


AI Dashboard is available on the Web, Apple, Google, and Microsoft, PRO version
What are some ways to increase precision or recall in machine learning?
What are some ways to Boost Precision and Recall in Machine Learning?
Sensitivity vs Specificity?
In machine learning, recall is the ability of the model to find all relevant instances in the data while precision is the ability of the model to correctly identify only the relevant instances. A high recall means that most relevant results are returned while a high precision means that most of the returned results are relevant. Ideally, you want a model with both high recall and high precision but often there is a trade-off between the two. In this blog post, we will explore some ways to increase recall or precision in machine learning.
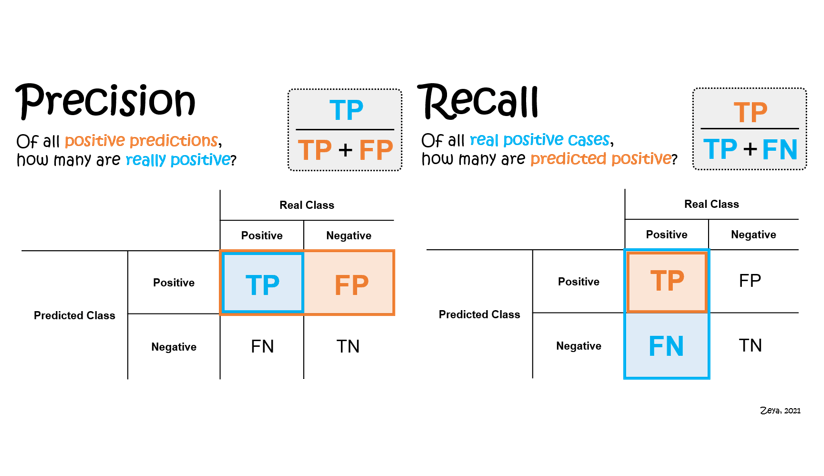
There are two main ways to increase recall:
by increasing the number of false positives or by decreasing the number of false negatives. To increase the number of false positives, you can lower your threshold for what constitutes a positive prediction. For example, if you are trying to predict whether or not an email is spam, you might lower the threshold for what constitutes spam so that more emails are classified as spam. This will result in more false positives (emails that are not actually spam being classified as spam) but will also increase recall (more actual spam emails being classified as spam).
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6

 Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more codes)
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more codes)

To decrease the number of false negatives,
you can increase your threshold for what constitutes a positive prediction. For example, going back to the spam email prediction example, you might raise the threshold for what constitutes spam so that fewer emails are classified as spam. This will result in fewer false negatives (actual spam emails not being classified as spam) but will also decrease recall (fewer actual spam emails being classified as spam).

There are two main ways to increase precision:
by increasing the number of true positives or by decreasing the number of true negatives. To increase the number of true positives, you can raise your threshold for what constitutes a positive prediction. For example, using the spam email prediction example again, you might raise the threshold for what constitutes spam so that fewer emails are classified as spam. This will result in more true positives (emails that are actually spam being classified as spam) but will also decrease precision (more non-spam emails being classified as spam).
To decrease the number of true negatives,
you can lower your threshold for what constitutes a positive prediction. For example, going back to the spam email prediction example once more, you might lower the threshold for what constitutes spam so that more emails are classified as spam. This will result in fewer true negatives (emails that are not actually spam not being classified as spam) but will also decrease precision (more non-spam emails being classified as spam).

