or if machine part is damaged, is vitally important. Making this determination usually requires people to inspect objects, which can be slow and error-prone. Some companies have applied automated image analysis—machine vision—to detect anomalies. While useful, these systems can be very difficult and expensive to maintain. In this session, learn how Amazon Lookout for Vision can automate visual inspection across your production lines in few days. Get started in minutes, and perform visual inspection and identify product defects using as few as 30 images, with no machine learning (ML) expertise required.
AWS Proton is a new service that enables infrastructure operators to create and manage common container-based and serverless application stacks and automate provisioning and code deployments through a self-service interface for their developers. Learn how infrastructure teams can empower their developers to use serverless and container technologies without them first having to learn, configure, and maintain the underlying resources.
Migrating applications from SQL Server to an open-source compatible database can be time-consuming and resource-intensive. Solutions such as the AWS Database Migration Service (AWS DMS) automate data and database schema migration, but there is often more work to do to migrate application code. This session introduces Babelfish for Aurora PostgreSQL, a new translation layer for Amazon Aurora PostgreSQL that enables Amazon Aurora to understand commands from applications designed to run on Microsoft SQL Server. Learn how Babelfish for Aurora PostgreSQL works to reduce the time, risk, and effort of migrating Microsoft SQL Server-based applications to Aurora, and see some of the capabilities that make this possible.
Over the past decade, we’ve witnessed a digital transformation in healthcare, with organizations capturing huge volumes of patient information. But this data is often unstructured and difficult to extract, with information trapped in clinical notes, insurance claims, recorded conversations, and more. In this session, explore how the new Amazon HealthLake service removes the heavy lifting of organizing, indexing, and structuring patient information to provide a complete view of each patient’s health record in the FHIR standard format. Come learn how to use prebuilt machine learning models to analyze and understand relationships in the data, identify trends, and make predictions, ultimately delivering better care for patients.
When business users want to ask new data questions that are not answered by existing business intelligence (BI) dashboards, they rely on BI teams to create or update data models and dashboards, which can take several weeks to complete. In this session, learn how Merlin lets users simply enter their questions on the Merlin search bar and get answers in seconds. Merlin uses natural language processing and semantic data understanding to make sense of the data. It extracts business terminologies and intent from users’ questions, retrieves the corresponding data from the source, and returns the answer in the form of a number, chart, or table in Amazon QuickSight.
When developers publish images publicly for anyone to find and use—whether for free or under license—they must make copies of common images and upload them to public websites and registries that do not offer the same availability commitment as Amazon ECR. This session explores a new Amazon public registry, Amazon ECR Public, built with AWS experience operating Amazon ECR. Here, developers can share georeplicated container software worldwide for anyone to discover and download. Developers can quickly publish public container images with a single command. Learn how anyone can browse and pull container software for use in their own applications.
Industrial companies are constantly working to avoid unplanned downtime due to equipment failure and to improve operational efficiency. Over the years, they have invested in physical sensors, data connectivity, data storage, and dashboarding to monitor equipment and get real-time alerts. Current data analytics methods include single-variable thresholds and physics-based modeling approaches, which are not effective at detecting certain failure types and operating conditions. In this session, learn how Amazon Lookout for Equipment uses data from your sensors to detect abnormal equipment behavior so that you can take action before machine failures occur and avoid unplanned downtime.
In this session, learn how Contact Lens for Amazon Connect enables your contact center supervisors to understand the sentiment of customer conversations, identify call drivers, evaluate compliance with company guidelines, and analyze trends. This can help supervisors train agents, replicate successful interactions, and identify crucial company and product feedback. Your supervisors can conduct fast full-text search on all transcripts to quickly troubleshoot customer issues. With real-time capabilities, you can get alerted to issues during live customer calls and deliver proactive assistance to agents while calls are in progress, improving customer satisfaction. Join this session to see how real-time ML-powered analytics can power your contact center.
AWS Local Zones places compute, storage, database, and other select services closer to locations where no AWS Region exists today. Last year, AWS launched the first two Local Zones in Los Angeles, and organizations are using Local Zones to deliver applications requiring ultra-low-latency compute. AWS is launching Local Zones in 15 metro areas to extend access across the contiguous US. In this session, learn how you can run latency-sensitive portions of applications local to end users and resources in a specific geography, delivering single-digit millisecond latency for use cases such as media and entertainment content creation, real-time gaming, reservoir simulations, electronic design automation, and machine learning.
Your customers expect a fast, frictionless, and personalized customer service experience. In this session, learn about Amazon Connect Customer Profiles—a new unified customer profile capability to allow agents to provide more personalized service during a call. Customer Profiles automatically brings together customer information from multiple applications, such as Salesforce, Marketo, Zendesk, ServiceNow, and Amazon Connect contact history, into a unified customer profile. With Customer Profiles, agents have the information they need, when they need it, directly in their agent application, resulting in improved customer satisfaction and reduced call resolution times (by up to 15%).
Preparing training data can be tedious. Amazon SageMaker Data Wrangler provides a faster, visual way to aggregate and prepare data for machine learning. In this session, learn how to use SageMaker Data Wrangler to connect to data sources and use prebuilt visualization templates and built-in data transforms to streamline the process of cleaning, verifying, and exploring data without having to write a single line of code. See a demonstration of how SageMaker Data Wrangler can be used to perform simple tasks as well as more advanced use cases. Finally, see how you can take your data preparation workflows into production with a single click.
To provide access to critical resources when needed and also limit the potential financial impact of an application outage, a highly available application design is critical. In this session, learn how you can use Amazon CloudWatch and AWS X-Ray to increase the availability of your applications. Join this session to learn how AWS observability solutions can help you proactively detect, efficiently investigate, and quickly resolve operational issues. All of which help you manage and improve your application’s availability.
Security is critical for your Kubernetes-based applications. Join this session to learn about the security features and best practices for Amazon EKS. This session covers encryption and other configurations and policies to keep your containers safe.
Don’t miss the AWS Partner Keynote with Doug Yeum, head of Global Partner Organization; Sandy Carter, vice president, Global Public Sector Partners and Programs; and Dave McCann, vice president, AWS Migration, Marketplace, and Control Services, to learn how AWS is helping partners modernize their businesses to help their customers transform.
Join Swami Sivasubramanian for the first-ever Machine Learning Keynote, live at re:Invent. Hear how AWS is freeing builders to innovate on machine learning with the latest developments in AWS machine learning, demos of new technology, and insights from customers.
Join Peter DeSantis, senior vice president of Global Infrastructure and Customer Support, to learn how AWS has optimized its cloud infrastructure to run some of the world’s most demanding womath.ceilrkloads and give your business a competitive edge.
Join Dr. Werner Vogels at 8:00AM (PST) as he goes behind the scenes to show how Amazon is solving today’s hardest technology problems. Based on his experience working with some of the largest and most successful applications in the world, Dr. Vogels shares his insights on building truly resilient architectures and what that means for the future of software development.
Cloud architecture has evolved over the years as the nature of adoption has changed and the level of maturity in our thinking continues to develop. In this session, Rudy Valdez, VP of Solutions Architecture and Training & Certification, walks
Organizations around the world are minimizing operations and maximizing agility by developing with serverless building blocks. Join David Richardson, VP of Serverless, for a closer look at the serverless programming model, including event-dri
AWS edge computing solutions provide infrastructure and software that move data processing and analysis as close to the endpoint where data is generated as required by customers. In this session, learn about new edge computing capabilities announced at re:Invent and how customers are using purpose-built edge solutions to extend the cloud to the edge.
Topics on simplifying container deployment, legacy workload migration using containers, optimizing costs for containerized applications, container architectural choices, and more.
Do you need to know what’s happening with your applications that run on Amazon EKS? In this session, learn how you can combine open-source tools, such as Prometheus and Grafana, with Amazon CloudWatch using CloudWatch Container Insights. Come to this session for a demo of Prometheus metrics with Container Insights.