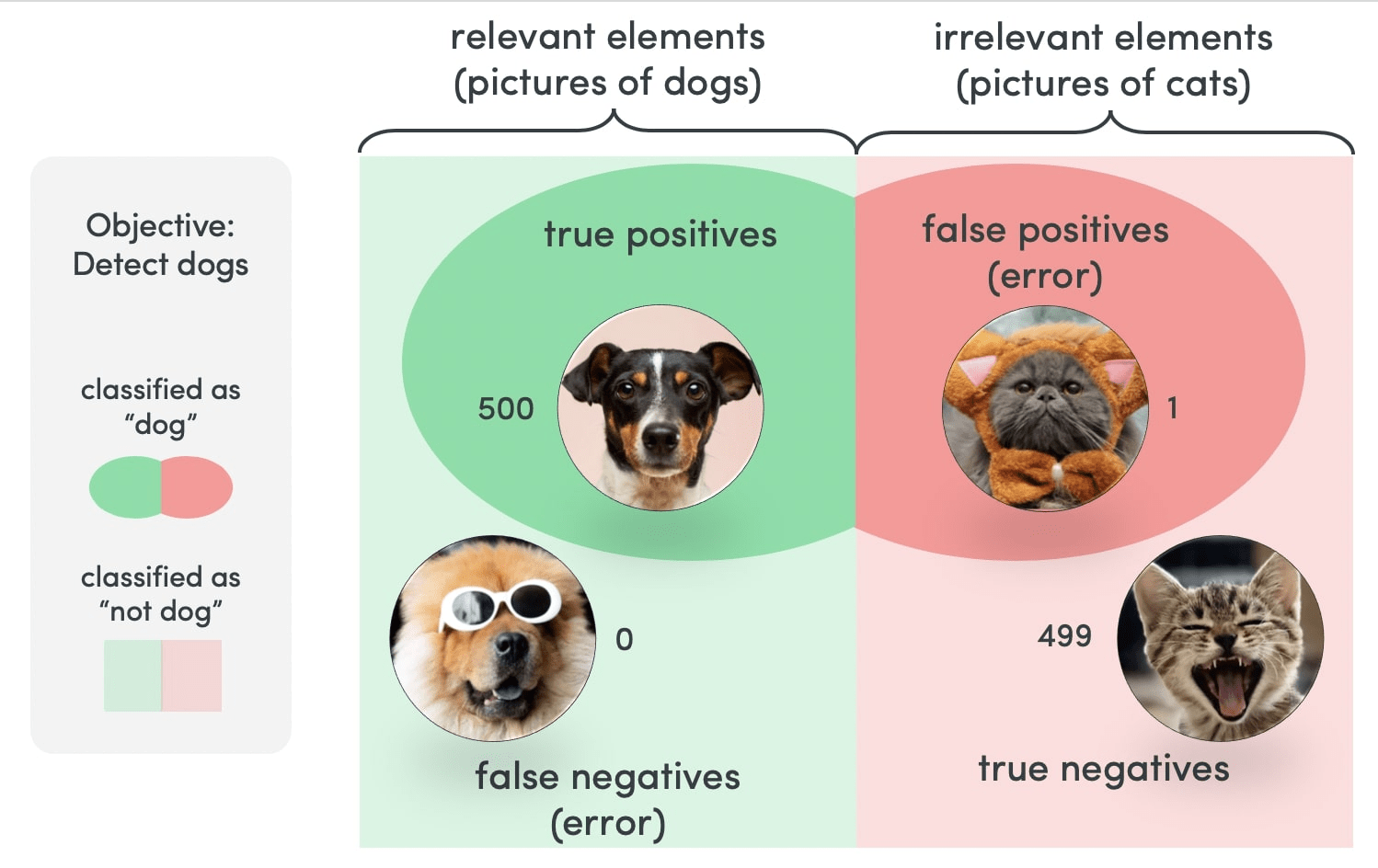
To summarize,
there are a few ways to increase precision or recall in machine learning. One way is to use a different evaluation metric. For example, if you are trying to maximize precision, you can use the F1 score, which is a combination of precision and recall. Another way to increase precision or recall is to adjust the threshold for classification. This can be done by changing the decision boundary or by using a different algorithm altogether.
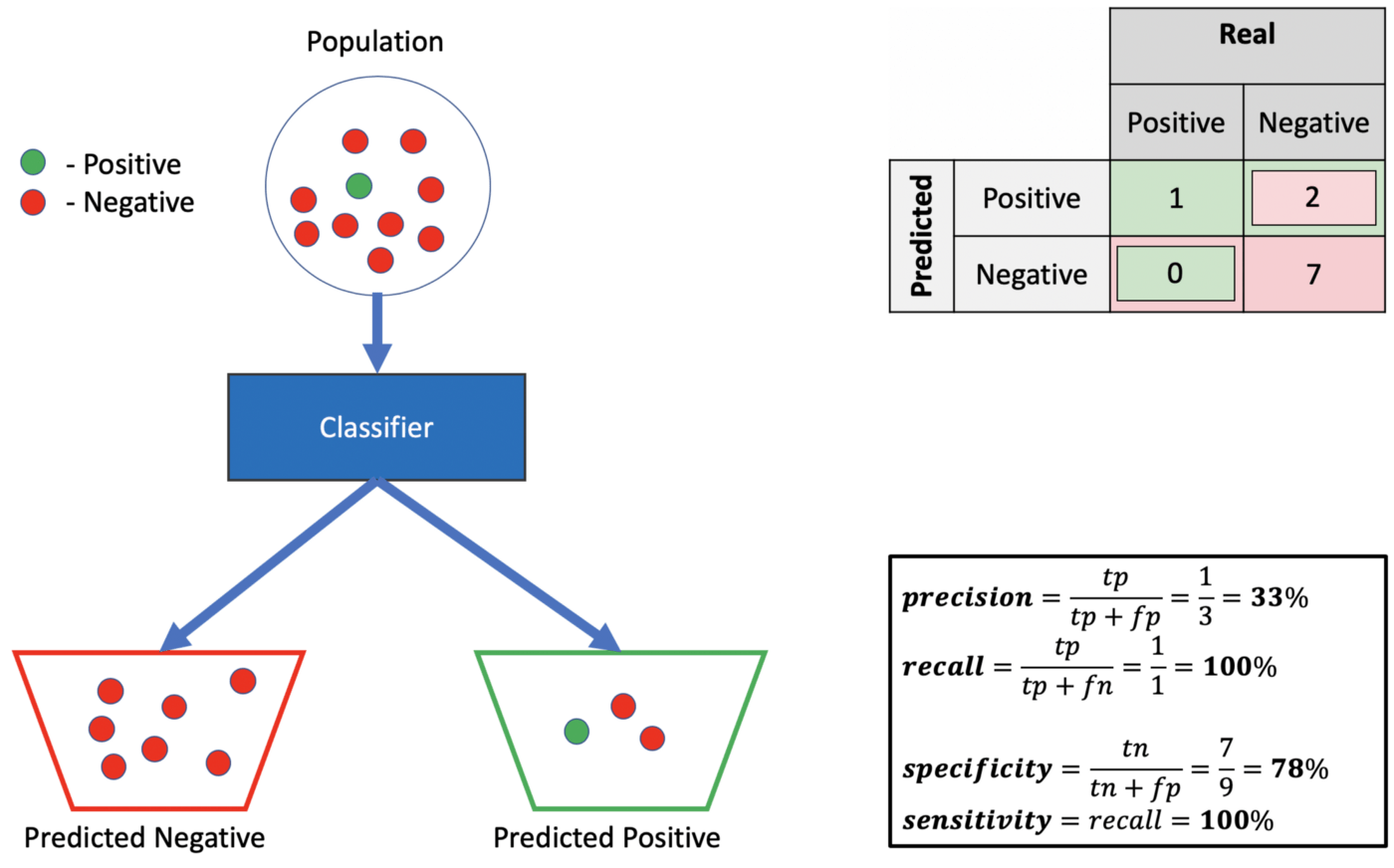
Sensitivity vs Specificity
In machine learning, sensitivity and specificity are two measures of the performance of a model. Sensitivity is the proportion of true positives that are correctly predicted by the model, while specificity is the proportion of true negatives that are correctly predicted by the model.
Google Colab For Machine Learning
State of the Google Colab for ML (October 2022)
Google introduced computing units, which you can purchase just like any other cloud computing unit you can from AWS or Azure etc. With Pro you get 100, and with Pro+ you get 500 computing units. GPU, TPU and option of High-RAM effects how much computing unit you use hourly. If you don’t have any computing units, you can’t use “Premium” tier gpus (A100, V100) and even P100 is non-viable.