The hard part is done. You and your team have spent weeks poring over pull requests, building microservices and containerizing them. Congrats! But what do you do now? How do you get those services on AWS? How do you manage multiple environments? How do you automate deployments? AWS Copilot is a new command line tool that makes building, developing, and operating containerized applications on AWS a breeze. In this session, learn how AWS Copilot can help you and your team manage your services and deploy them to production, safely and delightfully.
Five years ago, if you talked about containers, the assumption was that you were running them on a Linux VM. Fast forward to today, and now that assumption is challenged—in a good way. Come to this session to explore the best data plane option to meet your needs. This session covers the advantages of different abstraction models (Amazon EC2 or AWS Fargate), the operating system (Linux or Windows), the CPU architecture (x86 or Arm), and the commercial model (Spot or On-Demand Instances.)
Security is critical for your Kubernetes-based applications. Join this session to learn about the security features and best practices for Amazon EKS. This session covers encryption and other configurations and policies to keep your containers safe.
In this session, learn how the Commonwealth Bank of Australia (CommBank) built a platform to run containerized applications in a regulated environment and then replicated it across multiple departments using Amazon EKS, AWS CDK, and GitOps. This session covers how to manage multiple multi-team Amazon EKS clusters across multiple AWS accounts while ensuring compliance and observability requirements and integrating Amazon EKS with AWS Identity and Access Management, Amazon CloudWatch, AWS Secrets Manager, Application Load Balancer, Amazon Route 53, and AWS Certificate Manager.
Amazon EKS is a fully managed service that makes it easy to deploy, manage, and scale containerized applications using Kubernetes on AWS. Join this session to learn about how Verizon runs its core applications on Amazon EKS at scale. Verizon also discusses how it worked with AWS to overcome several post-Amazon EKS migration challenges and ensured that the platform was robust.
Containers have helped revolutionize modern application architecture. While managed container services have enabled greater agility in application development, coordinating safe deployments and maintainable infrastructure has become more important than ever. This session outlines how to integrate CI/CD best practices into deployments of your Amazon ECS and AWS Fargate services using pipelines and the latest in AWS developer tooling.
With Amazon ECS, you can run your containerized workloads securely and with ease. In this session, learn how to utilize the full spectrum of Amazon ECS security features and its tight integrations with AWS security features to help you build highly secure applications.
Do you have to budget your spend for container workloads? Do you need to be able to optimize your spend in multiple services to reduce waste? If so, this session is for you. It walks you through how you can use AWS services and configurations to improve your cost visibility. You learn how you can select the best compute options for your containers to maximize utilization and reduce duplication. This combined with various AWS purchase options helps you ensure that you’re using the best options for your services and your budget.
You have a choice of approach when it comes to provisioning compute for your containers. Some users prefer to have more direct control of their instances, while others could do away with the operational heavy lifting. AWS Fargate removes the need to provision and manage servers, lets you specify and pay for resources per application, and improves security through application isolation by design. This session explores the benefits and considerations of running on Fargate or directly on Amazon EC2 instances. You hear about new and upcoming features and learn how Amenity Analytics benefits from the serverless operational model.
Are you confused by the many choices of containers services that you can run on AWS? This session explores all your options and the advantages of each. Whether you are just beginning to learn Docker or are an expert with Kubernetes, join this session to learn how to pick the right services that would work best for you.
Leading containers migration and modernization initiatives can be daunting, but AWS is making it easier. This session explores architectural choices and common patterns, and it provides real-world customer examples. Learn about core technologies to help you build and operate container environments at scale. Discover how abstractions can reduce the pain for infrastructure teams, operators, and developers. Finally, hear the AWS vision for how to bring it all together with improved usability for more business agility.
As the number of services grow within an application, it becomes difficult to pinpoint the exact location of errors, reroute traffic after failures, and safely deploy code changes. In this session, learn how to integrate AWS App Mesh with Amazon ECS to export monitoring data and implement consistent communications control logic across your application. This makes it easy to quickly pinpoint the exact locations of errors and automatically reroute network traffic, keeping your container applications highly available and performing well.
Enterprises are continually looking to develop new applications using container technologies and leveraging modern CI/CD tools to automate their software delivery lifecycles. This session highlights the types of applications and associated factors that make a candidate suitable to be containerized. It also covers best practices that can be considered as you embark on your modernization journey.
Because of its security, reliability, and scalability capabilities, Amazon Elastic Kubernetes Service (Amazon EKS) is used by organization in their most sensitive and mission-critical applications. This session focuses on how Amazon EKS networking works with an Amazon VPC and how to expose your Kubernetes application using Elastic Load Balancing load balancers. It also looks at options for more efficient IP address utilization.
Network design is a critical component in your large-scale migration journey. This session covers some of the real-world networking challenges faced when migrating to the cloud. You learn how to overcome these challenges by diving deep into topics such as establishing private connectivity to your on-premises data center and accelerating data migrations using AWS Direct Connect/Direct Connect gateway, centralizing and simplifying your networking with AWS Transit Gateway, and extending your private DNS into the cloud. The session also includes a discussion of related best practices.
5G will be the catalyst for the next industrial revolution. In this session, come learn about key technical use cases for different industry segments that will be enabled by 5G and related technologies, and hear about the architectural patterns that will support these use cases. You also learn about AWS-enabled 5G reference architectures that incorporate AWS services.
AWS offers a breadth and depth of machine learning (ML) infrastructure you can use through either a do-it-yourself approach or a fully managed approach with Amazon SageMaker. In this session, explore how to choose the proper instance for ML inference based on latency and throughput requirements, model size and complexity, framework choice, and portability. Join this session to compare and contrast compute-optimized CPU-only instances, such as Amazon EC2 C4 and C5; high-performance GPU instances, such as Amazon EC2 G4 and P3; cost-effective variable-size GPU acceleration with Amazon Elastic Inference; and highest performance/cost with Amazon EC2 Inf1 instances powered by custom-designed AWS Inferentia chips.
When it comes to architecting your workloads on VMware Cloud on AWS, it is important to understand design patterns and best practices. Come join this session to learn how you can build well-architected cloud-based solutions for your VMware workloads. This session covers infrastructure designs with native AWS service integrations across compute, networking, storage, security, and operations. It also covers the latest announcements for VMware Cloud on AWS and how you can use these new features in your current architecture.
One of the most critical phases of executing a migration is moving traffic from your existing endpoints to your newly deployed resources in the cloud. This session discusses practices and patterns that can be leveraged to ensure a successful cutover to the cloud. The session covers preparation, tools and services, cutover techniques, rollback strategies, and engagement mechanisms to ensure a successful cutover.
AWS DeepRacer is the fastest way to get rolling with machine learning. Developers of all skill levels can get hands-on, learning how to train reinforcement learning models in a cloud based 3D racing simulator. Attend a session to get started, and then test your skills by competing for prizes and glory in an exciting autonomous car racing experience throughout re:Invent!
AWS DeepRacer gives you an interesting and fun way to get started with reinforcement learning (RL). RL is an advanced machine learning (ML) technique that takes a very different approach to training models than other ML methods. Its super power is that it learns very complex behaviors without requiring any labeled training data, and it can make short-term decisions while optimizing for a longer-term goal. AWS DeepRacer makes it fast and easy to build models in Amazon SageMaker and train, test, and iterate quickly and easily on the track in the AWS DeepRacer 3D racing simulator.
As more organizations are looking to migrate to the cloud, Red Hat OpenShift Service offers a proven, reliable, and consistent platform across the hybrid cloud. Red Hat and AWS recently announced a fully managed joint service that can be deployed directly from the AWS Management Console and can integrate with other AWS Cloud-native services. In this session, you learn about this new service, which delivers production-ready Kubernetes that many enterprises use on premises today, enhancing your ability to shift workloads to the AWS Cloud and making it easier to adopt containers and deploy applications faster. This presentation is brought to you by Red Hat, an AWS Partner.
Event-driven architecture can help you decouple services and simplify dependencies as your applications grow. In this session, you learn how Amazon EventBridge provides new options for developers who are looking to gain the benefits of this approach.