Google Colab Pro+ comes with Premium tier GPU option, meanwhile in Pro if you have computing units you can randomly connect to P100 or T4. After you use all of your computing units, you can buy more or you can use T4 GPU for the half or most of the time (there can be a lot of times in the day that you can’t even use a T4 or any kinds of GPU). In free tier, offered gpus are most of the time K80 and P4, which performs similar to a 750ti (entry level gpu from 2014) with more VRAM.
For your consideration, T4 uses around 2, and A100 uses around 15 computing units hourly.
Based on the current knowledge, computing units costs for GPUs tend to fluctuate based on some unknown factor.
Considering those:
- For hobbyists and (under)graduate school duties, it will be better to use your own gpu if you have something with more than 4 gigs of VRAM and better than 750ti, or atleast purchase google pro to reach T4 even if you have no computing units remaining.
- For small research companies, and non-trivial research at universities, and probably for most of the people Colab now probably is not a good option.
- Colab Pro+ can be considered if you want Pro but you don’t sit in front of your computer, since it disconnects after 90 minutes of inactivity in your computer. But this can be overcomed with some scripts to some extend. So for most of the time Colab Pro+ is not a good option.
If you have anything more to say, please let me know so I can edit this post with them. Thanks!

Conclusion:
In machine learning, precision and recall trade off against each other; increasing one often decreases the other. There is no single silver bullet solution for increasing either precision or recall; it depends on your specific use case which one is more important and which methods will work best for boosting whichever metric you choose. In this blog post, we explored some methods for increasing either precision or recall; hopefully this gives you a starting point for improving your own models!
What are some ways we can use machine learning and artificial intelligence for algorithmic trading in the stock market?
Machine Learning and Data Science Breaking News 2022 – 2023
- [P] [D] Is inference time the important performance metric for ML Models on edge/mobile?by /u/orcnozyrt (Machine Learning) on May 4, 2024 at 10:44 pm
I am currently engaged on a project that aims to give some insight to machine learning engineers about how their models perform on vast variety of mobile devices. It is starting to be a very popular practice to embed machine learning models within apps and use them without needing any api/network connection. You can see most examples especially for apps that use computer vision heavily. Passing each and every image to cloud for processing is simply unacceptable, data heavy and slow. With the latest improvements in the field, embedding ml models to apps gets easier and preferable. This comes with another price though. There are 1000s of mobile devices out there that come with different chipsets like Qualcomm, Exynos, Snapdragon etc. They also come with different gpu capabilities and on top of that different OS versions. All these combinations are very likely to create some uncertainty. Does my model performs the same way it does in the office's android test phone? After working on a computer vision and machine learning startup for more than 3 years as a lead mobile engineer who embedded 10s of models inside apps, answer to that question is very clear to me. No, my model will not perform same on a Xiaomi Android 11 phone as it performs on your office Samsung Android 13. And often you will not even know that. ML engineers will be highly isolated from the app environment. They can measure the performance of ml model already with their tools in the cloud when it comes to accuracy, recall etc. Which are very very important metrics. But, they already measure/evaluate that. When it comes to inference time, it heavily depends on the system it works on. It is not feasible to have each and every mobile device in the office available. To solve this issue, we have decided to develop mobile SDK and a platform for collecting/visualising some metrics. And we have decided the most important metric, at the heart of the issue, would be the inference time. I would like to ask you people if this makes sense and is reasonable. Is there other vital metrics you think a ml engineer would be interested in? The SDK we prepared collects all device related metadata( memory available, cpu usage, os, api level, battery etc.) and inference time parameter and shows charts like: OS System vs inference time Device model vs inference time Memory available vs inference time in a single session etc. submitted by /u/orcnozyrt [link] [comments]
- [D] UI-based Agents - the next big thing?by /u/Pretend-Map7430 (Machine Learning) on May 4, 2024 at 9:29 pm
Aka Interface / OS / system agents and LAM. Seems like many new projects are popping up in this space, curious to get your thoughts on whether these will stick around, and AI agents will become the center of every user interaction going forward. Some examples: francedot/Interface-Agent: InterfaceAgent: a versatile framework designed to create system and interface agents capable of managing mobile and desktop applications and features. (github.com) mnotgod96/AppAgent: AppAgent: Multimodal Agents as Smartphone Users, an LLM-based multimodal agent framework designed to operate smartphone apps. (github.com) microsoft/UFO: A UI-Focused Agent for Windows OS Interaction. (github.com) OpenInterpreter/open-interpreter: A natural language interface for computers (github.com)- microsoft/UFO: A UI-Focused Agent for Windows OS Interaction. (github.com) submitted by /u/Pretend-Map7430 [link] [comments]
- [D] Any-dimensional equivariant neural networksby /u/No-Natural36 (Machine Learning) on May 4, 2024 at 9:19 pm
I found this paper very interesting. We kind of make same assumptions, that the authors are making, while using covnet for computer vision. I was wondering can we extend for computer vision use cases Abstract Traditional supervised learning aims to learn an unknown mapping by fitting a function to a set of input-output pairs with a fixed dimension. The fitted function is then defined on inputs of the same dimension. However, in many settings, the unknown mapping takes inputs in any dimension; examples include graph parameters defined on graphs of any size and physics quantities defined on an arbitrary number of particles. We leverage a newly-discovered phenomenon in algebraic topology, called representation stability, to define equivariant neural networks that can be trained with data in a fixed dimension and then extended to accept inputs in any dimension. Our approach is user-friendly, requiring only the network architecture and the groups for equivariance, and can be combined with any training procedure. We provide a simple open-source implementation of our methods and offer preliminary numerical experiments. submitted by /u/No-Natural36 [link] [comments]
- [D] Seeking assistance with a personal projectby /u/SadHat4219 (Machine Learning) on May 4, 2024 at 6:22 pm
I'm currently engaged in a project employing the pre-trained Phi-3-mini model (utilizing ollama for execution). In this project, I've integrated RAG with ChromaDB as the vector store, and I've incorporated a local embedding model named nomic-embed-text. My objective is to inform the Phi-3 model that it's operating for XYZ company and for a specific purpose. Additionally, I need to ensure that the model is aware of everyday currency values. While I can retrieve these values daily, I'm seeking a method to notify the model only once per day. Moreover, I'm open to exploring alternative tools for the vector store and embedding model, as long as they align with the requirements of the project. I've opted for Phi-3 due to its suitability as a Small Language Model (SLM) for this task. submitted by /u/SadHat4219 [link] [comments]
- Moving to eBay as a Data Science Analyst?by /u/sg6128 (Data Science) on May 4, 2024 at 5:19 pm
Hey all, firstly, I don't want to sound disingenuous so I really hope this doesn't come off that way. I have a pretty non-traditional path to Data Science, I did a Bachelor of Commerce, and through a rotation program at a big Canadian bank got into a Data Science team, that was supportive and took me on despite me lacking technicals. I've been in the position now for 2 years, mostly working with NLP and unstructured data. Doing usual Power BI dashboard, KPI antics, all the way up to using transformer embeddings for email classification models. It has been a cool role, sadly plagued with bad management, and all at a slow bank. In recent times, the bank has gone through reorg, and we (data and analytics team) do not have the support from senior management, nor the funding that we did maybe even a year ago. Layoffs are a small possibility, but already I feel like we have been brushed to side, with not much expectations, nor no net new projects. Furthermore, my boss who had hired me might also be leaving, meaning I would be stuck with completely non-technical management, and I would learn nothing. Perhaps the one good thing is the pay, but that is making it hard for me to now find a new role. My current pay is around $95K CAD + last year, a 15% bonus. With new leadership now though, that doesn't support us, I doubt we will get a bonus as fat as that anymore. I have been interviewing with eBay for a Data Science Analyst position, working on their item buying page, and got the offer yesterday. I would report to a team in SF, but would be based in Canada. The role would be less model-building, a lot more A/B testing, from what I gathered. Pros of eBay: Data Science at Tech company gives validity to my otherwise non-technical resume (academically, at least) 1 week in office and flexibility to work from abroad (according to HR); so I can travel home internationally and not burn PTO, compared to 3 in office and no flexibility currently Hopefully newer tech stack than the bank (fr we don't even have a SQL server set up here lmfao) Been with the bank for 3 years in various roles, really tired and fed up, so would be a good change and refresh 20K sign on for first year, 10K sign on second year, conditional to me staying for a year after receiving bonuses, in addition to equity discount purchase options, and $30K USD equity package (25%/year vest) in compensation Cons: Only a 10% base-pay bump. Tech homies (though in SF) tell me to not settle for anything less than 20% bump between jobs. Not building models as much, which makes it more statistics-focused and less applied 80% focused on A/B testing from what I gathered Unsure of eBay market reputation these days, what are some companies that people end up working at after eBay? High rate of layoffs In addition to all of this, I am interviewing with Intuit and Robinhood, both for more technical Data Science positions. Those would likely pay in the 120K-140K CAD range from what I understand, eBay would be at 105k. The next step for these interviews would be the technicals, which I do not feel confident for at all (Python, SQL LeetCode Mediums + statistics and ML design questions). I haven't studied for this stuff that much, and would really be cramming. I have told eBay that I can let them know on Monday if the compensation is okay, I am tempted to go back to them and beg for $110K CAD, which would be a 15% bump, and mention that I am interested in the role, but the pay is just not working for me, especially that I am interviewing for two other positions that may pay better. So I want to request if I can continue the interview process with the other two, and get back to eBay with a final confirmation. Not sure how to phrase this, or if I should even show my hand like that. eBay HR was really nice, really felt like they were gunning for me, and the offer felt like the max they could squeeze out between Payroll and the Hiring team. I'm just confused. In light of all of this, where can/should I go? I was 65% in favour to take, 35% to reject, but given my friends/family advice that the pay is low and not worth moving, I am unsure. I'm also not sure how to buy myself time for the interveiws with RH and Intuit, and god if I can even do them. Is it really that bad to move for 10% base bump? Ignoring sign-on bonus, equity, quality of life? Lastly, I'm not sure if eBay is a boost to my career or a step down; is it a good place to work? Is it frowned upon by other companies as a "legacy tech company" or something? Thank you! submitted by /u/sg6128 [link] [comments]
- [D] Geometrical meaning of Layer Normalizationby /u/ApartmentEither4838 (Machine Learning) on May 4, 2024 at 5:11 pm
https://preview.redd.it/ws4d4qiczfyc1.png?width=639&format=png&auto=webp&s=241e5ceb3d40157deed93e78faaee4116f07b195 How does mean substraction operation project a vector onto a hyperplane and likewise scaling project it onto a hypersphere in Layer Normalization? submitted by /u/ApartmentEither4838 [link] [comments]
- How are large network attack datasets made? [p]by /u/OpeningDirector1688 (Machine Learning) on May 4, 2024 at 4:46 pm
Hi, I’m working on a ML system for network intusion detection. I’ve come across huge free datasets that have been really helpful but I’ve come to a point in my project where I need to make my own. I see the millions of simulated attacks on a network and can’t imagine that this is sone by hand. If anyone has any ideas it would be appreciated. Thanks submitted by /u/OpeningDirector1688 [link] [comments]
- [D] How do you Serve and Scale Your LLMs in Production?by /u/gamerx88 (Machine Learning) on May 4, 2024 at 4:43 pm
For people who have worked on self hosting your own models, I'm curious about your tech stack and architecture for model serving. Especially for those who are serving models larger than 30B. What optimizations and stack do you find effective for dealing with an environment where request volume is volatile (e.g can spike 10x in minutes), but responsiveness needs to be high? submitted by /u/gamerx88 [link] [comments]
- Actual Product vs Portfolio of Demosby /u/wage_slaving_sucks (Data Science) on May 4, 2024 at 4:05 pm
In your opinion, I was wondering which is better when searching for a data job-- a portfolio of small demos or an actual product that fills a void? For example, if my community has an information need such as analysis of schools, their suspension rate and other related features, would that be better than a bunch of small projects posted to github? I'm thinking an actual product is more beneficial in showcasing one's skills, because it's an end-to-end project (e.g., data collection, data cleaning, analysis, infrastructure, integrating data updates, etc). submitted by /u/wage_slaving_sucks [link] [comments]
- [D] using AI to train open low cost robotics?by /u/zelkovamoon (Machine Learning) on May 4, 2024 at 4:02 pm
So I've been looking into open robotics projects lately, with the desire of building something that can use ai. I've seen the deep mind video of robots playing soccer; I have no idea what kind of hardware is needed to run that inference on a robot, but I like the idea; build a chassis, and virtually train it and then let the robot use the model. I ran into a robotics project earlier today called Stack Chan, it runs on a M5Stack iot core; the project is designed to be extensible. Suppose I wanted to bolt wheels and an arm to this stack chan; would I be able to train that with ai? Or, would I have to get something like an Nvidia SBC to do this? submitted by /u/zelkovamoon [link] [comments]
- A Multi-Agent game where LLMs must trick each other as humans until one gets caught [P]by /u/AvvYaa (Machine Learning) on May 4, 2024 at 2:18 pm
Sharing a fun little random project I worked on last week where I made multiple LLMs interact with each other pretending to be humans… submitted by /u/AvvYaa [link] [comments]
- [D] How reliable is RAG currently?by /u/lapurita (Machine Learning) on May 4, 2024 at 1:52 pm
At it's essence I guess RAG is about retrieving relevant documents based on the prompt putting the documents into the context window Number 2 is very straight forward, while number 1 is where I guess more of the important stuff happens. IIRC, most often we do a similarity search here between the prompt embedding and the document embeddings, and retrieve the k-most similar documents. Ok, at this point we have k documents and put them into context. Now it's time for the LLM to give me an answer based on my prompt and the k documents, which a good LLM should be able to do given that the correct documents were retrieved. I tried doing some hobby projects with LlamaIndex but didn't get it to work so nicely. For example, I tried with NFL statistics as my data (one row per player, one column per feature) and hoped that GPT-4 together with these documents would be able to answer atleast 95% of my question correctly, but it was more like 70% which was surprisingly bad since I feel like this was a fairly basic project. Questions were of the kind "how many touchdowns did player x do in season y". Answers varied from being correct, to saying the information wasn't available, to hallucinating an incorrect answer. Hopefully I'm just doing something in suboptimal way, but it got me thinking of how widely used RAG is in production around the world. What are some applications on the market that successfully utilizes RAG? I assume something like perplexity.ai is using it, and of course all other chatbots that uses browsing in some way. An obvious application mentioned is often embedding your company documents, and then having an internal chatbot that uses RAG. Is that deployed anywhere? Not at my company, but I could see it being useful. Basically, is RAG mostly something that sounds good in theory and is currently hyped or is it actually something that is used in production around the world? submitted by /u/lapurita [link] [comments]