Amazon Timestream is a fast, scalable, and serverless time series database service for IoT and operational applications that makes it easy to store and analyze trillions of events per day at as little as one-tenth the cost of relational databases. In this session, dive deep on Amazon Timestream features and capabilities, including its serverless automatic scaling architecture, its storage tiering that simplifies your data lifecycle management, its purpose-built query engine that lets you access and analyze recent and historical data together, and its built-in time series analytics functions that help you identify trends and patterns in your data in near-real time.
Savings Plans is a flexible pricing model that allows you to save up to 72 percent on Amazon EC2, AWS Fargate, and AWS Lambda. Many AWS users have adopted Savings Plans since its launch in November 2019 for the simplicity, savings, ease of use, and flexibility. In this session, learn how many organizations use Savings Plans to drive more migrations and business outcomes. Hear from Comcast on their compute transformation journey to the cloud and how it started with RIs. As their cloud usage evolved, they adopted Savings Plans to drive business outcomes such as new architecture patterns.
The ability to deploy only configuration changes, separate from code, means you do not have to restart the applications or services that use the configuration and changes take effect immediately. In this session, learn best practices used by teams within Amazon to rapidly release features at scale. Learn about a pattern that uses AWS CodePipeline and AWS AppConfig that will allow you to roll out application configurations without taking applications out of service. This will help you ship features faster across complex environments or regions.
I watched (binged) the A Cloud Guru course in two days and did the 6 practice exams over a week. I originally was only getting 70%’s on the exams, but continued doing them on my free time (to the point where I’d have 15 minutes and knock one out on my phone lol) and started getting 90%’s. – A mix of knowledge vs memorization tbh. Just make sure you read why your answers are wrong.
I don’t really have a huge IT background, although will note I work in a DevOps (1 1/2 years) environment; so I do use AWS to host our infrastructure. However, the exam is very high level compared to what I do/services I use. I’m fairly certain with zero knowledge/experience, someone could pass this within two weeks. AWS is also currently promoting a “get certified” challenge and is offering 50% off.
Went through the entire CloudAcademy course. Most of the info went out the other ear. Got a 67% on their final exam. Took the ExamPro free exam, got 69%.
Was going to take it last Saturday, but I bought TutorialDojo’s exams on Udemy. Did one Friday night, got a 50% and rescheduled it a week later to today Sunday.
Took 4 total TD exams. Got a 50%, 54%, 67%, and 64%. Even up until last night I hated the TD exams with a passion, I thought they were covering way too much stuff that didn’t even pop up in study guides I read. Their wording for some problems were also atrocious. But looking back, the bulk of my “studying” was going through their pretty well written explanations, and their links to the white papers allowed me to know what and where to read.
Not sure what score I got yet on the exam. As someone who always hated testing, I’m pretty proud of myself. I also had to take a dump really bad starting at around question 25. Thanks to TutorialsDojo Jon Bonso for completely destroying my confidence before the exam, forcing me to up my game. It’s better to walk in way over prepared than underprepared.
I would like to thank this community for recommendations about exam preparation. It was wayyyy easier than I expected (also way easier than TD practice exams scenario-based questions-a lot less wordy on real exam). I felt so unready before the exam that I rescheduled the exam twice. Quick tip: if you have limited time to prepare for this exam, I would recommend scheduling the exam beforehand so that you don’t procrastinate fully.
Resources:
-Stephane’s course on Udemy (I have seen people saying to skip hands-on videos but I found them extremely helpful to understand most of the concepts-so try to not skip those hands-on)
-Tutorials Dojo practice exams (I did only 3.5 practice tests out of 5 and already got 8-10 EXACTLY worded questions on my real exam)
Previous Aws knowledge:
-Very little to no experience (deployed my group’s app to cloud via Elastic beanstalk in college-had 0 clue at the time about what I was doing-had clear guidelines)
Preparation duration: -2 weeks (honestly watched videos for 12 days and then went over summary and practice tests on the last two days)
I used Stephane Maarek on Udemy. Purchased his course and the 6 Practice Exams. Also got Neal Davis’ 500 practice questions on Udemy. I took Stephane’s class over 2 days, then spent the next 2 weeks going over the tests (3~4 per day) till I was constantly getting over 80% – passed my exam with a 882.
What an adventure, I’ve never really gieven though to getting a cert until one day it just dawned on me that it’s one of the few resources that are globally accepted. So you can approach any company and basically prove you know what’s up on AWS 😀
Passed with two weeks of prep (after work and weekends)
This was just a nice structured presentation that also gives you the powerpoint slides plus cheatsheets and a nice overview of what is said in each video lecture.
Udemy – AWS Certified Cloud Practitioner Practice Exams, created by Jon Bonso**, Tutorials Dojo**
These are some good prep exams, they ask the questions in a way that actually make you think about the related AWS Service. With only a few “Bullshit! That was asked in a confusing way” questions that popped up.
I took CCP 2 days ago and got the pass notification right after submitting the answers. In about the next 3 hours I got an email from Credly for the badge. This morning I got an official email from AWS congratulating me on passing, the score is much higher than I expected. I took Stephane Maarek’s CCP course and his 6 demo exams, then Neal Davis’ 500 questions also. On all the demo exams, I took 1 fail and all passes with about 700-800. But in the real exam, I got 860. The questions in the real exam are kind of less verbose IMO, but I don’t truly agree with some people I see on this sub saying that they are easier. Just a little bit of sharing, now I’ll find something to continue ^^
Passed the exam! Spent 25 minutes answering all the questions. Another 10 to review. I might come back and update this post with my actual score.
Background
– A year of experience working with AWS (e.g., EC2, Elastic Beanstalk, Route 53, and Amplify).
– Cloud development on AWS is not my strong suit. I just Google everything, so my knowledge is very spotty. Less so now since I studied for this exam.
Study stats
– Spent three weeks studying for the exam.
– Studied an hour to two every day.
– Solved 800-1000 practice questions.
– Took 450 screenshots of practice questions and technology/service descriptions as reference notes to quickly swift through on my phone and computer for review. Screenshots were of questions that I either didn’t know, knew but was iffy on, or those I believed I’d easily forget.
– Made 15-20 pages of notes. Chill. Nothing crazy. This is on A4 paper. Free-form note taking. With big diagrams. Around 60-80 words per page.
– I was getting low-to-mid 70%s on Neal Davis’s and Stephane Maarek’s practice exams. Highest score I got was an 80%.
– I got a 67(?)% on one of Stephane Maarek’s exams. The only sub-70% I ever got on any practice test. I got slightly anxious. But given how much harder Maarek’s exams are compared to the actual exam, the anxiety was undue.
– Finishing the practice exams on time was never a problem for me. I would finish all of them comfortably within 35 minutes.
Resources used
– AWS Cloud Practitioner Essentials on the AWS Training and Certification Portal
– AWS Certified Cloud Practitioner Practice Tests (Book) by Neal Davis
– 6 Practice Exams | AWS Certified Cloud Practitioner CLF-C01 by Stephane Maarek*
– Certified Cloud Practitioner Course by Exam Pro (Paid Version)**
– One or two free practice exams found by a quick Google search
*Regarding Exam Pro: I went through about 40% of the video lectures. I went through all the videos in the first few sections but felt that watching the lectures was too slow and laborious even at 1.5-2x speed. (The creator, for the most part, reads off of the slides, adding brief comments here and there.) So, I decided to only watch the video lectures for sections I didn’t have a good grasp on. (I believe the video lectures provided in the course are just split versions of the full length course available for free on YouTube under the freeCodeCamp channel, here.) The online course provides five practice exams. I did not take any of them.
**Regarding Stephane Maarek: I only took his practice exams. I did not take his study guide course.
Notes
– My study regimen (i.e., an hour to two every day for three weeks) was overkill.
– The questions on the practice exams created by Neal Davis and Stephane Maarek were significantly harder than those on the actual exam. I believe I could’ve passed without touching any of these resources.
– I retook one or two practice exams out of the 10+ I’ve taken. I don’t think there’s a need to retake the exams as long as you are diligent about studying the questions and underlying concepts you got wrong. I reviewed all the questions I missed on every practice exam the day before.
What would I do differently?
– Focus on practice tests only. No video lectures.