- [N] New Challenges in DIAMBRA Arena: 3 epic additions to our lineup of RL environments!by /u/DIAMBRA_AIArena (Machine Learning) on May 4, 2024 at 1:35 pm
submitted by /u/DIAMBRA_AIArena [link] [comments]
- Impact of different tool use on future job prospectsby /u/math_vet (Data Science) on May 4, 2024 at 1:01 pm
I'm in a senior DS role right now. This is my first data job after being a professor for a few years post PhD. I'm a modeler, that's my main focus on the job, which I absolutely love. However, the client (I'm a consultant) uses SAS miner and guide, and does not use Python at all. Partially because they always have and partially for security concerns. As I build my models, realistically the biggest issue is making sure I do things that our (imo outdated) tech stack can handle. I'd love to do a sexy GNN network based model for example but right now we struggle to execute a random forest. The experience I'm getting is great, I'll be about to make some solid quantifiable improvements, and I'm not looking to move jobs in the next <3 years. However, I worry that if I go on the market in the future, my lack of experience putting Python into prod will be an issue. Hopefully at that point I'll have some promotions under my belt and will be moreso managing a team than running code. If I'm in the future applying for more senior positions, will they care so much about what tools I've been using versus my experience leading a team/communicating with the business, etc? submitted by /u/math_vet [link] [comments]
- How do you prepare for performance reviews?by /u/Texas_Badger (Data Science) on May 4, 2024 at 12:44 pm
Hi, Currently I have a one note where I track different pieces of company desired goals/targets through the year. Some of the things they care about : 1) certs / continuing education 2) speaking events 3) individual contributions (projects etc) How are some of the ways you track your progress? And if you don’t…why? Any way you can resell yourself every review is great ammunition imo. submitted by /u/Texas_Badger [link] [comments]
- [R] Separating Semantics and Syntaxby /u/justinhjy1004 (Machine Learning) on May 4, 2024 at 12:06 pm
I’m tasked with figuring out how to separate syntax and semantics for a given text. To be more concrete, is there a way to say two text convey the same idea just with a different way of expressing it. The only method I know is to use embeddings and compare the cosine similarities of it but I don’t think that cuts it. I am pretty new to NLP and any recommendation is helpful submitted by /u/justinhjy1004 [link] [comments]
- [R] An Analysis of Linear Time Series Forecasting Modelsby /u/Gramious (Machine Learning) on May 4, 2024 at 11:24 am
Our work on analysing linear time series forecasting models was accepted to ICML. ArxiV: https://arxiv.org/abs/2403.14587 Abstract: Despite their simplicity, linear models perform well at time series forecasting, even when pitted against deeper and more expensive models. A number of variations to the linear model have been proposed, often including some form of feature normalisation that improves model generalisation. In this paper we analyse the sets of functions expressible using these linear model architectures. In so doing we show that several popular variants of linear models for time series forecasting are equivalent and functionally indistinguishable from standard, unconstrained linear regression. We characterise the model classes for each linear variant. We demonstrate that each model can be reinterpreted as unconstrained linear regression over a suitably augmented feature set, and therefore admit closed-form solutions when using a mean-squared loss function. We provide experimental evidence that the models under inspection learn nearly identical solutions, and finally demonstrate that the simpler closed form solutions are superior forecasters across 72% of test settings. Summary Several popular works have argued that linear regression is sufficient for forecasting (DLinear and FITs are examples for the discerning reader). It turns out that if you do the maths these models are essentially equivalent. We do the math and also the experiments. Perhaps most interestingly: the ordinary least squares (OLS) solution is almost always better than other linear models trained using gradient descent. Importantly: we did not do a hyper parameter search to set, for example, the regularisation coefficient. We reserve that for future work. OLS is extremely efficient - a model can be fit in the order of milliseconds if set up right. Finally, although we don't go to lengths to show this: many of our results are superior to large and complex models, begging the question of when and where such models are effective. submitted by /u/Gramious [link] [comments]
- [D] The "it" in AI models is really just the dataset?by /u/vijayabhaskar96 (Machine Learning) on May 4, 2024 at 10:47 am
submitted by /u/vijayabhaskar96 [link] [comments]
- What’s the deal with minimum 3 YOE on most of job postings?by /u/jesteartyste (Data Science) on May 4, 2024 at 10:14 am
Hello, I’m coming with question to maybe more experienced professionals or even people which are recruiting. In most job postings I see for DS, MLE, MLOps etc I see requirement of at least 3 YOE. In my personal experience I saw lot of devs with 1 YOE having much more knowledge and wider range of skills then devs with 6 YOE writing code in PHP and using only excel. I assume most people having less experience in their resume would be dropped immediately in early stage of reviewing candidates because of this factor. What’s the deal with this time boundary and is it really that important? submitted by /u/jesteartyste [link] [comments]
- [D] Analysis of Time To First Token (TTFT) of LLMs (10B-34B)by /u/rbgo404 (Machine Learning) on May 4, 2024 at 8:41 am
Hey folks, Recently spent time measuring the Time to First Token (TTFT) of various large language models (LLMs) when deployed within Docker containers, and the findings were quite interesting. For those who don't know, TTFT measures the speed from when you send a query to when you get the first response. Here are the key findings: Performance Across Token Sizes: Libraries like Triton-vLLM and vLLM are super quick (~25 milliseconds) with fewer tokens but slow down significantly (200-300 milliseconds) with more tokens. CTranslate-2 and Deepspeed-mii also slow down as you increase the token count. However, vLLM keeps things quick and efficient, even with more tokens. Handling Big Inputs: Libraries like Deepspeed-mii, vLLM, TGI, and Triton-vLLM can handle more tokens but get slower the more you push them. This shows some challenges in scaling up. Best Token Responses: While everything runs smoothly up to about 100 tokens, performance drops after 500 tokens. The ideal number of tokens for the quickest response seems to be around 20, with times ranging from about 25 to 60 milliseconds depending on the model. https://preview.redd.it/6n03xwbqddyc1.jpg?width=1600&format=pjpg&auto=webp&s=9464d6f85a2cdab685fc8e7cd7031a85600f00c1 These findings might help you pick the right models and libraries and set your expectations. Keen to hear if anyone else has tested TTFT or has tips on library performance! submitted by /u/rbgo404 [link] [comments]
Top 100 Data Science and Data Analytics and Data Engineering Interview Questions and Answers
What are some good datasets for Data Science and Machine Learning?
Active Hydrating Toner, Anti-Aging Replenishing Advanced Face Moisturizer, with Vitamins A, C, E & Natural Botanicals to Promote Skin Balance & Collagen Production, 6.7 Fl Oz