– Focus on the technologies domain. You can intuit your way through questions in the other domains.
I thank you all for helping me through this process! Couldn’t have done it without all of the recommendations and guidance on this page.
Background: I am a back-end developer that works 12 hours a day for corporate America, so no time to study (or do anything) but I made it work.
Could I have probably gone for SAA first? Yeah, but I wanted to prove to myself that I could do it. I studied for about a month. I used Maarek’s Udemy course at 1.5x speed and I couldn’t recommend it more. I also used his practice exams. I’ll be honest, I took 5 practice exams and got somehow managed to fail every single one in the mid 60’s lol. Cleared the exam with an 800. Practice exams WAY harder.
My 2 cents on must knows:
AWS Shared Security Model (who owns what)
Everything Billing (EC2 instance, S3, different support plans)
I had a few ML questions that caught me off guard
VPC concepts – i.e. subnets, NACL, Transit Gateway
I studied solidly for two weeks, starting with Tutorials Dojo (which was recommended somewhere on here). I turned all of their vocabulary words and end of module questions into note cards. I did the same with their final assessment and one free exam.
During my second week, I studied the cards for anywhere from one to two hours a day, and I’d randomly watch videos on common exam questions.
The last thing I did was watch a 3 hr long video this morning that walks you through setting up AWS Instances. The visual of setting things up filled in a lot of holes.
I had some PSI software problems, and ended up getting started late. I was pretty dejected towards the end of the exam, and was honestly (and pleasantly) surprised to see that I passed.
Hopefully this helps someone. Keep studying and pushing through – if you know it, you know it. Even if you have a bad start. Cheers 🍻
This time got worst. 665 All domains I sucked. Less on dx and bgp. More on lb with EKS, cloud formation with pam, on premise dns but resource is using ip address from on premise so I can't tell if this is supposed to be inbound or outbound endpoint. Macsec. There is one on data flow. Like which one comes first. Gateway endpoint or gateway load balancer. I've setup an endpoint which comes before load balancer since I have to reference it via route table. Something about 7300 and 7100. I nvr quite understand why we use them. Many choose 2 or three. I'll make sure I max my time before I call it quits. Fk. This is harder than cissp or I never force myself. submitted by /u/newbietofx [link] [comments]
I just want to thank this community for all the tips and tricks. I took the exam this morning, finished by 11 AM, and received the results by 6 PM. The exam was more difficult than I expected (which scared me, I thought I might fail). The resources I used included Stephane Maarek's course on Udemy, as well as his practice exam and TD's practice exams. Here's a breakdown of my practice exam scores, listed in the order I took them: Stephane Maarek's Practice Exams: Practice Test 1: 72% Practice Test 2: 69% Practice Test 3: 70% Practice Test 4: 76% Practice Test 5: 78% Practice Test 6: 55% (I'm not sure how this happened, lol) TD's Practice Exams: Timed Mode Set 1: 81.54% Timed Mode Set 2: 69.23% Timed Mode Set 3: 75.38% Timed Mode Set 4: 72.31% Review Mode Set 1: 83.08% Timed Mode Set 5: 66.15% Timed Mode Set 6: 67.69% Timed Mode Set 7: 63.08% Bonus Timed Mode Set 8: 77.78% I found that TD's questions were closer to the real exam. My final score was 810. I started Studying last May for 1-2 hrs everyday(on and off due to fulltime work) The explanations for each question in the practice tests really helped me understand and learn the services. submitted by /u/Rocket_Job [link] [comments]
I always get these questions about different ways to federate: there are AssumeRolesWithSAML, AssumeRolesWithWebIdentity, SAML 2.0, IdP, Active Directories, LDAP, etc and etc., and even though I reviewed it a million times, I still can't get the questions right. Adding to this complexity is whether or not we need to create IAM roles or policies, if we need ARNs, and mapping IdP to IAM roles. I really just want to master it once and for all, all of this federation stuff. How to learn this? submitted by /u/jesuisapprenant [link] [comments]
Hi, just wanted to hear some thoughts. I plan to take the AWS Cloud Practitioner in 3 months and I plan to study for it for a couple of hours per day around 2-3 hours and 5 days a week on top of my full-time job. I’m completely new to cloud and was wondering if it’s enough time for me to study? I’ve been hearing from some people that they studied for much longer for the exam and I’m worried because I want to pass it because the money i’ll spend is sponsored. Thank you in advance! submitted by /u/Ready_Manager2538 [link] [comments]
I've been through stephen maarke's course as well as a two practice tests from TD and I still failed my test. After looking at my weak areas for the exam, it seems to be centered around billing. How can I learn more on this topic without having to go through Maareks course again. Does anyone have any note cards by chance? Thanks in advance submitted by /u/keeponpushin1986 [link] [comments]
I am searching for a way to boost my AWS skills, and am trying to decide between attending AWS ReInvent or starting a certification. As a disclaimer, I am not doing this in an attempt to get a job or resume build. I am already somewhere between intermediate and advanced with a decent amount of AWS tools and searching for a way to get closer to an expert in at least a few of these topics. For people here who have done some of the more advanced certifications, do you feel like they are a good tool to increase your skills, or are they more of a way to prove/quantify the skills you already have? Also, any recommendations for which certifications are best for advanced data engineering / DevOps would be much appreciated! submitted by /u/ASAP_Beet [link] [comments]
I am planning to start the AWS cloud practitioner certificate, what are some resources available for free , to practice and get good idea of my potential result? Also, I have no cloud background but I am a Computer science student doing bachelors, how much time will it take for me to prepare ? submitted by /u/Bippity_Boppity69 [link] [comments]
https://preview.redd.it/lhm8f52dnied1.png?width=2000&format=png&auto=webp&s=8ba557a06b2eba22741f2f324e1bd07cd017704f I passed my exam Cloud Practitioner CLF-C02 exam 3 months ago. I was very excited and now I'm preparing for my other AWS Certification. All thanks to my youtube guides and to itexamshub for their source guide. submitted by /u/Commercial-Suit-7693 [link] [comments]
Mistral AI’s Mistral Large 2 (24.07) foundation model is now generally available in Amazon Bedrock. This model is the latest version of Mistral AI's flagship large language model, Mistral Large (24.02), with significant improvements on multilingual accuracy, conversational behavior, coding capabilities, reasoning and instruction-following behavior. With this new release of Mistral Large, you can leverage its multi-lingual proficiency to seamlessly communicate and process information in dozens of languages, including English, French, German, Spanish, Italian, Chinese, Japanese, Korean, Portuguese, Dutch, Polish, Arabic, and Hindi. It has an increased context window of 128k (compared to 32k in the original version), making it able to process more information in order to generate accurate responses. Its advanced coding capabilities enable you to develop software across various programming languages, such as Python, Java, C, C++, JavaScript, and Bash, as well as specialized languages like Swift and Fortran. The model also has best-in-class agentic capabilities with native function calling and JSON outputting allowing it to interact with external systems, APIs, and tools. Mistral AI’s Mistral Large 2 foundation model is now available on Amazon Bedrock in the US West (Oregon) region. To learn more read the Machine Learning blog, visit the Mistral AI on Amazon Bedrock product page, and read the documentation. To get started with Mistral Large on Amazon Bedrock, visit the Amazon Bedrock console.
Today, AWS open-sourced the AWS Signer plugin for Notation, giving customers flexibility and transparency in how they sign and verify container images with AWS Signer, a managed signing service. Notation is an open source tool developed by the Notary Project, an industry standard for securing software supply chains by authenticating container images and other OCI artifacts. The plugin extends Notation with Signer managed secrets and revocation capabilities. Customers can now incorporate the Signer plugin as a library inside their native tools to generate and verify container artifacts signatures. Notation can be used as a CLI executable or as a Golang library. With the open sourced Signer Plugin, you can now seamlessly incorporate signing and verification activities into your existing applications and tooling by adding a go-library. This removes the need for installing and invoking the plugin as an executable. Additionally, you get transparency in how AWS Signer APIs are used for signature generation and verification. If you prefer a CLI integration with Signer, you can now also build your own version of the Signer Plugin executable or continue downloading pre-built executables from AWS Signer documentation. AWS Signer Plugin is released as an open-source project under the Apache 2.0 license. You can access the source code and instructions to build the Signer plugin in the GitHub repository here. To learn more about container image signing refer this blog.
AWS DataSync now supports agentless cross-region data transfers between all regions in the commercial AWS partition, including opt-in regions. With this update, you can now transfer millions of files or objects between AWS Storage services such as Amazon S3, Amazon EFS, and Amazon FSx in different regions without deploying or managing a DataSync agent. AWS DataSync is an online data movement service that simplifies, automates, and accelerates the transfer of files and objects. It uses a purpose-built network protocol and scale-out architecture to move data quickly and securely between AWS Storage services, on-premises storage, edge locations, or other clouds. DataSync uses an agent to access storage systems that are located on premises or in other clouds while providing fully-managed access to storage in AWS. With this release, you can now transfer data between AWS Storage services in any region in the commercial partition, including opt-in regions, without deploying a DataSync agent. This enables you to easily replicate data between managed file systems for business continuity, as well as copy portions of your data to different buckets or file systems to meet evolving application requirements. Agentless cross-region transfers are now available in all AWS regions where AWS DataSync is available. To get started, visit the AWS DataSync console. To learn more, view the AWS DataSync documentation.
Hi Community, I bought Stephane Mareeks DEA-C01 practice exam course and posted 8 to 10 questions from last 3 weeks but not getting any response and posted the request in his another hands on course still no response. Exam is scheduled in 7 days. Not only for me for others as well same . How I can get him to respond to our queries? Shall I raise a udemy support ticket? Or request for a refund submitted by /u/Low-Tale-3532 [link] [comments]
Hey Cloud Guys Recommend me best course for AWS foundation and solution architecture for job I have 2 months to complete these courses submitted by /u/WhatsMueenUpto [link] [comments]
Note : This certification exam was just recently announced and is entering "BETA" in August. Last updated : 24-July-2024 Here is a master list of resources to help those who are interested in the new AWS Certified AI Practitioner exam. All my Exam Resource Posts : [CCP/CLF](https://www.reddit.com/r/AWSCertifications/comments/1d1xg1p/aws\_certified\_cloud\_practitioner\_clfc02\_ccp/) [SAA](https://www.reddit.com/r/AWSCertifications/comments/1d5kkuw/aws\_certified\_solutions\_architect\_associate/) [DVA](https://www.reddit.com/r/AWSCertifications/comments/1db1vhf/aws\_certified\_developer\_associate\_dvac02\_resources/) [DEA](https://www.reddit.com/r/AWSCertifications/comments/195sbcj/aws\_certified\_data\_engineer\_associate\_dea\_deac01/) [AIF] (this one!) If you find this post useful - upvote. This post is written for benefit of this community and hence I am happy to take feedback / suggestions / changes etc - please comment! tl;dr The exam was just announced and is not even live right now. It will open up in BETA from August 13. The official material behind the exam is yet to be published in detail. Even the "Exam Guide" (aka "Curriculum") is not yet out there and this means any training material is bound to change when its announced. However there are a lot of useful pointers / material we can generally get started on / watch out for and this post will be in "beta" mode itself till the exams are Generally Available. Exam Details The exam code is AIF-C01. AWS page with all the details : [https://aws.amazon.com/certification/certified-ai-practitioner/\](https://aws.amazon.com/certification/certified-ai-practitioner/) The first resource to usually read is the Exam Guide (tells you whats in / out of scope) : Yet to be published. Minimum Viable Path to Certification Most people usually need 2 things to pass the exam A single video based course introducing the exam curriculum Typically these are courses where someone reads from some slides, shows you the AWS console and how to use it and then gives you tips on what to remember. One good quality practice exam Note : do not fall for some random "dump" found on internet or any resource offerring you a Guarantee to pass. 1. Video Courses There aren't any video courses yet. Stephane Maarek and Andrew Brown have indicated they are preparing material. I will link to these when I hear of their release. There is an "Exam Prep" course from Skillbuilder but note that this just covers the high level domains but is not a comprehensive deep dive. [https://explore.skillbuilder.aws/learn/public/learning\_plan/view/2193/standard-exam-prep-plan-aws-certified-ai-practitioner-aif-c01\](https://explore.skillbuilder.aws/learn/public/learning\_plan/view/2193/standard-exam-prep-plan-aws-certified-ai-practitioner-aif-c01) Optional : There is a slightly extended version of this in the paid tier. Right now it seems to be identical to the free one but should be updated on 13th August with more (paid tier only) material. [https://explore.skillbuilder.aws/learn/public/learning\_plan/view/2194/enhanced-exam-prep-plan-aws-certified-ai-practitioner-aif-c01\](https://explore.skillbuilder.aws/learn/public/learning\_plan/view/2194/enhanced-exam-prep-plan-aws-certified-ai-practitioner-aif-c01) Please note that this course may not enough on its own to pass and you may want to try additional material below. 2. Practice Exams Official Practice exam : not yet published [Tutorialsdojo.com](http://Tutorialsdojo.com) seem to be working on some material here (as per threads where they broke the platform and said its because they are doing deployment to support the new question types) Alternative Gen AI learning material FREE courses on SkillBuilder Generative AI Learning Plan for Developers Amazon Bedrock - Getting Started Building Generative AI Applications using Amazon Bedrock AI Language Service Learning Plan Foundations of Prompt Engineering Subscription tier (paid) on Skillbuilder Cloud Quest - Gen AI is a game based learning platform - provides a digital badge on completion. You can follow the Twitch.tv video series aligned with this Quest for free here : https://pages.awscloud.com/GLOBAL-other-T2-Traincert-AWS-Cloud-Quest-Gen-AI-Season1-2024-reg.html [Simulearn - Gen AI](https://explore.skillbuilder.aws/learn/course/external/view/elearning/19378/aws-cloud-quest-generative-ai) is a Gen AI / Gamified learning platform that's new - its not free and does not provide a digital badge. FAQ What does BETA exams mean? BETA exams are actual certification exams but are discounted as they are new and may not be as polished as the final generally available exams. In return for the small discount and early access - test takers are basically providing feedback on the exam / exam questions in a way that allows AWS to then make it generally available for the public. This also allows content providers to take the exam and tailor their training / test material. Where can I find vouchers for the exam? The BETA exams are discounted by 33% during Beta phase. If you have a voucher for 50% off from passing another AWS exam or other source - you could try to see if that stacks on top - we would not for sure till someone has attempted this. When will I get my exam results. Unlike previous beta exams - these new one's are Does this exam format differ to the Cloud Practitioner exam? Yes - please see this post on new types of questions that you can expect on this exam https://www.reddit.com/r/AWSCertifications/comments/1ea16sa/new_question_types_for_new_exams Good Luck folks! submitted by /u/madrasi2021 [link] [comments]
I've been studying & it's relatively new to me, I was thinking when to book it. I've just learnt up to Amazon S3 on Stepehen Mareek's course but I really want to get my exam booked in & have a goal to focus to, any thoughts? submitted by /u/Theravrauli [link] [comments]
We have a corporate Udemy account and I have seen a lot of people recommending the TD Practice Tests. Are they the Jon Bonso tests? Thanks submitted by /u/jaron1978 [link] [comments]
Hi people, Is there any way we can appear for AWS Cloud Practitioner exam for free or discounted rate? My current organization will not provide me reimbursement so I'll think of giving it on my own. Any suggestions would be great. Thanks! submitted by /u/Conscious-Raccoon-01 [link] [comments]
I used Kodekloud AWS Solutions Architect Associate Certification course for video och and hands-on training then I bought the practice tests at Tuturialsdojo. If anyone have questions regarding any of those just ask along! submitted by /u/Pudge4tw [link] [comments]