Age Defying 0.3% Retinol Serum, Anti-Aging Dark Spot Remover for Face, Fine Lines & Wrinkle Pore Minimizer, with Vitamin E & Natural Botanicals


Firming Moisturizer, Advanced Hydrating Facial Replenishing Cream, with Hyaluronic Acid, Resveratrol & Natural Botanicals to Restore Skin's Strength, Radiance, and Resilience, 1.75 Oz

Skin Stem Cell Serum


Smartphone 101 - Pick a smartphone for me - android or iOS - Apple iPhone or Samsung Galaxy or Huawei or Xaomi or Google Pixel
Can AI Really Predict Lottery Results? We Asked an Expert.




Djamgatech

Read Photos and PDFs Aloud for me iOS
Read Photos and PDFs Aloud for me android
Read Photos and PDFs Aloud For me Windows 10/11
Read Photos and PDFs Aloud For Amazon
Get 20% off Google Workspace (Google Meet) Business Plan (AMERICAS): M9HNXHX3WC9H7YE (Email us for more)
Get 20% off Google Google Workspace (Google Meet) Standard Plan with the following codes: 96DRHDRA9J7GTN6(Email us for more)



FREE 10000+ Quiz Trivia and and Brain Teasers for All Topics including Cloud Computing, General Knowledge, History, Television, Music, Art, Science, Movies, Films, US History, Soccer Football, World Cup, Data Science, Machine Learning, Geography, etc....