I was trying to build a Lambda function in AWS CodeCommit and AWS CodeBuild, but this was tried in the ZIP mode. Unfortunately, it's exceeding the threshold defined for the zip by the lambda function: 50MB. Now that I want to do the same with it but in image mode, I can't seem to manage to push the code into ECR. Any help would be appreciated. My buildspec.yml: version: 0.2 env: variables: AWS_DEFAULT_REGION: "us-east-1" AWS_ACCOUNT_ID: "0123" IMAGE_REPO_NAME: "deployment" IMAGE_TAG: "latest" S3_BUCKET: "deployment" phases: install: runtime-versions: python: 3.11 commands: - nohup /usr/local/bin/dockerd --host=unix:///var/run/docker.sock --host=tcp://127.0.0.1:2375 --storage-driver=overlay2 & - timeout 15 sh -c "until docker info; do echo .; sleep 1; done" pre_build: commands: - echo Logging in to Amazon ECR... - aws ecr get-login-password --region $AWS_DEFAULT_REGION | docker login --username AWS --password-stdin $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com || true - REPOSITORY_URI=$AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME build: commands: - echo Build started on `date` - echo Building the Docker image... - docker build -t $IMAGE_REPO_NAME:$IMAGE_TAG . - docker tag $IMAGE_REPO_NAME:$IMAGE_TAG $REPOSITORY_URI:$IMAGE_TAG post_build: commands: - echo Build completed on `date` - echo Pushing the Docker image... - docker push $REPOSITORY_URI:$IMAGE_TAG - echo Writing image definitions file... - printf '[{"name":"container-name","imageUri":"%s"}]' $REPOSITORY_URI:$IMAGE_TAG > imagedefinitions.json - echo Updating Lambda function... - sed -i 's|0123.dkr.ecr.us-east-1.amazonaws.com/deployment|'$REPOSITORY_URI:$IMAGE_TAG'|' template.yaml - pip install aws-sam-cli - sam package --template-file template.yaml --s3-bucket $S3_BUCKET --output-template-file packaged.yaml artifacts: files: - packaged.yaml - imagedefinitions.json My template.yml : AWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Resources: MyLambdaFunction: Type: AWS::Serverless::Function Properties: PackageType: Image ImageUri: 0123.dkr.ecr.us-east-1.amazonaws.com/deployment MemorySize: 1024 Timeout: 150 Environment: Variables: PARAM1: "value1" Events: HttpApi: Type: HttpApi Properties: Path: / Method: GET Outputs: LambdaFunction: Description: "Lambda Function ARN" Value: !GetAtt MyLambdaFunction.Arn LambdaFunctionUrl: Description: "Lambda Function URL" Value: !GetAtt MyLambdaFunction.FunctionUrl Logs : logs logs submitted by /u/mohil-makwana31 [link] [comments]
For these two (AssumeRoleWithWebIdentity vs AssumeRoleWithSAML), if we are using an enterprise solution LDAP/Active Directory etc, we will be using AssumeRoleWithSAML right, and then if we are using social media, like Facebook, Google, via Cognito, it would be AssumeRoleWithWebIdentity? The thing is Cognito supports SAML as well, so why would someone choose AssumeRoleWithSAML over AssumeRoleWithWebIdentity? Thanks in advance submitted by /u/jesuisapprenant [link] [comments]
My job requires SysOps assc cert, after getting my ccp do I really need the SAA before getting SysOps? Is there any benefit there? I was always made to believe Solitions Architect is basically for ppl in sales. TIA submitted by /u/logan9053 [link] [comments]
Someone said there aren’t enough posts like this so… Barely passed. Don’t feel like the resources I used adequately prepared me for the exam, and I probably should have studied way harder. I’m a part of an AWS study group that is down to 2 members now. We’re deciding between data engineer or developer next. submitted by /u/escape00000 [link] [comments]
Welp taking the test next week at the testing center. I used Stefan on udemy and TD and I feel I have a good grasp on the material and went over CAF and well architect framework. submitted by /u/gbrot [link] [comments]
I write my exams in the next hour and I’m not so confident about it. Kinda thinking about rescheduling. submitted by /u/Competitive_Gift_539 [link] [comments]
AWS Cost Categories has added a new dimension “Billing Entity” to its rules. You can now use eight types of dimensions: “Linked Account”, “Charge Type”, “Service”, "Usage Type", “Cost Allocation Tags”, “Region”, “Billing Entity” and other “Cost Category” while creating cost categories rules. AWS Cost Categories is a feature within the AWS Cost Management product suite that enables you to group cost and usage information into meaningful categories based on your needs. You can create custom categories and map your cost and usage information into these categories based on the rules defined by you using various dimensions. Once cost categories are set up and enabled, you will be able to view and manage your AWS cost and usage information by these categories in AWS cost management services, e.g. understanding the ownership of your spend at the Cost Categories level in AWS Cost Explorer and AWS Cost and Usage Report (CUR). Cost categories can be applied to your AWS cost and usage at the beginning of the month or retroactively for up to 12 months. Adding Billing Entity gives customers more granular control over their cost categories. Billing Entity is the unit to identify whether customers’ invoices or transactions are for AWS Marketplace or for purchases of other AWS services. Cost categories is provided free of charge and this feature is available in all Commercial Regions. To get started with cost categories, please visit AWS Cost Categories product details page, AWS Cost Categories FAQs - Amazon Web Services.
This is my official “I passed DEA-C01” post. I was not planning to post, but it was requested by u/madrasi2021. His posts and comments have been very helpful, so I decided to post per his request. I found there were not as many resources available for DEA as for other certifications. I’m assuming this is because the cert is so new. I used a video course (Udemy - Maarek/Kane) that was pretty good but not as hands-on as Cantrill’s courses. (Unfortunately I don’t see DEA moving ahead on Cantrill’s roadmap. Maybe we can encourage him…) I also used practice tests from TutorialsDojo. There were only 3 practice test sets in TD for DEA (compared to 7 sets for SAA). The tests were still helpful, even though there were fewer questions to study. Now, I was able to pass the exam with these resources, but I didn’t think they covered the material as fully as other exams. Also, I have some background in data engineering, data analysis, and especially SQL going back several years, but only about a year experience with AWS services. Good luck to everyone who tackles this exam! submitted by /u/proliphery [link] [comments]
First, let me share my 4-week experience with those who are still undecisive on whether to go for it, or how. Just for context, this is my first experience with AWS ever, and my first AWS certification ever (I skipped Cloud Practitioner and Solutions Architect). 1. Stephane Maarek's course on Udemy. It contains 34-35 hours of contents. I truly appreciated how he touched base with the basic knowledge of AWS and common abbreviations that you should have already known. After each/most theory lecture or explanation, he will show a hands-on of how it would be applied in real life, and you are welcome to practice alongside. He also makes sure that you are always within the free tier wherever possible so that there are no charges to be paid. If there are, he will warn you before starting the hands-on. IMO, this course is super helpful to go through "quickly" to get a first glance at the wordings, contents, understanding of the workflows, what connects to what, order of execution etc. 2. TutorialDojo's Practice Exams. After quickly going through and understanding Stephane's course, practicing is ABSOLUTELY CRUCIAL to pass the exam. Practicing question papers or answering questions before the exams is always a prime rule of succeeding in any exam! Always remember! TD provides a detailed explanation and ref. links for every question, regardless if you answered it right or wrong. You can filter the explanations per topic, or filter only the questions that were wrongly answered. TD has 3 modes: a. Time-based -> You have 5 practice exams which are time-based, with the intention of simulating a real exam. You get your score at the end, and the explanations as well. b. Review mode -> You get 5 review mode exam question sets. This is a more "relaxed" exam simulation, where your answer is evaluated immediately after answering each question, and gives you the explanation for it. c. Topic-based -> You get 4 sets, one for each of the main topics that are evaluated in the exam. You will be receiving questions pertaining only to the topic which you selected, and it runs the same as in review mode (getting the explanation immediately after answering each question) Feel free to ask anything, I will try to help whenever and however I can! Question I just have a quick question for my fellow AWS certification holders. What next? Re-write your CV? Apply for DevOps jobs? Any advice on how to make the switch from IT Support to DevOps (with experience in SE)? submitted by /u/mayur2797 [link] [comments]
The most advanced and capable Meta Llama models to date, Llama 3.1, are now available in Amazon SageMaker JumpStart, a machine learning (ML) hub that offers pretrained models and built-in algorithms to help you quickly get started with ML. You can deploy and use Llama 3.1 models with a few clicks in SageMaker Studio or programmatically through the SageMaker Python SDK. Llama 3.1 models demonstrate significant improvements over previous versions due to increased training data and scale. The models support a 128K context length, an increase of 120K tokens from Llama 3. Llama 3.1 models have 16 times the capacity of Llama 3 models and improved reasoning for multilingual dialogue use cases in eight languages. The models can access more information from lengthy text passages to make more informed decisions and leverage richer contextual data to generate more refined responses. According to Meta, Llama 3.1 405B is one of the largest publicly available foundation models and is well suited for synthetic data generation and model distillation, both of which can improve smaller Llama models. For use of synthetic data to fine tune models, you must comply with Meta's license. Read the EULA for additional information. All Llama 3.1 models provide state-of-the-art capabilities in general knowledge, math, tool use, and multilingual translation. Llama 3.1 models are available today in SageMaker JumpStart in US East (Ohio), US West (Oregon), and US East (N. Virginia) AWS regions. To get started with Llama 3.1 models in SageMaker JumpStart, see documentation and blog.