List of Freely available programming books - What is the single most influential book every Programmers should read
- Bjarne Stroustrup - The C++ Programming Language
- Brian W. Kernighan, Rob Pike - The Practice of Programming
- Donald Knuth - The Art of Computer Programming
- Ellen Ullman - Close to the Machine
- Ellis Horowitz - Fundamentals of Computer Algorithms
- Eric Raymond - The Art of Unix Programming
- Gerald M. Weinberg - The Psychology of Computer Programming
- James Gosling - The Java Programming Language
- Joel Spolsky - The Best Software Writing I
- Keith Curtis - After the Software Wars
- Richard M. Stallman - Free Software, Free Society
- Richard P. Gabriel - Patterns of Software
- Richard P. Gabriel - Innovation Happens Elsewhere
- Code Complete (2nd edition) by Steve McConnell
- The Pragmatic Programmer
- Structure and Interpretation of Computer Programs
- The C Programming Language by Kernighan and Ritchie
- Introduction to Algorithms by Cormen, Leiserson, Rivest & Stein
- Design Patterns by the Gang of Four
- Refactoring: Improving the Design of Existing Code
- The Mythical Man Month
- The Art of Computer Programming by Donald Knuth
- Compilers: Principles, Techniques and Tools by Alfred V. Aho, Ravi Sethi and Jeffrey D. Ullman
- Gödel, Escher, Bach by Douglas Hofstadter
- Clean Code: A Handbook of Agile Software Craftsmanship by Robert C. Martin
- Effective C++
- More Effective C++
- CODE by Charles Petzold
- Programming Pearls by Jon Bentley
- Working Effectively with Legacy Code by Michael C. Feathers
- Peopleware by Demarco and Lister
- Coders at Work by Peter Seibel
- Surely You're Joking, Mr. Feynman!
- Effective Java 2nd edition
- Patterns of Enterprise Application Architecture by Martin Fowler
- The Little Schemer
- The Seasoned Schemer
- Why's (Poignant) Guide to Ruby
- The Inmates Are Running The Asylum: Why High Tech Products Drive Us Crazy and How to Restore the Sanity
- The Art of Unix Programming
- Test-Driven Development: By Example by Kent Beck
- Practices of an Agile Developer
- Don't Make Me Think
- Agile Software Development, Principles, Patterns, and Practices by Robert C. Martin
- Domain Driven Designs by Eric Evans
- The Design of Everyday Things by Donald Norman
- Modern C++ Design by Andrei Alexandrescu
- Best Software Writing I by Joel Spolsky
- The Practice of Programming by Kernighan and Pike
- Pragmatic Thinking and Learning: Refactor Your Wetware by Andy Hunt
- Software Estimation: Demystifying the Black Art by Steve McConnel
- The Passionate Programmer (My Job Went To India) by Chad Fowler
- Hackers: Heroes of the Computer Revolution
- Algorithms + Data Structures = Programs
- Writing Solid Code
- JavaScript - The Good Parts
- Getting Real by 37 Signals
- Foundations of Programming by Karl Seguin
- Computer Graphics: Principles and Practice in C (2nd Edition)
- Thinking in Java by Bruce Eckel
- The Elements of Computing Systems
- Refactoring to Patterns by Joshua Kerievsky
- Modern Operating Systems by Andrew S. Tanenbaum
- The Annotated Turing
- Things That Make Us Smart by Donald Norman
- The Timeless Way of Building by Christopher Alexander
- The Deadline: A Novel About Project Management by Tom DeMarco
- The C++ Programming Language (3rd edition) by Stroustrup
- Patterns of Enterprise Application Architecture
- Computer Systems - A Programmer's Perspective
- Agile Principles, Patterns, and Practices in C# by Robert C. Martin
- Growing Object-Oriented Software, Guided by Tests
- Framework Design Guidelines by Brad Abrams
- Object Thinking by Dr. David West
- Advanced Programming in the UNIX Environment by W. Richard Stevens
- Hackers and Painters: Big Ideas from the Computer Age
- The Soul of a New Machine by Tracy Kidder
- CLR via C# by Jeffrey Richter
- The Timeless Way of Building by Christopher Alexander
- Design Patterns in C# by Steve Metsker
- Alice in Wonderland by Lewis Carol
- Zen and the Art of Motorcycle Maintenance by Robert M. Pirsig
- About Face - The Essentials of Interaction Design
- Here Comes Everybody: The Power of Organizing Without Organizations by Clay Shirky
- The Tao of Programming
- Computational Beauty of Nature
- Writing Solid Code by Steve Maguire
- Philip and Alex's Guide to Web Publishing
- Object-Oriented Analysis and Design with Applications by Grady Booch
- Effective Java by Joshua Bloch
- Computability by N. J. Cutland
- Masterminds of Programming
- The Tao Te Ching
- The Productive Programmer
- The Art of Deception by Kevin Mitnick
- The Career Programmer: Guerilla Tactics for an Imperfect World by Christopher Duncan
- Paradigms of Artificial Intelligence Programming: Case studies in Common Lisp
- Masters of Doom
- Pragmatic Unit Testing in C# with NUnit by Andy Hunt and Dave Thomas with Matt Hargett
- How To Solve It by George Polya
- The Alchemist by Paulo Coelho
- Smalltalk-80: The Language and its Implementation
- Writing Secure Code (2nd Edition) by Michael Howard
- Introduction to Functional Programming by Philip Wadler and Richard Bird
- No Bugs! by David Thielen
- Rework by Jason Freid and DHH
- JUnit in Action
#BlackOwned #BlackEntrepreneurs #BlackBuniness #AWSCertified #AWSCloudPractitioner #AWSCertification #AWSCLFC02 #CloudComputing #AWSStudyGuide #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AWSBasics #AWSCertified #AWSMachineLearning #AWSCertification #AWSSpecialty #MachineLearning #AWSStudyGuide #CloudComputing #DataScience #AWSCertified #AWSSolutionsArchitect #AWSArchitectAssociate #AWSCertification #AWSStudyGuide #CloudComputing #AWSArchitecture #AWSTraining #AWSCareer #AWSExamPrep #AWSCommunity #AWSEducation #AzureFundamentals #AZ900 #MicrosoftAzure #ITCertification #CertificationPrep #StudyMaterials #TechLearning #MicrosoftCertified #AzureCertification #TechBooks
Top 1000 Canada Quiz and trivia: CANADA CITIZENSHIP TEST- HISTORY - GEOGRAPHY - GOVERNMENT- CULTURE - PEOPLE - LANGUAGES - TRAVEL - WILDLIFE - HOCKEY - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Top 1000 Africa Quiz and trivia: HISTORY - GEOGRAPHY - WILDLIFE - CULTURE - PEOPLE - LANGUAGES - TRAVEL - TOURISM - SCENERIES - ARTS - DATA VISUALIZATION

Exploring the Pros and Cons of Visiting All Provinces and Territories in Canada.


Exploring the Advantages and Disadvantages of Visiting All 50 States in the USA

Health Health, a science-based community to discuss health news and the coronavirus (COVID-19) pandemic
- Cargill Meat Solutions is recalling approximately 16,243 pounds of raw ground beef products that may be contaminated with E. coliby /u/James_Fortis on May 4, 2024 at 2:35 pm
submitted by /u/James_Fortis [link] [comments]
- We still don’t understand how one human apparently got bird flu from a cowby /u/barweis on May 4, 2024 at 11:50 am
submitted by /u/barweis [link] [comments]
- Companies Legally Use Poison to Make Your Decaf Coffeeby /u/nikola28 on May 4, 2024 at 11:34 am
submitted by /u/nikola28 [link] [comments]
- Study links gas stoves to 50,000 current cases of childhood asthmaby /u/Maxcactus on May 4, 2024 at 10:29 am
submitted by /u/Maxcactus [link] [comments]
- Report finds Nestlé adds sugars to baby food in low-income countriesby /u/nbcnews on May 4, 2024 at 12:20 am
submitted by /u/nbcnews [link] [comments]
Today I Learned (TIL) You learn something new every day; what did you learn today? Submit interesting and specific facts about something that you just found out here.
- TIL John Travolta was first considered for Forrest Gump but declined, opening the door for Tom Hanks. Bill Murray was also considered. Joe Pesci was a contender for Lieutenant Dan, but Gary Sinise got the role. Dave Chappelle rejected the role of Benjamin Buford Blue, thinking the film would flop.by /u/whstlngisnvrenf on May 4, 2024 at 2:21 pm
submitted by /u/whstlngisnvrenf [link] [comments]
- TIL that Rudolf Nureyev's grave in a Paris cemetery is draped with a beautiful, realistic mosaic of an oriental Kilim rug, in order to reflect the ballet dancer's life-long love of textiles and antiques.by /u/abaganoush on May 4, 2024 at 1:33 pm
submitted by /u/abaganoush [link] [comments]
- TIL that 26 bishops/archbishops of the Church of England have an automatic right to sit and vote in the House of Lords, the upper house of the UK parliamentby /u/shaggystuart on May 4, 2024 at 10:17 am
submitted by /u/shaggystuart [link] [comments]
- TIL more people died taking selfies (379) than from shark attacks (90) between 2008-2021.by /u/tyrion2024 on May 4, 2024 at 10:07 am
submitted by /u/tyrion2024 [link] [comments]
- TIL that Popcorn was present in South America as early as 4700 BC in the region that is now part of modern Peru.by /u/Desperate_Dirt_3041 on May 4, 2024 at 10:03 am
submitted by /u/Desperate_Dirt_3041 [link] [comments]
Reddit Science This community is a place to share and discuss new scientific research. Read about the latest advances in astronomy, biology, medicine, physics, social science, and more. Find and submit new publications and popular science coverage of current research.
- Big data reveals true climate impact of worldwide air travel. At 911 million tons, the total emissions from aviation are 50 per cent higher than the 604 million tons reported to the United Nations for that year.by /u/Wagamaga on May 4, 2024 at 2:10 pm
submitted by /u/Wagamaga [link] [comments]
- Psychedelics could make mental health worse in people with a personality disorderby /u/chrisdh79 on May 4, 2024 at 1:10 pm
submitted by /u/chrisdh79 [link] [comments]
- Metacognitive abilities may be more influenced by environment than geneticsby /u/deron666 on May 4, 2024 at 11:56 am
submitted by /u/deron666 [link] [comments]
- Researchers develop new device modeled on leeches for taking blood samples using microneedles and a suction cup instead of a large needle. It is low cost, helps people with needle phobia, reduces risk of needlestick injuries and can be used by people without medical training.by /u/mvea on May 4, 2024 at 11:11 am
submitted by /u/mvea [link] [comments]
- Aphantasia is where individuals cannot generate voluntary mental images—a function most people perform effortlessly—their mind’s eye is blind. A new study found that people with aphantasia do not show expected increase in brain activity that typically occurs when imagining or observing movements.by /u/mvea on May 4, 2024 at 10:57 am
submitted by /u/mvea [link] [comments]
Reddit Sports Sports News and Highlights from the NFL, NBA, NHL, MLB, MLS, and leagues around the world.
- Caitlin Clark completes her only objective for first WNBA preseason game with Indiana Feverby /u/onecommissioner on May 4, 2024 at 3:26 pm
submitted by /u/onecommissioner [link] [comments]
- IOC imposes 15-year ban on former Olympic power broker Sheikh Ahmad of Kuwaitby /u/Oldtimer_2 on May 4, 2024 at 2:45 pm
submitted by /u/Oldtimer_2 [link] [comments]
- Vegas use of injured reserve prompts questions about salary cap. Other NHL teams do same thingby /u/Oldtimer_2 on May 4, 2024 at 2:43 pm
submitted by /u/Oldtimer_2 [link] [comments]
- Quantifying the power of the 1st-pitch strikeby /u/Oldtimer_2 on May 4, 2024 at 2:40 pm
submitted by /u/Oldtimer_2 [link] [comments]
- Clark impresses with 21 points in WNBA debut: 'A lot to be proud ofby /u/PrincessBananas85 on May 4, 2024 at 8:33 am
submitted by /u/PrincessBananas85 [link] [comments]