The most advanced Meta Llama models to date, Llama 3.1, are now available in Amazon Bedrock. Amazon Bedrock offers a turnkey way to build generative AI applications with Llama. Llama 3.1 models are a collection of 8B, 70B, and 405B parameter size models offering new capabilities for your generative AI applications. All Llama 3.1 models demonstrate significant improvements over previous versions. The models support a 128K context length, have 16 times the capacity of Llama 3, and exhibit improved reasoning for multilingual dialogue use cases in eight languages. The models access more information from lengthy text to make more informed decisions and leverage richer contextual data to generate more subtle and refined responses. According to Meta, Llama 3.1 405B is one of the best and largest publicly available foundation models and is well suited for synthetic data generation and model distillation. Llama 3.1 models also provide state-of-the-art capabilities in general knowledge, math, tool use, and multilingual translation. Meta’s Llama 3.1 models are available in Amazon Bedrock in the US West (Oregon) Region. To learn more, read the AWS News launch blog, Llama in Amazon Bedrock product page, and documentation. To get started with Llama 3.1 in Amazon Bedrock, visit the Amazon Bedrock console. To request to be considered for access to the preview of Llama 3.1 405B in Amazon Bedrock, contact your AWS account team or submit a support ticket via the AWS Management Console. When creating the support ticket, select Bedrock as the Service and Models as the Category.
Today, AWS announces advanced targeting capabilities for AWS AppConfig feature flags. Customers can set up multiple values within flag data, and target those values to fine-grained and high-cardinality user segments. A common use-case for feature flag targets include allow lists, where a customer can specify user IDs or customer tiers, and only enable a new or premium feature for those segments. Another use-case is to split traffic to 15% of your user-base, and experiment with a user experience optimization for a limited cohort of users before rolling the feature out to all users. Customers can start using this powerful feature by creating an AWS AppConfig feature flag, set its value, and then create one or more variants of that flag with different variations of data. Customers then create rules to determine which variant should be targeted to specific segments. Once the flag, variants, and rules are created, customers use the latest version of the AWS AppConfig Agent running in EC2, Lambda, ECS, EKS, or on-premises to retrieve the flag data. When requesting flag data, customers pass in context, like user IDs or other user metadata, which are evaluated client-side against the flag rules to return the appropriate and specific data. AWS AppConfig’s feature flag targets, variants, and splits are available in all AWS Regions, including the AWS GovCloud (US) Regions. To get started, use the AWS AppConfig Getting Started Guide.
Amazon Elastic Container Service (Amazon ECS) now supports managing on-premises workloads running on Amazon Linux 2023, Fedora 40, Debian 11, Debian 12, Ubuntu 24, and CentOS Stream 9. Amazon ECS Anywhere is a feature of Amazon ECS that enables you to run and manage container-based applications on-premises, including on your own virtual machines (VMs) and bare metal servers. Amazon ECS Anywhere is available in all AWS Regions globally. To learn more visit the ECS Anywhere user guide.
Today, Amazon EKS announces new controls for Kubernetes version policy, allowing cluster administrators to configure end of standard support behavior for EKS clusters. This behavior can easily be set through the EKS Console and CLI. Kubernetes version policy control is available for Kubernetes versions in standard support. Controls for Kubernetes version policy makes it easier for you to choose which clusters should enter extended support and which clusters can be automatically upgraded at the end of standard support. This control provides the flexibility for you to balance version upgrades against business requirements depending on the environment or applications running per cluster. Controls for Kubernetes version policy is available in all AWS regions. To learn more about the controls for Kubernetes version policy, refer to the EKS documentation.
We are excited to announce public availability of Mainframe Modernization Code Conversion with mLogica. This new capability enables automated conversion of legacy code written in Assembler language to COBOL. The majority of mainframe environments include Assembler code that is expensive to maintain. Modernization of the code unblocks modernization projects to enable refactor projects, replatform projects, on-mainframe modernization initiatives, within AWS Mainframe Modernization toolchains, or to use alongside third-party modernization toolchains. AWS Mainframe Modernization service allows you to modernize and migrate on-premises mainframe applications to AWS. It offers automated refactor and replatform patterns, as well as augmentation patterns via data replication and file transfer. AWS Mainframe Modernization Code Conversion is available through the AWS Mainframe Modernization service console. To learn more, visit AWS Mainframe Modernization service product and documentation pages.
Hey Everyone! First off, super thankful for this community. I was browsing different posts here nonstop to find the best way to study and there were some super helpful posts. I only gave myself one month to study and take the exam. I just used TD and watched all their videos and did all their practice exams. I did it for a month every day and was able to pass the exam on my first try! I also heard back within a couple of hours after taking the exam that I passed. More than happy to answer any questions anyone has! submitted by /u/Parking-Tomorrow-600 [link] [comments]
https://preview.redd.it/orozyj4x9aed1.png?width=1768&format=png&auto=webp&s=39f08133f600688d4f5a41e2418aa4b0a45775e6 I keep getting redirected out of a Timed Mode exam and now I am seeing this. I know everyone praises them here but my experience has not been good so far. I still can't use the service I paid for. edit: Apologies for the harsh words but I was in the middle of a Timed Exam and was frustrated when I had to re-answer the questions again and again and then got this page. submitted by /u/dubai-dweller [link] [comments]
Amazon Connect Contact Lens now offers a new dashboard for outbound campaign analytics. You can now easily visualize and monitor campaign performance, track efficiency, measure compliance, and understand campaign outcomes for your voice workloads. You can view real-time and historical reports using custom time periods and benchmarks, track campaign progress and delivery status, and drill down into call classification outcomes (e.g., human answered, voicemail). You can also quickly identify trends and patterns across key metrics, such as dials attempted or abandonment rate, to monitor and enhance campaign performance. Additionally, these metrics are now available via API for custom reporting or integrations with other data sources. Outbound campaign analytics is available in Amazon Connect Contact Lens reports and the GetMetricDataV2 API in all AWS regions where Amazon Connect outbound campaigns is available. This includes US East (N. Virginia), US West (Oregon), Asia Pacific (Sydney), Canada (Central), Europe (Frankfurt), and Europe (London). For more information about outbound campaign analytics, consult the Amazon Connect Administrator Guide and Amazon Connect API Reference. To learn more about Amazon Connect Outbound Campaigns, please visit the outbound campaigns webpage.
Amazon DocumentDB (with MongoDB compatibility) now supports the ability to enable compression on existing collections, set a compression threshold for each collection, and enable compression on all new collections using a cluster-wide setting. Compressed documents in Amazon DocumentDB can be up to 7 times smaller than uncompressed documents, leading to lower storage costs, I/O costs, and improved query performance. Customers can enable document compression across their entire cluster using a single cluster-wide parameter group setting. With the compression setting enabled, all new collections created during a database migration or after upgrading the cluster will be compressed by default. The compression parameter also applies to collections created through insert operations or $out aggregation stage. Moreover, customers can now modify compression settings on existing collections using the new CollMod settings, without migrating its documents to a new compressed collection. CollMod now supports enabling compression on existing collection and setting a minimum compression threshold on document size. These compression settings will apply to both new and updated documents in the modified collections. These compression benefits are now supported in Amazon DocumentDB 5.0 instance-based clusters in all regions where Amazon DocumentDB is available. Please refer to document compression page in the developer guide for more details.
Amazon Relational Database Service (Amazon RDS) for PostgreSQL, MySQL, and MariaDB now supports M6i, R6i, M6g, R6g, and T4g database instances in Israel (Tel Aviv) Region. With this expansion, customers of RDS for open source engines in Israel (Tel Aviv) Region have more than double the number of available instance types to choose from. M6i and R6i database instance types offer a new maximum instance size for the region of 32xlarge. 32xlarge supports 128 vCPU, which is 33% more than the maximum size of M5 and R5 database instance types. For complete information on pricing and regional availability, please refer to the Amazon RDS pricing page. Get started by creating any of these fully managed database instance using the Amazon RDS Management Console. For more details, refer to the Amazon RDS User Guide.
Amazon Connect Contact Lens now provides generative AI-powered post-contact summaries within seconds after a contact ends, versus minutes previously, helping you get faster insights when reviewing contacts, save time on after-contact work, and more quickly identifying opportunities to improve contact quality and agent performance. These faster summaries are available via API and Kinesis data streams, enabling integrations with third-party agent workspace or CRM systems. You can also access these summaries natively within Amazon Connect through contact details and contact control panel (CCP). Generative AI-powered post-contact summaries are available in the US West (Oregon), and US East (Northern Virginia) regions. To learn more, please visit our documentation and our webpage. This feature is included with Contact Lens conversational analytics at no additional charge. For information about Contact Lens pricing, please visit our pricing page.
Starting today, Amazon Virtual Private Cloud (VPC) IP Address Manager (IPAM) supports Bring-Your-Own-IP (BYOIP) for IP addresses registered with any Internet Registry. Internet registries manage the allocation and registration of IP addresses within specific geographical regions. BYOIP allows you to bring IP addresses allocated to you by these registries, to AWS, and use them for your workloads. This new feature extends BYOIP support to previously unsupported Internet Registries, including JPNIC, LACNIC, and AFRINIC. When setting up BYOIP, AWS validates that you control the IP address space that you are bringing to AWS. This validation ensures that users cannot use IP ranges belonging to others, preventing routing and security issues. Previously, IPAM only supported validation via the Registration Data Access Protocol (RDAP), which not all internet registries supported. Now, you can use DNS records for validating that the IP addresses belong to you, and process does not rely on any internet registries. Once you have set up BYOIP, you can create Elastic IP addresses (IPv4) from your BYOIP address range and use them with AWS resources such as Amazon Elastic Compute Cloud (Amazon EC2) instances and NAT gateways. If you have BYOIPv6 addresses, you can associate them with subnets, Elastic Network Interfaces (ENI), and Amazon EC2 instances within your VPCs. This feature is currently available in all AWS Regions, except China (Beijing, operated by Sinnet), and China (Ningxia, operated by NWCD). For more information, review IPAM’s technical documentation.
Amazon DocumentDB (with MongoDB compatibility) now supports change streams on reader instances. With change stream on reader instances, customers can now isolate change stream workloads to specific reader instances, which reduces the load on cluster’s writer instance. Change stream tokens can be shared across writer and reader instances, enabling customers to resume change streams from a specific document or time from any Amazon DocumentDB instance during a cluster failover or maintenance event. This functionality is also available in Amazon DocumentDB global clusters – customers can now read change streams from reader instances from the secondary global cluster. These change stream enhancements are available in Amazon DocumentDB 5.0 instance-based clusters and global clusters in all regions where Amazon DocumentDB is supported. Amazon DocumentDB is a fully managed, native JSON database that makes it simple and cost-effective to operate critical document workloads at virtually any scale without managing infrastructure. To learn more, please visit the documentation, and get started by creating Amazon DocumentDB cluster from the AWS Management Console. For pricing and region availability, visit the pricing page.
AWS KMS has doubled default service quotas for cryptographic operations in all AWS Regions, including raising the symmetric cryptographic operation request rate from 50,000 to 100,000 in US East (N. Virginia), US West (Oregon), and Europe (Ireland). The request rate for cryptographic operations involving RSA and ECC KMS keys has also been increased from 500 to 1,000 in all AWS Regions. These default service quotas have been increased in all AWS Regions, including the AWS GovCloud (US) Regions. To learn more, see Request quotas section in the AWS KMS Developer Guide.
Amazon MQ now provides support for quorum queues, a replicated FIFO queue type offered by open-source RabbitMQ that uses the Raft consensus algorithm to maintain data consistency. Quorum queues are the replicated queue type recommended by open-source RabbitMQ maintainers. With quorum queues, developers can design highly available messaging systems with higher data consistency and fault tolerance. Quorum queues can detect network failures faster and recover more quickly, improving the resiliency of the message broker as a whole. Quorum queues also provide poison message handling which helps developers manage unprocessed messages more efficiently. Amazon MQ benchmarks show that quorum queues offer an increased throughput (up to 2 times higher) compared to classic mirrored queues on RabbitMQ brokers. Amazon MQ supports quorum queues only on RabbitMQ 3.13 and above. You can easily get started with quorum queues by declaring a new queue with queue type as ‘quorum’. To learn more about using quorum queues, see the Amazon MQ developer guide and the Amazon MQ release notes. Quorum queues are available in all the regions Amazon MQ is available in. For a full list of available regions see the AWS Region Table.
I am trying to deploy an AWS Lambda function using AWS CodeCommit and AWS CodeBuild. The pipeline works well—all are in the right order, and the build is successful—but it doesn't create the Lambda according to my code; an error appears during the deploy phase. And also, when creating a new Lambda function, the requirements.txt should contain Python requirements, so those requirements need to be installed as well. buildspec.yml : version: 0.2 env: variables: S3_BUCKET: agent-deployment-plan phases: install: runtime-versions: python: 3.11 commands: - pip install aws-sam-cli - pip install -r requirements.txt build: commands: - sam build post_build: commands: - sam package --s3-bucket $S3_BUCKET --output-template-file packaged.yaml artifacts: files: - packaged.yaml template.yml : AWSTemplateFormatVersion: '2010-09-09' Transform: 'AWS::Serverless-2016-10-31' Resources: MyLambdaFunction: Type: 'AWS::Serverless::Function' Properties: Handler: lambda_handler.lambda_handler Runtime: python3.11 CodeUri: s3://deployment/packaged.yaml MemorySize: 1024 Timeout: 100 Environment: Variables: PARAM1: "value1" Policies: - AWSLambdaBasicExecutionRole Error : AWS CloudFormation logs submitted by /u/mohil-makwana31 [link] [comments]
Hey guys, I wanted to develop the AWS lex-web-ui and add some custom buttons to it and edit the html itself. I cloned the repo tried running 'npm run dev' but it gave me error that lex-web-ui\dist\bundle is missing. I went to this folder ran 'npm run build' I have the dist folder created but don't have bundle inside that folder. Whatever changes I do to the components are not reflected to ui at all. How do I run for development and develop on top of this. I am not aware of anything in vue. Please help. submitted by /u/Global-Vermicelli925 [link] [comments]
Hi, I have started the AWS free training. I'm thinking of booking the exam for sept 20th 2024. I am hopping to complete the training within 2 weeks. I just wanted to get a sense of how long you guys took before you felt comfortable to take the exam. I've done 1 practice exam which I got a 50% before starting the training. Thank you submitted by /u/Icy-Alternative-3860 [link] [comments]
Today I Learned (TIL) You learn something new every day; what did you learn today? Submit interesting and specific facts about something that you just found out here.
Reddit Science This community is a place to share and discuss new scientific research. Read about the latest advances in astronomy, biology, medicine, physics, social science, and more. Find and submit new publications and popular science coverage of current research.